2. Literature Review
Various studies in the literature have explored how UAVs can be used to supplement cellular networks. Approaches to calculate the best UABS position and trajectory have been studied in [
4,
5,
6,
7,
8,
9,
10]. The authors in [
4] calculated the best trajectory for a single UABS, assumed that the MBS and UABS operated at orthogonal frequencies, and thus the effect of interference was ignored. Greedy and unsupervised learning-based algorithms to position a fleet of UAVs to maximize aggregate user received power were presented in [
5], while a sequential spiral algorithm was presented in [
6].
However, none of these works considered interference between UAVs and BSs. Interference between UAVs and BSs was taken into account in [
7,
8]. Interference was minimized by using a statistical interference map and orthogonal frequency assignment in [
7] to select optimal UAV locations, while multi-antenna beam-forming techniques were used in [
8]. None of the studies leveraged LTE 3GPP Release-10/11 interference management techniques, nor any machine learning techniques. Machine learning techniques were used to predict potential network congestion and deploy UAVs accordingly in [
10].
Interference between UAVs and BSs was assumed to be minimized using orthogonal frequency assignments and beamforming techniques rather than with LTE 3GPP Release-10/11 techniques. The authors in [
11] followed the intuition that UAVs should be placed at coverage holes to maximize coverage, and used machine learning to locate coverage holes. A greedy approach to position UAVs was used in [
12] to maximize the number of users covered, while ensuring that the QoS requirements of the users are satisfied.
Game-theory-based approaches were used in [
13] The use of a UAV to provide wireless service to an Internet of Things (IoT) network was studied in [
13], wherein IoT nodes harvest energy from a UAV before transmitting data on the uplink to the UAV. The nodes form coalitions with one node acting as the coalition head. The optimal trajectory of the UAV was calculated to maximize the energy available to the IoT coalition heads.
Novel approaches to optimally partition a geographical area into UABS and MBS cells were proposed in [
14,
15]. While [
14] used optimal transport theory with the aim of minimizing the transmission delay for all users in the area, ref. [
15] used a neural-based cost function in which user demand patterns are used to assign a cost and density to each area. Both studies, however, did not tackle interference mitigation challenges explicitly. Interference mitigation using 3GPP Release-10 enhanced inter-cell interference coordination techniques (eICIC) and Release-11 further enhanced inter-cell interference coordination (FeICIC) techniques in HetNets were studied in [
16,
17,
18,
19]. While [
16] jointly optimized the ICIC parameters, the UE cell association rules, and the spectrum resource sharing between the macro and pico cells, it did not use 3GPP Release-11 FeICIC or cell range expansion (CRE) techniques.
Moreover, ref. [
16] only studied LTE HetNets and not UAV HetNets. LTE UAV HetNets were also evaluated in [
20], which optimized the allocation of LTE physical resource blocks in addition to the UAV position in order to maximize coverage. However, LTE interference management techniques were not utilized. In [
17], the authors developed a stochastic-geometry-based framework to study and compare the effectiveness of 3GPP FeICIC techniques and eICIC techniques, but [
17] also did not study UAV HetNets. The use of 3GPP Release-10/11 techniques along with UABS mobility in UAV HetNets was evaluated in [
19]. However, this study did not individually optimize the 3GPP ICIC parameters, but rather applied the same ICIC parameter values to each MBS and UABS, which is sub-optimal, as we demonstrate. An overview of the existing literature that is related to our work is presented in
Table 1.
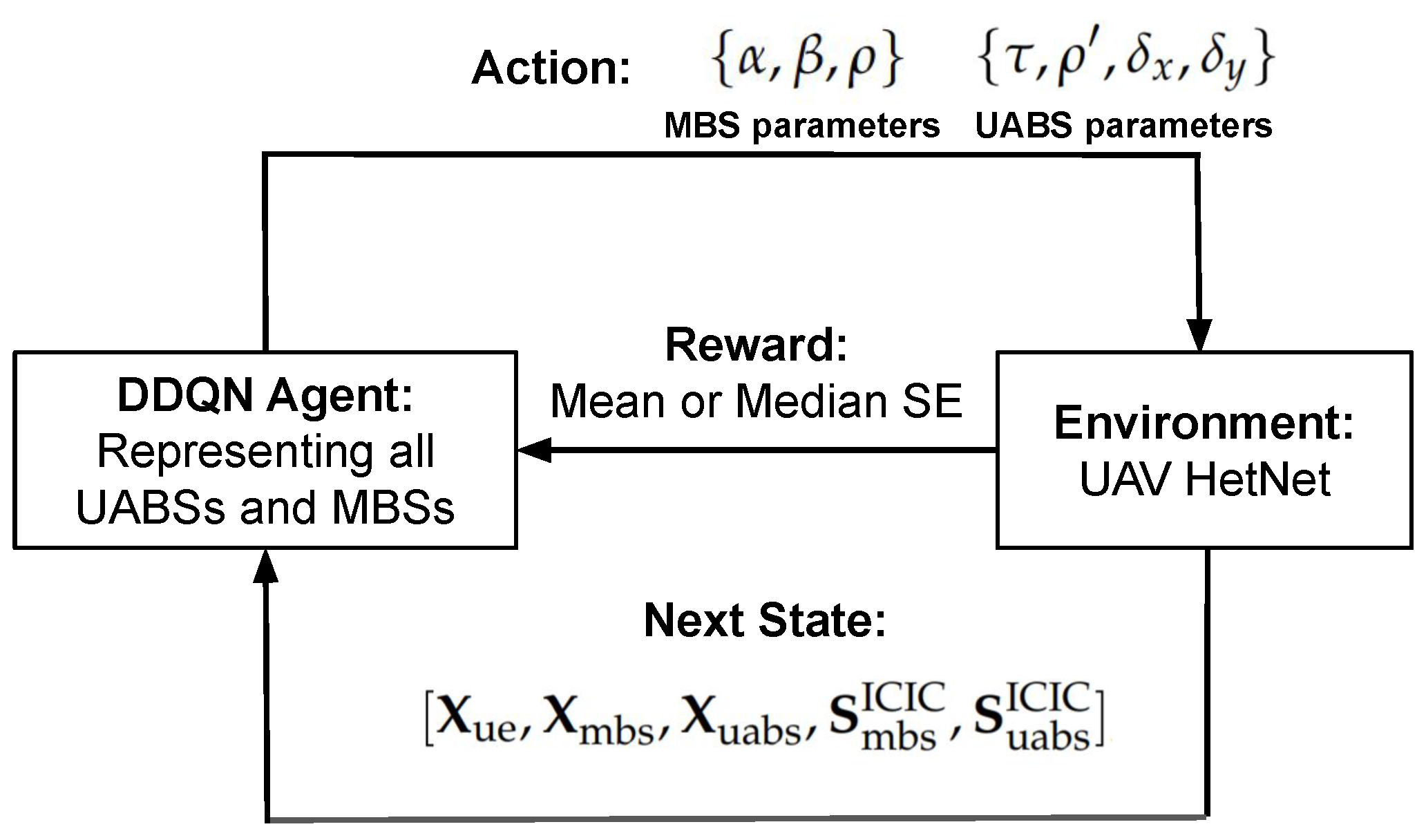
To the best of our knowledge, low complexity approaches to optimize 3GPP Release-10/11 interference management parameters in UAV HetNets have not been studied in the literature. Our contribution is that we propose a greedy algorithm and a double deep Q learning-based algorithm, to individually optimize 3GPP Release-10/11 interference coordination parameters and UABS position in order to maximize the mean and median SE. We also compare these two computationally efficient algorithms with an optimal but computationally complex brute force algorithm.
3. System Model
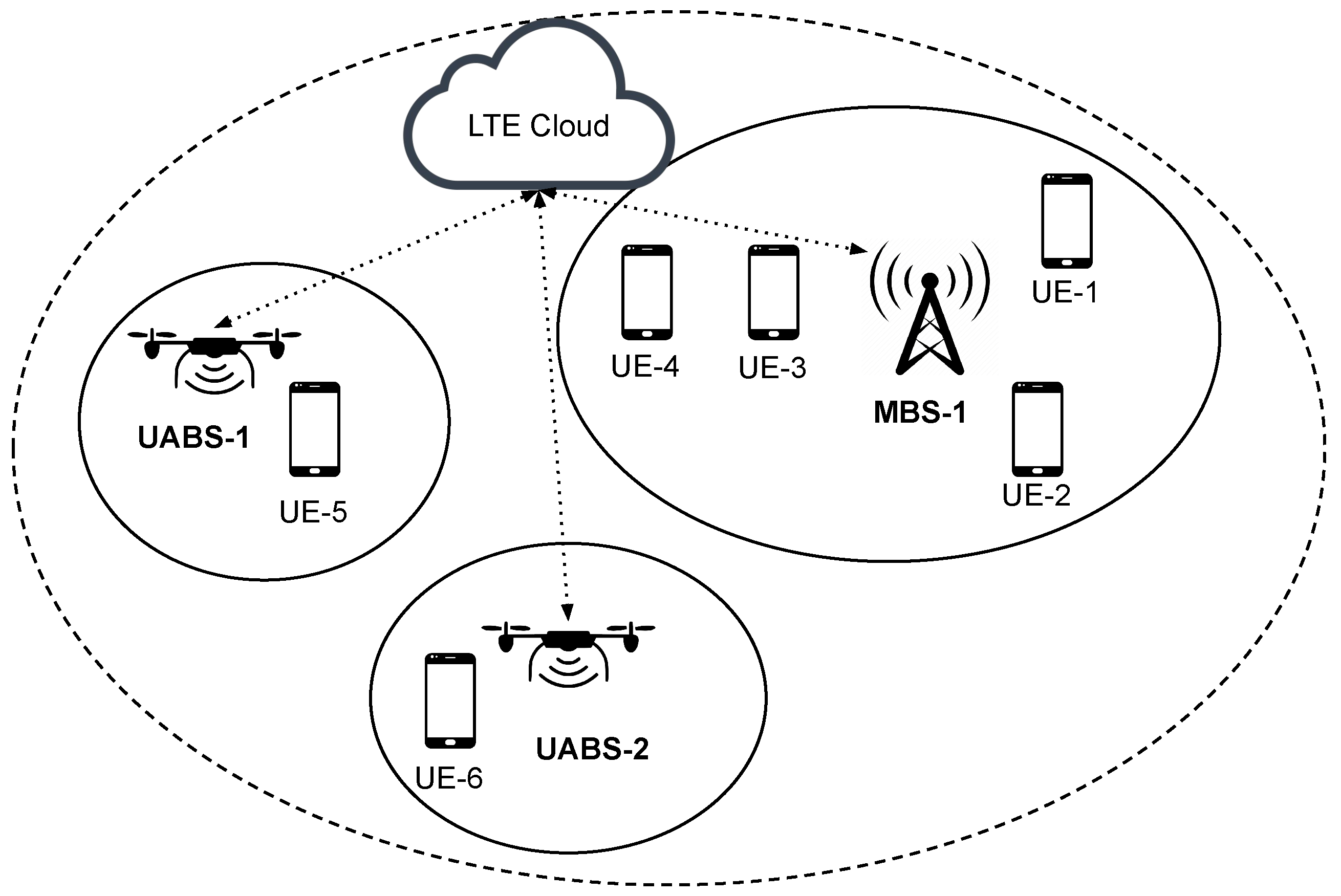
We consider a HetNet with MBSs and UABSs operation in two tiers, within a simulation area of
square meters as shown in
Figure 2. MBSs and UEs are randomly distributed in this area, according to a Poisson point process with the intensities
and
, respectively. The number of MBSs and UEs in the simulation can be calculated as
and
, respectively. The 3D locations of all the MBSs, UABSs, and UEs are represented by the matrices
,
, and
, respectively. The transmission power of each MBSs is
, while that of UABSs is
. Given the antenna gains of MBS and UABS as
K and
, respectively, the effective MBS and UABS transmission power is calculated as
and
, respectively.
We assume that the UABSs and MBSs exchange information over the X2 interfaces. We also consider that the downlink bandwidth available to an MBS or a UABS is shared equally among their served UEs. We assume that downlink data is always available for any UE—i.e., the downlink UE traffic buffers are always full. For an arbitrary UE n, where , we define the macro-cell of interest (MOI) as the nearest MBS, and the UAV-cell of interest (UOI) as the nearest UABS.
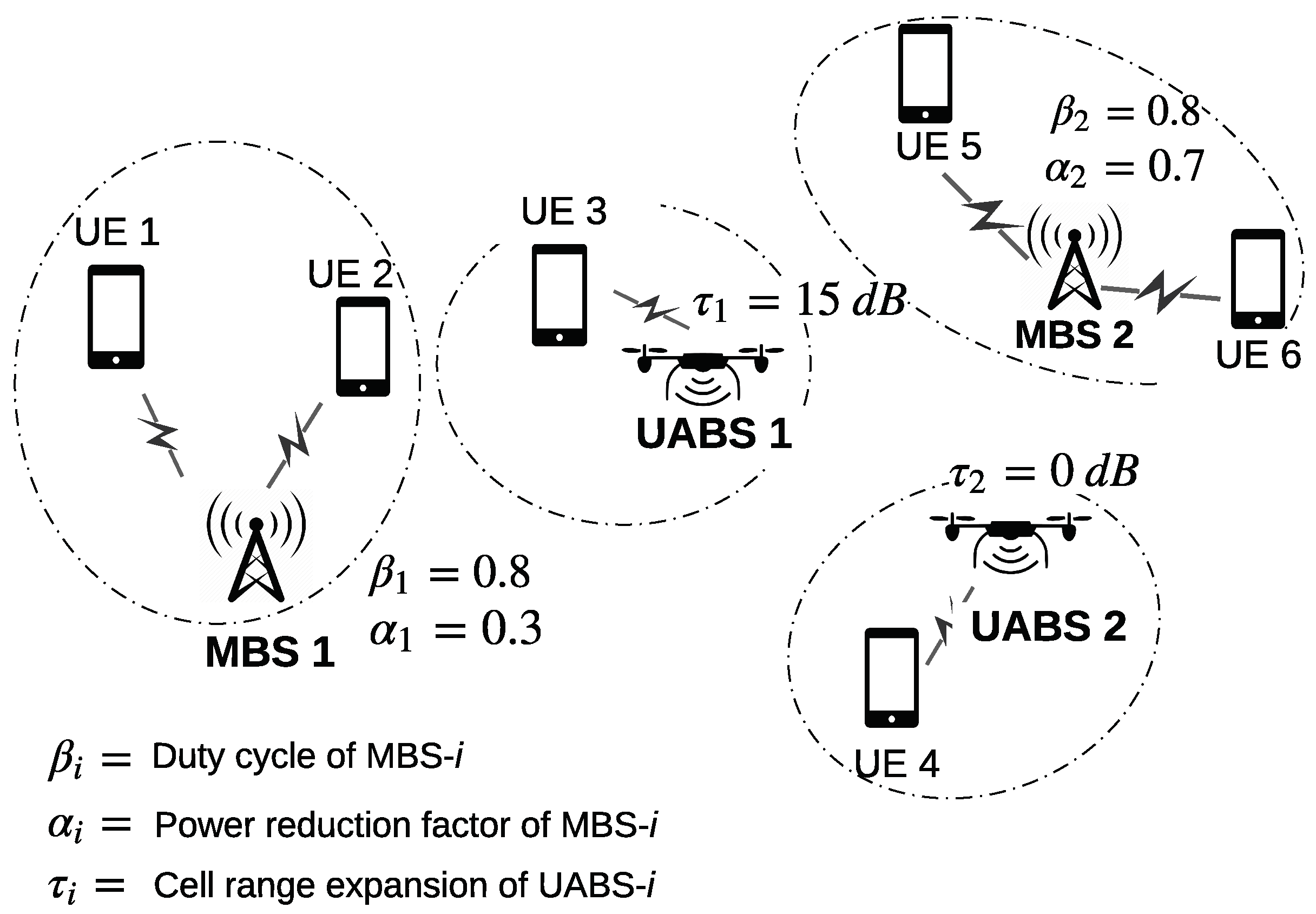
For example, in the specific scenario shown in
Figure 2, MBS 1 is the MOI for UEs 1 and 2, MBS 2 is the MOI for UEs 5 and 6, UABS 1 is the UOI of UE 2, and UABS 2 is the UOI of UE 3. We denote the reference symbol received power (RSRP) of the
nth UE from the MOI and the UOI as
and
, respectively, where
is the distance from the nearest MOI, and
is the distance from the nearest UOI for the
nth UE. We use the Okumura Hata suburban propagation model without any Rayleigh or Rician fading.
An arbitrary UE
n is always assumed to connect to the nearest MBS or UABS, where
. Then, for the
nth UE, the reference symbol received power (RSRP) from the macro-cell of interest (MOI) and the UAV-cell of interest (UOI) are given by
where
is the path-loss observed from MBS in dB,
is the path-loss observed from UABS in dB,
is the distance from the nearest MOI, and
is the distance from the nearest UOI.
The Okumura Hata path loss is a function of the carrier frequency, distance between the UE, serving cell, base station height, and UE antenna height. The path-loss (in dB) observed by the
nth UE from MOI and UOI is given by:
where the distances
and
are in km, and the factors
A,
B, and
C depend on the carrier frequency and antenna height. In a suburban environment, the factors
A,
B, and
C are given by
where
is the carrier frequency in MHz,
is the height of the base station in meters, and
is the correction factor for the UE antenna height
in meters, which is defined as
3.1. SE with 3GPP Release-10/11 ICIC Techniques
In a HetNet, the MBSs transmit at higher powers and have higher ranges compared to the lower power UABSs. Nevertheless, the UABSs can extend their coverage and associate a larger number of UEs by using the cell range expansion (CRE) technique defined in 3GPP Release-8. The CRE of a UABS is defined as the factor by which UEs are biased to associate with that UABS. For example, in
Figure 2, UABS 1 uses a CRE of 15 dB to force UE 4 to associate with itself. The use of CRE, however, results in increased interference to those UEs in the extended cell regions.
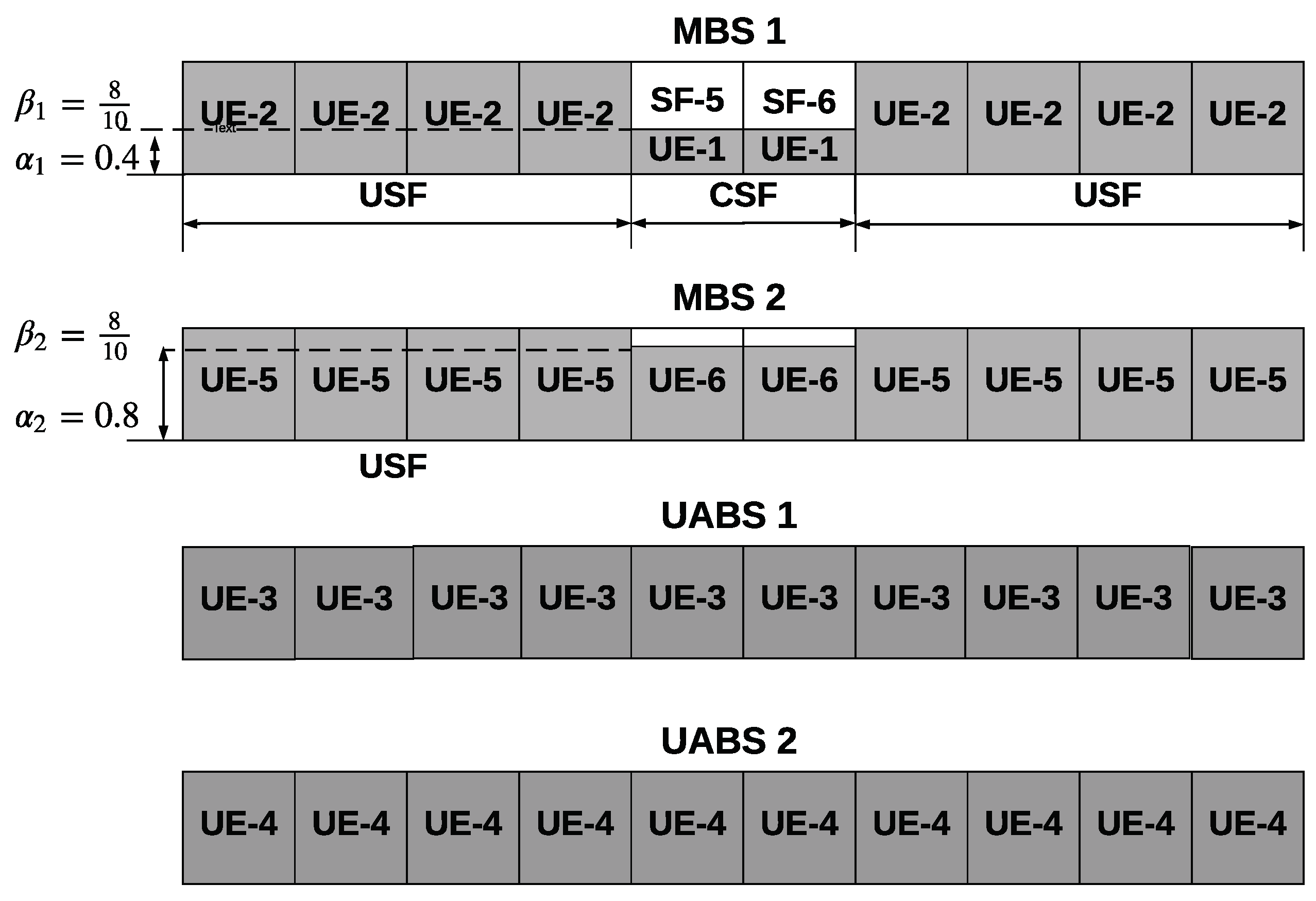
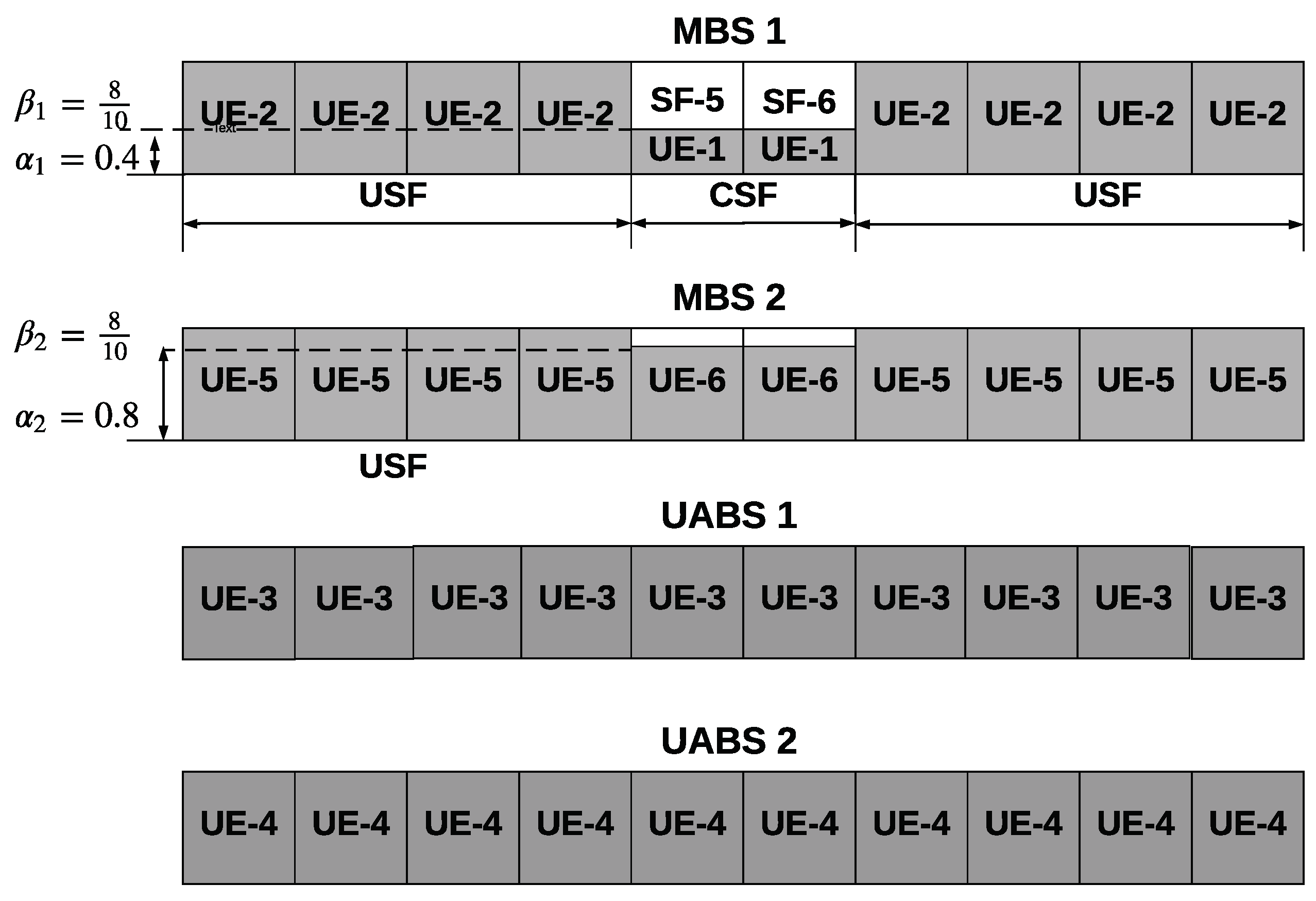
This interference from MBSs to UEs near the edge of range-extended UABS cells can be mitigated using time-domain-based ICIC techniques defined in 3GPP Release-10/11. These techniques require the MBS to transmit with reduced power during specific subframes on the physical downlink shared channel (PDSCH). Radio subframes with reduced power are termed coordinated subframes (CSF), and those with full power are termed uncoordinated subframes (USF).
We denote this power reduction factor by
where
. We note that
implies no ICIC, while eICIC techniques use
, and FeICIC techniques allow
to vary between 0 and 1. We use
to denote the USF duty cycle, and hence, the CSF duty cycle is given by
.
Figure 3 shows, for the scenario depicted in
Figure 2, how MBS 1 and MBS 2 use power reduction factors,
and
respectively, to reduce interference to UE 3. We note that
, as MBS 2, being farther away from UE 3, can transmit at a higher power without degrading the performance of UE 3.
Individual MBSs or UABSs can schedule their UEs in USF or CSF based on the scheduling thresholds and , respectively. Then, a UE may be served either by an MOI or UOI and by the CSF or USF resources of the MOI/UOI, resulting in four different association categories. Let denote the signal to interference ratio (SIR) at the MOI-USF, denotes the SIR at the UOI-USF, and denotes the CRE that positively biases the UABS SIR to expand its coverage. Then, the four different resource categories where a UE may be scheduled can be summarized as follows. If , we associate the UE with the MOI; otherwise, we schedule it with the UOI.
The intuition behind this condition is straightforward: associate the UE with the nearest base station that gives the best SIR, taking into account the CRE. On the other hand, if or , we schedule the UE in CSF, and otherwise in USF. This condition is based on the following intuition: scheduling a UE in the CSF of an MOI degrades that UE’s SIR, whereas scheduling a UE in the CSF of a UOI improves that UE’s SIR. Thus, the “stronger” UEs that have sufficiently high SIRs and are close to the MBS should be scheduled in the CSFs of that MBS, as these “stronger” UEs can take the performance hit. Similarly, the “weaker” UEs that have low SIRs and are close to the cell edge of a UABS should be scheduled in the CSF of that UABS, as they need to be protected as a priority.
Using this framework of eICIC and FeICIC and following an approach similar to that of [
17,
22] for a HetNet, the SIR (
,
,
,
) and the SE (
,
,
,
) experienced by an arbitrary UE
n can be defined for four different scenarios as follows:
UE associated with MOI and scheduled in USF:
UE associated with MOI and scheduled in CSF:
UE associated with UOI and scheduled in USF:
UE camped on UOI and scheduled in CSF:
In (
8)–(
11),
Z and
are, respectively, the interference at a UE from all the MBSs and the UABSs except the UOI and except the MOI. They have the same meaning but different values.
3.3. Parameter Optimization
The SE is a function of , , , , , and , which are our optimization space. Either these parameters can be optimized for individual MBSs and UABSs, or the same value of each parameter can be used for all MBS and UABS, which is sub-optimal but computationally less complex.
To show that optimizing the above parameters individually for each MBS and UABS gives a better performance than optimizing the ICIC parameters jointly, we consider the hypothetical situation depicted in
Figure 2. Here, UE 3 is the critical UE to be protected from interference. Intuitively, as MBS 1 is closer to UE 3 compared to MBS 2, it is desirable for MBS 1 to transmit at a lower power during CSFs. Mathematically,
. As UE 4, which is served by UABS 2, is farther away from all the MBSs, UABS 2 does not have to use a large CRE to encourage UE 4 to associate with itself. In contrast, UABS 1 would have to use a larger CRE to encourage UE 3 to associate with itself. Mathematically,
dB
dB. Therefore, optimizing the parameters individually for each MBS and UABS gives better performance.
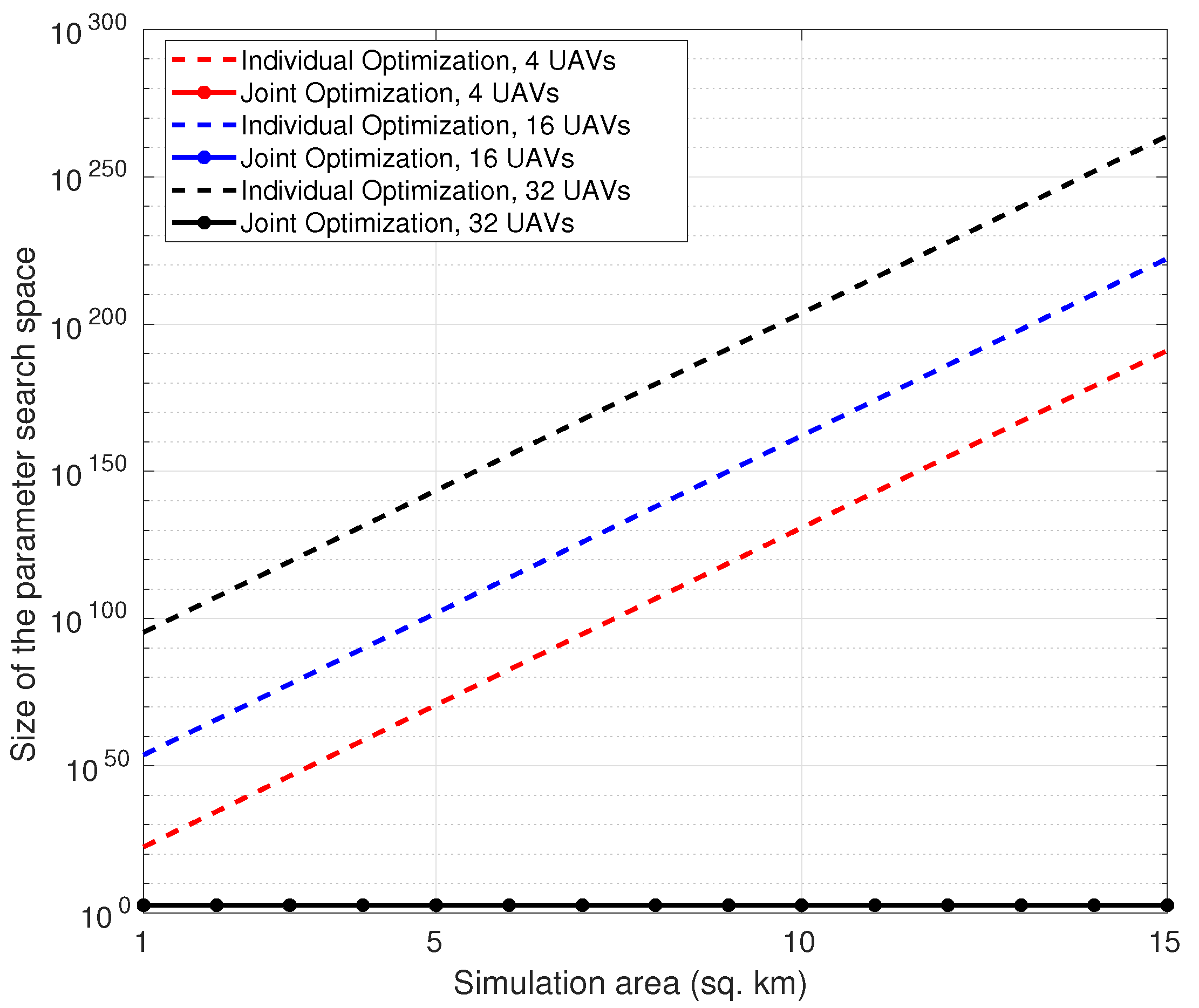
The large size of the search space can be appreciated by referring to
Table 2 and
Table 3, which list the range and size of the parameters to be optimized. In this table, the parameters
and
denote the step sizes for
coordinate of a UABS’s location, and
y coordinate of a UABS’s location, respectively, while
and
denote the lower bounds for
and
, respectively. Similarly,
and
denote the upper bounds for
and
, respectively. The actual size of the parameter space is depicted in
Figure 4, which shows the number of possible states in
, over which the individual or joint optimization algorithms have to search, in order to find the best state,
.
Figure 4 shows that, as the geographical area and correspondingly the number of MBSs and UABSs increase, the size of the search space increases much more rapidly for individual optimization than for joint optimization. This behavior can be understood by calculating the number of possible permutations of
for two MBSs considered by joint and individual optimization approaches, assuming that
can take four different values from 0 to 1.
While the joint optimization approach will only compare the SE metric at these four values of , the individual optimization approach will need to compare the SE metric for different permutations of values of the two MBSs. In this way, the parameter search size for joint optimization is agnostic to the number of MBSs or UABSs in the simulation area. The parameter search space of individual optimization, on the other hand, increases exponentially with number of MBSs and UABSs. We also observe that, for the individual optimization approach, the size of the state space exceeds a googol () of states as the simulation area increases beyond 15 km2.
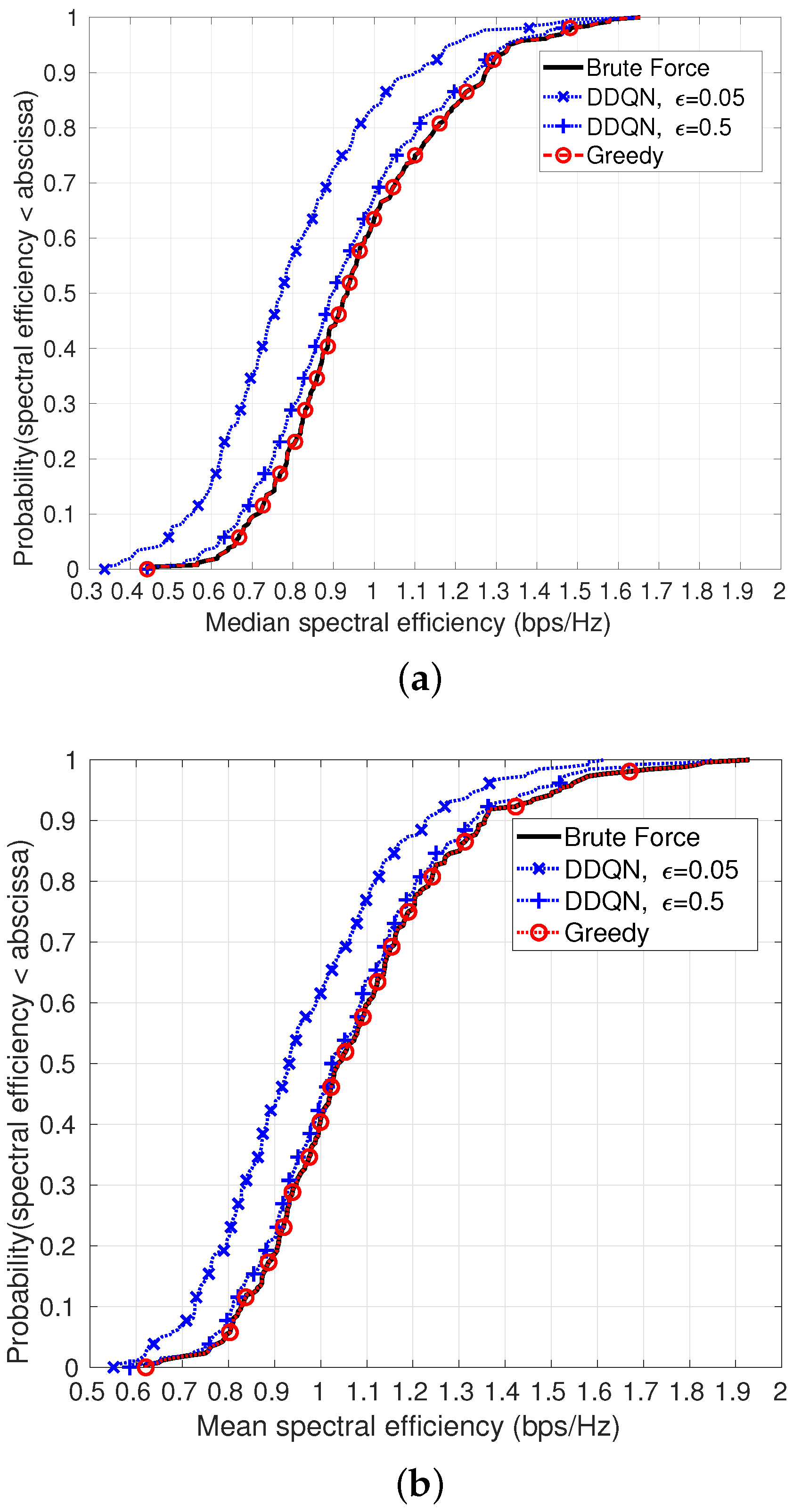
6. Simulation Results
The ICIC and UAV placement algorithms were evaluated in a UAV HetNet, and the parameters are as defined in
Table 5. The DDQN-based AI algorithm was implemented using Intel RL Coach [
29]. Intel RL Coach is a python framework, and it implements many state-of-the-art algorithms. These algorithms can be used through a set of application programming interfaces (APIs). The developer defines the environment and the optimization problem and calls the Intel RL Coach APIs to solve the problem. The UAV HetNet environment was created using python scripts, while Matlab scripts were used to simulate the path-loss model, associate UEs to BSs, and calculate the SE for a particular realization.
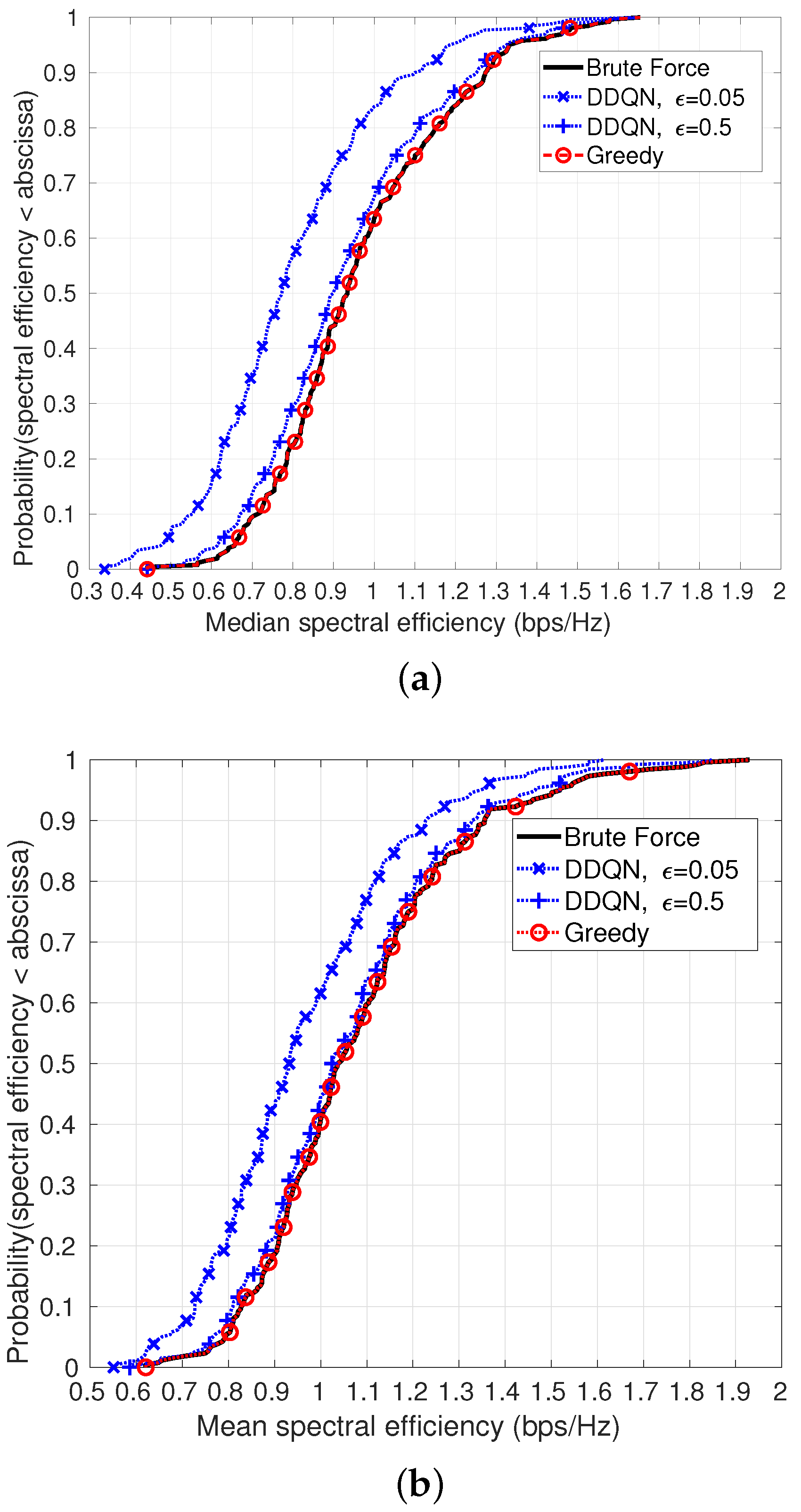
The agent was trained over 300 realizations and then evaluated over 250 realizations, where the location of UEs and BSs in each realization were generated using a random Poisson point process (PPP) with UE and MBS densities as indicated in
Table 5. The CDF of the median and mean SE achieved by the algorithms, calculated over multiple realizations, are shown in
Figure 6a,b, respectively, when the density of MBSs is 4 MBSs per km
, resulting in one MBS in the simulation area. Blue curves denote the CDF obtained using DDQN, red when using the greedy algorithm, and black when using the optimal exhaustive search.
It can be seen that the DDQN algorithm performs better when the value of the exploration–exploitation trade-off () during evaluation is (achieving of the optimal median SE and of the optimal mean SE), compared to when is (achieving of the optimal mean SE and of the optimal median SE). Using a higher implies that the agent takes more random actions, compensating for under-training and helping it to come out of local minima.
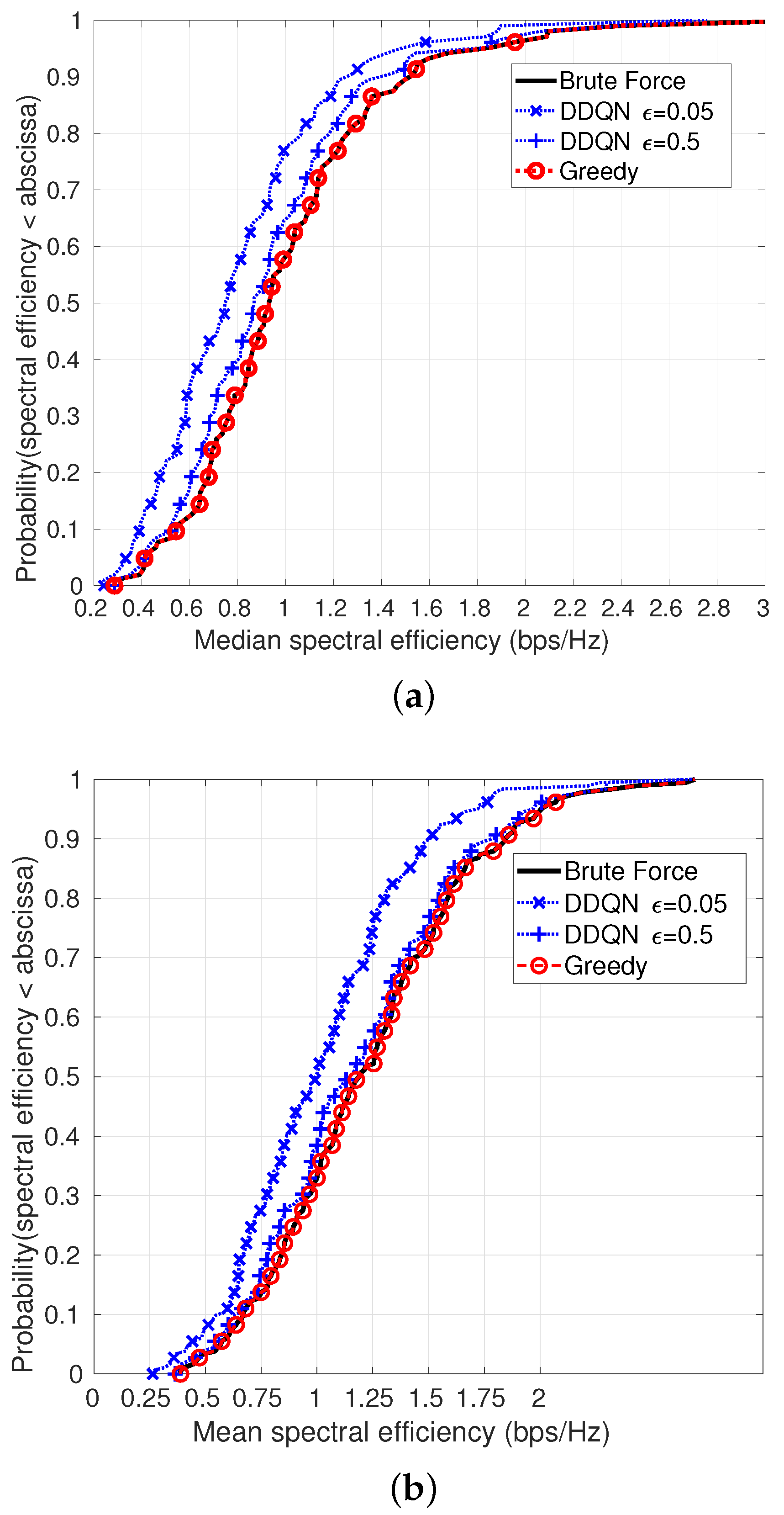
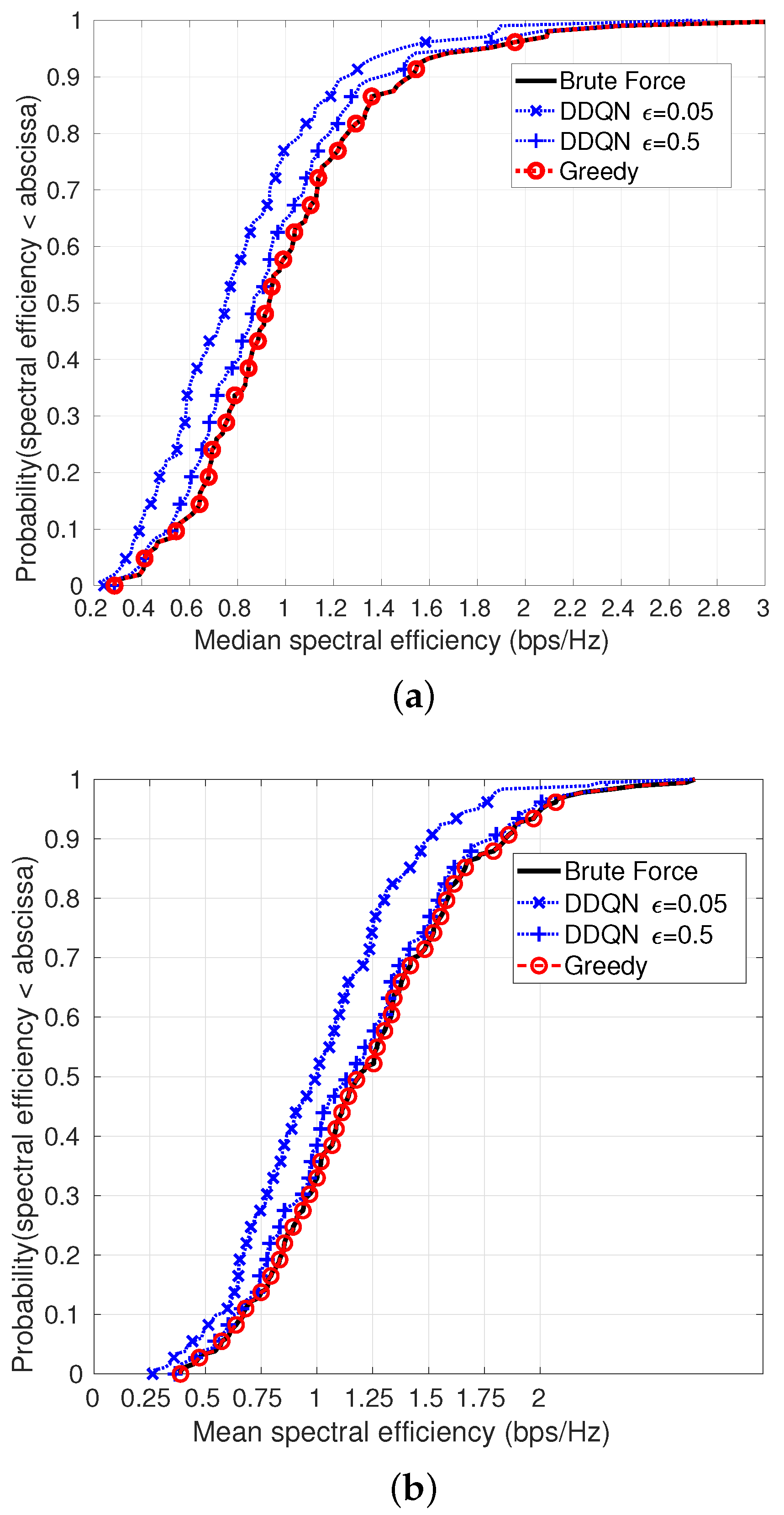
For 8 MBSs per km
(two MBSs in the simulation area), the CDF of median and mean SE achieved by the algorithms are shown in
Figure 7a,b, respectively. Again, the DDQN performance is better when using
(achieving
of the optimal median SE and
of the optimal mean SE), than when using an
(achieving
of the optimal median SE and
of the optimal mean SE). The greedy algorithm achieves the optimal results in the scenarios that we consider. The time complexity of the exhaustive search is exponential in the number of MBSs and UABSs and is given by:
Unlike the brute force algorithm, the greedy algorithm has linear time complexity, expressed as:
The time complexity of the DDQN approach during training is a function of the number of training steps,
where
is the number of training steps. However, after training is complete and the resultant neural network is used to optimize UAV HetNet parameters, the time complexity is the number of steps in the evaluation phase:
where
is the number of evaluation steps. To optimze all parameters for a realization consisting of two MBSs and one UABS, considering the range of parameters given in
Table 5, the brute force algorithm searches over
parameter combinations, the greedy approach evaluates 464 parameter combinations, while the searches over 500 parameter combinations, as per the policy learned after training.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}