
PVkNN: A Publicly Verifiable and Privacy-Preserving Exact kNN Query Scheme for Cloud-Based Location Services



Abstract
1. Introduction
1.1. Related Works
1.2. Challenges and Contributions
- Inability to protect the privacy of data access patterns [3].
- Verification is limited to confirming the authenticity of the data source for the query results returned by the cloud.
- Support is limited to private verification, where the verification algorithm requires the involvement of a private key. This restricts verification to designated verifiers and leads to the inability to achieve accurate arbitration when disputes arise between the querier and the cloud server.
- Formal Framework Establishment and Rigorous Theoretical Analysis: Although numerous privacy-preserving or verifiable kNN query schemes exist, to the best of our knowledge, no strict formal definition of privacy-preserving, publicly verifiable kNN queries has been proposed. Our first contribution is the establishment of the first formal framework for this purpose, clearly identifying its fundamental components and security definitions. Additionally, we conduct a rigorous and detailed theoretical analysis of our proposed scheme designed within this framework, laying a robust foundation for future research and practical advancements in the field.
- Robust Privacy: By adopting the two-non-colluding cloud servers model and leveraging the semantic security of Paillier’s homomorphic cryptosystem along with the Voronoi diagram-based index structure, we design and integrate a series of secure computation algorithms. These include Secure Division Computation (SDC), Secure Grid Computation (SGC), Secure Nearest-Neighbor (SNN) search, and Secure Voronoi Cell Read (SCR). Together, these algorithms enable secure kNN queries, ensuring the privacy of the original dataset, query data, and query results while also preserving the privacy of data access patterns.
- Public Verifiability: By integrating Paillier’s homomorphic cryptosystem with public-key signature techniques and a Voronoi diagram-based index structure, our scheme enables public verification of the authenticity and completeness of query results. Unlike previous designs, which restricted verification to designated verifiers, our approach removes this limitation, allowing for accurate arbitration in disputes between the querier and the cloud server.
- Optimized Computational Efficiency: To ensure the correctness of encryption and decryption, the proposed scheme refines the parameters of a series of secure protocols integrated with data packing techniques, addressing the ambiguous and inaccurate descriptions in Cui et al.’s design [8]. Additionally, it optimizes the Voronoi diagram-based ciphertext index structure. These improvements result in significant computational and communication savings compared to prior schemes, thereby enhancing overall performance and contributing to scalability and practical applicability in real-world scenarios.
1.3. Layout of This Paper
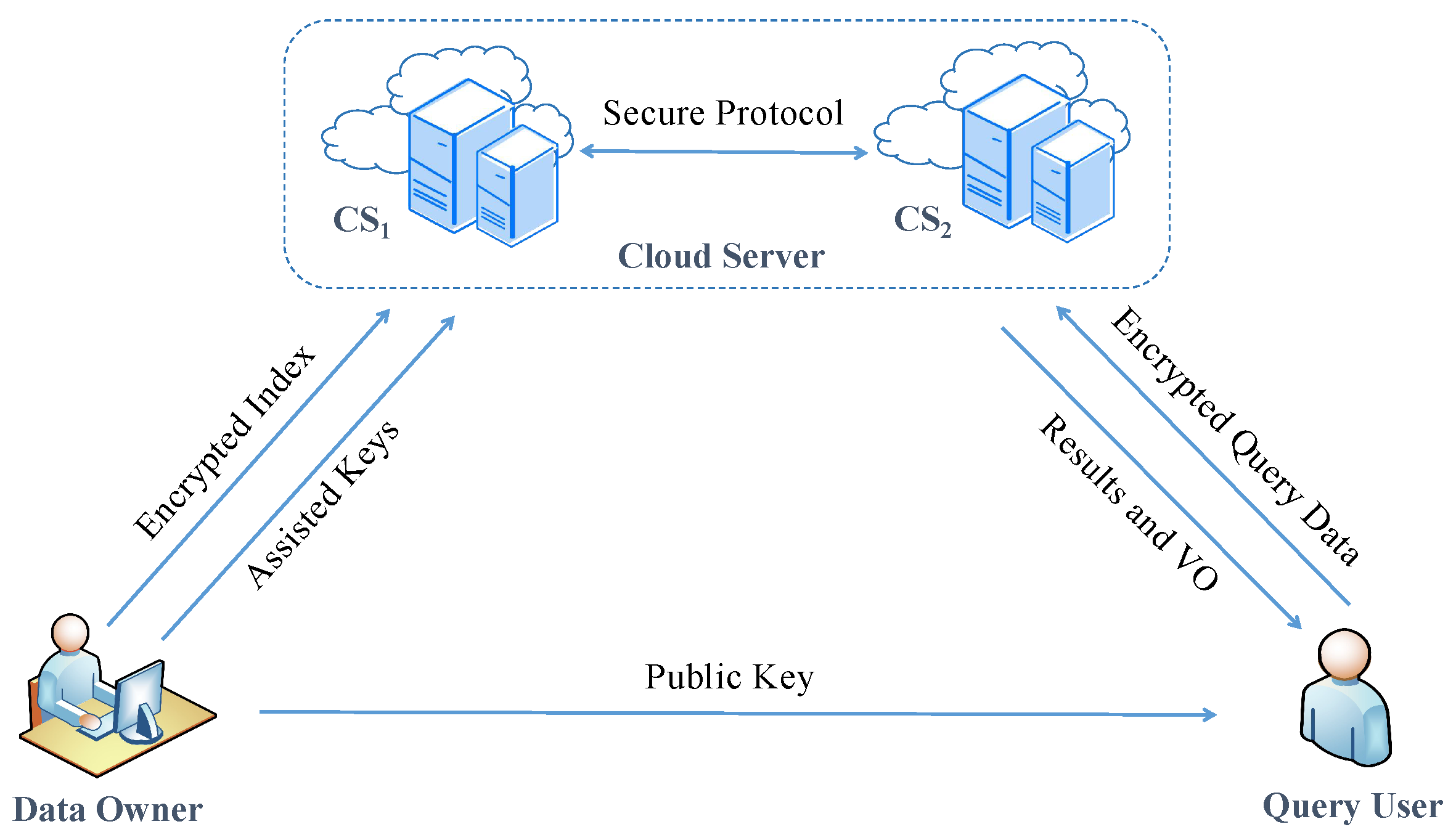
2. System Architecture, Threat Models, and Design Goals
2.1. System Architecture and Threat Models
- : Given a security parameter and dataset size n, this algorithm generates the public key and the secret key .
- : On inputting the dataset , the public key , and the secret key , the DO encrypts the dataset into a ciphertext dataset , where denotes the label set.
- : On inputting the query data point Q and the public key , this algorithms generates the encrypted query point .
- : On inputting the encrypted query , the encrypted dataset , and the public key , the search algorithm finds the query result and the associated proof .
- : On inputting the encrypted query , the query result , the proof , and the key pair , the verification algorithm checks whether is authentic and complete, producing an output .
- : With the query Q, the query result , the secret key and the indicator , if , this algorithm decrypts the returned result and recovers the set of k-nearest neighbors to Q. Otherwise, it rejects and outputs .
2.2. Design Goals
2.2.1. Correctness
2.2.2. Public Verifiability
| ; |
| ; |
2.2.3. Privacy
- Dataset privacy. Cloud servers cannot obtain any valuable information about the plaintext data in the dataset .
- Query data privacy. The QU’s query data should not be revealed to cloud servers.
- Query result privacy. Apart from the QU, other participants cannot learn the plaintext query result.
2.2.4. Efficiency
3. Preliminaries
3.1. Notations
3.2. Permutation
3.3. Paillier’s Additively Homomorphic Cryptosystem
- Homomorphic addition: The decrypted product of two ciphertexts equals the sum of their corresponding plaintexts, and the decrypted kth power of a ciphertext equals the product of k and its corresponding plaintext.
- Semantic security: If the decisional composite residuosity problem is hard, then the Paillier cryptosystem is -secure.
3.4. Digital Signature Algorithm DSA
3.5. Voronoi Diagram
3.6. Data Packing with Paillier’s Cryptosystem
- Data packing :
- Data encryption :
- Data decryption :
- Data unpacking : for where denotes the binary bits between the th position and the th position of x counting from the least significant bit.
4. Our Main Design
4.1. Design Intuition and Basic Idea
4.2. Our Main Outsourcing Protocol
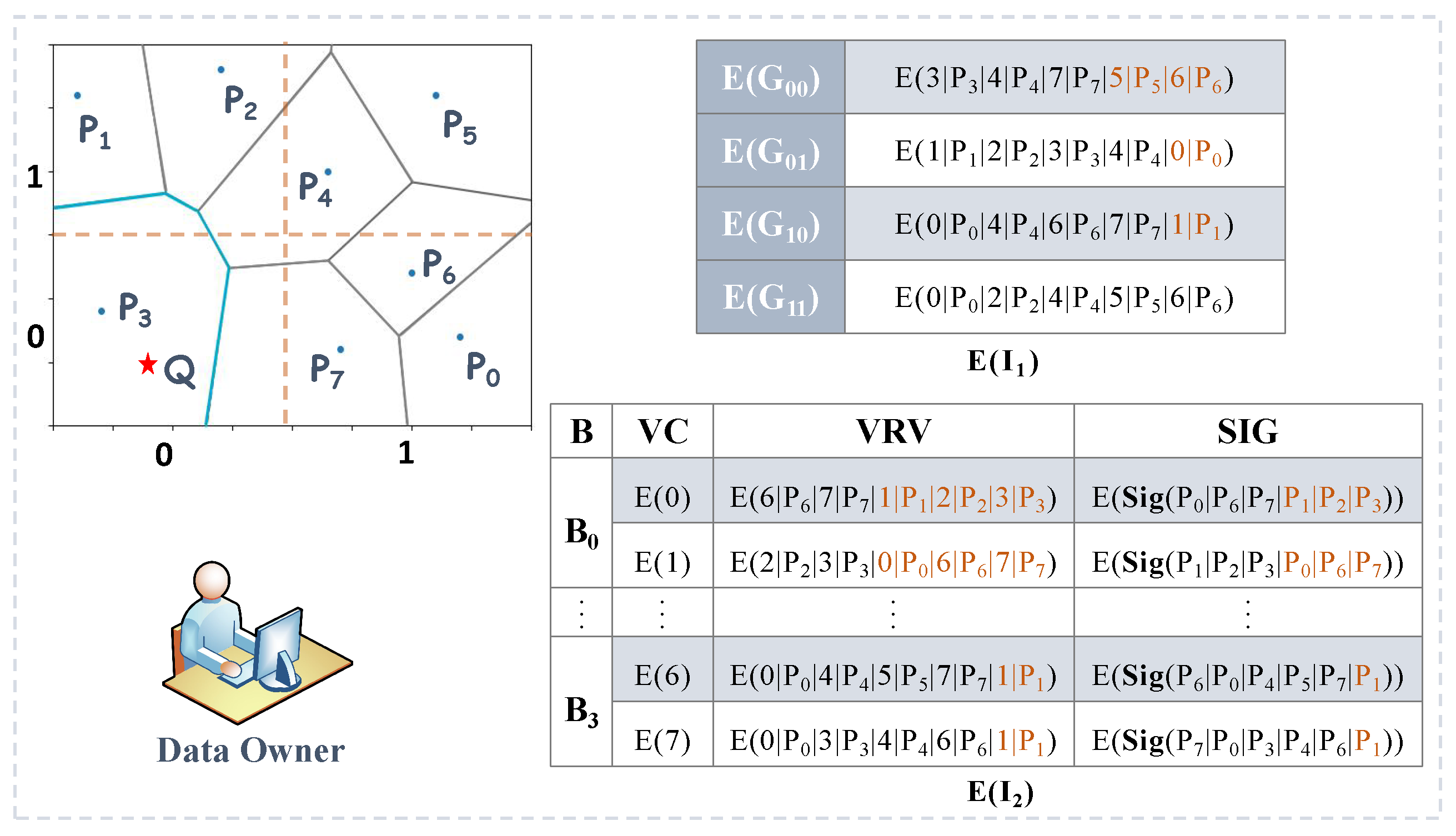
4.2.1. DO Dataset Preprocessing Stage
- Given a natural number m of appropriate size, the DO divides the region into small rectangular regions for .
- For each point , the DO finds its Voronoi-relevant vectors
- The DO constructs the index , where refers to a subset of and, for any point , .
- The DO constructs the index .
4.2.2. System Setup Stage:
4.2.3. Dataset Encryption Stage:
4.2.4. QU Query Encryption Stage:
4.2.5. CS Search Stage:
| Algorithm 1 kNN () |
| Input: CS2: the public-private key pair |
| Output: Result sets , , and verification sets , |
|
- (1)
- With the inputs , , and , and the public–private key pair , cloud servers and interact with each other to calculate the ciphertexts and using Algorithm 2.
- (2)
- With the inputs and , cloud servers and collaborate to execute Algorithm 3, traversing to locate the target grid with , which means that . The core idea of this algorithm is to determine based on verifying whether both and represent ciphertexts of 0 for some . Note that may be negative; the parameter T ensures that ensures that the results represents a ciphertext of a positive number.
| Algorithm 2 SDC () |
| Input: : , and a security parameter , : . |
| Output: obtains the quotients and |
|
| Algorithm 3 SGC () |
| Input: : , and security parameters satisfying , : |
| Output: the grid with and |
| 1: |
| 2: for to do |
| 3: generates random numbers with bits and a random number |
| 4: calculates |
| 5: |
| 6: for to do |
| 7: for to do |
| 8: generates a random numbers and calculates |
| 9: computes |
| 10: |
| 11: permutes the vectors and grid with two random permutations : |
| 12: |
| 13: |
| 14: packs , i.e., calculates and sends to |
| 15: decrypts and unpacks and : |
| 16: for to do |
| 17: for to do |
| 18: if and |
| 19: |
| 20: |
| 21: |
| 22: else |
| 23: sends and to |
| 24: permutes the matrix M with : |
| 25: calculates |
| 26: gets the target grid containing the query point: |
- (3)
- After identifying the correct grid , cloud servers CS1 and CS2 jointly execute Algorithm 4 to search within the grid in ciphertext form and locate the ciphertext () corresponding to the nearest neighbor to Q, where . It is worth noting that Algorithm 4 can trivially be adapted to handle scenarios where the input includes multiple packed ciphertext datasets and multiple ciphertext values. Specifically, the input format is , and the output is the ciphertext , where represents the nearest-neighbor point to Q, with the constraint that .
| Algorithm 4 SNN () |
| Input: : , and , : the private key |
| Output: (): the ciphertext of the nearest neighbor to Q with |
|
| 23: |
|
- (4)
- According to Lemma 2, the second-nearest neighbor to Q resides in the set . Therefore, leveraging , cloud servers and collaboratively execute Algorithm 5 to explore and identify . These results facilitate the discovery of the second-nearest neighbor and verification of the correctness of .
| Algorithm 5 SCR () |
| Input: : , and . : the public-private key pair |
| Output: and in |
|
- (5)
- Similarly, the jth () nearest neighbor to Q is in the set . Thus, for to k, cloud servers and recursively perform the following operations. First, they jointly invoke Algorithm 4 to traverse and find the ciphertext () of the jth nearest neighbor to Q. Then, they jointly perform Algorithm 5 to search in the ciphertext form and find , which is used to find the th nearest neighbor and verify the correctness of .
- (6)
- Through the above five steps, can obtain the encrypted query result and the encryption verification informationHowever, without the secret key , the QU cannot recover the plaintext of the query result and the verification information. Therefore, must leverage the private key stored in to assist the QU in obtaining the plaintext. To achieve this, through the homomorphic property, adds some random numbers to blind the encrypted query result and the verification information and sends them to . Finally, returns the sets and of random numbers to the QU, while decrypts the blinded results sent from and returns the decrypted sets and to the QU.
4.2.6. QU Verification and Decryption Stage: and
| Algorithm 6 Verify () |
| Input: . |
| Output: or |
|
5. Correctness and Security Analysis
5.1. Correctness Analysis
5.2. Public Verifiability
- (1)
- In Step 4, is the correct signature of the message .
- (2)
- In Step 15, .
5.3. Privacy
6. Efficiency Analysis and Performance Evaluation
6.1. Evaluation Methodology
6.2. Theoretical Analysis
6.3. Experimental Analysis
- (1)
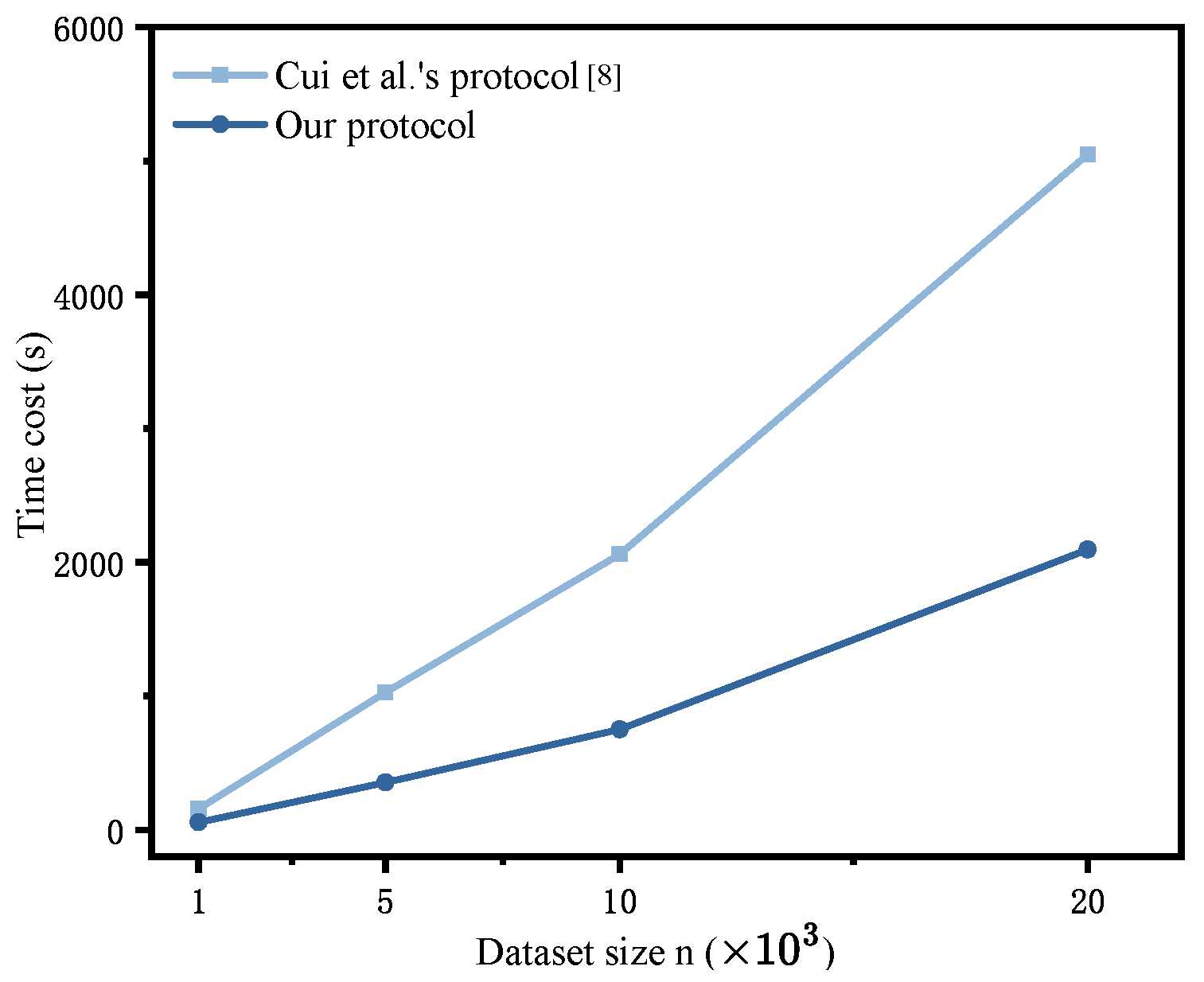
- Impact of varying n: With fixed parameters , , and , we systematically varied the dataset size n from 1000 to 20,000 to evaluate scalability. Table 7 presents the stage-wise execution times for both Cui et al.’s protocol [8] and our proposed protocol. Visually, Figure 3 further illustrates the comparative trends in the total cost of these two protocols as n increases. The results demonstrate that our protocol achieved a 58.5–65.5% reduction in time cost compared to the baseline, with the performance gap widening significantly for larger n.
- (2)
- Impact of varying m: Under fixed parameters , , and , we systematically evaluated the grid granularity to analyze algorithmic scalability. Table 8 presents a comparative analysis of computational latency (in seconds) between Cui et al.’s protocol [8] and our proposed method across these configurations. As shown in the table, the total cost of our design was about 32.7–35.4% of that of the baseline. Furthermore, as the grid granularity m primarily influences the search stages, Figure 4 visualizes the combined latencies of these phases. Notably, minimal computational overhead was achieved at , aligning closely with the theoretical optimum derived for uniform random datasets:The empirically observed optimum () reflects practical implementation constraints while remaining consistent with this theoretical boundary.
- (3)
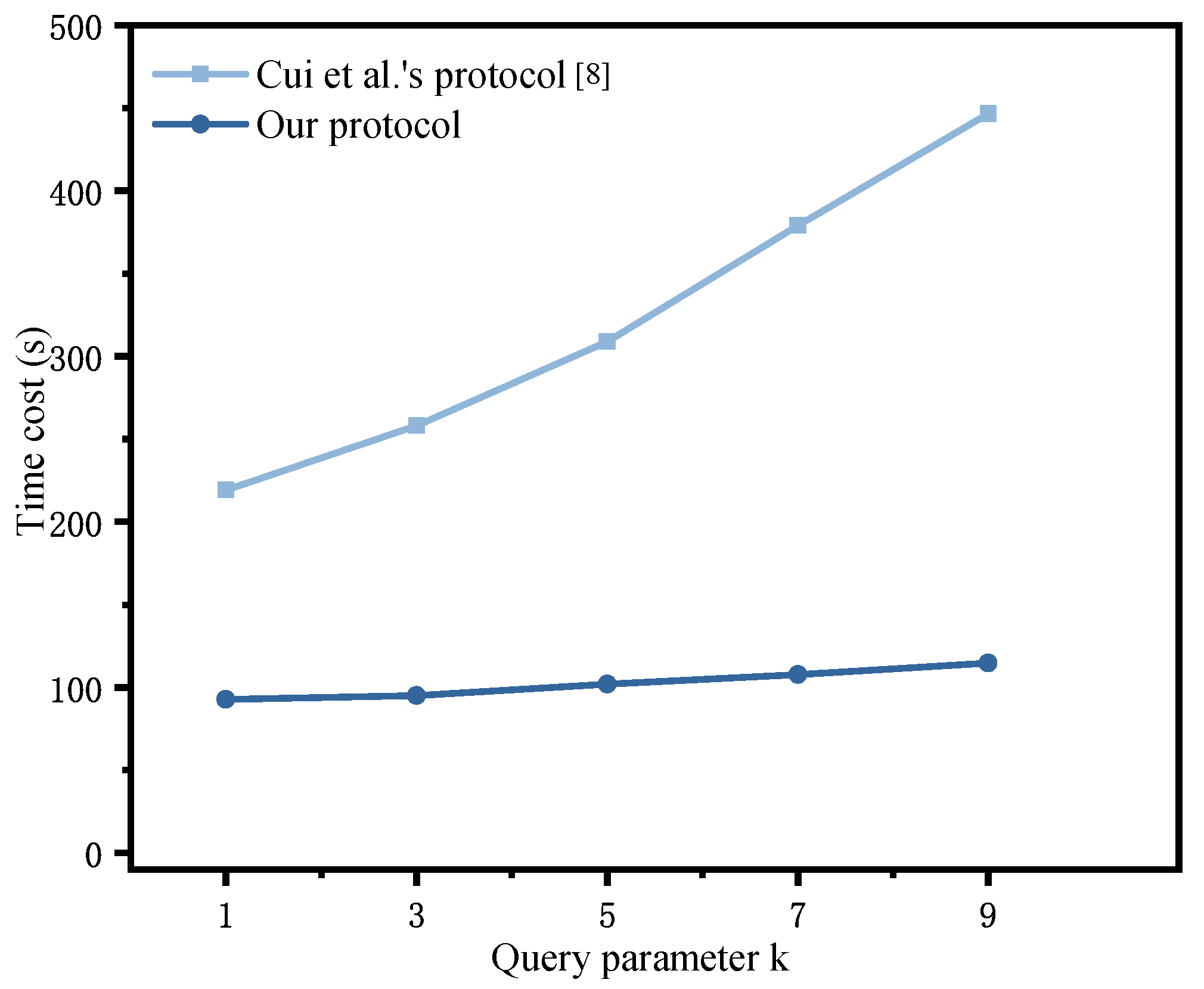
- Impact of varying k: As shown in Table 9, under fixed parameters , , and , we systematically evaluated the computational efficiency of each stage of our protocol against Cui et al.’s baseline [8] by varying the query parameter k in k-nearest-neighbor (kNN) searches from 1 to 10. Further, since the search, verification, and decryption stages are inherently dependent on k, whereas the setup, dataset encryption, and query encryption stages remain protocol-level invariants independent of k, Figure 5 illustrates the variance of the time cost of these two stages as k increases, demonstrating that the efficiency gains of our design became more pronounced as k increased.
- (4)
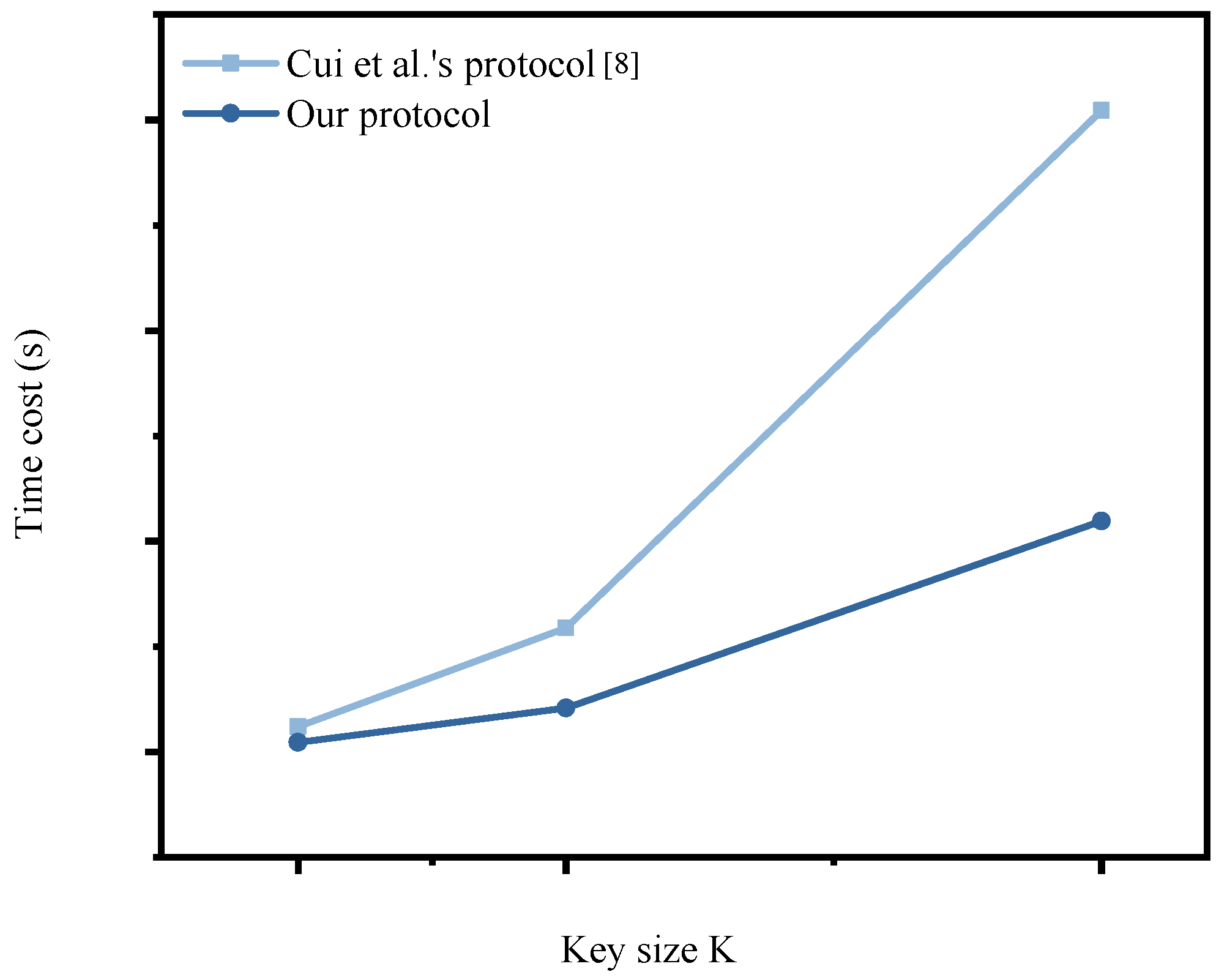
- Impact of varying K: Given that the modulus size K of N determines the security strength of both the DT-PKC and Paillier cryptosystems employed in our scheme, we conducted a comprehensive performance comparison between our proposed scheme and Cui et al.’s protocol [8] under varying security levels () for fixed parameters , , and . Table 10 presents the stage-wise computational latencies (e.g., setup, encryption, search, and verification) for both schemes, explicitly quantifying the trade-off between cryptographic robustness and operational efficiency. Also, Figure 6 illustrates the total execution time scaling with increasing K, showing that the total cost of our design was about 33.8–38.1% of that of Cui et al.’s protocol.
- (5)
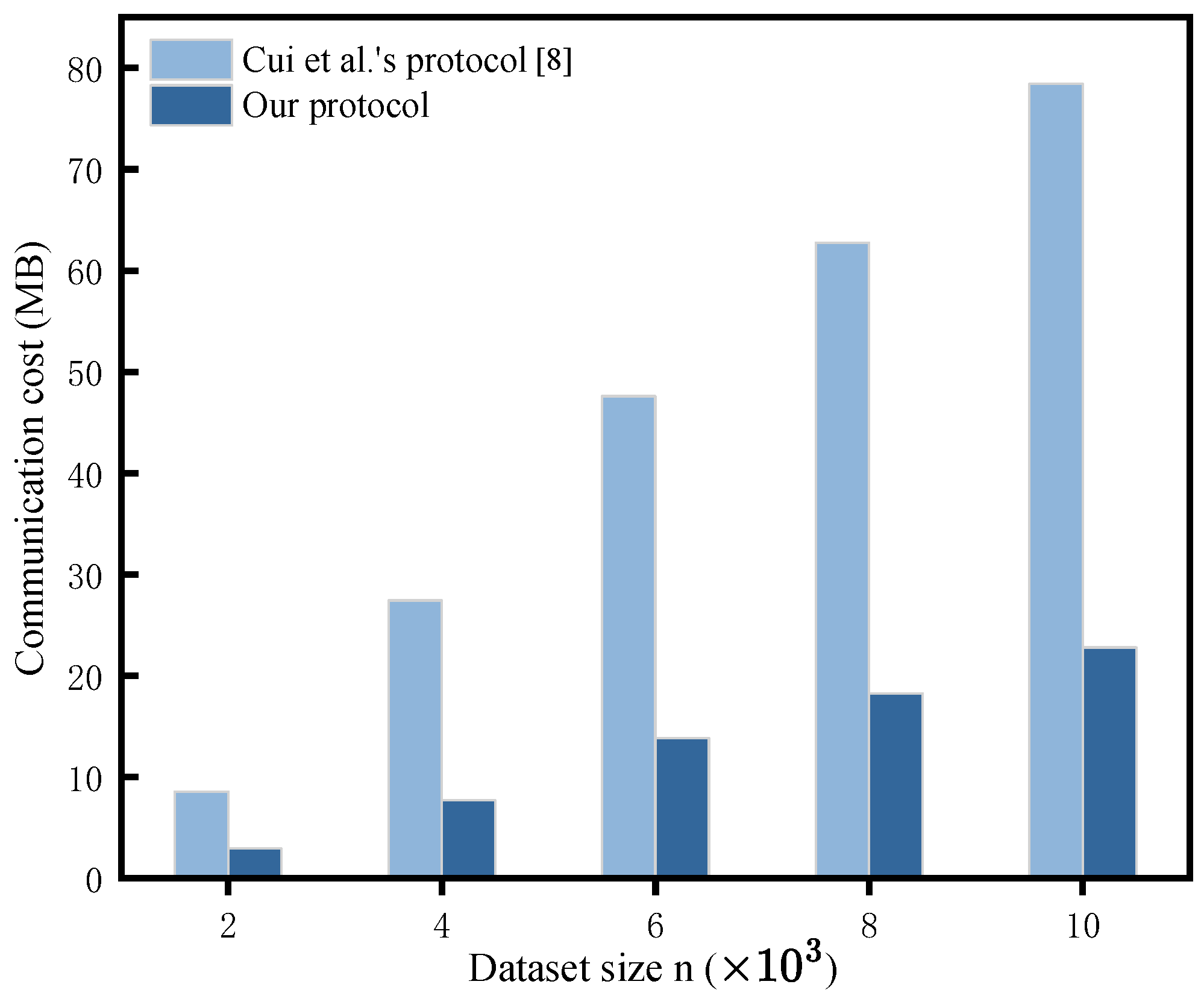
- Communication cost: We conducted an experimental evaluation of communication costs with fixed parameters, , , and , while systematically varying the dataset size n. As shown in our theoretical analysis (Table 6), the primary difference in communication cost between our protocol and Cui et al.’s protocol occurred during the stage. Figure 7 illustrates the difference in communication overhead between and in our protocol compared to Cui et al.’s protocol across various dataset sizes. The polyline in Figure 8 represents the comparison of data transfer times between CS1 and CS2 during the Search phase across varying dataset sizes. The data transfer time (communication latency) was calculated as the communication volume divided by the transfer rate, with the transfer rate simulated as 390 Mbps ≈ 48.75 MB/s. Our findings demonstrated that our protocol incurred lower costs, consistent with our theoretical analysis.
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Description |
|---|---|
| a permutation function | |
| the plaintext spatial dataset | |
| the ciphertext spatial dataset | |
| the least common multiple of two integers a and b | |
| Q | is the query data point |
| the index of the jth nearest neighbor to Q | |
| denotes the jth | |
| nearest neighbor to Q | |
| the set of Voronoi-relevant vectors of | |
| a cryptographic hash function | |
| the signature algorithm in DSA | |
| N | a large integer that is the product of two |
| prime numbers p and q | |
| K | the size of N |
| the multiplication group of the residue | |
| class modulo | |
| the residue class ring modulo N | |
| the concatenation of two numbers x and y | |
| the greatest integer, no larger than x | |
| the set | |
| the set | |
| the security parameter | |
| a negligible function of the security parameter | |
| n | the dataset size |
| m | the grid granularity |
| k | the query parameter |
| the number of lines in one bucket | |
| the number of packed points |
Appendix B
Appendix B.1. The Proof of Lemma 3
Appendix B.2. The Proof of Lemma 4
Appendix B.3. The Proof of Lemma 5
Appendix B.4. The Proof of Lemma 6
Appendix B.5. The Proof of Lemma 7
References
- Wang, J.; Chen, X. Efficient and Secure Storage for Outsourced Data: A Survey; Springer: Berlin/Heidelberg, Germany, 2016; Volume 1, pp. 178–188. [Google Scholar] [CrossRef]
- Lei, X.; Liu, A.X.; Li, R.; Tu, G.H. SecEQP: A Secure and Efficient Scheme for SkNN Query Problem Over Encrypted Geodata on Cloud. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 662–673. [Google Scholar] [CrossRef]
- Liu, Q.; Hao, Z.; Peng, Y.; Jiang, H.; Wu, J.; Peng, T.; Wang, G.; Zhang, S. SecVKQ: Secure and verifiable kNN queries in sensor–cloud systems. J. Syst. Archit. 2021, 120, 102300. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, B.; Zhao, Z. Secure k-NN Query With Multiple Keys Based on Random Projection Forests. IEEE Internet Things J. 2024, 11, 15205–15218. [Google Scholar] [CrossRef]
- Qi, J.; Jia, X.; Luo, M.; Feng, Q. A Privacy-Aware K-Nearest Neighbor Query Scheme for Location-Based Services. IEEE Internet Things J. 2024, 11, 10831–10842. [Google Scholar] [CrossRef]
- Cheng, K.; Wang, L.; Shen, Y.; Wang, H.; Wang, Y.; Jiang, X.; Zhong, H. Secure k-NN Query on Encrypted Cloud Data with Multiple Keys. IEEE Trans. Big Data 2021, 7, 689–702. [Google Scholar] [CrossRef]
- Sundarapandi, G.P.; Bokhary, S.; Samanthula, B.K.; Dong, B. A Probabilistic Approach for Secure and Verifiable Computation of kNN Queries in Cloud. In Proceedings of the 2023 IEEE Cloud Summit, Baltimore, MD, USA, 6–7 July 2023; pp. 15–20. [Google Scholar] [CrossRef]
- Cui, N.; Qian, K.; Cai, T.; Li, J.; Yang, X.; Cui, J.; Zhong, H. Towards Multi-User, Secure, and Verifiable kNN Query in Cloud Database. IEEE Trans. Knowl. Data Eng. 2023, 35, 9333–9349. [Google Scholar] [CrossRef]
- Cui, N.; Yang, X.; Wang, B.; Li, J.; Wang, G. SVkNN: Efficient Secure and Verifiable k-Nearest Neighbor Query on the Cloud Platform. In Proceedings of the 2020 IEEE 36th International Conference on Data Engineering (ICDE), Dallas, TX, USA, 20–24 April 2020; pp. 253–264. [Google Scholar] [CrossRef]
- Oliveira, S.R.; Zaiane, O.R. Privacy preserving clustering by data transformation. J. Inf. Data Manag. 2010, 1, 37. [Google Scholar]
- Wong, W.K.; Cheung, D.W.l.; Kao, B.; Mamoulis, N. Secure kNN computation on encrypted databases. In Proceedings of the 2009 ACM SIGMOD International Conference on Management of Data, New York, NY, USA, 29 June–2 July 2009; SIGMOD ’09. pp. 139–152. [Google Scholar] [CrossRef]
- Hu, H.; Xu, J.; Ren, C.; Choi, B. Processing private queries over untrusted data cloud through privacy homomorphism. In Proceedings of the 2011 IEEE 27th International Conference on Data Engineering, Hannover, Germany, 11–16 April 2011; pp. 601–612. [Google Scholar] [CrossRef]
- Yao, B.; Li, F.; Xiao, X. Secure nearest neighbor revisited. In Proceedings of the 2013 IEEE 29th International Conference on Data Engineering (ICDE), Brisbane, QLD, Australia, 8–12 April 2013; pp. 733–744. [Google Scholar] [CrossRef]
- Choi, S.; Ghinita, G.; Lim, H.S.; Bertino, E. Secure kNN Query Processing in Untrusted Cloud Environments. IEEE Trans. Knowl. Data Eng. 2014, 26, 2818–2831. [Google Scholar] [CrossRef]
- Wang, B.; Hou, Y.; Li, M. QuickN: Practical and Secure Nearest Neighbor Search on Encrypted Large-Scale Data. IEEE Trans. Cloud Comput. 2022, 10, 2066–2078. [Google Scholar] [CrossRef]
- Popa, R.A.; Li, F.H.; Zeldovich, N. An Ideal-Security Protocol for Order-Preserving Encoding. In Proceedings of the 2013 IEEE Symposium on Security and Privacy, Berkeley, CA, USA, 19–22 May 2013; pp. 463–477. [Google Scholar] [CrossRef]
- Zhu, Y.; Xu, R.; Takagi, T. Secure k-NN computation on encrypted cloud data without sharing key with query users. In Proceedings of the 2013 International Workshop on Security in Cloud Computing, Hangzhou, China, 8 May 2013; Cloud Computing ’13. pp. 55–60. [Google Scholar] [CrossRef]
- Zhu, Y.; Huang, Z.; Takagi, T. Secure and controllable k-NN query over encrypted cloud data with key confidentiality. J. Parallel Distrib. Comput. 2016, 89, 1–12. [Google Scholar] [CrossRef]
- Lei, X.; Tu, G.H.; Liu, A.X.; Xie, T. Fast and Secure kNN Query Processing in Cloud Computing. In Proceedings of the 2020 IEEE Conference on Communications and Network Security (CNS), Avignon, France, 29 June–1 July 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Li, R.; Liu, A.X.; Xu, H.; Liu, Y.; Yuan, H. Adaptive Secure Nearest Neighbor Query Processing Over Encrypted Data. IEEE Trans. Dependable Secur. Comput. 2022, 19, 91–106. [Google Scholar] [CrossRef]
- Zheng, Y.; Lu, R.; Zhang, S.; Shao, J.; Zhu, H. Achieving Practical and Privacy-Preserving kNN Query over Encrypted Data. In IEEE Transactions on Dependable and Secure Computing; IEEE: Piscataway, NJ, USA, 2024; pp. 1–13. [Google Scholar] [CrossRef]
- Elmehdwi, Y.; Samanthula, B.K.; Jiang, W. Secure k-nearest neighbor query over encrypted data in outsourced environments. In Proceedings of the 2014 IEEE 30th International Conference on Data Engineering, Chicago, IL, USA, 31 March–4 April 2014; pp. 664–675. [Google Scholar] [CrossRef]
- Guan, Y.; Lu, R.; Zheng, Y.; Shao, J.; Wei, G. Toward Oblivious Location-Based k-Nearest Neighbor Query in Smart Cities. IEEE Internet Things J. 2021, 8, 14219–14231. [Google Scholar] [CrossRef]
- Yiu, M.L.; Lo, E.; Yung, D. Authentication of moving kNN queries. In Proceedings of the 2011 IEEE 27th International Conference on Data Engineering, Hannover, Germany, 11–16 April 2011; pp. 565–576. [Google Scholar] [CrossRef]
- Rong, H.; Wang, H.; Liu, J.; Wu, W.; Xian, M. Efficient Integrity Verification of Secure Outsourced kNN Computation in Cloud Environments. In Proceedings of the 2016 IEEE Trustcom/BigDataSE/ISPA, Tianjin, China, 23–26 August 2016; pp. 236–243. [Google Scholar] [CrossRef]
- Jiang, S.; Zhu, X.; Guo, L.; Liu, J. Publicly Verifiable Boolean Query Over Outsourced Encrypted Data. IEEE Trans. Cloud Comput. 2019, 7, 799–813. [Google Scholar] [CrossRef]
- Wu, S.; Li, Q.; Li, G.; Yuan, D.; Yuan, X.; Wang, C. ServeDB: Secure, Verifiable, and Efficient Range Queries on Outsourced Database. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering (ICDE), Macao, China, 8–11 April 2019; pp. 626–637. [Google Scholar] [CrossRef]
- Liu, X.; Deng, R.H.; Choo, K.K.R.; Weng, J. An Efficient Privacy-Preserving Outsourced Calculation Toolkit With Multiple Keys. IEEE Trans. Inf. Forensics Secur. 2016, 11, 2401–2414. [Google Scholar] [CrossRef]
- Yi, X.; Paulet, R.; Bertino, E.; Varadharajan, V. Practical Approximate k Nearest Neighbor Queries with Location and Query Privacy. IEEE Trans. Knowl. Data Eng. 2016, 28, 1546–1559. [Google Scholar] [CrossRef]
- Benabbas, S.; Gennaro, R.; Vahlis, Y. Verifiable Delegation of Computation over Large Datasets. In Proceedings of the Advances in Cryptology—CRYPTO 2011, Santa Barbara, CA, USA, 14–18 August 2011; Rogaway, P., Ed.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 111–131. [Google Scholar]
- Gennaro, R.; Gentry, C.; Parno, B. Non-interactive Verifiable Computing: Outsourcing Computation to Untrusted Workers. In Proceedings of the Advances in Cryptology—CRYPTO 2010, Santa Barbara, CA, USA, 15–19 August 2010; Rabin, T., Ed.; Springer: Berlin/Heidelberg, Germany, 2010; pp. 465–482. [Google Scholar]
- Parno, B.; Raykova, M.; Vaikuntanathan, V. How to delegate and verify in public: Verifiable computation from attribute-based encryption. In Proceedings of the 9th International Conference on Theory of Cryptography, Sicily, Italy, 19–21 March 2012; Springer: Berlin/Heidelberg, Germany, 2012. TCC’12. pp. 422–439. [Google Scholar] [CrossRef]
- Wang, Q.; Zhou, F.; Zhou, B.; Xu, J.; Chen, C.; Wang, Q. Privacy-Preserving Publicly Verifiable Databases. IEEE Trans. Dependable Secur. Comput. 2022, 19, 1639–1654. [Google Scholar] [CrossRef]
- Liu, J.; Zhang, L.F. Privacy-Preserving and Publicly Verifiable Matrix Multiplication. IEEE Trans. Serv. Comput. 2023, 16, 2059–2071. [Google Scholar] [CrossRef]
- Paillier, P. Public-Key Cryptosystems Based on Composite Degree Residuosity Classes. In Advances in Cryptology—EUROCRYPT ’99; Stern, J., Ed.; Springer: Berlin/Heidelberg, Germany, 1999; pp. 223–238. [Google Scholar]
- National Institute of Standards and Technology. FIPS-186–3 FIPS 186-3, Digital Signature Standard (DSS)-NIST CSRC. Available online: https://csrc.nist.gov/files/pubs/fips/186-3/final/docs/fips_186-3.pdf (accessed on 10 April 2025).
- Okabe, A.; Boots, B.; Sugihara, K. Spatial Tessellations: Concepts and Applications of Voronoi Diagrams; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 1992. [Google Scholar]
- Kolahdouzan, M.; Shahabi, C. Voronoi-based K nearest neighbor search for spatial network databases. In Proceedings of the Thirtieth International Conference on Very Large Data Bases-Volume 30. VLDB Endowment, 2004, VLDB ’04, Toronto, ON, Canada, 30 August–3 September 2004; pp. 840–851. [Google Scholar]
- Liu, A.; Zhengy, K.; Liz, L.; Liu, G.; Zhao, L.; Zhou, X. Efficient secure similarity computation on encrypted trajectory data. In Proceedings of the 2015 IEEE 31st International Conference on Data Engineering, Seoul, Republic of Korea, 13–17 April 2015; pp. 66–77. [Google Scholar] [CrossRef]
- Liu, J.; Yang, J.; Xiong, L.; Pei, J. Secure Skyline Queries on Cloud Platform. In Proceedings of the 2017 IEEE 33rd International Conference on Data Engineering (ICDE), San Diego, CA, USA, 19–22 April 2017; pp. 633–644. [Google Scholar] [CrossRef]
- Yao, A.C.C. How to generate and exchange secrets. In Proceedings of the 27th Annual Symposium on Foundations of Computer Science (focs 1986), Toronto, ON, Canada, 27–29 October 1986; pp. 162–167. [Google Scholar] [CrossRef]


| Scheme | Privacy | Verifiability | kNN | System Model | |||||
|---|---|---|---|---|---|---|---|---|---|
| Dataset | Query | Result | Access Patterns | Private | Public | Appro | Exact | ||
| Wong et al. [11] | × | × | × | × | × | × | × | ✓ | 1 server |
| Hu et al. [12] | × | × | × | × | × | × | × | ✓ | 1 server |
| Yao et al. [13] | ✓ | ✓ | ✓ | × | × | × | ✓ | × | 1 server |
| Choi et al. [14] | ✓ | ✓ | ✓ | × | × | × | × | ✓ | 1 server |
| Zhu et al. [17,18] | ✓ | ✓ | ✓ | × | × | × | × | ✓ | 1 server |
| Yi [29] | ✓ | ✓ | ✓ | × | × | × | ✓ | × | 1 server |
| Lei et al. [2] | ✓ | ✓ | ✓ | × | × | × | ✓ | × | 1 server |
| Lei et al. [19] | ✓ | ✓ | ✓ | × | × | × | × | ✓ | 1 server |
| Li et al. [20] | ✓ | ✓ | ✓ | × | × | × | × | ✓ | 1 server |
| Zheng et al. [21] | ✓ | ✓ | ✓ | × | × | × | × | ✓ | 1 server |
| Elmehdwi et al. [22] | ✓ | ✓ | ✓ | ✓ | × | × | × | ✓ | 2 servers |
| Guan et al. [23] | ✓ | ✓ | ✓ | ✓ | × | × | × | ✓ | 2 servers |
| Qi et al. [5] | ✓ | ✓ | ✓ | × | × | × | × | ✓ | 2 servers |
| Yiu et al. [24] | × | × | × | × | ✓ | × | × | ✓ | 1 server |
| Rong et al. [25] | × | ✓ | ✓ | × | ✓★ | × | × | ✓ | 2 servers |
| Sundarapandi et al. [7] | ✓ | ✓ | ✓ | ✓ | ✓★ | × | × | ✓ | 2 servers |
| Liu et al. [3] | ✓ | ✓ | ✓ | × | ✓ | × | × | ✓ | 3 servers (2 clouds + 1 edge) |
| Zhang et al. [4] | ✓ | ✓ | ✓ | ✓ | ✓★★ | × | × | ✓ | 2 servers + 1 KGC |
| Cui et al. [9] | ✓ | ✓ | ✓ | ✓ | ✓ | × | × | ✓ | 2 servers |
| Cui et al. [8] | ✓ | ✓ | ✓ | ✓ | ✓ | × | × | ✓ | 2 servers + 1 CA |
| Ours | ✓ | ✓ | ✓ | ✓ | × | ✓ | × | ✓ | 2 servers |
| Notation | Description |
|---|---|
| a permutation function | |
| the plaintext spatial dataset | |
| the ciphertext spatial dataset | |
| the least common multiple of two integers a and b | |
| Q | is the query data point |
| the index of the jth nearest neighbor to Q | |
| denotes the jth | |
| nearest neighbor to Q | |
| the set of Voronoi-relevant vectors of | |
| a cryptographic hash function | |
| a DSA signature | |
| N | a large integer that is the product of two |
| prime numbers p and q | |
| the multiplicative group of the residue | |
| class modulo | |
| the residue class ring modulo N | |
| the concatenation of two numbers x and y | |
| the greatest integer no larger than x | |
| the set | |
| the set | |
| a negligible function of some input parameter |
| Entities | |||
|---|---|---|---|
| Algorithm | |||
| Algorithm 1 | |||
| Algorithm 2 | |||
| Algorithm 3 | |||
| Algorithm 4 | |||
| Algorithm 5 | |||
| Entities | QU | QU | |||
|---|---|---|---|---|---|
| Algorithm | |||||
| Algorithm 1 | |||||
| Algorithm 2 | − | − | |||
| Algorithm 3 | − | − | |||
| Algorithm 4 | − | − | |||
| Algorithm 5 | − | − | |||
| Protocol | Cui et al.’s Protocol [8] | Our Protocol | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Stages | |||||||||||
| Entities | |||||||||||
| − | − | − | − | − | − | − | |||||
| − | − | − | − | − | − | − | − | ||||
| − | − | − | − | − | − | − | − | ||||
| − | − | − | − | − | − | ||||||
| Protocol | Cui et al.’s Protocol [8] | Our Protocol | |||||
|---|---|---|---|---|---|---|---|
| Stages | |||||||
| Entities | |||||||
| − | − | − | − | − | |||
| − | − | − | − | − | |||
| − | − | − | − | − | |||
| − | − | − | − | − | |||
| − | − | − | − | ||||
| − | − | − | − | − | |||
| − | − | − | − | ||||
| − | − | − | − | ||||
| − | − | − | − | ||||
| − | − | − | − | ||||
| − | − | − | − | − | |||
| Protocol | Cui et al.’s Protocol [8] | Our Protocol | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Dataset Size | 1000 | 5000 | 10,000 | 20,000 | 1000 | 5000 | 10,000 | 20,000 | |
| Stages | |||||||||
| and | |||||||||
| Protocol | Cui et al.’s Protocol [8] | Our Protocol | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Grid Granularity | 4 | 8 | 12 | 16 | 32 | 64 | 4 | 8 | 12 | 16 | 32 | 64 | |
| Stages | |||||||||||||
| 1.009 | 1.188 | 1.462 | 1.692 | 1.914 | 1.687 | 0.291 | 0.285 | 0.240 | 0.207 | 0.463 | 0.871 | ||
| 181.751 | 182.137 | 184.899 | 172.719 | 218.232 | 225.192 | 86.298 | 85.202 | 90.337 | 92.901 | 103.423 | 115.173 | ||
| 0.057 | 0.058 | 0.056 | 0.056 | 0.058 | 0.055 | 0.023 | 0.022 | 0.023 | 0.023 | 0.023 | 0.024 | ||
| 114.947 | 102.155 | 110.785 | 120.766 | 133.233 | 137.680 | 11.147 | 10.255 | 10.811 | 11.175 | 11.708 | 12.942 | ||
| and | 0.243 | 0.221 | 0.230 | 0.205 | 0.277 | 0.251 | 0.004 | 0.004 | 0.005 | 0.004 | 0.005 | 0.005 | |
| Protocol | Cui et al.’s Protocol [8] | Our Protocol | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Query Parameter | 1 | 3 | 5 | 7 | 9 | 1 | 3 | 5 | 7 | 9 | |
| Stages | |||||||||||
| 1.317 | 1.402 | 1.692 | 1.566 | 1.477 | 0.286 | 0.256 | 0.317 | 0.279 | 0.263 | ||
| 180.479 | 185.852 | 186.317 | 178.708 | 183.617 | 89.623 | 88.044 | 92.901 | 91.075 | 92.367 | ||
| 0.057 | 0.058 | 0.056 | 0.057 | 0.057 | 0.023 | 0.022 | 0.023 | 0.022 | 0.023 | ||
| 37.263 | 70.774 | 120.766 | 201.474 | 261.221 | 2.827 | 6.855 | 11.175 | 16.411 | 21.933 | ||
| and | 0.031 | 0.094 | 0.205 | 0.258 | 0.322 | 0.002 | 0.003 | 0.004 | 0.008 | 0.013 | |
| Protocol | Cui et al.’s Protocol [8] | Our Protocol | |||||
|---|---|---|---|---|---|---|---|
| Key Size | 512 | 1024 | 2048 | 512 | 1024 | 2048 | |
| Stages | |||||||
| and | |||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, J.; Song, Y.; Tian, C.; Tian, W. PVkNN: A Publicly Verifiable and Privacy-Preserving Exact kNN Query Scheme for Cloud-Based Location Services. Modelling 2025, 6, 44. https://doi.org/10.3390/modelling6020044
Li J, Song Y, Tian C, Tian W. PVkNN: A Publicly Verifiable and Privacy-Preserving Exact kNN Query Scheme for Cloud-Based Location Services. Modelling. 2025; 6(2):44. https://doi.org/10.3390/modelling6020044
Chicago/Turabian StyleLi, Jingyi, Yuqi Song, Chengliang Tian, and Weizhong Tian. 2025. "PVkNN: A Publicly Verifiable and Privacy-Preserving Exact kNN Query Scheme for Cloud-Based Location Services" Modelling 6, no. 2: 44. https://doi.org/10.3390/modelling6020044
APA StyleLi, J., Song, Y., Tian, C., & Tian, W. (2025). PVkNN: A Publicly Verifiable and Privacy-Preserving Exact kNN Query Scheme for Cloud-Based Location Services. Modelling, 6(2), 44. https://doi.org/10.3390/modelling6020044