
Human Action Recognition from Videos Using Motion History Mapping and Orientation Based Three-Dimensional Convolutional Neural Network Approach

Abstract
1. Introduction
- In this paper, we have proposed a novel Motion History Mapping and Orientation-based Convolutional Neural Network (CNN) framework for Human Activity Recognition and classification using Machine Learning.
- A KNN-based classification technique is introduced to classify human activities.
- The exposure frames were trained with the Orientation-based 3D Convolutional Neural Network (CNN) model, thus increasing the Classification Correction Rate (CCR).
- This model has used four publicly available and challenging datasets containing movements of human activities.
- The proposed technique outperforms existing techniques used on the four publicly available and challenging datasets, in terms of higher precision and CCR. Therefore, it can be very advantageous for several accuracy-centric applications.
- The proposed model is also computationally efficient.
- Our model performs well even on low-resolution datasets such as UT-Tower, unlike the MediaPipe approach, which is generally not preferable for dark, blurry and noisy low-quality video datasets such as UT-Tower.
Paper Organization
2. Literature Review
- (i)
- 2D Feature Extraction Models
- (ii)
- 3D Feature Extraction Models
3. Proposed Methodology
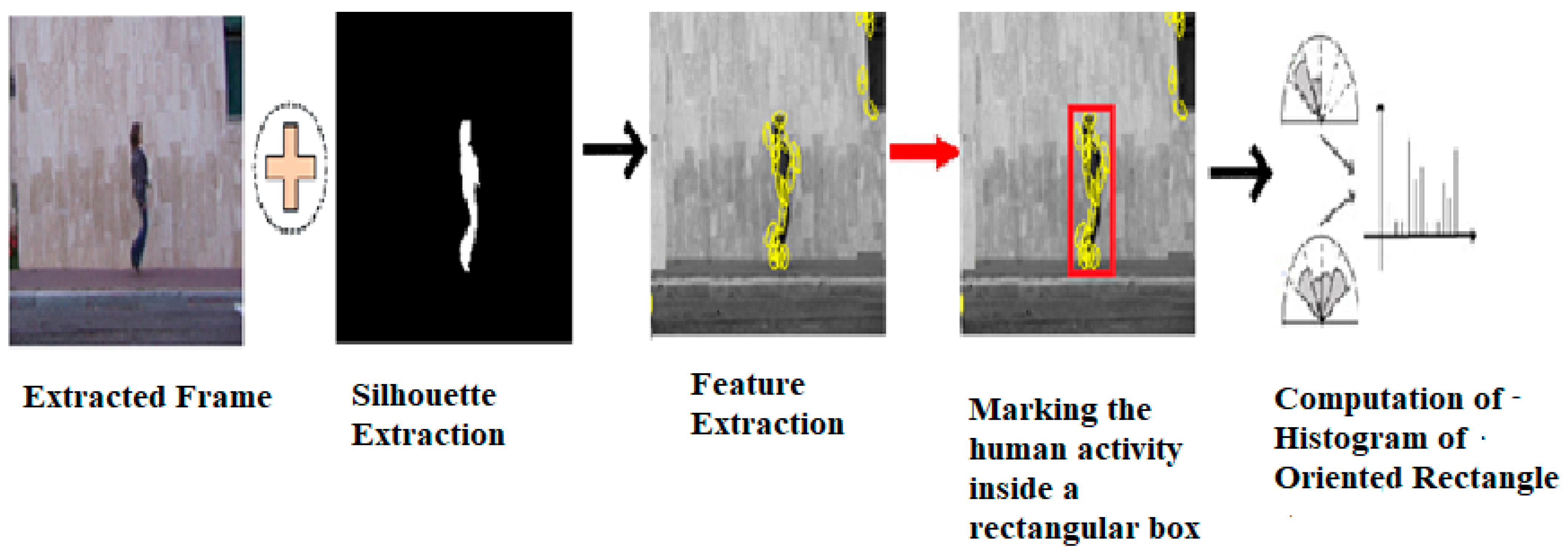
3.1. Rectangle Extraction
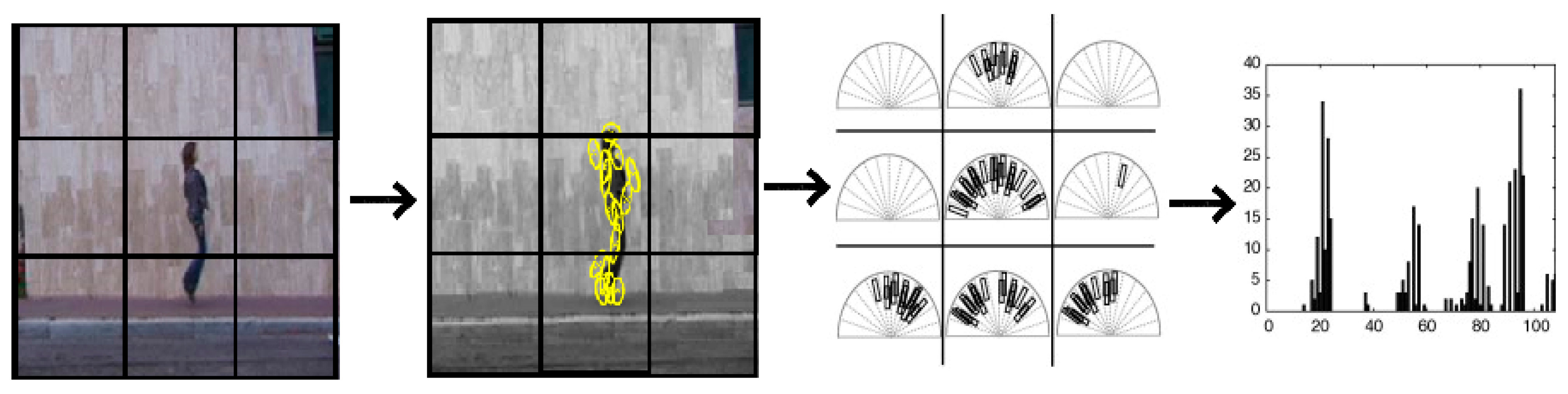
3.2. Histograms of Oriented Rectangles (HORs)—Pose Descriptor
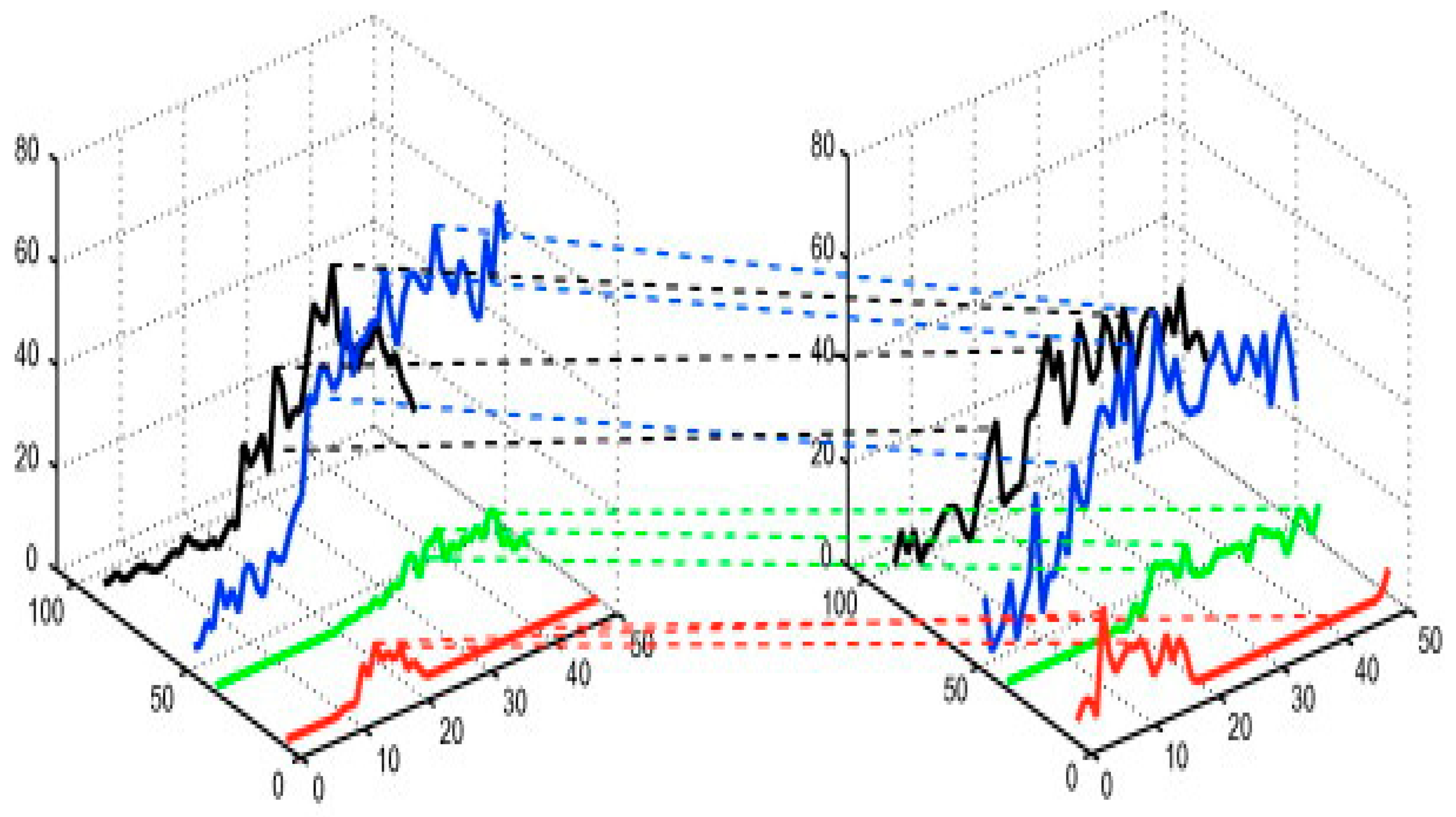
3.3. Capturing Local Dynamics
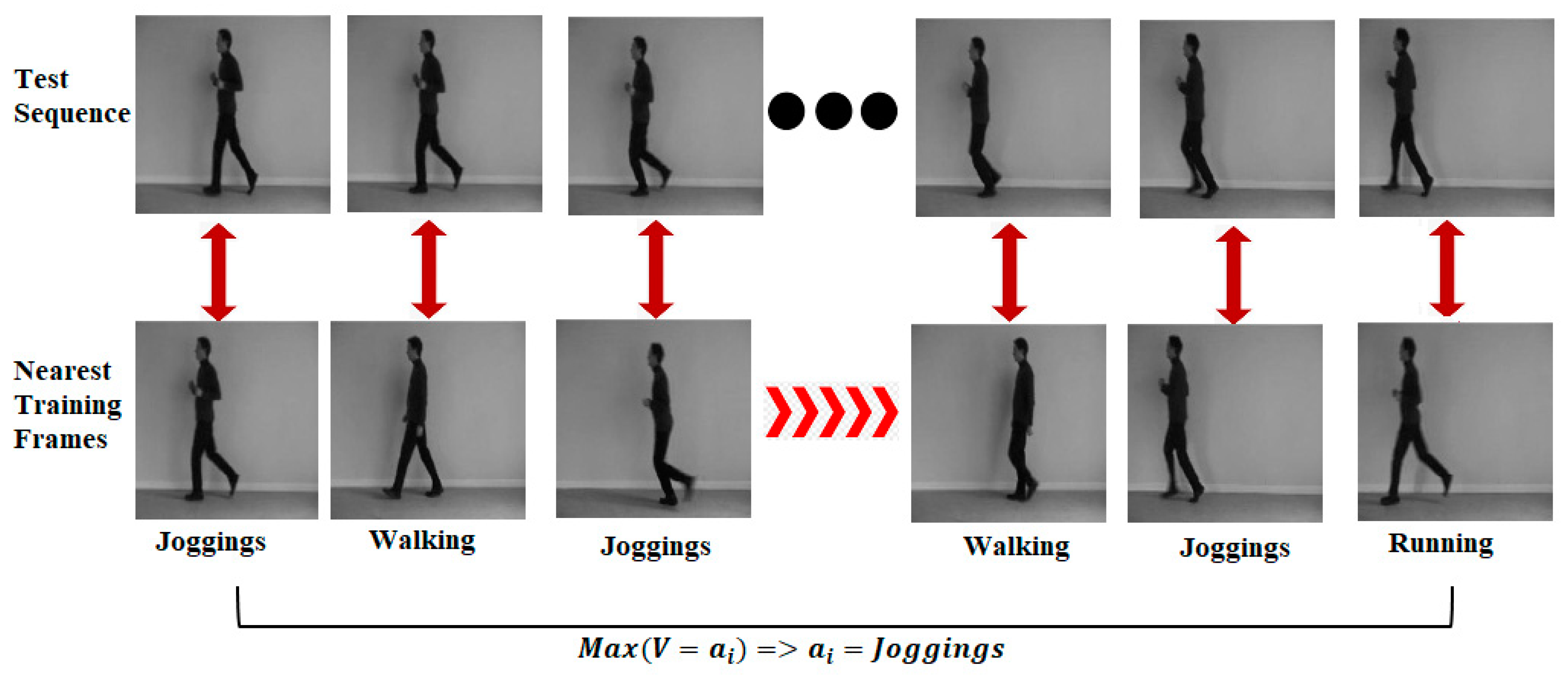
3.4. Train and Test Model
- Max-pooling Operator
- Full Connection Layer
3.5. Oriented Rectangle Histograms: Recognizing Activities
4. Experiments and Results Analysis
4.1. Datasets Used
4.2. Performance Evaluation Metrics
| TP | FN |
| FP | TN |
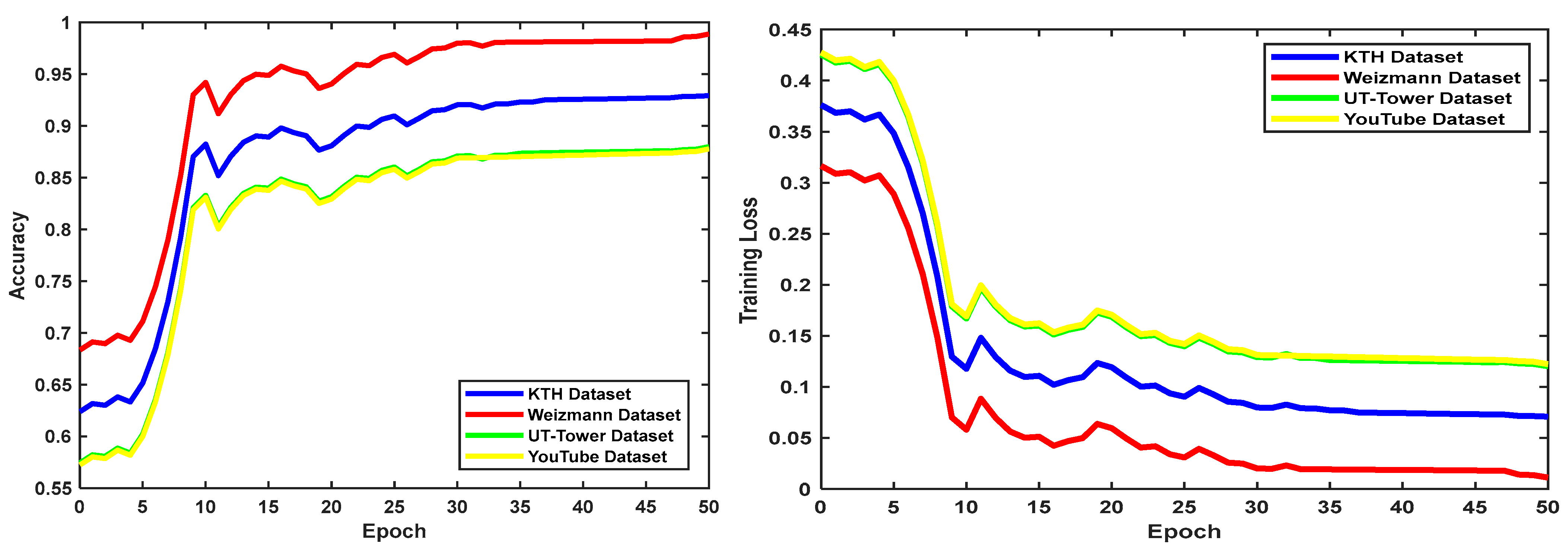
4.3. Result Analysis and Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, A.; Wu, Q.; Cui, R.; Wang, T.; Hang, W.; Hua, G.; Snoussi, H. Exploring a rich spatial–temporal dependent relational model for skeleton-based action recognition by bidirectional LSTM-CNN. Neurocomputing 2020, 414, 90–100. [Google Scholar] [CrossRef]
- Zhao, B.; Gong, M.; Li, X. Hierarchical multimodal transformer to summarize videos. Neurocomputing 2022, 468, 360–369. [Google Scholar] [CrossRef]
- Chang, Z.; Ban, X.; Shen, Q.; Guo, J. Research on Three-dimensional Motion History Image Model and Extreme Learning Machine for Human Body Movement Trajectory Recognition. Math. Probl. Eng. 2015, 2015, 528190. [Google Scholar] [CrossRef]
- Kanazawa, A.; Zhang, J.Y.; Felsen, P.; Malik, J. Learning 3D Human Dynamics From Video. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 5607–5616. [Google Scholar]
- Çalışkan, A. Detecting human activity types from 3D posture data using deep learning models. Biomed. Signal Process. Control. 2023, 81, 104479. [Google Scholar] [CrossRef]
- Luo, J.; Wang, W.; Qi, H. Spatio-temporal feature extraction and representation for RGB-D human action recognition. Pattern Recognit. Lett. 2014, 50, 139–148. [Google Scholar] [CrossRef]
- Hu, G.; Cui, B.; Yu, S. Joint Learning in the Spatio-Temporal and Frequency Domains for Skeleton-Based Action Recognition. IEEE Trans. Multimed. 2020, 22, 2207–2220. [Google Scholar] [CrossRef]
- Wang, B.; Ye, M.; Li, X.; Zhao, F.; Ding, J. Abnormal crowd behavior detection using high-frequency and spatio-temporal features. Mach. Vis. Appl. 2012, 23, 501–511. [Google Scholar] [CrossRef]
- Péteri, R.; Chetverikov, D. Dynamic Texture Recognition Using Normal Flow and Texture Regularity. In Pattern Recognition and Image Analysis; Marques, J.S., Pérez de la Blanca, N., Pina, P., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2005; Volume 3523, pp. 223–230. [Google Scholar] [CrossRef]
- Banerjee, T.; Keller, J.M.; Skubic, M.; Stone, E. Day or Night Activity Recognition From Video Using Fuzzy Clustering Techniques. IEEE Trans. Fuzzy Syst. 2014, 22, 483–493. [Google Scholar] [CrossRef]
- Yan, Y.; Ricci, E.; Liu, G.; Sebe, N. Egocentric Daily Activity Recognition via Multitask Clustering. IEEE Trans. Image Process. 2015, 24, 2984–2995. [Google Scholar] [CrossRef]
- Lin, W.; Chu, H.; Wu, J.; Sheng, B.; Chen, Z. A Heat-Map-Based Algorithm for Recognizing Group Activities in Videos. IEEE Trans. Circuits Syst. Video Technol. 2013, 23, 1980–1992. [Google Scholar] [CrossRef]
- Chen, D.-Y.; Huang, P.-C. Motion-based unusual event detection in human crowds. J. Vis. Commun. Image Represent. 2011, 22, 178–186. [Google Scholar] [CrossRef]
- Liu, C.; Yuen, P.C.; Qiu, G. Object motion detection using information theoretic spatio-temporal saliency. Pattern Recognit. 2009, 42, 2897–2906. [Google Scholar] [CrossRef]
- Tanberk, S.; Kilimci, Z.H.; Tukel, D.B.; Uysal, M.; Akyokus, S. A Hybrid Deep Model Using Deep Learning and Dense Optical Flow Approaches for Human Activity Recognition. IEEE Access 2020, 8, 19799–19809. [Google Scholar] [CrossRef]
- Cho, J.; Lee, M.; Chang, H.J.; Oh, S. Robust action recognition using local motion and group sparsity. Pattern Recognit. 2014, 47, 1813–1825. [Google Scholar] [CrossRef]
- Yamato, J.; Ohya, J.; Ishii, K. Recognizing human action in time-sequential images using hidden Markov model. In Proceedings of the 1992 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Champaign, IL, USA, 15–18 June 1992. [Google Scholar] [CrossRef]
- Bobick, A.; Davis, J. The recognition of human movement using temporal templates. IEEE Trans. Pattern Anal. Mach. Intell. 2001, 23, 257–267. [Google Scholar] [CrossRef]
- Niebles, J.C.; Wang, H.; Fei-Fei, L. Unsupervised Learning of Human Action Categories Using Spatial-Temporal Words. Int. J. Comput. Vis. 2008, 79, 299–318. [Google Scholar] [CrossRef]
- Seo, H.J.; Milanfar, P. Action Recognition from One Example. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 867–882. [Google Scholar] [CrossRef]
- Suk, H.-I.; Jain, A.K.; Lee, S.-W. A Network of Dynamic Probabilistic Models for Human Interaction Analysis. IEEE Trans. Circuits Syst. Video Technol. 2011, 21, 932–945. [Google Scholar] [CrossRef]
- Turaga, P.; Chellappa, R.; Subrahmanian, V.S.; Udrea, O. Machine Recognition of Human Activities: A Survey. IEEE Trans. Circuits Syst. Video Technol. 2008, 18, 1473–1488. [Google Scholar] [CrossRef]
- Hu, W.; Xie, N.; Li, L.; Zeng, X.; Maybank, S. A Survey on Visual Content-Based Video Indexing and Retrieval. IEEE Trans. Syst. Man Cybern. Part C Appl. Rev. 2011, 41, 797–819. [Google Scholar] [CrossRef]
- Fazli, M.; Kowsari, K.; Gharavi, E.; Barnes, L.; Doryab, A. HHAR-net: Hierarchical Human Activity Recognition using Neural Networks. In Intelligent Human Computer Interaction—IHCI 2020; Springer: Cham, Switzerland, 2020; pp. 48–58. [Google Scholar] [CrossRef]
- Ferrari, A.; Micucci, D.; Mobilio, M.; Napoletano, P. On the Personalization of Classification Models for Human Activity Recognition. IEEE Access 2020, 8, 32066–32079. [Google Scholar] [CrossRef]
- Jaouedi, N.; Boujnah, N.; Bouhlel, M.S. A new hybrid deep learning model for human action recognition. J. King Saud Univ. Comput. Inf. Sci. 2020, 32, 447–453. [Google Scholar] [CrossRef]
- Andrade-Ambriz, Y.A.; Ledesma, S.; Ibarra-Manzano, M.-A.; Oros-Flores, M.I.; Almanza-Ojeda, D.-L. Human activity recognition using temporal convolutional neural network architecture. Expert Syst. Appl. 2022, 191, 116287. [Google Scholar] [CrossRef]
- Khan, I.U.; Afzal, S.; Lee, J.W. Human Activity Recognition via Hybrid Deep Learning Based Model. Sensors 2022, 22, 323. [Google Scholar] [CrossRef]
- Xu, Y.; Qiu, T.T. Human Activity Recognition and Embedded Application Based on Convolutional Neural Network. J. Artif. Intell. Technol. 2021, 1, 51–60. [Google Scholar] [CrossRef]
- Ji, S.; Xu, W.; Yang, M.; Yu, K. 3D Convolutional Neural Networks for Human Action Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 221–231. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.-W. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Lin, C.-M.; Tsai, C.-Y.; Lai, Y.-C.; Li, S.-A.; Wong, C.-C. Visual Object Recognition and Pose Estimation Based on a Deep Semantic Segmentation Network. IEEE Sens. J. 2018, 18, 9370–9381. [Google Scholar] [CrossRef]
- Young, T.; Hazarika, D.; Poria, S.; Cambria, E. Recent Trends in Deep Learning Based Natural Language Processing. IEEE Comput. Intell. Mag. 2018, 13, 55–75. [Google Scholar] [CrossRef]
- Xue, H.; Liu, Y.; Cai, D.; He, X. Tracking people in RGBD videos using deep learning and motion clues. Neurocomputing 2016, 204, 70–76. [Google Scholar] [CrossRef]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Wang, W.; Zhou, T.; Porikli, F.; Crandall, D.; Van Gool, L. A survey on deep learning technique for video segmentation. arXiv 2021, arXiv:210701153. [Google Scholar]
- Tian, C.; Fei, L.; Zheng, W.; Xu, Y.; Zuo, W.; Lin, C.-W. Deep learning on image denoising: An overview. Neural Netw. 2020, 131, 251–275. [Google Scholar] [CrossRef]
- Yu, S.; Ma, J.; Wang, W. Deep learning for denoising. Geophysics 2019, 84, V333–V350. [Google Scholar] [CrossRef]
- Soleimani, E.; Nazerfard, E. Cross-subject transfer learning in human activity recognition systems using generative adversarial networks. Neurocomputing 2021, 426, 26–34. [Google Scholar] [CrossRef]
- Dollár, P.; Rabaud, V.; Cottrell, G.; Belongie, S. Behavior recognition via sparse spatio-temporal features. In Proceedings of the 2005 IEEE International Workshop on Visual Surveillance and Performance Evaluation of Tracking and Surveillance, Beijing, China, 15–16 October 2005; IEEE: Piscataway, NJ, USA, 2005; pp. 65–72. [Google Scholar]
- Rapantzikos, K.; Avrithis, Y.; Kollias, S. Dense saliency-based spatiotemporal feature points for action recognition. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1454–1461. [Google Scholar]
- Cao, L.; Liu, Z.; Huang, T.S. Cross-dataset action detection. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1998–2005. [Google Scholar]
- Li, C.; Zhang, B.; Chen, C.; Ye, Q.; Han, J.; Guo, G.; Ji, R. Deep Manifold Structure Transfer for Action Recognition. IEEE Trans. Image Process. 2019, 28, 4646–4658. [Google Scholar] [CrossRef]
- Zhang, J.; Shum, H.P.H.; Han, J.; Shao, L. Action Recognition From Arbitrary Views Using Transferable Dictionary Learning. IEEE Trans. Image Process. 2018, 27, 4709–4723. [Google Scholar] [CrossRef]
- Zhang, B.; Yang, Y.; Chen, C.; Yang, L.; Han, J.; Shao, L. Action Recognition Using 3D Histograms of Texture and a Multi-Class Boosting Classifier. IEEE Trans. Image Process. 2017, 26, 4648–4660. [Google Scholar] [CrossRef]
- Poppe, R. A survey on vision-based human action recognition. Image Vis. Comput. 2010, 28, 976–990. [Google Scholar] [CrossRef]
- Rogez, G.; Weinzaepfel, P.; Schmid, C. LCR-Net: Localization-ClassificationRegression for Human Pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3433–3441. [Google Scholar]
- Zhou, X.; Huang, Q.; Sun, X.; Xue, X.; Wei, Y. Towards 3D Human Pose Estimation in the wild: A weakly-supervised approach. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 398–407. [Google Scholar]
- Katircioglu, I.; Tekin, B.; Salzmann, M.; Lepetit, V.; Fua, P. Learning Latent Representations of 3D Human Pose with Deep Neural Networks. Int. J. Comput. Vis. 2018, 126, 1326–1341. [Google Scholar] [CrossRef]
- Kibet, D.; So, M.S.; Kang, H.; Han, Y.; Shin, J.-H. Sudden Fall Detection of Human Body Using Transformer Model. Sensors 2024, 24, 8051. [Google Scholar] [CrossRef] [PubMed]
- Guo, Z.; Lu, M.; Han, J. Temporal Graph Attention Network for Spatio-Temporal Feature Extraction in Research Topic Trend Prediction. Mathematics 2025, 13, 686. [Google Scholar] [CrossRef]
- Tsai, J.-K.; Hsu, C.-C.; Wang, W.-Y.; Huang, S.-K. Deep Learning-Based Real-Time Multiple-Person Action Recognition System. Sensors 2020, 20, 4758. [Google Scholar] [CrossRef]
- Gopalakrishnan, T.; Wason, N.; Krishna, R.J.; Krishnaraj, N. Comparative Analysis of Fine-Tuning I3D and SlowFast Networks for Action Recognition in Surveillance Videos. Eng. Proc. 2023, 59, 203. [Google Scholar]
- Vishwakarma, D.; Kapoor, R. Hybrid classifier based human activity recognition using the silhouette and cells. Expert Syst. Appl. 2015, 42, 6957–6965. [Google Scholar] [CrossRef]
- Yang, J.; Nguyen, M.N.; San, P.P.; Li, X.; Krishnaswamy, S. Deep convolutional neural networks on multichannel time series for human activity recognition. In Proceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 3995–4001. [Google Scholar]
- Wang, A.; Chen, G.; Yang, J.; Zhao, S.; Chang, C.-Y. A Comparative Study on Human Activity Recognition Using Inertial Sensors in a Smartphone. IEEE Sens. J. 2016, 16, 4566–4578. [Google Scholar] [CrossRef]
- Vishwakarma, D.K.; Singh, K. Human Activity Recognition Based on Spatial Distribution of Gradients at Sublevels of Average Energy Silhouette Images. IEEE Trans. Cogn. Dev. Syst. 2017, 9, 316–327. [Google Scholar] [CrossRef]
- Inoue, M.; Inoue, S.; Nishida, T. Deep recurrent neural network for mobile human activity recognition with high throughput. Artif. Life Robot. 2018, 23, 173–185. [Google Scholar] [CrossRef]
- Phyo, C.N.; Zin, T.T.; Tin, P. Deep Learning for Recognizing Human Activities Using Motions of Skeletal Joints. IEEE Trans. Consum. Electron. 2019, 65, 243–252. [Google Scholar] [CrossRef]
- Zhu, R.; Xiao, Z.; Li, Y.; Yang, M.; Tan, Y.; Zhou, L.; Lin, S.; Wen, H. Efficient Human Activity Recognition Solving the Confusing Activities Via Deep Ensemble Learning. IEEE Access 2019, 7, 75490–75499. [Google Scholar] [CrossRef]
- Dua, N.; Singh, S.N.; Semwal, V.B. Multi-input CNN-GRU based human activity recognition using wearable sensors. Computing 2021, 103, 1461–1478. [Google Scholar] [CrossRef]
- Rahayu, E.S.; Yuniarno, E.M.; Purnama, I.K.E.; Purnomo, M.H. A Combination Model of Shifting Joint Angle Changes with 3D-Deep Convolutional Neural Network to Recognize Human Activity. IEEE Trans. Neural Syst. Rehabil. Eng. 2024, 32, 1078–1089. [Google Scholar] [CrossRef]
- Song, Z.; Zhao, P.; Wu, X.; Yang, R.; Gao, X. An Active Control Method for a Lower Limb Rehabilitation Robot with Human Motion Intention Recognition. Sensors 2025, 25, 713. [Google Scholar] [CrossRef]
- Bsoul, A.A.R.K. Human Activity Recognition Using Graph Structures and Deep Neural Networks. Computers 2024, 14, 9. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Vrigkas, M.; Nikou, C.; Kakadiaris, I.A. A Review of Human Activity Recognition Methods. Front. Robot. AI 2015, 2, 28. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Yu, K.; Lin, Y.; Lafferty, J. Learning image representations from the pixel level via hierarchical sparse coding. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 1713–1720. [Google Scholar]
- Leung, T.; Malik, J. Representing and Recognizing the Visual Appearance of Materials using Three-dimensional Textons. Int. J. Comput. Vis. 2001, 43, 29–44. [Google Scholar] [CrossRef]
- Rubner, Y.; Tomasi, C.; Guibas, L.J. The Earth Mover’s Distance as a Metric for Image Retrieval. Int. J. Comput. Vis. 2000, 40, 99–121. [Google Scholar] [CrossRef]
- Ling, H.; Okada, K. Diffusion Distance for Histogram Comparison. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition—Volume 1 (CVPR’06), New York, NY, USA, 17–22 June 2006; IEEE: Piscataway, NJ, USA, 2006; pp. 246–253. [Google Scholar]
- Paramasivam, K.; Sindha, M.M.R.; Balakrishnan, S.B. KNN-Based Machine Learning Classifier Used on Deep Learned Spatial Motion Features for Human Action Recognition. Entropy 2023, 25, 844. [Google Scholar] [CrossRef] [PubMed]
- Ikizler, N.; Duygulu, P. Histogram of oriented rectangles: A new pose descriptor for human action recognition. Image Vis. Comput. 2009, 27, 1515–1526. [Google Scholar] [CrossRef]
- Gorelick, L.; Blank, M.; Shechtman, E.; Irani, M.; Basri, R. Actions as Space-Time Shapes. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 2247–2253. [Google Scholar] [CrossRef] [PubMed]
- Schuldt, C.; Laptev, I.; Caputo, B. Recognizing human actions: A local SVM approach. In Proceedings of the International Conference on Pattern Recognition, Cambridge, UK, 23–26 August 2004; IEEE: Piscataway, NJ, USA, 2004; Volume 3, pp. 32–36. [Google Scholar]
- Ryoo, M.S.; Chen, C.C.; Aggarwal, J.K.; Roy-Chowdhury, A. An Overview of Contest on Semantic Description of Human Activities (SDHA) 2010; ICPR 2010. Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6388. [Google Scholar] [CrossRef]
- Liu, J.; Luo, J.; Shah, M. Recognizing realistic actions from videos ‘in the wild’. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1996–2003. [Google Scholar]
- Guo, K.; Ishwar, P.; Konrad, J. Action Recognition From Video Using Feature Covariance Matrices. IEEE Trans. Image Process. 2013, 22, 2479–2494. [Google Scholar] [CrossRef]
- Wong, S.-F.; Cipolla, R. Extracting Spatiotemporal Interest Points using Global Information. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 1–8. [Google Scholar]
- Ali, S.; Shah, M. Human Action Recognition in Videos Using Kinematic Features and Multiple Instance Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2008, 32, 288–303. [Google Scholar] [CrossRef]
- Ikizler-Cinbis, N.; Sclaroff, S. Object, scene and actions: Combining multiple features for human action recognition. In Proceedings of the Computer Vision–ECCV 2010: 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010; Proceedings, Part I 11. Springer: Berlin/Heidelberg, Germany, 2010; pp. 494–507. [Google Scholar]
- Le, Q.; Zou, W.; Yeung, S.; Ng, A. Learning hierarchical invariant spatio-temporal features for action recognition with independent subspace analysis. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; IEEE: Piscataway, NJ, USA, 2011. [Google Scholar] [CrossRef]
- Wang, H.; Klaser, A.; Schmid, C.; Liu, C.-L. Action recognition by dense trajectories. In Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 3169–3176. [Google Scholar]
- Noguchi, A.; Yanai, K. A surf-based spatio-temporal feature for feature-fusion-based action recognition. In Proceedings of the Trends and Topics in Computer Vision: ECCV 2010 Workshops, Heraklion, Crete, Greece, 10–11 September 2010; Revised Selected Papers, Part I 11. Springer: Berlin/Heidelberg, Germany, 2012; pp. 153–167. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors | Dataset Used | Objectives and Proposed Method | Performance |
|---|---|---|---|
| [55] | Weizmann, Ballet and KTH | The author proposed a new method of recognizing human activity in a video sequence using critical poses of the human. silhouettes using Support Vector Machine (SVM)-Neural Network (NN) with Principal Component Analysis (PCA). | Overall accuracy: 96.70% |
| [56] | Opportunity activity recognition and hand gesture | Deep Convolutional Neural Networks (CNNs) automate feature learning from raw data. | Average Accuracy: 92.11% |
| [57] | Triaxial gyroscope and accelerometer | An approach to select discriminant features to construct a better generalizable online activity. recognizer was presented for smart phone-based HAR system. | Accuracy: 84.3% Precision: 84.5 and F1 Score: 84.3% |
| [58] | Weizmann, Ballet and KTH | The AESI, SDP, and modified SDG evidence were combined with motion evidence to. recognize human activity according to a new framework i.e., SVM-KNN with PCA. | Accuracy: 95.83% |
| [59] | HASC corpus | A Deep Recurrent Neural Network (DRNN) recognizes human activity with high throughput. | Accuracy: 95.42% |
| [60] | UTKinect Action-3D and CAD-60 | Human daily activities can be recognized by tracking skeletal joint movements using a depth sensor. | Accuracy: 97.00% |
| [61] | Opportunity, Skoda and Actitracker | CNN ensembles have been proposed to resolve the confusion between walking and going upstairs, two highly similar activities. CNN (two variants, CNN-2 and CNN-7) were proposed for recognizing human activities. | Accuracy: 96.11% |
| [62] | UCI-HAR, PAMAP2 and, WISDM | An end-to-end model using CNN and Gated Recurrent Units (GRUs) is proposed that performs automated feature extraction and activity classification. | Accuracy: 96.20%, 95.27% and 97.21% |
| [63] | UTKinect Action3D dataset | The joint angle shift method is combined with a Deep Convolutional Neural Network (DCNN) model to classify 3D datasets encompassing spatial–temporal information from RGB-D video image data. | Accuracy: 96.72% |
| [64] | Conducted real-life experiments of activities. | A muscle–machine interface is constructed using a Bi-Directional Long Short-Term Memory (BiLSTM) network, which decodes multichannel Surface Electromyography (sEMG) signals into flexion and extension angles of the hip and knee joints in the sagittal plane. | Accuracy: 92.8% |
| [65] | UCF 101 and Kinetics-400 dataset | Firefly Optimization Algorithm is applied to fine-tune the hyper parameters of both the graph-based model and a CNN baseline for comparison. | Accuracy: 88.9% |
| Layer Name | Stride | Input Dimension | Output Dimension | Filter Size | Parameter Size | Activation Function | Filter/Kernel Size |
|---|---|---|---|---|---|---|---|
| Conv 3D Layer1 | (1,1,1) | (16,64,64,1) | (14,62,62,20) | (3,3,3) | 560 | ReLu Activation | Convolution layer with 20 filters. |
| Max Pooling 3D Layer1 | (2,2,2) | (14,62,62,20) | (6,30,30,20) | - | - | Max pooling with 3 × 3 Kernel. | |
| Conv 3D Layer2 | (1,1,1) | (6,30,30,20) | (4,28,28,20) | (3,3,3) | 5420 | ReLu Activation | Second convolution layer with 20 filters. |
| Max Pooling 3D Layer2 | (2,2,2) | (4,28,28,20) | (1,13,13,20) | - | - | Max pooling to reduce the spatial dimensions further. | |
| Flatten Layer | - | (1,13,13,20) | (1,3380) | (3,3,3) | - | - | To flatten the output for the fully connected layers. |
| Fully Connected Layer1 | (1,3380) | 512 | (3,3,3) | 172,352 | ReLu Activation | Fully connected layer 1 with 512 neurons. | |
| Fully Connected Layer2 | 512 | 128 | 65,664 | ReLu Activation | Fully connected layer 2 with 128 neurons. | ||
| Output Layer | 128 | 11 | 1419 | This is the final output layer having 11 neurons for 11 classes. |
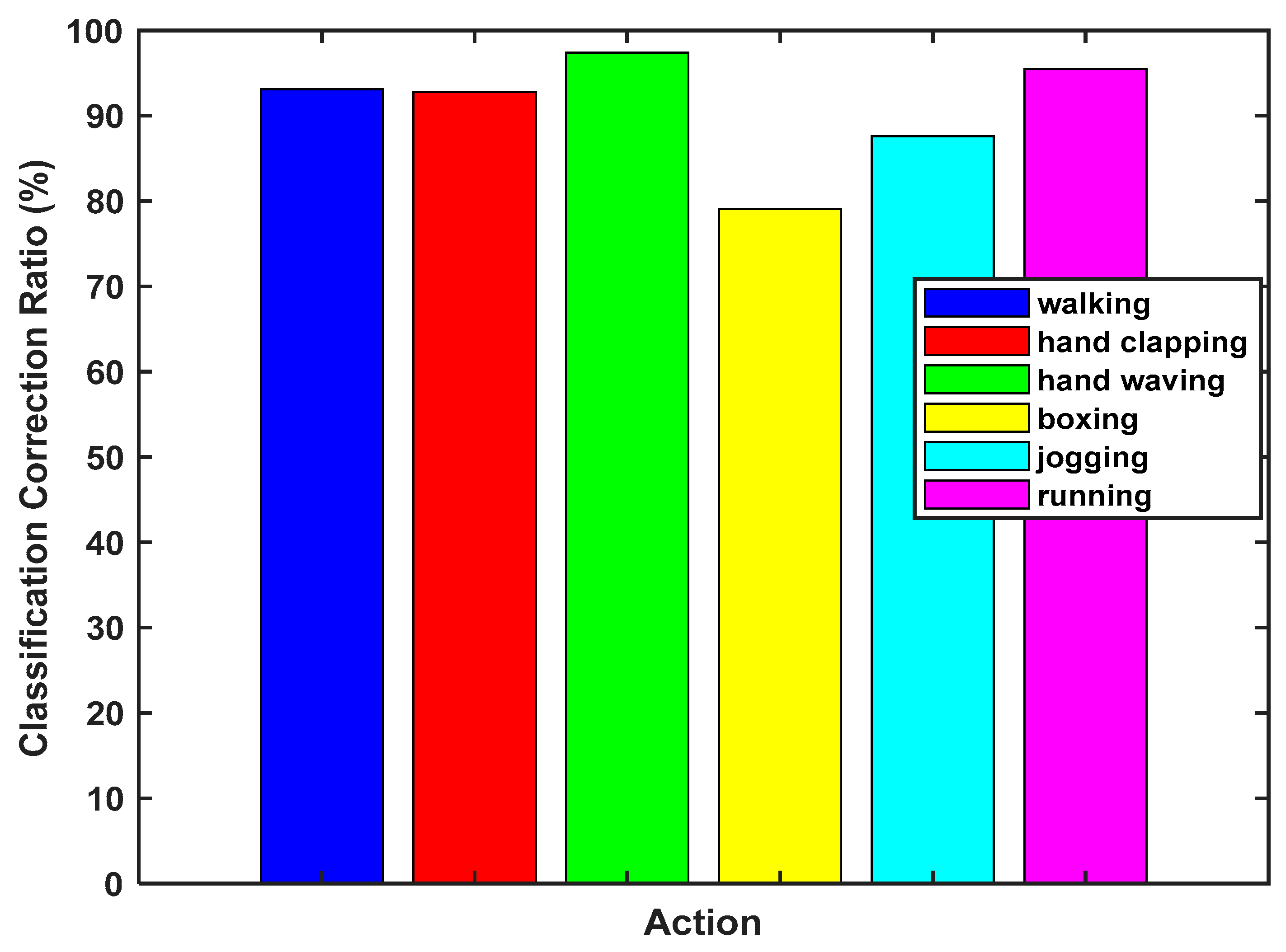
| Authors | Proposed Method | NN Classifier | SLA Classifier | Wong et al. | Dollar et al. |
|---|---|---|---|---|---|
| CCR (%) | 92.91 | 89.55 | 90.84 | 81 | 81.2 |
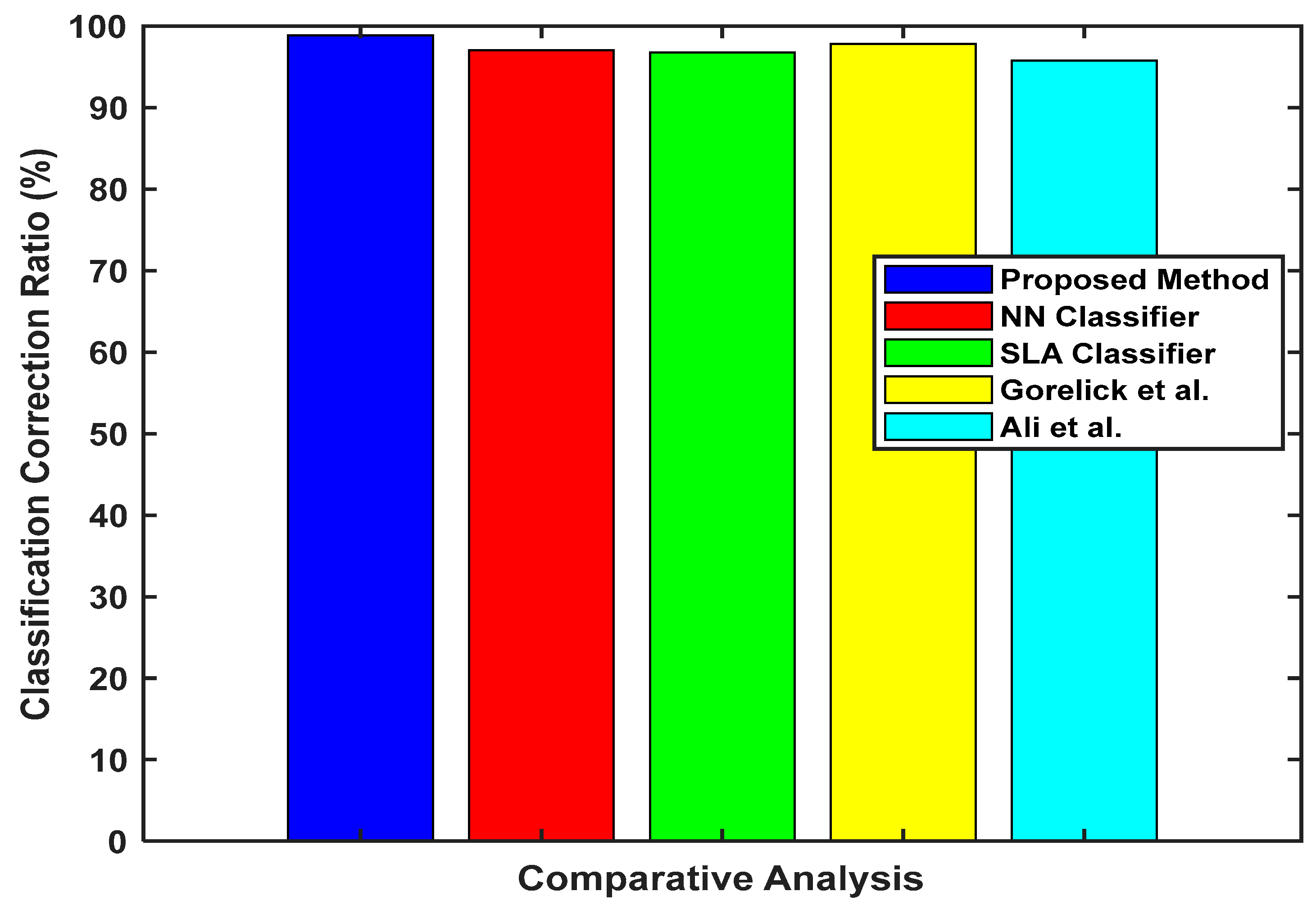
| Authors | Proposed Method | NN Classifier | SLA Classifier | Gorelick et al. | Ali et al. |
|---|---|---|---|---|---|
| CCR (%) | 98.88 | 97.05 | 96.74 | 97.83 | 95.75 |
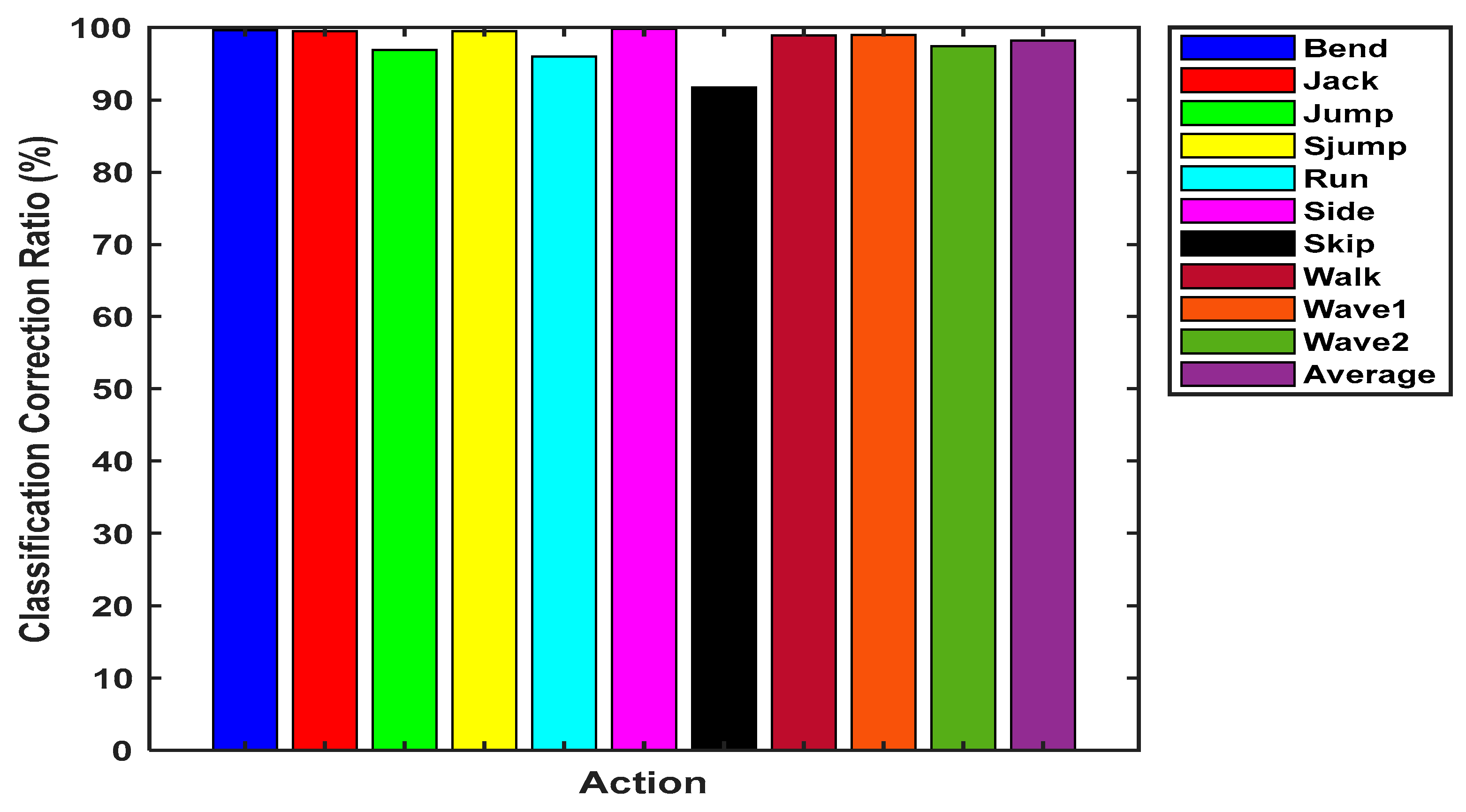
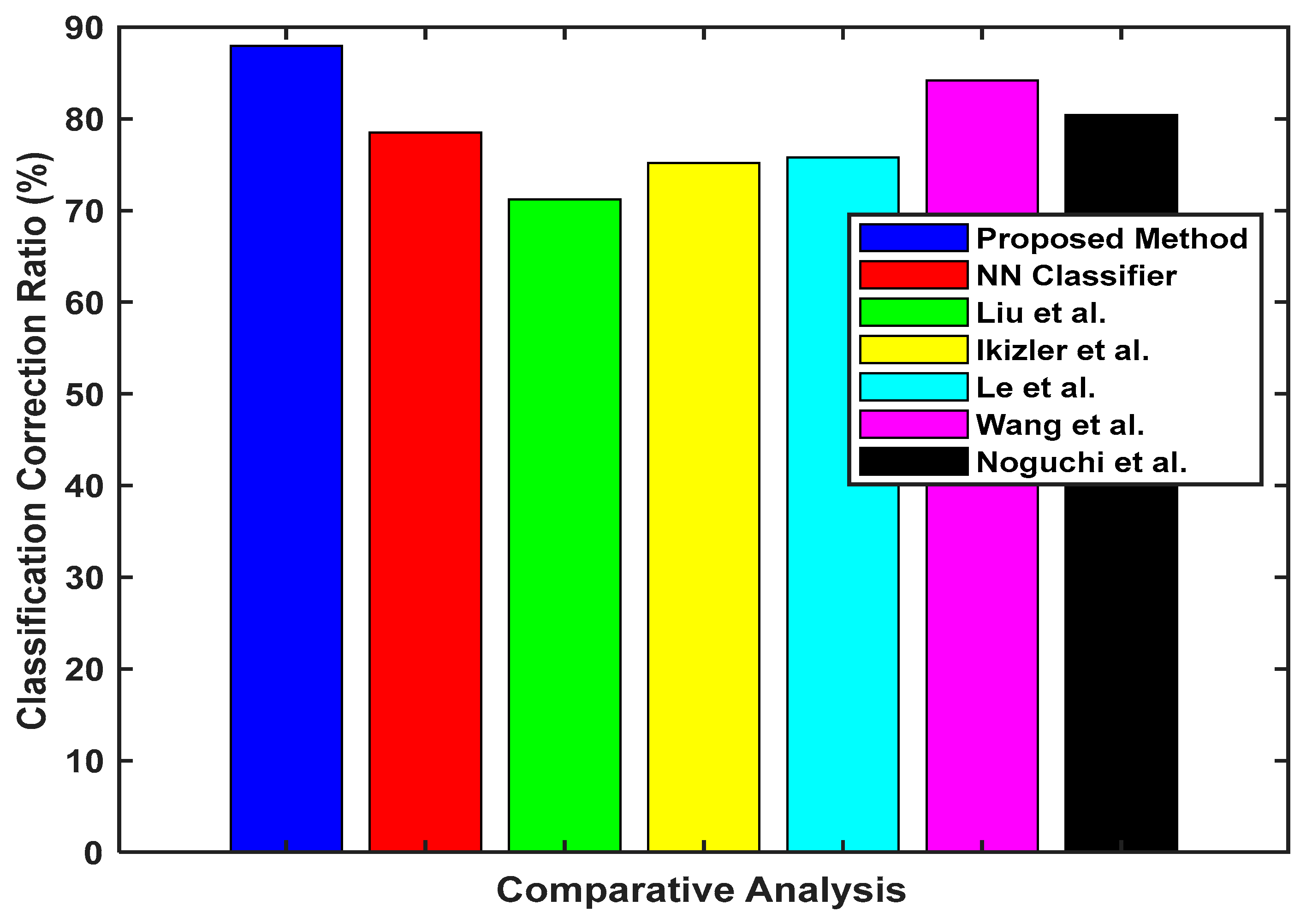
| Authors | Proposed Method | NN Classifier | Liu et al. | Ikizler et al. | Le et al. | Wang et al. | Noguchi et al. |
|---|---|---|---|---|---|---|---|
| CCR (%) | 87.97 | 78.5 | 71.2 | 75.2 | 75.8 | 84.2 | 80.4 |
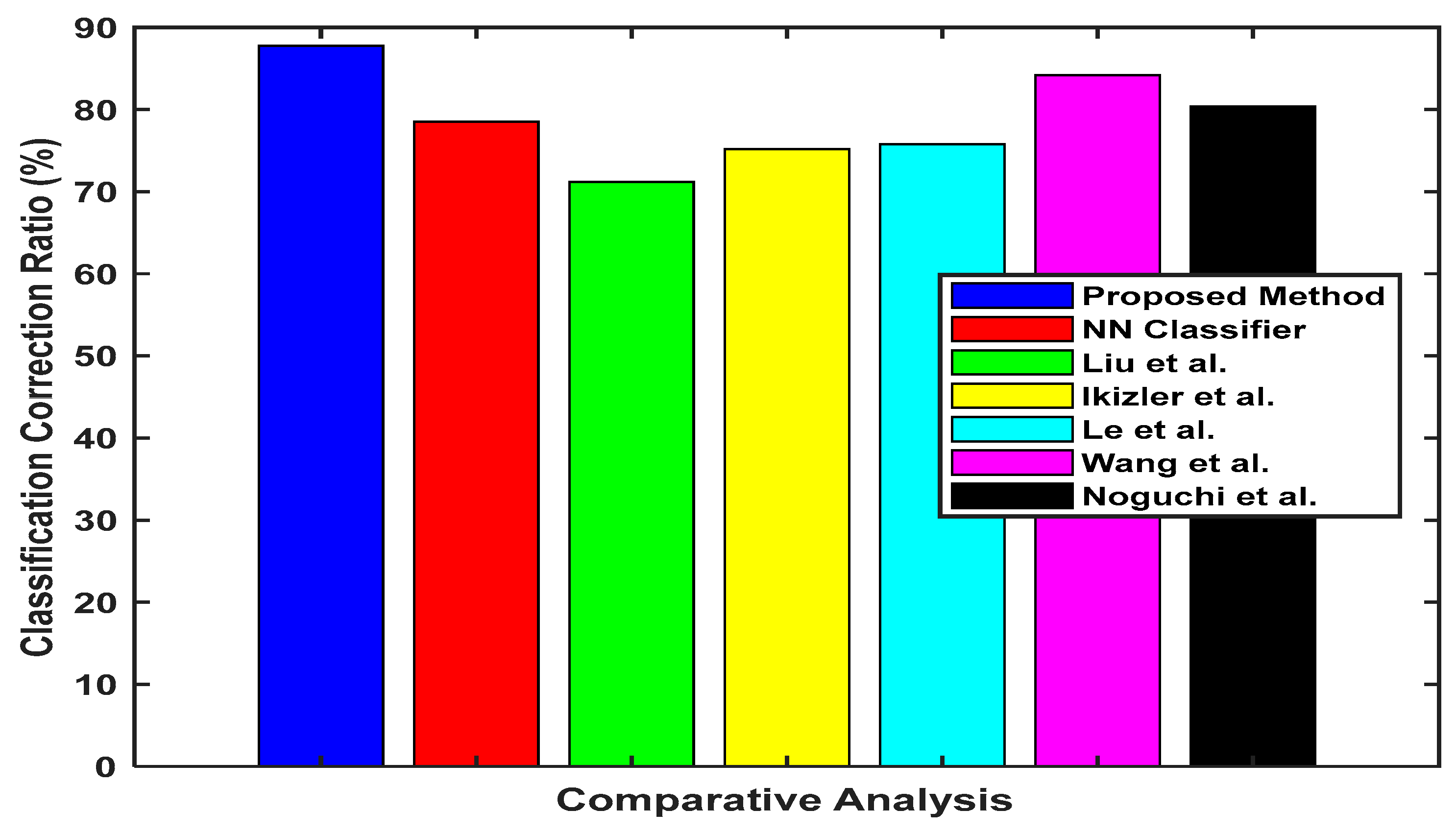
| Authors | Proposed Method | NN Classifier | Liu et al. | Ikizler et al. | Le et al. | Wang et al. | Noguchi et al. |
|---|---|---|---|---|---|---|---|
| CCR (%) | 87.77 | 78.5 | 71.2 | 75.2 | 75.8 | 84.2 | 80.4 |
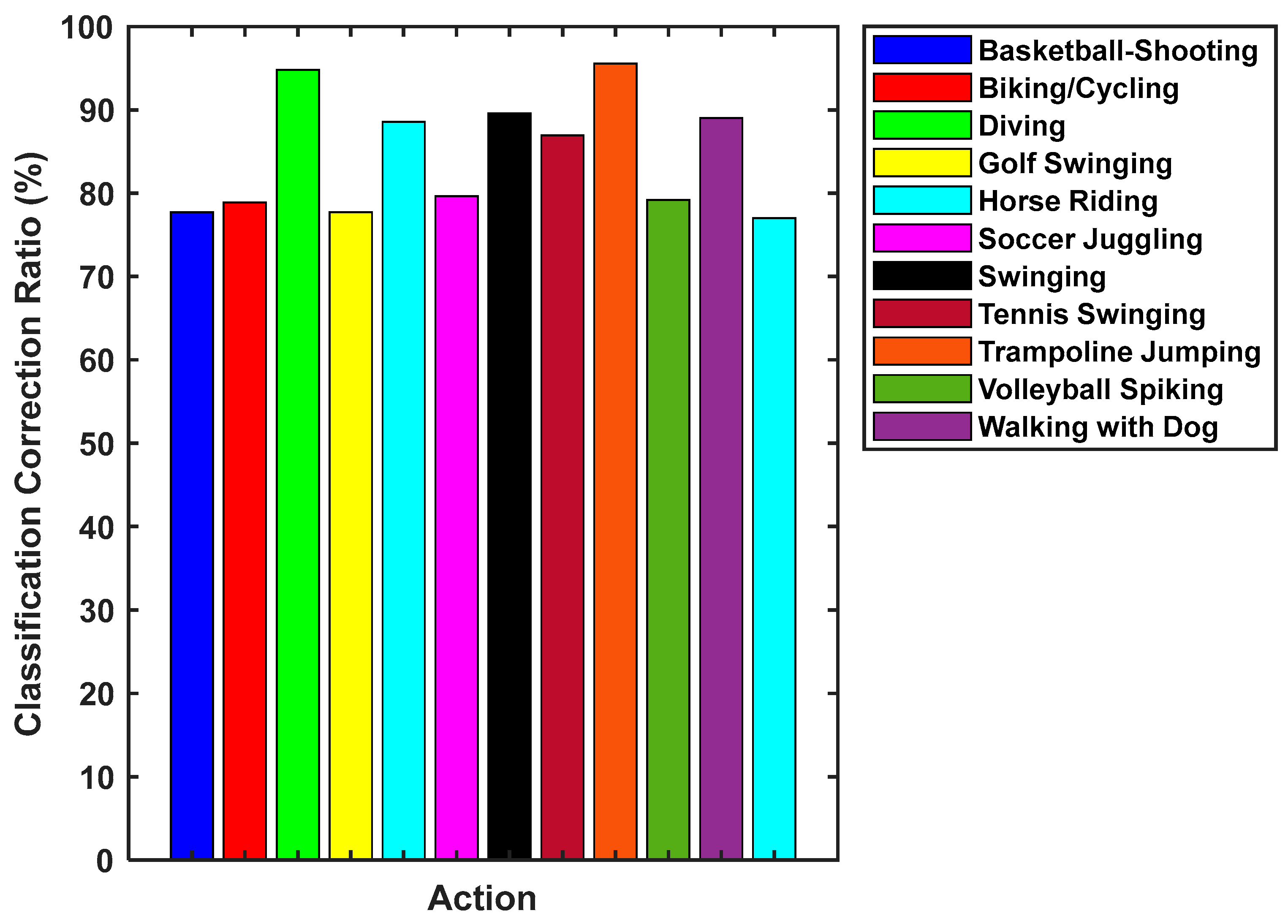
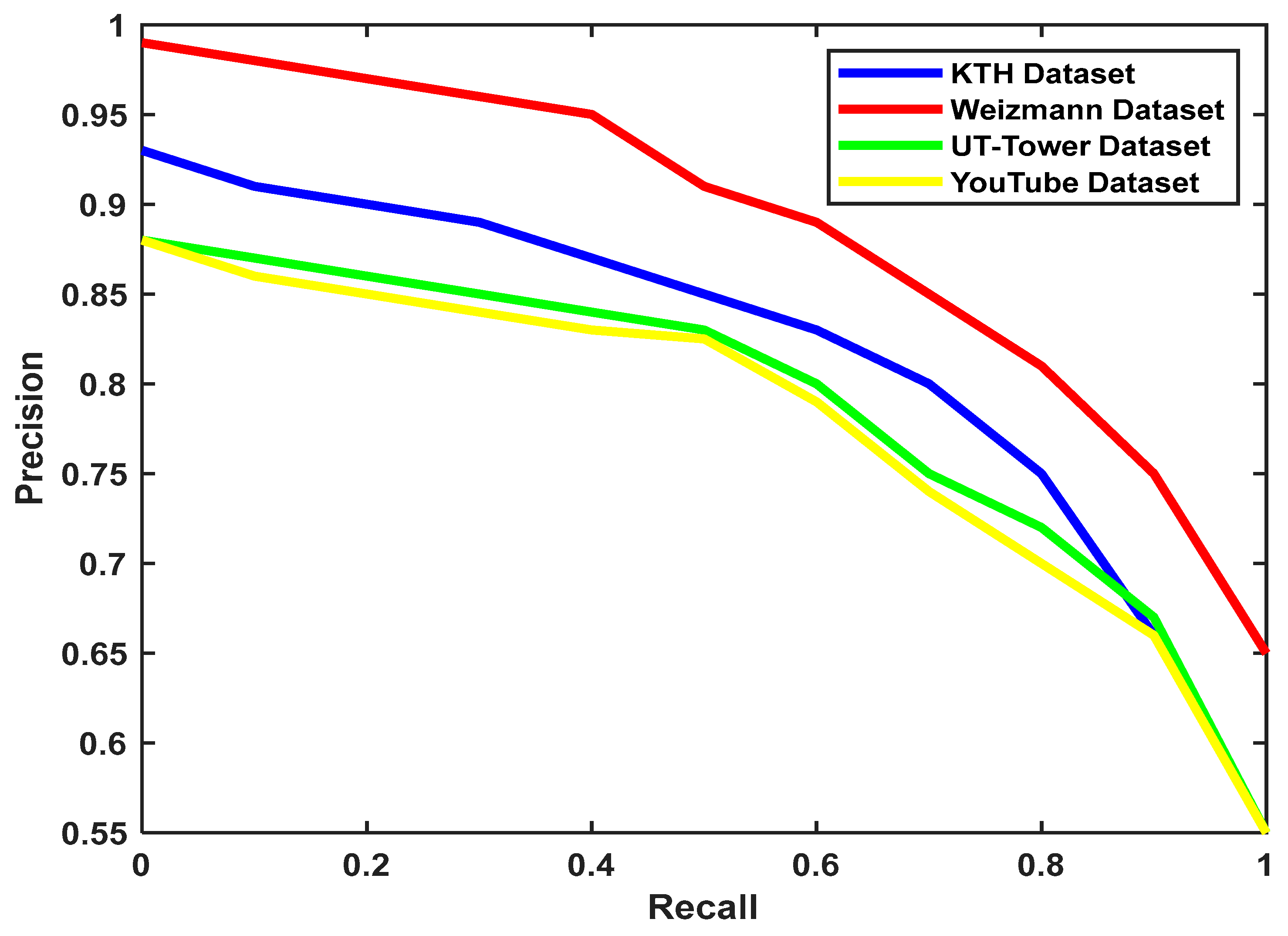
| Authors | Dataset Used for Comparison | Classification Correction Rate (CCR %) |
|---|---|---|
| Proposed Method | KTH Dataset | 92.91 |
| Weizmann Dataset | 98.88 | |
| UT-Tower Dataset | 87.97 | |
| YouTube Dataset | 87.77 | |
| NN Classifier | KTH Dataset | 89.55 |
| Weizmann Dataset | 97.05 | |
| UT-Tower Dataset | 78.50 | |
| YouTube Dataset | 78.50 | |
| SLA Classifier | KTH Dataset | 90.84 |
| Weizmann Dataset | 96.74 | |
| Wong et al. | KTH Dataset | 81.00 |
| Dollar et al. | KTH Dataset | 81.20 |
| Gorelick et al. | Weizmann Dataset | 97.83 |
| Ali et al. | Weizmann Dataset | 95.75 |
| Liu et al. | UT-Tower Dataset | 71.20 |
| YouTube Dataset | 71.20 | |
| Ikizler et al. | UT-Tower Dataset | 75.20 |
| YouTube Dataset | 75.20 | |
| Le et al. | UT-Tower Dataset | 75.80 |
| YouTube Dataset | 75.80 | |
| Wang et al. | UT-Tower Dataset | 84.20 |
| YouTube Dataset | 84.20 | |
| Noguchi et al. | UT-Tower Dataset | 80.40 |
| YouTube Dataset | 80.40 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Arora, I.; Gangadharappa, M. Human Action Recognition from Videos Using Motion History Mapping and Orientation Based Three-Dimensional Convolutional Neural Network Approach. Modelling 2025, 6, 33. https://doi.org/10.3390/modelling6020033
Arora I, Gangadharappa M. Human Action Recognition from Videos Using Motion History Mapping and Orientation Based Three-Dimensional Convolutional Neural Network Approach. Modelling. 2025; 6(2):33. https://doi.org/10.3390/modelling6020033
Chicago/Turabian StyleArora, Ishita, and M. Gangadharappa. 2025. "Human Action Recognition from Videos Using Motion History Mapping and Orientation Based Three-Dimensional Convolutional Neural Network Approach" Modelling 6, no. 2: 33. https://doi.org/10.3390/modelling6020033
APA StyleArora, I., & Gangadharappa, M. (2025). Human Action Recognition from Videos Using Motion History Mapping and Orientation Based Three-Dimensional Convolutional Neural Network Approach. Modelling, 6(2), 33. https://doi.org/10.3390/modelling6020033