1. Introduction
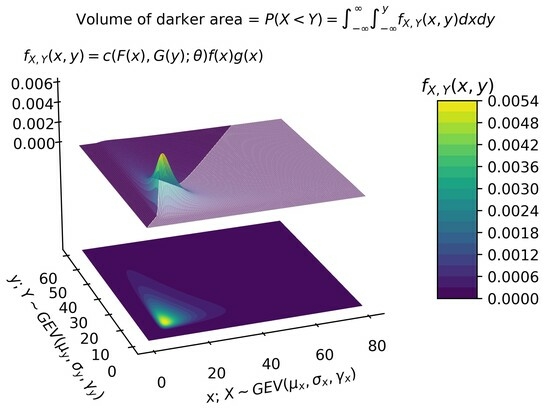
The probability of failure of a system or component can be calculated by statistically comparing the applied stress to its strength. Let
X (strength) and
Y (stress) be continuous random variables (RVs) with joint probability density function (PDF)
. The stress–strength probability (or reliability) is defined as
There are several applications of this framework, such as in asset selection [
1], household financial fragility [
2] and engineering [
3], among others. See Kotz et al. [
4] for more details.
Equation (
1) can only be evaluated when the analytical representation of the joint PDF is known (or any other equivalent statistical formula which can be transformed into
); thus, properly assessing this joint formulation is of utmost importance in stress–strength applications of type
. Finding an accurate representation of
involves two steps: understanding what the marginal distributions are and what the dependence structure of these RVs is.
Thus, at first, finding the best fitting marginal distributions for
X and
Y is of interest. In this regard, Quetelet’s pioneering investigations, which were focused on finding empirical regularities in biological and social data [
5], can be considered to be among the first experimentations of normally distributed (thin-tailed) RVs beyond the pure sciences. Their belief in the universality of the error law had repercussions on the development of 19th century science and statistics. Nevertheless, the experiments involving financial data in the 20th century pointed to the suitability of heavy-tailed distributions in modelling, either by means of
-stable processes (heavy-tailed alternative to the thin-tailed Brownian motion [
6]) or with heavy-tailed time-series models [
7,
8]. Although the literature proposes the general hypothesis that logarithmic returns in financial data follow an
-stable process with parameter
[
9] (and undefined variance), without loss of generality, results from the extreme value theory (EVT) regarding generalized extreme value (GEV) distributions [
10] present these distributions as an alternative to
-stable distributions. This approach can be considered valid, since the GEV distribution has fat-tailed behaviour and can be used as a proxy for fat-tailed distributions. From an economic point of view, it is well known that extreme share returns on stock markets can have important implications for financial risk management, and several studies have successfully applied the GEV to model financial data [
1,
11,
12,
13,
14]. Furthermore, heavy-tailed distributions like log-normal and Pareto are known for their suitability for embracing both the tails and the mode of empirical income density functions [
2]. However, some limitations of these distributions give the opportunity to apply other distributions that resemble fat-tailed behaviour but bring more flexibility in the parameter set [
15]. Nevertheless, exploring how the GEV distribution performs when modelling income and consumption data in a fragility evaluation framework is still of interest.
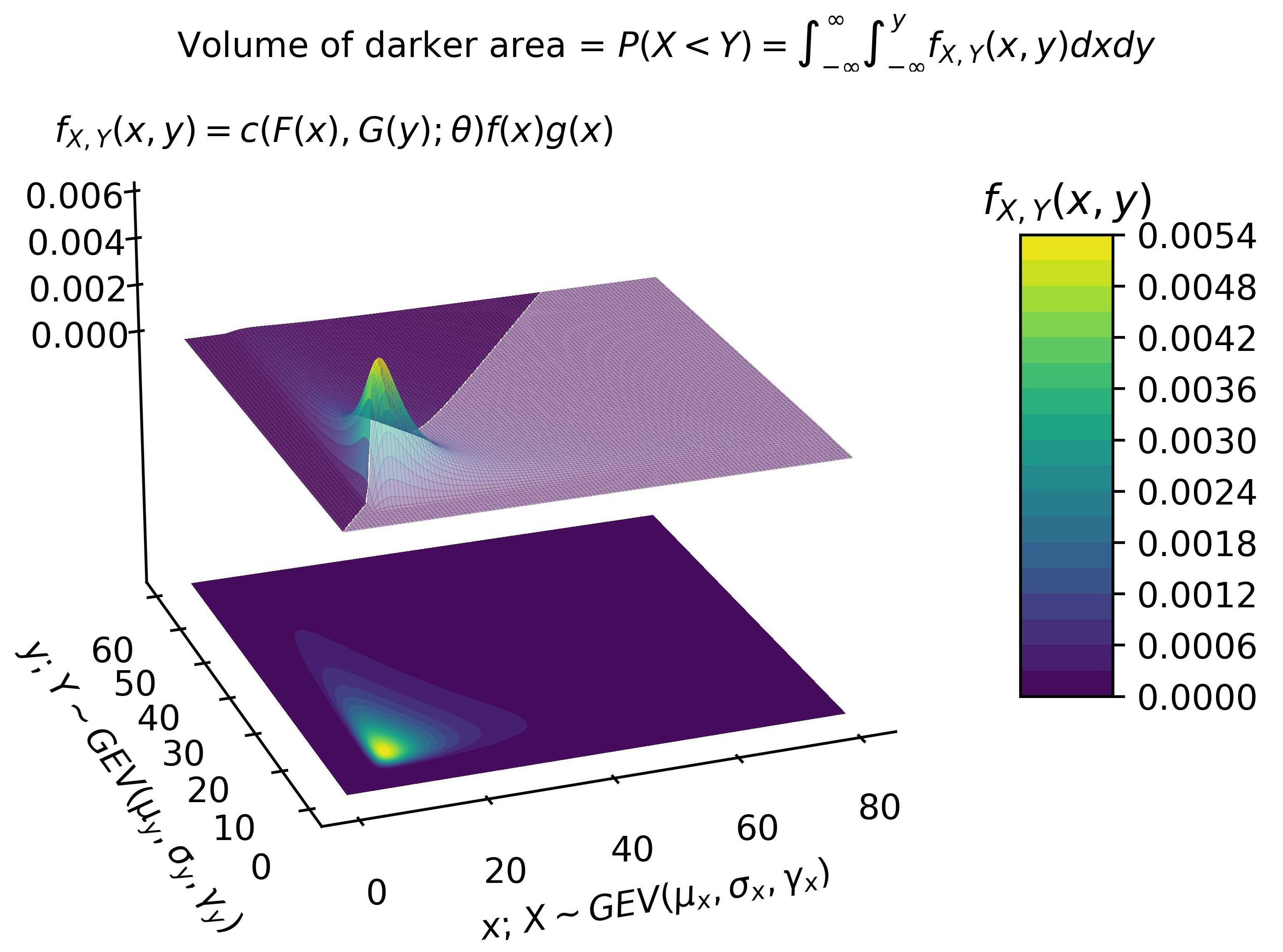
Moreover, Kotz and Nadarajah [
16] elucidated the characteristics of this distribution, highlighting its broad relevance in various domains, such as accelerated life testing, natural disasters, horse racing, rainfall, supermarket queues, sea currents, wind speeds, track race records, and more. As a result, GEV RVs prove to be suitable models for engineering data sets as well.
After selecting the marginals for
X and
Y, their dependence structure needs to be considered. The stress–strength reliability when
X and
Y are independent RVs following extreme distributions has been widely studied in the literature. Nadarajah [
17] considered the class of extreme value distributions and derived the corresponding forms for reliability (
R) in terms of special functions. Several authors have worked on the estimation and application of stress–strength probability for extreme distributions (e.g., [
18,
19,
20,
21]). The stress–strength probability for independent GEV distributions was studied by Quintino et al. [
1], who derived stress–strength reliability formulas and investigated the application of the reliability measure
in selecting financial assets with returns modelled by GEV distributions.
To the best of our knowledge, there is no work in the literature addressing stress–strength reliability for dependent GEV distributions. Thus, the main goal of this paper is to extend the approach of [
1] by studying (
1) when
X and
Y follow dependent GEV distributions, with the joint PDF being given by copulas. Therefore, our main contributions are:
To propose an estimation procedure for R and validate such a procedure via a simulation study;
To apply the estimation procedure on three real-life data sets;
To present the computational codes needed to implement the methodological framework hereby developed.
Using copulas to model the dependence structure of RVs is a direct consequence of Sklar’s theorem, which enables the creation of several copula families, each of which better captures specific dependence situations. Among the most explored copulas, the Gumbel–Hougaard copula better copes with upper tail dependence among variables. On the other hand, the Clayton copula is well suited for delineating lower tail dependence among variables, while the Frank copula excels at capturing symmetric tail dependence among variables (cf. [
22]). For a more detailed study on copula theory, the reader may refer to [
23]. Recent works explored copulas in different scenarios, like the use of the Frank copula to model financial assets with Dagum marginals for dependent asset portfolio management [
24], the application of copulas in data from insurance companies on losses and expenses [
22], the derivation of the bivariate distribution of monsoon rainfall in neighbouring meteorological subdivisions [
25], and a monthly streamflow simulation using a maximum entropy–Gumbel–Hougaard copula method [
26]. Theoretical properties of extreme value copulas can be also found in [
27,
28].
Considering their common usage in both financial and engineering applications, Gumbel–Hougaard, Frank, and Clayton copulas are considered in the present paper. Besides theoretical aspects, we explore the estimation procedures, proposing a general framework that can be applied by practitioners while considering GEV marginals with the three types of copula families mentioned. In that case, one may notice that the value of
R given in (
1) depends on the parameters of the marginal distributions (for GEV distributions, as shall be seen,
location,
scale, and
shape) and a dependence parameter,
(introduced by the copula model). Motivated by improvement in computational time, we opted for a two-step estimation, i.e., the marginals are modelled, and then the dependence parameter is estimated, which is the so-called method of inference functions for margins [
29].
The methodological framework hereby proposed is applied to estimate
R in three real situations. Firstly, we consider an asset selection situation where there exists a correlation between the returns of pairs of different stocks. In summary, when
X and
Y represent financial return random variables and
, it is advisable that the investor chooses the asset corresponding to variable
X. If
, the opposite occurs. The case where
is inconclusive. The measurement of household financial fragility is also considered a second real data set modelling situation. Using data from Bank of Italy’s 2008 Survey on Household Income and Wealth (cf. [
2]), we investigate how often households have their yearly consumption higher than their income. Finally, a third database is modelled, allowing one to compare the minimum monthly flow rate for the Piracicaba River in Brazil. Such comparison is useful to define contingency measures to complement the electric matrix, which is mostly dependent on hydraulic sources.
The paper is organized as follows: In
Section 2, all the general results needed to carry out the studies are presented. Thus, in this section, the cumulative distribution functions (CDFs) and PDFs of the Gumbel–Hougaard, Frank, and Clayton copulas are presented. Additionally, the PDF and some properties of the GEV distribution are also presented, as well as the estimation guidelines for
R.
Section 3 presents a simulation study. The performance of the maximum likelihood estimator of
R is evaluated and compared with a nonparametric estimator. In
Section 4, we deal with three real situations involving asset selection via comparison of log-returns, assessment of credit risk based on income and consumption data, and the comparison of minimum monthly flow rates. Then,
Section 5 presents the conclusions.
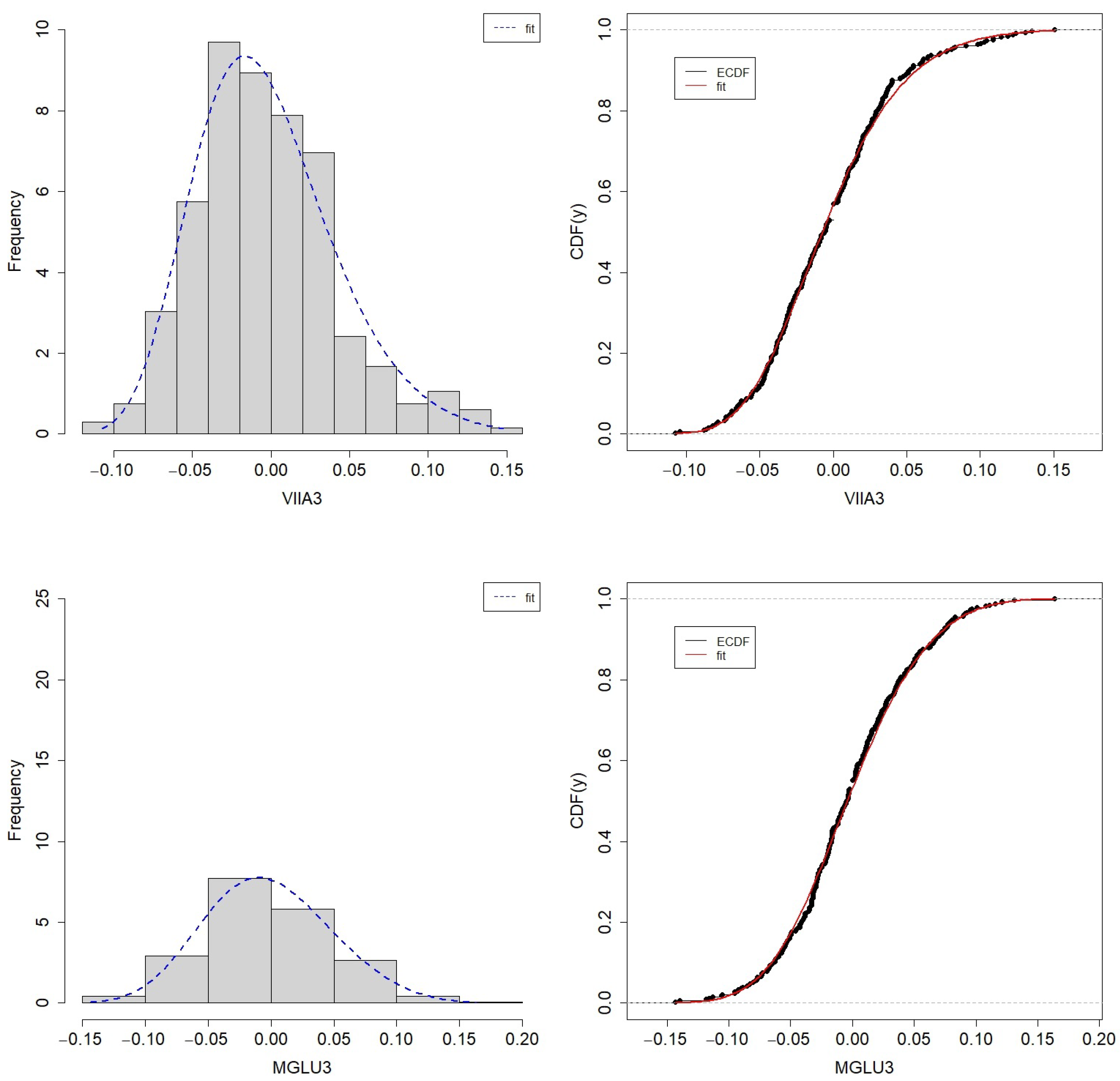
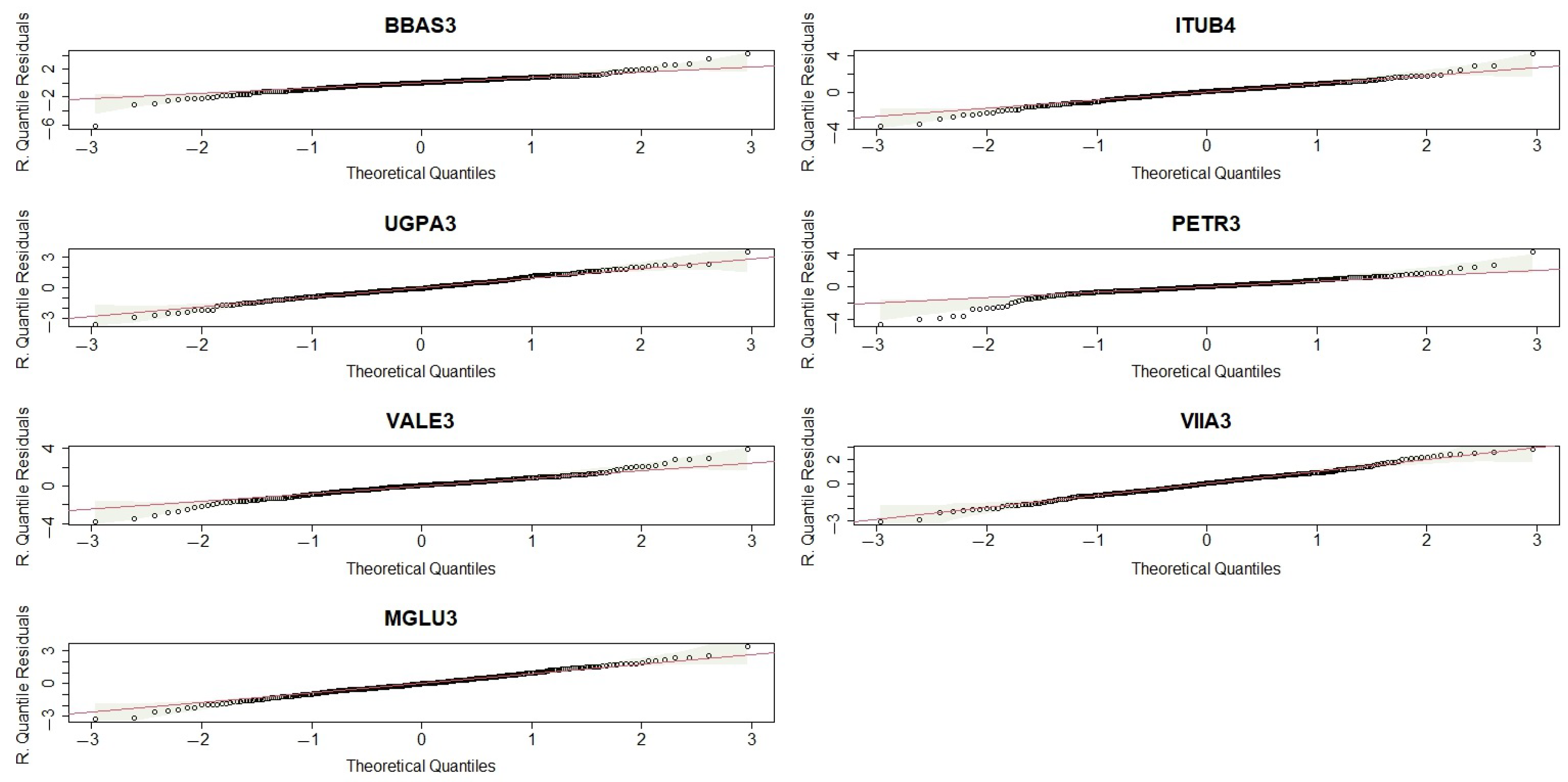
3. Simulation Results
To evaluate the performance of estimates
and
, we simulate random samples from the copulas given in (
2), (
3), and (
4) with GEV marginals. The random samples are simulated using the conditional distributions of random vectors
. In the bivariate case, we shall follow the steps described below [
30], given a copula
C:
Obtain a sample from , i.e., uniform on [0,1].
Compute the function (partial derivatives of each copula are presented in
Appendix A)
. This function is nothing but
.
Compute the generalized inverse
Obtain a sample v from , independent of .
Define , and take as the random vector of copula C.
Steps 1–5 described above give us a random vector with uniform marginal distributions (cf. [
31]). We can generate a random vector with distribution
C and marginals
and
as
where
denotes the CDF of GEV RVs.
The values of
and
and the sample size (
n) are pre-specified. Monte Carlo simulations were implemented in R [
32] with
replications. To compare the estimates, we take the mean
of the 100 bootstrap samples, the bias, and the root mean squared error (RMSE) when compared with the true
R.
The only R package utilized in our study was
extRemes to use the pdf and cdf of the GEV marginal distribution, in addition to the
fevd function. Following the adjustment of the marginals, we estimated the dependence parameter (
) using Equation (
5). All other algorithms employed in this study were programmed based on the procedures outlined in this work. In order to enable readers to apply the methodology hereby proposed, the codes are available at a public repository [
33].
In
Table 2,
Table 3 and
Table 4, we present the performance of estimators
and
for Gumbel–Hougard, Frank, and Clayton copulas with GEV marginals, respectively. Overall, estimators
seem to be better than
, presenting lower bias and RMSE.


 ,
, 


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}