
Logit Truncated-Exponential Skew-Logistic Distribution with Properties and Applications



Abstract
:1. Introduction
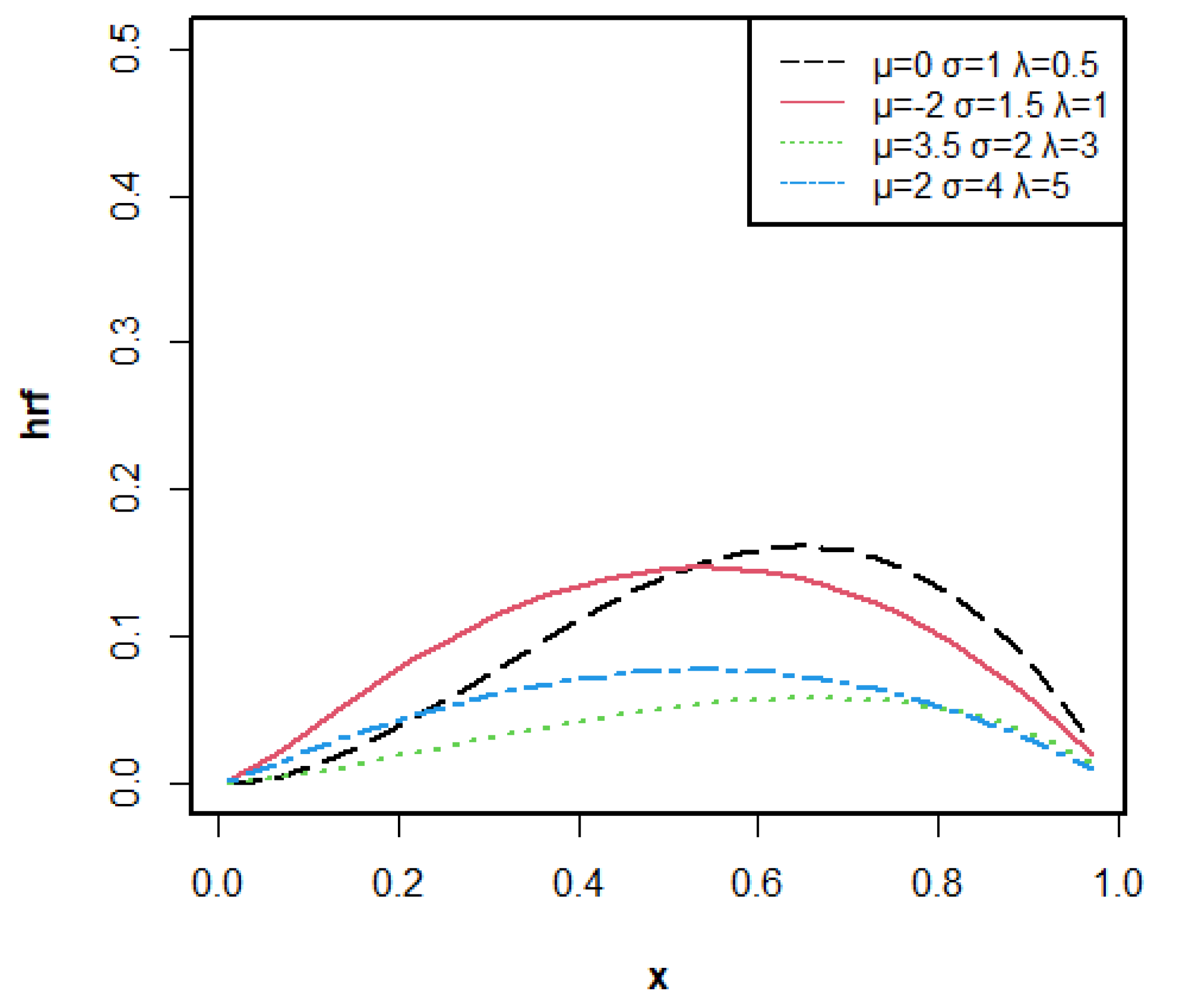
2. Logit Truncated-Exponential Skew-Logistic Distribution
3. Maximum-Likelihood Estimation
4. Simulation
- (i)
- Set , and .
- (ii)
- Simulate .
- (iii)
- Compute , then Y follows .
- (iv)
- Compute , then X follows .
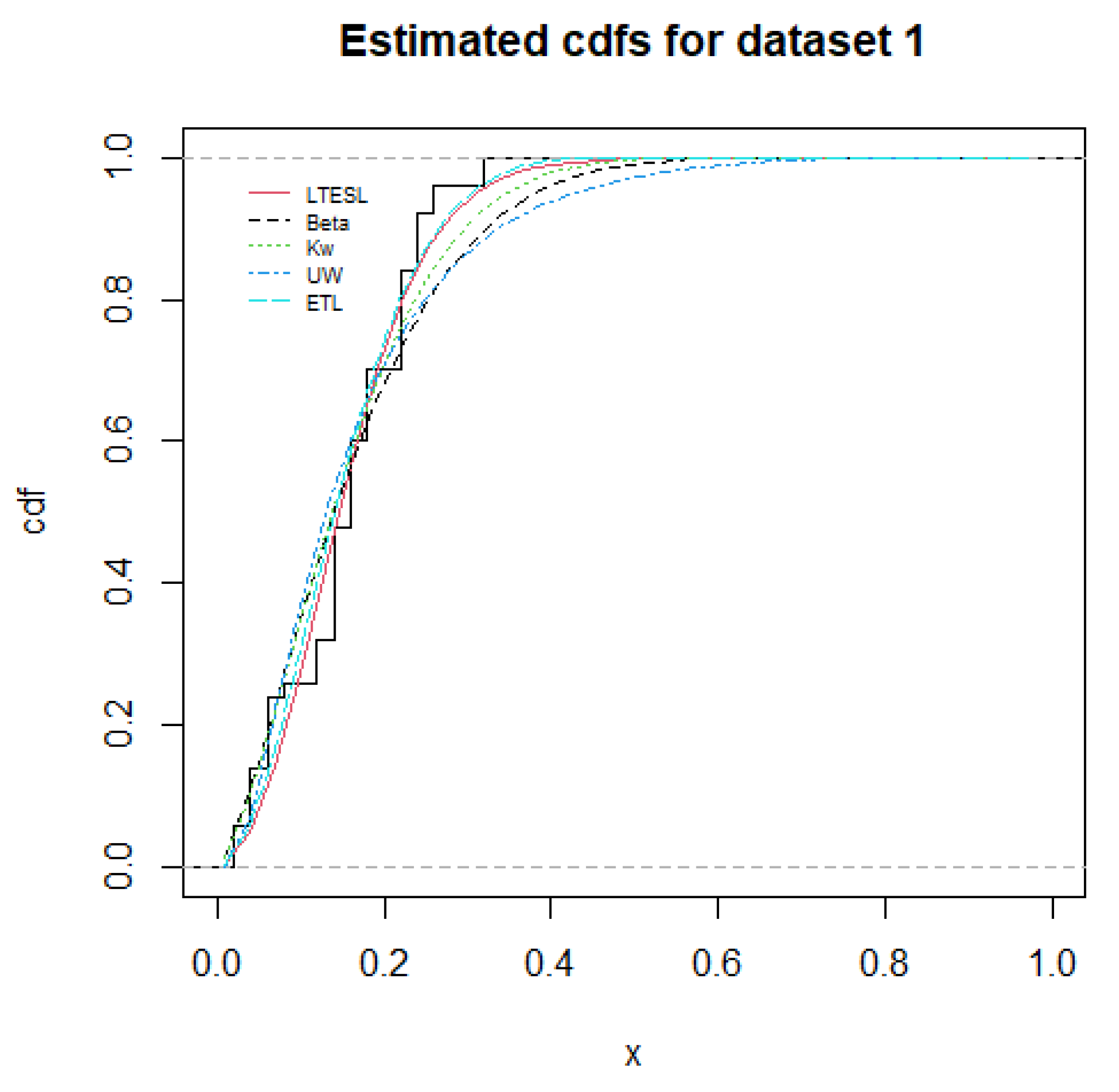
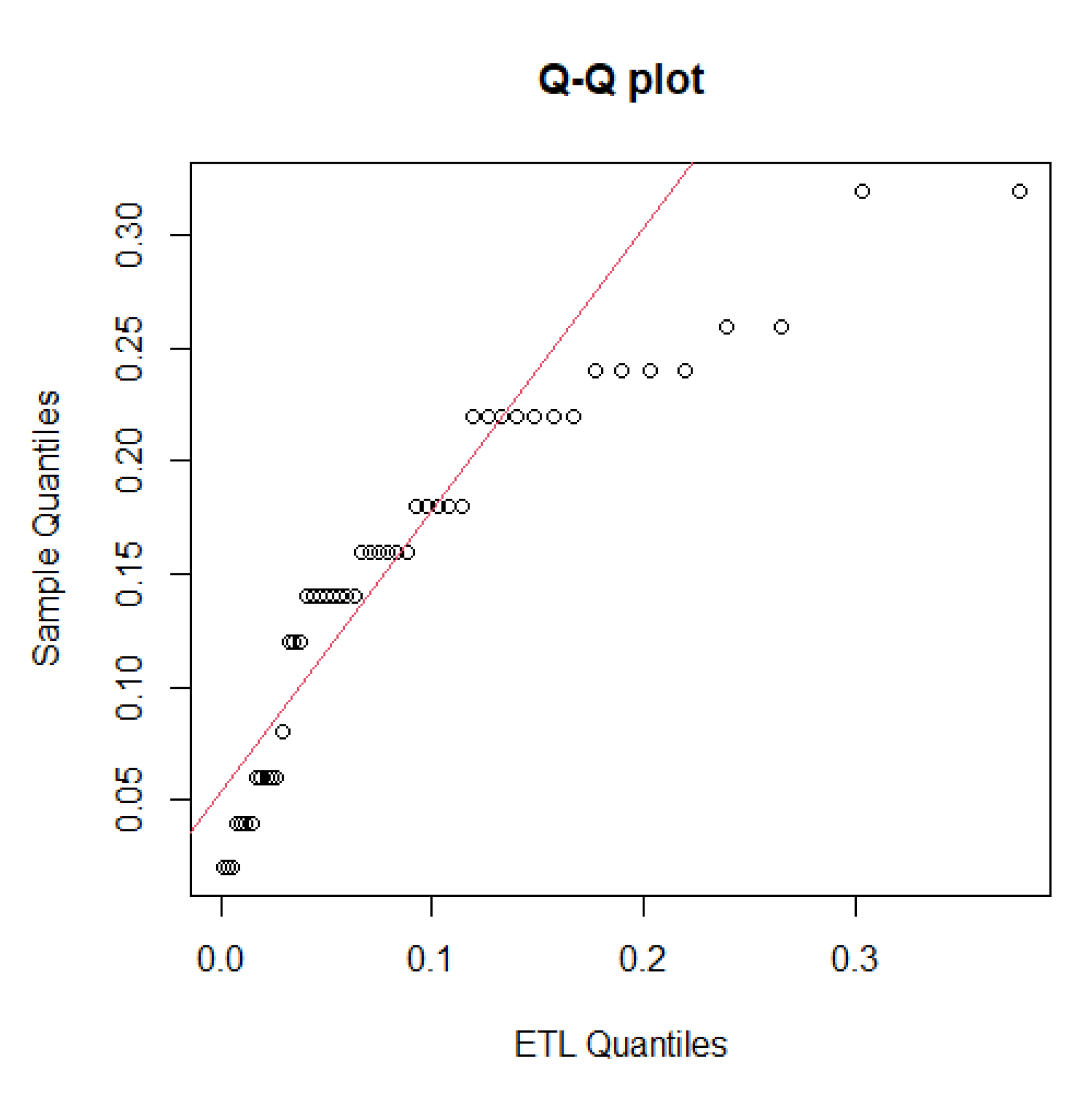
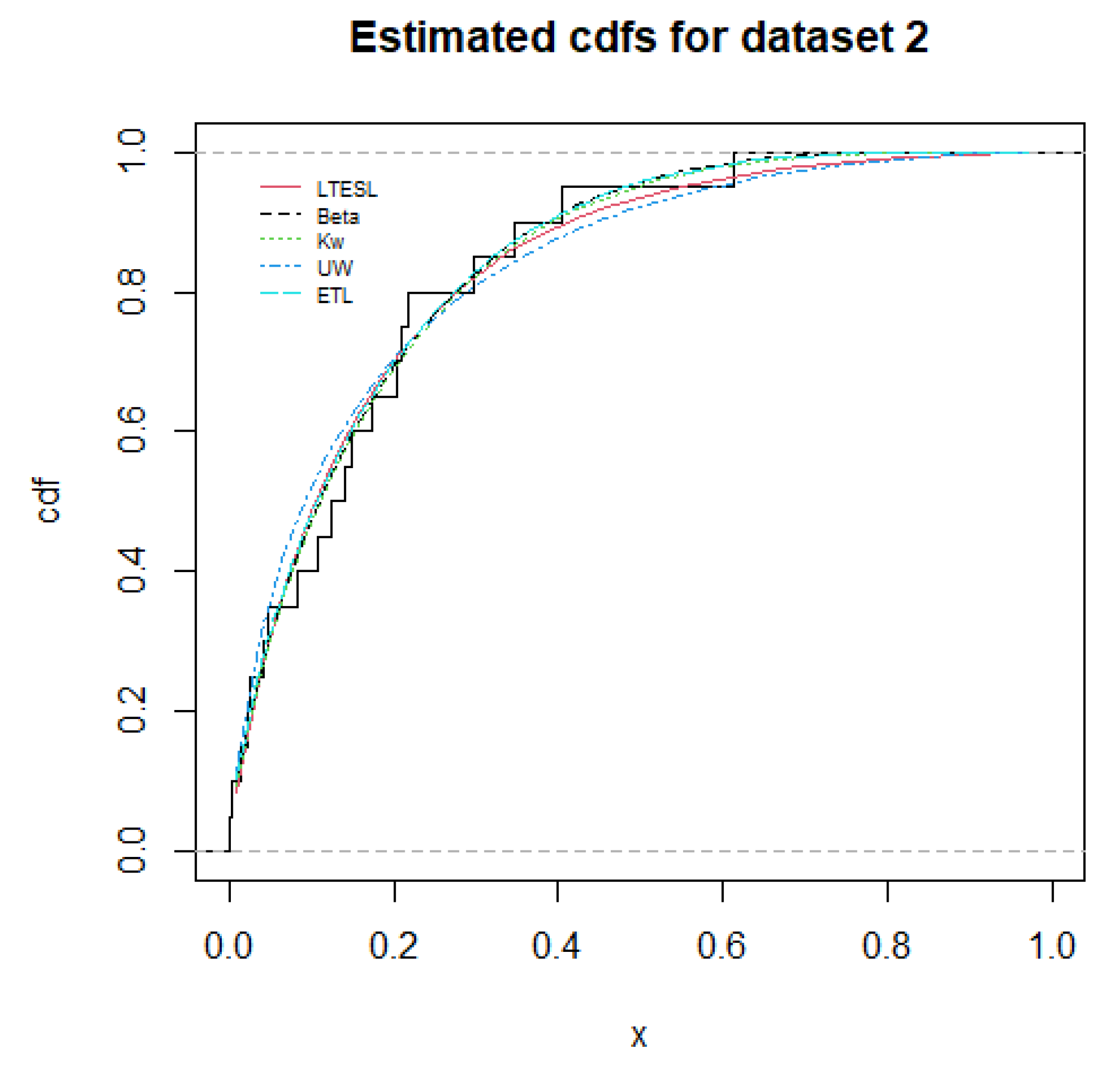
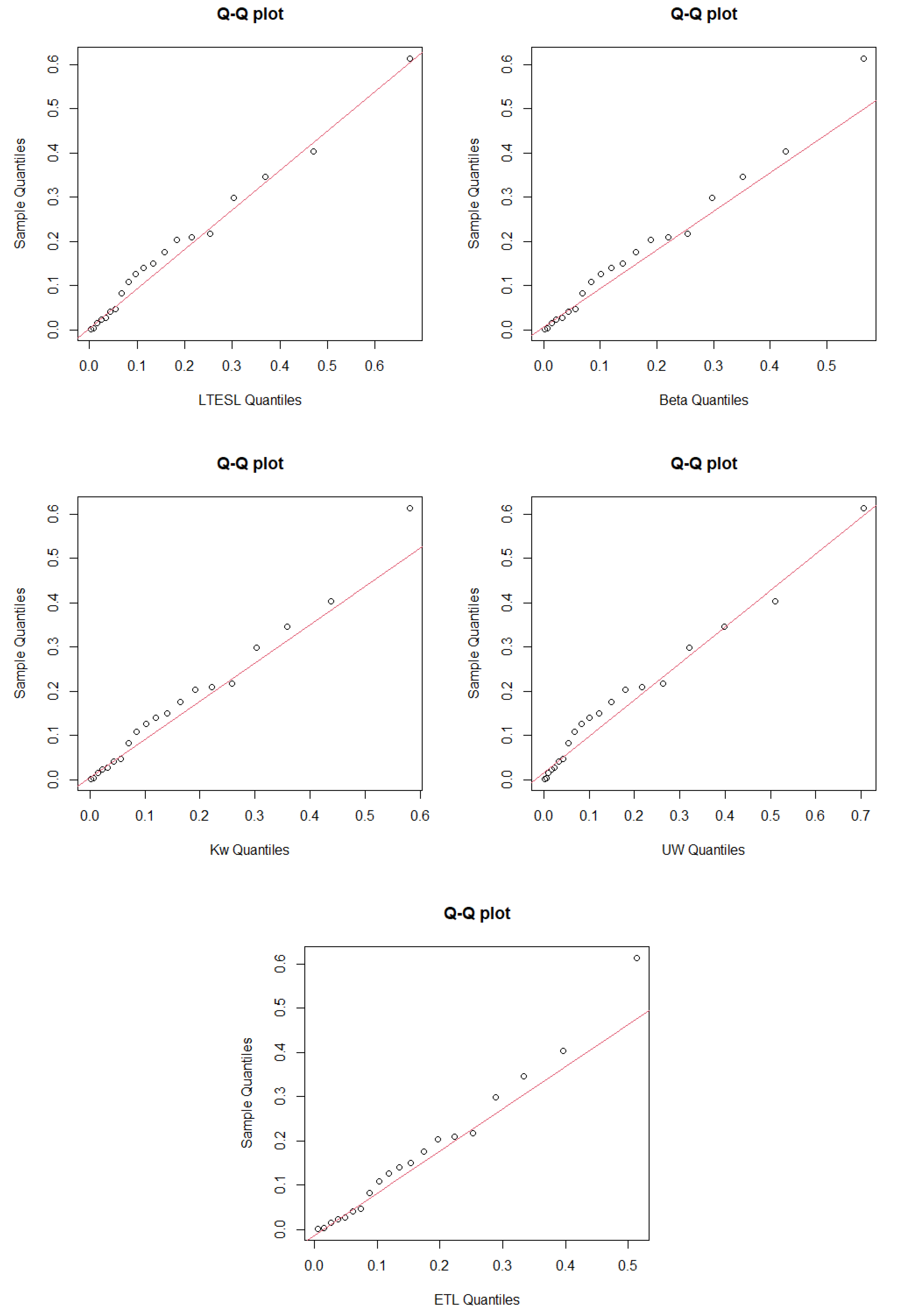
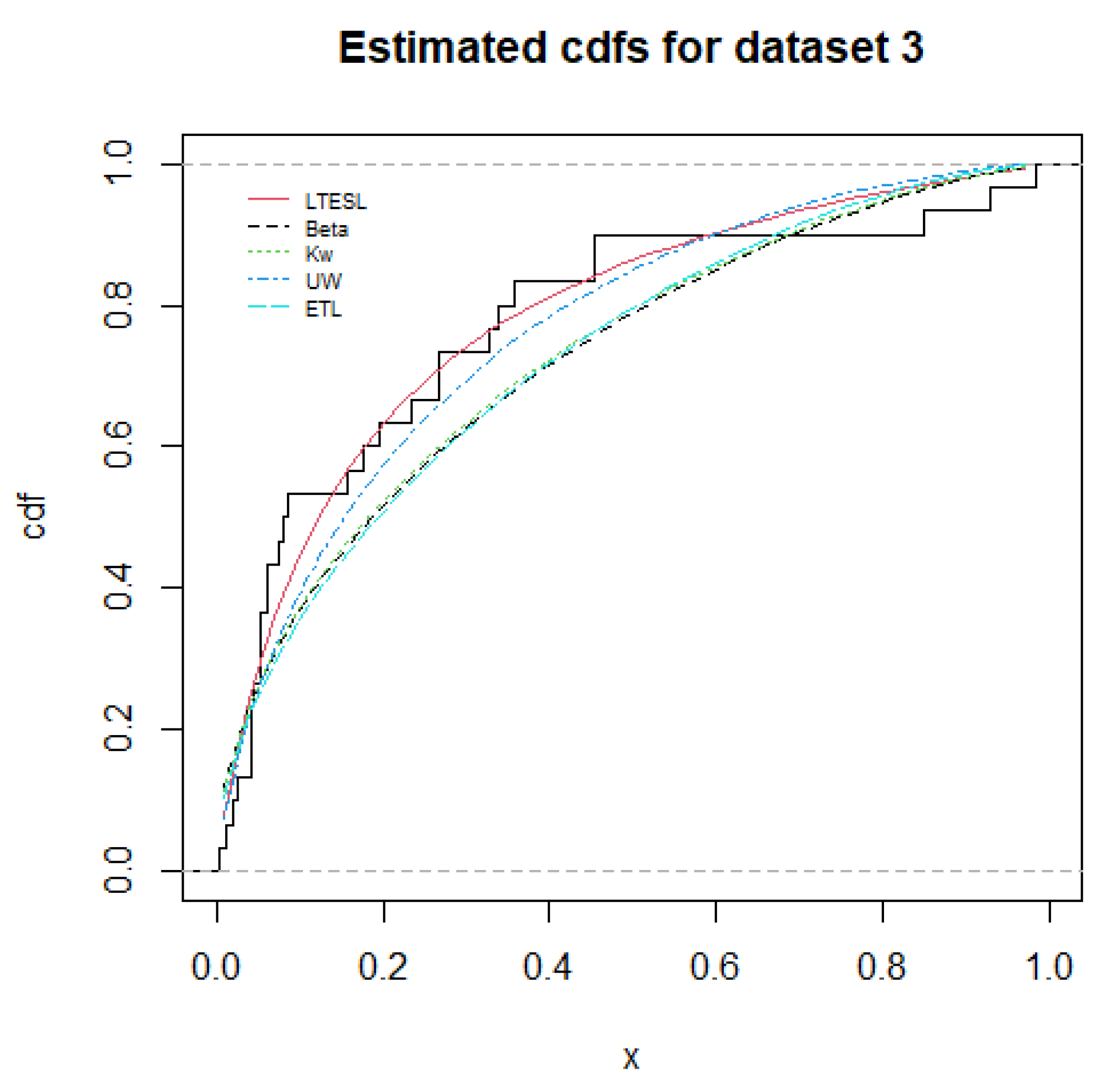
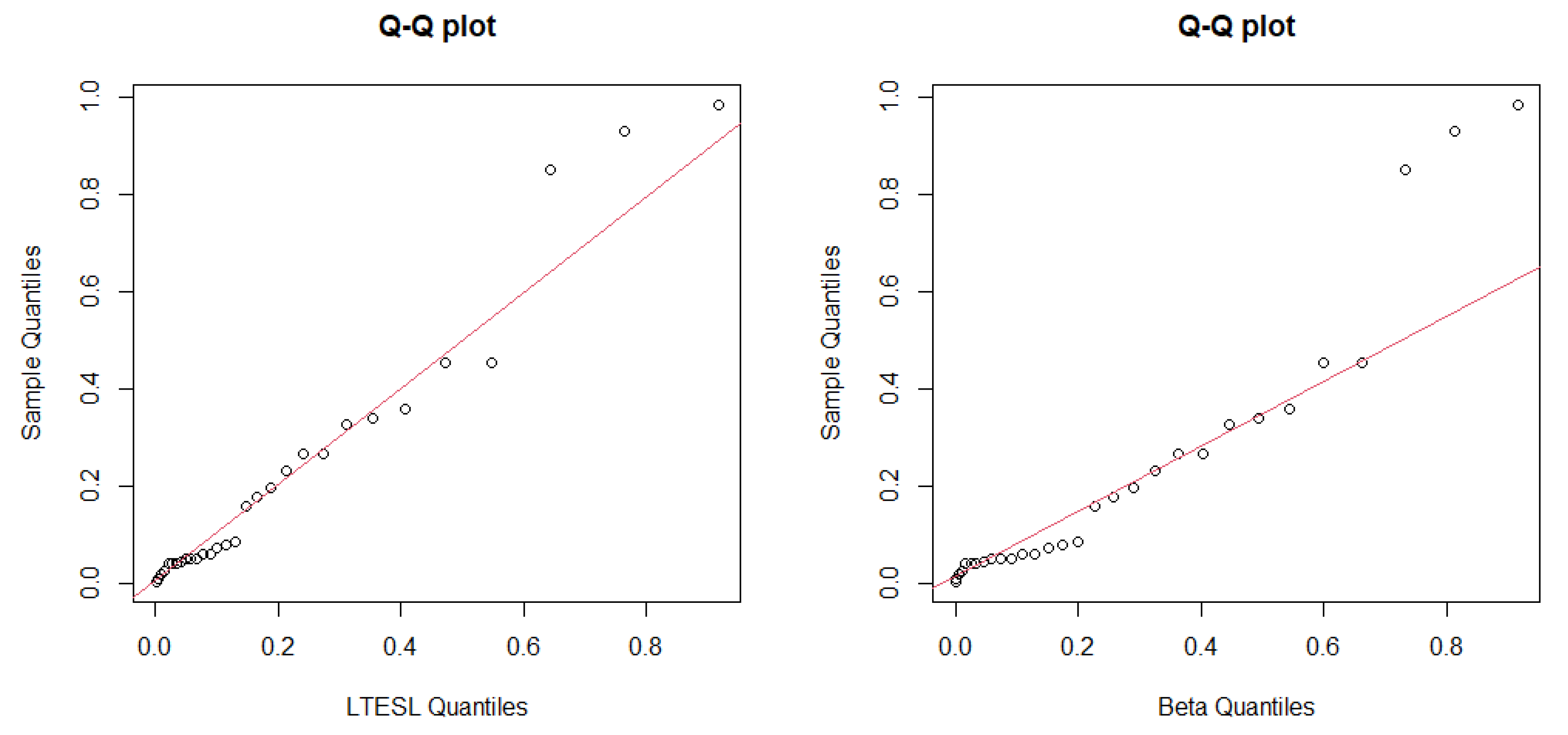
5. Applications
- (1)
- Beta distribution:where is the beta function.
- (2)
- Kw distribution:
- (3)
- UW distribution:
- (4)
- ETL distribution:
6. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Papke, L.E.; Wooldridge, J.M. Econometric methods for fractional response variables with an application to 401 (k) plan participation rates. J. Appl. Econom. 1996, 11, 619–632. [Google Scholar] [CrossRef] [Green Version]
- Topp, C.W.; Leone, F.C. A family of J-shaped frequency functions. J. Am. Stat. Assoc. 1955, 50, 209–219. [Google Scholar] [CrossRef]
- Pourdarvish, A.; Mirmostafaee, S.; Naderi, K. The exponentiated Topp-Leone distribution: Properties and application. J. Appl. Environ. Biol. Sci. 2015, 5, 251–256. [Google Scholar]
- Kumaraswamy, P. A generalized probability density function for double-bounded random processes. J. Hydrol. 1980, 46, 79–88. [Google Scholar] [CrossRef]
- Lemonte, A.J.; Barreto-Souza, W.; Cordeiro, G.M. The exponentiated Kumaraswamy distribution and its log-transform. Braz. J. Probab. Stat. 2013, 27, 31–53. [Google Scholar] [CrossRef]
- Gómez-Déniz, E.; Sordo, M.A.; Calder-Ojeda, E. The Log-Lindley distribution as an alternative to the beta regression model with applications in insurance. Insur. Math. Econ. 2014, 54, 49–57. [Google Scholar] [CrossRef]
- Altun, E.; Hamedani, G.G. The log-xgamma distribution with inference and application. J. Soc. Fr. Stat. 2018, 159, 40–55. [Google Scholar]
- Korkmaz, M.Ç. A new heavy-tailed distribution defined on the bounded interval: The logit slash distribution and its application. J. Appl. Stat. 2020, 47, 2097–2119. [Google Scholar] [CrossRef]
- Mazucheli, J.; Menezes, A.F.B.; Fernandes, L.B.; de Oliveira, R.P.; Ghitany, M.E. The unit-Weibull distribution as an alternative to the Kumaraswamy distribution for the modeling of quantiles conditional on covariates. J. Appl. Stat. 2020, 47, 954–974. [Google Scholar] [CrossRef]
- Altun, E. The log-weighted exponential regression model: Alternative to the beta regression model. Commun. Stat.-Theory Methods 2021, 50, 2306–2321. [Google Scholar] [CrossRef]
- Mirzadeh, S.; Iranmanesh, A. A new class of skew-logistic distribution. Math. Sci. 2019, 13, 375–385. [Google Scholar] [CrossRef] [Green Version]
- Dey, S.; Mazucheli, J.; Nadarajah, S. Kumaraswamy distribution: Different methods of estimation. Comput. Appl. Math. 2018, 37, 2094–2111. [Google Scholar] [CrossRef]
- Nigm, A.M.; Al-Hussaini, E.K.; Jaheen, Z.F. Bayesian one-sample prediction of future observations under Pareto distribution. Statistics 2003, 37, 527–536. [Google Scholar] [CrossRef]
- Linhart, H.; Zucchini, W. Model Selection; John Wiley Sons: Hoboken, NJ, USA, 1986. [Google Scholar]
- Bantan, R.A.; Chesneau, C.; Jamal, F.; Elgarhy, M.; Tahir, M.H.; Ali, A.; Zubair, M.; Anam, S. Some new facts about the unit-Rayleigh distribution with applications. Mathematics 2020, 8, 1954. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| n | ||||||
|---|---|---|---|---|---|---|
| 20 | 1.5 | 1 | 1 | 1.6977 (0.3829) | 1.0625 (0.1074) | 1.3455 (0.2259) |
| 1.5 | 2.5 | 1 | 1.7625 (0.4773) | 2.4766 (0.4686) | 1.3550 (0.4907) | |
| −2 | 1 | 0.5 | −1.8101 (0.4166) | 1.0638 (0.1090) | 0.8605 (0.4454) | |
| 3 | 2 | 4 | 3.0849 (0.6539) | 2.0994 (0.1882) | 4.1419 (1.0866) | |
| 5 | 4 | 6 | 4.3876 (3.0847) | 3.8286 (0.7388) | 6.4131 (3.2937) | |
| 30 | 1.5 | 1 | 1 | 1.6859 (0.3303) | 1.0602 (0.0911) | 1.3248 (0.2335) |
| 1.5 | 2.5 | 1 | 1.7364 (0.4327) | 2.4824 (0.3788) | 1.2900 (0.3991) | |
| −2 | 1 | 0.5 | −1.8222 (0.3509) | 1.0497 (0.0887) | 0.8521 (0.4058) | |
| 3 | 2 | 4 | 3.0685 (0.5513) | 2.0988 (0.1758) | 4.1102 (0.9704) | |
| 5 | 4 | 6 | 4.4552 (3.0493) | 3.8496 (0.6641) | 6.2602 (3.1702) | |
| 50 | 1.5 | 1 | 1 | 1.6675 (0.2621) | 1.0439 (0.0685) | 1.3241 (0.2327) |
| 1.5 | 2.5 | 1 | 1.6896 (0.3775) | 2.4642 (0.3013) | 1.2377 (0.3371) | |
| −2 | 1 | 0.5 | −1.8375 (0.3204) | 1.0449 (0.0694) | 0.8008 (0.3981) | |
| 3 | 2 | 4 | 3.0671 (0.5375) | 2.0633 (0.1155) | 4.0944 (0.8906) | |
| 5 | 4 | 6 | 4.6089 (2.9256) | 3.8809 (0.5423) | 6.3159 (2.9512) | |
| 100 | 1.5 | 1 | 1 | 1.6498 (0.1863) | 1.0336 (0.0508) | 1.2673 (0.1904) |
| 1.5 | 2.5 | 1 | 1.6414 (0.3251) | 2.4752 (0.2070) | 1.1693 (0.2482) | |
| −2 | 1 | 0.5 | −1.8869 (0.2727) | 1.0329 (0.0501) | 0.7207 (0.4003) | |
| 3 | 2 | 4 | 3.0612 (0.5065) | 2.0494 (0.0882) | 4.0814 (0.7698) | |
| 5 | 4 | 6 | 4.7179 (2.4738) | 3.9321 (0.4217) | 6.1701 (2.4982) | |
| 200 | 1.5 | 1 | 1 | 1.6055 (0.1407) | 1.0255 (0.0367) | 1.2033 (0.1506) |
| 1.5 | 2.5 | 1 | 1.6173 (0.2528) | 2.4899 (0.1435) | 1.1330 (0.1496) | |
| −2 | 1 | 0.5 | −1.9161 (0.2115) | 1.0246 (0.0367) | 0.6526 (0.3547) | |
| 3 | 2 | 4 | 3.0527 (0.4729) | 2.0395 (0.0652) | 4.0809 (0.6951) | |
| 5 | 4 | 6 | 4.8571 (1.7233) | 3.9687 (0.2688) | 6.0921 (1.6962) | |
| 500 | 1.5 | 1 | 1 | 1.5424 (0.0811) | 1.0135 (0.0213) | 1.0932 (0.0657) |
| 1.5 | 2.5 | 1 | 1.5315 (0.1407) | 2.4957 (0.0914) | 1.0526 (0.0784) | |
| −2 | 1 | 0.5 | −1.9879 (0.1547) | 1.0135 (0.0209) | 0.5145 (0.2679) | |
| 3 | 2 | 4 | 3.0489 (0.3303) | 2.0250(0.0427) | 4.0473 (0.4864) | |
| 5 | 4 | 6 | 4.8724 (1.3613) | 3.9602 (0.2689) | 6.0313 (1.3095) | |
| 1000 | 1.5 | 1 | 1 | 1.5134 (0.0551) | 1.0101 (0.0153) | 1.0196 (0.0142) |
| 1.5 | 2.5 | 1 | 1.5016 (0.1031) | 2.5001 (0.0642) | 1.0150 (0.0222) | |
| −2 | 1 | 0.5 | −1.9998 (0.1288) | 1.0104 (0.0156) | 0.5007 (0.2368) | |
| 3 | 2 | 4 | 3.0241 (0.2209) | 2.0162 (0.0285) | 4.0245 (0.3483) | |
| 5 | 4 | 6 | 4.9665 (0.9635) | 3.9914 (0.4599) | 6.0643 (1.0431) |
| Models | -Loglike | AIC | BIC | p-Value | ||||
|---|---|---|---|---|---|---|---|---|
| LTESL | −0.5314 | 0.5229 | 8.0339 | 39.8750 | 85.7499 | 91.4860 | 0.1360 | 0.2868 |
| Beta | 1.5924 | 8.1127 | - | 53.3012 | 110.6023 | 114.4264 | 0.1659 | 0.1137 |
| Kw | 1.4895 | 12.9468 | - | 55.1892 | 114.3783 | 118.2024 | 0.1706 | 0.0795 |
| UW | 0.0839 | 2.9690 | - | 49.9912 | 103.9823 | 107.8063 | 0.2014 | 0.0297 |
| ETL | 1.9888 | 9.6583 | - | 57.1006 | 118.2132 | 122.0372 | 0.1633 | 0.1242 |
| Models | -Loglike | AIC | BIC | p-Value | ||||
|---|---|---|---|---|---|---|---|---|
| LTESL | 0.0521 | 1.1282 | 5.5045 | 8.7928 | 23.5856 | 26.5728 | 0.0967 | 0.9828 |
| Beta | 0.7235 | 3.8239 | - | 17.2022 | 38.4404 | 40.4319 | 0.0990 | 0.9782 |
| Kw | 0.7748 | 3.4567 | - | 17.1707 | 38.3414 | 40.3329 | 0.0984 | 0.9797 |
| UW | 0.1546 | 1.7223 | - | 16.4145 | 36.8291 | 38.8205 | 0.1428 | 0.7580 |
| ETL | 0.7334 | 1.8797 | - | 17.1990 | 38.3979 | 40.3894 | 0.1075 | 0.9558 |
| Models | -Loglike | AIC | BIC | p-Value | ||||
|---|---|---|---|---|---|---|---|---|
| LTESL | −1.6004 | 1.0764 | 0.6850 | 9.2575 | 24.5150 | 28.7186 | 0.1253 | 0.6874 |
| Beta | 0.5082 | 1.3509 | - | 13. 429 | 30.4858 | 33.2882 | 0.1913 | 0.1953 |
| Kw | 0.5367 | 1.3541 | - | 13.5348 | 31.0696 | 33.8720 | 0.1879 | 0.2116 |
| UW | 0.2775 | 1.4576 | - | 15.1922 | 34.3845 | 37.1869 | 0.1733 | 0.2934 |
| ETL | 0.5239 | 0.8074 | - | 12.5732 | 29.1464 | 31.9487 | 0.2046 | 0.1406 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pang, L.; Tian, W.; Tong, T.; Chen, X. Logit Truncated-Exponential Skew-Logistic Distribution with Properties and Applications. Modelling 2021, 2, 776-794. https://doi.org/10.3390/modelling2040041
Pang L, Tian W, Tong T, Chen X. Logit Truncated-Exponential Skew-Logistic Distribution with Properties and Applications. Modelling. 2021; 2(4):776-794. https://doi.org/10.3390/modelling2040041
Chicago/Turabian StylePang, Liyuan, Weizhong Tian, Tingting Tong, and Xiangfei Chen. 2021. "Logit Truncated-Exponential Skew-Logistic Distribution with Properties and Applications" Modelling 2, no. 4: 776-794. https://doi.org/10.3390/modelling2040041
APA StylePang, L., Tian, W., Tong, T., & Chen, X. (2021). Logit Truncated-Exponential Skew-Logistic Distribution with Properties and Applications. Modelling, 2(4), 776-794. https://doi.org/10.3390/modelling2040041