Abstract
Deep neural networks have led to a substantial increase in multifaceted classification tasks by making use of large-scale and diverse annotated datasets. However, diverse optical coherence tomography (OCT) datasets in cardiovascular imaging remain an uphill task. This research focuses on improving the diversity and generalization ability of augmentation architectures while maintaining the baseline classification accuracy for coronary atrial plaques using a novel dual-generator and dynamically fused discriminator conditional generative adversarial network (DGDFGAN). Our method is demonstrated on an augmented OCT dataset with 6900 images. With dual generators, our network provides the diverse outputs for the same input condition, as each generator acts as a regulator for the other. In our model, this mutual regularization enhances the ability of both generators to generalize better across different features. The fusion discriminators use one discriminator for classification purposes, hence avoiding the need for a separate deep architecture. A loss function, including the SSIM loss and FID scores, confirms that perfect synthetic OCT image aliases are created. We optimize our model via the gray wolf optimizer during model training. Furthermore, an inter-comparison and recorded SSID loss of 0.9542 ± 0.008 and a FID score of 7 are suggestive of better diversity and generation characteristics that outperform the performance of leading GAN architectures. We trust that our approach is practically viable and thus assists professionals in informed decision making in clinical settings.
1. Introduction
Coronary artery disease (CAD) is a serious health challenge that is affecting a substantial number of individuals and imposes burdens on healthcare systems worldwide [1,2]. CAD is an artery narrowing and blockage, leading to severe complications like heart attacks and heart failure [3,4]. Collaborative efforts by researchers and professionals have resulted in advancements in treating and managing this disease. Evolving CAD prevention and management procedures embrace modern AI-driven architectures and cutting-edge diagnostics, including OCT [5,6,7]. OCT provides high-resolution images of the coronary artery walls for detailed analysis of plaque composition and identification of vulnerable plaques [8]. With OCT, different plaque components can be distinguished based on their optical properties, including fibrous tissue, lipid cores and calcium deposits [9]. OCT has enabled clinicians to detect vulnerable plaques and assess stent deployment efficacy with exceptional precision [10,11]. Recent studies have further expanded the role of OCT by integrating it with automated systems to improve diagnostic accuracy and risk stratification in CAD [12]. Moreover, intravascular imaging techniques, including OCT and intravascular ultrasound (IVUS), have been shown to complement each other in the assessment and management of CAD [13,14]. Despite its advantages, OCT faces limitations in the availability of diverse and annotated image datasets. Prior research has demonstrated that healed coronary plaques, imaged through OCT and validated histologically, exhibit considerable morphological variability, highlighting the need for synthetic data that reflect this diversity [15].
Recent advancements in artificial intelligence (AI) have enhanced the analysis of OCT imaging, particularly for plaque classification, and 3D reconstruction in CAD [16]. Techniques such as deep-learning-based identification of coronary calcifications [17] and automated diagnosis of plaque vulnerability [18] have demonstrated high diagnostic accuracy and potential for improving clinical outcomes. The integration of AI into cardiovascular imaging facilitates earlier detection and improved clinical decision making [19,20]. Moreover, AI-driven interpretation of coronary angiography and vulnerable plaque imaging has shown promise in enhancing image-based risk assessment and interventional planning [21,22]. However, the scarcity of diverse [23] and labeled OCT datasets [24] remains a critical limitation, restricting the generalizability and robustness of current AI models. In parallel, AI-based clinical decision support systems (CDSS) are evolving rapidly to incorporate such synthetic data for enhanced diagnostic reliability in real-world settings [25,26,27]. In [28], a fully automated, two-step deep-learning approach for characterizing coronary calcified plaque in intravascular optical coherence tomography (IVOCT) images is reported, where a 3D convolutional neural network (CNN) is used with a SegNet deep-learning model. Similarly, an automated atherosclerotic plaque characterization method that used a hybrid learning approach and self-attention-based U-Net architecture were reported elsewhere [29,30] for the better classification performance of coronary atrial plaques than existing methods.
Vision transformers (ViTs) are being employed for coronary plaque detection, especially in cases where global feature relationships are essential. In this regard, [31] explored the use of ViTs for coronary plaque detection, where ViTs outperformed CNN-based models for large datasets. Instead of relying on lumen segmentation, the proposed method identifies the bifurcation image using a ViT-based classification model and then estimates the bifurcation ostium points using a ViT-based landmark detection model. The performance of the proposed ViT-based models is 2.54% and 16.08% higher than that of traditional non-deep-learning methods [32]. For better generalization characteristics, a transformer-based pyramid network called AFS-TPNet was devised for robust, end-to-end segmentation of CCP from OCT images [33]. Researchers also used physics-informed deep network QOCT-Net to recover pixel-level optical attenuation coefficients directly from standard IVOCT B-scan images [34]. While these cutting-edge architectures delivered satisfactory results, from a clinical standpoint, acquiring large and diverse datasets of patients across different disease stages is stimulating, shadowing the real potential of proposed deep-learning architectures. To address this issue, data augmentation (DA) techniques were deployed to augment limited medical imaging training data that could be further fed to deep-learning algorithms for better insights. Generative adversarial networks (GANs) have offered promising solutions by generating high-quality images that closely resemble real OCT scans, thereby aiding in dataset augmentation, image enhancement and training of deep-learning classifiers. In [35], pseudo-labeling, using model predictions as labels for unlabeled data, was employed as a data augmentation technique. This method demonstrated improvements in model performance by increasing the effective size of the training dataset. The StyleGAN2 and Cyclic GAN frameworks were used to generate high-resolution synthetic patches for an improved data augmentation performance in cases of low data availability across three different OCT datasets, encompassing a range of scanning parameters [36,37]. To improvise generalization across different datasets, sparsity-constrained GANs with baseline accuracy are available in the literature [38].
However, recent works show that despite the high structural similarity between synthetic data and real images, a considerable distortion is observed in the frequency domain; therefore, dual- and triple-discriminator architectures, including Fourier acquisitive GAN (DDFA-GAN), have been proposed to generate more realistic OCT images [39,40,41]. By applying multiple discriminators, the proposed models were jointly trained with the Fourier and spatial details of the images, and the results were compared with popular GANs, including deep convolutional GAN (DCGAN), Wasserstein GAN with gradient penalty (WGAN-GP) and least-square GAN (LS-GAN). In [42], a multi-stage and multi-discriminatory generative adversarial network (Multi-SDGAN), designed specifically for super-resolution and segmentation of OCT scans, was proposed. This resulted in improved performance by satisfying all the discriminators at multiple scales and including a perceptual loss function. While the use of multiple discriminators in GANs has attracted much attention, due to overloading of a single generator in the network, the desired generalization and diversity in the generated images are still an ongoing problem.
The resolve of this study was to perform data augmentation on an OCT dataset using a novel dual-generator multiple-fusion discriminator network for synthesizing high-quality coronary images. The use of dual generators exploited in this paper helps achieve better generalization and generate a diversity of images of coronary arterial plaques. In our model, the two generators, G1 and G2, receive the same conditional input, y, but they generate different variations of the OCT images, as each generator acts as a regularizer for the other. In our model, one generator’s output can serve as a reference for improving the other, and this mutual regularization enhances the ability of both generators to generalize better across different features and conditions. Additionally, we avoided the need for a separate classification architecture and instead used a discriminator within our presented GAN architecture for classification of coronary atrial plaques into three classes. The objective functions of the generator and the five discriminators were set in competition against each other. We derived a novel objective function for DGDFGAN and optimized it during model training. This made the model training more stable and improved the quality and diversity of the generated images. Using assessments, we illustrated how populating real images with created instances during the training phase increased our confidence in reliable label prediction. Experimental results demonstrated that DGCGAN achieves optimal results in terms of the similarity and generalization characteristics. DGDFGAN offers a scalable and clinically applicable framework for OCT image synthesis and augmentation, as it directly tackles the core limitations of existing GAN-based methods and presents a promising path toward real-world clinical deployment of AI models with improved generalization and interpretability.
The main contributions of the paper are summarized as follows:
- A novel dual-generator architecture is designed using mutual regularization to achieve better generalization for OCT images of coronary arterial plaques. A discriminator (D1) within the network is used for classification, obviating the need for a separate classification architecture, resulting in computational efficiency.
- A novel architecture of dynamic multi-discriminator fusion is designed to play an adversarial game against two generators. We introduce a dynamic fusion mechanism to adjust the weighting of discriminators based on the specific conditions of the image.
- Essentially, we incorporate adversarial loss, perceptual loss, L1 loss, cross-entropy and diversity loss into our loss function for enhanced realism in the generated images.
2. Methods and Materials
Generally, CGAN takes two input data, namely the latent variable z and the conditional constraints, into both generator G and discriminator D, as illustrated in Figure 1. The G combines the initial noise input Z with label information to produce the generated output after reshaping to feature the transposed convolutions, batch normalization and activation functions, as presented in Figure 1. The final layer of the generator typically uses an activation function.
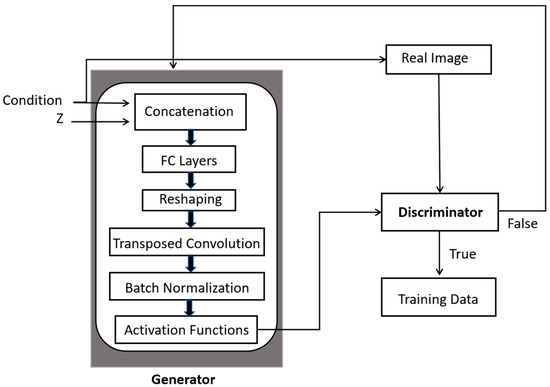
Figure 1.
A generic scheme of operations performed in CGANs for image augmentation.
2.1. OCT Dataset and Its Pre-Processing
A dataset of 51 patients was created using a commercially available OCT system. The OCT system available was the C7-XR (St. Jude Medical, St. Paul, MA, USA) using the C7 Dragonfly intravascular OCT catheter (St. Jude). This system provides spatial resolution up to 10 µm and tissue penetration up to 3 mm.
The focus of the study was on vessels affected by stenosis, though for simplicity, cases involving serial stenosis, mixed plaques and bypass graft stenosis were excluded. The ethical approval for this research was granted by the Galway Clinical Research Ethics Committee (GCREC), and informed consent was obtained from all participants.
Three clinicians independently annotated the OCT images, but final labels were determined through consensus agreement. The classification task was structured by designating a specific label in contrast to the others. Prior to model input, pre-processing steps were applied to the raw OCT images. Vulnerable plaques meeting the pre-defined fibrous cap thickness criteria were excluded from the analysis. Plaque characterization was based on signal intensity relative to the lumen, classifying plaques into three classes, namely “lipid plaques”, “calcified plaques” and “no plaque”. The pre-processing stage involved removal of motion artifacts, intensity normalization, cropping the region of interest to 256 × 256 and preparation of masks for fibrous, lipidic and calcified plaques.
2.2. Proposed Dual-Generator Multi-Fusion GAN
In our configuration of the dual generators presented in Figure 2A, each generator learns different plausible ways to generate an OCT image based on the same conditioning input y. The two generators G1 and G2 in Figure 2B learn to capture different aspects of the underlying OCT image structure. G1 focuses on capturing the fine details of the OCT image, while G2 emphasizes abstract features. This separation allows each generator to learn a different distribution, hence enabling more diverse image synthesis. Specifically, G1 is trained to simulate plaque-specific characteristics, such as fibrous, lipidic and calcified plaques. Conversely, G2 emphasizes structural consistency, image quality and perceptual realism.
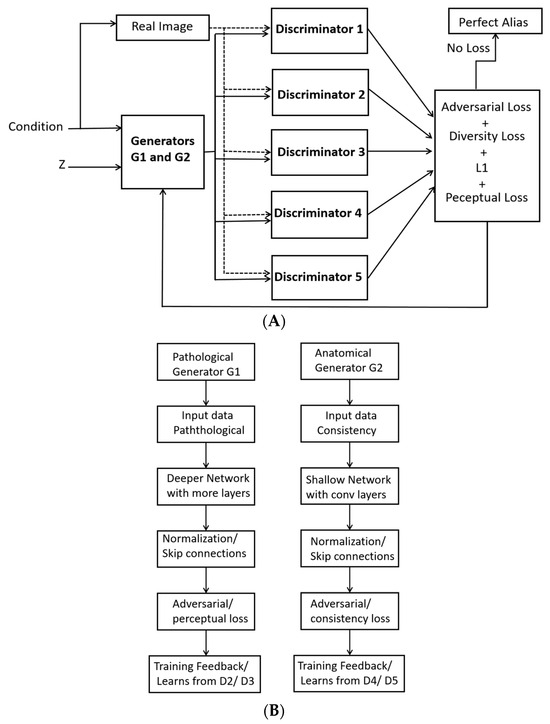
Figure 2.
Dual generators with fused multi-discriminators for generating synthetic images: (A) Pathological generator G1 and (B) Anatomical generator.
With dual generators, the risk of mode collapse is also reduced because each generator learns a distinct aspect of the data. In cases where one generator fails to cover the diversity of the distribution, the other generator fills in the missing modes, which helps ensure more realistic and varied synthetic OCT images. Likewise, the two generators learn different modes of data distribution, thus helping the model better generalize for unseen OCT data.
In the presented formulation, the role and parameters of each discriminator are illustrated in Figure 3. The ultimate aim of dynamic discriminator fusion is to improve the quality, realism and diversity of the generated OCT images. As presented in Figure 3, Discriminator 1 (D1) is used for the classification of coronary atrial plaques into three pre-defined classes, designed to focus on a different characteristic of the OCT image. D2 has the same architecture as D1 and is therefore represented by dotted lines. D2 evaluates the temporal consistency of the generated OCT images. D3 is a conditional discriminator that plays a critical role in enforcing conditional consistency during image generation. Specifically, D3 evaluates whether the generated OCT image accurately reflects the input condition y, such as a specific plaque type. During training, D3 receives both the generated image and its corresponding conditioning label, and its objective is to distinguish whether the image not only appears realistic but also corresponds correctly to the given condition. This ensures that the generator cannot produce arbitrary and mislabeled images, thereby maintaining semantic correctness and clinical reliability in the synthetic data.
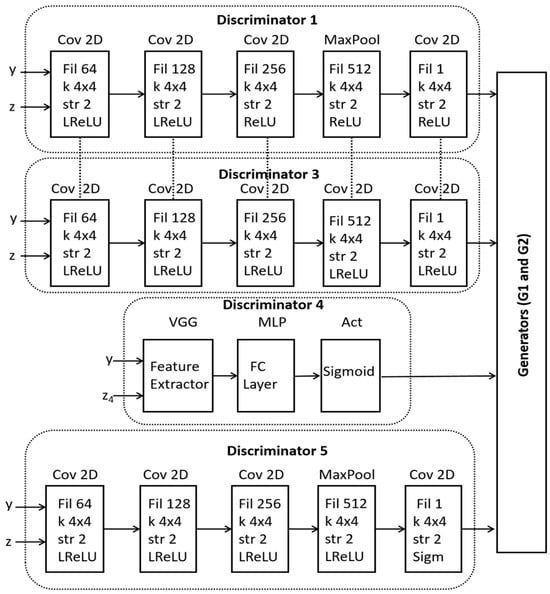
Figure 3.
A schematic of internal architectures within the dynamic fusion discriminators.
The role of D4 is to ensure global realism of the generated images by taking into account spatial and temporal features. D5 embeds perceptual loss, which is computed as the distance between the feature maps of the real and generated images. This loss is combined with the adversarial loss to guide the discriminators on high-level perceptual differences.
2.3. Mathematical Formulation
We use dual-generator CGANs and multi-discriminators for OCT synthetic image generation. The generator takes a latent vector z (random noise) and a label y, and it produces a synthetic OCT image x.
where z is the latent vector (random noise), y is the label, and x is the generated OCT image.
x = G (z, y)
The latent vector is sampled from a Gaussian distribution to introduce the variability into the generated images. In our model, z is a 1D latent vector of size 100, sampled from a standard Gaussian distribution. Vector z is concatenated with the condition vector y and passed through the generator, which outputs a 256 × 256 grayscale image. This latent vector controls diverse image synthesis, while y ensures class-specific structure.
The conditioning information in the form of one-hot vector, representing the class label of the OCT image, is concatenated with random noise z, which forms the initial input to the generators. Each discriminator receives the same generated image and label but has a slightly different focus in its evaluation. D1 is used for classification of the generated image using the expression given in Equation (2).
where represents the expected value (or average) of the output of the generator over the distribution of latent variables z; Pdata is the real data distribution; Pz is the distribution over the latent space; G(z) refers to the output blended image generated from a latent code z; and yc is the one-hot encoding vector indicating the true class of image x.
D2 performs label-specific evaluation of whether the generated image matches the expected distribution of the label using Equation (3).
where D2(x) is the probability that image x is real.
Discriminator 3 evaluates perceptual quality, which compares the high-level features of the generated and real images. This can be modeled using a perceptual loss based on the difference in feature representations between real and generated images, as given in Equation (4).
where x is the real OCT image; G(z) is the synthetic image generated from latent code z; and f(G(z)) indicates the features of the generated image.
Discriminator 4 evaluates the quality of the image, which can be linked to the luminance or image gradient loss. It attempts to measure how sharp and high-quality the generated images are using the L1 loss.
where x − G(z) denotes the L1 normalized between the real image x and the generated image G(z).
Discriminator 5 evaluates the consistency loss between the generated images to maintain style over different transformations of the input.
where z refers to a latent vector, and G−1(G(z)) represents the inverse transformation.
The total combined loss LT can be written as
where λ1 controls the importance of classification loss in Discriminator 1; λ2 controls the importance of realism loss via Discriminator 2; λ3 controls the importance of perceptual loss in Discriminator 3; λ4 controls the importance of quality loss in Discriminator 4; and λ5 controls the importance of consistency loss via Discriminator 5. The values of lambda optimized and used in the simulations for the expression in Equation (7) are = 0.7, = 1.1, = 0.2, = 0.3 and = 1.2. The lambda values were selected through a systematic hyperparameter tuning process. Initially, we conducted a grid search over a range of plausible values for each λ and the relative scale of each loss component in the preliminary experiments. The goal was to ensure that no single loss term dominated during training, which could lead to suboptimal convergence.
To refine these values, we monitored key performance metrics, including SSIM, FID and classification accuracy, across several validation runs. The chosen λ values yielded the best trade-off between image quality, structural fidelity and class-specific realism. Moreover, these values were cross-validated over multiple training runs to confirm their generalization across different subsets of the OCT dataset.
We use latent interpolation between the two generators to encourage diverse image generation. By interpolating between the latent space of G1 and G2, we force both generators to produce more diverse outputs, allowing them to explore a broader space of possibilities using Equation (9).
where z1 and z2 are two different latent codes, and α∈ [0, 1] is a blending factor that encourages diverse outputs. α modulates the latent vector before passing it to the generator. Its value is dynamic and sampled randomly from a distribution for the desired exploration in the latent space.
z′ = α·z1 + (1 − α)·z2
The generator now operates on the blended latent space, as outlined in Equation (10).
G1(z′∣y) and G2(z′∣y)
Gray wolf optimization (GWO) is used to explore the search space effectively for an optimal solution, where each wolf represents a candidate solution in the optimization space. We preferred GWO due to its adaptive exploration–exploitation balance and global search capabilities. This is particularly needed for our dual-generator framework, where balancing two generative paths is critical. GWO allows for more diverse convergence pathways and lower mode collapse frequency. Each wolf represents a set of parameters of the neural network, which is optimized by the GWO algorithm.
3. Results and Analysis
In this paper, the experiments were conducted according to the baseline architecture displayed in Figure 3. Our original dataset contained 27 “no plaque” images, 22 “calcified plaque” images and 20 “lipid plaque” images. After augmentation by a factor of 100, the dataset’s size was increased by 6900 images, with 2700 “no plaque” images, 2200 “calcified plaque” images and 2000 “lipid plaque” images. The samples generated by our model for each class are presented in Figure 4. Then, we applied cross-validation (10-CV) to estimate the generalization performance of the compared segmentation models on unseen data. During the implementation phase, the original OCT dataset acquired from real patients, labeled by experts and obtained under ethical approval/informed consent, was partitioned across all subsets. Overall, 60% of the images were used for training, 15% of the images were allocated for the validation phase, and the remaining 25% were used in the testing phase.
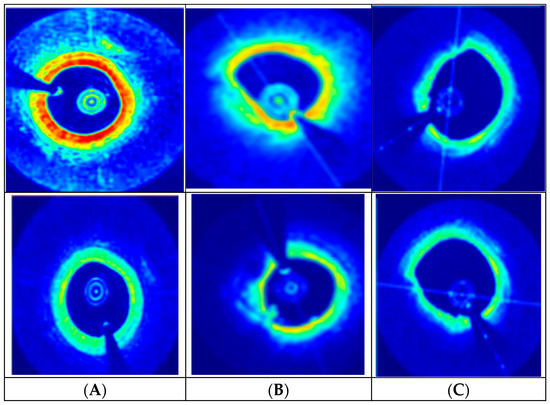
Figure 4.
DGDFGAN-generated synthetic images assigned to different classes: (A) Normal plaque, (B) Calcified plaque, (C) Lipid plaque.
From a clinical perspective, the images generated by the proposed model, as indicated in Figure 4, offer significant improvements in terms of realism and diagnostic utility as compared to conventional GAN-centric augmentation methods. The blue zones in Figure 4 indicate the background with low backscatter intensity and represent areas farther from the catheter probe. The red zones are highly backscattering regions, indicating the presence of plaques. Further green zones are interfaces between dense and plaque-rich areas. The proposed model achieves greater diversity in synthetic OCT data generation as compared to reported GAN architectures due to its modular and task-specific design. The introduction of two distinct generators allows the model to independently and effectively capture the complex interplay between plaque types and baseline anatomical variability. Similarly, unlike conventional models that generate images from a single latent space, this framework leverages dual latent distributions and supports an interpolation via a blending coefficient (α). This mechanism enables the model to produce a continuum of clinically relevant OCT synthetic samples with high diversity.
The DGDFGAN model is used for experimentation, and we tried different combinations where the multi-stage aspect or the multi-discriminatory aspect was treated incrementally. During the training phase, each loss weight parameter (λ1–λ5) controls the relative standing of specific learning objectives, and their values directly influence the features to be emphasized. Similarly, the latent interpolation factor (α) and the blend factor define the relative contribution of each generator in the final image. Similarly, the learning rate and GWO were used for stable and adaptive convergence. The learning rate tuning dictates how responsively G1 and G2 adapt to the feedback from their respective discriminators. The extended OCT dataset offered high diversity, clinical realism and controlled augmentation, leading to more robust training for classification.
We analyzed the structural similarity index measure (SSIM) loss and the Fréchet inception distance (FID) score as an additional cost function. All experiments were run for 100 epochs for each fold. The SSIM index is a metric that evaluates the degradation of images from a perceptual point of view, and the FID score underlines the diversity impact. We also included the L1 loss over 10-fold cross-validation (10-CV). L1 loss measures the absolute difference between predicted and ground-truth values. It is used to enforce pixel-wise similarity in image generation tasks.
An inter-comparison of our proposed model with the cutting-edge Multi-SDGAN model is presented in Table 1 in terms of SSIM, L1 and FID scores. It is evident that employing the dual generator and multi-discriminatory fusion module improves the performance in both similarity and diversity aspects. The dual generator helps in achieving an improved diversity in the generated images, as each generator focuses on different aspects of OCT image synthesis. This reduces mode collapse, where a single generator might otherwise get stuck producing similar images. Each generator interacts with different discriminators, ensuring that features are well learned from multiple perspectives for an enhanced feature representation. By training on different discriminators, the generators learn robust representations that can generalize better to unseen OCT images. As illustrated in Table 2, the two generators share the load, leading to faster convergence, resulting in lower FID (better realism) and higher SSIM (better structural similarity) compared to other approaches, including DDFAGAN, MHWGAN and Multi-SDGAN.

Table 1.
An inter-comparison of our proposed model with the leading architectures.
Table 2.
An inter-comparison on the basis of the number of discriminators in our proposed model with the leading architectures in our augmented OCT dataset.
We computed the SSIM loss, which is a perceptual loss function for evaluating the similarity between the original and generated OCT images. It exploits contrast and structure rather than merely pixel-wise differences. The algorithm and description of related parameters are presented in Figure 5.
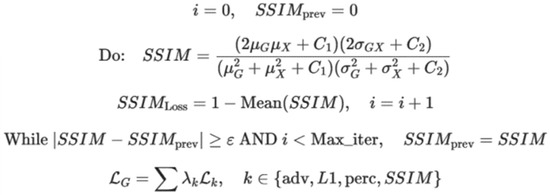
Figure 5.
The algorithm used to compute SSIM loss and the description of involved parameters.
In Figure 5, i represents the iteration counter; SSIMprev is the SSIM value from previous iteration; G is the generated image; x is the real image; μG, μx is the mean intensity of the generated and real images; σ2Gσ2x is the variance of the generated and real images; σGx is the covariance between the generated and real images; C1, C2 are the constants to stabilize calculations; SSIM indicates the structural similarity index; SSIMLoss is defined as 1-SSIM; ε is the convergence threshold; Maxiter are the maximum iterations; LG is the generator loss; and λk represents the weight coefficients for each loss term.
The FID score is used to measure similarity between the generated images and real OCT images by comparing their feature distributions. It exploits the mean and covariance of the feature embeddings. FID considers both realism and diversity in order to create a better generative model. The algorithm used and the relevant variables are illustrated in Figure 6.
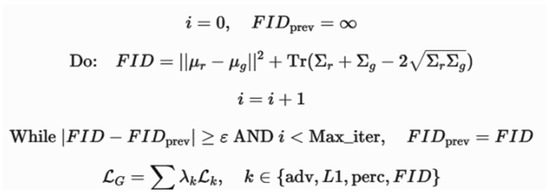
Figure 6.
The algorithm used to compute the FID score and the description of involved parameters.
In Figure 6, i represents the iteration counter; FIDprev is the FID score from previous iteration; μr,∑r is the mean and covariance of real image feature representations; μg,∑g is the mean and covariance of the generated images; ∑r,∑g are the covariance matrices of real and generated images; represents the differences in feature distributions; ε is the convergence threshold; Maxiter are the maximum iterations; LG is the generator loss; and λk represents the weight coefficients for each loss term.
As illustrated in Table 2, an increase of 10.81% in the SSIM index was observed as compared to leading SSIM measurements in the case of Multi-SDGAN [42]. This is indicative of achieving better structural similarity between the original and generated OCT images. An improvement of 41.66% in the FID score with baseline results of Multi-SDGAN confirms that our model significantly reduces the difference between the feature distributions of real and generated images. The L1 score reported in Table 2 is further suggestive of the fact that our model predictions are close to the ground truth. The dual-generator setup mitigates the problem of biased learning, where a single generator struggles to capture all variations in the OCT dataset. By working in parallel, the generators foster a more comprehensive understanding of data distribution. Consequently, the multi-discriminator framework enhances the FID scores by ensuring a richer adversarial signal to produce images with better realism and diversity. We run simulations for computational cost/inference latency and accuracy to assess the feasibility of real-world clinical deployment, as presented in Figure 7. DGDFGAN incurs higher computational cost (~2.3× baseline), primarily due to the dual generators and dynamic fusion of five discriminators. Latency increases to 78 ms per image (from a 40 ms baseline), still within acceptable limits for real-time clinical use (typically <100 ms). Despite higher latency, DGDFGAN shows a notable boost in classification accuracy, which supports its deployment in high-stakes clinical environments.
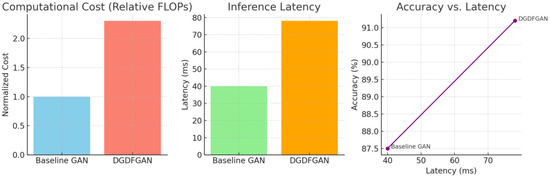
Figure 7.
Plots of computational cost and inference latency for validating the feasibility of real-world clinical deployment.
As indicated in Figure 8, the baseline GAN shows faster loss reduction initially but exhibits more fluctuations across training epochs. DGDFGAN demonstrates smoother convergence with reduced noise due to the mutual regularization effect of the dual generators and the stabilizing influence of multiple discriminators. Similarly, the baseline GAN has higher and more oscillating variance, implying unstable synthesis behavior, whereas DGDFGAN maintains a lower and more stable variance over time. It can be inferred from Figure 8 that the dual-generator and multi-discriminator framework effectively reduces instability by covering diverse feature distributions while regulating each other’s outputs. Our model allows for customization of plaque scenarios, which is not feasible with monolithic generators, especially in low-resource settings. However, the presented model is computationally intensive and contingent upon the biases in the source dataset, as indicated in Table 3. Additionally, a sophisticated control scheme is required to handle the disentanglement of anatomical and pathological features.
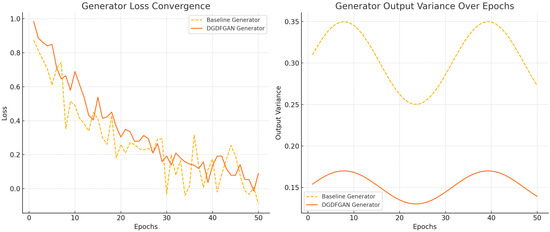
Figure 8.
The convergence and variance plots for our proposed DGDFGAN model.
Table 3.
An inter-comparison with leading models in terms of computational efficiency and training time per epoch.
As illustrated in Table 3, Pix2Pix GAN uses a single generator and a discriminator, which lack the detailed attention and diversity that are provided by ensemble models. However, networks like CycleGAN and StyleGAN can produce diverse outputs through multi-domain learning, but they fail to capture the extent of specialization in different domains. DDFA-GAN and Multi-SDGAN were re-implemented following their original architecture specifications, with hyperparameters tuned to match our dataset’s size and characteristics. StyleGAN2 was implemented using the official open-source codebase and fine-tuned on our OCT dataset, with modifications to the input resolution and training steps to align with our dual-generator setup. To ensure a fair comparison, all models were trained under identical data splits, hardware conditions and evaluation metrics (FID, SSIM and classification accuracy). The proposed model uses five discriminators, each focusing on different aspects of the generated images, hence guiding the generators to explore different features of the image space for broader diversity.
Our approach, while data-constrained, is designed to maximize diversity and realism through dual generators that explicitly model distinct features. To address pathological variability, two expert cardiologists blindly assessed 200 randomly sampled synthetic images. The box plot in Figure 9 represents the distribution of realism scores assigned by expert cardiologists to both real and synthetic OCT images, rated on a 5-point Likert scale. Real images consistently scored higher, with minimal variability and a median close to 4.5. In contrast, synthetic images, although scoring slightly lower in median realism (4.3), still fell within an acceptable range for clinical use. The wider interquartile range of synthetic images suggests slightly more variability in expert perception. Nonetheless, the overlap between the score distributions of real and synthetic images supports the claim that the synthetic data generated by the DGDFGAN framework achieve near-realistic visual fidelity.
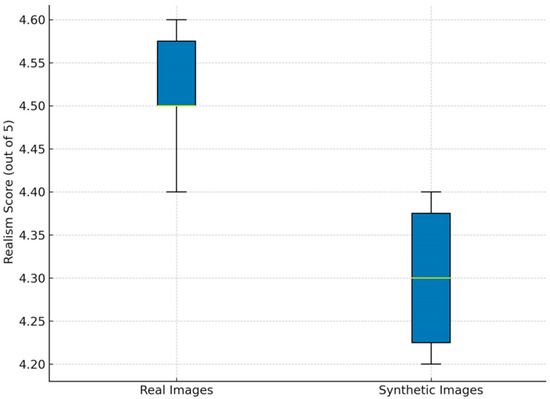
Figure 9.
An expert realism score for real and synthetic OCT images.
Figure 10 compares the misclassification rates for three plaque types when models are trained on real versus synthetic OCT images. For real images, the misclassification rates are low across all plaque types, with fibrous plaques at 2% and lipidic and calcified plaques at 1% each. Synthetic images show a slightly higher rate, with fibrous plaques at 4%, lipidic plaques at 3% and calcified plaques at 2%. Despite this modest increase, the misclassification rates remain within clinically acceptable thresholds. The ablation study evaluates several configurations that are derived from our proposed model for OCT image augmentation in terms of diversity, accuracy and realism. The results are presented in Figure 11, where the baseline model is compared with different settings, including three optimized scenarios.
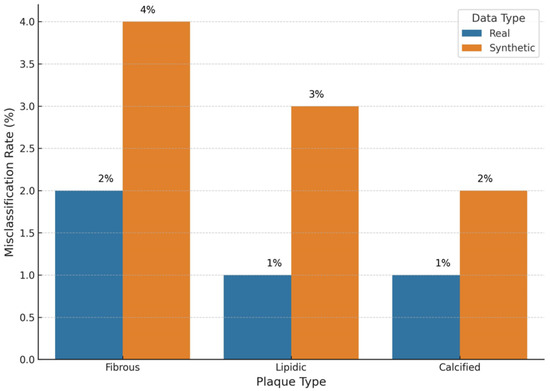
Figure 10.
An inter-comparison of plaque type misclassifications.
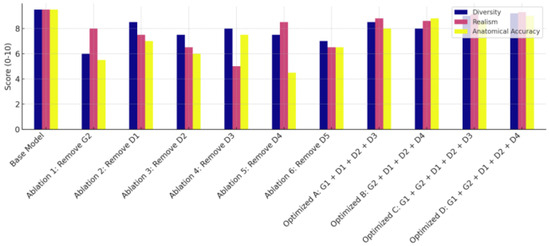
Figure 11.
Ablation study results including the optimized scenarios (A, B, C, D) for the proposed model.
The baseline configuration, integrating both generators (G1 and G2) with all five discriminators, delivers the best diversity, realism and highest performance across all metrics. It achieves a PSNR of 28.7 dB, a SSIM value of 0.94, a FID score of 9.6 and a Dice score of 0.91. This configuration outperforms every other variant and is indicative of component synergy. In Ablation 1, where G2 (the anatomical generator) is removed, the model achieves a PSNR of 26.1 dB, a SSIM value of 0.89, a FID score of 14.3 and a Dice score of 0.84. The drop in the SSIM and Dice score suggests diminished anatomical fidelity. The removal of D1 in Ablation 2 results in a PSNR of 27 dB, a SSIM of 0.91 and FID and Dice scores of 12.8 and 0.87, respectively. While image quality remains decent, the classification performance suffers, indicating that D1 is essential for ensuring class-discriminative features in the synthetic images. Removing D2 in Ablation 3 results in PSNR = 27.2 dB, SSIM = 0.90, FID = 13.1 and Dice score = 0.86. This moderate drop indicates that local fine-grained textures are compromised. The Ablation 4 version achieves PSNR = 26.5 dB, SSIM = 0.88, FID = 15.0 and Dice score = 0.83. The removal of D3 drastically impacts visual quality, increasing the FID score and reducing PSNR. The setup of Ablation 5 produces PSNR = 26.3 dB, SSIM = 0.87, FID = 14.7 and Dice score = 0.82. The low SSIM and Dice score reflect disruption in OCT layer alignment, whereas the removal of D5 in Ablation 6 negatively impacts perceptual quality.
The optimized scenarios A, B, C and D were examined, with scenario A only including G1, D1, D2 and D3. This scenario exhibits PSNR = 27.3 dB, SSIM = 0.91, FID = 12.2 and Dice score = 0.87. Scenario B only includes G2, D1, D3 and D4, with PSNR = 27.4 dB, SSIM = 0.92, FID = 11.8 and Dice score = 0.88. Configuration C only takes into consideration G1, G2, D1, D2 and D3 while discarding other blocks. The implementation of scenario D for optimized ablation embeds G1, G2, D1, D3 and D5, with PSNR = 27.9 dB, SSIM = 0.92, FID = 10.4 and Dice score = 0.88. All ablation configurations, including scenarios A, B, C and D, perform reasonably well, but they underperform compared with the proposed baseline model.
4. Conclusions
We presented DGDFGAN, a dual-generator GAN architecture that enhances diversity and generalization in synthetic OCT image generation. The two generators mutually regularize each other and improve image variability, while a built-in discriminator handles plaque classification. Our model achieved a SSIM loss of 0.9542 ± 0.008 and a FID score of 7, outperforming baseline GANs in image realism and diversity. Expert evaluation rated synthetic images 4.3/5 for realism, with misclassification rates below 5% across plaque types. These results confirm DGDFGAN’s potential to improve AI training datasets for reliable clinical decision support in OCT imaging.
Author Contributions
J.Z. and H.Z.; Methodology, J.Z., F.S. and H.Z.; Software, J.Z.; Validation, J.Z. and H.Z.; Formal analysis, J.Z. and H.Z.; Investigation, J.Z., F.S. and H.Z.; Resources, H.Z. Data curation, F.S.; Writing—original draft, J.Z., F.S. and H.Z.; Visualization, H.Z.; Supervision, H.Z.; Project administration, H.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The data presented in this study are available on request from the corresponding author.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Borrelli, N.; Merola, A.; Barracano, R.; Palma, M.; Altobelli, I.; Abbate, M.; Papaccioli, G.; Ciriello, G.D.; Liguori, C.; Sorice, D.; et al. The Unique Challenge of Coronary Artery Disease in Adult Patients with Congenital Heart Disease. J. Clin. Med. 2024, 13, 6839. [Google Scholar] [CrossRef]
- Available online: https://www.cdc.gov/heart-disease/about/coronary-artery-disease.html (accessed on 1 June 2025).
- Available online: https://www.ncbi.nlm.nih.gov/books/NBK355309/ (accessed on 1 June 2025).
- Młynarska, E.; Czarnik, W.; Fularski, P.; Hajdys, J.; Majchrowicz, G.; Stabrawa, M.; Rysz, J.; Franczyk, B. From Atherosclerotic Plaque to Myocardial Infarction—The Leading Cause of Coronary Artery Occlusion. Int. J. Mol. Sci. 2024, 25, 7295. [Google Scholar] [CrossRef]
- Yang, D.; Ran, A.R.; Nguyen, T.X.; Lin, T.P.H.; Chen, H.; Lai, T.Y.Y.; Tham, C.C.; Cheung, C.Y. Deep Learning in Optical Coherence Tomography Angiography: Current Progress, Challenges, and Future Directions. Diagnostics 2023, 13, 326. [Google Scholar] [CrossRef]
- Zafar, H.; Zafar, J.; Sharif, F. Automated Clinical Decision Support for Coronary Plaques Characterization from Optical Coherence Tomography Imaging with Fused Neural Networks. Optics 2022, 3, 8–18. [Google Scholar] [CrossRef]
- Zafar, H.; Zafar, J.; Sharif, F. GANs-Based Intracoronary Optical Coherence Tomography Image Augmentation for Improved Plaques Characterization Using Deep Neural Networks. Optics 2023, 4, 288–299. [Google Scholar] [CrossRef]
- Available online: https://onlinelibrary.wiley.com/doi/full/10.1002/tbio.201900034 (accessed on 1 June 2025).
- Available online: https://iopscience.iop.org/article/10.1088/2057-1976/aab640/meta (accessed on 1 June 2025).
- Araki, M.; Park, S.J.; Dauerman, H.L.; Uemura, S.; Kim, J.S.; Di Mario, C.; Johnson, T.W.; Guagliumi, G.; Kastrati, A.; Joner, M.; et al. Optical coherence tomography in coronary atherosclerosis assessment and intervention. Nat. Rev. Cardiol. 2022, 19, 684–703. [Google Scholar] [CrossRef] [PubMed]
- Oosterveer, T.T.M.; van der Meer, S.M.; Scherptong, R.W.C.; Jukema, J.W. Optical Coherence Tomography: Current Applications for the Assessment of Coronary Artery Disease and Guidance of Percutaneous Coronary Interventions. Cardiol. Ther. 2020, 9, 307–321. [Google Scholar] [CrossRef]
- Kumar, S.; Chu, M.; Sans-Roselló, J.; Fernández-Peregrina, E.; Kahsay, Y.; Gonzalo, N.; Salazar, C.H.; Alfonso, F.; Tu, S.; Garcia-Garcia, H.M. In-Hospital Heart Failure in Patients With Takotsubo Cardiomyopathy Due to Coronary Artery Disease: An Artificial Intelligence and Optical Coherence Tomography Study. Cardiovasc. Revascularization Med. 2023, 47, 40–45. [Google Scholar] [CrossRef]
- Mintz, G.S.; Guagliumi, G. Intravascular imaging in coronary artery disease. Lancet 2017, 390, 793–809. [Google Scholar] [CrossRef]
- Matthews, S.D.; Frishman, W.H. A Review of the Clinical Utility of Intravascular Ultrasound and Optical Coherence Tomography in the Assessment and Treatment of Coronary Artery Disease. Cardiol. Rev. 2017, 25, 68–76. [Google Scholar] [CrossRef]
- Shimokado, A.; Matsuo, Y.; Kubo, T.; Nishiguchi, T.; Taruya, A.; Teraguchi, I.; Shiono, Y.; Orii, M.; Tanimoto, T.; Yamano, T.; et al. In vivo optical coherence tomography imaging and histopathology of healed coronary plaques. Atherosclerosis 2018, 275, 35–42. [Google Scholar] [CrossRef]
- Carpenter, H.J.; Ghayesh, M.H.; Zander, A.C.; Li, J.; Di Giovanni, G.; Psaltis, P.J. Automated Coronary Optical Coherence Tomography Feature Extraction with Application to Three-Dimensional Reconstruction. Tomography 2022, 8, 1307–1349. [Google Scholar] [CrossRef] [PubMed]
- Avital, Y.; Madar, A.; Arnon, S.; Koifman, E. Identification of coronary calcifications in optical coherence tomography imaging using deep learning. Sci. Rep. 2021, 11, 11269. [Google Scholar] [CrossRef] [PubMed]
- Niioka, H.; Kume, T.; Kubo, T.; Soeda, T.; Watanabe, M.; Yamada, R.; Sakata, Y.; Miyamoto, Y.; Wang, B.; Nagahara, H.; et al. Automated diagnosis of optical coherence tomography imaging on plaque vulnerability and its relation to clinical outcomes in coronary artery disease. Sci. Rep. 2022, 12, 14067. [Google Scholar] [CrossRef]
- Yoon, M.; Park, J.J.; Hur, T.; Hua, C.-H.; Hussain, M.; Lee, S.; Choi, D.-J. Application and Potential of Artificial Intelligence in Heart Failure: Past, Present, and Future. Int. J. Hear. Fail. 2023, 6, 11–19. [Google Scholar] [CrossRef]
- Molenaar, M.A.; Selder, J.L.; Nicolas, J.; Claessen, B.E.; Mehran, R.; Bescós, J.O.; Schuuring, M.J.; Bouma, B.J.; Verouden, N.J.; Chamuleau, S.A.J. Current State and Future Perspectives of Artificial Intelligence for Automated Coronary Angiography Imaging Analysis in Patients with Ischemic Heart Disease. Curr. Cardiol. Rep. 2022, 24, 365–376. [Google Scholar] [CrossRef]
- Föllmer, B.; Williams, M.C.; Dey, D.; Arbab-Zadeh, A.; Maurovich-Horvat, P.; Volleberg, R.H.J.A.; Rueckert, D.; Schnabel, J.A.; Newby, D.E.; Dweck, M.R.; et al. Roadmap on the use of artificial intelligence for imaging of vulnerable atherosclerotic plaque in coronary arteries. Nat. Rev. Cardiol. 2024, 21, 51–64. [Google Scholar] [CrossRef]
- Seetharam, K.; Min, J.K. Artificial Intelligence and Machine Learning in Cardiovascular Imaging. Methodist DeBakey Cardiovasc. J. 2020, 16, 263–271. [Google Scholar] [CrossRef]
- Langlais, É.L.; Thériault-Lauzier, P.; Marquis-Gravel, G.; Kulbay, M.; So, D.Y.; Tanguay, J.-F.; Ly, H.Q.; Gallo, R.; Lesage, F.; Avram, R. Novel Artificial Intelligence Applications in Cardiology: Current Landscape, Limitations, and the Road to Real-World Applications. J. Cardiovasc. Transl. Res. 2023, 16, 513–525. [Google Scholar] [CrossRef]
- Thomas, T.; Kurian, A.N. Artificial Intelligence of Things for Early Detection of Cardiac Diseases. In Machine Learning for Critical Internet of Medical Things; Al-Turjman, F., Nayyar, A., Eds.; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Chen, S.-F.; Loguercio, S.; Chen, K.-Y.; Lee, S.E.; Park, J.-B.; Liu, S.; Sadaei, H.J.; Torkamani, A. Artificial Intelligence for Risk Assessment on Primary Prevention of Coronary Artery Disease. Curr. Cardiovasc. Risk Rep. 2023, 17, 215–231. [Google Scholar] [CrossRef]
- Bozyel, S.; Şimşek, E.; Koçyiğit Burunkaya, D.; Güler, A.; Korkmaz, Y.; Şeker, M.; Ertürk, M.; Keser, N. Artificial Intelligence-Based Clinical Decision Support Systems in Cardiovascular Diseases. Anatol. J. Cardiol. 2024, 28, 74–86. [Google Scholar] [CrossRef] [PubMed]
- Tang, K.X.; Wu, Y.L.; Shan, S.K.; Yuan, L.Q. Advancements in the application of deep learning for coronary artery calcification. Meta-Radiol. 2025, 3, 100134. [Google Scholar] [CrossRef]
- Lee, J.; Gharaibeh, Y.; Kolluru, C.; Zimin, V.N.; Dallan, L.A.P.; Kim, J.N.; Bezerra, H.G.; Wilson, D.L. Segmentation of Coronary Calcified Plaque in Intravascular OCT Images Using a Two-Step Deep Learning Approach. IEEE Access 2020, 8, 225581–225593. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.; Prabhu, D.; Kolluru, C.; Gharaibeh, Y.; Zimin, V.N.; Dallan, L.A.; Bezerra, H.G.; Wilson, D.L. Fully automated plaque characterization in intravascular OCT images using hybrid convolutional and lumen morphology features. Sci. Rep. 2020, 10, 2596. [Google Scholar] [CrossRef]
- Tang, H.; Zhang, Z.; He, Y.; Shen, J.; Zheng, J.; Gao, W.; Sadat, U.; Wang, M.; Wang, Y.; Ji, X.; et al. Automatic classification and segmentation of atherosclerotic plaques in the intravascular optical coherence tomography (IVOCT). Biomed. Signal Process. Control. 2023, 85, 104888. Infact 16. Available online: https://www.sciencedirect.com/science/article/abs/pii/S174680942300321X (accessed on 1 June 2025). [CrossRef]
- Li, X.; Cao, S.; Liu, H.; Yao, X.; Brott, B.C.; Litovsky, S.H.; Song, X.; Ling, Y.; Gan, Y. Multi-Scale Reconstruction of Undersampled Spectral-Spatial OCT Data for Coronary Imaging Using Deep Learning. IEEE Trans. Biomed. Eng. 2022, 69, 3667–3677. [Google Scholar] [CrossRef]
- Zhu, R.; Li, Q.; Ding, Z.; Liu, K.; Lin, Q.; Yu, Y.; Li, Y.; Zhou, S.; Kuang, H.; Jiang, J.; et al. Bifurcation detection in intravascular optical coherence tomography using vision transformer based deep learning. Phys. Med. Biol. 2024, 69, 155009. [Google Scholar] [CrossRef]
- Liu, Y.; Nezami, F.R.; Edelman, E.R. A transformer-based pyramid network for coronary calcified plaque segmentation in intravascular optical coherence tomography images. Comput. Med Imaging Graph. 2024, 113, 102347. [Google Scholar] [CrossRef]
- Zheng, S.; Shuyan, W.; Yingsa, H.; Meichen, S. QOCT-Net: A Physics-Informed Neural Network for Intravascular Optical Coherence Tomography Attenuation Imaging. IEEE J. Biomed. Health Inform. 2023, 27, 3958–3969. [Google Scholar] [CrossRef]
- Pokhrel, S.; Bhandari, S.; Vazquez, E.; Shrestha, Y.R.; Bhattarai, B. Cross-Task Data Augmentation by Pseudo-Label Generation for Region Based Coronary Artery Instance Segmentation. arXiv 2024, arXiv:2310.05990. Available online: https://arxiv.org/abs/2310.05990 (accessed on 1 June 2025).
- Kugelman, J.; Alonso-Caneiro, D.; Read, S.A.; Vincent, S.J.; Collins, M.J. Enhancing OCT patch-based segmentation with improved GAN data augmentation and semi-supervised learning. Neural Comput. Appl. 2024, 36, 18087–18105. [Google Scholar] [CrossRef]
- Li, X.; Shamouil, A.; Hou, X.; Brott, B.C.; Litovsky, S.H.; Ling, Y.; Gan, Y. Cross-Platform Super-Resolution for Human Coronary Oct Imaging Using Deep Learning. In Proceedings of the 2024 IEEE International Symposium on Biomedical Imaging (ISBI), Athens, Greece, 27–30 May 2024; pp. 1–5. [Google Scholar]
- Zhou, K.; Gao, S.; Cheng, J.; Gu, Z.; Fu, H.; Tu, Z.; Yang, J.; Zhao, Y.; Liu, J. Sparse-Gan: Sparsity-Constrained Generative Adversarial Network for Anomaly Detection in Retinal OCT Image. In Proceedings of the 2020 IEEE 17th International Symposium on Biomedical Imaging (ISBI), Iowa City, IA, USA, 3–7 April 2020; pp. 1227–1231. [Google Scholar]
- Ma, J.; Xu, H.; Jiang, J.; Mei, X.; Zhang, X.P. DDcGAN: A Dual-Discriminator Conditional Generative Adversarial Network for Multi-Resolution Image Fusion. IEEE Trans. Image Process. 2020, 29, 4980–4995. [Google Scholar] [CrossRef]
- Tajmirriahi, M.; Kafieh, R.; Amini, Z.; Lakshminarayanan, V. A Dual-Discriminator Fourier Acquisitive GAN for Generating Retinal Optical Coherence Tomography Images. IEEE Trans. Instrum. Meas. 2022, 71, 5015708. [Google Scholar] [CrossRef]
- Zhao, C.; Yang, P.; Zhou, F.; Yue, G.; Wang, S.; Wu, H.; Chen, J.; Wang, T.; Lei, B. MHW-GAN: Multidiscriminator Hierarchical Wavelet Generative Adversarial Network for Multimodal Image Fusion. IEEE Trans. Neural Netw. Learn. Syst. 2024, 35, 13713–13727. [Google Scholar] [CrossRef]
- Jeihouni, P.; Dehzangi, O.; Amireskandari, A.; Rezai, A.; Nasrabadi, N.M. MultiSDGAN: Translation of OCT Images to Superresolved Segmentation Labels Using Multi-Discriminators in Multi-Stages. IEEE J. Biomed. Health Inform. 2022, 26, 1614–1627. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).