

Optimized Interdisciplinary Research Team Formation Using a Genetic Algorithm and Publication Metadata Records

 , , , and
, , , and 
Abstract
1. Introduction
- The number of bibliometric metadata considered by the data-driven team formation methodology is increased by utilizing the number of citations and downloads, authors’ affiliations, and publication abstract in deriving the candidates’ personal and interpersonal skills.
- A theoretical model is proposed that describes the collaborative work of research teams that participate in interdisciplinary research. Teams are formed out of the representatives of the groups with diverse expertise. Then, the research work is carried out in collaborative environments to frame and analyze interdisciplinary needs, and in individual environments, when groups work quasi-independently on problems in their areas of expertise. The collaborative behavior is expressed by the cognitive contributions and social interactions that emerge during team and group work.
- Four novel synthetic indicators are provided to effectively describe experts’ knowledge and their collaborative prospects. The indicators reflect the features of the above theoretical model, and are computed from the bibliometric metadata.
- A novel multi-objective team formation optimization method is suggested that includes the candidate-related indicators calculated using bibliometric data.
- The proposed methodology is validated for a specified case study on forming an interdisciplinary research team.
2. Related Work
2.1. Team Formation Approaches Using Bibliometric Data
2.2. Evaluating Scholars’ Characteristics
3. Research Team Formation Based on Bibliometric Data
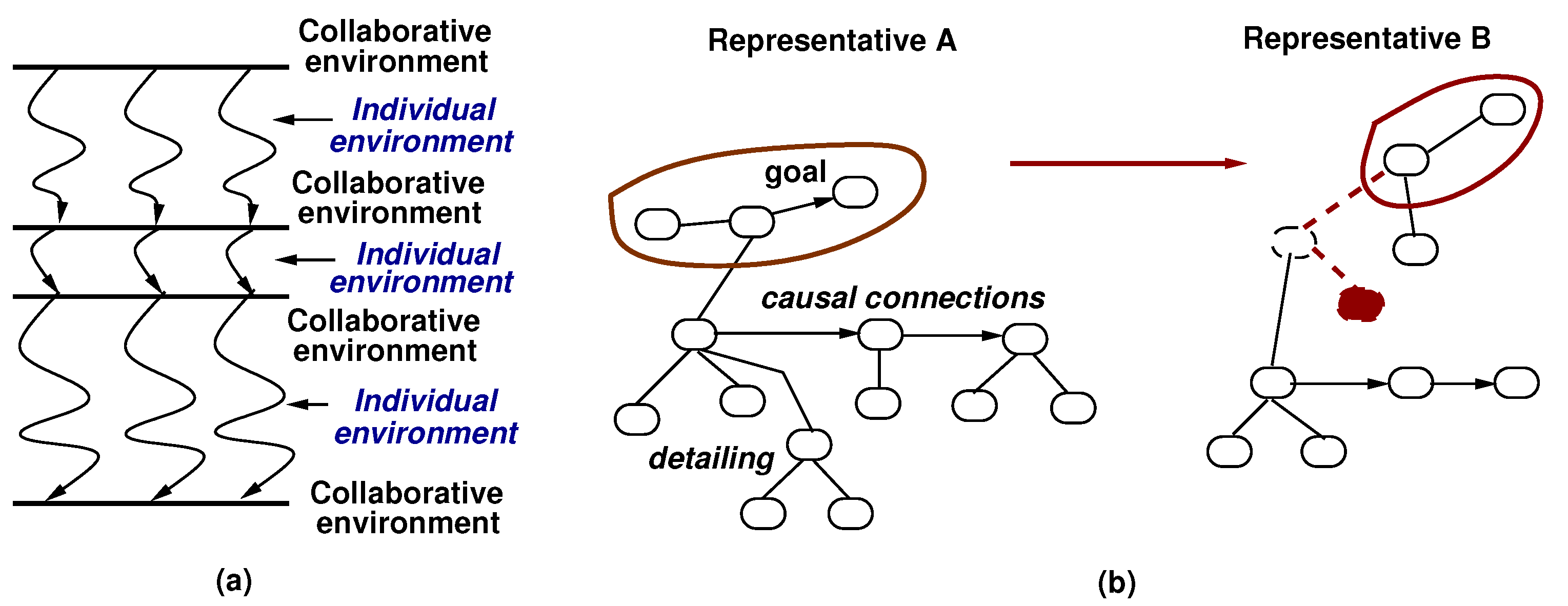
3.1. A Theoretical Model for Collaborative Work on Interdisciplinary Research Problems
- (1) <CE, , , >, (2) <CE, , , >,
- (3) <CE, , , >, (4) <CE, , , >,
- (5) <CE, , , >, (6) <CE, , , >,
- (7) <CE, , , >, (8) <CE, , , >,
- (9) <IE, , , >, (10) <IE, , , >,
- (11) <IE, , , >, (12) <IE, , , >,
- (13) <IE, , , >, (14) <IE, , , >,
- (15) <IE, , , >, (16) <IE, , , >.
- , : The improvement or reduction in the values of parameters are reflected by the nature, number, and impact of team outputs, like team publications. The nature of the team publications refers to (i) the degree to which publications include all the participants to a team (i.e., all the groups in a collaborative project), (ii) the expertise of the participants (i.e., the expertise of the groups), (iii) the evolution (e.g., gradient) with respect to the previous publications by the same team, including the similarity and novelty of the new work with respect to previous work, (iv) the flexibility of incorporating new ideas that were initially not part of any participant’s expertise, like identifying new research needs, and (v) the capacity to interact at different levels of abstraction. The impact is characterized by the degree to which the ideas of a team publication, such as that expressed by its keywords, overlaps with the ideas of subsequent papers, as well as the number of citations received by the paper.
- , : The increase and reduction in the values of parameters are described by the nature, number, and impact of the groups participating in a team project, like the publications of each of the groups. The nature of a group’s publications include (i) the amount of connections with the team publications, e.g., the overlapping of keywords, (ii) the degree to which the group’s papers explored the ideas expressed in team publications, (iii) the evolution of new papers by the group as compared to its previous papers, like the similarity and differences between papers, (iv) the nature of the publications, like analysis or new in-depth solutions, and (v) the links with the papers of other groups of the same team, including any ideas that were adopted by a group from another group and the flexibility to use the constraints expressed by collaborating groups. The impact of a group’s publication refer to the degree to which any insight and conclusion impact the work of the entire team, including any new goals and needs expressed in the team publications, and the number of citations received from the other groups of the team as well as from outside the team.
- , : The changes in the values of the parameters S describe the convergence and divergence of the ideas (i.e., topics) discussed in the team publications and group publications, like keywords that occurred in both group and team papers and keywords in group papers but not in the joint publications of the team. The role played by a group in a team is characterized by its participation to the team work as expressed by the way its expertise, i.e., shown by the keywords of its publications, impacts the work of other groups and the entire team. The need of a group to get the team’s assessment of its new ideas is reflected by situations in which new ideas of the group are continued or discontinued by the group, if the team did not adopt them. The management of conflicts is captured by the way that a group behaves after a situation, in which the group’s ideas are not embraced by the team. The group can remain involved with the team’s joint work, or can start to diverge by focusing only on its own group publications.
3.2. Employing Bibliometric Data in Candidates’ Assessment
- Identify a Researcher’s Areas of Expertise (RAE) based on the information in three paper metadata fields, namely title, keywords, and abstract, each of them being meant to effectively summarize the publication. For this, we extract the relevant key terms that best encapsulate the researcher’s scientific output using adequate NLP techniques and associate these key terms with scientific areas to establish thier areas of expertise. Parameter RAE is used to express the requirements of parameters and in the theoretical model.
- Compute four candidate-related indexes to reflect a researcher’s technical and teamwork skills. The four indexes are as follows:
- ⋄
- Researcher’s General Expertise (RGE) can be evaluated from the total number of publications, the total number of citations, and the total number of downloads. While the total number of publications of a given author may be obtained by counting the number of thier paper metadata records, the total number of citations or downloads may be computed by summing up the citation counts or download counts paper metadata fields. It is important to mention that the general level of expertise is a measure of a researcher’s reputation and represents an overall indicator that considers the entire scientific contribution of a researcher. Alternatively, if other indexes (e.g., h-index in WoS or Scopus databases) are available, they may also be employed. Parameter RGE is utilized to mainly describe the features of parameter of the theoretical model.
- ⋄
- Researcher’s Level of Expertise within a Given Area (RLEGA) can be evaluated based on the number of scientific publications in that area and their corresponding number of citations and number of downloads. The mechanism to obtain these three values is similar to that used for assessing RGE but considers only the publications, which have the scientific area’s characteristic key term or key terms between their relevant key terms. Parameter RLEGA serves to formulate the facets of parameter of the theoretical model.
- ⋄
- Researcher’s Collaboration Ability (RCA) can be evaluated by considering the total number of their co-authors and also the number of co-authors having other affiliations. While the former offers a general perspective on the researcher’s collaboration prospects, the latter may be increasingly important for research projects that presume multilingual, multicultural, or multinational teams. Parameter RCA helps to specify the elements of parameters and S of the theoretical model.
- ⋄
- Interpersonal Collaborations Inside Specified Groups (ICISG) of researchers can be evaluated using the total number of previous collaborations of that particular group. Here, a group of researchers may have two, three, or even more members, and their fruitful collaboration is characterized/specified by a higher total number of proven collaborations (i.e., all the group members are co-authors of the same publications). Parameter ICISG captures the elements of parameter S in the theoretical model.
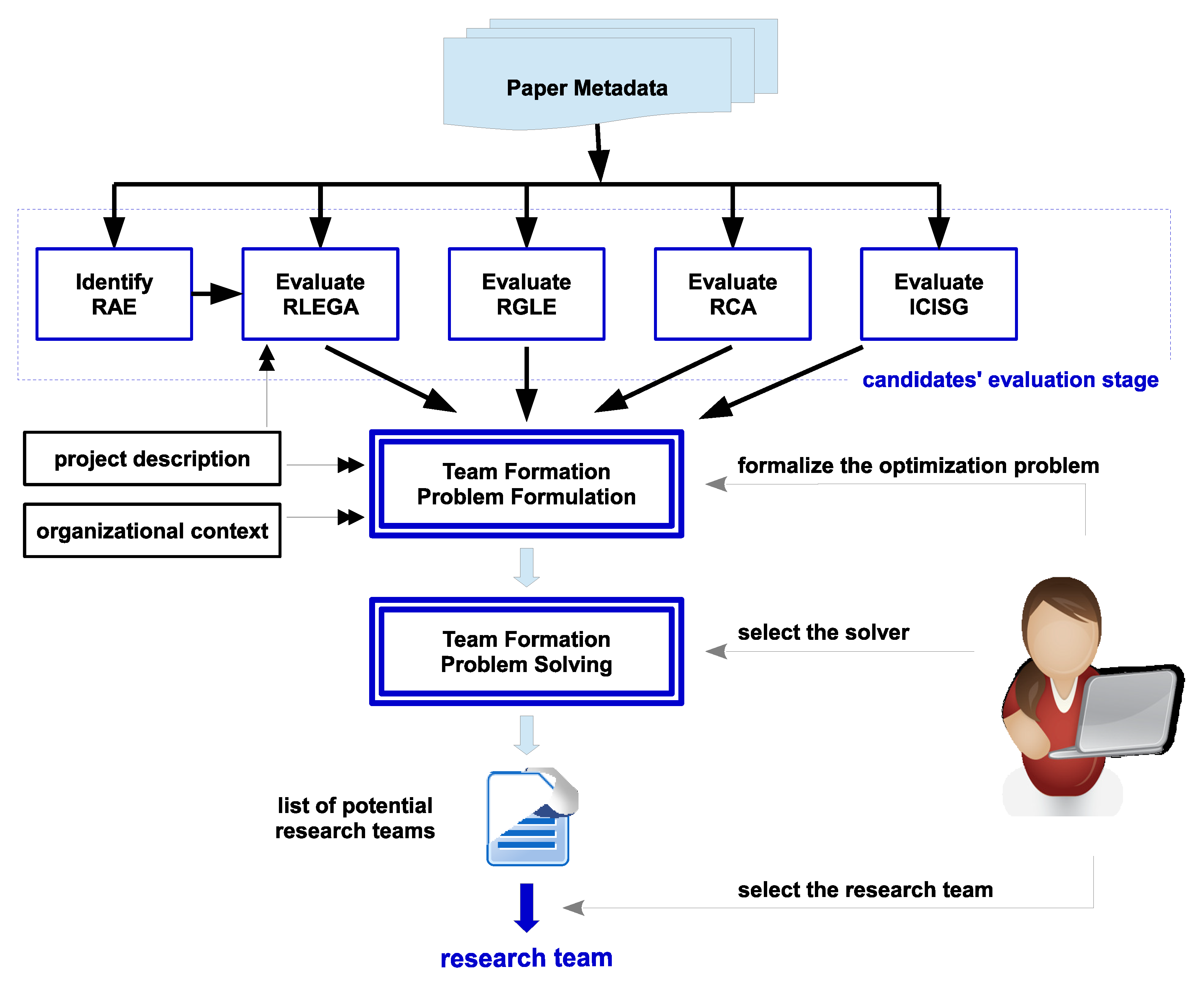
3.3. Proposed Bibliometric Data-Driven Egalitarian Team Formation Methodology
3.3.1. Team Formation Based on Bibliometric Data Inputs
| Notations: | |
| P | research project composed of a given set of tasks |
| e | element from P (task) |
| m | number of candidates |
| set of tasks from P that can be solved by candidate i, , | |
| binary flag corresponding to candidate i (, if candidate i is | |
| included in the team) | |
| S | collection of all individual abilities — a set of sets |
| jth product of k different flags , | |
| number of team members | |
| number of pairs of team members |
3.3.2. Description of the Candidates-Related Indexes
- A.
- Description of parameter RGE
- B.
- Description of parameter RCA
- C.
- Description of parameter ICISG
- D.
- Description of parameter RLEGA
3.3.3. Weights Selection
4. Problem-Solving
- -
- Solving the research team formation problem is not time-critical and, if the shortlist of candidates is no longer than two hundred, we can use a brute-force approach by computing all possible solutions and then deciding which one is the best.
- -
- If the objective functions can be ranked by their importance, which is often the case in team formation problems, a lexicographic method [28] can be used.
- -
- If the number of candidates is huge and approaches to reduce the initial number of objective functions (e.g., linear scalarization or -constraint method [29]) are ineffective, an evolutionary algorithm (e.g., NSGA-II or NSGA-III) can be utilized.
5. Case Study
5.1. Problem Description
5.2. Dataset
5.3. Parameters and Implementation
- [P1].
- Parameters used to derive the coefficients in the optimization problem:
- RGE-related parameters: , ,
- RCA-related parameters: ,
- ICISG-related parameters:
- RLEGA-related parameters: , , ,
- [P2].
- Parameters for candidates filtering
- Minimal number of papers relevant for the project: 1
- Minimal number of citations received for papers relevant for the project: 1
- [P3].
- Parameters of the NSGA-II solver
- Number of objectives: 4
- Number of constraints: 5
- Coverage redundancy:
- Optimization problem type: ElementwiseProblem—evaluates a single solution at a time
- Population size: 100
- Number of generations: 100
- Sampling type: binary random sampling
- Mutation type: bit flip mutation
- Crossover type: two-point crossover
- Python function used: NSGA2() from pymoo package
- Number of independent runs: 30.
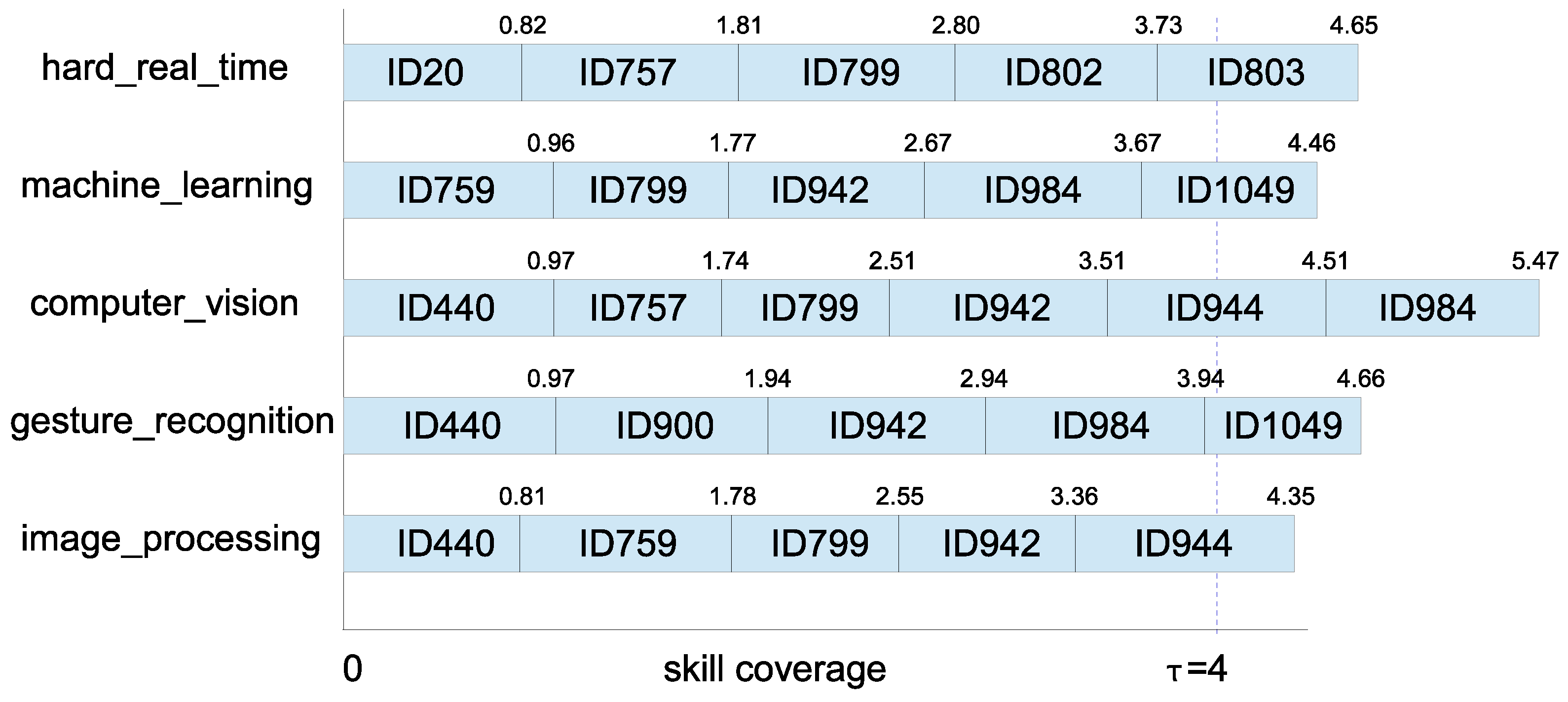
5.4. Experimental Results
Comparison with Similar Methods
- A more complex multi-objective optimization approach that supports the presented description of the research team formation problem (i.e, the approach has four optimization objectives, while the state-of-the-art methods contain at most three objectives [11]);
- The described method employs more paper metadata fields in attaining the candidates’ personal and interpersonal traits, which allows capturing some new insight. For example, considering ‘title’, ‘keywords’, and ‘abstract’ to obtain the key terms instead of only ‘title’ as in the existing work, provides a higher level of key term granularity, hence giving a greater control over the data-driven team formation process. Furthermore, using fields ‘citation count’ and ‘downloads count’ can offer a better evaluation of the researcher’s expertise in a given domain than using only the number of publications, while utilizing the ‘affiliation’ field by categorizing the co-authors as either from the same organization or from different organizations may better model candidates’ interpersonal prospects.
5.5. Limitations
- The methodology uses only insights from publication metadata, without considering other categories of research outputs, like products, video and audio materials, internal research reports, essays, policy papers or presentations;
- The methodology’s reliance on detailed bibliometric metadata that are generally extracted from subscription-based bibliographic databases, limits its accessibility for researchers with limited resources;
- Since the bibliographic records do not share a standard format accross all databases, the methodology needs slight adaptations when different databases are employed.
- The accuracy of our research team formation procedure is affected by bibliographic records that are corrupted or belong to fake or manipulated publications.
- Some qualitative aspects of teamwork, such as critical thinking, leadership, time management, accountability, responsibility, or conflict resolution, cannot be revealed by bibliometric records and, because of this, are not considered in our methodology.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Lappas, T.; Liu, K.; Terzi, E. Finding a team of experts in social networks. In Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, 28 June–1 July 2009; pp. 467–476. [Google Scholar]
- Hamidi Rad, R.; Fani, H.; Bagheri, E.; Kargar, M.; Srivastava, D.; Szlichta, J. A variational neural architecture for skill-based team formation. Acm Trans. Inf. Syst. 2023, 42, 1–28. [Google Scholar] [CrossRef]
- Juang, M.C.; Huang, C.C.; Huang, J.L. Efficient algorithms for team formation with a leader in social networks. J. Supercomput. 2013, 66, 721–737. [Google Scholar] [CrossRef]
- Srivastava, B.; Koppel, T.; Paladi, S.; Valluru, S.; Sharma, R.; Bond, O. ULTRA: A Data-driven Approach for Recommending Team Formation in Response to Proposal Calls. In Proceedings of the 2022 IEEE International Conference on Data Mining Workshops (ICDMW), Orlando, FL, USA, 28 November–1 December 2022; pp. 1002–1009. [Google Scholar]
- Mahajan, Y.; Guo, Z.; Cho, J.H.; Chen, I.R. Privacy-Preserving and Diversity-Aware Trust-based Team Formation in Online Social Networks. 2023. Available online: http://hdl.handle.net/10919/113973 (accessed on 20 March 2021).
- Neshati, M.; Beigy, H.; Hiemstra, D. Expert group formation using facility location analysis. Inf. Process. Manag. 2014, 50, 361–383. [Google Scholar] [CrossRef]
- Li, C.T.; Shan, M.K.; Lin, S.D. On team formation with expertise query in collaborative social networks. Knowl. Inf. Syst. 2015, 42, 441–463. [Google Scholar] [CrossRef]
- Kargar, M.; An, A. Discovering top-k teams of experts with/without a leader in social networks. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management, Scotland, UK, 24–18 October 2011; pp. 985–994. [Google Scholar]
- Rangapuram, S.; Bühler, T.; Hein, M. Towards realistic team formation in social networks based on densest subgraphs. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 1077–1088. [Google Scholar]
- Berktas, N.; Yaman, H. A branch-and-bound algorithm for team formation on social networks. INFORMS J. Comput. 2021, 33, 1162–1176. [Google Scholar] [CrossRef]
- Niveditha, M.; Swetha, G.; Poornima, U.; Senthilkumar, R. A genetic approach for tri-objective optimization in team formation. In Proceedings of the 2016 Eighth International Conference on Advanced Computing (ICoAC), Chennai, India, 19–21 January 2017; pp. 123–130. [Google Scholar]
- Wang, X.; Zhao, Z.; Ng, W. A comparative study of team formation in social networks. In Proceedings of the Database Systems for Advanced Applications: 20th International Conference, DASFAA 2015, Hanoi, Vietnam, 20–23 April 2015; Part I. Springer: Berlin/Heidelberg, Germany, 2015; pp. 389–404. [Google Scholar]
- Curiac, C.D.; Doboli, A.; Curiac, D.I. Co-occurrence-based double thresholding method for research topic identification. Mathematics 2022, 10, 3115. [Google Scholar] [CrossRef]
- Curiac, C.D.; Micea, M.; Plosca, T.R.; Curiac, D.I.; Doboli, S.; Doboli, A. Bibliometrics—An Essential Methodological Tool for Research Projects. In Chapter Automating Research Problem Framing and Exploration through Knowledge Extraction from Bibliometric Data; InTechOpen: London, UK, 2024; pp. 3_1–3_22. [Google Scholar]
- Rahman, H.; Thirumuruganathan, S.; Roy, S.; Amer-Yahia, S.; Das, G. Worker skill estimation in team-based tasks. Proc. VLDB Endow. 2015, 8, 1142–1153. [Google Scholar] [CrossRef]
- Li, L.; Tong, H.; Wang, Y.; Shi, C.; Cao, N.; Buchler, N. Is the whole greater than the sum of its parts? In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 295–304. [Google Scholar]
- Amin, N.; Khan, K.; Dolgorsuren, B.; Lee, Y.K. Extracting top-K interesting subgraphs with weighted query semantics. In Proceedings of the 2017 IEEE International Conference on Big Data and Smart Computing (BigComp), Jeju Island, Republic of Korea, 13–16 February 2017; pp. 366–373. [Google Scholar]
- Cronin, M.; Weingart, L. Conflict across representational gaps: Threats to and opportunities for improved communication. Proc. Natl. Acad. Sci. USA 2019, 116, 7642–7649. [Google Scholar] [CrossRef]
- Edmondson, A.; Kramer, R.; Cook, K. Psychological safety, trust, and learning in organizations: A group-level lens. Trust. Distrust Organ. Dilemmas Approaches 2004, 12, 239–272. [Google Scholar]
- Klimoski, R.; Mohammed, S. Team mental model: Construct or metaphor? J. Manag. 1994, 20, 403–437. [Google Scholar] [CrossRef]
- Doboli, A.; Umbarkar, A.; Doboli, S.; Betz, J. Modeling semantic knowledge structures for creative problem solving: Studies on expressing concepts, categories, associations, goals and context. Knowl.-Based Syst. 2015, 78, 34–50. [Google Scholar] [CrossRef]
- Doboli, A.; Curiac, D.I. Studying Consensus and Disagreement during Problem Solving in Teams through Learning and Response Generation Agents Model. Mathematics 2023, 11, 2602. [Google Scholar] [CrossRef]
- Doboli, A.; Duke, R. A Novel Model for Capturing the Multiple Representations during Team Problem Solving based on Verbal Discussions. arXiv 2023, arXiv:2308.06273. [Google Scholar]
- Doboli, A.; Umbarkar, A. The role of precedents in increasing creativity during iterative design of electronic embedded systems. Des. Stud. 2014, 35, 298–326. [Google Scholar] [CrossRef]
- Oprea, S.V.; Bâra, A. Transforming education with large language models: Trends, themes and untapped potential. IEEE Access 2025, 13, 87292–87312. [Google Scholar] [CrossRef]
- Fathian, M.; Saei-Shahi, M.; Makui, A. A new optimization model for reliable team formation problem considering experts’ collaboration network. IEEE Trans. Eng. Manag. 2017, 64, 586–593. [Google Scholar] [CrossRef]
- Selvarajah, K.; Zadeh, P.; Kobti, Z.; Palanichamy, Y.; Kargar, M. A unified framework for effective team formation in social networks. Expert Syst. Appl. 2021, 177, 114886. [Google Scholar] [CrossRef]
- Arora, J. Multi-Objective Optimum Design Concepts and Methods. Introduction to Optimum Design; Academic Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Miettinen, K. Nonlinear Multiobjective Optimization; Springer Science & Business Media: Berlin/Heidelberg, Germany, 1999; Volume 12. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef]
- Ferragina, P.; Scaiella, U. Tagme: On-the-fly annotation of short text fragments (by wikipedia entities). In Proceedings of the 19th ACM International Conference on Information and Knowledge Management, Toronto, ON, Canada, 26–30 October 2010; pp. 1625–1628. [Google Scholar]
- Curiac, C.D.; Micea, M.; Plosca, T.R.; Curiac, D.I.; Doboli, A. Dataset for Bibliometric Data-Driven Research Team Formation: Case of Politehnica University of Timisoara scholars for the interval 2010–2022. Data Brief 2024, 53, 110275. [Google Scholar] [CrossRef] [PubMed]
- Curiac, C.D.; Micea, M.; Plosca, T.R.; Curiac, D.I.; Doboli, A. Dataset for Bibliometric Data-Driven Research Team Formation. Mendeley Data 2023. [Google Scholar] [CrossRef]
- Blank, J.; Deb, K. Pymoo: Multi-objective optimization in python. IEEE Access 2020, 8, 89497–89509. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper Metadata Field | Identify RAE | Evaluate RGE | Evaluate RLEGA | Evaluate RCA | Evaluate ICISG |
|---|---|---|---|---|---|
| title | ✓ | – | – | – | – |
| abstract | ✓ | – | – | – | – |
| keywords | ✓ | – | – | – | – |
| author name | – | ✓ | ✓ | ✓ | ✓ |
| author affiliation | – | – | – | ✓ | – |
| citing paper count | – | ✓ | ✓ | – | – |
| citing patent count | – | ✓ | ✓ | – | – |
| downloads count | – | ✓ | ✓ | – | – |
| paper ID | – | ✓ | ✓ | ✓ | ✓ |
| Key Term | Value |
|---|---|
| hard_real_time | 0.423076 |
| machine_learning | 0.751253 |
| computer_vision | 0.776346 |
| gesture_recognition | 0.764705 |
| image_processing | 0.332503 |
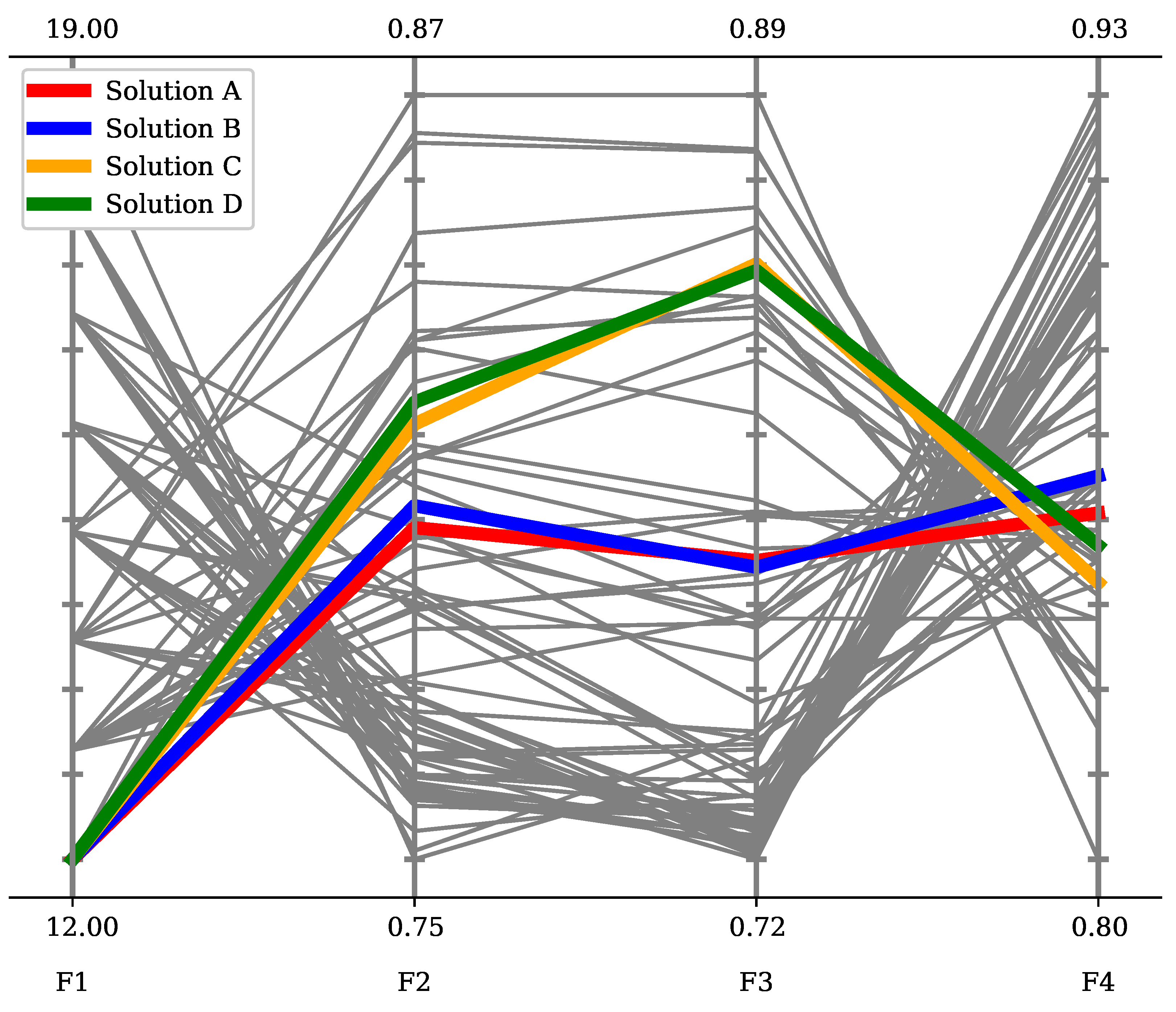
| Solution | F1 | F2 | F3 | F4 | Team Members |
|---|---|---|---|---|---|
| A | 12 | 0.799417 | 0.787422 | 0.857966 | ID20, ID440, ID757, ID759, ID799, ID802, ID803, ID900, ID942, ID944, ID984, ID1049 |
| B | 12 | 0.803007 | 0.785988 | 0.864100 | ID20, ID440, ID757, ID759, ID799, ID803, ID804, ID900, ID942, ID944, ID984, ID1049 |
| C | 12 | 0.81634 | 0.851387 | 0.846426 | ID20, ID440, ID757, ID759, ID793, ID799, ID802, ID803, ID900, ID942, ID984, ID1049 |
| D | 12 | 0.81993 | 0.849952 | 0.852561 | ID20, ID440, ID757, ID759, ID793, ID799, ID803, ID804, ID900, ID942, ID984, ID1049 |
| E | 12 | 0.823195 | 0.844692 | 0.850582 | ID440, ID732, ID757, ID759, ID773, ID799, ID802, ID803, ID900, ID942, ID984, ID1049 |
| F | 12 | 0.830031 | 0.84242 | 0.827504 | ID440, ID757, ID759, ID773, ID799, ID802, ID803, ID804, ID900, ID942, ID984, ID1049 |
| G | 12 | 0.83153 | 0.83979 | 0.849494 | ID20, ID440, ID757, ID759, ID773, ID799, ID803, ID804, ID900, ID942, ID984, ID1049 |
| H | 12 | 0.847529 | 0.863582 | 0.826959 | ID440, ID757, ID759, ID799, ID802, ID803, ID804, ID888, ID900, ID942, ID984, ID1049 |
| I | 13 | 0.77525 | 0.776073 | 0.894248 | ID20, ID138, ID732, ID757, ID759, ID793, ID799, ID803, ID848, ID942, ID944, ID984, ID1127 |
| Metadata Fields | Key Terms | Shortlisted Candidates | Team Members | |||||
|---|---|---|---|---|---|---|---|---|
| ’title’ | 1844 | 6.5105 | 0.7678 | 3.8345 | 4.4193 | 3.6055 | 11 | no team |
| ’keywords’ | 1254 | 0 | 18.0555 | 21.9328 | 7.6421 | 15.8878 | 56 | no team |
| ’title’ + ’keywords’ | 2651 | 6.5105 | 18.0555 | 21.9328 | 7.6851 | 17.5061 | 61 | 15 |
| ’title’ + ’keywords’ + ’abstract’ | 6493 | 6.5105 | 29.8370 | 30.1965 | 12.3179 | 27.5543 | 84 | 12 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Curiac, C.-D.; Micea, M.; Plosca, T.-R.; Curiac, D.-I.; Doboli, A. Optimized Interdisciplinary Research Team Formation Using a Genetic Algorithm and Publication Metadata Records. AI 2025, 6, 171. https://doi.org/10.3390/ai6080171
Curiac C-D, Micea M, Plosca T-R, Curiac D-I, Doboli A. Optimized Interdisciplinary Research Team Formation Using a Genetic Algorithm and Publication Metadata Records. AI. 2025; 6(8):171. https://doi.org/10.3390/ai6080171
Chicago/Turabian StyleCuriac, Christian-Daniel, Mihai Micea, Traian-Radu Plosca, Daniel-Ioan Curiac, and Alex Doboli. 2025. "Optimized Interdisciplinary Research Team Formation Using a Genetic Algorithm and Publication Metadata Records" AI 6, no. 8: 171. https://doi.org/10.3390/ai6080171
APA StyleCuriac, C.-D., Micea, M., Plosca, T.-R., Curiac, D.-I., & Doboli, A. (2025). Optimized Interdisciplinary Research Team Formation Using a Genetic Algorithm and Publication Metadata Records. AI, 6(8), 171. https://doi.org/10.3390/ai6080171