

Quantifying Claim Robustness Through Adversarial Framing: A Conceptual Framework for an AI-Enabled Diagnostic Tool

Abstract
1. Introduction
2. The Difficulty of Speaker-Independent Claim Validity Assessments
Speaker-Dependence and Cognitive Biases
- (a)
- The Confirmation Bias and Tribal Credentialing
- (b)
- Affective Polarization
- (c)
- Motivated Numeracy
- Algorithmic tribalism: Recommender systems increase partisan content exposure. In agreement with this, Ref. [57] find that content from US media outlets with a strong right-leaning bias are amplified more than content from left-leaning sources.
- Affective feedback loops: The MAD model of [58] proposes that people are motivated to share moral-emotional content based on their group identity, that such content is likely to capture attention, and that social-media platforms are designed to elicit these psychological tendencies and further facilitate its spread.
- Epistemic learned helplessness: 50% of Americans feel most national news organizations intend to mislead, misinform or persuade the public [59].
3. The Adversarial Claim Robustness Diagnostics (ACRD) Framework
3.1. A Three-Phase Diagnostic Tool: Mixing Game Theory and AI
- (a)
- Baseline phase—A statement P is spoken by a non-neutral speaker (here associated with group 1). Each group receives information regarding a scientific/expert consensus (made as ‘objective’ as possible), to which they each assign a level of trust. Of course this expert baseline neutrality can be challenged, and this will be reflected in the trust levels. To approximate neutrality, Ref. [6] define domain experts as scientists who have published peer-reviewed research in that domain. Each group’s prior validity assessment of P takes into account the degree of tie they have with their respective ideologies. They come up with their own evaluation as a result of a strategic game exhibiting a Bayesian-Nash equilibrium.
- (b)
- Reframing phase—Each group is presented with counterfactuals. Claim P is either framed as originating from an adversarial source or the reverse proposition ~P is assumed spoken by the original source in a “what if” thought-experiment (in that case, it is important to decide at the outset if the protocol is based on a test of P or ~P based on best experimental design considerations) or by using the Devil’s Advocate Approach [13]. Claims are adjusted via adversarial collaboration [12]. New evaluations are then proposed under the new updated beliefs. These again are solutions to the same strategic game, under new (posterior) beliefs. Here they adjust their trust level of the expert’s assessment, and the expert’s validity score itself. Actual field studies can operationalize this phase with dynamic calibration to adjust for adversarial intensity based for instance on response latency (<500 ms indicates affective rejection; [20]). Semantic similarity scores (detecting recognition of in-group rhetoric) can also be deployed there.
- (c)
- AI and Dynamic Calibration Phase—When deployed in field studies, AI-driven adjustments (e.g., GPT-4 generated counterfactuals; BERT-based semantic perturbations) will test boundary conditions where claims fracture using the Claim Robustness Index developed below. These AI aids can implement neural noise injections (e.g., minor phrasing variations) to disrupt affective tagging. They can also integrate intersubjective agreement gradients and longitudinal stability checks [64] correcting for both temporary reactance and consistency across repeated exposures. This phase can be used to adjust the final computation of the index below by making corrections based on the latency of these effects. More technical details on the role of AI are given in Section 6.
3.2. The Claim Robustness Index
- Initial judgments by each player: for i = 1, 2. This represents the baseline judgment, which is the outcome of optimized strategic behavior influenced by partisanship. A value of 1 means that statement P is accepted as 100% valid.
- Post-judgment after reframing: for i = 1, 2. Re-evaluations of these judgements after beliefs are stress-tested, again as the outcome of strategic behavior identified in the Bayesian-Nash equilibrium.
- Expert signal: D : is the expert consensus that can provide grounding for claim validity.
3.3. Example of CRI Index Computation
- = |0.62 − 0.60| = 0.02
- = |0.45 − 0.40| = 0.05
4. Modeling Strategic Interactions: ACRD as a Claim Validation Game
4.1. The Game Setup
- Players: Two players, i = 1, 2
- Strategy Space: Ji ∈ [0,1] (judgment of P’s validity)
- Expert Signal: D ∈ [0,1] (scientific consensus estimate of a truth value ∈ [0,1] that is unobserved)
- Prior Beliefs: TIE1 ∈ [0,1] for Player 1 and (1 − TIE2) ∈ [0,1] for Player 2
- Trust in Expert by Player i: TRUSTi ∈ [0,1] this level of trust, we assume is defined as an outcome of the reframing stage.
- Posterior Beliefs:Player 1:X1 = (1 − TRUST1) × TIE1 + TRUST1 × DPlayer 2:X2 = (1 − TRUST2) × (1 − TIE2) + TRUST2 × D
- Total Payoffs:where the payoff components are:Payoff i = COLLABi + TIEi − DISSENTi
- CollaborationWith a ∈ [0,1]COLLABi = 1 − a × TIEj × (1 − TIEj) × (Ji − Jj)2
- Cost of Dissentingwhere Fi = b × with b ∈ [0,1].DISSENTi = Fi × TIEi
4.2. The Bayesian-Nash Equilibrium Solution
4.3. Application to the CRI Index
5. Alternate Claim/Truth Validity Approaches
5.1. Existing Models for Assessing Claim Validity
5.2. Comparative Analysis: ACRD vs. GBM and BTS Frameworks
- (a)
- Links with GBM
- (b)
- Links with BTS
5.3. ACRD vs. Traditional Fact-Checking
- (a)
- Forcing adversarial engagement: By attributing claims to maximally oppositional sources, ACRD mimics the “veil of ignorance” [86], as much as possible disrupting tribal cognition.
- (b)
- Dynamic calibration: Real-time adjustment of speaker intensity (e.g., downgrading adversarial framing if response latency suggests reactance).
6. An AI-Augmented Adversarial Testing Process for ACRD
6.1. Large Language Models (LLMs) as Adversarial Simulators
- (a)
- Automated Speaker Swapping
- (b)
- Semantic Shift Detection
- (c)
- Resilience Profiling
6.2. Mitigating Epistemic Risks in AI-Assisted ACRD
7. Limitations and Future Directions
7.1. Limitations
7.2. Future Directions
- Phase 1: Laboratory Experiments—Controlled Validation Studies
- Phase 2: Social Media Deployment—Real-World Implementation
- Phase 3: Deliberative Democracy Integration—Institutional Implementation
8. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Glossary of Key Concepts
Appendix A

{kind=link}
| Scenario | Behavior |
|---|---|
| Polarized Stubbornness Agrmt: 0.39 Expert Aligmnt: 0.63 UP: 0.08 CRI: 0.4 | Players maintain entrenched positions despite expert evidence ( = 0.728, = 0.193, D = 0.50). Extreme initial disagreement (d* = 0.85) persists with substantial final disagreement (d** = 0.61). Minimal updating ( = 0.22, = 0.08) due to very low expert trust (TRUST1 = 0.05, TRUST2 = 0.1) and extreme ideological rigidity (TIE1 = 0.95, TIE2 = 0.9). Low collaboration incentives (a = 0.2) and high dissent costs (b = 0.8) reinforce resistance to convergence. Poor temporal stability (TS = 0.6) compounds robustness limitations. Alpha weighting (α = 0.77) shows Player 1’s ideological dominance cannot overcome fundamental collaboration barriers. |
| Expert-Driven Convergence Agrmt: 0.98 Expert Aligmnt: 0.66 UP: 0.19 CRI: 0.89–1 | Excellent convergence toward expert consensus ( = 0.328, = 0.351, D = 0.70). Very high expert trust (TRUST1 = 0.9, TRUST2 = 0.85) enables substantial updating ( = 0.27, = 0.10) despite moderate ideological ties (TIE1 = 0.6, TIE2 = 0.55). Strong collaboration incentives (a = 0.85) and low dissent costs (b = 0.15) facilitate consensus building with minimal residual disagreement (d** = 0.02). High temporal stability (TS = 0.9) ensures robust outcomes. Expert alignment moderately affected by distance from expert signal, but excellent agreement demonstrates successful expert-guided collaboration. |
| Moderately Balanced Disagreement Agrmt: 0.997 Expert Aligmnt: 0.75 UP: 0.29 CRI: 0.99 | Exceptional convergence through balanced parameters ( = 0.308, = 0.305, D = 0.55). Moderate ideological ties (TIE1 = 0.7, TIE2 = 0.6) provide flexibility while maintaining identity. Balanced expert trust (TRUST1 = 0.6, TRUST2 = 0.65) and moderate collaboration incentives (a = 0.6, b = 0.4) create optimal updating conditions ( = 0.39, = 0.10). Substantial disagreement reduction (d* = 0.10 → d** = 0.003) demonstrates effective adversarial collaboration. High temporal stability (TS = 0.85) ensures reliable outcomes. Represents ideal balanced scenario for robust claim evaluation with near-maximum robustness achievement. |
| Overcorrection Pattern Agrmt: 0.99 Expert Aligmnt: 0.72 UP: 0.56 CRI: 1 | Dramatic updating ( = 0.67, = 0.63) leads to exceptional convergence ( = 0.181, = 0.172, D = 0.40). Extreme collaboration incentives (a = 0.9) and minimal dissent costs (b = 0.1) overcome strong initial disagreement (d* = 0.05 → d** = 0.009). Very high expert trust (TRUST1 = 0.95, TRUST2 = 0.9) enables significant belief revision despite strong ideological priors (TIE1 = 0.85, TIE2 = 0.8). High temporal stability (TS = 0.85) supports robust outcomes. UP at near-maximum threshold indicates successful overcorrection toward expert consensus through intensive collaborative updating, achieving maximum robustness via extreme parameter conditions. |
Appendix B
- i.
- −2k1–2d1 < 0 (always true)1
- ii.
- det(H) = 4(k1 + d1)(k2 + d2) − 4k1k2 > 0 (always true)
Appendix C. Flow Chart for the ACRD Process
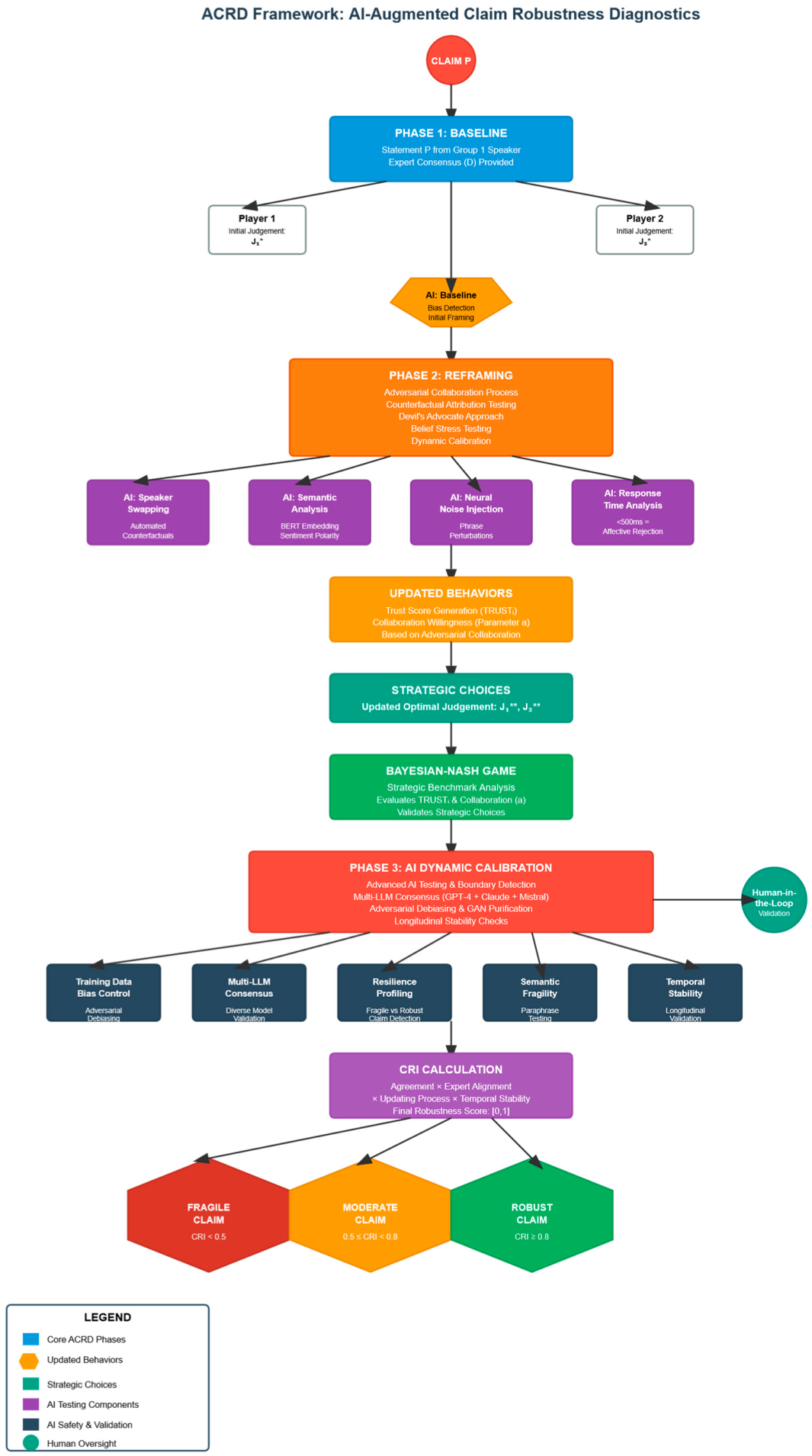
Appendix D
- i.
- AI Speaker Swapping
- ii.
- Semantic Analysis
- iii.
- Neural Noise Injection
- iv.
- Response Time Analysis (value chosen for illustrative purpose)
- i.
- Trust Calibration Questions
- ii.
- Collaboration Willingness Assessment
- iii.
- Evidence Sensitivity Testing
- i.
- Strategic Benchmark Validation
- ii.
- Equilibrium Analysis
- iii.
- Key Insights
References
- Chicago Sun-Times. In Chicago, former President Trump defends economic plan and downplays Jan. 6. Chicago Sun-Times. 16 October 2024. Available online: https://chicago.suntimes.com/elections/2024/10/15/president-trump-returns-chicago-tuesday-watch (accessed on 1 March 2025).
- Tarski, A. The semantic conception of truth and the foundations of semantics. Philos. Phenomenol. Res. 1944, 4, 341–376. [Google Scholar] [CrossRef]
- Mitchell, A.; Gottfried, J.; Stocking, G.; Walker, M.; Fedeli, S. Many Americans Say Made-Up News Is a Critical Problem That Needs to Be Fixed; Pew Research Center: Washington, DC, USA, 2019; Available online: https://www.pewresearch.org/wp-content/uploads/sites/20/2019/06/PJ_2019.06.05_Misinformation_FINAL-1.pdf (accessed on 4 March 2025).
- McDonald, J. Unreliable News Sites Saw Surge in Engagement in 2020; NewsGuard: New York, NY, USA, 2021. [Google Scholar]
- Fricker, M. Epistemic Injustice: Power and the Ethics of Knowing; Oxford University Press: Oxford, UK, 2007. [Google Scholar]
- Cook, J.; Oreskes, N.; Doran, P.T.; Anderegg, W.R.; Verheggen, B.; Maibach, E.W.; Carlton, J.S.; Lewandowsky, S.; Skuce, A.G.; Green, S.A.; et al. Consensus on consensus: A synthesis of consensus estimates on human-caused global warming. Environ. Res. Lett. 2016, 11, 048002. [Google Scholar] [CrossRef]
- Iyengar, S.; Lelkes, Y.; Levendusky, M.; Malhotra, N.; Westwood, S.J. The origins and consequences of affective polarization. Annu. Rev. Political Sci. 2019, 22, 129–146. [Google Scholar] [CrossRef]
- Nickerson, R.S. Confirmation bias: A ubiquitous phenomenon in many guises. Rev. Gen. Psychol. 1998, 2, 175–220. [Google Scholar] [CrossRef]
- Goldstein, J. Record-High Engagement with Deceptive Sites in 2020; German Marshall Fund: Washington, DC, USA, 2021. [Google Scholar]
- Nyhan, B.; Reifler, J. When corrections fail: The persistence of political misperceptions. Political Behav. 2010, 32, 303–330. [Google Scholar] [CrossRef]
- Druckman, J.N. The implications of framing effects for citizen competence. Political Behav. 2001, 23, 225–256. [Google Scholar] [CrossRef]
- Ceci, S.J.; Clark, C.J.; Jussim, L.; Williams, W.M. Adversarial collaboration: An undervalued approach in behavioral science. Am. Psychol. 2024; advance online publication. [Google Scholar] [CrossRef]
- Vrij, A.; Leal, S.; Fisher, R.P. Interviewing to detect lies about opinions: The Devil’s Advocate approach. Adv. Soc. Sci. Res. J. 2023, 10, 245–252. [Google Scholar] [CrossRef]
- Qu, S.; Zhou, Y.; Ji, Y.; Dai, Z.; Wang, Z. Robust maximum expert consensus modeling with dynamic feedback mechanism under uncertain environments. J. Ind. Manag. Optim. 2025, 21, 524–552. [Google Scholar] [CrossRef]
- Grice, H.P. Logic and conversation. In Syntax and Semantics 3: Speech Acts; Cole, P., Morgan, J.L., Eds.; Academic Press: Cambridge, MA, USA, 1975; pp. 41–58. [Google Scholar]
- Nash, J. Equilibrium points in n-person games. Proc. Natl. Acad. Sci. USA 1950, 36, 48–49. [Google Scholar] [CrossRef]
- Myerson, R.B. Game Theory: Analysis of Conflict; Harvard University Press: Cambridge, MA, USA, 1981. [Google Scholar]
- Argyle, L.P.; Busby, E.C.; Fulda, N.; Gubler, J.R.; Rytting, C.; Wingate, D. Out of one, many: Using language models to simulate human samples. Political Anal. 2023, 31, 337–351. [Google Scholar] [CrossRef]
- Jia, R.; Ramanathan, A.; Guestrin, C.; Liang, P. Generating pathologies via local optimization. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 July–2 August 2019; pp. 6295–6304. [Google Scholar] [CrossRef]
- Lodge, M.; Taber, C.S. The Rationalizing Voter; Cambridge University Press: Cambridge, UK, 2013. [Google Scholar] [CrossRef]
- Storek, A.; Subbiah, M.; McKeown, K. Unsupervised selective rationalization with noise injection. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, Toronto, ON, Canada, 9–14 July 2023; Volume 1, pp. 12647–12659. [Google Scholar] [CrossRef]
- De Martino, B.; Kumaran, D.; Seymour, B.; Dolan, R.J. Frames, biases, and rational decision-making in the human brain. Science 2006, 313, 684–687. [Google Scholar] [CrossRef]
- Gier, N.R.; Krampe, C.; Kenning, P. Why it is good to communicate the bad: Understanding the influence of message framing in persuasive communication on consumer decision-making processes. Front. Hum. Neurosci. 2023, 17, 1085810. [Google Scholar] [CrossRef] [PubMed]
- Habermas, J. The Theory of Communicative Action, Volume 1: Reason and the Rationalization of Society; McCarthy, T., Translator; Beacon Press: Boston, MA, USA, 1984. [Google Scholar]
- Lutzke, L.; Drummond, C.; Slovic, P.; Árvai, J. Priming critical thinking: Simple interventions limit the influence of fake news about climate change on Facebook. Glob. Environ. Chang. 2019, 58, 101964. [Google Scholar] [CrossRef]
- Kahan, D.M. Misconceptions, Misinformation, and the Logic of Identity-Protective Cognition; Cultural Cognition Project Working Paper Series No. 164; Yale University: New Haven, CT, USA, 2017. [Google Scholar] [CrossRef]
- Roozenbeek, J.; van der Linden, S. Fake news game confers psychological resistance against online misinformation. Palgrave Commun. 2019, 5, 65. [Google Scholar] [CrossRef]
- Austin, J.L. How To Do Things with Words; Oxford University Press: Oxford, UK, 1962. [Google Scholar]
- Mercier, H.; Sperber, D. The Enigma of Reason; Harvard University Press: Cambridge, MA, USA, 2017. [Google Scholar]
- Hovland, C.I.; Weiss, W. The influence of source credibility on communication effectiveness. Public Opin. Q. 1951, 15, 635–650. [Google Scholar] [CrossRef]
- Nguyen, C.T. Echo chambers and epistemic bubbles. Episteme 2020, 17, 141–161. [Google Scholar] [CrossRef]
- Brenan, M. Americans’ Trust in Media Remains near Record Low; Gallup: Washington, DC, USA, 2022; Available online: https://news.gallup.com/poll/403166/americans-trust-media-remains-near-record-low.aspx (accessed on 8 March 2025).
- Vosoughi, S.; Roy, D.; Aral, S. The spread of true and false news online. Science 2018, 359, 1146–1151. [Google Scholar] [CrossRef]
- Calvillo, D.P.; Ross, B.J.; Garcia, R.J.B.; Smelter, T.J.; Rutchick, A.M. Political ideology predicts perceptions of the threat of COVID-19. Soc. Psychol. Personal. Sci. 2020, 11, 1119–1128. [Google Scholar] [CrossRef]
- Altenmüller, M.S.; Wingen, T.; Schulte, A. Explaining polarized trust in scientists: A political stereotype-approach. Sci. Commun. 2024, 46, 92–115. [Google Scholar] [CrossRef]
- Kahan, D.M.; Peters, E.; Wittlin, M.; Slovic, P.; Ouellette, L.L.; Braman, D.; Mandel, G. The polarizing impact of science literacy and numeracy on perceived climate change risks. Nat. Clim. Change 2012, 2, 732–735. [Google Scholar] [CrossRef]
- Waldrop, M.M. The genuine problem of fake news. Proc. Natl. Acad. Sci. USA 2017, 114, 12631–12634. [Google Scholar] [CrossRef]
- Kahan, D.M. Ideology, motivated reasoning, and cognitive reflection. Judgm. Decis. Mak. 2013, 8, 407–424. [Google Scholar] [CrossRef]
- Mercier, H.; Sperber, D. Why do humans reason? Arguments for an argumentative theory. Behav. Brain Sci. 2011, 34, 57–74. [Google Scholar] [CrossRef]
- Lewandowsky, S.; Gignac, G.E.; Oberauer, K. The role of conspiracist ideation and worldviews in predicting rejection of science. PLoS ONE 2013, 8, e75637. [Google Scholar] [CrossRef]
- Pennycook, G.; Rand, D.G. Lazy, not biased: Susceptibility to partisan fake news. Cognition 2019, 188, 39–50. [Google Scholar] [CrossRef]
- Cohen, G.L. Party over policy: The dominating impact of group influence on political beliefs. J. Personal. Soc. Psychol. 2003, 85, 808–822. [Google Scholar] [CrossRef]
- Clarke, C.E.; Hart, P.S.; Schuldt, J.P.; Evensen, D.T.N.; Boudet, H.S.; Jacquet, J.B.; Stedman, R.C. Public opinion on energy development: The interplay of issue framing, top-of-mind associations, and political ideology. Energy Policy 2015, 81, 131–140. [Google Scholar] [CrossRef]
- Hazboun, S.O.; Howe, P.D.; Layne Coppock, D.; Givens, J.E. The politics of decarbonization: Examining conservative partisanship and differential support for climate change science and renewable energy in Utah. Energy Res. Soc. Sci. 2020, 70, 101769. [Google Scholar] [CrossRef]
- Mayer, A. National energy transition, local partisanship? Elite cues, community identity, and support for clean power in the United States. Energy Res. Soc. Sci. 2019, 50, 143–150. [Google Scholar] [CrossRef]
- Bugden, D.; Evensen, D.; Stedman, R. A drill by any other name: Social representations, framing, and legacies of natural resource extraction in the fracking industry. Energy Res. Soc. Sci. 2017, 29, 62–71. [Google Scholar] [CrossRef]
- Campbell, T.H.; Kay, A.C. Solution aversion: On the relation between ideology and motivated disbelief. J. Personal. Soc. Psychol. 2014, 107, 809–824. [Google Scholar] [CrossRef]
- Feygina, I.; Jost, J.T.; Goldsmith, R.E. System justification, the denial of global warming, and the possibility of ‘system-sanctioned change’. Personal. Soc. Psychol. Bull. 2010, 36, 326–338. [Google Scholar] [CrossRef] [PubMed]
- Bohr, J. Public views on the dangers and importance of climate change: Predicting climate change beliefs in the United States through income moderated by party identification. Clim. Change 2014, 126, 217–227. [Google Scholar] [CrossRef]
- McCright, A.M.; Marquart-Pyatt, S.T.; Shwom, R.L.; Brechin, S.R.; Allen, S. Ideology, capitalism, and climate: Explaining public views about climate change in the United States. Energy Res. Soc. Sci. 2016, 21, 180–189. [Google Scholar] [CrossRef]
- Sunstein, C.R. #Republic: Divided Democracy in the Age of Social Media; Princeton University Press: Princeton, NJ, USA, 2017. [Google Scholar]
- Druckman, J.N.; Lupia, A. Preference change in competitive political environments. Annu. Rev. Political Sci. 2016, 19, 13–31. [Google Scholar] [CrossRef]
- Westen, D.; Blagov, P.S.; Harenski, K.; Kilts, C.; Hamann, S. Neural bases of motivated reasoning: An fMRI study of emotional constraints on partisan political judgment in the 2004 U.S. presidential election. J. Cogn. Neurosci. 2006, 18, 1947–1958. [Google Scholar] [CrossRef]
- Lewandowsky, S.; Ecker, U.K.; Seifert, C.M.; Schwarz, N.; Cook, J. Misinformation and its correction: Continued influence and successful debiasing. Psychol. Sci. Public Interest 2012, 13, 106–131. [Google Scholar] [CrossRef]
- Drummond, C.; Fischhoff, B. Individuals with greater science literacy and education have more polarized beliefs on controversial science topics. Proc. Natl. Acad. Sci. USA 2017, 114, 9587–9592. [Google Scholar] [CrossRef]
- van Prooijen, J.W. Why education predicts decreased belief in conspiracy theories. Appl. Cogn. Psychol. 2017, 31, 50–58. [Google Scholar] [CrossRef]
- Huszár, F.; Ktena, S.I.; O’Brien, C.; Belli, L.; Schlaikjer, A.; Hardt, M. Algorithmic amplification of politics on Twitter. Proc. Natl. Acad. Sci. USA 2022, 119, e2025334119. [Google Scholar] [CrossRef] [PubMed]
- Brady, W.J.; Crockett, M.J.; Van Bavel, J.J. The MAD model of moral contagion: The role of motivation, attention, and design in the spread of moralized content online. Perspect. Psychol. Sci. 2021, 16, 978–1010. [Google Scholar] [CrossRef]
- Knight Foundation. American Views 2022: Trust, Media and Democracy; Knight Foundation: Miami, FL, USA, 2023. [Google Scholar]
- Mellers, B.; Hertwig, R.; Kahneman, D. Do frequency representations eliminate conjunction effects? An exercise in adversarial collaboration. Psychol. Sci. 2001, 12, 269–275. [Google Scholar] [CrossRef]
- Peters, B.; Blohm, G.; Haefner, R.; Isik, L.; Kriegeskorte, N.; Lieberman, J.S.; Ponce, C.R.; Roig, G.; Peters, M.A.K. Generative adversarial collaborations: A new model of scientific discourse. Trends Cogn. Sci. 2025, 29, 1–4. [Google Scholar] [CrossRef] [PubMed]
- Corcoran, A.W.; Hohwy, J.; Friston, K.J. Accelerating scientific progress through Bayesian adversarial collaboration. Neuron 2023, 111, 3505–3516. [Google Scholar] [CrossRef]
- Popper, K. Conjectures and Refutations: The Growth of Scientific Knowledge; Routledge: Abingdon-on-Thames, UK, 1963. [Google Scholar]
- Shrout, P.E.; Fleiss, J.L. Intraclass correlations: Uses in assessing rater reliability. Psychol. Bull. 1979, 86, 420–428. [Google Scholar] [CrossRef]
- van der Linden, S.; Leiserowitz, A.; Maibach, E. The gateway belief model: A large-scale replication. J. Environ. Psychol. 2021, 62, 49–58. [Google Scholar] [CrossRef]
- Cialdini, R.B.; Kallgren, C.A.; Reno, R.R. A focus theory of normative conduct: A theoretical refinement and reevaluation of the role of norms in human behavior. Adv. Exp. Soc. Psychol. 1991, 24, 201–234. [Google Scholar] [CrossRef]
- Darke, P.R.; Chaiken, S.; Bohner, G.; Einwiller, S.; Erb, H.P.; Hazlewood, J.D. Accuracy motivation, consensus information, and the law of large numbers: Effects on attitude judgment in the absence of argumentation. Personal. Soc. Psychol. Bull. 1998, 24, 1205–1215. [Google Scholar] [CrossRef]
- Lewandowsky, S.; Gignac, G.E.; Vaughan, S. The pivotal role of perceived scientific consensus in acceptance of science. Nat. Clim. Change 2013, 3, 399–404. [Google Scholar] [CrossRef]
- Mutz, D.C. Impersonal Influence: How Perceptions of Mass Collectives Affect Political Attitudes; Cambridge University Press: Cambridge, UK, 1998. [Google Scholar]
- Panagopoulos, C.; Harrison, B. Consensus cues, issue salience and policy preferences: An experimental investigation. N. Am. J. Psychol. 2016, 18, 405–417. [Google Scholar]
- Prelec, D. A Bayesian truth serum for subjective data. Science 2004, 306, 462–466. [Google Scholar] [CrossRef]
- Sunstein, C.R. Nudging: A very short guide. J. Consum. Policy 2014, 37, 583–588. [Google Scholar] [CrossRef]
- Adams, M.; Niker, F. Harnessing the epistemic value of crises for just ends. In Political Philosophy in a Pandemic: Routes to a More Just Future; Niker, F., Bhattacharya, A., Eds.; Bloomsbury Academic: London, UK, 2021; pp. 219–232. [Google Scholar]
- Grundmann, T. The possibility of epistemic nudging. Soc. Epistemol. 2021, 37, 208–218. [Google Scholar] [CrossRef]
- Miyazono, K. Epistemic libertarian paternalism. Erkenn 2025, 90, 567–580. [Google Scholar] [CrossRef]
- Beaver, D.; Stanley, J. Neutrality. Philos. Top. 2021, 49, 165–186. [Google Scholar] [CrossRef]
- Liu, X.; Qi, L.; Wang, L.; Metzger, M.J. Checking the fact-checkers: The role of source type, perceived credibility, and individual differences in fact-checking effectiveness. Commun. Res. 2023, onlinefirst. [Google Scholar] [CrossRef]
- Vrij, A.; Fisher, R.; Blank, H. A cognitive approach to lie detection: A meta-analysis. Leg. Criminol. Psychol. 2017, 22, 1–21. [Google Scholar] [CrossRef]
- Vrij, A.; Mann, S.; Leal, S.; Fisher, R.P. Combining verbal veracity assessment techniques to distinguish truth tellers from lie tellers. Eur. J. Psychol. Appl. Leg. Context 2021, 13, 9–19. [Google Scholar] [CrossRef]
- Bogaard, G.; Colwell, K.; Crans, S. Using the Reality Interview improves the accuracy of the Criteria-Based Content Analysis and Reality Monitoring. Appl. Cogn. Psychol. 2019, 33, 1018–1031. [Google Scholar] [CrossRef]
- Granhag, P.A.; Hartwig, M. The Strategic Use of Evidence (SUE) technique: A conceptual overview. In Deception Detection: Current Challenges and New Approaches; Granhag, P.A., Vrij, A., Verschuere, B., Eds.; Wiley: Hoboken, NJ, USA, 2015; pp. 231–251. [Google Scholar]
- Hartwig, M.; Granhag, P.A.; Luke, T. Strategic use of evidence during investigative interviews: The state of the science. In Credibility Assessment: Scientific Research and Applications; Raskin, D.C., Honts, C.R., Kircher, J.C., Eds.; Academic Press: Cambridge, MA, USA, 2014; pp. 1–36. [Google Scholar]
- Nahari, G. Verifiability approach: Applications in different judgmental settings. In The Palgrave Handbook of Deceptive Communication; Docan-Morgan, T., Ed.; Palgrave Macmillan: London, UK, 2019; pp. 213–225. [Google Scholar] [CrossRef]
- Palena, N.; Caso, L.; Vrij, A.; Nahari, G. The Verifiability Approach: A meta-analysis. J. Appl. Res. Mem. Cogn. 2021, 10, 155–166. [Google Scholar] [CrossRef]
- Sieck, W.; Yates, J.F. Exposition effects on decision making: Choice and confidence in choice. Organ. Behav. Hum. Decis. Process. 1997, 70, 207–219. [Google Scholar] [CrossRef]
- Rawls, J. A Theory of Justice; Harvard University Press: Cambridge, MA, USA, 1971. [Google Scholar]
- Zhang, B.H.; Lemoine, B.; Mitchell, M. Mitigating unwanted biases with adversarial learning. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, New Orleans, LA, USA, 2–3 February 2018; pp. 335–340. [Google Scholar] [CrossRef]
- González-Sendino, R.; Serrano, E.; Bajo, J. Mitigating bias in artificial intelligence: Fair data generation via causal models for transparent and explainable decision-making. Future Gener. Comput. Syst. 2024, 155, 384–401. [Google Scholar] [CrossRef]
- Srđević, B. Evaluating the Societal Impact of AI: A Comparative Analysis of Human and AI Platforms Using the Analytic Hierarchy Process. AI 2025, 6, 86. [Google Scholar] [CrossRef]
- Mergen, A.; Çetin-Kılıç, N.; Özbilgin, M.F. Artificial intelligence and bias towards marginalised groups: Theoretical roots and challenges. In AI and Diversity in a Datafied World of Work: Will the Future of Work Be Inclusive? Vassilopoulou, J., Kyriakidou, O., Eds.; Emerald Publishing: Leeds, UK, 2025; pp. 17–38. [Google Scholar] [CrossRef]
- Levay, K.E.; Freese, J.; Druckman, J.N. The demographic and political composition of Mechanical Turk samples. SAGE Open 2016, 6, 1–17. [Google Scholar] [CrossRef]
- Callegaro, M.; Baker, R.; Bethlehem, J.; Göritz, A.S.; Krosnick, J.A.; Lavrakas, P.J. Online panel research: History, concepts, applications, and a look at the future. In Online Panel Research: A Data Quality Perspective; Callegaro, M., Baker, R., Bethlehem, J., Göritz, A.S., Krosnick, J.A., Lavrakas, P.J., Eds.; Wiley: Hoboken, NJ, USA, 2014; pp. 1–22. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Kahneman, D.; Sibony, O.; Sunstein, C.R. Noise: A Flaw in Human Judgment; Little, Brown and Company: Boston, MA, USA, 2021. [Google Scholar]
- Zhang, W.E.; Sheng, Q.Z.; Alhazmi, A.; Li, C. Adversarial attacks on deep learning models in natural language processing: A survey. ACM Trans. Intell. Syst. Technol. 2020, 11, 1–41. [Google Scholar] [CrossRef]
- Qiu, S.; Liu, Q.; Zhou, S.; Huang, W. Adversarial attack and defense technologies in natural language processing: A survey. Neurocomputing 2022, 492, 278–307. [Google Scholar] [CrossRef]
- Yang, Z.; Meng, Z.; Zheng, X.; Wattenhofer, R. Assessing adversarial robustness of large language models: An empirical study. arXiv 2024, arXiv:2405.02764v2. [Google Scholar]
- Lin, G.; Tanaka, T.; Zhao, Q. Large language model sentinel: Advancing adversarial robustness by LLM agent. arXiv 2024, arXiv:2405.20770. [Google Scholar] [CrossRef]
- Chen, Y.; Zhou, J.; Wang, Y.; Liu, X.; Zhang, L. Hard label adversarial attack with high query efficiency against NLP models. Sci. Rep. 2025, 15, 1034. [Google Scholar] [CrossRef]
- Morris, J.; Lifland, E.; Yoo, J.Y.; Grigsby, J.; Jin, D.; Qi, Y. TextAttack: A framework for adversarial attacks, data augmentation, and adversarial training in NLP. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 119–126. [Google Scholar]
- Liu, Y.; Cong, T.; Zhao, Z.; Backes, M.; Shen, Y.; Zhang, Y. Robustness over time: Understanding adversarial examples’ effectiveness on longitudinal versions of large language models. arXiv 2023, arXiv:2308.07847. [Google Scholar] [CrossRef]
- Kwon, H. AudioGuard: Speech Recognition System Robust against Optimized Audio Adversarial Examples. Multimed. Tools Appl. 2024, 83, 57943–57962. [Google Scholar] [CrossRef]
- Thomsen, K. AI and We in the Future in the Light of the Ouroboros Model: A Plea for Plurality. AI 2022, 3, 778–788. [Google Scholar] [CrossRef]
- Davidson, D. Truth and meaning. Synthese 1967, 17, 304–323. [Google Scholar] [CrossRef]
- Hintikka, J. Knowledge and Belief: An Introduction to the Logic of the Two Notions; Cornell University Press: Ithaca, NY, USA, 1962. [Google Scholar]

| Variable | Value | Description |
|---|---|---|
| 0.60 | Initial judgment of Player 1 | |
| 0.40 | Initial judgment of Player 2 | |
| 0.62 | Post-reframing judgment of Player 1 | |
| 0.45 | Post-reframing judgment of Player 2 | |
| D | 0.55 | Expert signal |
| 0.10 | Bias adjustment parameter | |
| TS | 0.9 | Temporal stability |
| Metric | Value | Interpretation |
|---|---|---|
| Agreement Level | 0.83 | Good post-reframing consensus |
| Expert Alignment | 0.915 | Excellent alignment with expert signal |
| Updating Process | 0.0397 | A limited updating occurred |
| Temporal Stability | 0.9 | Good stability across trials |
| Final CRI | 0.821 | Good robustness |
| Scenarios | Expected Effects on Ji | Proximity to Expert (D) |
|---|---|---|
| High TRUSTi, Low TIEi | ≈ D | Strong |
| Low TRUSTi, High TIEi | ≈ TIEi | Weak |
| Moderate TIEj | Convergence to consensus | Moderate |
| High b (Dissent Cost) | ≈ Xi | Depends on TRUSTi |
| Case | Condition | Equilibrium |
|---|---|---|
| No Collaboration | a = 0 | = Xi |
| No Dissent Cost | b = 0 | = Weighted average of Xj |
| Parameter | Description | Value |
|---|---|---|
| a | Collaboration weight | 0.8 |
| b | Dissent cost weight | 0.2 |
| TIE1 | Player 1’s ideological tie | 0.6 |
| TIE2 | Player 2’s ideological tie | 0.4 |
| TRUST1 = TRUST2 | Trust in experts | 0.5 |
| Judgment | Equation |
|---|---|
| 0.24 + 0.45D | |
| 0.16 + 0.55D |
| Parameter | Value | Description |
|---|---|---|
| A | 0.7 | Collaboration weight |
| B | 0.3 | Dissent cost weight |
| Parameter/Variable | Value | Description |
|---|---|---|
| β | 0.70 | Ideological bias parameter |
| α | 0.630 | Weighting parameter |
| TRUST1 | 0.4 | Player 1’s trust in experts |
| TRUST2 | 0.5 | Player 2’s trust in experts |
| TIE1 | 0.70 | Player 1’s ideological tie |
| TIE2 | 0.25 | Player 2’s ideological tie |
| D | 0.55 | Expert signal |
| 0.700 | Initial judgment of Player 1 | |
| 0.750 | Initial judgment of Player 2 | |
| X1 | 0.640 | Player 1’s posterior belief |
| X2 | 0.650 | Player 2’s posterior belief |
| 0.272 | Final judgment of Player 1 | |
| 0.438 | Final judgment of Player 2 | |
| d* | 0.050 | Initial disagreement |
| d** | 0.166 | Final disagreement |
| 0.428 | Player 1’s judgment change | |
| 0.312 | Player 2’s judgement change |
| Failure Mode | Fact-Checking Approach | ACRD Solution |
|---|---|---|
| Backfire effects [10] | Direct correction | Adversarial reframing (e.g., presenting a climate claim as if coming from an oil lobbyist) |
| False consensus [36] | Assumes neutral arbiters exist | Measures divergence under adversarial attribution |
| Confirmation bias [8] | Relies on authority cues | Strips speaker identity, forcing content-based evaluation |
| Challenge | ACRD Solution | Theoretical Basis |
|---|---|---|
| False consensus | Expert-weighted CRI | [36] |
| Speaker salience overhang | Neural noise injection | [21] |
| Nuance collapse | Likert-scale writing rationale | [85] |
| Adversarial fatigue | Real-time calibration of attribution intensity | [10] |
| Risk | ACRD Safeguard | Technical Implementation |
|---|---|---|
| Training data bias | Adversarial debiasing [87,91] | Fine-tuning on counterfactual Q&A datasets |
| Oversimplified ideological models | Adversarial nets [93] | Multi-LLM consensus (GPT-4 + Claude + Mistral) |
| Semantic fragility | Neural noise injection [21] | Paraphrase generation via T5/DALL-E |
| Adversarial input manipulation | AudioGuard-style detection [102] | Noise vector validation for AI-generated counterfactuals |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Faugere, C. Quantifying Claim Robustness Through Adversarial Framing: A Conceptual Framework for an AI-Enabled Diagnostic Tool. AI 2025, 6, 147. https://doi.org/10.3390/ai6070147
Faugere C. Quantifying Claim Robustness Through Adversarial Framing: A Conceptual Framework for an AI-Enabled Diagnostic Tool. AI. 2025; 6(7):147. https://doi.org/10.3390/ai6070147
Chicago/Turabian StyleFaugere, Christophe. 2025. "Quantifying Claim Robustness Through Adversarial Framing: A Conceptual Framework for an AI-Enabled Diagnostic Tool" AI 6, no. 7: 147. https://doi.org/10.3390/ai6070147
APA StyleFaugere, C. (2025). Quantifying Claim Robustness Through Adversarial Framing: A Conceptual Framework for an AI-Enabled Diagnostic Tool. AI, 6(7), 147. https://doi.org/10.3390/ai6070147