
AEA-YOLO: Adaptive Enhancement Algorithm for Challenging Environment Object Detection


Abstract
1. Introduction
- The proposed adaptive enhancement algorithm framework aims to consolidate and expand upon classical image processing filters for object detection into six filters.
- The use of a PPN based on CCN for data-specific filter combinations and parameter ranges.
- The use of a DN detector based on YOLO.
- The proposed AEA-YOLO approach achieves promising performance in both normal and adverse weather conditions, and encouraging experimental results are achieved on synthetic testbeds, including both the VOC Foggy and real-world RTTS datasets.
2. Related Work
2.1. Object Detection
2.2. The Adaptation of Image
2.3. Object Detection and Domain Adaptation Under Challenging Environments
3. Proposed Method
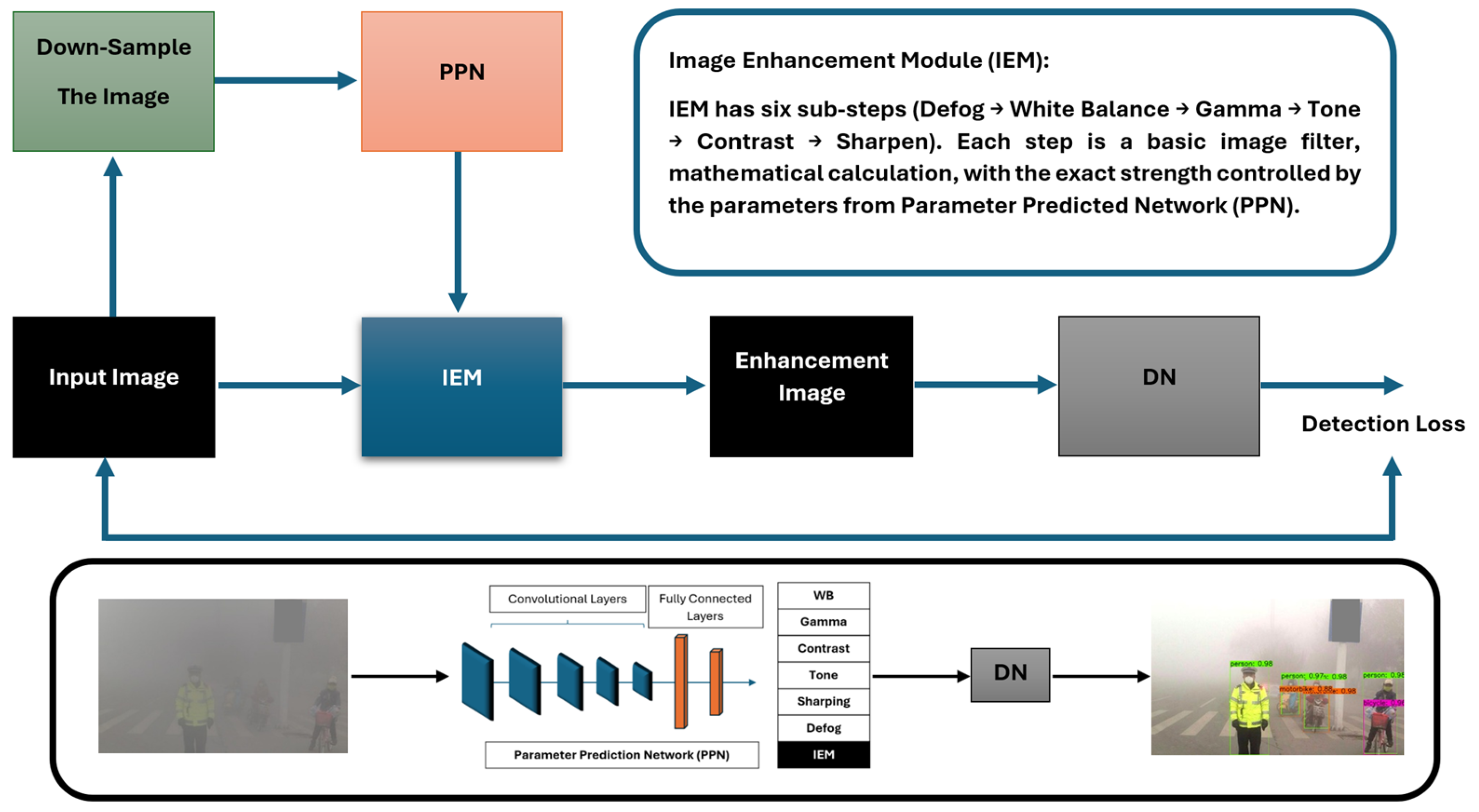
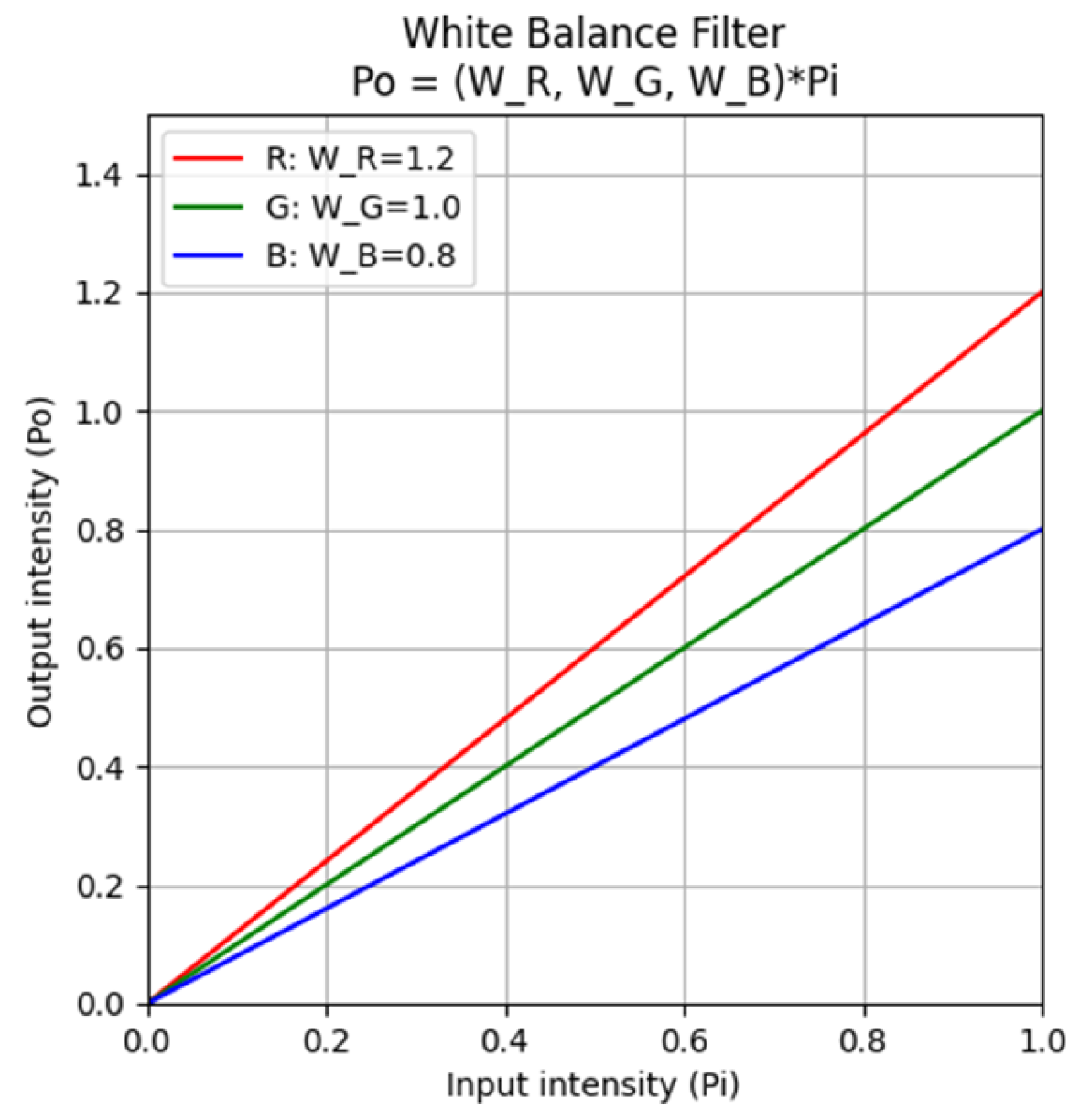
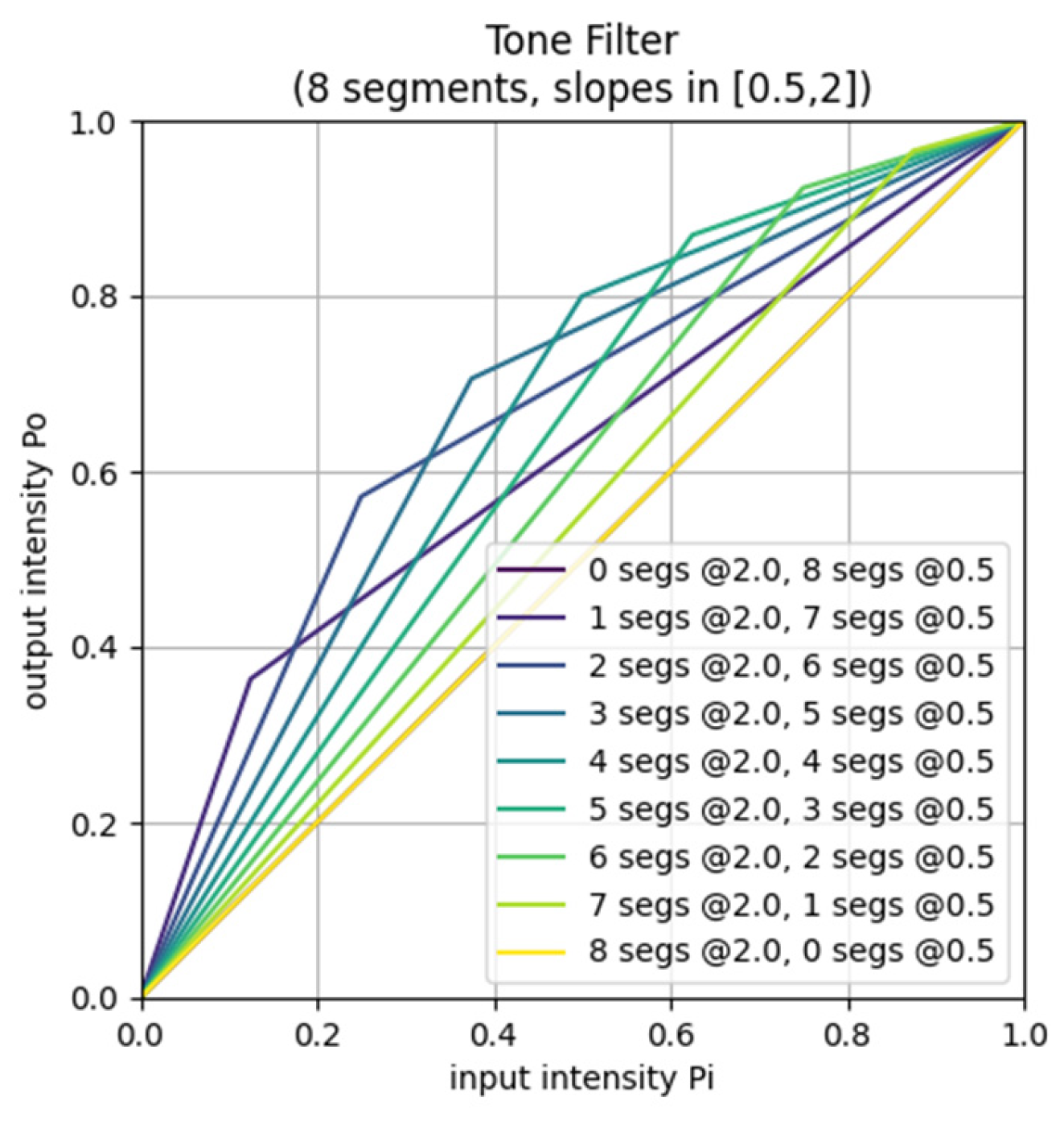
3.1. Image Enhancement Module (IEM)
3.2. Parameter Prediction Network (PPN)
- Dense fog: High defog strength (ω) and compressed tone curves.
- Low-light (nighttime): Gamma values below one and moderate contrast boosts.
- Glare: Blue-skewed white-balance gains and mild sharpening.
- Rain: Moderate ω and mid-tone steepening.
3.3. Detection Network (DN)
| Algorithm 1: Adaptive Enhancement Algorithm AEA-YOLO Training Methodology. |
| • Training dataset D containing images {x} with bounding box annotations. • Number of epochs E, batch size B. • Probability p of applying challenging environments simulation. • Initialized weights: – θ for the PPN network based on CNN. – β for YOLO detector. Output: • Trained weights (θ*, β*) for AEA-YOLO framework. 1: for epoch = 1 to E do 2: Shuffle D and partition into batches of size B 3: for each batch Db in D do 4: # --- STEP A: DATA AUGMENTATION AND CHALLENGING ENVIRONMENTS SIMULATION --- 5: for each image x in Db do 6: Generate a random number r ∈[0,1] 7: if r < p then 8: x ← Simulate Challenging Environment (x) # e.g., fog synthesis 9: end if 10: end for 11: # --- STEP B: PREDICT FILTER PARAMETERS --- 12: X-low ← Down sample Each (Db, target-size) 13: P ← PPN (X-low; θ) # P stores the IEM filter parameters (defog strength, gamma, etc.) 14: # --- STEP C: IMAGE ENHANCEMENT MODULE--- 15: X-enhancement ← IEM (Db, P) # Apply the IEM filters with parameters P to the full-resolution images 16: # --- STEP D: OBJECT DETECTION AND LOSS COMPUTATION --- 17: Y-pred ← YOLO(X- enhancement; β) 18: L-det ← Detection-Loss (Y-pred, Ygt) # Ygt denotes ground-truth bounding boxes for Db 19: # --- STEP E: BACKPROPAGATION AND WEIGHT UPDATE --- 20: (∂L-det/∂θ, ∂L-det/∂β) ← Backprop(L-det) 21: θ ← θ − η · ∂L-det/∂θ 22: β ← β − η · ∂L-det/∂β 23: end for 24: end for 25: return (θ*, β*) # Final trained parameters for AEA-YOLO |
4. Experimental Results
4.1. Experiment Dataset, Environment, and Parameters
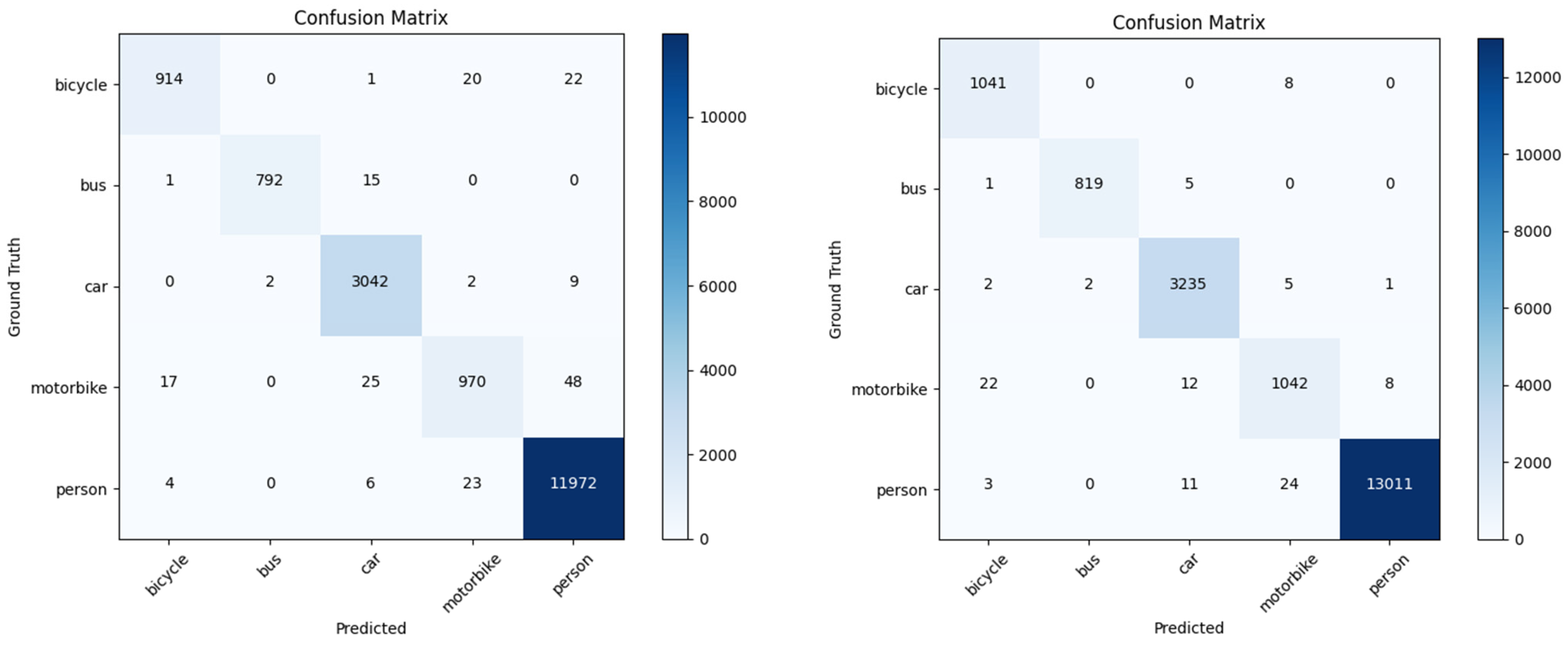
4.2. Ablation Experiment
4.3. Comparison of Existing Integrated Methods
- Weakly Supervised Parameter Prediction: We use bounding-box supervision only, allowing the Image Enhancement Module (IEM) to adapt its filter parameters automatically per image.
- Lightweight Enhancement: A small PPN based on CNN for parameter prediction adds minimal overhead, supporting near-real-time inference speeds, which is an aspect some other joint methods do not emphasize.
- Unified Hybrid Training: We combine normal and synthetic adverse images during training, enabling a single model to handle multiple conditions rather than specialized domain-adaptive modules.
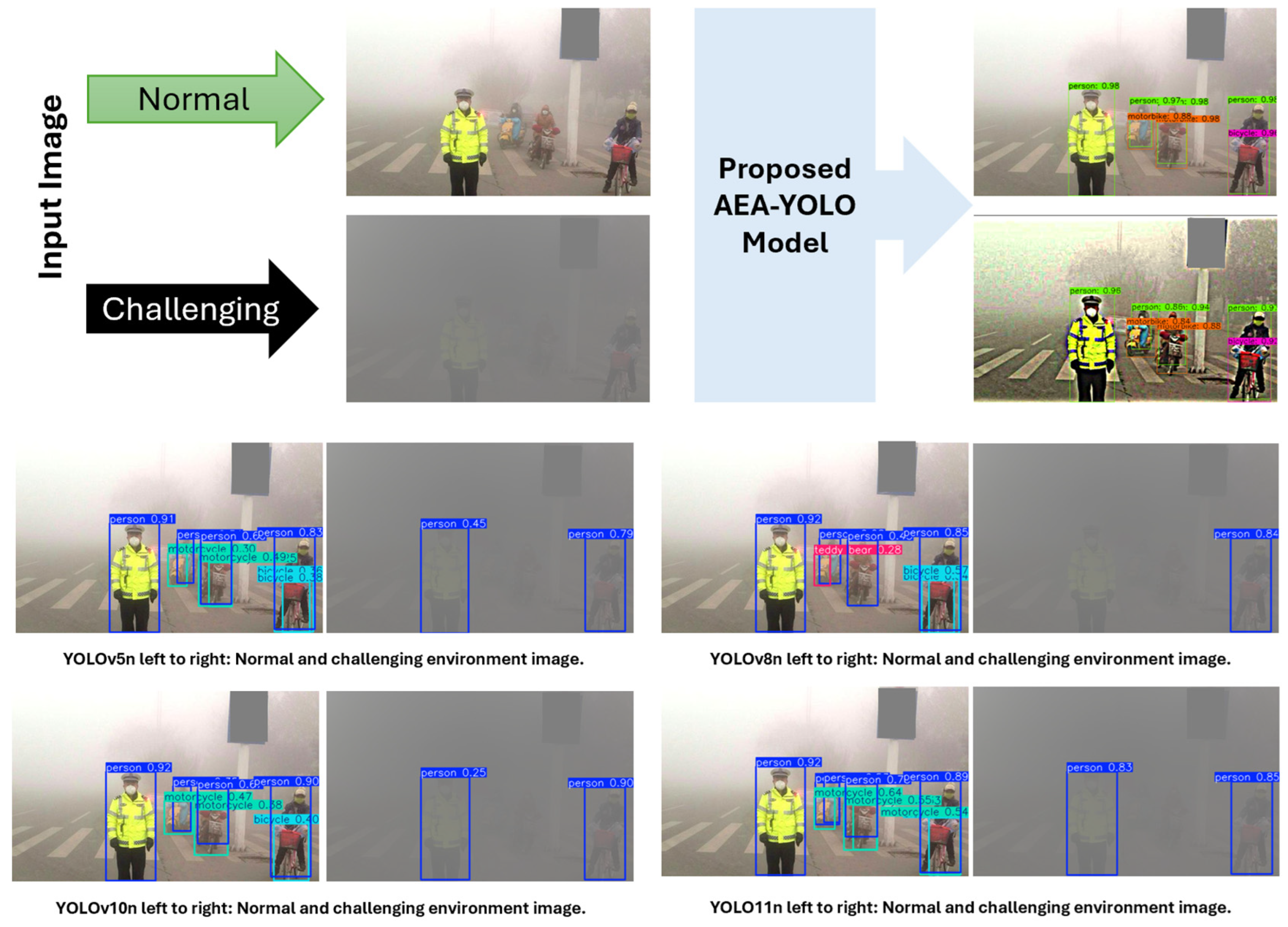
4.4. Testing on the Real-World Scenario Dataset
5. Limitations and Future Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| YOLO | You Only Look Once |
| CNN | Convolutional Neural Network |
| AI | Artificial Intelligence |
| AP | Average Precision |
| mAP | Mean Average Precision |
References
- Whitehill, J.; Omlin, C.W. Haar features for FACS AU recognition. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR06), Southampton, UK, 10–12 April 2006; p. 5. [Google Scholar]
- Lowe, D.G. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Corfu, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Farhadi, A.; Redmon, J. Yolov3: An incremental improvement. In Computer Vision and Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2018; Volume 1804, pp. 1–6. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. Technical Report. 2020. Available online: https://arxiv.org/abs/2004.10934 (accessed on 12 June 2025).
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Yifu, Z.; Wong, C.; Montes, D.; et al. Zenodo. 2020. Available online: https://zenodo.org/records/3983579 (accessed on 21 April 2025).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications. Technical Report. 2022. Available online: https://arxiv.org/abs/2209.02976 (accessed on 12 June 2025).
- Li, C.; Li, L.; Geng, Y.; Jiang, H.; Cheng, M.; Zhang, B.; Ke, Z.; Xu, X.; Chu, X. YOLOv6 v3.0: A full-scale reloading. (preprint). 2023. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 7464–7475. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. YOLOv8: Explore Ultralytics YOLOv8; Ultralytics: Frederick, MD, USA, 2023; Available online: https://docs.ultralytics.com/models/yolov8/ (accessed on 12 June 2025).
- Wang, C.Y.; Yeh, I.H.; Mark Liao, H.Y. Yolov9: Learning what you want to learn using programmable gradient information. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2024; pp. 1–21. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Jocher, G.; Qiu, J. YOLO11: Ultralytics YOLO11; Ultralytics: Frederick, MD, USA, 2024; Available online: https://docs.ultralytics.com/models/yolo11/ (accessed on 12 June 2025).
- Tian, Y.; Ye, Q.; Doermann, D. YOLOv12: Attention-Centric Real-Time Object Detectors; Ultralytics: Frederick, MD, USA, 2025; Available online: https://docs.ultralytics.com/zh/models/yolo12/ (accessed on 12 June 2025).
- Liu, W.; Hou, X.; Duan, J.; Qiu, G. End-to-end single image fog removal using enhanced cycle consistent adversarial networks. IEEE Trans. Image Process. 2020, 29, 7819–7833. [Google Scholar] [CrossRef]
- Li, C.; Guo, C.; Guo, J.; Han, P.; Fu, H.; Cong, R. PDR-Net: Perception-inspired single image dehazing network with refinement. IEEE Trans. Multimed. 2019, 22, 704–716. [Google Scholar] [CrossRef]
- Wang, Q.; Jiang, K.; Wang, Z.; Ren, W.; Zhang, J.; Lin, C.-W. Multi-scale progressive fusion network for single image deraining. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8346–8355. [Google Scholar]
- Hnewa, M.; Radha, H. Multiscale domain adaptive yolo for cross-domain object detection. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Online, 19–22 September 2021; pp. 3323–3327. [Google Scholar]
- Oreski, G. YOLO* C—Adding context improves YOLO performance. Neurocomputing 2023, 555, 126655. [Google Scholar] [CrossRef]
- Özcan, İ.; Altun, Y.; Parlak, C. Improving YOLO detection performance of autonomous vehicles in adverse weather conditions using metaheuristic algorithms. Appl. Sci. 2024, 14, 5841. [Google Scholar] [CrossRef]
- Ding, Q.; Li, P.; Yan, X.; Shi, D.; Liang, L.; Wang, W.; Xie, H.; Li, J.; Wei, M. CF-YOLO: Cross fusion YOLO for object detection in adverse weather with a high-quality real snow dataset. IEEE Trans. Intell. Transp. Syst. 2023, 24, 10749–10759. [Google Scholar] [CrossRef]
- Liu, G.; Huang, Y.; Yan, S.; Hou, E. RFCS-YOLO: Target Detection Algorithm in Adverse Weather Conditions via Receptive Field Enhancement and Cross-Scale Fusion. Sensors 2025, 25, 912. [Google Scholar] [CrossRef]
- Ho, T.T.; Kim, T.; Kim, W.J.; Lee, C.H.; Chae, K.J.; Bak, S.H.; Kwon, S.O.; Jin, G.Y.; Park, E.-K.; Choi, S. A 3D-CNN model with CT-based parametric response mapping for classifying COPD subjects. Sci. Rep. 2021, 11, 34. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.M.; Romero-González, J.A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Gavrilescu, R.; Zet, C.; Foșalău, C.; Skoczylas, M.; Cotovanu, D. Faster R-CNN: An approach to real-time object detection. In Proceedings of the 2018 International Conference and Exposition on Electrical and Power Engineering (EPE), Iasi, Romania, 18–19 October 2018; pp. 165–168. [Google Scholar]
- Law, H.; Deng, J. Cornernet: Detecting objects as paired keypoints. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 734–750. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Polesel, A.; Ramponi, G.; Mathews, V.J. Image enhancement via adaptive unsharp masking. IEEE Trans. Image Process. 2000, 9, 505–510. [Google Scholar] [CrossRef] [PubMed]
- Yu, Z.; Bajaj, C. A fast and adaptive method for image contrast enhancement. In Proceedings of the 2004 International Conference on Image Processing, ICIP’04, Singapore, 24–27 October 2004; Volume 2, pp. 1001–1004. [Google Scholar]
- Wang, W.; Chen, Z.; Yuan, X.; Guan, F. An adaptive weak light image enhancement method. In Proceedings of the Twelfth International Conference on Signal Processing Systems, Shanghai, China, 6–9 November 2020; Volume 11719, p. 1171902. [Google Scholar]
- Hu, Y.; He, H.; Xu, C.; Wang, B.; Lin, S. Exposure: A white-box photo post-processing framework. ACM Trans. Graph. (TOG) 2018, 37, 1–17. [Google Scholar] [CrossRef]
- Yu, R.; Liu, W.; Zhang, Y.; Qu, Z.; Zhao, D.; Zhang, B. DeepExposure: Learning to Expose Photos with Asynchronously Reinforced Adversarial Learning. Neural Inf. Process. Syst. 2018. Available online: https://proceedings.neurips.cc/paper/2018/file/a5e0ff62be0b08456fc7f1e88812af3d-Paper.pdf (accessed on 12 June 2025).
- Zeng, H.; Cai, J.; Li, L.; Cao, Z.; Zhang, L. Learning image-adaptive 3d lookup tables for high performance photo enhancement in real-time. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 2058–2073. [Google Scholar] [CrossRef]
- Liu, X.; Ma, Y.; Shi, Z.; Chen, J. Griddehazenet: Attention-based multi-scale network for image dehazing. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7314–7323. [Google Scholar]
- Dong, H.; Pan, J.; Xiang, L.; Hu, Z.; Zhang, X.; Wang, F.; Yang, M.H. Multi-scale boosted dehazing network with dense feature fusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2157–2167. [Google Scholar]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]
- Chen, Y.; Li, W.; Sakaridis, C.; Dai, D.; Van Gool, L. Domain adaptive faster r-cnn for object detection in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3339–3348. [Google Scholar]
- Huang, S.C.; Le, T.H.; Jaw, D.W. DSNet: Joint semantic learning for object detection in inclement weather conditions. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 2623–2633. [Google Scholar] [CrossRef]
- Sindagi, V.A.; Oza, P.; Yasarla, R.; Patel, V.M. Prior-based domain adaptive object detection for hazy and rainy conditions. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIV 16. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 763–780. [Google Scholar]
- Chen, K.; Franko, K.; Sang, R. Structured model pruning of convolutional networks on tensor processing units. In Proceedings of the 2021 IEEE International Conference on Artificial Intelligence Circuits and Systems (AICAS), Washington, DC, USA, 6–9 June 2021; pp. 1–5. [Google Scholar]
- Kalwar, S.; Patel, D.; Aanegola, A.; Konda, K.R.; Garg, S.; Krishna, K.M. Gdip: Gated differentiable image processing for object detection in adverse conditions. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 7083–7089. [Google Scholar]
- Fu, Z.; Chang, K.; Ling, M.; Zhang, Q.; Qi, E. Auxiliary Domain-Guided Adaptive Object Detection in Adverse Weather Conditions. In Asian Conference on Computer Vision; Springer: Singapore, 2025; pp. 312–329. [Google Scholar]
- Wang, Y.; Xu, T.; Fan, Z.; Xue, T.; Gu, J. Adaptiveisp: Learning an adaptive image signal processor for object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 112598–112623. [Google Scholar]
- Hu, J.; Wei, Y.; Chen, W.; Zhi, X.; Zhang, W. CM-YOLO: Typical Object Detection Method in Remote Sensing Cloud and Mist Scene Images. Remote Sens. 2025, 17, 125. [Google Scholar] [CrossRef]
- Khanum, A.; Lee, C.Y.; Yang, C.S. Involvement of deep learning for vision sensor-based autonomous driving control: A review. IEEE Sens. J. 2023, 23, 15321–15341. [Google Scholar] [CrossRef]
- Wang, W.; Zhang, J.; Zhai, W.; Cao, Y.; Tao, D. Robust object detection via adversarial novel style exploration. IEEE Trans. Image Process. 2022, 31, 1949–1962. [Google Scholar] [CrossRef]
- Shen, D.; Wu, G.; Suk, H.I. Deep learning in medical image analysis. Annu. Rev. Biomed. Eng. 2017, 19, 221–248. [Google Scholar] [CrossRef]
- Li, B.; Peng, X.; Wang, Z.; Xu, J.; Feng, D. An all-in-one network for dehazing and beyond. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4770–4778. [Google Scholar]
- Zamir, S.W.; Arora, A.; Khan, S.; Hayat, M.; Khan, F.S.; Yang, M.H.; Shao, L. Multi-stage progressive image restoration. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14821–14831. [Google Scholar]
- Peng, D.; Ding, W.; Zhen, T. A novel low light object detection method based on the YOLOv5 fusion feature enhancement. Sci. Rep. 2024, 14, 4486. [Google Scholar] [CrossRef]
- Varailhon, S.; Aminbeidokhti, M.; Pedersoli, M.; Granger, E. Source-Free Domain Adaptation for YOLO Object Detection. In *Computer Vision – ECCV 2024 Workshops*, Proceedings of the European Conference on Computer Vision (ECCV 2024), Tel Aviv, Israel, 23–27 October 2024; Springer: Berlin/Heidelberg, Germany; pp. 218–235. [Google Scholar] [CrossRef]
- Li, Y.; Zhang, S.; Liu, Y.; Yang, J. Loose to compact feature alignment for domain adaptive object detection. Pattern Recognit. Lett. 2024, 181, 92–98. [Google Scholar] [CrossRef]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep image prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9446–9454. [Google Scholar]
- Venkatakrishnan, S.V.; Bouman, C.A.; Wohlberg, B. Plug-and-play priors for model based reconstruction. In Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; pp. 945–948. [Google Scholar]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- He, K.; Sun, J.; Tang, X. Single image haze removal using dark channel prior. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 33, 2341–2353. [Google Scholar]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Arasimhan, S.G.; Nayar, S.K. Vision and the atmosphere. Int. J. Comput. Vis. 2002, 48, 233–254. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Gongguo, Z.; Junhao, W. An improved small target detection method based on Yolo V3. In Proceedings of the 2021 International Conference on Electronics, Circuits and Information Engineering (ECIE), Zhengzhou, China, 22–24 January 2021; pp. 220–223. [Google Scholar]
- Abbasi, H.; Amini, M.; Yu, F.R. Fog-aware adaptive yolo for object detection in adverse weather. In Proceedings of the 2023 IEEE Sensors Applications Symposium (SAS), Ottawa, ON, Canada, 18–20 July 2023; pp. 1–6. [Google Scholar]
- Chu, Z. D-YOLO: A Robust Framework for Object Detection in Adverse Weather Conditions. Technical Report. 2024. Available online: https://arxiv.org/abs/2403.09233 (accessed on 12 June 2025).
- Zhang, L.; Zhou, W.; Fan, H.; Luo, T.; Ling, H. Robust domain adaptive object detection with unified multi-granularity alignment. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 9161–9178. [Google Scholar] [CrossRef]
- Chen, Y.; Wang, Y.; Zou, Z.; Dan, W. GMS-YOLO: A Lightweight Real-Time Object Detection Algorithm for Pedestrians and Vehicles Under Foggy Conditions. IEEE Internet Things J. 2025. [Google Scholar] [CrossRef]
- Wang, H.; Shi, Z.; Zhu, C. Enhanced Multi-Scale Object Detection Algorithm for Foggy Traffic Scenarios. Comput. Mater. Contin. 2025, 82, 2451–2474. [Google Scholar] [CrossRef]
- Gharatappeh, S.; Sekeh, S.; Dhiman, V. Weather-Aware Object Detection Transformer for Domain Adaptation. Technical Report. 2025. Available online: https://arxiv.org/abs/2504.10877 (accessed on 12 June 2025).
- Li, B.; Ren, W.; Fu, D.; Tao, D.; Feng, D.; Zeng, W.; Wang, Z. Benchmarking single-image dehazing and beyond. IEEE Trans. Image Process. 2018, 28, 492–505. [Google Scholar] [CrossRef]
- Wang, Y.; Yan, X.; Zhang, K.; Gong, L.; Xie, H.; Wang, F.L.; Wei, M. Togethernet: Bridging image restoration and object detection together via dynamic enhancement learning. Comput. Graph. Forum 2022, 41, 465–476. [Google Scholar] [CrossRef]
- Wang, H.; Xu, Y.; He, Y.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. YOLOv5-Fog: A multiobjective visual detection algorithm for fog driving scenes based on improved YOLOv5. IEEE Trans. Instrum. Meas. 2022, 71, 1–12. [Google Scholar] [CrossRef]
- Hnewa, M.; Radha, H. Integrated multiscale domain adaptive yolo. IEEE Trans. Image Process. 2023, 32, 1857–1867. [Google Scholar] [CrossRef] [PubMed]
- Ma, J.; Lin, M.; Zhou, G.; Jia, Z. Joint Image Restoration for Domain Adaptive Object Detection in Foggy Weather Condition. In Proceedings of the 2024 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 27–30 October 2024; pp. 542–548. [Google Scholar]
- Ogino, Y.; Shoji, Y.; Toizumi, T.; Ito, A. ERUP-YOLO: Enhancing Object Detection Robustness for Adverse Weather Condition by Unified Image-Adaptive Processing. In Proceedings of the 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Tucson, AZ, USA, 26 February–6 March 2025; pp. 8597–8605. [Google Scholar]
- Agarwal, S.; Birman, R.; Hadar, O. WARLearn: Weather-Adaptive Representation Learning. In Proceedings of the 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Tucson, AZ, USA, 26 February–6 March 2025; pp. 4978–4987. [Google Scholar]
- Liu, Z.; Fang, T.; Lu, H.; Zhang, W.; Lan, R. MASFNet: Multi-scale Adaptive Sampling Fusion Network for Object Detection in Adverse Weather. IEEE Trans. Geosci. Remote Sens. 2025, 63, 1–15. [Google Scholar] [CrossRef]
- Zhu, X.; Su, W.; Lu, L.; Li, B.; Wang, X.; Dai, J. Deformable DETR: Deformable Transformers for End-to-End Object Detection. In Proceedings of the International Conference on Learning Representations (ICLR) 2021, Virtual Conference, 25–29 May 2021. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Chen, Z.; Yang, J.; Li, F.; Feng, Z.; Chen, L.; Jia, L.; Li, P. Foreign Object Detection Method for Railway Catenary Based on a Scarce Image Generation Model and Lightweight Perception Architecture. IEEE Trans. Circuits Syst. Video Technol. 2025. [Google Scholar] [CrossRef]
- Yan, L.; Wang, Q.; Zhao, J.; Guan, Q.; Tang, Z.; Zhang, J.; Liu, D. Radiance Field Learners as UAV First-Person Viewers. In European Conference on Computer Vision; Springer Nature: Cham, Switzerland, 2024; pp. 88–107. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Dimensions | Details |
|---|---|---|
| Input image (i) | 3 × i_size × i_size | Resized input image 256 × 256 |
| Conv Block 1 | 16 × 128 × 128 | 3 × 3, stride 2 |
| Conv Block 2 | 32 × 64 × 64 | 3 × 3, stride 2 |
| Conv Block 3 | 32 × 32 × 32 | 3 × 3, stride 2 |
| Conv Block 4 | 32 × 16 × 16 | 3 × 3, stride 2 |
| Conv Block 5 | 32 × 8 × 8 | 3 × 3, stride 2 |
| GAP | 32 | 32 × 8 × 8 feature tensor to a 32-D vector |
| FC1 | 128 | Liner layer |
| FC2 | N | 15 Output Parameters |
| Filter | Parameter (θ) | Count | Symbol(s) | Range |
|---|---|---|---|---|
| Defog | 0 | 1 | ω | [0.1, 1.0] |
| White balance | 1–3 | 3 | Wr, Wg, Wb | [0.91, 1.10] (that is 1 ± 10%) |
| Gamma | 4 | 1 | γ | [1/3, 3] |
| Tone | 5–12 | 8 | t0,…, t7 | [0.5, 2.0] |
| Contrast | 13 | 1 | λ | [1/3.5, 3.5] |
| Unsharp-mask | 14 | 1 | κ | [0, 5] |
| Total | - | 15 | - | - |
| Parameter | Value |
|---|---|
| Input image size | 640 × 640 |
| Training batch size | 6 |
| Initial learning rate | 1 × 10−4 |
| Momentum | 0.937 |
| Optimizer | Adam |
| Epoch | 250 |
| Mode | Bicycle AP | Bus AP | Car AP | Motorbike AP | Person AP | mAP@50 |
|---|---|---|---|---|---|---|
| DN | 85.76 | 94.75 | 91.52 | 91.92 | 84.65 | 89.72% |
| IEM + DN | 97.36 | 98.81 | 98.22 | 98.33 | 96.47 | 97.84% |
| Model | mAP@50 | Features/Domain |
|---|---|---|
| Fog-Aware YOLO [66] 2023 | 72.00% | An adaptive object detection block aims to determine the fogginess level of an image before object detection, avoiding pre-processing if fog levels are below the threshold, and applying the YOLOv3 algorithm. |
| D-YOLO [67] 2024 | 43.00% | A double-route network with an attention feature fusion module, incorporating hazy and dehazed features. A subnetwork for haze-free features. |
| MG-ADA [68] 2024 | 62.10% | Multi-granularity alignment (pixel, instance, category) for domain adaptation (SYNTHETIC TO REAL ADAPTATION DETECTION EXPERIMENT). |
| GMS-YOLO [69] 2025 | 64.70% | It is based on YOLOv10, which uses a Ghost Multi-Scale Convolution module and Shape Consistent Intersection over Union for localization loss function, with a Compensatory Consistency Matching Metric for sensitivity reduction. |
| Multi-Scale [70] 2025 | 81.07% | Enhances feature extraction with Triplet Attention, integrates the Diverse Branch Block for semantic information fusion, introduces a decoupled detection head, and uses Minimum Point Distance for faster training convergence. |
| PL-RT-DETR [71] 2025 | 90.90% | The domain adaptation strategy is for the weather adaptive attention mechanism and a weather fusion encoder to ensure feature-level consistency across domains and adapt to fog contexts. |
| AEA-YOLO (Ours) | 97.84% | Adaptable and learning-based filters that unify domain alignment with detection. |
| RTTS Dataset (4322 Images) | ||||||
|---|---|---|---|---|---|---|
| Class | Person | Car | Bicycle | Motorbike | Bus | All |
| Count | 7950 | 18,413 | 534 | 862 | 1838 | 29,597 |
| Model | Person | Car | Bicycle | Motorbike | Bus | mAP@50 |
|---|---|---|---|---|---|---|
| MS-DAYOLO [23] 2021 | 81.30 | 68.00 | 61.40 | 54.60 | 35.20 | 60.10% |
| TogetherNet [73] 2022 | 82.70 | 75.32 | 57.27 | 55.40 | 37.04 | 61.55% |
| YOLOv5-Fog [74] 2022 | - | - | - | - | - | 77.80% |
| IMS-DAYOLO [75] 2023 | 80.50 | 65.10 | 61.20 | 51.90 | 33.00 | 58.30% |
| YOLOv9 + CLEO [25] 2024 | - | - | - | - | - | 79.30% |
| DA-YOLOX [76] 2024 | 78.33 | 75.88 | 59.10 | 54.98 | 44.42 | 62.60% |
| ERUP-YOLO [77] 2025 | - | - | - | - | - | 49.81% |
| WARLearn [78] 2025 | - | - | - | - | - | 52.60% |
| AD-DAYOLO [47] 2025 | 82.40 | 71.10 | 65.10 | 59.10 | 38.60 | 63.20% |
| MASFNet [79] 2025 | 85.15 | 80.49 | 72.55 | 66.11 | 64.10 | 73.68% |
| YOLOv12n 2025 | 84.30 | 86.30 | 71.10 | 74.10 | 66.20 | 76.40% |
| YOLOv12x 2025 | 89.00 | 91.10 | 79.10 | 80.30 | 74.60 | 82.80% |
| AEA-YOLO (ours) | 93.79 | 94.49 | 95.92 | 96.69 | 97.16 | 95.61% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kariri, A.; Elleithy, K. AEA-YOLO: Adaptive Enhancement Algorithm for Challenging Environment Object Detection. AI 2025, 6, 132. https://doi.org/10.3390/ai6070132
Kariri A, Elleithy K. AEA-YOLO: Adaptive Enhancement Algorithm for Challenging Environment Object Detection. AI. 2025; 6(7):132. https://doi.org/10.3390/ai6070132
Chicago/Turabian StyleKariri, Abdulrahman, and Khaled Elleithy. 2025. "AEA-YOLO: Adaptive Enhancement Algorithm for Challenging Environment Object Detection" AI 6, no. 7: 132. https://doi.org/10.3390/ai6070132
APA StyleKariri, A., & Elleithy, K. (2025). AEA-YOLO: Adaptive Enhancement Algorithm for Challenging Environment Object Detection. AI, 6(7), 132. https://doi.org/10.3390/ai6070132