
Fusing Horizon Information for Visual Localization

Abstract
1. Introduction
2. Related Work
2.1. Visual Localization
2.2. Stixel Representation
2.3. Feature Matching in Place Recognition
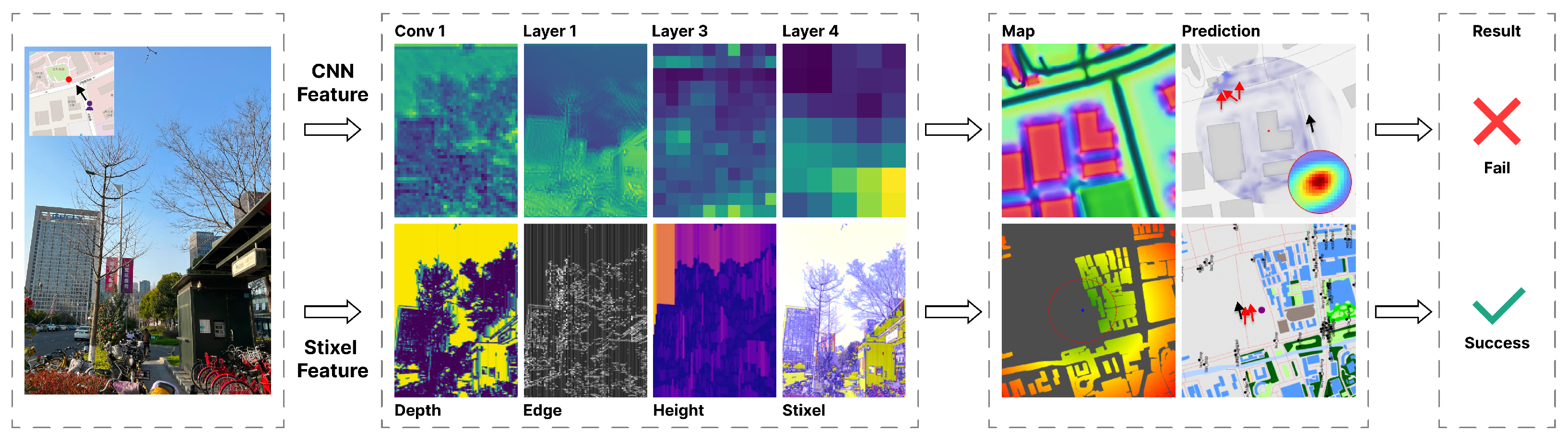
3. Method
3.1. Image-CNN
3.2. Map-CNN
3.3. Image-OSM-Stixel
- (i)
- Distance-weighted sum of building pixels
- (ii)
- Pixel count in angular interval
- (iii)
- Normalized orientation distribution
- (iv)
- Maximum distance in angular interval
3.4. Match
3.5. Loss
| Algorithm Fusing Horizon Information for Visual Localization |
|
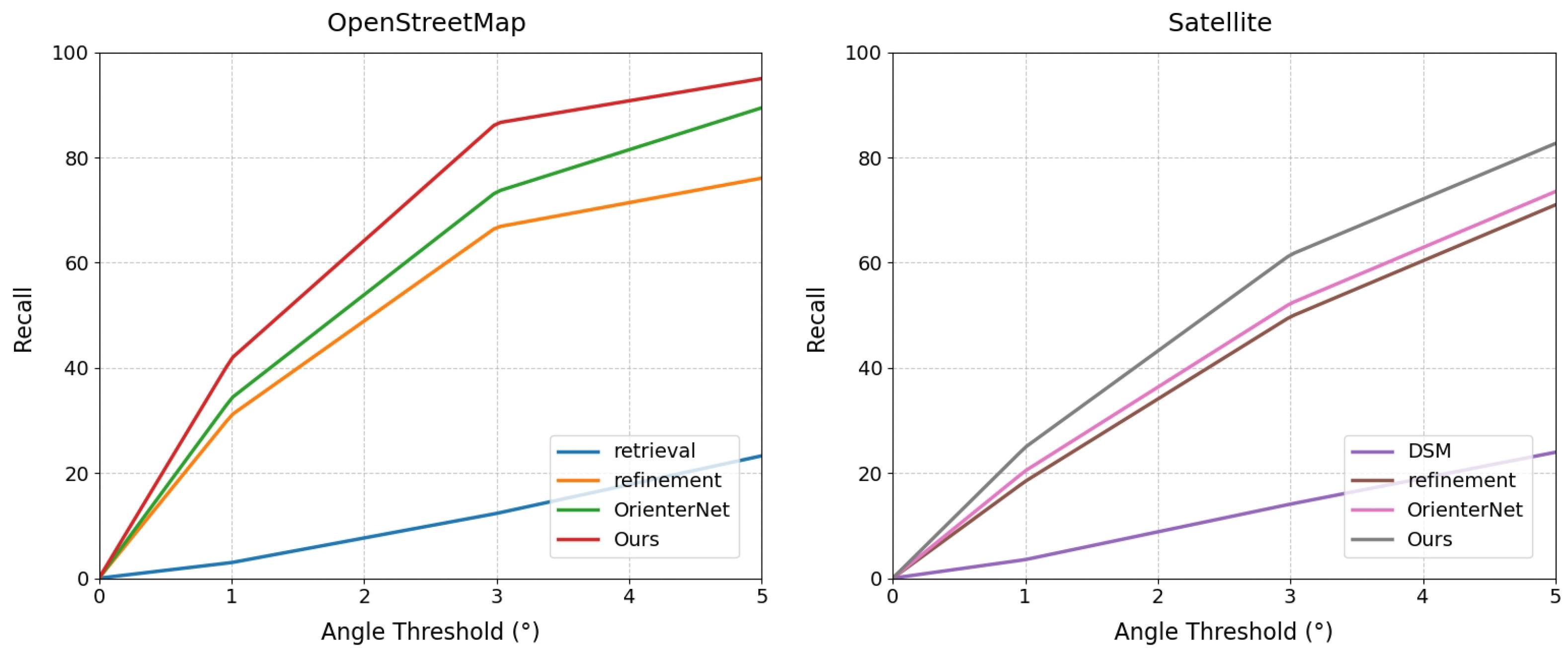
4. Experiments and Results
- Hardware: NVIDIA GeForce RTX 3090
- Code Language: python-3.9.21
- Framework: torch-2.5.1
- Data Source and Scale: MGL is collected from the Mapillary street view platform; it widely covers 12 major cities in Europe and America, with a total of 760,000 street view images. KITT is sourced from Karlsruhe, Germany, and its surrounding areas and was first released in 2012. It contains over 6 h of traffic scene recordings, covers a driving distance of about 39.2 km, and has over 200,000 3D-labeled objects and more than 30,000 pairs of stereo images.
- Capture Devices and Scenes: The capture devices of the MGL dataset are rich and diverse, including hand-held cameras, vehicle-mounted cameras, and bicycle-mounted cameras, thus capturing a variety of scenes, such as city streets, various buildings, and transportation facilities. Moreover, the perspectives of the images also show diversity in height and angle. The KITTI is collected using a modified Volkswagen Passat station wagon equipped with 2 PointGrey Flea2 color cameras (1392 × 512 pixels) and 2 PointGrey Flea2 grayscale cameras (1392 × 512 pixels), 1 Velodyne HDL-64E LiDAR, and 1 OXTS RT3003 high-precision GPS/IMU system. The scenes include urban roads, residential areas, highways, and rural roads and cover different weather and lighting conditions.
- Currently, studies focus on the localization technology between ground images and satellite images from different perspectives. Therefore, in addition to using OpenStreetMap (OSM), we have also employed satellite maps.
- Annotation Information and Acquisition Method: It has 6-Degree-of-Freedom pose information (6-DoF), including 3 translation parameters (x, y, z) and 3 rotation parameters (roll, pitch, yaw). This pose information is obtained through the combination of Structure from Motion (SfM) technology and GPS data fusion.
- Position Recall: The evaluation thresholds are set as 1 m, 3 m, and 5 m. The proportion of samples whose predicted position is within the corresponding threshold distance from the ground truth position to the total samples is calculated to evaluate the spatial accuracy of the model’s positioning.
- Orientation Recall: 1 degree, 3 degrees, and 5 degrees are used as the evaluation thresholds. The proportion of samples whose angle difference between the predicted orientation and the ground truth orientation is within the threshold is calculated to measure the accuracy of the model’s orientation estimation.
- Error Calculation: The position error is measured by the Euclidean distance between the predicted position and the ground truth position, and the orientation error is represented by the angle difference between the predicted orientation and the ground truth orientation.
5. Algorithm Complexity Analysis
- OrienterNet: The dominant computational step is exhaustive voting with complexity . Other steps include feature extraction , BEV projection , etc.
- Our Method: Additional computations introduced on top of OrienterNet:
- –
- Stixel generation and feature extraction:
- –
- OSM feature extraction:
- –
- Similarity computation:
- –
- Additional voting step:
Overall Complexity: - Theoretical Complexity: The theoretical complexity is approximately twice that of the original method, dominated by the two voting operations.
- Actual Runtime: The average measured increase is 46%, attributed to:
- –
- Reuse of intermediate results through hardware acceleration
- –
- Parallel execution of Stixel and OSM feature extraction
- –
- Reduced computational load via compressed feature representations
- OrienterNet: Major memory overheads include BEV features and voting templates .
- Our Method: Additional memory requirements:
- –
- Depth map:
- –
- Stixel and OSM features:
- –
- Second score tensor:
Overall Complexity: - Summary: The primary increase comes from storing the second score tensor, which is relatively small compared to the original method’s total memory footprint.
- Additional Stixel feature extractor: ∼68 K parameters
- Extra feature projection layers: ∼4 K parameters
- Total increase: relative to OrienterNet’s parameters
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhang, J.; Singh, S. LOAM: Lidar Odometry and Mapping. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Chicago, IL, USA, 14–18 September 2014; pp. 1271–1278. [Google Scholar]
- Zhao, B.; Yang, L.; Mao, M.; Bao, H.; Cui, Z. Pnerfloc: Visual localization with point-based neural radiance fields. Proc. AAAI Conf. Artif. Intell. 2024, 38, 7450–7459. [Google Scholar] [CrossRef]
- Sarlin, P.; DeTone, D.; Yang, T.; Avetisyan, A.; Straub, J.; Malisiewicz, T.; Bulo, S.; Newcombe, R.; Kontschieder, P.; Balntas, V. OrienterNet: Visual localization in 2D public maps with neural matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; pp. 21632–21642. [Google Scholar]
- Li, Q.; Wang, Y.; Wang, Y.; Zhao, H. Hdmapnet: An online hd map construction and evaluation framework. In Proceedings of the 2022 International Conference on Robotics and Automation (ICRA), Philadelphia, PA, USA, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 4628–4634. [Google Scholar]
- Muñoz-Bañón, M.A.; Velasco-Sánchez, E.; Candelas, F.A.; Torres, F. Openstreetmap-based autonomous navigation with lidar naive-valley-path obstacle avoidance. IEEE Trans. Intell. Transp. Syst. 2022, 23, 22284–22296. [Google Scholar] [CrossRef]
- Barros, T.; Garrote, L.; Pereira, R.; Premebida, C.; Nunes, U.J. Improving localization by learning pole-like landmarks using a semi-supervised approach. In Proceedings of the Robot 2019 The Fourth Iberian Robotics Conference, Porto, Portugal, 20–22 November 2020; Silva, M.F., Lima, J.L., Reis, L.P., Sanfeliu, A., Tardioli, D., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 255–266. [Google Scholar]
- Levi, D.; Garnett, N.; Fetaya, E.; Herzlyia, I. Stixelnet: A deep convolutional network for obstacle detection and road segmentation. In Proceedings of the British Machine Vision Conference 2015, Swansea, UK, 7–10 September 2015; Volume 1, p. 4. [Google Scholar]
- Samano, N.; Zhou, M.; Calway, A. You are here: Geolocation by embedding maps and images. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 502–518. [Google Scholar]
- O’Keefe, J.; Nadel, L. The Hippocampus as a Cognitive Map; Clarendon Press: Oxford, UK, 1978. [Google Scholar]
- Park, C.; Seo, E.; Lim, J. Heightlane: Bev heightmap guided 3d lane detection. arXiv 2024, arXiv:2408.08270. [Google Scholar]
- Wang, R.; Qin, J.; Li, K.; Li, Y.; Cao, D.; Xu, J. Bev-lanedet: A simple and effective 3d lane detection baseline. arXiv 2023, arXiv:2210.06006. [Google Scholar]
- He, Y.; Liang, S.; Rui, X.; Cai, C.; Wan, G. Egovm: Achieving precise ego-localization using lightweight vectorized maps. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 12248–12255. [Google Scholar]
- Lin, Z.; Wang, Y.; Qi, S.; Dong, N.; Yang, M.H. Bev-mae: Bird’s eye view masked autoencoders for point cloud pre-training in autonomous driving scenarios. arXiv 2024, arXiv:2212.05758. [Google Scholar] [CrossRef]
- Wu, H.; Zhang, Z.; Lin, S.; Mu, X.; Zhao, Q.; Yang, M.; Qin, T. Maplocnet: Coarse-to-fine feature registration for visual re-localization in navigation maps. In Proceedings of the 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Abu Dhabi, United Arab Emirates, 14–18 October 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 13198–13205. [Google Scholar]
- Sarlin, P.; Trulls, E.; Pollefeys, M.; Hosang, J.; Lynen, S. Snap: Self-supervised neural maps for visual positioning and semantic understanding. Adv. Neural Inf. Process. Syst. 2023, 36, 7697–7729. [Google Scholar]
- Lobben, A.K. Navigational map reading: Predicting performance and identifying relative influence of map-related abilities. Ann. Assoc. Am. Geogr. 2007, 97, 64–85. [Google Scholar] [CrossRef]
- Zhu, S.; Shah, M.; Chen, C. TransGeo: Transformer Is All You Need for Cross-view Image Geo-localization. arXiv 2022, arXiv:2204.00097. [Google Scholar]
- Sun, J.; Shen, Z.; Wang, Y.; Bao, H.; Zhou, X. LoFTR: Detector-Free Local Feature Matching with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021; pp. 1–9. [Google Scholar]
- Yin, H.; Wang, Y.; Tang, L.; Ding, X. LocNet: Global Localization in 3D Point Clouds for Mobile Robots. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1355–1360. [Google Scholar]
- Bai, X.; Hu, Z.; Zhu, X.; Huang, Q.; Chen, Y.; Fu, H.; Tai, C.-L. TransFusion: Robust LiDAR-Camera Fusion for 3D Object Detection with Transformers. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 1–10. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, T.; Rehfeld, M.; Enzweiler, R.; Benenson, U.; Franke, S.; Roth, B.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 3213–3223. [Google Scholar]
- Omama, M.; Inani, P.; Paul, P.; Yellapragada, S.C.; Jatavallabhula, K.M.; Chinchali, S.; Krishna, M. Alt-pilot: Autonomous navigation with language augmented topometric maps. arXiv 2023, arXiv:2310.02324. [Google Scholar]
- Antequera, M.L.; Gargallo, P.; Hofinger, M.; Bulo, S.R.; Kuang, Y.; Kontschieder, P. Mapillary planet-scale depth dataset. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; pp. 3–4. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The kitti dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Xia, Z.; Booij, O.; Manfredi, M.; Kooij, J.F. Visual cross-view metric localization with dense uncertainty estimates. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 2–13. [Google Scholar]
- Shi, Y.; Li, H. Beyond cross-view image retrieval: Highly accurate vehicle localization using satellite image. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 2–13. [Google Scholar]
- Shi, Y.; Yu, X.; Campbell, D.; Li, H. Where am i looking at? Joint location and orientation estimation by cross-view matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 2–7. [Google Scholar]
- Zhu, S.; Yang, T.; Chen, C. Vigor: Crossview image geo-localization beyond one-to-one retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 2–7. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Map | Approach | Training Dataset | Lateral@Xm | Runtime | ||
|---|---|---|---|---|---|---|
| 1 m | 3 m | 5 m | (ms) | |||
| OpenStreetMap | retrieval [8,25] | MGL | 37.47 | 66.24 | 72.89 | 145 |
| refinement [26] | MGL | 50.83 | 78.10 | 82.22 | 210 | |
| OrienterNet [3] | MGL | 53.51 | 88.85 | 94.47 | 125 | |
| BEV + Stixel | MGL | 56.00 | 88.20 | 95.10 | 85 | |
| BEV + Angle | MGL | 54.80 | 89.50 | 94.70 | 80 | |
| Ours | MGL | 57.25 | 87.65 | 95.62 | 105 | |
| Satellite | DSM [27] | KITTI | 10.77 | 31.37 | 48.24 | 180 |
| VIGOR [28] | KITTI | 17.38 | 48.20 | 70.79 | 155 | |
| refinement [26] | KITTI | 27.82 | 59.79 | 72.89 | 210 | |
| OrienterNet [3] | KITTI | 51.26 | 84.77 | 91.81 | 125 | |
| BEV + Stixel | KITTI | 53.50 | 84.10 | 92.00 | 87 | |
| BEV + Angle | KITTI | 53.00 | 85.00 | 92.50 | 82 | |
| Ours | KITTI | 54.84 | 83.56 | 92.35 | 107 | |
| Map | Approach | Training Dataset | Longitudinal R@Xm | Runtime | ||
|---|---|---|---|---|---|---|
| 1 m | 3 m | 5 m | (ms) | |||
| OpenStreetMap | retrieval [8,25] | MGL | 5.94 | 16.88 | 26.97 | 145 |
| refinement [26] | MGL | 17.75 | 40.32 | 52.40 | 210 | |
| OrienterNet [3] | MGL | 26.25 | 59.84 | 70.76 | 125 | |
| BEV + Stixel | MGL | 27.50 | 62.00 | 71.00 | 85 | |
| BEV + Angle | MGL | 26.80 | 61.50 | 70.90 | 80 | |
| Ours | MGL | 28.07 | 63.73 | 71.51 | 105 | |
| Satellite | DSM [27] | KITTI | 3.87 | 11.73 | 19.50 | 180 |
| VIGOR [28] | KITTI | 4.07 | 12.52 | 20.14 | 155 | |
| refinement [26] | KITTI | 5.75 | 16.36 | 26.48 | 210 | |
| OrienterNet [3] | KITTI | 22.39 | 46.79 | 57.81 | 125 | |
| BEV + Stixel | KITTI | 23.00 | 48.50 | 60.50 | 87 | |
| BEV + Angle | KITTI | 22.80 | 47.50 | 58.50 | 82 | |
| Ours | KITTI | 23.4 | 49.83 | 61.27 | 107 | |
| Map | Approach | Training Dataset | Orientation R@X° | Runtime | ||
|---|---|---|---|---|---|---|
| 1° | 3° | 5° | (ms) | |||
| OpenStreetMap | retrieval [8,25] | MGL | 2.97 | 12.32 | 23.27 | 145 |
| refinement [26] | MGL | 31.03 | 66.76 | 76.07 | 210 | |
| OrienterNet [3] | MGL | 34.26 | 73.51 | 89.45 | 125 | |
| BEV + Angle | MGL | 40.80 | 85.20 | 94.70 | 80 | |
| BEV + Stixel | MGL | 36.50 | 75.00 | 89.80 | 85 | |
| Ours | MGL | 41.80 | 86.55 | 95.01 | 105 | |
| Satellite | DSM [27] | KITTI | 3.53 | 14.09 | 23.95 | 180 |
| VIGOR [28] | KITTI | - | - | - | 155 | |
| refinement [26] | KITTI | 18.42 | 49.72 | 71.00 | 210 | |
| OrienterNet [3] | KITTI | 20.41 | 52.24 | 73.53 | 125 | |
| BEV + Angle | KITTI | 24.00 | 60.00 | 81.50 | 82 | |
| BEV + Stixel | KITTI | 22.00 | 55.00 | 78.00 | 87 | |
| Ours | KITTI | 24.90 | 61.51 | 82.68 | 107 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, C.; Yang, Y.; Wang, Y.; Zhang, H.; Li, G. Fusing Horizon Information for Visual Localization. AI 2025, 6, 121. https://doi.org/10.3390/ai6060121
Zhang C, Yang Y, Wang Y, Zhang H, Li G. Fusing Horizon Information for Visual Localization. AI. 2025; 6(6):121. https://doi.org/10.3390/ai6060121
Chicago/Turabian StyleZhang, Cheng, Yuchan Yang, Yiwei Wang, Helu Zhang, and Guangyao Li. 2025. "Fusing Horizon Information for Visual Localization" AI 6, no. 6: 121. https://doi.org/10.3390/ai6060121
APA StyleZhang, C., Yang, Y., Wang, Y., Zhang, H., & Li, G. (2025). Fusing Horizon Information for Visual Localization. AI, 6(6), 121. https://doi.org/10.3390/ai6060121