
A Pilot Study of an AI Chatbot for the Screening of Substance Use Disorder in a Healthcare Setting


Abstract
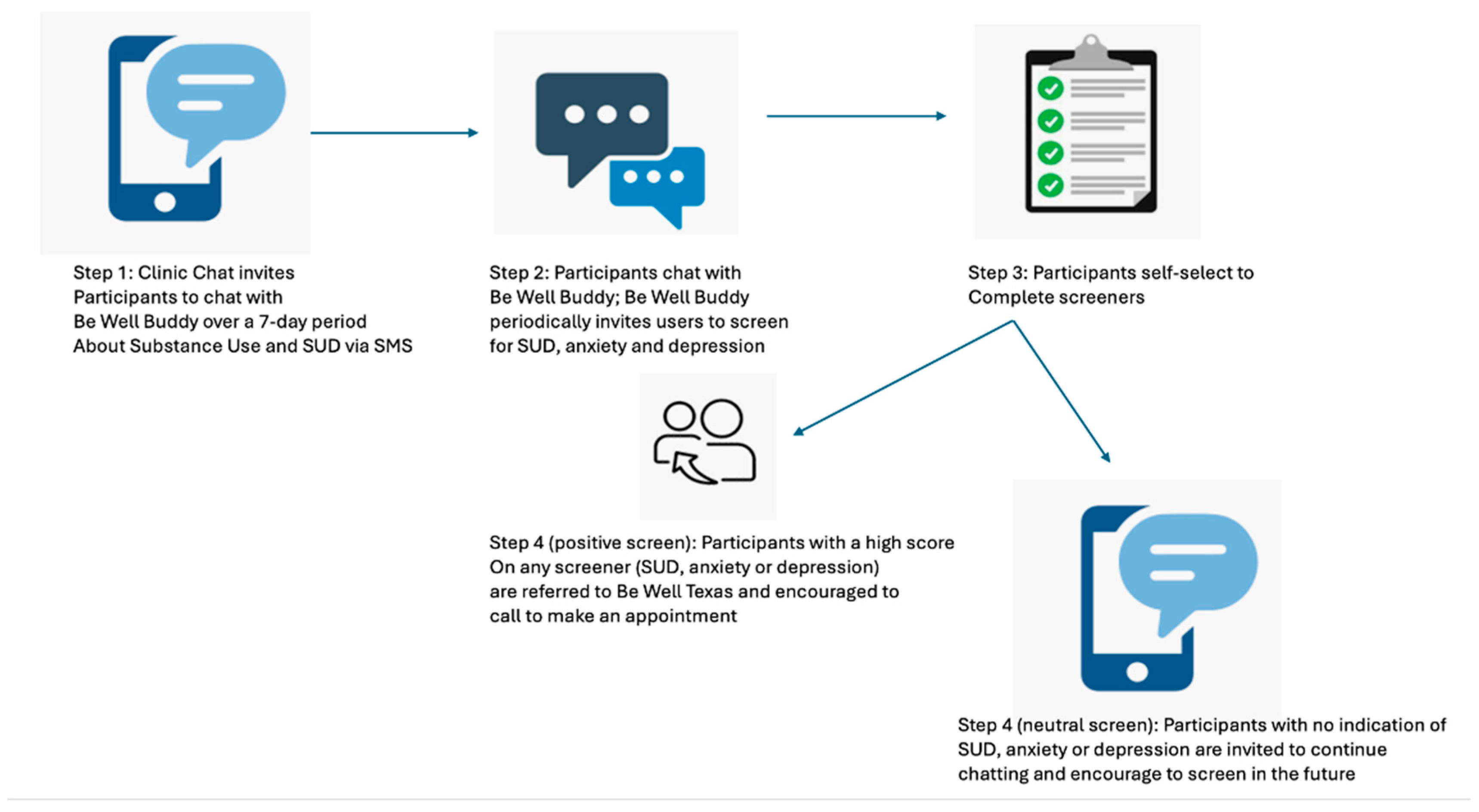
1. Introduction
2. Materials and Methods
2.1. Study Setting
2.2. Recruitment
2.3. Measures
3. Results
3.1. Usability
3.1.1. Memorability and Efficiency
3.1.2. Errors
3.1.3. Potential for Efficacy in Increased Screening for SUD
3.1.4. Satisfaction and Cognitive Load
“[I liked] that it checked in with me throughout the week, or throughout the day, so I might have a different mood one day, and you know, just to have something talk to or someone to talk to is really good. It was pretty easy, [to use] if I’m just playing on my phone or anything. I just go back and look through my messages and go back and text it, that was kind of cool. That was really great.”
3.2. Areas for Improvement
4. Discussion
4.1. Principal Results
4.2. Limitations
4.3. Comparisons with Other Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| SUD | Substance use disorder |
| AI | Artificial Intelligence |
| NIDA | National Institute of Drug Abuse |
| SBIRT | Screening, brief intervention, and referral to treatment |
| MAT | Medication-assisted therapy |
References
- Salazar, C.I.; Huang, Y. The burden of opioid-related mortality in Texas, 1999 to 2019. Ann. Epidemiol. 2022, 65, 72–77. [Google Scholar] [CrossRef] [PubMed]
- National Institute of Drug Abuse. Overdose Death Rates. Available online: https://nida.nih.gov/research-topics/trends-statistics/overdose-death-rates (accessed on 14 December 2022).
- Additional Texas Overdose Death Data. Available online: https://nasadad.org/wp-content/uploads/2024/09/Texas-SOR-Brief-Draft-2024_Final.pdf (accessed on 2 December 2022).
- Centers for Disease Control and Prevention. Polysubstance Use in the United States. Available online: https://www.cdc.gov/drugoverdose/deaths/other-drugs.html (accessed on 2 December 2022).
- Kulesza, M.; Matsuda, M.; Ramirez, J.J.; Werntz, A.J.; Teachman, B.A.; Lindgren, K.P. Towards greater understanding of addiction stigma: Intersectionality with race/ethnicity and gender. Drug Alcohol. Depend. 2016, 169, 85–91. [Google Scholar] [CrossRef] [PubMed]
- Medicaid Innovation Accelerator Program Reducing Substance Use Disorders. High Intensity Learning Collaborative Fact Sheet. Available online: https://www.google.com/search?q=https://www.medicaid.gov/state-resource-center/innovation-accelerator-program/iap-downloads/learn-hilciap.pdf (accessed on 7 November 2022).
- National Institute on Drug Abuse. Trends & Statistics: Costs of Substance Abuse. National Institutes of Health, June. 2020. Available online: https://nida.nih.gov (accessed on 2 December 2022).
- Substance Abuse and Mental Health Services Administration (US); Office of the Surgeon General (US). Facing Addiction in America: The Surgeon General’s Report on Alcohol, Drugs, and Health [online]; November; Chapter 7; Vision for the Future: A Public Health Approach; Department of Health and Human Services: Washington, DC, USA, 2016. Available online: https://www.ncbi.nlm.nih.gov/books/NBK424861/ (accessed on 2 December 2022).
- Sarraju, A.; Bruemmer, D.; Van Iterson, E.; Cho, L.; Rodriguez, F.; Laffin, L. Appropriateness of Cardiovascular Disease Prevention Recommendations Obtained From a Popular Online Chat-Based Artificial Intelligence Model. JAMA 2023, 329, 842–844. [Google Scholar] [CrossRef]
- National Institute on Drug Abuse. Addressing the Stigma that Surrounds Addiction. 22 April 2020. Available online: https://nida.nih.gov/about-nida/noras-blog/2020/04/addressing-stigma-surrounds-addiction (accessed on 7 November 2022).
- Bernstein, S.L.; D’Onofrio, G. Screening, treatment initiation, and referral for substance use disorders. Addict. Sci. Clin. Pract. 2017, 12, 18. [Google Scholar] [CrossRef]
- Saitz, R. ‘SBIRT’ is the answer? Probably not. Addiction 2015, 110, 1416–1417. [Google Scholar] [CrossRef]
- Glass, J.E.; Hamilton, A.M.; Powell, B.J.; Perron, B.E.; Brown, R.T.; Ilgen, M.A. Specialty substance use disorder services following brief alcohol intervention: A meta-analysis of randomized controlled trials. Addiction 2015, 110, 1404–1415. [Google Scholar] [CrossRef]
- Ray, L.A.; Meredith, L.R.; Kiluk, B.D.; Walthers, J.; Carroll, K.M.; Magill, M. Combined Pharmacotherapy and Cognitive Behavioral Therapy for Adults with Alcohol or Substance Use Disorders: A Systematic Review and Meta-analysis. JAMA Netw. Open 2020, 3, e208279. [Google Scholar] [CrossRef]
- Pew Research Center: Internet, Science & Tech. Demographics of Mobile Device Ownership and Adoption in the United States. Available online: https://www.pewresearch.org/internet/fact-sheet/mobile/ (accessed on 2 May 2021).
- Rhoades, H.; Wenzel, S.L.; Rice, E.; Winetrobe, H.; Henwood, B. No digital divide? Technology use among homeless adults. J. Soc. Distress Homeless. 2017, 26, 73–77. [Google Scholar] [CrossRef] [PubMed]
- Watson, T.; Simpson, S.; Hughes, C. Text messaging interventions for individuals with mental health disorders including substance use: A systematic review. Psychiatry Res. 2016, 243, 255–262. [Google Scholar] [CrossRef]
- Mason, M.; Ola, B.; Zaharakis, N.; Zhang, J. Text messaging interventions for adolescent and young adult substance use: A meta-analysis. Prev. Sci. 2015, 16, 181–188. [Google Scholar] [CrossRef]
- Snyder, L.B.; Hamilton, M.A.; Mitchell, E.W.; Kiwanuka-Tondo, J.; Fleming-Milici, F.; Proctor, D. A Meta-Analysis of the Effect of Mediated Health Communication Campaigns on Behavior Change in the United States. J. Health Commun. 2004, 9 (Suppl. 1), 71–96. [Google Scholar] [CrossRef] [PubMed]
- Avila-Tomas, J.F.; Olano-Espinosa, E.; MinuŽ-Lorenzo, C.; Martinez-Suberbiola, F.J.; Matilla-Pardo, B.; Serrano-Serrano, M.E.; Escortell-Mayor, E. Effectiveness of a chat-bot for the adult population to quit smoking: Protocol of a pragmatic clinical trial in primary care (Dejal@). BMC Med. Inform. Decis. Mak. 2019, 19, 249. [Google Scholar] [CrossRef] [PubMed]
- Oh, K.J.; Lee, D.; Ko, B.; Hyeon, J.; Choi, H.J. Empathy Bot: Conversational Service for Psychiatric Counseling with Chat Assistant. Stud. Health Technol. Inform. 2017, 245, 1235. [Google Scholar] [PubMed]
- Alam, R.; Cheraghi-Sohi, S.; Campbell, S.; Esmail, A.; Bower, P. The Effectiveness of Electronic Differential Diagnoses (DDX) Generators: A systematic review and meta-analysis. PLoS ONE 2016, 11, e0148991. [Google Scholar] [CrossRef]
- Jones, O.T.; Calanzani, N.; Saji, S.; Duffy, S.W.; Emery, J.; Hamilton, W.; Singh, H.; de Wit, N.J.; Walter, F.M. Artificial Intelligence Techniques That May Be Applied to Primary Care Data to Facilitate Earlier Diagnosis of Cancer: Systematic Review. J. Med. Internet Res. 2021, 23, e23483. [Google Scholar] [CrossRef]
- Millenson, M.; Baldwin, J.; Zipperer, L.; Singh, H. Beyond Dr. Google: The evidence on consumer-facing digital tools for diagnosis. Diagnosis 2018, 5, 95–105. [Google Scholar] [CrossRef]
- Elyoseph, Z.; Levkovich, I.; Shinan-Altman, S. Assessing prognosis in depression: Comparing perspectives of AI models, mental health professionals and the general public. Fam. Med. Community Health 2024, 12 (Suppl. 1), e002583. [Google Scholar] [CrossRef]
- Spallek, S.; Birrell, L.; Kershaw, S.; Devine, E.K.; Thornton, L. Can we use chatGPT for mental health and substance use education? Examining its quality and potential harms. JMIR Med. Educ. 2023, 9, e51243. [Google Scholar] [CrossRef]
- Howell, K. (University of Texas Health Sciences San Antonio: Antonio, TX, USA). Personal communication, 2024.
- Zhou, S.; Silvasstar, J.; Clark, C.; Salyers, A.; Chavez, C.; Bull, S. An Artificially Intelligent, Natural Language Processing Chatbot Designed to Promote COVID-19 Vaccination: A Proof-of-concept Pilot Study. Digital Health 2023, 9, 20552076231155679. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Bull, S.; Hood, S.; Mumby, S.; Hendrickson, A.; Silvasstar, J.; Salyers, A. Feasibility of using an artificially intelligent chatbot to increase access to information and sexual and reproductive health services. Digital Health 2024, 10, 20552076241308994. [Google Scholar] [CrossRef] [PubMed] [PubMed Central]
- Kaplan, J.; Macandlish, S.; Henighan, T.; Brown, T.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling laws for neural language models. arXiv 2020, arXiv:2001.08361. [Google Scholar] [CrossRef]
- Hatem, R.; Simmons, B.; Thornton, J.E. A Call to Address AI “Hallucinations” and How Healthcare Professionals Can Mitigate Their Risks. Cureus 2023, 15, e44720. [Google Scholar] [CrossRef]
- Nancy, S.; Dongre, A.R. Behavior Change Communication: Past, Present, and Future. Indian J. Community Med. 2021, 46, 186. [Google Scholar] [CrossRef]
- Mumby, S.; Wright, T.; Salyers, A.; Howell, K.; Bull, S. Development of an AI Chatbot to facilitate access to information, screening, and treatment referrals for substance use disorder. Front. Digit. Health 2025, in press. [Google Scholar]
- Kroenke, K.; Spitzer, R.L.; Williams, J.B. The Patient Health Questionnaire-2: Validity of a two-item depression screener. Med. Care. 2003, 41, 1284–1292. [Google Scholar] [CrossRef]
- Plummer, F.; Manea, L.; Trepel, D.; McMillan, D. Screening for anxiety disorders with the GAD-7 and GAD-2: A systematic review and diagnostic meta-analysis. Gen. Hosp. Psychiatry 2016, 39, 24–31. [Google Scholar] [CrossRef]
- Shirinbayan, P.; Salavati, M.; Soleimani, F.; Saeedi, A.; Asghari-Jafarabadi, M.; Hemmati-Garakani, S.; Vameghi, R. The Psychometric Properties of the Drug Abuse Screening Test. Addict. Health 2020, 12, 25–33. [Google Scholar] [CrossRef]
- Salyers, A.; Bull, S.; Silvasstar, J.; Howell, K.; Wright, T.; Banaei-Kashani, F. Building and Beta-Testing Be Well Buddy Chatbot, a Secure, Credible and Trustworthy AI Chatbot That Will Not Misinform, Hallucinate or Stigmatize Substance Use Disorder: Development and Usability Study. JMIR Hum Factors 2025, 12, e69144. [Google Scholar] [CrossRef]
- Harrison, R.; Flood, D.; Duce, D. Usability of mobile applications: Literature review and rationale for a new usability model. J. Interact. Sci. 2013, 1, 1. [Google Scholar] [CrossRef]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2024; Available online: https://www.R-project.org/ (accessed on 15 September 2024).
- SocioCultural Research Consultants, LLC. Dedoose; Version 10.0; SocioCultural Research Consultants, LLC: Los Angeles, CA, USA, 2025; Available online: https://www.dedoose.com/ (accessed on 3 December 2024).
- Wilson, L.; Marasoiu, M. The Development and Use of Chatbots in Public Health: Scoping Review. JMIR Hum. Factors 2022, 9, e35882. [Google Scholar] [CrossRef]
- Waughtal, J.; Glorioso, T.; Sandy, L.; Peterson, P.; Chavez, C.; Bull, S.; Ho, M.; Allen, L.; Thomas, J. Patient engagement with prescription refill text reminders across time and major societal events. Cardiovasc. Digit. Health J. 2023, 4, 133–136. [Google Scholar] [CrossRef] [PubMed]
- Premier Continuum. The IT Outage Explained. Available online: https://www.premiercontinuum.com/resources/microsoft-outbreak-july-2024 (accessed on 25 September 2024).
- Olmstead, T.A.; Yonkers, K.A.; Ondersma, S.J.; Forray, A.; Gilstad-Hayden, K.; Martino, S. Cost-effectiveness of electronic- and clinician-delivered screening, brief intervention and referral to treatment for women in reproductive health centers. Addiction 2019, 114, 1659–1669. [Google Scholar] [CrossRef] [PubMed]
- Bruguera, P.; Barrio, P.; Manthey, J.; Oliveras, C.; López-Pelayo, H.; Nuño, L.; Miquel, L.; López-Lazcano, A.; Blithikioti, C.; Caballeria, E.; et al. Mid and long-term effects of a SBIRT program for at-risk drinkers attending to an emergency department. Follow-up results from a randomized controlled trial. Eur. J. Emerg. Med. 2021, 28, 373–379. [Google Scholar] [CrossRef]
- Pickard, J.G.; van den Berk-Clark, C.; Johnson, S.D.; Taylor, M. Evaluation of an online SBIRT training program. Am. J. Drug Alcohol Abuse 2024, 50, 173–180. [Google Scholar] [CrossRef] [PubMed]
- Hall, A.K.; Cole-Lewis, H.; Bernhardt, J.M. Mobile text messaging for health: A systematic review of reviews. Annu. Rev. Public Health 2015, 36, 393–415. [Google Scholar] [CrossRef]
- App Signal. What Are Good and Acceptable Error Rates? Available online: https://www.appsignal.com/learning-center/what-are-good-and-acceptable-error-rates (accessed on 24 September 2024).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain: Barriers to Treatment | |
| How does this chatbot protect my privacy? | Any questions that you ask Be Well Buddy are anonymous and confidential. That means that the Be Well Buddy system doesn’t record your name. The system does collect data based on how well the responses match up with your questions so that it can continue to improve. But Be Well Buddy doesn’t share this information with anyone else. |
| Why do I need help with going through withdrawal? | Going through withdrawal (or detoxing) can be incredibly uncomfortable. You may feel things like intense nausea and vomiting, muscle pains, sweating, and depression or anxiety. One of the biggest reasons to get help going through withdrawal is that these symptoms can become overwhelming, and you may return to drugs for relief. Having someone there to help you through it can mean the difference between successfully getting off drugs and returning to drug use. Staff at Be Well Texas are trained in withdrawal treatment and are here to help. |
| Will people treat me with respect if I seek treatment? | Ben Alfeck, the Hollywood actor, has been open about his struggle with addiction. He says, “If you have a problem, getting help is a sign of courage, not weakness or failure.” And that’s what everyone at Be Well Texas thinks too! Seeking help is an act of courage and you will be treated with respect by all of your care team. |
| What if I don’t want to quit using? | If you don’t want to quit using drugs and/or alcohol, maybe take some time to reflect on your reasons for using and to consider the impact that drug use has on your life. Using drugs and alcohol can impact your health, relationships, finances, future, and overall well-being. Even if it feels challenging, seeking support from friends, family, or professionals can provide insights into your choices. Remember, support is available when you’re ready to explore healthier alternatives or address underlying issues contributing to your substance use. |
| Domain: Substances | |
| Am I at risk for an opioid overdose? | Anyone who uses opioids—whether they have been prescribed by a medical professional or not—can overdose. If you or someone you know uses opioids, be sure to learn everything you can about how to stay safe and avoid overdose. You can talk with a Be Well provider who will help you, without judgment, to reduce any risks you might have for overdose. https://BeWelltexasclinic.org/get-started/ (accessed on 21 April 2025) |
| How does Narcan work? | Opioids attach to parts of your nerves in the brain, and when this happens, your brain releases dopamine, a chemical that helps to block pain. Sometimes a person using opioids may stop breathing. Narcan works by attaching to these same nerves and helps the person breathe. Narcan will only work if someone has opiates in their system. Did you know? Narcan works to reverse an overdose in 7 to 10 out of 10 cases! It is one of the most effective tools we have to reduce death from opioid overdose. |
| Why do people use buprenorphine? | People choose buprenorphine because it works well to help reduce withdrawal symptoms that can happen when you want to quit opioids, & it is safe—you will not overdose when taking it. Be sure to talk with a medical provider about whether this is an option for you. Be Well can help you get started when you are ready. |
| Usability | Relevant Area of Exploration: To What Extent Is the System…. | Outcomes Measured |
|---|---|---|
| Memorability and Efficiency | …able to be used? | Timing and frequency of engagement/system use |
| Errors | …successfully delivered without errors? | Delivered accurately with minimal errors or breakdowns; level of precision in responses |
| Potential Efficacy | …successful in increasing access to care? | Number of screenings conducted and referrals made |
| Effectiveness | …potentially adaptable for delivery across multiple environments? | Able to be delivered in diverse settings + |
| Satisfaction and Cognitive Load | …judged as suitable, satisfying, or attractive to program deliverers? To program recipients? | Satisfaction * Intent to use/use * Easily understood, not confusing * |
| Total Sample (N = 91) | Participants Who Screened One or More Times (N = 29) | Participants Who Initiated Queries But Did Not Screen (N = 44) | |
|---|---|---|---|
| Number of participant-initiated queries, mean (S.D.) | 25.42 (23.42) | 55.10, (27.61) | 16.71, (16.17) |
| Range of queries initiated | 0–142 | 16–142 | 1–70 |
| Completed at least one screener | 29, 32% | 29, 100% | N/A |
| Completed GAD | 29, 32% | 29, 100% | |
| Referred for GAD | 24, 26% | 24, 83% of those screened | |
| Completed PHQ | 27, 30% | 27, 93% | |
| Referred for PHQ | 12, 13% | 12, 44% of those screened | |
| Completed DAST | 25, 27% | 25, 86% | |
| Referred for DAST | 15, 16% | 15, 60% of those screened | |
| Made an appointment with Be Well following referral | 12 of 24, or 50% of those referred |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wright, T.; Salyers, A.; Howell, K.; Harrison, J.; Silvasstar, J.; Bull, S. A Pilot Study of an AI Chatbot for the Screening of Substance Use Disorder in a Healthcare Setting. AI 2025, 6, 113. https://doi.org/10.3390/ai6060113
Wright T, Salyers A, Howell K, Harrison J, Silvasstar J, Bull S. A Pilot Study of an AI Chatbot for the Screening of Substance Use Disorder in a Healthcare Setting. AI. 2025; 6(6):113. https://doi.org/10.3390/ai6060113
Chicago/Turabian StyleWright, Tara, Adam Salyers, Kevin Howell, Jessica Harrison, Joshva Silvasstar, and Sheana Bull. 2025. "A Pilot Study of an AI Chatbot for the Screening of Substance Use Disorder in a Healthcare Setting" AI 6, no. 6: 113. https://doi.org/10.3390/ai6060113
APA StyleWright, T., Salyers, A., Howell, K., Harrison, J., Silvasstar, J., & Bull, S. (2025). A Pilot Study of an AI Chatbot for the Screening of Substance Use Disorder in a Healthcare Setting. AI, 6(6), 113. https://doi.org/10.3390/ai6060113