1. Introduction
An authorship attribution system is a method based on the writing style that predicts who is the most likely author of a text among a set of candidate authors [
1]. Through the texts that people write, it is possible to identify their authorship, since each person uses the elements of language in a certain order and frequency. Sequences and frequencies define an author’s writing patterns. Recently this same principle has made it possible to identify text generated using Large Language Models [
2,
3]. Writing style patterns are also used in tasks such as plagiarism detection [
4,
5], author profiling [
6,
7], author identification [
8,
9], and neurological disease detection [
10,
11].
In computational linguistics, writing style is the frequency of use of linguistic elements called style markers. The writing style analysis reveals recurring patterns in the writing of texts. Knowing these patterns allows the author to adjust vocabulary and sentence structure for more effective communication. On the other hand, writing style analysis is useful in identifying underlying problems in writing. In addition, it allows you to define a unique and distinctive writing style. Style markers are classified into four main categories as follows: character-based, word-based, POS tag-based, and n-gram based.
Character-based style markers include punctuation marks, uppercase characters, lowercase characters, alphabetic characters, numeric characters, and typos. These markers are easy to collect and are present in most languages. However, the spelling standards of many languages and people are the same; for example, a period followed by a capital letter. Also, these style markers are not frequently used, making it difficult to identify an author’s writing style. To address these problems, previous work uses more markers in the inference [
6,
12,
13,
14].
A function word is a word-based style marker. Function words are words without semantic information, such as prepositions, adverbs, pronouns, conjunctions, and verb conjugations. Function words are widely used because of their ability to relate to other words and the grammatical and semantic information they provide to a sentence [
15]. Furthermore, the extraction of function words is a simple and efficient process from a computational standpoint. Generally, the author does not use these words consciously [
16]. However, using only function words for authorship attribution leads to the loss of valuable information about the author’s sentence structure and writing style [
17,
18,
19,
20,
21].
The POS tag is another word-based style marker. A POS tag represents the grammatical category of a word. Examples of tags are verbs (VERB), adjectives (ADJ), adverbs (ADV), pronouns (PRON), nouns (NOUN), etc. POS tags are another topic-independent style marker. This style marker shows the category of words most frequently used by the author, providing favorable results in authorship attribution [
22,
23,
24,
25]. The tagging of a word requires contextual information from the surrounding words. However, when assigning the POS tag, sentence structure information is discarded. That is, word tagging is “shallow parsing” since it ignores information about the structure of the sentence. The interrelationship between words is only used to retrieve the POS tag. This is a major limitation in writing style analysis.
A
n-gram is an imaginary window that scrolls
n tokens from left to right to the end of the sentence. Tokens within the
n-gram can be characters, words, and POS tags [
26,
27,
28,
29,
30]. An
n-gram is a linear combination of tokens that allows us to identify new patterns in the author’s writing style. However, an
n-gram is processed as a single piece. For example, in a word 4-gram, four words are processed as a single token (word collocations), i.e.,
n-grams only identify sequences of tokens but not the underlying sentence structure. By ignoring non-linear connections between words, valuable information on sentence structure is lost.
Recently, deep learning has been used in authorship attribution. The text is converted into low-dimensional dense numerical vectors for processing in the neural network. The vectors as a whole are called
embeddings. For each token (words, characters), the embedding assigns a token a point in a continuous space, where its position captures semantic or contextual relationships [
31]. Examples of pre-trained word embeddings are Word2Vec, GloVe, FastText, and contextual embeddings such as BERT or GPT [
32,
33,
34]. Nowadays, Large Language Models (LLMs) are used for writing style analysis. An LLM is trained with large amounts of text to generate natural language. LLMs can learn lexical, syntactic, semantic, and contextual patterns. These models are based on deep neural network architectures such as transformers, some examples of models are GPT, BERT or LLaMA.
LLM research on authorship attribution is focused on two branches as follows: First, each language model generates texts with a particular style that manifests itself in lexical, syntactic, and grammatical patterns. Using simple style markers (character-based or word-based) it is possible to identify whether the author of the text is a machine or a human. Second, LLMs can perform authorship attribution tasks on texts written by humans. Moreover, due to their generative capacity, they justify the ‘stylistic reasons’ for their attribution. The results suggest that the ability of LLMs to identify linguistic styles is useful not only for the detection of generative models but also for forensic, literary, or academic applications related to authorship analysis [
35,
36,
37,
38,
39].
However, the embedding architecture defines how many tokens are evaluated in an execution. For example, BERT has a context window of 512 tokens [
40]. This is a significant drawback since an embedding detects local or global writing style patterns depending on the context window length. As the context window length increases, the computational processing demands also rise. Generally, this approach requires high-performance computers for model training.
- (1)
create a new style marker or
- (2)
propose embeddings with syntactic information for deep learning methods
Several approaches to creating syntactic style markers have been described as state-of-the-art methods. Tschuggnall and Specht [
41] present a method for authorship attribution based on the author’s grammatical profile, using syntax trees and pq-grams. These pq-grams are subsets of tree nodes, defined by two parameters
p and
q, where
p indicates how many vertical levels of the tree are included and
q defines how many nodes are considered horizontally. Evaluation results on three datasets (CC04, FED, and PAN12) show a high rate of correct attribution, suggesting that grammatical style is a significant feature for improving authorship attribution methods.
Patchala et al. [
42] defined author templates of Context-Free Grammar (CFG) production frequencies from training on Enron dataset e-mail messages. Patchala et al. extracted similar frequencies from a new email message to compare them with templates and identify the best match. Patchala et al. claimed that CFG production frequencies perform very well in attributing the authorship of email messages.
Martijn and Wietse [
43] developed a Support Vector Machine (SVM) model using a combination of lexical and syntactic features (character
n-grams, punctuation, tokens, POS tags, syntactic dependency relations, and Syntactic
n-grams) in four languages. The syntactic analysis was performed with UUParser [
44]. Martijn and Wietse argued that incorporating syntactic
n-grams of dependency labels can effectively capture the stylometric features of texts. Additionally, they improved the model’s performance when paired with other style markers.
Mehler et al. [
45] proposed a multidimensional syntactic dependency tree model using the MATE Parser [
46] to predict sentence authorship. The goal was to generate “fingerprints” to predict the author of the underlying sentences. Mehler et al. argued that syntactic dependency features are effective for authorship attribution. However, to achieve a better understanding of alignment in communication, other levels of language such as lexical and semantic aspects should be considered.
Lučić and Blake [
47] present a method for authorship attribution based on Local Syntactic Dependencies (LSDs) surrounding the mentions of proper names. The aim is to determine whether the syntactic patterns used when referring to persons is useful for authorship attribution. The article concludes that local syntactic dependencies surrounding proper names can be a useful stylistic marker for authorship attribution. It is also observed that consistency in an author’s writing style affects predictive performance. The results suggest that the approach can achieve good predictive performance with 1000 to 1500 sentences and 29 features.
Recently, deep learning methods have been proposed to exploit syntactic information. Zhang et al. [
48] proposed a strategy for encoding the syntactic tree of a sentence into a learnable distributed representation. For that, they construct an embedding vector for each word that encodes the path in the syntactic tree corresponding to the word. According to the authors, their model learns feature embeddings at the content and syntactic levels. The model consisted of five types of layers as follows: syntactic-level feature embeddings, content-level feature embeddings, convolution, max-pooling and SoftMax. The predictive performance of the Syntax-CNN approach was carried out with the CCAT10, CCAT50, IMDB62, blogs10, and blogs50 dataset. Zhang et al. pointed out that such syntax style embeddings can bring a significant accuracy gain to CNN strategies.
Jafariakinabad and Hua [
49] proposed a method based on a “Siamese” neural network with the following two subnetworks: a lexical one that processes word sequences and a syntactic one for structural tags (POS tags). The latter subnetwork encodes syntactic information of parse trees (constituencies) using the CoreNLP parser [
50]. Both subnetworks have the same architecture, as follows: a bidirectional LSTM network and a self-attention mechanism. POS tag parse trees are linearized into a sequence of structural tags following a depth-first traversal order. Predictive performance was performed with the CCAT10, CCAT50, BLOGS10, and BLOGS50 authorship attribution datasets. According to the authors, the proposed method consistently outperformed all benchmark models, including the models that used only lexical or syntactic information. In addition, they stated that using syntactic information explicitly provides valuable information for author identification beyond semantic content.
In 2021,Wu et al. [
51] developed a neural network called a Multichannel Self-Attribution Network (MCSAN) for authorship attribution. The method uses features in several dimensions as follows: style, content, syntax, and semantics. MCSAN integrates
n-grams of characters, words, POS tags, sentence structures, and dependency relations, using an attention mechanism to weight their importance. Syntactic features were obtained with Stanford CoreNLP from the well-known CCAT10, CCAT50, and IMDB62 datasets. Experimental results show a significant improvement in authorship attribution accuracy compared to state-of-the-art models, demonstrating the effectiveness of multidimensional feature integration. The ablation study showed that by removing syntactic information from the model, accuracy was considerably decreased.
In 2021, Murauer and Specht [
52] presented a language-independent feature named Dependency Tree grams (DT-grams) for cross-language authorship attribution. Murauer and Specht used
Stanza (
https://github.com/stanfordnlp/stanza, accessed on 1 May 2025) to obtain style markers. When obtaining the syntax tree, substructures of different sizes are selected to produce DT-grams of dependency relations, POS tags, and combinations of them. Style markers as baselines included character, word, and POS tag
n-grams (
n = {1, 2, 3, 4, 5}). Murauer and Specht stated that DT-grams showed promising performance in cross-language authorship attribution. Furthermore, they claimed that DT-grams outperformed POS tag
n-grams based on the original word order and that dependency relations and grammatical style contribute to an author’s stylometric fingerprint. However, Murauer and Specht also stated that the performance of DT-grams is below that of traditional methods applied to the machine translation of texts.
Jafariakinabad et al. [
53] developed a syntactic recurrent neural network to encode syntactic patterns. The model uses convolutional neural networks (CNNs) as short-term memories (LSTMs). The CNN captures the short-term dependencies between words and LSTM captures long-term relationships in sequences and represents a sentence by its overall syntactic pattern. The sentence encoder learns the syntactic representation of a document from the output of the POS encoder. The learned vector representation is fed into a SoftMax classifier to compute the probability distribution of class labels. The method was tested with the PAN12 (
https://pan.webis.de/clef12/pan12-web/authorship-attribution.html, accessed on 1 May 2025) authorship attribution dataset. The study concludes that the syntactic recurrent neural network model performs better in authorship attribution than lexical models and traditional
n-grams-based models. Jafariakinabad et al. reported that both CNN-LSTM and LSTM-LSTM correctly classified all 14 novels in the test set, suggesting that syntactic information is more effective than lexical information for authorship attribution, especially in texts of different topics and genres.
This paper proposes a methodology for authorship attribution formulated around the syntactic information contained in sentences’ dependency trees. This approach aims to model the writing style by analyzing the subtrees within the dependency tree. To capture the syntactic information of the subtrees, we propose to use a representation based on the generation of a particular type of syntactic n-grams (sn-grams) called mixed syntactic n-grams (mixed sn-grams).
The main contributions of this paper are as follows: (1) we design a method for authorship attribution that relies on a machine learning approach and utilizes mixed sn-grams as style markers, (2) develop a strategy for the generation of mixed sn-grams from dependency trees, (3) evaluate the use of mixed sn-grams as features for a machine learning approach to perform authorship attribution, and (4) compare the performance of mixed sn-grams with homogeneous sn-grams.
3. Results
This section outlines the experiments conducted to evaluate the usefulness of mixed sn-grams in authorship attribution. Two datasets specifically created for closed-class authorship attribution were used (described in
Section 2). These datasets offer diversity in text size, candidate authors, topics covered, and the number of texts available per author. The experimental setup and results are presented below.
3.1. Experimental Setting
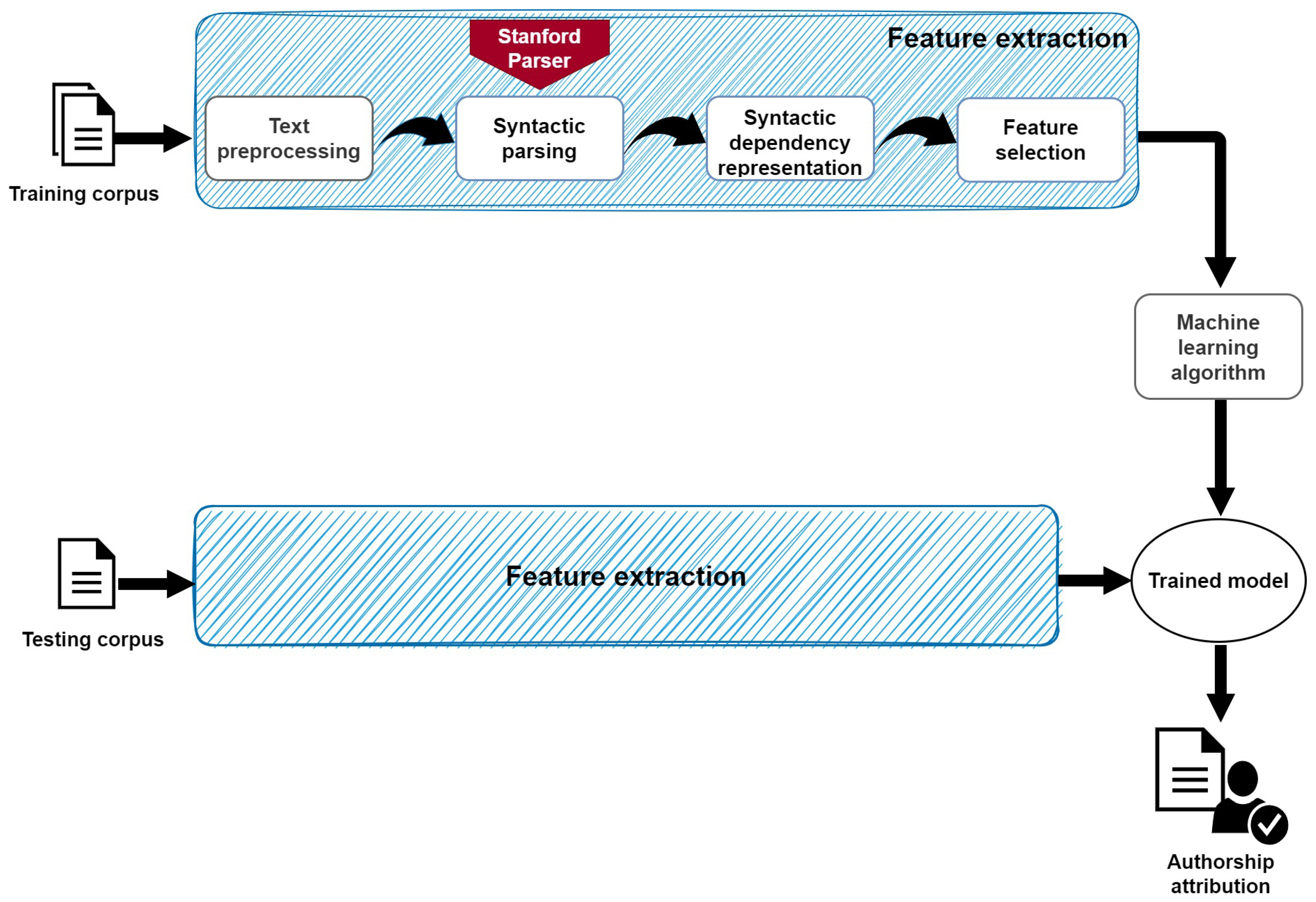
The experiments were performed as follows: (1) feature extraction in terms of mixed sn-grams and training of a machine learning algorithm to obtain a model, (2) model validation was performed to tune the hyperparameters, and (3) model evaluation using the test data with mixed sn-grams. The experiments employed widely adopted machine learning methods such as Support Vector Machines (SVMs), Multinomial Naive Bayes (MNB), and Logistic Regression (LR). These classifiers have proven effective in previous analyses of authorship attribution. Furthermore, the proposed style markers have been shown to generate high-dimensional vector spaces (greater than 100 dimensions), and these classifiers have demonstrated acceptable performance in such scenarios. Deep learning-based techniques were not considered, primarily due to the inability of the mixed sn-grams representation to achieve the necessary linearity in the input data and the insufficient size of the dataset for reliable model creation.
The experiments were carried out on a computer with Intel i5 @ 1.6 GHz CPU, Windows 11 operating system, and Python 3.9. The implementation of the classifiers and the evaluation of the models were performed with the Scikit-learn machine learning module [
67] version 1.3.0. A total of 80% of the training data was used to train the algorithms and the remaining 20% to validate the models.
The hyperparameters of the classifiers were selected through a semi-exhaustive search and the accuracy metric was used to verify the model performance. The hyperparameters used for the classifiers are described below. For the SVM classifier, the values used were as follows: linear kernel, the value of C was obtained by performing a semi-exhaustive search in the range of with increments of , and . The parameters for the MNB classifier were as follows: . The parameters for the LR classifier were the following: , , , and the value of C was obtained by performing a semi-exhaust search in the range of with increments of .
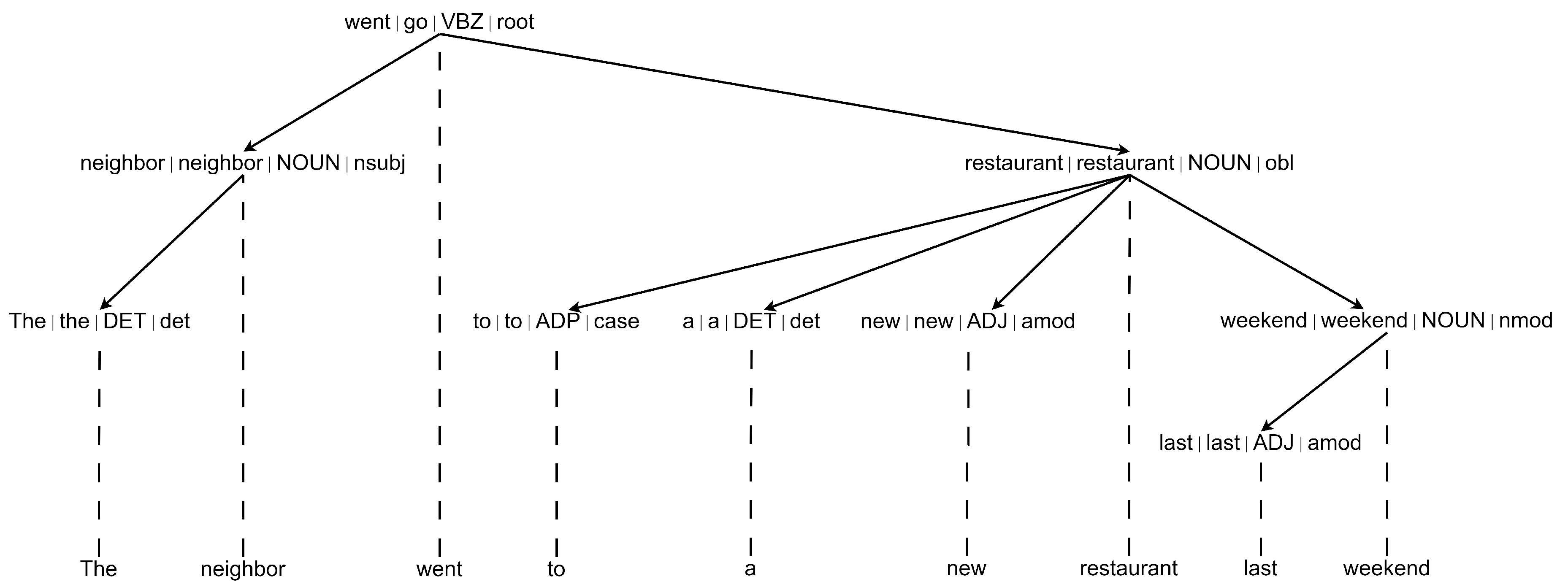
Three main types of elements were used to generate the syntactic
n-grams: Word, POS, and DR tags. From these elements, the following six combinations of mixed sn-grams were generated, obtained from the dependency trees of the sentences with the Stanza parser [
60]: Word-POS, Word-DR, DR-POS, DR-Word, POS-DR, and POS-Word. Only mixed sn-grams of lengths 2, 3, and 4 were considered.
Values higher than 3 could cause the data to become rather sparse [
68,
69,
70,
71]. As the value of
n increased, the number of features also increased. In contrast, high-order
n-grams have very low frequencies of occurrence. These two factors produce sparse data sets. These issues occur regardless of the type of
n-grams. The chosen size of sn-grams corresponds to that reported in recent studies employing
n-grams of characters and words [
51,
72].
The study utilized the Variance Threshold technique [
67] to select the features that were used to feed the model. This approach eliminates any features whose variance falls below a certain threshold. By default, it excludes features with zero variance or the same value in all samples. The threshold was determined by experimental analysis within the range of [0.01–0.001].
3.2. Runtime and Memory Usage Statistics
Aspects of the computational efficiency of the proposed method based on mixed sn-grams generation were evaluated by recording statistics on the execution time and memory consumption. The runtime was determined by comparing the time tag at the beginning and end of program execution using the libraries provided by the programming language and computer hardware described previously. The time of five program executions was measured, and the average time is reported. The memory consumption was determined using the Memory Profiler module version 0.61.0 (available at
https://pypi.org/project/memory-profiler/, accessed on 1 May 2025) and the maximum amount of memory used during program execution was recorded.
Table 4 presents the collected efficiency statistics for the CCAT50 and PAN 12 Task C corpora. The execution time is given in minutes (min) and the memory consumption in Megabytes (MB). The information is specified for three stages of interest of the proposed method as follows: (1) the preprocessing stage in which the input text syntactic analysis is performed, (2) the feature extraction stage in which the mixed sn-grams are obtained, and (3) the model training stage. The efficiency evaluation was carried out considering the sizes from 2 to 4 for the mixed sn-grams corresponding to the most demanding scenario. The POS-Word type was chosen to perform the evaluation indistinctly because the same algorithm is used for the generation of the other types.
The efficiency of the two methods considered as baselines was also evaluated using the same corpus. One method is based on the use of n-grams of words ranging in size from 2 to 4, and the other method is based on document embeddings using the doc2vec model.
The statistics indicate that the time it takes to process a document using the mixed sn-grams method depends on its length and increases proportionally. We can say that for texts with a length of around 6404 words, the average processing time is min. If the text length is around 584 words, the average processing time is min. In contrast, the method based on word n-grams has an average time of min, and the document embedding-based method has an average time of min. The proposed method has a higher memory footprint compared to sentence-level embedding and comparable memory usage to word n-grams. In the case of runtime, the difference is significantly greater. The proposed method is, therefore, recommended for scenarios where the amount of data is medium to small. Generally, the method has a higher time and memory consumption, mainly in the preprocessing stage, due to the use of a parser. However, some parsers start to offer alternative models that reduce processing time and memory consumption without significantly reducing accuracy.
3.3. Results with the PAN 2012 Corpus
The accuracy obtained by the SVM and MNB classifiers using the homogeneous sn-grams and the six types of mixed sn-grams proposed by experimenting with the corpus for Tasks A, C, and I of the PAN 12 is shown in
Table 5. For homogeneous sn-grams, the optimal result was achieved with a size of four (
n = 4), whereas for mixed sn-grams, the best performance was obtained with a size of three (
n = 3).
The accuracy of the proposed method, which is based on the use of mixed sn-grams, was compared with the accuracies obtained by the most representative teams that participated in the PAN 12 evaluation. The results of this comparison are shown in
Table 6. The line denoted by sn-grams indicates the highest efficiency achieved through the utilization of homogeneous sn-grams. The line represented by mixed sn-grams presents the maximum efficiency achieved by implementing this type of sn-gram. Most of the teams’ proposals relied on the use of character and word
n-grams and lexical features (verb conjugation tense analysis and vocabulary size). They used SVM and neural networks as classification methods.
3.4. Results with the CCAT 50 Corpus
In the experiments conducted with the CCAT 50 corpus, homogeneous sn-grams and the proposed mixed sn-grams were evaluated. For each type of sn-grams, the accuracy was reported for n = {2, 3, 4}, individually and jointly. The RL, SVM, and MNB classifiers were utilized.
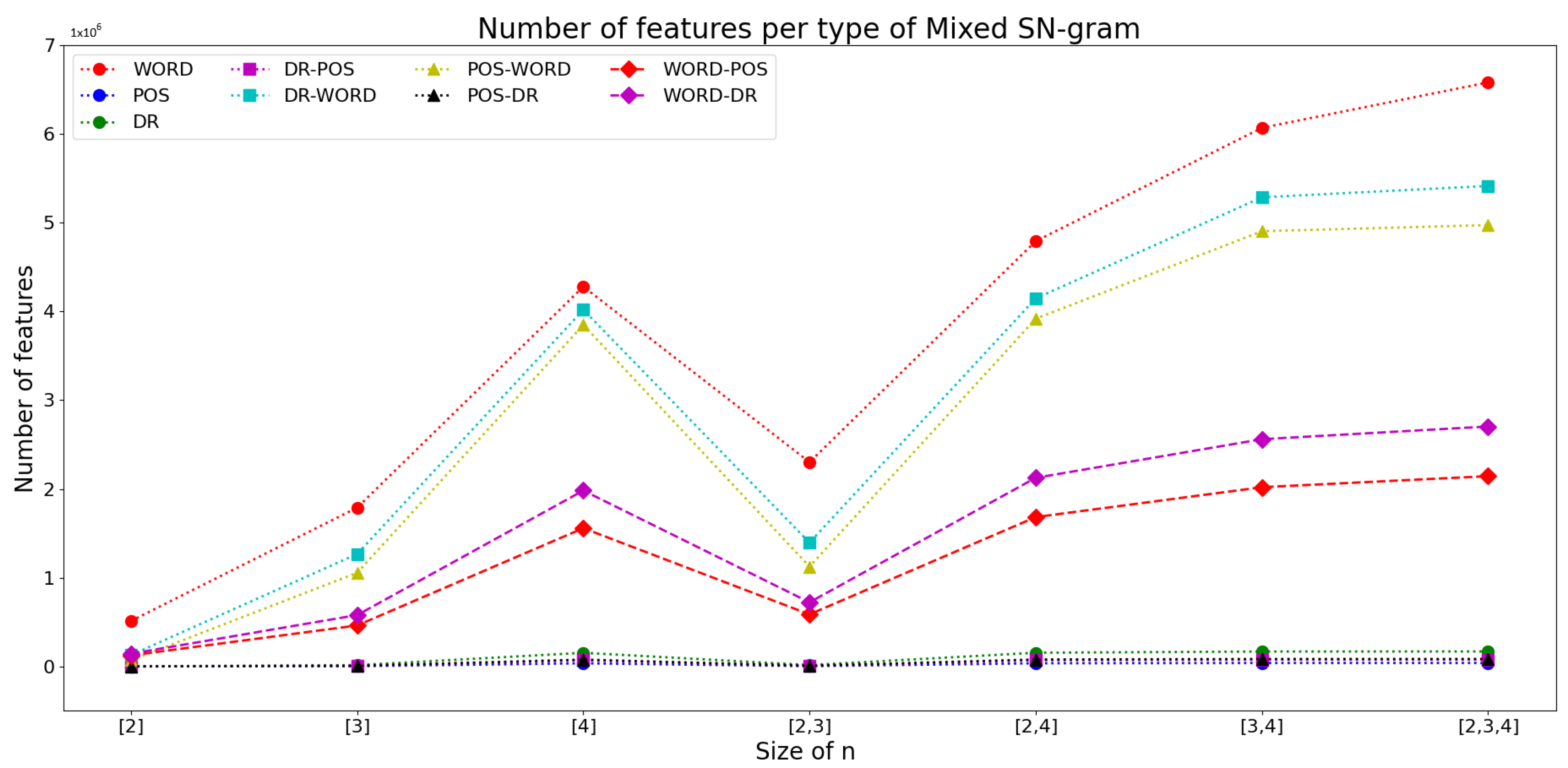
Figure 5 shows the number of features obtained for the different sizes and types of homogeneous and mixed sn-grams in the CCAT50 training corpus. The number of features of Word sn-grams and mixed sn-grams that include this information (DR-Word, POS-Word, Word-POS, and Word-DR) tends to be significantly higher compared to SN-grams that do not. The larger the size of the sn-grams, the larger the number of features obtained tends to be. This behavior is expected because sn-grams that include more features tend to repeat fewer times in sentences. For the CCAT50 corpus, it was observed that sn-grams using words in their structure and having a size equal to or greater than three generate features in the order of
.
Because of the large number of features that can be obtained with mixed sn-grams, some feature selection techniques were evaluated. We compared the efficiency of the proposed classifiers using the Principal Component Analysis (PCA) and the Variance Threshold technique.
Table 7 shows the accuracy achieved by the SVM classifier after applying the feature selection techniques for some of the mixed sn-grams using the CCAT50 corpus. For the PCA technique, the standard methodology of using only the three principal components (3-PCA) was followed. As shown in the table above, the Variance Threshold technique offers an improvement in efficiency by ≈4.38%. On the other hand, the PCA technique does not represent a suitable option to be employed with the mixed sn-grams. Experiments performed with the rest of the mixed sn-grams types confirm this tendency.
Table 8 presents the efficiency for each of the homogeneous sn-grams types and sizes indicated earlier. Each line in the table corresponds to a specific experiment, with the size of the sn-grams considered in each experiment being indicated on the respective line.
Table 9 presents the efficiency obtained by the LR, SVM, and MNB classifiers when employing mixed sn-grams for
n = {2, 3, 4}. The mark on each line indicates the size of the sn-grams that were considered in each corresponding experiment. The marks indicated on each line denote the dimensions of the sn-grams that were taken into consideration during each respective experiment.
Figure 6 shows the confusion matrix obtained using the SVM method with the sn-grams of a POS-Word type and size [2, 3]. The combination of the type and size of features, together with the classifier, corresponds to the one that obtained the best accuracy in the previous experiments (see
Table 9). It is observed that for most authors, a recognition equal or higher than
is achieved. Only in the case of authors Scott Hillis and Jan Lopatka can the model recognize only
of the documents.
According to the confusion matrix shown in
Figure 6, the trained model achieves poor efficiency in certain cases; for example, texts by author Jan Lopatka are often assigned to Edna Fernandes. To explain why the proposed method tends to confuse these authors, an exploratory analysis was performed on the instances of each author in the training corpus using some well-known NLP techniques.
Table 10 shows the findings of the analysis. The most frequently occurring POS-Word sn-grams for each of the authors are also shown.
Figure 7 and
Figure 8 show the word clouds representing the frequency of occurrence of words in the texts of authors Jan Lopatka and Edna Fernandes.
Based on the information retrieved in the analysis described above, some aspects can be highlighted that explain why the model tends to confuse the authors. It is observed that the topics about which of the authors wrote the text are different, even though the genre of the text is the same. Some of the keywords used overlap (e.g., said, year, would, percent), which could be attributed to the topic or genre of the text. However, the overlap between the keywords or vocabulary used does not exceed 50%.
The most frequent POS-Word sn-grams refer to sentence structures used in the construction of the text. In the case of sn-grams of size 3 and 4, it is observed that most begin with the root element ADJ, and they then include double quotation marks and a word. These types of structures refer to sentences that represent quotes about what a character has expressed, which is the reason why double quotation marks appear. Some examples of phrases encoded by mixed sn-grams include the following: “He added that…” and “…terms as well, he added.”. The use of this type of sentence can become common among authors who are colleagues in their profession.
An ablation analysis was performed to identify and evaluate the significance of the proposed features based on the mixed sn-grams. The features were divided into three groups for the analysis, considering the type of information used for their generation. The first group comprised sn-grams of the following types: POS, Word, Word-POS, and POS-Word. The second group included sn-grams of type DR, Word, Word-DR, and DR-Word. Finally, the third group included POS, DR, DR-POS, and POS-DR sn-grams. The efficiency obtained by homogeneous sn-grams and mixed sn-grams related to the same information type was analyzed for each group.
The ablation analysis was conducted to assess the significance of the type and size of the mixed sn-grams presented in the proposed method, using the accuracy achieved by a trained model. The SVM classifier was the unique classifier employed during the ablation analysis because it obtained the best overall performance in the preceding experiments (see
Table 9).
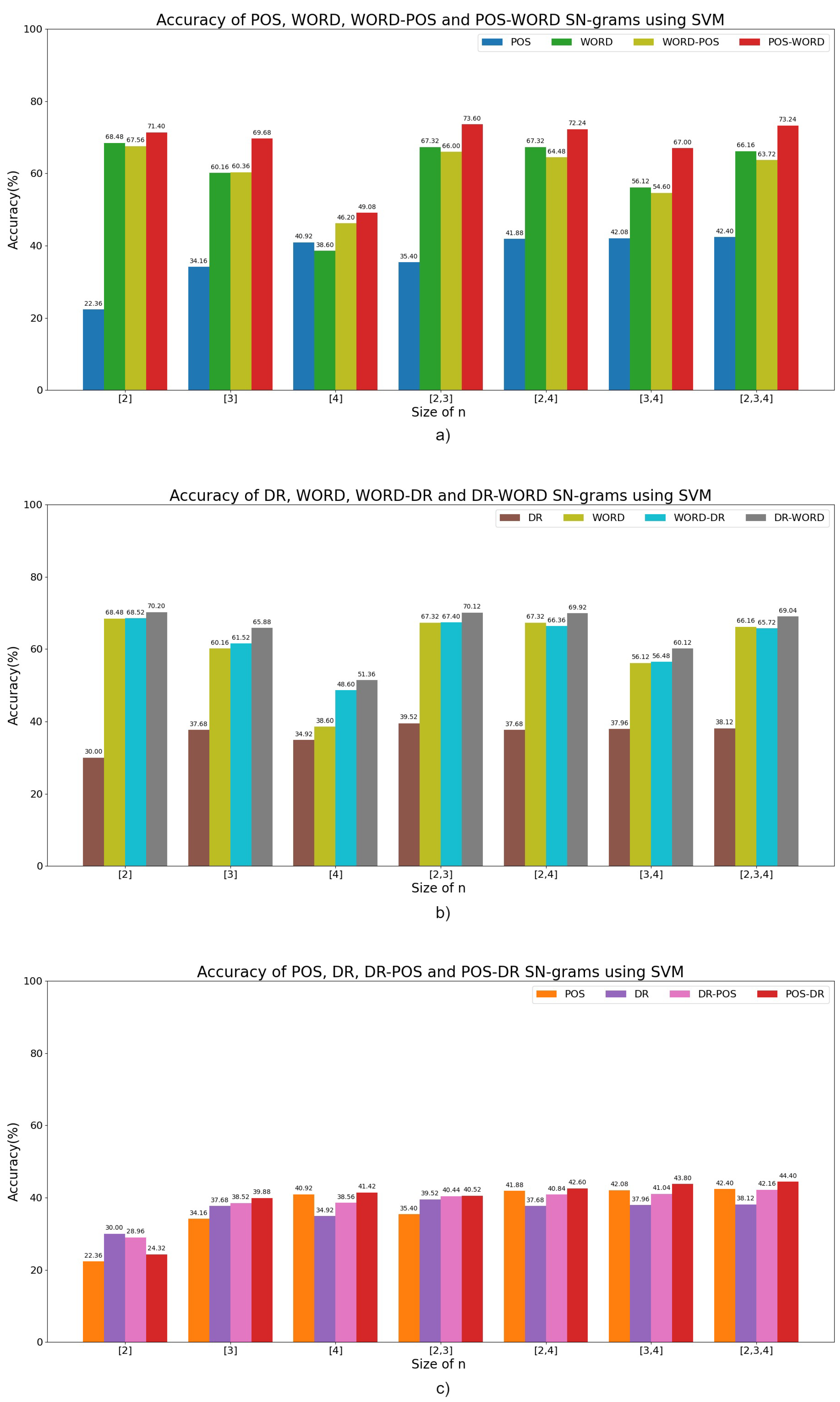
Figure 9 shows the graphs indicating the efficiency achieved for each group into which the proposed characteristics were divided.
Figure 9a depicts the results for the first group of features. It exhibits that the POS- Word sn-grams achieve the highest accuracy, while the Word-POS type obtains an accuracy that is 7.61% lower on average for the different sizes evaluated. Word sn-grams are the most contributing homogeneous sn-gram type compared to the POS type used for classification. The sn-grams of size
n = 2 contribute the most relevant features for the task, followed by the features of size
n = 3, and finally, the features of size
n = 4.
Figure 9b describes the results for the second group of features. The DR-Word sn-grams achieve the greatest accuracy, while the Word-DR type obtains an accuracy that is 3.14% lower on average for the different sizes evaluated. Word sn-grams are a type of homogeneous sn-grams that contributes the most to the classification compared to the DR type, and they even obtain values similar to those obtained by the Word-DR type. The sn-grams of size
n = 2 provide the most task-relevant features, followed by the features of size
n = 3 and, finally, features of size
n = 4.
Figure 9c describes the results for the third group of features. The POS-DR sn-grams achieve the best accuracy, while the DR-POS type obtains an accuracy that is 0.91% lower on average for the different sizes evaluated. POS sn-grams are a type of homogeneous sn-grams that contributes the most to the classification compared to the DR type. The sn-grams of sizes
n = 3 and
n = 4 provide the most relevant features for the task while size
n = 2 tasks are the least relevant features.
The use of two types of mixed sn-grams was also evaluated using the CCAT50 corpus. For the evaluation, the POS-Word sn-grams of size [2, 3] (the configuration that proved to obtain the highest accuracy) were selected, along with the best configurations of the other mixed sn-grams types (reported on
Table 9). The evaluation was performed using only the SVM classifier and the same configuration previously used to evaluate each type of mixed sn-grams.
Table 11 shows the accuracy obtained for each combination. Combining features from mixed POS-Word and DR-Word sn-grams improves accuracy compared to using each type individually by 0.76% and 4.16%, respectively.
Table 12 presents the accuracy achieved by previous works that have used the CCAT50 corpus for evaluation. Early work considers variants of character
n-grams and the application of machine learning methods such as SVM or NN. More recent work explores the incorporation of word
n-grams, POS tags, and syntactic information as features in combination with deep learning techniques. These features are introduced in sequence to the first layer of the network—
the embedding layer. This layer receives as input n-dimensional vectors obtained from pre-trained models, such as transformer-based embeddings like BERT [
77,
78,
79]. Alternatively, the embeddings can be created directly in the embedding layer, either via a CNN or RNN.
4. Discussion
Mixed sn-grams are style markers generated from the dependency tree that combine different types of information (lexical, POS tags, and Syntactic Dependency Relationships) for its generation. These markers can capture intrinsic information associated with the grammatical relationship between tokens. In traditional n-grams, words are captured according to the sequential order of the text (superficial textual analysis). In contrast, sn-grams capture the syntactic relations between words corresponding to the grammatical rules of the language (deep textual analysis).
Experiments on the PAN 2012 Authorship Attribution Corpus demonstrated the potential to model an author’s style through mixed sn-grams in the authorship attribution task. According to the
Table 5, mixed sn-grams outperformed homogeneous sn-grams in terms of accuracy, particularly in scenarios with larger input data. The experiments showed that the DR-POS combination achieved the best accuracy compared to the other mixed sn-grams combinations. The SVM classifier showed the best performance for both types of sn-grams (homogeneous and mixed). The findings suggest that combining dependency relations and POS tags of the syntactic information of a sentence improves the classifier’s accuracy by 12.50% for Task C and 25% for Task I, compared to the use of homogeneous sn-grams.
Comparing the proposed method with the papers presented at the PAN 2012 event (see
Table 6), it is observed that task A obtains the best efficiency, tying it with other papers. Task C obtains the second-best efficiency by a difference of 12.50% with respect to the best efficiency. Finally, the proposed method obtains the best reported accuracy for task I, which is considered the most complicated scenario of the competition due to the number of authors.
The CCAT50 corpus is more demanding because it considers 50 authors and offers thematic diversity in the instances. Furthermore, the average size of the texts is also considerably reduced (584 words) when compared to the PAN 12 corpus average size. The corpus was used in experiments with homogeneous sn-grams of size
n = {2, 3, 4} and machine learning algorithms RL, SVM and MNB. The results shown in
Table 8 demonstrate similar accuracy for all machine learning algorithms. The analysis revealed that Word sn-grams with
n = 2 yielded the optimal accuracy compared to other sn-grams types and n-values. On the other hand,
Table 9 shows that mixed sn-grams of size
n = 2 consistently produced optimal results. The POS-Word combination achieved the highest accuracy. The experiments in
Table 8 show that training the learning algorithm with mixed sn-grams as style markers outperforms homogeneous sn-grams by about 5%.
Table 12 analyzes previous works that used the CCAT50 corpus for evaluation. Currently, there are two approaches to address the authorship attribution task, using feature engineering and deep learning techniques. Our proposal is based on feature engineering. In this category, mixed sn-grams obtain results superior or equal to those of the state of the art (see
Table 12). On the other hand, DL-based SOTA approaches outperform mixed
n-grams. However, to achieve this, in most cases, they input not only syntactic information but also add morphological and lexical information to the network. Deep learning approaches based only on syntactic information [
48,
49] do not outperform mixed
n-grams. It is worth noting that mixed
n-grams achieve 74.36% accuracy, a performance close to 78% of DL approaches based on lexical information [
32,
83], outperformed by about 4%. The best results of 83.42% [
51] and 93.20% [
82] are obtained by combining the three types of information available in a sentence.
The proposal described in this paper outperforms proposals based only on the use of syntactic tree embeddings, without the need for additional information or the use of deep learning strategies. Mixed sn-grams offer the advantage of focusing on the frequency of occurrence of patterns in the dependency trees of sentences, and they also allow the representation of nonlinear relationships between words. Unlike other features that focus on the syntactic level, mixed sn-grams allow for the quantification of the writing style by repeating patterns that can be explained through the grammatical relationships between words.
5. Conclusions
Mixed sn-grams are reported to have comparable or superior efficiency compared to other approaches based on stylometric features (lexical or character level), at least 6.85% in the case of PAN 12 task I and at least 1% in the CCAT50 corpus. Comparing homogeneous sn-grams against mixed sn-grams, we found that the latter provides additional information to that obtained with the former. The mixed sn-grams identify the context of a syntactic tree element in three dimensions (lexical, POS tags, and dependency relations), which enables them to identify other style patterns, like subcategorization phenomena. The results achieved by mixed sn-grams generally exceed those achieved by homogeneous sn-grams by at least 12.5% for the PAN 12 corpus and 5.12% for the CCAT50 corpus, despite both being generated from dependency trees.
One drawback of the proposed method is its reliance on parsers. Memory consumption and runtime analyses indicate that the proposed method best suits small- or medium-sized datasets (texts no longer than tens of thousands of words). In data-scarce scenarios, the proposed method demonstrated competitive results. Furthermore, analysts seek alternative models that reduce processing time and memory consumption without significantly reducing accuracy. This would eventually allow the method to be applied in more realistic scenarios.
Unlike deep learning methods, our approach is efficient in scenarios with small to moderate datasets, where deep techniques tend to overfit or fail to generalize. Our method achieves 74% accuracy, which makes it suitable for cases where large amounts of labeled text are not available, such as in real authorship attribution cases. The model obtained through mixed sn-grams not only dispenses with GPUs, but its low computational requirement allows its application in devices with limited hardware, such as mobile devices or low-cost servers. This broadens the possibilities of adoption and scalability of the solution.
Our method offers a significant advantage in terms of interpretability. In authorship attribution, tracking and justifying attribution decisions through concrete and understandable linguistic features is crucial, especially in legal expertise, plagiarism detection, or forensic investigations. In contrast, deep learning models are treated as black boxes that achieve high classification rates but fail to justify the attribution process. Our approach provides transparency, confidence, and auditability in the attribution process.
In this article, we propose a method for solving the closed monolingual authorship attribution problem using mixed sn-grams. Experiments demonstrated that using mixed sn-grams as style markers creates a reliable writing style model that machine learning algorithms can learn. The proposed method offers comparable or even better accuracy than other works based on stylometric features. Comparing approaches using deep learning with the proposed method, the latter reports at least 28% higher accuracy than strategies such as syntax parse tree embeddings or syntactic parse tree embeddings with a bidirectional LSTM and self-attention mechanism. The proposed method also offers the advantage of being used in resource-limited scenarios (it does not require specialized hardware or large data volumes).
Future research directions include the following two potential courses of action: firstly, evaluating the impact of integrating mixed sn-grams with other feature types, including lexical or character-level features; and secondly, formulating a strategy to adapt mixed sn-grams for utilization by deep learning methods, followed by a performance evaluation. The proposed method can be applied to larger data sets, such as IMDB60, Blogs10, and Blogs50. To reduce runtime, a faster model or parser can be used. In the case of multilingual authorship attribution, the proposed method can also be used, provided the parser includes models for the languages involved.


 ,
, 




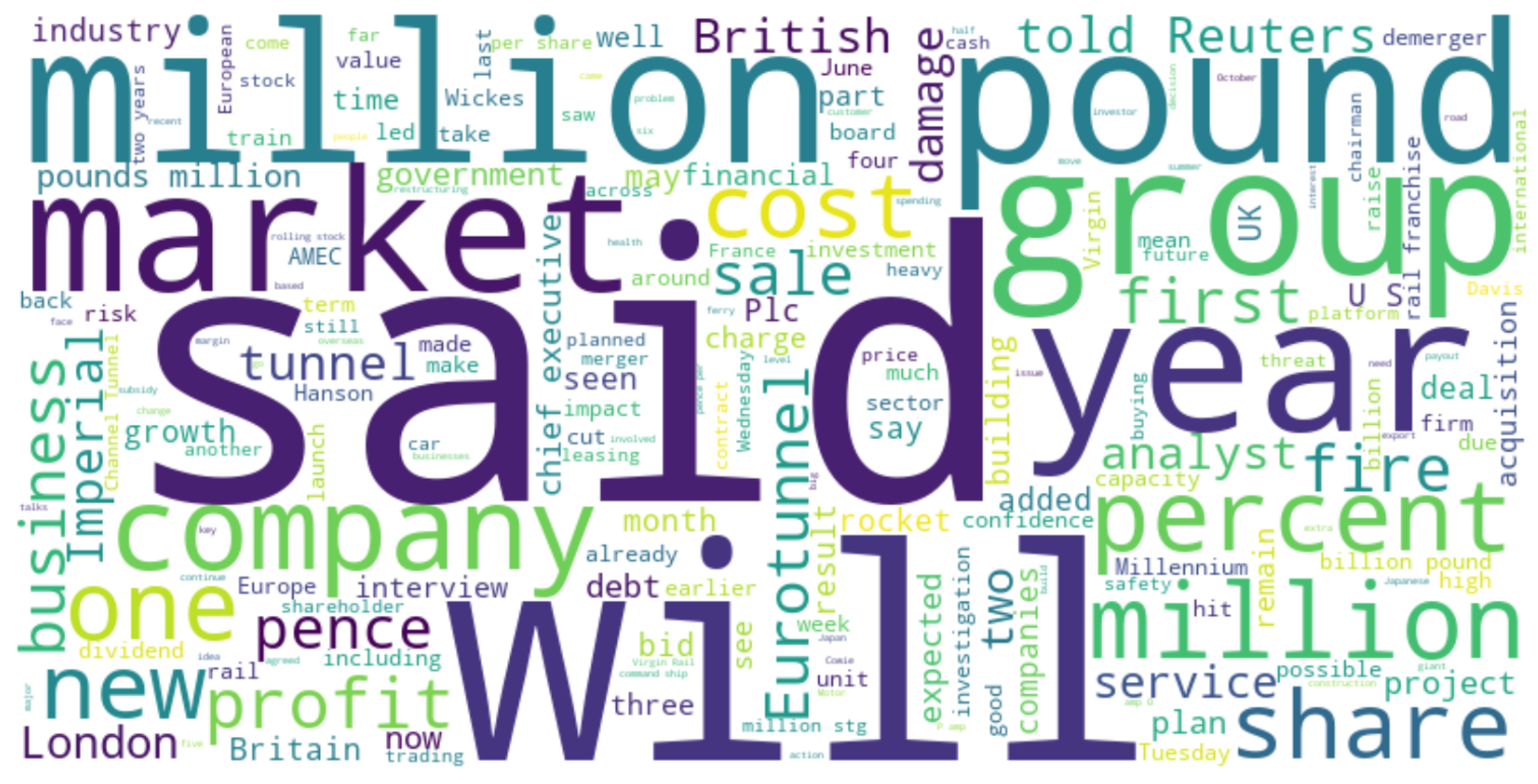

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}