1. Introduction
The growing demand for telemedicine has highlighted the need for efficient medical question classification and healthcare support [
1]. This shift has accelerated the adoption of telemedicine platforms like MDLive, Teladoc, American Well (Amwell), HealthTap [
2], and Altibbi, which provide accessible healthcare solutions [
1]. Altibbi, a cloud-based Arabic telemedicine platform, offers primary care services and has become a leading provider in the Middle East and North Africa [
3]. It hosts over 5 million medical consultations, 3 million verified medical articles, and 1 million digital health records [
1]. Its services include consultations via asynchronous replies, GSM calls, live chat, and video, making healthcare more accessible.
A key challenge in telemedicine is ensuring that patients are referred to the correct specialist, as many lack the medical knowledge to determine which specialty best fits their concerns. Altibbi employs a classification system where specialized doctors categorize medical questions into discrete classes to route them to the appropriate experts. However, medical questions often overlap across multiple specialties, making classification complex. Since Altibbi receives thousands of questions daily, manually assigning them to specialists is time consuming, costly, and prone to errors due to the high overlap of medical keywords across specialties. Automating this process using deep learning can significantly improve efficiency, accuracy, and scalability. This study addresses the challenge of imbalanced multi-class classification in Arabic telemedicine, where certain medical specialties have fewer training samples than others. Proper balancing is crucial because underrepresented specialties are essential for patient care but often lack sufficient data.
To enhance classification accuracy, this research applies oversampling techniques and loss functions to improve specialty detection in Arabic medical text. The increasing demand for telemedicine services further underscores the need for automation. For instance, during the COVID-19 pandemic, Altibbi handled over 2 million online consultations in 2020 alone, compared to 1 million between 2016 and 2019, highlighting the need for a scalable classification system [
1].
Inspired by the SMOTE (Synthetic Minority Oversampling Technique) method [
4], this study adopts DeepSMOTE, which extends SMOTE using deep neural networks to generate synthetic samples and balance class distributions [
5]. While initially designed for images, DeepSMOTE is adapted here for Arabic medical question classification, marking a novel application in this domain. The model is further optimized using loss functions such as cross-entropy loss, focal loss, class-balanced loss, and class-balanced focal loss, which help mitigate class imbalance by giving greater weight to underrepresented categories.
Loss functions are critical in deep learning, quantifying model performance, and driving optimization. They compute the difference between predicted and actual labels, influencing how well a model learns from data [
6]. The choice of loss function significantly affects model behavior and accuracy, particularly in handling imbalanced datasets [
7]. By integrating DeepSMOTE and tailored loss functions, this research aims to enhance classification performance, improve referral accuracy, and optimize telemedicine services by reducing the need for manual intervention.
The proposed system is expected to bring significant improvements in medical consultation workflows, including the following:
More accurate classification of Arabic medical questions.
Reduced workload for healthcare professionals.
Faster and more reliable patient referrals.
Enhanced efficiency in telemedicine service delivery.
This research focuses on building an effective medical question classifier by:
Addressing class imbalance, ensuring that rare but critical patient cases are not overlooked.
Comparing different oversampling techniques to balance data and improve model performance, evaluating both data-level and algorithmic-level methods to find the best approach.
Developing a deep learning model for medical question classification using pre-trained models with deep contextual embeddings.
This study specifically focuses on improving specialty detection in Arabic telemedicine consultations, a critical step in ensuring accurate and timely routing of patient inquiries in digital healthcare platforms. Our key contribution is the integration of DeepSMOTE with loss functions to address class imbalance and improve multi-class classification in Arabic medical contexts. This approach enables more precise question classification, benefiting complex healthcare settings.
The rest of the paper is structured as follows:
Section 2 covers challenges, techniques, and related work.
Section 3 details the methodology and proposed model.
Section 4 presents the experimental setup and results. Finally,
Section 5 discusses conclusions and future directions.
2. Literature Review
2.1. Imbalanced Learning
Class imbalance is a common challenge in machine learning, occurring when the minority class has significantly fewer instances than the majority class. This imbalance often leads to biased predictions, where models favor majority classes and overlook critical minority cases [
8,
9]. Additionally, imbalanced data can introduce other issues, such as class overlap, noise, and shifting distributions, making model development and evaluation even more complex [
10]. In multi-class classification, measuring imbalance is more complicated than in binary classification. It is often quantified using the Imbalance Ratio (IR), which compares the majority and minority class sizes. In multi-class settings, the IR is usually calculated as the maximum of all pairwise IRs between classes [
11]. The choice between binary and multi-class classification depends on the diversity of target classes.
Multiple factors can influence human and machine decision-making. Biases, emotions, first impressions, and majority voting impact human behavior [
12,
13]. Similarly, machine learning models trained on imbalanced datasets tend to favor majority classes, leading to skewed predictions [
14]. With global digitalization generating vast amounts of data, expected to increase from 64.2 zettabytes in 2020 to 394 zettabytes by 2028 [
15], class imbalance is becoming particularly critical in healthcare, fraud detection, and social media analysis, where underrepresented data points can hold vital insights. Therefore, addressing imbalanced data is essential for improving model accuracy and reliability.
Several studies have explored the impact of class imbalance on machine learning performance. Ref. [
16] conducted an extensive review, highlighting how data imbalance affects model accuracy, especially for minority classes. The study examined various resampling techniques used to mitigate imbalance and explored applications in healthcare, fraud detection, and social media analysis. In medical applications, recognizing rare cases accurately is crucial, yet imbalanced datasets often result in poor sensitivity for minority classes, negatively impacting decision-making [
17].
To address this issue, researchers typically use three main approaches: data-level methods (e.g., oversampling and undersampling) [
18], algorithmic techniques (e.g., modifying loss functions) [
19], and ensemble methods (e.g., combining multiple models to improve predictions) [
20]. These strategies reduce data skew and enhance model learning for underrepresented classes.
2.2. Data-Level Approaches
Data-level approaches are a preprocessing step, independent of the classifier used to balance datasets before training. These methods fall into three main categories: undersampling, oversampling, and hybrid approaches that combine both techniques.
Undersampling reduces the size of the majority class to balance class distribution [
21]. Clustering-based undersampling helps retain key information while minimizing data loss. However, more straightforward methods like random undersampling can be unstable, sometimes removing crucial instances. More strategic guided undersampling methods have been explored to address class imbalance; however, they remain underutilized [
22,
23].
Oversampling increases the size of the minority class by generating synthetic samples. One of the most widely used methods is SMOTE [
4], which creates synthetic data points by interpolating between existing minority class samples based on their nearest neighbors. This technique effectively enhances dataset balance but may introduce noise, particularly at class boundaries [
24]. This noise typically arises from synthetic samples created between minority class instances and neighboring majority class samples, leading to class overlap. These borderline synthetic samples can confuse the classifier by blurring decision boundaries, which may increase false positives or misclassifications, especially in high-dimensional or highly overlapping datasets. Such noise can degrade model generalizability and reduce classification precision.
DeepSMOTE [
5], inspired by the SMOTE method, was initially designed for image data and is commonly applied in fraud detection [
25]. Consequently, DeepSMOTE has also shown promising results in other domains, such as rare disease detection in healthcare [
26], anomaly detection in cybersecurity [
27], and predictive maintenance in industrial systems [
28]. These diverse applications demonstrate the versatility and effectiveness of DeepSMOTE in addressing class imbalance problems across various fields.
The success of SMOTE has led to the development of several advanced variants:
ADASYN (Adaptive Synthetic Sampling) [
29,
30] adjusts sample generation based on the distribution of minority instances. While ADASYN improves recall by focusing on hard-to-learn minority instances, it may diminish overall classification accuracy, particularly precision, due to the introduction of synthetic samples in highly overlapping or noisy regions [
31]. This reduction in accuracy was observed in cases where synthetic data generated near class boundaries increased the confusion between classes. Thus, while ADASYN is beneficial for recall-oriented tasks, its use may be less suitable in scenarios where minimizing false positives is critical [
31].
Borderline-SMOTE [
32] focuses on generating synthetic samples near the decision boundaries, specifically for minority class instances at risk of misclassification. However, it does not consider the full data distribution. This targeted approach can improve boundary sensitivity but may overlook the broader representational needs of the minority class. In contrast, ADASYN adapts the number of synthetic samples generated based on the difficulty of learning each minority instance, with more samples created for harder-to-learn examples. This dynamic sampling reflects the distribution of learning complexity rather than the spatial layout alone. The trade-off is that, while ADASYN can improve recall for challenging instances, it also risks introducing more noise in overlapping regions, potentially degrading precision. While Borderline-SMOTE is more focused, it may underrepresent complex minority patterns away from the boundaries.
SVM-SMOTE (Support Vector Machine SMOTE) [
33] generates synthetic samples around the decision boundary using support vectors by training an SVM classifier to identify the decision boundary between classes. Once the support vectors are identified, specifically those belonging to the minority class and near the boundary, synthetic samples are generated by interpolating between them and their neighbors. The rationale is that support vectors are critical data points that define the class margins, and generating synthetic samples around them helps strengthen the classifier’s ability to distinguish between classes in regions prone to misclassification. This focused approach improves minority class recognition while preserving decision boundary integrity.
DeepSMOTE, introduced by [
5], extends SMOTE into a deep learning framework to generate more realistic synthetic samples. It improves classification performance metrics like the Area Under the Precision–Recall Curve (AUPRC), making it particularly useful for addressing imbalances in healthcare diagnostics and defect detection. Unlike traditional SMOTE, which can produce inconsistent results, DeepSMOTE synthesizes instances in a latent feature space. This space refers to a lower-dimensional representation that the encoder learns in the DeepSMOTE architecture. Rather than generating synthetic samples directly in the input space, which can introduce unrealistic or noisy data, DeepSMOTE performs oversampling in this latent space. The advantage is that this space captures essential patterns and semantic relationships in the data, allowing the generation of more consistent synthetic samples with the underlying class distribution. After generation, these latent samples are decoded back into the input space for training the classifier, leading to more stable and reliable outcomes [
34]. DeepSMOTE’s stability and dependability in handling class imbalance have shown tangible benefits in medical domains. For instance, in breast cancer diagnosis tasks, DeepSMOTE-enhanced models achieved higher recall and F1-scores, ensuring more consistent detection of malignant cases even when such cases were underrepresented. Similarly, the technique reduced the number of false negatives in rare disease classification by generating high-quality synthetic samples that better represented the minority class. These improvements directly contribute to earlier and more accurate diagnoses, minimizing missed critical cases and enhancing clinical decision-making. Our experiments’ improved G-Mean and macro F1-scores illustrate DeepSMOTE’s contribution to balanced sensitivity across all classes, which is especially critical in healthcare settings.
A comparative study by [
35] evaluated various oversampling techniques, including DeepSMOTE, across several small and imbalanced datasets, including benchmark healthcare datasets related to diabetes detection and breast cancer diagnosis. These datasets typically feature high levels of class imbalance and subtle inter-class differences, making them suitable for evaluating oversampling strategies. The findings showed that DeepSMOTE outperforms traditional methods like SMOTE and ADASYN by generating high-quality synthetic samples where the data points closely resemble actual instances in terms of semantic and statistical properties. These samples maintain class coherence, enhance minority class representation, and contribute to improved classification performance. Quality is typically quantified using evaluation metrics such as precision, recall, F1-score, and G-Mean on downstream classification tasks and through visual or statistical similarity analyses between real and synthetic distributions in the latent space.
While the analysis in [
35] was limited to specific domains and dataset sizes, and thus the results support DeepSMOTE’s effectiveness, broader evaluations across diverse domains and larger datasets are necessary to generalize the findings and rule out dataset-specific bias.
2.3. Algorithm-Level Approaches
Algorithm-level techniques modify the learning process to give more importance to the minority class. Cost-sensitive learning is one such method, where models assign a higher penalty for misclassifying minority class instances to improve their recognition [
36]. This approach encourages the model to focus more on the underrepresented class, even when it appears less frequently in the training data.
A key strategy at this level involves specialized loss functions designed to compensate for class imbalance. According to [
37], these functions assign higher costs to misclassified minority instances, guiding the model toward better feature learning for rare classes. Loss functions are crucial in deep learning, optimizing model performance during training. Several loss functions have been developed to handle imbalanced datasets [
7]:
Focal loss, introduced by [
38], was designed to address class imbalance in dense object detection tasks. It reduces the relative loss for well-classified examples, shifting the model’s focus to harder-to-classify cases. This function has been widely used in medical image segmentation and object detection, where extreme class imbalances are common.
A deep convolutional neural network (CNN) with an ensemble learning architecture and class-balanced loss was proposed by [
39] to handle class imbalance in deep learning. This approach uses multiple auxiliary classifiers at different CNN hidden layers to correct misclassifications of minority class samples. The class-balanced loss component assigns weights based on class sample sizes, reducing bias toward majority classes and improving minority class predictions.
Class-balanced focal loss combines the benefits of focal loss and class-balanced loss by dynamically adjusting the loss weight based on class frequencies. This method ensures that difficult-to-classify samples receive more attention, making it particularly effective in handling extreme class imbalances [
40].
These algorithm-level approaches are critical in improving model performance, especially in fields like healthcare, where correctly identifying minority class cases is essential for accurate diagnosis and decision-making.
2.4. Ensemble Learning Approaches
Ensemble learning has demonstrated its ability to handle class imbalance by combining multiple models to improve predictions for the minority class [
41,
42]. Boosting methods, such as AdaBoost, adjust sample weights based on previous misclassifications, while Random Forest addresses class imbalance through bootstrap sampling [
41]. By aggregating diverse predictions, ensemble learning reduces bias and variance, leading to more balanced and accurate results. It improves prediction accuracy in imbalanced datasets by integrating multiple classifiers optimized for minority class detection, such as biased Random Forests [
43]. These strategies help machine learning models enhance minority class predictions and improve overall balance.
Despite extensive research on class imbalance in Natural Language Processing (NLP), most studies have focused on English and other widely used languages [
44], while a few addressed low-resource languages, such as Bengali [
45]. Arabic NLP remains underrepresented, primarily due to the lack of benchmark datasets and the language’s structural complexity. Existing research on Arabic NLP imbalance has relied mainly on basic oversampling techniques without comprehensive comparisons to advanced methods like DeepSMOTE [
46,
47,
48]. Furthermore, no benchmark study has evaluated DeepSMOTE against other imbalance-handling techniques in Arabic NLP.
This study bridges that gap by applying DeepSMOTE to Arabic text classification, offering a novel approach to addressing class imbalance in multi-class Arabic NLP tasks. Doing so contributes to developing more effective methods for handling imbalanced datasets in Arabic-language machine learning applications.
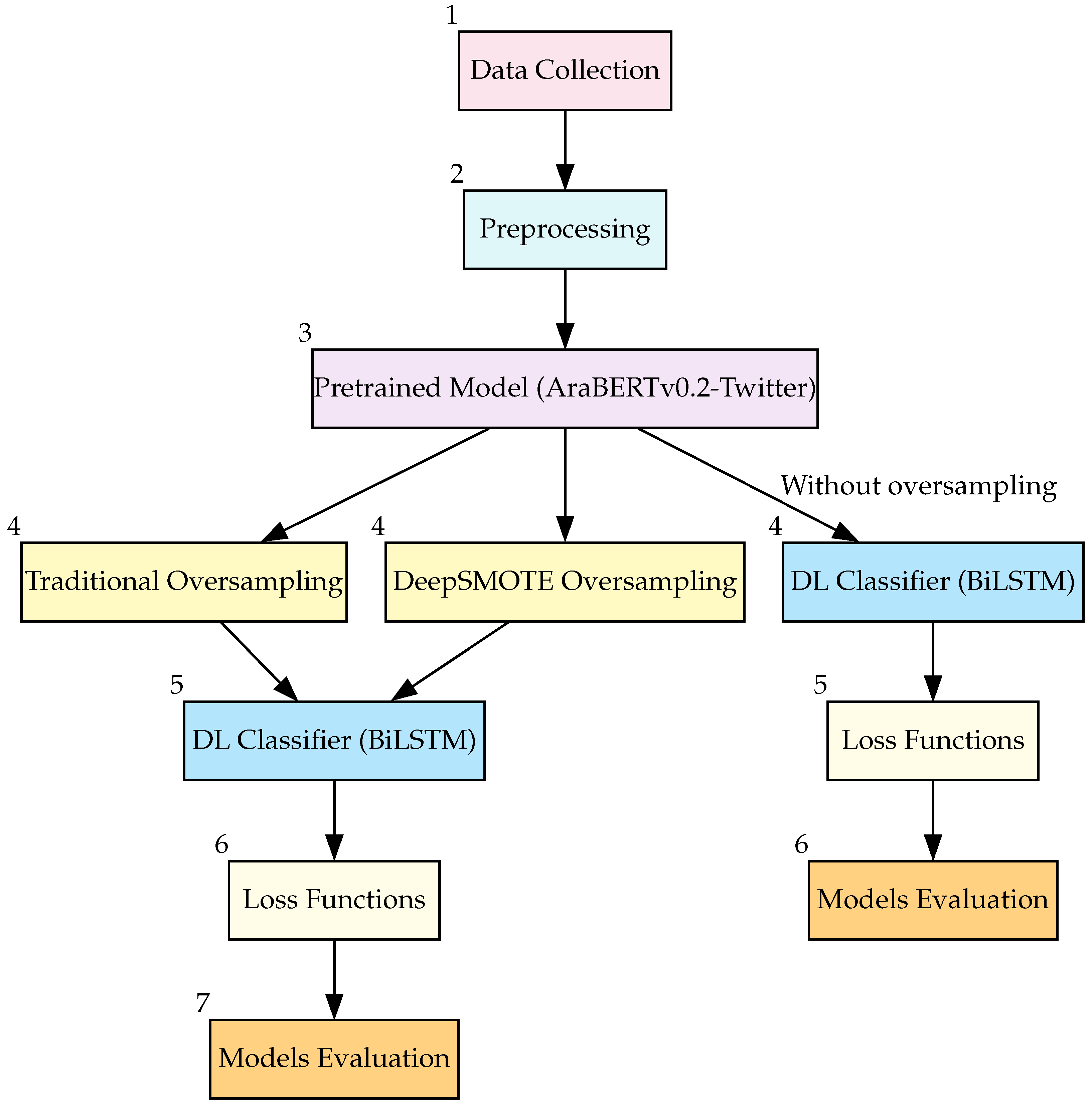
3. Methodology
The proposed methodology addresses two critical challenges in achieving reliable results: multi-class classification and dataset balancing. These challenges are particularly significant in healthcare-related machine learning applications, where data variability can greatly impact model accuracy and prediction performance.
Figure 1 illustrates the workflow of the proposed methodology.
3.1. Data Collection
This study utilizes a dataset from Altibbi’s platform, comprising approximately 5000 medical-related questions. These questions cover various topics, including disease symptoms, treatment methods, preventive measures, and medication information. The dataset is categorized into five medical specialties, each containing multiple questions. The five specialties are Gynecology, Pediatrics, Internal Medicine, Dermatology, and General Practice. They were selected based on their high consultation frequency and clinical importance in frontline digital healthcare. This selection ensures broad applicability and relevance to real-world routing scenarios. As shown in
Figure 2, the dataset exhibits a clear class imbalance, with certain specialties having significantly fewer samples than others.
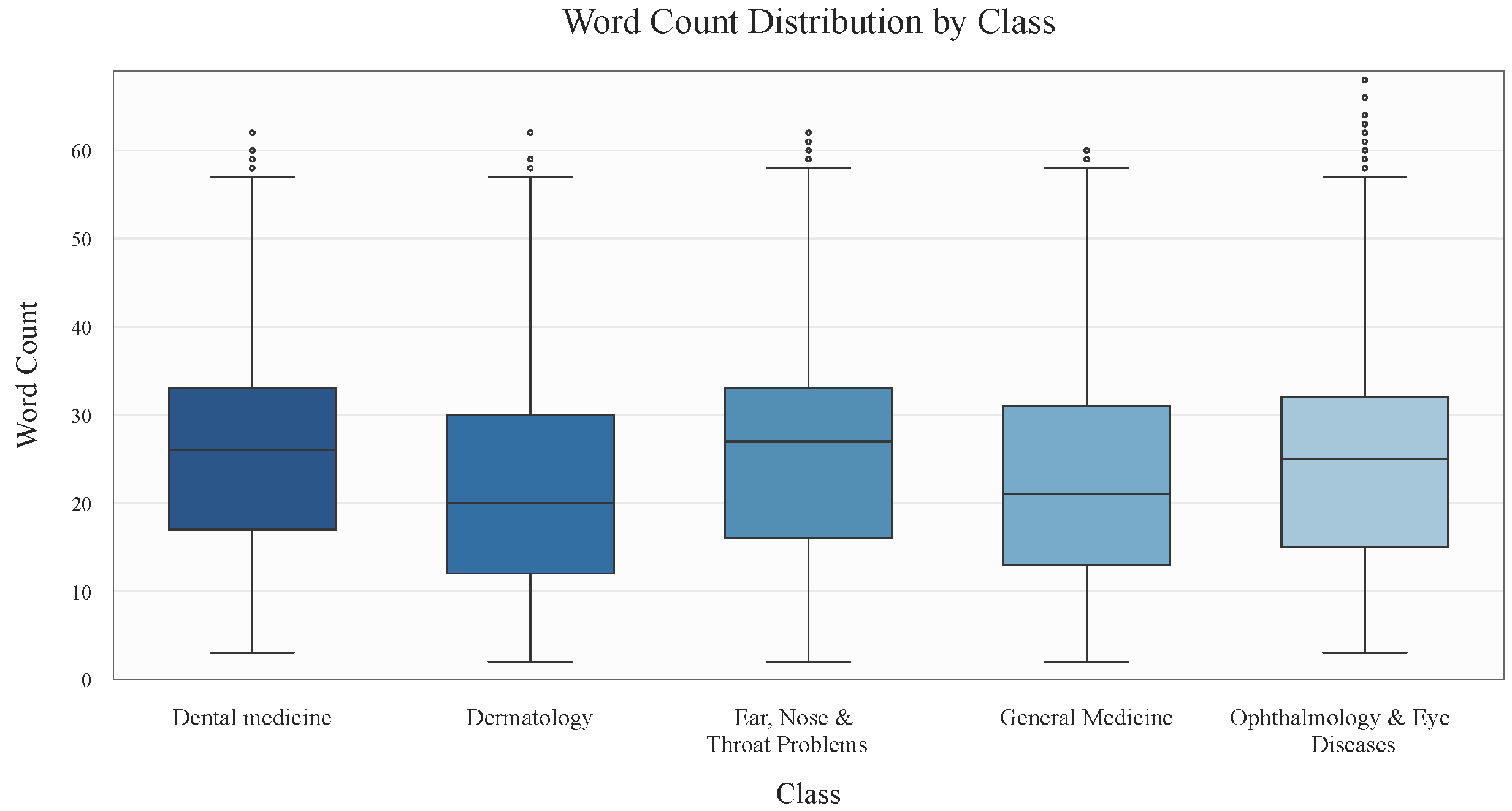
To better understand the dataset structure,
Figure 3 presents the question length distribution across different classes. Most questions fall within a 20–30 word range, though notable outliers exist in the “Dental Medicine” and “Ophthalmology & Eye Diseases” categories. Additionally,
Figure 4 illustrates the average word length, which remains consistently around 4–5 characters across all classes. However, some outliers feature words averaging 8–12 characters, particularly in “Dermatology” and “General Medicine”, where word lengths occasionally exceed 10 characters.
The dataset was obtained under Altibbi’s Terms and Conditions agreement, where users provided explicit consent for their data to be used in machine learning research and for improving healthcare services. All data were anonymized to ensure privacy and confidentiality so that individual users could not be identified. To ensure a proportional representation of each class during training and evaluation, we employed stratified sampling when splitting the data into training and testing sets. This preserved the original class distribution and helped reduce the effects of class imbalance.
This study also adhered to ethical research standards for working with human subjects, including by protecting user confidentiality by anonymizing personal data, ensuring data security, restricting unauthorized access, and minimizing potential risks to participants and researchers. This ethical framework ensured responsible data usage while maintaining the integrity of the study.
3.2. Data Preprocessing
The preprocessing stage ensures a clean and well-structured dataset before training the model. This process involves removing unnecessary data that could introduce noise, reducing computational complexity, and helping the model focus on the most relevant information. The following steps are performed:
Stopword removal: Arabic stop words (common words that do not contribute to meaning) are removed to enhance text clarity.
Non-alphabetical character filtering: Numbers, special characters, and symbols are eliminated to ensure consistency.
Greeting removal: Common greetings and irrelevant phrases are discarded to prevent them from influencing model predictions.
Duplicate removal: Identical or similar questions are removed to avoid bias and ensure fair model training.
Once the dataset is cleaned, the next step is tokenization. In this process, sentence boundaries are identified, unwanted punctuation is removed, and text is split into individual tokens, which are either recognized by the model or mapped to a pre-trained vocabulary. The model can effectively understand and process the input text by breaking questions into structured tokens, leading to better classification accuracy.
3.3. AraBERTv0.2-Twitter Pre-Trained Model
The AraBERTv0.2-Twitter model [
49] is a pre-trained, open-source word embedding specifically designed for informal Arabic language representation. It is based on Google’s BERT architecture but has been fine-tuned to better handle Arabic dialects and social media content, particularly tweets. The key reasons for selecting AraBERTv0.2-Twitter for this study are as follows:
It is optimized for informal Arabic: The dataset consists of user-generated medical questions, often written in colloquial, unstructured language, making this model highly suitable.
It is trained on millions of Arabic tweets: Its training data include large amounts of slang, abbreviations, and dialectal variations, enabling it to capture linguistic distinctions in informal medical queries.
It handles short texts effectively: Since medical questions are typically concise, AraBERTv0.2-Twitter’s ability to process short-length inputs aligns well with the dataset’s characteristics.
Given the colloquial and informal nature of the dataset, fine-tuning AraBERTv0.2-Twitter enabled transfer learning, allowing the model to adapt its knowledge for medical question classification. This process helped refine its ability to understand domain-specific terminology while preserving its expertise in handling Arabic dialects. Traditionally, feature engineering in NLP involves manually extracting linguistic features like word frequencies, n-grams, or statistical attributes (e.g., TF-IDF, bag of words). However, AraBERT embeddings provide a far more comprehensive, automated approach, including the following:
Deep contextual representation: Captures meaning, sentiment, and contextual nuances beyond basic word frequency.
More informative than traditional features: Unlike simple statistical models, AraBERT embeddings understand word relationships within sentences.
Seamless integration with the classifier: These embeddings serve as rich feature vectors, ensuring the model retains linguistic context when classifying medical questions.
By leveraging AraBERTv0.2-Twitter, this study achieves a context-aware, dialect-sensitive feature engineering approach, significantly improving classification accuracy in Arabic medical NLP tasks [
50].
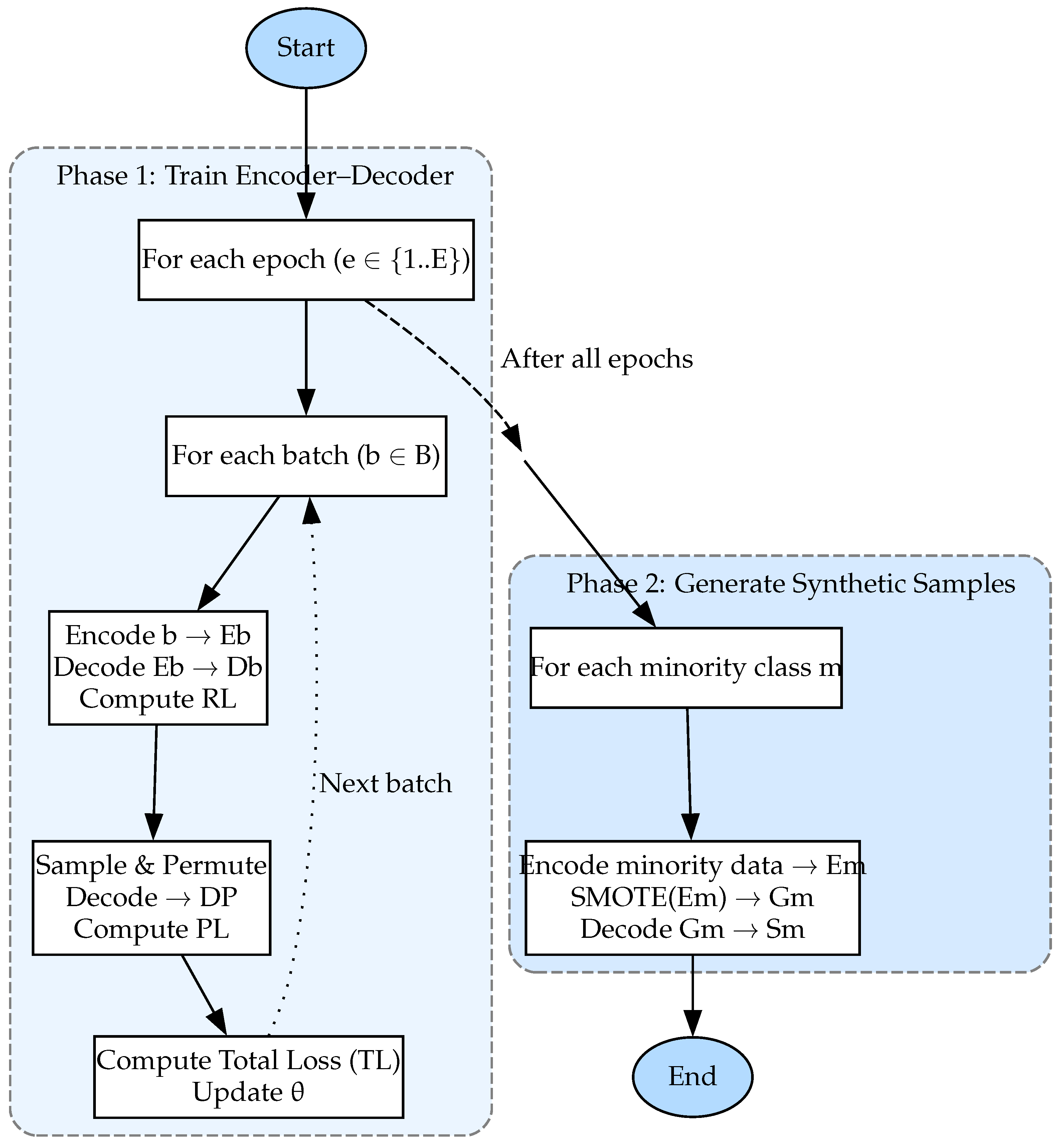
3.4. The DeepSMOTE Algorithm
The DeepSMOTE algorithm advances the original SMOTE (Synthetic Minority Oversampling Technique), integrating deep neural networks to create synthetic instances more effectively. Unlike classical SMOTE, which interpolates between existing samples, DeepSMOTE leverages deep learning to model complex, non-linear patterns, resulting in more realistic synthetic samples. DeepSMOTE consists of three primary components, as illustrated in
Figure 5: an encoder–decoder framework, an enhanced loss function, and SMOTE applied in latent space.
Encoder–decoder framework: At its core, DeepSMOTE employs a deep convolutional generative adversarial network (DCGAN) framework [
51], where the discriminator functions as an encoder extracting key features from input data and the generator serves as a decoder, reconstructing new instances. Unlike traditional autoencoders, this structure eliminates the need for fully connected layers, ensuring direct end-to-end training.
During training, the encoder–decoder framework processes imbalanced datasets in batches and applies reconstruction loss to ensure generalization across majority and minority classes. This approach is particularly beneficial in domains with shared structural patterns, such as medical questions, where different specialties may exhibit similar language structures (e.g., “What causes blurred vision?” vs. “What causes tooth sensitivity?”). Learning these patterns from the majority class enables better generalization and improves the classification of underrepresented classes.
Enhanced loss function: Beyond reconstruction loss, DeepSMOTE introduces a penalty term to increase diversity in synthetic samples. Unlike standard autoencoders, which produce outputs nearly identical to the inputs, DeepSMOTE employs random class sampling and feature permutation during training. A batch of samples is selected from a single class, encoded into a latent space, permuted, and then reconstructed—introducing variability and improving the model’s ability to generate diverse outputs.
Based on the mean squared error (MSE), this penalty term mimics SMOTE’s interpolation effect, allowing DeepSMOTE to generate more diverse instances without requiring a discriminator network. This makes the algorithm computationally efficient while retaining the ability to create high-quality synthetic data.
SMOTE in latent space: DeepSMOTE further enhances synthetic data generation by applying SMOTE in the latent space rather than the input space. Traditional SMOTE interpolates between minority class neighbors, but DeepSMOTE refines this process by incorporating distance-based interpolation within an embedded feature space. This technique, inspired by variational autoencoders (VAEs) [
52] and Wasserstein autoencoders (WAEs) [
53], improves diversity without requiring adversarial training. By eliminating the need for a discriminator, DeepSMOTE reduces computational overhead while retaining the benefits of synthetic data augmentation.
Through its advanced neural-network-based design, DeepSMOTE outperforms traditional resampling techniques, making it a powerful tool for addressing class imbalance in deep learning models. DeepSMOTE improves class imbalance handling by
Capturing non-linear data distributions: Unlike classical SMOTE, DeepSMOTE identifies and models complex relationships within minority class data.
Reducing synthetic data noise: The autoencoder-based filtering minimizes the risk of introducing unrealistic samples, improving classification precision and recall.
Enhancing model robustness: By generating higher-quality synthetic instances, DeepSMOTE helps models make more accurate predictions for minority classes.
Effectiveness in healthcare applications: Since medical datasets often suffer from severe class imbalance, DeepSMOTE provides significant performance gains, as demonstrated in medical diagnostics and rare disease classification [
5].
3.5. BiLSTM
A Bidirectional Long Short-Term Memory (BiLSTM) network [
54] is utilized for text classification due to its ability to capture hidden semantic relationships in text sequences. Understanding contextual dependencies within sentences is essential, especially in Arabic medical question classification, where the meaning of a term is often influenced by both preceding and following words.
To address their limitations, BiLSTM builds upon Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks. While RNNs struggle with long-term dependencies and face vanishing gradient issues, LSTM improves memory retention by incorporating gated mechanisms that selectively retain or forget information over long sequences. BiLSTM further enhances this by processing text bidirectionally, ensuring the model captures relationships within a sentence in both forward and backward directions. This bidirectional structure enables deeper semantic understanding, making BiLSTM particularly effective for colloquial Arabic text classification.
This study employs BiLSTM as the deep learning classifier due to its proven ability to analyze bidirectional contextual relationships in informal Arabic medical questions. The Results section further justifies this choice by comparing its empirical performance with prior research findings. The model uses PyTorch 2.6, which allows flexible fine-tuning for optimal classification performance. Additionally, dropout layers relieve overfitting and enhance generalization to unseen data [
55].
BiLSTM has demonstrated significant success in semantic analysis and Arabic text classification, making it a crucial component of this research. Considering preceding and subsequent words in a sequence enhances contextual awareness and improves classification accuracy in medical question datasets.
3.6. Loss Functions
Loss functions are critical in deep learning, as they optimize model performance during training. In classification tasks, especially those involving imbalanced datasets, specialized loss functions help relieve bias toward majority classes and improve minority class recognition [
7].
Several loss functions have been developed to address class imbalance, including focal loss, class-balanced loss, and class-balanced focal loss. These functions adjust the model’s learning dynamics by modifying the loss calculation, ensuring greater emphasis on minority class instances. Since they modify the model’s training process rather than the dataset, they are categorized as algorithm-level approaches to class imbalance mitigation.
3.6.1. Focal Loss
Focal loss [
38], an extension of cross-entropy loss, addresses class imbalance by reducing the influence of readily classified instances and emphasizing challenging examples. It introduces a modulating factor that adjusts the loss contribution based on prediction confidence.
where
is the focus parameter, and
is the actual class prediction probability. Reduced loss for well-classified cases (high
) occurs when
> 0, shifting the model’s attention to misclassified or hard-to-classify examples.
Focal loss is an algorithm-level approach since it modifies the training process rather than altering the dataset. Penalizing misclassified samples more heavily helps the model learn from minority class instances, modifying class imbalance without requiring oversampling or synthetic data generation.
3.6.2. Class-Balanced Loss
Class-balanced loss [
39] alleviates class imbalance by assigning higher weights to underrepresented classes based on their frequency. The weighting factor for each class is typically inversely proportional to its sample count. This approach reduces the loss contribution from overrepresented classes while increasing the impact of minority class errors, ensuring the model pays more attention to underrepresented categories.
Class-balanced loss is an algorithm-level technique because it modifies the loss function rather than adjusting the dataset. It is particularly useful when dealing with moderate-to-severe class imbalances, helping the model maintain balanced learning across all classes and improving minority class predictions.
3.6.3. Class-Balanced Focal Loss
Class-balanced focal loss [
40] combines focal loss with class-balanced loss to address class imbalance comprehensively. This hybrid approach ensures that underrepresented classes receive adequate attention by adjusting the loss to focus on more challenging examples and giving weights according to class frequency. The class weights are calculated similarly to in class-balanced loss based on class frequency. The focal loss component introduces the focusing parameter
, which reduces the contribution of easy-to-classify examples and emphasizes harder-to-classify instances, typically those from minority classes. The formula for class-balanced focal loss is as follows:
where
represents the class balancing weight,
n is the number of class samples,
is the focusing term using the focal loss modifying factor (
), and
is the cross-entropy loss. This combination allows the model to balance attention between underrepresented classes and hard-to-classify examples, ensuring that both are highly important during training.
3.7. Evaluating the Performance of Classifiers
The right evaluation metrics are critical for determining the best classifier [
56]. A variety of metrics enable comprehensive assessment and comparison between models. These metrics are derived from the fundamental concepts of true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN). The basic evaluation metrics are as follows:
Precision: The proportion of true-positive predictions to the total predicted positives.
Recall: The proportion of true-positive predictions out of the actual positives in the dataset. A higher recall indicates fewer false negatives.
F1-score: The harmonic mean of precision and recall, balancing both metrics, particularly in imbalanced datasets.
Building on these fundamental metrics, we can extend to multi-class classification metrics. In our study, we employ the following metrics [
57]:
Macro F1-score: Calculates and averages the F1-score for each class independently. It does not account for class imbalance, considering all classes equally.
where F1
i is the F1-score for class
i, and
N is the total number of classes.
Macro recall: Calculates recall for each class independently and averages them, treating all classes equally.
Macro precision: Computes the precision for each class separately and averages them. Macro precision can help determine the model’s ability to lower the number of false positives across all classes. Multi-class classification provides a balanced perspective of the model’s behavior because it contributes equally to all classes.
Weighted F1-score: The F1-score for each class is calculated, but each class’s score is weighted by its support (i.e., the number of true instances) [
58]. This metric is helpful for imbalanced datasets, giving more importance to frequent classes.
where w
i represents the percentage of each class’s instances compared to all instances. When the dataset lacks balance, this metric accurately represents the model’s performance across all classes, focusing on accurately representing the more common classes.
Geometric mean (G-Mean) metric: Assesses the balance between sensitivity (recall) and specificity across all classes [
56], which is particularly useful for imbalanced datasets. The geometric mean of recall values is calculated for all classes.
The G-Mean metric strives to balance class sensitivity so that the model can detect all classes equally well. This is crucial in fraud detection and medical diagnostics, as minority class detection holds significant importance. Macro precision can help determine the model’s ability to lower the number of false positives across all classes. Multi-class classification provides a balanced perspective of the model’s behavior because it contributes equally to all classes.
4. Experimental Results
4.1. Performance Evaluation of LSTM and BiLSTM Compared to Standard ML Models
This study builds on prior research in Arabic healthcare question classification. Previous work leveraged word embeddings extracted from various medical consultations to establish experimental methodologies for classifying Arabic healthcare queries [
59]. Among the tested models, BiLSTM demonstrated superior performance compared to LSTM, which produced lower classification accuracy [
59]. Similarly, a study focused on COVID-19-related medical questions from Altibbi further validated that BiLSTM outperforms both LSTM and RNN models, reinforcing its suitability for this task [
60].
The decision to adopt BiLSTM was substantiated by extensive empirical evaluations involving multiple classifiers. These classifiers utilize AraBERTv0.2-Twitter embeddings for feature extraction, leveraging contextual word representations to enhance classification performance. The models were assessed using five key evaluation metrics: macro precision, macro recall, macro F1-score, weighted F1-score, and G-Mean. BiLSTM consistently achieved the highest scores across all metrics, except for the weighted F1-score, where LSTM marginally outperformed it. This discrepancy is likely due to LSTM’s inherent bias toward the majority class, as the weighted F1-score is influenced by class distribution.
Table 1 summarizes the detailed model performance results.
Beyond model selection, data preprocessing, model construction, and evaluation play a fundamental role in this study. Early stopping is employed to optimize model generalization to relieve overfitting and prevent the model from converging in local minima. The diversity of the medical questions in the dataset introduced class imbalance, necessitating resampling techniques to enhance classification performance across underrepresented categories.
4.2. Experimental Setup for Training the Dataset Using the AraBERT Transformer-Based Model
The experiments were conducted using Google Colab Pro+, leveraging its robust computational resources for deep learning. The development environment is based on Python 3.10 and various deep learning libraries. PyTorch was chosen for model construction and training due to its flexibility and dynamic computation graph. The Transformers library facilitated the loading and fine-tuning of pre-trained Transformer models, with AutoModel and AutoTokenizer effectively handling text data.
4.2.1. The Computational Environment
Google Colab Pro+ provided a high-performance setup featuring the following:
CPU: 12-core Intel(R) Xeon(R) CPU @ 2.20 GHz.
RAM: 83.48 GB.
GPU: NVIDIA A100-SXM4-40GB, optimized for neural network computations.
These specifications enabled the efficient processing of large datasets, rapid model training, and extensive testing on Arabic healthcare question classification.
4.2.2. Data Processing and Sampling Techniques
During the data preparation phase, Pandas was used to manipulate the dataset. Scikit-Learn offers utilities for splitting the dataset into training and test sets and label encoding. Several sampling strategies, such as SMOTE, ADASYN, SVM-SMOTE, and borderline SMOTE from imbalanced-learn, were also used in the training process to handle the class imbalances in some experiments for comparison reasons. Matplotlibcharting was used to comprehensively examine the model’s performance in visualizing the results. The experimental setup used these Python libraries and tools to guarantee a stable and well-supported environment, which made it possible to quickly develop, optimize, and assess the deep learning model for categorizing Arabic healthcare issues.
4.2.3. Hyperparameter Optimization Using Grid Search
A grid search algorithm was employed to explore hyperparameter combinations systematically, optimizing the model for maximum performance. This approach surpasses manual tuning by eliminating trial-and-error inefficiencies. Several key parameters influence the model’s performance, including latent dimension, epoch number, and learning rate. The latent dimension holds the model’s depth of representation. If it is too low, the model underfits; if it is too high, it overfits. The number of epochs affects how much the model learns from the data, as too few leads to undertraining, while too many leads to overfitting.
The learning rate controls the magnitude of steps taken during weight updates. If it is too high, it might skip over optima; if it is too low, it converges too slowly or becomes stuck in poorer solutions. We applied grid search to optimize these parameters and ensure the best configuration. Additionally, for the loss function, grid search was also used. For focal loss, we attempted to fine-tune both alpha (
) and gamma (
) parameters to control the balancing factor and focusing mechanism. For class-balanced loss, we tried to find the best balancing class input weight by changing the beta (
) parameter, and, for class-balanced focal loss, which combines the focusing mechanism in focal loss with class balancing from class-balanced loss, we performed gamma
and beta (
) fine-tuning.
Table 2 lists the tested values and the selected optimal parameters.
4.3. Experimental Results of Handling the Imbalanced Dataset
4.3.1. Baseline Experiment: Using AraBERT Without Handling Data Imbalance
At the preliminary stage of this research, the AraBERTv0.2-Twitter–BiLSTM hybrid model was trained and evaluated on a multi-class Arabic text classification task without employing any techniques to address class imbalance. The dataset was partitioned into training and testing sets using a standard 80/20 stratified sampling strategy, ensuring that the proportional class distribution was preserved across both subsets. Using stratified sampling is crucial, particularly for imbalanced datasets, as it prevents minority classes from being excessively allocated to the training or testing set, thereby maintaining dataset integrity.
Figure 6 provides a detailed illustration of the stratified sampling approach and the overall class distribution, highlighting the classification challenges introduced by class imbalance.
To assess model performance, four loss functions were evaluated: cross-entropy loss, focal loss, class-balanced loss, and class-balanced focal loss. The cross-entropy loss was designated as the baseline loss function, and its corresponding model was used as a reference point for comparative analysis across all configurations.
Each combination of the AraBERTv0.2-Twitter–BiLSTM model and its respective loss function was analyzed independently to assess its effectiveness in handling class imbalance. This approach comprehensively understands the model’s capabilities without data-level interventions. Each configuration was evaluated using key metrics: macro precision, macro recall, macro F1-score, weighted F1-score, and G-Mean. The results of the experiments are presented in
Table 3. Each experimental model has been assigned a unique identifier (Model ID) to simplify the referencing and comparison throughout the study.
As shown in
Table 3, the focal loss function without oversampling techniques (M14) yielded the best results among the tested loss functions, achieving a macro F1-score of 0.9049 and a G-Mean of 0.9057, comparable to some oversampling methods. These findings highlight that algorithm-level balancing can be sufficient in addressing class imbalance, particularly in cases where oversampling techniques fail to generate meaningful synthetic samples.
4.3.2. Experimenting with Standard Oversampling Techniques and the Effect of Loss Functions on Performance
In the second stage of this study, we extended our investigation by incorporating four standard oversampling techniques: SMOTE, ADASYN, SVM-SMOTE, and Borderline-SMOTE. Our objective was to evaluate how these methods influence model performance when paired with each of the four previously tested loss functions and to identify the optimal strategy for handling class imbalance.
The results indicated that SMOTE improved recall, demonstrating its effectiveness in addressing class imbalance. However, Borderline-SMOTE outperformed other methods in most evaluation metrics. Combined with cross-entropy loss, the model (M4) achieved a macro F1-score of 0.9065 and a G-Mean of 0.9074, highlighting its strength in generating synthetic samples near decision boundaries.
SVM-SMOTE produced consistent but suboptimal results, never reaching the highest performance in either metric. For instance, when paired with class-balanced focal loss, the model (M9) achieved a macro F1-score of 0.9064 and a G-Mean of 0.9063, showing moderate improvement over SMOTE, but remained inferior to the proposed approach. ADASYN consistently underperformed compared to Borderline-SMOTE and the proposed approach. The only reasonable outcome was ADASYN combined with cross-entropy loss (M7), which yielded a macro F1-score of 0.9054 and a G-Mean of 0.9063.
Despite its effectiveness, Borderline-SMOTE combined with class-balanced focal loss was surpassed by all other combinations, unexpectedly performing worse than training without any oversampling technique. This outcome may have arisen because Borderline-SMOTE generates synthetic minority instances near the decision boundaries. When this process is integrated with class-balanced focal loss, which already focuses on hard-to-classify minority instances, the model may overfit these synthetic instances, leading to fuzzy decision boundaries and weaker overall performance.
4.3.3. Experimenting with DeepSMOTE and the Effect of Loss Functions on Performance
In this experiment, the AraBERTv0.2-Twitter–BiLSTM hybrid model was trained and evaluated on a multi-class Arabic text classification task using DeepSMOTE. To further assess the effectiveness of DeepSMOTE in handling multi-class imbalanced datasets, we analyzed its impact on model performance when combined with different loss functions. DeepSMOTE demonstrated the best recall performance, making it a strong candidate for addressing the class imbalance in Arabic healthcare question classification.
Among the tested configurations, DeepSMOTE with cross-entropy loss exhibited the highest overall performance across nearly all evaluation metrics. The model (M1) achieved a macro precision of 0.9158, the highest among DeepSMOTE models, a macro recall of 0.9077, a macro F1-score of 0.9111, the highest overall, a weighted F1-score of 0.9307, marking the best overall performance, and a G-Mean of 0.9117. These results indicate that cross-entropy loss is optimal when employing DeepSMOTE for class imbalance reduction.
DeepSMOTE combined with class-balanced loss (M2) performed slightly worse than cross-entropy loss. While it demonstrated competitive results, the class-balanced loss did not provide a significant improvement over the standard cross-entropy loss.
DeepSMOTE with focal loss (M3) yielded a worse performance than the previous two loss functions. This may be attributed to focal loss primarily emphasizing hard-to-classify examples, which, in this case, did not offer sufficient improvement over other loss functions.
Finally, DeepSMOTE, in conjunction with class-balanced focal loss (M19), recorded the worst performance among all DeepSMOTE models. This suggests that merging DeepSMOTE with class-balanced focal loss does not enhance model performance. One possible explanation is that the model struggled to learn effectively from the synthetic samples generated by DeepSMOTE, leading to suboptimal generalization.
5. Results
The comprehensive results in
Table 3 illustrate the impact of different loss functions and oversampling methods on model performance. Each model has been assigned a unique identifier (Model ID) to simplify the referencing and comparison throughout the study. The best value for each model is in bold typeface for clarity.
Figure 7 visually presents the following evaluation metrics across all tested models: macro precision, macro recall, macro F1-score, weighted F1-score, and G-Mean. These metrics were chosen to reflect performance on imbalanced data where traditional accuracy may be misleading. The geometric mean (G-Mean) is particularly emphasized for its ability to measure balanced performance across classes.
Figure 8 ranks the models based on their G-Mean scores, showcasing their ability to handle class imbalance.
Among the models, DeepSMOTE combined with cross-entropy loss (M1) achieved the best performance overall, with a macro precision of 0.9158, a macro recall of 0.9077, a macro F1-score of 0.9111, a weighted F1-score of 0.9307, and a G-Mean of 0.9117. Other DeepSMOTE configurations (M2 and M3) also performed well but slightly worse (M1).
Figure 9 compares the top performer (M1) and the fourth-ranked model, Borderline-SMOTE with cross-entropy loss (M4). M4 stands out as the best among non-DeepSMOTE models due to its ability to target borderline instances effectively.
5.1. Effect of Loss Functions on Model Performance
The choice of loss function significantly influences model performance. Cross-entropy loss demonstrated strong baseline performance across all oversampling methods. Class-balanced loss improved performance by compensating for class imbalance through inverse frequency weighting, which benefited minority classes.
While useful in theory for focusing on hard-to-classify examples, focal loss underperformed in several cases, possibly due to the over-penalization of minority class misclassifications. Class-balanced focal loss, combining both focal and class-balanced elements, yielded mixed results. Its performance was inconsistent and did not consistently outperform simpler alternatives like cross-entropy or class-balanced loss.
5.2. Statistical Validation of Results
To enhance the credibility and reliability of our findings, we conducted a series of statistical analyses to validate model performance under imbalanced conditions. These statistical validations support the soundness of our experimental design and reinforce the effectiveness of DeepSMOTE as a strategy for managing class imbalance in real-world healthcare applications.
A one-way ANOVA was conducted on macro F1-scores across all tested models, grouped by oversampling method. The analysis revealed a statistically significant difference in performance, with and . These results confirm that the observed differences among oversampling strategies, including DeepSMOTE, are unlikely to be due to chance.
Stratified sampling was used during the data split process to ensure representational consistency between the training and test datasets. This technique preserved class proportions across all five medical specialties, reducing evaluation bias and enhancing the fairness and generalizability of model comparisons, particularly important in multi-class medical classification.
We analyzed the standard deviation of key performance metrics, including macro F1-score and G-Mean, to assess model robustness across multiple independent runs. DeepSMOTE-based configurations consistently demonstrated lower variance in these metrics, indicating stronger generalization and resilience to class imbalance. These standard deviations (±values) are reported alongside each metric in
Table 3, providing insight into performance consistency and overall model stability.
In addition to the primary evaluation metrics, we report sensitivity and specificity for each model, as shown in
Table 3. Sensitivity measures the true-positive rate, reflecting the model’s ability to identify minority class instances correctly. Specificity measures the true-negative rate, indicating how well the model avoids false positives. While macro F1-score and G-Mean offer aggregate insights, sensitivity and specificity allow clinicians and domain experts to interpret how well the model detects and avoids errors in individual classes. This enhances the interpretability of our results and supports the real-world applicability of the model in healthcare triage and routing systems. The consistently strong performance of DeepSMOTE-based models across all four metrics highlights their balanced, stable, and clinically relevant behavior in imbalanced multi-class classification tasks.
6. Discussion
The results indicate that DeepSMOTE, when combined with cross-entropy loss, consistently outperformed other models across all key metrics. This highlights the effectiveness of structured oversampling in the latent feature space, where semantically coherent synthetic samples are generated. These samples enable more robust learning in highly imbalanced settings, particularly in Arabic healthcare text classification.
The superior performance of the model (M1) demonstrates the value of integrating both data-level (oversampling) and algorithm-level (loss function) strategies. In contrast, models using focal loss and class-balanced focal loss showed diminished performance, suggesting that their weighting mechanisms may over-penalize hard examples. When combined with synthetic data, this overemphasis appears to reduce learning stability.
Borderline-SMOTE (M4) emerged as the best-performing traditional oversampling method, affirming that focusing on borderline instances can enhance minority class detection. However, its performance still falls short of DeepSMOTE, which better preserves class boundaries through latent space sampling. Similarly, ADASYN and SVM-SMOTE achieved marginal gains over basic SMOTE but lacked consistency and computational efficiency compared to DeepSMOTE-based models.
Although SMOTE and its variants offer practical solutions to class imbalance, they are prone to introducing noise, particularly in boundary regions where class overlap is common. One of DeepSMOTE’s key advantages, and the focus of this study, is its ability to mitigate such noise by generating synthetic samples in a latent space learned through an encoder–decoder network. This approach promotes semantic consistency and reduces the likelihood of unrealistic or ambiguous instances, making DeepSMOTE a reliable tool in medical NLP tasks.
We evaluated the performance consistency using stratified training and testing splits. Specifically, we examined the macro F1-score and G-Mean variance across multiple model configurations. DeepSMOTE-based models demonstrated lower fluctuation in these metrics, indicating more stable generalization under class-imbalanced conditions. This consistency is especially important in sensitive domains such as healthcare, where reliable predictions across categories are critical. Performance metrics and their standard deviations are reported in
Table 3 to reflect accuracy and stability.
Despite its performance benefits, DeepSMOTE introduces additional computational complexity. Unlike traditional methods that rely on lightweight k-NN-based interpolation, DeepSMOTE requires training and inference through deep neural networks, which increases memory and processing demands. Consequently, while DeepSMOTE is well suited for offline or moderately sized applications, its use in large-scale or real-time systems may require GPU acceleration or further optimization.
Finally, while DeepSMOTE demonstrates superior performance in many scenarios, it has certain limitations. It requires substantial computational resources due to the training of encoder–decoder architectures, which may not be feasible in low-resource environments or with very large datasets. Additionally, its performance is sensitive to the quality of the learned latent space. If the encoder fails to capture meaningful representations, the generated synthetic samples may not be beneficial. Sometimes, simpler oversampling techniques such as SMOTE or ADASYN may outperform DeepSMOTE, particularly when the dataset is small, low-dimensional, or requires rapid deployment. Moreover, algorithmic-level solutions like class-balanced loss or focal loss can be more efficient and effective in contexts where model complexity and interpretability are priorities.
7. Conclusions
This study tackled the challenges associated with multi-class imbalanced Arabic text classification by analyzing the impact of different oversampling techniques and loss functions. By leveraging AraBERTv0.2-Twitter, the model extracted rich contextual Arabic embeddings, which were then processed by a BiLSTM classifier. This architecture enabled the model to learn forward and backward contextual dependencies, leading to a deeper understanding of sentence semantics and structure.
The experiments incorporated standard oversampling techniques: SMOTE, ADASYN, Borderline-SMOTE, SVM-SMOTE, and an advanced oversampling method, DeepSMOTE. These techniques were evaluated with four loss functions: cross-entropy loss, focal loss, class-balanced loss, and class-balanced focal loss. The results demonstrated that DeepSMOTE with cross-entropy loss consistently outperformed other configurations, achieving the highest macro F1-score (0.9108) and G-Mean (0.9114). This finding underscores DeepSMOTE’s ability to generate high-quality synthetic samples that enhance class balance while preserving the original data distribution.
Borderline-SMOTE and SVM-SMOTE exhibited competitive performance among classical oversampling techniques, though some synthetic samples introduced noise and overlap. Models that relied solely on algorithmic balancing via loss functions, such as focal loss and class-balanced loss, achieved decent results but consistently underperformed compared to oversampled models with a loss-balancing strategy.
Theoretically, this study highlights the importance of integrating advanced data-level balancing techniques (e.g., DeepSMOTE) with algorithm-level loss strategies to improve model generalization on imbalanced datasets. The findings offer valuable insights for Arabic text classification applications in domains where class imbalance is prevalent, such as digital health, customer service, and sentiment analysis.
Author Contributions
Conceptualization, B.A.-S., B.H., and H.F.; methodology, B.A.-S.; software, B.A.-S.; validation, B.H., H.F., and P.A.C.; formal analysis, B.A.-S.; investigation, B.A.-S.; data curation, H.F.; writing—original draft preparation, B.A.-S.; writing—review and editing, B.H.; visualization, B.A.-S.; supervision, B.H., H.F., and P.A.C.; funding acquisition P.A.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported by the Ministerio Español de Ciencia e Innovación under projects PID2020-115570GB-C22 MCIN/AEI/10.13039/501100011033 and PID2023-147409NB-C21 MICIU/AEI/10.13039/501100011033, the C-ING-027-UGR23 project, and the Cátedra de Empresa Tecnología para las Personas (UGR-Fujitsu).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Patient consent was waived because all personal data related to patients were fully anonymized before being accessed for this study. The dataset did not contain any personally identifiable information (PII) or sensitive health records that could be traced back to individual patients. Additionally, the study involved secondary data analysis without direct patient interaction, ensuring minimal participant risk.
Data Availability Statement
The dataset used in this study is proprietary to Altibbi and is not publicly available. However, access may be granted upon reasonable request to the third author, H.F., subject to Altibbi’s data-sharing policies and relevant ethical and institutional guidelines.
Acknowledgments
The authors would like to thank Altibbi for providing the dataset used in this study. Their support in facilitating access to Arabic medical question data was instrumental in conducting this research. This work was supported by the Ministerio Español de Ciencia e Innovación under projects PID2020-115570GB-C22 MCIN/AEI/10.13039/501100011033 and PID2023-147409NB-C21 MICIU/AEI/10.13039/501100011033, the C-ING-027-UGR23 project, and the Cátedra de Empresa Tecnología para las Personas (UGR-Fujitsu).
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| ADASYN | Adaptive Synthetic Sampling |
| AraBERT | Arabic BERT |
| BiLSTM | Bidirectional Long Short-Term Memory |
| CNN | Convolutional Neural Network |
| DCGAN | Deep Convolutional Generative Adversarial Network |
| FN | False Negative |
| FP | False Positive |
| G-Mean | Geometric Mean |
| IR | Imbalance Ratio |
| LSTM | Long Short-Term Memory |
| ML | Machine Learning |
| MSE | Mean Squared Error |
| NLP | Natural Language Processing |
| SMOTE | Synthetic Minority Oversampling Technique |
| SVM-SMOTE | Support Vector Machine SMOTE |
| TF-IDF | Term Frequency–Inverse Document Frequency |
| TN | True Negative |
| TP | True Positive |
| VAEs | Variational Autoencoders |
| WAEs | Wasserstein Autoencoders |
References
- Alomari, A.; Faris, H.; Castillo, P.A. Specialty detection in the context of telemedicine in a highly imbalanced multi-class distribution. PLoS ONE 2023, 18, e0290581. [Google Scholar]
- Shi, V.Y.; Komiak, S.; Komiak, P. Are You Willing to See Doctors on Mobile Devices? A Content Analysis of User Reviews of Virtual Consultation Apps. In HCI in Business, Government and Organizations. Interacting with Information Systems, Proceedings of the HCIBGO 2017, Vancouver, BC, Canada, 9–14 July 2017; Nah, F.F.H., Tan, C.H., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2017; Volume 10293. [Google Scholar] [CrossRef]
- Altibbi. Altibbi—Telemedicine Platform. 2024. Available online: https://altibbi.com (accessed on 1 March 2025).
- Chawla, N.; Bowyer, K.; Hall, L.; Kegelmeyer, W. SMOTE: Synthetic minority oversampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Dablain, D.; Krawczyk, B.; Chawla, N.V. DeepSMOTE: Fusing Deep Learning and SMOTE for Imbalanced Data. IEEE Trans. Neural Netw. Learn. Syst. 2022, 34, 6390–6404. [Google Scholar] [CrossRef] [PubMed]
- Terven, J.; Cordova-Esparza, D.M.; Ramirez-Pedraza, A.; Chavez-Urbiola, E.A.; Romero-Gonzalez, J.A. Loss Functions and Metrics in Deep Learning. arXiv 2023, arXiv:2307.02694. [Google Scholar]
- Janocha, K.; Czarnecki, W.M. On loss functions for deep neural networks in classification. arXiv 2017, arXiv:1702.05659. [Google Scholar] [CrossRef]
- Jafarigol, E.; Trafalis, T. A review of machine learning techniques in Imbalanced Data and Future trends. arXiv 2023, arXiv:2310.07917. [Google Scholar]
- Abd Elrahman, S.M.; Abraham, A. A review of class imbalance problem. J. Netw. Innov. Comput. 2013, 1, 9. [Google Scholar]
- Das, S.; Mullick, S.S.; Zelinka, I. On supervised class-imbalanced learning: An updated perspective and some key challenges. IEEE Trans. Artif. Intell. 2022, 3, 973–993. [Google Scholar] [CrossRef]
- Mullick, S.S.; Datta, S.; Dhekane, S.G.; Das, S. Appropriateness of performance indices for imbalanced data classification: An analysis. Pattern Recognit. 2020, 102, 107197. [Google Scholar] [CrossRef]
- Martin, D. Person perception and real-life electoral behaviour. Aust. J. Psychol. 1978, 30, 255–262. [Google Scholar] [CrossRef]
- Nilsson, A.; Schuitema, G.; Bergstad, C.J.; Martinsson, J.; Thorson, M. The road to acceptance: Attitude change before and after the implementation of a congestion tax. J. Environ. Psychol. 2016, 46, 1–9. [Google Scholar] [CrossRef]
- Hasanin, T.; Khoshgoftaar, T.M.; Leevy, J.L.; Bauder, R.A. Severely imbalanced big data challenges: Investigating data sampling approaches. J. Big Data 2019, 6, 107. [Google Scholar] [CrossRef]
- Digital 2023 Global Overview Report. Available online: https://datareportal.com/reports/digital-2023-global-overview-report (accessed on 1 March 2025).
- Kaur, H.; Pannu, H.S.; Malhi, A.K. A systematic review on imbalanced data challenges in machine learning: Applications and solutions. ACM Comput. Surv. (CSUR) 2019, 52, 79. [Google Scholar] [CrossRef]
- Guo, X.; Yin, Y.; Dong, C.; Yang, G.; Zhou, G. On the class imbalance problem. In Proceedings of the 2008 Fourth International Conference on Natural Computation, Jinan, China, 18–20 October 2008; IEEE: Piscataway, NJ, USA, 2008; Volume 4, pp. 192–201. [Google Scholar]
- Fernández, A.; del Río, S.; Chawla, N.V.; Herrera, F. An insight into imbalanced big data classification: Outcomes and challenges. Complex Intell. Syst. 2017, 3, 105–120. [Google Scholar] [CrossRef]
- Spelmen, V.S.; Porkodi, R. A review on handling imbalanced data. In Proceedings of the 2018 International Conference on Current Trends Towards Converging Technologies (ICCTCT), Coimbatore, India, 1–3 March 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–11. [Google Scholar]
- Chen, W.; Yang, K.; Yu, Z.; Shi, Y.; Chen, C.P. A survey on imbalanced learning: Latest research, applications and future directions. Artif. Intell. Rev. 2024, 57, 137. [Google Scholar] [CrossRef]
- Lin, W.C.; Tsai, C.F.; Hu, Y.H.; Jhang, J.S. Clustering-based undersampling in class-imbalanced data. Inf. Sci. 2017, 409, 17–26. [Google Scholar] [CrossRef]
- Sung, K.; Brown, W.E.; Moreno-Centeno, E.; Ding, Y. GUM: A guided undersampling method to preprocess imbalanced datasets for classification. In Proceedings of the 2022 IEEE 18th International Conference on Automation Science and Engineering (CASE), Mexico City, Mexico, 22–26 August 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1086–1091. [Google Scholar]
- Sun, Z.; Ying, W.; Zhang, W.; Gong, S. Undersampling method based on minority class density for imbalanced data. Expert Syst. Appl. 2024, 249, 123328. [Google Scholar] [CrossRef]
- Elreedy, D.; Atiya, A.F.; Kamalov, F. A theoretical distribution analysis of synthetic minority oversampling technique (SMOTE) for imbalanced learning. Mach. Learn. 2024, 113, 4903–4923. [Google Scholar] [CrossRef]
- Buda, M.; Maki, A.; Mazurowski, M.A. A systematic study of the class imbalance problem in convolutional neural networks. Neural Netw. 2018, 106, 249–259. [Google Scholar] [CrossRef]
- Gayathri, P.; Geetha, N.; Sridhar, M.; Kuchipudi, R.; Babu, K.S.; Maguluri, L.P.; Bala, B.K. Deep Learning Augmented with SMOTE for Timely Alzheimer’s Disease Detection in MRI Images. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 499–508. [Google Scholar] [CrossRef]
- Sarwar, M.N.; Arman, M.S.; Bhuiyan, T.; Rafiq, F.B. Optimizing Intrusion Detection with Hybrid Deep Learning Models and Data Balancing Techniques. In Proceedings of the 2025 IEEE 4th International Conference on AI in Cybersecurity (ICAIC), Houston, TX, USA, 5–7 February 2025; IEEE: Piscataway, NJ, USA, 2025; pp. 1–6. [Google Scholar]
- Ma, B.; Yang, J.; Shen, J.; Pei, Y.; Peng, X.; Jiang, K.; Liu, D.; Cao, K. Data Augment Method for Power System Transient Stability Assessment Based on DeepSMOTE. In Proceedings of the 2023 4th International Conference on Power Engineering (ICPE), Macau, China, 8–10 December 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 289–294. [Google Scholar]
- Maciejewski, T.; Stefanowski, J. Local neighbourhood extension of SMOTE for mining imbalanced data. In Proceedings of the 2011 IEEE Symposium on Computational Intelligence and Data Mining (CIDM), Paris, France, 11–15 April 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 104–111. [Google Scholar]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1322–1328. [Google Scholar]
- Baimakhanbetov, M.A.; Nurumov, K.S.; Ospanova, U.A.; Buldybayev, T.K.; Akoyeva, I.G. The effect of the adasyn method on widespread metrics of machine learning efficiency. Mod. Inf. Technol. IT-Educ. 2019, 15, 290–297. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new oversampling method in imbalanced data sets learning. In Proceedings of the International Conference on Intelligent Computing, Hefei, China, 23–26 August 2005; pp. 878–887. [Google Scholar]
- Sun, A.; Lim, E.P.; Liu, Y. On strategies for imbalanced text classification using SVM: A comparative study. Decis. Support Syst. 2009, 48, 191–201. [Google Scholar] [CrossRef]
- Mansourifar, H.; Shi, W. Deep synthetic minority oversampling technique. arXiv 2020, arXiv:2003.09788. [Google Scholar]
- Sabha, S.U.; Assad, A.; Din, N.M.U.; Bhat, M.R. Comparative Analysis of Oversampling Techniques on Small and Imbalanced Datasets Using Deep Learning. In Proceedings of the 2023 3rd International Conference on Artificial Intelligence and Signal Processing (AISP), Vijayawada, India, 18–20 March 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Sun, Y.; Kamel, M.S.; Wong, A.K.; Wang, Y. Cost-sensitive boosting for classification of imbalanced data. Pattern Recognit. 2007, 40, 3358–3378. [Google Scholar] [CrossRef]
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9268–9277. [Google Scholar]
- Lin, T. Focal Loss for Dense Object Detection. arXiv 2017, arXiv:1708.02002. [Google Scholar]
- Chen, Z.; Duan, J.; Kang, L.; Qiu, G. Class-imbalanced deep learning via a class-balanced ensemble. IEEE Trans. Neural Netw. Learn. Syst. 2021, 33, 5626–5640. [Google Scholar] [CrossRef]
- Priya, S.; Uthra, R.A. Deep learning framework for handling concept drift and class imbalanced complex decision-making on streaming data. Complex Intell. Syst. 2023, 9, 3499–3515. [Google Scholar] [CrossRef]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A review on ensembles for the class imbalance problem: Bagging-, boosting-, and hybrid-based approaches. IEEE Trans. Syst. Man, Cybern. Part C (Appl. Rev.) 2011, 42, 463–484. [Google Scholar] [CrossRef]
- García, S.; Zhang, Z.L.; Altalhi, A.; Alshomrani, S.; Herrera, F. Dynamic ensemble selection for multi-class imbalanced datasets. Inf. Sci. 2018, 445, 22–37. [Google Scholar] [CrossRef]
- Bader-El-Den, M.; Teitei, E.; Perry, T. Biased random forest for dealing with the class imbalance problem. IEEE Trans. Neural Netw. Learn. Syst. 2018, 30, 2163–2172. [Google Scholar] [CrossRef]
- Jung, V.; van der Plas, L. Understanding the effects of language-specific class imbalance in multilingual fine-tuning. arXiv 2024, arXiv:2402.13016. [Google Scholar]
- Rafi-Ur-Rashid, M.; Mahbub, M.; Adnan, M.A. Breaking the curse of class imbalance: Bangla text classification. Trans. Asian Low-Resour. Lang. Inf. Process. 2022, 21, 97. [Google Scholar] [CrossRef]
- Addi, H.A.; Ezzahir, R. Sampling techniques for Arabic sentiment classification: A comparative study. In Proceedings of the 3rd International Conference on Networking, Information Systems & Security, Marrakech, Morocco, 31 March–2 April 2020; pp. 1–6. [Google Scholar]
- Al-Khazaleh, M.J.; Alian, M.; Jaradat, M.A. Sentiment analysis of imbalanced Arabic data using sampling techniques and classification algorithms. Bull. Electr. Eng. Inform. 2024, 13, 607–618. [Google Scholar] [CrossRef]
- Aljohani, E. Enhancing Arabic Fake News Detection: Evaluating Data Balancing Techniques Across Multiple Machine Learning Models. Eng. Technol. Appl. Sci. Res. 2024, 14, 15947–15956. [Google Scholar] [CrossRef]
- AraBERT. AraBERTv0.2-Twitter Model. Available online: https://huggingface.co/aubmindlab/bert-base-arabertv02-twitter (accessed on 1 March 2025).
- Koshiry, A.M.E.; Eliwa, E.H.I.; Abd El-Hafeez, T.; Omar, A. Arabic toxic tweet classification: Leveraging the arabert model. Big Data Cogn. Comput. 2023, 7, 170. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational Bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Tolstikhin, I.; Bousquet, O.; Gelly, S.; Schoelkopf, B. Wasserstein auto-encoders. arXiv 2017, arXiv:1711.01558. [Google Scholar]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM and other neural network architectures. Neural Netw. 2005, 18, 602–610. [Google Scholar] [CrossRef]
- Khan, M.; Wang, H.; Riaz, A.; Elfatyany, A.; Karim, S. Bidirectional LSTM-RNN-based hybrid deep learning frameworks for univariate time series classification. J. Supercomput. 2021, 77, 7021–7045. [Google Scholar] [CrossRef]
- Hossin, M.; Sulaiman, M.N. A review on evaluation metrics for data classification evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1. [Google Scholar]
- Sokolova, M.; Lapalme, G. A systematic analysis of performance measures for classification tasks. Inf. Process. Manag. 2009, 45, 427–437. [Google Scholar] [CrossRef]
- Goutte, C.; Gaussier, E. A probabilistic interpretation of precision, recall and F-score, with implication for evaluation. In Proceedings of the European Conference on Information Retrieval, Lucca, Italy, 6–10 April 2025; Springer: Berlin/Heidelberg, Germany, 2005; pp. 345–359. [Google Scholar]
- Faris, H.; Habib, M.; Faris, M.; Alomari, A.; Castillo, P.A.; Alomari, M. Classification of Arabic healthcare questions based on word embeddings learned from massive consultations: A deep learning approach. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 1811–1827. [Google Scholar] [CrossRef]
- Al-Smadi, B.S. DeBERTa-BiLSTM: A multi-label classification model of Arabic medical questions using pre-trained models and deep learning. Comput. Biol. Med. 2024, 170, 107921. [Google Scholar] [CrossRef]
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}