1. Introduction
Acute appendicitis (AA) is among the most common causes of lower abdominal pain leading to emergency department visits and often to urgent abdominal surgery [
1]. As many as 95% of patients with uncomplicated acute appendicitis eventually undergo surgical treatment [
2].
The incidence of acute appendicitis (AA) has shown a steady decline worldwide since the late 1940s. In developed nations, the occurrence of AA ranges from 5.7 to 50 cases per 100,000 inhabitants annually, with the highest incidence observed in individuals between the ages of 10 and 30 years old [
3,
4]. Regional differences play a significant role in the lifetime risk of developing AA, with reported rates of 9% in the United States, 8% in Europe, and much lower than 2% in Africa [
5]. Furthermore, there is considerable variation in the clinical presentation of AA upon presentation at the doctor, the severity of the disease and the time it takes from the first onset of symptoms to the acute phase, the approach to radiological diagnosis, and the surgical management of patients, which is influenced by the economic status of the country, among other factors [
6].
The rate of appendiceal perforation, a serious complication of AA, varies widely, ranging from 16% to 40%. This complication is more frequently seen in younger patients, with perforation rates between 40% and 57%, and in those over 50 years of age, where rates range from 55% to 70% [
7]. Appendiceal perforation due to, e.g., delayed presentation is particularly concerning as it is linked to significantly higher morbidity and mortality compared to nonperforated cases of AA.
In one cohort [
8], perforation was found in 13.8% of the cases of acute appendicitis and presented mostly in the age group of 21–30 years. Patients presented with abdominal pain in 100% of cases, followed by vomiting (64.3%) and fever (38.9%). Patients with perforated appendicitis had a very high (72.2%) complication rate (mostly intestinal obstruction, intra-abdominal abscess, and incisional hernia). The mortality rate in this cohort with perforated appendicitis was 4.8%.
An intra-abdominal abscess (IAA) is another potentially severe complication occurring in 3% to 25% of patients following appendectomy [
9], the risk being the highest following complicated appendicitis. Risk factors for developing postoperative IAA remain controversial and poorly defined with no evidence for differences between open and laparoscopic surgery or between aspiration and peritoneal lavage [
9,
10].
The clinical diagnosis of AA is often challenging and involves a combination of clinical (e.g., physical examination findings such as a positive psoas, Rovsign sign, and McBurney sign that may indicate peritonitis), age, vital signs such as temperature and blood pressure, laboratory findings (e.g., CRP, leucocytes), and radiological findings (ultrasound as well as computed tomography, depending on patient constitution and clinician’s preference) [
11]. In the emergency department, when a patient is suspected of having appendicitis, a thorough workup is essential to make an accurate diagnosis and determine the appropriate treatment plan. As mentioned, time is of the essence as appendiceal perforation is associated with a high complication rate.
Appendectomy has been the standard treatment for appendicitis for a long time, even though the successful use of antibiotic therapy as an alternative was reported as early as 65 years ago [
12].
Evidence for antibiotics-first treatment has had renewed interest, with several randomized controlled trials concluding that a majority of patients with acute, uncomplicated (nonperforated) appendicitis (AUA) can be treated safely with an antibiotics-first strategy (conservatively), with rescue appendectomy if indicated [
13,
14,
15,
16,
17,
18].
With the recent worldwide coronavirus pandemic (COVID-19), health systems and professional societies, e.g., the American College of Surgeons [
16], have proposed reconsideration of many aspects of care delivery, including the role of antibiotics in the treatment of appendicitis without signs indicative of high risk for perforation, in individuals unfit for surgery (e.g., immunosuppressed patients) or those having concerns to undergo operation (choice to be made through shared decision-making between patient and clinician).
The ultimate decision between explorative laparoscopy/appendectomy and conservative treatment should be made on a case-by-case basis, and while simple and user-friendly scoring systems such as the Alvarado score have been used by clinicians as a structured algorithm to aid in predicting the risk stratum of AA [
1], such scoring systems are often unreliable, confusing, and not widely adopted by clinicians. In this light, algorithms that rely on high-throughput real-world data may be of current interest.
In recent years, the field of artificial intelligence (AI) has witnessed remarkable advancements, for instance, in the field of natural language processing (NLP), with the most prominent applications including chatbots, text classification, speech recognition, language translation, and the generation or summarization of texts.
In 2017, Vaswani et al. [
19] introduced the Transformer deep learning model architecture, replacing previously widely used recurrent neural networks (RNNs) [
20], deep learning models that are trained to process and convert a sequential data input into a specific sequential data output.
Transformers, characterized by their feedforward networks and specialized attention blocks, represent a significant advancement in neural network architecture, particularly in overcoming the limitations of recurrent neural networks (RNNs). Unlike RNNs, where each computation step depends on the previous one, Transformers can process input sequences in parallel, significantly improving computational efficiency. Additionally, the attention blocks within Transformers enable the model to learn long-term dependencies by selectively focusing on different segments of the input data [
21]. A basic Transformer network comprises an encoder and a decoder stack, each consisting of several identical feed-forward neural blocks [
19]. The encoder processes an input sequence to produce a set of context vectors, which are then used by the decoder to generate an output sequence. In the case of a Transformer, both the input and output are text sequences, where the words are tokenized (broken down into smaller units called tokens) and represented as elements in a high-dimensional vector [
21].
Large language models (LLMs) are large Transformer models trained on extensive datasets [
21].
ChatGPT-3.5 (Generative Pre-trained Transformer), an LLM, is one of the NLP architectures developed by OpenAI to output an AI chatbot that has been pre-trained on online journals, Wikipedia, and books [
22]. It is a so-called large language model (LLM) that uses deep learning techniques to achieve general-purpose language understanding and generation that has gained widespread attention for its ability to generate human-like text based on a given input. The technology has shown promise in various applications, including language translation, content generation, and summarization.
One of the primary challenges in the management of hospital medical records is the need to maintain the accuracy and consistency of information. Healthcare providers must be able to quickly access and update patient records, ensuring that the data is both accurate and up-to-date. GPTs can assist in this process by automatically generating summaries of medical records, allowing healthcare professionals to quickly review and update the information as needed. Moreover, GPTs can be utilized to improve the interoperability of medical records. As healthcare systems become more interconnected, the need for seamless data exchange between different providers and institutions becomes crucial. GPTs can help bridge the gap between disparate electronic health record systems by translating medical records into a standardized format, facilitating smoother data exchange and reducing the risk of miscommunication.
Clinical decision support systems (DSSs), continuously learning artificial intelligence platforms, can integrate all available data—clinical, imaging, biologic, genetic, and validated predictive models—and may help doctors by providing patient-specific recommendations. GPTs may be able to assist by interpreting these recommendations, explaining the rationale behind them, and answering related clinical questions, thereby enhancing the decision-making process.
There are several promising results in the current literature as of August 2024 with the use of GPTs in the high-data-throughput environment of a radiology department, for instance, in helping the radiologist with choosing the appropriate radiologic study and scanning protocol, with adequate differential diagnosis, and potentially even with automated reporting [
23,
24,
25,
26,
27]. ChatGPT nevertheless often faces criticism for its inaccuracies, limited functionality, lack of transparency in citation sources, and the need for thorough verification by the end-user. These limitations pose several potential risks, including plagiarism, hallucinations (where the model fabricates or misrepresents information), academic misconduct, and various other ethical concerns [
28,
29,
30]. Therefore, ChatGPT is in our opinion better suited as a supplementary tool in the medical field rather than a primary information resource as errors in the information generated by ChatGPT could have serious implications for an individual’s health. In our opinion, research should be focused on providing the algorithm with abundant real-world data, providing the algorithm with proper context, and seeing how it performs in comparison to individual healthcare domain experts.
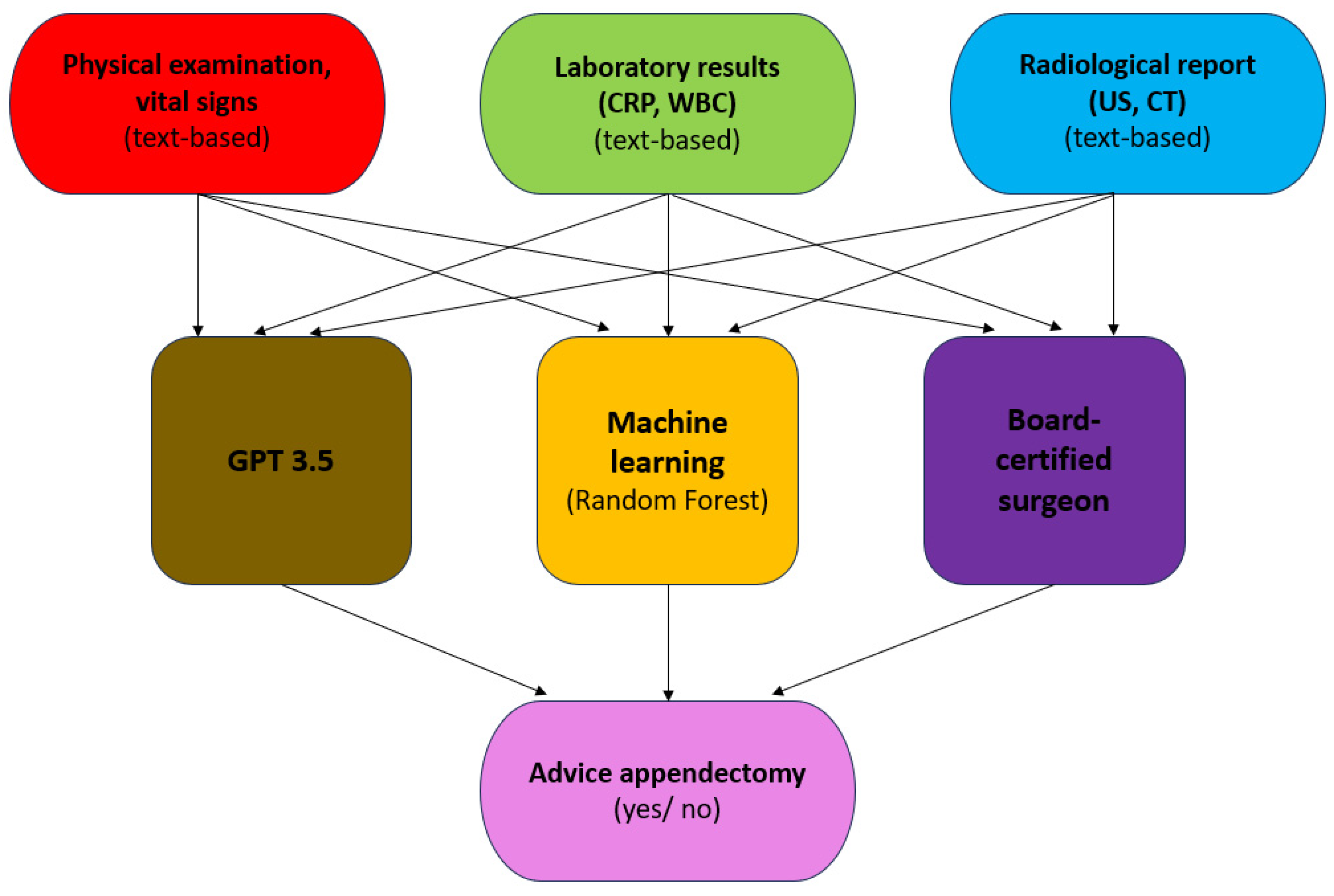
Our hypothesis in this study is that GPT-3.5 as well as a machine learning model, when provided high-throughput clinical, laboratory, and radiological text-based information, will come to clinical decisions similar to those of a board-certified surgeon on the requirement of explorative laparoscopic investigation/appendectomy or conservative treatment in patients presenting with acute abdominal pain at the emergency department.
2. Materials and Methods
This study received ethical approval (file number 23–1061-retro) from the Institutional Review Board (IRB) of GFO Kliniken Troisdorf, and informed consent was waived due to the retrospective design of this study. No patient-identifying information was provided to the artificial intelligence.
2.1. Workflow
We randomly collected n = 63 consecutive histopathologically confirmed appendicitis patients and n = 50 control patients presenting with right abdominal pain at the emergency department of two German hospitals (GFO, Troisdorf, and University Hospital Cologne) between October 2022 and October 2023.
For both groups, the following exclusion criteria were applied: (a) incomplete vital signs upon admission to the emergency department (temperature, blood pressure, and respiratory rate); (b) missing physical examination findings; (c) missing CRP and leucocyte count; (d) missing ultrasound examination findings for the surgically confirmed appendicitis cases that did not undergo an abdominal CT examination; (e) patient having contra-indications for surgery (e.g., inability to tolerate general anesthesia).
Physical examination signs taken into account were as follows [
11]: (a) McBurney sign (maximum pain in the middle of the imaginary connecting Monro line between the navel and the anterior superior dextra iliac spine); (b) Blumberg sign (contralateral release pain, e.g., pain on the right when releasing the compressed abdominal wall in the left lower abdomen); (c) right lower quadrant release pain; (d) Rovsign sign (pain in the right lower abdomen when extending the colon against the cecal pole); (e) Psoas sign (pain in the right lower abdomen when lifting the straight right leg against resistance).
Based on each patient’s clinical, laboratory, and radiological findings (full reports), GPT-3.5 was accessed via ChatGPT (
https://chat.openai.com/) (accessed on 24 October 2023) and asked to determine the optimal course of treatment, namely laparoscopic exploration/appendectomy or conservative treatment with antibiotics using zero-shot prompting, using same dialogue box for each case to potentially enhance the context awareness of the model. The choice of GPT-3.5 instead of GPT-4 was due to the temporary unavailability of GPT-4 at the time of prompting.
Additionally, a random-forest-based machine learning classifier was trained and validated to determine the optimal course of treatment based on the same information that was provided to GPT-3.5, albeit in a more structured data format.
An example of the prompt provided to GPT-3.5 is provided in
Appendix A.
It is important to mention that in all cases where GPT-3.5 did not provide a clear-cut answer, it was prompted to give its best guess estimate based on the provided information.
The results were compared with an expert decision determined by 6 board-certified surgeons with at least 2 years of experience, which was defined as the reference standard.
2.2. Statistical Analysis
Statistical analysis was performed using R, version 3.6.2, on RStudio, version 2023.03.0 + 386 (
https://cran.r-project.org/) (accessed on 12 November 2023). Overall agreement between the GPT-3.5 output and the reference standard was assessed by means of inter-observer kappa values as well as accuracy, sensitivity, specificity, and positive and negative predictive values with the “Caret” and “irr” packages.
Statistical significance was defined as p < 0.05.
2.3. Machine Learning Model Development
A random forest (RF) machine learning classifier was computed (default settings: 500 trees, mtry = √nr. of predictors, without internal cross-validation) and validated in an external validation cohort taking into account variables such as “age”, “physical examination”, “breathing rate”, “systolic/diastolic blood pressure”, “temperature”, “CRP”, “leucocyte count”, “ultrasound findings”, and “CT findings” indicative of appendicitis upon admission at the emergency department.
The “randomForest” package, which implements Breiman’s random forest algorithm (based on Breiman and Cutler’s original Fortran code) for both classification and regression tasks, was used.
The “predict” function was used to predict the label of a new set of data from the given trained model, while the “roc” function (pROC package v. 1.18.5) was used to build an ROC curve and return a “roc” object. McNemar’s Test was used to compare the predictive accuracy of the machine learning model versus the GPT-3.5 output (based on the correct/false classification according to the decision made by the board-certified surgeon.
3. Results
In total, n = 113 patients (n = 63 appendicitis patients confirmed by histopathology and n = 50 control patients presenting with lower abdominal pain) were included in the analysis across independent patient cohorts from two German hospitals (University Hospital Cologne and GFO Kliniken Troisdorf). Macroscopically mild, moderate, and severely inflamed appendix cases were included in the analysis.
In the first cohort from GFO Kliniken Troisdorf (n = 100), a total of n = 50 appendicitis patients confirmed by histopathology and n = 50 control patients presenting with lower abdominal pain were included (median age 35 y, 57% female). Upon admission to the emergency department, an ultrasound examination was performed for all patients, while for 29% of the patients, a CT examination was performed.
On average, 1.12 signs indicative of appendicitis were found upon physical examination (Psoas sign, Rovsign sign, McBurney/Lanz, release pain, etc.) in the appendicitis-confirmed group, while in the control group, only 0.24 physical examination signs were found on average.
The average temperature upon admission was 36.8 °C in the appendicitis-confirmed cases and 36.6 °C in the control group. The average CRP and leucocyte values were 5.85 mg/dL and 12.82/μL, respectively, in the appendicitis group and 1.19 mg/dL and 8.14/μL, respectively, in the control group.
In the second cohort from Cologne (n = 13), a total of n = 13 appendicitis patients confirmed by histopathology were included (median age 22 y, 38% female).
On average, 1.31 signs indicative of appendicitis were found upon physical examination (Psoas sign, Rovsign sign, McBurney/Lanz, release pain, etc.).
The average temperature upon admission was 36.5 °C, while the average CRP and leucocyte values were 3.51 mg/dL and 13.43/μL, respectively.
There was an agreement between the reference standard (expert decision—appendicitis confirmed by histopathology) and GPT-3.5 in 102 of 113 cases (accuracy 90.3%; 95% CI: 83.2, 95.0), with an inter-observer Cohen’s kappa of 0.81 (CI: 0.70, 0.91).
All cases where the surgeon decided upon conservative treatment were correctly classified by GPT-3.5. With a specificity of 100%, a positive GPT-3.5 result tends to rule in all patients that require surgery according to the surgeon, while the sensitivity of GPT-3.5 with respect to reference standard was 83%.
Table 1 presents the individual patient characteristics per hospital cohort, while
Figure 2 depicts a confusion matrix comparison constituting both cohorts between the specialist (board-certified surgeon) decision and GPT-3.5 decision on (explorative) appendectomy or conservative treatment.
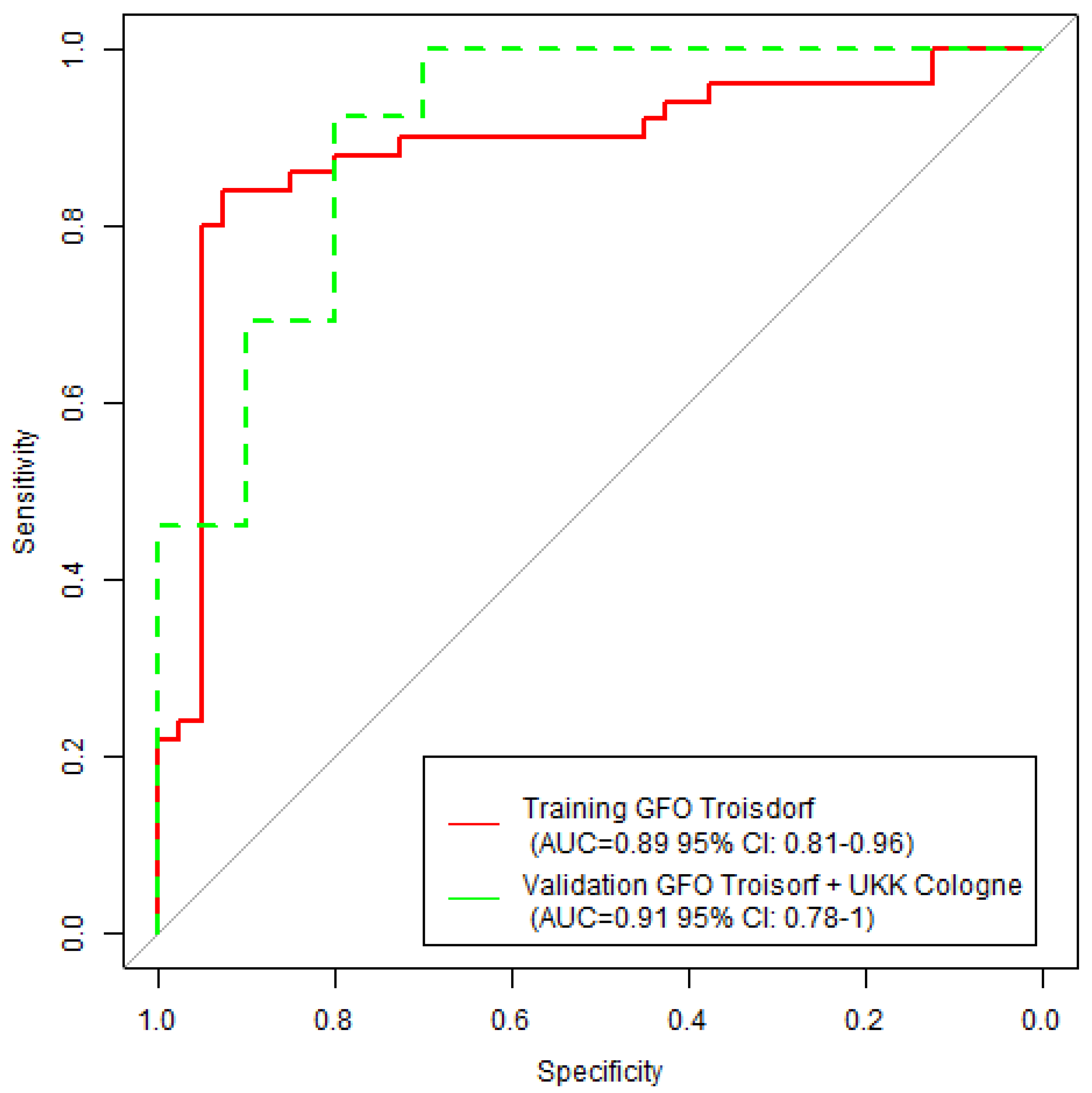
Figure 3 presents training and validation ROC curves obtained by machine learning with a random forest model. The training cohort (
n = 90) consisted of
n = 50 appendicitis-confirmed cases and
n = 40 controls from GFO Troisdorf, while the validation cohort (
n = 23) consisted of all
n = 13 appendicitis-confirmed cases from Cologne and
n = 10 remaining controls from GFO Troisdorf.
The random forest model reached an AUC of 0.89 (CI: 0.81, 0.96) in the training cohort and an AUC of 0.91 (CI: 0.78, 1.0) in the validation cohort.
The estimated machine learning model training accuracy was 83.3% (95% CI: 74.0, 90.4), while the validation accuracy for the model was 87.0% (95% CI: 66.4, 97.2). This is in comparison to the GPT-3.5 accuracy of 90.3% (95% CI: 83.2, 95.0), which did not perform significantly better in comparison to the machine learning model (McNemar p = 0.21).
4. Discussion
This multicenter study found a high degree of agreement between board-certified surgeons and GPT-3.5 in the clinical-, laboratory-, and radiological-parameter-informed decision for laparoscopic explorative surgery/appendectomy versus conservative treatment in patients presenting at the emergency department with lower abdominal pain.
Several medical studies were performed previously prompting GPT-3.5/4 to evaluate its performance in selecting correct imaging studies and protocols based on medical history and corresponding clinical questions extracted from Radiology Request Forms (RRFs) [
24], determining top differential diagnoses based on imaging patterns [
25], generating accurate differential diagnoses in undifferentiated patients based on physician notes recorded at initial ED presentation [
26], and acting as a chatbot-based symptom checker [
27].
In the emergency department, another study [
28] conducted an analysis to evaluate the effectiveness of ChatGPT in assisting healthcare providers with triage decisions for patients with metastatic prostate cancer in the emergency room. ChatGPT was found to have a high sensitivity of 95.7% in correctly identifying patients who needed to be admitted to the hospital. However, its specificity was much lower, at 18.2%, in identifying patients who could be safely discharged. Despite the low specificity, the authors concluded that ChatGPT’s high sensitivity indicates a strong ability to correctly identify patients requiring admission, accurately diagnose conditions, and offer additional treatment recommendations. As a result, the study suggests that ChatGPT could potentially improve patient classification, leading to more efficient and higher-quality care in emergency settings.
In the field of general surgery, a recent study [
29] compared ChatGPT-4 with junior and senior residents as well as attendings in identifying the correct operation to perform and recommending additional workup for postoperative complications in five clinical scenarios. Each clinical scenario was run through ChatGPT-4 and sent electronically to all general surgery residents and attendings at a single institution. The authors found that GPT-4 was significantly better than junior residents (
p = 0.009) but was not significantly different from senior residents or attendings.
Another study [
30] evaluated the performance of ChatGPT-4 on surgical questions, finding a near- or above-human-level performance. Performance was evaluated on the Surgical Council on Resident Education question bank and a second commonly used surgical knowledge assessment. This study revealed that the GPT model correctly answered 71.3% and 67.9% of multiple choice and 47.9% and 66.1% of open-ended questions for the Surgical Council on Resident Education question bank and the second surgical knowledge assessment, respectively. Common reasons for incorrect responses by the model included inaccurate information in a complex question (
n = 16, 36.4%), inaccurate information in a fact-based question (
n = 11, 25.0%), and accurate information with circumstantial discrepancy (
n = 6, 13.6%). The study highlights the need for further refinement of large language models to ensure safe and consistent application in healthcare settings. Despite its strong performance, the suitability of ChatGPT for assisting clinicians remains uncertain. A significant aspect of the ChatGPT model’s development is that its training primarily depends on general medical knowledge that is widely available on the internet. This approach is necessitated by the difficulty of integrating large datasets of patient-specific information into the model’s training process. The challenge arises from the stringent requirements to protect patient privacy and adhere to ethical standards, which limit access to detailed, real-world clinical data. As a result, ChatGPT’s responses to medical queries may lack the depth and specificity that come from direct exposure to extensive patient data. This reliance on publicly available information introduces a degree of non-scientific specificity to the model’s medical-related outputs. Consequently, while ChatGPT can provide general guidance and information, it may not always offer the precise or nuanced insights that are crucial in clinical decision-making, underscoring the importance of human oversight and verification when using the tool in a healthcare context.
In light of this current understanding, we have attempted to provide GPT with highly structured and comprehensive real-world patient data. Several findings are noteworthy in our own current study.
For instance, the relatively high AUC values in the machine learning validation cohort (higher than the training AUC) indicate that the machine learning model is generalizable and not likely to overfit.
In our cohort, GPT-3.5 outperforms machine learning in terms of accuracy, highlighting the possibility that when provided with full-text data on relevant clinical findings such as physical examination and medical imaging with specific prompts, it might be able to better understand the context and generate more relevant responses in comparison to the more traditional machine learning models.
On the other hand, machine learning, albeit being more time-consuming to train, offers a clearer insight into feature importance, making it easier to understand which variables contribute more to the predictions of the model and which features do less.
The results from the machine learning part of the analysis are in line with previous findings in the literature on the detection of individuals with acute appendicitis [
31,
32,
33,
34].
To our knowledge, this is the first study of the “intended use” for surgical treatment decisions in the literature that compares the decision-making of board-certified surgeons versus the GPT algorithm and machine learning based on comprehensive clinical, biochemical, and radiological information.
Certainly, there are a few limitations to our current study. The limitations of this study include the following: (1) The output of GPT-3.5 is not always straightforward, but is rather a piece of advice or recommendation to consult an external source of data. We have noticed that to achieve more precise responses, it is very important to prompt GPT-3.5 to provide the user with a resolute answer, in other words, to make a decision despite the uncertainties based on the data that were provided to the algorithm. (2) Another limitation is related to inherent biases, the inaccurate results of the LLM algorithm, and the inability of the current GPT-3.5 version to differentiate between reliable and unreliable sources. GPT-3.5 is only trained on content up to September 2021 from a limited number of online sources, which limits its accuracy on queries related to more recent events. GPT-4 is trained on data up through April 2023 or December 2023 (depending on the model version) and can browse the internet if it is prompted to do so. (3) There are significant legal, technological, and ethical concerns surrounding the use of ChatGPT in healthcare decision-making in general [
35,
36,
37,
38,
39]. Improper utilization of this technology could lead to violations of copyright laws, health regulations, and other legal frameworks. For instance, text generated by ChatGPT may include instances of plagiarism and can contribute to the creation of hallucinations, as previously mentioned, content produced by the model that is not grounded in reality, often fabricating narratives or data. These issues may arise due to biases in the training data, insufficient information, a limited understanding of real-world contexts, or other inherent algorithmic limitations. It is important to further recognize that ChatGPT is unable to discern the significance of information and can only replicate existing research, lacking the capability to generate novel insights like human scientists. Therefore, a thorough investigation into the ethical implications of ChatGPT is necessary, and there is a pressing need to establish global ethical standards for its use [
36], particularly as a medical chatbot, on an international scale.
While GPT-3.5′s role in the decision to perform an appendectomy should in our opinion be as a decision support tool rather than a replacement for clinical judgment, it has the potential to streamline the decision-making process, improve patient outcomes, and reduce the risk of unnecessary surgeries. We acknowledge that decision-making for appendectomy encompasses surgical judgment alongside patient preference. In cases where fast decisions must be made under time pressure and uncertainty (i.e., high risks for surgical complications, lack of patient cooperation), GPT-3.5 and later versions can in our opinion be a valuable aid in the decision-making process.
As with any medical application of AI, it is important to use GPT-3.5 and GPT-4 in conjunction with the expertise of trained healthcare professionals who can make the final decisions based on both the AI’s guidance and their clinical judgment [
40].
In our opinion, this study merely serves as a proof of concept, and clinical adoption possibilities of the proposed approach to use GPT-3.5 as well as more commonly used supervised machine learning algorithms as a clinical decision support system (CDSS) are still subject to regulatory review and approval (although the FDA and international regulatory authorities have already issued initial guideline documents for the development and approval of tools based on machine learning (ML)/artificial intelligence (AI)) [
41]. Such a clinical decision support tool, if used in a routine clinical setting in the EU, would very likely require certification as a Class II medical device under the MDR—Regulation (EU) 2017/745 of the European Parliament and of the Council of 5 April 2017 on medical devices, amending Directive 2001/83/EC, Regulation (EC) No 178/2002 and Regulation (EC) No 1223/2009 and repealing Council Directives 90/385/EEC and 93/42/EEC [
42].
The Internet of Things (IoT), referring to devices equipped with sensors, processing capabilities, software, and various technologies that communicate and share data with other devices and systems via the internet, has made a breakthrough within the surgical practice. One literature review [
43] revealed that telesurgical networks are routinely incorporated in many surgical centers and may encompass complex AI machine learning applications that aid in medical decision-making, such as ChatGPT. The IoT may play a role in suspected appendicitis in patient monitoring (monitoring patients’ vital signs during surgery and recovery, allowing for continuous assessment and quicker response to complications), data-driven decision-making (tracking patient recovery more efficiently and developing personalized treatment plans), and providing real-time intra-operative feedback for the surgeon by means of IoT-enabled instruments.
With the advent of newer versions such as GPT-4 that are pre-trained on ever larger amounts of information and that can accept images as input and pull text from web pages when you share a URL in the prompt, but also grant the user the possibility to provide the LLM with additional domain-specific and unbiased information (e.g., retrieval augmented generation (RAG) and fine-tuning), such tools hold the potential to improve clinical workflows, resource allocation, and cost-effectiveness.



 ,
, 


{kind=link}
{kind=link}
{kind=link}