1. Introduction
Diffusion models are a class of generative models that have recently gained prominence in the field of artificial intelligence, particularly in image synthesis and editing tasks. These models operate by simulating a gradual process of transforming noise into meaningful data, effectively “denoising” random Gaussian noise to produce high-quality images. The diffusion process involves a series of iterative steps, wherein each step incrementally refines the image towards a desired output. This method is inspired by non-equilibrium thermodynamics, where data points undergo a diffusion process that eventually reaches a target distribution.
The strength of diffusion models lies in their ability to generate highly realistic images that can be fine-tuned for specific tasks through various conditioning techniques. By integrating sophisticated mechanisms such as classifier-free guidance and multi-scale denoising, diffusion models have set a new standard in generating visually compelling digital content. As a result, they serve as the backbone for several state-of-the-art text-to-image generation frameworks and are central to current advancements in the AI-driven content creation landscape.
In the innovative landscape of artificial intelligence, fine-tuning diffusion models stands out as a transformative approach for generating persistent characters across varied contexts. The advent of techniques such as LoRA [
1,
2], DreamBooth [
3], Hypernetworks [
4], and Textual Inversion [
5] has ushered in a new era of customization in digital content creation. Despite the growing interest in fine-tuning methods for diffusion models, the landscape is muddled with fragmented and inconsistent information scattered across forums, blog posts, and YouTube tutorials. Most of the available resources do not provide a structured, comparative analysis, leaving practitioners with a fog of confusion when trying to understand the distinct advantages, limitations, and use cases of each approach. This article aims to bridge this gap by presenting a clear and comprehensive comparison of various fine-tuning techniques, such as DreamBooth, LoRA, Textual Inversion, and Hypernetworks. By doing so, it provides AI researchers, developers, and enthusiasts with a more robust foundation for selecting the right method based on their specific needs and constraints.
Optimization settings, particularly in contexts with limited VRAM, are crucial to achieving efficient and effective fine-tuning of diffusion models. These settings ensure that models operate within hardware constraints without compromising the quality of the generated images. Adjustments such as mixed precision training and memory-efficient algorithms are essential to optimize computational resources and manage memory usage effectively. These techniques allow for the training of robust models on less capable hardware, making advanced AI tools more accessible and practical for a wider range of applications.
This article delves into each method’s mechanics, evaluates their efficacy, and explores their applications in creating digital characters that are not only visually compelling but also contextually coherent [
6]. By comparing these approaches, this article aims to shed light on the most effective strategies for deploying diffusion models in character generation, paving the way for advancements in gaming, animation, and interactive media.
Conditioning diffusion models is are central in their ability to generate content that is not only diverse and of high quality but also specific and relevant to given inputs. This conditioning allows for diffusion models to be directed towards generating particular outcomes, rather than merely producing random variations [
7]. In the realm of character generation, this means creating images of characters that not only look realistic and maintain their identity across different scenarios but also adapt to new contexts or follow specific prompts. Effective conditioning transforms a generic diffusion model into a powerful tool for customized content creation. It enables the model to understand and interpret nuances of text prompts, environmental variables, or even emotional undertones, which can dictate the appearance, setting, and actions of characters.
Recent advances in fine-tuning techniques for diffusion models have introduced methods that enhance the precision and adaptability of text-to-image generation. Innovations like single-image editing (SINE) and reinforcement learning approaches (DDPO and DPOK) optimize image quality but are computationally intensive and less generalizable. Direct Reward Fine-Tuning (DRaFT) and its improved version, DRaFT+, offer more efficient alternatives by directly optimizing rewards for better prompt alignment and diversity. Curriculum Direct Preference Optimization (Curriculum DPO) further refines generated images by training models with progressively harder examples. Methods like Control NET and T2I Adapter provide more control over image generation but fall short of established techniques like LoRA and DreamBooth, which remain superior for high-fidelity, personalized character generation in complex scenarios.
2. Related Works
The exploration of fine-tuning techniques for diffusion models has expanded significantly, encompassing a range of innovative approaches tailored to enhance the precision and utility of generative models. This section reviews recent contributions that underline the advancements and diversity of methods employed in enhancing the adaptability and effectiveness of text-to-image diffusion models.
Recent research [
8] introduced a pioneering approach in “SINE: Single Image Editing with Text-to-Image Diffusion Models”, tackling the challenge of single-image editing. This methodology incorporates a novel model-based guidance framework built upon classifier-free guidance, specifically designed to mitigate overfitting issues and enable high-fidelity editing tasks such as style modifications and object manipulation. This method facilitates content creation from a singular image, setting a precedent for subsequent research in high-precision generative tasks.
SINE is limited compared to fine-tuning techniques like LoRA or DreamBooth, due to its specific focus on single-image editing and model-based guidance frameworks that mitigate overfitting during high-fidelity tasks. This focus restricts SINE’s ability to generalize across diverse datasets or create new content beyond the constraints of the initial image, unlike LoRA and DreamBooth, which are designed to fine-tune models across multiple images to create consistent character representations. SINE also lacks the flexibility of methods like Hypernetworks and Textual Inversion, which can adapt model behaviors or embeddings and switch between foundational models to handle diverse prompts. While SINE is computationally efficient for its intended tasks, it does not match the scalability or adaptability of techniques like LoRA, which are optimized for environments with limited computational resources and are capable of broader generative tasks, making them more versatile and effective for generating consistent characters or handling complex generative requirements across different contexts.
Another work in “Fine-tuning Diffusion Models with Limited Data” [
9] explored fine-tuning diffusion models under limited data constraints, introducing the Adapter-Augmented Attention Fine-Tuning (A3FT) method. This technique aims to address the challenge of overfitting that occurs when pre-trained diffusion models are adapted to small target datasets. By selectively fine-tuning attention blocks within the diffusion model while employing a novel time-aware adapter module, A3FT enables efficient fine-tuning with minimal overfitting. The time-aware adapter modulates the model’s intermediate feature representations based on time-step information, ensuring robust performance even when the domain gap between the pre-training and fine-tuning data is large. Compared to traditional methods, A3FT demonstrates superior performance in terms of both the fidelity and diversity of generated images. This approach contrasts with methods like DreamBooth and LoRA, which also focus on fine-tuning but typically operate with larger datasets or more extensive architectural modifications.
However, while A3FT excels in avoiding overfitting with limited data and achieves improvements in both fidelity and diversity, it does not offer the same level of flexibility and scalability as methods like LoRA or DreamBooth. LoRA, for instance, is highly optimized for environments with limited computational resources and allows for fine-tuning across a wider range of tasks with minimal retraining. LoRA and DreamBooth can adapt to different base models more effectively and can integrate more complex styles or concepts from larger datasets. Additionally, the architectural modifications required by A3FT, such as the time-aware adapter, add extra computational overhead, making it less efficient in cases where rapid, lightweight fine-tuning is needed.
Given the noticeable success of reinforcement learning from human feedback (RLHF) methods in large language model (LLM) fine-tuning, the generative text-to-image community has tested similar ideas to improve image generation fidelity. With these approaches, the diffusion process is treated as a full reinforcement learning (RL) trajectory and guided using a text-to-image scoring model. In this context, further advancing the integration of deep learning techniques in diffusion model training helps in exploring the use of reinforcement learning in “Training Diffusion Models with Reinforcement Learning” [
10] and “DPOK: Reinforcement Learning for Fine-tuning Text-to-Image Diffusion Models” [
11]. Specifically, DDPO (Denoising Diffusion Policy Optimization) [
10] utilizes policy gradients to optimize diffusion models for specific tasks like image quality and alignment, employing feedback from vision–language models for enhanced text-to-image generation. Conversely, DPOK (Distributed Policy Optimization with K-level Reasoning) [
11] integrates hierarchical strategic reasoning into policy optimization, improving interaction handling in multi-agent environments. Both approaches advance diffusion model capabilities and reinforcement learning to tackle complex, interactive scenarios more effectively.
However, these methods suffer from two drawbacks. First, reinforcement learning samples are inefficient and computationally expensive training procedures. Second, they are only successful in a narrow domain of prompts and lack generalizability across diverse prompts. To address these issues, and as an alternative to RL, current studies presented Direct Reward Fine-Tuning (DRaFT) [
12], which capitalizes on differentiable rewards of fine-tuning diffusion models. This method suggests directly backpropagating the differentiable reward through the diffusion process. Although simpler than the RL process, this method achieves significantly better alignment between text and input prompts at a larger scale with computation times orders of magnitude faster. Moreover, since the original DRaFT method is prone to reward over-optimization, mode collapse, and lack of diversity for the same prompt, the latest findings introduced DRaFT+ [
13], which adds a regularization term to enhance generation diversity, control reward over-optimization, and prevent mode collapse.
The primary differences between fine-tuning techniques like LoRA, DreamBooth, Hypernetworks, and Textual Inversion compared to DRaFT+ revolve around their optimization focus, adaptability, and intended use cases. LoRA, DreamBooth, Hypernetworks, and Textual Inversion focus on modifying model architecture, embedding space, or specific parameters to integrate new styles, subjects, or concepts, and enabling consistent character or style generation across diverse contexts. In contrast, DRaFT+ directly optimizes diffusion models using differentiable rewards to enhance text–image alignment and aesthetic quality, with a regularization term to control reward over-optimization and prevent mode collapse, making it particularly suited for tasks requiring precise alignment between text prompts and image outputs. LoRA, DreamBooth, and Hypernetworks offer high adaptability to different base models or generative contexts, making them suitable for a variety of tasks such as creating specific characters or enhancing visual styles. DRaFT+, however, is specialized in aligning outputs to specific textual prompts, which may limit its versatility across broader generative use cases. While DRaFT+ excels in achieving high fidelity and alignment for specific prompts, it may suffer from over-optimization and reduced diversity in outputs, making it less effective for general-purpose fine-tuning where variety and generalization are needed. Moreover, LoRA and similar methods are optimized for environments with limited computational resources, efficiently fine-tuning model components with minimal retraining, whereas DRaFT+ may require significant computational power to calculate differentiable rewards and perform extensive fine-tuning, which could be less efficient in resource-constrained settings. Thus, while LoRA, DreamBooth, Hypernetworks, and Textual Inversion provide versatility and adaptability for various generative tasks, DRaFT+ is more specialized for improving text–image alignment through reward-based optimization, which can limit its flexibility and general applicability.
An important work in the context of fine-tuning diffusion models is introduced in “Specialist Diffusion: Plug-and-Play Sample-Efficient Fine-Tuning of Text-to-Image Diffusion Models to Learn Any Unseen Style” [
14], a framework designed for ultra-sample-efficient fine-tuning of text-to-image diffusion models. Specialist Diffusion focuses on learning highly specialized and unseen styles using only a handful of images (fewer than 10), making it highly effective in low-shot scenarios. The framework introduces a plug-and-play set of fine-tuning techniques that includes customized data augmentations and content loss to facilitate style–content disentanglement, combined with sparse diffusion step updating to improve training efficiency. This approach outperforms existing few-shot methods, such as DreamBooth and Textual Inversion, in synthesizing highly unusual styles with minimal data, as it retains content fidelity while capturing complex stylistic elements. However, Specialist Diffusion may not match the flexibility or scalability of techniques like LoRA and DreamBooth in broader generative contexts. While its few-shot style learning excels in scenarios with limited data, it may be less suitable for applications requiring fine-tuning across a broader range of tasks or datasets. In contrast, methods like LoRA are optimized for efficient model component fine-tuning, enabling greater adaptability and scalability in environments with limited computational resources. Additionally, Specialist Diffusion’s reliance on sparse updating and data augmentation may introduce additional complexity and overhead, which could be less practical in situations requiring rapid, large-scale fine-tuning.
In the ever-evolving field of artificial intelligence, the development of techniques like Control NET [
15] and Text-to-Image Adapter (T2I Adapter) [
16] has expanded the possibilities for constraining generative models beyond simple text prompts. These methods enhance the control over the generation process, offering a more specific direction to the synthesis of images. These approaches represent a valuable addition to strategies aimed at refining the functionality and application scope of generative models. For instance, some T2I Adapters have demonstrated the capability to even reproduce faces from a single image. However, despite these advancements, these methods have heavy limitations, such as pose reproducibility and image-related pose dependence, and do not achieve the same level of flexibility and image quality as more established fine-tuning techniques. Fine-tuning approaches like LoRA or DreamBooth still lead in their ability to adapt diffusion models for highly personalized character image generation. This superiority is particularly evident in their application to complex scenarios where a nuanced understanding of the character’s face is required, maintaining high fidelity to the original subject traits while seamlessly integrating them into diverse contextual settings.
Together, these studies not only contribute to the theoretical and practical enhancements in diffusion model technology but also pave the way for future innovations in the field of generative models.
3. Methodologies
This section delves into the specific methodologies employed for fine-tuning diffusion models to generate persistent characters. DreamBooth, LoRA, Hypernetworks, and Textual Inversion techniques are explored, each tailored to enhance the pre-trained models’ ability to produce consistent and contextually adapted character images. These fine-tuning approaches were selected due to the large diffusion in an AI context and the good tradeoff between output quality and training time. Furthermore, the possibility of running the processes locally was crucial for this research.
The methodologies discussed not only vary in approach but also in the intricacies of implementation, reflecting their unique advantages and suitability for different AI-driven applications. This comparative analysis provides a clear understanding of how each method operates and is optimized, setting the stage for a detailed examination of their individual and combined effectiveness in creating compelling digital characters. To find the optimal hyperparameters, a systematic “trial and error” process based on the final generated image was used. During the fine-tuning, most of the parameters were kept fixed, changing one at a time to find the best and most consistent result. The best parameters were determined by evaluating the aesthetic quality of the generated images rather than relying only on training loss, as the loss often did not decrease significantly from the initial value. Despite the lack of noticeable reduction in loss, the model still demonstrated learning, highlighting the importance of visually assessing the outputs to ensure high-quality and appealing results.
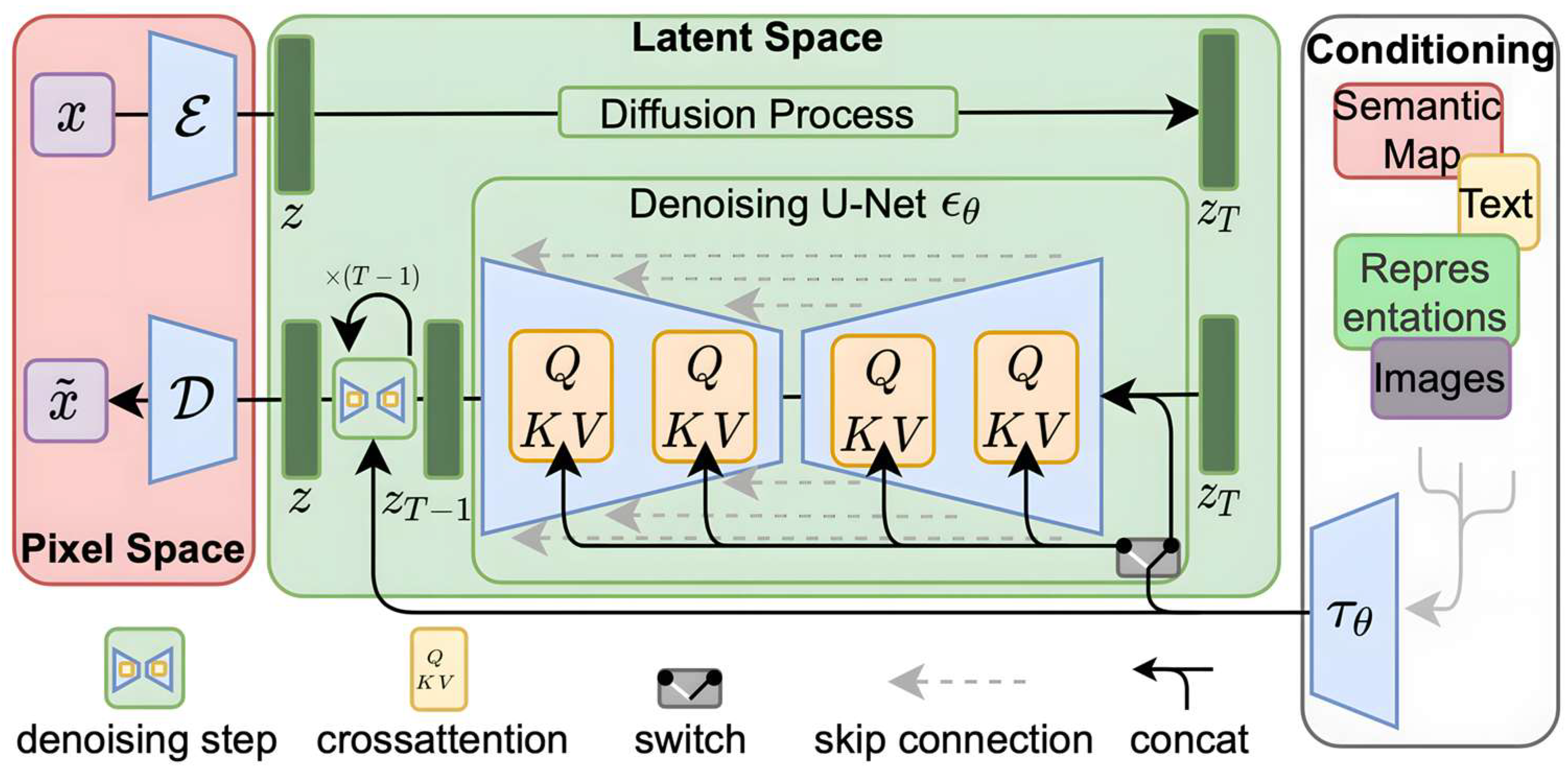
All the training described below is carried out utilizing the Stable Diffusion 1.5 pipeline with an image size of 512 × 512. Stable Diffusion 1.5 is a latent text-to-image diffusion model based on the architecture shown in
Figure 1.
Thanks to a computer donation from Stability AI and support from LAION, the model was trained on 512 × 512 images from a subset of the LAION-5B database. This model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight [
18].
In particular, “RealisticVisionV51_v20Novae” was used for this use case to achieve photorealistic results. This model was fine-tuned starting with the Stable Diffusion 1.5 model with 3400 training images in 724 k training steps [
19].
The setup used for all types of training includes the following hardware, which reflects a typical configuration with limited VRAM at disposal: Intel i9-11900k, 64 GB RAM DDR4, and Nvidia 3070TI with 8 GB of VRAM.
3.1. DreamBooth and LoRA
The DreamBooth methodology leverages fine-tuning on pre-existing text-to-image diffusion models to train subject-specific models, enabling the generation of photorealistic images that closely depict a specified subject across various poses and settings while retaining its unique visual traits. This process is facilitated using the DreamBooth extension [
20] alongside Automatic 1111 (A1111) [
21], a user-friendly interface for Stable Diffusion that simplifies the process by eliminating the need for direct coding. In contrast, the LoRA methodology, initially created for LLMs, applies low-rank modifications specifically to the query (q), key (k), and value (v) matrices of the cross-attention layers within the model. This targeted approach allows for efficient adaptation of large models to new tasks with minimal retraining. In this context, LoRA’s training is conducted using the Kohya_SS [
22], which provides an accessible interface for users to interact with and fine-tune the model’s parameters effectively. In both Kohya_SS and Automatic1111 GUIs, the algorithm specifications are hidden from the user; these user interfaces encapsulate the formulations found in the original papers of DreamBooth [
3], LoRA [
1], Hypernetworks [
4], and Textual Inversion [
5]. Unlike DreamBooth, which focuses on subject-specific image generation by learning directly from images of the subject, LoRA strategically modifies essential components of the model’s architecture to maintain its broad generative capabilities while integrating new data.
Dataset preparation:
Images: The training utilized 25 high-resolution images (2000 × 2000 pixels, 1:1 aspect ratio) of the subject (the author Luca Martini). Optimal results were achieved with images where the background was blurred to minimize the learning of extraneous elements. Additionally, it was imperative to capture the subject in various head positions, facial expressions, and mid-waist angles to enhance the model’s understanding of the subject. During LoRA training, images were augmented using random cropping and rotation (available in Kohya SS) by a factor of 20, resulting in 500 training images. Instead, in DreamBooth, horizontal flipping was applied randomly during training by A1111, which does not specify the exact number of augmentations. However, tests indicate that a random horizontal flip occurs approximately every three images during training.
Captioning: Initial captions were generated using the WD14 tagger algorithm [
23] and were meticulously refined manually via BooruDatasetManager [
24] to ensure they accurately described the content and context of each image. A crucial aspect of the captioning process was the selection of a unique instance token (in this scenario, “lucmr97” was used to represent the subject, avoiding common descriptors that could lead the model to lose the generalization capability, leading to all generated class images looking like the subject trained).
Regularization: To stabilize training and prevent overfitting, regularization images were created using a factor of 10. The best results were obtained by generating these images through inferences made by the base model, using prompts like “photo of a man”. Utilizing randomly sourced class images proved to produce less effective results as they seem to deviate too much from the pre-trained features, resulting in a harder training process where it becomes difficult to learn the facial features in the training dataset.
Training configuration for both DreamBooth and LoRA in low VRAM contexts (6–12 GB):
Base Model: Since the purpose of this fine-tuning is to recreate a realistic digital character without any specific style, “RealisticVisionV51_v20Novae” was used.
Batch Size: The batch size was limited to 1 in the case of DreamBooth. Since the LoRA process is less intensive, it is possible to use up to 4 as a batch size in the scenario of 12 GB of VRAM. Increasing the batch size further in a VRAM-constrained environment would necessitate substantial RAM allocation, thereby prolonging the training duration.
Gradient Checkpointing: This is the process of selectively saving certain layer outputs during the forward pass and discarding others. These discarded outputs are then recomputed as needed during the backward pass to calculate gradients. This method reduces memory demand by not holding all intermediate data at once, allowing for larger model training within memory constraints [
25].
Cache Latents: This approach was adopted to utilize more VRAM but enhance training speed by caching latents [
25].
Memory Optimization: The Xformers library [
26] was utilized to reduce VRAM usage and accelerate image generation, applicable solely to Nvidia GPUs.
Optimizer: An AdamW optimizer with 8-bit precision was implemented to balance computational efficiency and performance robustly. The Exponential Moving Average (EMA) technique was excluded as it provided no discernible benefits, thus extending the training period unnecessarily.
Prior Loss: Emphasis was placed on using prior preservation loss to maintain output diversity during the fine-tuning of a narrow image set. The optimal range for prior loss was determined to be between 0.5 and 0.75.
Specific training configuration for DreamBooth in low VRAM contexts (6–12 GB):
Epoch: The model underwent training across 60 epochs with a batch size of 1.
Learning Rate: A conservative learning rate of 1 × 10−6 was implemented to prevent the catastrophic forgetting of previously learned features, critical in fine-tuning scenarios.
Mixed Precision: Training incorporated mixed precision as floating-point 16 bit (fp16), with trials in brain floating-point 16 bit (bf16) yielding suboptimal outcomes.
Specific training configuration for LoRA in low VRAM Contexts (6–12 GB):
Epoch: The model underwent training across 10 epochs with a batch size limited to 2.
Learning Rate: A learning rate of 1 × 10−4 was implemented.
Mixed Precision: Training incorporated mixed precision as bf16 because, in this scenario, it does not result in worse results than when using fp16. Thus, bf16 could lead to faster training time.
Network Rank and Network Alpha: Network Rank specifies the number of neurons in the hidden layer added by LoRA. The larger the number of neurons, the more learning information can be stored, but the possibility of learning unnecessary information other than the learning target increases, and the LoRA file size also increases. Network Alpha was introduced instead as a convenience measure to prevent weights from being rounded to 0 when saving LoRA. Due to the structure of LoRA, the weight value of the neural network tends to be small, and if it becomes too small, it may become indistinguishable from zero. Therefore, a technique was proposed in which the actual (stored) weight value is kept large, but the weight is always weakened at a constant rate during learning to make the weight value appear smaller. Network Alpha determines this “weight weakening rate”. How much the weight weakens when used is calculated by “Network_Alpha ÷ Network_Rank” [
25].
The sweet spot between quality, LoRA size, and training time was found to be 64. For the Network Alpha value, 16 was used but good image results were found also with using 1 or a value equal to half of the Network Rank.
In a comparative analysis of DreamBooth and LoRA methodologies, LoRA training consistently demonstrates superior results, primarily due to its efficient parameter-tweaking capabilities enabled by faster training times. Additionally, as shown in
Figure 2 and
Figure 3, LoRA tends to produce more photorealistic results in most situations. The details of the hair, eyes, and beard generated by LoRA are substantially better than those produced by DreamBooth, showcasing finer textures and more accurate representations of these features. This advantage becomes particularly significant in low VRAM contexts, where DreamBooth’s more resource-intensive requirements lead to prolonged training durations. Furthermore, the training duration for DreamBooth is extended due to the requirement for more epochs, in contrast to LoRA, which necessitates fewer epochs for effective adaptation. In this context, DreamBooth took around 4 h to train while LoRA took 30 min on average.
The rapid adaptability of LoRA is facilitated by its focus on fine-tuning specific low-rank matrices within the cross-attention layers, allowing for quick adjustments that directly influence model performance without the need for extensive computational resources. Moreover, DreamBooth, while effective in achieving high-fidelity and personalized image generation, tends to require more time to achieve optimal results, especially when VRAM is limited and powerful AI GPUs are not available. This is due to its approach of training with high-resolution images and complex model adjustments, which inherently demand more memory and processing power. In contrast, LoRA’s streamlined adjustments are less demanding on system resources, making it a more practical choice in environments with hardware constraints.
From a technical perspective, the ability to specifically target and modify the q, k, and v matrices in LoRA not only conserves computational resources but also preserves the integrity and breadth of the pre-trained model’s capabilities. This targeted approach avoids the broader, often resource-intensive recalibrations required by DreamBooth, making LoRA a more efficient and scalable solution for image generation tasks across various computational settings.
It is important to point out that the DreamBooth method outputs a totally new fine-tuned model while LoRA outputs a smaller file of about 200/300 MB that must be attached to the pre-trained model during inference. Finally, it is also crucial to note that the final generated images depend not only on the fine-tuning technique used but they are the result of a combination of different sampler, scheduler, seed, CFG (classifier-free guidance), and dataset augmentations. These elements play significant roles, independent of the training parameters, in shaping the quality and attributes of the generated images.
3.2. Hypernetworks
Hypernetworks represent a sophisticated fine-tuning approach within the realm of AI-driven image generation. Comprising a straightforward yet effective fully connected network with dropout and activation functions, Hypernetworks intervene in the model’s architecture by specifically targeting the cross-attention mechanism. They achieve this by inserting networks that transform the key and query vectors, effectively modifying the original cross-attention module [
4,
27]. This approach is distinct yet conceptually similar to LoRA models, which also focus on enhancing the cross-attention layer but employ different modifications to achieve this. While LoRA typically injects and trains new low-rank matrices in the layer to refine its function, Hypernetworks introduce additional network layers that dynamically adapt the model’s parameters in response to the training dataset. A1111’s “train” tab was used for Hypernetworks training.
The dataset preparation process was the same as before with some differences:
The BLIP [
28] model was used for captioning instead of the WD14 tagger. They both work quite well but they require some additional manual retouching for precise meta-tagging.
No image augmentation process was utilized.
Regularization images were not used.
Training configuration for Hypernetworks in low-VRAM contexts (6–12 GB):
Base Model: Unlike the previous methodologies, Hypernetworks’ files can be used with other pre-trained models because they are not tied to a specific model. Thus, for the training model, it is better to use the Stable Diffusion 1.5 base one called “v1-5-pruned-emaonly”. In doing so, better generalization capabilities are guaranteed across different models.
Batch Size: Even here, the batch size was limited to 4 for the maximum due to VRAM constraint.
Epoch: A1111 does not allow users to directly choose the epoch number, but only the maximum steps can be chosen. A total of 3000 steps was used, resulting in 240 epochs (batch size 2) from the formula steps ÷ (images ÷ batch size).
Learning Rate: 2 × 10−5.
Network Structure: The optimal combination was 1,2,1 or 1,2,2,1 with no dropout during tests.
Activation Function: Both Linear (no activation function) and Swish worked well.
Several experiments with Hypernetworks demonstrated that the training phase tends to be slightly faster compared to LoRA: it is 10 min faster on average resulting in a training time of around 15–20 min. However, the overall quality of the results obtained with Hypernetworks was observed to be somewhat inferior, as shown in
Figure 4.
3.3. Textual Inversion
Textual Inversion [
6] stands out among fine-tuning techniques for its efficiency in adapting pre-trained models. Unlike full model retraining techniques like DreamBooth, which is data- and resource-intensive, Textual Inversion modifies a model’s embedding space by introducing specific tokens to represent new concepts. This allows for seamless integration of these concepts into model outputs with minimal computational overhead. In contrast, techniques like LoRA and Hypernetworks add external components to adjust the model’s behavior without altering core parameters, maintaining the model’s integrity but often requiring more complex adjustments. Textual Inversion offers a streamlined and effective approach for personalized model adaptations, balancing adaptability and computational efficiency.
The process of dataset preparation was the same as Hypernetworks.
Training Configuration for Embeddings in Low VRAM Contexts (6–12 GB):
Base Model: Like Hypernetworks, Textual Inversion files can be used with other pre-trained models because they are not tied to a specific model. Thus, the base one called “v1-5-pruned-emaonly” was used for better generalization.
Batch Size: Since Textual Inversion is less intensive, here, the batch size ranges from 2 to 5 due to VRAM constraint.
Epoch: A1111 does not allow users to directly choose the epoch number, but only the maximum steps can be chosen. A total of 2000 steps was used, resulting in 240 epochs (batch size 3) from the formula steps ÷ (images ÷ batch size).
Learning Rate: 5 × 10−3
Textual Inversion is noted for its quick adaptability in customizing pre-trained models using new concepts. This efficiency, however, comes with variations in the stability and quality of the results, particularly when applied to generating persistent character representations. For instance, when using a small dataset of around 25 images, the outcomes were generally poor, exhibiting inconsistent character features, as shown in
Figure 5.
Despite these challenges, Textual Inversion has demonstrated success in specific applications, such as style training, even with small datasets. Interestingly, some successful cases found online show promising results with as few as 15 images. This suggests that the effectiveness of Textual Inversion heavily depends on the choice and number of images, which varies significantly depending on the subject. For one character, 15 images might suffice, while for another, more than 150 images could be necessary to achieve satisfactory results. However, this increase in dataset size extends the training duration, reducing the attractiveness of Textual Inversion’s rapid training capability. Considering these factors, for high-quality characters with a small number of images, LoRA proves to be a superior alternative. LoRA can deliver higher-quality outputs with just 25 images, offering a more consistent and efficient solution for generating detailed character features.
4. Results
In the comparative analysis of fine-tuning techniques for diffusion models, each method has demonstrated unique strengths and suitability for specific contexts.
DreamBooth excels at generating high-quality, consistent character images, positioning it as the best choice for quality when robust hardware is available. However, its reliance on substantial computational resources limits its suitability in low-VRAM environments.
LoRA emerges as the most efficient alternative, achieving excellent results quickly. LoRA’s ability to work effectively with just a small number of images underlines its practicality for scenarios with limited computational resources.
Textual Inversion is more effective for style training rather than character faces and works well with small datasets. Nonetheless, its performance heavily depends on the specific subjects used and the necessary image quantity varies dramatically by subject ranging from 15 to over 150 images to achieve satisfactory results. This inconsistency can diminish its appeal when quick turnaround times are prioritized. Combining the style of Textual Inversion with LoRA characters may lead to the best results, indicating that a multi-technique approach could be highly advantageous in certain scenarios.
Hypernetworks, while offering a slight advantage in training speed over LoRA, generally do not match LoRA in terms of image quality. However, their flexibility remains appealing as they can be applied across multiple models, similar to Textual Inversion embeddings. This adaptability makes Hypernetworks a viable option for those who value the ability to switch between different foundational models for specific use cases.
Overall, LoRA is recommended for most applications requiring high-quality and efficient image generation, particularly when working with limited numbers of training images and under hardware constraints. The selection of a fine-tuning technique should consider both the specific project requirements and the hardware capacity available.
Furthermore, as demonstrated in the preceding sections, each methodology exhibits substantial differences in training and performance outcomes. For instance, training for 240 epochs using embeddings can be completed much more rapidly than just 10 epochs of LoRA. This stark contrast underscores the unique configurations and dependencies of each method, influenced by various factors such as the dataset characteristics, the application of regularization images, and the batch size employed.
As shown in
Table 1, LoRA demonstrated the most efficient VRAM usage, averaging approximately 6.5 GB with a batch size of 2. This makes LoRA particularly suitable for environments with limited VRAM, as it allows for effective training while maintaining a relatively low memory footprint.
Hypernetworks used a slightly larger batch size of 3, resulting in an average VRAM consumption of around 6.2 GB. Despite the higher batch size, Hypernetworks still managed to remain efficient, making it a good choice for scenarios where moderate VRAM is available. In contrast, DreamBooth exhibited the highest VRAM consumption, averaging 7.5 GB with a smaller batch size of 1. This higher memory requirement, even with a reduced batch size, suggests that DreamBooth is more suitable for environments where ample VRAM is available, as its resource demands can be prohibitive on less powerful systems.
Textual Inversion showed moderate VRAM usage, averaging around 7 GB with a batch size of 2. This places it between the highly efficient methods like LoRA and the more resource-intensive DreamBooth. Textual Inversion’s VRAM efficiency, coupled with its ability to adapt quickly, makes it a viable option depending on the task’s specific requirements and the available hardware.
These results indicate that while DreamBooth is effective in generating high-quality, personalized images, its higher VRAM demands, even with a smaller batch size, limit its practicality on systems with constrained resources. On the other hand, LoRA and Hypernetworks, with their efficient use of VRAM at larger batch sizes, offer a balanced performance that is ideal for scenarios with varying hardware capabilities. Textual Inversion provides a middle ground, offering moderate VRAM usage and flexibility, but lower quality generated images.
These results were achieved by carefully tweaking
hyperparameters such as the learning rate and the choice of optimizer for each
fine-tuning technique. For instance, LoRA benefited significantly from a
learning rate of 1 × 10−4 and the use of
optimizers like Adam8bit, which provided a good balance between computational
efficiency and training performance. This combination facilitated faster
convergence within 3000 steps.
In contrast, DreamBooth required more intricate
adjustments to achieve optimal results. A conservative learning rate of 1 × 10−6 was chosen to prevent the
catastrophic forgetting of previously learned features, a common challenge in
fine-tuning large models. The optimizer used was again 8-bit AdamW, yet the
overall training process was more resource-intensive, reflected in higher VRAM
usage and slower convergence.
For Hypernetworks, a more dynamic learning rate of
2 × 10−5 and careful selection of
activation functions and layer structures (such as 1,2,1 or 1,2,2,1) proved
crucial in managing the training stability and efficiency. This approach
allowed for moderate VRAM usage of around 6.5 GB with a batch size of 2 while achieving
satisfactory results in a shorter training time compared to DreamBooth.
However, for Textual Inversion, the most critical factors influencing the final results were the choice of images used in training and the base model selected, rather than hyperparameter settings. Unlike the other techniques, changing hyperparameters such as the learning rate or optimizer showed minimal impact on the quality of the generated images. The effectiveness of Textual Inversion heavily depends on selecting the right set of images that accurately represent the desired concepts and using a suitable base model that aligns well with the new concepts being introduced. The choice of the base model can significantly affect the adaptability and quality of the results; for instance, a model that better aligns with the style or features of the training images can yield more consistent and compelling outputs.
By fine-tuning hyperparameters in each technique, except for Textual Inversion, the model was optimized to perform effectively within specific hardware constraints and task requirements. For Textual Inversion, the emphasis shifts more towards curating a suitable image dataset and selecting an appropriate base model to achieve optimal results, underscoring the unique dependencies of this method.
5. Conclusions
In conclusion, as diffusion models continue to expand in size and complexity, fine-tuning techniques such as LoRA, DreamBooth, Hypernetworks, and Textual Inversion remain essential tools for generating customized and contextually coherent outputs. However, these techniques face significant limitations when applied to larger models like Stable Diffusion XL due to heightened VRAM requirements, making them less practical for users with limited computational resources. Among these techniques, LoRA has emerged as the most effective, offering a superior balance between efficiency and quality. Its ability to deliver high-quality results with minimal computational overhead makes it the preferred choice in low-VRAM environments, outperforming more resource-intensive methods like DreamBooth. Looking ahead, the growing hardware demands of models like Stable Diffusion 3 [
29] emphasize the need for balanced development strategies that prioritize both model performance and accessibility. As fine-tuning methods evolve, achieving a balance between resource efficiency and high-quality output will be crucial in democratizing these powerful AI tools, ensuring their utility across diverse hardware environments.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}