_Zheng.png)
Generative Adversarial Networks for Synthetic Data Generation in Finance: Evaluating Statistical Similarities and Quality Assessment



Abstract
1. Introduction
- Expansion of Dataset Size—Our methodology successfully expands the size of the original financial dataset, addressing the issue of limited data availability for training and producing diverse sizes of correlated samples.
- Enhanced Model Performance—Using synthetic data improves the performance of different models by providing more examples and diverse data, helping the models understand different scenarios and handle outliers and rare events more effectively.
- Cost-Effective Solution—Generating synthetic data proves to be a cost-effective alternative to the difficult and expensive processes involved in gathering, cleaning, and processing new datasets.
- Balanced Feature Distributions—Our method has the potential to address imbalances in non-continuous columns in the input dataset. By generating synthetic data, it effectively balances out these uneven feature distributions, enhancing its usefulness for machine-learning tasks.
2. Related Work
2.1. Synthetic Data Generation without GANs
2.2. Synthetic Data Generation with VAEs
2.3. Synthetic Data Generation with GANs
3. Description of the Task
- Limited Data Availability—The small size of the dataset in terms of rows poses constraints on our models, limiting their ability to learn effectively.
- Missing Data—Certain portions of the dataset lack information, creating challenges in understanding complete stock market trends. This might be due to privacy concerns or other data availability issues.
- Impact on Model Performance—Anomalies within the dataset significantly disrupt the accuracy and reliability of our models. Furthermore, the presence of missing or duplicated rows creates inconsistencies that negatively impact model performance.
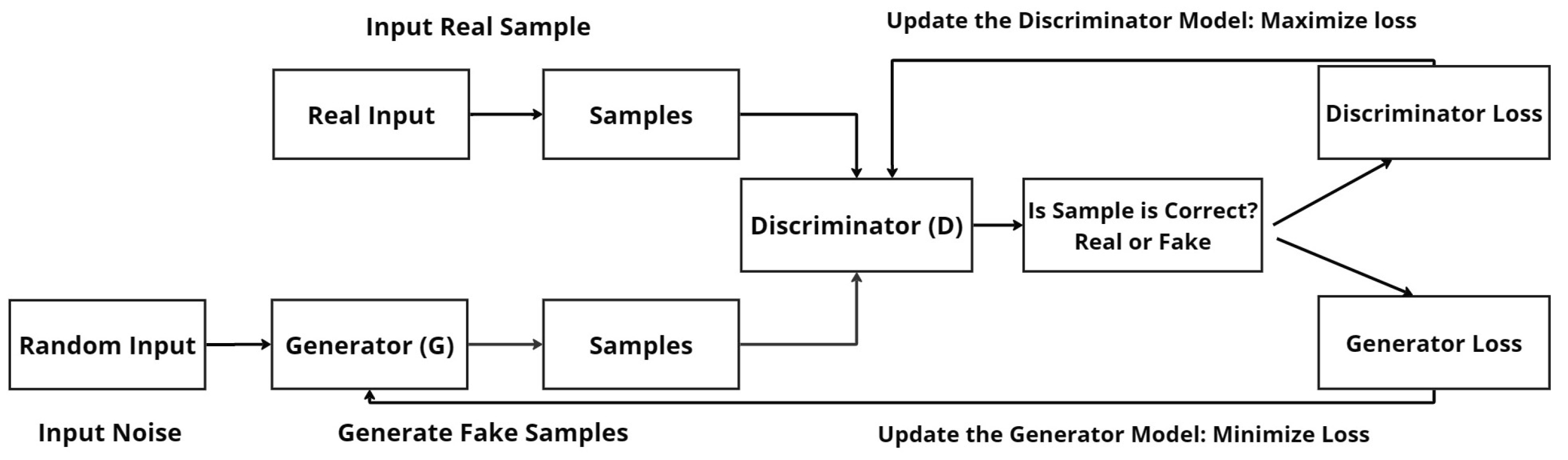
4. The Proposed Generative Adversarial Network
- D(x) represents the output of the discriminator (D) when given a real instance (x) as input. It estimates the probability that the instance is real.
- is the expected value operator applied to all real instances. It represents the average value of the discriminator’s output given a real instance x as input.
- G(z) represents the output of the generator (G) when given a random input (noise or latent point) denoted as z. The generator uses this input to generate synthetic or fake samples.
- D(G(z)) represents the output of the discriminator when given the generated sample (G(z)) as input. It represents the discriminator’s classification or estimation of whether the generated sample is real or fake.
- is the expected value operator applied to all random inputs to the generator. It represents the average value of the discriminator’s output when given generated sample z as input.
- Capturing Data Distribution: GANs learn the underlying data distribution directly from the input dataset without relying on explicit assumptions or predefined models. This enables the generation of synthetic data that closely resembles the real data distribution, capturing both global and local data patterns.
- Flexibility and Adaptability: GANs are highly flexible and adaptable, making them suitable for various data types and domains. They can support various data modalities, such as images, text, and numerical data, making them highly versatile for generating synthetic data across diverse domains.
- Non-linear Data Transformation: GANs can capture complex, non-linear relationships within the data, allowing for the generation of synthetic samples that exhibit intricate patterns and structures present in the real data. This is particularly beneficial for domains with intricate data dependencies, such as finance.
- Enhanced Privacy and Security: by generating synthetic data, GANs offer a means to share data for research or collaboration while preserving privacy and confidentiality. Synthetic data can be used in place of sensitive real data, reducing the risk of privacy breaches or data leaks.
- Continuous Improvement: GANs can be trained iteratively to enhance their performance and generate more realistic synthetic data over time. By fine-tuning the model architecture and training parameters, GANs can progressively improve their ability to generate data samples that align with the underlying data distribution.
Model Setting and Parameters
- Epochs: Determining the number of iterations the entire dataset passes through the network during training is critical. While a higher number of epochs can allow the model to learn more complex patterns, excessive epochs may lead to overfitting. In our FinGAN model, we carefully adjusted the epoch value, set to 500 in the baseline model, which proved insufficient for capturing complex network patterns. Excessively high epoch values risk memorizing training data instead of achieving effective generalization. Therefore, an optimal experimental setting was required, providing the value of 1000 epochs to be an optimal trade-off.
- Batch Size: The number of samples processed before updating the model’s parameters, known as batch size, plays a crucial role. Larger batch sizes, such as the baseline GAN model’s 500, might speed up training but come with increased memory demands. In FinGAN, we experimentally reduced the batch size to 128, aiming to enhance stability and potentially expedite convergence.
- Learning Rate: The learning rate, controlling the step size of parameter updates during training, is another important parameter. A higher learning rate can lead to faster convergence but may cause instability. In FinGAN, we experimentally opted for a lower learning rate of 0.0001, enhancing stability during convergence, in contrast to the baseline model’s use of 0.02. It is important to note that striking the right balance is key, as an excessively small learning rate may impede convergence speed.
- Early Stopping: Introducing early stopping as a mechanism for halting training when certain criteria are met is also important. This prevents overfitting by stopping training before the model starts fitting noise in the data, and it also helps conserve computational resources. FinGAN incorporates early stopping, whereas the baseline GAN model lacks this feature.
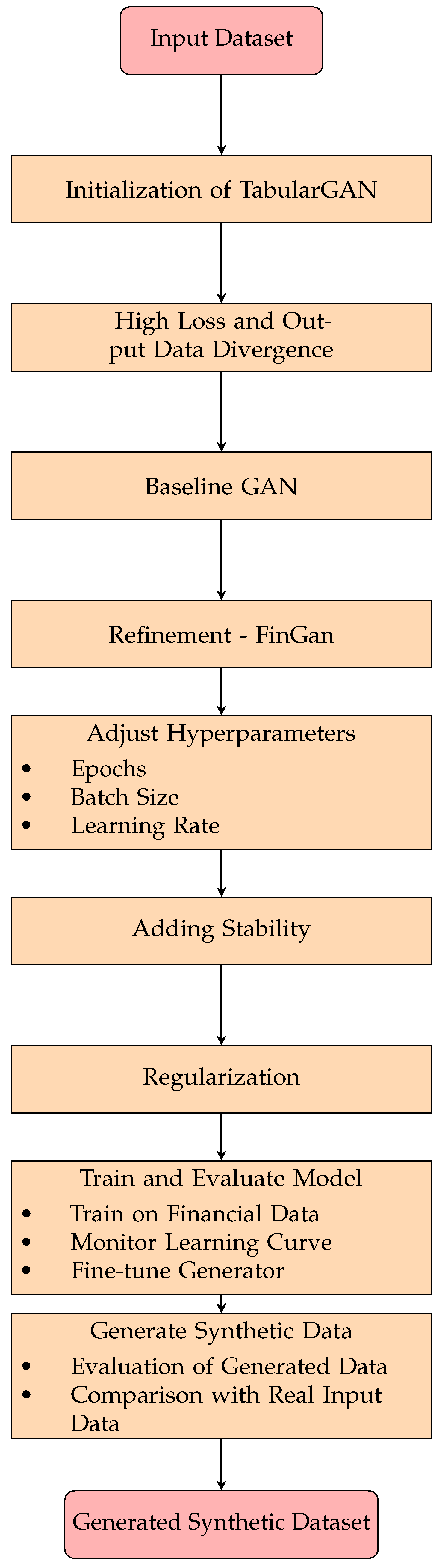
- Input Dataset: This represents the financial continuous dataset, which serves as the input data for the subsequent steps.
- Initialization of TabularGAN: Initially, we established the TabularGAN model as the starting point for our workflow.
- High Loss and Output Data Divergence: Throughout this process, we experienced high loss and divergence in the output data, particularly concerning the application of the TabularGAN model to our dataset.
- Baseline GAN: Then, we switched from the TabularGAN model to the baseline GAN model as an alternative approach.
- Refinement–FinGan: We refine the baseline GAN model to better suit financial data by modifying both the Generator (G) and Discriminator (D) architecture. This adaptation results in the creation of the FinGAN model.
- Adjust Hyperparameters: Fine-tuning of hyperparameters such as “Epochs”, “Batch Size”, and “Learning Rate” is performed to optimize the performance of the FinGAN model.
- Adding Stability: Additional features such as “Early Stopping” and “Batch Normalization” are incorporated into the FinGAN model to improve its stability and performance.
- Regularization: Techniques for controlling the latent space are applied, specifically using regularization to confine the range of generated data points.
- Train and Evaluate Model: The FinGAN model is trained on financial data, and its performance is evaluated. This involves monitoring the learning curve and fine-tuning the generator.
- Generated Synthetic Dataset: In the last phase of our workflow, we utilized the trained FinGAN model to generate the synthetic dataset that replicates the traits of the original financial data. This process entails employing the trained generator network to produce artificial data points that closely mirror the patterns and distributions found in the input real financial dataset.
5. Performance Evaluation
5.1. Experimental Setup
- The KL Divergence measures the difference between two probability distributions, ranging from 0 (perfect similarity) to positive infinity (complete dissimilarity). Values close to zero imply similar distributions, while higher values indicate greater dissimilarity, serving to differentiate between two continuous distributions [49].
- The Wasserstein Distance is a widely applied metric for continuous data, measuring the distance between two probability distributions in continuous spaces. It gauges the transformation needed to align one distribution with another, where smaller values signify higher similarity and larger values denote substantial dissimilarity [50].
- The Energy Distance, like the KL Divergence and the Wasserstein Distance, is another measure used to compare two probability distributions. It quantifies the difference between distributions in a continuous space, assessing how much they differ. Smaller values indicate greater similarity, while larger values suggest more significant dissimilarity between the two distributions [51].
- The Maximum Mean Discrepancy (MMD) is a statistical measure used to assess the dissimilarity between two datasets or probability distributions. It quantifies the difference between distributions by estimating the maximum difference in means between data samples drawn from each distribution. Smaller values of MMD indicate greater similarity, while larger values signify more substantial dissimilarities between the distributions [52].
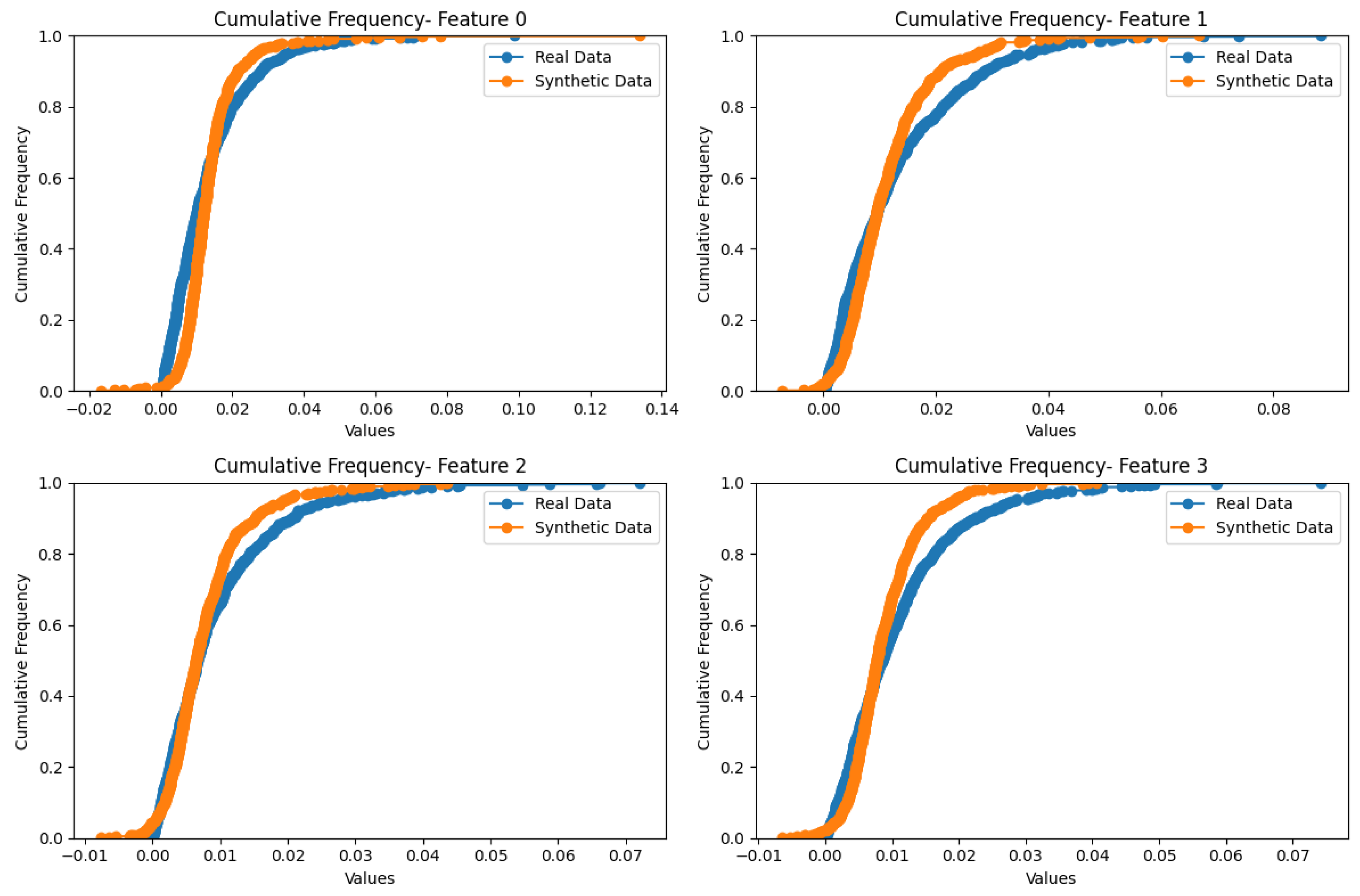
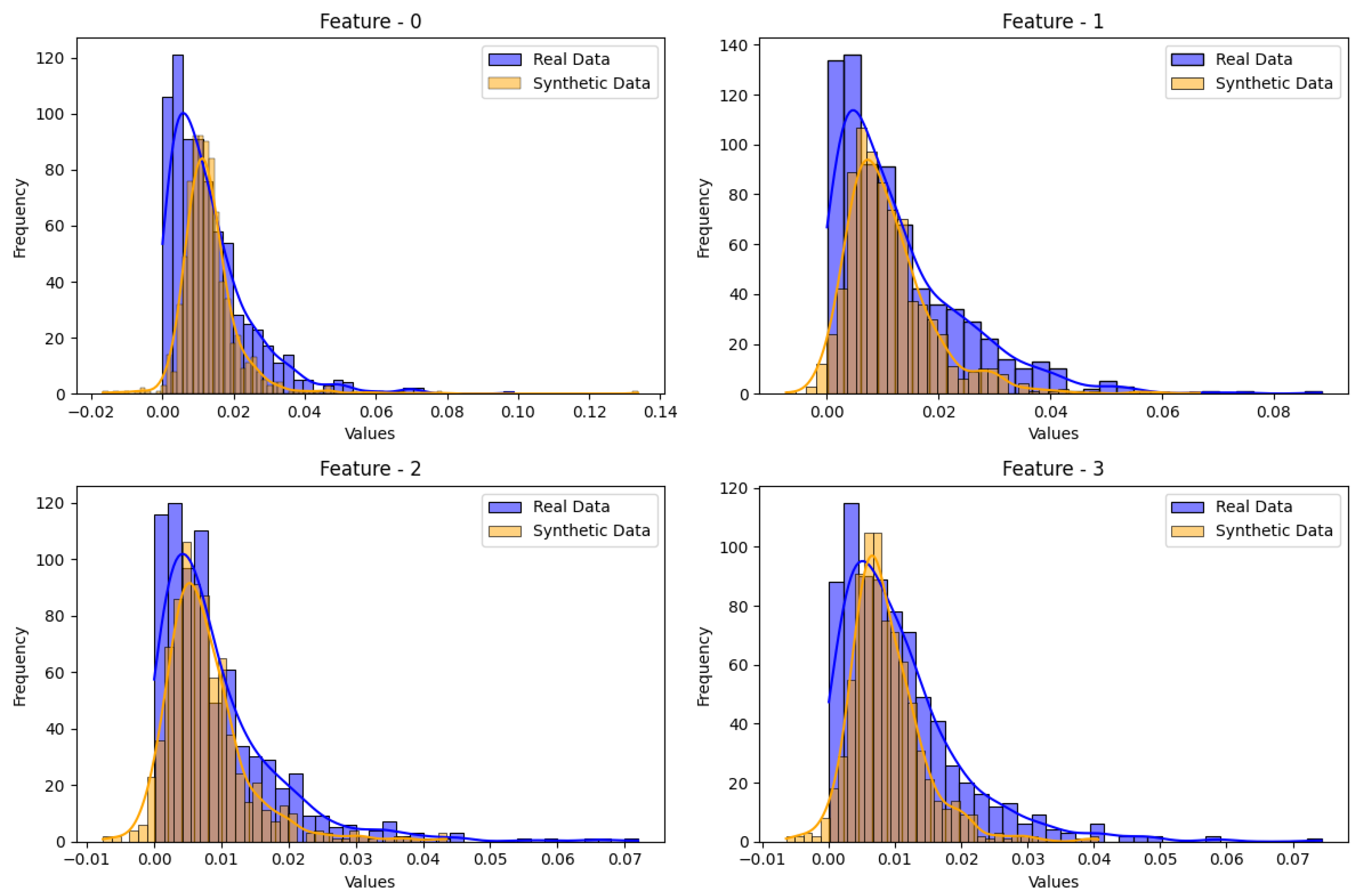
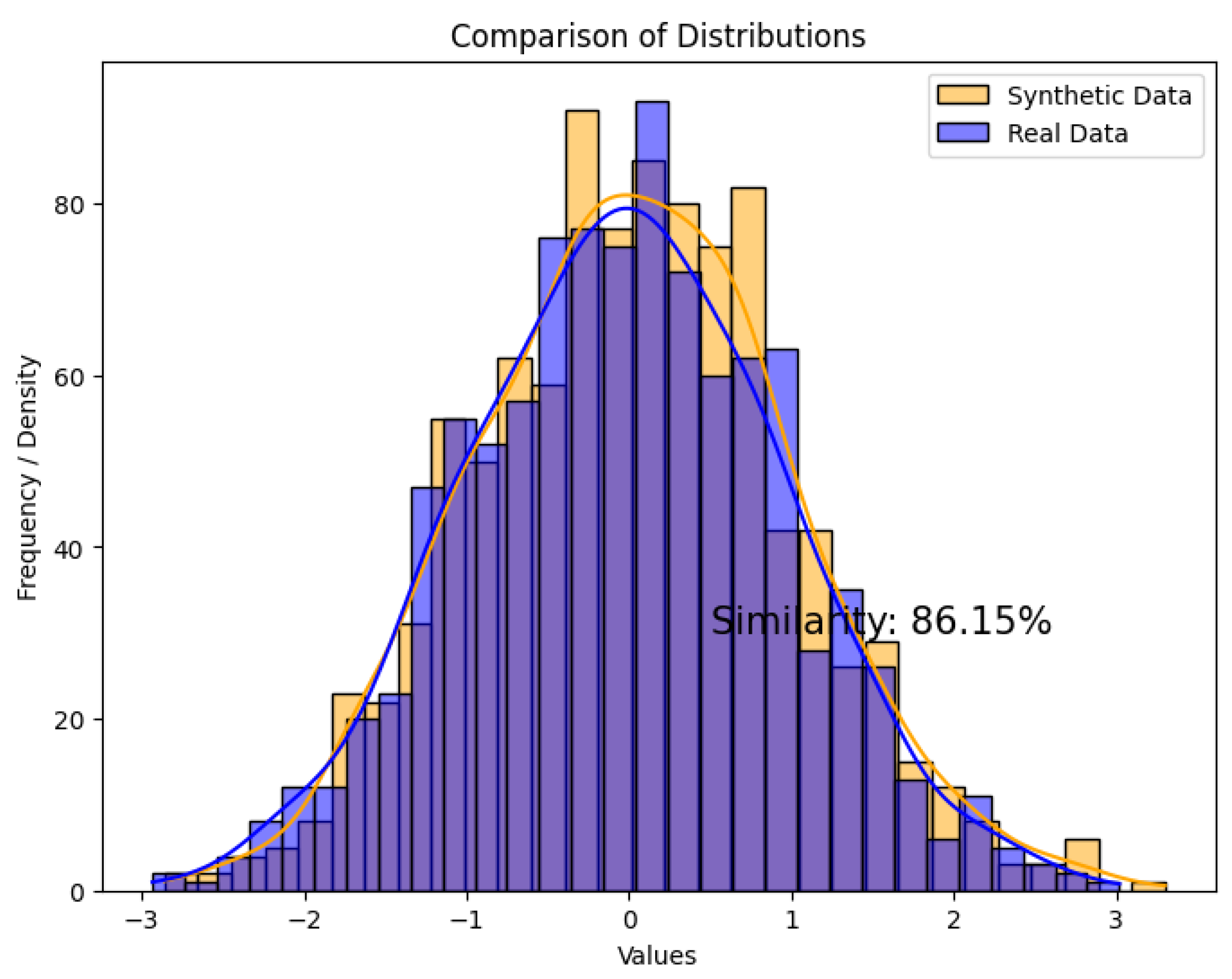
5.2. Analysis of the Results
5.3. Study Limitations
5.4. Benefits and Usage of Synthetic Datasets
- Data Scarcity Mitigation: Newly generated synthetic datasets serve as a solution to overcome data scarcity issues often encountered in financial datasets. By generating additional synthetic data points, we augment the original dataset, enabling more robust analyses and model training.
- Inconsistency Resolution: This synthetic data generation also addresses inconsistencies present in the original data by ensuring that our synthetic dataset maintains coherence and consistency across various data attributes. This contributes to more reliable and accurate analyses and model development.
- Diversity Enhancement: Synthetic dataset incorporates diversity to compensate for situations where the original data might lack diversity or suffer from bias. This diversity is crucial for capturing a broader range of scenarios and ensuring the robustness of analytical models.
- Completeness Compensation: In scenarios where the original data are incomplete or restricted in access, a newly generated synthetic dataset provides a comprehensive and complete representation of the underlying data distribution. This completeness enhances the reliability and effectiveness of data-driven analyses and decision-making processes.
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| GAN | Generative Adversarial Network |
| AI | Artificial Intelligence |
| VAE | Variational Auto-Encoder |
| KDE | Kernel Density Estimation |
| SDE | Stochastic Differential Equations |
| OVAE | Oblivious Variational Auto-Encoder |
| ODT | Oblivious Decision Tree |
| WGAN | Wasserstein GAN |
| MACD | Moving Average Convergence Divergence |
| ReLU | Rectified Linear Activation |
| JS | Jensen–Shannon |
| KL | Kullback–Leibler |
| MMD | Maximum Mean Discrepancy |
References
- Sivarajah, U.; Kamal, M.M.; Irani, Z.; Weerakkody, V. Critical analysis of Big Data challenges and analytical methods. J. Bus. Res. 2017, 70, 263–286. [Google Scholar] [CrossRef]
- Consoli, S.; Recupero, D.R.; Petkovic, M. (Eds.) Data Science for Healthcare–Methodologies and Applications; Springer: Cham, Switzerland, 2019. [Google Scholar] [CrossRef]
- Daniel, B. Big Data and analytics in higher education: Opportunities and challenges. Br. J. Educ. Technol. 2015, 46, 904–920. [Google Scholar] [CrossRef]
- Ramzan, F.; Ayyaz, M. A comprehensive review on Data Stream Mining techniques for data classification; and future trends. EPH-Int. J. Sci. Eng. 2023, 9, 1–29. [Google Scholar] [CrossRef]
- Alzubaidi, L.; Bai, J.; Al-Sabaawi, A.; Santamaría, J.; Albahri, A.S.; Al-dabbagh, B.S.N.; Fadhel, M.A.; Manoufali, M.; Zhang, J.; Al-Timemy, A.H.; et al. A survey on deep learning tools dealing with data scarcity: Definitions, challenges, solutions, tips, and applications. Big Data 2023, 10, 46. [Google Scholar] [CrossRef]
- Cauli, N.; Recupero, D.R. Survey on Videos Data Augmentation for Deep Learning Models. Future Internet 2022, 14, 93. [Google Scholar] [CrossRef]
- Carta, S.; Medda, A.; Pili, A.; Recupero, D.R.; Saia, R. Forecasting E-Commerce Products Prices by Combining an Autoregressive Integrated Moving Average (ARIMA) Model and Google Trends Data. Future Internet 2019, 11, 5. [Google Scholar] [CrossRef]
- Carta, S.; Podda, A.S.; Recupero, D.R.; Stanciu, M.M. Explainable AI for Financial Forecasting. In Proceedings of the Machine Learning, Optimization, and Data Science–7th International Conference, LOD 2021, Grasmere, UK, 4–8 October 2021; Nicosia, G., Ojha, V., Malfa, E.L., Malfa, G.L., Jansen, G., Pardalos, P.M., Giuffrida, G., Umeton, R., Eds.; Revised Selected Papers, Part II; Lecture Notes in Computer Science. Springer: Cham, Switzerland, 2021; Volume 13164, pp. 51–69. [Google Scholar] [CrossRef]
- Carta, S.; Consoli, S.; Piras, L.; Podda, A.S.; Recupero, D.R. Event detection in finance using hierarchical clustering algorithms on news and tweets. PeerJ Comput. Sci. 2021, 7, e438. [Google Scholar] [CrossRef]
- Barra, S.; Carta, S.M.; Corriga, A.; Podda, A.S.; Recupero, D.R. Deep learning and time series-to-image encoding for financial forecasting. IEEE CAA J. Autom. Sin. 2020, 7, 683–692. [Google Scholar] [CrossRef]
- Akhtar, M.M.; Zamani, A.S.; Khan, S.; Shatat, A.S.A.; Dilshad, S.; Samdani, F. Stock market prediction based on statistical data using machine learning algorithms. J. King Saud Univ.-Sci. 2022, 34, 101940. [Google Scholar] [CrossRef]
- Ranjbaran, G.; Recupero, D.R.; Lombardo, G.; Consoli, S. Leveraging augmentation techniques for tasks with unbalancedness within the financial domain: A two-level ensemble approach. EPJ Data Sci. 2023, 12, 24. [Google Scholar] [CrossRef]
- Nikolenko, S.I. Synthetic Data for Deep Learning. arXiv 2019. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014; Conference Track Proceedings. Bengio, Y., LeCun, Y., Eds.; ArXiv: Ithaca, NY, USA, 2014. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. Assoc. Comput. Mach. 2020, 63, 139–144. [Google Scholar] [CrossRef]
- Zhao, S.; Liu, Z.; Lin, J.; Zhu, J.; Han, S. Differentiable Augmentation for Data-Efficient GAN Training. In Proceedings of the Advances in Neural Information Processing Systems 33: Annual Conference on Neural Information Processing Systems 2020, NeurIPS 2020, Virtual, 6–12 December 2020; Larochelle, H., Ranzato, M., Hadsell, R., Balcan, M., Lin, H., Eds.; Curran Associates, Inc.: Glasgow, UK, 2020. [Google Scholar]
- Wagner, F.; König, T.; Benninger, M.; Kley, M.; Liebschner, M. Generation of synthetic data with low-dimensional features for condition monitoring utilizing Generative Adversarial Networks. In Proceedings of the Knowledge-Based and Intelligent Information & Engineering Systems: Proceedings of the 26th International Conference KES-2022, Verona, Italy and Virtual Event, 7–9 September 2022; Cristani, M., Toro, C., Zanni-Merk, C., Howlett, R.J., Jain, L.C., Eds.; Procedia Computer Science. Elsevier: Amsterdam, The Netherlands, 2022; Volume 207, pp. 634–643. [Google Scholar] [CrossRef]
- Plesovskaya, E.; Ivanov, S. An Empirical Analysis of KDE-based Generative Models on Small Datasets. Procedia Comput. Sci. 2021, 193, 442–452. [Google Scholar] [CrossRef]
- dos Santos Tanaka, F.H.K.; Aranha, C. Data Augmentation Using GANs. arXiv 2019. [Google Scholar] [CrossRef]
- Wang, Z.; She, Q.; Ward, T.E. Generative Adversarial Networks in Computer Vision: A Survey and Taxonomy. Assoc. Comput. Mach. Comput. Surv. 2022, 54, 37. [Google Scholar] [CrossRef]
- Gan, G.; Valdez, E.A. Nested Stochastic Valuation of Large Variable Annuity Portfolios: Monte Carlo Simulation and Synthetic Datasets. Data 2018, 3, 31. [Google Scholar] [CrossRef]
- Lafortune, E. Mathematical Models and Monte Carlo Algorithms for Physically Based Rendering. Ph.D. Thesis, Katholieke Universiteit Leuven, Leuven, Belgium, 1996. Volume 20. p. 4. Available online: https://lirias.kuleuven.be/handle/123456789/134595 (accessed on 8 May 2024).
- Patton, A.J. Copula–Based Models for Financial Time Series. In Handbook of Financial Time Series; Mikosch, T., Kreiß, J.P., Davis, R.A., Andersen, T.G., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 767–785. [Google Scholar] [CrossRef]
- Meyer, D.; Nagler, T.; Hogan, R.J. Copula-based synthetic data generation for machine learning emulators in weather and climate: Application to a simple radiation model. arXiv 2020. [Google Scholar] [CrossRef]
- Li, Z.; Zhao, Y.; Fu, J. SynC: A Copula based Framework for Generating Synthetic Data from Aggregated Sources. In Proceedings of the 20th International Conference on Data Mining Workshops, ICDM Workshops 2020, Sorrento, Italy, 17–20 November 2020; Fatta, G.D., Sheng, V.S., Cuzzocrea, A., Zaniolo, C., Wu, X., Eds.; IEEE: Piscataway, NJ, USA, 2020; pp. 571–578. [Google Scholar] [CrossRef]
- Pu, Y.; Gan, Z.; Henao, R.; Yuan, X.; Li, C.; Stevens, A.; Carin, L. Variational Autoencoder for Deep Learning of Images, Labels and Captions. In Advances in Neural Information Processing Systems; Lee, D., Sugiyama, M., Luxburg, U., Guyon, I., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2016; Volume 29. [Google Scholar]
- Wu, J.; Plataniotis, K.N.; Liu, L.Z.; Amjadian, E.; Lawryshyn, Y.A. Interpretation for Variational Autoencoder Used to Generate Financial Synthetic Tabular Data. Algorithms 2023, 16, 121. [Google Scholar] [CrossRef]
- Wan, Z.; Zhang, Y.; He, H. Variational autoencoder based synthetic data generation for imbalanced learning. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence, SSCI 2017, Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–7. [Google Scholar] [CrossRef]
- Vardhan, L.V.H.; Kok, S. Generating privacy-preserving synthetic tabular data using oblivious variational autoencoders. In Proceedings of the Workshop on Economics of Privacy and Data Labor at the 37 th International Conference on Machine Learning (ICML), Virtual, 13–18 July 2020. [Google Scholar]
- Figueira, A.; Vaz, B. Survey on Synthetic Data Generation, Evaluation Methods and GANs. Mathematics 2022, 10, 2733. [Google Scholar] [CrossRef]
- Assefa, S.A.; Dervovic, D.; Mahfouz, M.; Tillman, R.E.; Reddy, P.; Veloso, M. Generating Synthetic Data in Finance: Opportunities, Challenges and Pitfalls. In Proceedings of the First Association for Computing Machinery International Conference on AI in Finance, New York, NY, USA, 15–16 October 2020. ICAIF ’20. [Google Scholar] [CrossRef]
- Smith, K.E.; Smith, A.O. Conditional GAN for timeseries generation. arXiv 2020. [Google Scholar] [CrossRef]
- Eckerli, F.; Osterrieder, J. Generative Adversarial Networks in finance: An overview. arXiv 2021, arXiv:2106.06364. [Google Scholar] [CrossRef]
- Dogariu, M.; Stefan, L.; Boteanu, B.A.; Lamba, C.; Kim, B.; Ionescu, B. Generation of Realistic Synthetic Financial Time-series. Association Comput. Mach. Trans. Multim. Comput. Commun. Appl. 2022, 18, 96. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein Generative Adversarial Networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Sivakumar, J.; Ramamurthy, K.; Radhakrishnan, M.; Won, D. GenerativeMTD: A deep synthetic data generation framework for small datasets. Knowl.-Based Syst. 2023, 280, 110956. [Google Scholar] [CrossRef]
- Hassan, C.; Salomone, R.; Mengersen, K.L. Deep Generative Models, Synthetic Tabular Data, and Differential Privacy: An Overview and Synthesis. arXiv 2023. [Google Scholar] [CrossRef]
- Saxena, D.; Cao, J. Generative Adversarial Networks (GANs): Challenges, Solutions, and Future Directions. Association Comput. Mach. Comput. Surv. 2022, 54, 63. [Google Scholar] [CrossRef]
- Jabbar, A.; Li, X.; Omar, B. A Survey on Generative Adversarial Networks: Variants, Applications, and Training. Association Comput. Mach. Comput. Surv. 2022, 54, 157. [Google Scholar] [CrossRef]
- Xu, L.; Skoularidou, M.; Cuesta-Infante, A.; Veeramachaneni, K. Modeling Tabular data using Conditional GAN. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2019; Volume 32. [Google Scholar]
- Agarap, A.F. Deep Learning using Rectified Linear Units (ReLU). arXiv 2018. [Google Scholar] [CrossRef]
- Dubey, S.R.; Singh, S.K.; Chaudhuri, B.B. Activation functions in deep learning: A comprehensive survey and benchmark. Neurocomputing 2022, 503, 92–108. [Google Scholar] [CrossRef]
- Kodali, N.; Abernethy, J.D.; Hays, J.; Kira, Z. How to Train Your DRAGAN. arXiv 2017. [Google Scholar] [CrossRef]
- Dong, H.; Yang, Y. Training Generative Adversarial Networks with Binary Neurons by End-to-end Backpropagation. arXiv 2018. [Google Scholar] [CrossRef]
- Ashrapov, I. Tabular GANs for uneven distribution. arXiv 2020. [Google Scholar] [CrossRef]
- Lee, M.; Seok, J. Regularization Methods for Generative Adversarial Networks: An Overview of Recent Studies. arXiv 2020. [Google Scholar] [CrossRef]
- Baskin, C.; Zheltonozhkii, E.; Rozen, T.; Liss, N.; Chai, Y.; Schwartz, E.; Giryes, R.; Bronstein, A.M.; Mendelson, A. NICE: Noise Injection and Clamping Estimation for Neural Network Quantization. Mathematics 2021, 9, 2144. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, W.; Chen, Z.; Li, K.; Wang, J. On the Properties of Kullback-Leibler Divergence between Gaussians. arXiv 2021. [Google Scholar] [CrossRef]
- Stéphanovitch, A.; Tanielian, U.; Cadre, B.; Klutchnikoff, N.; Biau, G. Optimal 1-Wasserstein Distance for WGANs. arXiv 2022. [Google Scholar] [CrossRef]
- Ji, F.; Zhang, X.; Zhao, J. α-EGAN: α-Energy distance GAN with an early stopping rule. Comput. Vis. Image Underst. 2023, 234, 103748. [Google Scholar] [CrossRef]
- Gao, H.; Shao, X. Two Sample Testing in High Dimension via Maximum Mean Discrepancy. J. Mach. Learn. Res. 2023, 24, 1–33. [Google Scholar] [CrossRef]
- Friedman, M. A comparison of alternative tests of significance for the problem of m rankings. Ann. Math. Stat. 1940, 11, 86–92. [Google Scholar] [CrossRef]
- Corder, G.W.; Foreman, D.I. Nonparametric Statistics for Non-Statisticians: A Step-by-Step Approach; John Wiley & Sons: Hoboken, NJ, USA, 2011; pp. 1–536. [Google Scholar]
- Nemenyi, P.B. Distribution-Free Multiple Comparisons. Ph.D. Thesis, Princeton University, Princeton, NJ, USA, 1963. [Google Scholar]
- Brown, I.; Mues, C. An experimental comparison of classification algorithms for imbalanced credit scoring data sets. Expert Syst. Appl. 2012, 39, 3446–3453. [Google Scholar] [CrossRef]
- Madjarov, G.; Kocev, D.; Gjorgjevikj, D.; Džeroski, S. An extensive experimental comparison of methods for multi-label learning. Pattern Recognit. 2012, 45, 3084–3104. [Google Scholar] [CrossRef]
- Demśar, J. Statistical comparison of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation Method | Baseline GAN | FinGAN |
|---|---|---|
| KL Divergence | 0.357 | 0.107 |
| Wasserstein Distance | 0.060 | 0.002 |
| Energy Distance | 0.220 | 0.017 |
| MMD | 0.196 | 0.0093 |
| # | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| count | 746 | 746 | 746 | 746 |
| mean | 0.013144 | 0.012822 | 0.009366 | 0.010788 |
| std | 0.011914 | 0.011712 | 0.009283 | 0.009338 |
| min | 0.000012 | 0.000057 | 0.000014 | 0.000067 |
| 25% | 0.004761 | 0.003878 | 0.003202 | 0.004226 |
| 50% | 0.01003 | 0.009423 | 0.006641 | 0.008508 |
| 75% | 0.017771 | 0.01781 | 0.012354 | 0.014221 |
| max | 0.098709 | 0.088502 | 0.072016 | 0.074291 |
| # | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| count | 775 | 775 | 775 | 775 |
| mean | 0.013919 | 0.009105 | 0.007335 | 0.013329 |
| std | 0.008142 | 0.004921 | 0.005163 | 0.005591 |
| min | −0.00868 | −0.01218 | −0.00442 | −0.00534 |
| 25% | 0.0076 | 0.006267 | 0.004463 | 0.009149 |
| 50% | 0.012524 | 0.008376 | 0.006556 | 0.012491 |
| 75% | 0.018594 | 0.011219 | 0.009099 | 0.016423 |
| max | 0.051123 | 0.037024 | 0.078994 | 0.038933 |
| # | 0 | 1 | 2 | 3 |
|---|---|---|---|---|
| Pearson Correlation Coefficient | 0.9415 | 0.9112 | 0.9968 | 0.9179 |
| p-value | 0.0015 | 0.004 | 1.05 × 10−6 | 0.0035 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ramzan, F.; Sartori, C.; Consoli, S.; Reforgiato Recupero, D. Generative Adversarial Networks for Synthetic Data Generation in Finance: Evaluating Statistical Similarities and Quality Assessment. AI 2024, 5, 667-685. https://doi.org/10.3390/ai5020035
Ramzan F, Sartori C, Consoli S, Reforgiato Recupero D. Generative Adversarial Networks for Synthetic Data Generation in Finance: Evaluating Statistical Similarities and Quality Assessment. AI. 2024; 5(2):667-685. https://doi.org/10.3390/ai5020035
Chicago/Turabian StyleRamzan, Faisal, Claudio Sartori, Sergio Consoli, and Diego Reforgiato Recupero. 2024. "Generative Adversarial Networks for Synthetic Data Generation in Finance: Evaluating Statistical Similarities and Quality Assessment" AI 5, no. 2: 667-685. https://doi.org/10.3390/ai5020035
APA StyleRamzan, F., Sartori, C., Consoli, S., & Reforgiato Recupero, D. (2024). Generative Adversarial Networks for Synthetic Data Generation in Finance: Evaluating Statistical Similarities and Quality Assessment. AI, 5(2), 667-685. https://doi.org/10.3390/ai5020035