
Remote Sensing Crop Water Stress Determination Using CNN-ViT Architecture



Abstract
1. Introduction
2. Materials and Methods
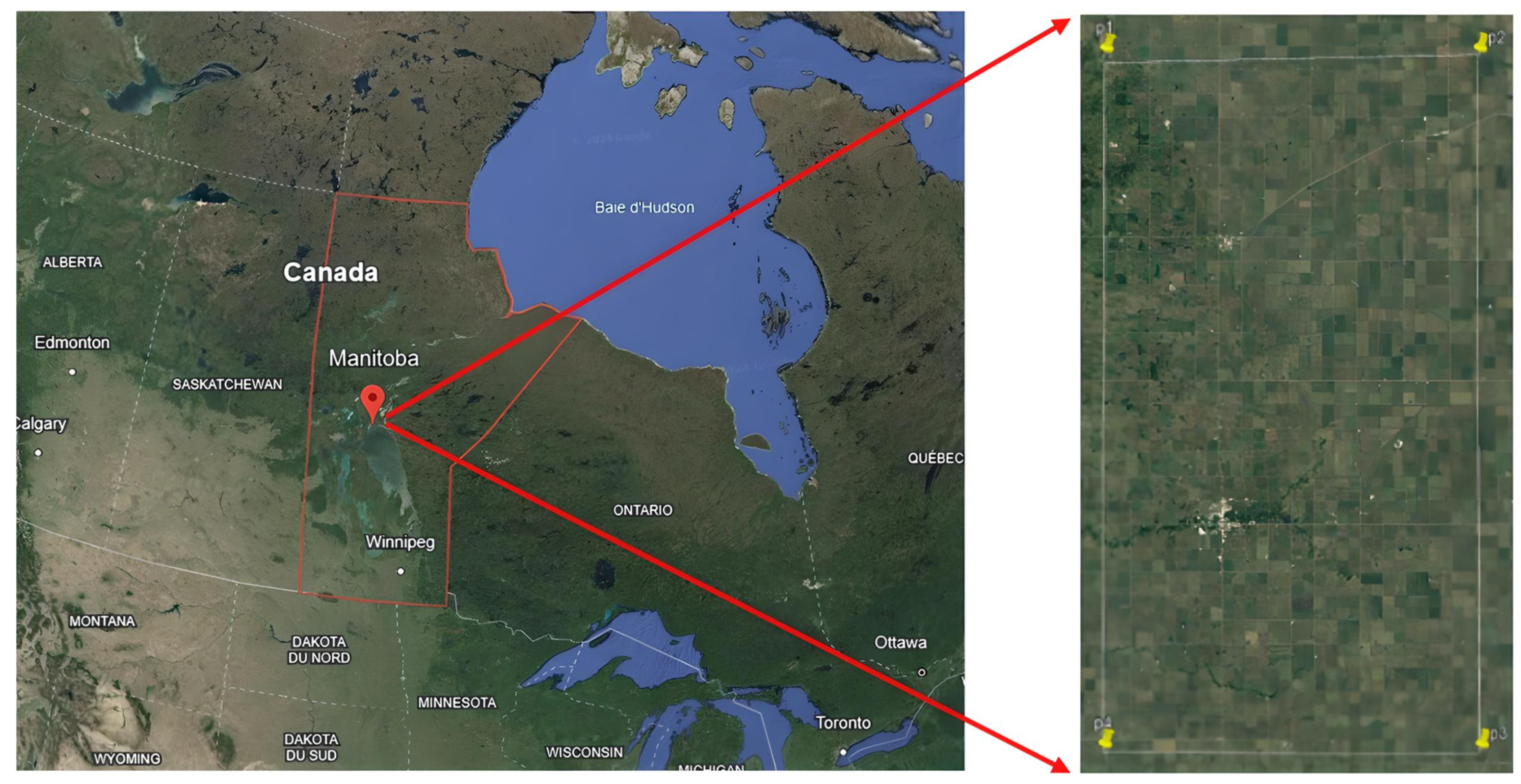
2.1. Study Area
2.2. Data
2.2.1. Ground Truth Data
- a
- Dataset composition
- b
- Measured variables
- Expressed as a fraction (m3/m3);
- Derived from PALS brightness temperature measurements using an algorithm [24];
- The accuracy of soil moisture measurements was assessed using field-collected and laboratory-determined data. Measurement uncertainties are provided as attributes in the data file.
- Expressed in kilograms of water per square meter (kg/m2);
- Estimated from optical satellite observations calibrated with field measurements. For each crop class, a least squares method was employed to establish the relationship (Equation (1)) between the Normalised Difference Vegetation Index (NDVI) and the measured VWC.
- -
- NDVImax: This parameter refers to the maximum annual NDVI at a given location. Like NDVI, it is closely related to land cover types;
- -
- NDVImin: This parameter refers to the minimum annual NDVI at a given location;
- -
- Stem_factor: It is an estimate of the maximum amount of water present in the stems.
2.2.2. Remote Sensing Data
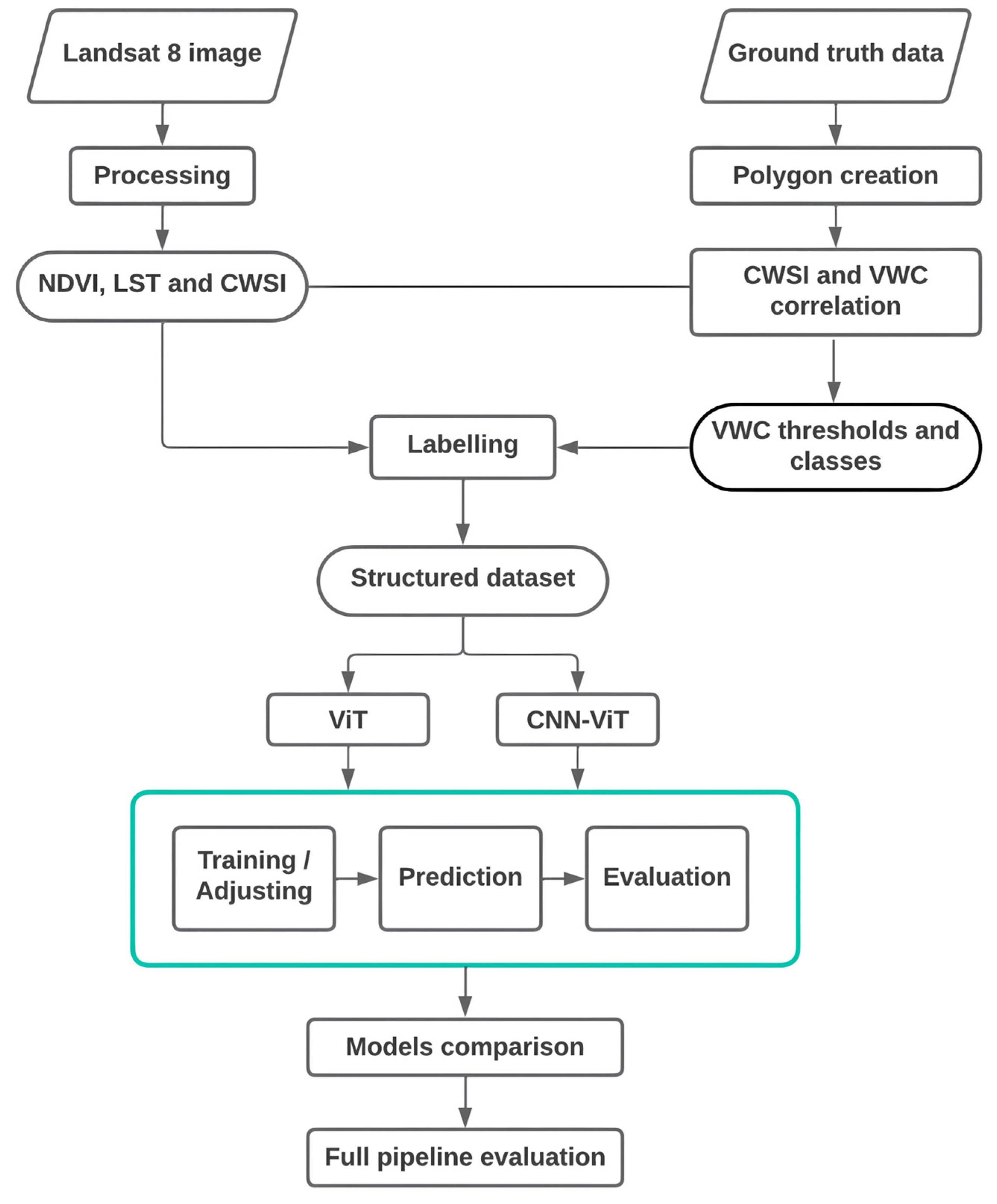
2.3. Methodology
2.3.1. Data Processing
- a
- Ground truth data processing
- b
- Remote sensing data processing
- c
- NDVI and LST calculation
- d
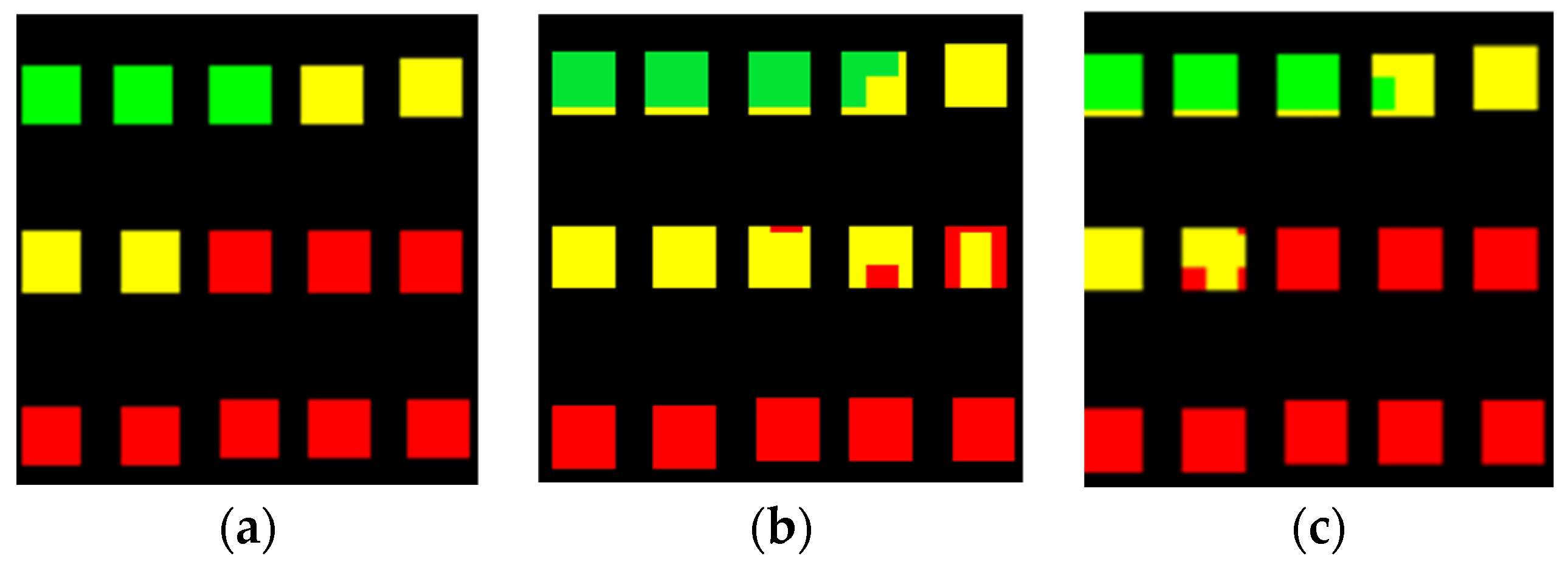
- Crop water stress classes
- CWSI calculation
- -
- TS: Land surface temperature, LST.
- -
- TCold: Temperature of the ‘coldest’ vegetated pixel.
- -
- THot: Temperature of the ‘hottest’ vegetated pixel.
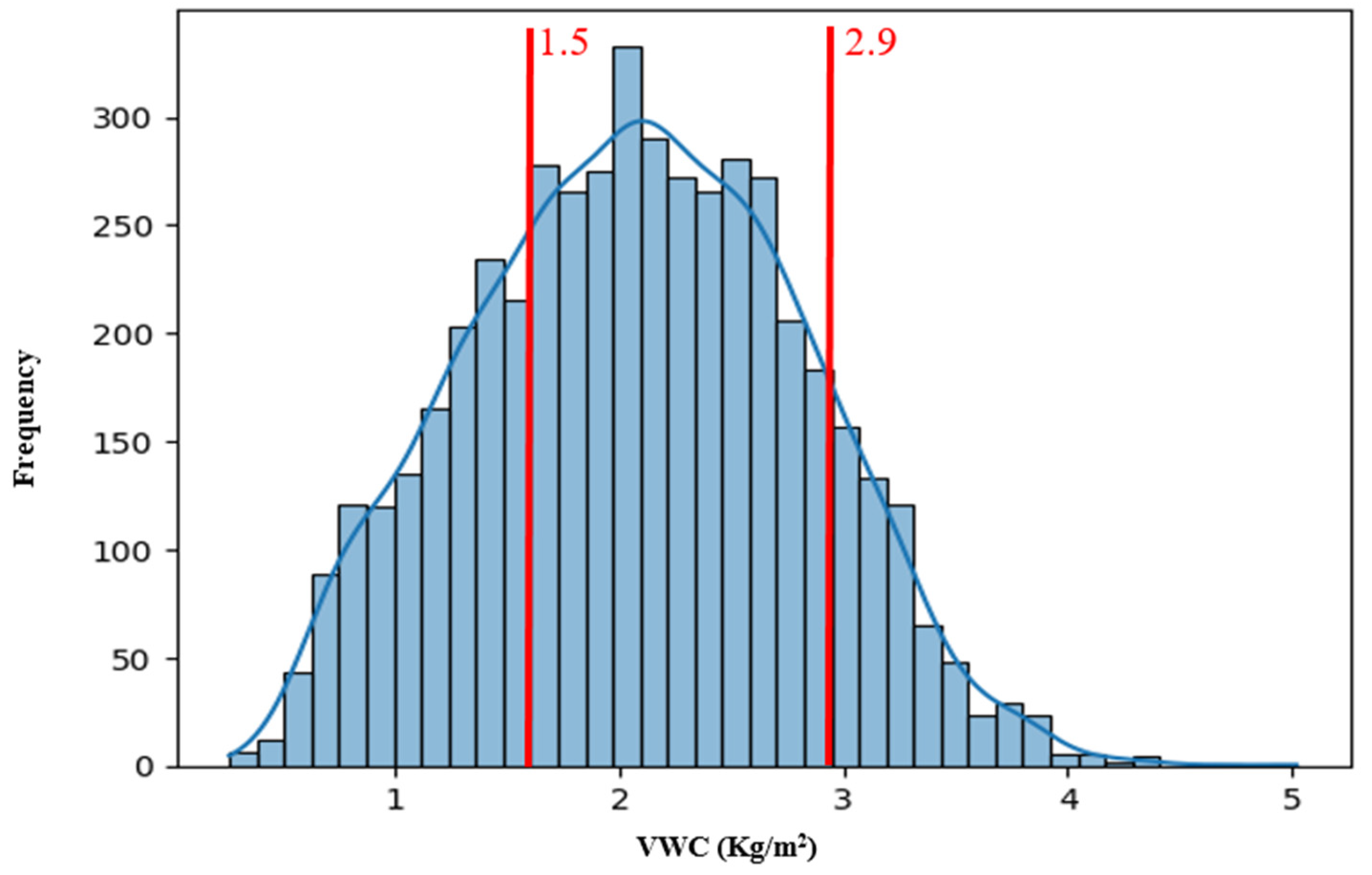
- Correlation between CWSI and VWC
- CWSI thresholds
- e
- Dataset labelling
2.3.2. Visual Transformers
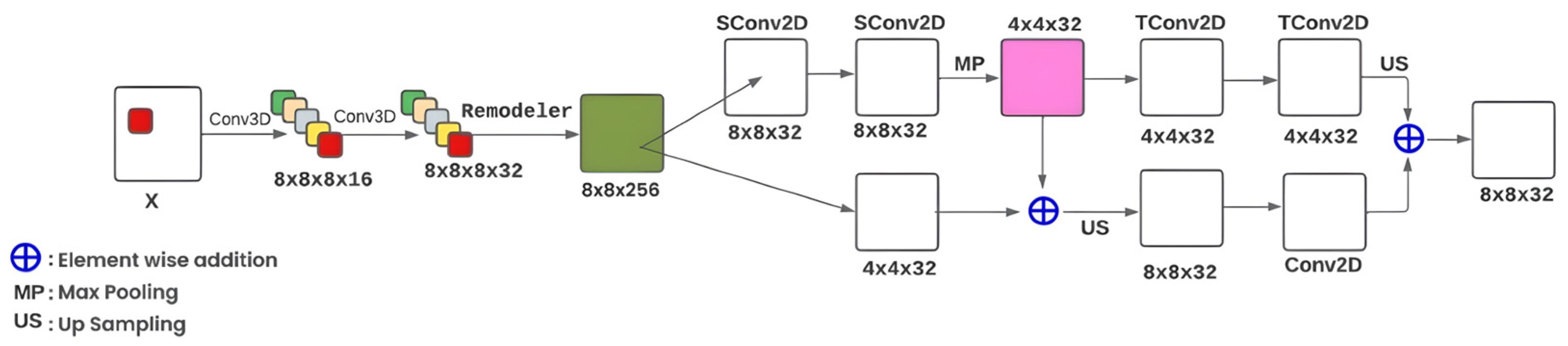
2.3.3. CNN-ViT
2.3.4. Implementation Details
- a
- Hyperparameter optimisation
- b
- Regularisation techniques
- Random horizontal flipping;
- Random rotation of images with a rotation factor of 0.02 radians;
- Random zooming of images by adjusting their height and width with a factor of 0.2.
- c
- Evaluation metrics
3. Results
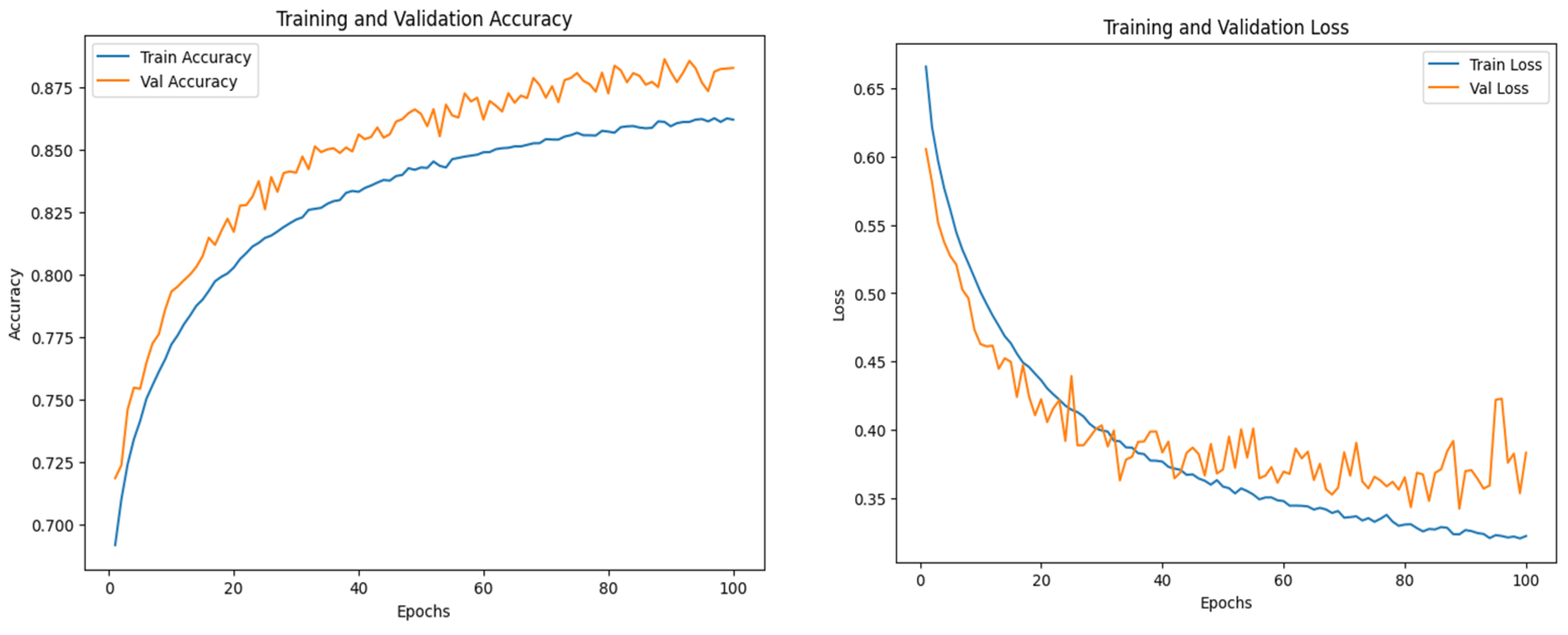
3.1. Visual Transformer
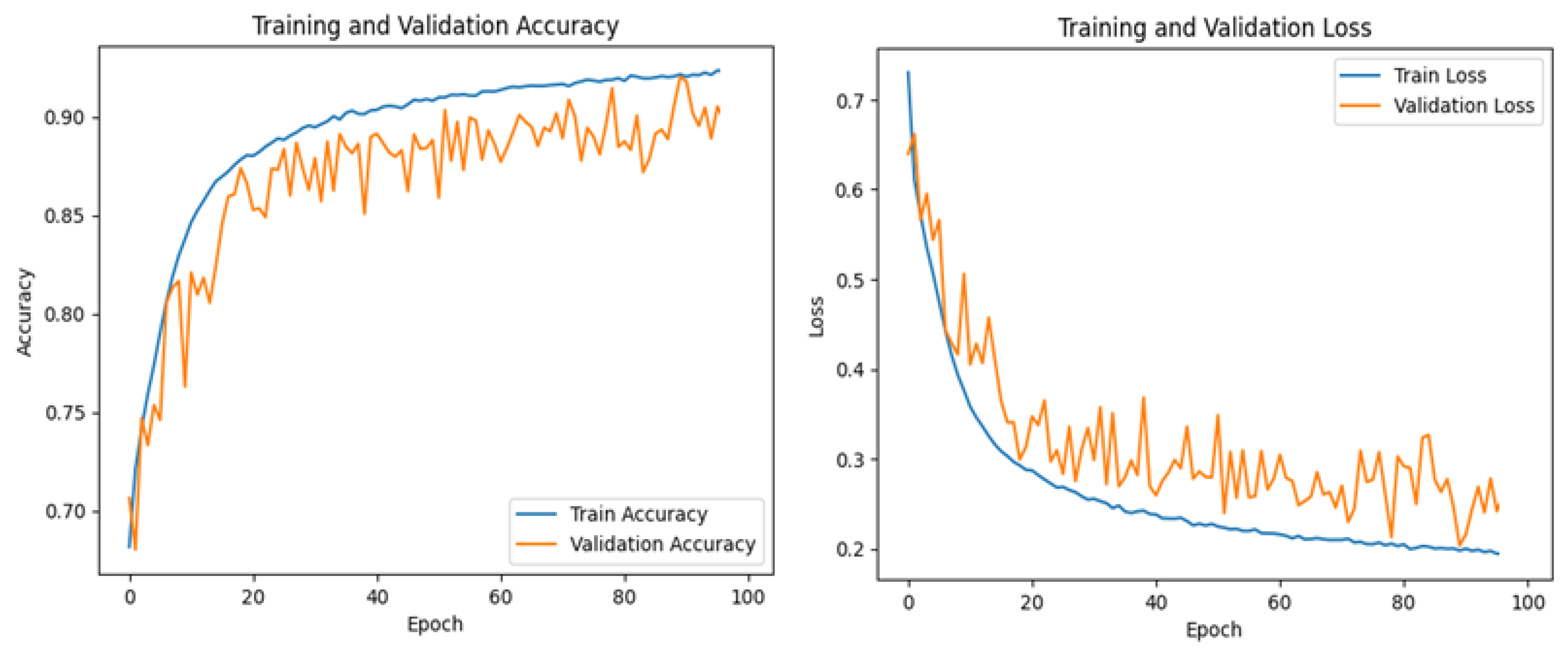
3.2. CNN-ViT
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Katimbo, A.; Rudnick, D.R.; DeJonge, K.C.; Lo, T.H.; Qiao, X.; Franz, T.E.; Nakabuye, H.N.; Duan, J. Crop water stress index computation approaches and their sensitivity to soil water dynamics. Agric. Water Manag. 2022, 266, 107575. [Google Scholar] [CrossRef]
- Virnodkar, S.S.; Pachghare, V.K.; Patil, V.C.; Jha, S.K. Remote sensing and machine learning for crop water stress determination in various crops: A critical review. Precis. Agric. 2020, 21, 1121–1155. [Google Scholar] [CrossRef]
- Dutta, S.K.; Laing, A.M.; Kumar, S.; Gathala, M.K.; Singh, A.K.; Gaydon, D.; Poulton, P. Improved water management practices improve cropping system profitability and smallholder farmers’ incomes. Agric. Water Manag. 2020, 242, 106411. [Google Scholar] [CrossRef]
- Martinho, V.J.P.D. Efficient water management: An analysis for the agricultural sector. Water Policy 2020, 22, 396–416. [Google Scholar] [CrossRef]
- Altalak, M.; Uddin, M.A.; Alajmi, A.; Rizg, A. Smart Agriculture Applications Using Deep Learning Technologies: A Survey. Appl. Sci. 2022, 12, 5919. [Google Scholar] [CrossRef]
- Safdar, M.; Shahid, M.A.; Sarwar, A.; Rasul, F.; Majeed, M.D.; Sabir, R.M. Crop Water Stress Detection Using Remote Sensing Techniques. Environ. Sci. Proc. 2023, 25, 20. [Google Scholar] [CrossRef]
- Chandel, N.S.; Chakraborty, S.K.; Rajwade, Y.A.; Dubey, K.; Tiwari, M.K.; Jat, D. Identifying crop water stress using deep learning models. Neural Comput. Appl. 2021, 33, 5353–5367. [Google Scholar] [CrossRef]
- Ihuoma, S.O.; Madramootoo, C.A. Recent advances in crop water stress detection. Comput. Electron. Agric. 2017, 141, 267–275. [Google Scholar] [CrossRef]
- Kamarudin, M.H.; Ismail, Z.H.; Saidi, N.B. Deep Learning Sensor Fusion in Plant Water Stress Assessment: A Comprehensive Review. Appl. Sci. 2021, 11, 1403. [Google Scholar] [CrossRef]
- Wang, D.; Cao, W.; Zhang, F.; Li, Z.; Xu, S.; Wu, X. A Review of Deep Learning in Multiscale Agricultural Sensing. Remote. Sens. 2022, 14, 559. [Google Scholar] [CrossRef]
- Alibabaei, K.; Gaspar, P.D.; Lima, T.M.; Campos, R.M.; Girão, I.; Monteiro, J.; Lopes, C.M. A Review of the Challenges of Using Deep Learning Algorithms to Support Decision-Making in Agricultural Activities. Remote. Sens. 2022, 14, 638. [Google Scholar] [CrossRef]
- Virnodkar, S.S.; Pachghare, V.K.; Patil, V.C.; Jha, S.K. DenseResUNet: An Architecture to Assess Water-Stressed Sugarcane Crops from Sentinel-2 Satellite Imagery. Trait. Signal 2021, 38, 1131–1139. [Google Scholar] [CrossRef]
- Polivova, M.; Brook, A. Detailed Investigation of Spectral Vegetation Indices for Fine Field-Scale Phenotyping. In Vegetation Index and Dynamics; Carmona, E.C., Ortiz, A.C., Canas, R.Q., Musarella, C.M., Eds.; IntechOpen: London, UK, 2022. [Google Scholar] [CrossRef]
- Duarte-Carvajalino, J.M.; Silva-Arero, E.A.; Góez-Vinasco, G.A.; Torres-Delgado, L.M.; Ocampo-Paez, O.D.; Castaño-Marín, A.M. Estimation of Water Stress in Potato Plants Using Hyperspectral Imagery and Machine Learning Algorithms. Horticulturae 2021, 7, 176. [Google Scholar] [CrossRef]
- Fu, Z.; Ciais, P.; Feldman, A.F.; Gentine, P.; Makowski, D.; Prentice, I.C.; Stoy, P.C.; Bastos, A.; Wigneron, J.-P. Critical soil moisture thresholds of plant water stress in terrestrial ecosystems. Sci. Adv. 2022, 8, eabq7827. [Google Scholar] [CrossRef] [PubMed]
- Qin, A.; Ning, D.; Liu, Z.; Li, S.; Zhao, B.; Duan, A. Determining Threshold Values for a Crop Water Stress Index-Based Center Pivot Irrigation with Optimum Grain Yield. Agriculture 2021, 11, 958. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. Available online: http://arxiv.org/abs/2010.11929 (accessed on 25 September 2023).
- Fu, Z. Vision Transformer: Vit and Its Derivatives. arXiv 2022, arXiv:2205.11239. Available online: http://arxiv.org/abs/2205.11239 (accessed on 15 October 2023).
- Khan, A.; Rauf, Z.; Sohail, A.; Khan, A.R.; Asif, H.; Asif, A.; Farooq, U. A survey of the vision transformers and their CNN-transformer based variants. Artif. Intell. Rev. 2023, 56 (Suppl. 3), 2917–2970. [Google Scholar] [CrossRef]
- Parvaiz, A.; Khalid, M.A.; Zafar, R.; Ameer, H.; Ali, M.; Fraz, M.M. Vision Transformers in medical computer vision—A contemplative retrospection. Eng. Appl. Artif. Intell. 2023, 122, 106126. [Google Scholar] [CrossRef]
- Jamali, A.; Roy, S.K.; Ghamisi, P. WetMapFormer: A unified deep CNN and vision transformer for complex wetland mapping. Int. J. Appl. Earth Obs. Geoinf. 2023, 120, 103333. [Google Scholar] [CrossRef]
- Maurício, J.; Domingues, I.; Bernardino, J. Comparing Vision Transformers and Convolutional Neural Networks for Image Classification: A Literature Review. Appl. Sci. 2023, 13, 5521. [Google Scholar] [CrossRef]
- Ulhaq, A.; Akhtar, N.; Pogrebna, G.; Mian, A. Vision Transformers for Action Recognition: A Survey. arXiv 2022, arXiv:2209.05700. Available online: http://arxiv.org/abs/2209.05700 (accessed on 13 October 2023).
- Colliander, A.; Misra, S.; Cosh, M. SMAPVEX16 Manitoba PALS Brightness Temperature and Soil Moisture Data, Version 1’ [VSM_20160718, VWC_20160718]. Boulder, Colorado USA. NASA National Snow and Ice Data Center Distributed Active Archive Center, 2019. Available online: https://nsidc.org/data/sv16m_pltbsm/versions/1 (accessed on 28 July 2023).
- Zhou, Z.; Majeed, Y.; Naranjo, G.D.; Gambacorta, E.M. Assessment for crop water stress with infrared thermal imagery in precision agriculture: A review and future prospects for deep learning applications. Comput. Electron. Agric. 2021, 182, 106019. [Google Scholar] [CrossRef]
- Sarwar, A.; Khan, M. Technologies for Crop Water Stress Monitoring; Springer: Cham, Switzerland, 2023; pp. 1–15. [Google Scholar] [CrossRef]
- Avdan, U.; Jovanovska, G. Algorithm for Automated Mapping of Land Surface Temperature Using LANDSAT 8 Satellite Data. J. Sens. 2016, 2016, 1480307. [Google Scholar] [CrossRef]
- Ahmad, U.; Alvino, A.; Marino, S. A Review of Crop Water Stress Assessment Using Remote Sensing. Remote. Sens. 2021, 13, 4155. [Google Scholar] [CrossRef]
- de Melo, L.L.; de Melo, V.G.M.L.; Marques, P.A.A.; Frizzone, J.A.; Coelho, R.D.; Romero, R.A.F.; Barros, T.H.d.S. Deep learning for identification of water deficits in sugarcane based on thermal images. Agric. Water Manag. 2022, 272, 107820. [Google Scholar] [CrossRef]
- Veysi, S.; Naseri, A.A.; Hamzeh, S.; Bartholomeus, H. A satellite based crop water stress index for irrigation scheduling in sugarcane fields. Agric. Water Manag. 2017, 189, 70–86. [Google Scholar] [CrossRef]
- García-Tejero, I.; Hernández, A.; Padilla-Díaz, C.; Diaz-Espejo, A.; Fernández, J. Assessing plant water status in a hedgerow olive orchard from thermography at plant level. Agric. Water Manag. 2017, 188, 50–60. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Band | Description | Wavelength (μm) | Resolution (m) |
|---|---|---|---|
| SR-B2 | Blue (OLI) | 0.45–0.51 | 30 |
| SR-B3 | Green (OLI) | 0.53–0.59 | 30 |
| SR-B4 | Red (OLI) | 0.64–0.67 | 30 |
| SR-B5 | NIR (OLI) | 0.85–0.88 | 30 |
| SR-B6 | SWIR1(OLI) | 1.57–1.65 | 30 |
| SR-B7 | SWIR2 (OLI) | 2.11–2.29 | 30 |
| SR-B10 | Thermal Infrared 1 (TIRS) | 10.60–11.19 | 100 |
| CWS Class | CWSI Threshold | Corresponding VWC Threshold (Kg/m2) | Number of Elements in the Dataset |
|---|---|---|---|
| Low | 0 to 0.2 | > to 2.9 | 613 |
| Moderate | 0.2 to 0.5 | 1.5 to 2.9 | 2767 |
| High | 0.5 to 0.8 | 0 to 1.5 | 977 |
| Sequence | Layer Type | Kernel Size/Operation | Input(s) | Output | Description and Details |
|---|---|---|---|---|---|
| 1 | Feature Extractor | - | X_patch | Feature Map | The feature extractor takes an image patch as input and extracts spectral and spatial features. |
| Depth-Wise Convolution block | |||||
| 2 | DW Convolution 2D | (1,1) | Feature Map | Y_1 | Applies a small, focused filter to the input to detect fine details. |
| 3 | DW Convolution 2D | (3,3) | Feature Map | Y_2 | Uses a medium-sized filter to capture broader features. |
| 4 | DW Convolution 2D | (5,5) | Feature Map | Y_3 | Employs a large filter to gather more contextual information. |
| Combination and Normalisation | |||||
| 5 | Element-wise Addition | - | Y_1,Y_2, Y_3 | Y | Combines the different detail scales from previous convolutions. |
| 6 | Normalisation | - | Y | Norm(Y) | Standardises the feature map to stabilise learning. |
| 7 | Local Window Attention (LWA) | - | Norm(Y) | Lx | Focuses on local patterns within the feature map to capture local details and spatial relationships. |
| Output Processing | |||||
| 8 | Element-wise Addition | - | Feature Map, Lx, Norm(Y) | Z | Integrates the attention-focused features with the normalised map. |
| 9 | Normalisation | - | Z | Norm(Z) | Further normalises the combined features for the final prediction steps. |
| Prediction Layers | |||||
| 10 | Linear Transformation | - | Norm(Z) | Inter. Out 1 | Transforms features linearly for high-level abstraction. |
| 11 | Activation function (GELU) | - | Inter. Out 1 | Inter. Out 2 | Applies a non-linear activation function to introduce complexity. |
| 12 | Linear Transformation | - | Inter. Out 2 | O | Produces the final output as a prediction probability. |
| Sequence | Layer Type/Operation | Kernel Size/Stride | Filter Numbers | Input(s) | Output | Description and Details |
|---|---|---|---|---|---|---|
| 1 | Input Reshape | - | - | 8 × 8 × 8 | 8 × 8 × 8 × 1 | Initial reshape of input data into a 4D tensor. |
| Input Convolution Layers | ||||||
| 2 | 3D Convolution | 1 × 1 × 3 | 16 | 8 × 8 × 8 × 1 | 8 × 8 × 8 × 16 | First 3D convolution layer with 16 filters. |
| 3 | 3D Convolution | 1 × 1 × 5 | 32 | 8 × 8 × 8 × 16 | 8 × 8 × 8 × 32 | Second 3D convolution layer with 32 filters. |
| 4 | Reshape to 2D | - | - | 8 × 8 × 8 × 32 | 8 × 8 × 256 | Reshaping the 3D feature map to 2D for further processing. |
| Branch F1—Encoder Network | ||||||
| 5 | Separable Conv2D | 3 × 3 | 32 | 8 × 8 × 256 | 8 × 8 × 32 | First separable 2D convolution in encoder branch. |
| 6 | Separable Conv2D | 3 × 3 | 32 | 8 × 8×32 | 8 × 8 × 32 | Second separable 2D convolution in encoder branch. |
| 7 | Max Pooling | 2 × 2 (Stride 2) | - | 8 × 8 × 32 | 4 × 4 × 32 | Max pooling reduces spatial dimensions by factor of 2. |
| Branch F1—Decoder Network | ||||||
| 8 | Transpose Conv2D | - | - | 4 × 4 × 32 | 4 × 4 × 32 | First transpose convolution in decoder branch. |
| 9 | Transpose Conv2D | - | - | 4 × 4 × 32 | 4 × 4 × 32 | Second transpose convolution in decoder branch. |
| 10 | 2D Up-sampling | - | - | 4 × 4 × 32 | 8 × 8 × 32 | Up-sampling to increase spatial dimensions to match input size. |
| Branch F2 | ||||||
| 11 | 2D Convolution | 3 × 3/stride 2 | 32 | 8 × 8 × 256 | 4 × 4 × 32 | 2D convolution with stride reduces dimensions to match output of F1’s encoder. |
| 12 | Element-wise Addition | - | - | 4 × 4 × 32 | 4 × 4 × 32 | Summing the outputs of Sequence 7 from F1 and Sequence 11 from F2. |
| 13 | 2D Up-sampling (US) | - | - | 4 × 4 × 32 | 8 × 8 × 32 | Up-sampling to increase spatial dimensions to match input size. |
| 14 | 2D Convolution | - | - | 8 × 8 × 32 | 8 × 8 × 32 | Final 2D convolution layer. |
| Combination and output | ||||||
| 15 | Element-wise Addition | - | - | 8 × 8 × 32 | 8 × 8 × 32 | Summing the outputs of the decoder from F1 and F2 and producing the final feature map output. |
| Metric | Accuracy | Precision | Recall | F1 Score | Coefficient Kappa |
|---|---|---|---|---|---|
| ViT | 0.8814 | 0.8765 | 0.8255 | 0.8501 | 0.7695 |
| CNN-ViT | 0.9042 | 0.8774 | 0.8876 | 0.8825 | 0.8195 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lehouel, K.; Saber, C.; Bouziani, M.; Yaagoubi, R. Remote Sensing Crop Water Stress Determination Using CNN-ViT Architecture. AI 2024, 5, 618-634. https://doi.org/10.3390/ai5020033
Lehouel K, Saber C, Bouziani M, Yaagoubi R. Remote Sensing Crop Water Stress Determination Using CNN-ViT Architecture. AI. 2024; 5(2):618-634. https://doi.org/10.3390/ai5020033
Chicago/Turabian StyleLehouel, Kawtar, Chaima Saber, Mourad Bouziani, and Reda Yaagoubi. 2024. "Remote Sensing Crop Water Stress Determination Using CNN-ViT Architecture" AI 5, no. 2: 618-634. https://doi.org/10.3390/ai5020033
APA StyleLehouel, K., Saber, C., Bouziani, M., & Yaagoubi, R. (2024). Remote Sensing Crop Water Stress Determination Using CNN-ViT Architecture. AI, 5(2), 618-634. https://doi.org/10.3390/ai5020033