



Application of YOLOv8 and Detectron2 for Bullet Hole Detection and Score Calculation from Shooting Cards


Abstract
1. Introduction
- Seven models from two architecturally different object detection domains are used for performance comparison.
- The dataset was manually collected by capturing images from the shooting range.
- The dataset was improved and made publicly available to be used by other researchers for the detection and classification of points from shooting cards.
- Multiple performance evaluation metrics are used to gain a better insight into the performances of different models.
2. Related Work
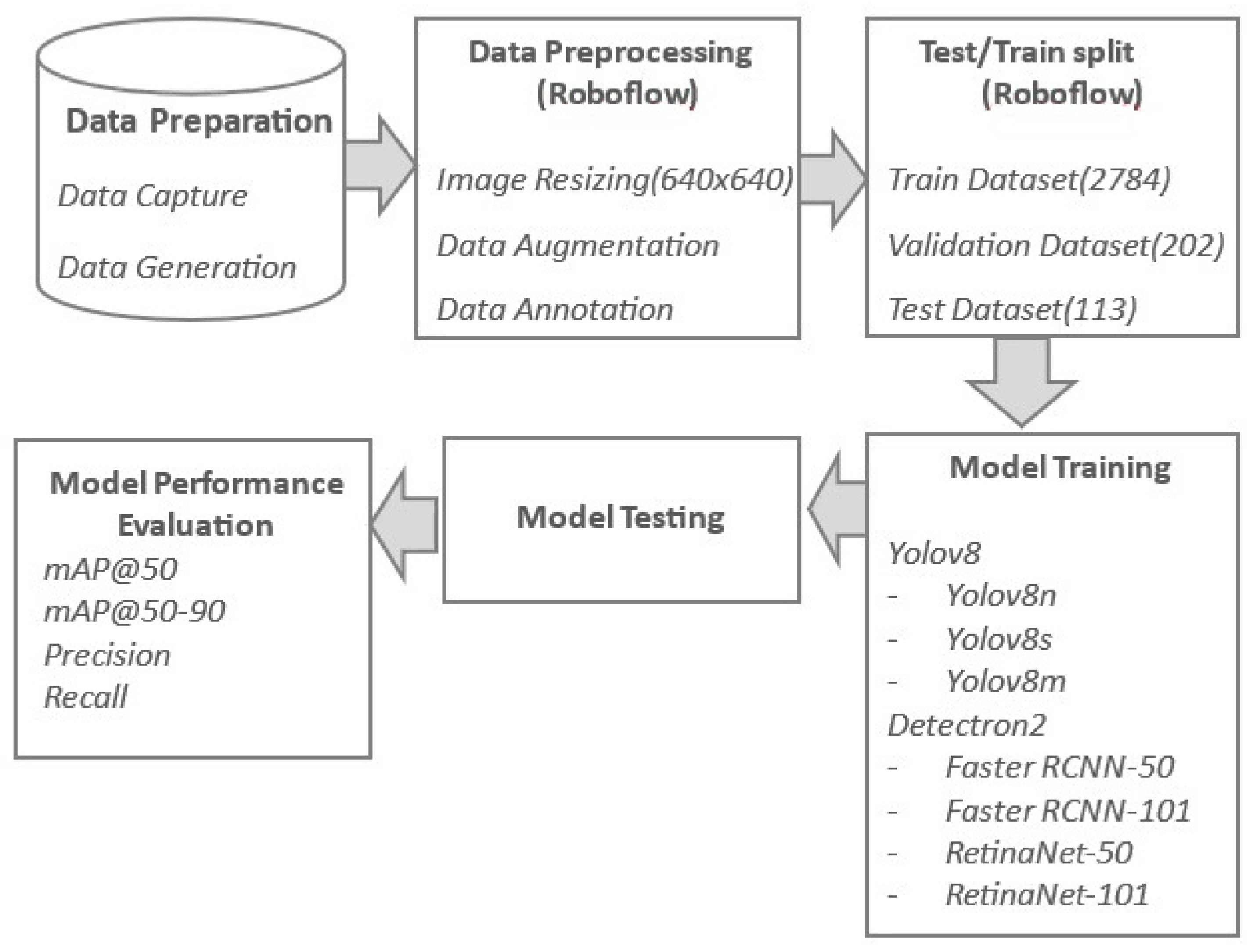
3. Materials and Methods
3.1. Dataset and Preprocessing
3.1.1. Initial Data Collection
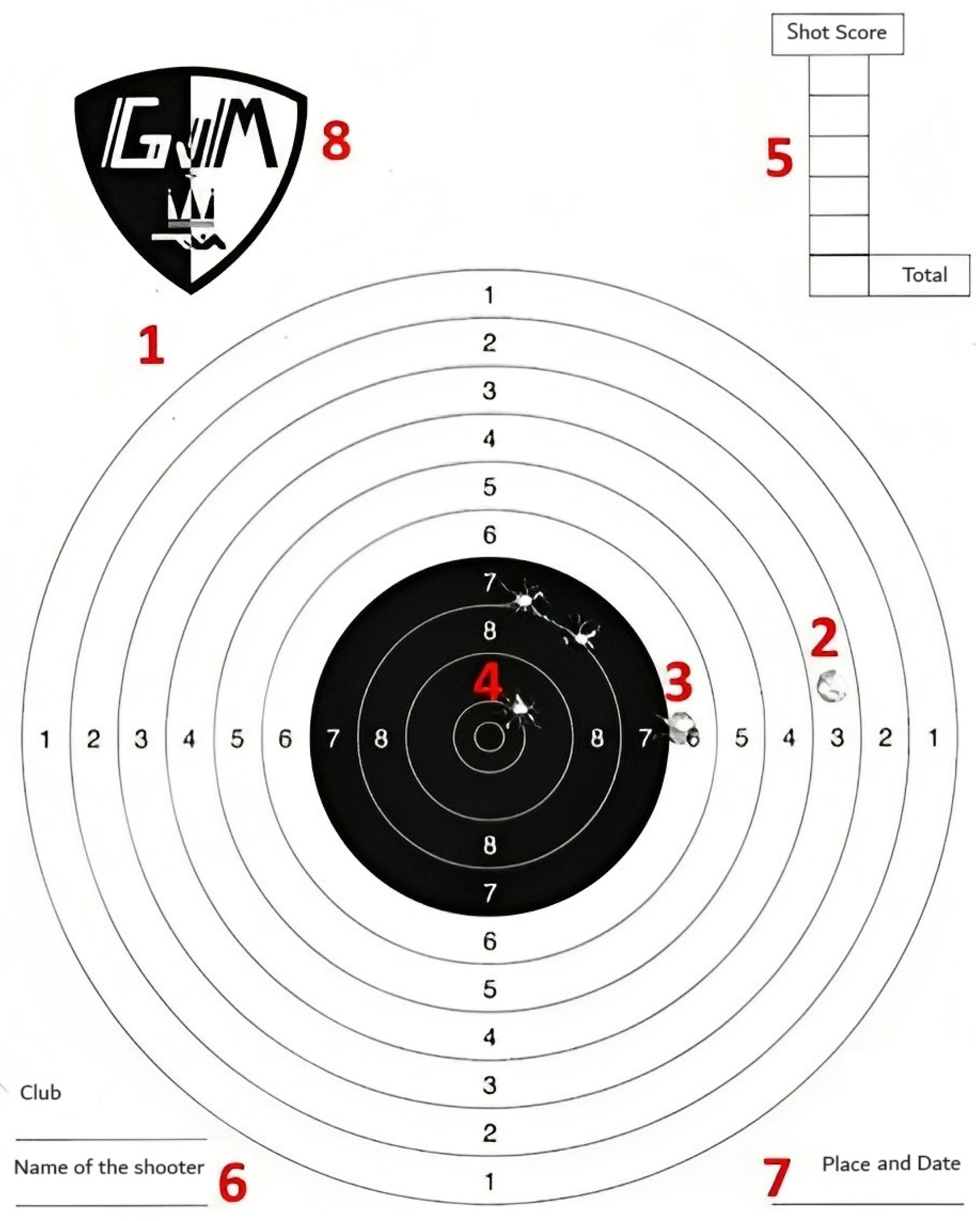
- a.
- Label 1 is the main target of 10 concentric rings, with the outer ring worth 1 point and the bull’s eye worth 10 points.
- b.
- Label 2 is a bullet hole representing a shot fired by a shooter with a score of 2.
- c.
- Label 3 is a bullet hole that crosses the next ring and refers to a bullet hole where the major part was shot in the 6-point area, but the mark touches the 7-point boundary. In such cases, a score of 7 is awarded to the shooter.
- d.
- Label 4 is a bullet hole that crosses the next ring and denotes a shot fired on the bullseye line, where the highest score ring is considered for scoring purposes. In this instance, the shooter hits the bullseye, and a score of 10 is assigned for this shot.
- e.
- Label 5 is the Shot score, where the shooter records the score for each of the five shots fired during the session. These scores are added to obtain the total score.
- f.
- Label 6 is the club’s and shooter’s names.
- g.
- Label 7 is where the shooter indicates the shooting range’s location and the session’s date.
- h.
- Label 8 is the logo of the shooting club.
3.1.2. Data Generation
3.1.3. Data Annotation
3.1.4. Data Augmentation
3.2. Models
3.2.1. You Only Look Once (YOLO)
3.2.2. Detectron2
3.3. Evaluation Metrics
3.3.1. Precision and Recall
3.3.2. Average Precision and Mean Average Precision
- AP75: This metric calculates the average precision at 75% overlap. It measures the precision at different recall values, considering a detection as TP if the IoU overlap is at least 75%.
- APl: The “average precision (large)” calculates the precision at different recall values for objects with large sizes (area > 962). It focuses on evaluating the performance of detecting larger objects accurately.
- APm: This metric is the average precision (medium) and measures the precision at different recall values for objects with medium sizes (322 > area > 962). It is used to assess the performance of detecting objects of moderate dimensions.
- APs: The “average precision (small)” calculates the precision at different recall values for objects with small sizes (area < 322). It evaluates the model’s ability to detect smaller objects accurately
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Jiang, H.; Wang, J.; Gong, Y.; Rong, N.; Chai, Z.; Zheng, N. Online Multi-Target Tracking with Unified Handling of Complex Scenarios. IEEE Trans. Image Process. 2015, 24, 3464–3477. [Google Scholar] [CrossRef] [PubMed]
- Issa, A.H.; Hasan, S.D.; Ali, W.H. Automation of Real-Time Target Scoring System Based on Image Processing Technique. J. Mech. Eng. Res. Dev. 2021, 44, 316–323. [Google Scholar]
- Du, F.; Zhou, Y.; Chen, W.; Yang, L. Bullet Hole Detection Using Series Faster-RCNN and Video Analysis. In Proceedings Volume 11041, Eleventh International Conference on Machine Vision (ICMV 2018), Munich, Germany, 1–3 November 2018; SPIE: Bellingham, WA, USA, 2019; Volume 11041. [Google Scholar] [CrossRef]
- Yu, Y.; Cao, M.W.; Yu, F. Evibe: An Improved Vibe Algorithm for Detecting Moving Objects. Chin. J. Sci. Instrum. 2014, 35, 925–932. [Google Scholar]
- Gao, Y.; Wang, A.M.; Wang, F.H. Application of Improved Wavelet Transform Algorithm in Image Fusion. Laser Technol. 2013, 37, 690–695. [Google Scholar]
- Luo, J.; Zhang, Z.; Zeng, G. A Bullet Holes Detection Algorithm Based on Wavelet Transform and Image Fusion. In Proceedings of the 2nd Information Technology and Mechatronics Engineering Conference (ITOEC 2016), Chongqing, China, 21–22 May 2016. [Google Scholar] [CrossRef]
- Liu, Q.; Chen, Y. Research on Automatic Target-Scoring Method Based on Video Image Analysis. Comput. Eng. 2019, 41, 212–215. [Google Scholar]
- Ruolin, Z.; Jianbo, L.; Yuan, Z.; Xiaoyu, W. Recognition of Bullet Holes Based on Video Image Analysis. IOP Conf. Ser. Mater. Sci. Eng. 2018, 261, 012020. [Google Scholar] [CrossRef]
- Ali, F.; Mansoor, A.B. Computer Vision Based Automatic Scoring of Shooting Targets. In Proceedings of the 2008 IEEE International Multitopic Conference, Karachi, Pakistan, 23–24 December 2008; pp. 515–519. [Google Scholar] [CrossRef]
- Rudzinski, J.; Luckner, M. Low–Cost Computer Vision Based Automatic Scoring of Shooting Targets. In Knowledge Engineering, Machine Learning and Lattice Computing with Applications; Graña, M., Toro, C., Howlett, R.J., Jain, L.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7828. [Google Scholar] [CrossRef]
- Zin, T.T.; Oka, I.; Sasayama, T.; Ata, S.; Watanabe, H.; Sasano, H. Image Processing Approach to Automatic Scoring System for Archery Targets. In Proceedings of the 2013 Ninth International Conference on Intelligent Information Hiding and Multimedia Signal Processing, Beijing, China, 16–18 October 2013; pp. 259–262. [Google Scholar] [CrossRef]
- Su, Z.; Chen, W. Effective Target Extraction of Automatic Target-Scoring System. In Proceedings of the 2019 IEEE 4th Advanced Information Technology, Electronic and Automation Control Conference (IAEAC), Chengdu, China, 20–22 December 2019; pp. 1402–1406. [Google Scholar] [CrossRef]
- Yun, J.; Jiang, D.; Liu, Y.; Sun, Y.; Tao, B.; Kong, J.; Tian, J.; Tong, X.; Xu, M.; Fang, Z. Real-Time Target Detection Method Based on Lightweight Convolutional Neural Network. Front. Bioeng. Biotechnol. 2022, 10, 861286. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Xiao, F.; Tong, X.; Tao, B.; Xu, M.; Jiang, G.; Chen, B.; Cao, Y.; Sun, N. Manipulator Trajectory Planning Based on Work Subspace Division. Concurr. Comput. 2022, 34, e6710. [Google Scholar] [CrossRef]
- Ren, F.; Bao, Y. A Review on Human-Computer Interaction and Intelligent Robots. Int. J. Info. Tech. Dec. Mak. 2020, 19, 5–47. [Google Scholar] [CrossRef]
- Zhan, W.; Sun, C.; Wang, M.; She, J.; Zhang, Y.; Zhang, Z.; Sun, Y. An Improved YOLOv5 Real-Time Detection Method for Small Objects Captured by UAV. Soft Comput. 2022, 26, 361–373. [Google Scholar] [CrossRef]
- Zhu, X.; Lyu, S.; Wang, X.; Zhao, Q. Tph-YOLOv5: Improved YOLOv5 Based on Transformer Prediction Head for Object Detection on Drone-Captured Scenarios. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 2778–2788. [Google Scholar]
- Chen, S.; Liao, Y.; Lin, F.; Huang, B. An Improved Lightweight YOLOv5 Algorithm for Detecting Strawberry Diseases. IEEE Access 2023, 11, 54080–54092. [Google Scholar] [CrossRef]
- Saydirasulovich, S.N.; Abdusalomov, A.; Jamil, M.K.; Nasimov, R.; Kozhamzharova, D.; Cho, Y.-I. A YOLOv6-Based Improved Fire Detection Approach for Smart City Environments. Sensors 2023, 23, 3161. [Google Scholar] [CrossRef] [PubMed]
- Jiang, D.; Li, G.; Sun, Y.; Kong, J.; Tao, B.; Chen, D. Grip Strength Forecast and Rehabilitative Guidance Based on Adaptive Neural Fuzzy Inference System Using sEMG. Pers. Ubiquit. Comput. 2019, 26, 1215–1224. [Google Scholar] [CrossRef]
- Liu, G.; Hu, Y.; Chen, Z.; Guo, J.; Ni, P. Lightweight Object Detection Algorithm for Robots with Improved YOLOv5. Eng. Appl. Artif. Intell. 2023, 123, 106217. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Sportelli, M.; Apolo-Apolo, O.E.; Fontanelli, M.; Frasconi, C.; Raffaelli, M.; Peruzzi, A.; Perez-Ruiz, M. Evaluation of YOLO Object Detectors for Weed Detection in Different Turfgrass Scenarios. Appl. Sci. 2023, 13, 8502. [Google Scholar] [CrossRef]
- Reis, D.; Kupec, J.; Hong, J.; Daoudi, A. Real-Time Flying Object Detection with YOLOv8. arXiv 2023, arXiv:2305.09972. [Google Scholar]
- Meng, X.; Liu, Y.; Fan, L.; Fan, J. YOLOv5s-Fog: An Improved Model Based on YOLOv5s for Object Detection in Foggy Weather Scenarios. Sensors 2023, 23, 5321. [Google Scholar] [CrossRef]
- Kulkarni, U.; Naregal, K.; Farande, V.; Guttigoli, S.; Angadi, A.; Ujwane, R. An Object Detection Approach for Automated Detection of Groove Line in Tube Yoke. ITM Web Conf. 2023, 53, 01007. [Google Scholar] [CrossRef]
- Ju, R.Y.; Cai, W. Fracture Detection in Pediatric Wrist Trauma X-ray Images Using YOLOv8 Algorithm. arXiv 2023, arXiv:2304.05071. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Dollar, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Proceedings of the Advances in Neural Information Processing Systems; Cortes, C., Lawrence, N., Lee, D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; Volume 28. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Dang, F.; Chen, D.; Lu, Y.; Li, Z. YOLOWeeds: A Novel Benchmark of Yolo Object Detectors for Multi-Class Weed Detection in Cotton Production Systems. Comput. Electron. Agric. 2023, 205, 107655. [Google Scholar] [CrossRef]
- Kubera, E.; Kubik-Komar, A.; Kurasiński, P.; Piotrowska-Weryszko, K.; Skrzypiec, M. Detection and Recognition of Pollen Grains in Multilabel Microscopic Images. Sensors 2022, 22, 2690. [Google Scholar] [CrossRef] [PubMed]
- Yang, G.; Wang, J.; Nie, Z.; Yang, H.; Yu, S. A Lightweight YOLOv8 Tomato Detection Algorithm Combining Feature Enhancement and Attention. Agronomy 2023, 13, 1824. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
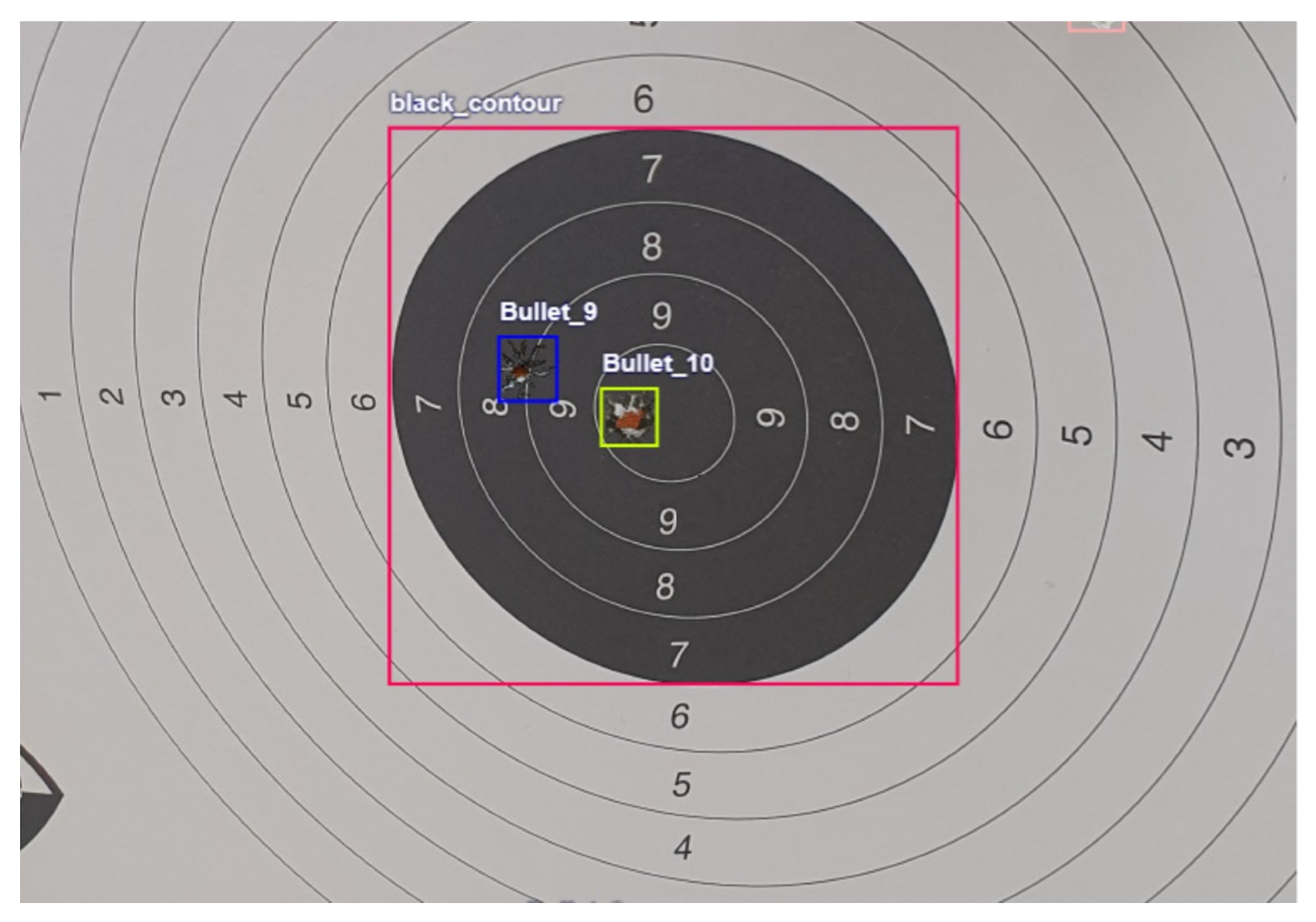
| Class | Description | Numbers of Annotations |
|---|---|---|
| Target | Bounding box around the biggest circle | 1257 |
| Black_contour | Bounding box around the black circle, which contains the 7, 8, 9, and 10 | 1250 |
| Bullet_0 | A bullet hole on paper but not in any rings | 839 |
| Bullet_1 | Bullet hole in the first ring | 376 |
| Bullet_2 | Bullet hole in the second ring | 440 |
| Bullet_3 | Bullet hole in the third ring | 506 |
| Bullet_4 | Bullet hole in the fourth ring | 480 |
| Bullet_5 | Bullet hole in the fifth ring | 555 |
| Bullet_6 | Bullet hole in the sixth ring | 595 |
| Bullet_7 | Bullet hole in the seventh ring | 712 |
| Bullet_8 | Bullet hole in the eighth ring | 588 |
| Bullet_9 | Bullet hole in the ninth ring | 541 |
| Bullet_10 | Bullet hole in the tenth ring | 257 |
| Techniques Used | Value |
|---|---|
| Flipping | Horizontal, Vertical |
| Grayscale | 25% of all images |
| Saturation | Between −72% and +72% |
| Brightness | Between −30% and +0% |
| Category (Classes) | Faster RCNN-50 | RetinaNet-50 | Faster RCNN-101 | RetinaNet-101 |
|---|---|---|---|---|
| 2 | 23.666 | 24.454 | 18.122 | 18.720 |
| 5 | 50.966 | 31.049 | 53.827 | 30.420 |
| 8 | 40.085 | 41.225 | 41.675 | 35.022 |
| Target | 97.385 | 96.411 | 96.247 | 96.810 |
| 0 | 50.096 | 46.978 | 39.134 | 45.852 |
| 3 | 44.570 | 34.778 | 57.490 | 35.819 |
| 6 | 44.623 | 28.234 | 40.767 | 28.667 |
| 9 | 33.359 | 25.177 | 40.149 | 22.677 |
| Black contour | 95.930 | 97.095 | 97.740 | 97.630 |
| 1 | 51.011 | 52.828 | 50.459 | 39.879 |
| 4 | 48.688 | 40.167 | 60.042 | 38.381 |
| 7 | 37.617 | 34.934 | 38.748 | 26.850 |
| 10 | 24.600 | 20.027 | 16.765 | 22.617 |
| Model | AP IoU = 0.50–0.95 | AP50 | AP75 | APs | APm | APl | AR | ARs | ARm | ARl |
|---|---|---|---|---|---|---|---|---|---|---|
| Faster RCNN-50 | 49.431 | 83.531 | 45.332 | 40.981 | 55.116 | 96.616 | 0.615 | 0.546 | 0.637 | 0.982 |
| RetinaNet-50 | 44.104 | 71.332 | 40.071 | 34.697 | 43.582 | 97.184 | 0.610 | 0.540 | 0.542 | 0.986 |
| Faster RCNN-101 | 50.090 | 83.554 | 47.379 | 41.546 | 51.866 | 97.074 | 0.596 | 0.520 | 0.612 | 0.981 |
| RetinaNet-101 | 41.488 | 66.416 | 38.722 | 31.775 | 41.374 | 97.636 | 0.610 | 0.541 | 0.495 | 0.989 |
| Category (Classes) | YOLOv8n mAP50 | YOLOv8n mAP50-95 | YOLOv8s mAP50 | YOLOv8s mAP50-95 | YOLOv8m mAP50 | YOLOv8m mAP50-95 |
|---|---|---|---|---|---|---|
| 0 | 0.946 | 0.524 | 0.981 | 0.535 | 0.963 | 0.529 |
| 1 | 0.934 | 0.501 | 0.958 | 0.532 | 0.964 | 0.555 |
| 10 | 0.964 | 0.554 | 0.995 | 0.593 | 0.995 | 0.526 |
| 2 | 0.926 | 0.557 | 0.929 | 0.565 | 0.918 | 0.586 |
| 3 | 0.967 | 0.61 | 0.982 | 0.623 | 0.985 | 0.634 |
| 4 | 0.942 | 0.606 | 0.959 | 0.621 | 0.949 | 0.616 |
| 5 | 0.932 | 0.569 | 0.943 | 0.57 | 0.939 | 0.579 |
| 6 | 0.941 | 0.564 | 0.94 | 0.593 | 0.968 | 0.607 |
| 7 | 0.962 | 0.575 | 0.952 | 0.592 | 0.972 | 0.601 |
| 8 | 0.84 | 0.464 | 0.939 | 0.558 | 0.938 | 0.555 |
| 9 | 0.946 | 0.569 | 0.98 | 0.634 | 0.987 | 0.615 |
| Target | 0.995 | 0.99 | 0.995 | 0.993 | 0.995 | 0.993 |
| Black contour | 0.991 | 0.987 | 0.993 | 0.989 | 0.994 | 0.991 |
| Model | Precision | Recall | mAP50 | mAP50-95 | Speed (ms) |
|---|---|---|---|---|---|
| YOLOv8n | 0.921 | 0.912 | 0.945 | 0.621 | 2.69 |
| YOLOv8s | 0.947 | 0.936 | 0.965 | 0.646 | 2.312 |
| YOLOv8m | 0.937 | 0.94 | 0.967 | 0.645 | 5.718 |
| Model | AP50-95/mAP50-95 (%) | AP50/mAP50(%) | AR/Recall (%) | Speed (ms) |
|---|---|---|---|---|
| Faster RCNN-50 | 49.431 | 83.531 | 61.5 | -- |
| Retinanet-50 | 44.104 | 71.332 | 61.0 | -- |
| Faster RCNN-101 | 50.090 | 83.554 | 59.6 | -- |
| Retinanet-101 | 41.488 | 66.416 | 61.0 | -- |
| YOLOv8n | 62.1 | 94.5 | 91.2 | 2.69 |
| YOLOv8s | 64.6 | 96.5 | 93.6 | 2.312 |
| YOLOv8m | 64.5 | 96.7 | 94.0 | 5.718 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Butt, M.; Glas, N.; Monsuur, J.; Stoop, R.; de Keijzer, A. Application of YOLOv8 and Detectron2 for Bullet Hole Detection and Score Calculation from Shooting Cards. AI 2024, 5, 72-90. https://doi.org/10.3390/ai5010005
Butt M, Glas N, Monsuur J, Stoop R, de Keijzer A. Application of YOLOv8 and Detectron2 for Bullet Hole Detection and Score Calculation from Shooting Cards. AI. 2024; 5(1):72-90. https://doi.org/10.3390/ai5010005
Chicago/Turabian StyleButt, Marya, Nick Glas, Jaimy Monsuur, Ruben Stoop, and Ander de Keijzer. 2024. "Application of YOLOv8 and Detectron2 for Bullet Hole Detection and Score Calculation from Shooting Cards" AI 5, no. 1: 72-90. https://doi.org/10.3390/ai5010005
APA StyleButt, M., Glas, N., Monsuur, J., Stoop, R., & de Keijzer, A. (2024). Application of YOLOv8 and Detectron2 for Bullet Hole Detection and Score Calculation from Shooting Cards. AI, 5(1), 72-90. https://doi.org/10.3390/ai5010005