
MultiWave-Net: An Optimized Spatiotemporal Network for Abnormal Action Recognition Using Wavelet-Based Channel Augmentation


Abstract
1. Introduction
- A novel integrated serial channel augmentation (ISCA) block to generate wavelet-transformed images for feature extraction to mitigate the trade-off between accuracy and efficiency.
- The combination of the optimized MobileNetV2 CNN architecture with ConvLSTM for spatiotemporal classification.
- A detailed experimental study to prove the importance of each part of the network used with the proposed ISCA block in the form of an ablation study.
- Competitive performance compared to the current state-of-the-art models across different benchmark datasets in terms of accuracy and efficiency defined as the number of trainable parameters.
2. Related Work
2.1. Image Processing and Machine Learning Approaches
2.2. CNN Spatial-Based Approaches
2.3. CNN and Sequence Models Approaches
2.4. Wavelet-Based Approaches
2.5. Transformers Approaches
2.6. Discussion on Literature and Research Gap
3. Materials and Methods
3.1. Video Segmentation Using Sparse Sampling
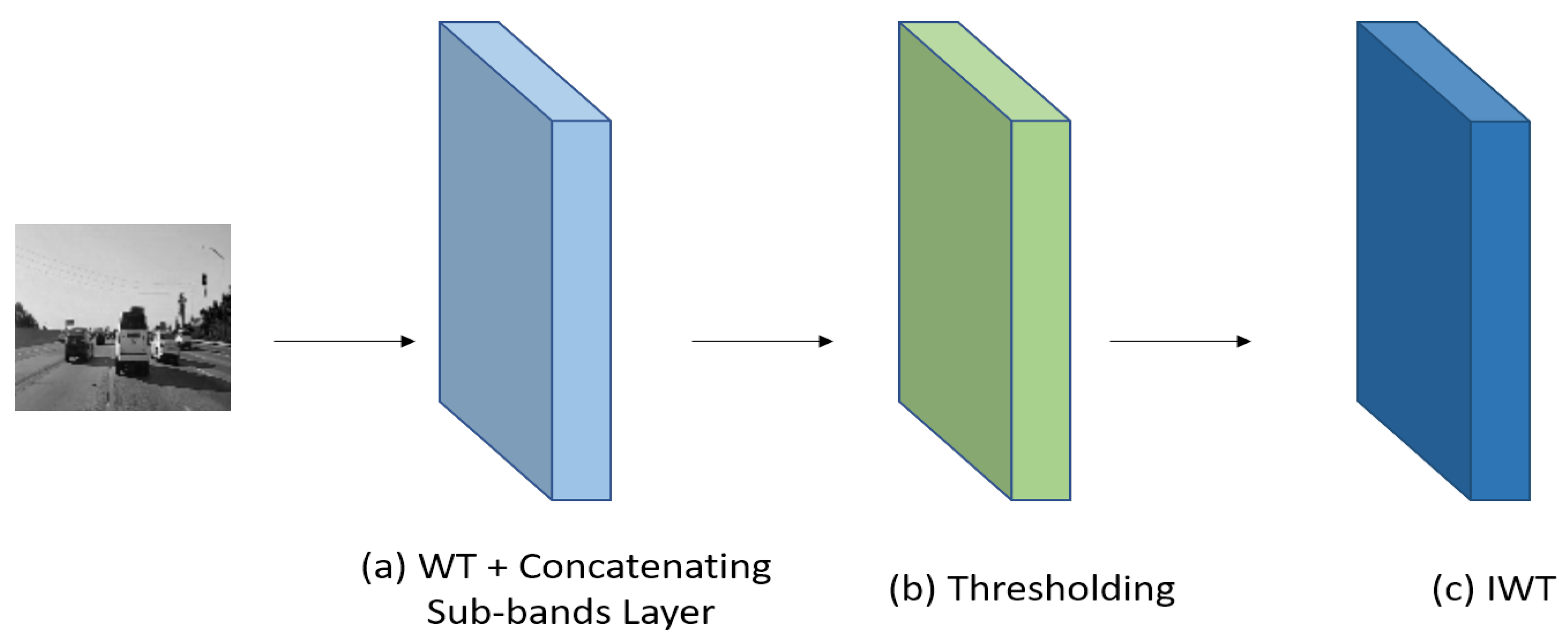
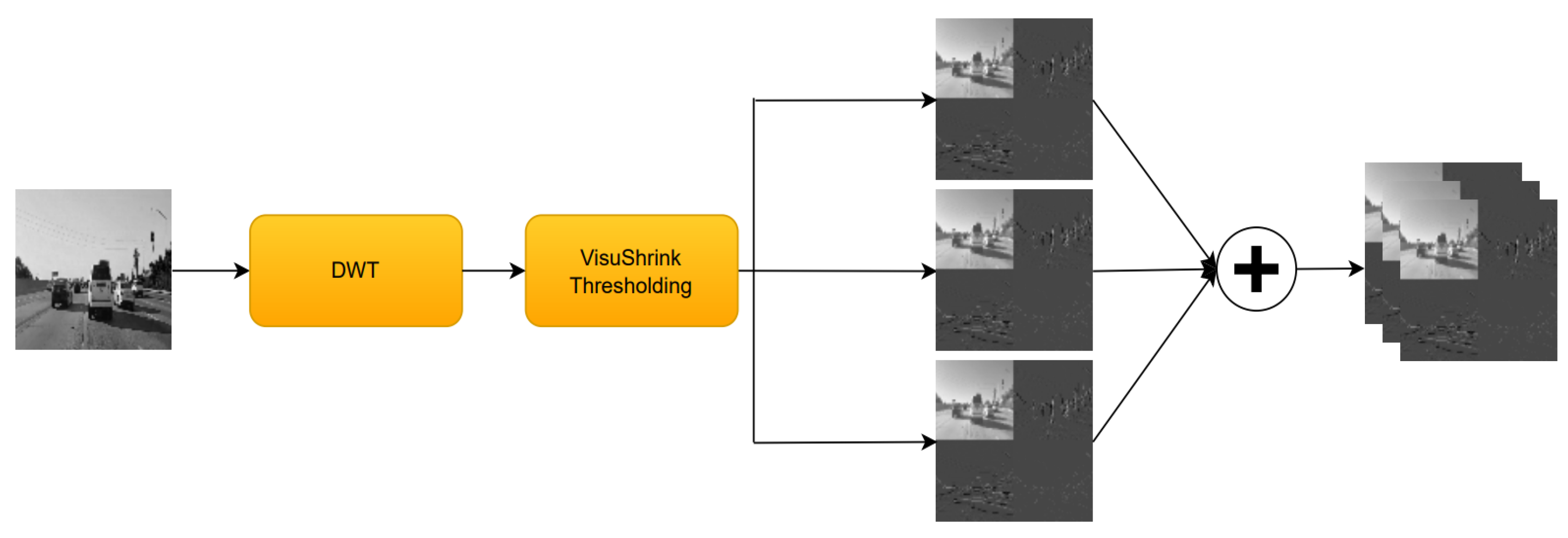
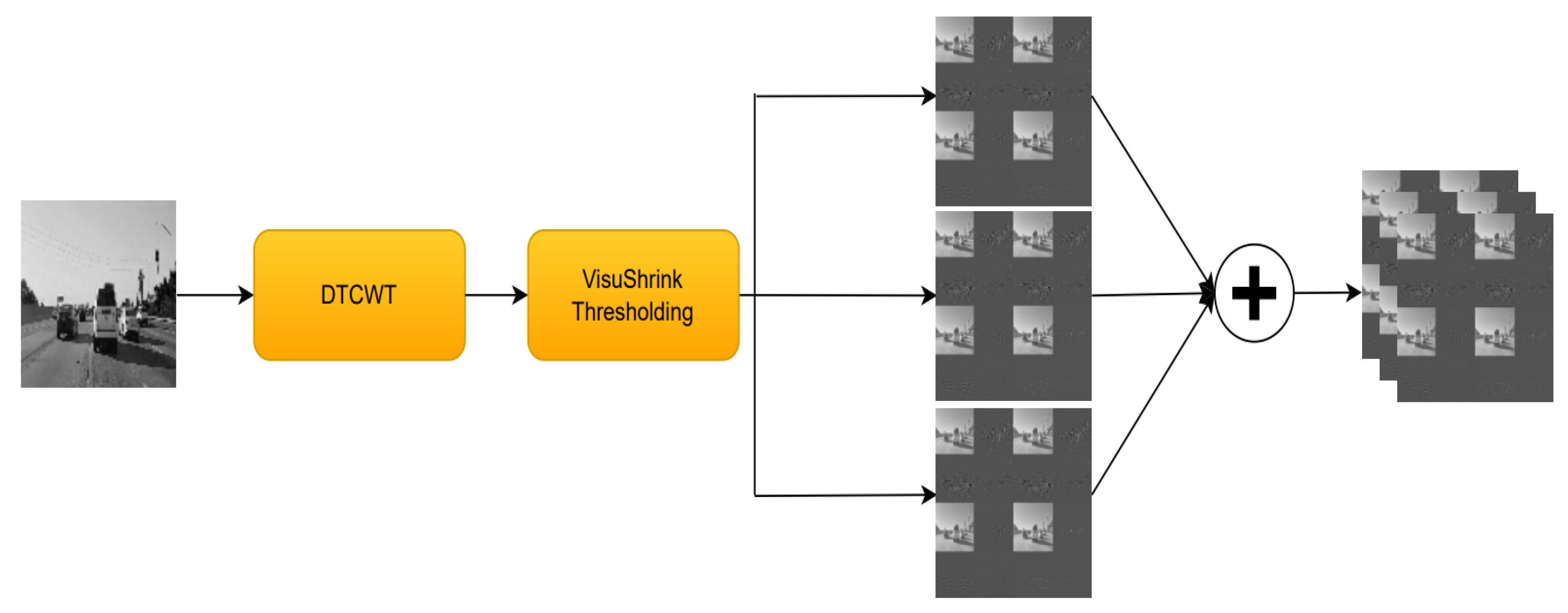
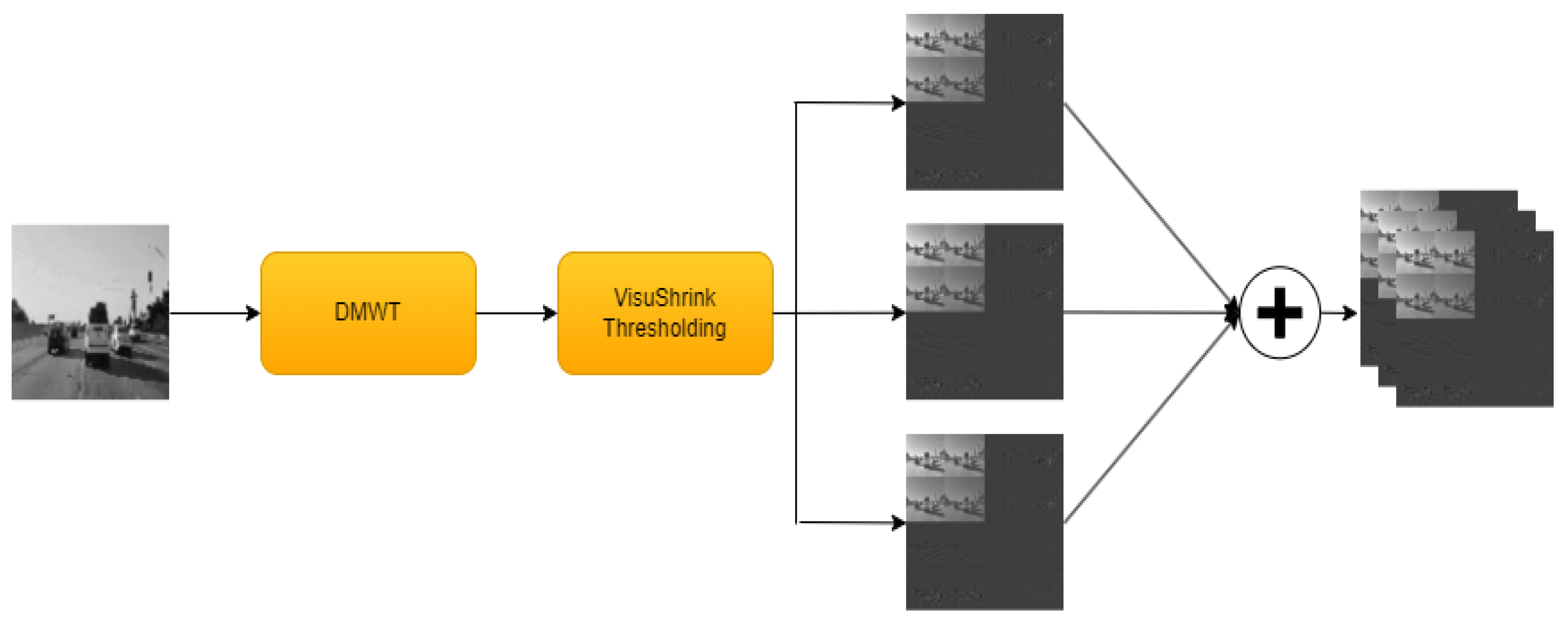
3.2. Wavelet Transform
3.2.1. Discrete Wavelet Transform
3.2.2. Dual-Tree Complex Wavelet Transform
3.2.3. Discrete Multi-Wavelet Transform
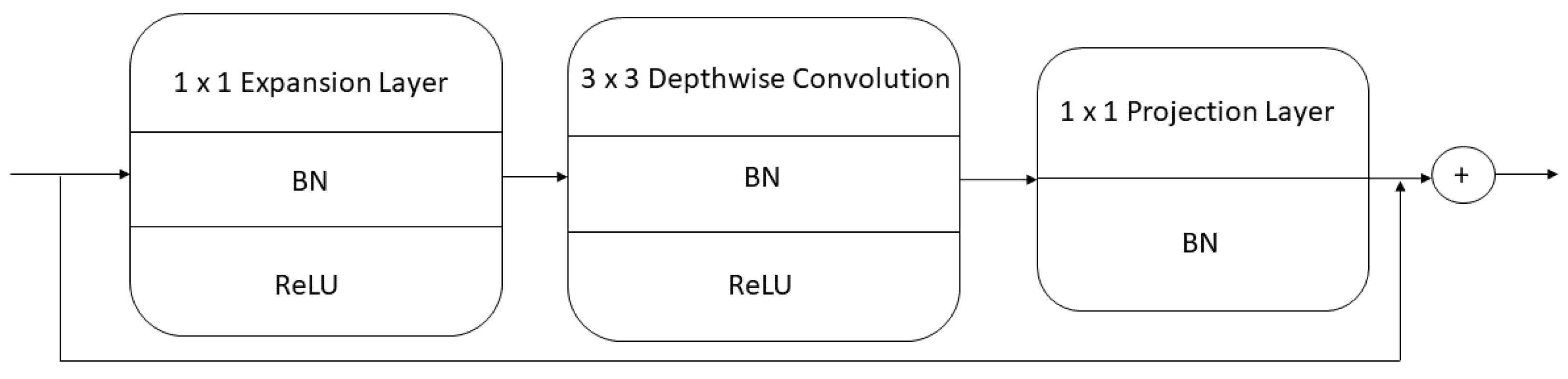
3.3. Spatial Feature Extraction and Transfer Learning
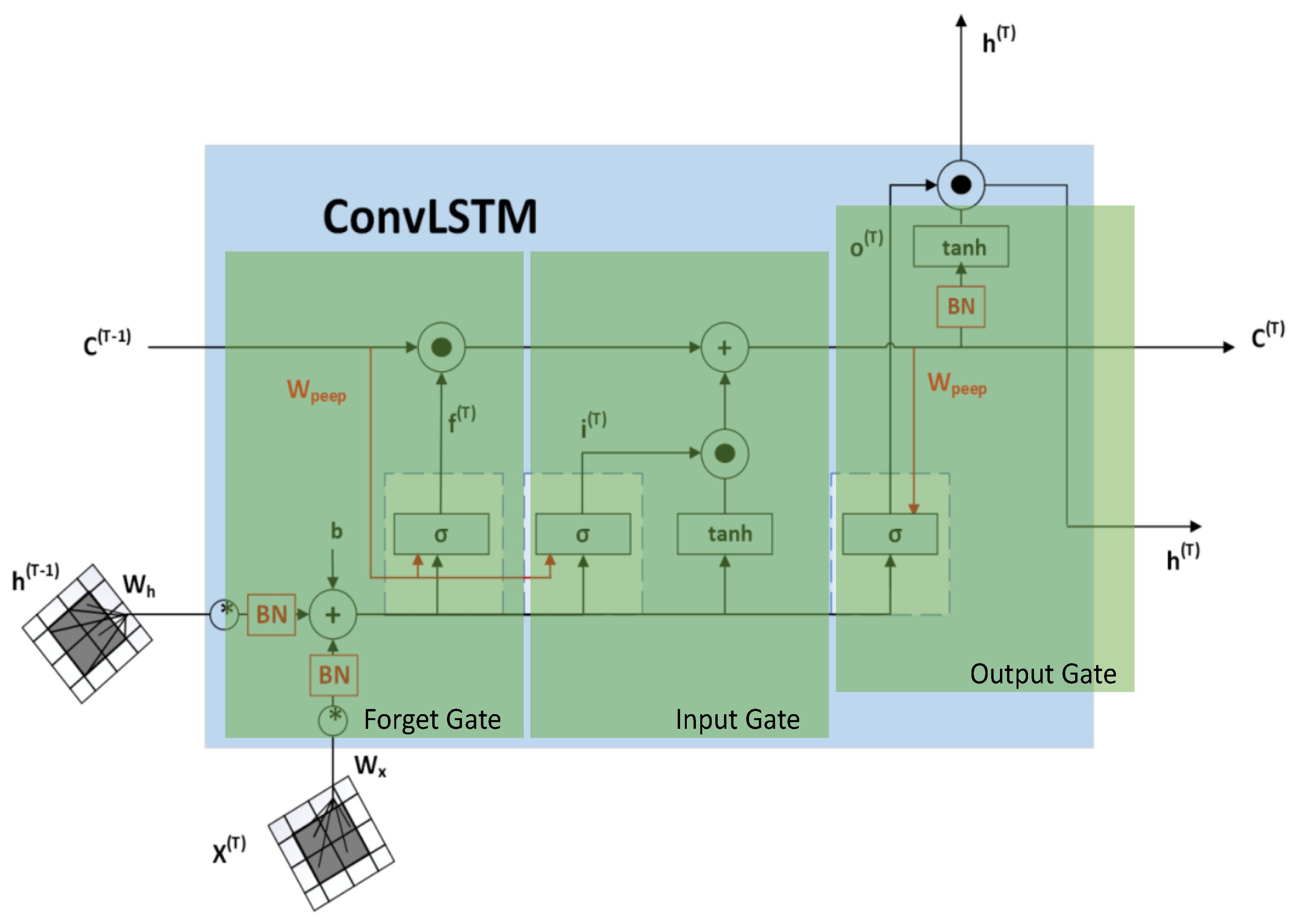
3.4. Temporal Feature Extraction
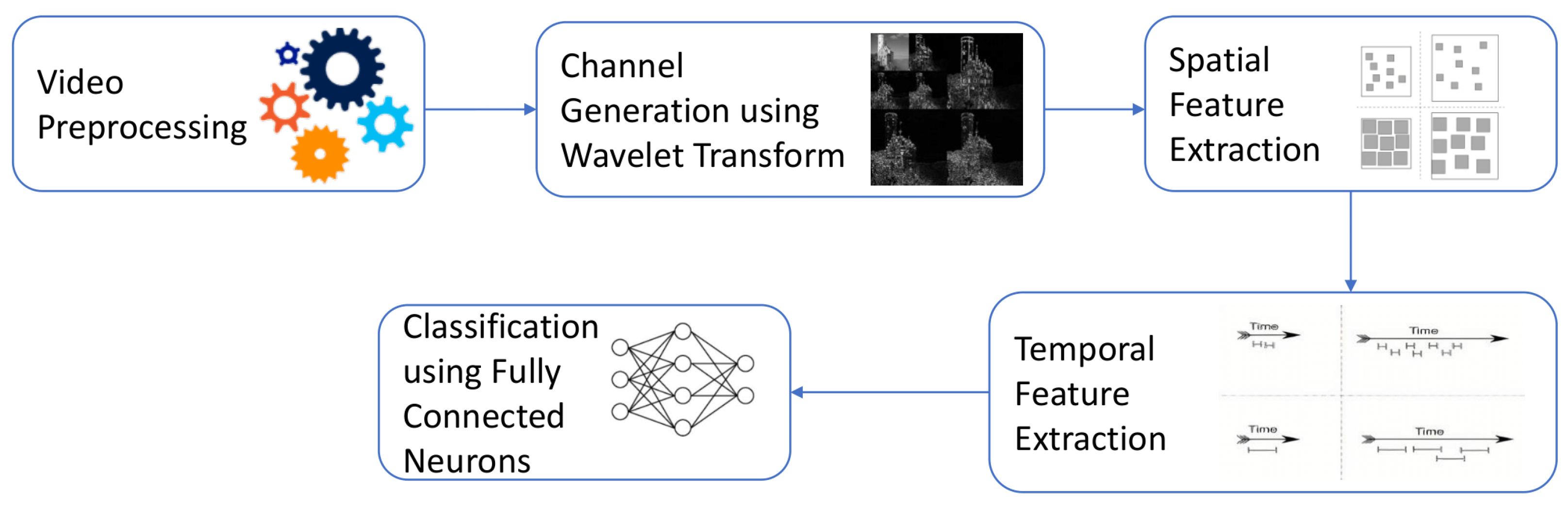
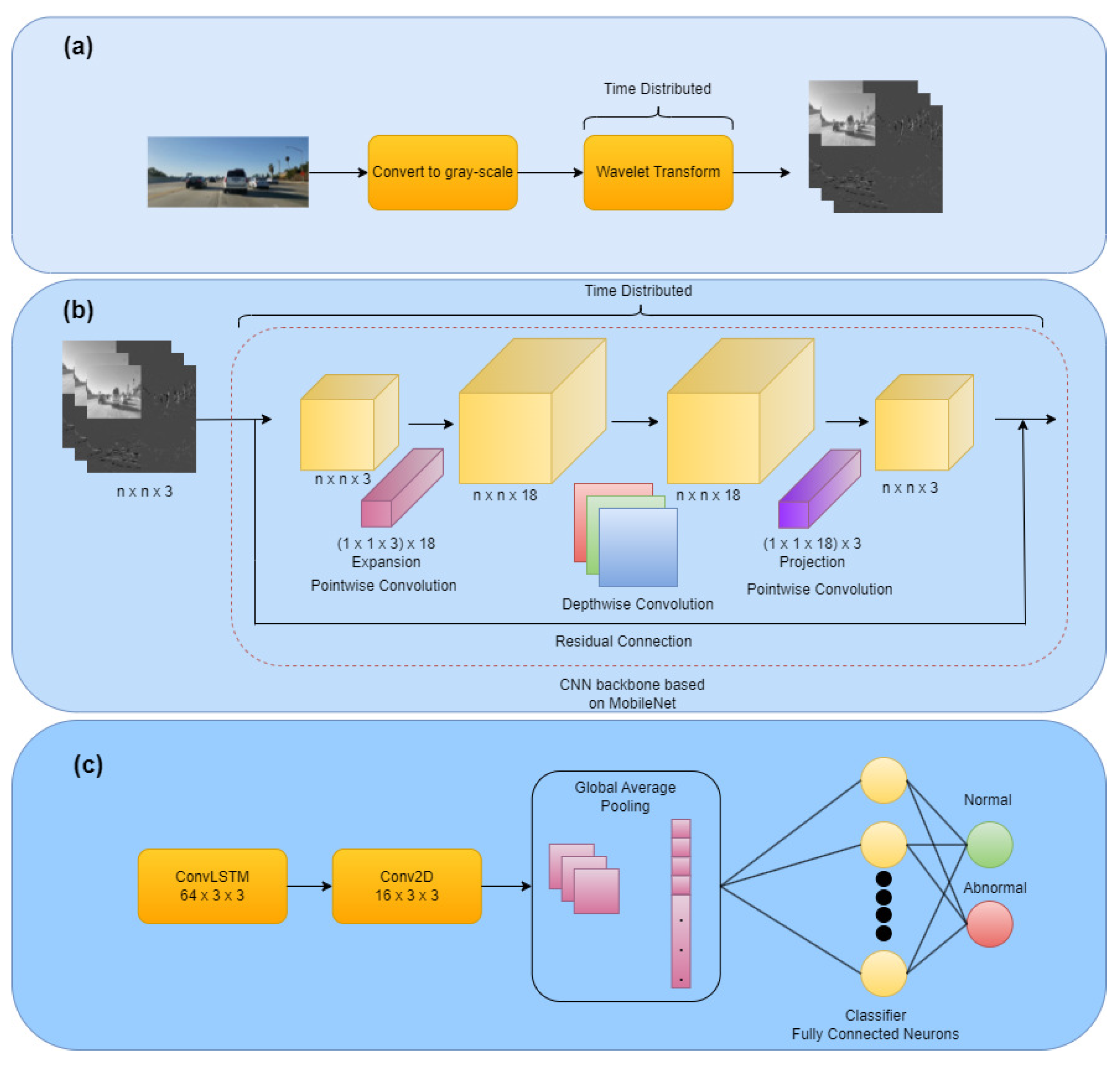
3.5. Proposed Model Architecture
- Time Distributed Layer: this layer is considered a wrapper. It has memory and connects features extracted along a sequence of frames. This wrapper uses the same instance of a layer for all the input sequences while sharing the same weights for all the input instances, which makes this layer very computationally efficient. A sequence of frames of shapes . The overall shape of such a sequence would be .
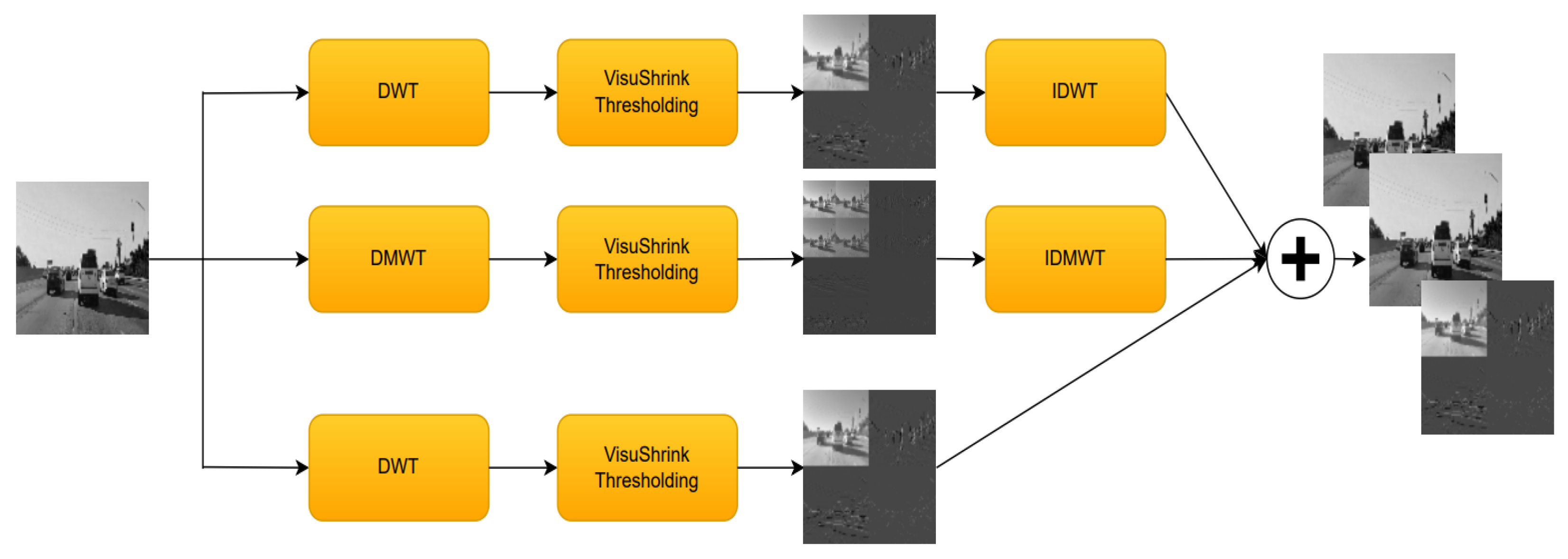
- ISCA Block: this block is responsible for the channel augmentation; it has multiple layers that are used to generate wavelet-based features using different wavelet transform techniques like DWT, DTCWT, DMWT, and their corresponding synthesis transform layers. This block also contains thresholding layers. This block is wrapped by a time distributed layer to apply this operation to every frame in the sequence. The output shape after applying this block would be .
- Convolutional Layer: this layer performs convolution operation over input data. MobileNetV2 is used here for spatial feature extraction with 40 trainable layers only as transfer learning is applied. MobileNetV2 is encapsulated with the time distribution layer so that an instance of MobileNetV2 is applied to each frame in the sequence.
- ConvLSTM Layer: it contains Convolution and LSTM layers. The internal matrix multiplications that exist in a typical FC-LSTM are exchanged with convolution operations. Consequently, the input data that goes through the ConvLSTM cells keeps the input dimension as 3D instead of a 1D vector. A total of 64 units were used. The internal convolution performed inside them is performed with a window of and the padding is ’same’.
- Batch Normalization (BN) Layer: this layer is applied to a patch of training data to maintain the mean output close to zero and the output standard deviation close to one.
- Dropout Layer: it is a regularization layer. It is added to reduce overfitting.
- Global Average Pooling Layer: this layer converts a matrix to a vector by moving with an average window. It is usually used right before the classification part.
- Dense Layer: it is a layer of fully connected neurons, it is usually used for feature extraction in the middle layers or used as the last layer in the model where the classification takes place. It contains fully connected neurons.
4. Results
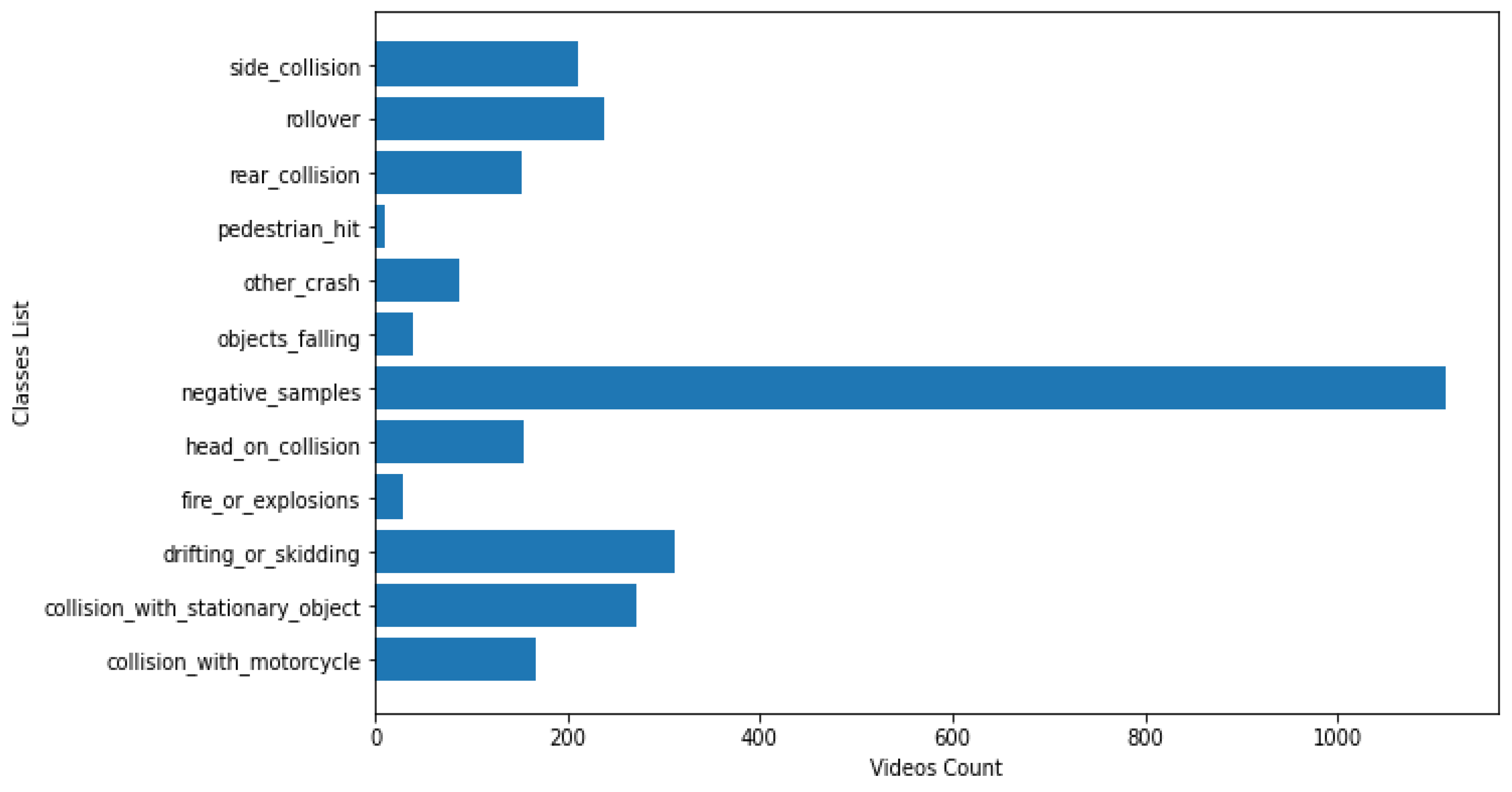
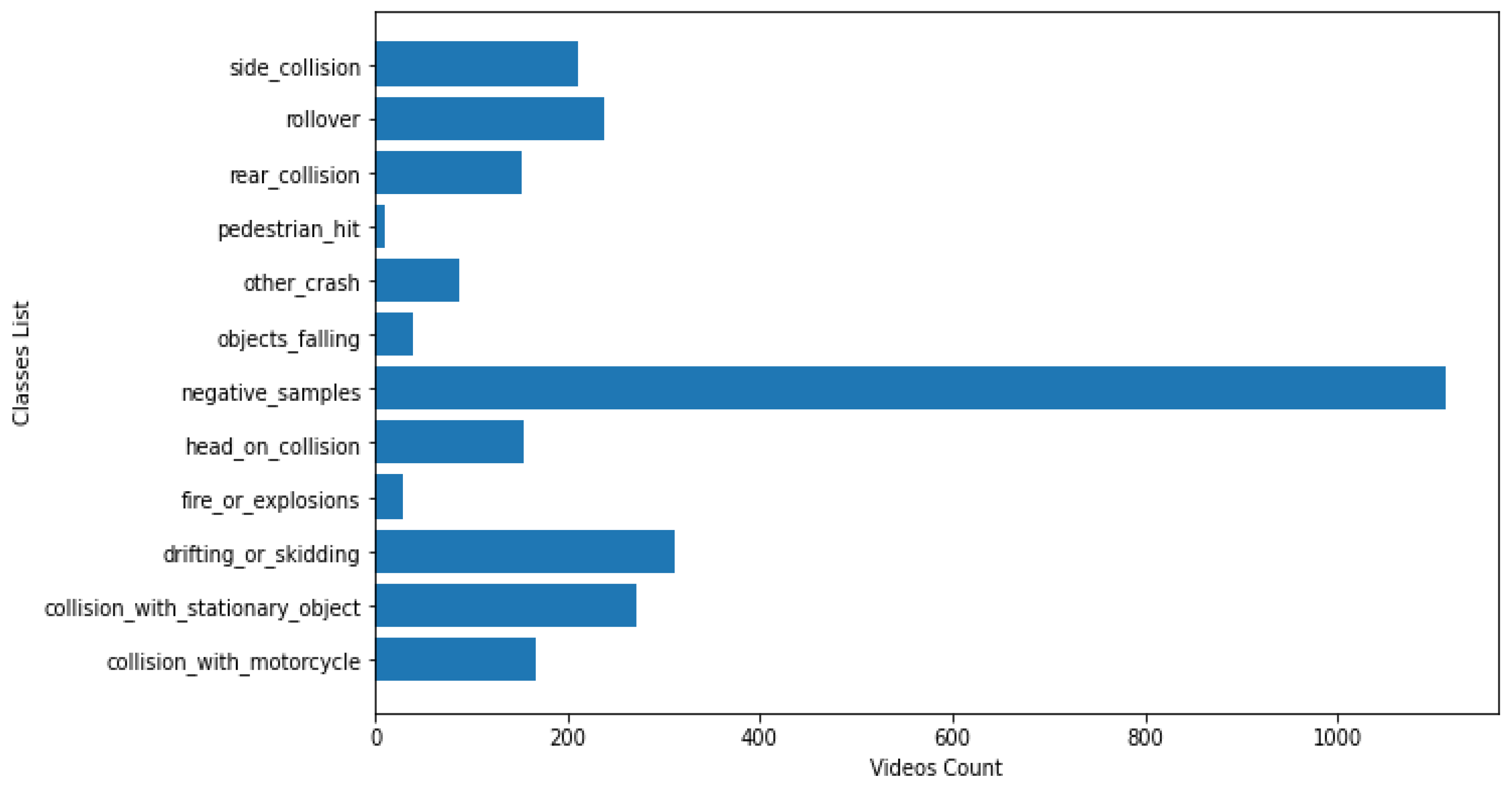
4.1. Datasets
4.1.1. Highway Incidents Detection Dataset
4.1.2. Real Life Violence Situations Dataset
4.1.3. Movie Fights and Hockey Fights Datasets
4.1.4. Datasets Observations and Analysis
4.2. Training Environment and Tools Used
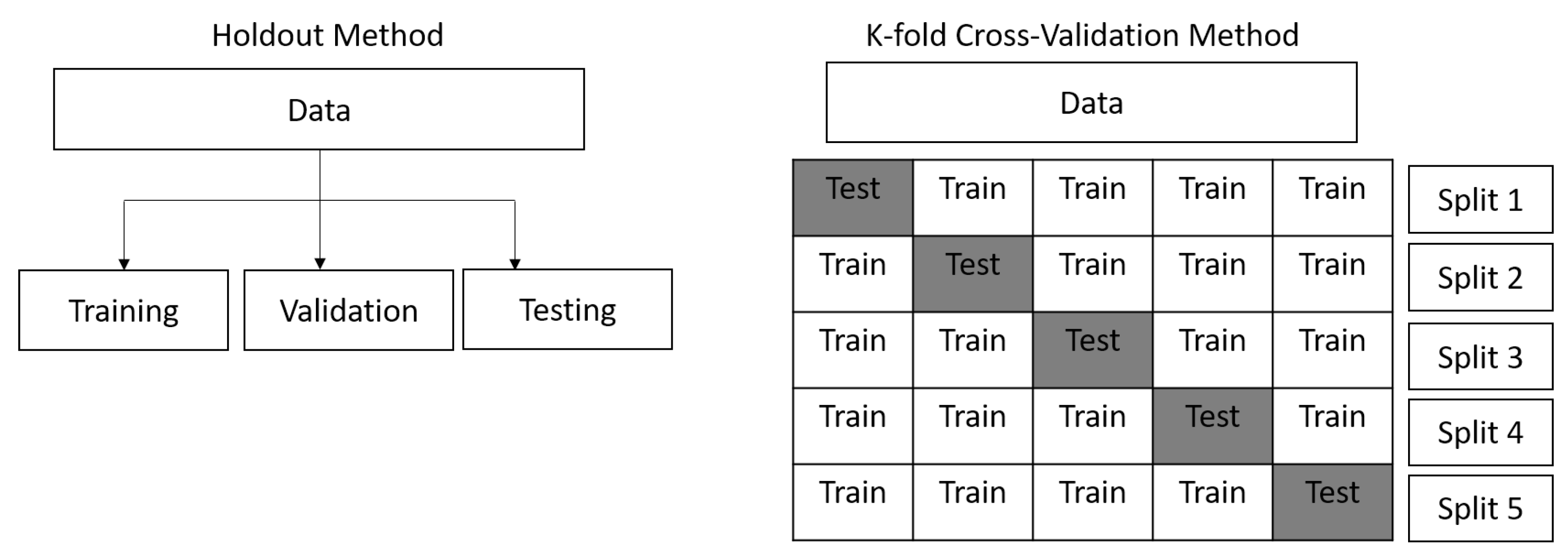
4.3. Evaluation Metrics and Methods Used
4.4. Models Evaluation
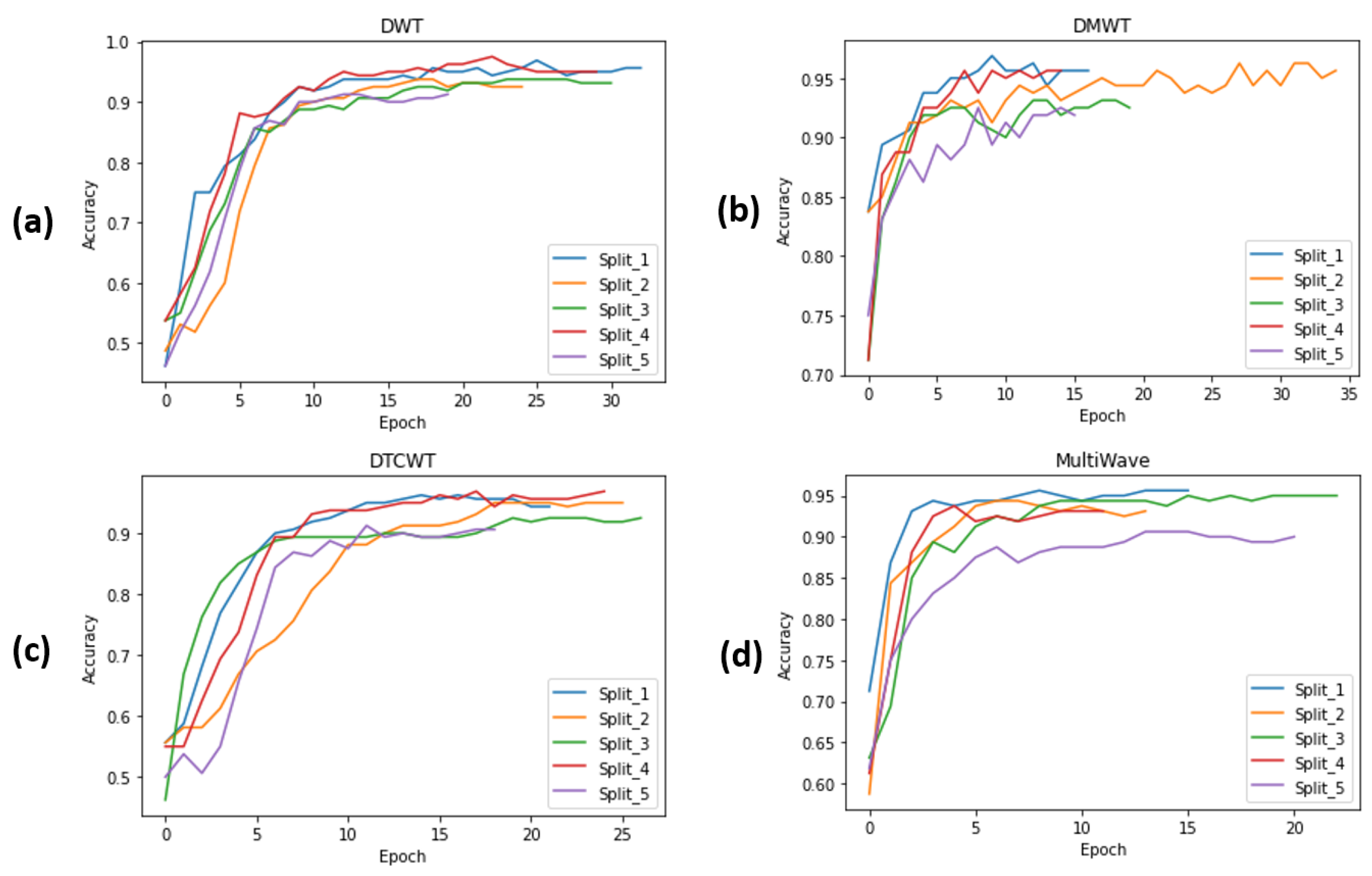
4.4.1. Evaluating Different Proposed ISCA Blocks by Holdout Method
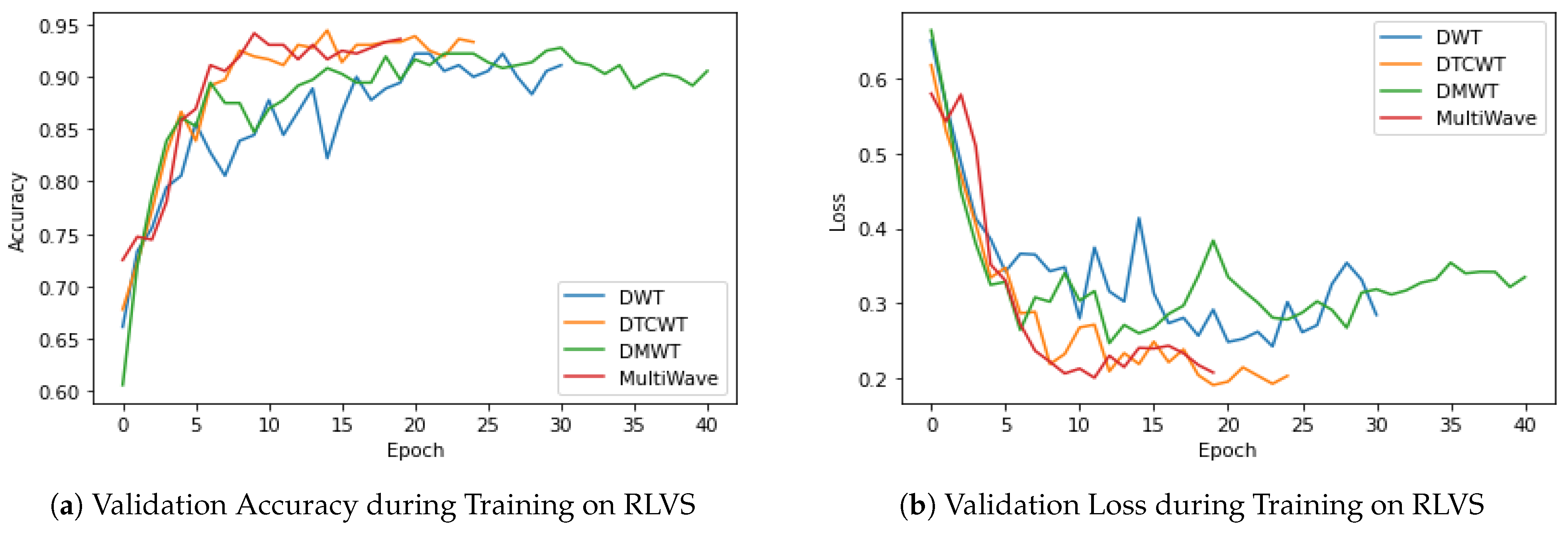
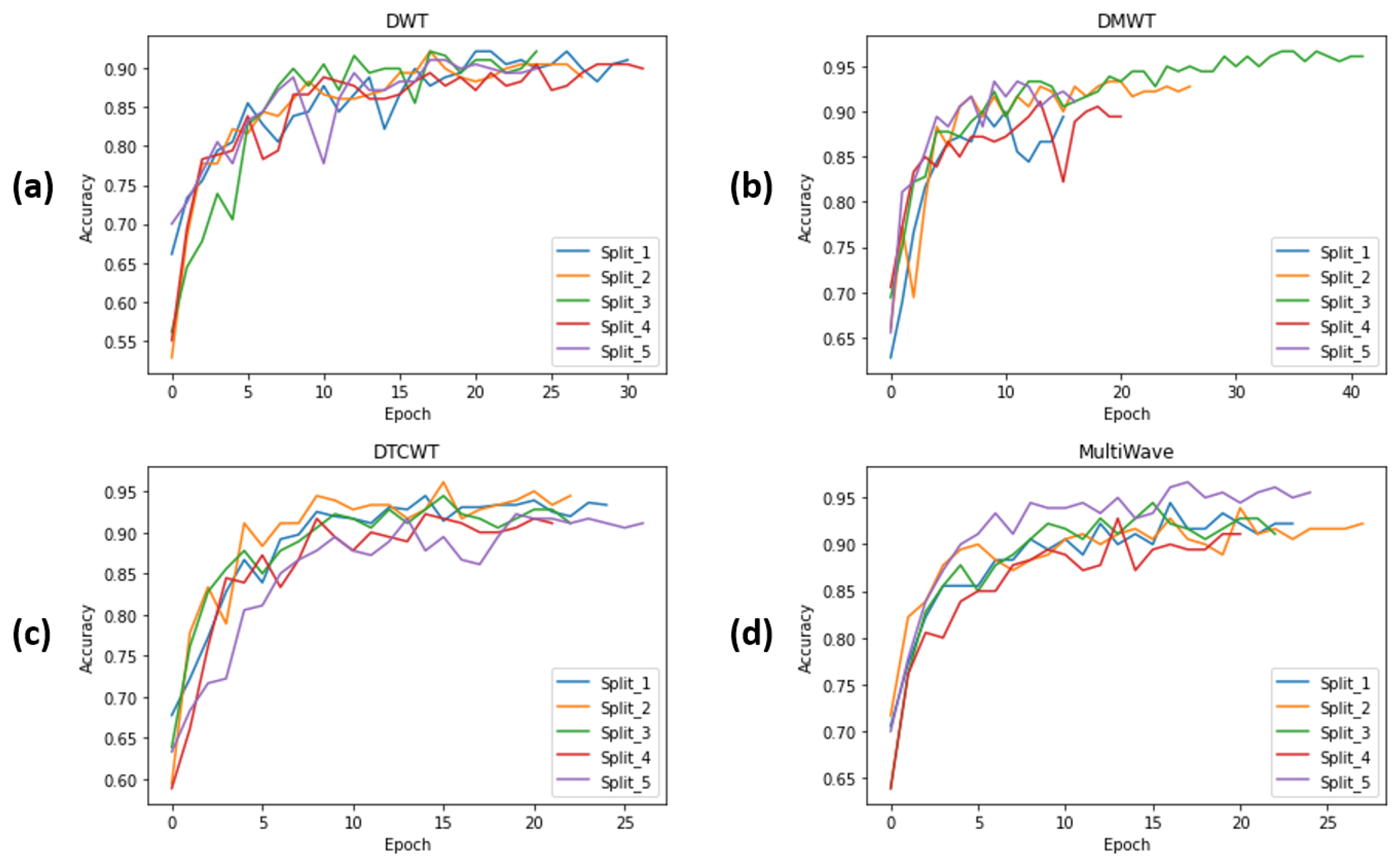
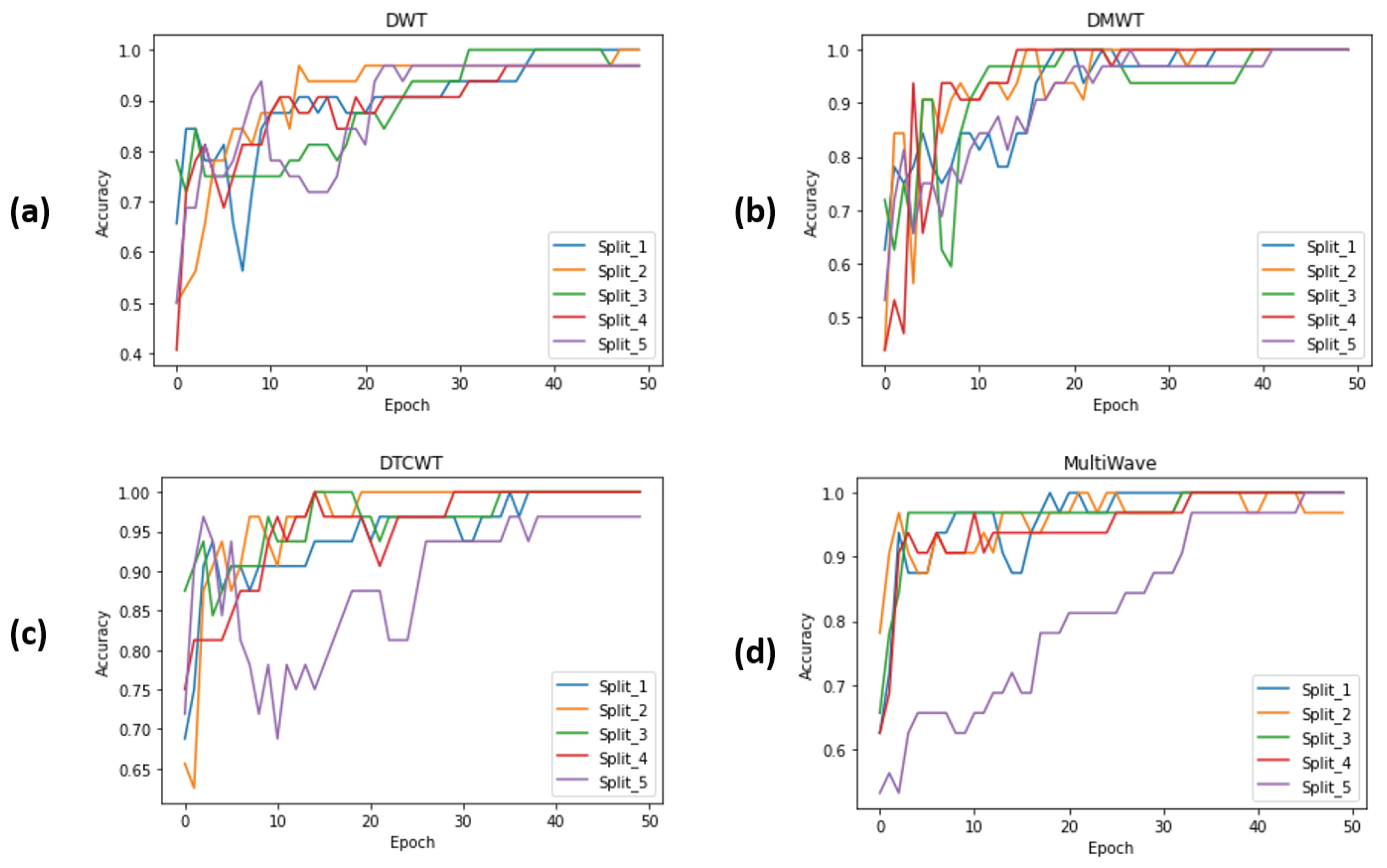
4.4.2. Evaluating Different Proposed ISCA Blocks by Cross-Validation on RLVS Dataset
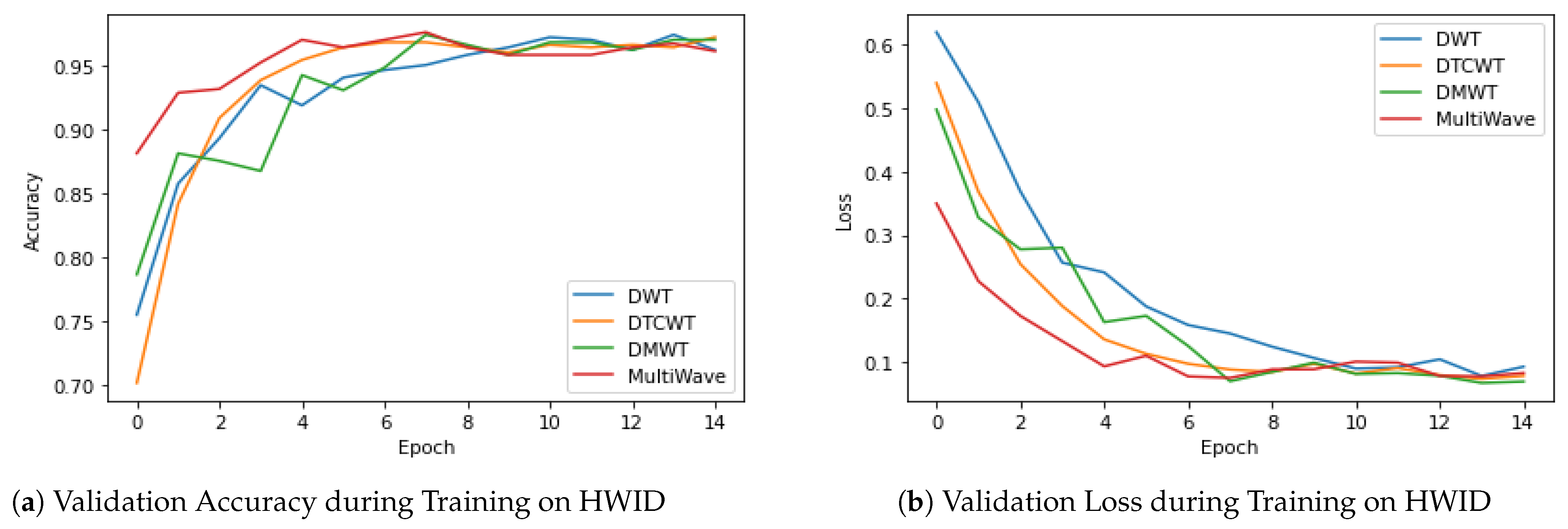
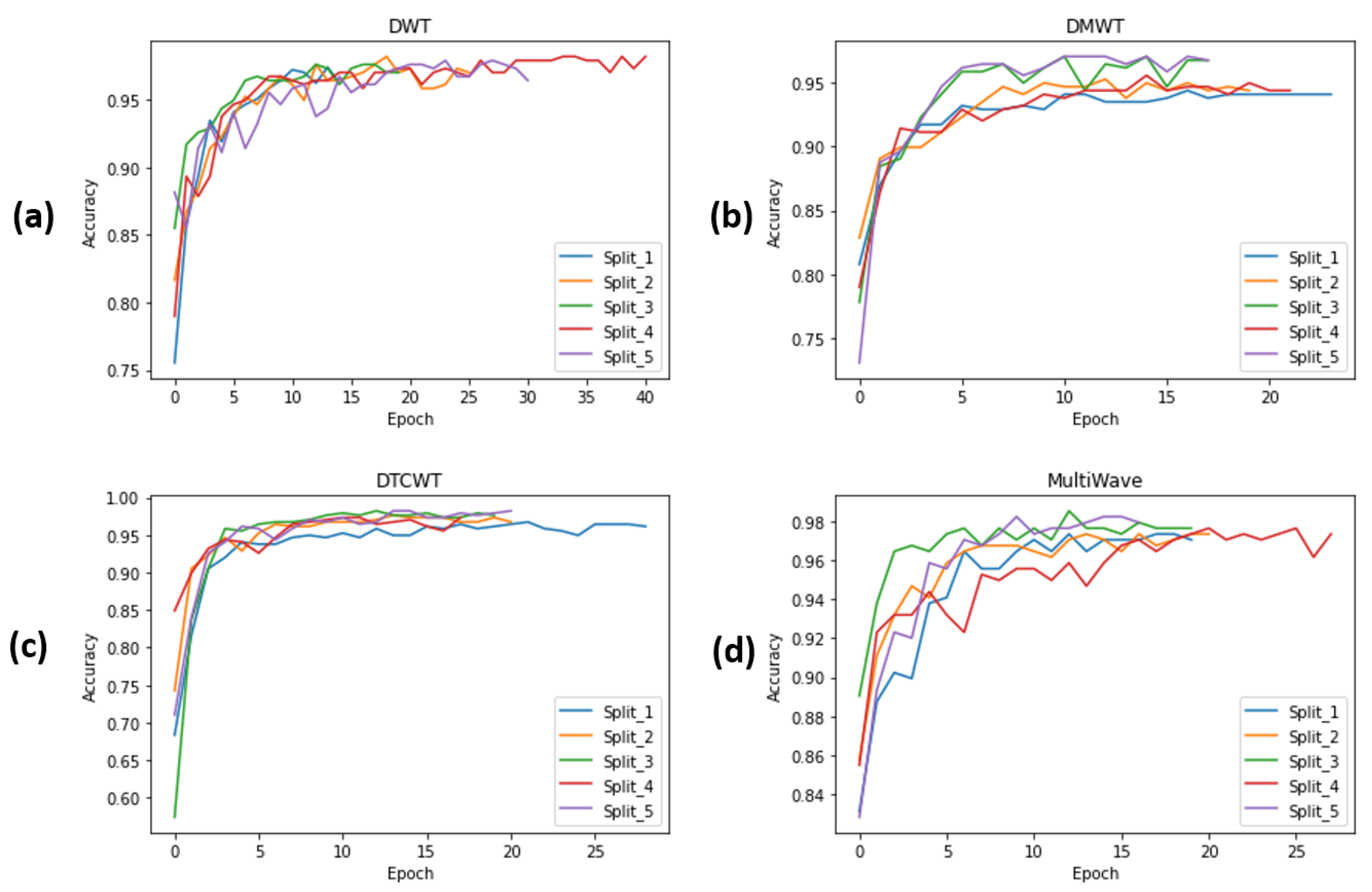
4.4.3. Evaluating Different Proposed ISCA Blocks by Cross-Validation on HWID Dataset
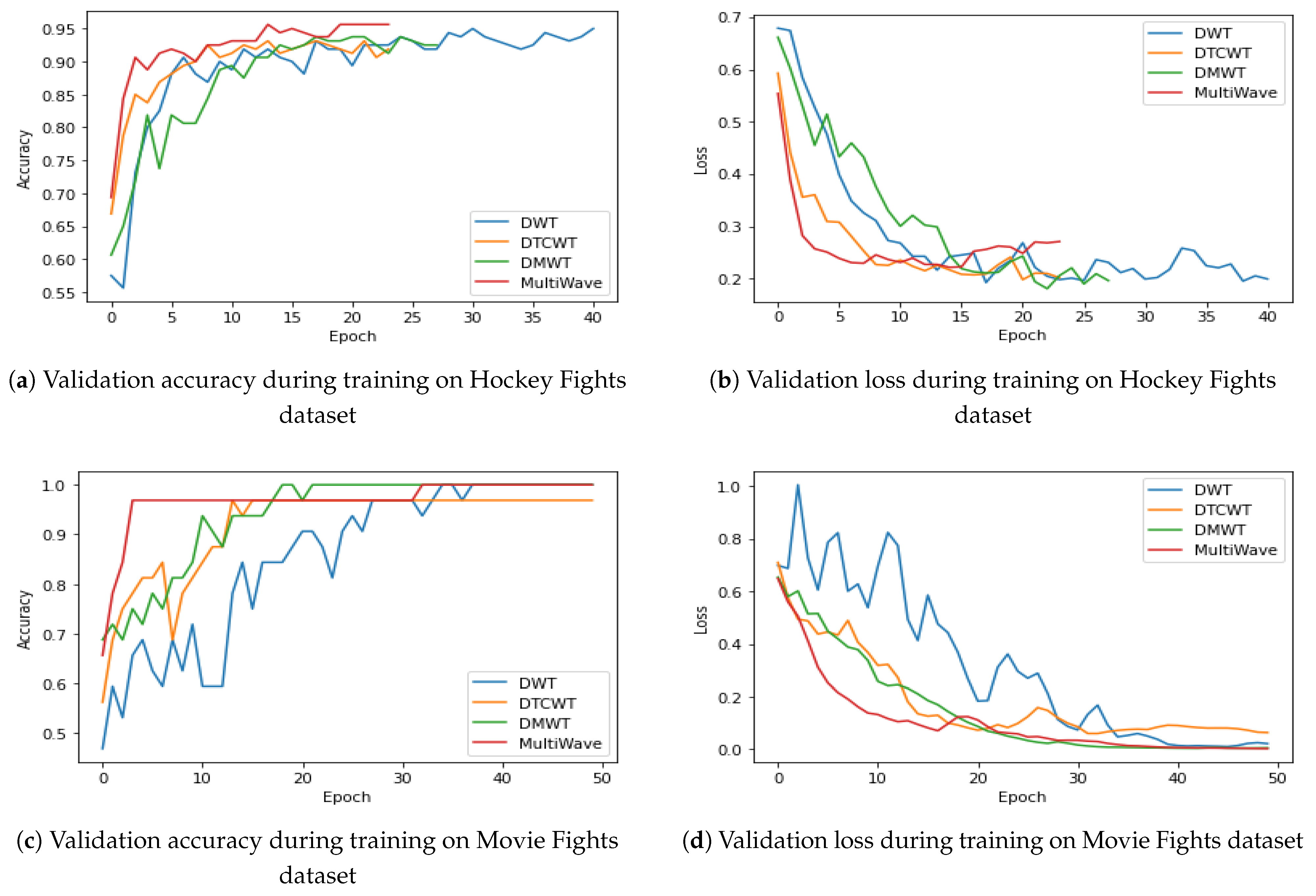
4.4.4. Evaluating Different Proposed ISCA Blocks by Cross-Validation on Hockey Fight Dataset
4.4.5. Evaluating Different Proposed ISCA Blocks by Cross-Validation on Movies Dataset
4.4.6. Evaluating Inference Time of Different ISCA Blocks
4.4.7. Model Evaluation Discussion and Main Takeaways
4.5. Ablation Study
4.5.1. Testing Different Input Sizes and Sequence Lengths
4.5.2. Testing Different Spatial Backbones
4.5.3. Testing Different Temporal Units
4.6. Comparison with Other Methods
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| ISCA | Integrated Serial Channel Augmentation |
| WT | Wavelet Transform |
| CWT | Continuous Wavelet Transform |
| DWT | Discrete Wavelet Transform |
| DMWT | Discrete Multi-Wavelet Transform |
| DTCWT | Dual-Tree Complex Wavelet Transform |
| ConvLSTM | Convolutional Long-Short Term Memory |
| RLVS | Real Live Violence Situations |
| HWID | Highway Incident Detection |
References
- Shoukry, N.; Abd El Ghany, M.A.; Salem, M.A.M. Multi-Modal Long-Term Person Re-Identification Using Physical Soft Bio-Metrics and Body Figure. Appl. Sci. 2022, 12, 2835. [Google Scholar] [CrossRef]
- Fahmy, M.; Fahmy, O. A new image denoising technique using orthogonal complex wavelets. In Proceedings of the 2018 35th National Radio Science Conference (NRSC), Cairo, Egypt, 20–22 March 2018; pp. 223–230. [Google Scholar] [CrossRef]
- Fahmy, G.; Fahmy, O.; Fahmy, M. Fast Enhanced DWT based Video Micro Movement Magnification. In Proceedings of the 2019 IEEE International Symposium on Signal Processing and Information Technology (ISSPIT), Ajman, United Arab Emirates, 10–12 December 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Alaba, S.; Ball, J. WCNN3D: Wavelet Convolutional Neural Network-Based 3D Object Detection for Autonomous Driving. Sensors 2022, 22, 7010. [Google Scholar] [CrossRef] [PubMed]
- Yao, T.; Pan, Y.; Li, Y.; Ngo, C.W.; Mei, T. Wave-ViT: Unifying Wavelet and Transformers for Visual Representation Learning. In Proceedings of the Computer Vision—ECCV 2022, Tel Aviv, Israel, 23–27 October 2022; pp. 328–345. [Google Scholar] [CrossRef]
- Zhao, X.; Huang, P.; Shu, X. Wavelet-Attention CNN for image classification. Multimed. Syst. 2022, 28, 915–924. [Google Scholar] [CrossRef]
- Williams, T.; Li, R. Wavelet Pooling for Convolutional Neural Networks. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Fujieda, S.; Takayama, K.; Hachisuka, T. Wavelet Convolutional Neural Networks for Texture Classification. arXiv 2017, arXiv:1707.07394. [Google Scholar]
- Huang, H.; He, R.; Sun, Z.; Tan, T. Wavelet-SRNet: A Wavelet-Based CNN for Multi-scale Face Super Resolution. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1698–1706. [Google Scholar] [CrossRef]
- Ridha Ilyas, B.; Beladgham, M.; Merit, K.; Taleb Ahmed, A. Improved Facial Expression Recognition Based on DWT Feature for Deep CNN. Electronics 2019, 8, 324. [Google Scholar] [CrossRef]
- Youyi, J.; Xiao, L. A Method for Face Recognition Based on Wavelet Neural Network. In Proceedings of the 2010 Second WRI Global Congress on Intelligent Systems, Wuhan, China, 16–17 December 2010; Volume 3, pp. 133–136. [Google Scholar] [CrossRef]
- Liu, P.; Zhang, H.; Zhang, K.; Lin, L.; Zuo, W. Multi-level Wavelet-CNN for Image Restoration. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 886–88609. [Google Scholar] [CrossRef]
- Wang, H.; Wu, X.; Huang, Z.; Xing, E. High-Frequency Component Helps Explain the Generalization of Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 8681–8691. [Google Scholar] [CrossRef]
- Lahiri, D.; Dhiman, C.; Vishwakarma, D. Abnormal human action recognition using average energy images. In Proceedings of the In 2017 Conference on Information and Communication Technology (CICT), Gwalior, India, 3–5 November 2017; pp. 1–5. [Google Scholar] [CrossRef]
- Dhiman, C.; Vishwakarma, D. A Robust Framework for Abnormal Human Action Recognition using R-Transform and Zernike Moments in Depth Videos. IEEE Sens. J. 2019, 19, 5195–5203. [Google Scholar] [CrossRef]
- Vishwakarma, D.; Dhiman, C. A unified model for human activity recognition using spatial distribution of gradients and difference of Gaussian kernel. Vis. Comput. 2019, 35, 1–19. [Google Scholar] [CrossRef]
- Ayman, O.; Marzouk, N.; Atef, E.; Salem, M.; Salem, M.A.M.M. Abnormal Action Detection In Video Surveillance. In Proceedings of the 9th IEEE International Conference on Intelligent Computing and Information Systems, Cairo, Egypt, 8–9 December 2020. [Google Scholar] [CrossRef]
- Tay, N.; Connie, T.; Ong, T.S.; Goh, K.; Teh, P.S. A Robust Abnormal Behavior Detection Method Using Convolutional Neural Network. In Proceedings of the 5th ICCST 2018, Kota Kinabalu, Malaysia, 29–30 August 2018; pp. 37–47. [Google Scholar] [CrossRef]
- Arunnehru, J.; Chamundeeswari, G.; Bharathi, S. Human Action Recognition using 3D Convolutional Neural Networks with 3D Motion Cuboids in Surveillance Videos. Procedia Comput. Sci. 2018, 133, 471–477. [Google Scholar] [CrossRef]
- Vršková, R.; Hudec, R.; Kamencay, P.; Sykora, P. Human Activity Classification Using the 3DCNN Architecture. Appl. Sci. 2022, 12, 931. [Google Scholar] [CrossRef]
- Dhiman, C.; Vishwakarma, D.; Agarwal, P. Part-wise Spatio-temporal Attention Driven CNN-based 3D Human Action Recognition. ACM Trans. Multimed. Comput. Commun. Appl. 2021, 17, 1–24. [Google Scholar] [CrossRef]
- Chen, B.; Tang, H.; Zhang, Z.; Tong, G.; Li, B. Video-based action recognition using spurious-3D residual attention networks. IET Image Process. 2022, 16, 3097–3111. [Google Scholar] [CrossRef]
- Qian, H.; Zhou, X.; Zheng, M. Abnormal Behavior Detection and Recognition Method Based on Improved ResNet Model. Comput. Mater. Contin. 2020, 65, 2153–2167. [Google Scholar] [CrossRef]
- Magdy, M.; Fakhr, M.; Maghraby, F. Violence 4D: Violence detection in surveillance using 4D convolutional neural networks. IET Comput. Vision 2022, 17, 282–294. [Google Scholar] [CrossRef]
- Vršková, R.; Hudec, R.; Kamencay, P.; Sykora, P. A New Approach for Abnormal Human Activities Recognition Based on ConvLSTM Architecture. Sensors 2022, 22, 2946. [Google Scholar] [CrossRef] [PubMed]
- Vijeikis, R.; Raudonis, V.; Dervinis, G. Efficient Violence Detection in Surveillance. Sensors 2022, 22, 2216. [Google Scholar] [CrossRef] [PubMed]
- Rendón-Segador, F.; Alvarez-Garcia, J.; Enriquez, F.; Deniz, O. ViolenceNet: Dense Multi-Head Self-Attention with Bidirectional Convolutional LSTM for Detecting Violence. Electronics 2021, 10, 1601. [Google Scholar] [CrossRef]
- Kalfaoglu, E.; Kalkan, S.; Alatan, A. Late Temporal Modeling in 3D CNN Architectures with BERT for Action Recognition. In Proceedings of the Computer Vision–ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020. [Google Scholar]
- Moaaz, M.; Mohamed, E. Violence Detection In Surveillance Videos Using Deep Learning. Inform. Bull. Fac. Comput. Artif. Intell. 2020, 2, 6. [Google Scholar] [CrossRef]
- Ullah, A.; Ahmad, J.; Muhammad, K.; Sajjad, M.; Baik, S. Action Recognition in Video Sequences using Deep Bi-directional LSTM with CNN Features. IEEE Access 2017, 6, 1155–1166. [Google Scholar] [CrossRef]
- Chen, W.; Zheng, F.; Gao, S.; Hu, K. An LSTM with Differential Structure and Its Application in Action Recognition. Math. Probl. Eng. 2022, 2022, 7316396. [Google Scholar] [CrossRef]
- Al-berry, M.; Salem, M.A.M.M.; Ebied, H.; Hussein, A.; Tolba, M. Action Recognition Using Stationary Wavelet-Based Motion Images. In Intelligent Systems’ 2014, Proceedings of the 7th IEEE International Conference Intelligent Systems IS’2014, Warsaw, Poland, 24--26 September 2014; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; Volume 323, pp. 743–753. [Google Scholar] [CrossRef]
- Al-berry, M.; Salem, M.A.M.M.; Ebied, H.; Hussein, A.; Tolba, M. Action Classification Using Weighted Directional Wavelet LBP Histograms. In Proceedings of the 1st International Conference on Advanced Intelligent System and Informatics (AISI2015), Beni Suef, Egypt, 28–30 November 2015. [Google Scholar] [CrossRef]
- Chatterjee, R.; Halder, R. Discrete Wavelet Transform for CNN-BiLSTM-based Violence Detection. In Proceedings of the International Conference on Emerging Trends and Advances in Electrical Engineering and Renewable Energy, Bhubaneswar, India, 5–6 March 2020; Springer Nature: Singapore, 2020. [Google Scholar]
- Nedorubova, A.; Kadyrova, A.; Khlyupin, A. Human Activity Recognition using Continuous Wavelet Transform and Convolutional Neural Networks. arXiv 2021, arXiv:2106.12666. [Google Scholar] [CrossRef]
- Neimark, D.; Bar, O.; Zohar, M.; Asselmann, D. Video Transformer Network. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), Montreal, BC, Canada, 11–17 October2021; pp. 3156–3165. [Google Scholar] [CrossRef]
- Girdhar, R.; Carreira, J.; Doersch, C.; Zisserman, A. Video Action Transformer Network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Sargano, A.B.; Angelov, P.; Habib, Z. A Comprehensive Review on Handcrafted and Learning-Based Action Representation Approaches for Human Activity Recognition. Appl. Sci. 2017, 7, 110. [Google Scholar] [CrossRef]
- Mumtaz, N.; Ejaz, N.; Habib, S.; Mohsin, S.M.; Tiwari, P.; Band, S.S.; Kumar, N. An overview of violence detection techniques: Current challenges and future directions. Artif. Intell. Rev. 2023, 56, 4641–4666. [Google Scholar] [CrossRef]
- Malik, Z.; Shapiai, M.I.B. Human action interpretation using convolutional neural network: A survey. Mach. Vis. Appl. 2022, 33, 37. [Google Scholar] [CrossRef]
- Ulhaq, A.; Akhtar, N.; Pogrebna, G.; Mian, A. Vision Transformers for Action Recognition: A Survey. arXiv 2022, arXiv:2209.05700. [Google Scholar]
- Debnath, L.; Antoine, J.P. Wavelet Transforms and Their Applications. Phys. Today 2003, 56, 68. [Google Scholar] [CrossRef]
- Skodras, N. Discrete Wavelet Transform: An Introduction; Hellenic Open University Technical Report; Hellenic Open University: Patras, Greece, 2003; Volume 2, pp. 1–26. [Google Scholar]
- Selesnick, I.; Baraniuk, R.; Kingsbury, N. The dual-tree complex wavelet transform. Signal Process. Mag. IEEE 2005, 22, 123–151. [Google Scholar] [CrossRef]
- Geronimo, J.; Hardin, D.; Massopust, P. Fractal Functions and Wavelet Expansion Based on Several Scaling Functions. J. Approx. Theory 1994, 78, 373–401. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2020, 109, 43–76. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Li, F.F. ImageNet: A Large-Scale Hierarchical Image Database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Shi, X.; Chen, Z.; Wang, H.; Yeung, D.Y.; Wong, W.k.; Woo, W.c. Convolutional LSTM Network: A Machine Learning Approach for Precipitation Nowcasting. arXiv 2015, arXiv:1506.04214. [Google Scholar] [CrossRef]
- Sernani, P.; Falcionelli, N.; Tomassini, S.; Contardo, P.; Dragoni, A.F. Deep Learning for Automatic Violence Detection: Tests on the AIRTLab Dataset. IEEE Access 2021, 9, 160580–160595. [Google Scholar] [CrossRef]
- Chen, S.; Xu, X.; Zhang, Y.; Shao, D.; Zhang, S.; Zeng, M. Two-stream convolutional LSTM for precipitation nowcasting. Neural Comput. Appl. 2022, 34, 13281–13290. [Google Scholar] [CrossRef]
- Shibuya, E.; Hotta, K. Cell image segmentation by using feedback and convolutional LSTM. Vis. Comput. 2021, 38, 3791–3801. [Google Scholar] [CrossRef]
- Wei, H.; Li, K.; Li, H.; Lyu, Y.; Hu, X. Detecting Video Anomaly with a Stacked Convolutional LSTM Framework. In Proceedings of the International Conference on Computer Vision Systems, Thessaloniki, Greece, 23–25 September 2019; Springer International Publishing: Cham, Switzerland, 2019; pp. 330–342. [Google Scholar] [CrossRef]
- Donoho, D. De-noising by soft-thresholding. IEEE Trans. Inf. Theory 1995, 41, 613–627. [Google Scholar] [CrossRef]
- Donoho, D.L.; Johnstone, I.M. Adapting to Unknown Smoothness via Wavelet Shrinkage. J. Am. Stat. Assoc. 1995, 90, 1200–1224. [Google Scholar] [CrossRef]
- Kezebou, L.; Oludare, V.; Panetta, K.; Intriligator, J.; Agaian, S. Highway accident detection and classification from live traffic surveillance cameras: A comprehensive dataset and video action recognition benchmarking. In Proceedings of the Multimodal Image Exploitation and Learning, Orlando, FL, USA, 3 April–12 June 2022; SPIE: Bellingham, WA, USA, 2022; Volume 12100, pp. 240–250. [Google Scholar]
- Soliman, M.M.; Kamal, M.H.; El-Massih Nashed, M.A.; Mostafa, Y.M.; Chawky, B.S.; Khattab, D. Violence Recognition from Videos using Deep Learning Techniques. In Proceedings of the 2019 Ninth International Conference on Intelligent Computing and Information Systems (ICICIS), Cairo, Egypt, 8–10 December 2019; pp. 80–85. [Google Scholar] [CrossRef]
- Nievas, E.B.; Suarez, O.D.; Garcia, G.B.; Sukthankar, R. Hockey Fight Detection Dataset. In Computer Analysis of Images and Patterns; Springer: Berlin/Heidelberg, Germany, 2011; pp. 332–339. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. arXiv 2015, arXiv:1603.04467. Available online: tensorflow.org (accessed on 2 January 2024).
- Bradski, G. The OpenCV Library. Dr. Dobb’S J. Softw. Tools 2000, 25, 120–123. [Google Scholar]
- Lee, G.R.; Gommers, R.; Waselewski, F.; Wohlfahrt, K.; Leary, A. PyWavelets: A Python package for wavelet analysis. J. Open Source Softw. 2019, 4, 1237. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June2016; pp. 770–778. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 2261–2269. [Google Scholar]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; PMLR: London, UK, 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. arXiv 2014, arXiv:1409.1259. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Graves, A.; Schmidhuber, J. Framewise phoneme classification with bidirectional LSTM networks. In Proceedings of the 2005 IEEE International Joint Conference on Neural Networks, Montreal, QC, Canada, 31 July–4 August 2005; Volume 4, pp. 2047–2052. [Google Scholar] [CrossRef]
- Bi, Y.; Li, D.; Luo, Y. Combining Keyframes and Image Classification for Violent Behavior Recognition. Appl. Sci. 2022, 12, 8014. [Google Scholar] [CrossRef]
- Jain, B.; Paul, A.; Supraja, P. Violence Detection in Real Life Videos using Deep Learning. In Proceedings of the 2023 Third International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Bhilai, India, 5–6 January 2023; pp. 1–5. [Google Scholar] [CrossRef]
- Rathi, S.; Sharma, S.; Ojha, S.; Kumar, K. Violence Recognition from Videos Using Deep Learning. In Proceedings of the International Conference on Recent Trends in Computing, Mysuru, India, 16–17 March 2023; Mahapatra, R.P., Peddoju, S.K., Roy, S., Parwekar, P., Eds.; Springer Nature: Singapore, 2023; pp. 69–77. [Google Scholar]
- Jain, A.; Vishwakarma, D.K. Deep NeuralNet For Violence Detection Using Motion Features from Dynamic Images. In Proceedings of the 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 August 2020; pp. 826–831. [Google Scholar] [CrossRef]
- Hassner, T.; Itcher, Y.; Kliper-Gross, O. Violent flows: Real-time detection of violent crowd behavior. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Garcia-Cobo, G.; SanMiguel, J.C. Human skeletons and change detection for efficient violence detection in surveillance videos. Comput. Vis. Image Underst. 2023, 233, 103739. [Google Scholar] [CrossRef]
- Ding, C.; Fan, S.; Zhu, M.; Feng, W.; Jia, B. Violence Detection in Video by Using 3D Convolutional Neural Networks. In Proceedings of the Advances in Visual Computing, Las Vegas, NV, USA, 8–10 December 2014; Bebis, G., Boyle, R., Parvin, B., Koracin, D., McMahan, R., Jerald, J., Zhang, H., Drucker, S.M., Kambhamettu, C., El Choubassi, M., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 551–558. [Google Scholar]
- Carneiro, S.A.; da Silva, G.P.; Guimaraes, S.J.F.; Pedrini, H. Fight Detection in Video Sequences Based on Multi-Stream Convolutional Neural Networks. In Proceedings of the 2019 32nd SIBGRAPI Conference on Graphics, Patterns and Images (SIBGRAPI), Rio de Janeiro, Brazil, 28–30 October 2019; pp. 8–15. [Google Scholar] [CrossRef]
- Sharma, M.; Baghel, R. Video Surveillance for Violence Detection Using Deep Learning. In Proceedings of the Advances in Data Science and Management; Borah, S., Emilia Balas, V., Polkowski, Z., Eds.; Springer: Singapore, 2020; pp. 411–420. [Google Scholar]
- Deniz, O.; Serrano, I.; Bueno, G.; Kim, T.K. Fast violence detection in video. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; Volume 2, pp. 478–485. [Google Scholar]
- Velisavljevic, V.; Beferull-Lozano, B.; Vetterli, M.; Dragotti, P. Directionlets: Anisotropic Multidirectional representation with separable filtering. IEee Trans. Image Process. Publ. IEEE Signal Process. Soc. 2006, 15, 1916–1933. [Google Scholar] [CrossRef] [PubMed]
- Fahmy, O.; Fahmy, M. An Efficient Bivariate Image Denoising Technique Using New Orthogonal CWT Filter Design. IET Image Process. 2018, 12, 1354–1360. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | Reference(s) | Strengths | Weaknesses |
|---|---|---|---|
| Image Processing and Machine Learning | [38] | Computationally light, depending on the algorithm complexity used. | Poor generalization capability depending on the application and scenarios tackled. |
| CNN and Sequence Models | [39] | They can have good classification accuracy and can be computationally light depending on the number of layers used. They also can adapt to new data. | They can be memory demanding for training if the sequence length used for training is large. They can easily overfit/underfit data during training depending on the training setting used. |
| Spatiotemporal 3D CNN | [40] | Good classification accuracy, and can adapt to new data. | Some architectures are computationally extensive, while others lack effective representation. |
| Transformers | [41] | Good classification accuracy, and can adapt to new data. | Computationally extensive, due to the large number of trainable parameters, and the self-attention mechanism that processes long sequences of data at once. |
| Layer (Type) | Output Shape | Parameters |
|---|---|---|
| ISCA | (16, 100, 100, 3) | 0 |
| MobileNetV2 | (16, 3, 3, 1280) | 2,257,984 |
| ConvLSTM | (3, 3, 64) | 3,096,832 |
| BN | (3, 3, 64) | 256 |
| Conv2D | (3, 3, 16) | 9232 |
| Dropout | (3, 3, 16) | 0 |
| Global Avg. Pool | (16) | 0 |
| Fully Connected Neurons | (256) | 4352 |
| Dropout | (256) | 0 |
| Fully Connected Neurons | (2) | 514 |
| Dataset | Number of Videos | Number of Normal Videos | Number of Abnormal Videos | Duration (s) | Resolution | FPS |
|---|---|---|---|---|---|---|
| RLVS | 2000 | 1000 | 1000 | 3–7 | High | 10.5–37 |
| HWID | 2410 | 1110 | 1300 | 3–8 | High | 30 |
| Hockey Fights | 1000 | 500 | 500 | 1.6–1.96 | Low | 25 |
| Movie Fights | 200 | 100 | 100 | 1.66–2.04 | Low | 25–30 |
| ISCA Block Type | TP | FP | FN | TN |
|---|---|---|---|---|
| DWT | 85 | 14 | 6 | 95 |
| DMWT | 91 | 8 | 10 | 91 |
| DTCWT | 92 | 7 | 5 | 96 |
| MultiWave | 96 | 3 | 5 | 96 |
| ISCA Block Type | TP | FP | FN | TN |
|---|---|---|---|---|
| DWT | 320 | 15 | 18 | 370 |
| DMWT | 331 | 4 | 19 | 369 |
| DTCWT | 326 | 9 | 9 | 379 |
| MultiWave | 387 | 9 | 4 | 323 |
| ISCA Block Type | TP | FP | FN | TN |
|---|---|---|---|---|
| DWT | 87 | 9 | 8 | 96 |
| DMWT | 95 | 5 | 12 | 88 |
| DTCWT | 91 | 5 | 11 | 93 |
| MultiWave | 88 | 8 | 8 | 96 |
| ISCA Block Type | TP | FP | FN | TN |
|---|---|---|---|---|
| DWT | 18 | 2 | 0 | 20 |
| DMWT | 19 | 1 | 0 | 20 |
| DTCWT | 19 | 1 | 0 | 20 |
| MultiWave | 20 | 0 | 0 | 20 |
| ISCA Block Type | RLVS | HWID | Hockey Fights | Movie Fights |
|---|---|---|---|---|
| DWT | 90.00 | 95.44 | 91.50 | 95 |
| DMWT | 91.00 | 97.00 | 91.50 | 97.50 |
| DTCWT | 94 | 97.51 | 92.00 | 97.50 |
| MultiWave | 96 | 98.20 | 92.00 | 100 |
| ISCA Block Type | Split 1 | Split 2 | Split 3 | Split 4 | Split 5 | Mean Accuracy |
|---|---|---|---|---|---|---|
| DWT | 90.5 | 91.5 | 88.4 | 87 | 91 | 89.73 |
| DMWT | 89 | 92.5 | 91 | 91 | 94.5 | 91.50 |
| DTCWT | 93 | 96 | 92 | 89.5 | 94.5 | 93.16 |
| MultiWave | 92 | 94.5 | 92 | 93 | 92 | 93.25 |
| Metric | DWT | DMWT | DTCWT | MultiWave |
|---|---|---|---|---|
| Precision | 0.910 | 0.920 | 0.934 | 0.930 |
| Recall | 0.918 | 0.916 | 0.932 | 0.930 |
| F1-score | 0.916 | 0.914 | 0.928 | 0.930 |
| ISCA Block Type | Split 1 | Split 2 | Split 3 | Split 4 | Split 5 | Mean Accuracy |
|---|---|---|---|---|---|---|
| DWT | 95.44 | 97.00 | 97.09 | 97.37 | 97.90 | 96.70 |
| DMWT | 95.15 | 94.88 | 96.82 | 96.40 | 97.79 | 96.34 |
| DTCWT | 98.06 | 96.95 | 96.96 | 95.71 | 97.79 | 97.16 |
| MultiWave | 96.82 | 97.65 | 96.54 | 97.37 | 96.69 | 97.21 |
| Metric | DWT | DMWT | DTCWT | MultiWave |
|---|---|---|---|---|
| Precision | 0.968 | 0.962 | 0.972 | 0.972 |
| Recall | 0.968 | 0.962 | 0.972 | 0.972 |
| F1-score | 0.968 | 0.962 | 0.972 | 0.972 |
| ISCA Block Type | Split 1 | Split 2 | Split 3 | Split 4 | Split 5 | Mean Accuracy |
|---|---|---|---|---|---|---|
| DWT | 91.50 | 89.90 | 93.00 | 94.50 | 90.50 | 91.70 |
| DMWT | 91.50 | 93.00 | 95.50 | 91.50 | 94.50 | 93.00 |
| DTCWT | 92.00 | 91.00 | 92.50 | 95.00 | 94.00 | 92.75 |
| MultiWave | 90.50 | 92.00 | 93.00 | 92.00 | 92.00 | 91.91 |
| Metric | DWT | DMWT | DTCWT | MultiWave |
|---|---|---|---|---|
| Precision | 0.922 | 0.936 | 0.930 | 0.920 |
| Recall | 0.920 | 0.932 | 0.930 | 0.920 |
| F1-score | 0.916 | 0.928 | 0.928 | 0.918 |
| ISCA Block Type | Split 1 | Split 2 | Split 3 | Split 4 | Split 5 | Mean Accuracy |
|---|---|---|---|---|---|---|
| DWT | 95.00 | 95.00 | 100.00 | 95.00 | 95.00 | 95.83 |
| DMWT | 97.50 | 95.00 | 100.00 | 97.50 | 100.00 | 98.00 |
| DTCWT | 97.50 | 92.50 | 95.00 | 97.50 | 95.00 | 95.83 |
| MultiWave | 97.50 | 92.50 | 100.00 | 100.00 | 95.00 | 97.50 |
| Metric | DWT | DMWT | DTCWT | MultiWave |
|---|---|---|---|---|
| Precision | 0.960 | 0.982 | 0.958 | 0.972 |
| Recall | 0.960 | 0.978 | 0.954 | 0.970 |
| F1-score | 0.960 | 0.978 | 0.952 | 0.970 |
| Block | Minimum Inference Time (ms) | Maximum Inference Time (ms) | Standard Deviation | Average Inference Time (ms) |
|---|---|---|---|---|
| DWT | 82 | 101.66 | 3.62 | 88.19 |
| DMWT | 87.7 | 1371.27 | 137.78 | 108.97 |
| DTCWT | 88.7 | 2881.19 | 300.36 | 128.95 |
| MultiWave | 76 | 110.23 | 5.88 | 90.44 |
| Block | Reliable Training Performance | Reliable Generalization on Test Data | Suitability for Real-Time |
|---|---|---|---|
| DWT | Yes | No | Yes |
| DMWT | Yes | Yes | No |
| DTCWT | Yes | Yes | No |
| MultiWave | Yes | Yes | Yes |
| Sequence Length | Accuracy |
|---|---|
| 4 | 92.50 |
| 8 | 93.50 |
| 12 | 94.50 |
| 16 | 96.00 |
| Input Size | Accuracy |
|---|---|
| 79.00 | |
| 86.00 | |
| 96.00 |
| Backbone | Backbone Inference Time (ms) | Total Model Parameters | Accuracy |
|---|---|---|---|
| ResNet-50 [63] | 58.2 | 28,468,370 | 76 |
| Inception-V3 [64] | 42.2 | 26,683,442 | 89 |
| DenseNet-121 [65] | 77.1 | 9,558,866 | 94 |
| EfficientNetB5 [66] | 579.2 | 7,160,757 | 62 |
| MobileNet-V2 [48] | 25.9 | 5,369,170 | 96 |
| Temporal Unit | Total Model Parameters | Accuracy |
|---|---|---|
| GRU [67] | 2,533,570 | 94 |
| LSTM [68] | 2,619,458 | 94 |
| Bi-LSTM [69] | 2,980,162 | 92 |
| ConvLSTM [49] | 5,369,170 | 96 |
| Method | Accuracy | Efficiency |
|---|---|---|
| 2D-Convolution + LSTM [29] | 92% | ≈4.6 m |
| ViolenceNet Pseudo-Optical Flow [27] | 94.10% | m |
| Keyframe-based ResNet18 [70] | 94.60% | ≈11.6 m |
| U-NET + LSTM [71] | 94% | ≈4 m |
| VGG-16 + LSTM [57] | 88.2% | ≈140 m |
| MobileNetV2 [72] | 94% | ≈3.2 m |
| Motion Features + Inception-ResNet [73] | 86.78% | ≈59.6 m |
| Proposed Model | 96% | for wavelet transform, m |
| Method | Movies | Hockey | Efficiency |
|---|---|---|---|
| ViF + SVM [74] | - | 82.90% | Fast, but not Robust. |
| ConvLSTM [75] | 95% | 91% | ≈62.5 k |
| 3D-CNN [76] | - | 96% | ≈78 m |
| Multistream-VGG16 [77] | 100% | 89.10% | ≈138 m |
| ResNet50 + ConvLSTM [78] | 88.74% | 83.19% | ≈24.7 m |
| Radon Transform [79] | 98% | 90.01% | Fast, but not Robust. |
| Motion Features + Inception-ResNetV2 [73] | 100% | 93.33% | ≈59.6 m |
| Proposed Model | 99.5% | 92% | for wavelet transform, m |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Elmasry, R.M.; Abd El Ghany, M.A.; Salem, M.A.-M.; Fahmy, O.M. MultiWave-Net: An Optimized Spatiotemporal Network for Abnormal Action Recognition Using Wavelet-Based Channel Augmentation. AI 2024, 5, 259-289. https://doi.org/10.3390/ai5010014
Elmasry RM, Abd El Ghany MA, Salem MA-M, Fahmy OM. MultiWave-Net: An Optimized Spatiotemporal Network for Abnormal Action Recognition Using Wavelet-Based Channel Augmentation. AI. 2024; 5(1):259-289. https://doi.org/10.3390/ai5010014
Chicago/Turabian StyleElmasry, Ramez M., Mohamed A. Abd El Ghany, Mohammed A.-M. Salem, and Omar M. Fahmy. 2024. "MultiWave-Net: An Optimized Spatiotemporal Network for Abnormal Action Recognition Using Wavelet-Based Channel Augmentation" AI 5, no. 1: 259-289. https://doi.org/10.3390/ai5010014
APA StyleElmasry, R. M., Abd El Ghany, M. A., Salem, M. A.-M., & Fahmy, O. M. (2024). MultiWave-Net: An Optimized Spatiotemporal Network for Abnormal Action Recognition Using Wavelet-Based Channel Augmentation. AI, 5(1), 259-289. https://doi.org/10.3390/ai5010014