
Bibliometric Mining of Research Trends in Machine Learning


Abstract
1. Introduction
2. Literature Reviews
2.1. Studies of Research Trends and Directions in ML
2.2. Bibliometric Analysis and Tools
2.3. Research Gaps
3. Methodology
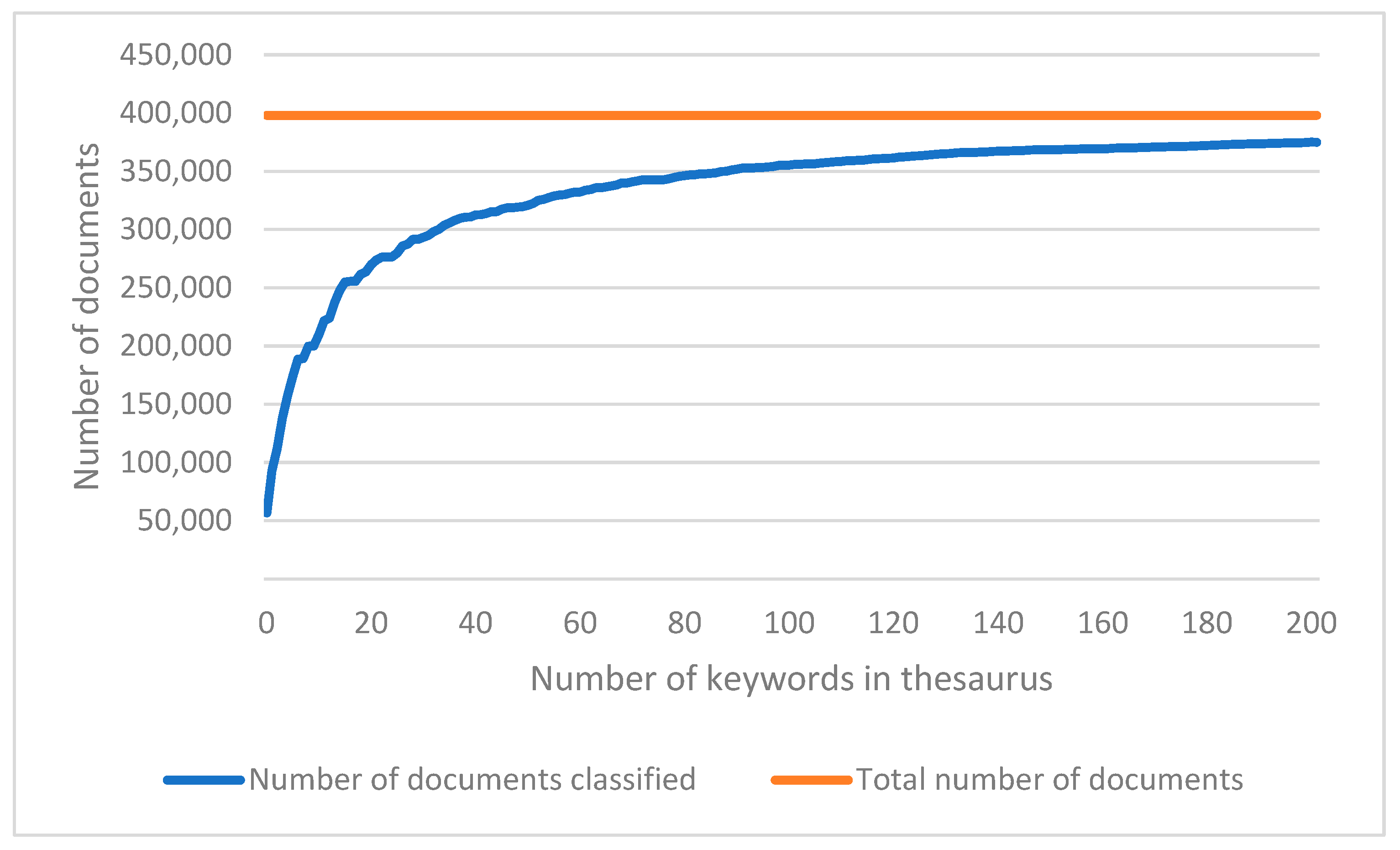
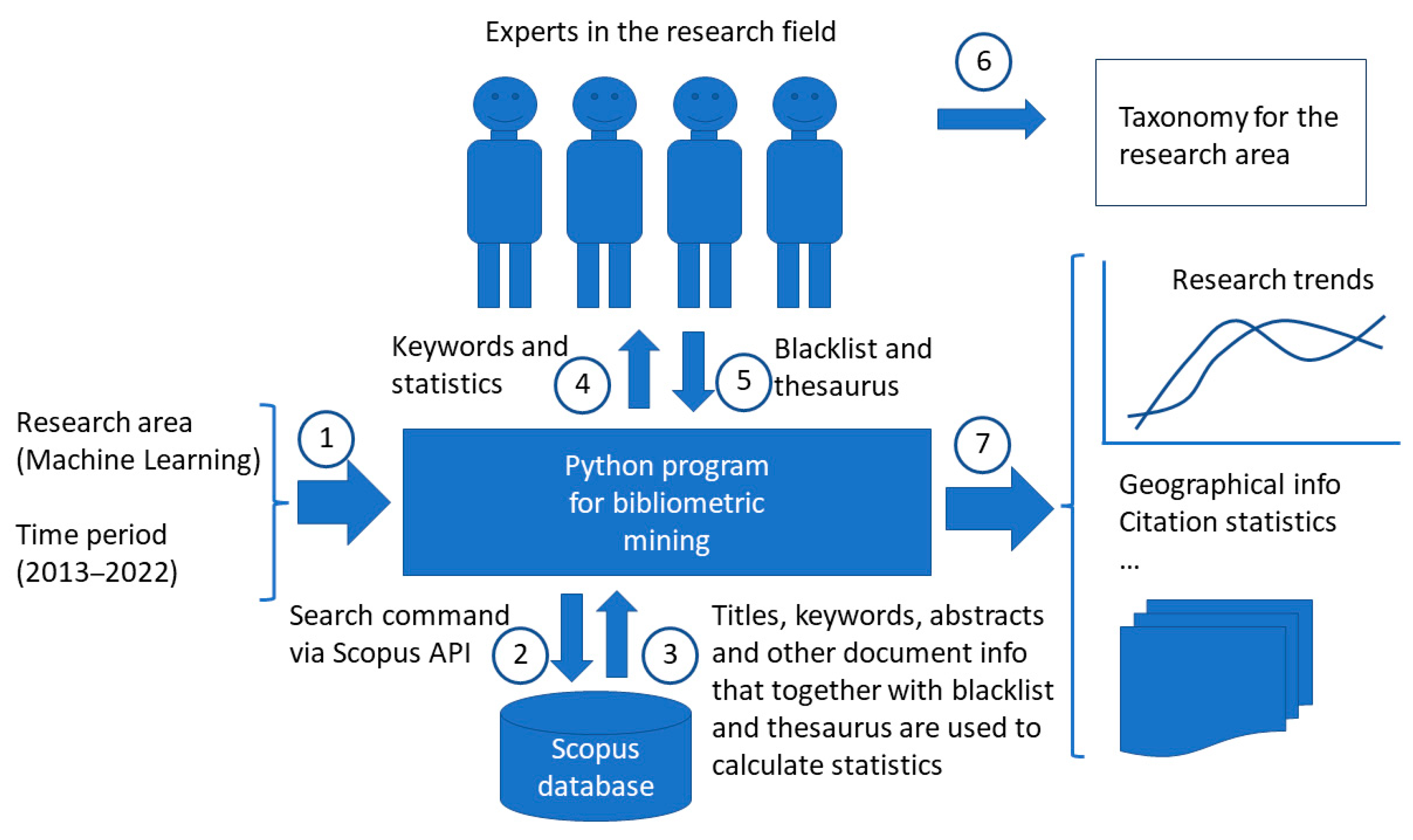
3.1. The Mining Process
3.2. Data from the Mining Process
3.2.1. Data Related to Research Directions
3.2.2. Data Related to Geographic Information
3.2.3. Data Related to Authors and Document Sources
3.3. The Program for Bibliometric Mining
4. Results
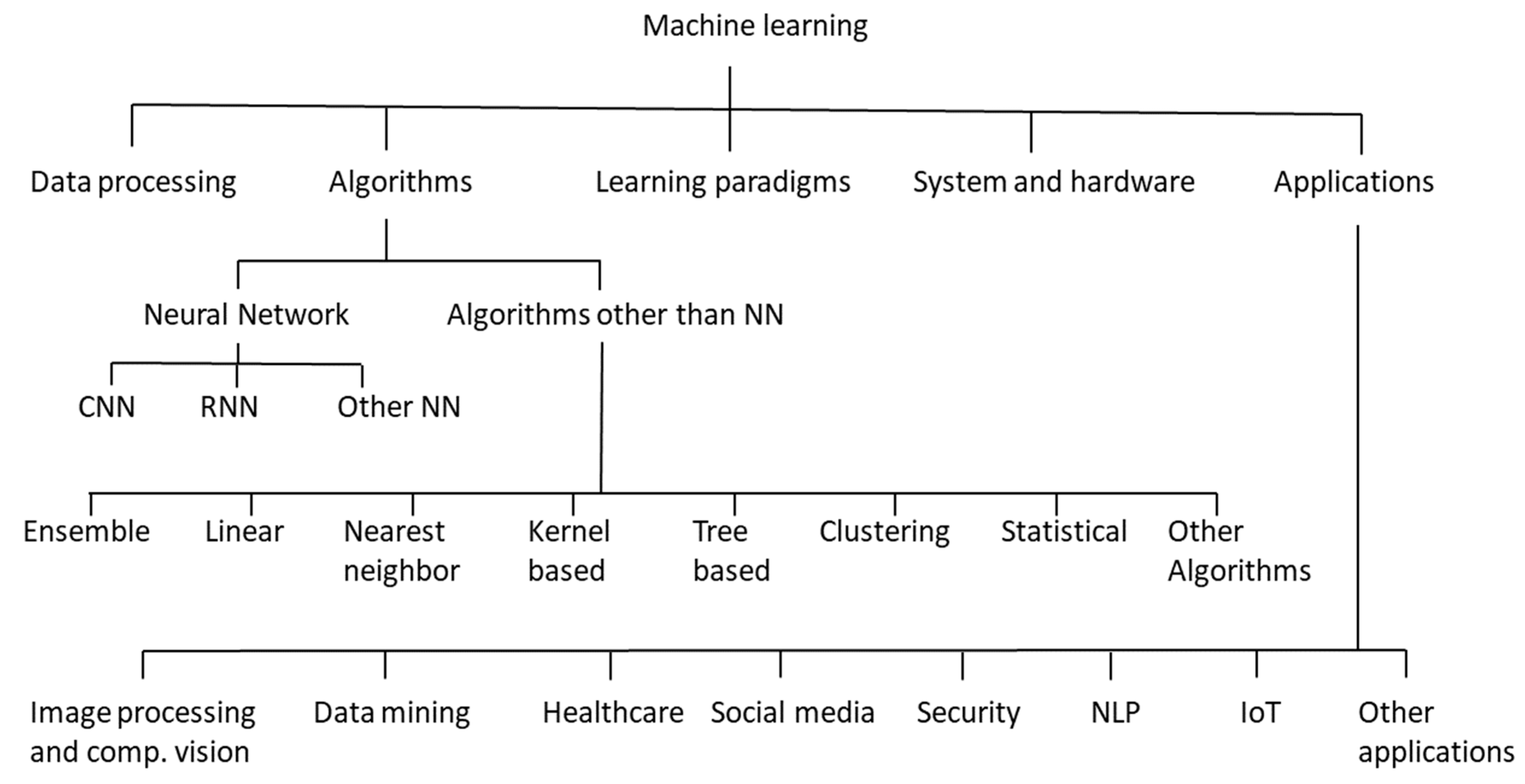
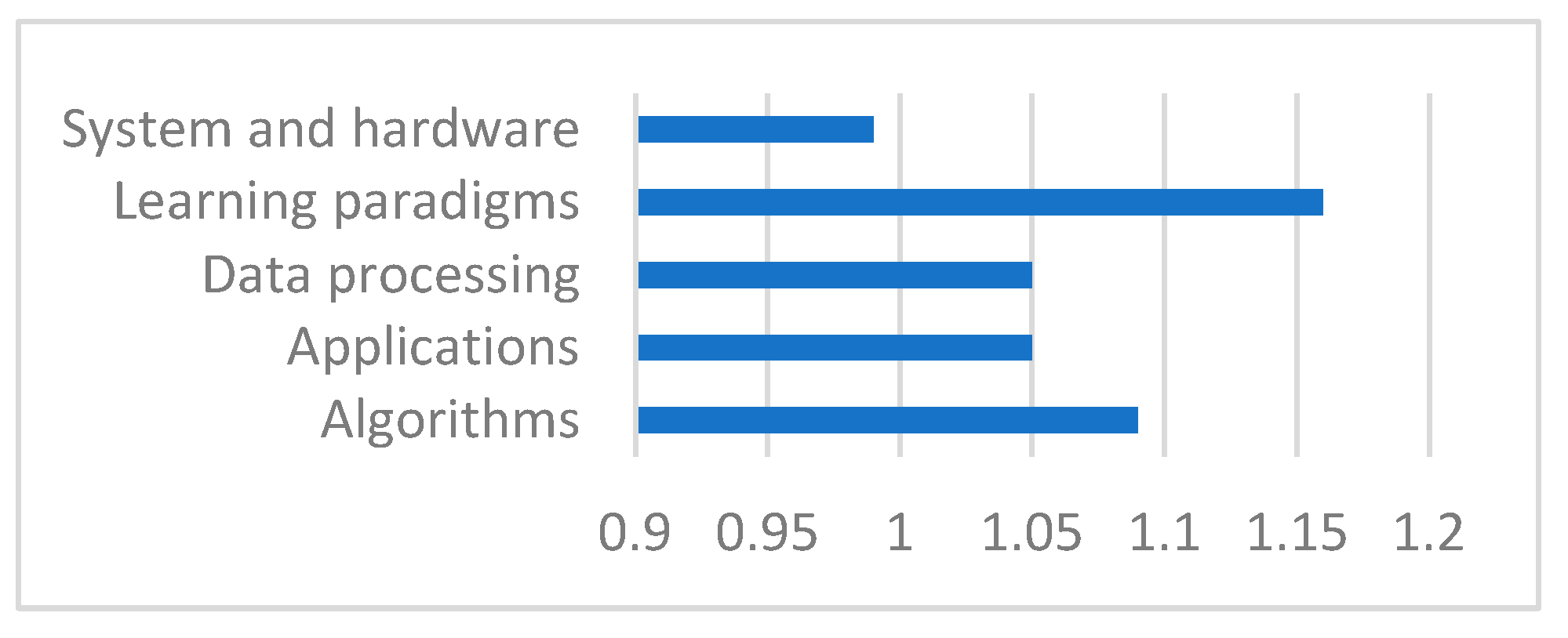
4.1. Directions in ML Research
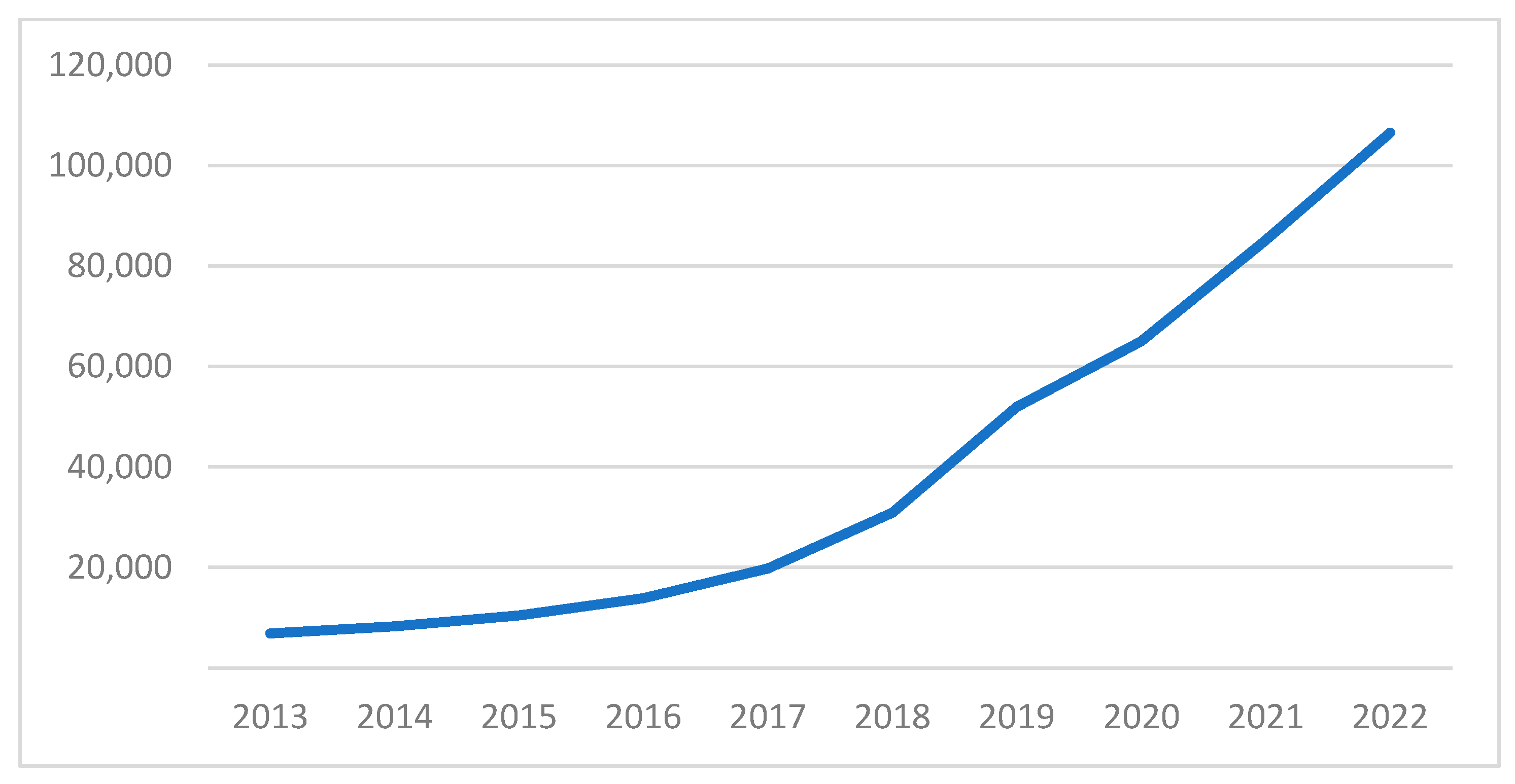
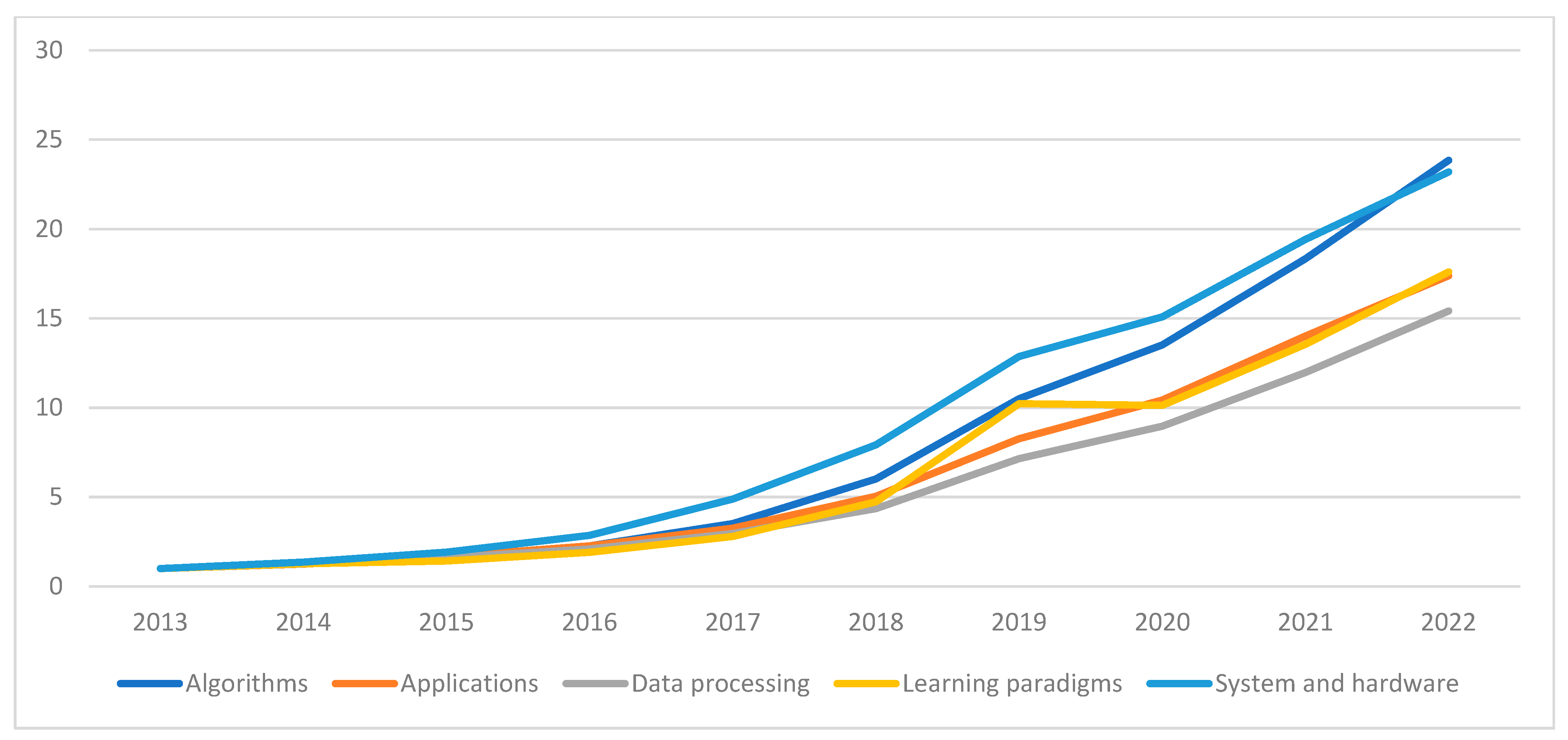
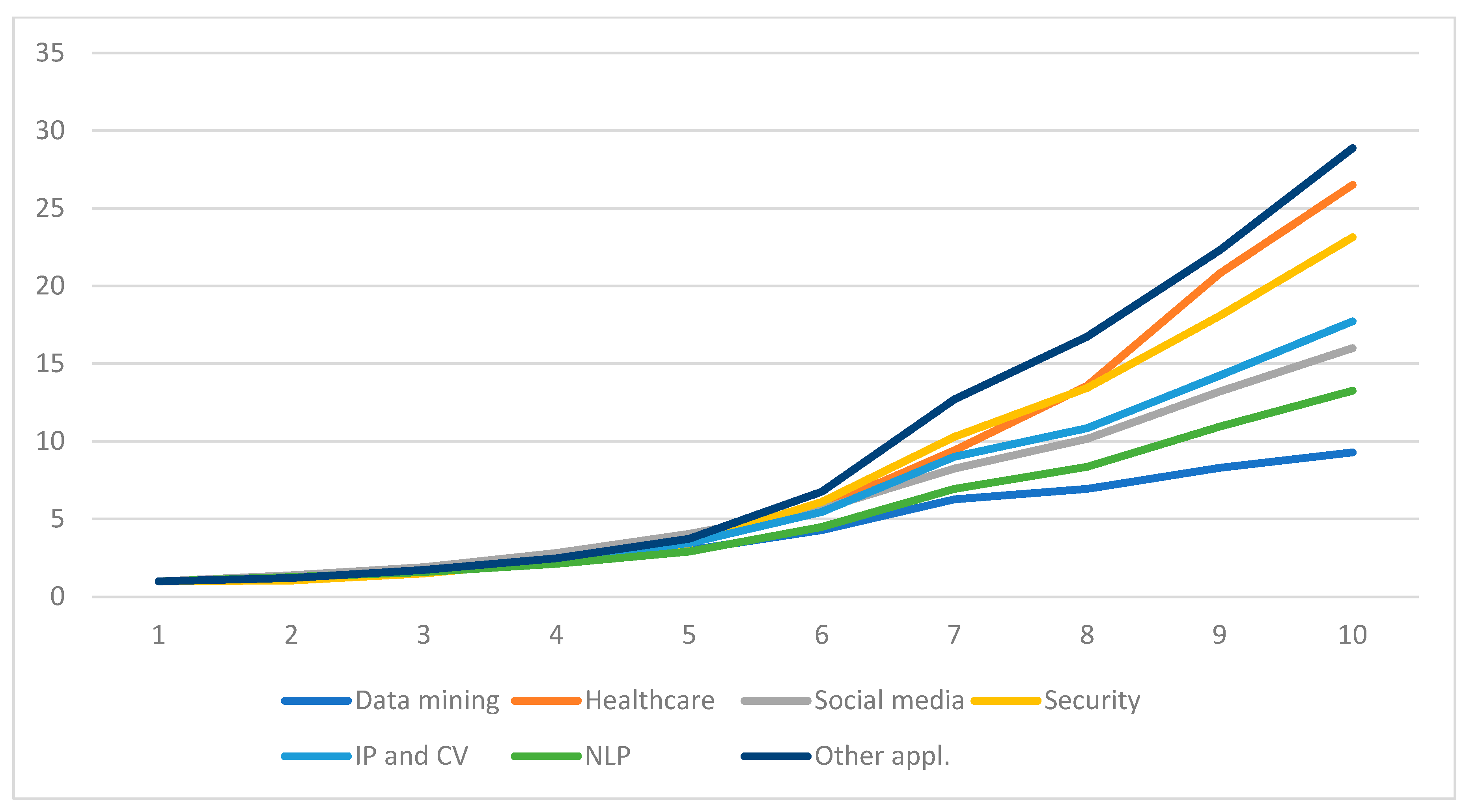
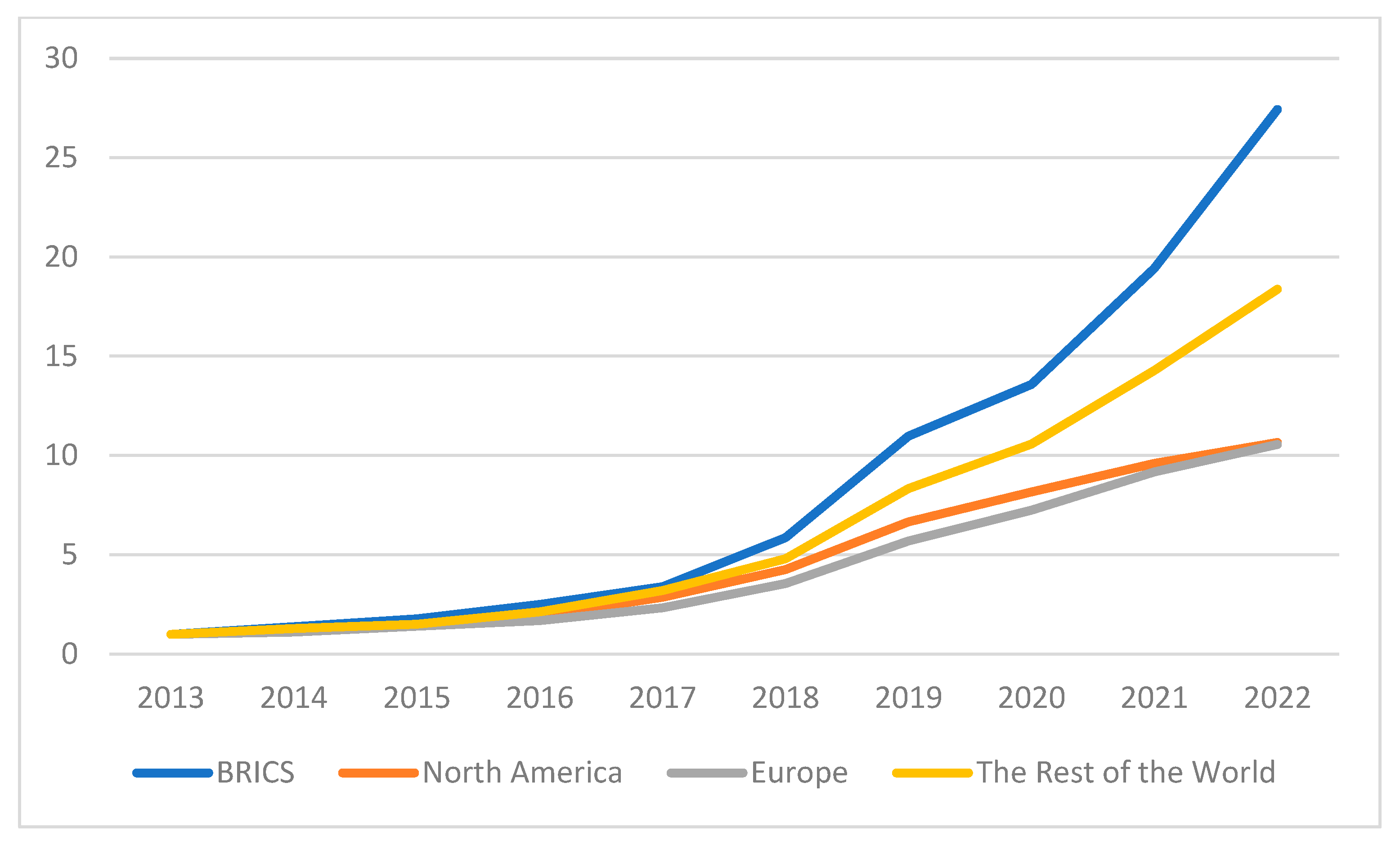
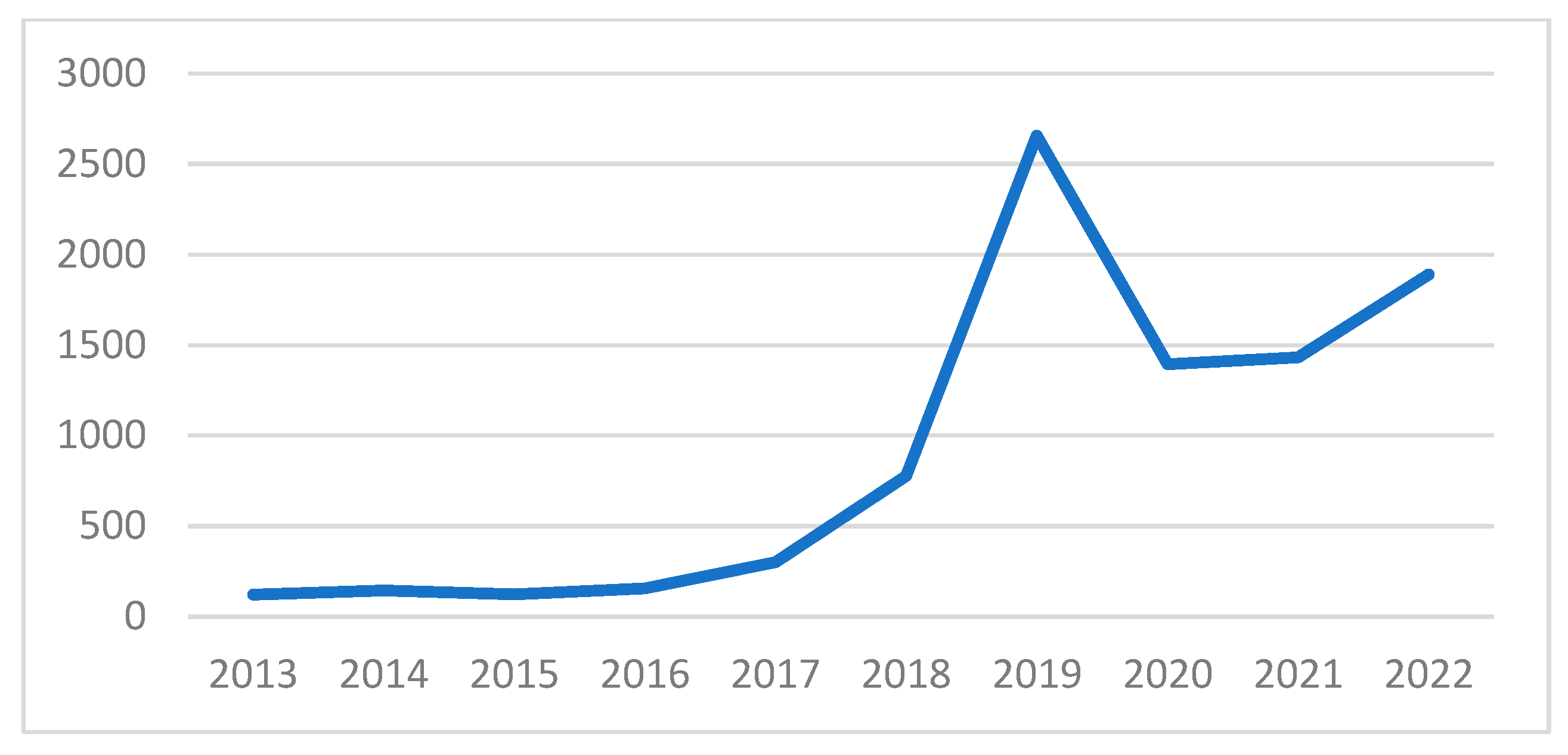
4.2. Trends in ML Research
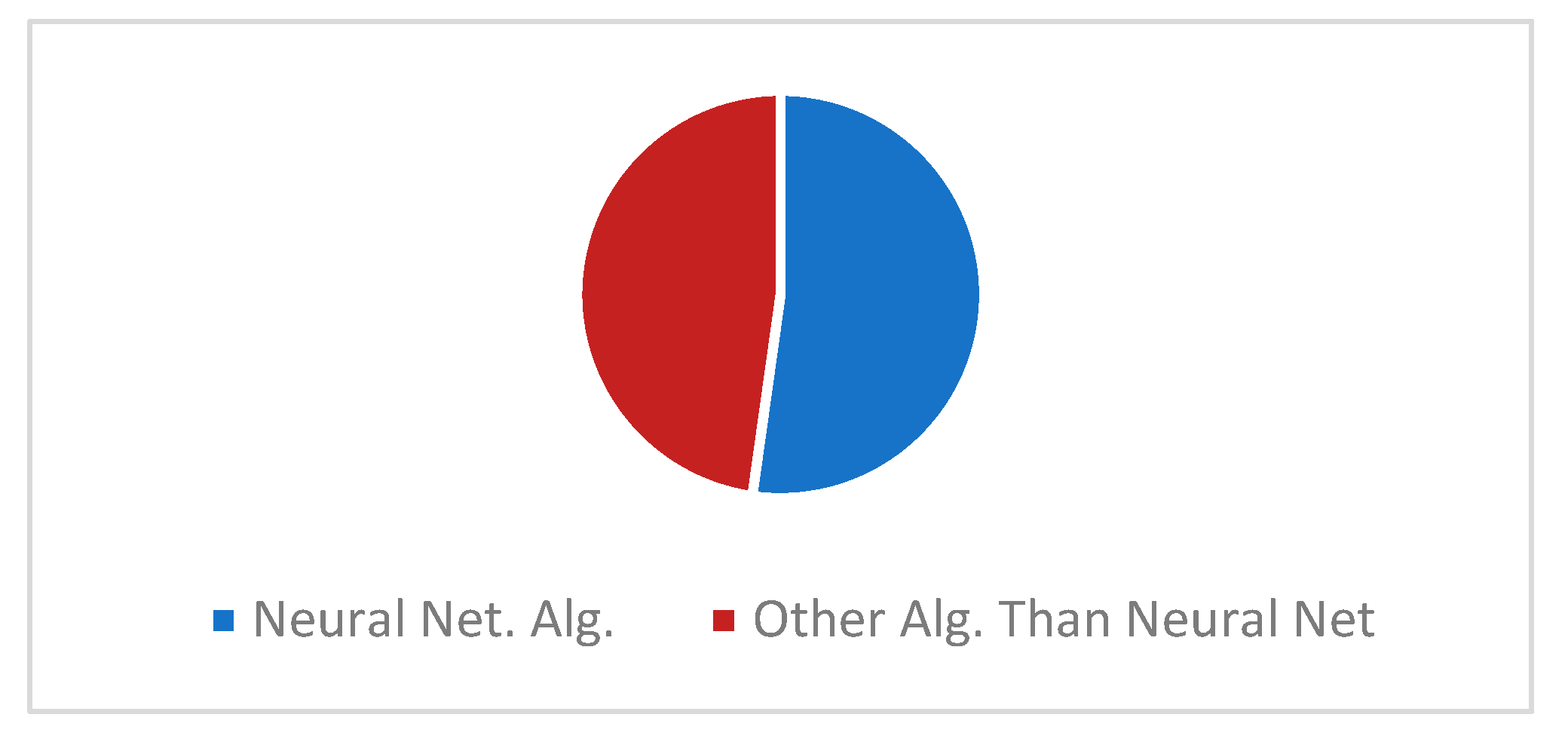
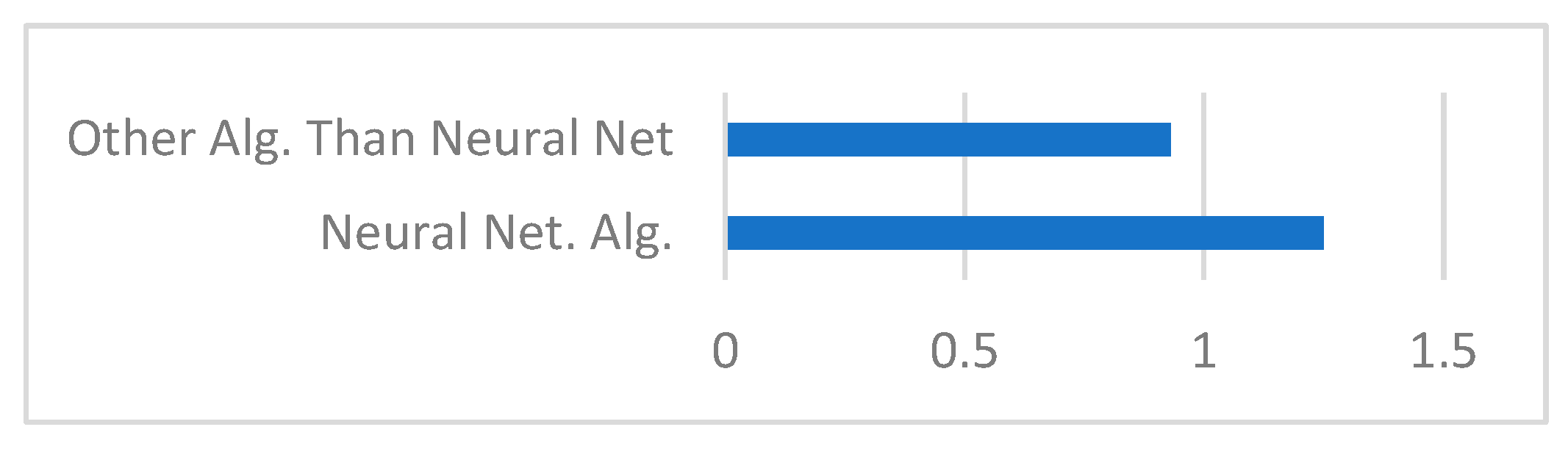
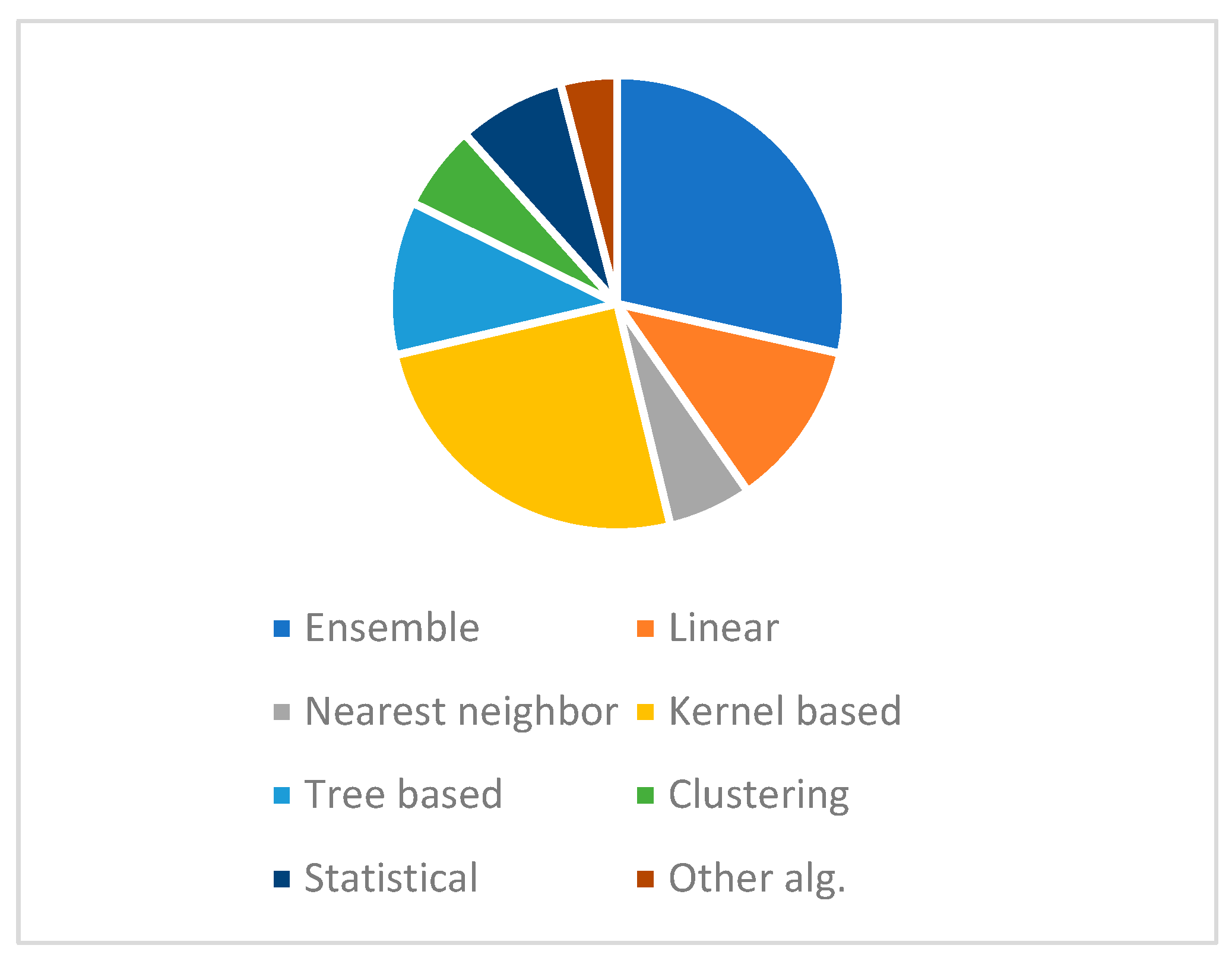
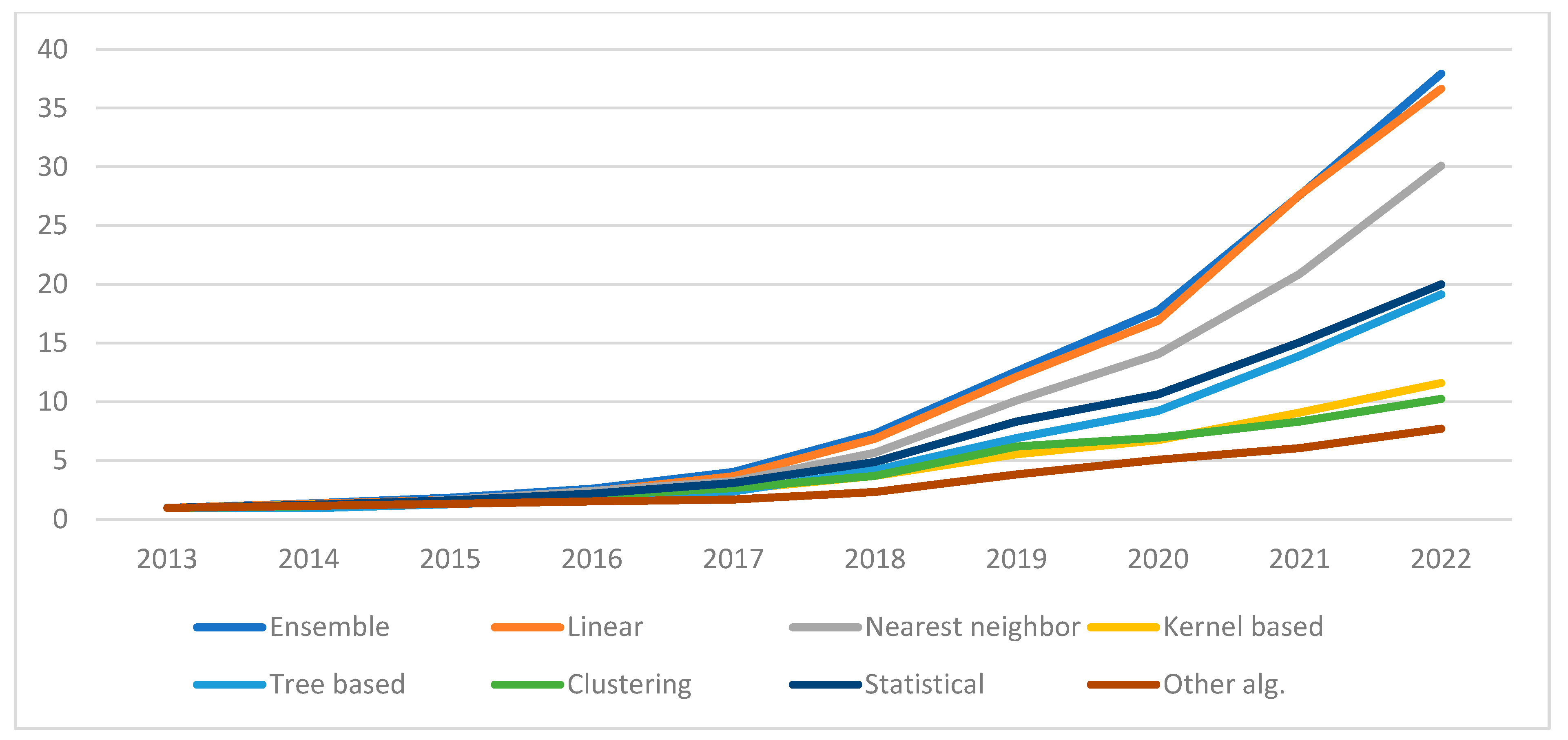
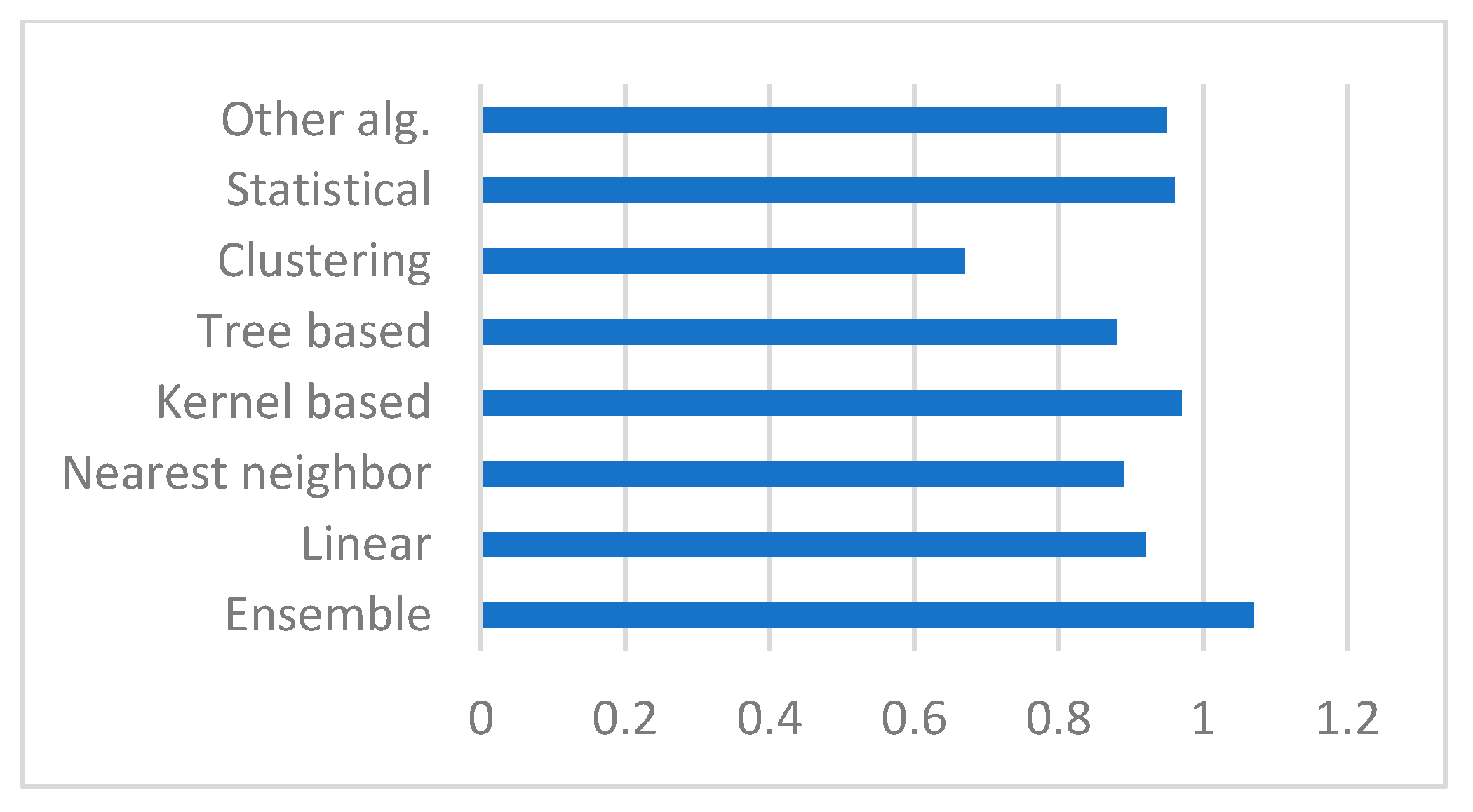
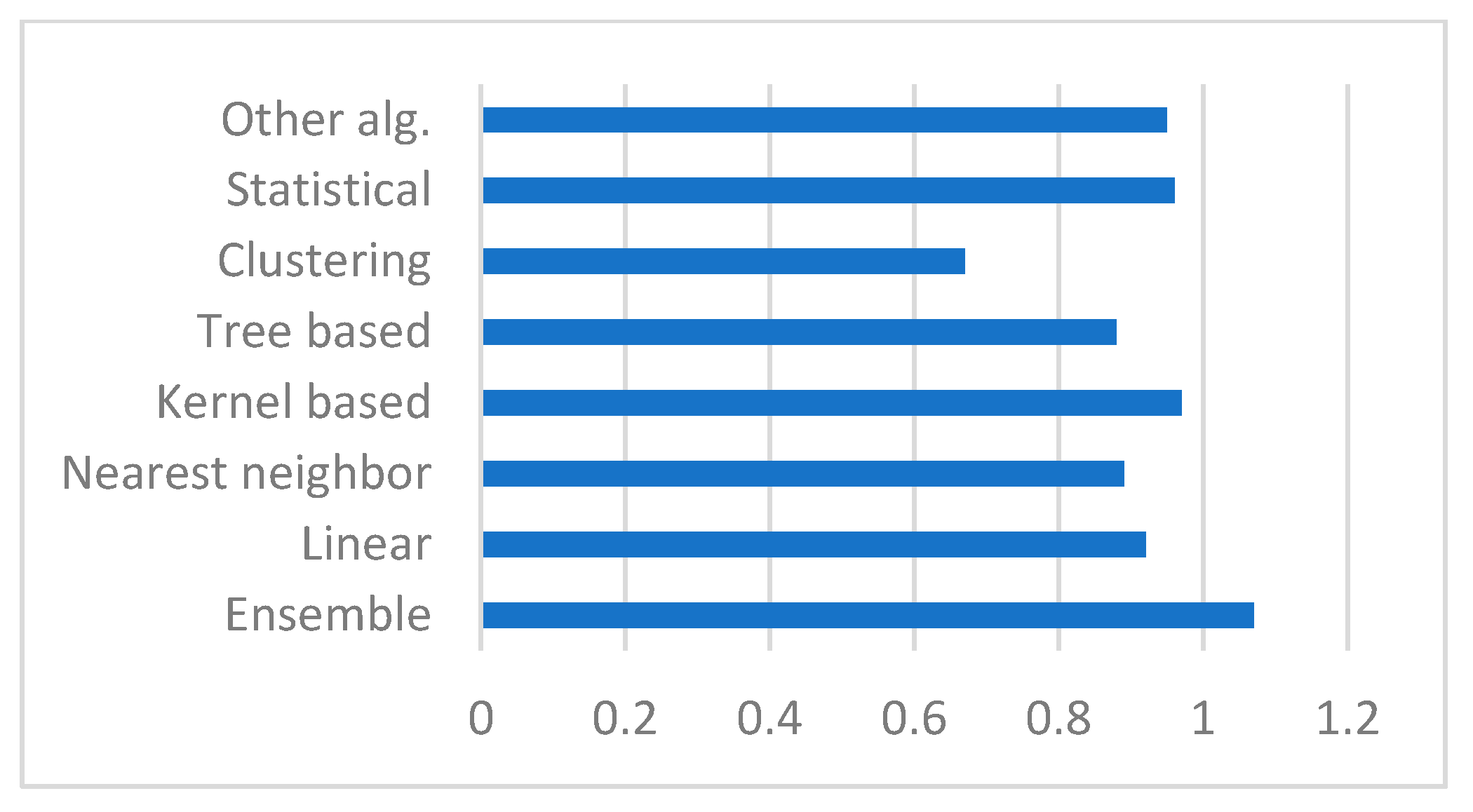
4.2.1. Trends for the Direction Algorithms in ML Research
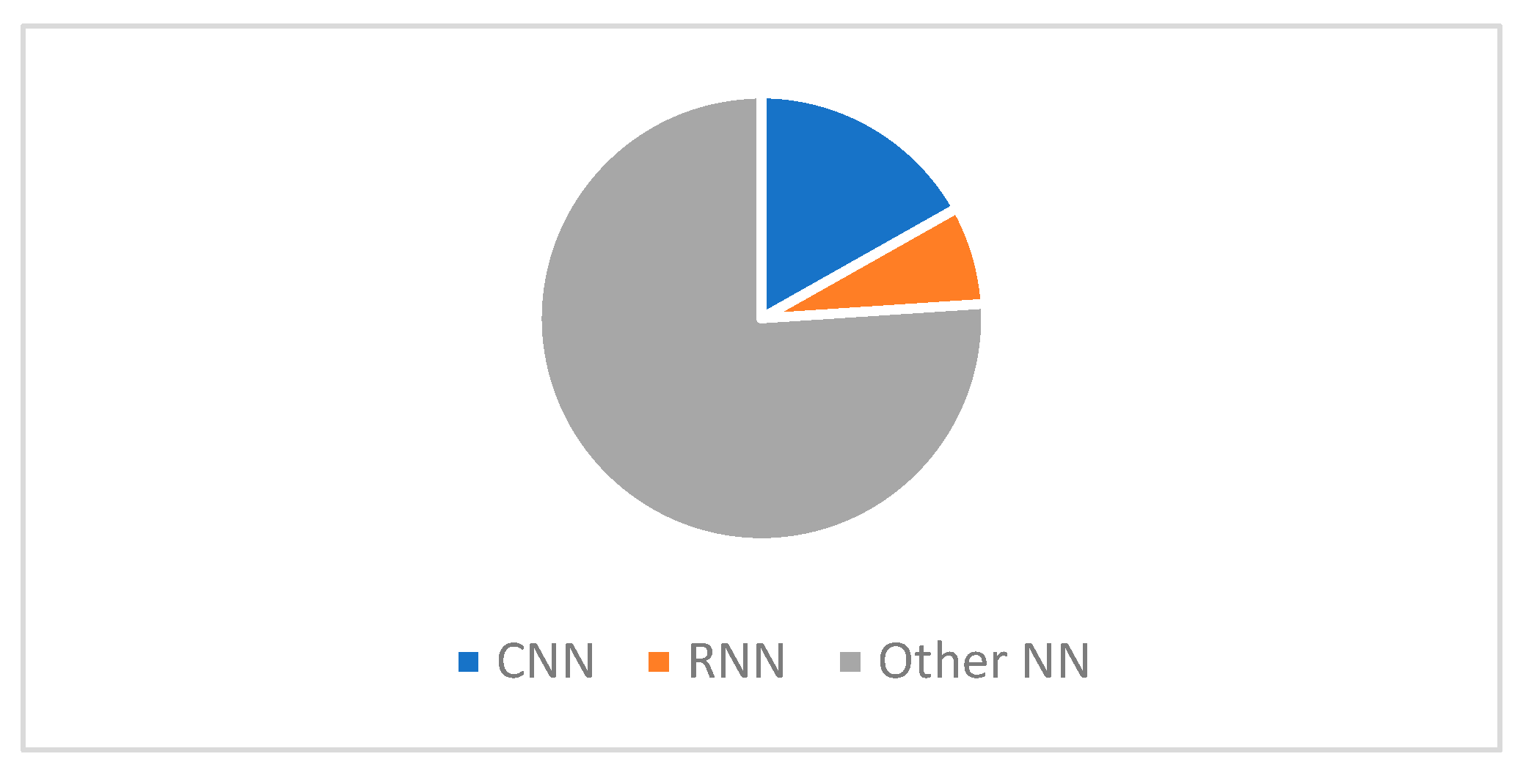
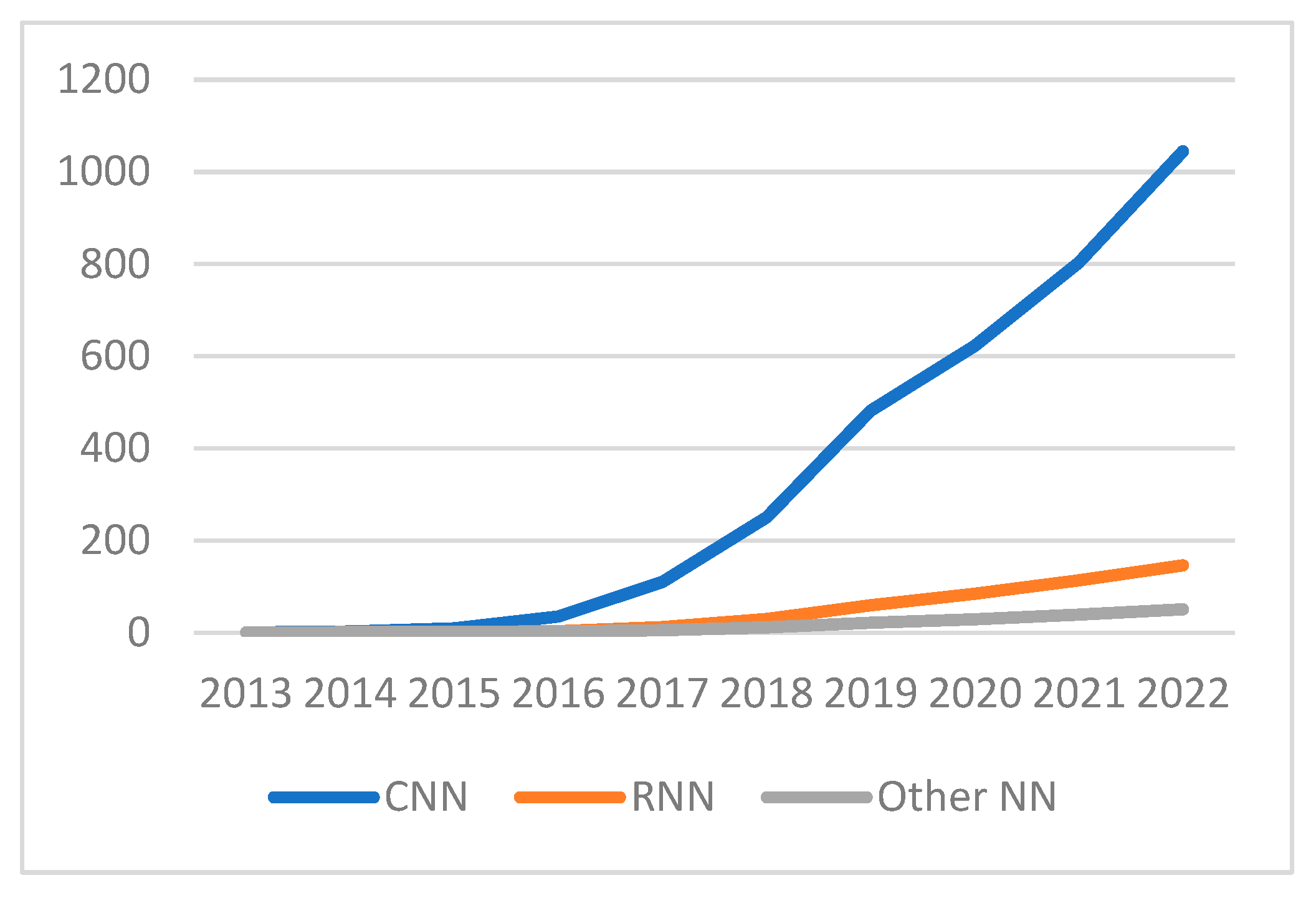
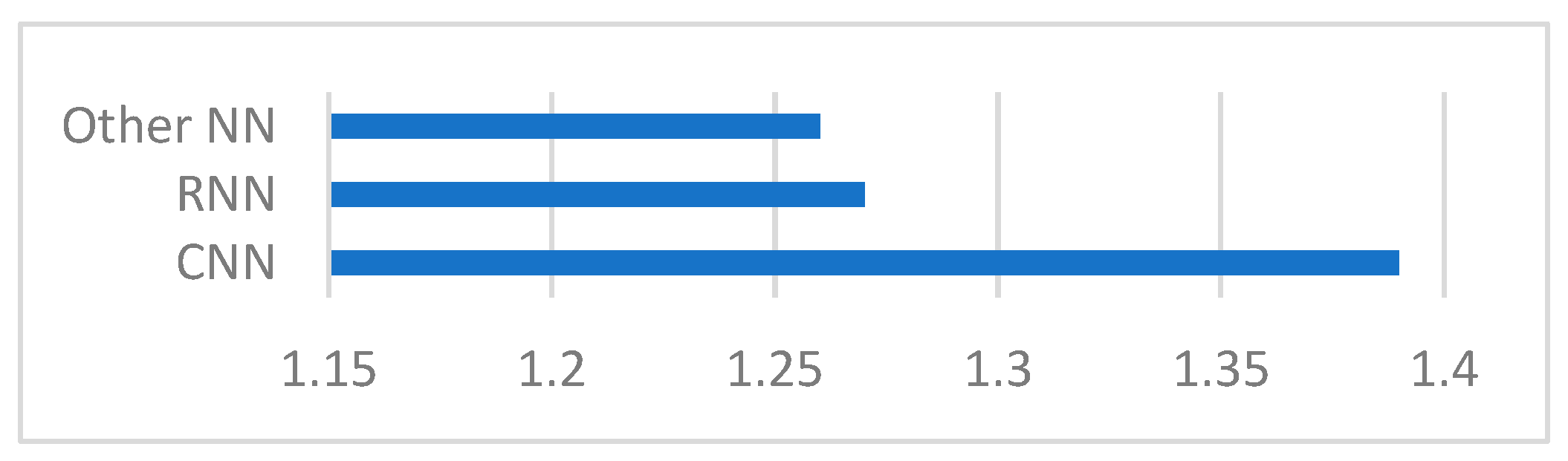
4.2.2. Trends for Research on Neural Networks
4.2.3. Trends for Research on Algorithms Other than Neural Networks
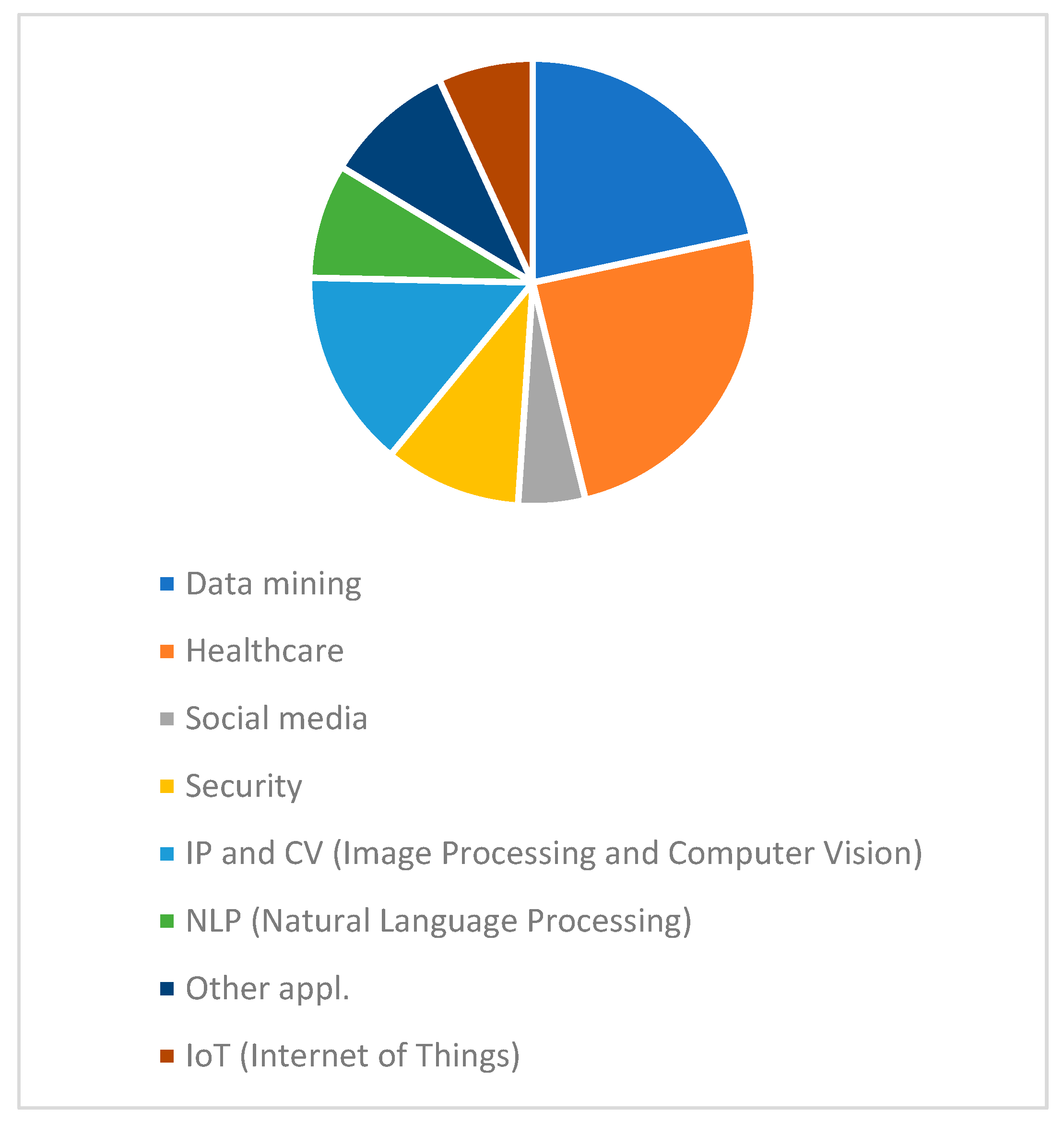
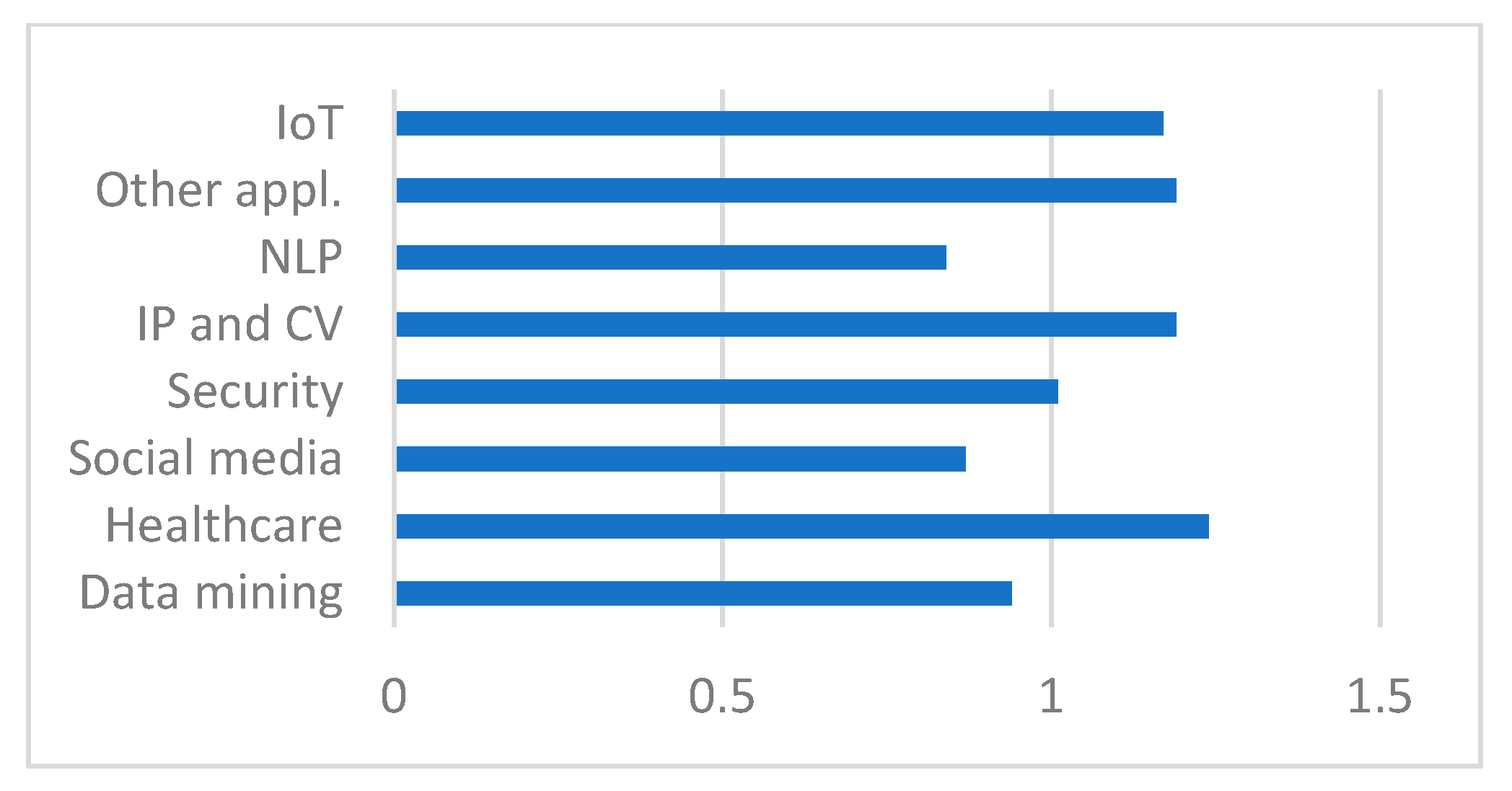
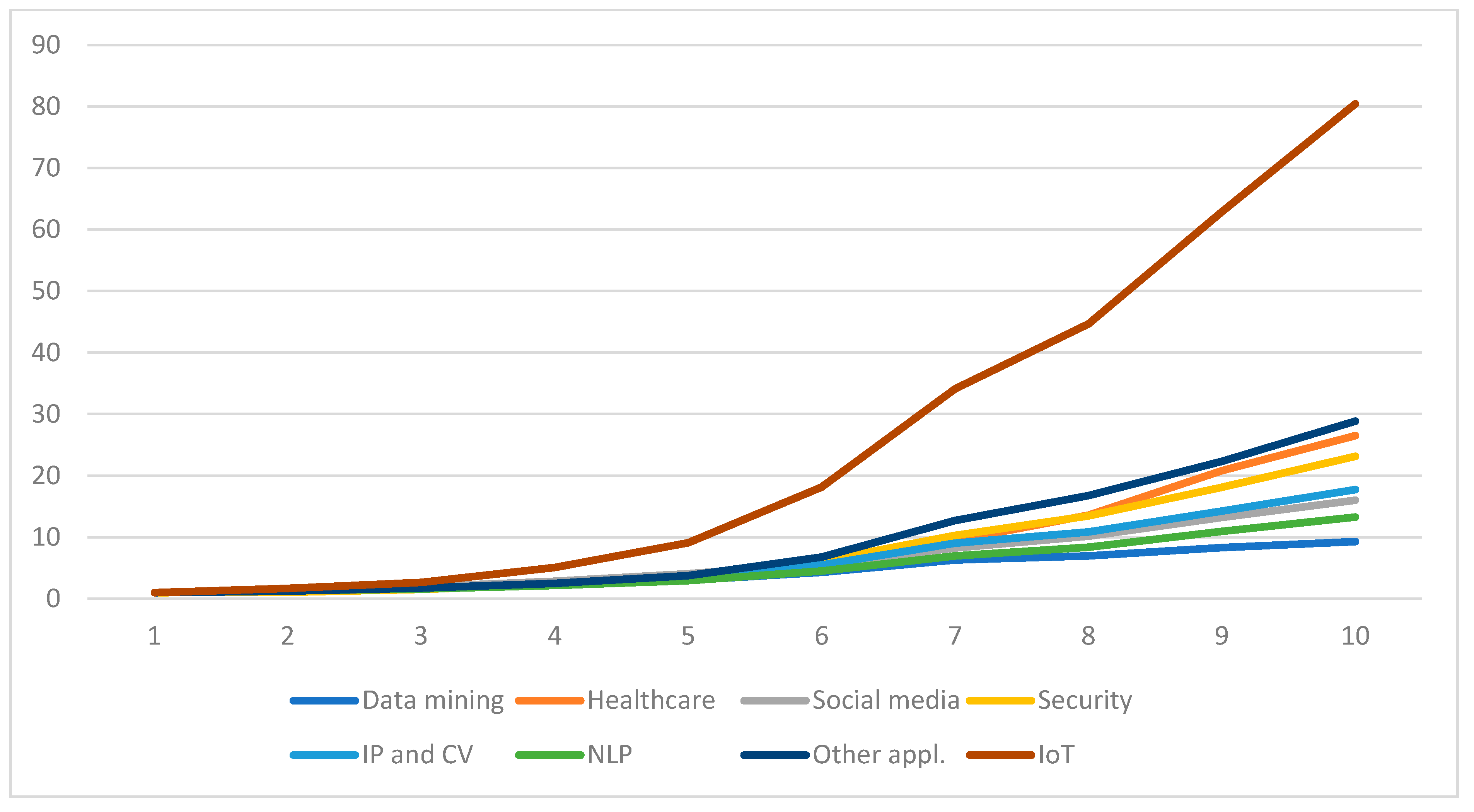
4.2.4. Trends for the Direction Applications in ML Research
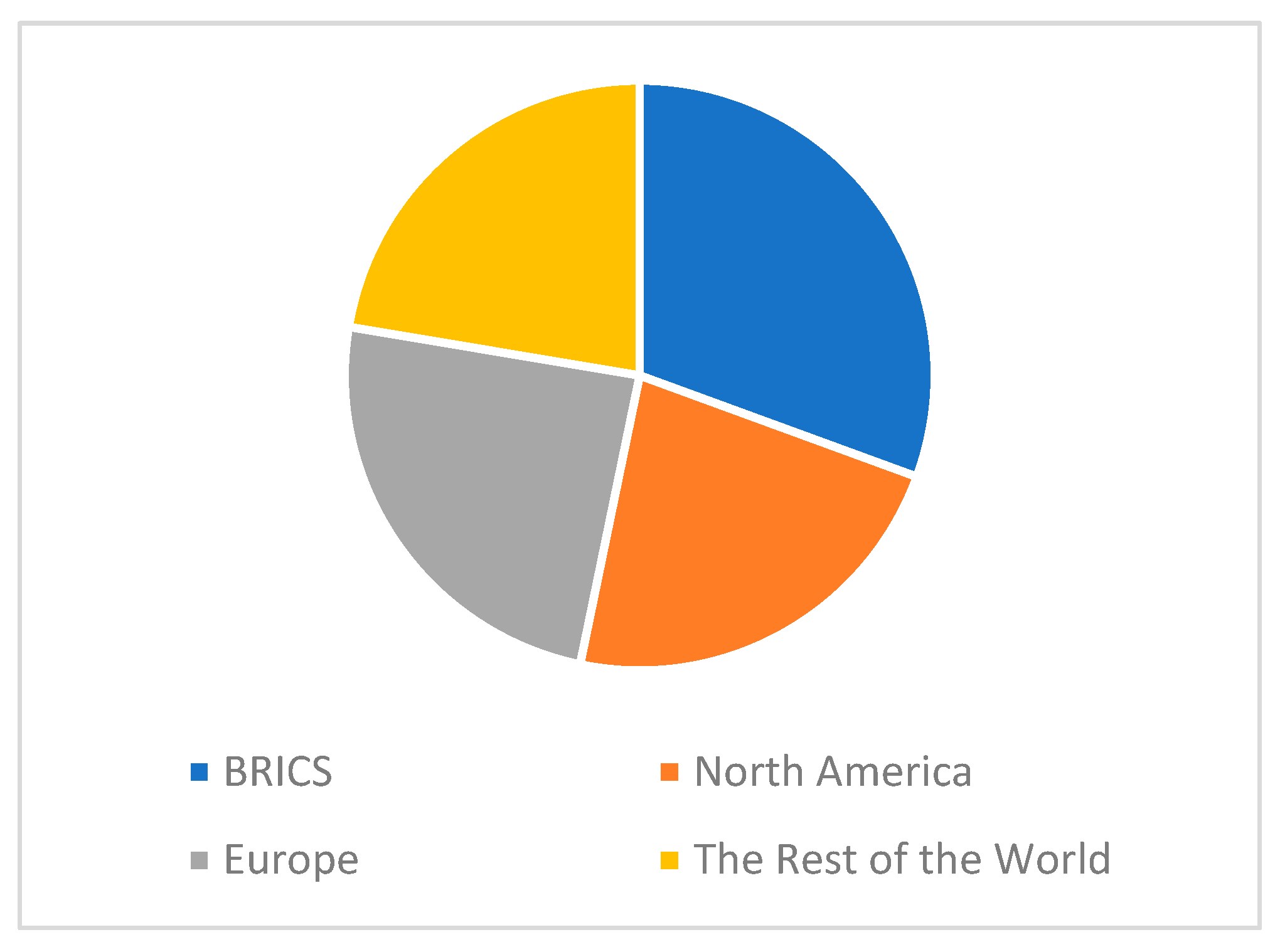
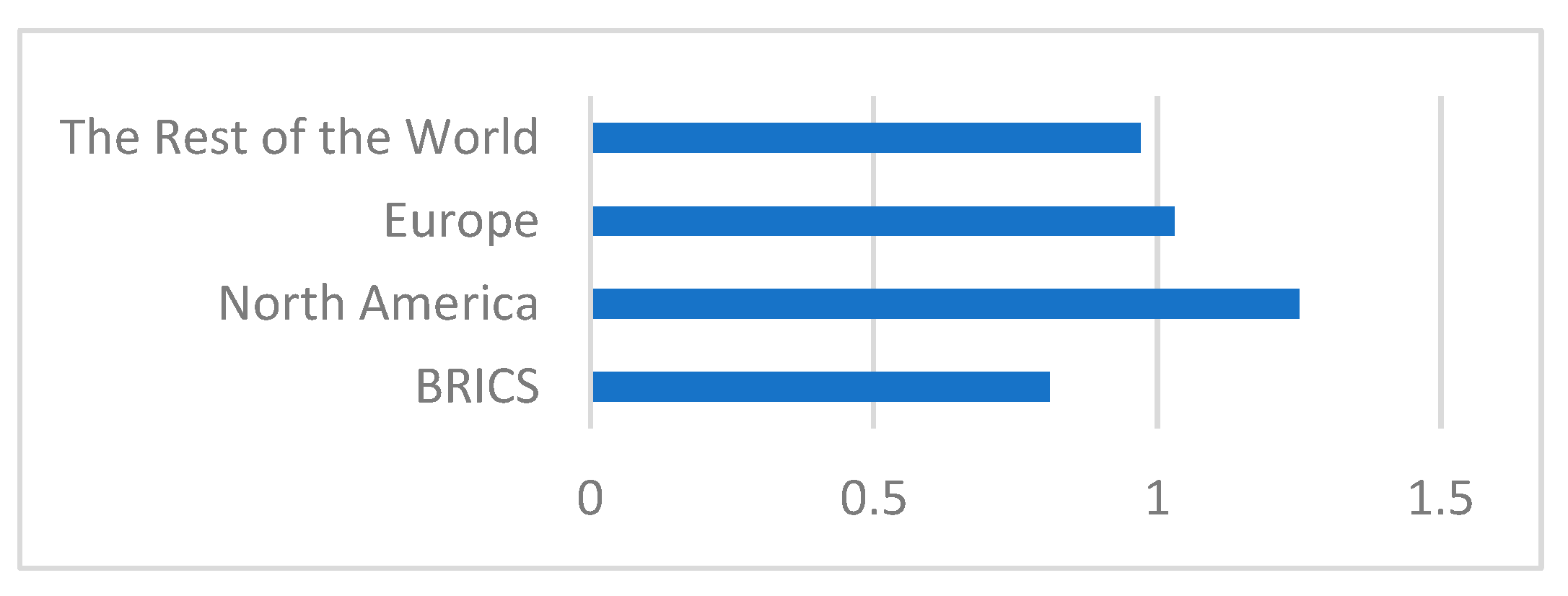
4.3. Geographic Regions in ML Research
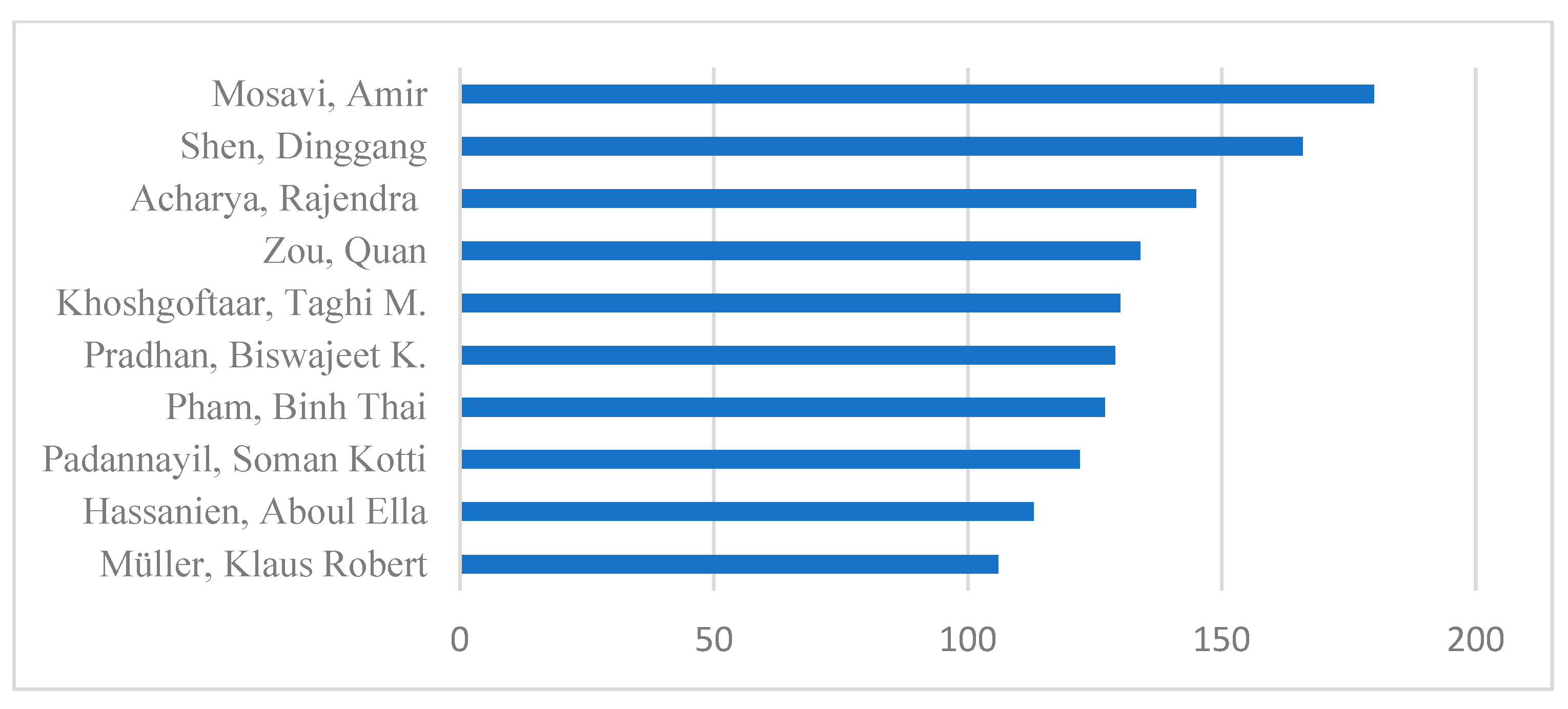
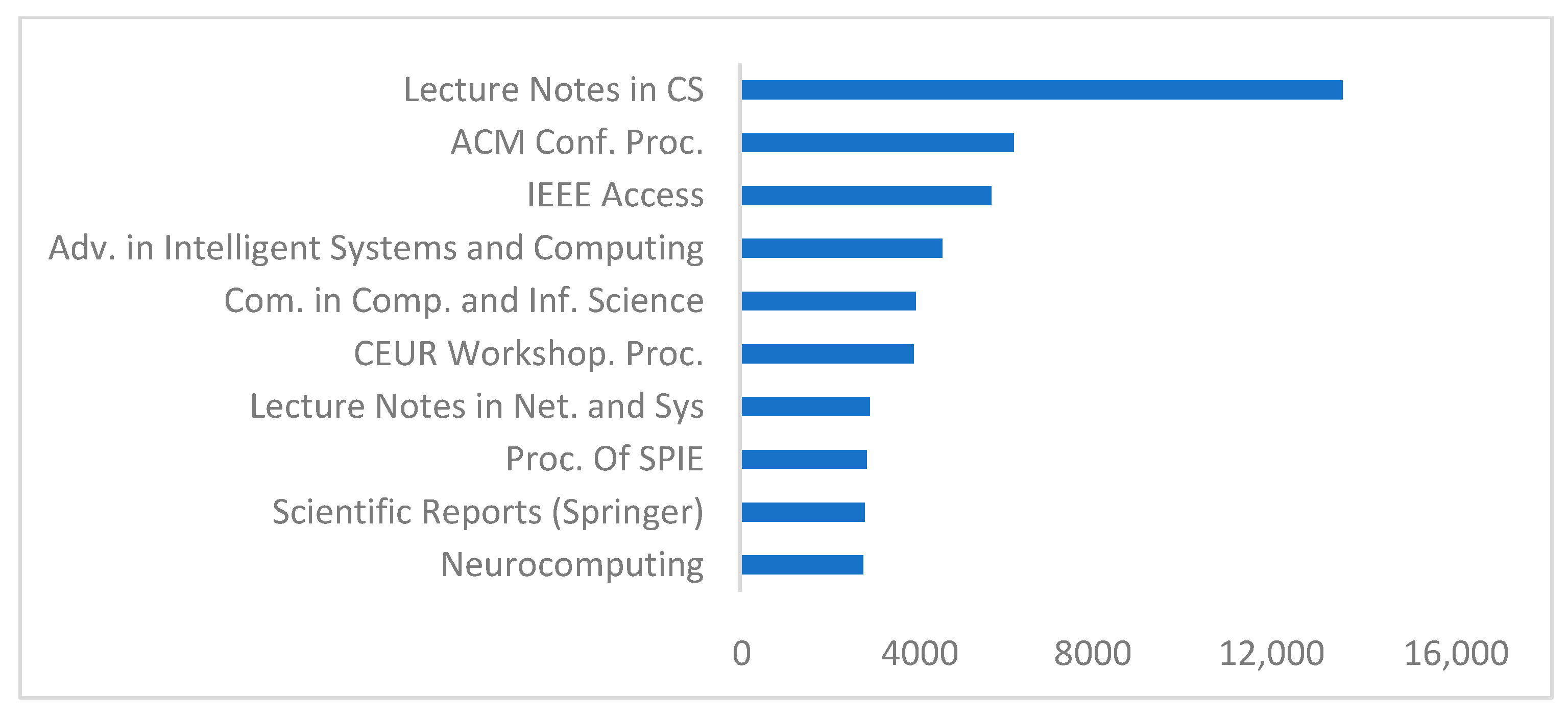
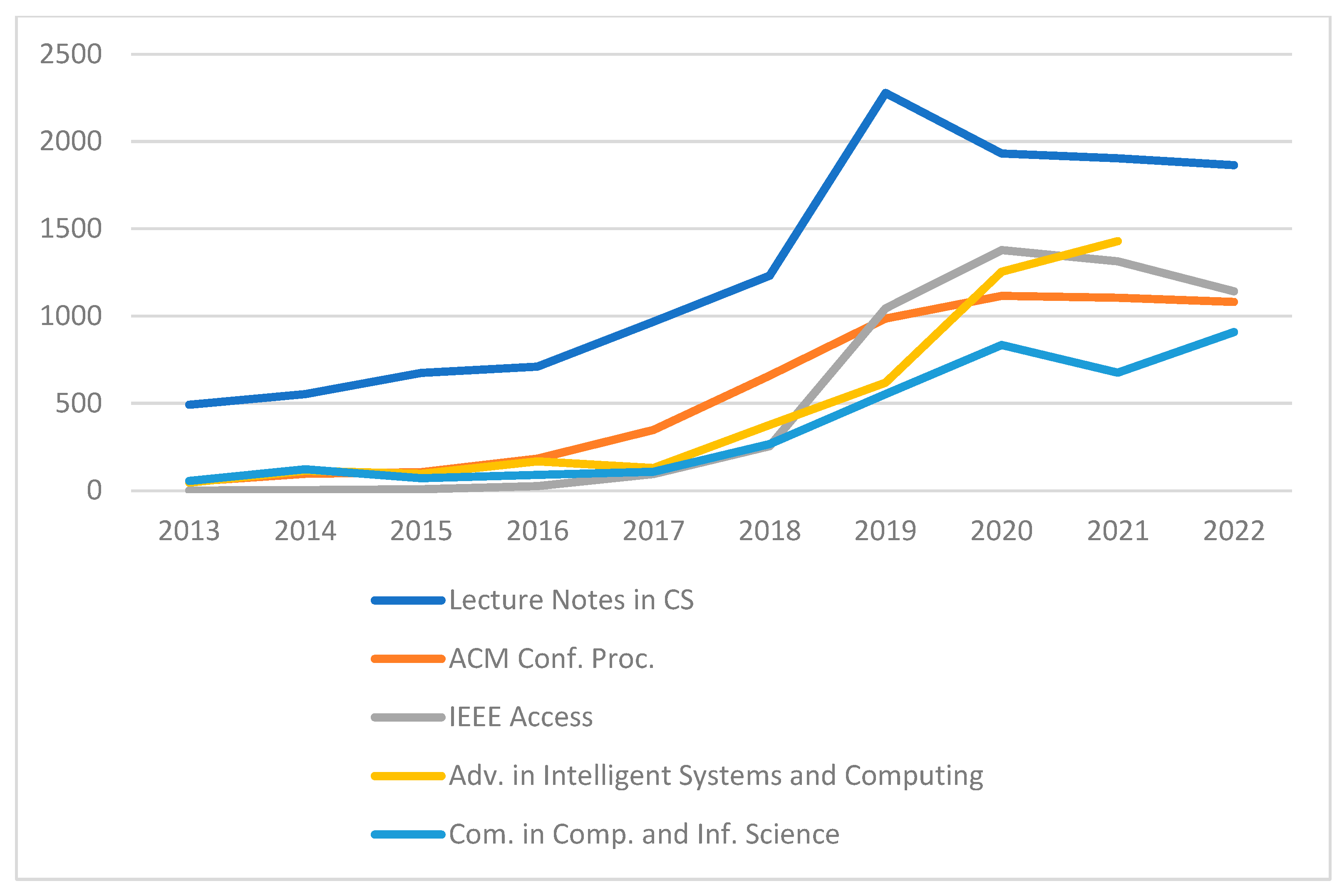
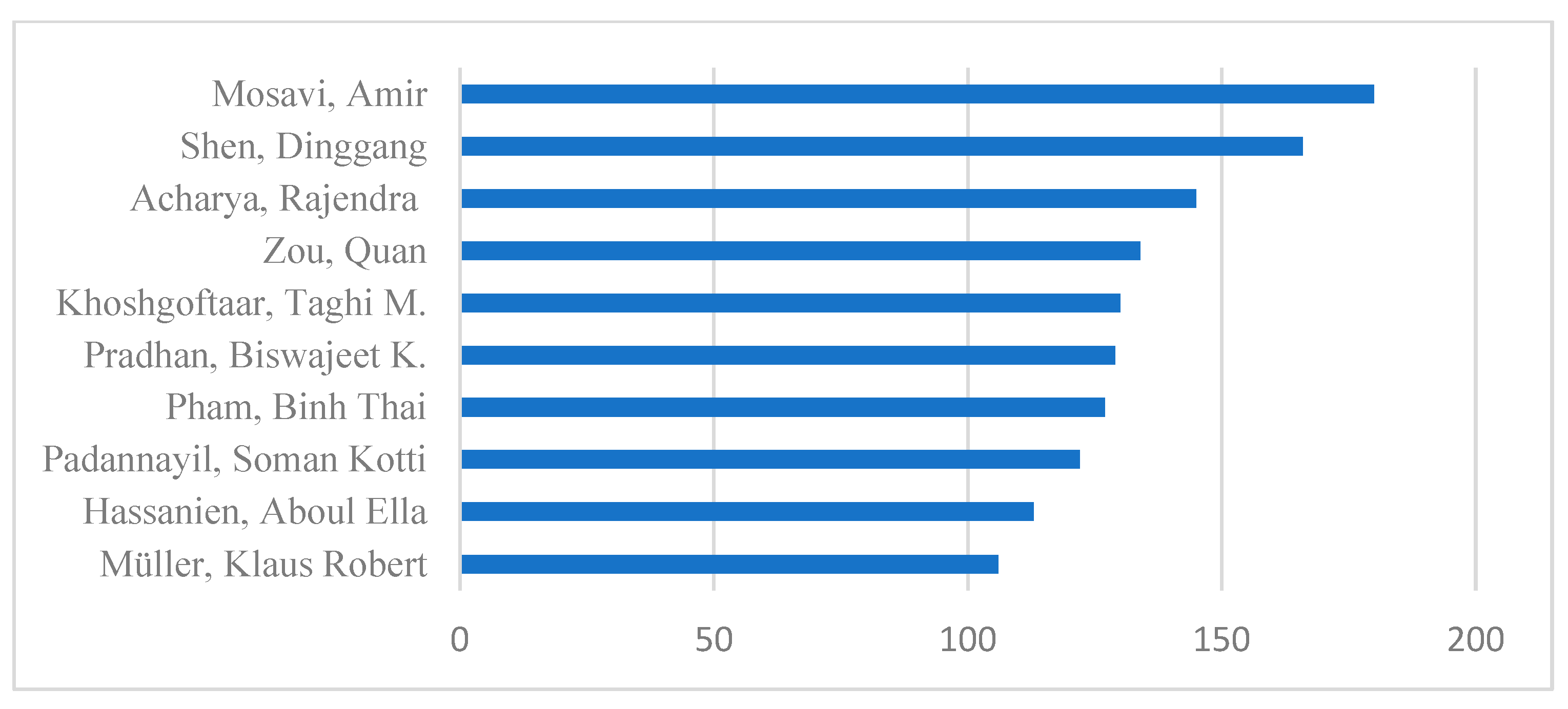
4.4. Important Authors and Document Sources for ML Research
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Expert Competence
| Position | Professor, Since 2007 |
| Age | 57 years |
| Year Ph.D. degree | 1995 |
| Years working in the AI/ML domain | 2011–2023 |
| Total number of publications | Two book chapters, 32 journal articles, 68 peer-reviewed conference papers, and 20 peer-reviewed international workshop papers |
| Number of citations (Google scholar) | 2461 |
| H-index (Google scholar) | 23 |
| i10-index (Google scholar) | 47 |
| Number of AI/ML publications | 2 book chapters, 10 journal articles, 40 peer-reviewed conference and workshop papers |
| Program committees, AI/ML conferences | 17 in AI/ML since 2015, including, e.g., AAAI, IJCAI-ECAI, UAI, AISTATS, GreenDataMining, etc. In total, 59 PC memberships |
| Reviewing, AI/ML conferences | Regular (annually) reviewer since 2016 for NeurIPS, AISTATS, ICLR, ICML, IJCAI, etc. |
| Position | Associate Professor, Since 2019 |
| Age | 46 years |
| Year Ph.D. degree | 2010 |
| Years working in the AI/ML domain | 2008–2023 |
| Total number of publications | 19 journal articles, 17 peer-reviewed conference papers, and 8 peer-reviewed workshop papers |
| Number of citations (Google Scholar) | 1268 |
| H-index (Google Scholar) | 16 |
| i10-index (Google Scholar) | 24 |
| Number of AI/ML publications | 12 journal articles, 19 peer-reviewed conference and workshop papers |
| Program committees, AI/ML conferences | European Intelligence and Security Informatics Conference (EISIC) 2018; Swedish Artificial Intelligence Society Workshop (SAIS 2023) |
| Reviewing, AI/ML conferences | Have reviewed submissions for a number of AI/ML conferences and journals, e.g., AAAI, NIPS, AISTATS, UAI, LOD. |
| Position | Associate Professor, Since 2023 |
| Age (?) | 37 years |
| Year Ph.D. degree | 2014 |
| Years working in the AI/ML domain | 2009–2023 |
| Total number of publications | 12 journal articles, 17 peer-reviewed conference papers, and 2 peer-reviewed international workshop papers |
| Number of citations (Google Scholar) | 555 |
| H-index (Google Scholar) | 12 |
| i10-index (Google Scholar) | 13 |
| Number of AI/ML publications | 12 journal articles, 19 peer-reviewed conference and workshop papers |
| Program committees, AI/ML conferences | European Intelligence and Security Informatics Conference (EISIC) 2018; Swedish Artificial Intelligence Society Workshop (SAIS 2023) |
| Reviewing, AI/ML conferences | Regular reviewer for the European Intelligence and Security Informatics Conference (EISIC), Swedish Artificial Intelligence Society Workshop (SAIS), The International Conference on Machine Learning, Optimization, and Data Science (LOD), European Network Intelligence Conference (ENIC), The International Conference on Complex Networks and their Applications (COMPLEX NETWORKS) |
| Position | Professor, Since 1999 |
| Age | 61 years |
| Year Ph.D. degree | 1993 |
| Years working in the AI/ML domain | 2015–2023 |
| Total number of publications | 4 book chapters, 53 journal articles, 100 peer-reviewed conference papers, and 32 peer-reviewed international workshop papers |
| Number of citations (Google Scholar) | 3070 |
| H-index (Google Scholar) | 27 |
| i10-index (Google Scholar) | 71 |
| Number of AI/ML publications | 5 journal articles, 10 peer-reviewed conference and workshop papers |
| Program committees, AI/ML conferences | 12 in AI/ML since 2014 |
Appendix B. Blacklist and Thesaurus
References
- Rosenblatt, F. Two Theorems of Statistical Separability in the Perceptron. In Proceedings of the Symposium on the Mechanisation of Thought Processes, London, UK, 24–27 November 1958; H.M. Stationary Office: London, UK; Volume I. [Google Scholar]
- Rosenblatt, F. Perceptron Simulation Experiments. Proc. Inst. Radio Eng. 1960, 18, 301–309. [Google Scholar] [CrossRef]
- Mitchell, T. Machine Learning; McGraw Hill: New York, NY, USA, 1997. [Google Scholar]
- Speretta, M.; Gauch, S.; Lakkaraju, P. Using CiteSeer to analyze trends in the ACM’s computing classification system. In Proceedings of the 3rd International Conference on Human System Interaction, Rzeszow, Poland, 13–15 May 2010. [Google Scholar] [CrossRef]
- Dong, Y. NLP-Based Detection of Mathematics Subject Classification. In Mathematical Software—ICMS 2018; Lecture Notes in Computer, Science; Davenport, J., Kauers, M., Labahn, G., Urban, J., Eds.; Springer: Cham, Switzerland, 2018; Volume 10931. [Google Scholar] [CrossRef]
- Biju, A.K.V.N.; AThomas, S.; Thasneem, J. Examining the research taxonomy of artificial intelligence, deep learning & machine learning in the financial sphere—A bibliometric analysis. Qual. Quant. 2023, 1–30, Online ahead of print. [Google Scholar]
- Ajibade, S.M.; Bekun, F.V.; Adedoyin, F.F.; Gyamfi, B.A.; Adediran, A.O. Machine Learning Applications in Renewable Energy (MLARE) Research: A Publication Trend and Bibliometric Analysis Study (2012–2021). Clean Technol. 2023, 5, 497–517. [Google Scholar] [CrossRef]
- Zhang, J.Z.; Srivastava, P.R.; Sharma, D.; Eachempati, P. Big data analytics and machine learning: A retrospective overview and bibliometric analysis. Expert Syst. Appl. 2021, 184, 115561. [Google Scholar] [CrossRef]
- Diéguez-Santana, K.; González-Díaz, H. Machine learning in antibacterial discovery and development: A bibliometric and network analysis of research hotspots and trends. Comput. Biol. Med. 2023, 155, 106638. [Google Scholar] [CrossRef]
- Xu, Z.; Yu, D.; Wang, X. A bibliometric overview of International Journal of Machine Learning and Cybernetics between 2010 and 2017. Int. J. Mach. Learn. Cybern. 2019, 10, 2375–2387. [Google Scholar] [CrossRef]
- Kitchenham, B.; Brereton, O.P.; Budgen, D.; Turner, M.; Bailey, J.; Linkman, S. Systematic literature reviews in software engineering—A systematic literature review. Inf. Softw. Technol. 2009, 51, 7–15. [Google Scholar] [CrossRef]
- Lundberg, L. Bibliometric mining of research directions and trends for big data. J. Big Data 2023, 10, 112–127. [Google Scholar] [CrossRef]
- Ajibade, S.M.; Zaidi, A.; Al Luhayb, A.S.M.; Adediran, A.O.; Voumik, L.C.; Rabbi, F. New Insights into the Emerging Trends Research of Machine and Deep Learning Applications in Energy Storage: A Bibliometric Analysis and Publication Trends. Int. J. Energy Econ. Policy 2023, 13, 303–314. [Google Scholar] [CrossRef]
- Su, M.; Peng, H.; Li, S. A visualized bibliometric analysis of mapping research trends of machine learning in engineering (MLE). Expert Syst. Appl. 2021, 186, 115728. [Google Scholar] [CrossRef]
- García-Pineda, V.; Valencia-Arias, A.; Patiño-Vanegas, J.C.; Flores Cueto, J.J.; Arango-Botero, D.; Rojas Coronel, A.M.; Rodríguez-Correa, P.A. Research Trends in the Use of Machine Learning Applied in Mobile Networks: A Bibliometric Approach and Research Agenda. Informatics 2023, 10, 73. [Google Scholar] [CrossRef]
- Baminiwatta, A. Global trends of machine learning applications in psychiatric research over 30 years: A bibliometric analysis. Asian J. Psychiatry 2022, 69, 102986. [Google Scholar] [CrossRef] [PubMed]
- Dindorf, C.; Bartaguiz, E.; Gassmann, F.; Fröhlich, M. Conceptual Structure and Current Trends in Artificial Intelligence, Machine Learning, and Deep Learning Research in Sports: A Bibliometric Review. Int. J. Environ. Res. Public Health 2022, 20, 173. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Zhu, H.; Wang, J.; Chen, Y.; Li, Y.; Chen, X.; Liu, W. Machine learning in non-small cell lung cancer radiotherapy: A bibliometric analysis. Front. Oncol. 2023, 13, 1082423. [Google Scholar] [CrossRef] [PubMed]
- El-Alfy, E.M.; Mohammed, S.A. A review of machine learning for big data analytics: Bibliometric approach. Technol. Anal. Strateg. Manag. 2020, 32, 984–1005. [Google Scholar] [CrossRef]
- Ahmed, S.; Alshater, M.M.; El Ammari, A.; Hammami, H. Artificial intelligence and machine learning in finance: A bibliometric review. Res. Int. Bus. Financ. 2022, 61, 101646. [Google Scholar] [CrossRef]
- Goodell, J.W.; Kumar, S.; Lim, W.M.; Pattnaik, D. Artificial intelligence and machine learning in finance: Identifying foundations, themes, and research clusters from bibliometric analysis. J. Behav. Exp. Financ. 2021, 32, 100577. [Google Scholar] [CrossRef]
- Jain, S.; Kaur, N.; Verma, S.; Kavita Hosen, A.S.; Sehgal, S.S. Use of Machine Learning in Air Pollution Research: A Bibliographic Perspective. Electronics 2022, 11, 3621. [Google Scholar] [CrossRef]
- Angarita-Zapata, J.S.; Maestre-Gongora, G.; Calderín, J.F. A bibliometric analysis and benchmark of machine learning and automl in crash severity prediction: The case study of three colombian cities. Sensors 2021, 21, 8401. [Google Scholar] [CrossRef]
- Bidwe, R.V.; Mishra, S.; Patil, S.; Shaw, K.; Vora, D.R.; Kotecha, K.; Zope, B. Deep Learning Approaches for Video Compression: A Bibliometric Analysis. Big Data Cogn. Comput. 2022, 6, 44. [Google Scholar] [CrossRef]
- Zhang, B.; Fan, T. Knowledge structure and emerging trends in the application of deep learning in genetics research: A bibliometric analysis [2000–2021]. Front. Genet. 2022, 13, 951939. [Google Scholar] [CrossRef] [PubMed]
- Chen, K.; Zhai, X.; Wang, S.; Li, X.; Lu, Z.; Xia, D.; Li, M. Emerging trends and research foci of deep learning in spine: Bibliometric and visualization study. Neurosurg. Rev. 2023, 46, 81. [Google Scholar] [CrossRef] [PubMed]
- Feng, C.; Zhou, X.; Wang, H.; He, Y.; Li, Z.; Tu, C. Research hotspots and emerging trends of deep learning applications in orthopedics: A bibliometric and visualized study. Front. Public Health 2022, 10, 949366. [Google Scholar] [CrossRef] [PubMed]
- Zhang, K.; Fan, Y.; Long, K.; Lan, Y.; Gao, P. Research Hotspots and Trends of Deep Learning in Critical Care Medicine: A Bibliometric and Visualized Study. J. Multidiscip. Healthc. 2023, 16, 2155–2166. [Google Scholar] [CrossRef] [PubMed]
- Khairi, S.S.M.; Bakar MA, A.; Alias, M.A.; Bakar, S.A.; Liong, C.Y.; Rosli, N.; Farid, M. Deep Learning on Histopathology Images for Breast Cancer Classification: A Bibliometric Analysis. Healthcare 2021, 10, 10. [Google Scholar] [CrossRef] [PubMed]
- Bai, Y.; Sun, X.; Ji, Y.; Huang, J.; Fu, W.; Shi, H. Bibliometric and visualized analysis of deep learning in remote sensing. Int. J. Remote Sens. 2022, 43, 5534–5571. [Google Scholar] [CrossRef]
- Li, Y.; Xu, Z.; Wang, X.; Wang, X. A bibliometric analysis on deep learning during 2007–2019. Int. J. Mach. Learn. Cybern. 2020, 11, 2807–2826. [Google Scholar] [CrossRef]
- Keramatfar, A.; Rafiee, M.; Amirkhani, H. Graph Neural Networks: A bibliometrics overview. Mach. Learn. Appl. 2022, 10, 100401. [Google Scholar] [CrossRef]
- Kenger, Ö.N.; Özceylan, E. Fuzzy min–max neural networks: A bibliometric and social network analysis. Neural Comput. Appl. 2023, 35, 5081–5111. [Google Scholar] [CrossRef]
- Pande, M.; Mulay, P. Bibliometric Survey of Quantum Machine Learning. Sci. Technol. Libr. 2020, 39, 369–382. [Google Scholar] [CrossRef]
- Lou, T.; Hung, W. Revival of Classical Algorithms: A Bibliometric Study on the Trends of Neural Networks and Genetic Algorithms. Symmetry 2023, 15, 325. [Google Scholar] [CrossRef]
- Yu, D.; Xu, Z.; Wang, X. Bibliometric analysis of support vector machines research trend: A case study in China. Int. J. Mach. Learn. Cybern. 2020, 11, 715–728. [Google Scholar] [CrossRef]
- Gupta, B.M.; Dhawan, S.M. Indian Research on Artificial Neural Networks: A Bibliometric Assessment of Publications Output during 1999–2018. Int. J. Knowl. Content Dev. Technol. 2020, 10, 29–46. [Google Scholar]
- Ezugwu, A.E.; Oyelade, O.N.; Ikotun, A.M.; Agushaka, J.O.; Ho, Y.S. Machine Learning Research Trends in Africa: A 30 Years Overview with Bibliometric Analysis Review. Arch. Comput. Methods Eng. 2023, 30, 4177–4207. [Google Scholar] [CrossRef] [PubMed]
- Herrera-Viedma, E.; Martinez, M.A.; Herrera, M. Bibliometric tools for discovering information in database. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Fujita, H., Ed.; Springer International Publishing: Cham, Switzerland, 2016; pp. 193–203. [Google Scholar]
- Gutiérrez-Salcedo, M.; Martínez M, Á.; Moral-Munoz, J.A.; Herrera-Viedma, E.; Cobo, M.J. Some bibliometric procedures for analyzing and evaluating research fields. Appl. Intell. 2018, 48, 1275–1287. [Google Scholar] [CrossRef]
- Jappe, A. Professional standards in bibliometric research evaluation? A meta-evaluation of European assessment practice 2005–2019. PLoS ONE 2020, 15, e0231735. [Google Scholar] [CrossRef]
- Sharma, B.; Boet, S.; Grantcharov, T.; Shin, E.; Barrowman, N.J.; Bould, M.D. The h-index outperforms other bibliometrics in the assessment of research performance in general surgery: A province-wide study. Surgery 2013, 153, 493–501. [Google Scholar] [CrossRef]
- Mazov, N.A.; Gureev, V.N.; Glinskikh, V.N. The Methodological Basis of Defining Research Trends and Fronts. Sci. Tech. Inf. Process. 2020, 47, 221–231. [Google Scholar] [CrossRef]
- Clarivate Analytics. Research Fronts 2021. 2022. Available online: https://discover.clarivate.com/ResearchFronts2021_EN (accessed on 29 April 2023).
- Van Eck, N.J.; Waltman, L. Visualizing bibliometric networks. In Measuring Scholarly Impact; Springer International Publishing: Cham, Switzerland, 2014; pp. 285–320. [Google Scholar]
- Amjad, T.; Shahid, N.; Daud, A.; Khatoon, A. Citation burst prediction in a bibliometric network. Scientometrics 2022, 127, 2773–2790. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, G.; Zhu, D.; Lu, J. Scientific evolutionary pathways: Identifying and visualizing relationships for scientific topics. J. Assoc. Inf. Sci. Technol. 2017, 68, 1925–1939. [Google Scholar] [CrossRef]
- Boyack, K.W.; Newman, D.; Duhon, R.J.; Klavans, R.; Patek, M.; Biberstine, J.R.; Schijvenaars, B.; Skupin, A.; Ma, N.; Börner, K. Clustering more than two million biomedical publications: Comparing the accuracies of nine text-based similarity approaches. PLoS ONE 2011, 6, e18029. [Google Scholar] [CrossRef]
- Sánchez, M.V.G. “Chen, C. CiteSpace: A Practical Guide for Mapping Scientific Literature [CiteSpace: Una Guía Práctica para el Mapeo de la Literatura Científica]; Hauppauge, N.Y., Ed.; Nova Science: Hauppauge, NY, USA, 2016; 169p; ISBN 978-1-53610-280-2; eBook: 978-1-53610-295-6”. Investig. Bibl. 2017, 31, 293–295. [Google Scholar]
- Wong, D. VOSviewer. Tech. Serv. Q. 2018, 35, 219–220. [Google Scholar] [CrossRef]
- Van Eck, N.J.; Waltman, L. Text mining and visualization using VOSviewer. arXiv 2011, arXiv:1109.2058. [Google Scholar]
- Markscheffel, B.; Schröter, F. Comparison of two science mapping tools based on software technical evaluation and bibliometric case studies. Collnet J. Scientometr. Inf. Manag. 2021, 15, 365–396. [Google Scholar] [CrossRef]
- Flach, P. Machine Learning: The Art and Science of Algorithms That Make Sense of Data; Cambridge University Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Norvig, P.R. Intelligence SA. A Modern Approach; Rani, M., Nayak, R., Vyas, O.P., Eds.; Prentice Hall: Upper Saddle River, NJ, USA, 2015. [Google Scholar]
- Rani, M.; Nayak, R.; Vyas, O.P. An ontology-based adaptive personalized e-learning system, assisted by software agents on cloud storage. Knowl. Based Syst. 2002, 90, 33–48. [Google Scholar] [CrossRef]
- Von Rueden, L.; Mayer, S.; Beckh, K.; Georgiev, B.; Giesselbach, S.; Heese, R.; Kirsch, B.; Pfrommer, J.; Pick, A.; Ramamurthy, R.; et al. Informed machine learning—A taxonomy and survey of integrating prior knowledge into learning systems. IEEE Trans. Knowl. Data Eng. 2021, 35, 614–633. [Google Scholar] [CrossRef]
- Shyam, R.; Singh, R. A taxonomy of machine learning techniques. J. Adv. Robot. 2021, 8, 18–25. [Google Scholar]
- Sammet, J.E.; Ralston, A. The new (1982) computing reviews classification system—Final version. Commun. ACM 1982, 25, 13–25. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Rose, M.E.; Kitchin, J.R. Pybliometrics: Scriptable bibliometrics using a Python interface to Scopus. Softwarex 2019, 10, 100263. [Google Scholar] [CrossRef]
- Corder, G.W.; Foreman, D.I. Nonparametric Statistics: A Step-by-Step Approach, 2nd ed.; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Wan, Z.; Liu, C.; Zhang, M.; Fu, J.; Wang, B.; Cheng, S.; Ma, L.; Quilodrán-Casas, C.; Arcucci, R. Med-UniC: Unifying Cross-Lingual Medical Vision-Language Pre-Training by Diminishing Bias. In Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2023), New Orleans, LA, USA, 10–16 December 2023. [Google Scholar]
- Delbrouck, J.-B.; Saab, K.; Varma, M.; Eyuboglu, S.; Chambon, P.; Dunnmon, J.; Zambrano, Z.; Chaudhari, A.; Langlotz, C. ViLMedic: A framework for research at the intersection of vision and language in medical AI. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics System Demonstrations, Dublin, Ireland, 22–27 May 2022; pp. 23–34. [Google Scholar]
- Robertson, S. Understanding inverse document frequency: On theoretical arguments for IDF. J. Doc. 2004, 60, 503–520. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | #Docs | Databases | Tools/Graphs | Parameters Analyzed | Years | Appl. Area |
|---|---|---|---|---|---|---|
| [13] | 969 | Scopus | VOSviewer, line, pie and bar charts | productivity, citations, subject areas, journals, authors, geographic distribution, keywords | 2012–2022 | Energy storage |
| [7] | 1218 | Scopus | VOSviewer, line, pie and bar charts | productivity, citations, subject areas, document type, journals, authors, geographic distribution, funding, keywords | 2012–2021 | Renewable energy |
| [14] | 3057 | WoS Core Collection | VOSviewer, line and bar charts | productivity, geographic distribution, authors, journals, citations, keywords | 2000–2019 | Engineering |
| [15] | 260 | Scopus and WoS | line and bar charts, point and network plots | productivity, citations, geographic distribution, journals, authors, keywords | 2006–2022 | Mobile networks |
| [9] | 1596 | Scopus | VOSviewer, line and bar charts, word cloud, point plots | productivity, geographic distribution, authors, keywords, trends | 2006–2022 | Antibacterial discovery & development |
| [16] | 1671 | WoS | VOSviewer, CiteSpace, line chart | productivity, research directions, citations. | 1991–2020 | Psychiatry |
| [17] | 1215 | Scopus | VOSviewer, line and bar charts, word cloud | productivity, citations, journals, geographic distribution, authors, keywords, trends. | 1988–2022 | Sports |
| [18] | 197 | WoS Core Collection | VOSviewer, Bibliometrix, line and bar charts | productivity, citations, journals, authors, keywords, | 2000–2022 | Lung cancer radiotherapy |
| [19] | 1587 | WoS | VOSviewer, line, pie and bar charts | productivity, citations, research area, journals, geographic distribution, keywords | 1998–2018 | Big data analytics |
| [20] | 348 | Scopus | VOSviewer, line and bar charts | productivity, citations, geographic distribution, journals, authors, keywords | 2011–2021 | Finance |
| [21] | 283 | Scopus | bar charts, network plots | productivity, citations, influential topics | 1986–2021 | Finance |
| [6] | 723 | WoS | VOSviewer, bar charts, treemap, point plots | productivity, citations, geographic distribution, authors, keywords | 1993–2022 | Finance |
| [22] | 924 | WoS | VOSviewer, Bibliometrix, line and pie charts | productivity, document type, research areas, keywords, authors, journals, geographic distribution, | 1990–2022 | Air pollution |
| [23] | 2318 | Scopus and IEEE | VOSviewer, line and bar charts | productivity, citations, geographic distribution, keywords | 2010–2020 | Traffic accidents |
| [24] | 86 | Scopus and WoS | VOSviewer, bar and pie charts, alluvial diagram, treemap | productivity, citations, document type, geographic distribution, authors, keywords | 2011–2021 | Video compression |
| [25] | 1754 | Science Citation Ind. Exp. | VOSviewer, CiteSpace, line and bar charts | productivity, citations, geographic distribution, journals, keywords | 2000–2021 | Genetics research |
| [26] | 273 | WoS | VOSviewer, CiteSpace, bar chart. | productivity, citations, geographic distribution, journals | 2016–2022 | Spine research |
| [27] | 822 | WoS Core Collection | CiteSpace, line and bar charts | productivity, geographic distribution, authors, journals, keywords | 2015–2021 | Orthopedics |
| [28] | 1708 | WoS | VOSviewer, CiteSpace, Bibliometrix, line and bar charts | productivity, citations, geographic distribution, authors, journals, keywords | 2012–2022 | Critical care medicine |
| [29] | 373 | Scopus | VOSviewer, Bibliometrix, | productivity, citations, geographic distribution, authors, journals, keywords | 2014–2021 | Breast cancer research |
| [30] | 2467 | WoS Core Collection | CiteSpace, line charts | productivity, citations, journals, authors, geographic distribution, keywords | 2014–2020 | Remote sensing |
| Ref. | #Docs | Databases | Tools/Graphs | Parameters Analyzed | Years | Focus |
|---|---|---|---|---|---|---|
| [31] | 5722 | WoS | VOSviewer, CiteSpace, bar charts, treemap, | productivity, citations, geographic distribution, authors | 2007–2019 | Deep learning |
| [8] | 2160 | Scopus | VOSviewer, Bibliometrix, Gephi, line, pie and bar charts, network plots, word cloud | productivity, citations, geographic distribution, emerging topics, keywords | 2006–2020 | Big data analytics and machine learning |
| [32] | 1280 | Scopus | VOSviewer, Bibexcel, line and bar charts, treemap, word clouds | productivity, citations, document type, subject categories, geographic distribution, authors, keywords | 2004–2020 | Graph neural networks |
| [33] | 262 | Scopus and WoS | VOSviewer, line, pie and bar charts, treemap, | productivity, citations, document type, geographic distribution, authors, application areas, journals, keywords | 1992–2022 | Fuzzy min-max neural networks |
| [34] | 430 | Scopus and WoS | line, pie and bar charts, treemap | productivity, research area, authors, journals | 2006–2019 | Quantum machine learning |
| [35] | 1829 | Social Science Citation Index | Line charts | productivity, citations, geographic distribution, document type, research area, journal, authors | 2002–2021 | Neural networks and genetic alg. |
| [10] | 544 | International journal of machine learning and cybernetics | VOSviewer | Citations, geographic distribution, authors, keywords, | 2010–2017 | International journal of machine learning and cybernetics |
| [36] | 13,224 | Science Citation Index Expanded and Social Science Citation Index | VOSviewer, bar and line charts. | Productivity, citations, trends, geographic distribution, authors, journals, keywords | 2000–2018 | Support vector machines and China |
| [37] | 8260 | Scopus | Line and bar charts, | productivity, citations, application areas, geographic distribution, journals, authors | 1999–2018 | Artificial neural networks and India |
| [38] | 2761 | Science Citation Index Expanded | Line and bar charts, | productivity, citations, application areas, geographic distribution | 1993–2021 | Africa |
| Country | Number of Documents | Country | Number of Documents |
|---|---|---|---|
| United States of America | 95,912 | South Korea | 11,807 |
| China | 73,829 | Spain | 10,895 |
| India | 48,818 | Brazil | 7604 |
| United Kingdom | 26,415 | Netherlands | 6998 |
| Germany | 22,689 | Saudi Arabia | 6866 |
| Canada | 15,766 | Switzerland | 6606 |
| Italy | 14,286 | Russian Federation | 6527 |
| Australia | 12,491 | Turkey | 6010 |
| Japan | 12,457 | Malaysia | 5660 |
| France | 12,172 | Taiwan | 5591 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lundberg, L.; Boldt, M.; Borg, A.; Grahn, H. Bibliometric Mining of Research Trends in Machine Learning. AI 2024, 5, 208-236. https://doi.org/10.3390/ai5010012
Lundberg L, Boldt M, Borg A, Grahn H. Bibliometric Mining of Research Trends in Machine Learning. AI. 2024; 5(1):208-236. https://doi.org/10.3390/ai5010012
Chicago/Turabian StyleLundberg, Lars, Martin Boldt, Anton Borg, and Håkan Grahn. 2024. "Bibliometric Mining of Research Trends in Machine Learning" AI 5, no. 1: 208-236. https://doi.org/10.3390/ai5010012
APA StyleLundberg, L., Boldt, M., Borg, A., & Grahn, H. (2024). Bibliometric Mining of Research Trends in Machine Learning. AI, 5(1), 208-236. https://doi.org/10.3390/ai5010012