
Evaluation of an Arabic Chatbot Based on Extractive Question-Answering Transfer Learning and Language Transformers


Abstract
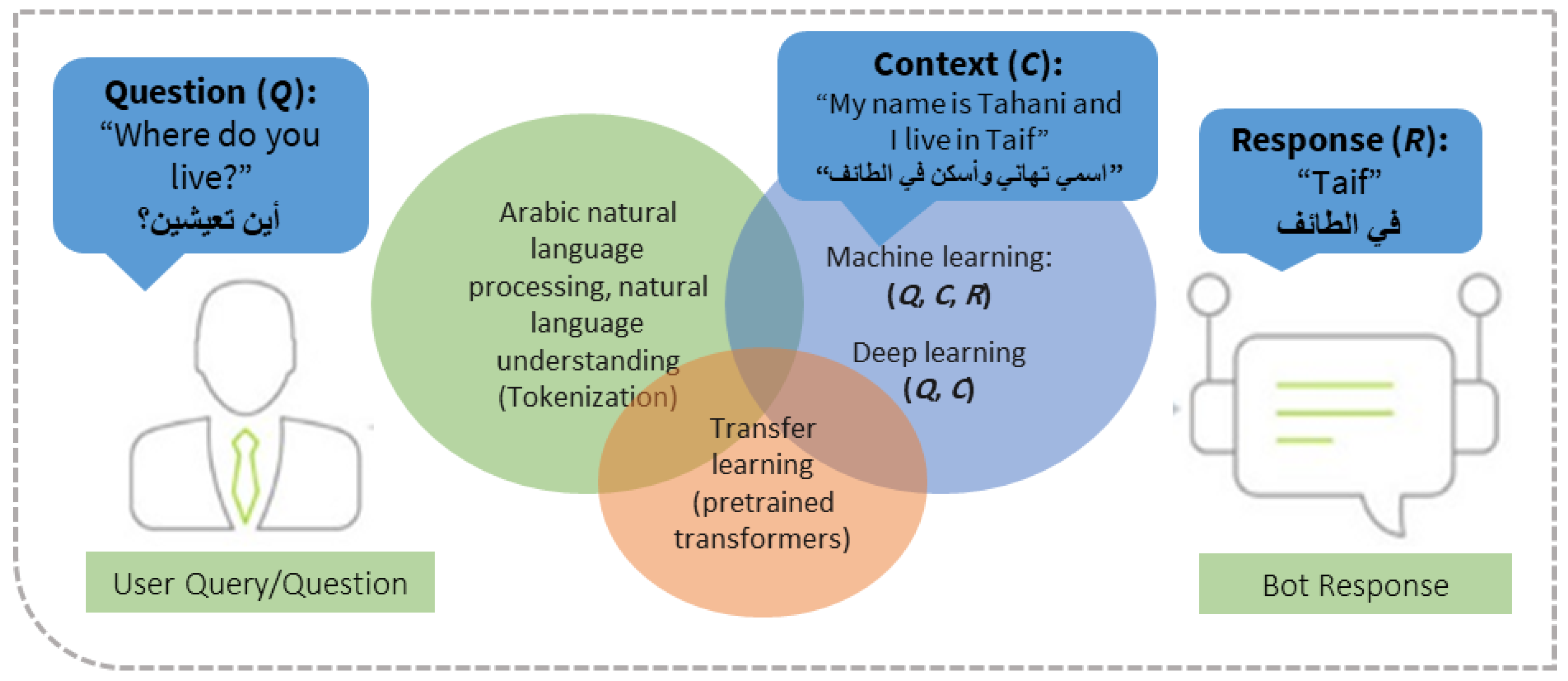
:1. Introduction
- First, BERT-like language transformers that were pre-trained on large collections of Arabic were explored for use in an Arabic QA chatbot.
- Second, the transfer learning method was investigated for Arabic chatbots using Arabic language transformers, namely, AraBERT, CAMeLBERT, AraElectra-SQuAD, and AarElectra (Generator/Discriminator).
- Third, the proposed methods were evaluated with NLP evaluation metrics and by using two Arabic QA datasets, which demonstrated that Arabic chatbots can meaningfully understand the conversations’ contexts and respond naturally.
2. Literature Review
2.1. Chatbot System Architecture and Applications
2.2. Chatbot Methods
2.2.1. Rules-Based Methods
2.2.2. Corpus-Based and Retrieval-Based Methods
2.2.3. Extractive-Based and Generative-Based Methods
2.3. Discussions and Research Gap
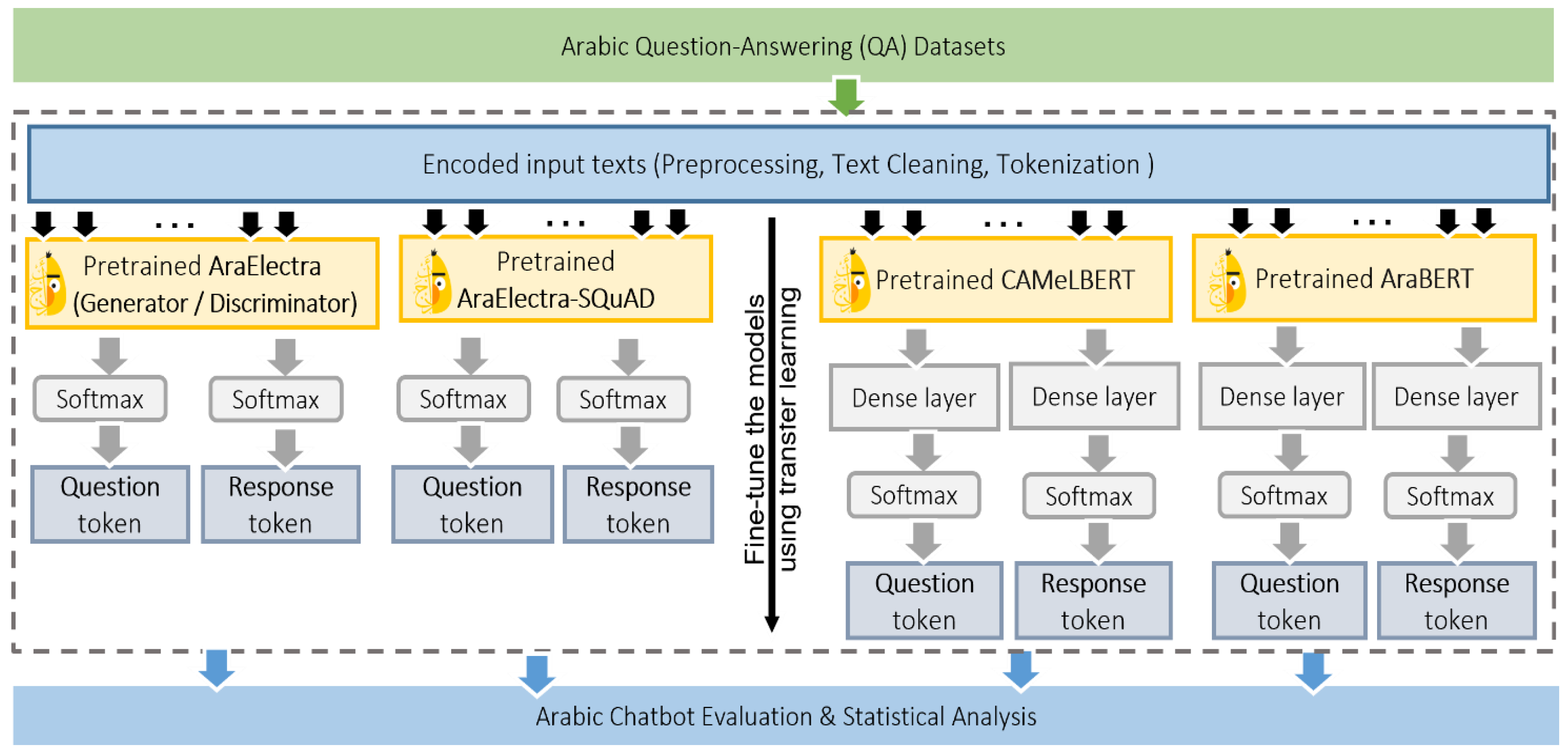
3. Methodology
3.1. General Framework
3.2. Details of Extractive QA and the Transfer Learning Method for Arabic Chatbots
- Dataset preprocessing: We utilized large datasets of questions and their corresponding answers, together with a large corpus collection of textual documents, that contain the contexts in which these questions and answers were taken. During this step, we implemented various pre-reprocessing steps to remove any unwanted elements such as special characters, stop words, or noisy words. Furthermore, we cleaned the corpus by removing any irrelevant or misleading information.
- Initialization: In this study, we used several pre-trained transformers. The final fully connected layer(s) of the pre-trained network were removed and replaced with new layer(s) that represent the questions/queries and responses/answers. This process saved a lot of time and computational resources compared to training a network from scratch, as the network can start from a good initial state based on its prior experience. Several parameters were initialized, such as the patch size, the number of epochs, and the learning rate, wherein we used initialization settings similar to those of state-of-the-art studies in QA tasks in English.
- Fine-tuning: Several BERT-like transformers in Arabic were fine-tuned using large datasets of annotated QA pairs for the task of extractive QA. This step was crucial to achieving the aims of our study, whereby the goal of the model was to read a passage of text and extract a concise answer to a given question from the passage. To elaborate, we first provided the model with a dataset of questions and their corresponding answers, as well as the passage from which the answer was extracted. The model was then trained to predict the correct answer given a passage and a question. During the fine-tuning process, the transformers’ last (i.e., added) layers were trained using a task-specific loss function that aimed to optimize the model to generate the correct answer for a given question. The model was trained to select the answer by identifying the start and end positions of the answer in the passage. The fine-tuning process involved adjusting the weights of the pre-trained transformers using backpropagation to optimize the model’s output. The loss function was minimized in several epochs to improve the model’s accuracy in predicting the correct answer to a given question.
- Answer extraction and evaluation: Once the fine-tuning was complete, our models were used for extractive QA in an Arabic chatbot. When a user asks a question, the chatbot can feed the question into the model, which will then provide an answer based on corpus collection with a confidence score. Hence, our proposed models were tested on different datasets and real-world scenarios to check their robustness and accuracy. In order to compute the confidence and similarity scores, several semantic embedding models were used. A semantic embedding model is an NLP method that allows words or phrases to be represented as vectors of numbers in a multi-dimensional space. The idea behind this model is that words that are similar in meaning will be located close to each other in this space, while words that are dissimilar will be located far apart. In this study, variants of distilbert and BERT-based models for Arabic were employed to predict the answers or responses based on their surrounding context.
| Algorithm 1 Transfer learning and extractive QA method for Arabic chatbot |
| # Input: INDEXDIR : path to the index directory that contains the documents from which answers are extracted QUESTIONS: dataset of questions to be evaluated # Models: _model(str) : name of BERT/SQUAD model to be fine-tuned on the corpus dataset. _emb_model(str): name of BERT model to use to generate embeddings for semantic similarity. # Output: answer, context, similarity, confidence, doc_index #Stage 1: Preprocessing (text cleaning, tokenization) foreach doc in dataset: doc = remove_punctuations(doc) doc = remove_diacritics(doc) doc = tokenizer.from_pretrained(_emb_model, doc) save(doc, dataset) in INDEXDIR #Stage 2: Hyperparameters initialization batch_size(int) : number of question-context pairs fed to model at each iteration n_docs_retrieved(int): number of top relevant documents that will be searched for answer n_answers(int) : maximum number of candidate answers to return epochs(int) : number of iterations learning_rate(float): learning rate during training (fit) the model #Stage 3: Fine-tuning:implementing transfer learning base_model = _model if base_model is AraBERT or CAMeLBERT: model = sequential() model.add(base_model) model.flatten() model.add(dense_layer) model.add(softmax_layer) model.compile() model.fit(dataset in INDEXDIR) # minimize loss function in several epochs to improve the accuracy elseif base_model is AraElectra-SQuAD or AraElectra Generator/Discriminator: model = sequential() model.add(base_model) model.flatten() model.add(softmax_layer) model.compile() model.fit(dataset in INDEXDIR) # minimize loss function in several epochs to improve the accuracy #Stage 4: Answer extraction: submit question to obtain candidate answers. question(str): question in the form of a string foreach question in QUESTIONS: answer, context, doc_index = get_answer(question, model) confidence = P(answer|question,context) * P(question|context)/P(answer) similarity =(question∙answer.T)/(norm(question)* norm(answer)) |
4. Experimental Setup
4.1. Datasets
4.2. Resources and Tools
4.3. Evaluation
5. Experimental Results
5.1. Initial Results Using a Sample of Selected Questions from the MSA-QA and DA-QA Datasets
5.2. Initial Results Using a Sample of Selected Questions from the MSA-QA and ARCD-QA Datasets
5.3. Experimental Results Using All Questions from the MSA-QA and ARCD-QA Datasets
6. Conclusions and Future Works
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Caldarini, G.; Jaf, S.; McGarry, K.; McGarry, K. A Literature Survey of Recent Advances in Chatbots. Information 2022, 13, 41. [Google Scholar] [CrossRef]
- Ali, D.A.; Habash, N. Botta: An Arabic Dialect Chatbot. In Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: System Demonstrations; The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 208–212. [Google Scholar]
- Al-Ghadhban, D.; Al-Twairesh, N. Nabiha: An Arabic Dialect Chatbot. Int. J. Adv. Comput. Sci. Appl. (IJACSA) 2020, 11. [Google Scholar] [CrossRef]
- Joukhadar, A.; Saghergy, H.; Kweider, L.; Ghneim, N. Arabic dialogue act recognition for textual chatbot systems. In Proceedings of the First International Workshop on NLP Solutions for Under Resourced Languages (NSURL 2019) Co-Located with ICNLSP 2019-Short Papers, Trento, Italy, 11–12 September 2019; pp. 43–49. [Google Scholar]
- Shi, N.; Zeng, Q.; Lee, R. Language Chatbot-The Design and Implementation of English Language Transfer Learning Agent Apps. In Proceedings of the 2020 IEEE 3rd International Conference on Automation, Electronics and Electrical Engineering (AUTEEE), Shenyang, China, 20–22 November 2020; pp. 403–407. [Google Scholar]
- Vasilev, I.; Slater, D.; Spacagna, G.; Roelants, P.; Zocca, V. Python Deep Learning: Exploring Deep Learning Techniques and Neural Network Architectures with PyTorch, Keras, and TensorFlow, 2nd ed.; Packt Publishing: Birmingham, UK, 2019. [Google Scholar]
- Cai, L.Z.; Shaheen, A.; Jin, A.; Fukui, R.; Yi, J.S.; Yannuzzi, N.; Alabiad, C. Performance of Generative Large Language Models on Ophthalmology Board–Style Questions. Am. J. Ophthalmol. 2023, 254, 141–149. [Google Scholar] [CrossRef] [PubMed]
- Kamnis, S. Generative pre-trained transformers (GPT) for surface engineering. Surf. Coat. Technol. 2023, 466, 129680. [Google Scholar] [CrossRef]
- Eke, D.O. ChatGPT and the rise of generative AI: Threat to academic integrity? J. Responsible Technol. 2023, 13, 100060. [Google Scholar] [CrossRef]
- Kocoń, J.; Cichecki, I.; Kaszyca, O.; Kochanek, M.; Szydło, D.; Baran, J.; Bielaniewicz, J.; Gruza, M.; Janz, A.; Kanclerz, K.; et al. ChatGPT: Jack of all trades, master of none. Inf. Fusion 2023, 99, 101861. [Google Scholar] [CrossRef]
- Sohail, S.S.; Farhat, F.; Himeur, Y.; Nadeem, M.; Madsen, D.Ø.; Singh, Y.; Atalla, S.; Mansoor, W. Decoding ChatGPT: A Taxonomy of Existing Research, Current Challenges, and Possible Future Directions. J. King Saud Univ.—Comput. Inf. Sci. 2023, 35, 101675. [Google Scholar] [CrossRef]
- Alhassan, N.A.; Saad Albarrak, A.; Bhatia, S.; Agarwal, P. A Novel Framework for Arabic Dialect Chatbot Using Machine Learning. Comput. Intell. Neurosci. 2022, 2022, 1844051. [Google Scholar] [CrossRef]
- Alruily, M. ArRASA: Channel Optimization for Deep Learning-Based Arabic NLU Chatbot Framework. Electronics 2022, 11, 3745. [Google Scholar] [CrossRef]
- Ghaddar, A.; Wu, Y.; Bagga, S.; Rashid, A.; Bibi, K.; Rezagholizadeh, M.; Xing, C.; Wang, Y.; Xinyu, D.; Wang, Z.; et al. Revisiting Pre-trained Language Models and their Evaluation for Arabic Natural Language Understanding. arXiv 2022, arXiv:2205.10687. [Google Scholar] [CrossRef]
- Suta, P.; Lan, X.; Wu, B.; Mongkolnam, P.; Chan, J.H. An overview of machine learning in chatbots. Int. J. Mech. Eng. Robot. Res. 2020, 9, 502–510. [Google Scholar] [CrossRef]
- Adamopoulou, E.; Moussiades, L. Chatbots: History, technology, and applications. Mach. Learn. Appl. 2020, 2, 100006. [Google Scholar] [CrossRef]
- Ali, A.; Zain Amin, M. Conversational AI Chatbot Based on Encoder-Decoder Architectures with Attention Mechanism Application of Multilayer Perceptron (MLP) for Data Mining in Healthcare Operations View project Performance Evaluation of Supervised Machine Learning Classifiers for Predicting Healthcare Operational Decisions View project Conversational AI Chatbot Based on Encoder-Decoder Architectures with Attention Mechanism. Artif. Intell. Festiv. 2019, 2, 1–11. [Google Scholar] [CrossRef]
- Majid, R.; Santoso, H.A. Conversations Sentiment and Intent Categorization Using Context RNN for Emotion Recognition. In Proceedings of the 2021 7th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 19–20 March 2021; pp. 46–50. [Google Scholar]
- Ilievski, V.; Musat, C.; Hossmann, A.; Baeriswyl, M. Goal-Oriented chatbot dialog management bootstrapping with transfer learning. In Proceedings of the IJCAI International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 13–19 July 2018; pp. 4115–4121. [Google Scholar]
- Bălan, C. Chatbots and Voice Assistants: Digital Transformers of the Company–Customer Interface—A Systematic Review of the Business Research Literature. J. Theor. Appl. Electron. Commer. Res. 2023, 18, 995–1019. [Google Scholar]
- Nguyen, T.T.; Le, A.D.; Hoang, H.T.; Nguyen, T. NEU-chatbot: Chatbot for admission of National Economics University. Comput. Educ. Artif. Intell. 2021, 2, 100036. [Google Scholar] [CrossRef]
- Moriuchi, E.; Landers, V.M.; Colton, D.; Hair, N. Engagement with chatbots versus augmented reality interactive technology in e-commerce. J. Strateg. Mark. 2021, 29, 375–389. [Google Scholar] [CrossRef]
- Zota, R.D.; Cîmpeanu, I.A.; Dragomir, D.A. Use and Design of Chatbots for the Circular Economy. Sensors 2023, 23, 4990. [Google Scholar] [CrossRef] [PubMed]
- Siglen, E.; Vetti, H.H.; Lunde, A.B.F.; Hatlebrekke, T.A.; Strømsvik, N.; Hamang, A.; Hovland, S.T.; Rettberg, J.W.; Steen, V.M.; Bjorvatn, C. Ask Rosa—The making of a digital genetic conversation tool, a chatbot, about hereditary breast and ovarian cancer. Patient Educ. Couns. 2022, 105, 1488–1494. [Google Scholar] [CrossRef] [PubMed]
- Khadija, A.; Zahra, F.F.; Naceur, A. AI-Powered Health Chatbots: Toward a general architecture. Procedia Comput. Sci. 2021, 191, 355–360. [Google Scholar] [CrossRef]
- Mathew, R.B.; Varghese, S.; Joy, S.E.; Alex, S.S. Chatbot for Disease Prediction and Treatment Recommendation using Machine Learning. In Proceedings of the 2019 3rd International Conference on Trends in Electronics and Informatics (ICOEI), Tirunelveli, India, 23–25 April 2019; pp. 851–856. [Google Scholar]
- Wang, R.; Wang, J.; Liao, Y.; Wang, J. Supervised machine learning chatbots for perinatal mental healthcare. In Proceedings of the Proceedings—2020 International Conference on Intelligent Computing and Human-Computer Interaction (ICHCI), Sanya, China, 4–6 December 2020; pp. 378–383. [Google Scholar]
- Rakib, A.B.; Rumky, E.A.; Ashraf, A.J.; Hillas, M.M.; Rahman, M.A. Mental Healthcare Chatbot Using Sequence-to-Sequence Learning and BiLSTM. In Proceedings of the Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), Kolkata, India, 15–18 December 2021; pp. 378–387. [Google Scholar]
- Chow, J.C.L.; Sanders, L.; Li, K. Design of an Educational Chatbot Using Artificial Intelligence in Radiotherapy. AI 2023, 4, 319–332. [Google Scholar] [CrossRef]
- Koundinya, H.; Palakurthi, A.K.; Putnala, V.; K., A.K. Smart College Chatbot using ML and Python. In Proceedings of the 2020 International Conference on System, Computation, Automation and Networking (ICSCAN), Pondicherry, India, 3–4 July 2020; pp. 1–5. [Google Scholar]
- Chempavathy, B.; Prabhu, S.N.; Varshitha, D.R.; Vinita; Lokeswari, Y. AI based Chatbots using Deep Neural Networks in Education. In Proceedings of the 2nd International Conference on Artificial Intelligence and Smart Energy (ICAIS), Coimbatore, India, 23–25 February 2022; pp. 124–130. [Google Scholar]
- Almurayh, A. The Challenges of Using Arabic Chatbot in Saudi Universities. IAENG Int. J. Comput. Sci. 2021, 48, 190–201. [Google Scholar]
- Zahour, O.; Benlahmar, E.H.; Eddaoui, A.; Ouchra, H.; Hourrane, O. A system for educational and vocational guidance in Morocco: Chatbot e-orientation. Procedia Comput. Sci. 2020, 175, 554–559. [Google Scholar] [CrossRef]
- Chuang, C.-H.; Lo, J.-H.; Wu, Y.-K. Integrating Chatbot and Augmented Reality Technology into Biology Learning during COVID-19. Electronics 2023, 12, 222. [Google Scholar] [CrossRef]
- Yu, C.-S.; Hsu, M.-H.; Wang, Y.-C.; You, Y.-J. Designing a Chatbot for Helping Parenting Practice. Appl. Sci. 2023, 13, 1793. [Google Scholar] [CrossRef]
- Vyawahare, S.; Chakradeo, K. Chatbot assistant for english as a second language learners. In Proceedings of the 2020 International Conference on Convergence to Digital World—Quo Vadis (ICCDW), Mumbai, India, 18–20 February 2020. [Google Scholar]
- Gowda, M.P.C.; Srivastava, A.; Chakraborty, S.; Ghosh, A.; Raj, H. Development of Information Technology Telecom Chatbot: An Artificial Intelligence and Machine Learning Approach. In Proceedings of the 2021 2nd International Conference on Intelligent Engineering and Management (ICIEM), London, UK, 28–30 April 2021; pp. 216–221. [Google Scholar]
- Baha, T.A.I.T.; Hajji, M.E.L.; Es-Saady, Y.; Fadili, H. Towards highly adaptive Edu-Chatbot. Procedia Comput. Sci. 2022, 198, 397–403. [Google Scholar] [CrossRef]
- Thorat, S.A.; Jadhav, V. A Review on Implementation Issues of Rule-based Chatbot Systems. In Proceedings of the International Conference on Innovative Computing & Communications (ICICC) 2020, Delhi, India, 2 April 2020. [Google Scholar] [CrossRef]
- Singh, J.; Joesph, M.H.; Jabbar, K.B.A. Rule-based chabot for student enquiries. In Journal of Physics: Conference Series; IOP Publishing: Philadelphia, PA, USA, 2019. [Google Scholar]
- Maeng, W.; Lee, J. Designing a Chatbot for Survivors of Sexual Violence: Exploratory Study for Hybrid Approach Combining Rule-based Chatbot and ML-based Chatbot. In Proceedings of the 5th Asian CHI Symposium, Yokohama, Japan, 7–8 May 2021; pp. 160–166. [Google Scholar]
- Alsheddi, A.S.; Alhenaki, L.S. English and Arabic Chatbots: A Systematic Literature Review. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 662–675. [Google Scholar] [CrossRef]
- Rokaya, A.; Md Touhidul Islam, S.; Zhang, H.; Sun, L.; Zhu, M.; Zhao, L. Acceptance of Chatbot based on Emotional Intelligence through Machine Learning Algorithm. In Proceedings of the Proceedings—2022 2nd International Conference on Frontiers of Electronics, Information and Computation Technologies (ICFEICT), Wuhan, China, 19–21 August 2022; pp. 610–616. [Google Scholar]
- Achuthan, S.; Balaji, S.; Thanush, B.; Reshma, R. An Improved Chatbot for Medical Assistance using Machine Learning. In Proceedings of the 5th International Conference on Inventive Computation Technologies, ICICT 2022—Proceedings, Lalitpur, Nepal, 20–22 July 2022; pp. 70–75. [Google Scholar]
- Goel, R.; Arora, D.K.; Kumar, V.; Mittal, M. A Machine Learning based Medical Chatbot for detecting diseases. In Proceedings of the 2nd International Conference on Innovative Practices in Technology and Management (ICIPTM), Pradesh, India, 23–25 February 2022; pp. 175–181. [Google Scholar]
- Goel, R.; Goswami, R.P.; Totlani, S.; Arora, P.; Bansal, R.; Vij, D. Machine Learning Based Healthcare Chatbot. In Proceedings of the 2022 2nd International Conference on Advance Computing and Innovative Technologies in Engineering (ICACITE), Greater Noida, India, 28–29 April 2022; pp. 188–192. [Google Scholar]
- Mahanan, W.; Thanyaphongphat, J.; Sawadsitang, S.; Sangamuang, S. College Agent: The Machine Learning Chatbot for College Tasks. In Proceedings of the 7th International Conference on Digital Arts, Media and Technology, DAMT 2022 and 5th ECTI Northern Section Conference on Electrical, Electronics, Computer and Telecommunications Engineering (NCON), Chiang Rai, Thailand, 26–28 January 2022; pp. 329–332. [Google Scholar] [CrossRef]
- Prasetyo, A.; Santoso, H.A. Intents Categorization for Chatbot Development Using Recurrent Neural Network (RNN) Learning. In Proceedings of the 2021 7th International Conference on Advanced Computing and Communication Systems, ICACCS 2021, Coimbatore, India, 19–20 March 2021; pp. 551–556. [Google Scholar]
- Dhyani, M.; Kumar, R. An intelligent Chatbot using deep learning with Bidirectional RNN and attention model. Mater. Today Proc. 2021, 34, 817–824. [Google Scholar]
- Patil, S.; Mudaliar, V.M.; Kamat, P.; Gite, S. LSTM based Ensemble Network to enhance the learning of long-term dependencies in chatbot. Int. J. Simul. Multidisci. Des. Optim. 2020, 11, 25. [Google Scholar]
- Pathak, K.; Arya, A. A Metaphorical Study of Variants of Recurrent Neural Network Models for A Context Learning Chatbot. In Proceedings of the 2019 4th International Conference on Information Systems and Computer Networks (ISCON), Mathura, India, 21–22 November 2019; pp. 768–772. [Google Scholar]
- Kasthuri, E.; Balaji, S. Natural language processing and deep learning chatbot using long short term memory algorithm. Mater. Today Proc. 2021, 81, 690–693. [Google Scholar] [CrossRef]
- Anki, P.; Bustamam, A.; Al-Ash, H.S.; Sarwinda, D. High Accuracy Conversational AI Chatbot Using Deep Recurrent Neural Networks Based on BiLSTM Model. In Proceedings of the 2020 3rd International Conference on Information and Communications Technology (ICOIACT), Yogyakarta, Indonesia, 24–25 November 2020; pp. 382–387. [Google Scholar]
- Jalaja, T.; Adilakshmi, D.T.; Sharat Chandra, M.S.; Imran Mirza, M.; Kumar, M. A Behavioral Chatbot Using Encoder-Decoder Architecture: Humanizing conversations. In Proceedings of the 2022 Second International Conference on Interdisciplinary Cyber Physical Systems (ICPS), Chennai, India, 9–10 May 2022; pp. 51–54. [Google Scholar]
- Boussakssou, M.; Ezzikouri, H.; Erritali, M. Chatbot in Arabic language using seq to seq model. Multimed. Tools Appl. 2022, 81, 2859–2871. [Google Scholar] [CrossRef]
- Rajamalli Keerthana, R.; Fathima, G.; Florence, L. Evaluating the performance of various deep reinforcement learning algorithms for a conversational chatbot. In Proceedings of the 2021 2nd International Conference for Emerging Technology (INCET), Belagavi, India, 21–23 May 2021. [Google Scholar]
- Cuayáhuitl, H.; Lee, D.; Ryu, S.; Cho, Y.; Choi, S.; Indurthi, S.; Yu, S.; Choi, H.; Hwang, I.; Kim, J. Ensemble-based deep reinforcement learning for chatbots. Neurocomputing 2019, 366, 118–130. [Google Scholar] [CrossRef]
- Li, S.; Sun, C.; Liu, B.; Liu, Y.; Ji, Z. Modeling Extractive Question Answering Using Encoder-Decoder Models with Constrained Decoding and Evaluation-Based Reinforcement Learning. Mathematics 2023, 11, 1624. [Google Scholar] [CrossRef]
- Kulkarni, A.; Shivananda, A.; Kulkarni, A. Building a Chatbot Using Transfer Learning. In Natural Language Processing Projects: Build Next-Generation NLP Applications Using AI Techniques; Apress: Berkeley, CA, USA, 2022; pp. 239–255. [Google Scholar] [CrossRef]
- Aksu, I.T.; Chen, N.F.; D’Haro, L.F.; Banchs, R.E. Reranking of Responses Using Transfer Learning for a Retrieval-Based Chatbot. In Increasing Naturalness and Flexibility in Spoken Dialogue Interaction: 10th International Workshop on Spoken Dialogue Systems; Marchi, E., Siniscalchi, S.M., Cumani, S., Salerno, V.M., Li, H., Eds.; Springer: Singapore, 2021; pp. 239–250. [Google Scholar] [CrossRef]
- Tran, Q.-D.L.; Le, A.-C. Exploring Bi-Directional Context for Improved Chatbot Response Generation Using Deep Reinforcement Learning. Appl. Sci. 2023, 13, 5041. [Google Scholar] [CrossRef]
- Vijayaraghavan, V.; Cooper, J.B.; Rian Leevinson, R.L. Algorithm Inspection for Chatbot Performance Evaluation. Procedia Comput. Sci. 2020, 171, 2267–2274. [Google Scholar]
- Ahmed, A.; Ali, N.; Alzubaidi, M.; Zaghouani, W.; Abd-alrazaq, A.; Househ, M. Arabic chatbot technologies: A scoping review. Comput. Methods Programs Biomed. Update 2022, 2, 100057. [Google Scholar] [CrossRef]
- Wolf, T.; Sanh, V.; Chaumond, J.; Delangue, C. TransferTransfo: A Transfer Learning Approach for Neural Network Based Conversational Agents. arXiv 2019, arXiv:1901.08149. [Google Scholar]
- Aljawarneh, E. Arabic Questions Dataset. Available online: https://github.com/EmranAljawarneh/Arabic-questions-dataset (accessed on 9 February 2023).
- Mozannar, H.; Hajal, K.E.; Maamary, E.; Hajj, H. Neural Arabic Question Answering. arXiv 2019, arXiv:1906.05394. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Industry/Application | Description | Pros. | Cons. | Ref. |
|---|---|---|---|---|
| Customer service | Sentiment and intent analysis and emotion recognition in customer service chatbots | supports emotions and sentiment analysis | accuracy is not high | [18] |
| Goal-oriented conversation management bootstrapping | transfers learning and improves accuracy | low data and domain specific | [19] | |
| Chatbots and voice assistants: digital transformers of the company and customer service | has an extensive literature review | - | [20] | |
| e-Commerce, Economy,and Telecom | Engagement with chatbots versus augmented reality interactive technology in e-commerce | tests consumers’ attitude and engagement | cannot be generalised | [22] |
| Information technology telecom chatbot | can be integrated into other online platforms | rule based chatbot | [37] | |
| Use and design of chatbots for the circular economy | analysis of five existing chatbots | no practical implementation | [23] | |
| Healthcare and Medicaldiagnosis | Ask Rosa: digital genetic conversation chatbot about hereditary breast and ovarian cancer | extensive user and formal usability testing | manual building of the database | [24] |
| AI-Powered health chatbots general architecture using NLP and NLU | gives response from pre-formatted data | no practical implementation | [25] | |
| Chatbot for disease prediction and treatment recommendation | great for daily check-ups | no practical implementation | [26] | |
| Mental healthcare chatbots | assists mental healthcare using deep learning | low datasets for this domain | [27,28] | |
| Design of an educational chatbot in radiotherapy | disseminates topics in radiotherapy | limited data | [29] | |
| Education | Highly adaptive educational chatbot | can detect the student’s intent | no practical implementation | [38] |
| NEU-chatbot: chatbot for admission of National Economics University | students get daily updates instantly | - | [21] | |
| Educational and smart chatbots for colleges and universities | uses NLP and ready-to-use platforms | no detailed explanation of the methods | [30,31,32,33,34] | |
| Designing a chatbot for helping parenting practice | solves problems encountered by novice parents | no detailed explanation of the methods | [35] | |
| Language learning | Chatbot assistant for English as a second language learners | used in real-world applications | no evaluation methods used | [5,36] |
| Method | Description | Dataset | Acc. | Pros. | Cons. | Ref. |
|---|---|---|---|---|---|---|
| NLP NLU | AI-powered healthcare chatbots NLU chatbot framework | - | - | utilizes NLP, NLU, NLG, deep learning | inaccurate data decrease accuracy | [13,21,25,30] |
| ML | Acceptance of chatbot based on emotional intelligence through machine learning algorithm | international students with experience in using chatbot | 97% | TAM and EI theory to predict users’ intentions | data limited to international students, difficult to interpret | [43] |
| An improved chatbot for medical assistance using machine learning | various sources: medical journals, online forums, and websites | 93% | streamlines medical processes and save time | SVM’s accuracy may not be perfect | [44] | |
| Chatbot for disease prediction and treatment recommendation using machine learning | comprised of patient data, medical history, and symptoms | - | alternative to hospital visits-based diagnosis | not as accurate as traditional hospital visits | [26] | |
| Supervised machine learning chatbots for perinatal mental healthcare | pregnant women, newborns, and their families | - | reduces barriers and helps clinicians make accurate diagnoses | cannot accurately detect subtle changes in mental health | [27] | |
| A novel framework for Arabic dialect chatbot using machine learning | extracted IT problems/solutions from multiple domains | accuracy, response time | no explanation of how ML was employed | [12] | ||
| RNN | Intents categorization for chatbot development using Recurrent Neural Network (RNN) Learning | university guest book available from its website | 81% | understands variations in sentence expression | requires big data, difficult or expensive to implement | [48] |
| Conversations sentiment and intent categorization using context RNN for emotion recognition | conversations inside a movie | 79% | successful in recognizing emotions in text-based dialogs | only uses a single dataset for testing the algorithm | [18] | |
| Deep learning with bidirectional RNN and attention model | Reddit dataset | - | performs English-to-English translation | No accuracy measured | [49] | |
| LSTM | LSTM-based ensemble network to enhance the learning of long-term dependencies in chatbot | Cornell Movie Dialog Corpus | 71.59% | retains contextual meaning of conversations | - | [50] |
| A metaphorical study of variants of recurrent neural network models for context learning chatbot | Facebook bAbi dataset | 96% | helps to create chatbots for web applications | only tests RNN models on a single dataset | [51] | |
| Natural language processing and deep learning chatbot using long-short term memory algorithm | conversations with users and assessments | - | understands questions and provide detailed answers | does not address accuracy and reliability | [52] | |
| AI based chatbots using deep neural networks in education | set of answer and question pairs | - | provides accurate and useful responses to student queries | incorrect/difficulty handling complex queries | [31] | |
| AI chatbot using deep Recurrent Neural Networks based on BiLSTM model | Cornell Movie Dialog Corpus | 99% | outperforms other chatbots in accuracy and response time | only compares with a few other systems | [53] | |
| GRU | A metaphorical study of variants of Recurrent Neural Network models for a context learning chatbot | Facebook bAbi dataset | 72% | - | - | [51] |
| Encoder-Decoder | AI chatbot based on encoder-decoder architectures with attention | Cornell Movie Subtitle Corpus | - | improves the experience and interaction | lack of review of similar methods | [17] |
| Behavioural chatbot using encoder-decoder architecture | - | - | increases replicability | focuses on mimicking fictional characters | [54] | |
| Highly adaptive educational chatbot using encoder-decoder framework for intent recognition | - | - | bidirectional transformer (CamemBERT) | no experimental evaluation | [38] | |
| Seq2seq | Chatbot in Arabic language using Seq-2-Seq model. | ~81,659 pairs of conversations | - | uses common conversational topics | no detailed description of the dataset, making it difficult to replicate | [55] |
| Mental healthcare chatbot using Seq2Seq Learning and BiLSTM | The Mental Health FAQ | - | assists mental healthcare | - | [28] | |
| Transfer Learning | Goal-oriented chatbot dialog management bootstrapping with transfer learning | - | - | overcomes low in-domain data availability | focuses on technical aspects not chatbot performance | [19] |
| The design and implementation of English language transfer learning agent apps | English Language Robot | - | integrates recognition service from Google and GPT-2 | no comparison with existing chatbots for language learning | [5] | |
| Building chatbot using transfer learning: end-to-end implementation and evaluation | - | shows fine-tuning and optimizing | no comparison evaluation | [59] | ||
| Reranking of responses using transfer learning for a retrieval-based Chatbot | WOCHAT dataset Ubuntu dialogue dataset | highest ratings from the human subjects | - | [60] | ||
| Reinforcement Learning | Evaluating the performance of various deep reinforcement learning | Cornell Movie-dialogs corpus and CoQA | - | comprehensive review of methods | difficult to compare to other approaches | [56] |
| Ensemble-based deep reinforcement learning for chatbots | Chitchat data | - | training ensemble of agents improved chatbot performance | requires more training time | [57] | |
| Modeling extractive QA encoder-decoder reinforcement learning | SQuAD dataset | - | combines different reward functions | results need to be improved | [58] | |
| Exploring Bi-Directional Context for Improved Chatbot Response Generation | some generated samples | - | combines different models | qualitative evaluation | [61] |
| Transformer Name (Based on Huggingface) | Size | Task | Description | Pre-Training Datasets |
|---|---|---|---|---|
| aubmindlab/bert-base-arabertv02 aubmindlab/bert-base-arabertv2 aubmindlab/bert-base-arabertv01 aubmindlab/bert-base-arabert (https://huggingface.co/aubmindlab/bert-base-arabert (accessed on 3 March 2023)) | base | Text generation | AraBERT is a pre-trained Arabic language model with pre-segmented text, trained and evaluated similarly to the original BERT in English. | OSCAR, Arabic Wikipedia, Arabic Books collected from various sources, Arabic News Articles and Arabic text collected from social media platforms, such as Twitter and online forums. |
| aubmindlab/bert-large-arabertv2 aubmindlab/bert-large-arabertv02 | large | Text generation | ||
| aubmindlab/araelectra-base-generator (https://huggingface.co/aubmindlab/araelectra-base-generator (accessed on 3 March 2023)) | base | Text prediction, QA | This generator model, which generates new text based on learned patterns from training data, achieved state-of-the-art performance on Arabic QA datasets. | OSCAR unshuffled and filtered, Arabic Wikipedia dump from 1 September 2020, the 1.5 B words Arabic Corpus, the OSIAN Corpus, and Assafir news articles. |
| aubmindlab/araelectra-base-discriminator (https://huggingface.co/aubmindlab/araelectra-base-discriminator (accessed on 3 March 2023)) | base | Text prediction, QA | This discriminator model classifies or makes predictions based on input features. | |
| CAMeL-Lab/bert-base-arabic-camelbert-mix (https://huggingface.co/CAMeL-Lab/bert-base-arabic-camelbert-mix (accessed on 3 March 2023)) CAMeL-Lab/bert-base-arabic-camelbert-ca CAMeL-Lab/bert-base-arabic-camelbert-da CAMeL-Lab/bert-base-arabic-camelbert-msa | base | Text generation | Pre-trained BERT models for Arabic texts with different dialects and structures, formal and informal Arabic. | MSA: Arabic Gigaword, Abu El-Khair Corpus, OSIAN corpus, Arabic Wikipedia, Arabic OSCAR DA: A collection of dialectal data CA: OpenITI (Version 2020.1.2). |
| ZeyadAhmed/AraElectra-Arabic-SQuADv2-QA (https://huggingface.co/ZeyadAhmed/AraElectra-Arabic-SQuADv2-QA (accessed on 3 March 2023)) | base | QA | AraElectra-based model fine-tuned on QA pairs to predict unanswerable questions. | Arabic-SQuADv2.0 dataset. |
| Dataset | Number of Documents | Description | ||
|---|---|---|---|---|
| Questions | Answers | Corpus | ||
| MSA-QA | 398 | 398 | 398 | This repository of Arabic Questions Dataset (https://github.com/EmranAljawarneh/Arabic-questions-dataset (accessed on 25 April 2023)) provides an Arabic question for data science and machine learning. |
| ARCD-QA | 1395 | 1395 | 365,568 | The corpus contains a comprehensive Arabic Wikipedia dump 2021 (https://www.kaggle.com/datasets/z3rocool/arabic-wikipedia-dump-2021?datasetId=1179369 (accessed on 1 May 2023)), including articles, discussions, and textual information from 2021. The questions were created by crowd-workers in ARCD (https://www.kaggle.com/datasets/thedevastator/unlocking-arabic-language-comprehension-with-the (accessed on 1 May 2023)). |
| DA-QA | 98,422 | 98,422 | 98,422 | Arabic AskFM dataset collection of questions and answers mostly about Islamic topics by various authors in dialectal Arabic (DA) on the AskFM platform. |
| Question | AraBERT | AraElectra-SQuAD | ||||||
|---|---|---|---|---|---|---|---|---|
| Base | Large | Base | Large | |||||
| Sim. | Conf. | Sim. | Conf. | Sim. | Conf. | Sim. | Conf. | |
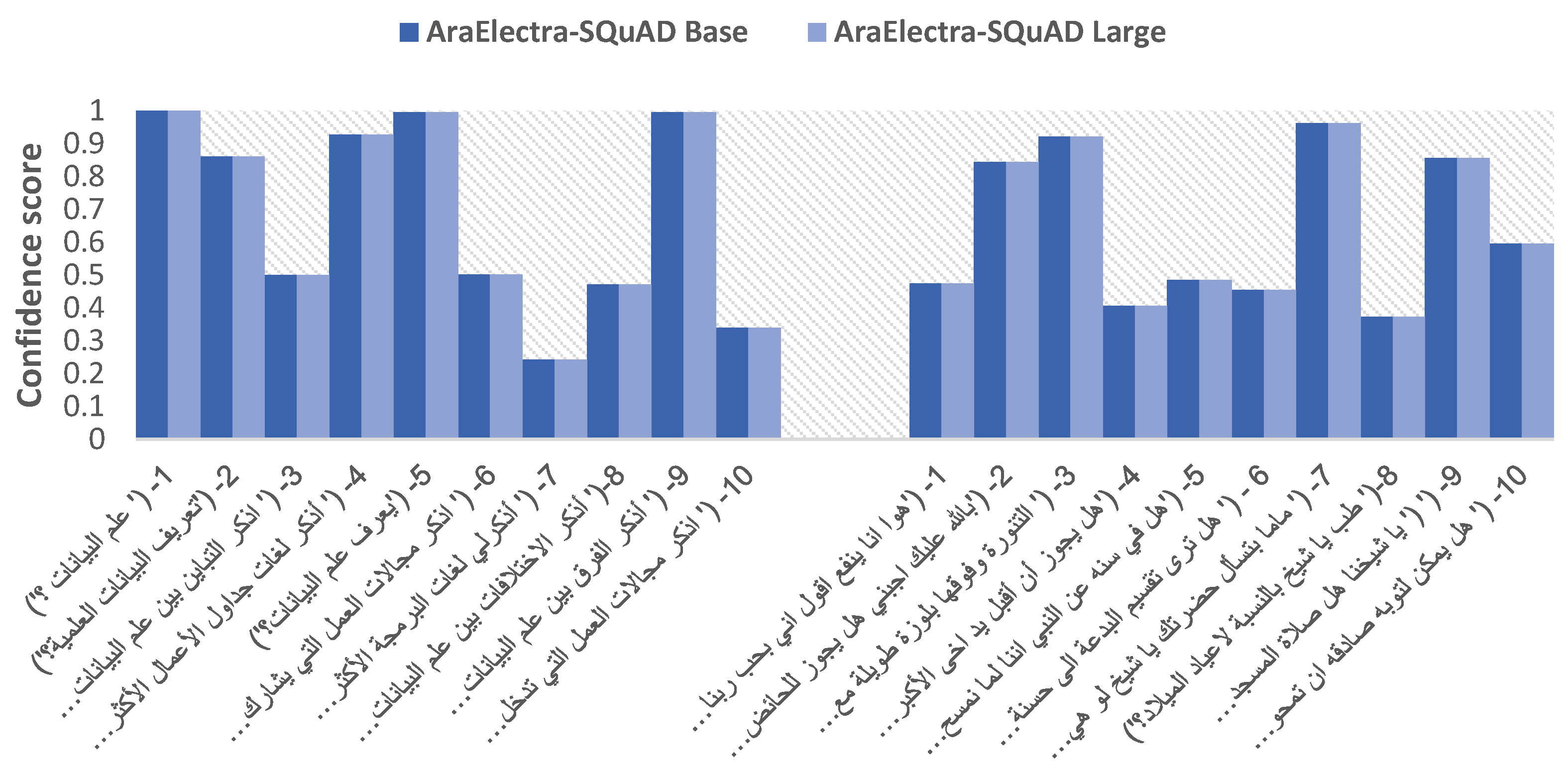
| 1-(‘ علم البيانات ؟’) | 0.8890 | 0.3355 | 0.9284 | 0.1700 | 0.9191 | 0.9993 | 0.6480 | 0.9993 |
| 2-(‘تعريف البيانات العلمية؟’) | 0.9447 | 0.1249 | 0.9486 | 0.1867 | 0.9652 | 0.8601 | 0.6321 | 0.8601 |
| 3-(‘ اذكر التباين بين علم البيانات والذكاء الاصطناعي؟’) | 0.9980 | 1.0 | 0.9291 | 0.1234 | 0.9801 | 0.5006 | 0.7498 | 0.5006 |
| 4-(‘ أذكر لغات جداول الأعمال الأكثر شيوعًا في مجال علم البيانات؟’) | 0.9905 | 0.5 | 0.9531 | 0.1741 | 0.9778 | 0.9276 | 0.8334 | 0.9276 |
| 5- (’يعرف علم البيانات؟’) | 0.9424 | 0.25 | 0.9384 | 0.2627 | 0.9343 | 0.9951 | 0.6901 | 0.9951 |
| 6-(‘ اذكر مجالات العمل التي يشارك فيها علم البيانات؟’) | 0.9585 | 0.1250 | 0.9895 | 0.5 | 0.9747 | 0.5020 | 0.8945 | 0.5020 |
| 7-(‘ أذكرلي لغات البرمجة الأكثر شيوعًا في مجال علم البيانات؟’) | 0.9908 | 0.1702 | 0.9887 | 0.1184 | 0.9847 | 0.2424 | 0.8175 | 0.2424 |
| 8-(‘ أذكر الاختلافات بين علم البيانات والذكاء الاصطناعي؟’) | 0.9670 | 1.0 | 0.9419 | 0.5476 | 0.9817 | 0.4718 | 0.8070 | 0.4718 |
| 9-(‘ أذكر الفرق بين علم البيانات والمثقفين الاصطناعي؟’) | 0.9851 | 0.5102 | 0.9453 | 0.2202 | 0.9831 | 0.9954 | 0.8256 | 0.9954 |
| 10-(‘ اذكر مجالات العمل التي تدخل فيها البيانات علميا؟’) | 0.9470 | 0.5 | 0.9677 | 0.1448 | 0.9686 | 0.3397 | 0.8673 | 0.3397 |
| Question | AraBERT | AraElectra-SQuAD | ||||||
|---|---|---|---|---|---|---|---|---|
| Base | Large | Base | Large | |||||
| Sim. | Conf. | Sim. | Conf. | Sim. | Conf. | Sim. | Conf. | |
| 1-(‘هوا انا ينفع اقول اني بحب ربنا اووي عشان هوا عسل وبيحبنا؟’) | 0.9825 | 0.2331 | 0.9366 | 0.1322 | 0.9729 | 0.4737 | 0.8815 | 0.4737 |
| 2-(‘بالله عليك اجبني هل يجوز للحائض زيارة المقابر ضروري بالله عليك؟’) | 0.9801 | 0.1713 | 0.9848 | 0.1724 | 0.9710 | 0.8436 | 0.7874 | 0.8436 |
| 3-(‘ التنورة وفوقها بلوزة طويلة مع طرحة تغطي الصدر كده حجاب شرعي؟’) | 0.9902 | 0.4014 | 0.9603 | 0.2438 | 0.9767 | 0.9217 | 0.8508 | 0.9217 |
| 4-(‘هل يجوز أن أقبل يد اخى الأكبر كشكر وعرفان لفضله عليا منذ صغرى ؟’) | 0.9809 | 0.2571 | 0.9936 | 0.3674 | 0.9827 | 0.4069 | 0.9191 | 0.4069 |
| 5-(‘هل في سنه عن النبي اننا لما نمسح الارض بالمياه نحط عليها ملح ؟؟’) | 0.9858 | 0.1859 | 0.975 | 0.1683 | 0.9762 | 0.4853 | 0.8186 | 0.4853 |
| 6 - (' هل ترى تقسيم البدعة الى حسنة وسيئة؟’) | 0.9842 | 0.3012 | 0.9371 | 0.2435 | 0.9675 | 0.4547 | 0.6798 | 0.4547 |
| 7-(‘ماما بتسأل حضرتك يا شيخ لو هي شارية ليا حاجات للمستقبل أدوات منزلية وغيره هل عليها زكاة أم لا ؟’) | 0.986 | 0.3289 | 0.9763 | 0.1594 | 0.9838 | 0.9624 | 0.8619 | 0.9624 |
| 8-(' طب يا شيخ بالنسبة لاعياد الميلاد؟’) | 0.9846 | 0.3816 | 0.946 | 0.1539 | 0.9584 | 0.3724 | 0.7328 | 0.3724 |
| 9-(‘ (' يا شيخنا هل صلاة المسجد للرجال فرض وتاركه آثم غير مقبول صلاته ؟ | 0.9408 | 0.2420 | 0.9839 | 0.1719 | 0.9764 | 0.8567 | 0.8407 | 0.8567 |
| 10-(‘ هل يمكن لتوبه صادقه ان تمحو ما قبلها فكأنما ما أذنب المرء قط ؟ا) | 0.9469 | 0.4698 | 0.9851 | 0.1635 | 0.9792 | 0.5950 | 0.8337 | 0.5950 |
| Dataset | Transformer | Semantic Embeddings Model | Avg. Sim. | Avg. Conf. |
|---|---|---|---|---|
| MSA-QA | bert-base-arabertv02 | bert-base-arabertv02 | 0.8457 | 0.3304 |
| bert-large-arabertv02 | bert-large-arabertv02 | 0.6657 | 0.4504 | |
| bert-base-arabertv2 | bert-base-arabertv2 | 0.8915 | 0.1695 | |
| bert-large-arabertv2 | bert-large-arabertv2 | 0.7727 | 0.3989 | |
| bert-base-arabertv01 | bert-base-arabertv01 | 0.8183 | 0.2779 | |
| bert-base-arabert | bert-base-arabert | 0.7776 | 0.2452 | |
| bert-base-arabic-camelbert-mix | bert-base-arabic-camelbert-mix | 0.47667 | 0.3876 | |
| bert-base-arabic-camelbert-ca | bert-base-arabic-camelbert-ca | 0.9625 | 0.1935 | |
| bert-base-arabic-camelbert-da | bert-base-arabic-camelbert-da | 0.8168 | 0.4612 | |
| bert-base-arabic-camelbert-msa | bert-base-arabic-camelbert-msa | 0.5394 | 0.2493 | |
| ARCD-QA | bert-base-arabertv02 | bert-base-arabertv02 | 0.7599 | 0.3320 |
| bert-large-arabertv02 | bert-large-arabertv02 | 0.6774 | 0.4816 | |
| bert-base-arabertv2 | bert-base-arabertv2 | 0.6491 | 0.1822 | |
| bert-large-arabertv2 | bert-large-arabertv2 | 0.6519 | 0.2913 | |
| bert-base-arabertv01 | bert-base-arabertv01 | 0.8635 | 0.2271 | |
| bert-base-arabert | bert-base-arabert | 0.8507 | 0.4800 | |
| bert-base-arabic-camelbert-mix | bert-base-arabic-camelbert-mix | 0.9122 | 0.2598 | |
| bert-base-arabic-camelbert-ca | bert-base-arabic-camelbert-ca | 0.9352 | 0.2972 | |
| bert-base-arabic-camelbert-da | bert-base-arabic-camelbert-da | 0.8664 | 0.2937 | |
| bert-base-arabic-camelbert-msa | bert-base-arabic-camelbert-msa | 0.7378 | 0.3381 |
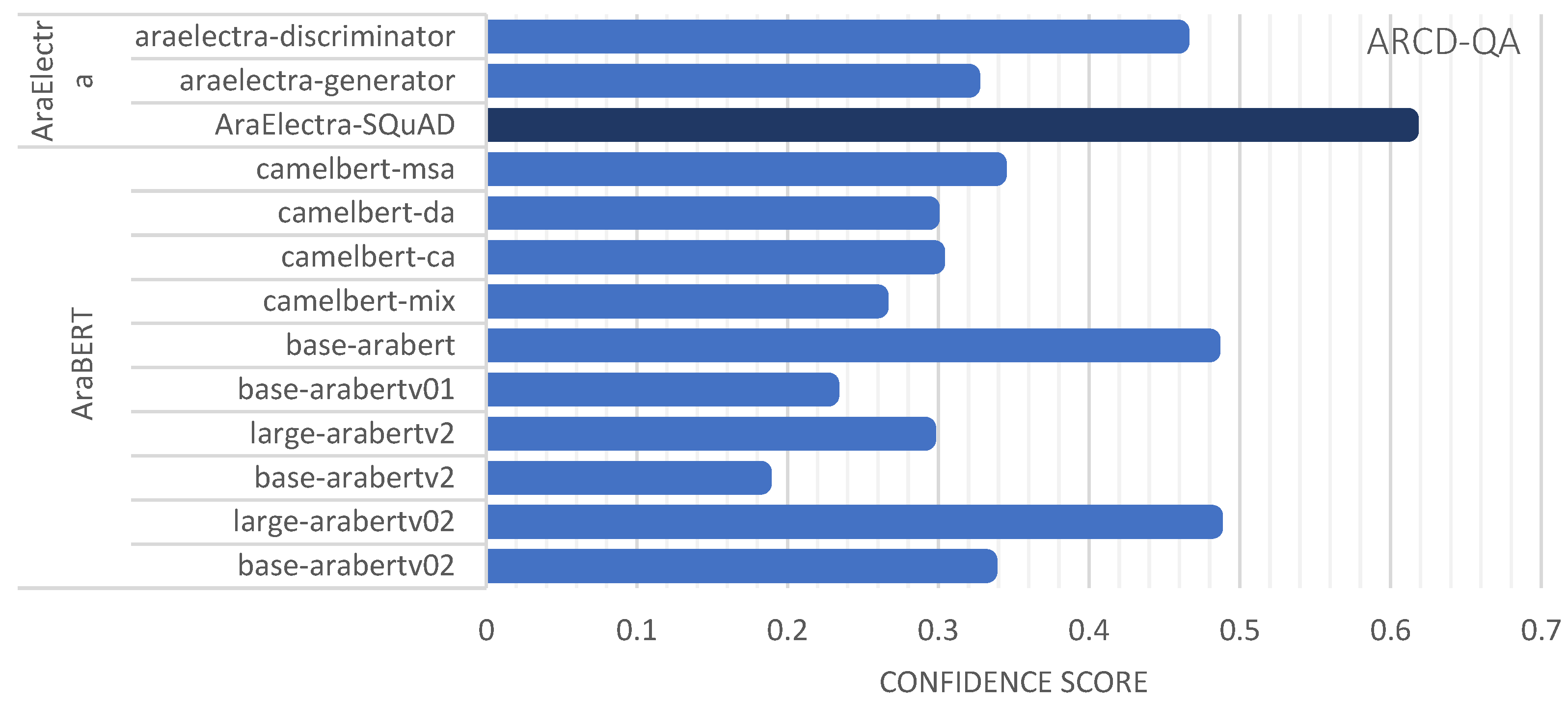
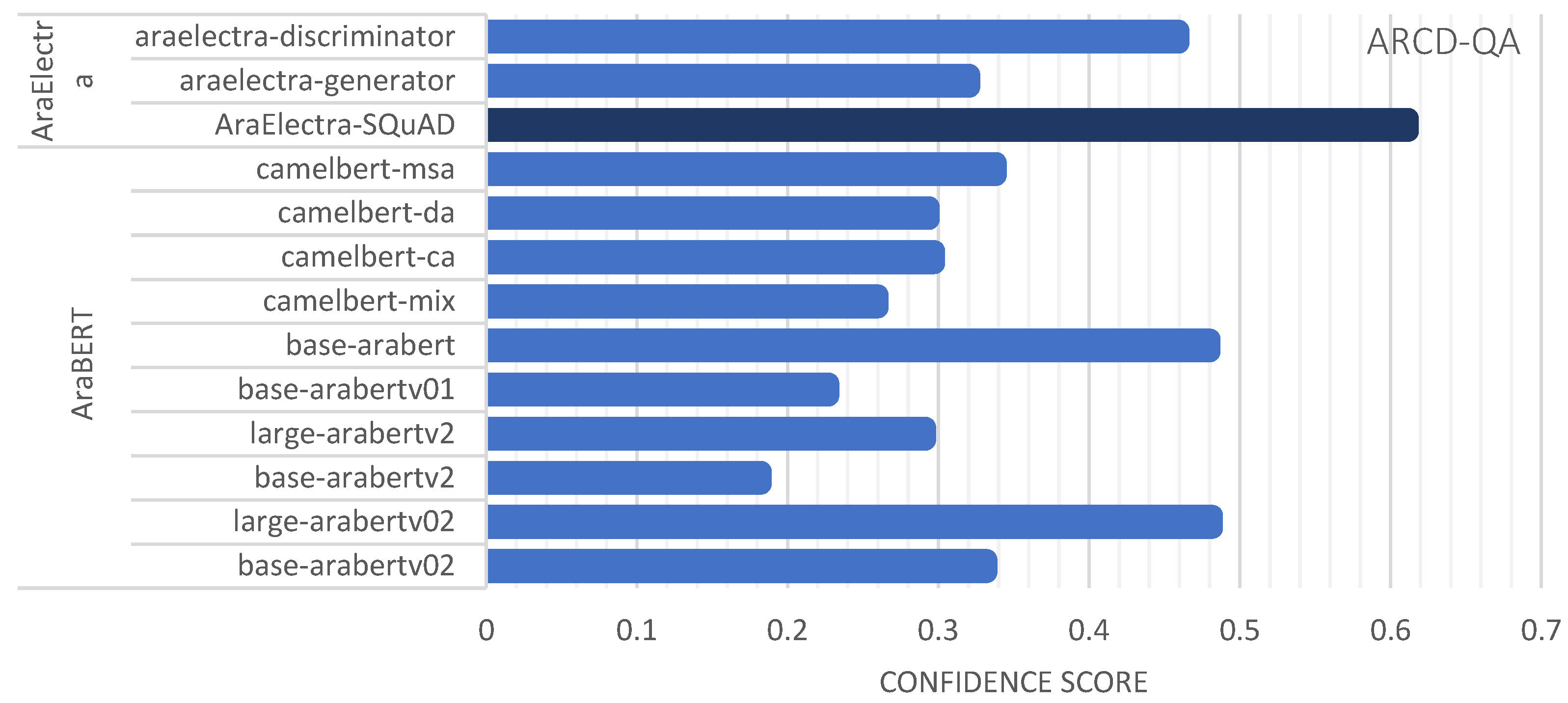
| Dataset | Transformer | Semantic Embeddings Model | Avg. Sim. | Avg. Conf. |
|---|---|---|---|---|
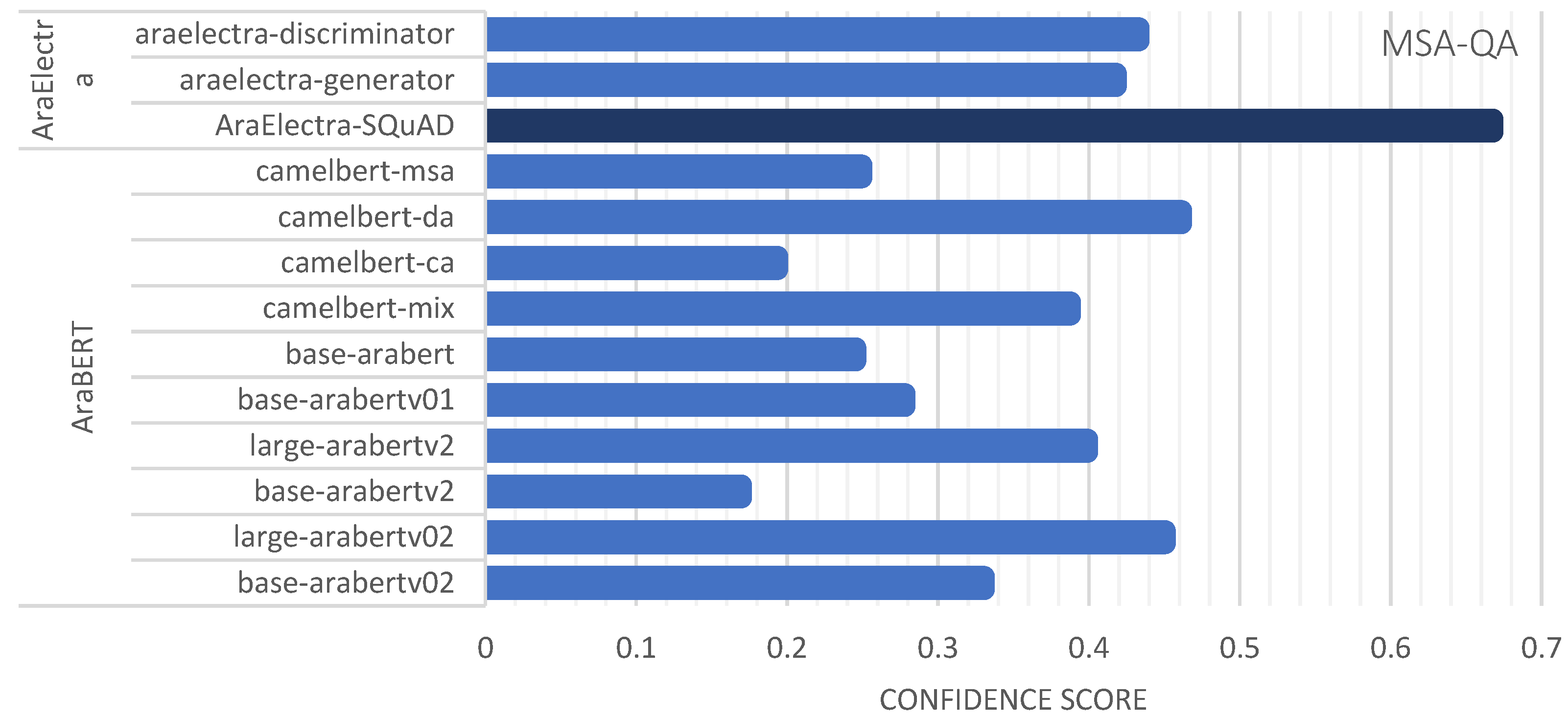
| MSA-QA | AraElectra-Arabic-SQuADv2-QA | bert-base-arabertv2 | 0.8242 | 0.6675 |
| AraElectra-Arabic-SQuADv2-QA | distilbert-base-uncased | 0.9786 | 0.6675 | |
| araelectra-base-generator | bert-base-arabertv2 | 0.6434 | 0.4179 | |
| araelectra-base-discriminator | bert-base-arabertv2 | 0.7652 | 0.4329 | |
| araelectra-base-generator | distilbert-base-uncased | 0.9687 | 0.3043 | |
| araelectra-base-discriminator | distilbert-base-uncased | 0.5688 | 0.4286 | |
| ARCD-QA | AraElectra-Arabic-SQuADv2-QA | bert-base-arabertv2 | 0.6952 | 0.6116 |
| AraElectra-Arabic-SQuADv2-QA | distilbert-base-uncased | 0.9806 | 0.6116 | |
| araelectra-base-generator | bert-base-arabertv2 | 0.7385 | 0.1957 | |
| araelectra-base-discriminator | bert-base-arabertv2 | 0.7388 | 0.2086 | |
| araelectra-base-generator | distilbert-base-uncased | 0.9166 | 0.3206 | |
| araelectra-base-discriminator | distilbert-base-uncased | 0.8962 | 0.4593 |
| Dataset | Transformer | Semantic Embeddings Model | Avg. Sim. | Avg. Conf. | |
|---|---|---|---|---|---|
| AraBERT-based | MSA-QA | bert-base-arabertv02 | bert-base-arabertv02 | 0.8256 | 0.3897 |
| bert-large-arabertv02 | bert-large-arabertv02 | 0.8365 | 0.2128 | ||
| bert-large-arabertv2 | bert-large-arabertv2 | 0.7673 | 0.4251 | ||
| bert-base-arabic-camelbert-da | bert-base-arabic-camelbert-da | 0.9229 | 0.3634 | ||
| ARCD-QA | bert-base-arabertv02 | bert-base-arabertv02 | 0.6986 | 0.2038 | |
| bert-large-arabertv02 | bert-large-arabertv02 | 0.6241 | 0.5465 | ||
| bert-base-arabert | bert-base-arabert | 0.9396 | 0.2426 | ||
| bert-base-arabic-camelbert-msa | bert-base-arabic-camelbert-msa | 0.7727 | 0.1901 | ||
| AraElectra-based | MSA-QA | AraElectra-Arabic-SQuADv2-QA | bert-base-arabertv2 | 0.8268 | 0.6422 |
| AraElectra-Arabic-SQuADv2-QA | distilbert-base-uncased | 0.9773 | 0.6422 | ||
| araelectra-base-generator | bert-base-arabertv2 | 0.7013 | 0.3616 | ||
| araelectra-base-discriminator | bert-base-arabertv2 | 0.7218 | 0.3291 | ||
| ARCD-QA | AraElectra-Arabic-SQuADv2-QA | bert-base-arabertv2 | 0.6852 | 0.6657 | |
| AraElectra-Arabic-SQuADv2-QA | distilbert-base-uncased | 0.9660 | 0.6658 | ||
| araelectra-base-generator | distilbert-base-uncased | 0.9036 | 0.2908 | ||
| araelectra-base-discriminator | distilbert-base-uncased | 0.8573 | 0.4147 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alruqi, T.N.; Alzahrani, S.M. Evaluation of an Arabic Chatbot Based on Extractive Question-Answering Transfer Learning and Language Transformers. AI 2023, 4, 667-691. https://doi.org/10.3390/ai4030035
Alruqi TN, Alzahrani SM. Evaluation of an Arabic Chatbot Based on Extractive Question-Answering Transfer Learning and Language Transformers. AI. 2023; 4(3):667-691. https://doi.org/10.3390/ai4030035
Chicago/Turabian StyleAlruqi, Tahani N., and Salha M. Alzahrani. 2023. "Evaluation of an Arabic Chatbot Based on Extractive Question-Answering Transfer Learning and Language Transformers" AI 4, no. 3: 667-691. https://doi.org/10.3390/ai4030035
APA StyleAlruqi, T. N., & Alzahrani, S. M. (2023). Evaluation of an Arabic Chatbot Based on Extractive Question-Answering Transfer Learning and Language Transformers. AI, 4(3), 667-691. https://doi.org/10.3390/ai4030035