

Recent Advances in Infrared Face Analysis and Recognition with Deep Learning



Abstract
1. Introduction
- Face detection: Scanning the full image to identify whether or not the candidate area is a face.
- Face preprocessing: Performed on the detected area, which may consist of noise reduction, contrast enhancement, or similar operations.
- Feature extraction: The extraction of facial features such as eyes, nose, mouth, brows, and cheeks and the geometrical relation between them from the preprocessed facial image. In addition to Face recognition, the feature extraction step is used for emotion and pain detection.
- Feature matching: Use the extracted Feature vector to perform a comparison with a set of known faces.
1.1. Classic Face Recognition Methods
1.2. Contributions and Outline
2. IR Datasets

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | #Images | #Subjects | Accessories | Variations | Spectrum |
|---|---|---|---|---|---|
| CASIA [53] | 3940 | 197 | glasses | HO, FE | NIR |
| PolyU [54] | 3500 | 350 | - | HO, FE | VIS, NIR |
| USTC-NVIE [55] | - | 215 | glasses | HO, FE | VIS, thermal |
| Oulu-CASIA [35] | 80 | - | FE | VIS, NIR | |
| IRIStcite [56] | 4190 | 30 | - | HO, FE | Thermal |
| CSIST [57] | 1000 | 50 | - | - | VIS, NIR |
| UL-FMTV [58] | - | 238 | glasses | HO, FE | Thermal |
| High-Resolution Thermal Face Dataset [59] | 300 | 30 | glasses | HO, FE | Thermal |
| Fully Annotated Thermal Face dataset [60] | 2500 | 90 | - | HO, FE | Thermal |
| RGB-D-T [61] | 45,900 | 51 | - | HO, FE | VIS, thermal |
| HIT LAB2 [57] | 2000 | 50 | - | HO, FE | VIS, NIR |
| SunWin [62] | 4000 | 100 | - | HO, FE | VIS, NIR |
| University of Notre Dame’s UND collection X1 [63] | 4584 | 82 | - | HO, FE | VIS, LWIR |
| -faces dataset [64] | 11,660 | 35 | glasses | HO, FE | VIS, NIR, MWIR, LWIR |
| ARLV-TF [65] | 500,000 | 395 | glasses | HO, FE | VIS, LWIR |
| BUAA-VIS-NIR [66] | 2700 | 150 | - | HO, FE | VIS, NIR |
| ND-NIVL [67] | 24,605 | 574 | - | - | VIS, NIR |
| Polarimetric thermal dataset [68] | 800 | 60 | - | HO, FE | VIS, LWIR |
| SC3000-DB [69] | 766 | 40 | - | - | NIR |
| CARL [70] | 7380 | 41 | - | - | VIS, Thermal, NIR |
| Terravic [71] | - | 20 | glasses | HO, FE | Thermal |
| The IIIT Delhi occluded dataset [72] | 1362 | 75 | multiple | HO, FE | VIS, Thermal |
| INF [73] | 470 | 94 | - | - | NIR |
| TUFTS [74] | 10,000 | 113 | glasses | HO, FE | VIS, NIR, Thermal |
| Charlotte-ThermalFace database [75] | 1000 | 10 | - | HO, FE | Thermal |
2.1. CASIA NIR Dataset
2.2. PolyU NIR Face Dataset
2.3. USTC-NVIE Dataset
2.4. Oulu-CASIA NIR-VIS Dataset
2.5. IRIS Dataset
2.6. CSIST Dataset
2.7. UL-FMTV
2.8. RGB-D-T Face Dataset
2.9. ND-NIVL
2.10. CARL Dataset
2.11. University of Notre Dame’s UND Collection X1
2.12. Faces Dataset
2.13. ARLV-TF Dataset
2.14. UNC Charlotte Thermal Face Database
2.15. Small Datasets
2.16. Private Datasets
3. Metrics
3.1. Receiver Operating Characteristic (ROC)
3.2. Mean Accuracy (ACC)
3.3. Validation Rate (VAL) and False Accept Rate (FAR)
3.4. Cumulative Matching Characteristics (CMC)
3.5. Precision-Coverage Curve
3.6. Minimum Squared Error (MSE)
4. Loss Functions
4.1. Softmax Loss
4.2. Triplet Loss
4.3. Center Loss
4.4. Mutual Component Analysis Loss
4.5. Modality Discrepancy Loss
4.6. Component Adaptive Triplet Loss
5. Deep Learning Methods
5.1. Synthesis Methods
5.2. Feature Learning Methods
5.3. NIR-VIS Alignment Methods
5.4. Applications
6. Discussion
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| FR | Face Recognition |
| HO | Head Orientation |
| FE | Facial Expression |
| NIR | Near Infrared |
| VIS | Visible |
| MWIR | Middle Wavelength Infrared |
| LWIR | Long Wavelength Infrared |
| VIS FR | Visible Face Recognition |
| IR FR | Infrared Face Recognition |
| NIR FR | Near Infrared Face Recognition |
References
- Turk, M.; Pentland, A. Face recognition using eigenfaces. In Proceedings of the 1991 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Maui, HI, USA, 3–6 June 1991; pp. 586–591. [Google Scholar]
- Sun, Y.; Liang, D.; Wang, X.; Tang, X. DeepID3: Face Recognition with Very Deep Neural Networks. arXiv 2015, arXiv:1502.00873. [Google Scholar]
- AbdAlmageed, W.; Wu, Y.; Rawls, S.; Harel, S.; Hassner, T.; Masi, I.; Choi, J.; Lekust, J.; Kim, J.; Natarajan, P.; et al. Face recognition using deep multi-pose representations. In Proceedings of the 2016 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Placid, NY, USA, 7–10 March 2016; pp. 1–9. [Google Scholar]
- Liu, W.; Wen, Y.; Yu, Z.; Li, M.; Raj, B.; Song, L. SphereFace: Deep Hypersphere Embedding for Face Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6738–6746. [Google Scholar]
- Mittal, S.; Agarwal, S.; Nigam, M.J. Real Time Multiple Face Recognition: A Deep Learning Approach. In Proceedings of the 2018 International Conference on Digital Medicine and Image Processing; Association for Computing Machinery: New York, NY, USA, 2018; pp. 70–76. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar]
- Ghiass, R.S.; Arandjelovic, O.; Bendada, H.; Maldague, X. Infrared face recognition: A literature review. arXiv 2013, arXiv:1306.1603. [Google Scholar]
- Zhao, W.; Chellappa, R.; Phillips, P.J.; Rosenfeld, A. Face Recognition: A Literature Survey. ACM Comput. Surv. 2003, 35, 399–458. [Google Scholar] [CrossRef]
- Akhloufi, M.; Bendada, A.; Batsale, J.C. State of the art in infrared face recognition. Quant. Infrared Thermogr. J. 2008, 5, 3–26. [Google Scholar] [CrossRef]
- Farokhi, S.; Flusser, J.; Ullah Sheikh, U. Near infrared face recognition: A literature survey. Comput. Sci. Rev. 2016, 21, 1–17. [Google Scholar] [CrossRef]
- Ouyang, S.; Hospedales, T.; Song, Y.Z.; Li, X.; Loy, C.C.; Wang, X. A survey on heterogeneous face recognition: Sketch, infra-red, 3D and low-resolution. Image Vis. Comput. 2016, 56, 28–48. [Google Scholar] [CrossRef]
- Jin, X.; Jiang, Q.; Yao, S.; Zhou, D.; Nie, R.; Hai, J.; He, K. A survey of infrared and visual image fusion methods. Infrared Phys. Technol. 2017, 85, 478–501. [Google Scholar] [CrossRef]
- Dey, T. A survey on different fusion techniques of visual and thermal images for human face recognition. Int. J. Electron. Commun. Comput. Eng. 2013, 4, 10–15. [Google Scholar]
- Kakkirala, K.R.; Chalamala, S.R.; Jami, S.K. Thermal Infrared Face Recognition: A Review. In Proceedings of the 2017 UKSim-AMSS 19th International Conference on Computer Modelling & Simulation (UKSim), Cambridge, UK, 5–7 April 2017; pp. 55–60. [Google Scholar] [CrossRef]
- Turk, M.; Pentland, A. Eigenfaces for Recognition. J. Cogn. Neurosci. 1991, 3, 71–86. [Google Scholar] [CrossRef] [PubMed]
- Etemad, K.; Chellappa, R. Discriminant analysis for recognition of human face images. J. Opt. Soc. Am. A 1997, 14, 1724–1733. [Google Scholar] [CrossRef]
- Liu, C.; Wechsler, H. Comparative assessment of independent component analysis (ICA) for face recognition. In Proceedings of the International Conference on Audio and Video Based Biometric Person Authentication, Washington, DC, USA, 22–23 March 1999; pp. 22–24. [Google Scholar]
- Jonsson, K.; Matas, J.; Kittler, J.; Li, Y. Learning support vectors for face verification and recognition. In Proceedings of the Fourth IEEE International Conference on Automatic Face and Gesture Recognition (Cat. No. PR00580), Grenoble, France, 28–30 March 2000; pp. 208–213. [Google Scholar] [CrossRef]
- Heo, J.; Kong, S.; Abidi, B.; Abidi, M. Fusion of Visual and Thermal Signatures with Eyeglass Removal for Robust Face Recognition. In Proceedings of the 2004 Conference on Computer Vision and Pattern Recognition Workshop, Washington, DC, USA, 27 June–2 July 2004; p. 122. [Google Scholar] [CrossRef]
- Chen, X.; Jing, Z.; Xiao, G. Fuzzy Fusion for Face Recognition. In Proceedings of the Fuzzy Systems and Knowledge Discovery; Wang, L., Jin, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 672–675. [Google Scholar] [CrossRef]
- Ralescu, D.; Adams, G. The fuzzy integral. J. Math. Anal. Appl. 1980, 75, 562–570. [Google Scholar] [CrossRef]
- Akhloufi, M.A.; Bendada, A. Fusion of active and passive infrared images for face recognition. In Proceedings of the Thermosense: Thermal Infrared Applications XXXV; Stockton, G.R., Colbert, F.P., Eds.; International Society for Optics and Photonics, SPIE: Baltimore, MD, USA, 2013; Volume 8705, pp. 84–93. [Google Scholar] [CrossRef]
- Bebis, G.; Gyaourova, A.; Singh, S.; Pavlidis, I. Face recognition by fusing thermal infrared and visible imagery. Image Vis. Comput. 2006, 24, 727–742. [Google Scholar] [CrossRef]
- Kong, S.G.; Heo, J.; Boughorbel, F.; Zheng, Y.; Abidi, B.R.; Koschan, A.; Yi, M.; Abidi, M.A. Multiscale Fusion of Visible and Thermal IR Images for Illumination-Invariant Face Recognition. Int. J. Comput. Vis. 2007, 71, 215–233. [Google Scholar] [CrossRef]
- Heo, J.; Abidi, B.; Paik, J.; Abidi, M. Face recognition: Evaluation report for FaceIt identification and surveillance. In Proceedings of the SPIE 5132, Sixth International Conference on Quality Control by Artificial Vision, Gatlinburg, TE, USA, 1 May 2003. [Google Scholar] [CrossRef]
- Akhloufi, M.A.; Bendada, A.; Batsale, J.C. Multispectral face recognition using non linear dimensionality reduction. In Proceedings of the Visual Information Processing XVIII; Rahman, Z.U., Reichenbach, S.E., Neifeld, M.A., Eds.; International Society for Optics and Photonics, SPIE: Orlando, FL, USA, 2009; Volume 7341, pp. 152–161. [Google Scholar] [CrossRef]
- Brahnam, S.; Jain, L.C.; Nanni, L.; Lumini, A. Local Binary Patterns: New Variants and Applications; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar] [CrossRef]
- Li, S.Z.; Chu, R.; Liao, S.; Zhang, L. Illumination Invariant Face Recognition Using Near-Infrared Images. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 627–639. [Google Scholar] [CrossRef]
- Belhumeur, P.; Hespanha, J.; Kriegman, D. Eigenfaces vs. Fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef]
- Gandhi, R. Boosting Algorithms: AdaBoost, Gradient Boosting and XGBoost. 2018. Available online: https://hackernoon.com/boosting-algorithms-adaboost-gradient-boosting-and-xgboost-f74991cad38c (accessed on 1 February 2023).
- Méndez, H.; Martín, C.S.; Kittler, J.; Plasencia, Y.; García-Reyes, E. Face Recognition with LWIR Imagery Using Local Binary Patterns. In Proceedings of the Advances in Biometrics; Tistarelli, M., Nixon, M.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 327–336. [Google Scholar] [CrossRef]
- Akhloufi, M.A.; Bendada, A. Infrared face recognition using texture descriptors. In Proceedings of the Thermosense XXXII; Dinwiddie, R.B., Safai, M., Eds.; International Society for Optics and Photonics, SPIE: Orlando, FL, USA, 2010; Volume 7661, pp. 49–58. [Google Scholar] [CrossRef]
- Huang, D.; Wang, Y.; Wang, Y. A Robust Method for Near Infrared Face Recognition Based on Extended Local Binary Pattern. In Proceedings of the Advances in Visual Computing; Bebis, G., Boyle, R., Parvin, B., Koracin, D., Paragios, N., Tanveer, S.M., Ju, T., Liu, Z., Coquillart, S., Cruz-Neira, C., et al., Eds.; Springer: Berlin/Heidelberg, Germany, 2007; pp. 437–446. [Google Scholar] [CrossRef]
- Liu, L.; Zhao, L.; Long, Y.; Kuang, G.; Fieguth, P. Extended local binary patterns for texture classification. Image Vis. Comput. 2012, 30, 86–99. [Google Scholar] [CrossRef]
- Zhao, G.; Huang, X.; Taini, M.; Li, S.Z.; Pietikäinen, M. Facial expression recognition from near-infrared videos. Image Vis. Comput. 2011, 29, 607–619. [Google Scholar] [CrossRef]
- Hong, X.; Xu, Y.; Zhao, G. LBP-TOP: A Tensor Unfolding Revisit. In Proceedings of the Computer Vision—ACCV 2016 Workshops; Chen, C.S., Lu, J., Ma, K.K., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 513–527. [Google Scholar] [CrossRef]
- Xie, Z. Infrared face recognition based on LBP co-occurrence matrix. In Proceedings of the 33rd Chinese Control Conference, Nanjing, China, 28–30 July 2014; pp. 4817–4820. [Google Scholar] [CrossRef]
- Sujatha, B.; Kumar, V.; Harini, P. A new logical compact LBP co-occurrence matrix for texture analysis. Int. J. Sci. Eng. Res. 2012, 3, 1–5. [Google Scholar]
- Lowe, D. Object recognition from local scale-invariant features. In Proceedings of the Seventh IEEE International Conference on Computer Vision, Kerkyra, Greece, 20–27 September 1999; Volume 2, pp. 1150–1157. [Google Scholar] [CrossRef]
- Yang, J.; Liao, S.; Li, S.Z. Automatic Partial Face Alignment in NIR Video Sequences. In Proceedings of the Advances in Biometrics; Tistarelli, M., Nixon, M.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; pp. 249–258. [Google Scholar] [CrossRef]
- Zou, X.; Kittler, J.; Messer, K. Face Recognition Using Active Near-IR Illumination. In Proceedings of the British Machine Vision Conference, Oxford, UK, 5–8 September 2005. [Google Scholar] [CrossRef]
- Hall, M.; Frank, E.; Holmes, G.; Pfahringer, B.; Reutemann, P.; Witten, I.H. The WEKA Data Mining Software: An Update. SIGKDD Explor. Newsl. 2009, 11, 10–18. [Google Scholar] [CrossRef]
- Friedrich, G.; Yeshurun, Y. Seeing People in the Dark: Face Recognition in Infrared Images. In Proceedings of the Biologically Motivated Computer Vision Second International Workshop, BMCV 2002, Tübingen, Germany, 22–24 November 2002; Bülthoff, H.H., Lee, S., Poggio, T.A., Wallraven, C., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2002; Volume 2525, pp. 348–359. [Google Scholar] [CrossRef]
- Wu, S.Q.; Song, W.; Jiang, L.J.; Xie, S.L.; Pan, F.; Yau, W.Y.; Ranganath, S. Infrared Face Recognition by Using Blood Perfusion Data. In Proceedings of the Audio- and Video-Based Biometric Person Authentication; Kanade, T., Jain, A., Ratha, N.K., Eds.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 320–328. [Google Scholar] [CrossRef]
- Akhloufi, M.; Bendada, A. Thermal Faceprint: A New Thermal Face Signature Extraction for Infrared Face Recognition. In Proceedings of the 2008 Canadian Conference on Computer and Robot Vision, Windsor, ON, Canada, 28–30 May 2008; pp. 269–272. [Google Scholar] [CrossRef]
- Huang, G.B.; Mattar, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database forStudying Face Recognition in Unconstrained Environments. In Workshop on Faces in ‘Real-Life’ Images: Detection, Alignment, and Recognition; Erik Learned-Miller and Andras Ferencz and Frédéric Jurie: Marseille, France, 2008. [Google Scholar]
- Zhang, Z.; Song, Y.; Qi, H. Age Progression/Regression by Conditional Adversarial Autoencoder. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, 21–26 July 2017; pp. 4352–4360. [Google Scholar] [CrossRef]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar] [CrossRef]
- Wolf, L.; Hassner, T.; Maoz, I. Face recognition in unconstrained videos with matched background similarity. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011; pp. 529–534. [Google Scholar] [CrossRef]
- Nech, A.; Kemelmacher-Shlizerman, I. Level Playing Field for Million Scale Face Recognition. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3406–3415. [Google Scholar] [CrossRef]
- Phillips, P.; Wechsler, H.; Huang, J.; Rauss, P.J. The FERET database and evaluation procedure for face-recognition algorithms. Image Vis. Comput. 1998, 16, 295–306. [Google Scholar] [CrossRef]
- Marszalec, E.A.; Martinkauppi, J.B.; Soriano, M.N.; Pietikaeinen, M. Physics-based face database for color research. J. Electron. Imaging 2000, 9, 32–38. [Google Scholar] [CrossRef]
- Li, S.Z.; Yi, D.; Lei, Z.; Liao, S. The CASIA NIR-VIS 2.0 Face Database. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Portland, OR, USA, 23–28 June 2013; pp. 348–353. [Google Scholar] [CrossRef]
- Zhang, B.; Zhang, L.; Zhang, D.; Shen, L. Directional binary code with application to PolyU near-infrared face database. Pattern Recognit. Lett. 2010, 31, 2337–2344. [Google Scholar] [CrossRef]
- Wang, S.; Liu, Z.; Lv, S.; Lv, Y.; Wu, G.; Peng, P.; Chen, F.; Wang, X. A Natural Visible and Infrared Facial Expression Database for Expression Recognition and Emotion Inference. IEEE Trans. Multimed. 2010, 12, 682–691. [Google Scholar] [CrossRef]
- IRIS Thermal/Visible Face Database. Available online: http://vcipl-okstate.org/pbvs/bench/ (accessed on 14 September 2021).
- Xu, Y.; Zhong, A.; Yang, J.; Zhang, D. Bimodal biometrics based on a representation and recognition approach. Opt. Eng. 2011, 50, 037202. [Google Scholar] [CrossRef]
- Shoja Ghiass, R. Face Recognition Using Infrared Vision. Ph.D. Thesis, Université Laval, Quebec, Canada, 2018. [Google Scholar]
- Kowalski, M.; Grudzień, A. High-resolution thermal face dataset for face and expression recognition. Metrol. Meas. Syst. 2018, 25, 403–415. [Google Scholar] [CrossRef]
- Kopaczka, M.; Kolk, R.; Merhof, D. A fully annotated thermal face database and its application for thermal facial expression recognition. In Proceedings of the 2018 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Houston, TX, USA, 14–17 May 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Simón, M.O.; Corneanu, C.; Nasrollahi, K.; Nikisins, O.; Escalera, S.; Sun, Y.; Li, H.; Sun, Z.; Moeslund, T.B.; Greitans, M. Improved RGB-D-T based face recognition. IET Biom. 2016, 5, 297–303. [Google Scholar] [CrossRef]
- Guo, K.; Wu, S.; Xu, Y. Face recognition using both visible light image and near-infrared image and a deep network. CAAI Trans. Intell. Technol. 2017, 2, 39–47. [Google Scholar] [CrossRef]
- Flynn, P.J.; Bowyer, K.W.; Phillips, P.J. Assessment of Time Dependency in Face Recognition: An Initial Study. In Proceedings of the Audio- and Video-Based Biometric Person Authentication; Kittler, J., Nixon, M.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 44–51. [Google Scholar] [CrossRef]
- Akhloufi, M.A.; Bendada, A. A multistep approach for infrared face recognition in texture space. In Proceedings of the Thermosense: Thermal Infrared Applications XXXV; Stockton, G.R., Colbert, F.P., Eds.; International Society for Optics and Photonics, SPIE: Baltimore, MD, USA, 2013; Volume 8705, p. 87050C. [Google Scholar] [CrossRef]
- Poster, D.; Thielke, M.; Nguyen, R.; Rajaraman, S.; Di, X.; Fondje, C.N.; Patel, V.M.; Short, N.J.; Riggan, B.S.; Nasrabadi, N.M.; et al. A Large-Scale, Time-Synchronized Visible and Thermal Face Dataset. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 1558–1567. [Google Scholar] [CrossRef]
- Huang, D.; Sun, J.; Wang, Y. The Buaa-Visnir Face Database Instructions. School Comput. Sci. Eng., Beihang Univ., Beijing, China, Tech. Rep. IRIP-TR-12-FR-001. 2012. Available online: https://scholar.google.com/citations?view_op=view_citation&hl=en&user=oqFMIuwAAAAJ&citation_for_view=oqFMIuwAAAAJ:qjMakFHDy7sC (accessed on 14 September 2021).
- Bernhard, J.; Barr, J.; Bowyer, K.W.; Flynn, P. Near-IR to visible light face matching: Effectiveness of pre-processing options for commercial matchers. In Proceedings of the 2015 IEEE 7th International Conference on Biometrics Theory, Applications and Systems (BTAS), Arlington, VA, USA, 8–11 September 2015; pp. 1–8. [Google Scholar] [CrossRef]
- Hu, S.; Short, N.J.; Riggan, B.S.; Gordon, C.; Gurton, K.P.; Thielke, M.; Gurram, P.; Chan, A.L. A Polarimetric Thermal Database for Face Recognition Research. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 187–194. [Google Scholar] [CrossRef]
- Szankin, M.; Kwasniewska, A.; Ruminski, J. Influence of Thermal Imagery Resolution on Accuracy of Deep Learning based Face Recognition. In Proceedings of the 2019 12th International Conference on Human System Interaction (HSI), Richmond, VA, USA, 25–27 June 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Espinosa-Duró, V.; Faundez-Zanuy, M.; Mekyska, J. A New Face Database Simultaneously Acquired in Visible, Near-Infrared and Thermal Spectrums. Cogn. Comput. 2013, 5, 119–135. [Google Scholar] [CrossRef]
- Ariffin, S.M.Z.S.Z.; Jamil, N.; Rahman, P.N.M.A. Terravic Facial IR Database/IRIS Thermal/Visible Face Database/CBSR NIR Face Dataset. In Proceedings of the 2016 Signal Processing: Algorithms, Architectures, Arrangements, and Applications (SPA); IEEE: Poznan, Poland, 2016; pp. 191–195. [Google Scholar] [CrossRef]
- Dhamecha, T.I.; Nigam, A.; Singh, R.; Vatsa, M. Disguise detection and face recognition in visible and thermal spectrums. In Proceedings of the 2013 International Conference on Biometrics (ICB), Madrid, Spain, 4–7 June 2013; pp. 1–8. [Google Scholar] [CrossRef]
- Wu, F.; You, W.; Smith, J.S.; Lu, W.; Zhang, B. Image-Image Translation to Enhance Near Infrared Face Recognition. In Proceedings of the 2019 IEEE International Conference on Image Processing (ICIP), Taipei, Taiwan, 22–25 September 2019; pp. 3442–3446. [Google Scholar] [CrossRef]
- Panetta, K.; Wan, Q.; Agaian, S.; Rajeev, S.; Kamath, S.; Rajendran, R.; Rao, S.P.; Kaszowska, A.; Taylor, H.A.; Samani, A.; et al. A Comprehensive Database for Benchmarking Imaging Systems. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 509–520. [Google Scholar] [CrossRef]
- Ashrafi, R.; Azarbayjani, M.; Tabkhi, H. Charlotte-ThermalFace: A Fully Annotated Thermal Infrared Face Dataset with Various Environmental Conditions and Distances. Infrared Phys. Technol. 2022, 124, 104209. [Google Scholar] [CrossRef]
- Hanley, J.A. Receiver operating characteristic (ROC) methodology: The state of the art. Crit. Rev. Diagn. Imaging 1989, 29, 307–335. [Google Scholar] [PubMed]
- Aggarwal, G.; Biswas, S.; Flynn, P.J.; Bowyer, K.W. Predicting performance of face recognition systems: An image characterization approach. In Proceedings of the CVPR 2011 WORKSHOPS, Colorado Springs, CO, USA, 20–25 June 2011; pp. 52–59. [Google Scholar] [CrossRef]
- Johnson, A.Y.; Sun, J.; Bobick, A.F. Predicting Large Population Data Cumulative Match Characteristic Performance from Small Population Data. In Proceedings of the Audio- and Video-Based Biometric Person Authentication; Kittler, J., Nixon, M.S., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 821–829. [Google Scholar] [CrossRef]
- Kumar, B.V.; Mahalanobis, A.; Song, S.; Sims, S.R.F.; Epperson, J.F. Minimum squared error synthetic discriminant functions. Opt. Eng. 1992, 31, 915–922. [Google Scholar] [CrossRef]
- Wen, Y.; Zhang, K.; Li, Z.; Qiao, Y. A Discriminative Feature Learning Approach for Deep Face Recognition. In Proceedings of the Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 499–515. [Google Scholar] [CrossRef]
- Deng, Z.; Peng, X.; Li, Z.; Qiao, Y. Mutual Component Convolutional Neural Networks for Heterogeneous Face Recognition. IEEE Trans. Image Process. 2019, 28, 3102–3114. [Google Scholar] [CrossRef]
- Deng, Z.; Peng, X.; Qiao, Y. Residual Compensation Networks for Heterogeneous Face Recognition. Proc. AAAI Conf. Artif. Intell. 2019, 33, 8239–8246. [Google Scholar] [CrossRef]
- Xu, R.; Cho, M.; Lee, S. A NIR-to-VIS face recognition via part adaptive and relation attention module. arXiv 2021, arXiv:2102.00689. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Lai, K.; Yanushkevich, S.N. Multi-Metric Evaluation of Thermal-to-Visual Face Recognition. In Proceedings of the 2019 Eighth International Conference on Emerging Security Technologies (EST), Colchester, UK, 22–24 July 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Litvin, A.; Nasrollahi, K.; Escalera, S.; Ozcinar, C.; Moeslund, T.B.; Anbarjafari, G. A novel deep network architecture for reconstructing RGB facial images from thermal for face recognition. Multimed. Tools Appl. 2019, 78, 25259–25271. [Google Scholar] [CrossRef]
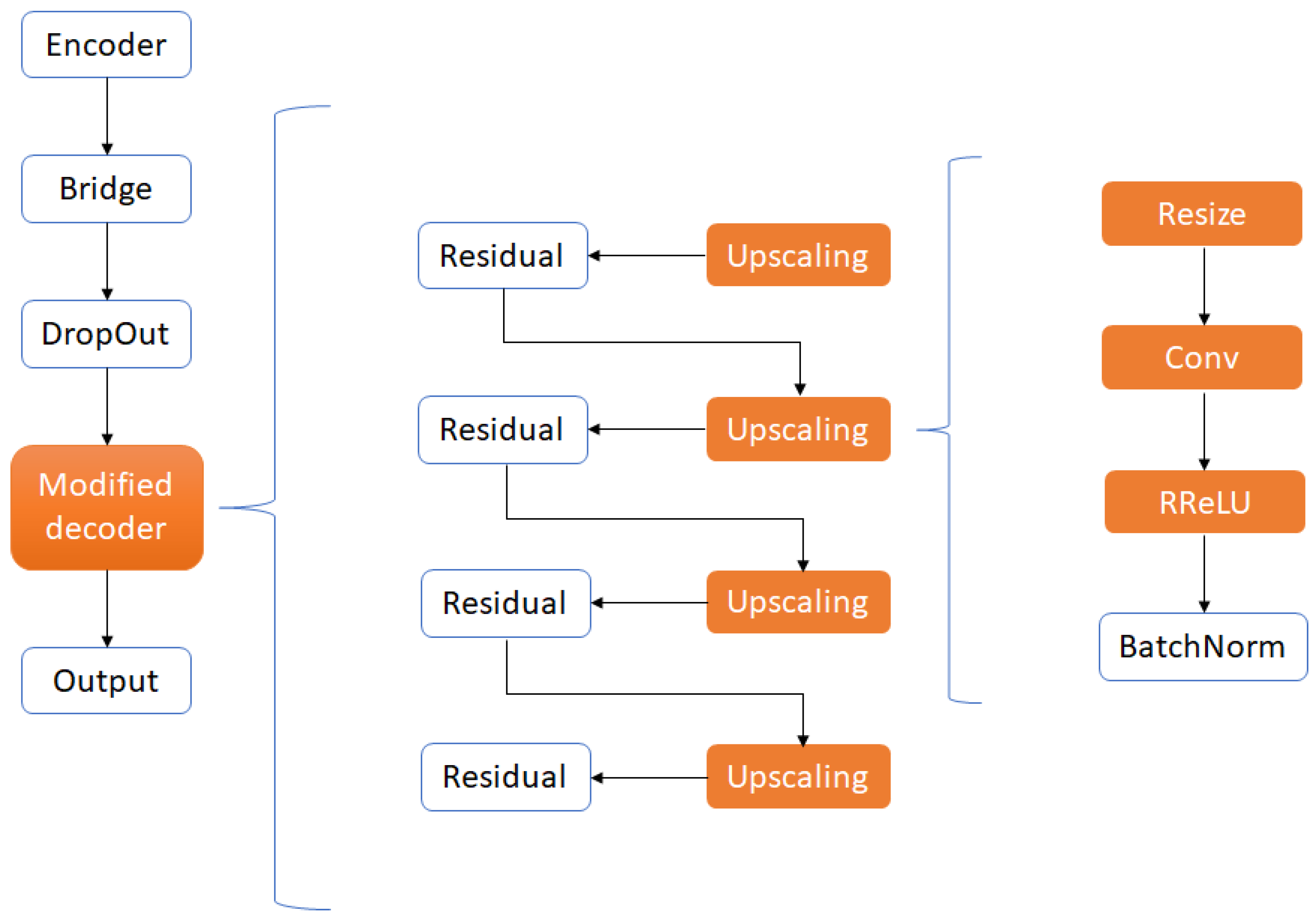
- Quan, T.M.; Hildebrand, D.G.C.; Jeong, W.K. FusionNet: A Deep Fully Residual Convolutional Neural Network for Image Segmentation in Connectomics. Front. Comput. Sci. 2021, 3, 34. [Google Scholar] [CrossRef]
- Maas, A.L.; Hannun, A.Y.; Ng, A.Y. Rectifier nonlinearities improve neural network acoustic models. Proc. icml. Citeseer 2013, 30, 3. [Google Scholar]
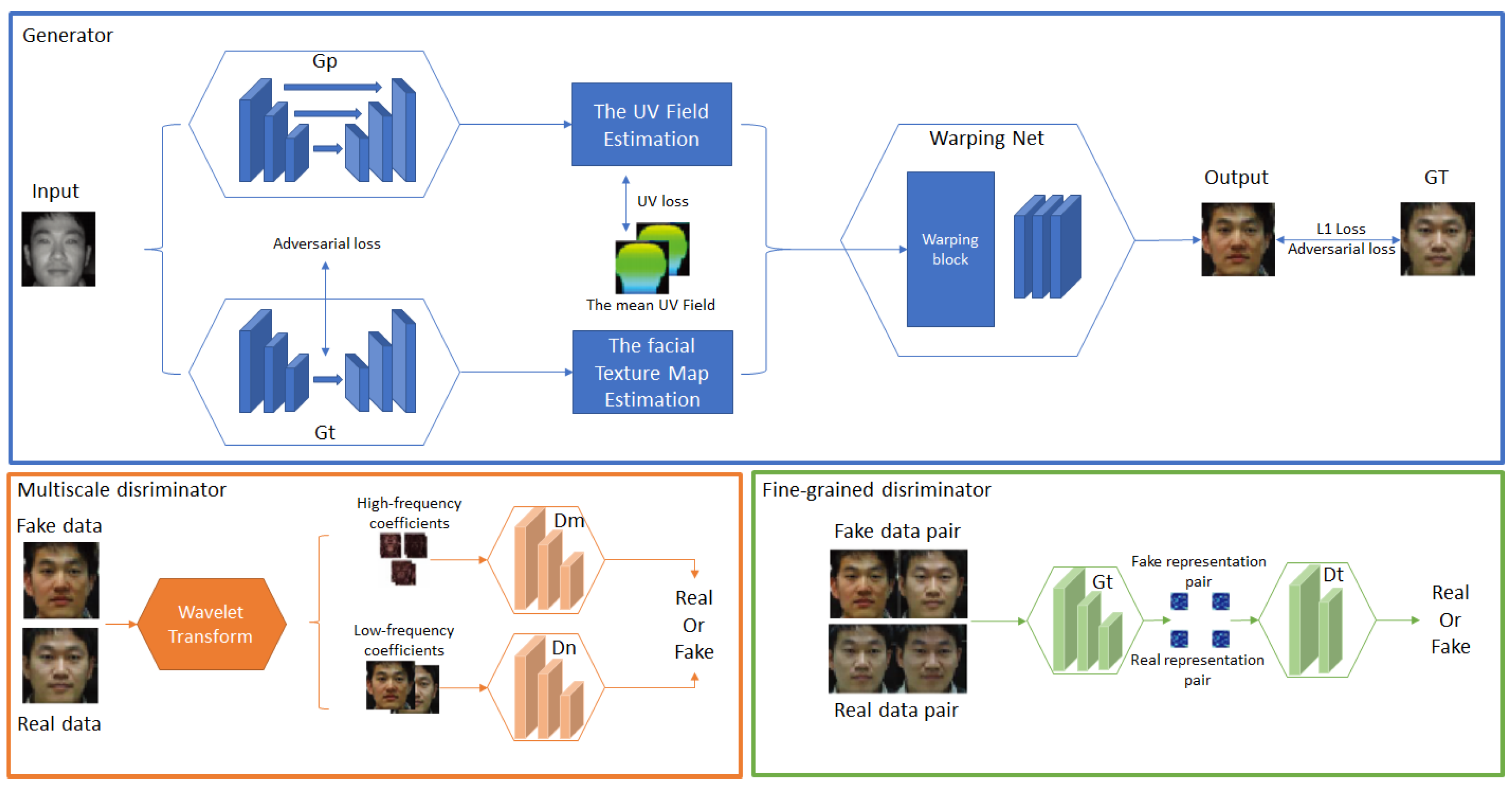
- He, R.; Cao, J.; Song, L.; Sun, Z.; Tan, T. Cross-spectral Face Completion for NIR-VIS Heterogeneous Face Recognition. arXiv 2019, arXiv:1902.03565. [Google Scholar]
- Wu, X.; Huang, H.; Patel, V.M.; He, R.; Sun, Z. Disentangled Variational Representation for Heterogeneous Face Recognition. Proc. AAAI Conf. Artif. Intell. 2019, 33, 9005–9012. [Google Scholar] [CrossRef]
- Wu, X.; He, R.; Sun, Z.; Tan, T. A Light CNN for Deep Face Representation with Noisy Labels. IEEE Trans. Inf. Forensics Secur. 2018, 13, 2884–2896. [Google Scholar] [CrossRef]
- Guo, Y.; Zhang, L.; Hu, Y.; He, X.; Gao, J. MS-Celeb-1M: A Dataset and Benchmark for Large-Scale Face Recognition. In Proceedings of the Computer Vision—ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; pp. 87–102. [Google Scholar] [CrossRef]
- Guei, A.C.; Akhloufi, M.A. Deep generative adversarial networks for infrared image enhancement. In Proceedings of the Thermosense: Thermal Infrared Applications XL; Burleigh, D., de Vries, J., Eds.; International Society for Optics and Photonics, SPIE: Orlando, FL, USA, 2018; Volume 10661, p. 106610B. [Google Scholar] [CrossRef]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. arXiv 2015, arXiv:1511.06434. [Google Scholar] [CrossRef]
- Immidisetti, R.; Hu, S.; Patel, V.M. Simultaneous Face Hallucination and Translation for Thermal to Visible Face Verification using Axial-GAN. In Proceedings of the 2021 IEEE International Joint Conference on Biometrics (IJCB), Shenzhen, China, 4–7 August 2021; pp. 1–8. [Google Scholar] [CrossRef]
- Kim, J.; Ra, M.; Kim, W.Y. A DCNN-Based Fast NIR Face Recognition System Robust to Reflected Light From Eyeglasses. IEEE Access 2020, 8, 80948–80963. [Google Scholar] [CrossRef]
- Luo, Y.; Pi, D.; Pan, Y.; Xie, L.; Yu, W.; Liu, Y. ClawGAN: Claw connection-based generative adversarial networks for facial image translation in thermal to RGB visible light. Expert Syst. Appl. 2022, 191, 116269. [Google Scholar] [CrossRef]
- Wu, Z.; Peng, M.; Chen, T. Thermal face recognition using convolutional neural network. In Proceedings of the 2016 International Conference on Optoelectronics and Image Processing (ICOIP), Warsaw, Poland, 10–12 June 2016; pp. 6–9. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef]
- de Freitas Pereira, T.; Anjos, A.; Marcel, S. Heterogeneous Face Recognition Using Domain Specific Units. IEEE Trans. Inf. Forensics Secur. 2019, 14, 1803–1816. [Google Scholar] [CrossRef]
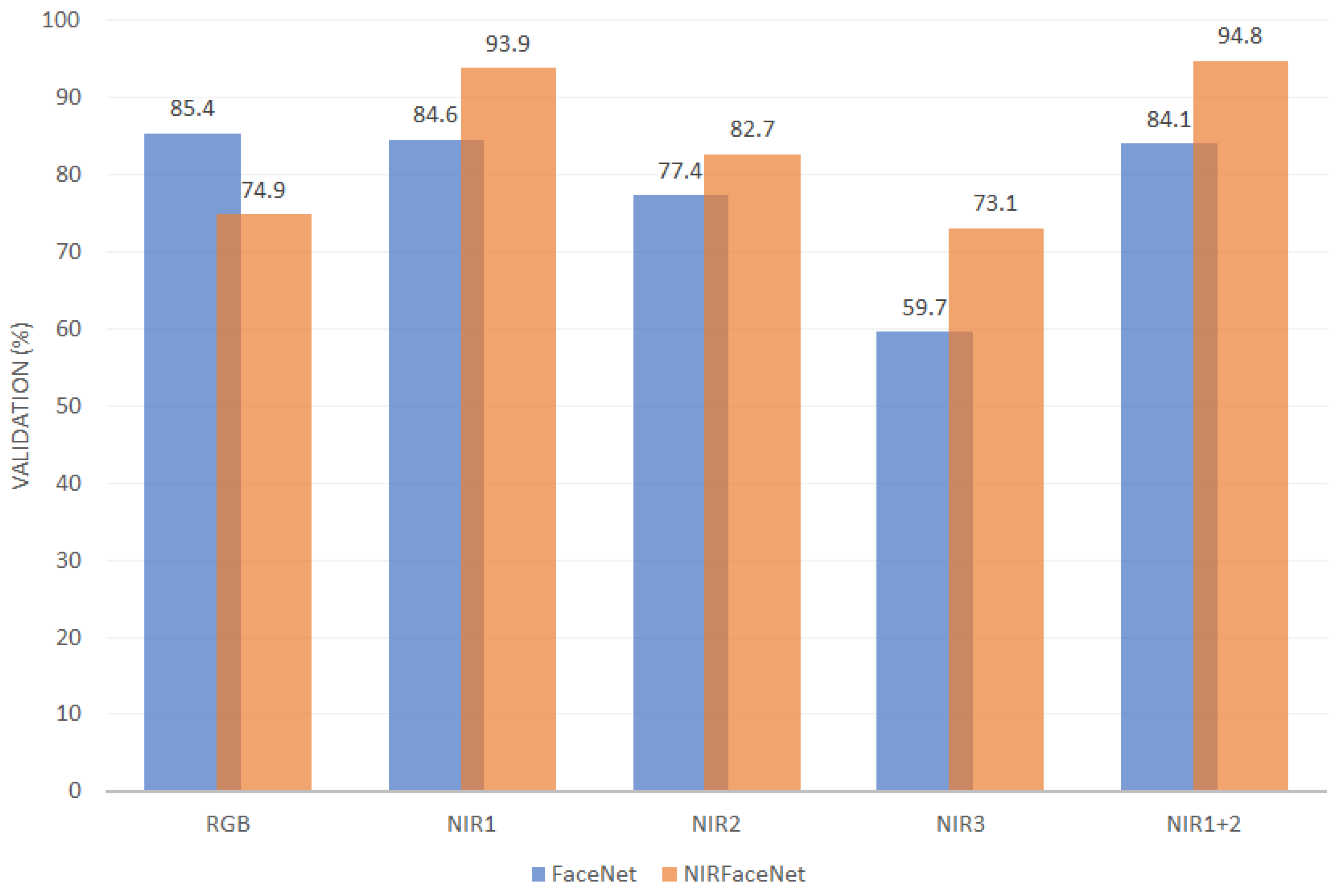
- Peng, M.; Wang, C.; Chen, T.; Liu, G. NIRFaceNet: A Convolutional Neural Network for Near-Infrared Face Identification. Information 2016, 7, 61. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper With Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef]
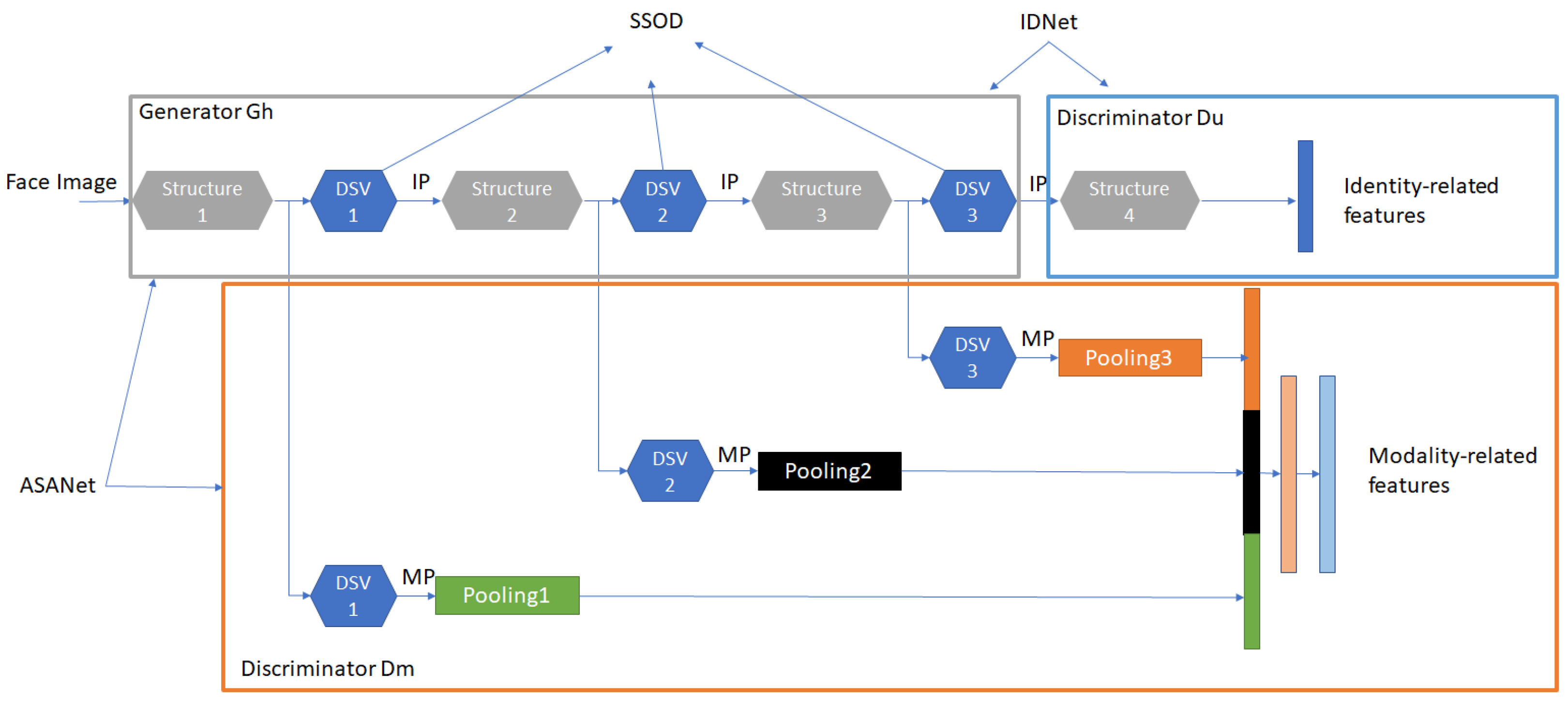
- Hu, W.; Hu, H. Disentangled Spectrum Variations Networks for NIR–VIS Face Recognition. IEEE Trans. Multimed. 2020, 22, 1234–1248. [Google Scholar] [CrossRef]
- Kim, J.; Jo, H.; Ra, M.; Kim, W.Y. Fine-tuning Approach to NIR Face Recognition. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 2337–2341. [Google Scholar] [CrossRef]
- Shavandi, M.; Afrakoti, I.E.P. Face Recognition in Thermal Images based on Sparse Classifier. Int. J. Eng. 2019, 32, 78–84. [Google Scholar] [CrossRef]
- Mahouachi, D.; Akhloufi, M.A. Adaptive deep convolutional neural network for thermal face recognition. In Proceedings of the Thermosense: Thermal Infrared Applications XLIII; Zalameda, J.N., Mendioroz, A., Eds.; International Society for Optics and Photonics, SPIE: Online Only, 2021; Volume 11743, p. 1174304. [Google Scholar] [CrossRef]
- Mahouachi, D.E.; Akhloufi, M.A. Deep adaptive convolutional neural network for near infrared and thermal face recognition. In Proceedings of the Infrared Technology and Applications XLVIII; Andresen, B.F., Fulop, G.F., Zheng, L., Eds.; International Society for Optics and Photonics, SPIE: Orlando, FL, USA, 2022; Volume 12107, p. 121071R. [Google Scholar] [CrossRef]
- Jo, H.; Kim, W.Y. NIR Reflection Augmentation for DeepLearning-Based NIR Face Recognition. Symmetry 2019, 11, 1234. [Google Scholar] [CrossRef]
- Gavini, Y.; Mehtre, B.M.; Agarwal, A. Thermal to Visual Face Recognition using Transfer Learning. In Proceedings of the 2019 IEEE 5th International Conference on Identity, Security, and Behavior Analysis (ISBA), Hyderabad, India, 22–24 January 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Wang, P.; Bai, X. Regional parallel structure based CNN for thermal infrared face identification. Integr.-Comput.-Aided Eng. 2018, 25, 247–260. [Google Scholar] [CrossRef]
- He, R.; Wu, X.; Sun, Z.; Tan, T. Wasserstein CNN: Learning Invariant Features for NIR-VIS Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 1761–1773. [Google Scholar] [CrossRef]
- Lezama, J.; Qiu, Q.; Sapiro, G. Not Afraid of the Dark: NIR-VIS Face Recognition via Cross-Spectral Hallucination and Low-Rank Embedding. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6807–6816. [Google Scholar] [CrossRef]
- Cho, M.; Kim, T.; Kim, I.J.; Lee, K.; Lee, S. Relational Deep Feature Learning for Heterogeneous Face Recognition. IEEE Trans. Inf. Forensics Secur. 2021, 16, 376–388. [Google Scholar] [CrossRef]
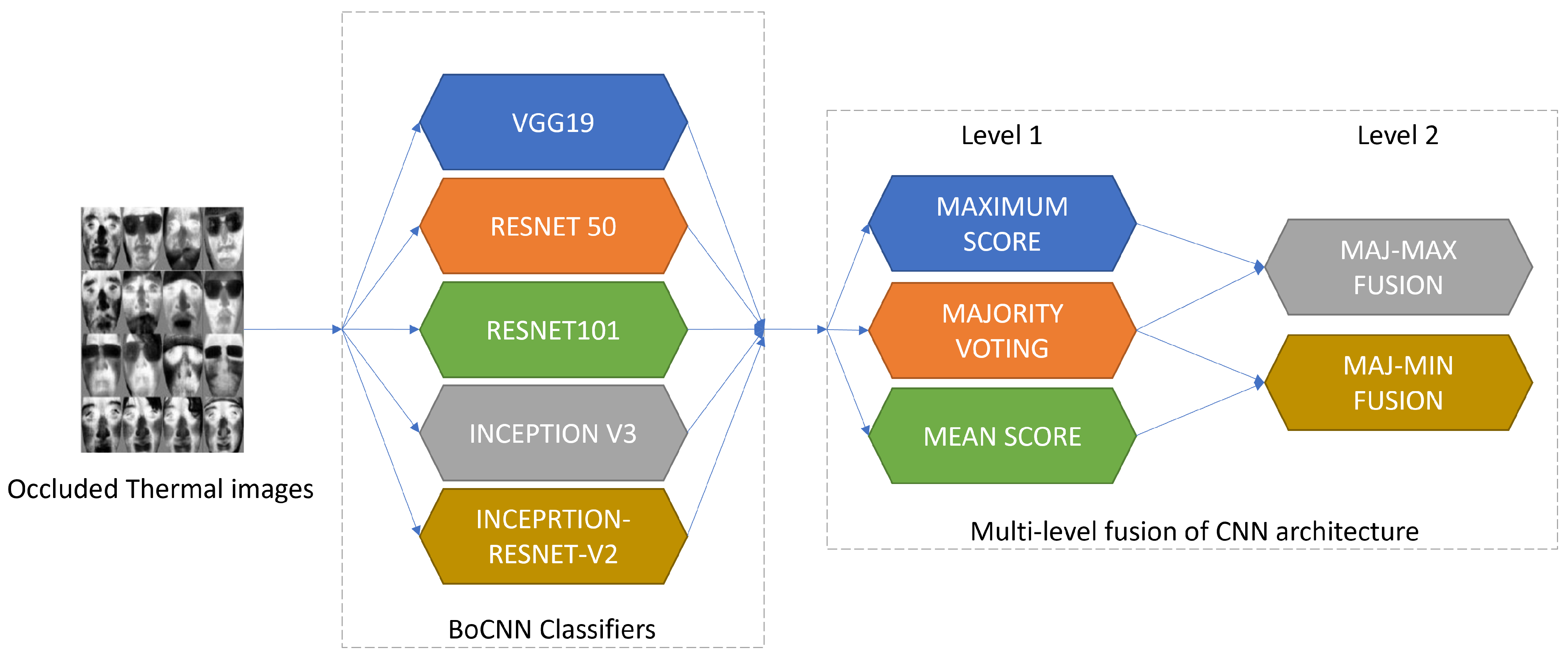
- Kumar, S.; Singh, S.K. Occluded Thermal Face Recognition Using Bag of CNN (BoCNN). IEEE Signal Process. Lett. 2020, 27, 975–979. [Google Scholar] [CrossRef]
- Sarfraz, M.S.; Stiefelhagen, R. Deep Perceptual Mapping for Thermal to Visible Face Recognition. arXiv 2015, arXiv:1507.02879. [Google Scholar] [CrossRef]
- He, R.; Wu, X.; Sun, Z.; Tan, T. Learning Invariant Deep Representation for NIR-VIS Face Recognition. Proc. AAAI Conf. Artif. Intell. 2017, 31. [Google Scholar] [CrossRef]
- Zhang, K.; Zhang, Z.; Li, Z.; Qiao, Y. Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks. IEEE Signal Process. Lett. 2016, 23, 1499–1503. [Google Scholar] [CrossRef]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar] [CrossRef]
- Wang, Y.; Li, Y.; Wang, S. Parallel-Structure-based Transfer Learning for Deep NIR-to-VIS Face Recognition. In Proceedings of the Image and Graphics; Zhao, Y., Barnes, N., Chen, B., Westermann, R., Kong, X., Lin, C., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 146–156. [Google Scholar] [CrossRef]
- Liu, X.; Song, L.; Wu, X.; Tan, T. Transferring deep representation for NIR-VIS heterogeneous face recognition. In Proceedings of the 2016 International Conference on Biometrics (ICB), Halmstad, Sweden, 13–16 June 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Zhao, P.; Zhang, F.; Wei, J.; Zhou, Y.; Wei, X. SADG: Self-Aligned Dual NIR-VIS Generation for Heterogeneous Face Recognition. Appl. Sci. 2021, 11, 987. [Google Scholar] [CrossRef]
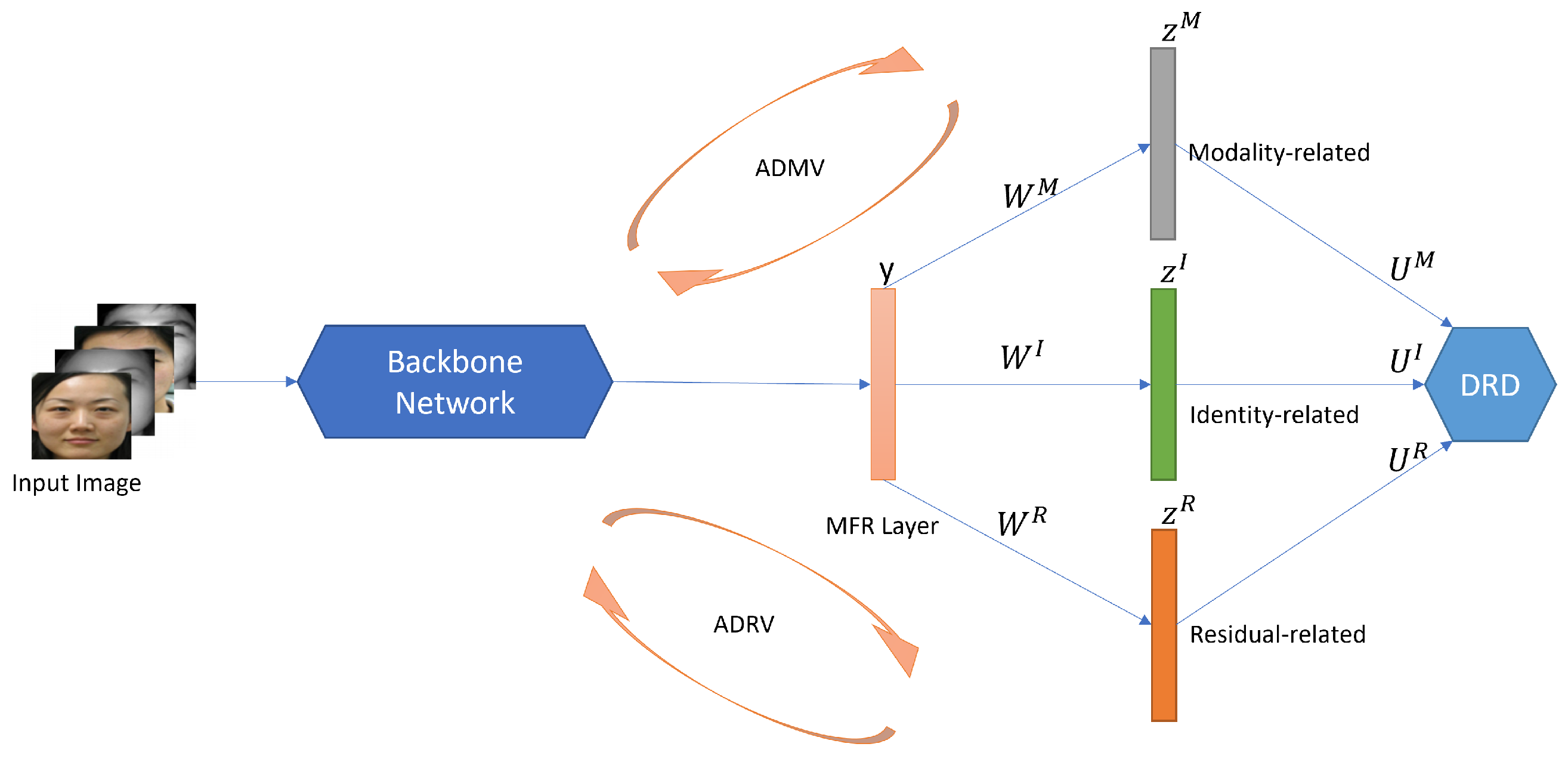
- Hu, W.; Hu, H. Dual Adversarial Disentanglement and Deep Representation Decorrelation for NIR-VIS Face Recognition. IEEE Trans. Inf. Forensics Secur. 2021, 16, 70–85. [Google Scholar] [CrossRef]
- Sun, R.; Shan, X.; Zhang, H.; Gao, J. Data gap decomposed by auxiliary modality for NIR-VIS heterogeneous face recognition. IET Image Process. 2022, 16, 261–272. [Google Scholar] [CrossRef]
- Cheema, U.; Ahmad, M.; Han, D.; Moon, S. Heterogeneous Visible-Thermal and Visible-Infrared Face Recognition Using Cross-Modality Discriminator Network and Unit-Class Loss. Comput. Intell. Neurosci. 2022, 2022, 4623368. [Google Scholar] [CrossRef] [PubMed]
- Menon, S.; J., S.; S.K., A.; Nair, A.P.; S., S. Driver Face Recognition and Sober Drunk Classification using Thermal Images. In Proceedings of the 2019 International Conference on Communication and Signal Processing (ICCSP), Chennai, India, 4–6 April 2019; pp. 400–404. [Google Scholar] [CrossRef]
- M., S.K.K.; Rajendran, R.; Wan, Q.; Panetta, K.; Agaian, S.S. TERNet: A deep learning approach for thermal face emotion recognition. In Proceedings of the Mobile Multimedia/Image Processing, Security, and Applications 2019; Agaian, S.S., Asari, V.K., DelMarco, S.P., Eds.; International Society for Optics and Photonics, SPIE: Baltimore, FL, USA, 2019; Volume 10993, p. 1099309. [Google Scholar] [CrossRef]
- Mohamed, S.; Ghoneim, A.; Youssif, A. Visible/Infrared face spoofing detection using texture descriptors. MATEC Web Conf. 2019, 292, 04006. [Google Scholar] [CrossRef]
- Du, H.; Shi, H.; Liu, Y.; Zeng, D.; Mei, T. Towards NIR-VIS Masked Face Recognition. IEEE Signal Process. Lett. 2021, 28, 768–772. [Google Scholar] [CrossRef]
- Wang, X.; Tang, X. Face Photo-Sketch Synthesis and Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 1955–1967. [Google Scholar] [CrossRef] [PubMed]
- Chingovska, I.; Erdogmus, N.; Anjos, A.; Marcel, S. Face Recognition Systems Under Spoofing Attacks. In Face Recognition Across the Imaging Spectrum; Springer International Publishing: Cham, Switzerland, 2016; pp. 165–194. [Google Scholar] [CrossRef]
















| References | Methods | Metrics | Datasets |
|---|---|---|---|
| Lai and Yanushkevich [85] | CycleGAN InceptionV3 Xception MobileNet | 95.35% (Rank-1 acc) | Carl dataset [70] |
| Litvin et al. [89] | FusionNet+RReLu VGG classifier | 97.52% (Rank-1 acc) | RGB-D-T [61] |
| He et al. [92] | CFC (pose correction +texture inpainting +fusion wrapping) | 99.21% (Rank-1 acc) 99.70% (Rank-1 acc) 99.90%\(Rank-1 acc) | CASIA NIR VIS 2.0 [53] BUAA-Vis-Nir [66] Oulu-Casia [35] |
| Wu et al. [93] | DVR (LightCNN-9, LightCNN-29) | 99.10% 99.70% (Rank-1 acc) 99.30% 100.00% (Rank-1 acc) 97.90% 99.20% (Rank-1 acc) | CASIA NIR VIS 2.0 [53] Oulu-CASIA [35] BUAA-VIS-NIR [66] |
| Guei and Akhloufi [96] | DCGAN (DeepSIRF2.0) | 243.21 ( MSE ) 140.16 ( MSE ) 140.16 ( MSE ) | Terravic Facial IR [71] CBSR NIR [53] CASIA NIR VIS 2.0 [53] |
| Immidisetti et al. [98] | Axial-attention layers C-GAN | 94.40% (AUC) | ARL-VTF dataset [65] |
| Kim et al. [99] | Glasses2Non-glasses (G2NG) data augmentation CycleGAN | 94.60% (VR@FAR + 0.1%) | LFW [46] |
| Luo et al. [100] | Claw-GAN | 95.70% (AUC) | IRIS dataset [56] |
| References | Methods | Metrics | Datasets |
|---|---|---|---|
| Zhan Wu et al. [101] | CNN | 98,00% (acc) | RGB-D-T [61] |
| Pereira et al. [103] | DCNN (Inception Resenet v2 + adapting bias and kernels ) | 90.10% (Rank-1 acc) 92.20% (Rank-1 acc) 50.90% (Rank-1 acc) | CASIA NIR-VIS2.0 [53] NIVL NIR VIS [67] Pola Thermal [68] |
| Peng et al. [104] | Modified GoogleLeNet (NIRFaceNet) | 98.28% (acc) | CASIA NIR [53] |
| Hu and Hu [106] | Stepwise spectrum orthogonal decomposition (SSOD), spectrum adversarial discriminative feature learning(SaDF) (IDNet, ASANet) | 99.00% (Rank-1 acc) 100.00% (Rank-1 acc) | CASIA NIR VIS 2.0 [53] Oulu-CASIA [35] |
| Kim et al. [107] | Fine tuning pre-trained CNN models for RGB FR (FaceNet) | 94.47% (VR@FAR = 0.7%) | PolyU-NIRFD [54] |
| Shavandi andAfrakoti [108] | Sparse processing classification (minimizing normed zero-norm, orthogonal matching pursuit) | 96.50% (acc without any noise) | USTC NVIN [55] CBSR NIR [53] |
| Szankin et al. [69] | DNN (FaceNet) Face enhancement | 99.33% (acc) 81.87% (acc) | SC3000DB [69] IRIS [56] |
| Mahouachi et Akhloufi [109] | FaceNet MTCNN Fine tuning | 88.81% (VR@FAR = 50.66%) | USTC-NVIE [55] |
| Mahouachi et Akhloufi [110] | FaceNet MTCNN Fine tuning | 96.68% (VR@FAR = 0.001%) 94.57% (VR@FAR = 49.01%) | CASIA NIR VIS 2.0 [53] USTC-NVIE [55] |
| Jo and Kim [111] | FaceNet NIRFaceNet Data augmentation | 94.80% (VR@FAR = 0.1% without augmentation) 96.40% (VR@FAR + 0.1% with augmentation) | CASIA NIR-VIS 2.0 [53] +PolyU-NIRFD [54] +ND-NIVL [67] |
| Gavini et al. [112] | Transfer learning | 94.32% (acc) 90.33% (acc) | RGB-D-T [61] UND-X1 [63] |
| Deng et al. [82] | Residual Compensation Convolutional Neural Network, Modality Descripency loss | 99.32% (Rank-1 acc) 99.44% (Rank-1 acc) | CASIA NIR VIS 2.0 [53] CUHK NIR VIS [132] |
| Guo et al. [62] | DNN Cosine distance Adaptive score fusion | 99.56% (acc weak light), 95.31% (acc strong light) 99.89% (acc weak light), 93.98% (acc strong light) | Sun Win [62] HIT LAB2 [57] |
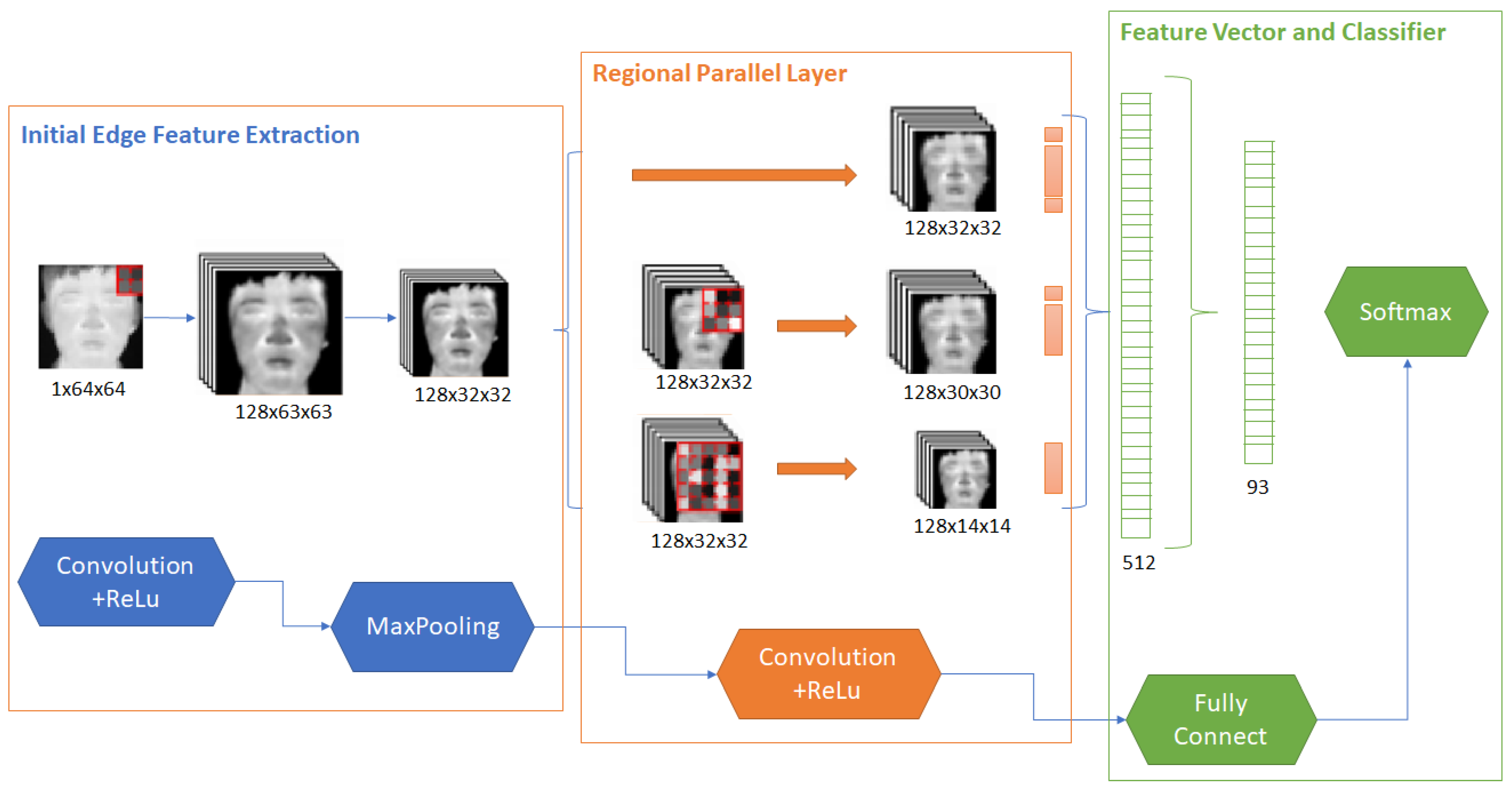
| Wang and Bai [113] | RPSNet (edge feature extraction, multi-scale feature extraction, feature vector classification) | 95.97% (acc) | Private dataset |
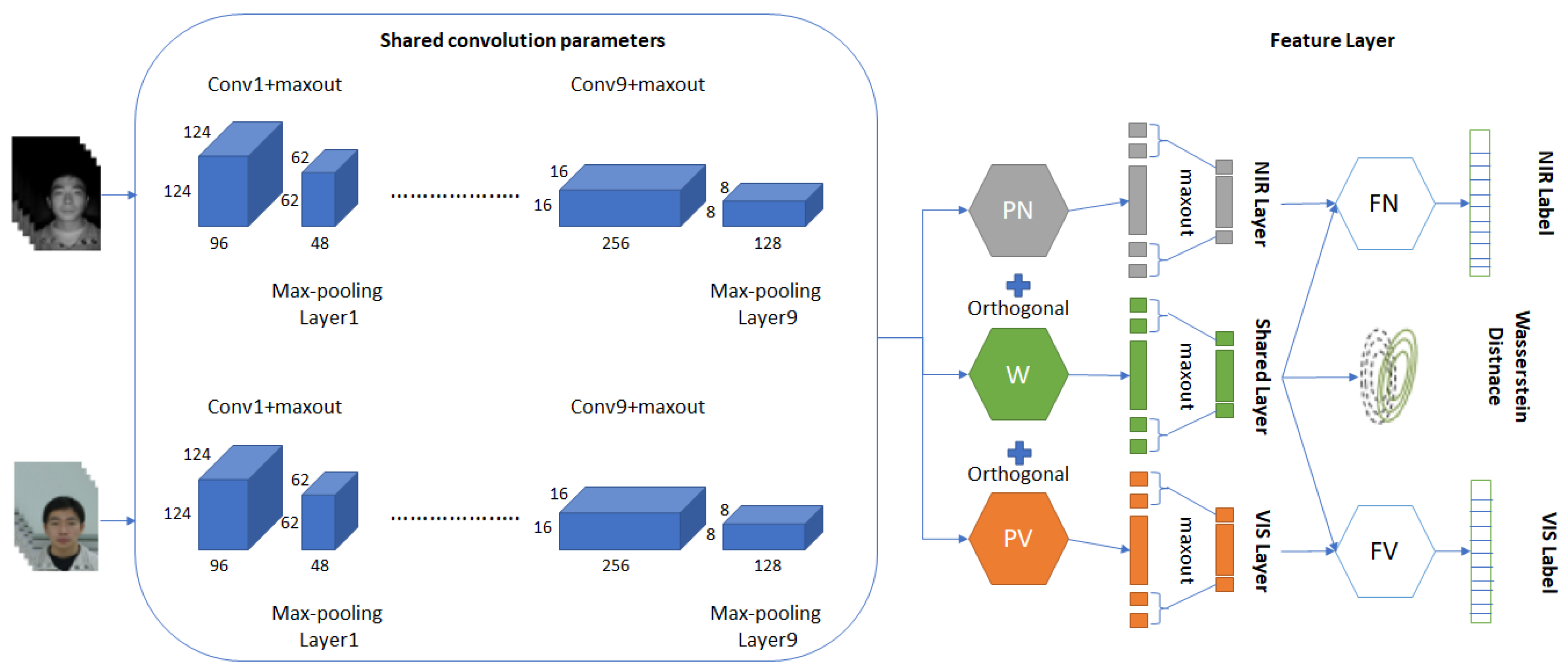
| He et al. [114] | W-CNN Low rank correlation constraint | 98.70% (Rank-1 acc) 98.00% (Rank-1 acc) 97.40%\(Rank-1 acc) | CASIA NIR VIS 2.0 [53] Oulu [35] BUAA NIR VIS [66] |
| Lezama et al. [115] | Deep Cross-spectral Hallucination Low Rank Embedding | 96.41% (acc) | CASIA NIR VIS 2.0 [53] |
| Kim et al. [99] | Lighten DCNN | 94.60% (VR@FAR + 0.1%) | LFW [46] |
| Cho et al. [116] | Relational Graph Module | 95.97% (VR@FAR = 0.1%) 99.22% (VR@FAR = 1%) | CASIA NIR VIS 2.0 [53] BUAA NIR VIS [66] |
| Kumar et al. [117] | Bag of CNN(BoCNN) VGG-19, Resnet-50, Resnet-101, Inception-V3, InceptionResnetV2 | 99.20% (mean score acc) | IIIT Delhi occluded thermal face dataset [72] |
| Xu et al. [83] | Part relationship attention module (PRAM) lightCNN-9 | 97.94% (VR@FAR = 0.1%) 98.44% (VR@FAR = 1%) | CASIA NIR VIS 2.0 [53] BUAA NIR VIS [66] |
| References | Methods | Metrics | Datasets |
|---|---|---|---|
| Sarfraz and Stiefelhagen [118] | Feed Forward DNN Non-linear mapping | 83.73% (Rank-1 acc) | UND X1 [63] |
| He et al. [119] | DNN Orthogonal subspace embedding | 95.82% (VF@FAR = 0.1%) | CASIA NIR VIS 2.0 [53] |
| Wu et al. [73] | MTCNN CycleGAN | 99.80% (acc) 99.60% (acc on Lab1), 90.70% (acc on Lab2) | INF [73] CSIST [57] |
| Deng et al. [81] | Mutual Component Convolutional Neural Network, MCA loss | 99.22% (Rank-1 acc) 99.44% (Rank-1 acc) | CASIA NIR-VIS2.0 [53] CUHK NIR VIS [132] |
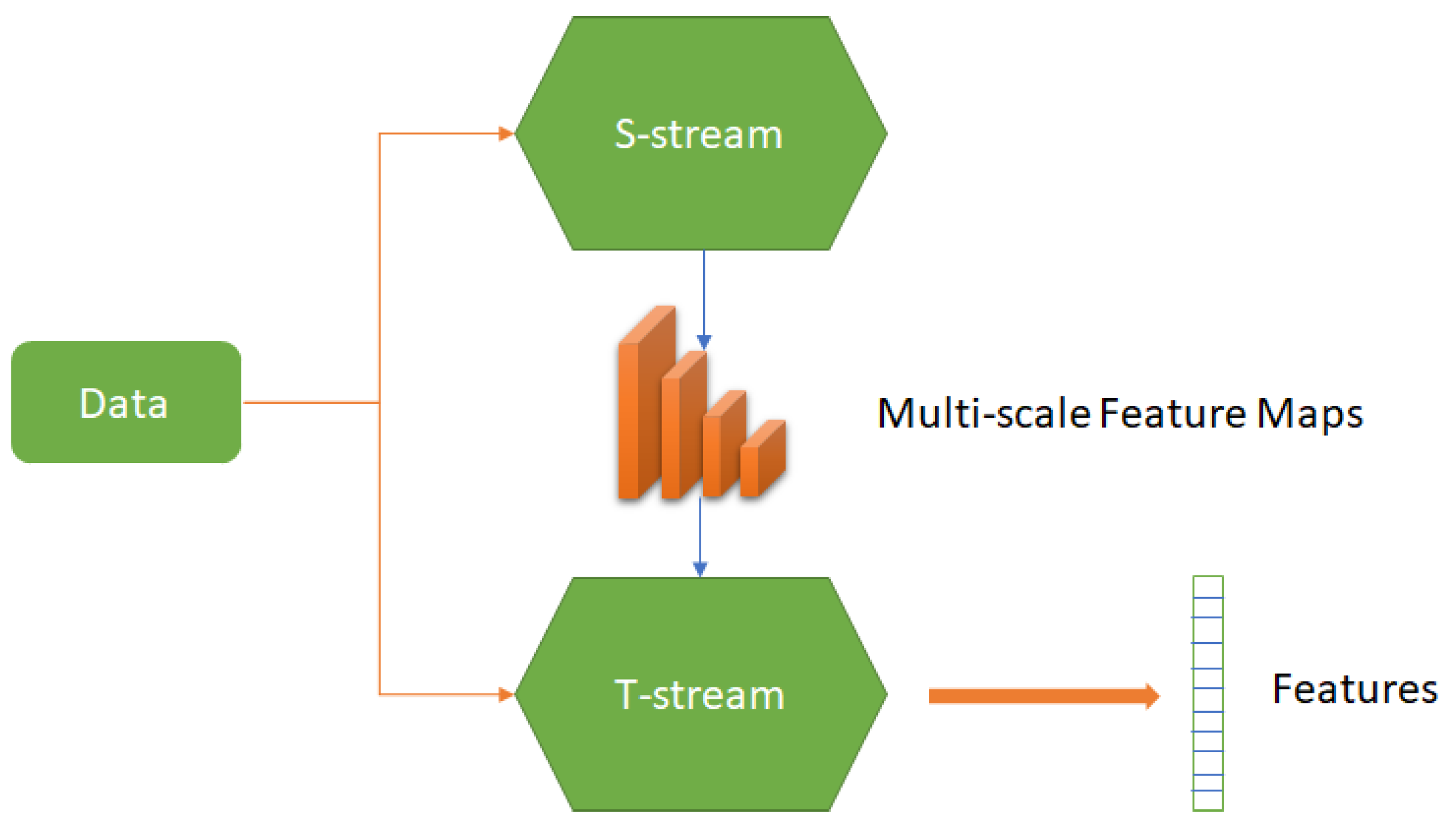
| Wang et al. [122] | Transfer Learning Multi-Scalefeature mapping | 99.96% (Rank-1 acc) | CASIA NIR VIS 2.0 [53] |
| Xiaoxiang Liu et al. [123] | DNN Max-Feature-Map Fine-tuning Triplet loss | 95.74% (Rank-1 acc) 91.03% (VR@FAR = 0.1%) | CASIA NIR VIS 2.0 [53] |
| Zhao et al. [124] | Self-aligned generation architecture Multi-scale patch discriminator | 99.60% (VR@FAR = 0.1%) 93.20% (VR@FAR = 0.1%) 97.30% (VR@FAR = 0.1%) | CASIA NIR VIS 2.0 [53] Oulu CASIA [35] BUAA NIR VIS [66] |
| Hu et al. [125] | Dual Adversarial Disentanglement and Deep Representation Decorrelation | 97.60% (VR@FAR = 0.1%) 92.90% (VR@FAR = 0.1%) 99.30% (VR@FAR = 0.1%) | CASIA NIR VIS 2.0 [53] Oulu CASIA [35] BUAA NIR VIS [66] |
| Sun et al. [126] | Dual Adversarial DGD | 99.80% (VR@FAR = 1%) 85.30% (VR@FAR = 1%) | CASIA NIR VIS 2.0 [53] Oulu CASIA [35] |
| Cheema et al. [127] | End-to-end cross-modality discrimination network for HFR Unit-Class Loss | 95.21% (Rank-1 acc) 98.50% ((Rank-1 acc) 99.70% (Rank-1 acc) 99.50% (Rank-1 acc) | TUFTS [74] UND-X1 [63] USTC-NVIE [55] CASIA NIR VIS 2.0 [53] |
| References | Methods | Metrics | Datasets |
|---|---|---|---|
| Menon et al. [128] | CNN Gaussian mixture model Fisher Linear Discriminant | 97.00% (acc) | Private Dataset |
| Kamath et al. [129] | CNN Transfer Learning | 96.20% (acc) | TUFTs dataset [74] |
| Mohamed et al. [130] | CNN | 96.78% (acc) | Msspoof Dataset [133] |
| Du et al. [131] | Heterogeneous semi-Siamese method 3D face reconstruction | 98.58% (VR@FAR = 0.1%) 83.0 % (VR@FAR = 0.1%) 70.6% (VR@FAR = 0.1%) | CASIA NIR VIS 2.0 [53] Oulu CASIA [35] BUAA NIR VIS [66] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mahouachi, D.; Akhloufi, M.A. Recent Advances in Infrared Face Analysis and Recognition with Deep Learning. AI 2023, 4, 199-233. https://doi.org/10.3390/ai4010009
Mahouachi D, Akhloufi MA. Recent Advances in Infrared Face Analysis and Recognition with Deep Learning. AI. 2023; 4(1):199-233. https://doi.org/10.3390/ai4010009
Chicago/Turabian StyleMahouachi, Dorra, and Moulay A. Akhloufi. 2023. "Recent Advances in Infrared Face Analysis and Recognition with Deep Learning" AI 4, no. 1: 199-233. https://doi.org/10.3390/ai4010009
APA StyleMahouachi, D., & Akhloufi, M. A. (2023). Recent Advances in Infrared Face Analysis and Recognition with Deep Learning. AI, 4(1), 199-233. https://doi.org/10.3390/ai4010009