1. Introduction
1.1. Background
Social media have become the major avenue for the public to receive health information from health agencies and news outlets and to share their own opinions on emerging health issues, especially during pandemics such as the 2009 H1N1 pandemic influenza, 2014 Ebola, 2015 Zika, and COVID-19. They have also become an important source for various health agencies and researchers to understand the public opinion and promote certain health campaigns. During the pandemic of 2014 Ebola, researchers noticed the significant upward trend of Twitter posts and Google search in the USA [
1,
2]. Moreover, during the 2016 Zika pandemic, multiple health agencies started to use social media as communication channels and adopted effective communication strategies to improve the dissemination of public health-related issues [
3]. COVID-19 has become one of the most discussed topics on social media platforms across the globe.
Pandemics always involve issues beyond medical and health aspects alone. They are often associated with cultural, social, economic, and political issues [
4,
5]. In the early stage of COVID-19, the majority of the discussions and debates on social media were about intervention policies such as quarantine and social distancing. As the pandemic progressed, the discussion shifted towards mask wearing; the government’s handling of the crisis; and vaccine development, roll-out, and mandates. COVID-19 is still one of the most popular topics on social media [
6], and a lot of internet users retrieve COVID-19-related information from and share their opinions on social media platforms.
1.2. Relevant Work
Research on the monitoring and surveillance of social media discussions about health issues, commonly known as health infoveillance, started in 2000. Current infoveillance is achieved with the combination of natural language processing (NLP), time-series analysis, and geospatial analysis techniques. Various NLP applications, including topic modeling, topic classification, sentiment analysis, and semantic analysis, can give a comprehensive understanding of the topic, sentiment, and semantic of public opinion and sentiment regarding a health issue. Monitoring the trend of certain topics helps predict the outbreak and progress of an epidemic, such as influenza [
7,
8,
9,
10,
11,
12,
13], Zika virus [
14], and the recent COVID-19 [
15,
16]. More specific topics are of interest in infoveillance, especially during the COVID-19 pandemic. Non-pharmaceutical interventions (NPIs), including social distancing, stay-at-home orders, quarantine, and mask wearing, have been effective yet controversial ways to reduce airborne disease transmission [
17,
18,
19,
20,
21].
Large pandemics, including COVID-19, have never been an isolated medical or health issue and are always associated with multiple aspects beyond health. Current NLP-based infoveillance can generate more comprehensive characterizations of the diverse topics and sentiments using textual data based on the rich linguistic, sentiment, and semantic features. There are word frequency-based NLP approaches, such as term frequency–inverse document frequency (TF-IDF) and latent Dirichlet allocation (LDA) [
22]. Another approach is to apply the encoding of text with pre-trained embeddings, including Word2Vec [
23], GloVe [
24], and BERT [
25]. The embeddings are then fed into certain machine learning or deep learning methods, such as convolutional neural networks (CNNs) or recurrent neural networks (RNNs), for downstream tasks.
In this study, we focused on word- or sentence-level embedding to understand the contextual information of online discussions on COVID-19 on Twitter. Word embedding is the process of transforming textual words into numerical vectors. There are traditional static word embeddings, such as Word2Vec, FastText [
26], and GloVe, where the embedding is trained based on a large cohort of texts. However, this kind of static embedding cannot effectively reveal the true meanings of the word in different contexts. Another potential problem is that these text embeddings are usually trained in a more general corpus as embedding news to be versatile in different contexts. However, such embeddings often perform not as well in certain specific contexts. As shown in this study, the language used in social media can be very different from the corpus upon which these text embeddings are trained; thus, this can result in low performance in the topic modeling tasks.
To address these problems, pre-trained embedding models such as BERT, ELMO [
27], XLNet [
28], and GPT-2 [
29] have been developed to provide richer and more dynamic context-dependent information. BERT is one of these pre-trained embedding models for various NLP applications. BERT learns context from the input textual data with its initial embedding and positional information. Most importantly, BERT is able to infer a word’s distinct meanings in different contexts by providing unequal vector representations, which static embeddings are not capable of achieving. BERT makes it possible to pre-train the model on the specific domain, such as health, using transfer learning techniques. Transfer learning usually ensures a better representation of the specific domain that the model is fine-tuned upon and leads to better performance in downstream tasks. Regarding medical and health domains, BioBERT [
30], BlueBERT [
31], and Med-BERT [
32] are a few examples that have been pre-trained on biomedical publications and electronic health records. Regarding social media applications, examples include BERTweet and the more specific COVID-Twitter-BERT [
6], trained on COVID-related tweets. These more specifically pre-trained BERT variants show substantial performance improvements over the original BERT model. In addition to token-level embedding, there have been semantic embeddings for sentences, such as SentenceBERT [
33].
2. Method
2.1. Data Source and Sampling
Twitter is one of the most popular social media platforms for online discussions about COVID-19. In this study, we used Twitter samples to analyze the trend and sentiment of COVID-related topics in the USA.
First, we used a relatively small tweet sample to develop the topic classification model. We randomly sampled 2000 tweets from 2020 using the keywords listed in
Table 1. A filter was applied during the sampling process to ensure that the tweets had a geolocation tag in the USA. For this task, only English tweets were collected. In addition, we also excluded tweets that had fewer than 10 tokens for better semantic meaning and more accurate BERT classification. We also ensured that each user could only be sampled once. This criterion avoided the potential sampling bias of a few active users or bots who excessively tweeted about COVID-19. The key terms for sampling are provided in
Table 1. Note that certain terms were discriminatory (e.g., China virus). However, we still included these inappropriate terms to increase sampling coverage for research purposes.
Based on the sampled tweets, our team with a domain expert in COVID-19 developed the codebook in
Table 2. After high inter-coder reliability was established, the final codebook covered 5 major topic categories, and a single tweet could belong to multiple topics and multiple sub-topics. Each sampled tweet was annotated by at least two annotators, and if discrepancies occurred, the tweet was then sent to the domain expert for the final determination of the topic category.
For analyzing the trends of topics and sentiments of COVID-related tweets, we used a larger dataset than the previous dataset for topic identification. We randomly collected 12,000 English tweets from 1-March-2020 to 31-May-2021 with COVID-19-related terms using Twitter’s Academic API V2. In total, 6000 of the 120,000 daily tweets were geo-tagged, with their geolocation being in the USA The remaining 6000 daily tweets were without geo-tags for comparison.
2.2. Preprocessing
Prior to training the BERT topic classification model, each tweet went through a series of preprocessing steps. User names and URLs in the tweet text were replaced with a common text token. We also replaced all emojis or emoticons with textual representations using the Python emoji library. The title of the URLs and hashtags were preserved as additional features in addition to the tweet text. Each tweet was treated as a text input and then fed into the BERT model. The 280-character limitation of a tweet was within the longest sequence input limitation of the BERT model.
2.3. Text Embedding
Text embedding was an essential part of BERT in this project to reflect the contextual, sentiment, and semantic features of the text. The accurate embedding of the text resulted in a better representation of the text and subsequently more accurate topic modeling. In order to further increase model performance and efficiency, we adopted COVID-Twitter-BERT, which was specifically pre-trained on COVID-19-related tweets and aligned with the tasks in this study. Our preliminary analysis showed that COVID-Twitter-BERT had substantial performance improvement over the generic BERT-Base model.
2.4. Topic Classification
Once the tweet was embedded, we then used the embedding to develop a multi-label (multinomial) machine learning classification model that was able to accurately identify the topics of each tweet. Since each tweet could have multiple topic labels out of a total of five possible topics, we further turned this multi-label classification task into 5 independent binary classification tasks. Five different binary classifiers were trained to identify the topic of each tweet. During the training stage, imbalanced issues were present, as the classifier used one class against the remaining four classes. The weight of each classifier was further fine-tuned to ensure that the classifiers were able to generate tweet topic labels that reflected the true percentage of tweets in the dataset.
The performance of topic classification based on the text embedding of the BERT model and traditional logistic regression was evaluated. In addition, we also compared the classification performance of the generic BERT-Base model against the specifically pre-trained COVID-Twitter-BERT.
2.5. Sentiment Analysis
After the content topics were identified, we further evaluated the sentiments of the tweets. Sentiment analyses based on VADER (Valence Aware Dictionary and sEntiment Reasoner) and BERT were performed. VADER is a lexicon- and rule-based sentiment analysis tool specifically tuned to sentiments expressed in social media. VADER not only identifies the binary positive or negative sentiment of a tweet but also quantifies the degree of the positive or negative sentiment of the post. Similar to the topic classification task, BERT was also used to train a sentiment classifier. In this study, BERT was applied to develop a 3-class sentiment classifier: positive, neutral, or negative sentiment of a tweet. In this study, the sentiment of a tweet was assumed to be mutually exclusive, that is, each tweet could only have one specific sentiment. This assumption could be relaxed in future studies.
2.6. Performance Evaluation
The performance of the classifiers was evaluated using the corresponding confusion matrix obtained by testing sets with four elements: true positive (), true negative (), false positive (), and false negative (). Classification performance metrics included accuracy (), precision (), recall (), and . High , , , and scores indicated robust model performance, indicating that the classification models were validated. These metrics also allowed us to compare different text embedding and classification models so that the most accurate and reliable models could be identified.
The complete analytical framework was written in Python 3.7 with necessary supporting NLP and machine learning libraries. The codes are freely available upon request.
3. Results
3.1. Topic Classification
We developed and compared the classification performance of the generic BERT-Base and COVID-Twitter-BERT models.
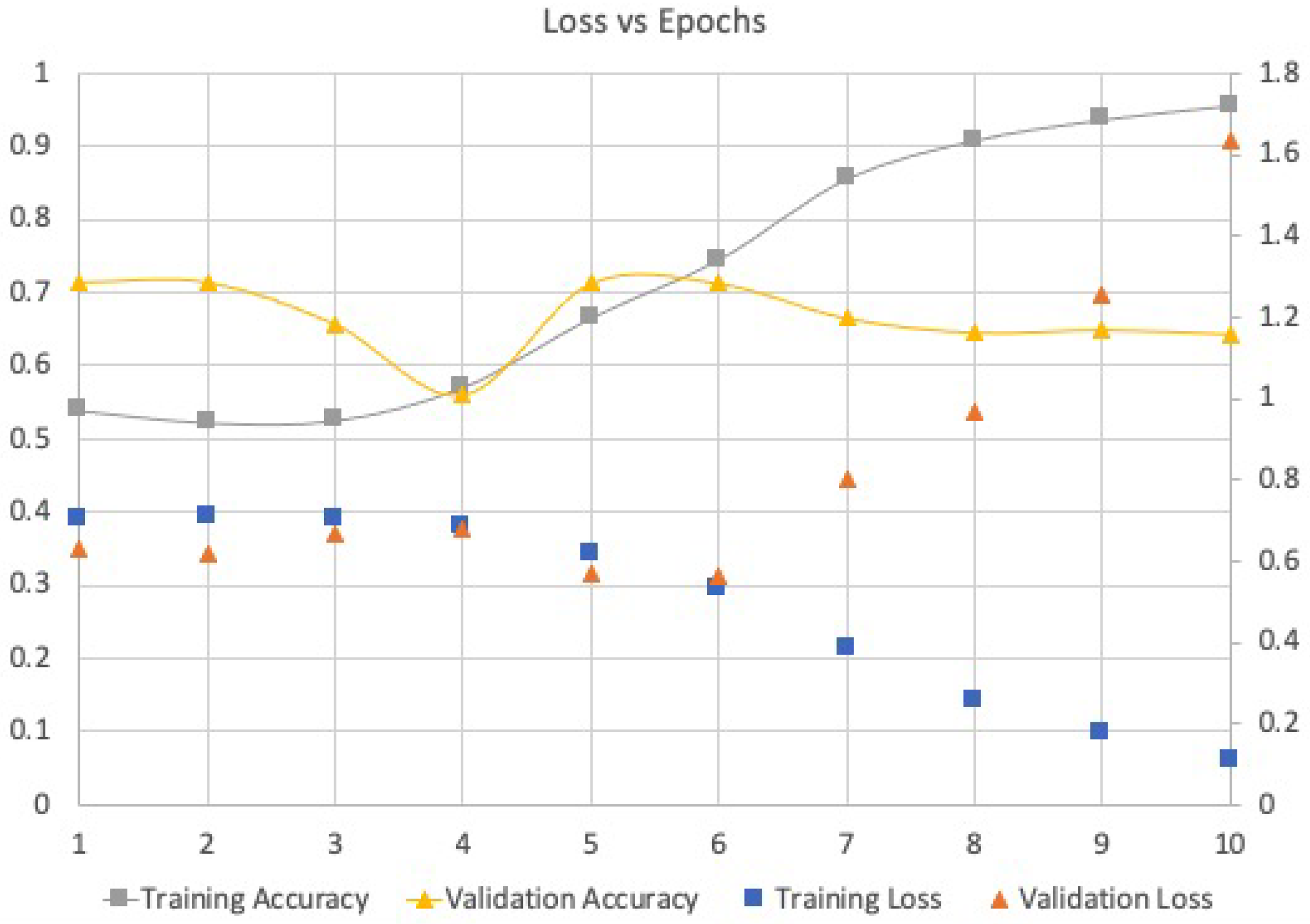
Figure 1 shows that the optimal number of epochs to balance training loss and validation loss, as well as to reduce overfitting, was five.
The comparison among the different models showed that the deep learning-based BERT models significantly outperformed the traditional logistic regression models based on classification accuracy (
). In addition, COVID-Twitter-BERT also showed improved performance over the generic BERT-Base model. These results demonstrated the advantage of large-scale deep neural networks that are pre-trained on specific domain data (
Table 3).
In this study, we focused on two topics that were specifically related to the COVID-19 pandemic: confounded social issues and non-pharmaceutical interventions (NPIs). The NPI topic was the combination of certain sub-topics in the classes of countermeasures and policies, and the related topics included masks, other PPE, disinfection, social distancing, stay-at-home, and shelter-in-place. The performance is shown in
Table 4 and
Table 5. Overall, the two BERT classifications models for social issues and NPIs both showed excellent performance, with accuracy of over 87%, as well as high precision and recall.
3.2. Sentiment Classification
Next, we investigated how BERT identified sentiments in COVID-19 discussions on Twitter. There were three classes: positive, neutral, and negative sentiments. For sentiment analysis, eight epochs were chosen instead of five as in the previous topic classification, because sentiments were more challenging to model and took more training to update the optimal model parameters. Practically, it was also more difficult to identify the sentiments of tweets, as online discussions could be frequently sarcastic or informal. We compared the sentiment analysis performance of the VADER and BERT models. Labels 0, 1, and 2 corresponded to negative, neutral, and positive sentiments.
The sentiment classification performance is shown in
Table 6 and
Table 7. Overall, BERT was able to achieve the accuracy of 0.7 in the three-class sentiment classification task, significantly outperforming the previous benchmark method, VADER (
). These results demonstrate the capability of NLP methods based on deep neural networks, especially transformers, which are able to further identify contexts in texts.
3.3. Analysis of Topic Trends and Sentiments
Once accurate COVID-19 topic and sentiment classification models were developed using BERT, we further applied the topic and sentiment classifiers on a much larger scale, i.e., to a 4 million-tweet sample, to comprehensively understand the spatio-temporal variability of COVID-19 discussions on Twitter. The trend analysis data input was smoothed using a 7-day Gaussian smoother with standard deviation of 3.
3.3.1. Comparison between Geo-Tagged and Non-Geo-Tagged Tweets
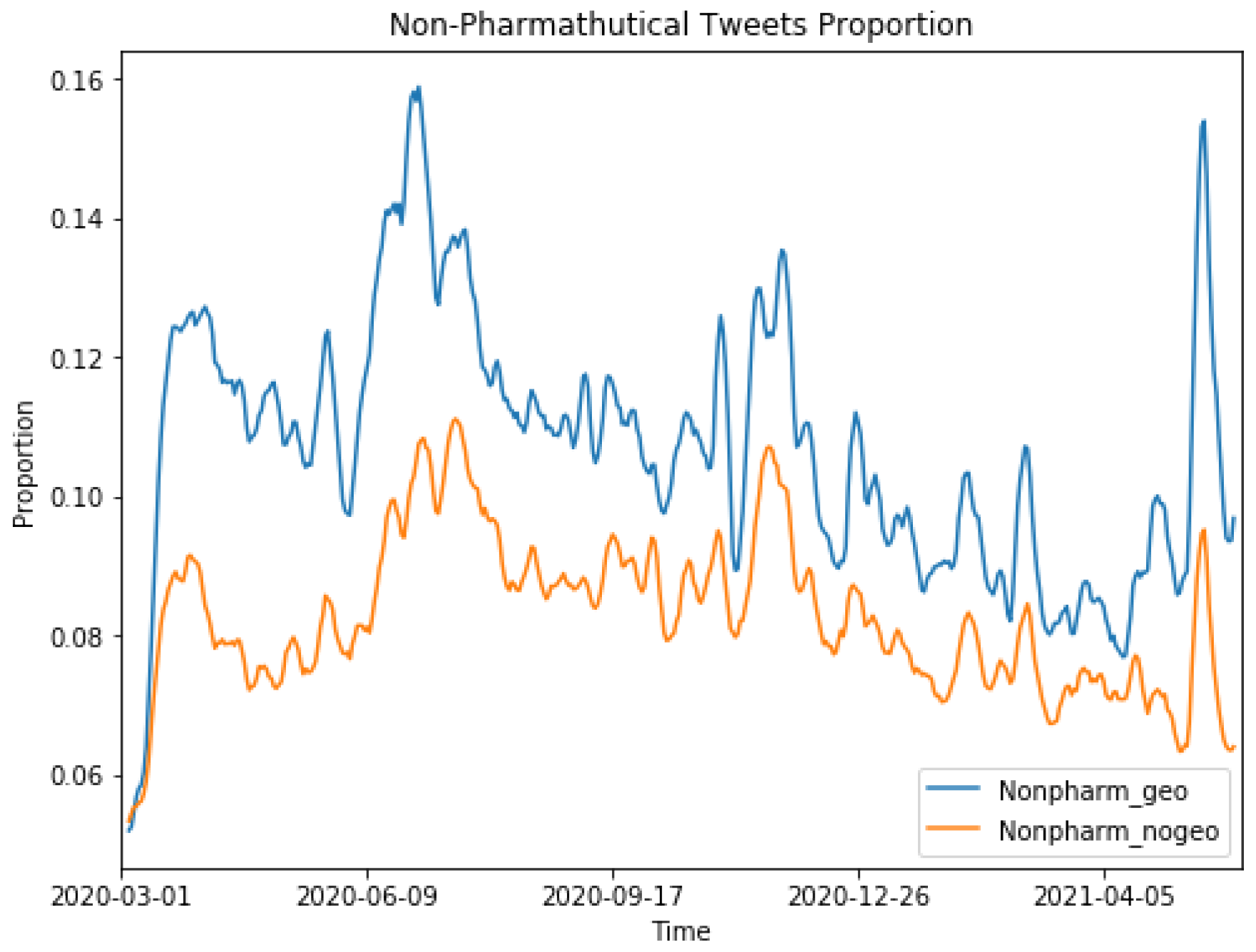
A total of 6000 geo-tagged tweets per day and 6000 non-geo-tagged tweets were sampled and analyzed to evaluate differences in topic distributions and trends between the two groups.
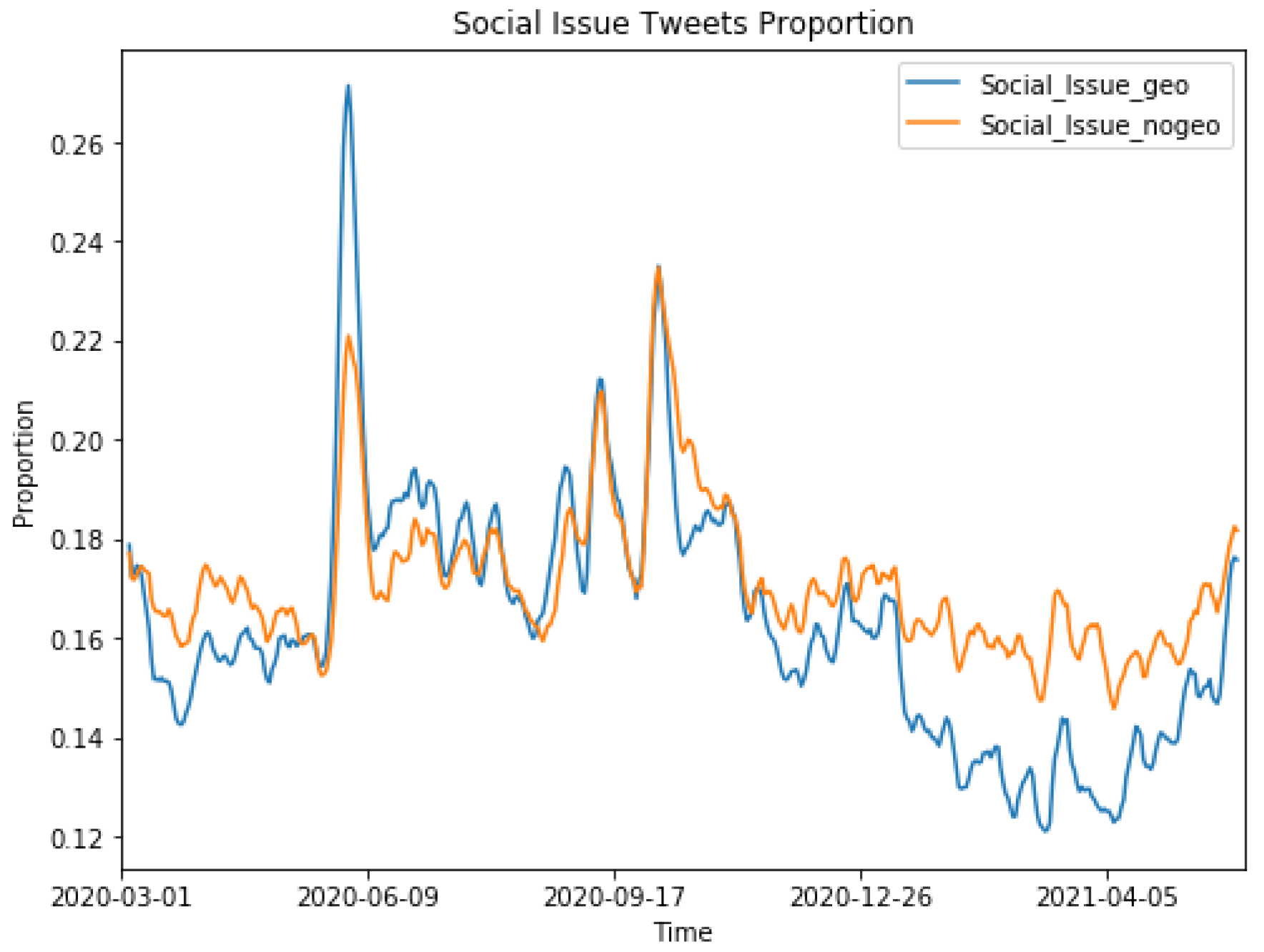
Figure 2 and
Figure 3 show that the topics were very similar and highly correlated between the two groups. The Pearson correlation coefficients were 0.79 and 0.8 for the topics of NPIs and social issues, respectively, showing that the topic being discussed in geo-tagged tweets were highly correlated with tweets without geo-tags. We also found that the proportion of NPI topics was significantly higher in geo-tagged tweets than in non-geo-tagged tweets, indicating that users who shared their geo-tags were more engaged in discussing NPI-related issues. On the other hand, users without geo-tags showed more interests in social issue-related topics.
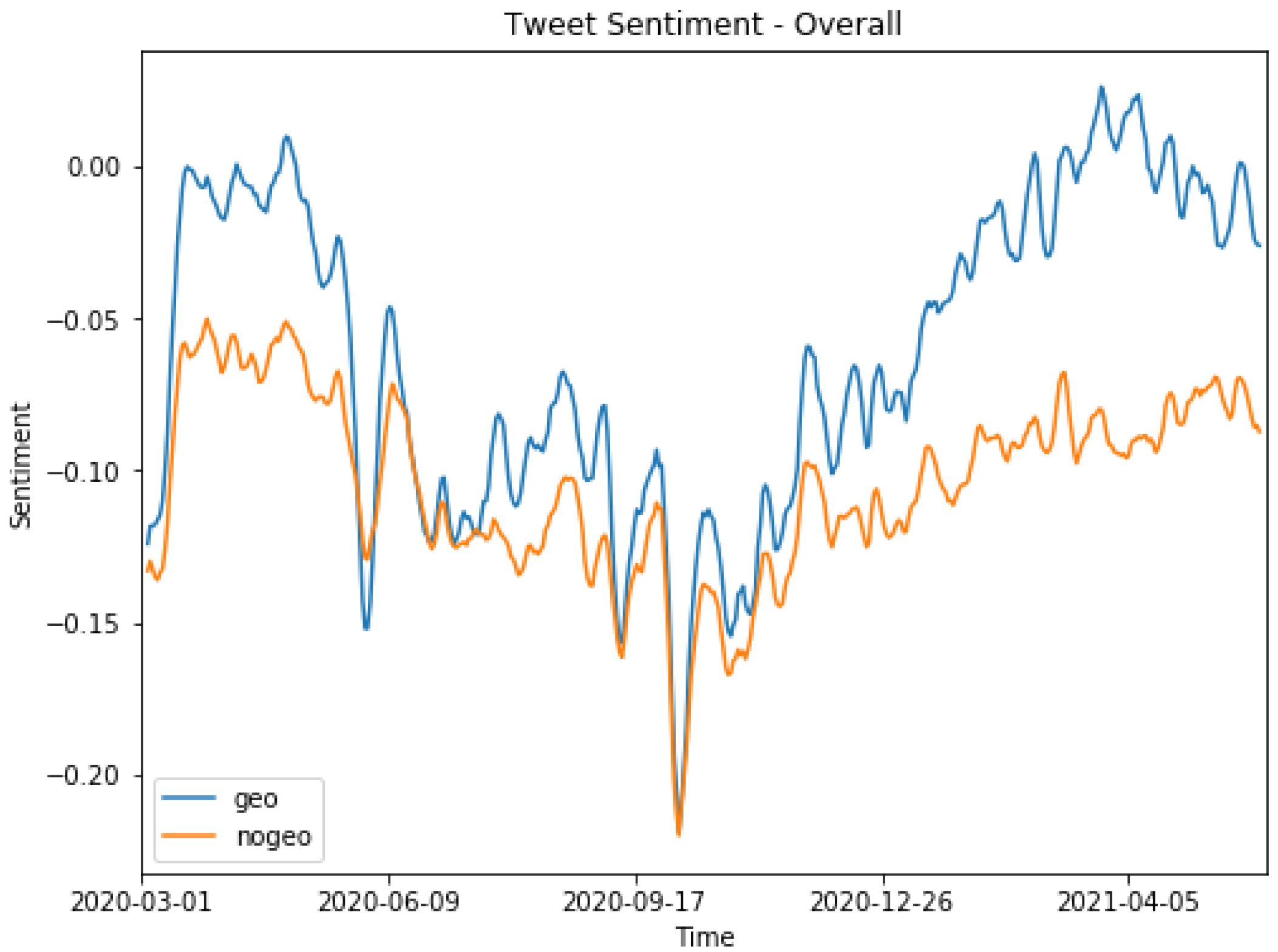
We also compared sentiments in tweets with and without geo-tags. The overall sentiments were based on the arithmetic mean sentiment across all sampled tweets per day in the two groups. Overall sentiments ranged from
to 1, where 0 indicated a neutral sentiment. The sentiment trends in the two groups are shown in
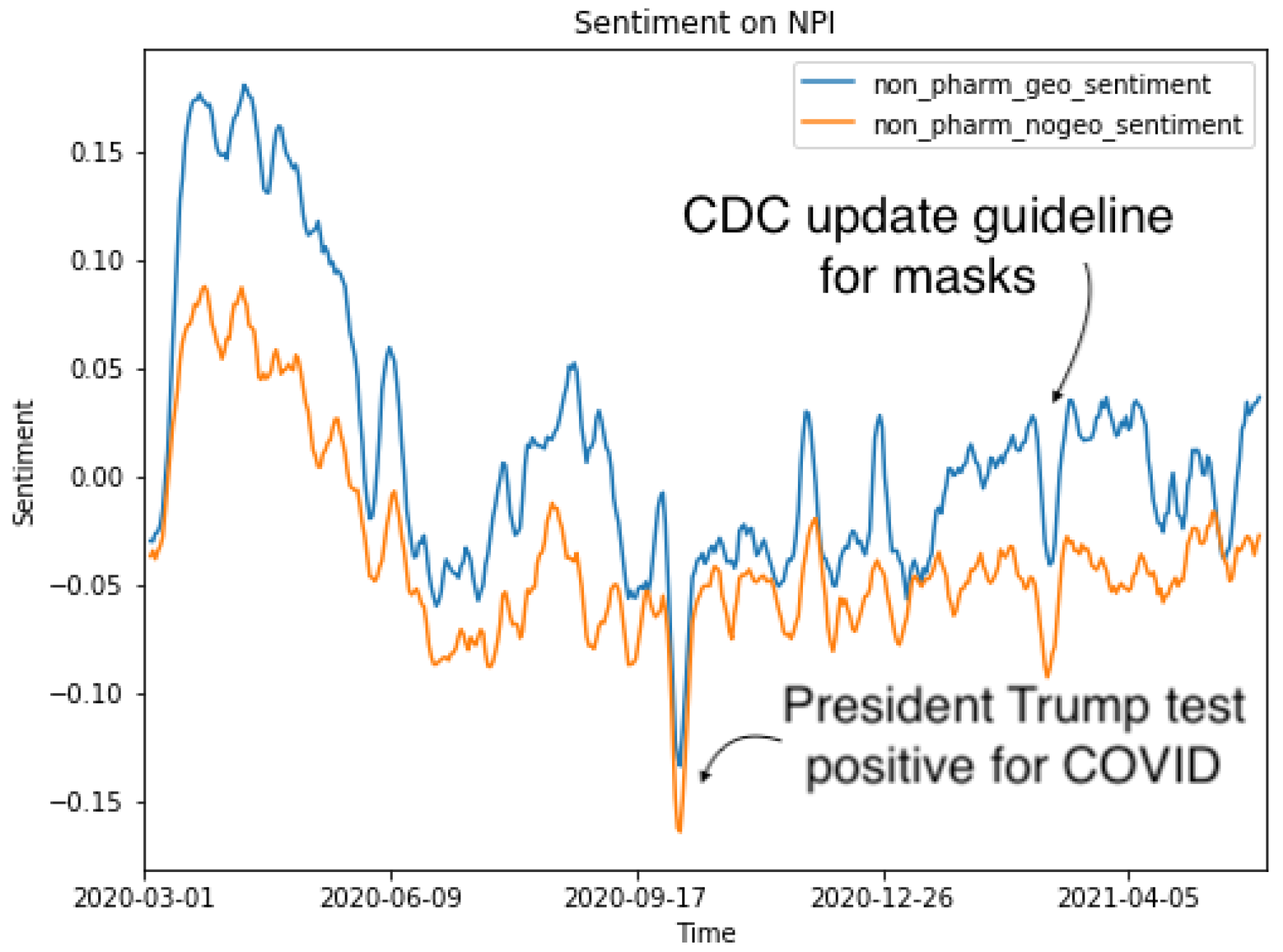
Figure 4.
Figure 4 shows substantial overall sentiment differences between tweets with geo-tags and tweets without geo-tags. Nevertheless, the Pearson correlation coefficient of 0.84 showed that the sentiments of the two sets were highly correlated. Overall, tweets with geo-tags had significantly higher sentiment scores (i.e., more positive sentiments) than tweets without geo-tags.
We further compared sentiments towards NPIs and social issues.
Figure 5 shows sentiments towards the topic of NPIs. Tweets with geo-tags had more positive sentiments than tweets without geo-tags. There were several sudden changes in sentiment towards NPIs. Based on the time frame of these abrupt sentiment changes, we hypothesized that such changes were caused by the real-world events of former President Trump testing positive for COVID-19 and the CDC updating the guideline on mask mandates. The two topics were highly associated with NPIs, showing that our BERT sentiment classification model was able to successfully capture the changes.
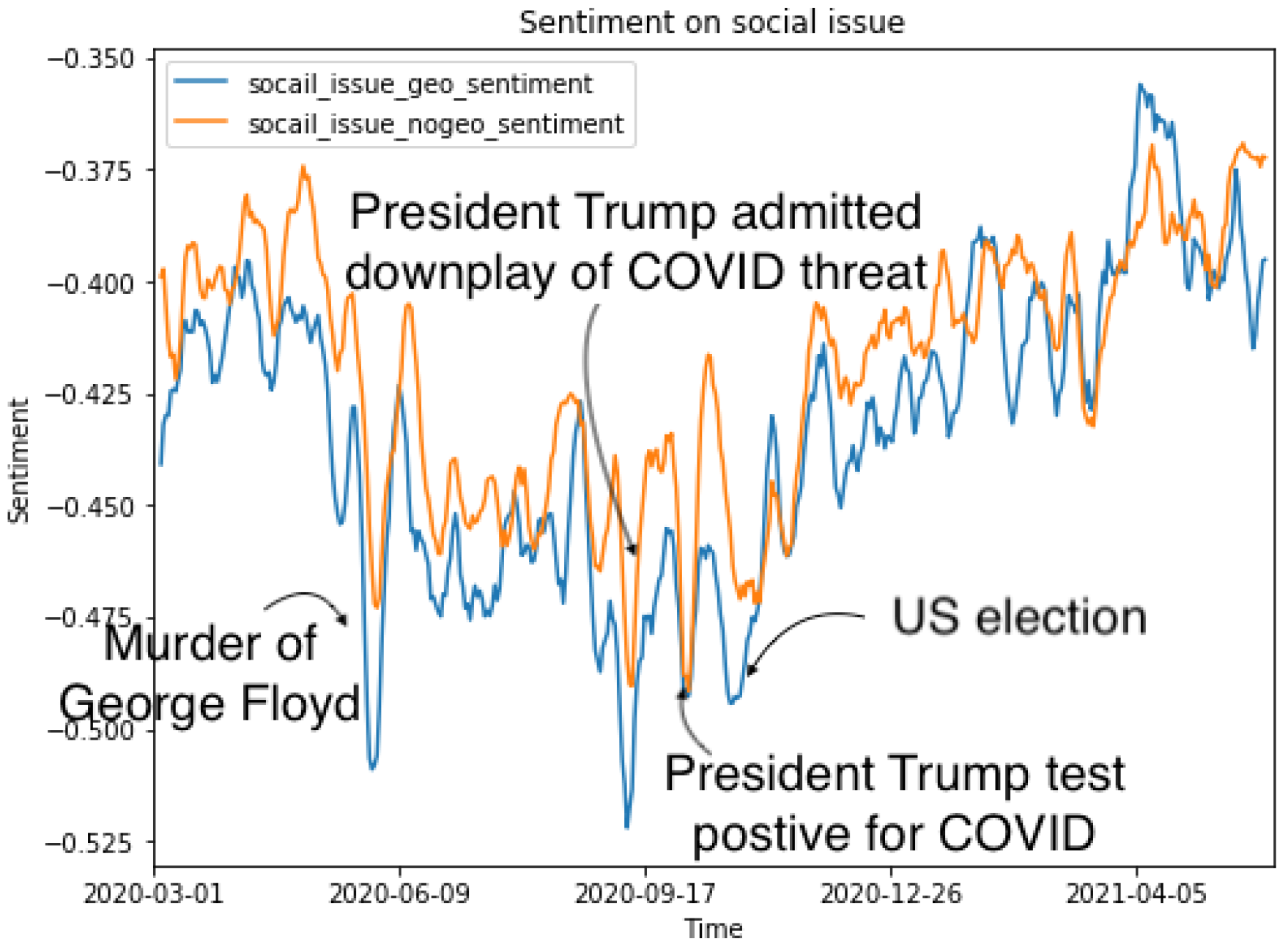
Figure 6 shows that the overall sentiment towards social issues was more negative in tweets with geo-tags than in tweets without geo-tags. Compared with NPIs, the sentiment towards social issues was
(i.e., overall negative), while the sentiment towards NPIs was 0 (i.e., overall neutral). Therefore, overall public sentiments on social media significantly differed between the two topics. Similar to NPI sentiment changes, we were able to identify some key real-world events that caused the sudden changes in public sentiments towards social issues. Examples included the murder of George Floyd, former President Trump admitting downplay of COVID-19 threat, Trump being diagnosed with COVID-19, and the 2020 US election. Some of these events were not reflected in the sentiments towards NPIs (e.g., murder of Floyd), indicating that the BERT model was capable of identifying and separating non-relevant tweets.
3.3.2. Comparison between Top 50 Cities and the Rest of the Country
In this section, we further present the comparison of content topic trends and sentiment trends between tweets geo-tagged in the top 50 most populous cities in the USA and the rest of the geo-tagged tweets. There were a total of 13,299 cities in the 2 million-geo-tagged-tweet sample, with the top 50 cities contributing 36.5% of the sample. The top 50 cities with their number of tweets are presented in
Table 8.
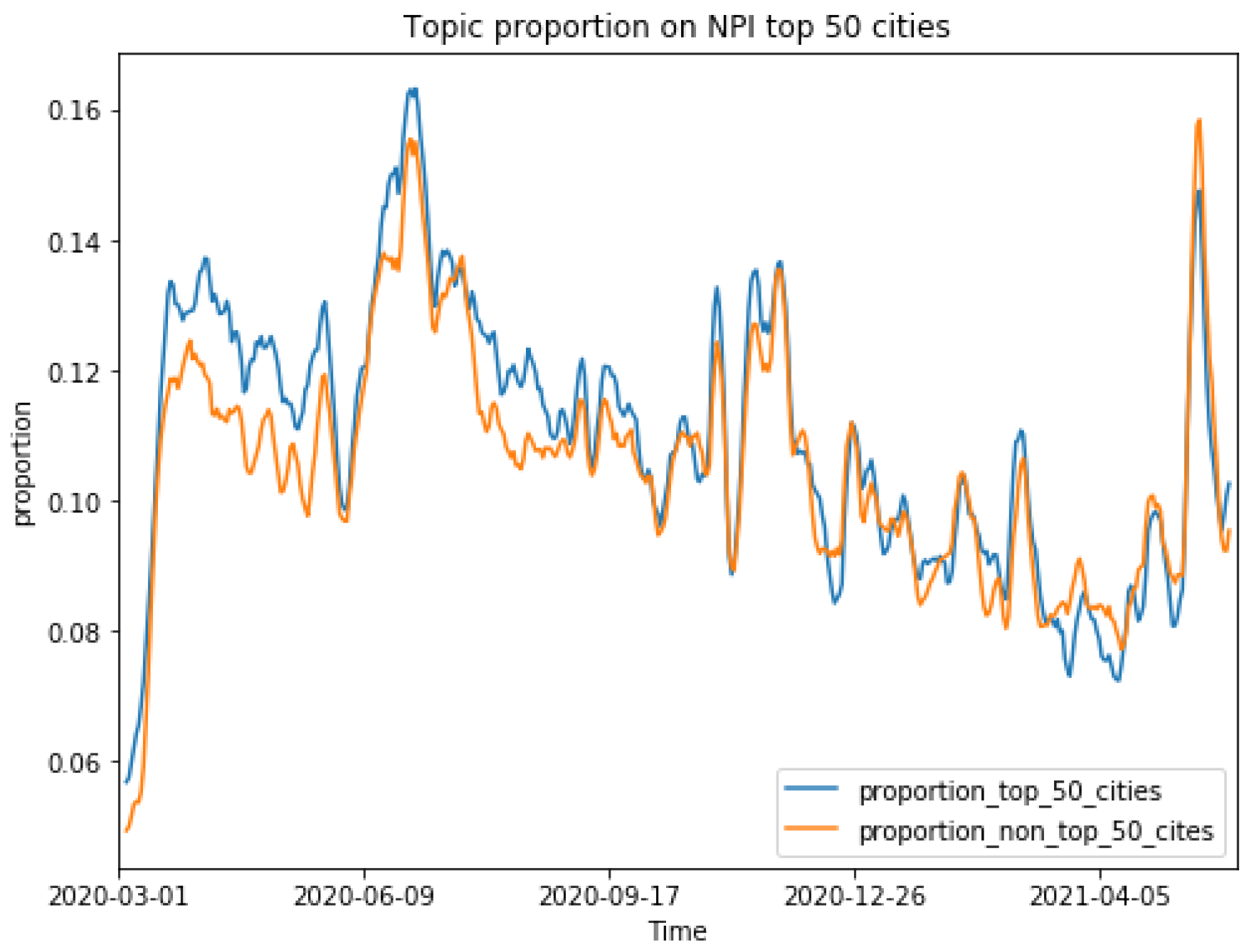
First, we compared the proportions of NPI and social issue topics in the top 50 cities and the rest of the country.
Figure 7 shows that the proportion of NPI topics was around 11% of the overall tweets. At the beginning of the pandemic (April 2020 to August 2020) people who lived in the top 50 most populous cities were more likely to discuss NPIs on social media than people from less populous areas. We also observed a convergence in NPI discussions between populous, large metropolitan areas and less populous regions after September 2020. This matched the trajectory of the COVID-19 pandemic in the USA, as major metropolitan areas were impacted the most at the beginning; thus, people in these populous regions were more concerned about NPIs and engaged in NPI-related topics on social media.
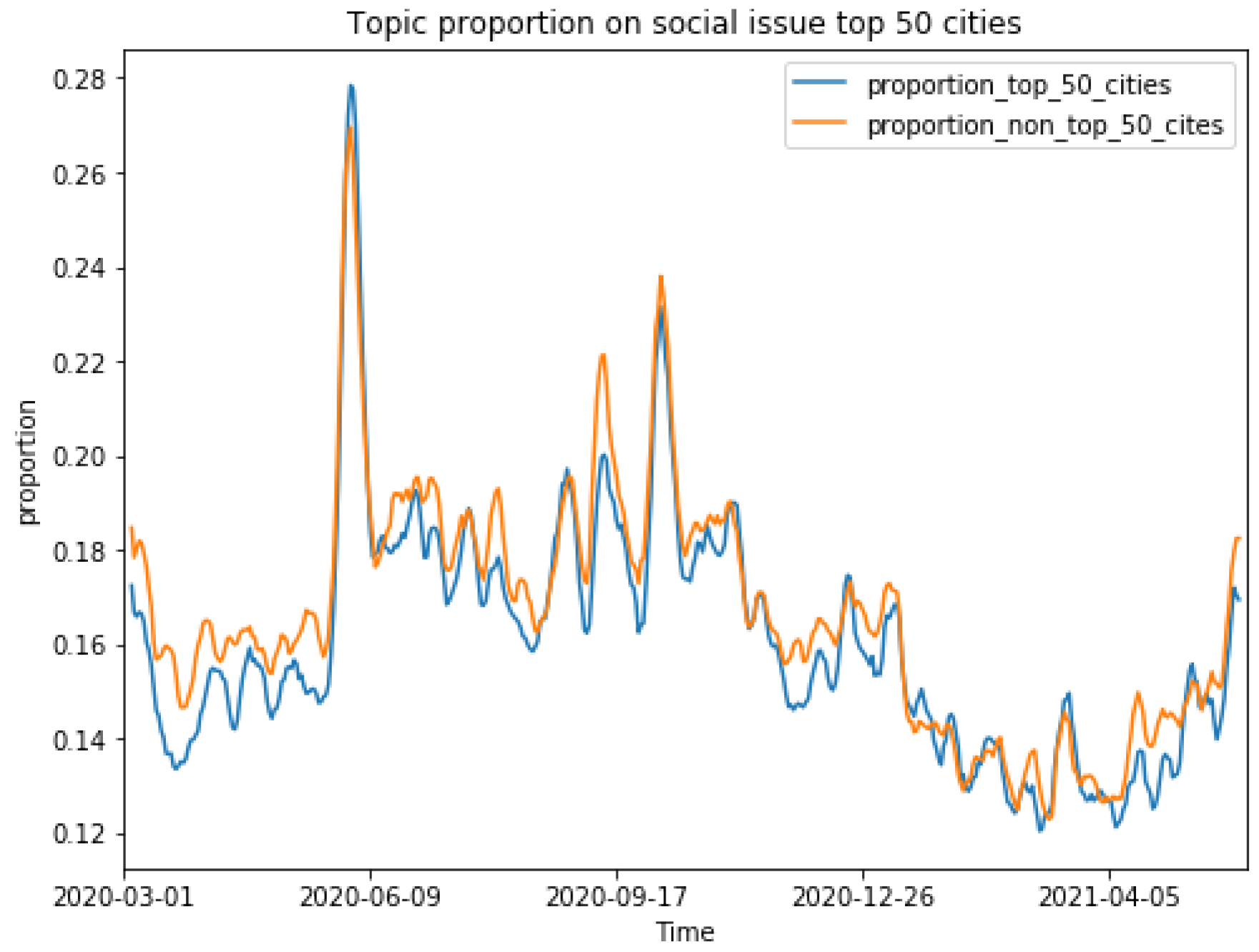
Regarding the social issue topic, as
Figure 8 shows, the proportion was generally around 16% of the overall tweets. Topics on social issues could abruptly arise when some real-world events happened, as we discuss above. In contrast to NPI topics, users in the top 50 most populous cities showed lower interest in social issues during the pandemic than the rest of the country. Nevertheless, people in large metropolitan regions discussed social issues more than other regions around late May 2020, when George Floyd was murdered.
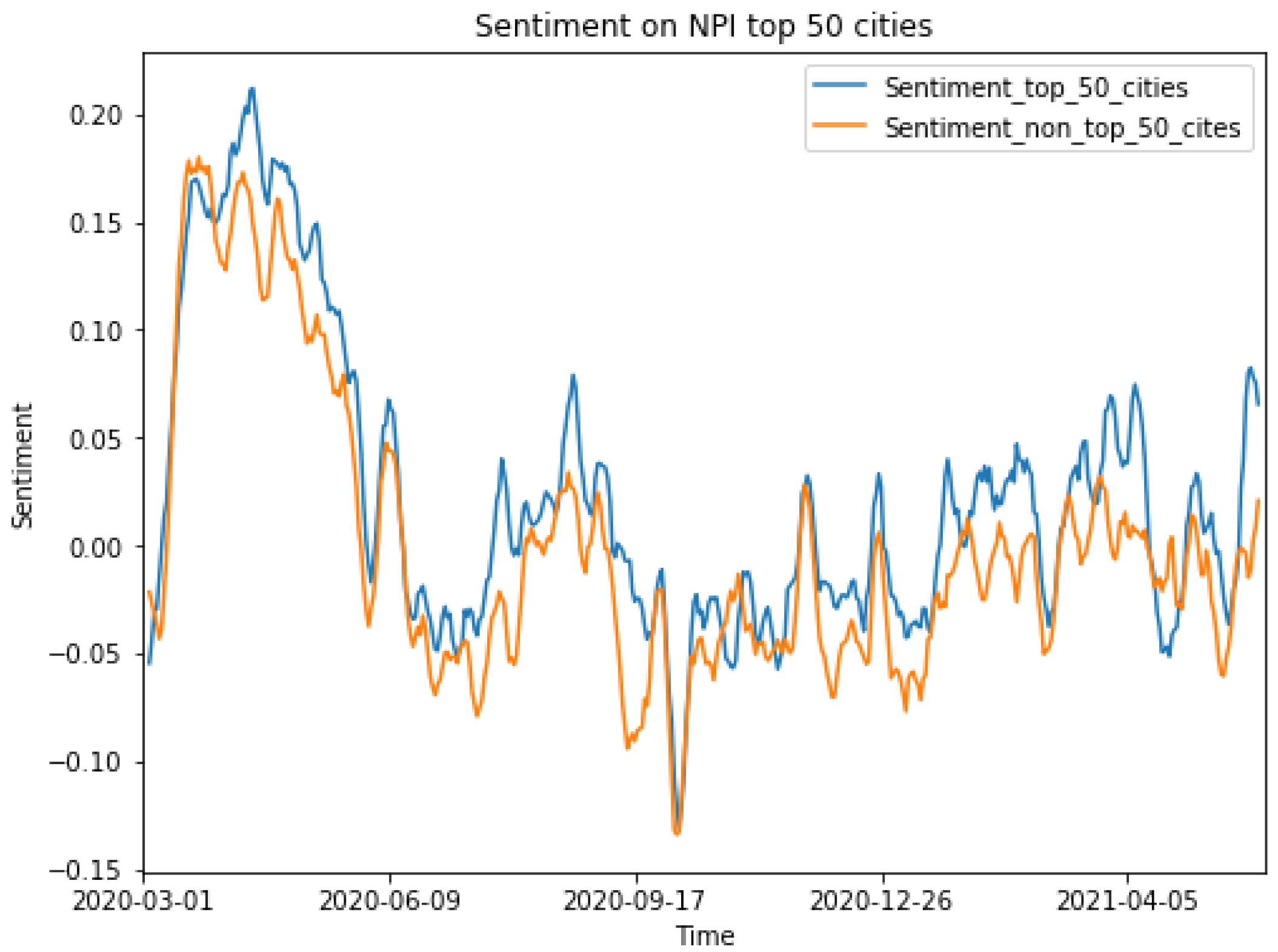
We compared overall sentiments between the tweets generated in the top 50 most populous cites and tweets from the rest of the country. As
Figure 9 shows, there was a clear and consistent difference throughout the study period, as users from the top 50 cities generally expressed more positivity than users from the rest of the country. While the overall sentiments between the two groups were highly correlated, with a Pearson correlation coefficient of 0.92, there was a substantial 0.03 sentiment difference. Tweets sent from the top 50 cities were generally 22% more positive regarding the pandemic.
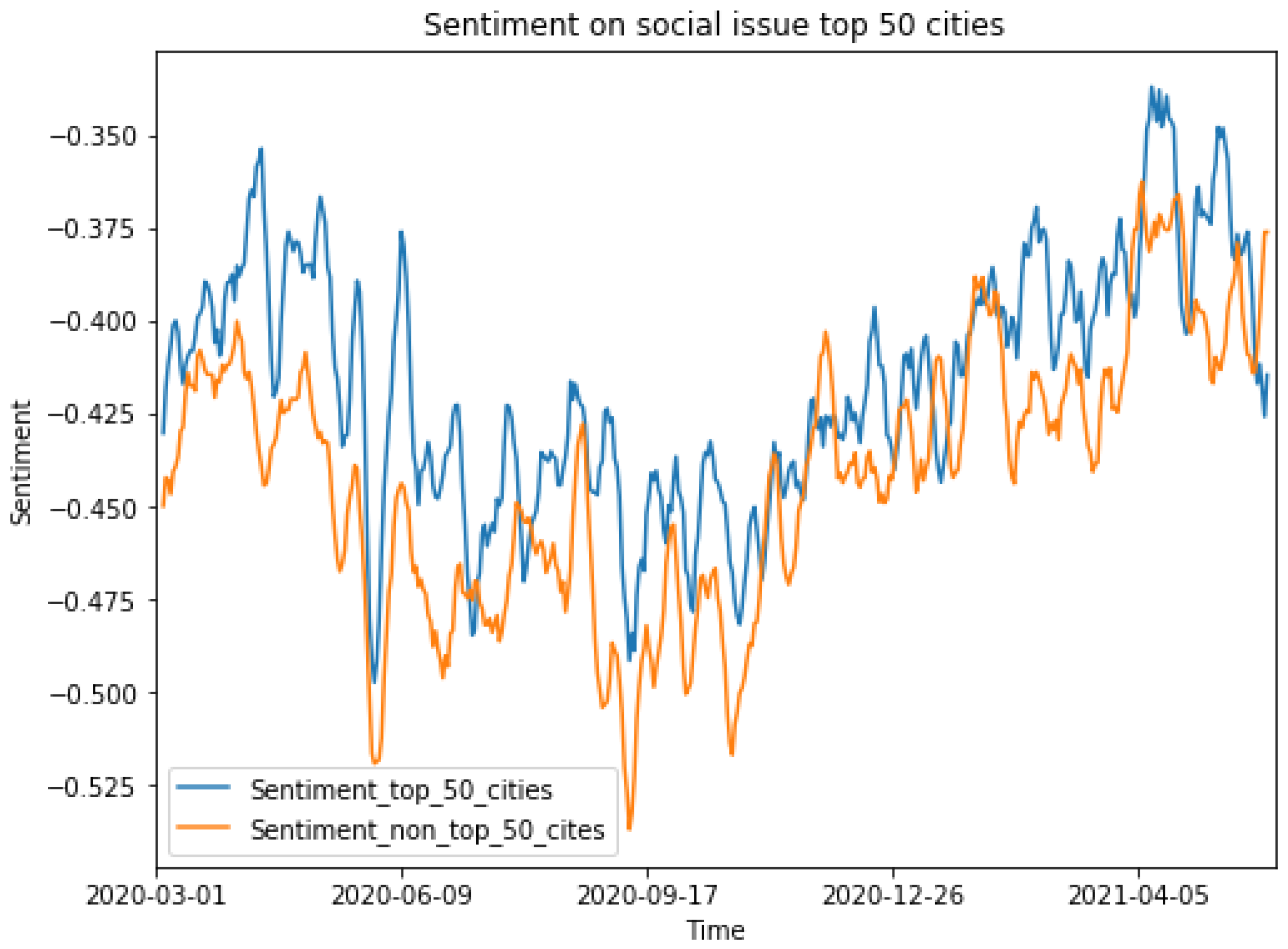
We also compared the sentiments specifically regarding NPIs and social issues between the two regions. As
Figure 10 and
Figure 11 show, the sentiments of tweets from the top 50 cities were more positive towards NPIs than those of tweets from the rest of the country. We also observed a substantial drop in sentiments towards NPIs around September 2020, which was probably due to the unclear messages that the CDC sent regarding mask mandates. The public then began to show negative sentiments towards NPIs.
Regarding social issues, the sentiments of tweets from the top 50 cities were consistently more positive than those of tweets from the rest of the USA. However, the Pearson correlation coefficient was only 0.51 for sentiments towards social issues. On the other hand, the Pearson correlation coefficient was 0.72 for the comparison of NPI sentiments between the top cities and the rest of the USA.
4. Discussion
In this study, we developed an innovative BERT-based NLP workflow for effective content topic and sentiment infoveillance during the COVID-19 pandemic. We first developed a content topic classifier and a sentiment classifier based on a smaller sample of COVID-19-related tweets using the COVID-twitter-BERT variant. We compared the performance of the baseline BERT models and the more specifically tuned COVID-Twitter-BERT models. The COVID-Twitter-BERT models demonstrated higher performance in classifying content topics and sentiments than the baseline BERT-Base models and significantly outperformed non-deep learning logistic regression models.
We then applied the developed BERT topic classification and sentiment classification models to more than 4 million COVID-19-related English tweets over 15 months. We were able to characterize the overall temporal dynamics of COVID-19 discussions on Twitter, as well as the temporal dynamics of more specific content topics and sentiments. Using the NPI and social issue topics as examples, we were able to accurately characterize the dynamic changes in public awareness of these topics over time, as well as sentiment shifts during different stages of the pandemic. In general, we found that the public had an overall neutral sentiment towards NPIs, but an overall negative sentiment towards various social issues. Compared with many infoveillance studies during the COVID-19 pandemic, our study is one of the few that utilized advanced AI NLP techniques to identify the real-time content topics and sentiments of online discussions from massive social media data. In addition, we also developed a highly effective BERT-based content and sentiment classification model for health-related discussions.
Our granular-level intelligent infoveillance is based on the deep learning NLP technique BERT. It enables public health practitioners to perform scalable infoveillance to zoom in and zoom out of an issue of interest (e.g., the overall COVID-19 pandemic) and understand various content topics associated with the issue (e.g., different aspects of COVID-19, such as clinical/epidemiological information of the disease itself, NPIs, vaccination, policies and politics, social issues, etc.). By understanding how public awareness and sentiment vary across time and space during different stages of the pandemic, public health practitioners can develop more effective and targeted health communication strategies and better address public concerns towards specific content topics, such as vaccination, NPIs, and social issues, including health disparity and inequality during the pandemic and other health emergencies.
5. Future Work
An extension of this study using the current BERT-based NLP infoveillance workflow is to quantify the spatio-temporal variability of public sentiment towards vaccination, one of the most discussed topics during the COVID-19 pandemic in the USA and across the globe. We demonstrated that our infoveillance workflow could successfully monitor public awareness and sentiment towards NPIs. Similarly, public perception towards vaccination could also be explicitly evaluated. Similar to our study on NPIs, public health practitioners could quickly respond to abrupt drops in sentiment towards vaccination and effectively identify potential external influencing events to develop countermeasures.
Our infoveillance workflow is also spatially explicit. We compared tweets generated in the top 50 most populous cities and in the rest of the cities in the USA. We observed a substantial sentiment gap between these major metropolitan areas and less populated regions. Social media users in major metropolitan areas expressed more positive sentiments towards the pandemic, NPIs, and social issues in their tweets. Future improvement in this workflow could incorporate more scalable geospatial information, such as identifying content topics and sentiments across geospatial scales, from the county level to the nation level. Public health practitioners could not only zoom in and understand more granular content topics but also zoom across geospatial scales to understand the spatial heterogeneity of content topics and sentiments. By incorporating more spatially explicit variables, for instance, various social and structural determinants of health (SDOHs), public health practitioners could identify key influencing factors for certain content topics at granular spatial scales.
Our BERT infoveillance workflow is modularly designed and is able to be integrated with other analytical techniques, e.g., time-series analysis and signal processing, to detect certain key events during the pandemic that could have driven the abrupt changes in public sentiment towards NPIs and social issues. The future version of this infoveillance system is expected to automatically detect the key turning points of public perception towards a specific content topic and effectively identify potential external real-world drivers of the sudden sentiment changes.
The modular design of our BERT-based NLP infoveillance workflow can also be adapted for future applications such as misinformation detection. Using NLP and other analytical techniques, we could quickly find potential misinformation content topics and promptly respond to emerging misinformation topics. More granular characterization of online discussion reveals more specific contents and sentiments that are highly associated with misinformation, similar to the “digital antigen”. Therefore, the infoveillance workflow is also able to actively send alarms to public health practitioners when certain key content topics of emerging misinformation match the “digital antigen” of misinformation.
Another extension of our infoveillance workflow is to further investigate content topic and sentiment shifts in social networks, using graph and network analysis. For instance, we could collect all replies to a specific original post, construct the network of information dissemination, and evaluate potential content and sentiment shifts from the original post in the network. We could then identify key vertices in the network that contribute to sentiment shifts, i.e., online influencers. Network metrics, such as various centrality scores, can be used to quantify the potential effectiveness of influencers in driving online discussions on social media.
In summary, we successfully developed a highly effective BERT-based infoveillance workflow for content and sentiment analysis. The workflow serves as a cornerstone for more extensive research and applications of large-scale social media analytics beyond the public health context.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}