
Cyberattack and Fraud Detection Using Ensemble Stacking



Abstract
:1. Introduction
2. Related Work
2.1. IoT Layers
2.1.1. Perception or Physical Layer
2.1.2. Network Layer
2.1.3. Application or Web Layer
2.2. Classification of Attacks
- DoS attack: Denial of Service attacks (DoS attacks) disrupt system services by creating multiple redundant requests. DoS attacks are common in IoT applications. Many of the devices used in the IoT world are low-end, leaving them vulnerable to attacks [15].
- Network injection: Hackers can use this attack to create their device, which acts as a sender of IoT data and sends data like it is part of the IoT network [13].
- Man in the middle attacks: In this scenario, attackers are trying to be a part of the communication system, where the attack is directly connected to another device [16]. IoT network nodes are all connected to the gateway for communication. All devices which receive and transmit data will be compromised if the server is attacked [17].
- Malicious input attacks: In this case, an attacker can inject malicious scripts into an application and make them available to all users. Any input type may be stored in a database, a user forum, or any other mechanism that stores input. Malicious input attacks lead to financial loss, increased power consumption, and the degradation of wireless networks [18].
- Data tampering: Physical access to an IoT device is required for an attacker to gain full control. This involves physically damaging or replacing a node within the device. The attackers manipulate the information of the user to disrupt their privacy. Smart devices that carry information about the location of the user, fitness levels, billing prices, and other essential details are vulnerable to these data tampering attacks [19].
- Data leakage: Devices connected to the Internet carry confidential and sensitive information. If the data are leaked, the information could be misused. When an attacker is aware of an application’s vulnerabilities, the risk of data stalling increases [22].
- Malicious code: Malicious code can be uploaded if the attacker knows a vulnerability in the application, such as SQL injection or fake data injection. Code that causes undesired effects, security breaches, or damage to an operating system is maliciously inserted into a software system or web script [23].
- Reverse engineering model: An attacker can obtain sensitive information by reverse engineering embedded systems. Cybercriminals use this method to discover data left behind by software engineers, like hardcoded credentials and bugs. The attackers use the information once they have recovered it to launch future attacks against embedded systems [22].
2.3. Cyberattack Detection in IoT Systems
2.4. Fraud Attack Detection in IoT Systems
3. Methodology
Preprocessing
4. Experimental Results
4.1. Datasets
4.1.1. NSL-KDD
4.1.2. UNSW-NB15
4.1.3. Credit Card Fraud Detection Dataset
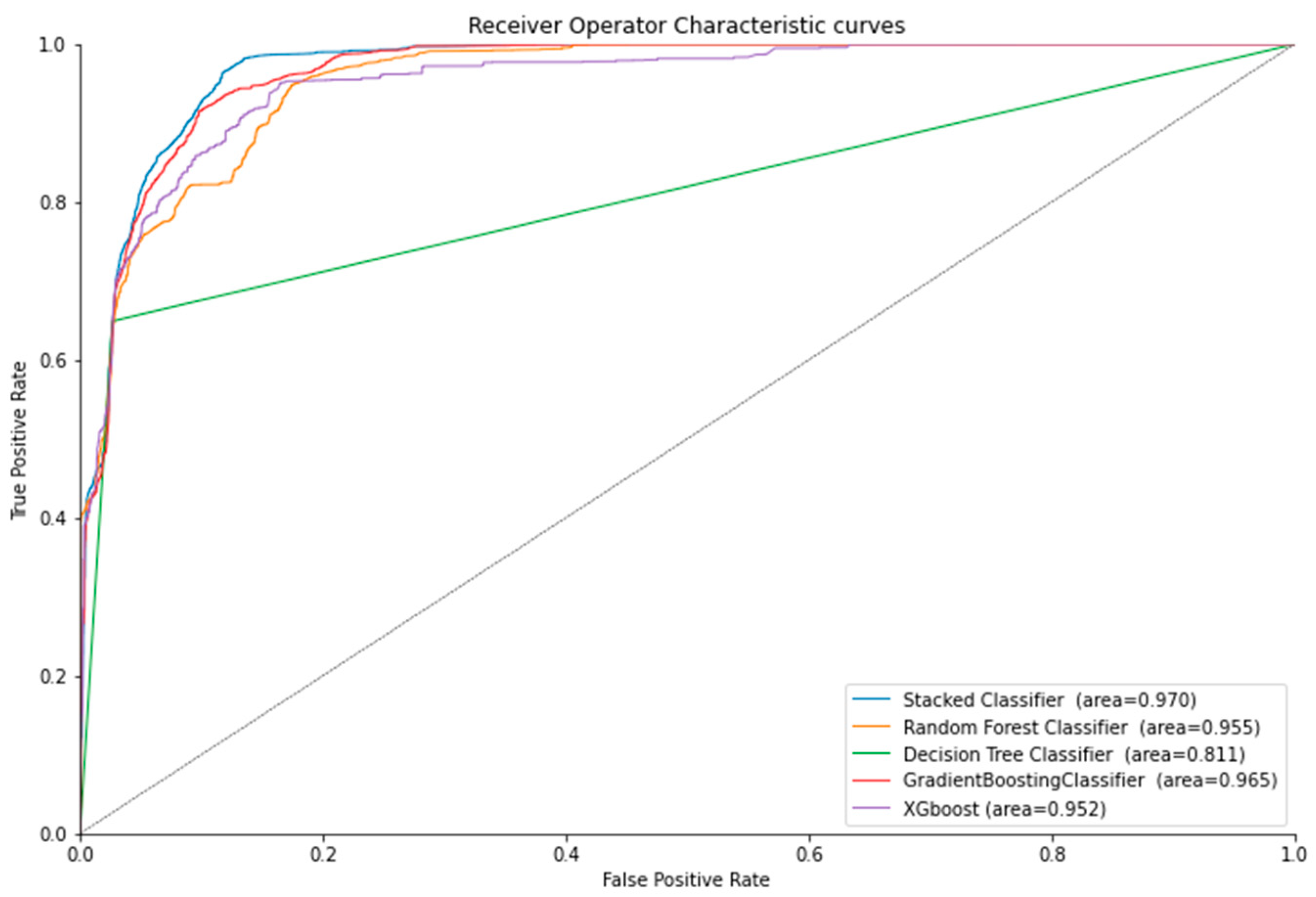
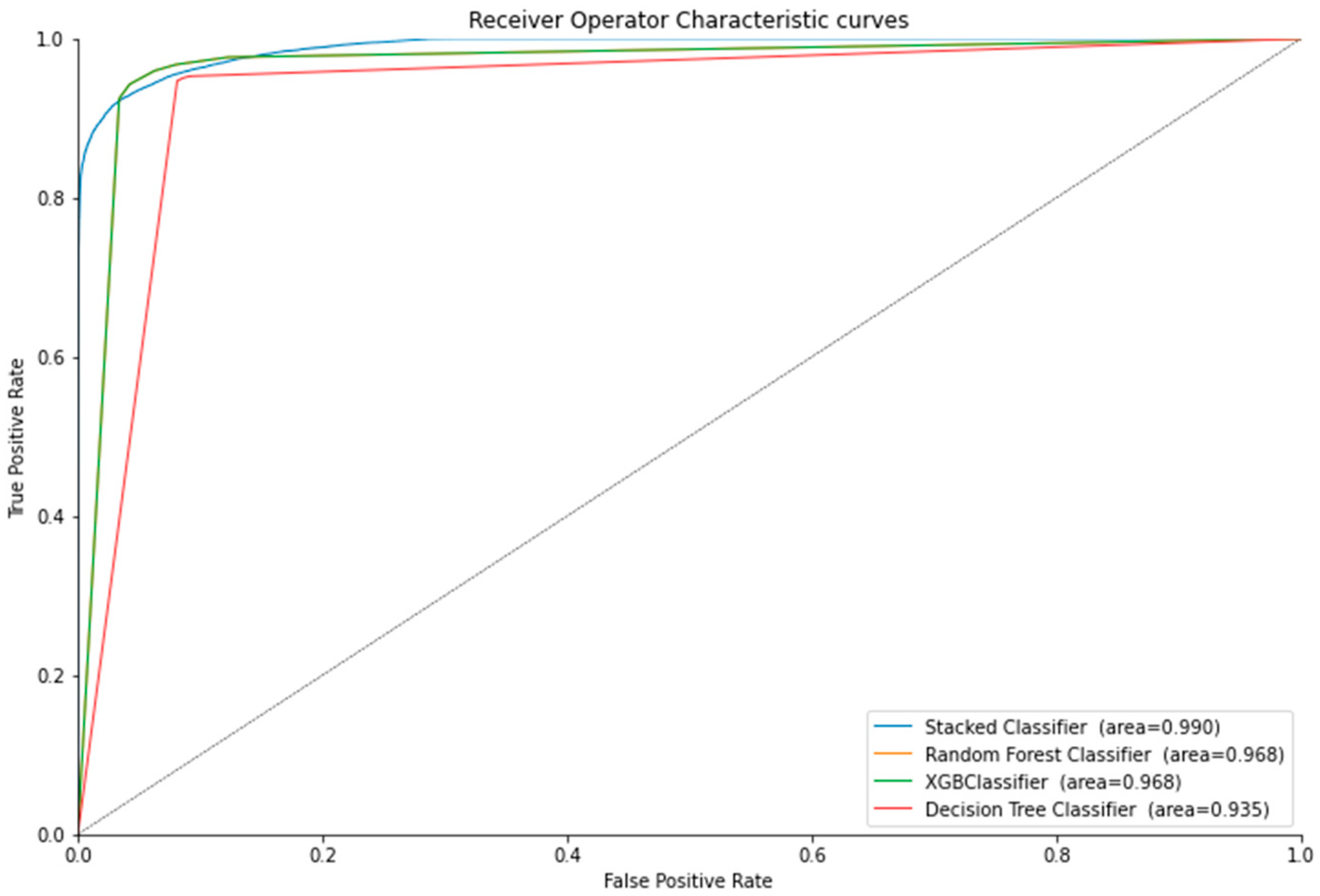
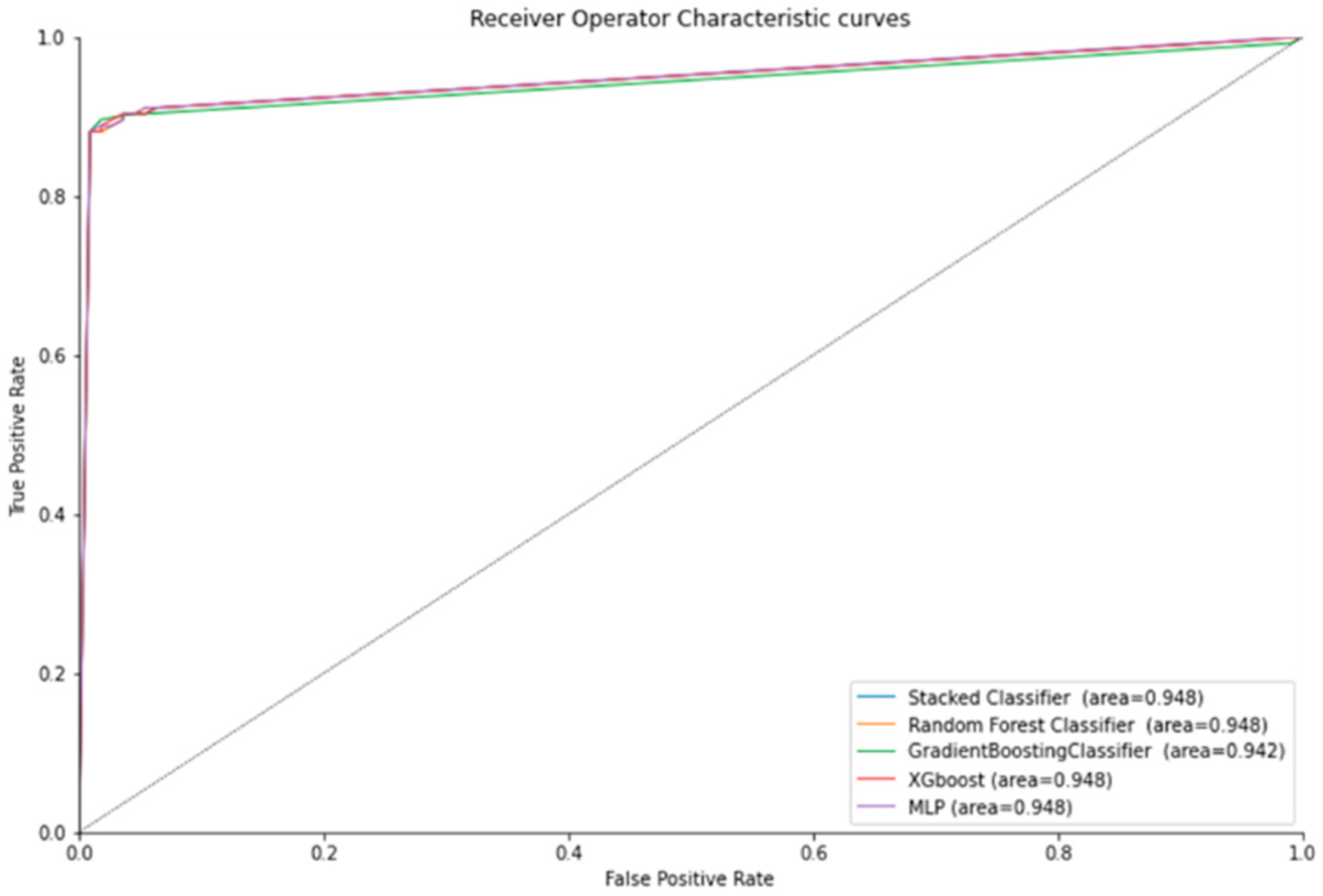
4.2. Experimental Results
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Rizvi, S.; Kurtz, A.; Pfeffer, J.; Rizvi, M. Securing the internet of things (IoT): A security taxonomy for iot. In Proceedings of the 2018 17th IEEE International Conference On Trust, Security and Privacy in Computing and Communications/12th IEEE International Conference On Big Data Science And Engineering (TrustCom/BigDataSE), New York, NY, USA, 1–3 August 2018; pp. 163–168. [Google Scholar]
- Miraz, M.H.; Ali, M.; Excell, P.S.; Picking, R. A review on internet of things (iot), internet of everything (ioe) and internet of nano things (iont). In Proceedings of the 2015 Internet Technologies and Applications (ITA), Wrexham, UK, 8–11 September 2015; IEEE: Manhattan, NY, USA, 2015; pp. 219–224. [Google Scholar]
- Burhan, M.; Rehman, R.A.; Khan, B.; Kim, B.-S. IoT Elements, Layered Architectures and Security Issues: A Comprehensive Survey. Sensors 2018, 18, 2796. [Google Scholar] [CrossRef] [Green Version]
- Gates, T.; Jacob, K. Payments fraud: Perception versus reality—A conference summary. Econ. Perspect. 2009, 33, 7–15. [Google Scholar]
- Radanliev, P.; De Roure, D.; van Kleek, M.; Cannady, S. Artificial Intelligence and Cyber Risk Super-forecasting. Connect. Q. J. 2020, 2, 1–7. [Google Scholar] [CrossRef]
- Alam, T. A reliable communication framework and its use in internet of things (iot). Int. J. Sci. Res. Comput. Sci. Eng. Inf. Technol. 2018, 3, 450–456. [Google Scholar]
- Alaba, F.A.; Othman, M.; Hashem, I.A.T.; Alotaibi, F. Internet of Things security: A survey. J. Netw. Comput. Appl. 2017, 88, 10–28. [Google Scholar] [CrossRef]
- Sethi, P.; Sarangi, S.R. Internet of things: Architectures, protocols, and applications. J. Electr. Comput. Eng. 2017, 2017, 9324035. [Google Scholar] [CrossRef] [Green Version]
- Sezer, O.B.; Dogdu, E.; Ozbayoglu, A.M. Context-aware computing, learning, and big data in internet of things: A survey. IEEE Internet Things J. 2017, 5, 1–27. [Google Scholar] [CrossRef]
- Singh, A.; Payal, A.; Bharti, S. A walkthrough of the emerging iot paradigm: Visualizing inside functionalities, key features, and open issues. J. Netw. Comput. Appl. 2019, 143, 111–151. [Google Scholar] [CrossRef]
- Geetha, R.; Thilagam, T. A review on the effectiveness of machine learning and deep learning algorithms for cyber security. Arch. Comput. Methods Eng. 2021, 28, 2861–2879. [Google Scholar] [CrossRef]
- Mohammed, A.H.K.; Jebamikyous, H.; Nawara, D.; Kashef, R. Iot cyber-attack detection: A comparative analysis. In Proceedings of the International Conference on Data Science, E-Learning and Information Systems, Ma’an, Jordon, 5–7 April 2021; pp. 117–123. [Google Scholar]
- Sajjad, H.; Arshad, M. Evaluating Security Threats for Each Layers of IOT System. 2019. Volume 10, pp. 20–28. Available online: https://www.researchgate.net/publication/336149742_Evaluating_Security_Threats_for_each_Layers_of_IoT_System (accessed on 25 December 2021).
- Mohanta, B.K.; Jena, D.; Satapathy, U.; Patnaik, S. Survey on IoT security: Challenges and solution using machine learning, artificial intelligence and blockchain technology. Internet Things 2020, 11, 100227. [Google Scholar] [CrossRef]
- Baig, Z.; Sanguanpong, S.; Firdous, S.N.; Vo, V.N.; Nguyen, T.; So-In, C. Averaged dependence estimators for DoS attack detection in IoT networks. Futur. Gener. Comput. Syst. 2020, 102, 198–209. [Google Scholar] [CrossRef]
- Li, C.; Qin, Z.; Novak, E.; Li, Q. Securing SDN Infrastructure of IoT–Fog Networks From MitM Attacks. IEEE Internet Things J. 2017, 4, 1156–1164. [Google Scholar] [CrossRef]
- Krishna, B.S.; Gnanasekaran, T. A systematic study of security issues in Internet-of-Things (IoT). In Proceedings of the 2017 International Conference on I-SMAC (IoT in Social, Mobile, Analytics and Cloud) (I-SMAC), Palladam, India, 10–11 February 2017; pp. 107–111. [Google Scholar]
- Zhou, J.; Cao, Z.; Dong, X.; Vasilakos, A.V. Security and Privacy for Cloud-Based IoT: Challenges. IEEE Commun. Mag. 2017, 55, 26–33. [Google Scholar] [CrossRef]
- Shah, Y.; Sengupta, S. A survey on Classification of Cyber-attacks on IoT and IIoT devices. In Proceedings of the 2020 11th IEEE Annual Ubiquitous Computing, Electronics & Mobile Communication Conference (UEMCON), New York, NY, USA, 28–31 October 2020; pp. 406–413. [Google Scholar]
- Zhang, P.; Nagarajan, S.G.; Nevat, I. Secure location of things (slot): Mitigating localization spoofing attacks in the internet of things. IEEE Internet Things J. 2017, 4, 2199–2206. [Google Scholar] [CrossRef]
- López, M.; Peinado, A.; Ortiz, A. An extensive validation of a sir epidemic model to study the propagation of jamming attacks against iot wireless networks. Comput. Netw. 2019, 165, 106945. [Google Scholar] [CrossRef]
- Panchal, A.C.; Khadse, V.M.; Mahalle, P.N. Security issues in iiot: A comprehensive survey of attacks on iiot and its countermeasures. In Proceedings of the 2018 IEEE Global Conference on Wireless Computing and Networking (GCWCN), Lonavala, India, 23–24 November 2018; pp. 124–130. [Google Scholar]
- Aktukmak, M.; Yilmaz, Y.; Uysal, I. Sequential Attack Detection in Recommender Systems; IEEE: Manhattan, NY, USA, 2021. [Google Scholar]
- Anthi, E.; Williams, L.; Slowinska, M.; Theodorakopoulos, G.; Burnap, P. A Supervised Intrusion Detection System for Smart Home IoT Devices. IEEE Internet Things J. 2019, 6, 9042–9053. [Google Scholar] [CrossRef]
- AlZubi, A.A.; Al-Maitah, M.; Alarifi, A. Cyber-attack detection in healthcare using cyber-physical system and machine learning techniques. Soft Comput. 2021, 25, 12319–12332. [Google Scholar] [CrossRef]
- Rashid, M.M.; Kamruzzaman, J.; Imam, T.; Kaisar, S.; Alam, M.J. Cyber attacks detection from smart city applications using artificial neural network. In Proceedings of the 2020 IEEE Asia-Pacific Conference on Computer Science and Data Engineering (CSDE), Gold Coast, Australia, 16–18 December 2020; pp. 1–6. [Google Scholar]
- Taheri, S.; Gondal, I.; Bagirov, A.; Harkness, G.; Brown, S.; Chi, C. Multisource cyber-attacks detection using machine learning. In Proceedings of the 2019 IEEE International Conference on Industrial Technology (ICIT), Melbourne, Australia, 13–15 February 2019; pp. 1167–1172. [Google Scholar]
- Cristiani, A.L.; Lieira, D.D.; Meneguette, R.I.; Camargo, H.A. A fuzzy intrusion detection system for identifying cyber-attacks on iot networks. In Proceedings of the 2020 IEEE Latin-American Conference on Communications (LATINCOM), Santo Domingo, Dominican Republic, 18–20 November 2020; pp. 1–6. [Google Scholar]
- Rathore, S.; Park, J.H. Semi-supervised learning based distributed attack detection framework for IoT. Appl. Soft Comput. 2018, 72, 79–89. [Google Scholar] [CrossRef]
- Jahromi, A.N.; Karimipour, H.; Dehghantanha, A.; Choo, K.K.R. Toward detection and attribution of cyber-attacks in iot-enabled cyber-physical systems. IEEE Internet Things J. 2021, 8, 13712–13722. [Google Scholar] [CrossRef]
- Singh, S.; Fernandes, S.V.; Padmanabha, V.; Rubini, P.E. Mcids-multi classifier intrusion detection system for iot cyber attack using deep learning algorithm. In Proceedings of the 2021 Third International Conference on Intelligent Communication Technologies and Virtual Mobile Networks (ICICV), Tirunelveli, India, 4–6 February 2021; pp. 354–360. [Google Scholar]
- Battisti, F.; Bernieri, G.; Carli, M.; Lopardo, M.; Pascucci, F. Detecting integrity attacks in iot-based cyber physical systems: A case study on hydra testbed. In Proceedings of the 2018 Global Internet of Things Summit (GIoTS), Bilbao, Spain, 4–7 June 2018; pp. 1–6. [Google Scholar]
- Diro, A.A.; Chilamkurti, N. Distributed attack detection scheme using deep learning approach for internet of things. Future Gener. Comput. Syst. 2018, 82, 761–768. [Google Scholar] [CrossRef]
- Moussa, M.M.; Alazzawi, L. Cyber attacks detection based on deep learning for cloud-dew computing in automotive iot applications. In Proceedings of the 2020 IEEE International Conference on Smart Cloud (SmartCloud), Washington, DC, USA, 6–8 November 2020; pp. 55–61. [Google Scholar]
- Soe, Y.N.; Feng, Y.; Santosa, P.I.; Hartanto, R.; Sakurai, K. Towards a lightweight detection system for cyber attacks in the iot environment using corresponding features. Electronics 2020, 9, 144. [Google Scholar] [CrossRef] [Green Version]
- Abu Al-Haija, Q.; Zein-Sabatto, S. An Efficient Deep-Learning-Based Detection and Classification System for Cyber-Attacks in IoT Communication Networks. Electronics 2020, 9, 2152. [Google Scholar] [CrossRef]
- Mishra, K.N.; Pandey, S.C. Fraud Prediction in Smart Societies Using Logistic Regression and k-fold Machine Learning Techniques. Wirel. Pers. Commun. 2021, 119, 1341–1367. [Google Scholar] [CrossRef]
- Pajouh, H.H.; Javidan, R.; Khayami, R.; Dehghantanha, A.; Choo, K.-K.R. A Two-Layer Dimension Reduction and Two-Tier Classification Model for Anomaly-Based Intrusion Detection in IoT Backbone Networks. IEEE Trans. Emerg. Top. Comput. 2016, 7, 314–332. [Google Scholar] [CrossRef]
- Choi, D.; Lee, K. An Artificial Intelligence Approach to Financial Fraud Detection under IoT Environment: A Survey and Implementation. Secur. Commun. Netw. 2018, 2018, 5483472. [Google Scholar] [CrossRef] [Green Version]
- Zhou, H.; Sun, G.; Fu, S.; Wang, L.; Hu, J.; Gao, Y. Internet financial fraud detection based on a distributed big data approach with node2vec. IEEE Access 2021, 9, 43378–43386. [Google Scholar] [CrossRef]
- Ram, S.; Gupta, S.; Agarwal, B. Devanagri character recognition model using deep convolution neural network. J. Stat. Manag. Syst. 2018, 21, 593–599. [Google Scholar] [CrossRef]
- Zhang, Y.; You, F.; Liu, H. Behavior-based credit card fraud detecting model. In Proceedings of the 2009 Fifth International Joint Conference on INC, IMS and IDC, Seoul, Korea, 25–27 August 2009; pp. 855–858. [Google Scholar]
- Save, P.; Tiwarekar, P.; Jain, K.N.; Mahyavanshi, N. A Novel Idea for Credit Card Fraud Detection using Decision Tree. Int. J. Comput. Appl. 2017, 161, 6–9. [Google Scholar] [CrossRef]
- Ravisankar, P.; Ravi, V.; Rao, G.R.; Bose, I. Detection of financial statement fraud and feature selection using data mining techniques. Decis. Support Syst. 2011, 50, 491–500. [Google Scholar] [CrossRef]
- Marchal, S.; Szyller, S. Detecting organized ecommerce fraud using scalable categorical clustering. In Proceedings of the 35th Annual Computer Security Applications Conference, San Juan, PR, USA, 9–13 December 2019; pp. 215–228. [Google Scholar]
- Revathi, S.; Malathi, A. A detailed analysis on nsl-kdd dataset using various machine learning techniques for intrusion detection. Int. J. Eng. Res. Technol. 2013, 2, 1848–1853. [Google Scholar]
- Moustafa, N.; Slay, J. Unsw-nb15: A comprehensive data set for network intrusion detection systems. In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar]
- Creditcard Fraud Dataset. Available online: https://www.kaggle.com/mlg-ulb/creditcardfraud (accessed on 23 November 2021).
- Kashef, R. A boosted SVM classifier trained by incremental learning and decremental unlearning approach. Expert Syst. Appl. 2021, 167, 114154. [Google Scholar] [CrossRef]
- Nawara, D.; Kashef, R. IoT-based Recommendation Systems–An Overview. In Proceedings of the 2020 IEEE International IOT, Electronics and Mechatronics Conference (IEMTRONICS), Vancouver, BC, Canada, 9–12 September 2020; pp. 1–7. [Google Scholar]
- Kashef, R.F. Ensemble-Based Anomaly Detetction using Cooperative Learning. In KDD 2017 Workshop on Anomaly Detection in Finance; PMLR: Halifax, Canada, 2018; pp. 43–55. [Google Scholar]
- Close, L.; Kashef, R. Combining Artificial Immune System and Clustering Analysis: A Stock Market Anomaly Detection Model. J. Intell. Learn. Syst. Appl. 2020, 12, 83–108. [Google Scholar] [CrossRef]
- Kashef, R. Enhancing the Role of Large-Scale Recommendation Systems in the IoT Context. IEEE Access 2020, 8, 178248–178257. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Method | Application | Dataset | Evaluation Metric | Limitation |
|---|---|---|---|---|---|
| [23] | Semi-Supervised ML (Latent Variable Model) | Recommender Systems (Sequential Attack) | MovieLens, BookCrossing, LastFM | Area under the curve | The accuracy of the proposed method is not shown |
| [24] | Various Supervised ML | Intrusion Detection System for Smart Homes | Network activity data | F-measure, precision, and recall | Overall accuracy is not measured |
| [25] | Cognitive Machine Learning | Cyberattack Detection in Healthcare | Information from a trusted device | Prediction ratio, accuracy, communication cost, delay, and efficiency | Evaluation methods were not clear |
| [26] | Artificial Neural Network | Cyberattack Detection for Smart Cities | UNSW NB15 | Accuracy, recall, precision, and F1 score | Methodology used on a partial dataset |
| [27] | Machine Learning | Cyberattack Detection for Multisource Applications | MSRWCS | Accuracy | Not enough validation metrics |
| [28] | Machine Learning (Fuzzy Clustering) | Cyberattacks on IoT Networks | UNSW-NB15 | Classification rate | Not enough validation metrics |
| [29] | Semi-Supervised Algorithm | Detecting Attacks in IoT Systems with Distributed Security | NSL-KDD | Accuracy, PPV, sensitivity | No testing on real-world data |
| Ref. | Method | Application | Dataset | Evaluation Metric | Limitation |
|---|---|---|---|---|---|
| [30] | Two-Level Decision Tree-Based Deep Representation Learning and Deep Neural Network | Cyberattack detection and attribution in gas pipeline and water treatment systems | SWaT and Mississippi State University Gas Pipeline Data | Accuracy, recall, precision, and F-score | High computational cost |
| [31] | Convolutional Neural Network (CNN) | Multi-Classifier Intrusion Detection System (MCIDS) | UNSW-NB15 | Accuracy and false positives | No evaluation data shown |
| [32] | Fibonacci p-Sequence and Key-Based Numeric Sequence | Tampered data detection in water distribution system | NSL-KDD | Accuracy, precision, recall, and F1 measure | No information about the shallow model |
| [33] | Deep Learning Model | Attack detection in social IoT | NSL-KDD | Precision, recall, F1 score, and F2 score | Data are limited to a single region |
| [34] | Systemic Neural Network with Autoencoder as Feature Extractor | Cyberattack detection for cloud dew computing in automotive IoT | NSL-KDD | Accuracy | Not enough validation metrics |
| [35] | Correlated Set Thresholding on Gain Ratio (CST-GR) | Lightweight intrusion detection in IoT systems | BoT-IoT | Accuracy and processing time | Can only detect three kinds of attacks |
| [36] | Convolutional Neural Networks (CNNs) | Intrusion detection and classification in IoT environment | NSL-KDD | K-fold cross-validation, TP, TN, FP, and FN | No testing results in real-world applications |
| Ref. | Method | Application | Dataset | Evaluation Metric | Metric Value | Limitation |
|---|---|---|---|---|---|---|
| [37] | Logistic Regression and k-Fold Machine Learning | Fraud prediction in IoT smart societal environments | 2015 European Data | Accuracy, recall mean, and recall score | (%97.0), (%61.90), (%96.11) | High computational cost |
| [38] | Two-Tier Dimension Reduction and Classification Model | Anomaly detection in financial IoT environments | NSL-KDD dataset | Detection rate and false alarm rate | (%84.86), (%4.86) | Prone to missing information |
| [39] | Machine Learning and Artificial Neural Networks Model | Fraud detection in financial IoT environments | Real transaction data in IoT environment in Korea | F-measure | (%74.75) | Not enough validation metrics |
| [40] | Node2vec | Fraud detection in telecommunications | Fraud samples obtained from a large Chinese provider | Precision, recall, F1-score, and F2-score | (%75), (%65), (%70), (%68) | Data are limited to a single region |
| [41] | CNN | Fraud detection in credit cards | Real-time credit card fraud data | Accuracy | (%96.9) | Not enough validation metrics |
| [42] | Self-Organized Map | Fraud detection in credit cards | Single credit card data | NA | No performance evaluation | |
| [43,44] | Decision Tree Model | Fraud detection in credit cards | Single credit card data | NA | No performance evaluation | |
| [45] | Clustering | Fraud detection in e-commerce | Real-world orders placed on an e-commerce website | Recall, precision, and FPR | (%26.4), (%35.3), (%0.1) | Falsely classifies cancelled orders |
| Model | Accuracy | Precision | Sensitivity | Specificity | F1 Score | Training Time (Second) |
|---|---|---|---|---|---|---|
| Ensemble Stacking (Poor) | 0.934959 | 0.968504 | 0.911111 | 0.963964 | 0.938931 | 8.42 |
| Extra Trees Classifier | 0.906504 | 1.000000 | 0.82963 | 1.000000 | 0.906883 | 8.34 |
| Decision Tree Classifier | 0.886179 | 0.879433 | 0.918519 | 0.846847 | 0.898551 | 0.19 |
| Gaussian NB | 0.914634 | 0.983051 | 0.859259 | 0.981982 | 0.916996 | 0.05 |
| Ensemble Stacking (Strong) | 0.930894 | 0.968254 | 0.903704 | 0.963964 | 0.934866 | 21.71 |
| Random Forest Classifier | 0.922764 | 0.991525 | 0.866667 | 0.990991 | 0.924901 | 3.06 |
| MLP Classifier | 0.934959 | 0.96124 | 0.918519 | 0.954955 | 0.939394 | 11.86 |
| XGB Classifier | 0.922764 | 0.946154 | 0.911111 | 0.936937 | 0.928302 | 1.37 |
| Gradient Boosting Classifier | 0.918699 | 0.952756 | 0.896296 | 0.945946 | 0.923664 | 2.1 |
| Model | Accuracy | Precision | Sensitivity | Specificity | F1 Score | Training Time (Second) |
|---|---|---|---|---|---|---|
| Ensemble Stacking (Poor) | 0.812819 | 0.804843 | 0.884194 | 0.719406 | 0.842655 | 37.95 |
| Random Forest Classifier | 0.778665 | 0.877789 | 0.708138 | 0.870968 | 0.783889 | 4.5 |
| Extra Trees Classifier | 0.74562 | 0.965017 | 0.571987 | 0.972862 | 0.718251 | 14.33 |
| Gaussian NB | 0.512752 | 0.542305 | 0.900235 | 0.005632 | 0.676864 | 0.89 |
| Ensemble Stacking (Strong) | 0.791306 | 0.965497 | 0.655859 | 0.969215 | 0.781112 | 273.84 |
| Decision Tree Classifier | 0.779774 | 0.966092 | 0.634375 | 0.970754 | 0.765857 | 1.32 |
| Ada Boost Classifier | 0.770016 | 0.932916 | 0.641016 | 0.939456 | 0.759898 | 90.96 |
| Gradient Boosting Classifier | 0.772233 | 0.962583 | 0.623047 | 0.968189 | 0.756462 | 12.46 |
| Model | Accuracy | Precision | Sensitivity | Specificity | F1 Score | Training Time (Second) |
|---|---|---|---|---|---|---|
| Ensemble Stacking (Poor) | 0.776215 | 0.969723 | 0.626432 | 0.974153 | 0.761161 | 849.76 |
| Random Forest Classifier | 0.766723 | 0.968225 | 0.610224 | 0.973535 | 0.748626 | 22.14 |
| Extra Trees Classifier | 0.730216 | 0.973223 | 0.540949 | 0.980332 | 0.695382 | 67.65 |
| Gaussian NB | 0.450319 | 0.936634 | 0.036858 | 0.996705 | 0.070925 | 0.61 |
| Ensemble Stacking (Strong) | 0.78349 | 0.960398 | 0.646303 | 0.964782 | 0.772649 | 1669.04 |
| Decision Tree Classifier | 0.78868 | 0.969948 | 0.648874 | 0.973432 | 0.77757 | 8.71 |
| XGB Classifier | 0.794668 | 0.969659 | 0.659939 | 0.972711 | 0.785367 | 112.53 |
| Random Forest Classifier | 0.769029 | 0.968543 | 0.614198 | 0.973638 | 0.751705 | 84.79 |
| Model | Accuracy | Precision | Sensitivity | Specificity | F1 Score | Training Time (Second) |
|---|---|---|---|---|---|---|
| Ensemble Stacking (Poor) | 0.951536 | 0.964738 | 0.959357 | 0.937624 | 0.96204 | 565.65 |
| Random Forest Classifier | 0.951521 | 0.964737 | 0.959333 | 0.937624 | 0.962027 | 69.65 |
| Extra Trees Classifier | 0.87291 | 0.836791 | 0.995659 | 0.65456 | 0.909339 | 94.49 |
| Gaussian NB | 0.634471 | 0.919672 | 0.470039 | 0.926969 | 0.622117 | 1.39 |
| Ensemble Stacking (Strong) | 0.95062 | 0.963758 | 0.95892 | 0.935855 | 0.961333 | 690.82 |
| Random Forest Classifier | 0.951722 | 0.964476 | 0.959939 | 0.937106 | 0.962202 | 155.37 |
| XGB Classifier | 0.933032 | 0.943711 | 0.952179 | 0.898973 | 0.947926 | 108.76 |
| Decision Tree Classifier | 0.93741 | 0.952274 | 0.949827 | 0.915322 | 0.951049 | 12.82 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Soleymanzadeh, R.; Aljasim, M.; Qadeer, M.W.; Kashef, R. Cyberattack and Fraud Detection Using Ensemble Stacking. AI 2022, 3, 22-36. https://doi.org/10.3390/ai3010002
Soleymanzadeh R, Aljasim M, Qadeer MW, Kashef R. Cyberattack and Fraud Detection Using Ensemble Stacking. AI. 2022; 3(1):22-36. https://doi.org/10.3390/ai3010002
Chicago/Turabian StyleSoleymanzadeh, Raha, Mustafa Aljasim, Muhammad Waseem Qadeer, and Rasha Kashef. 2022. "Cyberattack and Fraud Detection Using Ensemble Stacking" AI 3, no. 1: 22-36. https://doi.org/10.3390/ai3010002
APA StyleSoleymanzadeh, R., Aljasim, M., Qadeer, M. W., & Kashef, R. (2022). Cyberattack and Fraud Detection Using Ensemble Stacking. AI, 3(1), 22-36. https://doi.org/10.3390/ai3010002