Deep Learning Models for Automatic Makeup Detection

Abstract
:1. Introduction
2. Related Work
3. Materials and Method
3.1. Materials
3.2. Method
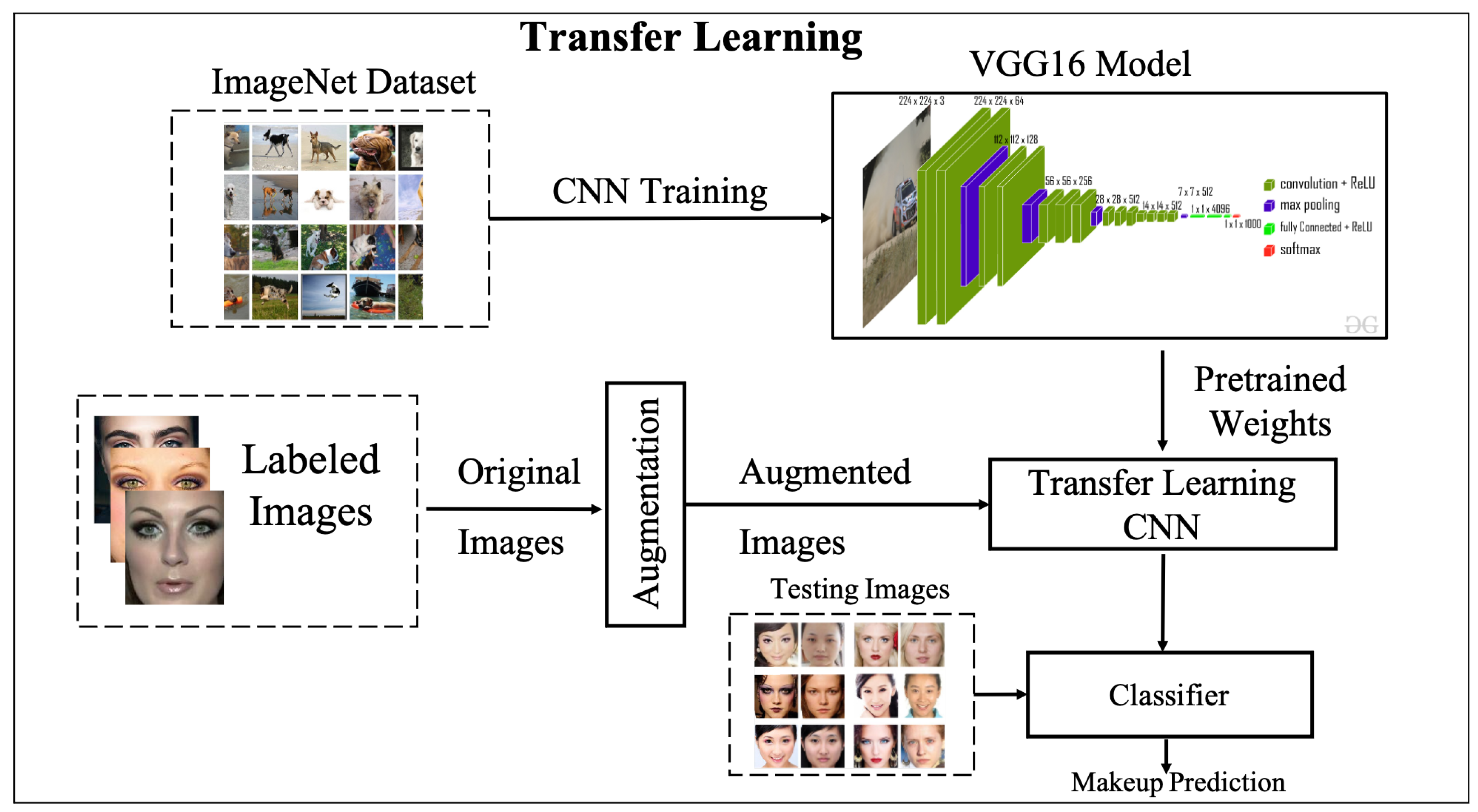
- 1
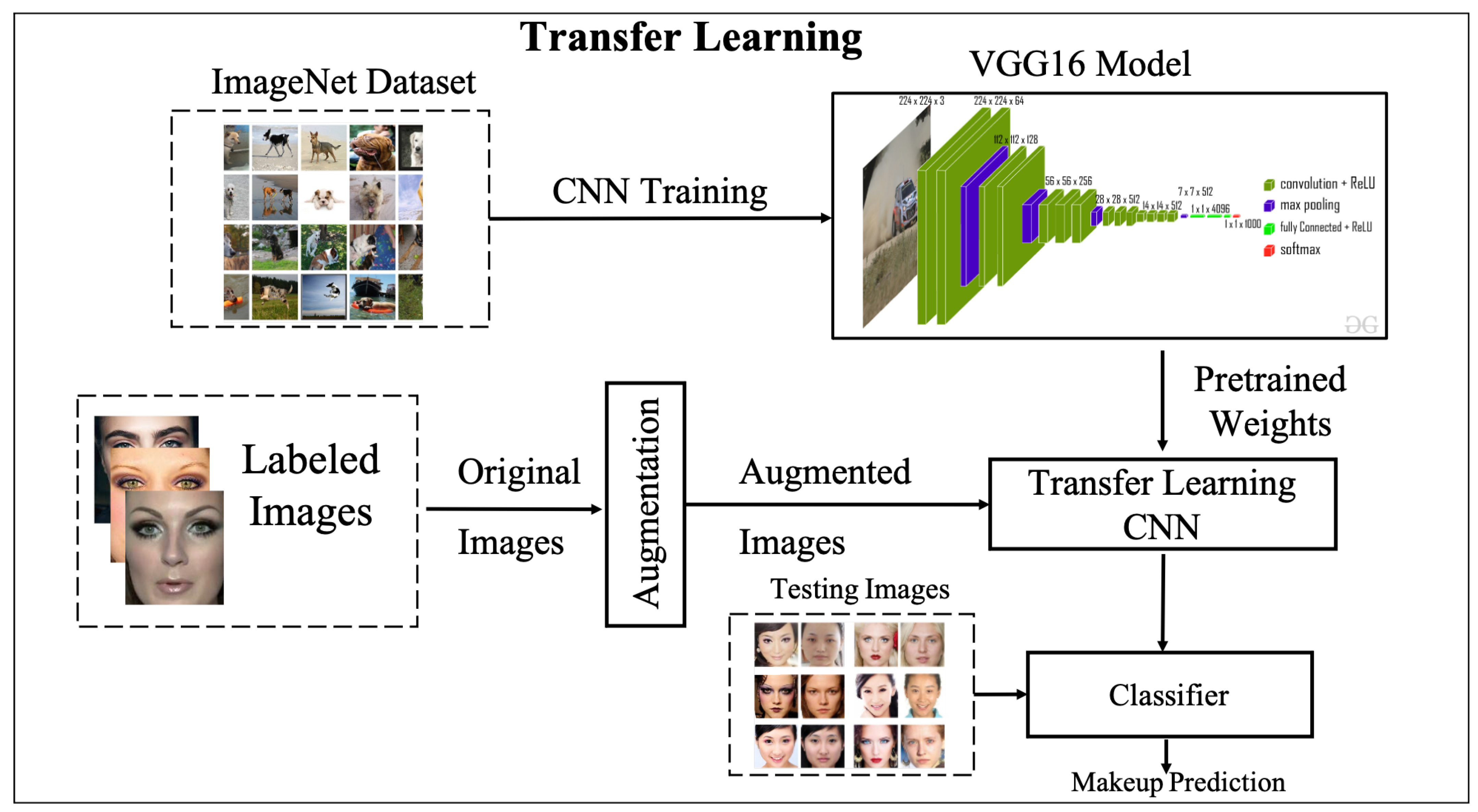
- Supervised Transfer Learning of Pre-trained VGG16 CNN: pre-trained VGG16 network [42] is fine-tuned on labelled data to extract the facial features and produce a makeup classifier (absence or presence of makeup).
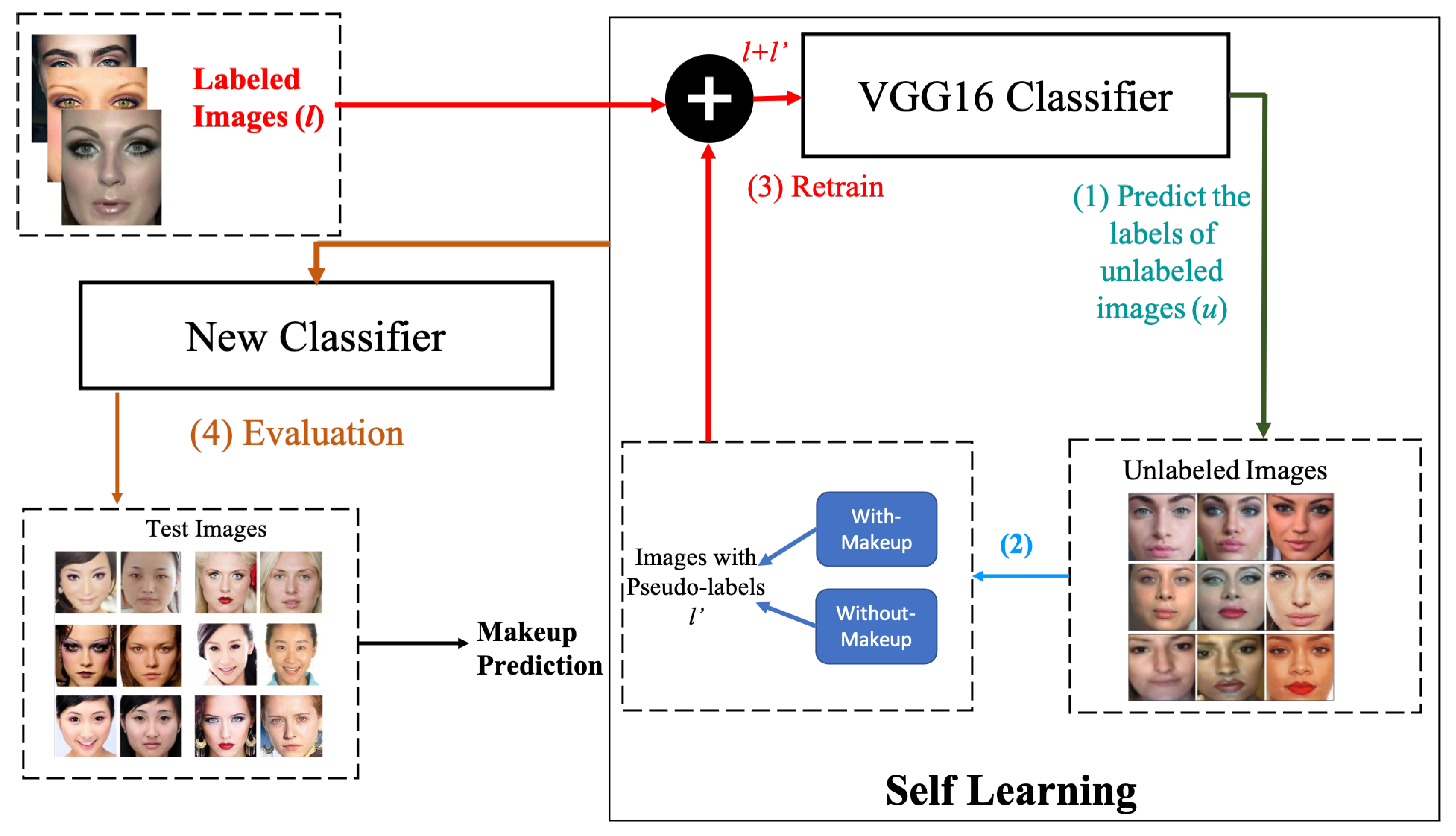
- 2
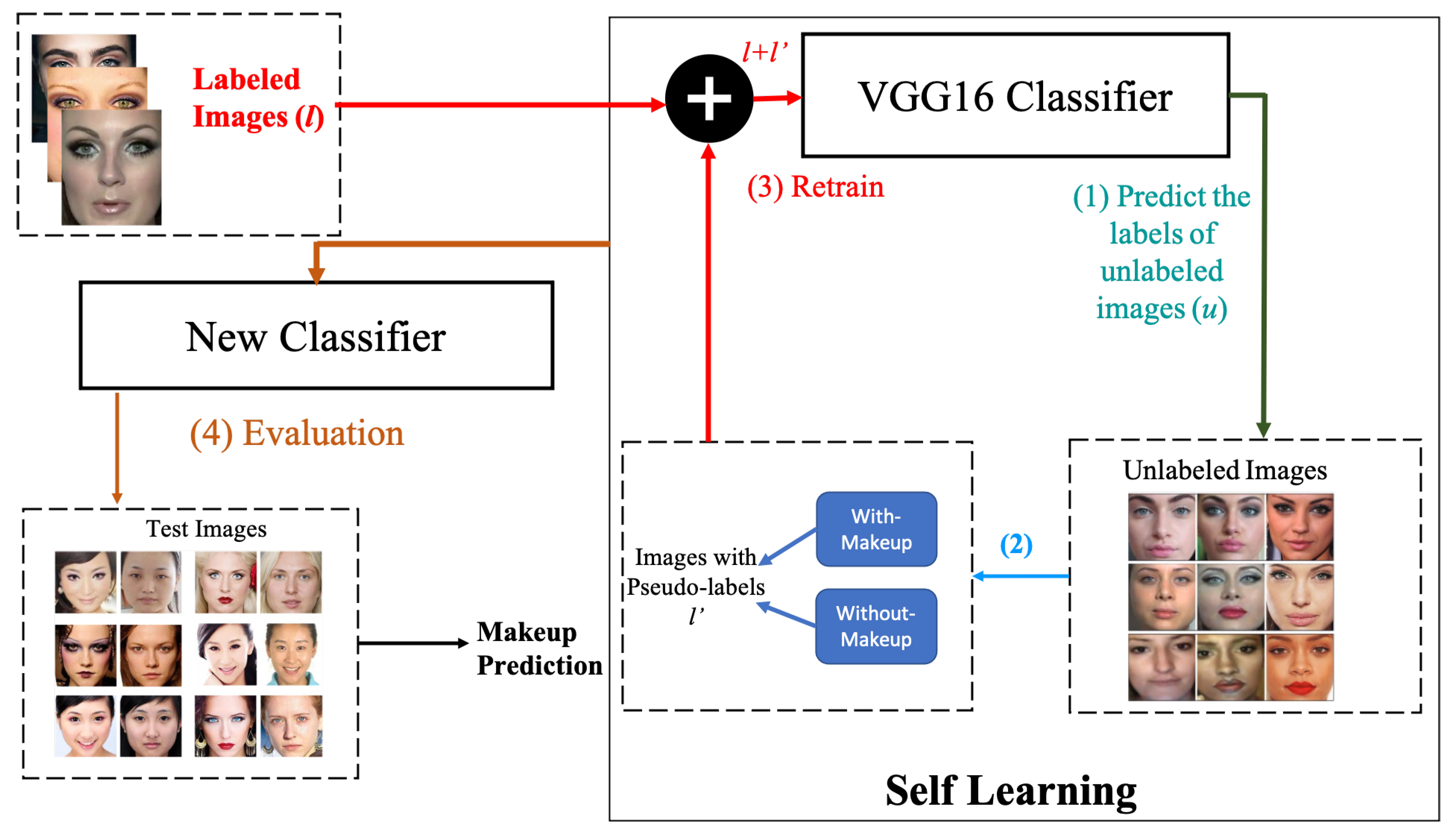
- Semi-Supervised CNN with Self-Learning: the fine-tuned VGG16 network resulting from the previous stage can be combined with a self-learning algorithm developed in [23] which is trained on unlabelled data to produce a semi-supervised learning scheme.
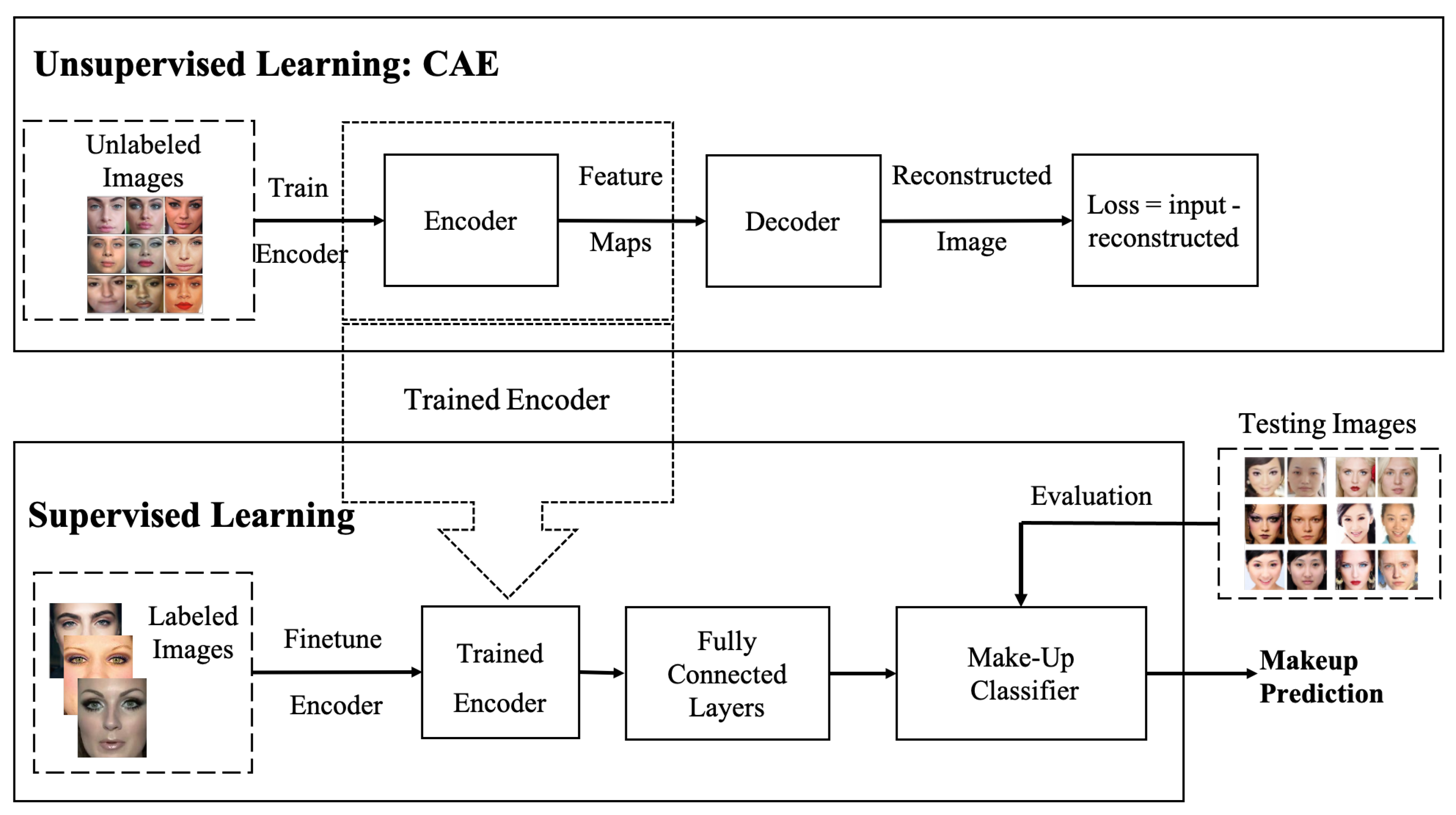
- 3
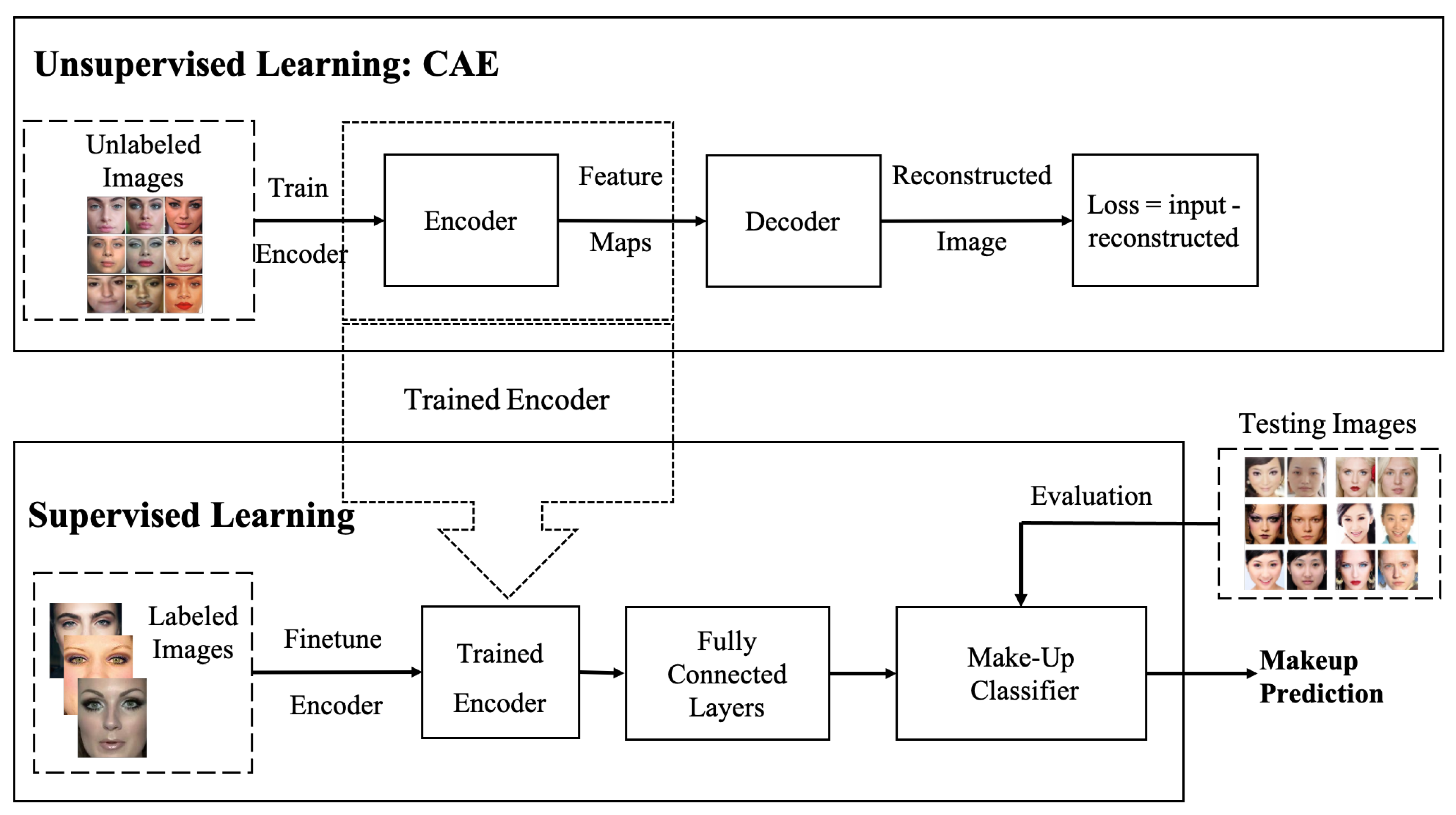
- Semi-supervised CNN with Convolutional Auto-encoder (CAE): in this model, CAE [20] is used to extract the salient visual features in an unsupervised learning manner using the unlabelled makeup data. The trained CAE is then used for initialising the weights of supervised CNN. Whereas the weights of fully connected layers are trained using the labelled data.
3.2.1. Supervised Learning with Pre-Trained CNN
- 1
- Re-training the entire pre-trained CNN architecture on the target dataset, yet avoiding the random weight initialisation by starting from the pre-trained weight values.
- 2
- Training the new classifier (fully connected layers) related to the target task and freezing the other layers (convolutional and all other layers). In this transfer learning strategy, the pre-trained CNN works as a feature extractor where the weights of the CNN layers, except fully connected layers, are retained without change.
- 3
- Training some of the convolutional layers, especially the top layers of CNN, and the classifier (fully connected layers). The original weights are exploited as a starting point for learning.
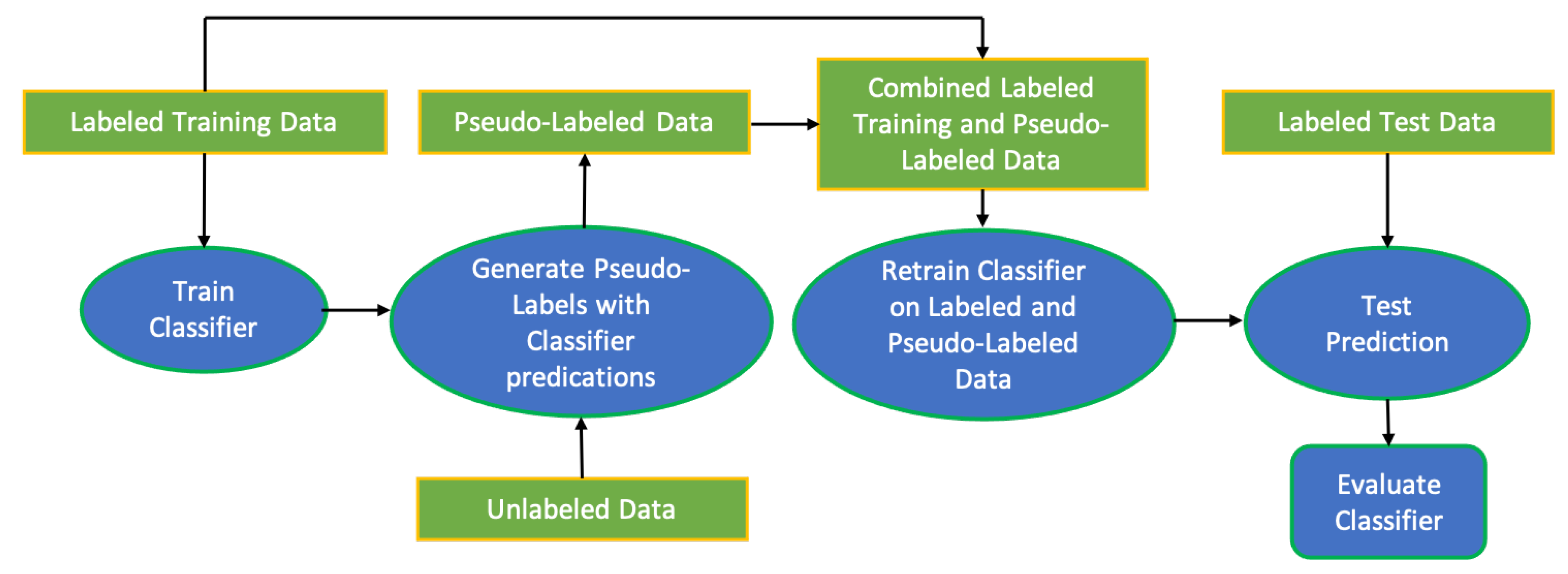
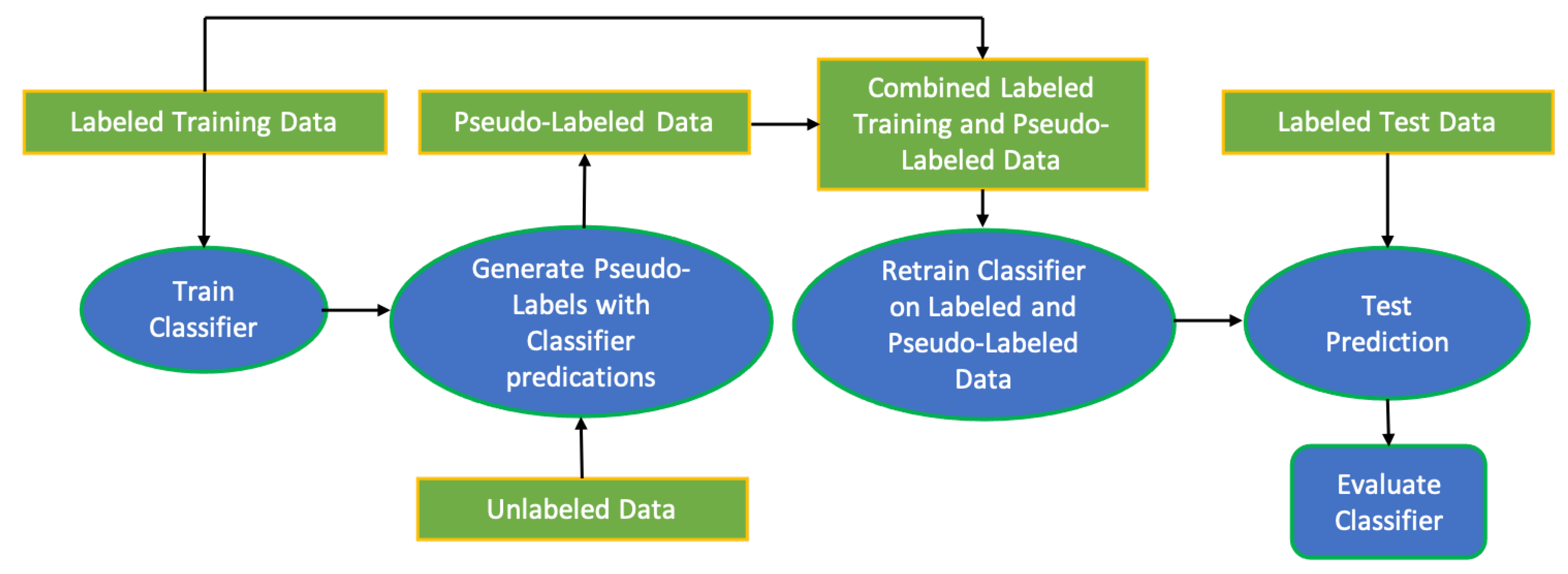
3.2.2. Semi-Supervised Learning with Self-Learning Pseudo-Labelling
- 1
- The pre-trained VGG16 is used to predict the labels of the unlabelled images u.
- 2
- The prediction scores with highest confidence rates ( pseudo-labels) obtained from applying VGG16 model are selected and combined with label images l.
- 3
- The combined pseudo-label images and labelled images are then used to train the classifier. The loss function can be represented as .
3.2.3. Semi-Supervised Learning with Convolutional Auto-Encoder
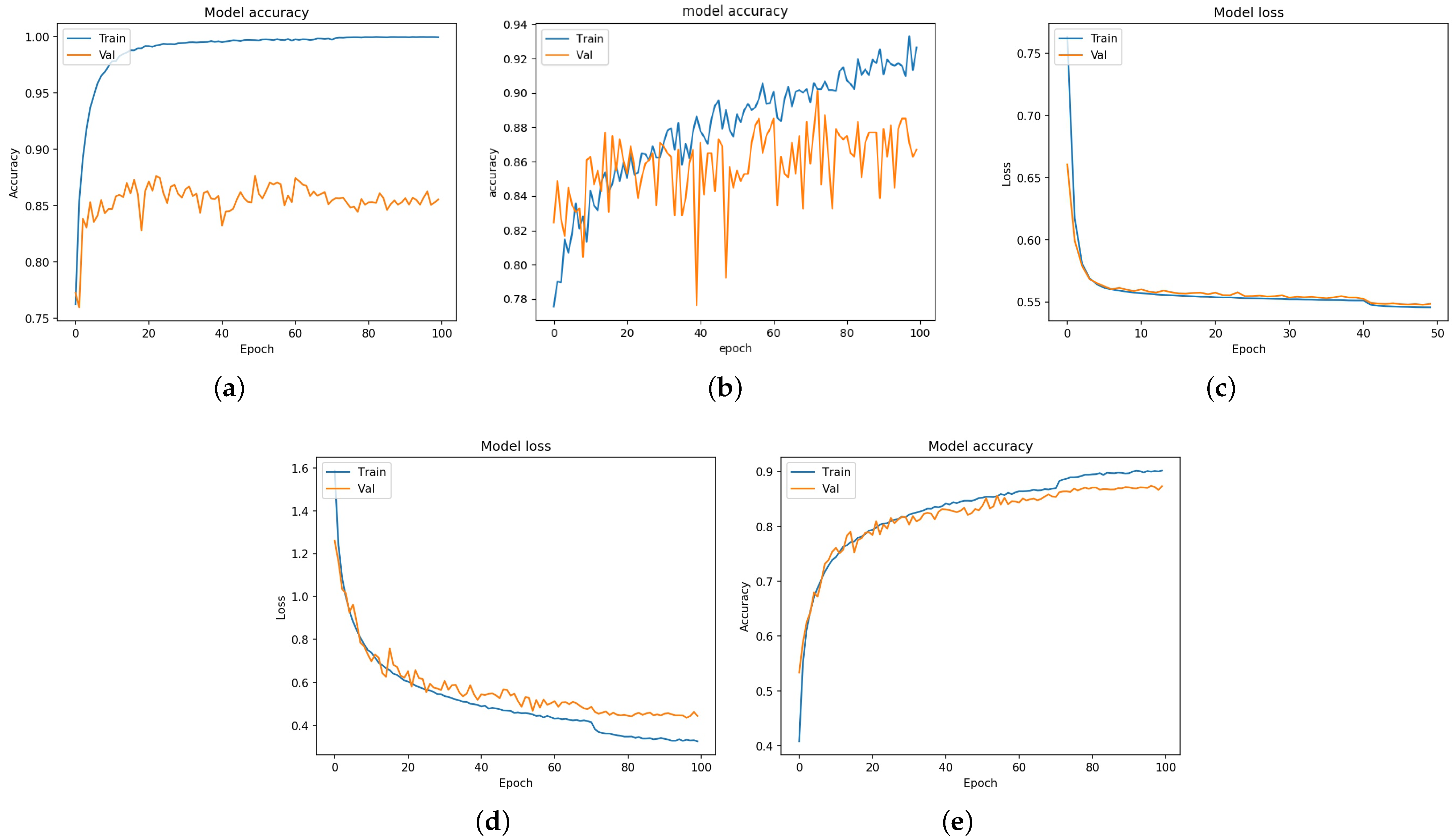
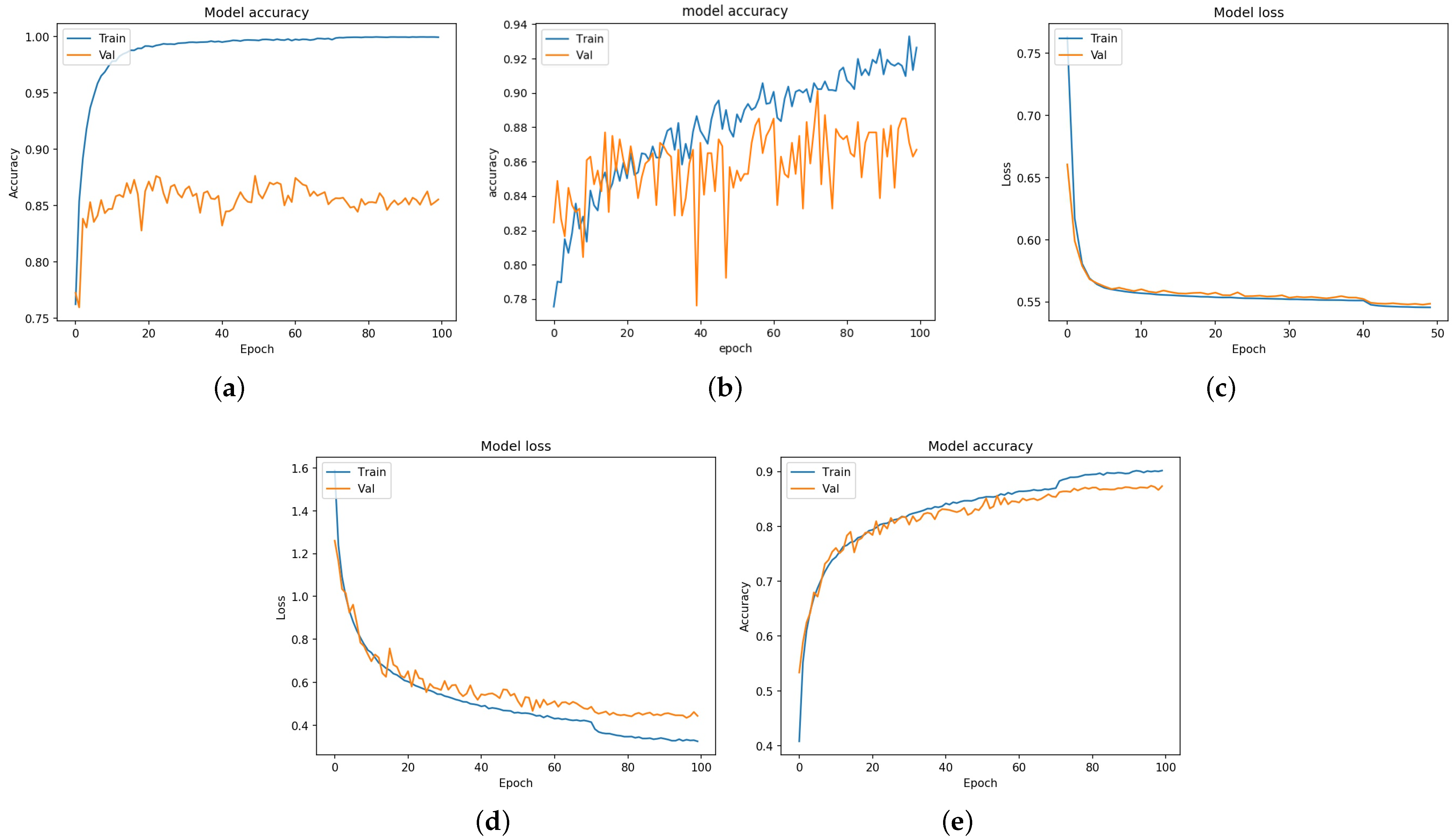
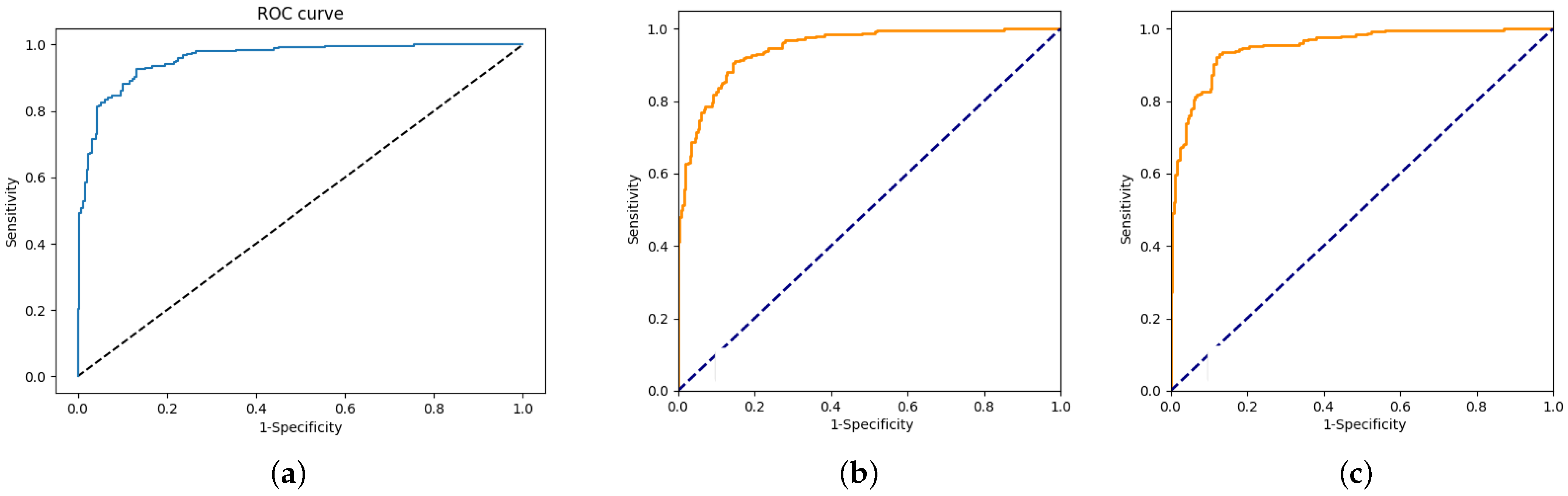
4. Experimental Results and Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| DL | Deep Learning |
| CNN | Convolutional Neural Networks |
| YMU | YouTube Makeup |
| VMU | Virtual Makeup |
| MIW | Makeup in the Wild |
| MIFS | Makeup Induced Face Spoofing |
| FAM | FAce Makeup |
| CAE | Convolutioanl Auto-Encoder |
References
- Guéguen, N. The effects of women’s cosmetics on men’s courtship behaviour. N. Am. J. Psychol. 2008, 10, 221–228. [Google Scholar]
- Dantcheva, A.; Dugelay, J. Female facial aesthetics based on soft biometrics and photo-quality. In Proceedings of the 2011 IEEE International Conference on Multimedia and Expo (ICME’11), Washington, DC, USA, 11–15 July 2011; Volume 2. [Google Scholar]
- Liu, X.; Li, T.; Peng, H.; Chuoying Ouyang, I.; Kim, T.; Wang, R. Understanding beauty via deep facial features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 246–256. [Google Scholar]
- Guo, G.; Wen, L.; Yan, S. Face authentication with makeup changes. IEEE Trans. Circuits Syst. Video Technol. 2013, 24, 814–825. [Google Scholar]
- Wang, S.; Fu, Y. Face behind makeup. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Rathgeb, C.; Dantcheva, A.; Busch, C. Impact and detection of facial beautification in face recognition: An overview. IEEE Access 2019, 7, 152667–152678. [Google Scholar] [CrossRef]
- Rathgeb, C.; Satnoianu, C.I.; Haryanto, N.; Bernardo, K.; Busch, C. Differential detection of facial retouching: A multi-biometric approach. IEEE Access 2020, 8, 106373–106385. [Google Scholar] [CrossRef]
- Sajid, M.; Ali, N.; Dar, S.H.; Iqbal Ratyal, N.; Butt, A.R.; Zafar, B.; Shafique, T.; Baig, M.J.A.; Riaz, I.; Baig, S. Data augmentation-assisted makeup-invariant face recognition. Math. Probl. Eng. 2018, 2018, 2850632. [Google Scholar] [CrossRef]
- Dong, X.; Yan, Y.; Ouyang, W.; Yang, Y. Style aggregated network for facial landmark detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 379–388. [Google Scholar]
- Li, Y.; Song, L.; Wu, X.; He, R.; Tan, T. Anti-makeup: Learning a bi-level adversarial network for makeup-invariant face verification. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Li, Y.; Song, L.; Wu, X.; He, R.; Tan, T. Learning a bi-level adversarial network with global and local perception for makeup-invariant face verification. Pattern Recognit. 2019, 90, 99–108. [Google Scholar] [CrossRef]
- Shen, X. Facebook and Huawei Are the Latest Companies Trying to Fool Facial Recognition. 2019. Available online: https://www.scmp.com/abacus/tech/article/3035451/facebook-and-huawei-are-latest-companies-trying-fool-facial-recognition (accessed on 27 September 2021).
- Valenti, L. Can Makeup Be an Anti-Surveillance Tool? 2020. Available online: https://www.vogue.com/article/anti-surveillance-makeup-cv-dazzle-protest (accessed on 27 September 2021).
- Valenti, L. Yes, There Is a Way to Outsmart Facial Recognition Technology—And It Comes Down to Your Makeup. 2018. Available online: https://www.vogue.com/article/computer-vision-dazzle-anti-surveillance-facial-recognition-technology-moma-ps1 (accessed on 27 September 2021).
- Gafni, O.; Wolf, L.; Taigman, Y. Live face de-identification in video. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27–28 October 2019; pp. 9378–9387. [Google Scholar]
- Alzahrani, T.; Al-Nuaimy, W. Face segmentation based object localisation with deep learning from unconstrained images. In Proceedings of the 10th International Conference on Pattern Recognition Systems (ICPRS-2019), Tours, France, 8–10 July 2019. [Google Scholar]
- Alzahrani, T.; Al-Nuaimy, W.; Al-Bander, B. Hybrid feature learning and engineering based approach for face shape classification. In Proceedings of the 2019 International Conference on Intelligent Systems and Advanced Computing Sciences (ISACS), Taza, Morocco, 26–27 December 2019; pp. 1–4. [Google Scholar]
- Alzahrani, T.; Al-Nuaimy, W.; Al-Bander, B. Integrated Multi-Model Face Shape and Eye Attributes Identification for Hair Style and Eyelashes Recommendation. Computation 2021, 9, 54. [Google Scholar] [CrossRef]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.A. Extracting and composing robust features with denoising autoencoders. In Proceedings of the 25th International Conference on Machine Learning, New York, NY, USA, 5–9 July 2008; pp. 1096–1103. [Google Scholar]
- Masci, J.; Meier, U.; Cireşan, D.; Schmidhuber, J. Stacked convolutional auto-encoders for hierarchical feature extraction. In Proceedings of the International Conference on Artificial Neural Networks, Espoo, Finland, 14–17 June 2011; pp. 52–59. [Google Scholar]
- Kingma, D.P.; Mohamed, S.; Jimenez Rezende, D.; Welling, M. Semi-supervised learning with deep generative models. Adv. Neural Inf. Process. Syst. 2014, 27, 3581–3589. [Google Scholar]
- Odena, A. Semi-supervised learning with generative adversarial networks. arXiv 2016, arXiv:1606.01583. [Google Scholar]
- Lee, D.H. Pseudo-label: The simple and efficient semi-supervised learning method for deep neural networks. In Proceedings of the Workshop on Challenges in Representation Learning, ICML, Daegu, Korea, 3–7 November 2013; Volume 3. [Google Scholar]
- Dantcheva, A.; Chen, C.; Ross, A. Can facial cosmetics affect the matching accuracy of face recognition systems? In Proceedings of the 2012 IEEE Fifth International Conference on Biometrics: Theory, Applications and Systems (BTAS), Arlington, VA, USA, 23–27 September 2012; pp. 391–398. [Google Scholar]
- Chen, C.; Dantcheva, A.; Ross, A. Automatic facial makeup detection with application in face recognition. In Proceedings of the 2013 International Conference on Biometrics (ICB), Madrid, Spain, 4–7 June 2013; pp. 1–8. [Google Scholar]
- Hu, J.; Ge, Y.; Lu, J.; Feng, X. Makeup-robust face verification. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 2342–2346. [Google Scholar]
- Dantcheva, A.; Dugelay, J.L. Assessment of female facial beauty based on anthropometric, non-permanent and acquisition characteristics. Multimed. Tools Appl. 2015, 74, 11331–11355. [Google Scholar] [CrossRef]
- Bharati, A.; Singh, R.; Vatsa, M.; Bowyer, K.W. Detecting facial retouching using supervised deep learning. IEEE Trans. Inf. Forensics Secur. 2016, 11, 1903–1913. [Google Scholar] [CrossRef]
- Kamil, I.A.; Are, A.S. Makeup-invariant face identification and verification using fisher linear discriminant analysis-based Gabor filter bank and histogram of oriented gradients. Int. J. Signal Imaging Syst. Eng. 2017, 10, 257–270. [Google Scholar] [CrossRef]
- Fu, Y.; Shuyang, W. System for Beauty, Cosmetic, and Fashion Analysis. U.S. Patent 10,339,685, 2 July 2019. Available online: https://patents.google.com/patent/US20170076474A1/en (accessed on 13 October 2021).
- Li, M.; Li, Y.; He, Y. Makeup Removal System with Deep Learning; Technical Report, CS230 Deep Learning; Stanford University: Stanford, CA, USA, 2018. [Google Scholar]
- Rathgeb, C.; Drozdowski, P.; Fischer, D.; Busch, C. Vulnerability assessment and detection of makeup presentation attacks. In Proceedings of the 2020 8th International Workshop on Biometrics and Forensics (IWBF), Porto, Portugal, 29–30 April 2020; pp. 1–6. [Google Scholar]
- Rathgeb, C.; Botaljov, A.; Stockhardt, F.; Isadskiy, S.; Debiasi, L.; Uhl, A.; Busch, C. PRNU-based detection of facial retouching. IET Biom. 2020, 9, 154–164. [Google Scholar] [CrossRef]
- Rathgeb, C.; Drozdowski, P.; Busch, C. Makeup Presentation Attacks: Review and Detection Performance Benchmark. IEEE Access 2020, 8, 224958–224973. [Google Scholar] [CrossRef]
- Fu, Y.; Guo, G.; Huang, T.S. Age synthesis and estimation via faces: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1955–1976. [Google Scholar] [PubMed]
- Kotwal, K.; Mostaani, Z.; Marcel, S. Detection of age-induced makeup attacks on face recognition systems using multi-layer deep features. IEEE Trans. Biom. Behav. Identity Sci. 2019, 2, 15–25. [Google Scholar] [CrossRef]
- Kaggle. Makeup or No Makeup. 2018. Available online: https://www.kaggle.com/petersunga/make-up-vs-no-make-up (accessed on 1 November 2020).
- Chen, C.; Dantcheva, A.; Ross, A. An ensemble of patch-based subspaces for makeup-robust face recognition. Inf. Fusion 2016, 32, 80–92. [Google Scholar] [CrossRef]
- Chen, C.; Dantcheva, A.; Swearingen, T.; Ross, A. Spoofing faces using makeup: An investigative study. In Proceedings of the 2017 IEEE International Conference on Identity, Security and Behavior Analysis (ISBA), New Delhi, India, 22–24 February 2017; pp. 1–8. [Google Scholar]
- NIST. Face Recognition Grand Challenge (FRGC). 2018. Available online: http://www.nist.gov/itl/iad/ig/frgc.cfm (accessed on 1 November 2020).
- Taaz. TAAZ Makeover Technology. Available online: http://www.taaz.com/ (accessed on 1 November 2020).
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Torrey, L.; Shavlik, J. Transfer learning. In Handbook of Research on Machine Learning Applications and Trends: Algorithms, Methods, and Techniques; IGI Global: Pennsylvania, PA, USA, 2010; pp. 242–264. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Bengio, Y.; Lamblin, P.; Popovici, D.; Larochelle, H. Greedy layer-wise training of deep networks. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007; pp. 153–160. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the International Conference on Computer Vision & Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer (Type) | Output Shape | #Param |
|---|---|---|
| input-1(InputLayer) | (128, 128, 3) | 0 |
| conv-1(Conv2D) | (128, 128, 32) | 896 |
| batchnormalisation | (128, 128, 32) | 128 |
| conv-1-2 (Conv2D) | (128, 128, 32) | 9248 |
| batchnormalisation-1 | (128, 128, 32) | 128 |
| pool-1(MaxPooling2D) | (64, 64, 32) | 0 |
| dropout(Dropout) | (64, 64, 32) | 0 |
| conv-2(Conv2D) | (64, 64, 64) | 18,496 |
| batchnormalisation-2 | (64, 64, 64) | 256 |
| conv-2-2(Conv2D) | (64, 64, 64) | 36,928 |
| batchnormalisation-3 | (64, 64, 64) | 256 |
| pool-2(MaxPooling2D) | (32, 32, 64) | 0 |
| dropout1(Dropout) | (32, 32, 64) | 0 |
| conv-3(Conv2D) | (32, 32, 128) | 73,856 |
| batchnormalisation-4 | (32, 32, 128) | 512 |
| conv-3-2(Conv2D) | (32, 32, 128) | 147,584 |
| batchnormalisation-5 | (32, 32, 128) | 512 |
| pool-3(MaxPooling2D) | (16, 16, 128) | 0 |
| dropout-2(Dropout) | (16, 16, 128) | 0 |
| conv-4(Conv2D) | (16, 16, 256) | 295,168 |
| batchnormalisation-6 | (16, 16, 256) | 1024 |
| conv-4-2(Conv2D) | (16, 16, 256) | 590,080 |
| batchnormalisation-7 | (16, 16, 256) | 1024 |
| pool-4(MaxPooling2D) | (8, 8, 256) | 0 |
| dropout-3(Dropout) | (8, 8, 256) | 0 |
| flatten(Flatten) | (, 16,384) | 0 |
| latent-feats(Dense) | (, 1024) | 16,778,240 |
| reshape(Reshape) | (2, 2, 256) | 0 |
| upsample-4(UpSampling2D) | (4, 4, 256) | 0 |
| upconv-4(Conv2D) | (4, 4, 256) | 590,080 |
| batchnormalisation-8 | (4, 4, 256) | 1024 |
| upconv-4-2(Conv2D) | (4, 4, 256) | 590,080 |
| batchnormalisation-9 | (4, 4, 256) | 1024 |
| upsample-3(UpSampling2D) | (8, 8, 256) | 0 |
| dropout-4(Dropout) | (8, 8, 256) | 0 |
| upconv-3(Conv2D) | (8, 8, 128) | 295,040 |
| batchnormalisation-10 | (8, 8, 128) | 512 |
| upconv-3-2(Conv2D) | (8, 8, 128) | 147,584 |
| batchnormalisation-11 | (8, 8, 128) | 512 |
| upsample-2(UpSampling2D) | (16, 16, 128) | 0 |
| dropout-5(Dropout) | (16, 16, 128) | 0 |
| upconv-2(Conv2D) | (16, 16, 64) | 73,792 |
| batchnormalisation-12 | (16, 16, 64) | 256 |
| upconv-2-2(Conv2D) | (16, 16, 64) | 36,928 |
| batchnormalisation-13 | (16, 16, 64) | 256 |
| upsample-1(UpSampling2D) | (32, 32, 64) | 0 |
| dropout-6(Dropout) | (32, 32, 64) | 0 |
| upconv-1(Conv2D) | (32, 32, 32) | 18,464 |
| batchnormalisation-14 | (32, 32, 32) | 128 |
| upconv-1-2(Conv2D) | (32, 32, 32) | 9248 |
| batchnormalisation-15 | (32, 32, 32) | 128 |
| upconv-final(Conv2D) | (32, 32, 3) | 867 |
| Method | Accuracy | AUROC |
|---|---|---|
| VGG16 CNN | 86.69% | 92.30% |
| CNN with Self-Learning | 87.40% | 94.69% |
| Autoencoder-Classifier | 88.33% | 95.15% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alzahrani, T.; Al-Bander, B.; Al-Nuaimy, W. Deep Learning Models for Automatic Makeup Detection. AI 2021, 2, 497-511. https://doi.org/10.3390/ai2040031
Alzahrani T, Al-Bander B, Al-Nuaimy W. Deep Learning Models for Automatic Makeup Detection. AI. 2021; 2(4):497-511. https://doi.org/10.3390/ai2040031
Chicago/Turabian StyleAlzahrani, Theiab, Baidaa Al-Bander, and Waleed Al-Nuaimy. 2021. "Deep Learning Models for Automatic Makeup Detection" AI 2, no. 4: 497-511. https://doi.org/10.3390/ai2040031
APA StyleAlzahrani, T., Al-Bander, B., & Al-Nuaimy, W. (2021). Deep Learning Models for Automatic Makeup Detection. AI, 2(4), 497-511. https://doi.org/10.3390/ai2040031