Abstract
Automating the analysis of digital microscopic images to identify the cell sub-types or the presence of illness has assumed a great importance since it aids the laborious manual process of review and diagnosis. In this paper, we have focused on the analysis of white blood cells. They are the body’s main defence against infections and diseases and, therefore, their reliable classification is very important. Current systems for leukocyte analysis are mainly dedicated to: counting, sub-types classification, disease detection or classification. Although these tasks seem very different, they share many steps in the analysis process, especially those dedicated to the detection of cells in blood smears. A very accurate detection step gives accurate results in the classification of white blood cells. Conversely, when detection is not accurate, it can adversely affect classification performance. However, it is very common in real-world applications that work on inaccurate or non-accurate regions. Many problems can affect detection results. They can be related to the quality of the blood smear images, e.g., colour and lighting conditions, absence of standards, or even density and presence of overlapping cells. To this end, we performed an in-depth investigation of the above scenario, simulating the regions produced by detection-based systems. We exploit various image descriptors combined with different classifiers, including CNNs, in order to evaluate which is the most suitable in such a scenario, when performing two different tasks: Classification of WBC subtypes and Leukaemia detection. Experimental results have shown that Convolutional Neural Networks are very robust in such a scenario, outperforming common machine learning techniques combined with hand-crafted descriptors. However, when exploiting appropriate images for model training, even simpler approaches can lead to accurate results in both tasks.
1. Introduction
Blood contains three types of cells: platelets or thrombocytes, red blood cells (RBCs) or erythrocytes, and white blood cells (WBCs) or leukocytes. Platelets play an important role in haemostasis, leading to the formation of blood clots when there is an injury to blood vessels or other haemorrhages [1]. Red blood cells are important for the transport of oxygen from the heart to all tissues and carry away carbon dioxide [2]. White blood cells have important functions for the immune system, as they are the body’s main defence against infection and disease [3]. Consequently, their reliable classification is important for recognising their different types and potential diseases. All leukocytes contain a nucleus and can be grouped into two main types, according to the appearance of the structure: granulocytes and agranulocytes. These broader categories can be further subdivided into five subtypes: the first includes basophils, eosinophils and neutrophils, while lymphocytes and monocytes belong to the second [4]. Some examples are shown in Figure 1.
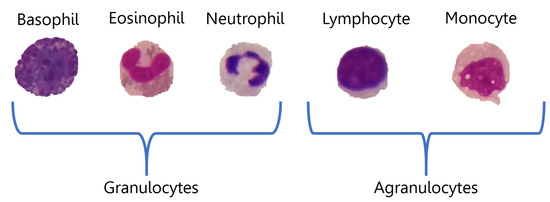
Figure 1.
Representation of the WBC sub-types categorisation.
Haematology is the branch of medicine concerned with the study of the blood and the prevention of blood-related diseases. Many diseases can affect the number and type of blood cells produced, their function and lifespan. Usually, only normal, mature or nearly mature cells are released into the bloodstream, but certain circumstances may cause the bone marrow to release immature or abnormal cells into the circulation. Therefore, several manual visual examinations performed by experienced pathologists are essential to detect or monitor these conditions. Microscopic examination of the peripheral blood smear (PBS) slides by clinical pathologists is considered the gold standard for detecting various disorders [5]. Depending on the disorder being inspected (blood cancer, anaemia, presence of parasites), it may require manual counting of cells, classification of cell types and analysis of their morphological characteristics. The disadvantages of this manual inspection are several. It is time-consuming, repetitive and error-prone, and it is subjective because different operators may produce different interpretations of the same scene. Therefore, to avoid misdiagnosis, an automated procedure is increasingly necessary, especially in emerging countries. Among existing blood diseases, leukaemia is a malignant tumour, which can be further grouped into four main types: Acute Lymphoblastic Leukaemia (ALL), Acute Myeloid Leukaemia (AML), Chronic Lymphocytic Leukaemia (CLL), and Chronic Myeloid Leukaemia (CML) [6]. This disease causes the bone marrow to produce abnormal and undeveloped white blood cells, called blasts or leukaemia cells [7]. Their dark purple appearance makes them distinguishable, although analysis and further treatment can be complex due to their variability in shape and consistency. Indeed, different types of WBCs can differ significantly in shape and size, which is one of the most challenging aspects, even considering that they are surrounded by other blood components such as red blood cells and platelets. To address these problems, several computer-aided diagnosis (CAD) systems have been proposed to automate the described manual tasks using image processing techniques and classical Machine Learning (ML) [8,9,10,11,12], and also Deep Learning (DL) approaches [13,14,15], especially after the proposal of Convolutional Neural Network (CNN) [16,17].
CAD systems for PBS analysis can differ greatly from each other because they deal with different medical problems and focus on different tasks, ranging from simple cell counting to complete cell analysis. Despite these significant differences, they generally consist of the same steps: Image pre-processing, segmentation or detection, feature extraction and classification. Not all CAD systems take advantage of all the steps mentioned. As the images captured by new digital microscopes are of excellent quality, the pre-processing step may not be necessary. Furthermore, methods that focus on cell counting do not need feature extraction and classification. On the contrary, some steps may be present several times to address different issues related to the type of images under investigation. For example, multiple segmentation steps might be performed to identify cells and then separate their components. Other times, segmentation steps are combined with detection steps, especially when it is necessary to identify adjacent or clustered cells [10,12,18] As a general rule, CAD systems for PBS analysis can be grouped into two types: segmentation-based or detection-based. Segmentation-based systems are preferred for fine-grained [19] analysis, e.g., for pathology grading, analysis of various cellular components, checking for inclusions or parasites. Detection-based systems, on the other hand, are preferred for quantitative or coarse-grained analyses, such as cataloguing and counting cells [10,12,18,20]. Nowadays, detection-based methods are often preferred to segmentation-based methods, as the generated Bounding Boxes (BBs) can be directly used as input for modern feature extractors or CNNs [21]. Moreover, a particular type of CNNs, Regional CNNs (R-CNNs), perform both the detection phase, mainly exploiting regional proposals, and the classification phase [22]. In this way, it is possible to filter out all those BBs produced by the regional proposal, whose cataloguing process does not reach a high confidence value. However, this process has two main disadvantages: some relevant BBs can be filtered out due to their low confidence value or, even worse, some inaccurate BBs can reach high confidence but with wrong classifications. In this work, we study how accurate the BBs produced by a detection system must be in order to generate a robust classification model and at the same time correctly classify new bounding boxes, both accurate and inaccurate. To this end, we performed several experiments simulating a real-world application scenario in which a model is trained using near-perfect manually annotated BBs and deployed on automatically generated BBs. In the literature, many works deal with the classification of white blood cells [17,23,24,25,26], also proposing Unsupervised Domain Adaptation methods to address the Domain Shift present between different datasets [27]. However, to the best of our knowledge, no one has ever thoroughly investigated whether and to what extent specific features, such as bounding box size and quality, can be crucial for extracting representative features and creating robust models for WBCs classification.
Motivated by these observations, in this work, we propose an in-depth investigation of the above scenario by simulating the BBs produced by detection-based systems with different quality levels. We exploited different image descriptors combined with different classifiers, including CNNs, to assess which is the most suitable in such a scenario in performing two different tasks: Classification of WBC subtypes and Leukaemia detection.
The contribution of this paper is not to create a classification system that can reach or outperform state-of-the-art methods. It instead consists of evaluating the state of the art methods in a scenario different from standard laboratory tests to provide some valuable suggestions/guidelines for creating real CAD systems. For this purpose in our experiments, we performed a quantitative evaluation to assess the single descriptor/classifier; therefore, we discarded all combinations of descriptors or ensembles of classifiers. The rest of the manuscript is organised as follows. Section 2 discusses related work, in particular recent methods for the classification of white blood cells from microscopic images. In Section 3 we illustrate the used data sets, the methods and the experimental setup. The results are presented and discussed in Section 4, and finally, in Section 5 we draw the conclusions and directions for future works.
2. Related Work
Current CAD systems that perform WBC analysis address several tasks ranging from simple counting to disease detection and classification. Since in this work, we focus on two main tasks: Classification of subtypes of WBCs and detection of ALL, in this section, we describe related work that has addressed these two tasks.
Classification of White Blood Cells sub-types. The classification of WBCs sub-types is one of the most ordered laboratory tests since it allows monitoring the proportion of WBCs into the bloodstream that could be affected by numerous diseases and conditions. Even if the WBCs are easily identifiable inside the PBS, this task is very challenging due to wide variations in cell shape, dimensions and edges [1], which are even higher with the presence of a disease. For this reason, most recent works addressing this task exploited CNN-based systems, being more suited to cope with such variability. The authors in [23] performed a concatenation of pre-trained AlexNet and GoogleNet’s feature vectors by taking their maximum values. Then, they classify lymphocytes, monocytes, eosinophils, and neutrophils with the Support Vector Machine (SVM) strategy. The results are higher than 97% for both data sets investigated. Semerjian et al. [24] proposed a built-in customisable CNN, trained with several WBC templates, extracted from the used data set with a segmentation step. They reached a correlation of 90% in recognising different WBCs. Yao et al. [25] proposed a two-module weighted optimised deformable CNN for WBC classification, achieving the best F1-scores (F1) of 95.7%, 94.5% and 91.6% in testing for low-resolution and noisy undisclosed data sets, and BCCD [28] data set, respectively. Qin et al. [17] realised Cell3Net, a fine-grained leukocyte classification method for microscopic images, based on deep residual learning theory and medical domain knowledge. Their method uses a convolutional layer to extract the overall shape feature of the cell body at first, and then three residual blocks (each composed of two convolutional layers and a residual layer) to extract fine features from various aspects. Finally, the last fully connected layers produce a compact feature representation for 40 different types of white blood cells. Ridoy et.al [26] realised a novel CNN architecture to distinguish among eosinophils, lymphocytes, monocytes, and neutrophils, obtaining 86%, 99%, 97%, and 85% of F1-score, respectively.
Acute Lymphoblastic Leukaemia Detection. The detection of a disease is partially related to the previous task since most diseases affect a particular cell sub-types. In particular, ALL affect the lymphocytes that are released prematurely into the bloodstream. Lymphocytes affected by ALL, called lymphoblasts, present morphological changes that increment with increasing severity of the disease [6]. Thus the analysis in this task is more fine-grained, and the systems must distinguish little morphological variations and small cavities inside the nucleus and cytoplasm. Recently, even in this task, CNNs have gained more attention and they have been used both as feature extractor [29,30,31] and to directly classify the images [32,33,34,35,36]. In [32], the author proposed a novel CNN architecture to differentiate normal and abnormal leukocytes, reaching 96.43% accuracy on ALL-IDB1 data set (described in Section 3.1). Khandekar et al. [33] proposed an ALL detection system, composed of a modified version of the YOLOv4 detector, by adjusting the number of filters to support custom data sets used. They reached an F1-score of 92% and weighted F1-score (WFS) of 92% on ALL-IDB1, and C-NMC (accessed on 10 June 2021) [37] data sets, respectively. Mondal et al. [34] proposed a weighted automated CNN-based ensemble model, trained with centre-cropped images to detect ALL. It has been based on Xception, VGG-16, DenseNet-121, MobileNet, and InceptionResNet-V2. They reached 81.6% WFS on C-NMC data set. The authors in [29] used transfer learning to extract images features for further classification from three different CNN architectures both separately and jointly. Moreover, the features were selected according to their gain ratios and used as input to the SVM classifier. The authors also proposed a new, hybrid data set from the union of three distinct databases and aimed to diagnose leukaemia without a segmentation process, achieving accuracy, precision and recall above 99%. Huang et al. [35] realised a WBCs classification framework that combined a modulated Gabor wavelet and deep CNN kernels for each convolutional layer. The authors state that, in this way, the features learned by modulated kernels at different frequencies and orientations are more representative and discriminative for the task. In particular, they tested their method on a data set of hyperspectral images of blood cells. The authors in [30] employed a VGG architecture (described in Section 3.3.3) for extracting features from WBC images and then filtered them using a statistically Enhanced Salp Swarm Algorithm. Finally, using SVM classifier, they reach average accuracy of 96.11%, and 87.9%, on ALL-IDB2, and C-NMC, respectively. Togacar et al. [31] used the Maximal Information Coefficient and Ridge feature selection methods on the combination of features extracted by AlexNet, GoogLeNet, and ResNet-50 (described in Section 3.3.3). Finally, quadratic discriminant analysis was used as a classifier. The overall accuracy on BCCD data set [28] was 97.95% in the classification of white blood cells. In [36], the authors realised a system to classify WBCs through the Attention-aware Residual Network-based Manifold Learning model that exploits the first and second-order category-relevant image-level features. It reached average classification accuracy of 95.3% on a proprietary microscopic WBCs images data set collected from Shandong Shengli Hospital. The authors in [38] proposed a new CNN to deal with ALL detection. They reached an accuracy of 88.25% on a 10-fold cross-validation average. However, they pinpointed that the best fold achieved an accuracy of 99.3%, outperforming most of the works for this task. It appears they cannot outperform the work in [39], which achieved 99.50% accuracy for leukaemia detection on ALL-IDB2 by employing fine-tuned Alexnet and extensive data augmentation, which also comprised an analysis of different colour spaces. Nevertheless, the latter did not specify how they select training and testing samples or use a cross-validation strategy.
In most of the cited works dealing with one of the WBC analysis tasks, the authors have used reference datasets in which the images present single centred cells. It represents the ideal scenario where salient and high discriminative features can be extracted from the images [34]. Of course, this is valid under the assumption that the crops are still performed manually by the pathologists or that the detection systems provide perfect crops. However, this assumption is not verified in real application scenarios, as the systems are fully automated, and therefore the crops are not always precise or perfectly centred. Indeed, the BBs produced by a detection system could be larger, including a large background region, or too narrow and cut off a portion of the cell. Although, until now, no one has performed an exhaustive analysis on this, we believe that these factors can significantly influence the performance of a classification system. For this reason, we performed an in-depth investigation to verify if and to what extent the mentioned issues can affect the performance of automated systems for WBCs sub-type classification and leukaemia detection. Furthermore, we also investigated hand-crafted features combined with common ML methods; even if the reported related work (that are also the most recent) exploited mainly CNN-based methods, they do not provide clear evidence on which one to prefer for this task.
3. Materials and Methods
This section describes the materials and methods used in this work to perform the above evaluation. We first describe the datasets used, the methods employed, and the experimental setup.
3.1. Data Sets
We used two well-known benchmark data sets: the Acute Lymphoblastic Leukaemia Image Database (ALL-IDB) [3], proposed for ALL detection, and Raabin-WBC (R-WBC) [40], a recently proposed data set for WBC sub-types classification.
3.1.1. ALL-IDB2
The ALL-IDB is a dataset of public PBS images from healthy individuals and leukaemia patients, collected at the M. Tettamanti Research Centre for Childhood Leukaemia and Haematological Diseases, Monza, Italy. It is organised in two versions: ALL-IDB1, which presents 108 complete RGB images containing many cells and clusters, and ALL-IDB2, a collection of single WBCs extracted from ALL-IDB1. Since we are only interested in evaluating classification performance in this work, we only used the ALL-IDB2 version. It contains 260 images in JPG format with 24-bit colour depth, and each image presents a single centred leukocyte, 50% of which are lymphoblasts. The images were taken with a light laboratory microscope with different magnifications, ranging from 300 to 500, coupled to two different cameras: an Olympus Optical C2500L and a Canon PowerShot G5. This leads to several variations in terms of colour, brightness, scale and cell size, making this a very challenging dataset. Figure 2 shows a healthy leukocyte and a lymphoblast, taken from ALL-IDB2.
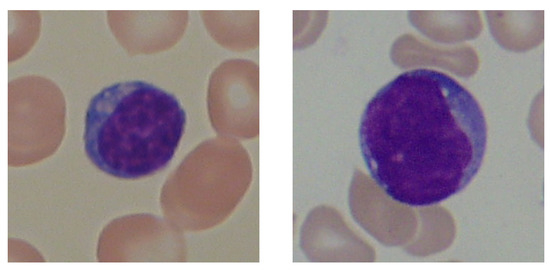
Figure 2.
WBC categories from ALL-IDB2: healthy lymphocyte (left) and lymphoblast (right).
3.1.2. R-WBC
R-WBC is a large open-access dataset collected from several laboratories: the Razi Hospital laboratory in Rasht, the Gholhak laboratory, the Shahr-e-Qods laboratory and the Takht-e Tavous laboratory in Tehran, Iran. The images were taken with Olympus CX18 and Zeiss microscopes at 100× magnification, paired with Samsung Galaxy S5 and LG G3 camera smartphones, respectively. For this reason, this data set is also very challenging; even though the scale is fixed, it has several variations in terms of illuminations and colours. After the imaging process, the images were labelled and processed to provide multiple subsets for different tasks. We exploited the subset containing WBC bounding boxes and the ground truth of the nucleus and cytoplasm in this work. This subset contains 1145 images of selected WBCs, including 242 lymphocytes, 242 monocytes, 242 neutrophils, 201 eosinophils and 218 basophils. Thus, unlike the previous data set, the task is to identify the different sub-types of WBCs. A sample image for each WBC sub-type, taken from R-WBC, is shown in Figure 3.
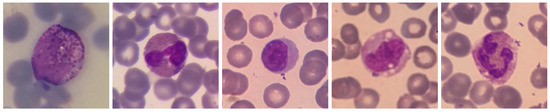
Figure 3.
WBC sub-type images from R-WBC. From left to right: Basophil, Eosinophil, Lymphocyte, Monocyte and Neutrophil.
3.2. Data Pre-Processing
As it can be observed from Figure 2 and Figure 3, in both data set images, each WBC is perfectly located in the BB centre and, at the same time, the BB is larger than the WBC size, and many other cells (mainly RBCs) are present in the images. Given that we are investigating how the quality of the extracted BB influences the classification performance, for each original data set, from now on called large, we created three alternative versions from now on called tight, eroded and dilated. As it can be guessed, the tight versions contain images where the BBs are perfectly fit to the WBC size, which should simulate the ideal case. Instead, the remaining versions are the more realistic ones concerning the current detection-based systems, given that in most cases, the provided BBs are not precise. Indeed, it could happen that the WBC is not entirely enclosed inside the BB (like in the eroded version) or that the WBC is not perfectly centred, and a consistent portion of the background is still present in the BB (like in the dilated version). To create these alternative versions, we exploited the pixel-wise ground truth in the form of a binary mask (for ALL-IDB2, whose ground truth was not proposed by the authors, we provided a copy at ALL-IDB2 masks), (accessed on 10 June 2021) where the foreground contains the WBCs only. We extracted the contours extreme points (left, right, top and bottom) to re-crop the RGB images from the foreground. The tight version has been re-cropped, adding just 3 pixels for each side of the box. The eroded/dilated version has been re-cropped, removing/adding 30 pixels for ALL-IDB and 60 pixels for R-WBC (whose resolution is double) from one side of the box randomly drawn. A sample image for each version of healthy leukocyte and lymphoblast, taken from ALL-IDB2 and for each WBC subtype, taken from R-WBC, is shown in Figure 4.
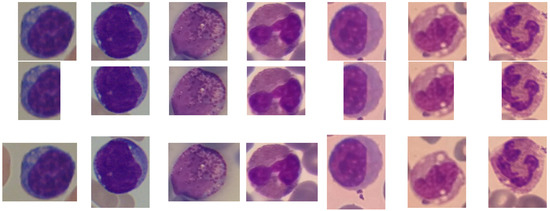
Figure 4.
Tight (top), eroded (middle) and dilated (bottom) versions of ALL-IDB2 (first two columns) and R-WBC (remaining columns) data sets.
3.3. Methods
Here we describe the methods used in our evaluation: hand-crafted image descriptors, classic machine learning, and deep learning approaches.
3.3.1. Hand-Crafted Image Descriptors
We evaluated different hand-crafted image descriptors that we grouped into four important classes: invariant moments, texture, colour and wavelet features. As Invariant Moments we computed Legendre and Zernike moments. Legendre moments were first introduced in image analysis by Teague [41] and have been used extensively in many pattern recognition and features extraction applications due to their invariance to scale, rotation and reflection changes [42,43]. They are computed from the Legendre polynomials. Zernike moments also have been used as features set in many applications [44], as they can represent the properties of an image with no redundancy or overlapping of information between moments. They are constructed as the mapping of an image onto a set of complex Zernike polynomials [41]. In both cases, the order of the moments is equal to 5, since a higher-order would have decreased system performance, adding too specif features more useful for image reconstruction rather than for image classification [45].
The Texture Features computed were the rotation invariant Gray Level Co-occurrence Matrix (GLCM) features, as proposed in [46], and the rotation invariant Local Binary Pattern (LBP) features [47]. In both cases we focused on fine textures, thus we computed four GLCMs with and , and the LBP map in the neighbourhood identified by r and n equal to 1 and 8 respectively. From the GLCMs we extracted thirteen features [48] and converted into rotationally invariant ones (for more details see [46]). The LBP map is then converted into a rotationally invariant one, and its histogram is used as a feature vector [47].
As Colour Features, we extracted basic colour histogram and colour auto-correlogram features [49]. The colour histogram features describe the global colour distribution in the image. We computed seven well-known descriptors: mean, standard deviation, smoothness, skewness, kurtosis, uniformity and entropy, which are calculated from images converted in shades of grey. The auto-correlogram combines the colour information with the spatial correlation between colours. In particular, it stores the probability of finding two pixels with the same colour at a distance d. Here, we used four distance values: . Finally, the four probability vectors are concatenated to create a single feature vector.
As Wavelet Features, we computed the Gabor [50] and Haar [51] wavelets. Gabor wavelet filter bank is an efficient tool for the analysis of local time-frequency characteristics. It uses a set of specific filters with fixed directions and scales to describe the time-frequency coefficients for each direction and scale. Here we used a common filter bank composed of 40 filters, 5 scales and 8 directions, of size . Haar wavelet has been used in many different applications, mostly in combination with other techniques. Here we directly applied the Haar wavelet on the original images using three different levels. From each level, we extracted the approximated image and computed the smoothed histogram with 64 bins. The three histograms are finally concatenated to create a single feature vector.
3.3.2. Classic Machine Learning
The classification accuracy was estimated using three different classifiers: the k-Nearest Neighbor (k-NN) classifier [52], the Support Vector Machine (SVM) [53] and Random Forest (RF) [54]. The k-NN was used because it is one of the simplest and can document the effectiveness of the extracted features rather than assessing the classifier’s performance. Here we used , computed using the Euclidean distance. The SVM, on the other hand, is one of the most used in biomedical application [12,23,29,30]. Here we use a Gaussian radial basis function (RBF) trained using the one VS rest approach. To speed up the selection of the SVM hyperparameters, we employed an error-correcting output code mechanism [55] with 5-fold cross-validation to fit and automatically tune the hyperparameters. The RF was chosen because it combines many decision trees’ results, thus reducing over-fitting and improving generalisation. Here we used a forest consisting of 100 trees.
3.3.3. Deep Learning
In this work, we also employed DL approaches as both classifier and feature extractor. We evaluated different well known CNN architectures which are: AlexNet, VGG-16, VGG-19, ResNet-18, ResNet-50, ResNet-101, GoogleNet and Inceptionv3. They were all pre-trained on a well-known natural image dataset (ImageNet [56]) and adapted to medical image tasks, following an established procedure for transfer learning and fine-tuning CNN models [57]. AlexNet [16], VGG-16 and the VGG-19 [58] are very simple architectures, but, at the same time, are the most used for transfer learning and fine-tuning [57], since they gained popularity for their excellent performance in many classification tasks [16]. They are quite similar except for the number of layers, which is 8 for AlexNet, 16 for VGG-16 and 19 for VGG-19. The three ResNet architectures are slightly more complex, but being based on residual learning, they are easier to optimise even when the depth increases considerably [59]. They present 18, 50, 101 layers for ResNet-18, ResNet-50 and ResNet-101, respectively. GoogleNet [60] and Inceptionv3 [61] are both based on the Inception layer; indeed, Inceptionv3 is a variant of GoogleNet, exploiting only a few additional layers. They also differ in the number of layers, 100 and 140 for GoogleNet and InceptionV3, respectively. For transfer learning, we followed the approach used in [57], preserving all the CNN layers except the last fully-connected one. We replaced it with a new layer, which has been freshly initialised and set up in order to accommodate the new object categories.
CNNs can be even used to replace traditional feature extractors since they have a solid ability to extract complex features that describe the image in much more detail [31,35]. Therefore we leveraged them both for classification and feature extraction. We acted in different ways depending on the end-use of CNN. We considered the entire CNN architecture by taking its prediction values when used as a classifier, while we only leveraged a portion of CNN when used as a feature extractor. In particular, we extracted features from the penultimate fully connected layer (FC7) on AlexNet, VGG-16 and VGG-19, and the last (only one) on the ResNet and Inception architectures.
3.4. Experimental Setup
In order to perform a fair comparison, we split all the above-mentioned data sets/versions into three parts. Indeed, in order to have a sufficient number of samples for the training process while preserving a sufficient number of samples for performance evaluation, we first split the data sets into two parts, namely training and testing set, with about 70% and 30% of images, respectively. Given that the data sets are well balanced, we used a stratified sampling procedure to keep the splits balanced. Then we further split the original training set into a training and a validation set (used during CNN training), with about 80% and 20% of images, respectively. Even in this split, we have tried to keep intact the proportions between the various classes. Also, to further ease reproducibility, the splits were not created randomly but by taking the images in lexicographic order from each class. We conducted all the experiments on a single machine with the following configuration: Intel(R) Core(TM) i9-8950HK @ 2.90GHz CPU with 32 GB RAM and NVIDIA GTX1050 Ti 4GB GPU.
To evaluate the classification performance, we used five common metrics that are Accuracy (A), Precision (P), Recall (R), Specificity (S) and F1-score (F1). They all range over the interval . On ALL-IDB, which is a two-class problem, the above metrics are used as they are, while on R-WBC, which is a multi-class problem, the above measures are used to compute the per-class performance, and then, we computed the weighted average to obtain a single performance measure.
As mentioned in Section 3.3.3, we fine-tuned the CNN architectures exploited on both data sets in order to extract more meaningful features. In particular, we used the hyper-parameters defined in Table 1. Furthermore, considering that we did not produce any image augmentation, we set the regularisation factor L2 in order to avoid a possible over-fitting during the training phase.

Table 1.
Hyper-parameters settings for CNNs fine-tuning.
4. Experimental Results
As mentioned before, in this work, we are interested in investigating how the quality of the extracted BB influences the classification performance; thus, we performed different experiments involving the mentioned data sets/versions. The first experiments are devoted to comparing the performance of the different features and classifiers in a controlled (ideal) environment, as it happens in most benchmark data sets created specifically for model training, where the BBs are precise. In this experiments, from now on called “single-version”, we compared the original (large) versions of the data sets with the tight versions in order to evaluate if and to what extent the presence of a large portion of background in the BBs can influence the extracted features and consequently also the created classification models.
The subsequent experiments are devoted to evaluating the robustness of the different features and classifiers in an uncontrolled (real) environment, where the features to train the classification models could still be extracted from controlled benchmark data sets. However, the classification models are deployed in a real scenario. To simulate this scenario in this experiments, from now on called “cross-version”, we exploited the classification models already trained during the previous experiments, that is using the training sets from the large and tight versions of the data sets, but this time they are tested using the test sets belonging to the other versions of the data sets.
4.1. Results
For the sake of brevity, we have reported the results of experiments performed on a single table for each version of the source data sets. It means that in the Table 2 and Table 3 and in the Table 4 and Table 5 we reported the performance obtained when the source models are created exploiting the large and tight versions of the data sets respectively, and then tested using all versions of the data sets (large, tight, eroded and dilated) in turn. To emphasise the performance on the same-version, all corresponding columns in the tables have been highlighted in grey. In addition, we have reported the average performance value of each classifier on the different feature sets to facilitate comparisons.
Table 2.
ALL-IDB2 performance obtained with source models created exploiting the large data set version and tested using in turn (from the left) the large, tight, eroded and dilated versions. Same-version performance are highlighted in grey.
Table 3.
R-WBC performance obtained with source models created exploiting the large data set version and tested using in turn (from the left) the large, tight, eroded and dilated versions. Same-version performance are highlighted in grey.
Table 4.
ALL-IDB2 performance obtained with source models created exploiting the tight data set version and tested using in turn (from the left) the large, tight, eroded and dilated versions. Same-version performance are highlighted in grey.
Table 5.
R-WBC performance obtained with source models created exploiting the tight data set version and tested using in turn (from the left) the large, tight, eroded and dilated versions. Same-version performance are highlighted in grey.
As it can be observed from the same-version experiments on ALL-IDB2 data sets, reported in Table 2 and Table 4, the performance is very similar on both the large and tight data set version, on average. More in detail, looking at the AVG rows of every single classifier, it is possible to notice that, on ALL-IDB, the large to large achieve slightly better performance with the kNN classifier. In contrast, for the remaining classifiers, the tight to tight produced better (considerably better with the CNNs) performance. A similar trend occurs on R-WBC data sets (see Table 3 and Table 5), in which the only clear difference from ALL-IDB2 comes from the CNN results. Indeed, their performance are very similar in both the large on large and tight to tight versions.
The cross-version experiments are aimed to verify which combinations of descriptors and classifiers are more robust in a real scenario, where the testing images could differ from those used for training. In this scenario, performance can be expected to worsen quickly; however, this trend has not occurred in all cases. In particular, on ALL-IDB2 data sets, when the large version is exploited for creating the models, reported in Table 2, the CNNs alone demonstrated to be very robust, and in many cases, the performance obtained in the cross-version is even better than the ones obtained with the same-version. On average, from this table, it can be observed that the highest drop in performance (about 30%) corresponds to the large to eroded crossing, for which SVM proved to be the best among the classic ML classifiers. On the contrary, on the same data sets, when the tight version is exploited for creating the models, reported in Table 4, the highest drop in performance (about 20% for all classifiers) corresponds to the tight to large crossing, while for the other crossings the drop is less evident (about 10%). On average, even in the crossing cases, the CNNs proved to be the most robust, still followed by the SVM.
The trends just mentioned are confirmed for R-WBC data set on both large and tight versions, reported in Table 3 and Table 5. Indeed the highest drops in performance correspond to the eroded to eroded and tight to large crossings. In this case, the CNNs have a consistent decline in the worst case (about 30% when tested in eroded and large, respectively), but, in the other cases, they proved to be very robust, especially with models created with the tight version.
4.2. Discussion
Going into more detail on the individual descriptors on both data sets and comparing the performance obtained with the large and tight versions, it can be seen that the hand-crafted descriptors perform better with the tight versions. In fact, the tight version invariant moments and texture features outperformed their corresponding large version, particularly on R-WBC, by about 30% and 20% with all classifiers, respectively. In addition, on ALL-IDB2, several colour descriptors produced comparable results to the absolute best. For example, kNN and SVM trained with the Haar feature on the large case, auto-correlogram and Gabor with kNN on the tight case produced comparable results with the same classifiers trained with CNN features.
On the contrary, features extracted from CNNs show a counter-trend and always perform better on the large version. It is most likely due to filtering operations that slowly degrade the information present at the edges of the images, which strongly penalises tight BBs.
Furthermore, the trend regarding the CNNs is that they performed better when used for feature extraction to feed SVM or RF classifiers while performing slightly worse on their own.
On average, the tables show that CNN models trained with tight versions produced excellent results when tested on tight, eroded and dilated versions compared to the remaining classifiers. This trend is even more evident on R-WBC. On the same three crosses defined above, the performance is higher than 90%. Therefore, it seems that the tight versions of the data sets are more suitable for training CNNs. As a general rule, the tight version is preferable to the large version because of the cross-over performance. A detection or segmentation method can rarely produce large bounding boxes, such as those provided in the original versions of the data set.
Deepening individual descriptors on both data sets when exploiting the large version, CNNs, especially the simplest ones (AlexNet, VGG-16, and VGG-19), showed superior performance even though they suffered the most significant drop, particularly on the R-WBC data set. In contrast, several descriptors proved to be robust when exploiting the tight version, particularly Legendre moment on ALL-IDB2 and Haar wavelet on R-WBC with all classifiers.
In general, the following observations can be made from the results obtained:
- 1
- HC descriptors are more appropriate for both tasks when they are extracted from the tight version of the data sets (in particular invariant moments and texture), which makes them more robust to BBs variations;
- 2
- on the ALL-IDB2 task (ALL vs. Healthy cells detection), which is finer and more difficult, several HC descriptors (in particular Haar from large, and Gabor from tight) produced results in line with the descriptors extracted from CNNs;
- 3
- CNNs used as feature extractors produced better results than CNNs alone in practically all cases, although the large version is certainly more suitable than the tight one for feature extraction;
- 4
- however, CNNs alone, when trained on the tight versions, have proven to be very robust to every variation of BBs except the large case. Nevertheless, it is a rare case in real application scenarios.
5. Conclusions
In this work, we proposed an in-depth investigation of current white blood cell analysis methods in a real application scenario. In such a scenario, the regions of interest are automatically extracted from a region detector or a proposal and, as a result, are inaccurate. Furthermore, cells are not well centred or even not completely included. In order to assess if and to what extent such factors can affect the performance of classification systems for WBC sub-types classification and leukaemia detection, we evaluated both hand-crafted and deep features combined with different classifiers and also Convolutional Neural Networks. Obviously, in this work, we did not want to create a classification system capable of competing with state-of-the-art methods but only to make a quantitative evaluation of the single descriptor/classifier; therefore, we have discarded a priori all combinations of descriptors or ensembles of classifiers. Experimental results confirmed that Convolutional Neural Networks are very robust in a scenario where there is a large variability, and the testing images differ a lot from the training ones. Nevertheless, compared with the hand-crafted features combined with traditional classifiers, the gap in performance is limited or none at all, especially when exploiting appropriate images for training the models. In such case, the images used for training are well centred and present the smallest portion of the background, which is a valid assumption even in a real application scenario, given that the images used for training could still be produced manually, or better, they could be produced automatically and double-checked by an operator. In the future, we aim to investigate a similar scenario where the regions of interest are produced by a segmentation-based system rather than a detection-based one. It could be interesting also to investigate features created ad-hoc for peripheral blood image analysis in such a scenario.
Author Contributions
Conceptualisation, A.L. and L.P.; Methodology, A.L. and L.P.; Investigation, A.L. and L.P.; software, A.L. and L.P.; writing—original draft, A.L. and L.P.; writing—review and editing, A.L. and L.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
All the features extracted and the models produced in this study are available at the following url: GitHub repository accessed on 21 June 2021.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| PBS | Peripheral Blood Smear |
| RBC | Red Blood Cells |
| WBC | White Blood Cells |
| ALL | Acute Lymphoblastic Leukaemia |
| AML | Acute Myeloid Leukaemia |
| CLL | Chronic Lymphocytic Leukaemia |
| CML | Chronic Myeloid Leukaemia |
| CAD | Computer-Aided Diagnosis |
| ALL-IDB | Acute Lymphoblastic Leukaemia Image Database |
| R-WBC | Raabin-WBC |
| BB | Bounding Boxes |
| ML | Machine Learning |
| DL | Deep Learning |
| CNN | Convolutional Neural Network |
| LBP | Local Binary Pattern |
| GLCM | Gray Level Co-occurrence Matrix |
| FC | Fully Connected |
| TP | True Positive |
| TN | True Negative |
| FN | False Negative |
| FP | False Positive |
| A | Accuracy |
| P | Precision |
| R | Recall |
| S | Specificity |
| F1 | F1-score |
| WFS | Weighted F1-score |
References
- Ciesla, B. Hematology in Practice; FA Davis: Philadelphia, PA, USA, 2011. [Google Scholar]
- Biondi, A.; Cimino, G.; Pieters, R.; Pui, C.H. Biological and therapeutic aspects of infant leukemia. Blood 2000, 96, 24–33. [Google Scholar] [CrossRef]
- Labati, R.D.; Piuri, V.; Scotti, F. All-IDB: The acute lymphoblastic leukemia image database for image processing. In Proceedings of the IEEE ICIP International Conference on Image Processing, Brussels, Belgium, 29 December 2011; pp. 2045–2048. [Google Scholar]
- University Of Leeds The Histology Guide. 2021. Available online: https://www.histology.leeds.ac.uk/blood/blood_wbc.php (accessed on 10 June 2021).
- Bain, B.J. A Beginner’s Guide to Blood Cells; Wiley Online Library: New York, NY, USA, 2004. [Google Scholar]
- Cancer Treatment Centers of America, Types of Leukemia. 2021. Available online: https://www.cancercenter.com/cancer-types/leukemia/types (accessed on 11 June 2021).
- United States National Cancer Institute, Leukemia. 2021. Available online: https://www.cancer.gov/types/leukemia/hp (accessed on 11 June 2021).
- Madhloom, H.T.; Kareem, S.A.; Ariffin, H.; Zaidan, A.A.; Alanazi, H.O.; Zaidan, B.B. An automated white blood cell nucleus localization and segmentation using image arithmetic and automatic threshold. J. Appl. Sci. 2010, 10, 959–966. [Google Scholar] [CrossRef] [Green Version]
- Putzu, L.; Caocci, G.; Di Ruberto, C. Leucocyte classification for leukaemia detection using image processing techniques. AIM 2014, 62, 179–191. [Google Scholar] [CrossRef] [Green Version]
- Alomari, Y.M.; Sheikh Abdullah, S.N.H.; Zaharatul Azma, R.; Omar, K. Automatic detection and quantification of WBCs and RBCs using iterative structured circle detection algorithm. Comput. Math. Methods Med. 2014, 2014. [Google Scholar] [CrossRef] [Green Version]
- Mohapatra, S.; Patra, D.; Satpathy, S. An ensemble classifier system for early diagnosis of acute lymphoblastic leukemia in blood microscopic images. Neural Comput. Appl. 2014, 24, 1887–1904. [Google Scholar] [CrossRef]
- Ruberto, C.D.; Loddo, A.; Putzu, L. A leucocytes count system from blood smear images Segmentation and counting of white blood cells based on learning by sampling. Mach. Vis. Appl. 2016, 27, 1151–1160. [Google Scholar] [CrossRef]
- Vincent, I.; Kwon, K.; Lee, S.; Moon, K. Acute lymphoid leukemia classification using two-step neural network classifier. In Proceedings of the 2015 21st Korea-Japan Joint Workshop on Frontiers of Computer Vision, Mokpo, South Korea, 28–30 January 2015; pp. 1–4. [Google Scholar] [CrossRef]
- Singh, G.; Bathla, G.; Kaur, S. Design of new architecture to detect leukemia cancer from medical images. Int. J. Appl. Eng. Res. 2016, 11, 7087–7094. [Google Scholar]
- Di Ruberto, C.; Loddo, A.; Puglisi, G. Blob Detection and Deep Learning for Leukemic Blood Image Analysis. Appl. Sci. 2020, 10, 1176. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Proceedings of the 25th International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 1, pp. 1097–1105. [Google Scholar]
- Qin, F.; Gao, N.; Peng, Y.; Wu, Z.; Shen, S.; Grudtsin, A. Fine-grained leukocyte classification with deep residual learning for microscopic images. Comput. Methods Programs Biomed. 2018, 162, 243–252. [Google Scholar] [CrossRef]
- Mahmood, N.H.; Lim, P.C.; Mazalan, S.M.; Razak, M.A.A. Blood cells extraction using color based segmentation technique. Int. J. Life Sci. Biotechnol. Pharma Res. 2013, 2. [Google Scholar] [CrossRef]
- Sipes, R.; Li, D. Using convolutional neural networks for automated fine grained image classification of acute lymphoblastic leukemia. In Proceedings of the 3rd International Conference on Computational Intelligence and Applications; Institute of Electrical and Electronics Engineers Inc.: New York, NY, USA, 2018; pp. 157–161. [Google Scholar]
- Ruberto, C.D.; Loddo, A.; Putzu, L. Detection of red and white blood cells from microscopic blood images using a region proposal approach. Comput. Biol. Med. 2020, 116, 103530. [Google Scholar] [CrossRef]
- Zhao, Z.; Zheng, P.; Xu, S.; Wu, X. Object Detection With Deep Learning: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.B.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [Green Version]
- Çınar, A.; Tuncer, S.A. Classification of lymphocytes, monocytes, eosinophils, and neutrophils on white blood cells using hybrid Alexnet-GoogleNet-SVM. SN Appl. Sci. 2021, 3, 1–11. [Google Scholar] [CrossRef]
- Semerjian, S.; Khong, Y.F.; Mirzaei, S. White Blood Cells Classification Using Built-in Customizable Trained Convolutional Neural Network. In Proceedings of the 2021 International Conference on Emerging Smart Computing and Informatics (ESCI), Pune, India, 5–7 March 2021; pp. 357–362. [Google Scholar]
- Yao, X.; Sun, K.; Bu, X.; Zhao, C.; Jin, Y. Classification of white blood cells using weighted optimized deformable convolutional neural networks. Artif. Cells Nanomed. Biotechnol. 2021, 49, 147–155. [Google Scholar] [CrossRef] [PubMed]
- Ridoy, M.A.R.; Islam, M.R. An automated approach to white blood cell classification using a lightweight convolutional neural network. In Proceedings of the 2020 2nd International Conference on Advanced Information and Communication Technology, Dhaka, Bangladesh, 28–29 November 2020; pp. 480–483. [Google Scholar]
- Pandey, P.; Kyatham, V.; Mishra, D.; Dastidar, T.R. Target-Independent Domain Adaptation for WBC Classification Using Generative Latent Search. IEEE Trans. Med. Imaging 2020, 39, 3979–3991. [Google Scholar] [CrossRef] [PubMed]
- Mooney, P. Blood Cell Images Data Set. 2014. Available online: https://github.com/Shenggan/BCCD_Dataset (accessed on 11 June 2021).
- Vogado, L.H.; Veras, R.M.; Araujo, F.H.; Silva, R.R.; Aires, K.R. Leukemia diagnosis in blood slides using transfer learning in CNNs and SVM for classification. Eng. Appl. Artif. Intell. 2018, 72, 415–422. [Google Scholar] [CrossRef]
- Sahlol, A.T.; Kollmannsberger, P.; Ewees, A.A. Efficient Classification of White Blood Cell Leukemia with Improved Swarm Optimization of Deep Features. Sci. Rep. 2020, 10, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Toğaçar, M.; Ergen, B.; Cömert, Z. Classification of white blood cells using deep features obtained from Convolutional Neural Network models based on the combination of feature selection methods. Appl. Soft Comput. J. 2020, 97, 106810. [Google Scholar] [CrossRef]
- Ttp, T.; Pham, G.N.; Park, J.H.; Moon, K.S.; Lee, S.H.; Kwon, K.R. Acute leukemia classification using convolution neural network in clinical decision support system. CS IT Conf. Proc. 2017, 7, 49–53. [Google Scholar]
- Khandekar, R.; Shastry, P.; Jaishankar, S.; Faust, O.; Sampathila, N. Automated blast cell detection for Acute Lymphoblastic Leukemia diagnosis. Biomed. Signal Process. Control. 2021, 68, 102690. [Google Scholar] [CrossRef]
- Mondal, C.; Hasan, M.K.; Jawad, M.T.; Dutta, A.; Islam, M.R.; Awal, M.A.; Ahmad, M. Acute Lymphoblastic Leukemia Detection from Microscopic Images Using Weighted Ensemble of Convolutional Neural Networks. arXiv 2021, arXiv:2105.03995. [Google Scholar]
- Huang, Q.; Li, W.; Zhang, B.; Li, Q.; Tao, R.; Lovell, N.H. Blood Cell Classification Based on Hyperspectral Imaging with Modulated Gabor and CNN. IEEE J. Biomed. Health Inform. 2020, 24, 160–170. [Google Scholar] [CrossRef]
- Huang, P.; Wang, J.; Zhang, J.; Shen, Y.; Liu, C.; Song, W.; Wu, S.; Zuo, Y.; Lu, Z.; Li, D. Attention-Aware Residual Network Based Manifold Learning for White Blood Cells Classification. IEEE J. Biomed. Health Inform. 2020, 25, 1206–1214. [Google Scholar] [CrossRef] [PubMed]
- Duggal, R.; Gupta, A.; Gupta, R.; Mallick, P. SD-layer: Stain deconvolutional layer for CNNs in medical microscopic imaging. In International Conference on Medical Image Computing and Computer-Assisted Intervention; Springer: New York, NY, USA, 6–10 September 2017; pp. 435–443. [Google Scholar]
- Ahmed, N.; Yigit, A.; Isik, Z.; Alpkocak, A. Identification of Leukemia Subtypes from Microscopic Images Using Convolutional Neural Network. Diagnostics 2019, 9, 104. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Shafique, S.; Tehsin, S. Acute Lymphoblastic Leukemia Detection and Classification of Its Subtypes Using Pretrained Deep Convolutional Neural Networks. Technol. Cancer Res. Treat. 2018, 17, 1533033818802789. [Google Scholar] [CrossRef] [Green Version]
- Kouzehkanan, S.Z.M.; Saghari, S.; Tavakoli, E.; Rostami, P.; Abaszadeh, M.; Satlsar, E.S.; Mirzadeh, F.; Gheidishahran, M.; Gorgi, F.; Mohammadi, S.; et al. Raabin-WBC: A large free access dataset of white blood cells from normal peripheral blood. bioRxiv 2021. [Google Scholar] [CrossRef]
- Teague, M.R. Image analysis via the general theory of moments. J. Opt. Soc. Am. 1980, 70, 920–930. [Google Scholar] [CrossRef]
- Chong, C.W.; Raveendran, P.; Mukundan, R. Translation and scale invariants of Legendre moments. Pattern Recognit. 2004, 37, 119–129. [Google Scholar] [CrossRef]
- Ma, Z.; Kang, B.; Ma, J. Translation and scale invariant of Legendre moments for images retrieval. J. Inf. Comput. Sci. 2011, 8, 2221–2229. [Google Scholar]
- Oujaoura, M.; Minaoui, B.; Fakir, M. Image annotation by moments. Moments-Moment-Invariants Theory Appl. 2014, 1, 227–252. [Google Scholar]
- Di Ruberto, C.; Putzu, L.; Rodriguez, G. Fast and accurate computation of orthogonal moments for texture analysis. Pattern Recognit. 2018, 83, 498–510. [Google Scholar] [CrossRef] [Green Version]
- Putzu, L.; Di Ruberto, C. Rotation Invariant Co-occurrence Matrix Features. In 19th International Conference ICIAP on Image Analysis and Processing; Springer International Publishing: Cham, Switzerland, 2017; Volume 10484, pp. 391–401. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikäinen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary pattern. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Haralick, R.M.; Shanmugam, K.; Dinstein, I.H. Textural Features for Image Classification. IEEE Trans. Syst. Man Cybern. 1973, SMC-3, 610–621. [Google Scholar] [CrossRef] [Green Version]
- Mitro, J. Content-based image retrieval tutorial. arXiv 2016, arXiv:1608.03811. [Google Scholar]
- Samantaray, A.; Rahulkar, A. New design of adaptive Gabor wavelet filter bank for medical image retrieval. IET Image Process. 2020, 14, 679–687. [Google Scholar] [CrossRef]
- Singha, M.; Hemachandran, K.; Paul, A. Content-based image retrieval using the combination of the fast wavelet transformation and the colour histogram. IET Image Process. 2012, 6, 1221–1226. [Google Scholar] [CrossRef]
- Cover, T.M.; Hart, P.E. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Lin, Y.; Lv, F.; Zhu, S.; Yang, M.; Cour, T.; Yu, K.; Cao, L.; Huang, T.S. Large-scale image classification: Fast feature extraction and SVM training. In Proceedings of the 24th IEEE Conference on Computer Vision and Pattern Recognition, Colorado Springs, CO, USA, 20–25 June 2011; pp. 1689–1696. [Google Scholar]
- Breiman, L. Random Forests. Mach. Learn. 2001, 4, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Bagheri, M.A.; Montazer, G.A.; Escalera, S. Error correcting output codes for multiclass classification: Application to two image vision problems. In Proceedings of the 16th CSI International Symposium on Artificial Intelligence and Signal Processing, Shiraz, Iran, 2–3 May 2012; 3 May 2012; pp. 508–513. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Shin, H.; Roth, H.R.; Gao, M.; Lu, L.; Xu, Z.; Nogues, I.; Yao, J.; Mollura, D.; Summers, R.M. Deep Convolutional Neural Networks for Computer-Aided Detection: CNN Architectures, Dataset Characteristics and Transfer Learning. IEEE Trans. Med. Imaging 2016, 35, 1285–1298. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 2818–2826. [Google Scholar] [CrossRef] [Green Version]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).