Performance Evaluation of 3D Descriptors Paired with Learned Keypoint Detectors †

Abstract
:1. Introduction
1.1. 3D Local Feature Detectors and Descriptors
1.1.1. Hand-Crafted Feature Detectors
1.1.2. Learned Feature Detectors
1.1.3. Hand-Crafted Feature Descriptors
1.1.4. Learned Feature Descriptors
2. Materials and Methods
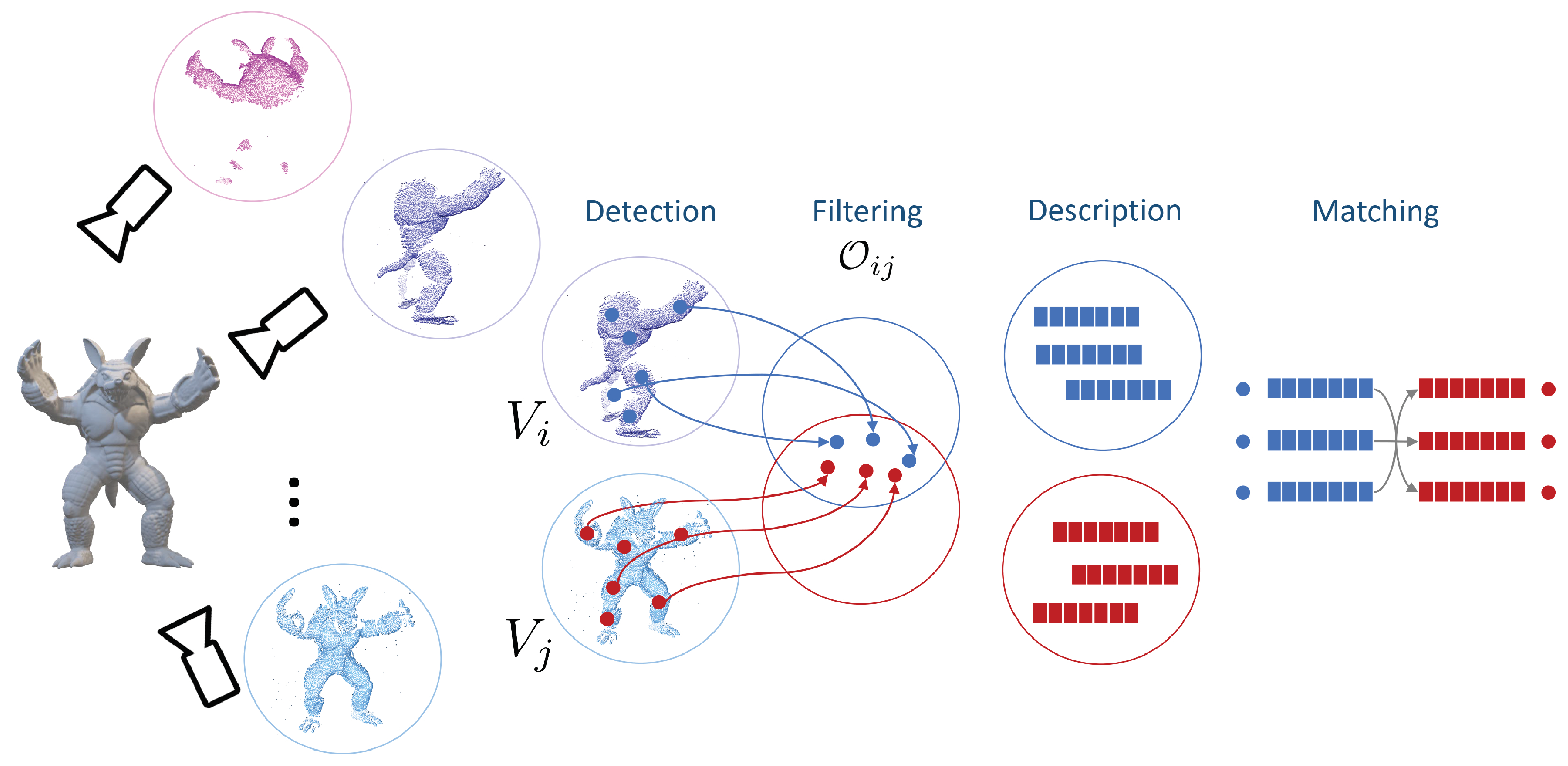
2.1. Keypoint Learning
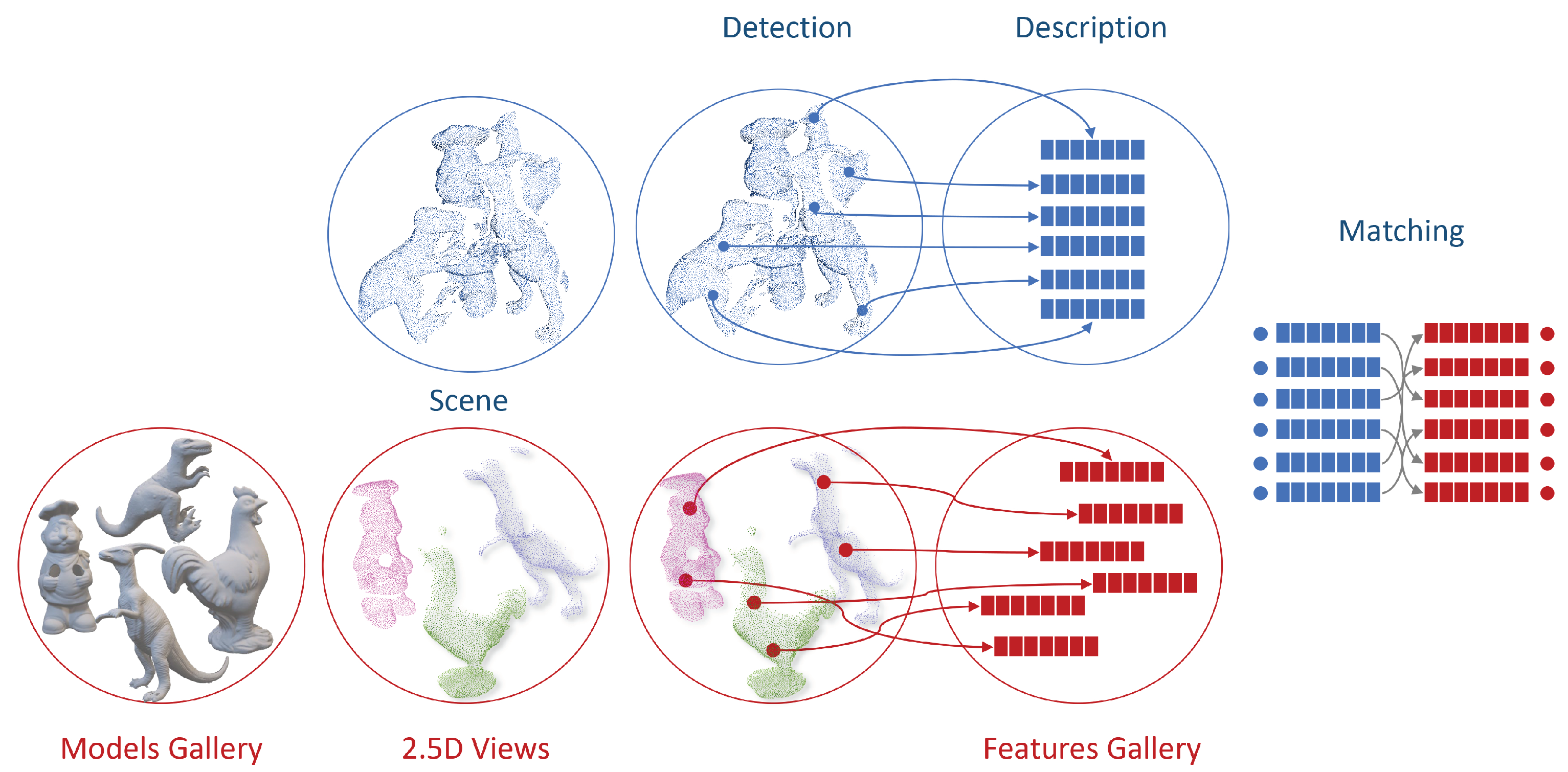
2.2. Evaluation Methodology
2.2.1. Object Recognition
2.2.2. Surface Registration
2.2.3. Datasets
- UWA dataset, introduced by Mian et al. [34]. This dataset consists of 4 full 3D models and 50 scenes wherein models significantly occlude each other. To create some clutter, scenes contain also an object which is not included in the model gallery. As scenes are scanned by a Minolta Vivid 910 scanner, they are corrupted by real sensor noise.
- Random Views dataset, based on the Stanford 3D scanning repository (3 http://graphics.stanford.edu/data/3Dscanrep/ accessed on 14 November 2020) and originally proposed in [1]. This dataset comprises 6 full 3D models and 36 scenes obtained by synthetic renderings of random model arrangements. Scenes feature occlusions but no clutter. Moreover, scenes are corrupted by different levels of synthetic noise. In the experiments we consider scenes with Gaussian noise equal to mesh resolution units.
2.2.4. Implementation
3. Results and Discussion
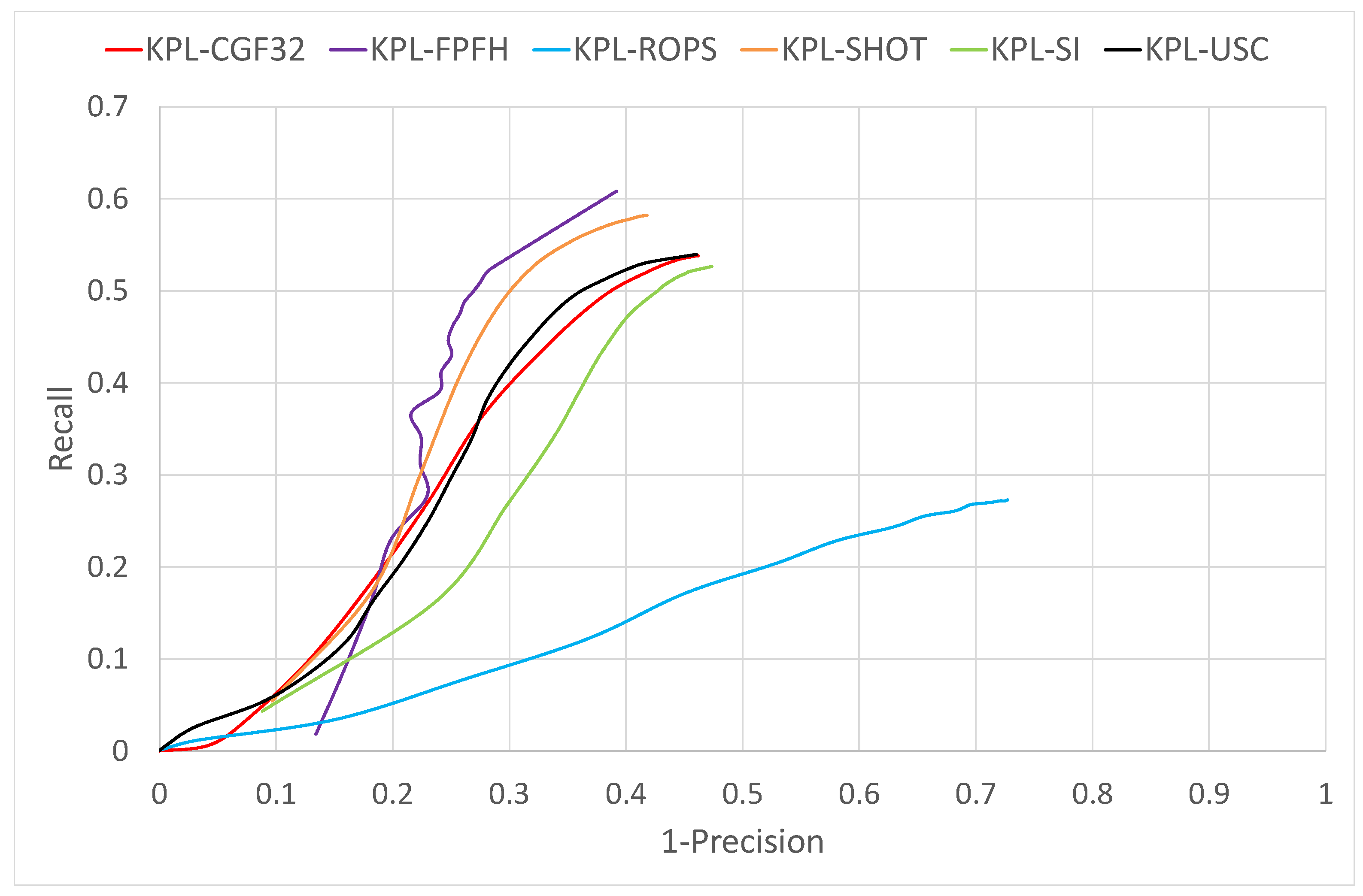
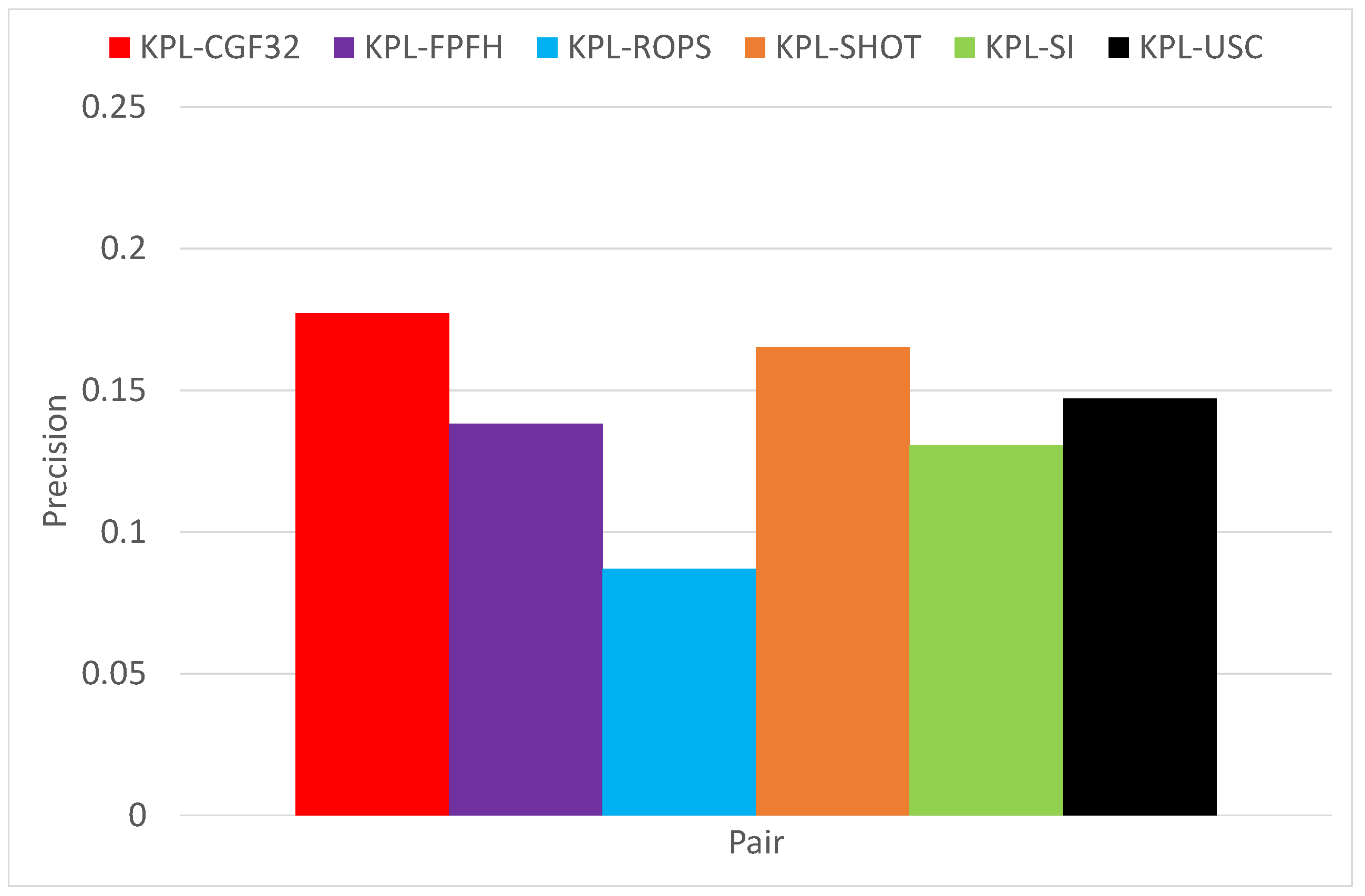
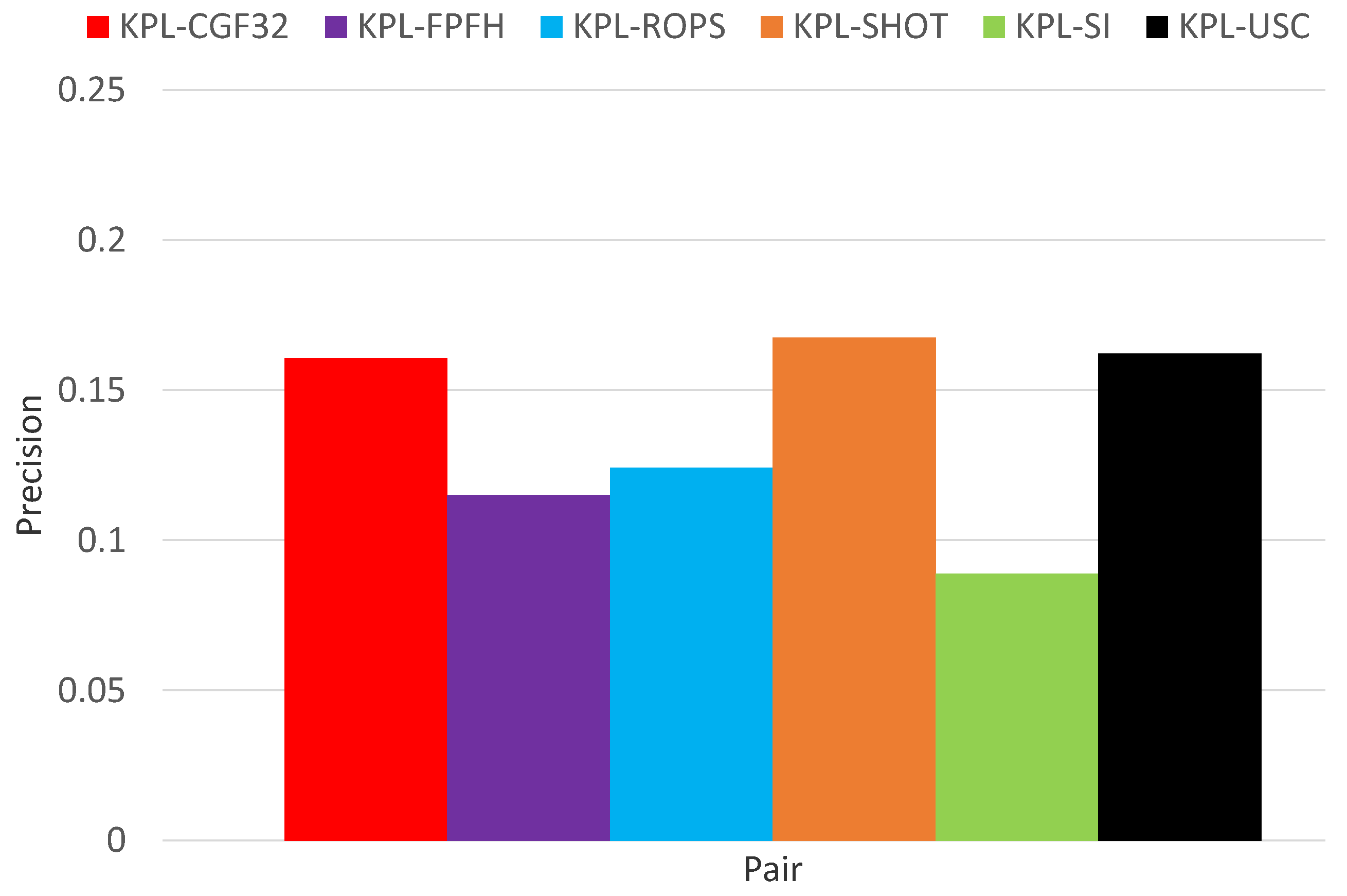
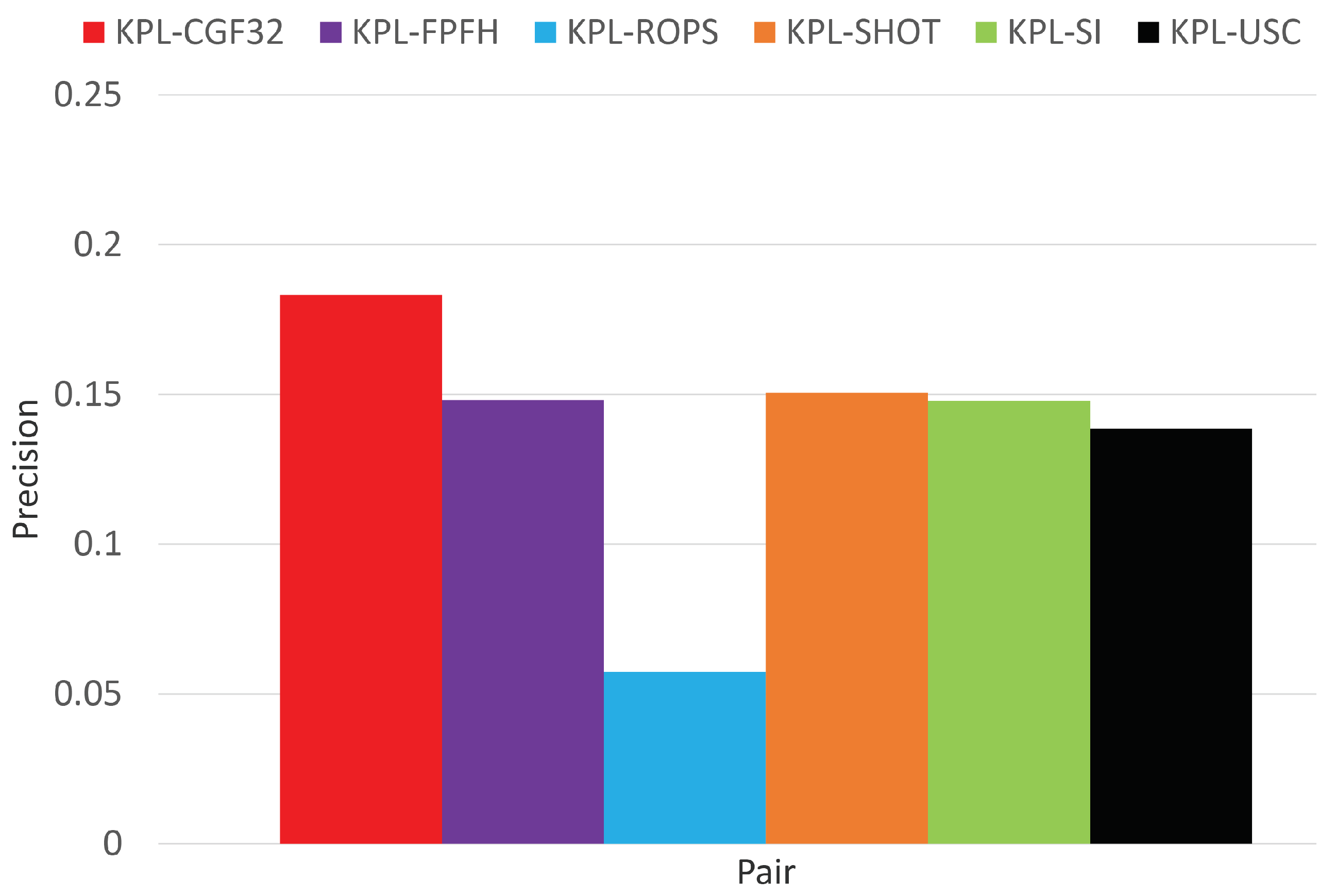
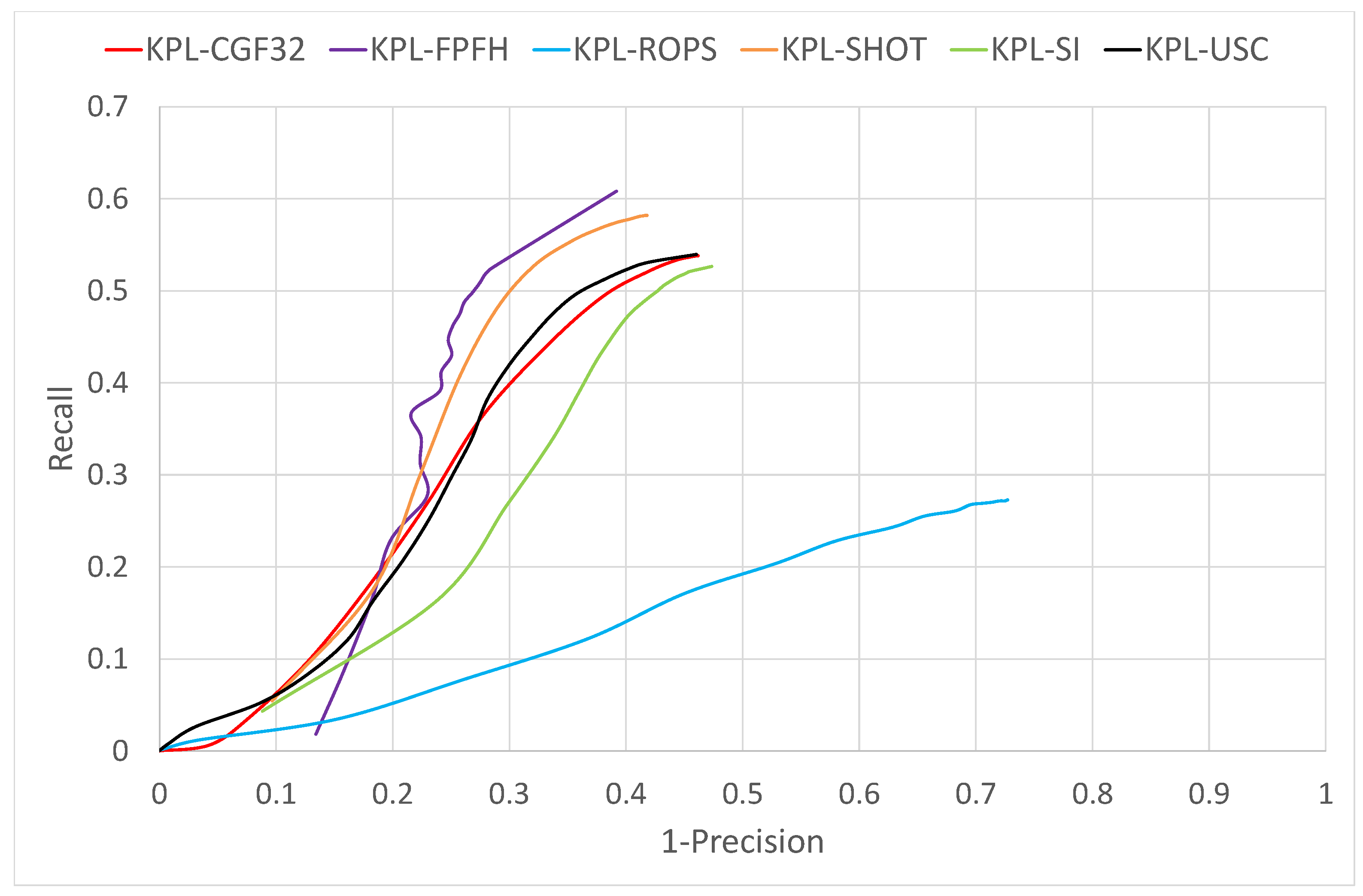
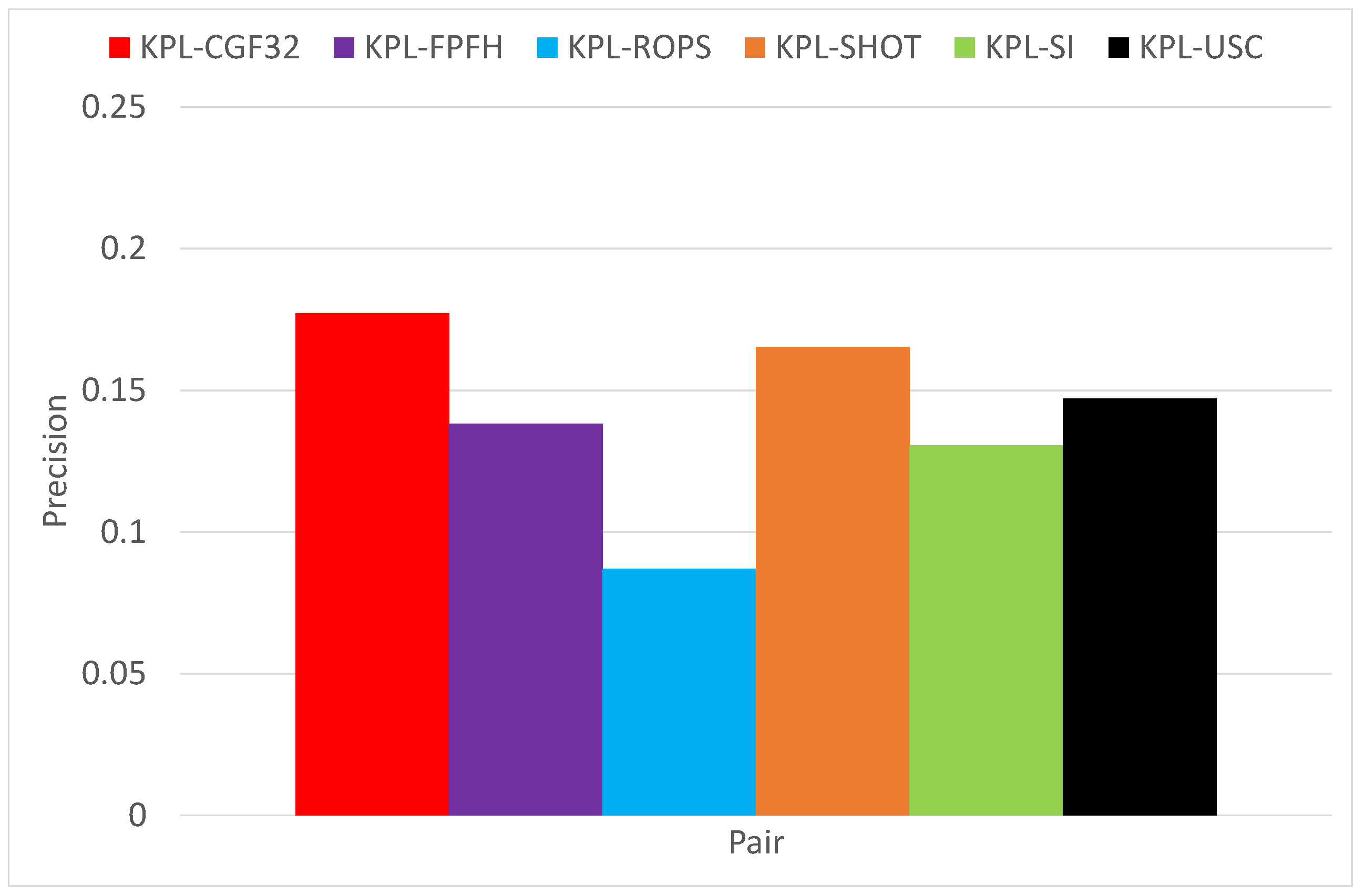
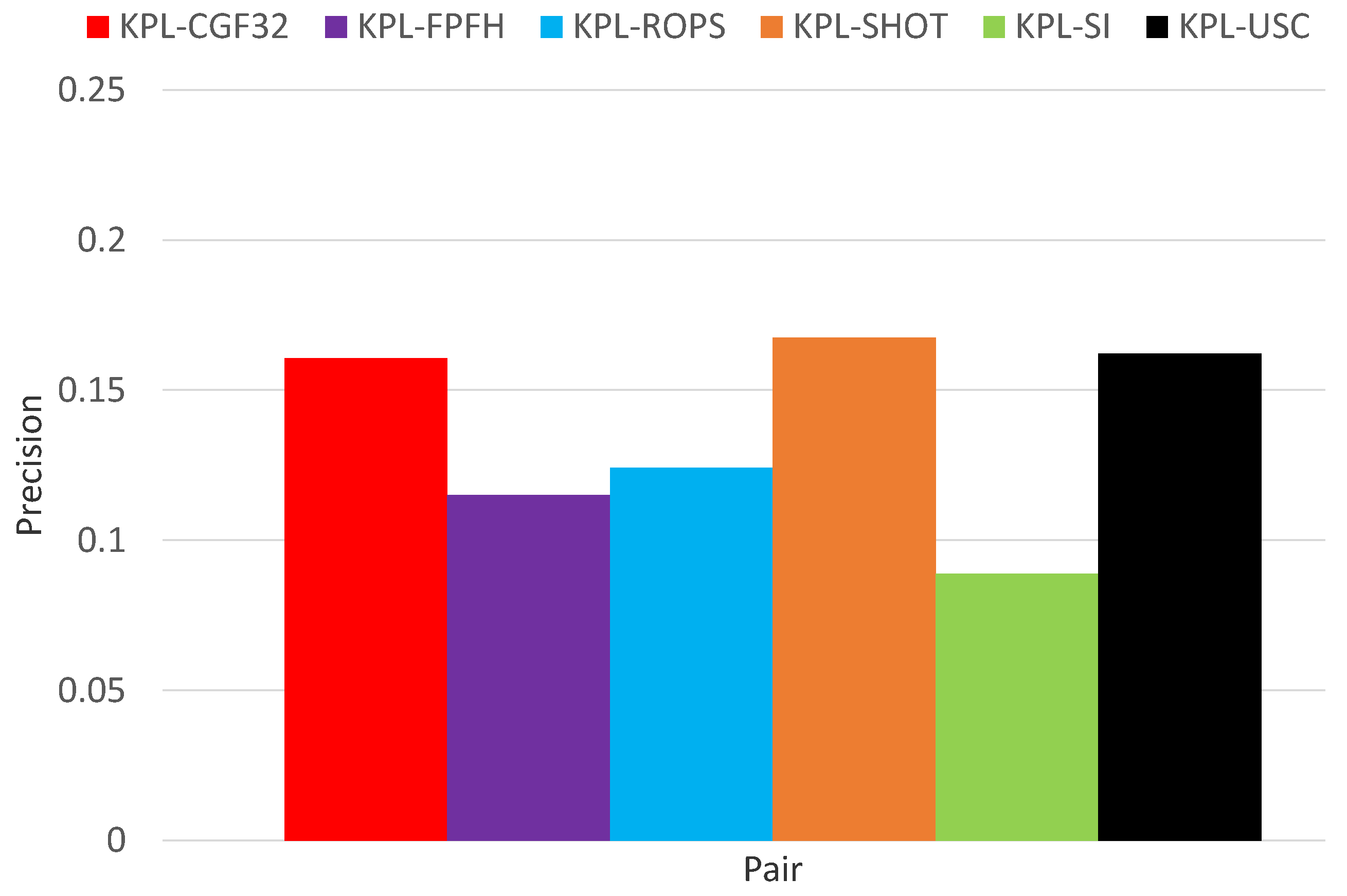
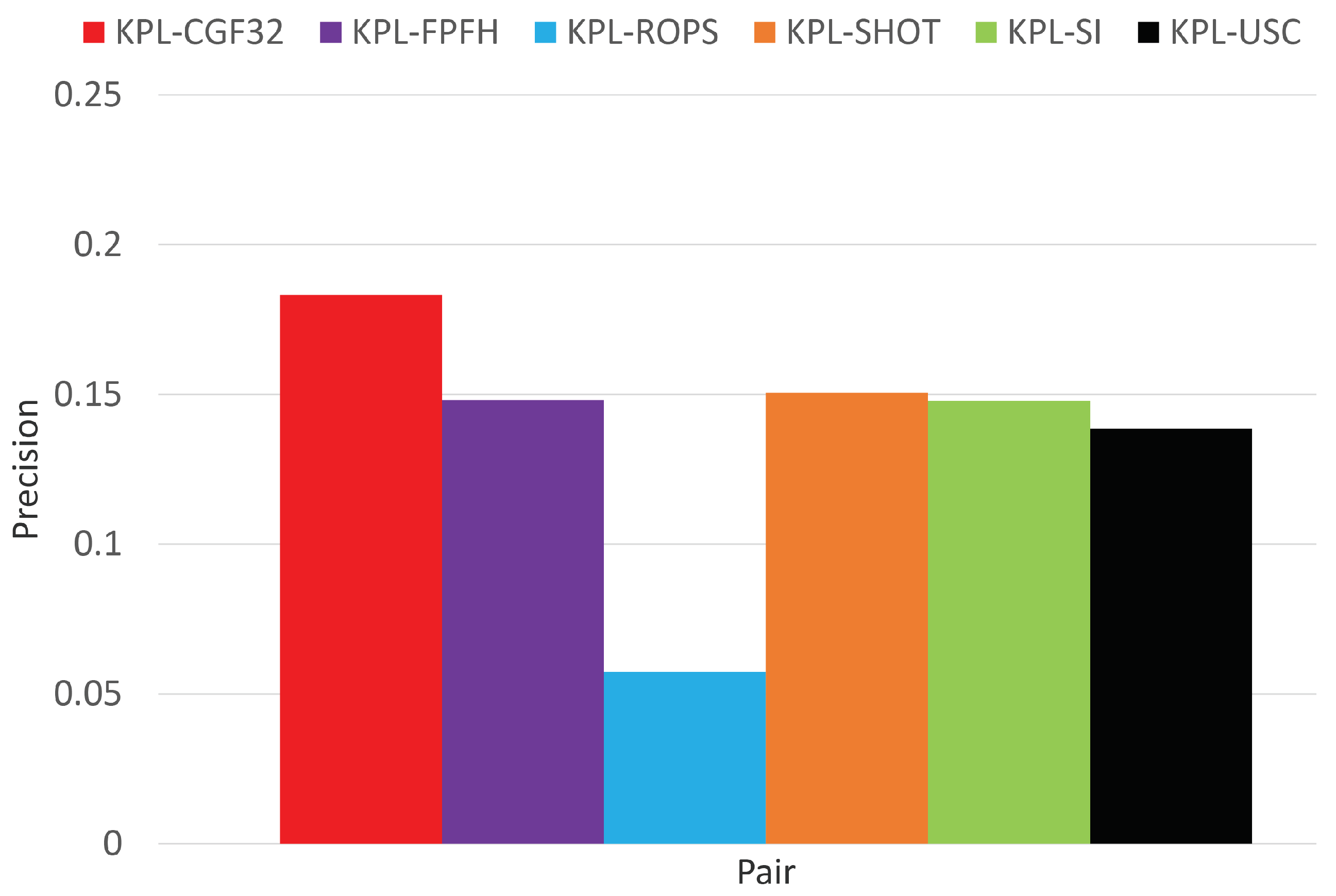
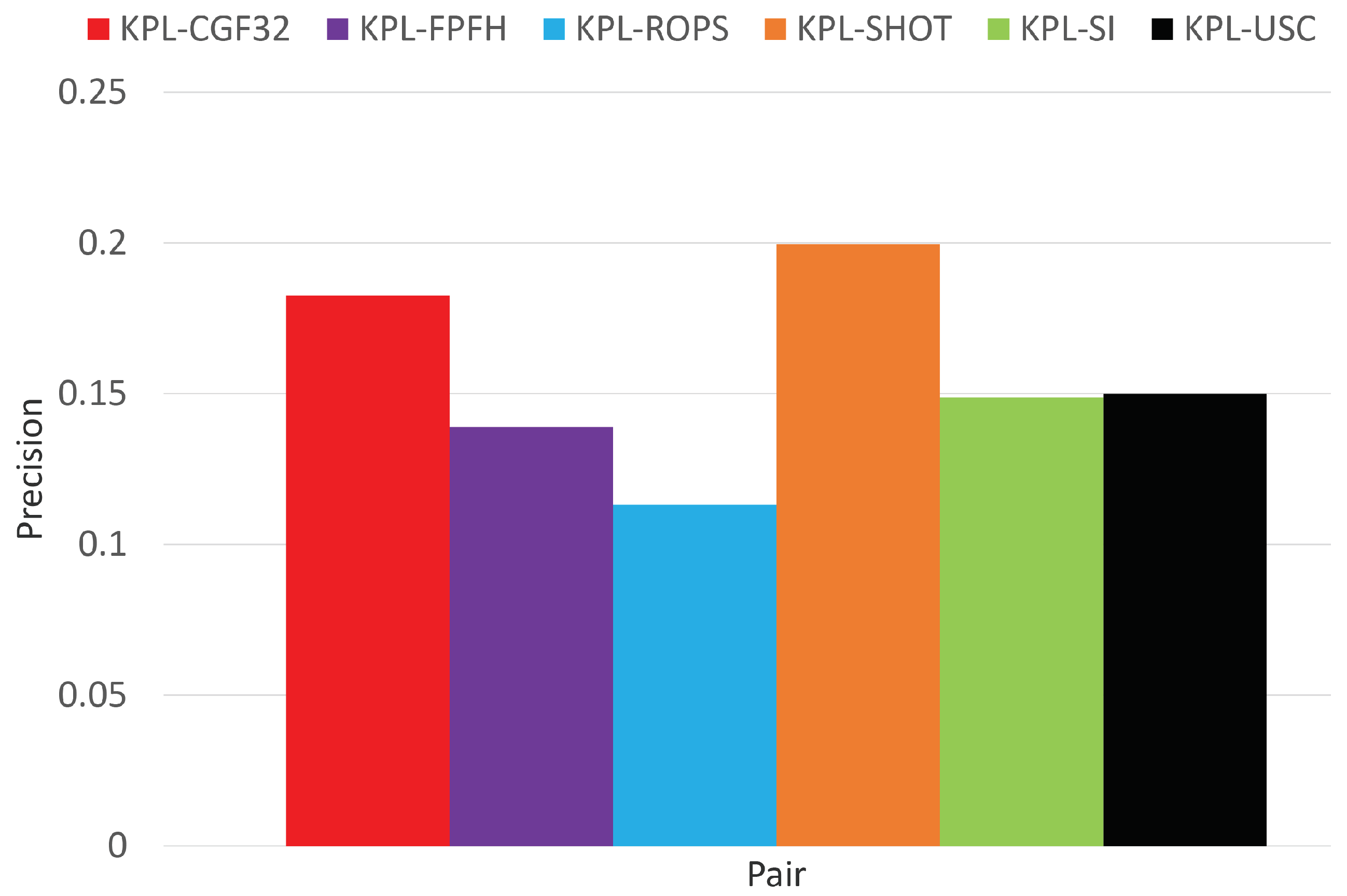
3.1. Object Recognition
3.2. Surface Registration
4. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- Tombari, F.; Salti, S.; Di Stefano, L. Performance evaluation of 3D keypoint detectors. Int. J. Comput. Vis. 2013, 102, 198–220. [Google Scholar] [CrossRef]
- Guo, Y.; Bennamoun, M.; Sohel, F.; Lu, M.; Wan, J.; Kwok, N.M. A comprehensive performance evaluation of 3D local feature descriptors. Int. J. Comput. Vis. 2016, 116, 66–89. [Google Scholar] [CrossRef]
- Salti, S.; Petrelli, A.; Tombari, F.; Di Stefano, L. On the affinity between 3D detectors and descriptors. In Proceedings of the 2012 Second International Conference on 3D Imaging, Modeling, Processing, Visualization & Transmission, Zurich, Switzerland, 13–15 October 2012; pp. 424–431. [Google Scholar]
- Salti, S.; Tombari, F.; Spezialetti, R.; Di Stefano, L. Learning a descriptor-specific 3d keypoint detector. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015; pp. 2318–2326. [Google Scholar]
- Tonioni, A.; Salti, S.; Tombari, F.; Spezialetti, R.; Di Stefano, L. Learning to Detect Good 3D Keypoints. Int. J. Comput. Vis. 2018, 126, 1–20. [Google Scholar] [CrossRef]
- Tombari, F.; Salti, S.; Di Stefano, L. Unique Signatures of Histograms for Local Surface Description. In Proceedings of the 11th European Conference on Computer Vision Conference on Computer Vision: Part III, Crete, Greece, 5–11 September 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 356–369. [Google Scholar]
- Johnson, A.E.; Hebert, M. Using spin images for efficient object recognition in cluttered 3D scenes. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 433–449. [Google Scholar] [CrossRef] [Green Version]
- Rusu, R.B.; Bradski, G.; Thibaux, R.; Hsu, J. Fast 3d recognition and pose using the viewpoint feature histogram. In Proceedings of the 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems, Taipei, Taiwan, 18–22 October 2010; pp. 2155–2162. [Google Scholar]
- Zhong, Y. Intrinsic shape signatures: A shape descriptor for 3d object recognition. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 689–696. [Google Scholar]
- Sipiran, I.; Bustos, B. Harris 3D: A robust extension of the Harris operator for interest point detection on 3D meshes. Vis. Comput. 2011, 27, 963. [Google Scholar] [CrossRef]
- Steder, B.; Rusu, R.B.; Konolige, K.; Burgard, W. NARF: 3D range image features for object recognition. In Workshop on Defining and Solving Realistic Perception Problems in Personal Robotics at the IEEE/RSJ Int. Conf. on Intelligent Robots and Systems (IROS); 2010; Volume 44, Available online: https://www.researchgate.net/publication/260320178_NARF_3D_Range_Image_Features_for_Object_Recognition?enrichId=rgreq-8976992b9b5ce6b1365b18388cdf9865-XXX&enrichSource=Y292ZXJQYWdlOzI2MDMyMDE3ODtBUzoxODU1NjExNjM3NzE5MDhAMTQyMTI1MjYzNzk5MQ%3D%3D&el=1_x_2&_esc=publicationCoverPdf (accessed on 20 November 2020).
- Tombari, F.; Salti, S.; Di Stefano, L. Unique shape context for 3D data description. In Proceedings of the ACM Workshop on 3D Object Retrieval, Firenze, Italy, 25–29 October 2010; pp. 57–62. [Google Scholar]
- Guo, Y.; Sohel, F.; Bennamoun, M.; Lu, M.; Wan, J. Rotational projection statistics for 3D local surface description and object recognition. Int. J. Comput. Vis. 2013, 105, 63–86. [Google Scholar] [CrossRef] [Green Version]
- Khoury, M.; Zhou, Q.Y.; Koltun, V. Learning compact geometric features. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 153–161. [Google Scholar]
- Harris, C.; Stephens, M. A combined corner and edge detector. In Alvey Vision Conference; Citeseer: University Park, PA, USA, 1988; Volume 15, pp. 10–5244. [Google Scholar]
- Frome, A.; Huber, D.; Kolluri, R.; Bülow, T.; Malik, J. Recognizing objects in range data using regional point descriptors. In European Conference on Computer Vision; Springer: New York, NY, USA, 2004; pp. 224–237. [Google Scholar]
- Rusu, R.B.; Blodow, N.; Marton, Z.C.; Beetz, M. Aligning point cloud views using persistent feature histograms. In Proceedings of the 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems, Nice, France, 22–26 September 2008; pp. 3384–3391. [Google Scholar]
- Zeng, A.; Song, S.; Nießner, M.; Fisher, M.; Xiao, J.; Funkhouser, T. 3dmatch: Learning local geometric descriptors from rgb-d reconstructions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 199–208. [Google Scholar]
- Gojcic, Z.; Zhou, C.; Wegner, J.D.; Andreas, W. The Perfect Match: 3D Point Cloud Matching with Smoothed Densities. In Proceedings of the International Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- Weinberger, K.Q.; Saul, L.K. Distance metric learning for large margin nearest neighbor classification. J. Mach. Learn. Res. 2009, 10, 207–244. [Google Scholar]
- Schultz, M.; Joachims, T. Learning a distance metric from relative comparisons. In Advances in Neural Information Processing Systems; Springer: New York, NY, USA, 2004; pp. 41–48. [Google Scholar]
- Li, L.; Zhu, S.; Fu, H.; Tan, P.; Tai, C.L. End-to-End Learning Local Multi-view Descriptors for 3D Point Clouds. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1919–1928. [Google Scholar]
- Deng, H.; Birdal, T.; Ilic, S. PPF-FoldNet: Unsupervised Learning of Rotation Invariant 3D Local Descriptors. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 602–618. [Google Scholar]
- Zhao, Y.; Birdal, T.; Deng, H.; Tombari, F. 3D Point Capsule Networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Birdal, T.; Ilic, S. Point pair features based object detection and pose estimation revisited. In Proceedings of the 2015 International Conference on 3D Vision, Lyon, France, 19–22 October 2015; pp. 527–535. [Google Scholar]
- Drost, B.; Ulrich, M.; Navab, N.; Ilic, S. Model globally, match locally: Efficient and robust 3D object recognition. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 998–1005. [Google Scholar]
- Yang, Y.; Feng, C.; Shen, Y.; Tian, D. FoldingNet: Point Cloud Auto-Encoder via Deep Grid Deformation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 206–215. [Google Scholar]
- Spezialetti, R.; Salti, S.; Stefano, L.D. Learning an Effective Equivariant 3D Descriptor Without Supervision. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Groueix, T.; Fisher, M.; Kim, V.G.; Russell, B.C.; Aubry, M. A Papier-Mâché Approach to Learning 3D Surface Generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 216–224. [Google Scholar]
- Cohen, T.S.; Geiger, M.; Köhler, J.; Welling, M. Spherical CNNs. arXiv 2018, arXiv:1801.10130. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Teran, L.; Mordohai, P. 3d interest point detection via discriminative learning. In European Conference on Computer Vision; Springer: New York, NY, USA, 2014; pp. 159–173. [Google Scholar]
- Mian, A.; Bennamoun, M.; Owens, R. On the repeatability and quality of keypoints for local feature-based 3d object retrieval from cluttered scenes. Int. J. Comput. Vis. 2010, 89, 348–361. [Google Scholar] [CrossRef] [Green Version]
- Kolluri, R.; Shewchuk, J.R.; O’Brien, J.F. Spectral surface reconstruction from noisy point clouds. In Proceedings of the 2004 Eurographics/ACM SIGGRAPH Symposium on Geometry Processing; ACM: New York, NY, USA, 2004; pp. 11–21. [Google Scholar]
- Rusu, R.B.; Cousins, S. 3d is here: Point cloud library (pcl). In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 1–4. [Google Scholar]
- Wang, M.; Deng, W. Deep Visual Domain Adaptation: A Survey. Neurocomputing 2018, 312, 135–153. [Google Scholar] [CrossRef] [Green Version]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | ||||||||
|---|---|---|---|---|---|---|---|---|
| UWA | 40 | 20 | 0.85 | 7 | 4 | 2 | 4 | 0.8 |
| Random Views | 40 | 20 | - | 7 | - | - | 4 | 0.8 |
| Model Name | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| Angel | 40 | 20 | 0.85 | 7 | 4 | 2 | - | - | - |
| Bimba | 40 | 20 | 0.85 | 7 | 4 | 2 | - | - | - |
| Bunny | 40 | 20 | 0.65 | 7 | 4 | 2 | - | - | - |
| Chinese Dragon | 40 | 20 | 0.65 | 7 | 4 | 2 | - | - | - |
| Armadillo | 40 | 20 | - | 7 | - | - | 2 | 4 | 0.5 |
| Buddha | 40 | 20 | - | 7 | - | - | 2 | 4 | 0.5 |
| Stanford Dragon | 40 | 20 | - | 7 | - | - | 2 | 4 | 0.5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Spezialetti, R.; Salti, S.; Di Stefano, L. Performance Evaluation of 3D Descriptors Paired with Learned Keypoint Detectors. AI 2021, 2, 229-243. https://doi.org/10.3390/ai2020014
Spezialetti R, Salti S, Di Stefano L. Performance Evaluation of 3D Descriptors Paired with Learned Keypoint Detectors. AI. 2021; 2(2):229-243. https://doi.org/10.3390/ai2020014
Chicago/Turabian StyleSpezialetti, Riccardo, Samuele Salti, and Luigi Di Stefano. 2021. "Performance Evaluation of 3D Descriptors Paired with Learned Keypoint Detectors" AI 2, no. 2: 229-243. https://doi.org/10.3390/ai2020014
APA StyleSpezialetti, R., Salti, S., & Di Stefano, L. (2021). Performance Evaluation of 3D Descriptors Paired with Learned Keypoint Detectors. AI, 2(2), 229-243. https://doi.org/10.3390/ai2020014