
A Real-Time Energy Consumption Minimization Framework for Electric Vehicles Routing Optimization Based on SARSA Reinforcement Learning



Abstract
1. Introduction
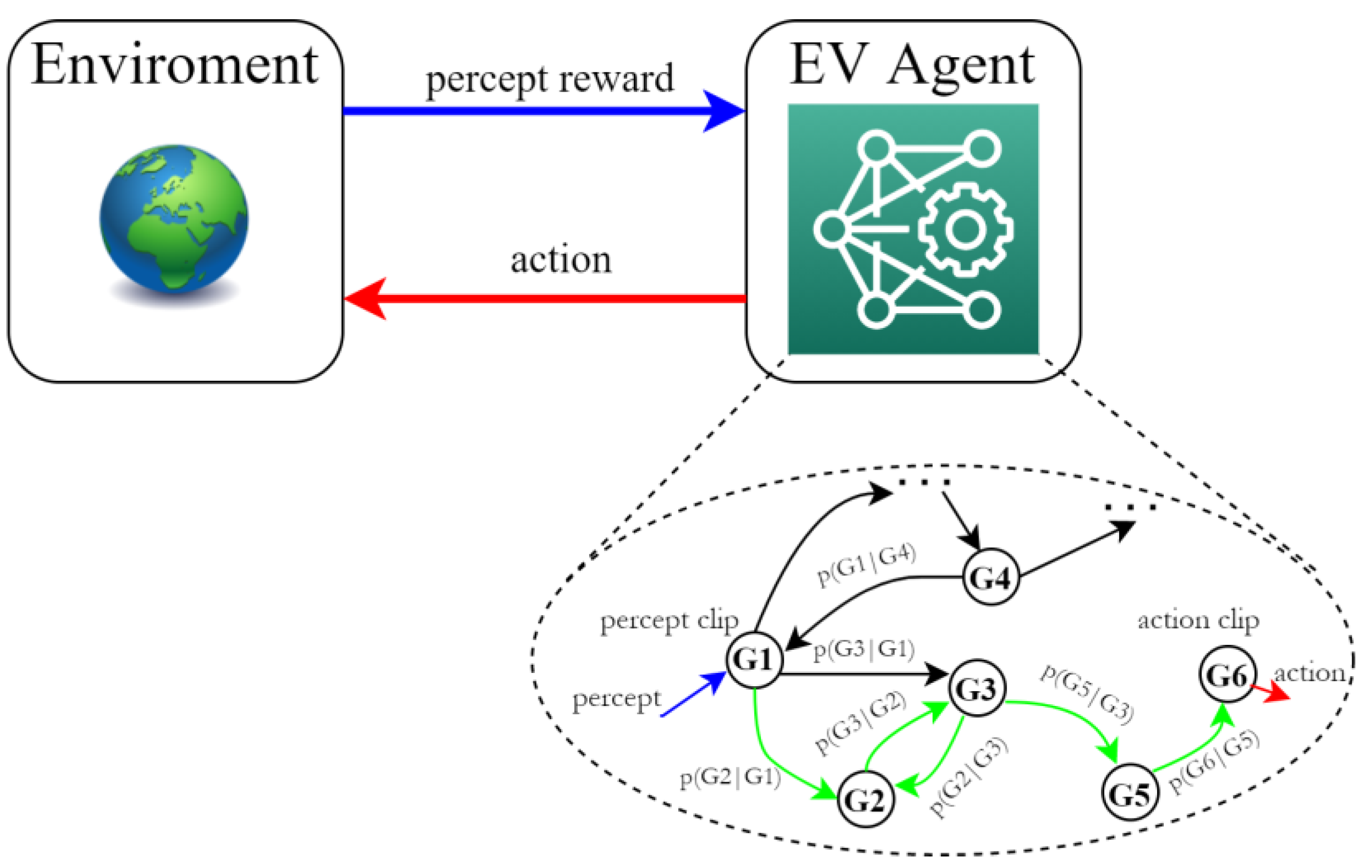
2. Reinforcement Learning
2.1. State–Action–Reward–State–Action (SARSA) Algorithm
2.2. Operation Modes
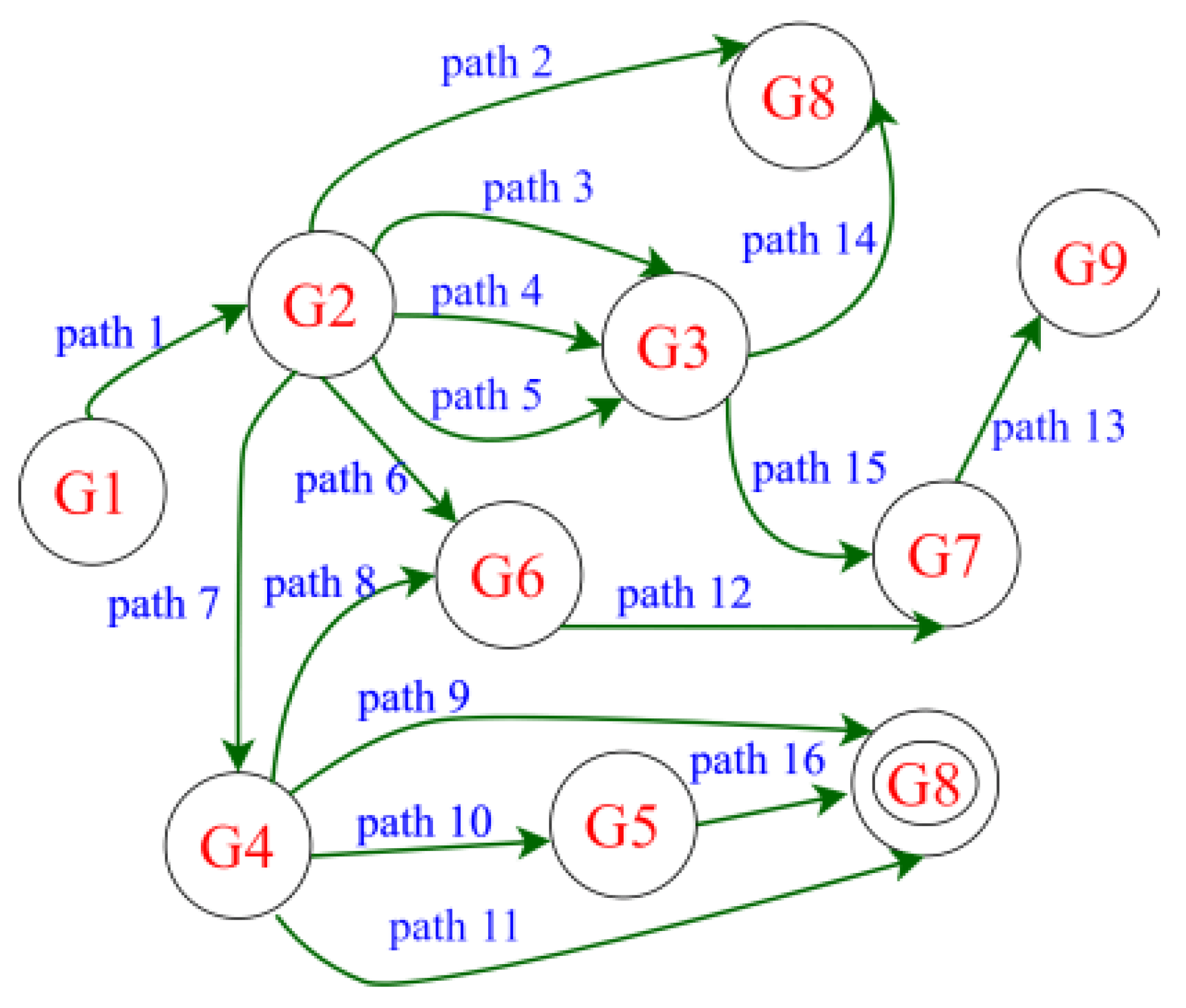
2.3. Markov Chain Modeling of the Traffic Dynamics
3. Application of the SARSA Algorithm to Solve the EV Routing Optimization
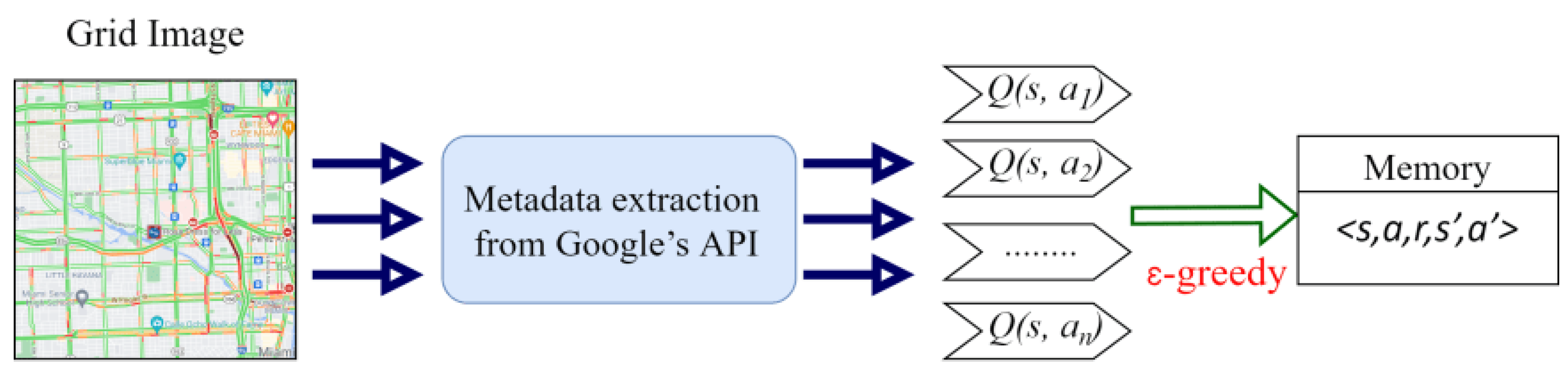
3.1. Real-Time Metadata Extraction from Google’s API
3.2. EV Energy Consumption in the MCM Traffic Model
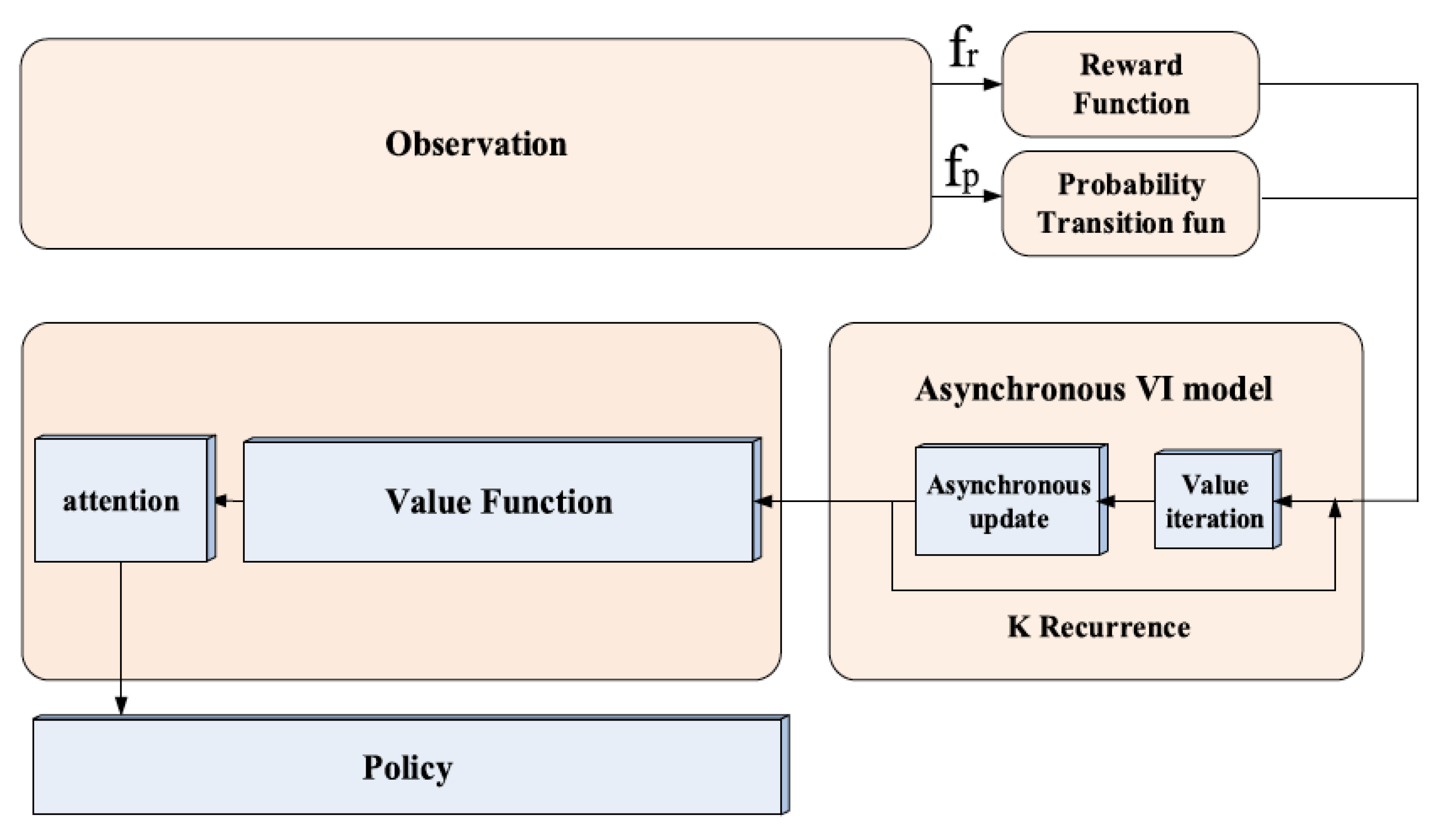
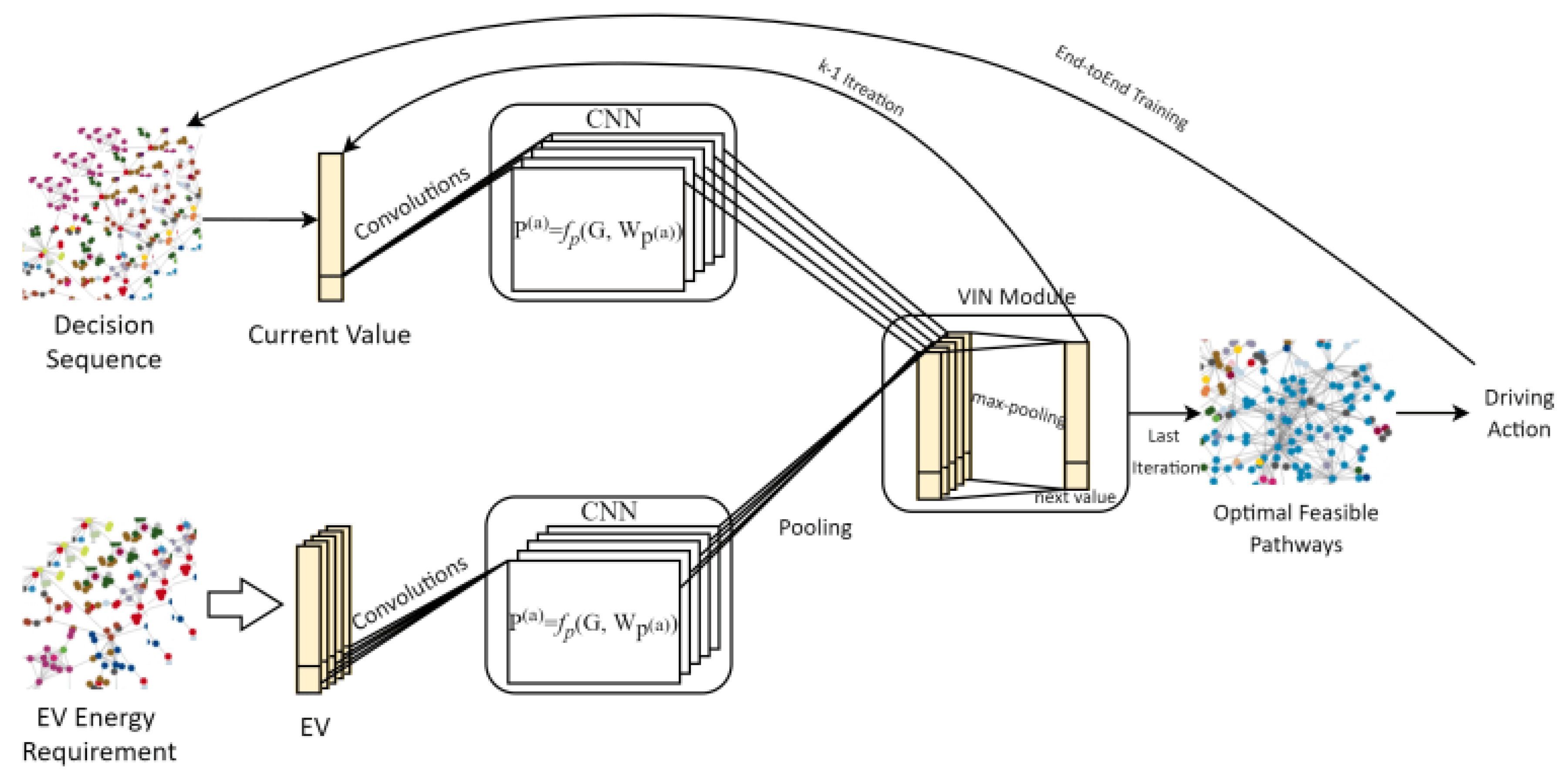
3.3. Value Iteration Network (VIN) Model
3.4. Experimental Modeling of the EV’s Battery
3.5. Impact of Regenerative Braking
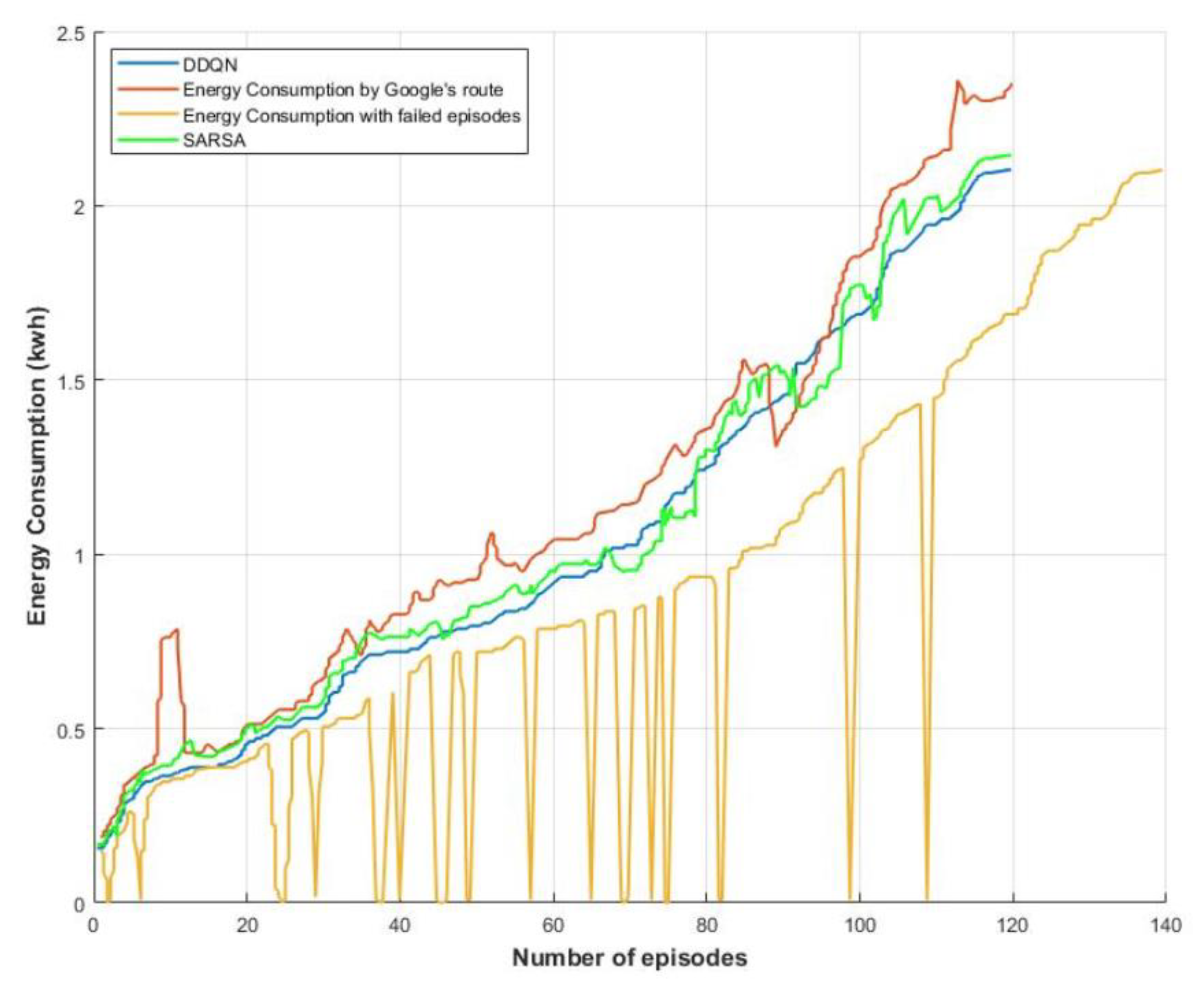
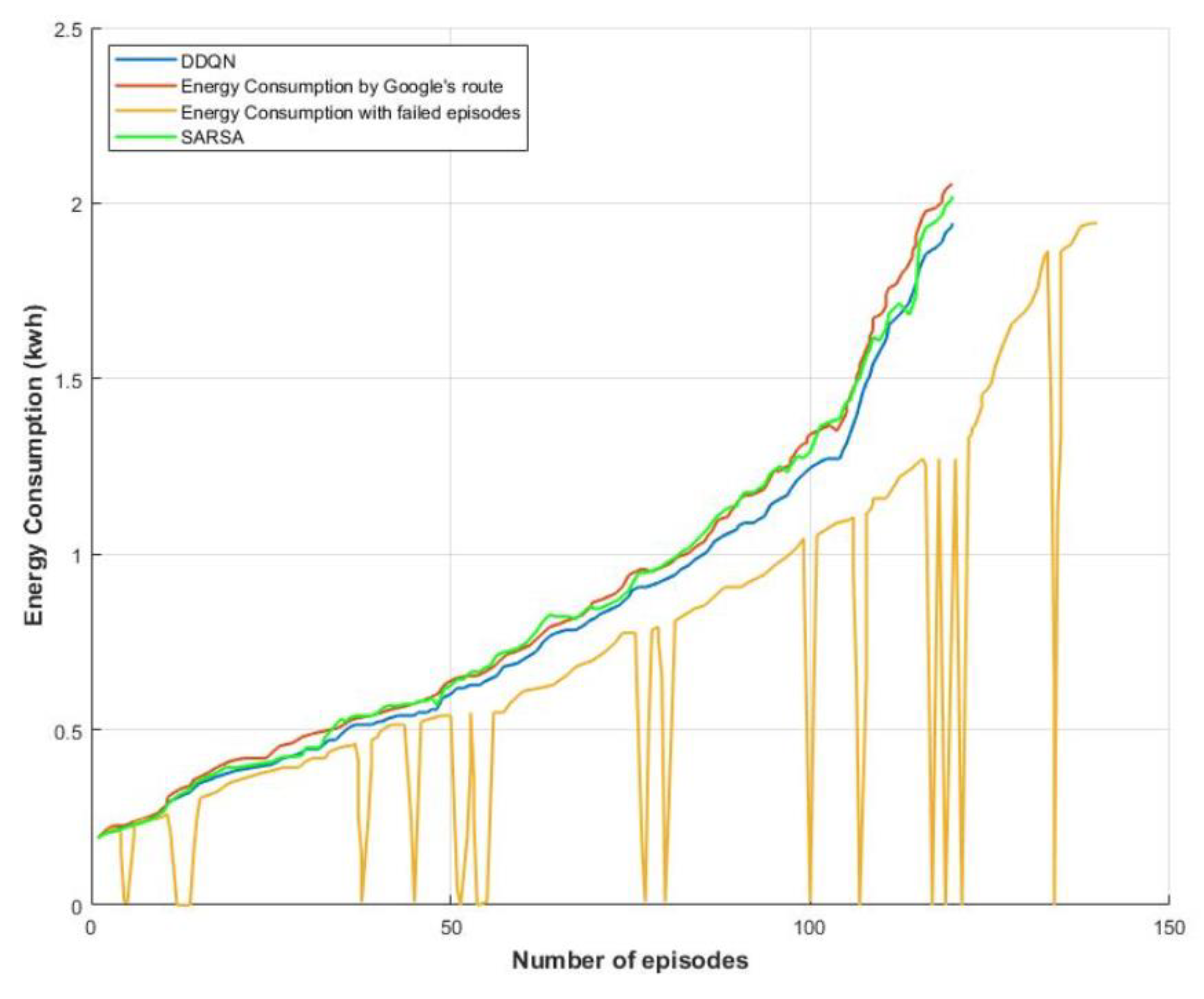
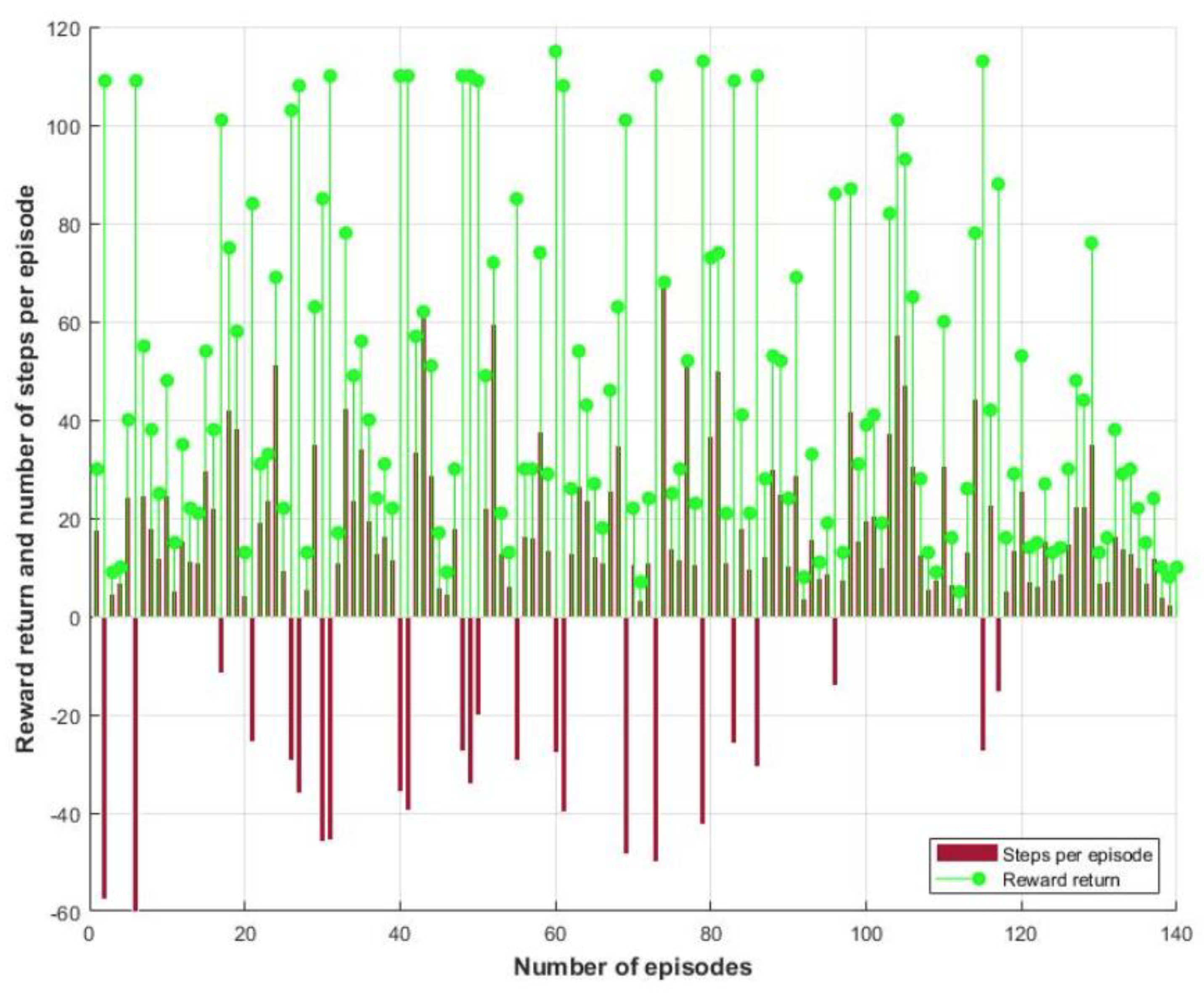
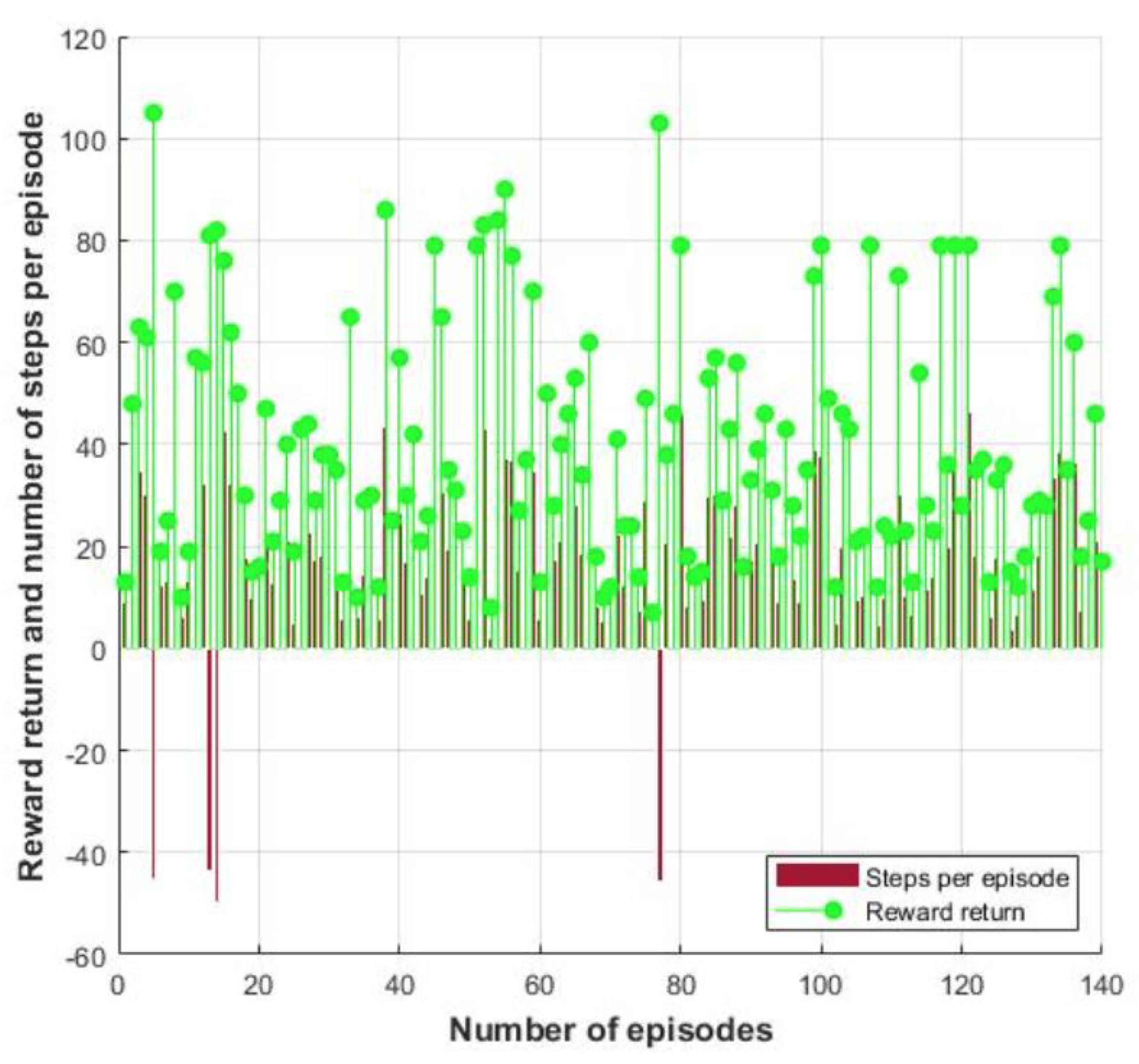
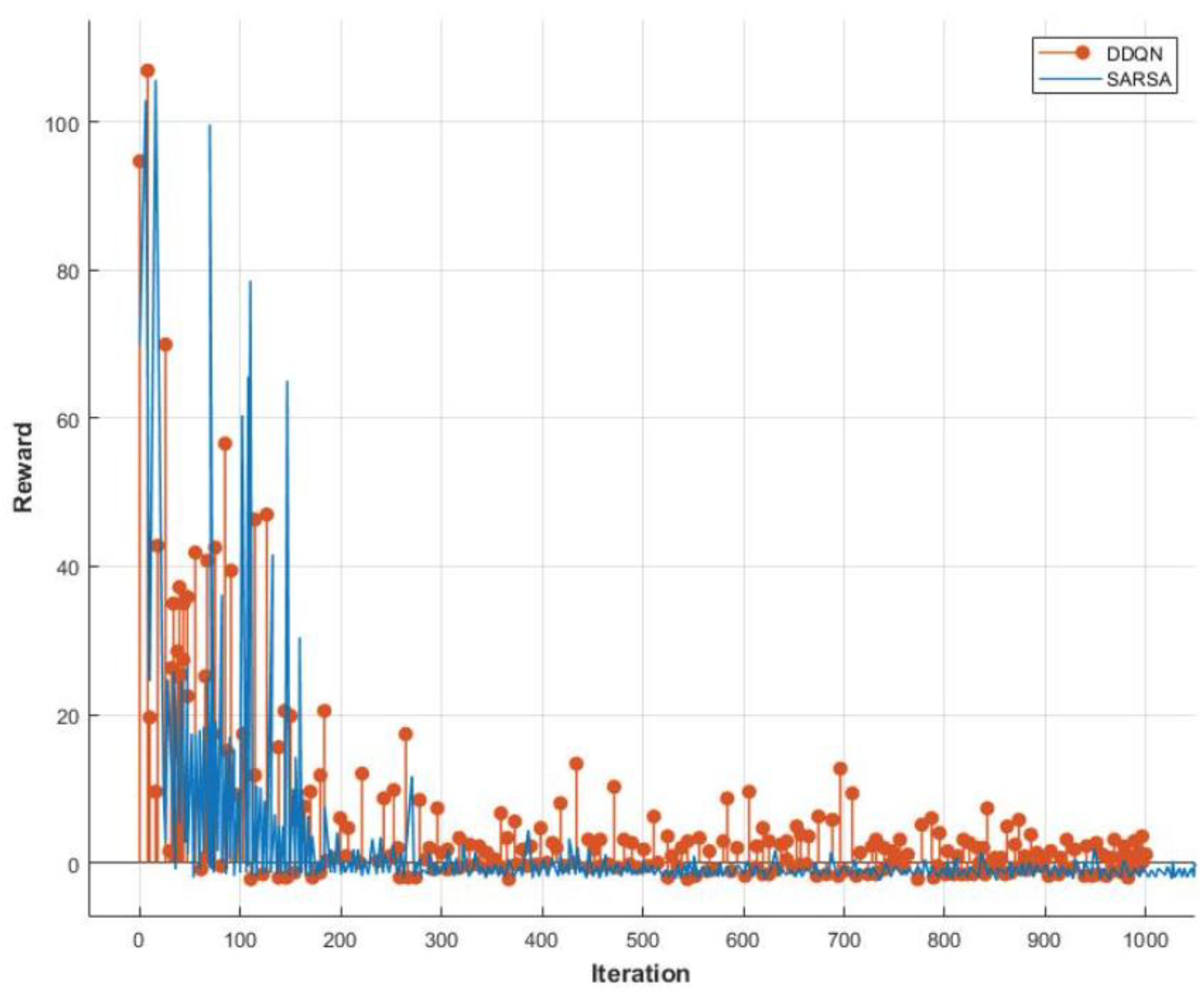
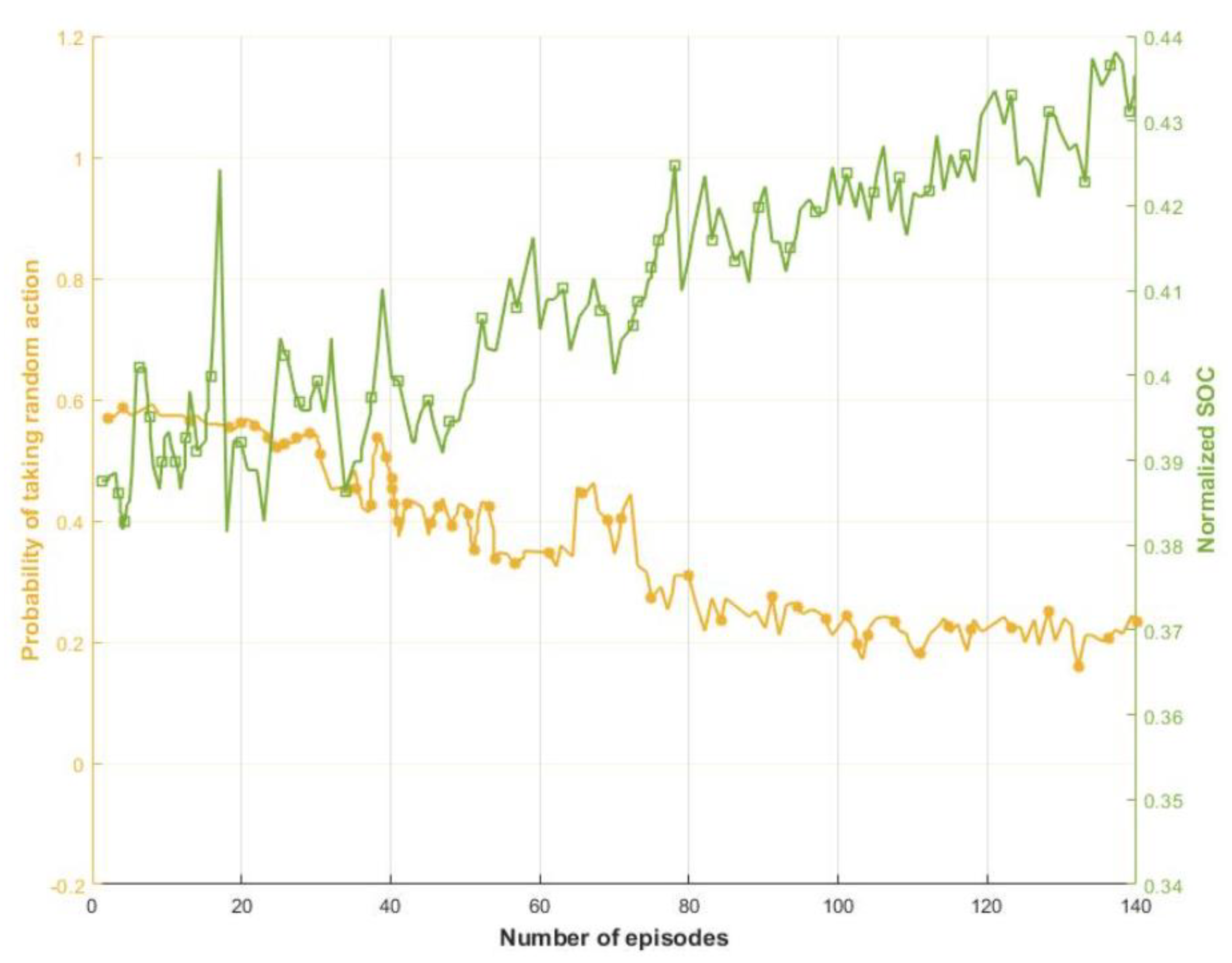
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pevec, D.; Babic, J.; Carvalho, A.; Ghiassi-Farrokhfal, Y.; Ketter, W.; Podobnik, V. Electric vehicle range anxiety: An obstacle for the personal transportation (r) evolution? In Proceedings of the 2019 4th International Conference on Smart and Sustainable Technologies (SpliTech), Split, Croatia, 18–21 June 2019; pp. 1–8. [Google Scholar]
- Kim, S.; Rhee, W.; Choi, D.; Jang, Y.J.; Yoon, Y. Characterizing Driver Stress Using Physiological and Operational Data from Real-World Electric Vehicle Driving Experiment. Int. J. Automot. Technol. 2018, 19, 895–906. [Google Scholar] [CrossRef]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. Proc. Conf. AAAI Artif. Intell. 2016, 30. [Google Scholar] [CrossRef]
- Aljohani, T.M.; Ebrahim, A.; Mohammed, O. Real-Time metadata-driven routing optimization for electric vehicle energy consumption minimization using deep reinforcement learning and Markov chain model. Electr. Power Syst. Res. 2021, 192, 106962. [Google Scholar] [CrossRef]
- Valogianni, K.; Ketter, W.; Collins, J.; Zhdanov, D. Effective management of electric vehicle storage using smart charging. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Liu, T.; Zou, Y.; Liu, D.; Sun, F. Reinforcement Learning of Adaptive Energy Management With Transition Probability for a Hybrid Electric Tracked Vehicle. IEEE Trans. Ind. Electron. 2015, 62, 7837–7846. [Google Scholar] [CrossRef]
- Qi, X.; Wu, G.; Boriboonsomsin, K.; Barth, M.; Gonder, J. Data-Driven Reinforcement Learning–Based Real-Time Energy Management System for Plug-In Hybrid Electric Vehicles. Transp. Res. Rec. J. Transp. Res. Board 2016, 2572, 1–8. [Google Scholar] [CrossRef]
- Remani, T.; Jasmin, E.A.; Ahamed, T.P.I. Residential Load Scheduling With Renewable Generation in the Smart Grid: A Reinforcement Learning Approach. IEEE Syst. J. 2018, 13, 3283–3294. [Google Scholar] [CrossRef]
- Rocchetta, R.; Bellani, L.; Compare, M.; Zio, E.; Patelli, E. A reinforcement learning framework for optimal operation and maintenance of power grids. Appl. Energy 2019, 241, 291–301. [Google Scholar] [CrossRef]
- Ye, Y.; Qiu, D.; Sun, M.; Papadaskalopoulos, D.; Strbac, G. Deep Reinforcement Learning for Strategic Bidding in Electricity Markets. IEEE Trans. Smart Grid 2019, 11, 1343–1355. [Google Scholar] [CrossRef]
- Perrusquía, A.; Yu, W.; Li, X. Multi-agent reinforcement learning for redundant robot control in task-space. Int. J. Mach. Learn. Cybern. 2021, 12, 231–241. [Google Scholar] [CrossRef]
- Brunke, L.; Greeff, M.; Hall, A.W.; Yuan, Z.; Zhou, S.; Panerati, J.; Schoellig, A.P. Safe Learning in Robotics: From Learning-Based Control to Safe Reinforcement Learning. Annu. Rev. Control. Robot. Auton. Syst. 2022, 5, 411–444. [Google Scholar] [CrossRef]
- Wang, Z.; He, H.; Wan, Z.; Sun, Y.L. Coordinated Topology Attacks in Smart Grid Using Deep Reinforcement Learning. IEEE Trans. Ind. Inform. 2020, 17, 1407–1415. [Google Scholar] [CrossRef]
- An, D.; Yang, Q.; Liu, W.; Zhang, Y. Defending Against Data Integrity Attacks in Smart Grid: A Deep Reinforcement Learning-Based Approach. IEEE Access 2019, 7, 110835–110845. [Google Scholar] [CrossRef]
- Oh, S.-Y.; Lee, J.-H.; Choi, D.-H. A new reinforcement learning vehicle control architecture for vision-based road following. IEEE Trans. Veh. Technol. 2000, 49, 997–1005. [Google Scholar]
- Barrett, E.; Howley, E.; Duggan, J. Applying reinforcement learning towards automating resource allocation and application scalability in the cloud. Concurr. Comput. 2013, 25, 1656–1674. [Google Scholar] [CrossRef]
- Liu, W.; Qin, G.; He, Y.; Jiang, F. Distributed Cooperative Reinforcement Learning-Based Traffic Signal Control That Integrates V2X Networks’ Dynamic Clustering. IEEE Trans. Veh. Technol. 2017, 66, 8667–8681. [Google Scholar] [CrossRef]
- Huang, X.; Yuan, T.; Qiao, G.; Ren, Y. Deep Reinforcement Learning for Multimedia Traffic Control in Software Defined Networking. IEEE Netw. 2018, 32, 35–41. [Google Scholar] [CrossRef]
- Ortiz, A.; Al-Shatri, H.; Li, X.; Weber, T.; Klein, A. Reinforcement learning for energy harvesting point-to-point communications. In Proceedings of the 2016 IEEE International Conference on Communications (ICC), Kuala Lumpur, Malaysia, 22–27 May 2016; pp. 1–6. [Google Scholar]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.-C.; Kim, D.I. Applications of Deep Reinforcement Learning in Communications and Networking: A Survey. IEEE Commun. Surv. Tutorials 2019, 21, 3133–3174. [Google Scholar] [CrossRef]
- Wang, S.; Bi, S.; Zhang, Y.J.A. Reinforcement Learning for Real-Time Pricing and Scheduling Control in EV Charging Stations. IEEE Trans. Ind. Inform. 2019, 17, 849–859. [Google Scholar] [CrossRef]
- Aladdin, S.; El-Tantawy, S.; Fouda, M.M.; Eldien, A.S.T. MARLA-SG: Multi-Agent Reinforcement Learning Algorithm for Efficient Demand Response in Smart Grid. IEEE Access 2020, 8, 210626–210639. [Google Scholar] [CrossRef]
- Wang, D.; Liu, B.; Jia, H.; Zhang, Z.; Chen, J.; Huang, D. Peer-to-peer electricity transaction decision of user-side smart energy system based on SARSA reinforcement learning method. CSEE J. Power Energy Syst. 2020, 8, 826–837. [Google Scholar]
- Parque, V.; Kobayashi, M.; Higashi, M. Reinforced explorit on optimizing vehicle powertrains. In Proceedings of the International Conference on Neural Information Processing, Daegu, Korea, 3–7 November 2013; Springer: Berlin/Heidelberg, Germany, 2013; pp. 579–586. [Google Scholar]
- Kouche-Biyouki, S.A.; Naseri-Javareshk, S.M.A.; Noori, A.; Javadi-Hassanehgheh, F. Power management strategy of hybrid vehicles using sarsa method. In Proceedings of the Electrical Engineering (ICEE), Mashhad, Iran, 8–10 May 2018; pp. 946–950. [Google Scholar]
- Noel, L.; de Rubens, G.Z.; Sovacool, B.K.; Kester, J. Fear and loathing of electric vehicles: The reactionary rhetoric of range anxiety. Energy Res. Soc. Sci. 2019, 48, 96–107. [Google Scholar] [CrossRef]
- Rummery, G.A.; Niranjan, M. On-Line Q-Learning Using Connectionist Systems; Department of Engineering, University of Cambridge: Cambridge, UK, 1994; Volume 37, p. 20. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Cybenko, G. Approximation by superpositions of a sigmoidal function. Math. Control. Signals, Syst. 1989, 2, 303–314. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. “A fast learning algorithm for deep belief nets” _(PDF). Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Kumar, V. Reinforcement Learning: Temporal-Difference, SARSA, Q-Learning & Expected Sarsa on Python. Medium. Available online: https://towardsdatascience.com/reinforcement-learning-temporal-difference-sarsa-q-learning-expected-sarsa-on-python-9fecfda7467e (accessed on 12 May 2021).
- Froyland, G. Extracting dynamical behavior via Markov models. In Nonlinear Dynamics and Statistics; Birkhauser: Boston, MA, USA, 2001; pp. 281–321. [Google Scholar]
- Maia, R.; Silva, M.; Araujo, R.; Nunes, U. Electric vehicle simulator for energy consumption studies in electric mobility systems. In Proceedings of the IEEE Forum on Integrated and Sustainable Transportation Systems, Vienna, Austria, 29 June–1 July 2011; pp. 227–232. [Google Scholar]
- Schlote Crisostomi, E.S.; Kirkland, R.; Shorten, R. Traffic modelling framework for electric vehicles. Int. J. Control 2012, 85, 880–897. [Google Scholar] [CrossRef]
- Crisostomi, E.; Kirkland, S.; Shorten, R. Markov Chain based emissions models: A precursor for green control. In Green IT: Technologies and Applications; Kim, J.H., Lee, M.J., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 381–400. [Google Scholar]
- Apostolaki-Iosifidou, E.; Codani, P.; Kempton, W. Measurement of power loss during electric vehicle charging and discharging. Energy 2017, 127, 730–742. [Google Scholar] [CrossRef]
- Tamar, A.; Wu, Y.; Thomas, G.S.; Levine; Abbeel, P. Value iteration networks. Adv. Neural Inf. Process. Syst. 2016, 9, 2146–2154. [Google Scholar]
- Gold, S. A PSPICE macromodel for lithium-ion batteries. In Proceedings of the 12th Annual Battery Conference on Applications and Advances, Long Beach, CA, USA, 14–17 January 1997; pp. 215–222. [Google Scholar]
- Kroeze, R.C.; Krein, P.T. Electrical battery model for use in dynamic electric vehicle simulations. In Proceedings of the 2008 IEEE Power Electronics Specialists Conference, Rhodes, Greece, 15–19 June 2008; pp. 1336–1342. [Google Scholar]
- Chen, M.; Rincon-Mora, G.A. Accurate electrical battery model capable of predicting runtime and I-V performance. IEEE Trans. Energy Convers. 2006, 21, 504–511. [Google Scholar] [CrossRef]
- Schweighofer, B.; Raab, K.M.; Brasseur, G. Modeling of high-power automotive batteries by the use of an automated test system. IEEE Trans. Instrum. Meas. 2003, 52, 1087–1091. [Google Scholar] [CrossRef]
- Gao, L.; Liu, S.; Dougal, R. Dynamic lithium-ion battery model for system simulation. IEEE Trans. Components Packag. Technol. 2002, 25, 495–505. [Google Scholar]
- Sun, C.; Moura, S.J.; Hu, X.; Hedrick, J.K.; Sun, F. Dynamic Traffic Feedback Data Enabled Energy Management in Plug-in Hybrid Electric Vehicles. IEEE Trans. Control Syst. Technol. 2015, 23, 1075–1086. [Google Scholar]
- Aljohani, T.M. Distribution System Reliability Analysis for Smart Grid Applications; University of Southern California: Los Angeles, CA, USA, 2014. [Google Scholar]
- Aljohani, T.M.; Beshir, M.J. Matlab code to assess the reliability of the smart power distribution system using monte carlo simulation. J. Power Energy Eng. 2017, 5, 30–44. [Google Scholar] [CrossRef]
- Alqahtani, M.; Hu, M. Dynamic energy scheduling and routing of multiple electric vehicles using deep reinforcement learning. Energy 2022, 244, 122626. [Google Scholar] [CrossRef]
- Aljohani, T.M.; Ebrahim, A.F.; Mohammed, O.A. Dynamic real-time pricing mechanism for electric vehicles charging considering optimal microgrids energy management system. IEEE Trans. Ind. Appl. 2021, 57, 5372–5381. [Google Scholar] [CrossRef]
- Yang, T.; Zhao, L.; Li, W.; Zomaya, A.Y. Reinforcement learning in sustainable energy and electric systems: A survey. Annu. Rev. Control. 2020, 49, 145–163. [Google Scholar] [CrossRef]
- Aljohani, T.M. Cyberattacks on Energy Infrastructures: Modern War Weapons. arXiv 2022, arXiv:2208.14225. [Google Scholar]
- Hariri, A.; El Hariri, M.; Youssef, T.; Mohammed, O. Systems and Methods for Electric Vehicle Charging Decision Support System. U.S. Patent 10,507,738, 17 December 2019. [Google Scholar]
- Dini, P.; Saponara, S. Processor-in-the-Loop Validation of a Gradient Descent-Based Model Predictive Control for Assisted Driving and Obstacles Avoidance Applications. IEEE Access 2022, 10, 67958–67975. [Google Scholar] [CrossRef]
- Ramstedt, S.; Pal, C. Real-time reinforcement learning. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; p. 32. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SARSA Algorithm |
|---|
|
| Parameter | Value |
|---|---|
| Gravity force (g) | 9.81 m/s2 |
| Air density constant (P) | 1.2 kg/m3 |
| Rolling resistance ( | 0.01 |
| Drag coefficient (Cd) | 0.35 |
| Forward air area (A) | 1.6 |
| Acceleration constant (a1) | 3.5 m/s2 |
| Deceleration constant (a2) | −3.5 m/s2 |
| Mass of EV (m) | 1961 kg |
| Simulated Trips | Starting Geocodes | Destination Geocodes | Energy by SARSA | Energy by Google’s Routes | Energy from Regenerative Braking | Simulation Time |
|---|---|---|---|---|---|---|
| FIU College of Engineering–Doral EV Charging Station | 25.768506–80.366891 | 25.809732–80.331379 | 2.1305 Kwh at 21 min | 2.3949 Kwh at 19 min | Negligible | 3112 s |
| J. Paul Getty Museum -Ventura EV Charging Station | 34.077823–118.475863 | 34.158980–118.49994 | 2.0501 Kwh at 25 min | 2.1748 at 22 min | 0.191 Kwh | 2680 s |
| Simulated Trips | No. of Episode | No. of Failed Step | Steps | Unreachable Positions |
|---|---|---|---|---|
| First Trip | 140 | 20 | 5715 | 1711 |
| Second Trip | 143 | 18 | 7226 | 1501 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aljohani, T.M.; Mohammed, O. A Real-Time Energy Consumption Minimization Framework for Electric Vehicles Routing Optimization Based on SARSA Reinforcement Learning. Vehicles 2022, 4, 1176-1194. https://doi.org/10.3390/vehicles4040062
Aljohani TM, Mohammed O. A Real-Time Energy Consumption Minimization Framework for Electric Vehicles Routing Optimization Based on SARSA Reinforcement Learning. Vehicles. 2022; 4(4):1176-1194. https://doi.org/10.3390/vehicles4040062
Chicago/Turabian StyleAljohani, Tawfiq M., and Osama Mohammed. 2022. "A Real-Time Energy Consumption Minimization Framework for Electric Vehicles Routing Optimization Based on SARSA Reinforcement Learning" Vehicles 4, no. 4: 1176-1194. https://doi.org/10.3390/vehicles4040062
APA StyleAljohani, T. M., & Mohammed, O. (2022). A Real-Time Energy Consumption Minimization Framework for Electric Vehicles Routing Optimization Based on SARSA Reinforcement Learning. Vehicles, 4(4), 1176-1194. https://doi.org/10.3390/vehicles4040062