
Examining and Improving the Gender and Language DIF in the VERA 8 Tests


Abstract
1. Introduction
- 1.a.
- Which items in the VERA tests demonstrate DIF across the gender and language groups?
- 1.b.
- Does using a better-fitted model improve bias items on the subtests and subgroups?
- 2.
- What is the effect of the misfit items on the proficiency classifications?
2. Materials and Methods
2.1. The VERA Assessment
2.2. Datasets
2.3. Study Design
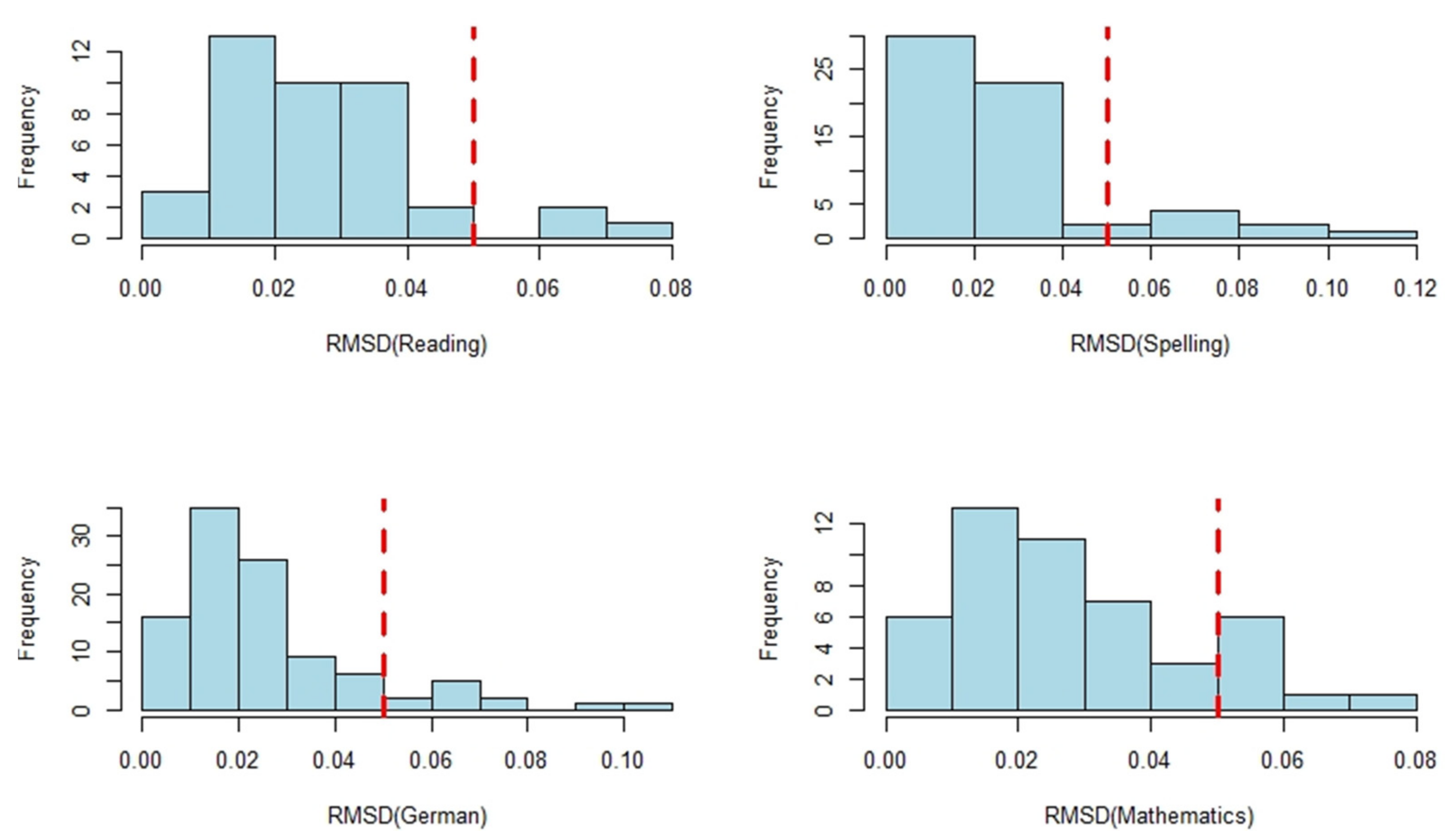
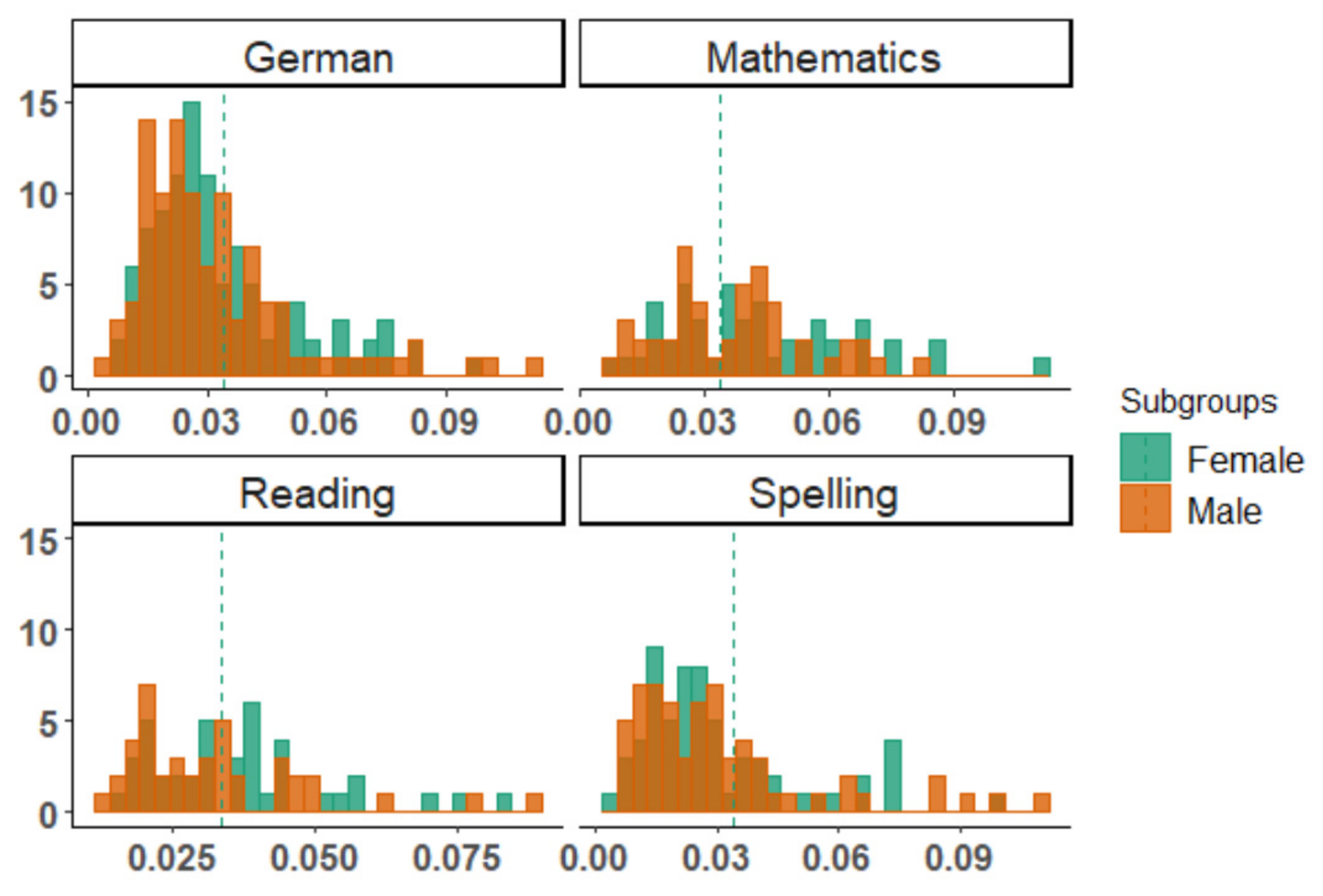
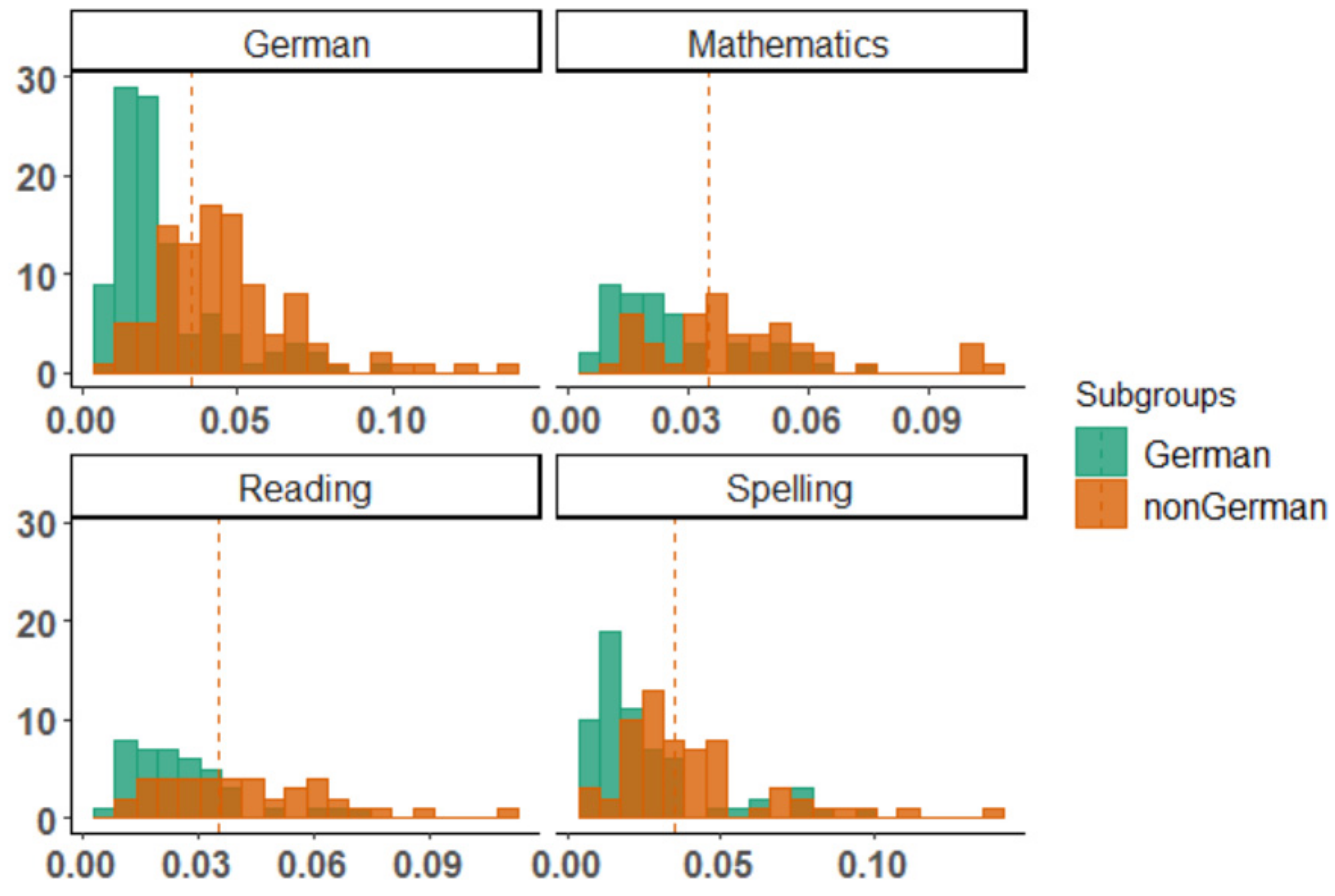
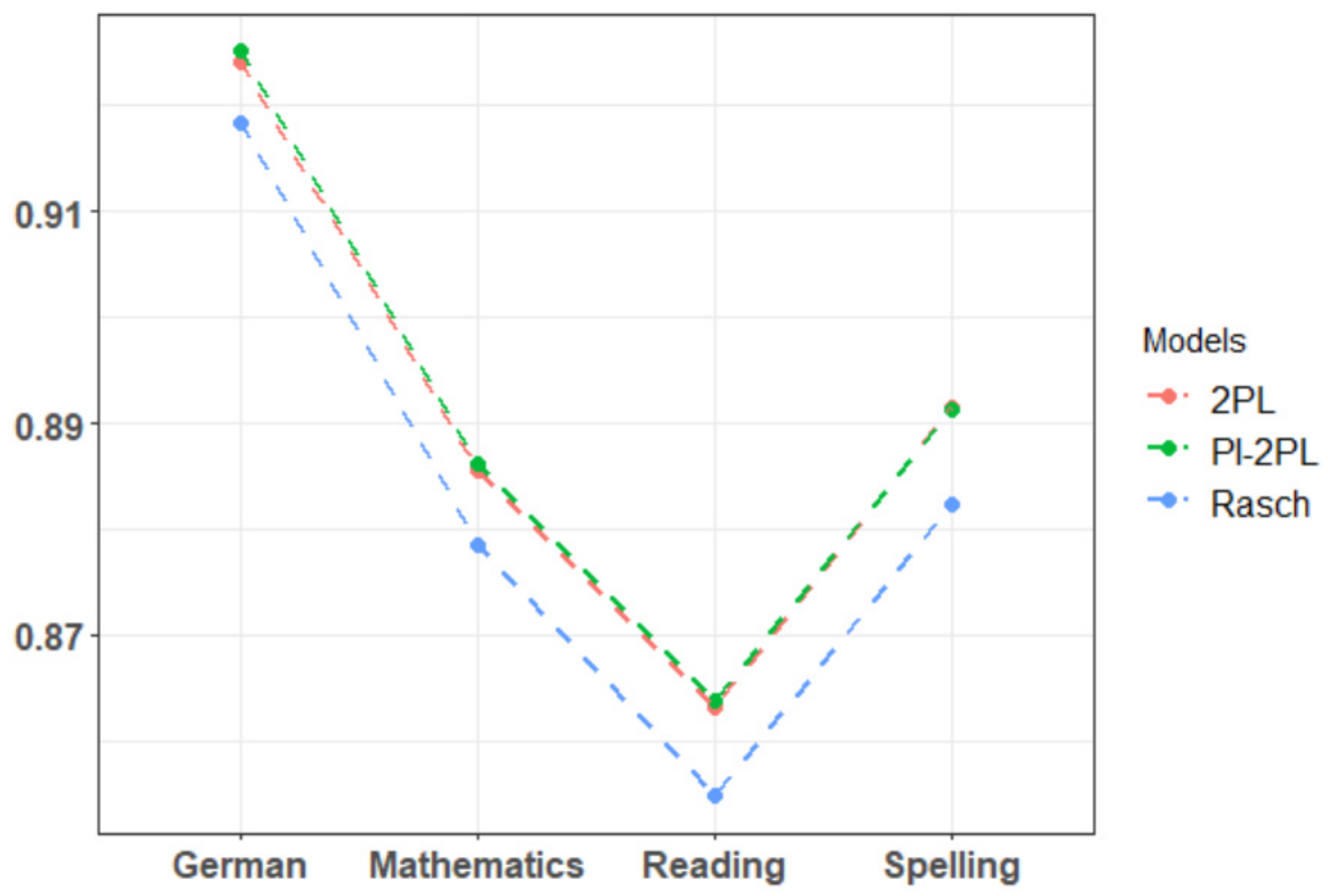
3. Results
4. Discussion
Supplementary Materials
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kim, S.; Robin, F. An Empirical Investigation of the Potential Impact of Item Misfit on Test Scores. ETS Res. Rep. Ser. 2017, 2017, 1–11. [Google Scholar] [CrossRef][Green Version]
- Reise, S.P.; Widaman, K.F.; Pugh, R.H. Confirmatory factor analysis and item response theory: Two approaches for exploring measurement invariance. Psychol. Bull. 1993, 114, 552–566. [Google Scholar] [CrossRef] [PubMed]
- Angoff, W.H. Perspectives on differential item functioning methodology. In Differential Item Functioning; Holland, P.W., Wainer, H., Eds.; Erlbaum: Mahwah, NJ, USA, 1993; pp. 3–23. [Google Scholar]
- Dorans, N.J.; Holland, P.W. DIF detection and description: Mantel-Haenszel and standardization. In Differential Item Functioning; Holland, P.W., Wainer, H., Eds.; Erlbaum: Hillsdale, NJ, USA, 1993; pp. 35–66. ISBN 978-0-7879-5301-0. [Google Scholar]
- Raju, N.S.; Ellis, B.B. Differential item and test functioning. In Measuring and Analyzing Behavior in Organizations: Advances in Measurement and Data Analysis; Drasgow, F., Schmitt, N., Eds.; Jossey-Bass: San Francisco, CA, USA, 2002; pp. 156–188. ISBN 978-0-787-95301-0. [Google Scholar]
- Oliveri, M.; Ercikan, K.; Zumbo, B. Analysis of Sources of Latent Class Differential Item Functioning in International Assessments. Int. J. Test. 2013, 13, 272–293. [Google Scholar] [CrossRef]
- Lafontaine, D.; Monseur, C. Gender Gap in Comparative Studies of Reading Comprehension: To What Extent Do the Test Characteristics Make a Difference? Eur. Educ. Res. J. 2009, 8, 69–79. [Google Scholar] [CrossRef]
- Fischer, J.; Praetorius, A.K.; Klieme, E. The impact of linguistic similarity on cross-cultural comparability of students’ perceptions of teaching quality. Educ. Assess. Eval. Account. 2019, 31, 201–220. [Google Scholar] [CrossRef]
- Borgonovi, F.; Greiff, S. Societal level gender inequalities amplify gender gaps in problem solving more than in academic disciplines. Intelligence. 2020, 79, 101422. [Google Scholar] [CrossRef]
- Oliden, P.E.; Lizaso, J.M. Invariance levels across language versions of the PISA 2009 reading comprehension tests in Spain. Psicothema 2013, 25, 390–395. [Google Scholar]
- Robitzsch, A.; Lüdtke, O. Mean Comparisons of Many Groups in the Presence of DIF: An Evaluation of Linking and Concurrent Scaling Approaches. J. Educ. Behav. Stat. 2022, 47, 36–68. [Google Scholar] [CrossRef]
- Lee, S.S.; von Davier, M. Improving measurement properties of the PISA home possessions scale through partial invariance modeling. Psychol. Assess. 2020, 62, 55–83. [Google Scholar]
- Oliveri, M.E.; von Davier, M. Investigation of model fit and score scale comparability in international assessments. Psychol. Test Assess. Model. 2011, 53, 315–333. [Google Scholar]
- Oliveri, M.E.; von Davier, M. Toward increasing fairness in score scale calibrations employed in international large-scale assessments. Int. J. Test. 2014, 14, 1–21. [Google Scholar] [CrossRef]
- Yamamoto, K.; Khorramdel, L.; von Davier, M. Scaling PIAAC Cognitive Data. In Organisation for Economic Co-Operation and Development; Technical Report of the Survey of Adult Skills (PIAAC); OECD Publishing: Paris, France, 2013; pp. 406–438. Available online: https://www.oecd.org/skills/piaac/PIAAC%20Tech%20Report_Section%205_update%201SEP14.pdf (accessed on 8 June 2022).
- Buchholz, J.; Hartig, J. Measurement invariance testing in questionnaires: A comparison of three Multigroup-CFA and IRT-based approaches. Psychol. Test Assess. Model. 2020, 62, 29–53. [Google Scholar]
- Camilli, G. Test Fairness. In Educational Measurement, 4th ed.; Brennan, R., Ed.; American Council on Education and Praeger: Westport, CT, USA, 2006; pp. 221–256. [Google Scholar]
- Penfield, R.D.; Camilli, G. Differential item functioning and item bias. In Handbook of Statistics, Volume 26: Psychometrics; Rao, C.R., Sinharay, S., Eds.; Routledge: Oxford, UK, 2007; pp. 125–167. [Google Scholar]
- Robitzsch, A. On the Choice of the Item Response Model for Scaling PISA Data: Model Selection Based on Information Criteria and Quantifying Model Uncertainty. Entropy 2022, 24, 760. [Google Scholar] [CrossRef]
- Robitzsch, A. Robust and Nonrobust Linking of Two Groups for the Rasch Model with Balanced and Unbalanced Random DIF: A Comparative Simulation Study and the Simultaneous Assessment of Standard Errors and Linking Errors with Resampling Techniques. Symmetry 2021, 13, 2198. [Google Scholar] [CrossRef]
- Jerrim, J.; Parker, P.; Choi, A.; Chmielewski, A.K.; Salzer, C.; Shure, N. How robust are cross-country comparisons of PISA scores to the scaling model used? Educ. Meas. 2018, 37, 28–39. [Google Scholar] [CrossRef]
- Berk, R.A.; Brown, L.D.; Buja, A.; George, E.I.; Pitkin, E.; Zhang, K.; Zhao, L. Misspecified Mean Function Regression: Making Good Use of Regression Models That Are Wrong. Sociol. Methods Res. 2014, 43, 422–451. [Google Scholar] [CrossRef]
- White, H. Maximum likelihood estimation of misspecified models. Econometrica 1982, 50, 1–25. [Google Scholar] [CrossRef]
- Schult, J.; Wagner, S. VERA 3 in Baden-Württemberg 2019 (Beiträge zur Bildungsberichterstattung); Institut für Bildungsanalysen Baden-Württemberg: Stuttgart, Germany, 2019; Available online: https://ibbw.kultus-bw.de/site/pbs-bw-new/get/documents/KULTUS.Dachmandant/KULTUS/Dienststellen/ibbw/Systemanalysen/Bildungsberichterstattung/Ergebnisberichte/VERA_3/Ergebnisse_VERA3_2019.pdf (accessed on 8 June 2022).
- Schult, J.; Wagner, S. VERA 8 in Baden-Württemberg 2019 (Beiträge zur Bildungsberichterstattung); Institut für Bildungsanalysen Baden-Württemberg: Stuttgart, Germany, 2019; Available online: https://ibbw.kultus-bw.de/site/pbs-bw-km-root/get/documents_E-56497547/KULTUS.Dachmandant/KULTUS/Dienststellen/ibbw/Systemanalysen/Bildungsberichterstattung/Ergebnisberichte/VERA_8/Ergebnisse_VERA8_2019.pdf (accessed on 8 June 2022).
- Kuhl, P.; Harych, P.; Vogt, A. VERA 3: Vergleichsarbeiten in der Jahrgangsstufe 3 im Schuljahr 2009/2010; Länderbericht; Institut für Schulqualität der Länder Berlin und Brandenburg e.V. (ISQ): Berlin, Germany, 2011; Available online: https://nbn-resolving.org/urn:nbn:de:0168-ssoar-333539 (accessed on 8 June 2022).
- Spoden, C.; Leutner, D. Vergleichsarbeiten. 2011. Available online: https://www.pedocs.de/frontdoor.php?source_opus=10749 (accessed on 8 June 2022).
- Weis, M.; Müller, K.; Mang, J.; Heine, J.-H.; Mahler, N.; Reiss, K. Soziale Herkunft, Zuwanderungshintergrund und Lesekompetenz [Social and migrational backgound and reading competence]. In PISA 2018. Grundbildung im Internationalen Vergleich [figPISA 2018. Education Considered in an Internationally Comparative Context]; Reiss, K., Weis, M., Klieme, E., Köller, O., Eds.; Waxmann: Münster, Germany; New York, NY, USA, 2019; pp. 129–162. [Google Scholar] [CrossRef]
- Wagner, I.; Loesche, P.; Bißantz, S. Low-stakes performance testing in Germany by the VERA assessment: Analysis of the mode effects between computer-based testing and paper-pencil testing. Eur. J. Psychol. Educ. 2021, 37, 531–549. [Google Scholar] [CrossRef]
- Rasch, G. Studies in Mathematical Psychology: I. Probabilistic Models for Some Intelligence and Attainment Tests; Nielsen & Lydiche: Oxford, UK, 1960. [Google Scholar]
- Birnbaum, A. Some latent trait models and their use in inferring a student’s ability. In Statistical Theories of Mental Test Scores; Lord, F.M., Novick, M.R., Eds.; Addison-Wesley: Reading, MA, USA, 1968; pp. 397–479. [Google Scholar]
- Mantel, N.; Haenszel, W. Statistical Aspects of the Analysis of Data from Retrospective Studies of Disease. J. Natl. Cancer Inst. 1959, 22, 19–748. [Google Scholar]
- Swaminathan, H.; Rogers, H.J. Detecting differential item functioning using logistic regression procedures. J. Educ. Meas. 1990, 27, 361–370. [Google Scholar] [CrossRef]
- Thissen, D.; Steinberg, L.; Wainer, H. Detection of differential item functioning using the parameters of item response models. In Differential Item Functioning; Holland, P.W., Wainer, H., Eds.; Erlbaum: Mahwah, NJ, USA, 1993; pp. 23–33. [Google Scholar]
- Khorramdel, L.; Pokropek, A.; Seang-Hwane, J.; Kirsch, I.; Halderman, L. Examining gender DIF and gender differences in the PISA 2018 reading literacy scale: A partial invariance approach. Psychol. Test Assess. Model. 2020, 62, 179–231. [Google Scholar]
- Buchholz, J.; Hartig, J. Comparing Attitudes Across Groups: An IRT-Based Item-Fit Statistic for the Analysis of Measurement Invariance. Appl. Psychol. Meas. 2019, 43, 241–250. [Google Scholar] [CrossRef] [PubMed]
- Köhler, C.; Robitzsch, A.; Hartig, J. A Bias-Corrected RMSD Item Fit Statistic: An Evaluation and Comparison to Alternatives. J. Educ. Behav. Stat. 2020, 45, 251–273. [Google Scholar] [CrossRef]
- OECD. PISA 2015. Technical Report. In Organisation for Economic Co-Operation and Development; OECD: Paris, France, 2017; Available online: https://www.oecd.org/pisa/data/2015-technical-report/PISA2015_TechRep_Final.pdf (accessed on 8 June 2022).
- Kunina-Habenicht, O.; Rupp, A.A.; Wilhelm, O. A practical illustration of multidimensional diagnostic skills profiling: Comparing results from confirmatory factor analysis and diagnostic classification models. Stud. Educ. Eval. 2009, 35, 64–70. [Google Scholar] [CrossRef]
- OECD. Education at a Glance 2016. In Organisation for Economic Co-Operation and Development; OECD: Paris, France, 2016. [Google Scholar] [CrossRef]
- Bock, R.D. Estimating item parameters and latent ability when responses are scored in two or more nominal categories. Psychometrika 1972, 37, 29–51. [Google Scholar] [CrossRef]
- Yen, W.M. Effects of local item dependence on the fit and equating performance of the three-parameter logistic model. Appl. Psychol. Meas. 1984, 8, 125–145. [Google Scholar] [CrossRef]
- Orlando, M.; Thissen, D. Likelihood-based item fit indices for dichotomous item response theory models. Appl. Psychol. Meas. 2000, 24, 50–64. [Google Scholar] [CrossRef]
- Orlando, M.; Thissen, D. Further investigation of the performance of S-X2: An item fit index for use with dichotomous item response theory models. Appl. Psychol. Meas. 2003, 27, 289–298. [Google Scholar] [CrossRef]
- Wright, B.D.; Masters, G.N. Rating Scale Analysis; MESA Press: Chicago, IL, USA, 1982. [Google Scholar]
- Liang, T.; Wells, C.S.; Hambleton, R.K. An assessment of the nonparametric approach for evaluating the fit of item response models. J. Educ. Meas. 2014, 51, 1–17. [Google Scholar] [CrossRef]
- Chon, K.H.; Lee, W.; Ansley, T.N. An empirical investigation of methods for assessing item fit for mixed format tests. Appl. Meas. Educ. 2013, 26, 1–15. [Google Scholar] [CrossRef]
- Tijmstra, J.; Liaw, Y.; Bolsinova, M.; Rutkowski, L.; Rutkowski, D. Sensitivity of the RMSD for detecting item-level misfit in low-performing countries. J. Educ. Meas. 2020, 57, 566–583. [Google Scholar] [CrossRef]
- Wainer, H. Model-based standardized measurement of an item’s differential impact. In Differential Item Functioning; Holland, P.W., Wainer, H., Eds.; Erlbaum: Mahwah, NJ, USA, 1993; pp. 123–135. ISBN 978-0-7879-5301-0. [Google Scholar]
- Chalmers, R.P. mirt: A multidimensional item response theory package for the R environment. J. Stat. Softw. 2012, 48, 1–29. [Google Scholar] [CrossRef]
- Chen, W.H.; Thissen, D. Local dependence indexes for item pairs using item response theory. J. Educ. Behav. Stat. 1997, 22, 265–289. [Google Scholar] [CrossRef]
- Cai, L.; Thissen, D.; du Toit, S.H.C. IRTPRO for Windows. Lincolnwood; Scientific Software International: Skokie, IL, USA, 2011. [Google Scholar]
- De Ayala, R.J. The Theory and Practice of Item Response Theory; Guilford Press: New York, NY, USA, 2009. [Google Scholar]
- Van der Ark, L.A. Mokken scale analysis In R. J. Stat. Softw. 2007, 20, 1–19. [Google Scholar] [CrossRef]
- Van der Ark, L.A. New Developments in Mokken Scale Analysis in R. J. Stat. Softw. 2012, 48, 1–27. [Google Scholar] [CrossRef]
- Embretson, S.; Reise, S. Item Response Theory for Psychologists; Erlbaum: Mahwah, NJ, USA, 2000; ISBN 0585347824. [Google Scholar]
- Hambleton, R.K.; Swaminathan, H. Item Response Theory: Principles and Applications; Kluwer-Nijhoff: Boston, MA, USA, 1985; ISBN 978-94-017-1988-9. [Google Scholar]
- Akaike, H. A new look at the statistical model identification. IEEE Trans. Autom. Control 1974, 19, 716–723. [Google Scholar] [CrossRef]
- Schwarz, G. Estimating the dimension of a model. Ann. Stat. 1978, 6, 461–464. Available online: https://www.jstor.org/stable/2958889 (accessed on 8 April 2022).
- Robitzsch, A.; Kiefer, T.; Wu, M. TAM: Test Analysis Modules. R Package Version 3.6-45. 2021. Available online: https://cran.r-project.org/web/packages/TAM/TAM.pdf (accessed on 24 February 2022).
- Desjardins, C.D.; Bulut, O. Handbook of Educational Measurement and Psychometrics Using R; Chapman & Hall/CRC: Boca Raton, FL, USA; London, UK; New York, NY, USA, 2018; ISBN 9781498770132. [Google Scholar]
- Bock, R.D.; Zimowski, M.F. Multiple Group IRT. In Handbook of Modern Item Response Theory; van der Linden, W.J., Hambleton, R.K., Eds.; Springer: New York, NY, USA, 1997. [Google Scholar] [CrossRef]
- Paek, I.; Cole, I. Using R for Item Response Theory Applications; Routledge: London, UK, 2019. [Google Scholar] [CrossRef]
- Köhler, C.; Hartig, J. Practical significance of item misfit in low-stakes educational assessment. Appl. Psychol. Meas. 2017, 41, 388–400. [Google Scholar] [CrossRef]
- Van Rijn, P.W.; Sinharay, S.; Haberman, S.J.; Johnson, M.S. Assessment of fit of item response theory models used in large-scale educational survey assessments. Large-Scale Assess. Educ. 2016, 4, 10. [Google Scholar] [CrossRef]
- Crişan, D.R.; Tendeiro, J.N.; Meijer, R.R. Investigating the practical consequences of model misfit in unidimensional IRT models. Appl. Psychol. Meas. 2017, 41, 439–455. [Google Scholar] [CrossRef]
- Sinharay, S.; Haberman, S.J. How often is the misfit of item response theory models practically significant? Educ. Meas. 2014, 33, 23–35. [Google Scholar] [CrossRef]
- RStudio Team. RStudio: Integrated Development Environment for R; RStudio Team: Boston, MA, USA, 2015; Available online: http://www.rstudio.com/ (accessed on 8 June 2022).
- Bock, R.D.; Aitkin, M. Marginal Maximum Likelihood Estimation of Item Parameters: Application of an EM Algorithm. Psychometrika 1981, 46, 443–459. [Google Scholar] [CrossRef]
- Warm, T.A. Weighted likelihood estimation of ability in item response theory. Psychometrika 1989, 54, 427–450. [Google Scholar] [CrossRef]
- Rapp, J.; Borgonovi, F. Gender gap in mathematics and in reading: A withinstudent perspective. J. Educ. Policy 2019, 9, 6–56. [Google Scholar] [CrossRef]
- Reilly, D.; Neumann, D.L.; Andrews, G. Gender differences in reading and writing achievement: Evidence from the National Assessment of Educational Progress (NAEP). Am. Psychol. 2019, 74, 445. [Google Scholar] [CrossRef] [PubMed]
- Pae, T.-I. Causes of gender DIF on an EFL language test: A multiple-data analysis over nine years. Lang. Test. 2012, 29, 533–554. [Google Scholar] [CrossRef]
- Cheng, C.P.; Chen, C.-C.; Shih, C.-L. An Exploratory Strategy to Identify and Define Sources of Differential Item Functioning. Appl. Psychol. Meas. 2020, 44, 548–560. [Google Scholar] [CrossRef] [PubMed]
- Liu, R.; Bradley, K.D. Differential Item Functioning Among English Language Learners on a Large-Scale Mathematics Assessment. Front. Psychol. 2021, 12, 657335. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Levels | Cut Values | Standard Values |
|---|---|---|
| I | <390 | Below minimum standard |
| II | 390–464 | Minimum standard |
| III | 465–539 | Normative standard |
| IV | 540–614 | Normative standard “plus” |
| V | ≥615 | Optimal standard |
| Sample Sizes | Tests | Female | Male | German | Non-German | ||||
|---|---|---|---|---|---|---|---|---|---|
| N | % | N | % | N | % | N | % | ||
| Overall Data | German | 24,154 | 46.20 | 28,134 | 53.80 | 52,291 | 81.85 | 9489 | 18.15 |
| Mathematics | 23,848 | 45.94 | 28,060 | 54.06 | 44,721 | 86.15 | 7187 | 13.85 | |
| VERA 8 | N 1 | M2* | df | RMSEA | SRMR | TLI | CFI | Cronbach’s Alpha | Q3 | Mon. |
|---|---|---|---|---|---|---|---|---|---|---|
| Reading | 41 | 55,469.7 | 779 | 0.037 | 0.032 | 0.928 | 0.931 | 0.86 | 1 | - |
| Spelling | 62 | 340,401.1 | 1829 | 0.060 | 0.057 | 0.789 | 0.795 | 0.88 | 30 | 2 |
| German | 103 | 567,597.3 | 5150 | 0.046 | 0.044 | 0.836 | 0.839 | 0.92 | 45 | 2 |
| Mathematics | 48 | 64,062.6 | 1080 | 0.034 | 0.031 | 0.943 | 0.945 | 0.88 | 4 | - |
| Tests | Groups | Rasch | 2PL | |||||||
|---|---|---|---|---|---|---|---|---|---|---|
| a1 | d | θ | RMSD | a1 | d | θ | RMSD | |||
| Reading | Female | Mean | 1.00 | 0.33 | 0.00 | 0.03 | 0.90 | 0.31 | 0.00 | 0.01 |
| SD | 0.00 | 1.07 | 0.96 | 0.02 | 0.29 | 1.06 | 0.96 | 0.01 | ||
| Male | Mean | 1.00 | 0.04 | −0.01 | 0.03 | 0.91 | 0.03 | −0.01 | 0.01 | |
| SD | 0.00 | 0.07 | 0.98 | 0.02 | 0.26 | 1.00 | 1.10 | 0.01 | ||
| German | Mean | 1.00 | 0.30 | 0.00 | 0.03 | 0.85 | 0.30 | −0.01 | 0.01 | |
| SD | 0.00 | 1.02 | 0.93 | 0.01 | 0.24 | 1.01 | 1.11 | 0.01 | ||
| Non-German | Mean | 1.00 | −0.45 | −0.01 | 0.03 | 0.93 | −0.47 | −0.01 | 0.01 | |
| SD | 0.00 | 1.08 | 0.99 | 0.02 | 0.31 | 1.12 | 1.12 | 0.01 | ||
| Spelling | Female | Mean | 1.00 | 0.78 | 0.00 | 0.03 | 0.85 | 0.81 | 0.00 | 0.01 |
| SD | 0.00 | 1.33 | 0.88 | 0.02 | 0.34 | 1.35 | 1.08 | 0.01 | ||
| Male | Mean | 1.00 | 0.32 | 0.00 | 0.03 | 0.87 | 0.33 | −0.01 | 0.01 | |
| SD | 0.00 | 1.27 | 0.87 | 0.02 | 0.31 | 1.28 | 1.08 | 0.01 | ||
| German | Mean | 1.00 | 0.61 | 0.00 | 0.03 | 0.86 | 0.64 | 0.00 | 0.01 | |
| SD | 0.00 | 1.27 | 0.97 | 0.02 | 0.33 | 1.29 | 1.08 | 0.01 | ||
| Non-German | Mean | 1.00 | 0.14 | 0.00 | 0.03 | 0.94 | 0.15 | −0.01 | 0.01 | |
| SD | 0.00 | 1.38 | 0.97 | 0.02 | 0.32 | 1.38 | 1.07 | 0.01 | ||
| German | Female | Mean | 1.00 | 0.59 | 0.00 | 0.03 | 0.78 | 0.59 | 0.00 | 0.01 |
| SD | 0.00 | 1.22 | 0.80 | 0.02 | 0.24 | 1.23 | 1.05 | 0.01 | ||
| Male | Mean | 1.00 | 0.21 | 0.00 | 0.03 | 0.79 | 0.20 | 0.00 | 0.01 | |
| SD | 0.00 | 1.15 | 0.82 | 0.02 | 0.23 | 1.16 | 1.05 | 0.01 | ||
| German | Mean | 1.00 | 0.48 | 0.00 | 0.02 | 0.76 | 0.49 | 0.00 | 0.01 | |
| SD | 0.00 | 1.16 | 0.78 | 0.02 | 0.23 | 1.17 | 1.05 | 0.01 | ||
| Non-German | Mean | 1.00 | −0.10 | 0.00 | 0.03 | 0.86 | −0.10 | 0.00 | 0.01 | |
| SD | 0.00 | 1.27 | 0.87 | 0.02 | 0.26 | 1.29 | 1.05 | 0.01 | ||
| Mathematics | Female | Mean | 1.00 | 0.15 | 0.00 | 0.03 | 0.97 | 0.16 | 0.00 | 0.01 |
| SD | 0.00 | 1.40 | 1.05 | 0.02 | 0.29 | 1.45 | 1.08 | 0.01 | ||
| Male | Mean | 1.00 | 0.30 | 0.00 | 0.03 | 1.03 | 0.31 | 0.00 | 0.01 | |
| SD | 0.00 | 1.36 | 1.07 | 0.02 | 0.25 | 1.40 | 1.08 | 0.01 | ||
| German | Mean | 1.00 | 0.24 | 0.00 | 0.03 | 0.89 | 0.22 | 0.01 | 0.01 | |
| SD | 0.00 | 1.07 | 0.92 | 0.02 | 0.31 | 1.14 | 1.09 | 0.01 | ||
| Non-German | Mean | 1.00 | −0.28 | 0.00 | 0.04 | 0.86 | −0.32 | 0.00 | 0.02 | |
| SD | 0.00 | 1.08 | 0.87 | 0.02 | 0.35 | 1.16 | 1.08 | 0.01 | ||
| Sample | Tests | RMSD (Cut Value = 0.03) | RMSD (Cut Value = 0.05) | |||||
|---|---|---|---|---|---|---|---|---|
| Groups | Rasch | 2PL | PI-2PL | Rasch | 2PL | PI-2PL | ||
| Without Sampling Weights | Reading | Female | 63.42 | 26.83 | 0.00 | 17.07 | 4.88 | 0.00 |
| Male | 48.78 | 14.63 | 2.44 | 7.32 | 2.44 | 0.00 | ||
| Spelling | Female | 33.87 | 8.07 | 1.61 | 16.13 | 0.00 | 0.00 | |
| Male | 41.94 | 9.68 | 1.61 | 14.52 | 0.00 | 0.00 | ||
| German | Female | 44.44 | 20.37 | 0.93 | 17.48 | 1.94 | 0.00 | |
| Male | 39.82 | 12.04 | 3.70 | 12.62 | 1.94 | 0.00 | ||
| Mathematics | Female | 64.58 | 52.08 | 2.08 | 33.33 | 8.33 | 0.00 | |
| Male | 58.33 | 31.25 | 2.08 | 18.75 | 6.25 | 0.00 | ||
| With Sampling Weights | Reading | Female | 63.42 | 24.39 | 0.00 | 14.63 | 0.00 | 0.00 |
| Male | 51.22 | 21.95 | 4.88 | 7.32 | 2.44 | 0.00 | ||
| Spelling | Female | 33.87 | 9.68 | 1.61 | 14.52 | 0.00 | 0.00 | |
| Male | 41.94 | 9.68 | 1.61 | 14.52 | 0.00 | 0.00 | ||
| German | Female | 42.59 | 19.44 | 7.41 | 17.60 | 1.85 | 0.00 | |
| Male | 42.59 | 14.82 | 5.56 | 12.96 | 1.85 | 0.00 | ||
| Mathematics | Female | 62.50 | 54.17 | 2.08 | 31.25 | 8.33 | 0.00 | |
| Male | 64.58 | 43.75 | 0.00 | 18.75 | 6.25 | 0.00 | ||
| Sample | Tests | Groups | RMSD (Cut Value = 0.03) | RMSD (Cut Value = 0.05) | ||||
|---|---|---|---|---|---|---|---|---|
| Rasch | 2PL | PI-2PL | Rasch | 2PL | PI-2PL | |||
| Without Sampling Weights | Reading | German | 29.27 | 0.00 | 0.00 | 7.32 | 0.00 | 0.00 |
| Non-German | 65.85 | 29.27 | 2.44 | 31.71 | 4.88 | 0.00 | ||
| Spelling | German | 25.81 | 0.00 | 0.00 | 12.90 | 0.00 | 0.00 | |
| Non-German | 58.07 | 30.65 | 8.07 | 25.81 | 8.07 | 0.00 | ||
| German | German | 25.00 | 0.00 | 0.00 | 9.71 | 0.00 | 0.00 | |
| Non-German | 74.07 | 51.85 | 4.63 | 32.04 | 9.71 | 0.00 | ||
| Mathematics | German | 31.25 | 0.00 | 0.00 | 14.58 | 0.00 | 0.00 | |
| Non-German | 75.00 | 47.92 | 6.25 | 31.25 | 10.42 | 0.00 | ||
| With Sampling Weights | Reading | German | 41.46 | 2.44 | 0.00 | 9.76 | 0.00 | 0.00 |
| Non-German | 56.10 | 17.07 | 2.44 | 26.83 | 0.00 | 0.00 | ||
| Spelling | German | 40.32 | 6.45 | 3.23 | 12.90 | 0.00 | 0.00 | |
| Non-German | 46.77 | 11.29 | 3.23 | 14.52 | 0.00 | 0.00 | ||
| German | German | 40.74 | 10.19 | 3.70 | 13.89 | 0.00 | 0.00 | |
| Non-German | 59.26 | 22.22 | 2.78 | 21.30 | 3.70 | 0.00 | ||
| Mathematics | German | 50.00 | 18.75 | 6.25 | 14.58 | 0.00 | 0.00 | |
| Non-German | 68.75 | 20.83 | 12.50 | 35.42 | 12.50 | 0.00 | ||
| Tests | Proficiency Levels | Female | Male | ||||
|---|---|---|---|---|---|---|---|
| Rasch | 2PL | PI-2PL | Rasch | 2PL | PI-2PL | ||
| Reading | V | 11.32 | 13.84 | 13.76 | 6.71 | 8.73 | 8.45 |
| IV | 26.34 | 24.35 | 24.59 | 20.88 | 20.20 | 19.66 | |
| III | 30.02 | 29.48 | 29.40 | 29.69 | 29.37 | 29.64 | |
| II | 23.76 | 20.30 | 20.13 | 28.70 | 23.50 | 23.88 | |
| Ib | 5.93 | 7.92 | 7.96 | 8.79 | 10.79 | 10.91 | |
| Ia | 2.63 | 4.11 | 4.16 | 5.23 | 7.42 | 7.47 | |
| Spelling | V | 8.29 | 12.77 | 12.75 | 3.25 | 5.46 | 5.42 |
| IV | 38.33 | 32.08 | 32.13 | 24.74 | 20.47 | 20.65 | |
| III | 39.27 | 37.46 | 37.50 | 42.88 | 38.92 | 39.18 | |
| II | 11.01 | 12.25 | 12.19 | 20.77 | 21.82 | 21.74 | |
| Ib | 2.77 | 4.16 | 4.14 | 7.14 | 9.78 | 9.57 | |
| Ia | 0.33 | 1.28 | 1.30 | 1.23 | 3.54 | 3.44 | |
| Mathematics | V | 4.45 | 6.17 | 6.11 | 6.66 | 9.05 | 8.84 |
| IV | 16.62 | 15.83 | 15.84 | 22.10 | 20.66 | 20.14 | |
| III | 31.58 | 31.36 | 31.63 | 32.13 | 33.29 | 32.46 | |
| II | 32.17 | 30.19 | 30.02 | 26.81 | 24.25 | 24.84 | |
| Ib | 12.58 | 12.80 | 12.69 | 9.63 | 9.38 | 10.01 | |
| Ia | 2.60 | 3.65 | 3.72 | 2.67 | 3.37 | 3.70 | |
| Tests | Proficiency Levels | German | Non-German | ||||
|---|---|---|---|---|---|---|---|
| Rasch | 2PL | PI-2PL | Rasch | 2PL | PI-2PL | ||
| Reading | V | 10.42 | 13.89 | 13.90 | 1.74 | 2.67 | 2.88 |
| IV | 26.13 | 24.12 | 24.11 | 11.07 | 10.68 | 10.87 | |
| III | 31.06 | 29.58 | 29.55 | 24.33 | 23.12 | 22.71 | |
| II | 24.47 | 20.48 | 20.52 | 35.20 | 26.92 | 26.62 | |
| Ib | 5.50 | 7.85 | 7.86 | 16.35 | 18.55 | 18.35 | |
| Ia | 2.42 | 4.08 | 4.07 | 11.32 | 18.07 | 18.58 | |
| Spelling | V | 8.29 | 12.66 | 12.64 | 3.01 | 4.87 | 4.83 |
| IV | 35.94 | 32.46 | 32.41 | 22.28 | 20.39 | 20.15 | |
| III | 41.38 | 36.89 | 36.95 | 44.19 | 38.28 | 38.50 | |
| II | 11.46 | 12.50 | 12.54 | 21.18 | 22.10 | 22.04 | |
| Ib | 2.59 | 4.35 | 4.33 | 7.67 | 10.03 | 10.27 | |
| Ia | 0.34 | 1.14 | 1.13 | 1.67 | 4.33 | 4.23 | |
| Mathematics | V | 4.67 | 6.14 | 6.12 | 0.96 | 1.28 | 1.29 |
| IV | 15.15 | 16.09 | 16.11 | 5.37 | 6.07 | 5.80 | |
| III | 36.42 | 31.64 | 31.69 | 22.61 | 19.38 | 19.47 | |
| II | 28.02 | 29.70 | 29.69 | 30.76 | 31.65 | 31.84 | |
| Ib | 12.72 | 12.81 | 12.75 | 25.77 | 25.46 | 25.67 | |
| Ia | 3.03 | 3.62 | 3.64 | 14.53 | 16.15 | 15.93 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Temel, G.Y.; Rietz, C.; Machunsky, M.; Bedersdorfer, R. Examining and Improving the Gender and Language DIF in the VERA 8 Tests. Psych 2022, 4, 357-374. https://doi.org/10.3390/psych4030030
Temel GY, Rietz C, Machunsky M, Bedersdorfer R. Examining and Improving the Gender and Language DIF in the VERA 8 Tests. Psych. 2022; 4(3):357-374. https://doi.org/10.3390/psych4030030
Chicago/Turabian StyleTemel, Güler Yavuz, Christian Rietz, Maya Machunsky, and Regina Bedersdorfer. 2022. "Examining and Improving the Gender and Language DIF in the VERA 8 Tests" Psych 4, no. 3: 357-374. https://doi.org/10.3390/psych4030030
APA StyleTemel, G. Y., Rietz, C., Machunsky, M., & Bedersdorfer, R. (2022). Examining and Improving the Gender and Language DIF in the VERA 8 Tests. Psych, 4(3), 357-374. https://doi.org/10.3390/psych4030030