
Automated Essay Scoring Using Transformer Models

 , ,
, ,
Abstract
:1. Introduction
- To what extent does a transformer-based NLP model produce benefits compared to a traditional regression-based approach for AES?
- In which ways can transformer-based AES be used to increase the accuracy of scores by human raters?
2. Methodological Background for Automated Essay Scoring and NLP Based on Neural Networks
2.1. Terms and General Methodological Background
2.2. Traditional Approaches
2.3. Approaches Based on Neural Networks
2.3.1. Methodological Background on Recurrent Neural Nets (RNN)
2.3.2. Results of Recurrent Neural Networks for Automated Essay Scoring Tasks
2.3.3. Methodological Background on Transformer Models
2.3.4. Results of Transformer Models for Automated Essay Scoring Tasks
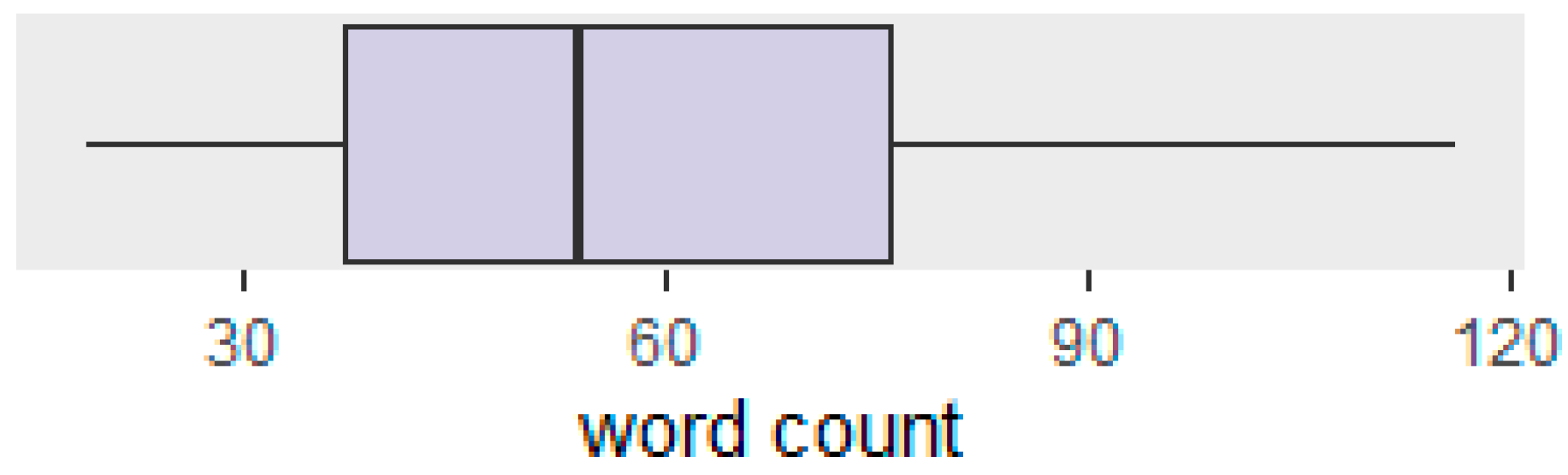
3. Data
4. Method
4.1. Basic Data Preparation Used in Both Approaches
- from sklearn.model_selection import train_test_split
- train_text_series, test_text_series, train_label_series,
- test_label_series = train_test_split(data[“text”], data[“label”],
- test_size = 0.30, random_state = 42)
- train_text = train_text_series.to_list()
- test_text = test_text_series.to_list()
- train_label = train_label_series.to_list()
- test_label = test_label_series.to_list()
4.2. Regression Model Estimation
- Creating a frequency dictionary, with the information on how often a word was used in a polite or impolite response, and
- Computing for each response a sum score for politeness and for impoliteness, based on the words included in the responses and their values in the frequency dictionary.
- # Create frequency dictionary
- freqs = build_freqs(train_text, train_label)
- # Extract features
- train_features = np.zeros((len(train_text), 2))
- for i in range(len(train_text)):
- train_features[i, :]= extract_features(train_text[i], freqs)
- from sklearn.linear_model import LogisticRegression
- log_model = LogisticRegression(class_weight=
- ‘balanced’).fit(train_features, train_label)
- from sklearn import metrics
- print(“Confusion Matrix:\n”, metrics.confusion_matrix(test_label,
- log_model.predict(test_features)))
- print(“Mean Accuracy:\n”, log_model.score(test_features, test_label))
- print(“F1 Score:\n”, metrics.f1_score(test_label,
- log_model.predict(test_features)))
- print(“ROC AUC:\n”, metrics.roc_auc_score(test_label,
- log_model.predict(test_features)))
- print(“Cohen’s Kappa:\n”, metrics.cohen_kappa_score(test_label,
- log_model.predict(test_features)))
4.3. Transformer Based Classification
- from transformers import AutoTokenizer
- checkpoint = “deepset/gbert-base”
- tokenizer = AutoTokenizer.from_pretrained(checkpoint)
- train_encodings = dict(tokenizer(train_text, padding = True,
- truncation = True, return_tensors = ‘np’))
- unique, counts = numpy.unique(train_label, return_counts = True)
- class_weight = {0: counts[1]/counts[0], 1: 1.0}
- # Definition of batch size and number of epochs
- batch_size = 8
- num_epochs = 3
- # Definition of the learning rate scheduler
- # The number of training steps is the number of samples in the
- dataset, divided by the batch size then multiplied by the
- total number of epochs
- num_train_steps = (len(train_label) // batch_size) * num_epochs
- lr_scheduler = PolynomialDecay(initial_learning_rate = 5e-5,
- end_learning_rate = 0, decay_steps = num_train_steps)
- # Definition of the optimizer using the learning rate scheduler
- opt = Adam(learning_rate = lr_scheduler)
- # Definition of the model architecture and initial weights
- model = TFAutoModelForSequenceClassification.from_pretrained(
- checkpoint, num_labels = 2)
- # Definition of the loss function
- loss = SparseCategoricalCrossentropy(from_logits = True)
- # Definition of the full model for training (or fine-tuning)
- model.compile(optimizer = opt, loss = loss, metrics = [‘accuracy’])
- model.fit(train_encodings, np.array(train_label),
- class_weight = class_weight, batch_size = batch_size,
- epochs = num_epochs)
- import tensorflow as tf
- test_pred_prob = tf.nn.softmax(model.predict(dict(test_encodings))[‘logits’])
- test_pred_class = np.argmax(test_pred_prob, axis = 1)
5. Results
6. Discussion
7. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A
Appendix A.1
Appendix A.2
Appendix A.3
References
- Chen, L.; Chen, P.; Lin, Z. Artificial Intelligence in Education: A Review. IEEE Access 2020, 8, 75264–75278. [Google Scholar] [CrossRef]
- Dikli, S. An Overview of Automated Scoring of Essays. J. Technol. Learn. Assess. 2006, 5, 36. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Application Checkpointing. 2021. Available online: https://en.wikipedia.org/wiki/Application_checkpointing (accessed on 24 August 2021).
- Transformer Models-Hugging Face Course. Available online: https://huggingface.co/course/ (accessed on 24 August 2021).
- Andersen, N.; Zehner, F. ShinyReCoR: A Shiny Application for Automatically Coding Text Responses Using R. Psych 2021, 3, 422–446. [Google Scholar] [CrossRef]
- Wu, Y.; Schuster, M.; Chen, Z.; Le, Q.V.; Norouzi, M.; Macherey, W.; Krikun, M.; Cao, Y.; Gao, Q.; Macherey, K.; et al. Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation. arXiv 2016, arXiv:1609.08144. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. arXiv 2016, arXiv:1508.07909. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models Are Few-Shot Learners. arXiv 2020, arXiv:2005.14165. [Google Scholar]
- Kudo, T.; Richardson, J. SentencePiece: A Simple and Language Independent Subword Tokenizer and Detokenizer for Neural Text Processing. arXiv 2018, arXiv:1808.06226. [Google Scholar]
- Kudo, T. Subword Regularization: Improving Neural Network Translation Models with Multiple Subword Candidates. arXiv 2018, arXiv:1804.10959. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Papers with Code Papers with Code-Language Modelling. Available online: https://paperswithcode.com/task/language-modelling (accessed on 28 April 2021).
- Page, E.B. The Imminence of Grading Essays by Computer. Phi Delta Kappan 1966, 47, 238–243. [Google Scholar]
- Page, E.B. Grading Essays by Computer: Progress Report. In Proceedings of the 1966 Invitational Conference on Testing Problems, New York, NY, USA, 29 October 1966; Educational Testing Service: Princeton, NJ, USA, 1967. [Google Scholar]
- Page, E.B. The Use of the Computer in Analyzing Student Essays. Int. Rev. Educ. 1968, 14, 210–225. [Google Scholar] [CrossRef]
- Chung, G.K.; O’Neil, H.F., Jr. Methodological Approaches to Online Scoring of Essays; CSE Technical Report 461; ERIC: Washington, DC, USA, 1997. [Google Scholar]
- Hearst, M.A. The Debate on Automated Essay Grading. IEEE Intell. Syst. Their Appl. 2000, 15, 22–37. [Google Scholar] [CrossRef]
- Chen, Y.-Y.; Liu, C.-L.; Chang, T.-H.; Lee, C.-H. An Unsupervised Automated Essay Scoring System. IEEE Intell. Syst. 2010, 25, 61–67. [Google Scholar] [CrossRef]
- Leacock, C.; Chodorow, M. C-Rater: Automated Scoring of Short-Answer Questions. Comput. Humanit. 2003, 37, 389–405. [Google Scholar] [CrossRef]
- Mahana, M.; Johns, M.; Apte, A. Automated Essay Grading Using Machine Learning. J. Phys. Conf. Ser. 2012, 1000, 012030. [Google Scholar]
- Jurafsky, D.; Martin, J.H. Speech and Language Processing. In Speech and Language Processing; Pearson: London, UK, 2020; Volume 3. [Google Scholar]
- Zhang, Y.; Jin, R.; Zhou, Z.-H. Understanding Bag-of-Words Model: A Statistical Framework. Int. J. Mach. Learn. Cyber. 2010, 1, 43–52. [Google Scholar] [CrossRef]
- Burstein, J.; Kulcich, K.; Wolff, S.; Lut, C.; Chodorowl, M. Enriching Automated Essay Scoring Using Discourse Marking. ERIC 2001, 11, 1–9. [Google Scholar]
- Ke, Z.; Ng, V. Automated Essay Scoring: A Survey of the State of the Art. In Proceedings of the IJCAI International Joint Conferences on Artificial Intelligence, Macao, China, 10–16 August 2019. [Google Scholar]
- Foltz, P.W.; Gilliam, S.; Kendall, S. Supporting Content-Based Feedback in On-Line Writing Evaluation with LSA. Int. Learn. Environ. 2000, 8, 111–127. [Google Scholar] [CrossRef]
- Foltz, P.W.; Laham, D.; Landauer, T.K. The Intelligent Essay Assessor: Applications to Educational Technology. Int. Multimed. Electron. J. Comput. Enhanc. Learn. 1999, 1, 939–944. [Google Scholar]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations Using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Peters, M.E.; Neumann, M.; Iyyer, M.; Gardner, M.; Clark, C.; Lee, K.; Zettlemoyer, L. Deep Contextualized Word Representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Hochreiter, S. The Vanishing Gradient Problem During Learning Recurrent Neural Nets and Problem Solutions. Int. J. Unc. Fuzz. Knowl. Based Syst. 1998, 6, 107–116. [Google Scholar] [CrossRef] [Green Version]
- Taghipour, K.; Ng, H.T. A Neural Approach to Automated Essay Scoring. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 1882–1891. [Google Scholar]
- Alikaniotis, D.; Yannakoudakis, H.; Rei, M. Automatic Text Scoring Using Neural Networks. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Erk, K., Smith, N.A., Eds.; Volume 1: Long Papers. Association for Computational Linguistics: Stroudsburg, PA, USA, 2016; pp. 715–725. [Google Scholar] [CrossRef]
- Mayfield, E.; Black, A.W. Should You Fine-Tune BERT for Automated Essay Scoring? In Proceedings of the Fifteenth Workshop on Innovative Use of NLP for Building Educational Applications, Seattle, WA, USA, 10 July 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 151–162. [Google Scholar]
- Li, X.; Chen, M.; Nie, J.-Y. SEDNN: Shared and Enhanced Deep Neural Network Model for Cross-Prompt Automated Essay Scoring. Knowl. Based Syst. 2020, 210, 106491. [Google Scholar] [CrossRef]
- Jin, C.; He, B.; Hui, K.; Sun, L. TDNN: A Two-Stage Deep Neural Network for Prompt-Independent Automated Essay Scoring. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; Volume 1: Long Papers. Association for Computational Linguistics: Stroudsburg, PA, USA, 2018; pp. 1088–1097. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2016, arXiv:1409.0473. [Google Scholar]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling Laws for Neural Language Models. arXiv 2020, arXiv:2001.08361. [Google Scholar]
- Huang, X.; Khetan, A.; Cvitkovic, M.; Karnin, Z. TabTransformer: Tabular Data Modeling Using Contextual Embeddings. arXiv 2020, arXiv:2012.06678. [Google Scholar]
- Wu, N.; Green, B.; Ben, X.; O’Banion, S. Deep Transformer Models for Time Series Forecasting: The Influenza Prevalence Case. arXiv 2020, arXiv:2001.08317. [Google Scholar]
- Hu, R.; Singh, A. UniT: Multimodal Multitask Learning with a Unified Transformer. arXiv 2021, arXiv:2102.10772. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale. arXiv 2021, arXiv:2010.11929. [Google Scholar]
- Galanis, N.-I.; Vafiadis, P.; Mirzaev, K.-G.; Papakostas, G.A. Machine Learning Meets Natural Language Processing—The Story so Far. arXiv 2021, arXiv:2104.10213. [Google Scholar]
- Papers with Code-Browse the State-of-the-Art in Machine Learning. Available online: https://paperswithcode.com/sota (accessed on 2 September 2021).
- Sharir, O.; Peleg, B.; Shoham, Y. The Cost of Training NLP Models: A Concise Overview. arXiv 2020, arXiv:2004.08900. [Google Scholar]
- Strubell, E.; Ganesh, A.; McCallum, A. Energy and Policy Considerations for Deep Learning in NLP. arXiv 2019, arXiv:1906.02243. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Lan, Z.; Chen, M.; Goodman, S.; Gimpel, K.; Sharma, P.; Soricut, R. ALBERT: A Lite BERT for Self-Supervised Learning of Language Representations. arXiv 2020, arXiv:1909.11942. [Google Scholar]
- Uto, M. A Review of Deep-Neural Automated Essay Scoring Models. Behaviormetrika 2021, 48, 459–484. [Google Scholar] [CrossRef]
- Puri, R.; Catanzaro, B. Zero-Shot Text Classification With Generative Language Models. arXiv 2019, arXiv:1912.10165. [Google Scholar]
- Howard, J.; Ruder, S. Universal Language Model Fine-Tuning for Text Classification. arXiv 2018, arXiv:1801.06146. [Google Scholar]
- Rodriguez, P.U.; Jafari, A.; Ormerod, C.M. Language Models and Automated Essay Scoring. arXiv 2019, arXiv:1909.09482. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. arXiv 2020, arXiv:1906.08237. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a Distilled Version of BERT: Smaller, Faster, Cheaper and Lighter. arXiv 2020, arXiv:1910.01108. [Google Scholar]
- Rausch, A.; Seifried, J.; Wuttke, E.; Kögler, K.; Brandt, S. Reliability and Validity of a Computer-Based Assessment of Cognitive and Non-Cognitive Facets of Problem-Solving Competence in the Business Domain. Empirical Res. Vocat. Educ. Train. 2016, 8, 1–23. [Google Scholar] [CrossRef]
- Sembill, D.; Rausch, A.; Wuttke, E.; Seifried, J.; Wolf, K.D.; Martens, T.; Brandt, S. Modellierung und Messung domänenspezifischer Problemlösekompetenz bei Industriekaufleuten (DomPL-IK). Zeitschrift für Berufs-und Wirtschaftspädagogik 2015, 111, 189–207. [Google Scholar]
- Seifried, J.; Brandt, S.; Kögler, K.; Rausch, A. The Computer-Based Assessment of Domain-Specific Problem-Solving Competence—A Three-Step Scoring Procedure. Cogent Educ. 2020, 7, 1719571. [Google Scholar] [CrossRef]
- Brandt, S.; Rausch, A.; Kögler, K. A Scoring Procedure for Complex Assessments Focusing on Validity and Appropriate Reliability. Scoring Proced. Complex Assess. 2016, 20, 1–20. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media: Sebastopol, CA, USA, 2019; ISBN 1-4920-3261-1. [Google Scholar]
- Attali, Y.; Burstein, J. Automated Essay Scoring with E-Rater® V. J. Technol. Learn. Assess. 2006, 4. [Google Scholar] [CrossRef] [Green Version]
- Haberman, S.J.; Sinharay, S. The Application of the Cumulative Logistic Regression Model to Automated Essay Scoring. J. Educ. Behav. Stat. 2010, 35, 586–602. [Google Scholar] [CrossRef]
- Bird, S.; Loper, E.; Klein, E. Natural Language Processing with Python; O’Reilly Media Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Chawla, N.V. Data Mining for Imbalanced Datasets: An Overview. In Data Mining and Knowledge Discovery Handbook; Maimon, O., Rokach, L., Eds.; Springer: New York, NY, USA, 2005; pp. 853–867. ISBN 978-0-387-24435-8. [Google Scholar]
- Chinchor, N. MUC-4 Evaluation Metrics. In Proceedings of the Proceedings of the 4th Conference on Message Understanding, McLean, VA, USA, 16–18 June 1992; Association for Computational Linguistics: Stroudsburg, PA, USA; pp. 22–29.
- Hanley, J.A.; McNeil, B.J. The Meaning and Use of the Area under a Receiver Operating Characteristic (ROC) Curve. Radiology 1982, 143, 29–36. [Google Scholar] [CrossRef] [Green Version]
- Cohen, J. A Coefficient of Agreement for Nominal Scales. Educ. Psychol. Meas. 1960, 20, 37–46. [Google Scholar] [CrossRef]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. HuggingFace’s Transformers: State-of-the-Art Natural Language Processing. arXiv 2020, arXiv:1910.03771. [Google Scholar]
- Chan, B.; Schweter, S.; Möller, T. German’s Next Language Model. arXiv 2020, arXiv:2010.10906. [Google Scholar]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Chollet, F. Others Keras. 2015. Available online: https://github.com/fchollet/keras (accessed on 6 December 2021).
- Powers, D.M.W. Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness and Correlation. arXiv 2020, arXiv:2010.16061. [Google Scholar]
- Ben-David, A. About the Relationship between ROC Curves and Cohen’s Kappa. Eng. Appl. Art. Intell. 2008, 21, 874–882. [Google Scholar] [CrossRef]
- McHugh, M.L. Interrater Reliability: The Kappa Statistic. Biochem. Med. 2012, 22, 276–282. [Google Scholar] [CrossRef]
- Mandrekar, J.N. Receiver Operating Characteristic Curve in Diagnostic Test Assessment. J. Thoracic Oncol. 2010, 5, 1315–1316. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hernandez, D.; Brown, T.B. Measuring the Algorithmic Efficiency of Neural Networks. arXiv 2020, arXiv:2005.04305. [Google Scholar]
- Moore, G.E. Cramming More Components onto Integrated Circuits. Electronics 1965, 38, 6. [Google Scholar] [CrossRef]
- Engelhard, G. Examining Rater Errors in the Assessment of Written Composition With a Many-Faceted Rasch Model. J. Educ. Meas. 1994, 31, 93–112. [Google Scholar] [CrossRef]
- Liao, D.; Xu, J.; Li, G.; Wang, Y. Hierarchical Coherence Modeling for Document Quality Assessment. Proc. AAAI Conf. Artif. Intell. 2021, 35, 13353–13361. [Google Scholar]
- Conneau, A.; Khandelwal, K.; Goyal, N.; Chaudhary, V.; Wenzek, G.; Guzmán, F.; Grave, E.; Ott, M.; Zettlemoyer, L.; Stoyanov, V. Unsupervised Cross-Lingual Representation Learning at Scale. arXiv 2019, arXiv:1911.02116. [Google Scholar]

{kind=link}
| Study | Task | Data | Model | Kappa |
|---|---|---|---|---|
| Taghipour & Ng (2016) | Scoring essay answers to eight different questions, some of which depend upon source information | 12,978 essays with a length of 150 to 550 words | LSTM + CNN | 0.76 |
| Alikaniotis et al. (2016) | Scoring essay answers to eight different questions, some of which depend upon source information | 12,978 essays with a length of 150 to 550 words | LSTM combined with score-specific word embeddings | 0.96 |
| Architecture | Examples | Tasks |
|---|---|---|
| Encoder | ALBERT, BERT, DistilBERT, ELECTRA, RoBERTa | Sentence classification, named entity recognition, extractive question answering |
| Decoder | CTRL, GPT, GPT-2, GPT-3, Transformer XL, GPT-J-6B, Codex | Text generation |
| Encoder-decoder | BART, T5, Marian, mBART | Summarization, translation, generative question answering |
| Study | Task | Data | Model | Kappa |
|---|---|---|---|---|
| Rodriguez et al. (2019) | Scoring essay answers to eight different questions, some of which depend upon source information | 12,978 essays with a length of 150 to 550 words | BERT XLNet | 0.75 0.75 |
| Mayfield, & Black (2020) | Scoring essay answers to five different questions, some of which depend upon source information | 1800 essays for each of the five questions, each with a length of 150 to 350 words | N-Gram DistilBERT | 0.76 0.75 |
| Actual\Predicted | Impolite | Polite |
|---|---|---|
| Regression results for test data | ||
| Impolite | 31 | 15 |
| Polite | 87 | 494 |
| German BERT (small) results for test data | ||
| Impolite | 29 | 17 |
| Polite | 35 | 546 |
| German BERT (large) results for test data | ||
| Impolite | 32 | 14 |
| Polite | 24 | 557 |
| Model | Accuracy | F1 Score | ROC AUC Score | Cohen’s Kappa |
|---|---|---|---|---|
| Logistic Regression | 0.84 | 0.91 | 0.76 | 0.30 |
| German BERT (small) | 0.92 | 0.95 | 0.77 | 0.52 |
| German BERT (large) | 0.94 | 0.97 | 0.82 | 0.59 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ludwig, S.; Mayer, C.; Hansen, C.; Eilers, K.; Brandt, S. Automated Essay Scoring Using Transformer Models. Psych 2021, 3, 897-915. https://doi.org/10.3390/psych3040056
Ludwig S, Mayer C, Hansen C, Eilers K, Brandt S. Automated Essay Scoring Using Transformer Models. Psych. 2021; 3(4):897-915. https://doi.org/10.3390/psych3040056
Chicago/Turabian StyleLudwig, Sabrina, Christian Mayer, Christopher Hansen, Kerstin Eilers, and Steffen Brandt. 2021. "Automated Essay Scoring Using Transformer Models" Psych 3, no. 4: 897-915. https://doi.org/10.3390/psych3040056
APA StyleLudwig, S., Mayer, C., Hansen, C., Eilers, K., & Brandt, S. (2021). Automated Essay Scoring Using Transformer Models. Psych, 3(4), 897-915. https://doi.org/10.3390/psych3040056