Abstract
Nowadays, Internet of Things (IoT) application systems are broadly applied to various sectors of society for efficient management by monitoring environments using sensors, analyzing sampled data, and giving proper feedback. For their fast deployment, we have developed Smart Environmental Monitoring and Analysis in Real Time (SEMAR) as an integrated IoT application server platform and implemented the input setup assistance service using prompt engineering and a generative AI model to assist connecting sensors to SEMAR with step-by-step guidance. However, the current service cannot assist in connections of the sensors not learned by the AI model, such as newly released ones. To address this issue, in this paper, we propose an extension to the service for handling unlearned sensors by utilizing datasheets with four steps: (1) users input a PDF datasheet containing information about the sensor, (2) key specifications are extracted from the datasheet and structured into markdown format using a generative AI, (3) this data is saved to a vector database using chunking and embedding methods, and (4) the data is used in Retrieval-Augmented Generation (RAG) to provide additional context when guiding users through sensor setup. Our evaluation with five generative AI models shows that OpenAI’s GPT-4o achieves the highest accuracy in extracting specifications from PDF datasheets and the best answer relevancy (0.987), while Gemini 2.0 Flash delivers the most balanced results, with the highest overall RAGAs score (0.76). Other models produced competitive but mixed outcomes, averaging 0.74 across metrics. The step-by-step guidance function achieved a task success rate above 80%. In a course evaluation by 48 students, the system improved the student test scores, further confirming the effectiveness of our proposed extension.
1. Introduction
The expansion of Internet of Things (IoT) application systems has transformed various aspects of modern society. These systems enable efficient environmental management and monitoring through broad deployment of sensors [1], real-time analysis of sampled data [2], and delivery of timely feedback [3].
To facilitate the rapid deployment of IoT systems, we previously developed the Smart Environmental Monitoring and Analysis in Real Time (SEMAR) platform as an integrated IoT application server platform [4]. As a part of this effort, we implemented a sensor input setup assistance service. This service utilizes prompt engineering and generative AI to provide step-by-step guidance for connecting sensors to SEMAR [5]. However, the currently implemented service is limited in its ability to assist with sensors not yet learned by the generative AI model, such as newly released ones.
Past studies have successfully demonstrated integrations of information extraction techniques using Portable Document Format (PDF) file extraction across various domains, including healthcare [6,7], education [8], and industrial applications [9]. Additionally, embedding extracted information as additional context to generative AI has been shown to improve its accuracy and effectiveness [10,11,12].
In this paper, we extend our sensor setup assistant service to handle sensors not learned by generative AI. In this extension, we utilize generative AI to extract information from PDF datasheets, convert it to a structured markdown format, and then save the extracted data via a chunking strategy. The results are then embedded as additional context for Retrieval-Augmented Generation (RAG), facilitating the step-by-step guidance function or the question-and-answer function.
To evaluate our proposal, we made the OULTX125 smart light sensor, OUTTX110 smart environmental sensor, and OUPWM48 smart PID control by combining common sensor functionalities, as completely new sensors that are not learned by a generative AI. Datasheets for these new sensors were prepared with diverse layout structures and without explicit mention of the original common sensors.
Five generative AI models including OpenAI’s GPT-4o [13], Anthropic Claude 3.5 Haiku [14], Google Gemini 2.0 Flash [15], Mistral Small [16], and Llama 3.3 [16] were integrated into the service. They had knowledge cutoffs ranging from late 2023 to mid-2024. Then, we compare the quality of each model’s extraction results and assess the performance of the RAG functions to assist AI models in answering questions and guiding users in setting up unlearned sensors.
For the PDF extraction, we compared correctly formatted markdown information with the outputs of generative AI models. The results show that the top-performing model, OpenAI’s GPT-4o, achieves the highest accuracy in extracting key specifications from datasheets. For the general chat function, we extended the evaluation using the RAGA framework, which measures faithfulness, answer relevancy, context precision, and context recall. In this setting, GPT-4o consistently achieved the highest answer relevancy score (0.987), while Gemini 2.0 Flash delivered the best balance across retrieval and generation, reaching the highest overall RAGA score of 0.76. Other models, including LLaMA 3.3, Mistral Small, and Claude 3.5, showed competitive but mixed outcomes, with an overall average score of 0.74.
For the step-by-step guidance function, which directs users in setting up unlearned sensors, we applied the task success rate benchmark. Across all models, the guidance function achieved an overall task success rate exceeding 80%. These results confirm the effectiveness of our proposed extension in enhancing the sensor input setup assistance service, enabling it to support unlearned sensors with accurate specification extraction, consistent responses, and reliable setup guidance.
To further validate these findings in a practical context, we conducted a course evaluation with 48 undergraduate students in Indonesia. The results showed that the system improved student performance, raising average test scores from 85.42 in the manual phase to 90.42 in the assisted phase, and received an overall usability score of 5.22 out of 7.
The remainder of this paper is organized as follows: Section 2 reviews related works in the literature. Section 3 introduces the concepts and software utilized in our proposal. Section 4 reviews the SEMAR platform. Section 5 describes the implementation for this extension. Section 6 presents evaluation results and discussions. Finally, Section 7 concludes the paper and outlines future work.
2. Related Works
In this section, we introduce works in the literature related to this study.
2.1. PDF File Extraction Methods
Various techniques and tools have been developed over the past few years in an effort to extract information from PDF files.
In [17], Zhu et al. presented PDFDataExtractor, a ChemDataExtractor plugin for the chemical literature, using a template-based architecture and fivestage workflow, achieving >60% precision for most metadata on Elsevier’s dataset. It excels at titles, abstracts, and DOIs but struggles with formulae, tables, and reference sequencing, with lower precision for journals (60.0%) and references (48.7%) due to layout variations.
In [18], Shen et al. introduced VILA methods (I-VILA and H-VILA) for structured content extraction from scientific PDFs, leveraging visual layout groups. I-VILA improves token classification accuracy by 1.9% Macro F1 using special tokens, while H-VILA cuts inference time by up to 47% with minimal accuracy loss via hierarchical encoding. Requiring only fine-tuning, VILA matches state-of-the-art performance at a 1–5% training cost, validated by the S2-VLUE benchmark with a manually annotated dataset.
In [19], Martsinkevich et al. developed algorithms to extract lines and paragraphs from complex PDFs by analyzing symbol positions, interline intervals, and indentations, assigning properties like font and bold type. Testing revealed issues with center-aligned captions and title-to-paragraph transitions.
In [20], Soliman proposed an unsupervised linguistic-based model using NLP techniques like pattern recognition and POS tagging to extract glossary terms from PDF textbooks, achieving an average recall of 64.7% and a precision of 16%.
In [21], Paudel et al. compared PDF parsing and OCR for Nepali text extraction, evaluating PyMuPDF, PyPDF2, PyTesseract, and EasyOCR. PDF parsers are fast and accurate for unicode-compatible fonts but struggle with incompatible fonts and image-embedded text. PyTesseract provides consistent accuracy across all PDF types, outperforming EasyOCR in speed, making it preferable for Nepali PDFs despite slower processing than parsers.
2.2. Sensor PDF File Extraction Methods
Several studies have been conducted on the specific topic of information extracted from sensor datasheets in PDF files.
In [22], Hsiao et al. used the Fonduer framework for machine-learning-based extraction of hardware component data from PDF datasheets, achieving a 75 F1 score across transistors, amplifiers, and connectors. It surpasses Digi-Key by 12 F1 points, boosting recall by 24% via weak supervision and multi-modal feature extraction, despite noisy PDF parsing issues.
In [23], Hauser et al. developed a modular Python tool to extract hardware description data from microcontroller PDF documentation, converting it to HTML and a knowledge graph with 96.5% accuracy. It processes device identifiers, interruption tables, pinouts, and register maps, matching 93–99.88% of data points, reducing manual effort for embedded software porting.
In [24], Opasjumruskit et al. introduced DSAT, an ontology-based tool that extracts information from PDF datasheets using PDFminer.six and Camelot, supporting MBSE tools by populating a database with semantically enriched data. It features a web-based interface for manual and automatic data extraction, with user feedback improving ontologies and extraction quality for spacecraft design and other domains.
In [25], Tian et al. developed a novel AI-based tool that automates the extraction of nonlinear dynamic properties from semiconductor datasheets using CenterNet for figure segmentation, OCR for text conversion, and morphological image processing, significantly reducing data collection time for power transistor modeling. The tool enhances power loss estimation for efficient power converter design with high accuracy, though specific metrics are not provided.
2.3. Information Embeddings for Generative AI
Over the past few years, many research areas have benefited from embedding extra context from documents into generative AI models using various techniques.
In [26], Anton studied an information embedding pipeline comparing GPT-2 and TF-IDF for news article relevance scoring and classification, with GPT-2 slightly outperforming TF-IDF in accuracy (0.8482 higher) but requiring significantly more training time, showing promise for efficient information retrieval with reduced computational cost.
In [27], Zin et al. introduced an unsupervised two-step information-embedding pipeline that extracts top-k relevant sentences from lengthy legal contracts using BM25, Bi-Encoder, and Cross-Encoder models for query-based summarization, followed by GPT-3.5 for entity extraction. It achieves state-of-the-art performance on the CUAD dataset (510 contracts, 41 entity types), overcoming token limitations and data scarcity without domain-specific training.
In [28], Thapa et al. outlined an information embedding pipeline tracing the evolution from non-contextualized embeddings with Word2Vec and GloVe to contextualized embeddings using Bidirectional Encoder Representations from Transformers (BERTs), a Generated Pre-trained Transformer (GPT), and a T5 Embedding Model, highlighting their improved syntactic and semantic capabilities.
In [29], Wu et al. employed the GPT-3.5-turbo and GPT-4 Generative AI models in an information embedding pipeline to automatically construct a Chinese medical knowledge graph from manually annotated textual data, using filtering and mapping rules to align with a predefined schema.
In [30], Chen et al. introduced LM4HPC, which facilitates generative AI applications in high-performance computing (HPC) with HPC-specific datasets and pipelines. It utilizes an information embedding pipeline for code preprocessing and integration with LangChain. Preliminary results show gpt-3.5-turbo’s strong performance across HPC tasks.
In [31], Jeong introduced an information embedding pipeline using RAG and LangChain to enable Generative AI like GPT-3.5-turbo to utilize diverse company data (PDFs, videos, web pages) via vector database storage for accurate retrieval. The RAG approach minimizes hallucinations, handles unknown queries, and supports scalable, secure enterprise applications with open-source tools.
In [32], Pokhrel et al. proposed a framework for building customized chatbots that summarize documents and answer questions, leveraging OpenAI’s GPT models, LangChain, and Streamlit to combat information overload. The system efficiently processes PDF documents by chunking text, generating embeddings, and storing them in a vector store for semantic search, enabling the LLM to provide rapid and accurate responses.
3. Concept and Software in the Proposal
In this section, we introduce the concepts and software used in this proposal, including information chunking methods, and information embeddings for RAG.
3.1. Chunking Method for PDF Extraction
Chunking refers to the process of dividing large sets of information into smaller, manageable segments [33]. This strategy has recently gained popularity in optimizing retrieval processes for generative AI applications [34,35], allowing information to fit within the limited context window of the generative AI. Figure 1 visualizes how the information is divided into several color-coded segments.
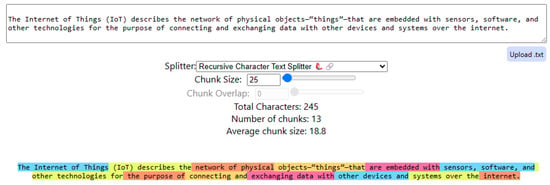
Figure 1.
Visualization of the information chunking [36]. The colors represent different segments of the chunked information.
A variety of chunking strategies exist, ranging from simple word-based splitting to more advanced machine-learning-driven methods that create structured and semantically coherent segments [37].
In this study, we implement the RecursiveCharacterTextSplitter strategy [38] as the optimal choice for markdown processing in RAG systems, with 7.0% higher precision and 6.9% better IoU metrics [39]. This strategy is used to process the output from generative AI that prepares the data before it is stored as vector representations. This strategy primarily divides large blocks of information using the newline character (\n) as a delimiter.
3.2. Embedding Information for Generative AI
Embeddings work by grouping the meaning of text information in a high-dimensional vector format that generative AI can understand. Studies show that embeddings improve generative AI accuracy and performance by providing structured relevant data as context, reducing the need for costly model retraining or fine-tuning [40,41]. This makes embeddings an efficient and affordable way to enhance generative AI accuracy.
3.2.1. Storing Embeddings in Vector Database
To create and retrieve embeddings, a specialized AI model converts information into a numerical format suitable for storage in a vector database [42]. Various embedding models exist, each designed for specific tasks, like OpenAI’s text embeddings for general text, BERT for understanding context, and Sentence Transformers for comparing sentences.
This study uses the LangChain RAG framework version 0.2 to handle the embedding model. It is also known for its fast and efficient development of generative AI applications [43]. For the vector database, we utilized the Qdrant Vector database version 1.4.1, which is known for its high performance and scalability [44].
3.2.2. Retrieving Embeddings for RAG
Using the same embedding model used to store the information, the RAG framework retrieves the relevant embeddings based on the user query. User query then processed by the embedding model as a vector representation and then used to search the vector database for a relevant chunk of information.
This study uses semantic search with cosine similarity to retrieve the relevant information from the vector database. The cosine similarity measures the angle between two vectors, indicating how similar they are. The smaller the angle, the more similar the vectors are, and thus, the more relevant the information is to the user query [45]. Figure 2 shows an example of the similarity and top-K ranked results from the chunked database with a similarity threshold of 0.3.
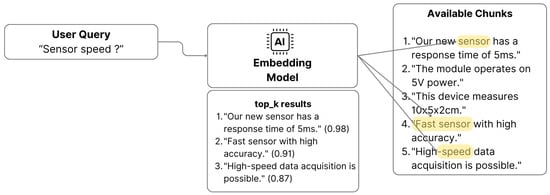
Figure 2.
How similarity and top-K ranked results are retrieved from the chunked database. In the figure, we can see that the embedding model can look for the relevant word that is semantically related to the user query.
The chunked results are ranked based on the cosine similarity score, and the top results are returned to the user based on the similarity threshold. Numbers like 0.98, 0.91, and 0.87 represent the cosine similarity scores, indicating how closely related each chunk is to the user’s query.
3.3. RAG Evaluation with RAGAS Framework
RAGAS (Retrieval-Augmented Generation Assessment) is a reference-free, fully automated evaluation framework designed for RAG pipelines [46]. It evaluates the retrieval and generation part of the system, enabling quicker and more flexible testing of RAG architectures.
We use four core RAGAS metrics to measure how well a RAG system works, covering both retrieval and generation aspects; this metric includes:
- (1)
- Faithfulness (F): This shows how accurate the response is compared to the retrieved context. It ranges from 0 to 1, with a higher score meaning better accuracy and consistency. A response is called faithful when all of its claims are supported by the retrieved context. It will find all claims in the response, check if each is supported by the context, and then compute faithfulness like this:where is the number of claims in the response that are supported, and is the total number of claims in the response.
- (2)
- Answer relevancy (AR) judges how well the answer aligns with the user query. This is done by generating several auxiliary questions from the answer using LLM prompting, embedding both the original query and the generated questions, and then computing their similarity. The AR score is obtained aswhere is the embedding of the user query, is the embedding of the i-th generated question, and N is the number of generated questions (default is 3).
- (3)
- Context precision (CP) measures how many chunks in the retrieved context are actually relevant, following a ranking-based evaluation similar to the commonly used Pass@k metric in code generation [47]. In retrieval, follows the same principle by assessing how much of the top-ranked context is truly relevant rather than relying only on token-level matches. It calculates the precision at each rank k, then averages across ranks usingandwhere K is the number of chunks retrieved, is 1 if the chunk at rank k is relevant (0 otherwise), and and are the true positives and false positives at rank k. Both and highlight that what appears earlier in the ranking is most important for practical utility.
- (4)
- Context recall (CR) measures how complete the retrieval is. This will break the reference answer into claims and check how many of those are found in the retrieved context:
4. Review of SEMAR IoT Platform and Setup Service Assistant
In this section, we discuss the SEMAR IoT application server platform, a unified system designed to make it easier and faster to create and launch IoT applications, including its sensor input assistant service.
4.1. SEMAR IoT Platform
SEMAR is designed to efficiently collect, process, analyze, and display data from various sensors and IoT devices [4]. Its modular structure makes it a flexible and comprehensive solution adaptable to a wide range of IoT applications. Additionally, SEMAR includes a plug-in feature that allows users to add new functions for future expansion, such as an indoor navigation system [48], an indoor localization system [49], or an outdoor Visual SLAM data analyzer [50].
Figure 3 illustrates the connection and visualization features of SEMAR. Figure 3 on the left demonstrates the steps for users to connect their IoT devices to SEMAR, while Figure 3 on the right shows how users can view the data visualization within the platform.
Figure 3.
Data input and visualization features of SEMAR.
SEMAR supports data collection from multiple sources using communication protocols like Hyper Text Transfer Protocol (HTTP), Message Queue Telemetry Transport (MQTT), and WebSocket, all hosted on a single cloud server, making it easier to manage diverse data streams.
However, setting up and integrating IoT devices with the SEMAR IoT Platform can be challenging for novice users with limited technical skills. To address this, previous research integrated a sensor input setup assistance service powered by generative AI into SEMAR, simplifying the setup process and enabling users with limited expertise to seamlessly connect IoT devices to the platform.
4.2. Sensor Input Setup Assistant Service in SEMAR
The sensor input setup assistance service for SEMAR utilizes generative AI and prompt engineering to simplify complex IoT setups for users with limited technical skills [5]. The service processes user input through an intent classifier, retrieves relevant information via RAG, and combines this with chat histories and SEMAR setup guides to provide step-by-step instructions for sensor connections, processing board configuration, and communication protocol setup. Figure 4 shows the system overview of the sensor input setup assistant service for SEMAR.
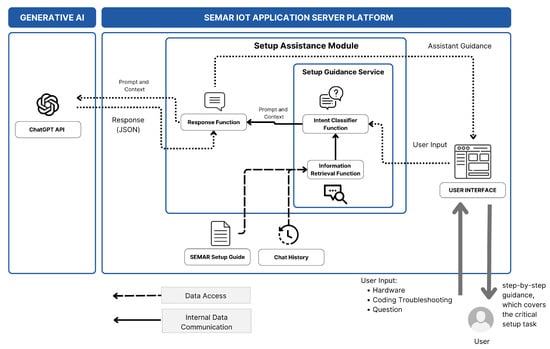
Figure 4.
Sensor input setup assistant service overview [5].
The prompt engineering techniques in the service are also designed to break down the setup process via step-by-step guidance phases, including a requirement gathering phase and a guidance phase. In the requirement gathering phase, users were asked about their project, hardware, and connectivity needs, while the guidance phase provides instructions on connecting hardware, coding, and linking to SEMAR using the selected connectivity. Figure 5 demonstrates how each phase directs generative AI to provide step-by-step guidance for configuring IoT devices.
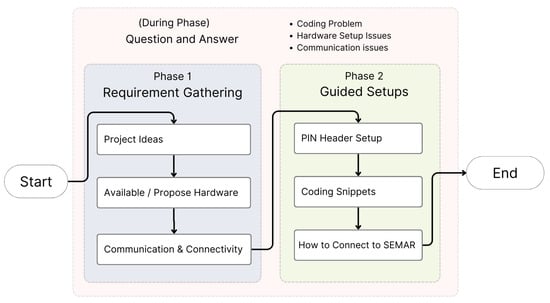
Figure 5.
SEMAR Assistance service flow for Step-by-step guidance for complex setup [5].
The evaluations of university students, as novice users, found the service helpful in simplifying complex IoT setups, but it still fails to recognize unlearned sensors. The aim of this paper is to propose an extension of the service that will enhance the service and enable it to provide better support to users integrating unlearned sensors into users’ IoT projects.
5. Implementation of Proposed Extension
In this section, we present the implementation of the extension of the sensor input setup assistant service.
5.1. Extension Overview
The sensor input setup assistant service for SEMAR has now been improved to handle unlearned sensor questions and provide the step-by-step guidance for setting up these sensors.
We achieved this by improving existing features, such as separating the response function into a general chat function for user queries and a setup guidance function to handle step-by-step guidance inquiries. Separating the response function into two distinct functions enables us to use different prompts for each function. That means the current response function is designed only to handle the JSON response from the generative AI. We also improved the information retrieval function with RAG so that it can communicate with the vector database. Figure 6 illustrates how the improved functions communicate with the new additions.
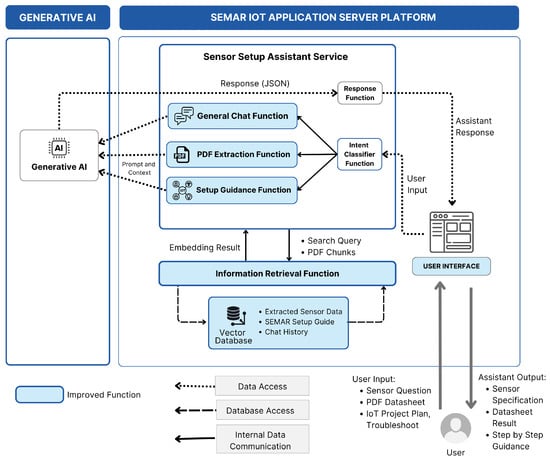
Figure 6.
Overview of the extended sensor input setup assistance service.
The PDF extraction function is a new function that extracts information from PDF datasheets of unlearned sensors, which is then processed by the Information Retrieval Function to create embeddings for the vector database; to support this, we added a new User Interface (UI) to allow users to upload the PDF datasheets of unlearned sensors. Finally, we improved the database part to support the retrieval of current text data of chat history and the extracted embedding information from the PDF datasheets and SEMAR setup guide.
A user can give input a question in text or upload a PDF datasheet of an unlearned sensor to the User Interface (UI). This input is then processed by the intent classifier function to identify the user intent, which is then routed to the appropriate function. If the user input is a question about a general IoT, common, or unlearned sensor, it is routed to the general chat function. PDF documents’ input is routed to the PDF extraction function to extract the information from the uploaded PDF datasheet. If the user input is a question about setting up an IoT project, it will be routed to the guidance function.
All these functions send the processed input to the generative AI along with a prompt and context information. The context information includes the chat history, the extracted information from the PDF datasheet of unlearned sensors, and the setup guide of SEMAR managed by the information retrieval function using RAG.
Generative AI sometimes produces a hallucinated sensor specification. To address this, we implemented a manual hallucination confirmation process inside the general chat function’s input processing and response handler. This confirmation will allow users to upload the correct datasheet or continue to develop the IoT project with the provided information.
5.2. PDF Extraction Function
PDF files are often unstructured, which complicates data extraction [17], while the RAG function works best with structured data [51]. Sensor data sheets may contain single-column, double-column, or mixed-column text, as well as multiple tables and images like diagrams or graphs. To address this, we developed a PDF extraction process that combines several Python libraries, including PyMuPDF and PyPDF2, to extract raw text from the data sheets. Figure 7 below explains how our PDF extraction process works.
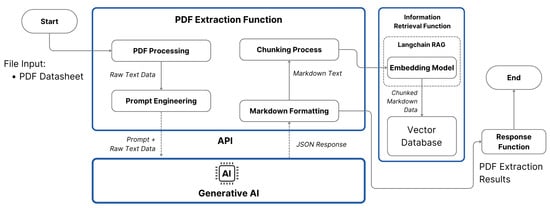
Figure 7.
PDF extraction process flow.
The extracted raw text is then processed by generative AI models to generate a structured markdown format that has proven effective for generative AI [52]. Drawing from datasheet extraction studies, we structured the information as shown in Table 1 below.

Table 1.
Markdown categories from PDF datasheets.
Our proposal for the PDF extraction process targets text from paragraphs and tables. However, the current scope does not support extracting information from images due to the need for advanced algorithms. As a result, data from images, such as charts or diagrams, is not extracted.
Before the generated markdown is saved by the information retrieval function to the vector database, we use the RecursiveCharacterTextSplitter chunking strategies to divide the markdown into smaller, manageable pieces for efficient retrieval process for the LangchainRAGfunction by separating the information with (\n) character. Table 2 shows an example of the raw text extracted from a PDF datasheet, the generated markdown format, and the chunking result using the RecursiveCharacterTextSplitter strategy.
Table 2.
Text extraction and processing from PDF datasheets.
5.3. General Chat and Guidance Function
Once the extracted datasheet information is stored in the vector database, we use the LangChain RAG function to embed this information as extra context for the general chat and guidance function. Figure 8 illustrates how the general chat and guidance functions work with RAG to retrieve relevant information from the vector database.
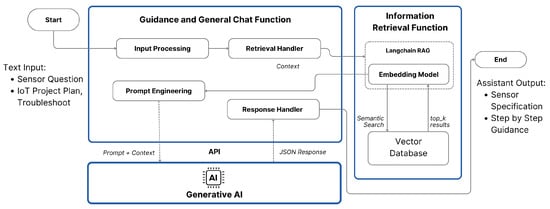
Figure 8.
General chat and guidance functions with RAG to retrieve information from the vector database.
The process in the general chat and guidance function is similar. The difference is that the prompt used for the general chat function is designed to generate accurate responses based on user queries, while the guidance function uses the prompt to provide step-by-step instructions for setting up IoT projects [53] based on prior research in Figure 5
The RAG function retrieves relevant information from the vector database using similarity search, which is configured with a similarity threshold of 0.3 (k = 3). This threshold determines how closely the retrieved data matches the user query, ensuring that only relevant information is returned. Table 3 shows how the user input is processed to look for relevant information in the vector database using the similarity search.
Table 3.
Sample user inputs and RAG top_k results.
5.4. Generative AI Model
The assistant service also allows users to interact with various generative AI models for the general chat, PDF extraction, and guidance functions. Users can select their preferred models through a dropdown menu in the user interface (UI). Table 4 shows all the generative AI models that are used to evaluate the proposal. All models are configured with a temperature of 0.7 for balanced creativity and a top_p of 1 to include all possible responses, ensuring consistent performance across tasks.
Table 4.
Generative AI models for extension.
Context length limits input tokens. A parameter size such as 24B and 70B indicates billions of parameters, reflecting model complexity. Notably, only Meta LLaMA 3.3 (70B) and Mistral Small 3.1 (24B) publicly disclose their parameter counts; the other does not.
For the embedding model, we used SFR-Embedding by Salesforce Research [54] model, which performs well for summarization and retrieval [55]. This model is managed via the RAG function to store chunked data from the PDF extraction function and retrieve results from the vector database using similarity search with a configuration for a similarity threshold of 0.3.
5.5. User Interface (UI)
We made a new UI for the proposal to enhance user interactions with the extended sensor input assistant service. The UI is designed to be user-friendly, allowing users to easily navigate between different functions such as general chat, guidance, and PDF extraction. Figure 9 illustrates these enhanced UI features.
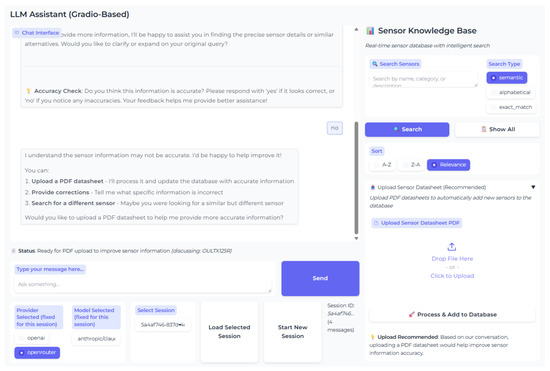
Figure 9.
UI to help the user navigate between functions.
The right panel displays the current sensor database, showing available sensor information, and supports actions like uploading PDFs for data extraction.
6. Evaluation
In this section, we evaluate the proposal using unlearned sensor data.
6.1. Unlearned Sensor Data
To test the ability of our proposal to handle unlearned sensors, we created three new sensors with unique functions and manually crafted datasheets. We used the three sensors that solve similar projects with our previous works [5], a smart light project, a smart room temperature, and a smart water heater. We named these sensors OULTX125R, OUPWM48, and OUTTX12. These sensors simulate new IoT devices unknown to the system, allowing us to evaluate how well it handles unfamiliar data.
Each sensor has a unique function, such as detecting light ambience, managing water heating, or measuring the room temperature comfort index and comes with a manually crafted datasheet. To evaluate the PDF extraction function, we designed each datasheet with a different layout, from single-column to multi-column formats, and we also included tables in every datasheet. Table 5 summarizes the sensors’ characteristics.
Table 5.
Characteristics of unlearned sensors.
All the datasheets for unlearned sensors, common sensors, and the ESP32 DevkitC are available in our repository [53].
6.1.1. Smart Light Sensor—OULTX125R
OULTX125R is a light sensor made with two pieces of LM393 photoresistor sensor and an ESP32 Arduino DevkitC. Figure 10 below shows a photo of the completed sensor and its single-column datasheet layout.

Figure 10.
OULTX125R light sensor.
This dual-light sensor system is designed for the measurement of ambient and directional light levels in IoT applications. The output from this unlearned sensor is a structured text that is sent over a serial wire connection (UART). An example from this sensor datasheet is shown in Listing 1 below.
| Listing 1. OULTX125R response sample. |
 |
The ambient value is the average of the two sensors, while the directional value is the difference in timing between light detection to indicate the direction in which we attached a blue and a red LED.
6.1.2. Smart Environmental Sensor—OUTTX110
OUTTX110 is a smart environmental sensor designed to measure room temperature and humidity with DHT22 along with atmospheric pressure using BMP280, built with an ESP32 Arduino DevkitC. It outputs the data in a structured text format via HTTP over WiFi. Figure 11 below shows a photo of the completed sensor and its two-column datasheet layout. Listing 2 shows a sample of the sensor output in JSON format.

Figure 11.
OUTTX110 environmental sensor.
| Listing 2. OUTTX110 response sample. |
 |
We calculate the sample comfort index using Equation (6) below, which is a simple formula to assess the comfort level based on temperature, humidity, and pressure readings.
6.1.3. Smart PID Control—OUPWM48
OUPWM48 is a smart PID control sensor for water heating, built with a DHT22 temperature and humidity sensor, a DS18B20 water temperature sens, or and an ESP32 Arduino DevkitC.
This sensor works by measuring the water temperature and ambient temperature, then calculating the error between the current and target temperatures, and gives the output of the Pulse Width Modulation (PWM) via MQTT. To calculate the output, we use a proportional integral derivative (PID).
Figure 12 below shows a photo of the completed sensor and its mixed column datasheet layout, while Listing 3 shows a sample of the sensor output and MQTT topic.

Figure 12.
Improvement of UI to help the user navigate between functions.
| Listing 3. OUPWM48 Sample topic and results. |
 |
6.2. Evaluation for PDF Extraction Result
6.2.1. Evaluation Method
We evaluate the PDF extraction function to assess its ability to extract accurate information from the unlearned sensor datasheets. Figure 13 shows the method used to evaluate the PDF extraction.
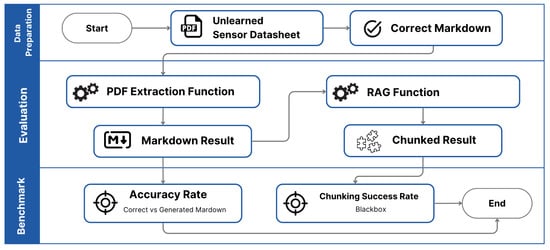
Figure 13.
PDF extraction evaluation process.
The evaluation followed a three-step process. First, in the data preparation process, we prepared a correct markdown file with the expected structured information for each unlearned sensor datasheet, which includes Performance (PF), Electrical (EL), Mechanical (MC), and Environmental (EV). Second, we asked the system to extract the information from the unlearned sensor datasheets using the PDF Extraction Function. Third, we manually checked the extracted information against the correct markdown file and recorded whether each category was extracted correctly. Table 6 shows the scoring we used to evaluate the extraction results.
Table 6.
Scoring for PDF extraction evaluation.
6.2.2. Evaluation Results—OULTX125
Table 7 shows the result for the manual checking of OULTX125R single-column datasheet extraction. The table shows the categories and whether the model was able to extract the information correctly.
Table 7.
Generative AI accuracy for OULTX125R datasheet extraction.
Appendix A Table A1 shows samples’ accuracy for EL categories. Generative AI models successfully extract information about control voltage and interface. These results indicate that the generative AI overall performed well in extracting information from the single-column datasheet.
6.2.3. Evaluation Results—OUTTX110
For OUTTX110 two-column datasheet extraction, we evaluated the model’s ability to extract information from a more complex layout. Table 8 shows the results of the evaluation for this datasheet.
Table 8.
Generative AI accuracy for OUTTX110 datasheet extraction.
Appendix A Table A2 shows several samples for the poor extraction from PF. The ChatGPT-4o and Meta LLaMA models performed the best overall, achieving good ratings in most categories, particularly in EL. It provided a comprehensive overview of the sensor’s features and specifications, including the comfort index formula. Google Gemini 2.0 also performed well, especially in the MC categories, but struggled with PF. The other models, while showing some strengths in MF and MC, generally provided less detailed information in the other categories.
This indicates that while the generative AI models were able to extract information from the two-column datasheet, they struggled with the complexity of the layout.
6.2.4. Evaluation Results—OUPWM48
For OUPWM48 multi-column datasheet extraction, we evaluated the model’s ability to extract information from a more complex layout with multiple columns and tables. Table 9 shows the results of the evaluation for this datasheet.
Table 9.
Generative AI accuracy for OUPWM48 datasheet extraction.
The analysis revealed varied performance in extracting and structuring datasheet information into markdown across categories, with Google Gemini 2.0 and ChatGPT-4o leading at an overall mid rating, excelling in EL, particularly in MQTT details, while Claude 3.5 and Mistral Small 3.1 maintained consistent mid performance, except for Claude’s poor EI rating, and LLaMA 3.3 underperformed with poor ratings in most categories, resulting in an overall poor rating.
No model achieved an overall good rating, highlighting challenges in accurately handling complex multi-column datasheet layouts.
A black box test is conducted for the chunking process by checking for the existence of the database and the formatting of the data in the vector database. All extracted results for each generative AI for all unlearned sensors are confirmed to be stored in a chunked format. This indicates that the proposed chunking functionalities are working well.
6.3. Evaluation for the General Chat Function
This section explains how we tested the system’s ability to answer user queries about unlearned sensors.
6.3.1. Evaluation Methods
We used the good result from the PDF extraction function to evaluate the general chat function. The goal was to see how well the system could answer user questions about unlearned sensors and see how the RAG functions retrieved chunked data from the vector database. The evaluation process is shown in Figure 14.
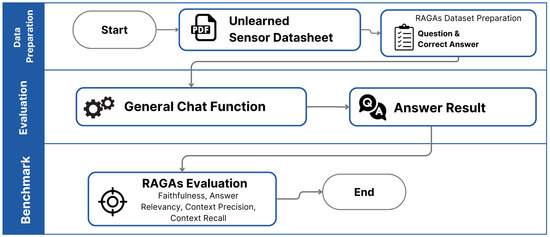
Figure 14.
Process for evaluating general chat function.
We prepared a dataset of 30 questions and correct answers about the unlearned sensors as ground truth data for RAGA, along with the expected context that should be retrieved from the vector database. Then, we asked the same questions to the system and recorded the responses. Finally, we benchmarked the system responses using the RAGA metrics, which include faithfulness, answer relevancy, context precision, and context recall.
This process allows us to measure not only whether the system’s answers are correct, but also how well they align with retrieved information and how relevant the responses are. Table 10 shows a sample of the ground truth data used for evaluation.
Table 10.
Sample Ground Truth Data.
6.3.2. Evaluation Results
We evaluated the system responses using the RAGA metrics: faithfulness (F), answer relevancy (AR), context precision (CP), and context recall (CR). These metrics provide a more complete understanding of performance by checking not only whether answers are correct, but also how well they align with retrieved evidence and how relevant they are to the original query.
Table 11, Table 12 and Table 13 summarize the results for different generative AI models across the three unlearned sensors.
Table 11.
RAGA results for the OU-LTX125R sensor.
Table 12.
RAGA results for the OU-PWM48 sensor.
Table 13.
RAGA results for the OU-TTX110 sensor.
Table 11 shows the RAGAs evaluation for the OU-LTX125R sensor. The results indicate that Gemini 2.0 Flash achieved the highest faithfulness score at 0.76, meaning its responses were more consistent with the retrieved context compared to other models. At the same time, Mistral Small 24B and GPT-4o delivered stronger answer relevancy scores, showing they produced responses closely aligned with the original queries. However, context precision scores remain relatively low across all models, suggesting that many retrieved chunks were not directly relevant. Overall, most models performed similarly, with average scores clustering around 0.74 to 0.75.
Table 12 presents the RAGAs metrics for the OU-PWM48 sensor. Here, Gemini 2.0 Flash again led with a balanced performance, showing the highest overall score (0.76) due to strong faithfulness and solid retrieval balance. GPT-4o achieved the highest answer relevancy at 0.985, indicating highly query-matched outputs, but its context recall was slightly lower, reducing consistency. Llama 3.3 70 B Instruct also performed competitively with strong context precision (0.70), showing better filtering of relevant chunks. Across this dataset, models demonstrated stronger retrieval alignment than in OU-LTX125R, as indicated by higher precision values.
Table 13 summarizes the metrics for the OU-TTX110 sensor. In this case, Gemini 2.0 Flash produced the most balanced results, with the highest faithfulness (0.714) and a solid overall score of 0.656. GPT-4o showed excellent answer relevancy (0.978) but relatively lower faithfulness, meaning its answers were fluent and query-relevant but not always fully supported by retrieved evidence. Llama 3.3 70B Instruct achieved the highest answer relevancy at 0.987, though with weaker faithfulness. Compared to other sensors, this dataset exposed more gaps in both retrieval and grounding, as indicated by lower recall values across all models.
Across the three unlearned sensor evaluations, no single model dominated all RAGA metrics. GPT-4o consistently achieved the highest answer relevancy, showing a strong ability to generate responses closely matched to user queries. However, its faithfulness scores were lower than Gemini 2.0 Flash, which more often produced answers grounded in the retrieved context. Llama 3.3 70B Instruct also performed well in relevancy but with weaker consistency, while Mistral Small 24B and Claude 3.5 Haiku showed mixed performance. Overall, GPT-4o excelled in producing highly relevant answers, but Gemini 2.0 Flash delivered a more balanced performance across retrieval and generation, slightly outperforming others in terms of overall RAGA scores.
6.4. Evaluation of Guidance Function
This section explains how we tested the system’s ability to guide users through connecting unlearned sensors to their IoT projects.
6.4.1. Evaluation Method
Our main goal in evaluating the guidance function was to see if the system could effectively lead a user, step-by-step, to successfully integrate an unlearned sensor into an IoT project. We also wanted to understand if the RAG helps the models to guide the users through the integration process. The overall steps for this evaluation are shown in Figure 15.
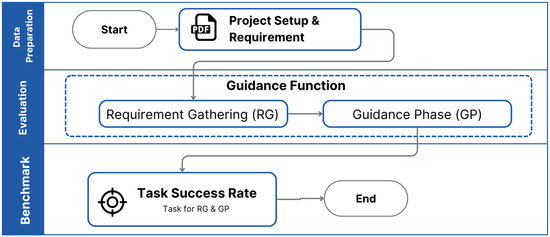
Figure 15.
Process for evaluating guidance function.
First, we prepared a project setup and requirement that explain what kind of project we want to build using each unlearned sensor. Then, we try to integrate real devices through the requirement gathering (RG) phase and the guidance phase (GP). Each project has a number of tasks that varies. After the project is completed or after a 1 h limit, we record the result of the guidance function. The result is recorded as a task success rate (TSR) which is the percentage of tasks that were successfully completed by the user.
The whole project uses Raspberry Pi 4 as the main controller; we added extra hardware, such asa resistor and LED, based on the generative AI model’s guidance. The project is considered successful if the user can complete all the tasks and get the sensor to send data to Raspberry Pi 4.
6.4.2. Smart Light System Project with OULTX125R
This smart light system project using the OULTX125R light sensor aims to measure ambient and directional light levels. The project is for recording the ambient levels in a room and controlling the LED that acts as the room lighting. OULTX125R’s HIGH output will turn on the LED, while LOW output will turn off the LED. Table 14 shows the TSR for this project.
Table 14.
Task success rate for the smart light system project.
In this project, the models were able to guide the users through the RG phase with an of a 87% success rate. ChatGPT-4o achieved the highest RG, followed by Gemini 2.0. Most of the models struggled to guide the users about the detailed specification of Raspberry Pi 4, such as the correct GPIO PIN types. However, all models were able to guide the user through the GP phase, which was about coding and LED integration. Failure in the GP phase is mostly caused by the step that was not properly saved on the vector database, causing the connection to the platform to fail.
6.4.3. Smart Room Temperature Project System with OUTTX110
The smart room temperature project using OUTTX110 aims to turn on the room air conditioning system when the comfort index is below 80%. The air conditioning guidance system is simulated by an LED. The project is considered successful if the user can connect the OUTTX110 sensor to Raspberry Pi 4 via HTTP over Wi-Fi, and the LED will be turned on. Table 15 shows the TSR for this project.
Table 15.
Task success rate for smart room temperature project.
In this project, the models were able to guide the users through the RG phase with an average of an 86% success rate. ChatGPT-4o achieved the highest RG, followed by Gemini 2.0. Most of the models struggled to guide the users about the detailed specification of Raspberry Pi 4 and correct HTTP connection, because the sensors have two ways to connect, using either UART or HTTP over WiFi. In the GP phase, the models were able to guide the user through the coding and LED integration. The failure in the GP phase is mostly due to the models not providing correct HTTP connection settings and SEMAR IoT connection platform configuration.
6.4.4. Smart Heater System Project with OUPWM48
The smart water heater system project using OUPWM48 aims to control the heating element of a water heater based on the PWM signal from the OUPWM48 sensor. The project is considered successful if the user can connect the OUPWM48 sensor to Raspberry Pi 4 via MQTT, and the water heater can be controlled based on the temperature input from the sensor. Table 16 shows the TSR for this project.
Table 16.
Task success rate for the smart heater system project.
In this project, the models were able to guide the users through the RG phase with an average of a78% success rate. The drop in the success rate is caused by the complexity of the MQTT connection of the project that relays the data to the SEMAR platform. With the limited information about SEMAR, ChatGPT-4o achieved the highest RG, followed by Gemini 2.0. Most of the models struggled to guide the users about the detailed specification of Raspberry Pi 4.
Within the one-hour limit evaluation for each generative AI model, overall, the guidance function achieved an RG task success rate of 83.4%, while the GP task success rate was 88.8%. The result shows that the system is able to guide the user through the integration process of unlearned sensors, with some limitations in the RG phase due to the complexity of the project and the limited information about SEMAR.
6.5. Evaluation Through Course Assignment
This evaluation was conducted during an IoT course assignment with 48 undergraduate students in Indonesia. The goal was to measure how the system supports students’ knowledge about new sensors using translated datasheets and interacting with the assistant during the task.
6.5.1. Experiment Composition
In this evaluation, we tested the general chat function in three steps. First, we conducted a pre-test to measure students’ prior knowledge of IoT. Second was the main test, where students answered questions about new sensors in two phases: Manual QnA, without system assistance, and Assisted QnA, with support from the proposed system. Finally, we carried out a post-test survey using the UMUX-Lite instrument [56] to assess system usability across multiple dimensions. The overall evaluation process is illustrated in Figure 16.
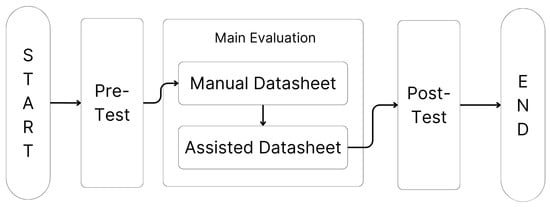
Figure 16.
Evaluation process for course assignment.
The main test consisted of multiple-choice questions about the new sensors. Each question was worth 20 points, with a maximum of five questions per phase, resulting in a maximum score of 100 points each for Manual QnA and Assisted QnA. Table 17 presents an example of the question-and-answer format used in the main test.
Table 17.
Sample Question and Options for the Main Test.
6.5.2. System Usability Questionnaire in Post-Test
After completing the assignment, students participated in a post-test survey to evaluate the usability of the system. We adopted the UMUX-Lite instrument [56], which has been successfully applied in past research to measure application usability across diverse user backgrounds [57]. The instrument evaluates usability along five dimensions: ease of use, usefulness, learning curve, efficiency, and error handling. Each item was rated on a seven-point Likert scale, ranging from complete disagreement (1) to complete agreement (7).
Table 18 lists the questionnaire items as translated into Bahasa Indonesia for this study. Using these dimensions allowed us to capture how students perceived the system in terms of practicality, ease of learning, and reliability within the course assignment.
Table 18.
Sample UMUX-Lite Questions (English).
6.5.3. Local Language Translation
To ensure accessibility, the system was presented in Bahasa, Indonesia. For this purpose, we modified the system prompt so that the AI consistently returned responses in Bahasa Indonesia. In addition, the sensor datasheets were translated to help students identify the correct answers during the main test. All questions used in the experiment were also translated into Bahasa, Indonesia, to create a consistent local-language environment. The translated prompts and supporting materials are available in our repository [53]
6.5.4. Pre-Test Result
Before the main task, students were asked about their expertise in IoT. As shown in Table 19, most students had little to no prior knowledge. Specifically, 64.6% reported they had only heard of IoT without understanding it, 27.1% were somewhat familiar, 4.2% were very familiar or experienced, and another 4.2% had never heard of IoT at all. Table 19 confirms that the participants represented mostly beginners.
Table 19.
IoT Knowledge Distribution (Pre-Test).
6.5.5. Main Test Result
In the manual phase, students downloaded translated datasheets and answered several questions about new sensors without system assistance. Their mean score in this stage was 85.42, showing wide variation in performance across students. In the assisted phase, students uploaded the same datasheets into the system and answered a new set of questions with the help of the assistant. Their average score improved to 90.42, reflecting the positive effect of AI-supported guidance. Table 20 summarizes the results of both phases.
Table 20.
Manual vs. Assisted Datasheet QnA Scores.
6.5.6. Post-Test Result
After completing the assignment, students answered the UMUX-Lite survey. The results show that the system was rated highly on ease of use (6.12), usefulness (5.77), and learning curve (6.04). Efficiency (4.27) and error handling (3.90) were rated lower, showing areas where improvements are needed. The overall UMUX-Lite score was 5.22 out of 7, confirming good usability but pointing to efficiency and error recovery as future work. Figure 17 summarizes these findings.
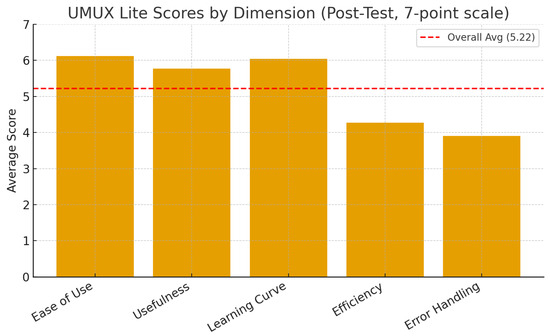
Figure 17.
UMUX-Lite Results for Course Assignment.
The course evaluation confirms that the system improved student performance when answering questions about new sensors, as shown by the score increase from manual to assisted tests. Students also rated the system highly for usability, especially in ease of use, usefulness, and learnability, with efficiency and error handling identified as key areas for further improvement. The inclusion of local language support proved important for accessibility, showing that translation of prompts and datasheets can help broaden system adoption in non-English settings. These results suggest that the system is promising for educational use, though future work should focus on better efficiency and robust error recovery.
6.6. Discussion
In this section, we discuss the implications of our findings and contributions to IoT sensor integrations and user assistance.
6.6.1. Generative AI Model for Datasheet Extraction
For the extraction of unlearned sensor datasheets, we used a similar model context length of 128K tokens, where only Gemini 2.0 Flash has a larger context length of 1M tokens. The parameter size of each model varies, with only the known parameter size of 70B for LLaMA 3.3 and 24B for Mistral Small. The results from ChatGPT-4o, outperforming other models, show that the context length of a model is not the only factor that determines the performance. We also found that the correct raw data extraction for the PDF extraction single-column layout or multi-column is crucial for the generative AI model to provide accurate extraction results. This limitation will be addressed in future work by improving the model’s ability to handle diverse PDF layouts by using an adaptive or layout-aware algorithm to enhance the extraction results.
6.6.2. Efficient RAG for Unlearned Sensor
Evaluations of the general chat and guidance functions revealed that the correct embedding model and the search method for vector database retrieval are crucial for accurate responses. Models struggled to answer queries when source data used abbreviations, such as “220 to GND” instead of “220 Ohm to Ground” due to the RAG retrieval focusing on word forms rather than meanings, highlighting a limitation of the current RAG system. Chunking PDF datasheet content proved efficient, enabling models to only send relevant information rather than full context. With proper chunking and data quality, we demonstrate that smaller models like LLaMA 3.3 and Mistral Small, which faced challenges in PDF extractions, successfully answered user queries about unlearned sensors.
6.6.3. Security Considerations and Data Poisoning Risks
Recent research has shown that data poisoning attacks are a serious threat to AI systems that rely on external documents [58]. We are aware of this risk in our setting, since the system depends on datasheets that may not always come from trusted sources. In this research, we reduce th is risk by ensuring that the datasheet sources we use are well-written and reliable. In future work, we plan to address this issue more directly by adding safeguards in the data preprocessing and retrieval stages of the system, so that tampered-with or malicious datasheets can be detected before they affect the results.
6.6.4. Fairness and Accessibility
Fairness and accessibility are important considerations when deploying AI systems that depend on datasheets. The quality, structure, and language of datasheets can vary widely between vendors. If the system performs better on well-formatted English datasheets from large manufacturers and worse on those from smaller or non-English-speaking suppliers, it may introduce disparities in usability and coverage.
In response to this concern, we conducted an additional evaluation with a class of 48 students in Indonesia. The results show that the system can be modified to handle multilingual support for both system interaction and datasheet extraction. This suggests that inclusiveness can be improved, and the approach is not limited to English-only datasets. However, the current system still cannot fully provide both functionalities at the same time. Addressing this limitation will be an important part of our future research, with the goal of making the system more accessible and fair across diverse documentation sources.
7. Conclusions
The paper demonstrated that the proposed assistant function integrating generative AI models with RAG helps users to integrate unlearned sensors into their IoT projects in the SEMAR IoT application server platform. The ability to extract and structure information from PDF sensor datasheets, combined with correct data preparation, allows for accurate responses and guidance. Our evaluations showed that the model context length is not the only factor that determines the performance of the model, as ChatGPT-4o outperformed other models in extracting information from unlearned sensor datasheets. The ability to chunk and store extracted data in a vector database enables efficient retrieval, allowing even smaller models to deliver accurate responses. Future works could enhance the layout-aware algorithm for extracting PDF datasheets, automate PDF datasheet retrieval using search agents, add more accessibility to multilingual datasheets or users, and improve vector database accuracy by expanding abbreviation handling to enhance semantic similarity search and extraction robustness.
Author Contributions
Conceptualization, I.N.D.K., N.F. and Y.Y.F.P.; Methodology, I.N.D.K.; Software, I.N.D.K.; Validation, I.N.D.K. and A.A.S.P.; Resources, N.; Data curation, I.N.D.K. and K.C.B.; writing—original draft preparation, I.N.D.K., Y.Y.F.P. and K.C.B.; writing—review and editing, N.F. and Y.Y.F.P. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data are contained within the article.
Acknowledgments
The authors thank the reviewers for their thorough reading and helpful comments, and all the colleagues in the Distributed System Laboratory, Okayama University, who were involved in this study.
Conflicts of Interest
The authors declare no conflicts of interest.
Appendix A
Table A1.
Quality of the Generative AI Model for OULTX125R.
Table A1.
Quality of the Generative AI Model for OULTX125R.
| Generative AI | EL—Electrical Results |
|---|---|
| ChatGPT4o | - Power Supply: - Operating Voltage: 3.3V DC or 5V DC. - Power Consumption: <500 mW. - Interface Options: - GPIO13: For integration with microcontrollers (e.g., Raspberry Pi, Arduino). - UART Serial Interface: USB Type-C connection for debugging and monitoring at 115,200 baud rate. |
| Claude 3.5 Haiku | - Power Supply: 3.3 V or 5 V DC - Power Consumption: <500 mW - Interfaces: - GPIO Digital Output - UART Serial (115,200 baud) |
| Gemini 2.0 Flash | - Power Supply: - Operating Voltage: 3.3V DC or 5V DC - Power Consumption: <500 mW - Alternative Power Method: 5V DC via VIN pin (500 mA minimum) - Interface: - External Controller Integration: GPIO13 digital output (e.g., Raspberry Pi, Arduino) - Debugging and Monitoring: UART Serial (115,200 baud) |
| Llama 3.370b | - Power Supply: - Operating Voltage: 3.3 V DC or 5 V DC - Power Consumption: Less than 500 mW - Interface Options: - External Controller Integration: Seamless integration via GPIO13 digital output - Debugging and Monitoring: UART Serial interface (baud rate: 115,200) |
| Mistral Small 3.1 24b | - Power Supply: - Operating Voltage: 3.3 V DC or 5 V DC - Primary Power Method: 5 V DC via USB Type-C port, minimum current of 500 mA. - Interface: - Integration with microcontrollers via GPIO13 digital output. - UART Serial interface accessible over USB Type-C, baud rate 115,200. |
Table A2.
Quality of the Generative AI Model for OUTTX110.
Table A2.
Quality of the Generative AI Model for OUTTX110.
| Generative AI | PF—Sensor Performance Specification |
|---|---|
| ChatGPT4o | Performance: Comfort Index: Formula: 100 - (|temp - 22| * 2 + |humidity - 50| * 1.5 + |pressure - 1013| * 0.05) |
| Claude 3.5 Haiku | No Comfort Index Formula |
| Gemini 2.0 Flash | No Comfort Index Formula |
| Llama 3.370b | Comfor Index Formula provided |
| Mistral Small 3.1 24b | Non Existing Performance Section |
References
- Kumar, S.; Tiwari, P.; Zymbler, M. Internet of Things is a revolutionary approach for future technology enhancement: A review. J. Big Data 2019, 6, 111. [Google Scholar] [CrossRef]
- Desnanjaya, I.G.M.N.; Nugraha, I.M.A. Real-time monitoring system for blood pressure monitoring based on internet of things. Indones. J. Electr. Eng. Comput. Sci. 2024, 35, 62–69. [Google Scholar] [CrossRef]
- Ray, P.P. Internet of Things (IoT), Applications and Challenges: A Comprehensive Review. Wirel. Pers. Commun. 2020, 114, 1687–1721. [Google Scholar] [CrossRef]
- Panduman, Y.Y.F.; Funabiki, N.; Puspitaningayu, P.; Kuribayashi, M.; Sukaridhoto, S.; Kao, W.C. Design and Implementation of SEMAR IoT Server Platform with Applications. Sensors 2022, 22, 6436. [Google Scholar] [CrossRef]
- Kotama, I.N.D.; Funabiki, N.; Panduman, Y.Y.F.; Brata, K.C.; Pradhana, A.A.S.; Noprianto.; Desnanjaya, I.G.M.N. Implementation of Sensor Input Setup Assistance Service Using Generative AI for SEMAR IoT Application Server Platform. Information 2025, 16, 108. [Google Scholar] [CrossRef]
- Lee, S.K.; Kim, J.H.; Kwon, Y.B. Unsupervised Extraction of Body-Text from Clinical PDF Documents. Stud. Health Technol. Informatics 2024, 310, 382–389. [Google Scholar] [CrossRef]
- Gérardin, C.; Wajsbürt, P.; Dura, B.; Calliger, A.; Moucher, A.; Tannier, X.; Bey, R. Detecting automatically the layout of clinical documents to enhance the performances of downstream natural language processing. arXiv 2023, arXiv:2305.13817. [Google Scholar] [CrossRef]
- Meuschke, N.; Jagdale, A.; Spinde, T.; Mitrović, J.; Gipp, B. A Benchmark of PDF Information Extraction Tools Using a Multi-task and Multi-domain Evaluation Framework for Academic Documents. In International Conference on Information; Springer Nature: Cham, Switzerland, 2023; Volume 13972, pp. 421–433. [Google Scholar] [CrossRef]
- Hansen, M.; Pomp, A.; Erki, K.; Meisen, T. Data-Driven Recognition and Extraction of PDF Document Elements. Technologies 2019, 7, 65. [Google Scholar] [CrossRef]
- Callaway, E. Has your paper been used to train an AI model? Almost certainly. Nature 2024, 620, 707–708. [Google Scholar] [CrossRef]
- Huang, Y.; Huang, J.X. Exploring ChatGPT for next-generation information retrieval: Opportunities and challenges. Web Intell. 2024, 22, 31–44. [Google Scholar] [CrossRef]
- Min, L.; Fan, Z.; Dou, F.; Sun, J.; Luo, C.; Lv, Q. Adaption BERT for Medical Information Processing with ChatGPT and Contrastive Learning. Electronics 2024, 13, 2431. [Google Scholar] [CrossRef]
- OpenAI. Introducing 4o Image Generation. 2025. Available online: https://openai.com/index/gpt-4o-and-more-tools-to-chatgpt-free/ (accessed on 15 June 2025).
- Anthropic. 3.5 Models and Computer Use. 2024. Available online: https://www.anthropic.com/news/3-5-models-and-computer-use (accessed on 15 June 2025).
- Google DeepMind. Introducing Gemini 2.0: Our New AI Model for the Agentic Era. 2024. Available online: https://blog.google/technology/google-deepmind/google-gemini-ai-update-december-2024/ (accessed on 15 June 2025).
- Meta Llama. Llama-3.3-70B-Instruct. 2024. Available online: https://huggingface.co/meta-llama/Llama-3.3-70B-Instruct (accessed on 15 June 2025).
- Zhu, M.; Cole, J.M. PDFDataExtractor: A Tool for Reading Scientific Text and Interpreting Metadata from the Typeset Literature in the Portable Document Format. J. Chem. Inf. Model. 2022, 62, 1633–1643. [Google Scholar] [CrossRef]
- Shen, Z.; Lo, K.; Wang, L.L.; Kuehl, B.; Weld, D.S.; Downey, D. VILA: Improving Structured Content Extraction from Scientific PDFs Using Visual Layout Groups. Trans. Assoc. Comput. Linguist. 2022, 10, 376–392. [Google Scholar] [CrossRef]
- Martsinkevich, V.; Berezhkov, A.; Tereshchenko, V.; Gorlushkina, N.; Tretjakova, V. Algorithms for extracting lines, paragraphs with their properties in PDF documents. E3S Web Conf. 2023, 389, 08024. [Google Scholar] [CrossRef]
- Soliman, A. An unsupervised linguistic-based model for automatic glossary term extraction from a single PDF textbook. Educ. Inf. Technol. 2023, 28, 16089–16125. [Google Scholar] [CrossRef]
- Paudel, P.; Khadka, S.; Ranju, G.C.; Shah, R. Optimizing Nepali PDF Extraction: A Comparative Study of Parser and OCR Technologies. arXiv 2024, arXiv:2407.04577. [Google Scholar] [CrossRef]
- Hsiao, L.; Wu, S.; Chiang, N.; Ré, C.; Levis, P. Automating the Generation of Hardware Component Knowledge Bases. In Proceedings of the 20th ACM SIGPLAN/SIGBED Conference on Languages, Compilers, and Tools for Embedded Systems, New York, NY, USA, 23 June 2019; pp. 163–176. [Google Scholar] [CrossRef]
- Hauser, N.; Pennekamp, J. Automatically Extracting Hardware Descriptions from PDF Technical Documentation. J. Syst. Res. 2023, 3. [Google Scholar] [CrossRef]
- Opasjumruskit, K.; Schindler, S.; Peters, D. Automatic Data Sheet Information Extraction for Supporting Model-based Systems Engineering. In Proceedings of the Cooperative Design, Visualization, and Engineering: 18th International Conference, Bangkok, Thailand, 24–27 October 2021; Volume 28, pp. 97–102. [Google Scholar]
- Tian, F.; Sui, Q.; Cobaleda, D.B.; Martinez, W. Automated Extraction of Data From MOSFET Datasheets for Power Converter Design Automation. IEEE J. Emerg. Sel. Top. Power Electron. 2024, 12, 5648–5660. [Google Scholar] [CrossRef]
- Bjöörn, A. Employing a Transformer Language Model for Information Retrieval and Document Classification Using OpenAl’s generative pre-trained transformer, GPT-2. Master’s Thesis, KTH Royal Institute of Technology, School of Electrical Engineering and Computer Science, Stockholm, Sweden, 2020. [Google Scholar]
- Zin, M.M.; Nguyen, H.T.; Satoh, K.; Sugawara, S.; Nishino, F. Information Extraction from Lengthy Legal Contracts: Leveraging Query-Based Summarization and GPT-3.5. Leg. Knowl. Inf. Syst. 2023, 379, 177–186. [Google Scholar] [CrossRef]
- Thapa, M.; Kapoor, P.; Kaushal, S.; Sharma, I. A Review of Contextualized Word Embeddings and Pre-Trained Language Models, with a Focus on GPT and BERT. In Proceedings of the 1st International Conference on Cognitive & Cloud Computing (IC3Com 2024), SCITEPRESS, Chi Minh City, Vietnam, 26–28 November 2025; pp. 205–214. [Google Scholar] [CrossRef]
- Wu, L.I.; Su, Y.; Li, G. Zero-Shot Construction of Chinese Medical Knowledge Graph with GPT-3.5-turbo and GPT-4. ACM Trans. Manag. Inf. Syst. 2025, 16, 1–17. [Google Scholar] [CrossRef]
- Chen, L.; Lin, P.H.; Vanderbruggen, T.; Liao, C.; Emani, M.; de Supinski, B. LM4HPC: Towards Effective Language Model Application in High-Performance Computing. In OpenMP: Advanced Task-Based, Device and Compiler Programming; Springer Nature: Cham, Switzerland, 2023; pp. 18–33. [Google Scholar] [CrossRef]
- Jeong, C. Generative AI service implementation using LLM application architecture: Based on RAG model and LangChain framework. J. Intell. Inf. Syst. 2023, 29, 129–164. [Google Scholar] [CrossRef]
- Pokhrel, S.; Ganesan, S.; Akther, T.; Karunarathne, L. Building Customized Chatbots for Document Summarization and Question Answering using Large Language Models using a Framework with OpenAI, Lang chain, and Streamlit. J. Inf. Technol. Digit. World 2024, 6, 70–86. [Google Scholar] [CrossRef]
- Liu, P.; Xiong, Y. Enhanced Chunk Screening in LangChain Framework by Supervised Learning Augmentation Based on Deep Learning. In Proceedings of the 4th International Conference on Artificial Intelligence and Computer Engineering, ACM, ICAICE 2023, Dalian, China, 17–19 November 2023; pp. 696–702. [Google Scholar] [CrossRef]
- Prem Jacob, T.; Bizotto, B.L.S.; Sathiyanarayanan, M. Constructing the ChatGPT for PDF Files with Langchain—AI. In Proceedings of the 2024 International Conference on Inventive Computation Technologies (ICICT), Kathmandu, Nepal, 24–26 April 2024; pp. 835–839. [Google Scholar] [CrossRef]
- Bhatia, S. Next-Generation Healthcare Information Systems: Integrating Chain-of-Thought Reasoning and Adaptive Retrieval in Large-Scale Document Analysis. SSRN Electron. J. 2025. [Google Scholar] [CrossRef]
- gkamradt. ChunkViz: Visualize Different Text Splitting Methods. GitHub Repository. 2025. Available online: https://github.com/gkamradt/ChunkViz (accessed on 27 June 2025).
- Yepes, A.J.; You, Y.; Milczek, J.; Laverde, S.; Li, R. Financial Report Chunking for Effective Retrieval Augmented Generation. arXiv 2024, arXiv:2402.05131. [Google Scholar] [CrossRef]
- LangChain. RecursiveCharacterTextSplitter. 2024. Available online: https://api.python.langchain.com/en/latest/character/langchain_text_splitters.character.RecursiveCharacterTextSplitter.html (accessed on 24 June 2025).
- Chroma Research. Evaluating Chunking. 2025. Available online: https://research.trychroma.com/evaluating-chunking (accessed on 17 June 2025).
- Vizniuk, A.; Diachenko, G.; Laktionov, I.; Siwocha, A.; Xiao, M.; Smoląg, J. A comprehensive survey of retrieval-augmented large language models for decision making in agriculture: Unsolved problems and research opportunities. J. Artif. Intell. Soft Comput. Res. 2024, 15, 115–146. [Google Scholar] [CrossRef]
- Ning, L.; Liu, L.; Wu, J.; Wu, N.; Berlowitz, D.; Prakash, S.; Green, B.; O’Banion, S.; Xie, J. User-LLM: Efficient LLM Contextualization with User Embeddings. In Proceedings of the Companion Proceedings of the ACM on Web Conference 2025, New York, NY, USA, 28 April–2 May 2025; pp. 1219–1223. [Google Scholar]
- Han, Y.; Liu, C.; Wang, P. A Comprehensive Survey on Vector Database: Storage and Retrieval Technique, Challenge. arXiv 2023, arXiv:2310.11703. [Google Scholar] [CrossRef]
- Mavroudis, V. LangChain v0.3. Preprints 2024. [Google Scholar] [CrossRef]
- Qdrant. Local Quickstart—Qdrant —Qdrant.tech. 2025. Available online: https://qdrant.tech/documentation/quickstart/ (accessed on 27 June 2025).
- Sidorov, G.; Gelbukh, A.; Gómez-Adorno, H.; Pinto, D. Soft similarity and soft cosine measure: Similarity of features in vector space model. Comput. Sist. 2014, 18, 491–504. [Google Scholar] [CrossRef]
- Es, S.; James, J.; Espinosa-Anke, L.; Schockaert, S. RAGAS: Automated Evaluation of Retrieval Augmented Generation. arXiv 2023, arXiv:2309.15217. [Google Scholar] [CrossRef]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; de Oliveira Pinto, H.P.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating Large Language Models Trained on Code. arXiv 2021, arXiv:2107.03374. [Google Scholar] [CrossRef]
- Fajrianti, E.; Panduman, Y.; Funabiki, N.; Haz, A.; Brata, K.; Sukaridhoto, S. A user location reset method through object recognition in indoor navigation system using Unity and a smartphone (INSUS). Network 2024, 4, 295–312. [Google Scholar] [CrossRef]
- Puspitaningayu, P.; Funabiki, N.; Huo, Y.; Hamazaki, K.; Kuribayashi, M.; Kao, W.C. A Fingerprint-Based Indoor Localization System Using IEEE 802.15.4 for Staying Room Detection. Int. J. Mob. Comput. Multimed. Commun. 2022, 13, 1–21. [Google Scholar] [CrossRef]
- Brata, K.C.; Funabiki, N.; Riyantoko, P.A.; Panduman, Y.Y.F.; Mentari, M. Performance Investigations of VSLAM and Google Street View Integration in Outdoor Location-Based Augmented Reality under Various Lighting Conditions. Electronics 2024, 13, 2930. [Google Scholar] [CrossRef]
- Fan, W.; Ding, Y.; Ning, L.; Wang, S.; Li, H.; Yin, D.; Chua, T.S.; Li, Q. A Survey on RAG Meeting LLMs: Towards Retrieval-Augmented Large Language Models. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, ACM, Barcelona, Spain, 25–29 August 2024; pp. 6491–6501. [Google Scholar] [CrossRef]
- Chen, Z.; Liu, Y.; Shi, L.; Wang, Z.J.; Chen, X.; Zhao, Y.; Ren, F. MDEval: Evaluating and enhancing markdown awareness in large language models. In Proceedings of the ACM on Web Conference 2025, New York, NY, USA, 28 April–2 May 2025; pp. 2981–2991. [Google Scholar]
- dkotama. Unlearned-Sensor-Setup-Assistant-Repository. 2025. Available online: https://github.com/dkotama/unlearned-sensor-setup-assistant-repository (accessed on 15 June 2025).
- Meng, R.; Liu, Y.; Joty, S.R.; Xiong, C.; Zhou, Y.; Yavuz, S. SFR-Embedding-Mistral: Enhance Text Retrieval with Transfer Learning. Salesforce AI Res. Blog 2024, 3, 6. [Google Scholar]
- Muennighoff, N.; Tazi, N.; Magne, L.; Reimers, N. MTEB: Massive Text Embedding Benchmark. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics, Dubrovnik, Croatia, 2–6 May 2023; pp. 2014–2037. [Google Scholar] [CrossRef]
- Lewis, J.R.; Utesch, B.S.; Maher, D.E. UMUX-LITE: When there’s no time for the SUS. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 September–2 May 2013; pp. 2099–2102. [Google Scholar]
- Batubulan, K.S.; Funabiki, N.; Brata, K.C.; Kotama, I.N.D.; Kyaw, H.H.S.; Hidayati, S.C. A Map Information Collection Tool for a Pedestrian Navigation System Using Smartphone. Information 2025, 16, 588. [Google Scholar] [CrossRef]
- Jiang, Y.; Shen, J.; Liu, Z.; Tan, C.W.; Lam, K.Y. Toward Efficient and Certified Recovery From Poisoning Attacks in Federated Learning. Trans. Info. For. Sec. 2025, 20, 2632–2647. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).