3.1. Context and Background
The platform implemented for the project is an improvement on a previous release, developed by CRS4 as a deliverable of the Joint Innovation Center project related to IoT for Smart Cities, partially supported by the Sardinian Local Government (RAS), within the Joint Innovation Center (JIC) project [
25]. The new release has undergone significant redesign and includes new features and modules, making it more scalable and adaptable to various contexts. It remains a valuable decision-making tool for Smart Cities. These new activities are part of the “Cagliari Digital Lab” project, which is co-funded by the Ministry for Enterprises and Made in Italy (MIMIT). Cagliari Digital Lab is an interdisciplinary technological research and innovation hub where stakeholders and startups can develop new ideas.
The new release of the platform is one of the practical laboratories, which are at the core of the project.
The platform for the Smart Cities laboratory has been improved to include multi-tenancy, smart data definition, data flow management, and a user-friendly front-end.
The platform also needed to integrate external services for data analysis and to run AI and optimization algorithms that could provide useful functionalities, such as intelligent transportation services and decision support systems, tailored to the needs of a Smart City. This requires an effective and efficient solution to integrate these services within the platform, adding another level of complexity. This article describes an example of integration, involving a service that optimizes vehicle itineraries to be displayed on the front-end map. It is important to note that the operation and algorithms of the optimizer service are beyond the scope of this article, which focuses solely on the description of its integration into the platform. As described in
Section 3.5, the proposed solution for the CDL platform considers the service as a device managed through the FIWARE IoT agent [
26].
To present the information stored within the platform to the user, an effective visualization tool is necessary. This tool should go beyond the basic features of a 2D map and utilize modern three-dimensional WebGIS systems.
One important consideration when using client-side applications is that the client has to be a public client as there is no secure way to store client credentials in a client-side application. Therefore, it is necessary to take particular care to ensure security and multi-tenancy. To manage both aspects, a JavaScript client was developed for the presentation layer. The client is based on the open-source library CesiumJS for the interactive 3D map part and integrates Keycloak’s JavaScript adapter for the security and multi-tenancy aspects.
3.2. Overall Architecture
This section provides an overview of the platform and outlines each component developed to address the challenges listed in
Section 2.
Due to the reasons elucidated in the previous sections, the architecture of the platform for the CDL project follows a microservice-oriented approach to facilitate scalability and to enhance interoperability. The platform is designed to handle various standards for IoT formats and protocols, making it easier to extend to additional application domains. To streamline development, certain components of the framework FIWARE have been integrated. As is known, FIWARE consists of a set of open-source components that expose open standard APIs (like NGSI-LD), which prove valuable in the development of smart solutions in general. The FIWARE Foundation, established in 2016 with co-funding from the European Commission, originated from work initiated in 2010 as a back-end platform developed for the Future Internet Public–Private Partnership program (Future Internet PPP). Initially named the Future Internet Core Platform in the EU-funded FI-ware project [
27,
28], it represents a solution capable of addressing issues related to interoperability, accessibility, resource efficiency, security, and trustworthiness.
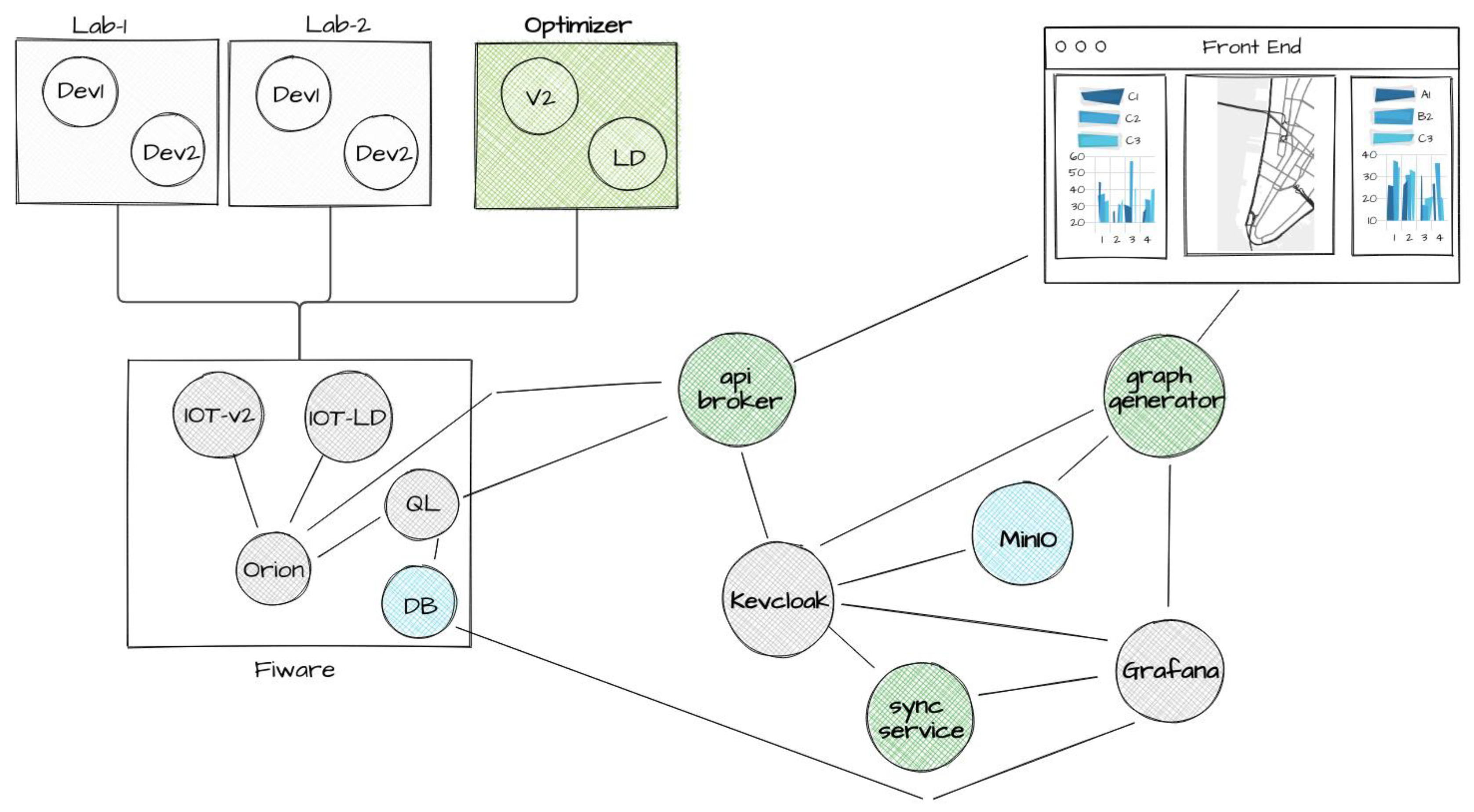
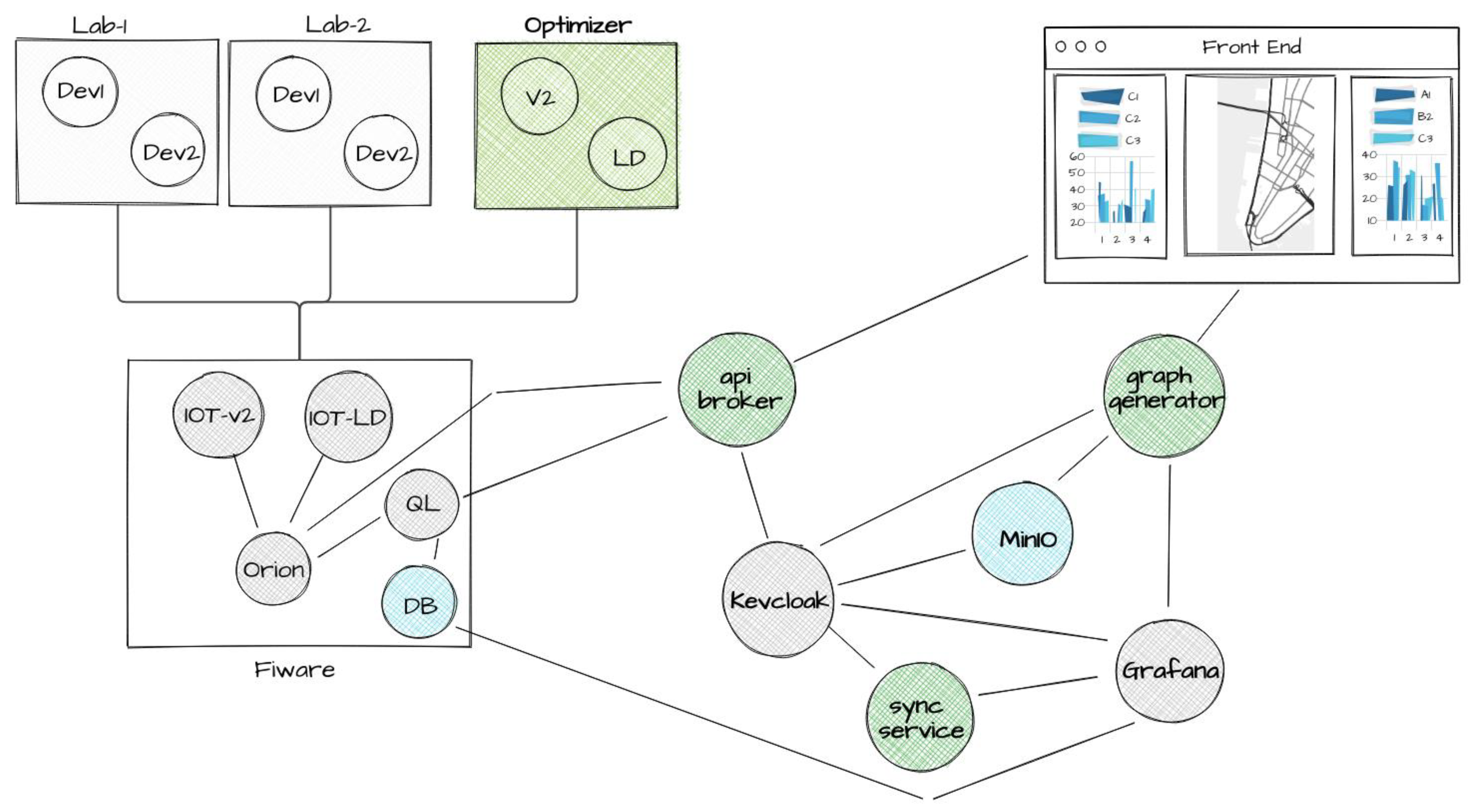
The platform utilizes a collection of components from the open-source community to provide fundamental services, including:
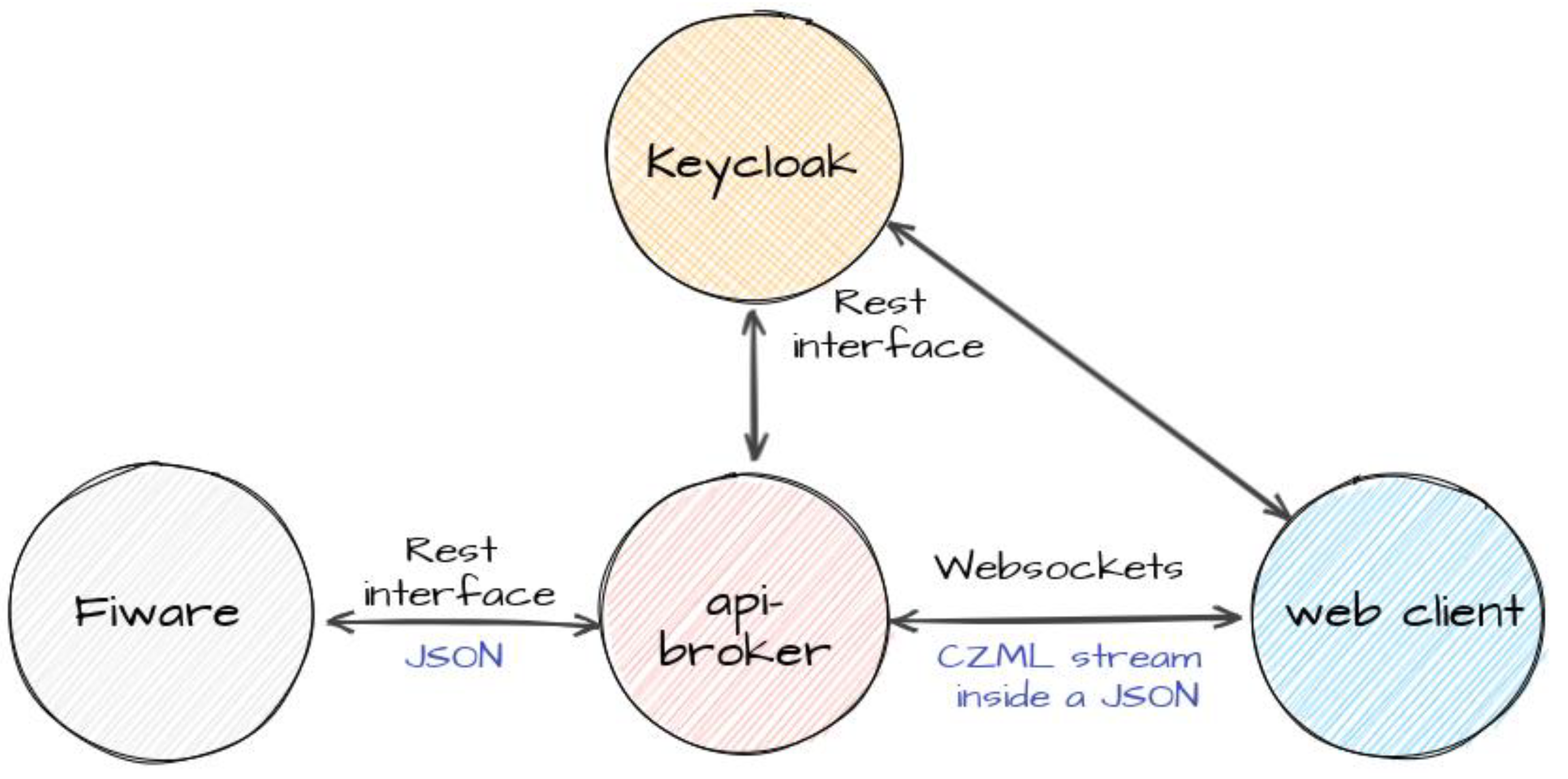
Figure 1 shows the services and components used to deliver basic functionalities and their connections, highlighted in green.
For the CDL project’s specific implementation, the front-end comprises two main parts: a 3D satellite interactive map and the side panels displaying statistics.
The infrastructure relies on two core components: one manages user information to feed presentation systems linked to the front-end, while the other manages the internal communication system responsible for transporting and dispatching messages.
3.3. Multi-Tenancy
The platform needed to be accessible to users from multiple groups, so multi-tenancy and multi-user management were necessary features. Specifically, addressing the multi-tenancy of user groups was crucial for smooth operation across all levels and components, from the back-end services to the front-end layer.
In this complex system, where the user interacts with multiple autonomous services, a username-and-password-based solution is limiting and complicated to implement. Therefore, the CDL lab has chosen to adopt a consolidated identity and access management (IAM) solution such as Keycloak [
29,
30], which is an open-source software developed mainly by Red Hat Inc. This system is essential to ensure the efficient and secure management of user identities in an IT system, for many reasons, as explained below. The first reason is that an IAM system, such as Keycloak [
31], helps to centralise and standardise user authentication, thereby simplifying the login process and reducing the risk of vulnerabilities due to weak passwords or insecure authentication practices. Another reason is that by providing granular access control, an IAM can effectively manage user privileges, ensuring that each user has only the access they need to perform their job, reducing the risk of unauthorised access or security breaches. In addition, Keycloak provides advanced session and permission management capabilities, making it easy for the system administrator to monitor and track user activity, improving overall system security. Ultimately, adopting an IAM such as Keycloak is critical to ensuring security and efficient management and also facilitates compliance with General Data Protection Regulation (GDPR).
Keycloak has numerous features, including Single Sign-On (SSO), which enables users to authenticate only once to access multiple applications without having to enter credentials repeatedly. This feature is particularly useful in the context of the CDL, where users will be interested in working using many different applications during the same session. Another important feature is that Keycloak can be used either as a standalone service or integrated into existing applications, such as the microservice-based architecture of the platform for the CDL. Keycloak offers the ability to manage users, identities, and related authentication through various methods, including username/password, two-factor authentication, and identity federation using protocols, such as OpenID Connect and SAML. This feature also simplifies integration with other applications and services that comply with these standards.
Keycloak offers a comprehensive authorization system that enables the precise definition and management of user access rights to resources. This ensures that only authorised individuals can access private data or functionalities.
Additionally, the platform administrator has complete control over the authentication flow, including the ability to define session duration and securely manage logout, thanks to the session management system.
Specifically, the platform exploits several peculiarities to ensure consistent authentication between modules’ manage authentication in a secure and efficient manner. Microservices can use regenerable tokens for authentication, allowing each service to identify the correct user of the generated data flow.
The platform ecosystem includes several services that authorize users based on their group membership. This means that Keycloak users can access authorized resources only for their respective groups.
Keycloak centralizes permission control, allowing operations to be performed only once, during token issuance. This avoids services having to repeat the operation each time. Furthermore, the validation of the token’s information can be performed directly by the relevant service, providing an alternative to calling Keycloak introspection endpoints and, expediting the processing of the information.
Although Keycloak has many advantages, it also has some disadvantages. It is a complex and reliable system, with a strong development momentum, which means that significant changes can occur between releases. For instance, approximately seven years after the first release, the major release 20.0.0 was launched in July 2023 and introduced behaviours that were incompatible with previous versions. However, due to the abundance of existing materials and tutorials, many developers did not adapt to the changes, resulting in the need to determine what no longer functions.
3.4. The Components of the Front-End Service
This section explains the organization of the front-end, the developed components, and the main challenges.
The front-end is a web application that allows users to access and navigate the different application domains and the data associated, based on the type of user.
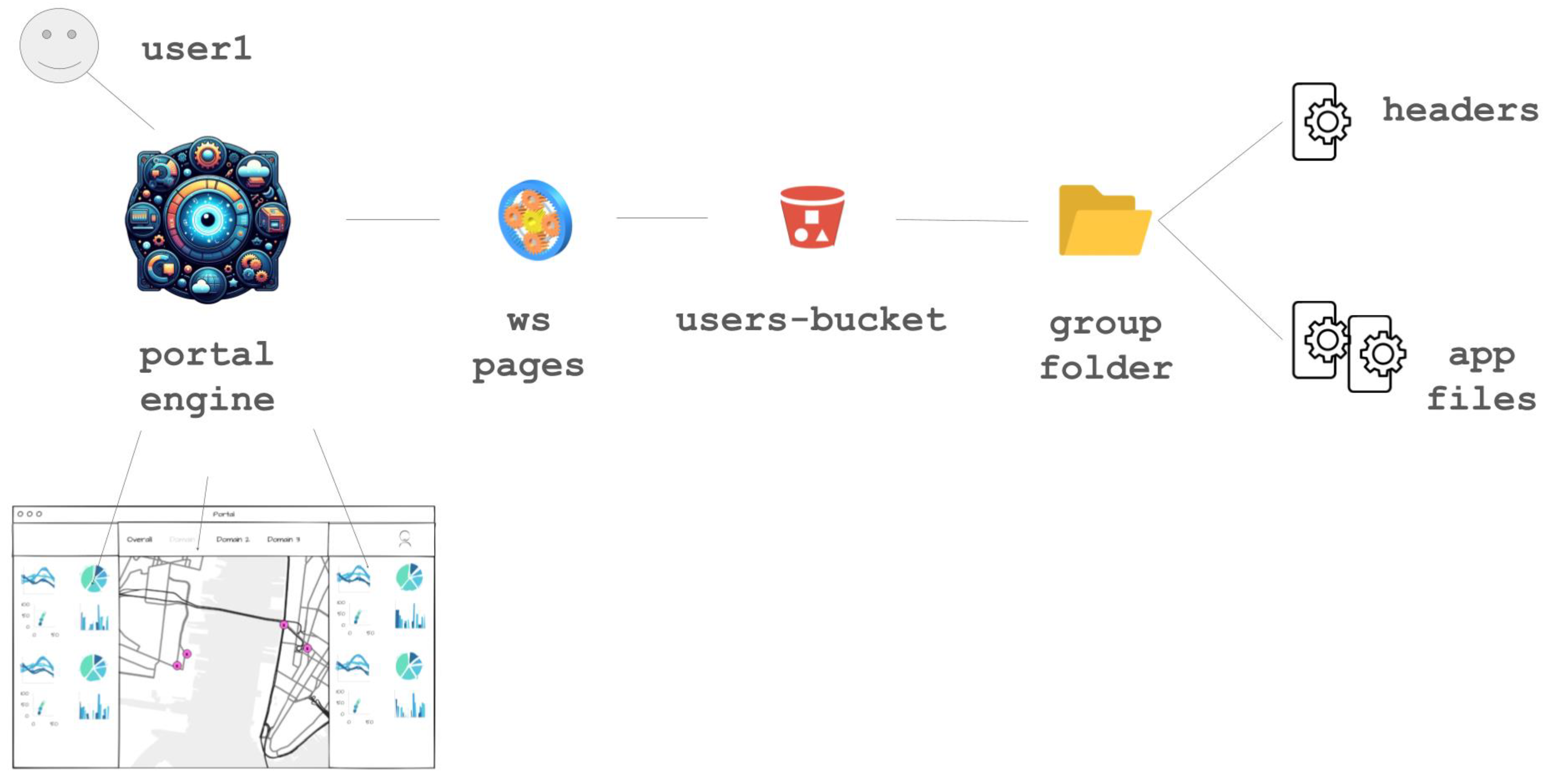
The portal’s structure is based on four elements, as shown in
Figure 2:
Each element in the front-end is available depending on the group (or groups) of the specific user logged in. It is, therefore, possible to customize, with a reasonable level of detail, the type of information to show, depending on the user.
In
Figure 2, point 1 concerns the classic concept of a “menu”, where all the different themes are listed, providing the possibility of selecting and exploring a single domain in detail.
In
Figure 2, points 2 and 3 show the analytics, with in-depth dashboards on time series and related contents; the ways they can be used and aligned are the subject of the following sections.
In
Figure 2, point 4 is the primary component of the front-end, providing a navigable map where georeferenced points of interest are displayed with their related real-time values; the Points of Interest (PoIs) are presented as dots in fuchsia color.
3.4.1. The Dashboard Creation System
This section describes the “graph generator” component shown in
Figure 1. Its purpose is essentially to provide analytical reports in the form of graphs related to the data of the context of interest. As expected, the information available at the front-end is filtered according to the group (or groups) of the logged-in user.
The implementation of this system could basically follow two paths: The first choice implied the direct use of libraries, such as D3.js, Chart.js, or Plotly charts, to produce graphs; these libraries work at a very low level, requiring the creation of the ecosystem to manage data access and automation in the presentation layer. The other choice implied the use of an open-source platform that already provides the developer with the necessary features, while leaving freedom in data access management, choice of components (and related types), and user federation.
After an overview of the main platforms available dedicated to this purpose, two systems that could meet the needs were studied: Apache Superset [
32] and Grafana [
33]. The following sections will describe these systems.
Apache Superset is an open-source business intelligence platform that aims to make data analysis easier. It has interactive dashboards, access to many data sources, connectivity to Apache Druid and relational databases, and an SQL Lab module for building SQL queries. Users can inspect real-time data, create graphical visualisations, and use data exploration tools. Superset allows for custom widgets and customisation to meet specific needs. The platform encourages collaboration by allowing users to share dashboards and visualisations while providing security and advanced permissions. As an open-source project maintained by the Apache Software Foundation, Superset benefits from an active community of developers. In summary, Apache Superset facilitates data analysis by providing a versatile, collaborative, and accessible platform.
Grafana is an open-source visualization and monitoring software designed to effectively analyse and present data. It provides interactive dashboards that allow users to combine and view data from different sources, such as databases, cloud services, and monitoring systems. Grafana offers a wide range of plug-ins, allowing for easy integration with systems, such as Prometheus, InfluxDB, and others. To monitor data in real time, the platform allows for the creation of custom panels, charts, and alarms. Grafana is renowned for its user-friendly interface and its ability to produce engaging and informative visualisations. It also provides a very versatile data analysis experience, with customisable drill-down capabilities, filters, and themes. Grafana is often used in system and application monitoring because it provides advanced query and analysis capabilities to effectively support decision makers through proactive performance monitoring.
Ultimately, a comparison of the two systems favours Grafana because it is more versatile in use, allows dashboard customisation, and is designed to be integrated into a modular ecosystem, where Keycloak handles identity and access management. These are the reasons why Grafana was chosen to be integrated into the platform, but there were some hurdles to its adoption. In fact, the key issue in its integration into the platform is the mapping between how Keycloak understands users/groups/roles and how Grafana understands them; for this mapping, Grafana’s Team Sync [
34] is only available in the paid tiers Premium Enterprise and Cloud versions. For the CDL platform, the Grafana Community Edition was chosen, which is free, so this important mapping between Keycloak and Grafana had to be developed.
Although hooks can be used for Keycloak events, it is recommended to use calls via the system’s normal API.
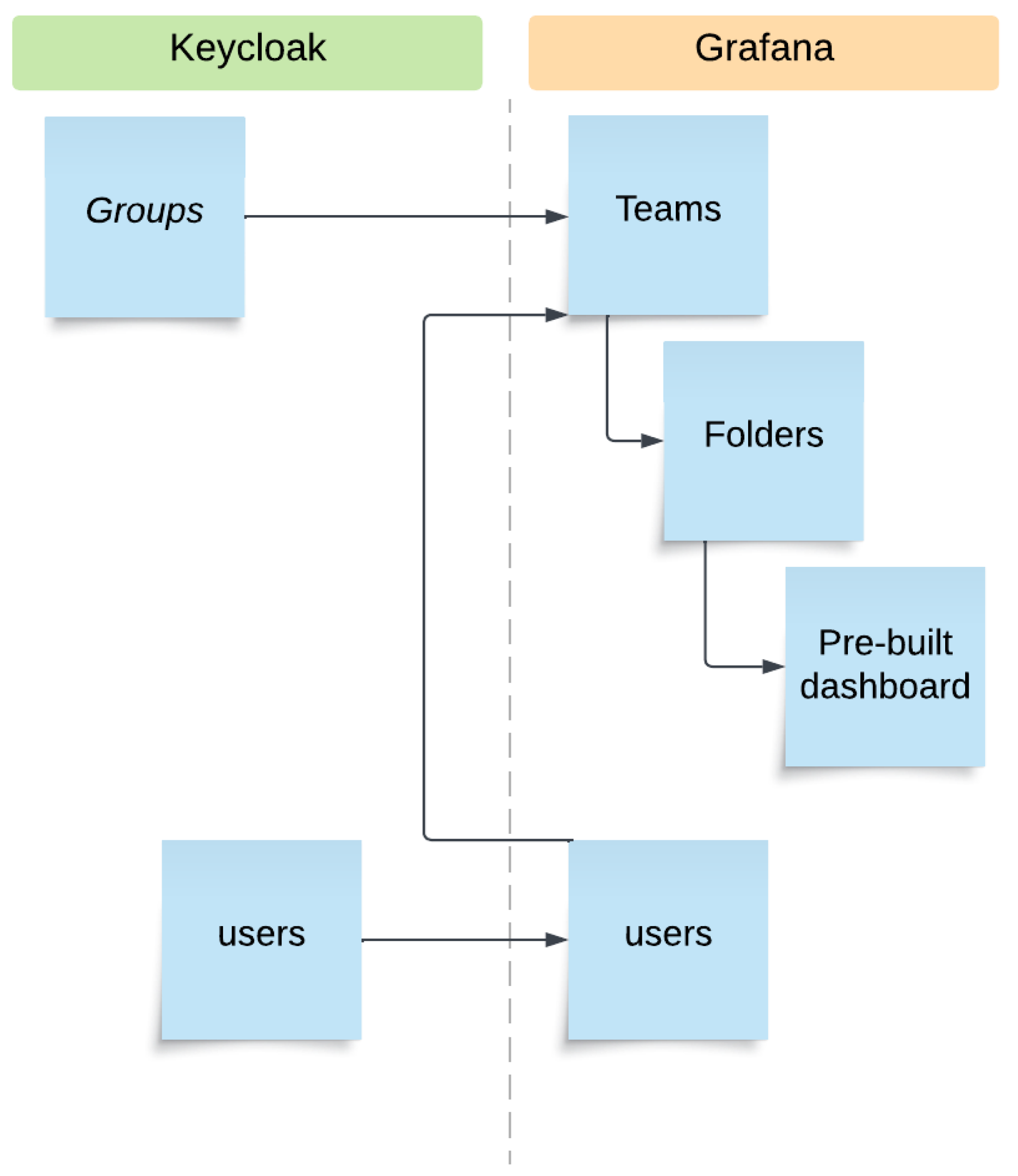
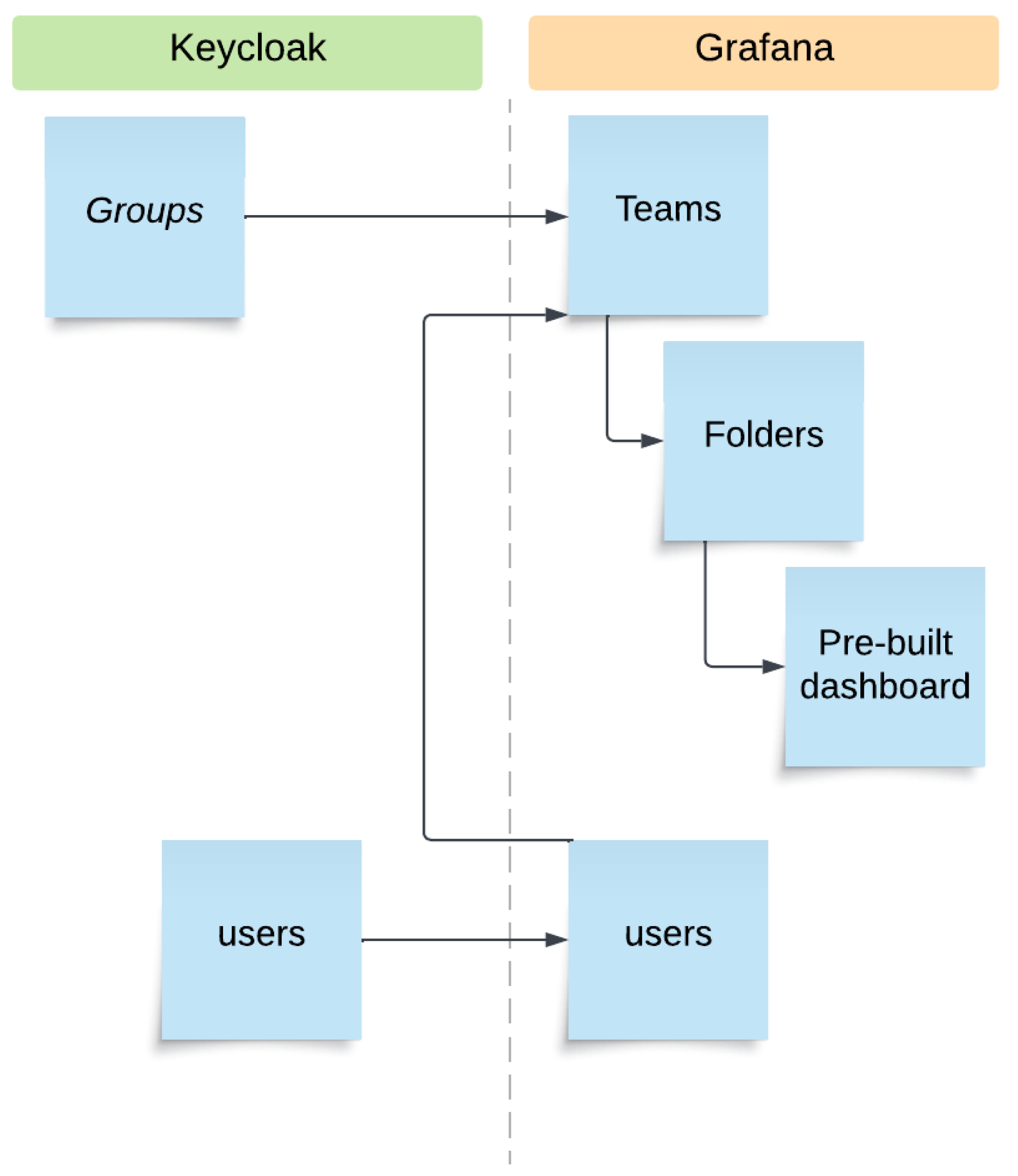
Table 1 presents mapping of the main key concepts between Keycloak and Grafana.
In
Figure 3, the dotted line separates the two environments, and the arrows between environments show the mapping between the key concepts and how to match them using the services we developed.
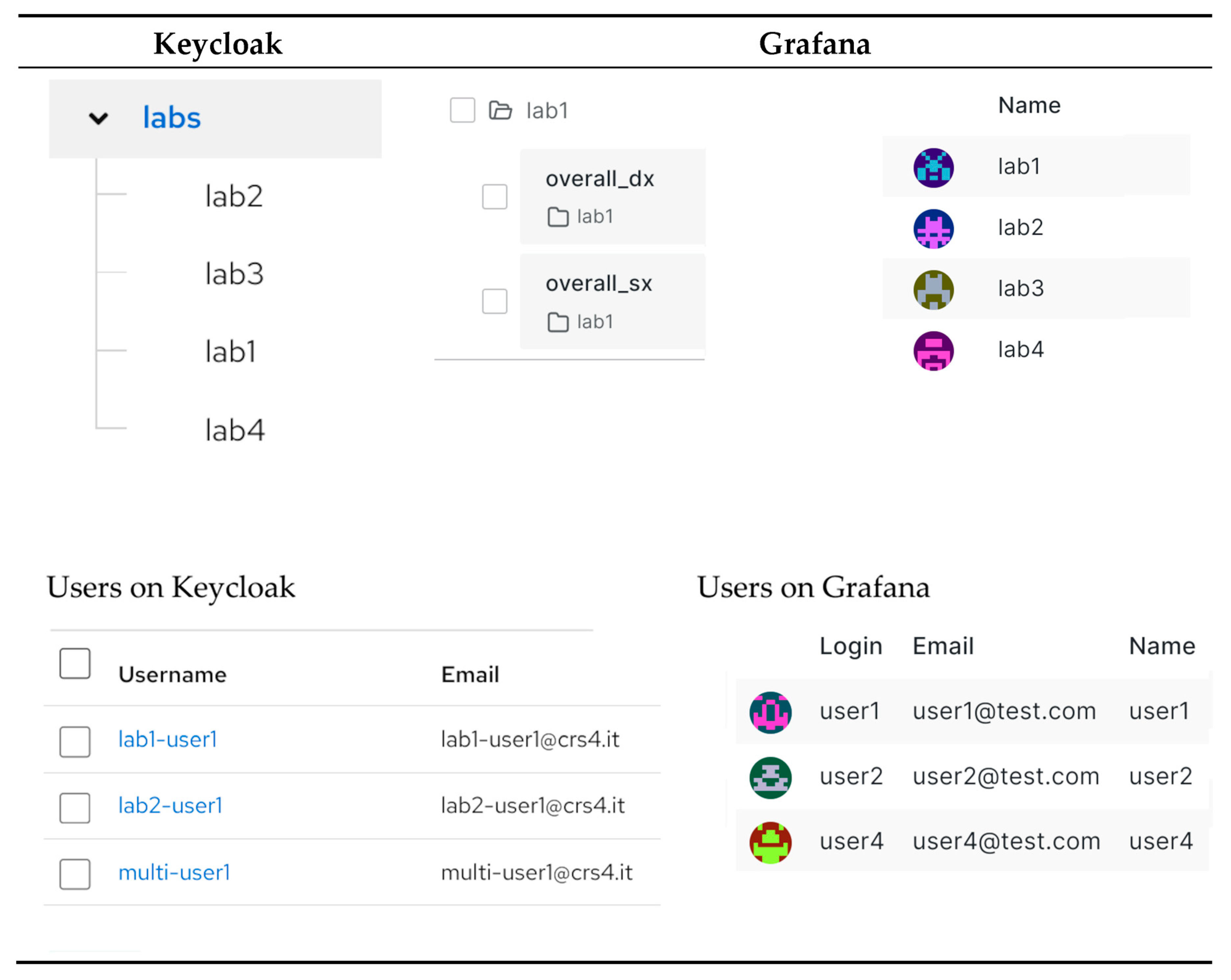
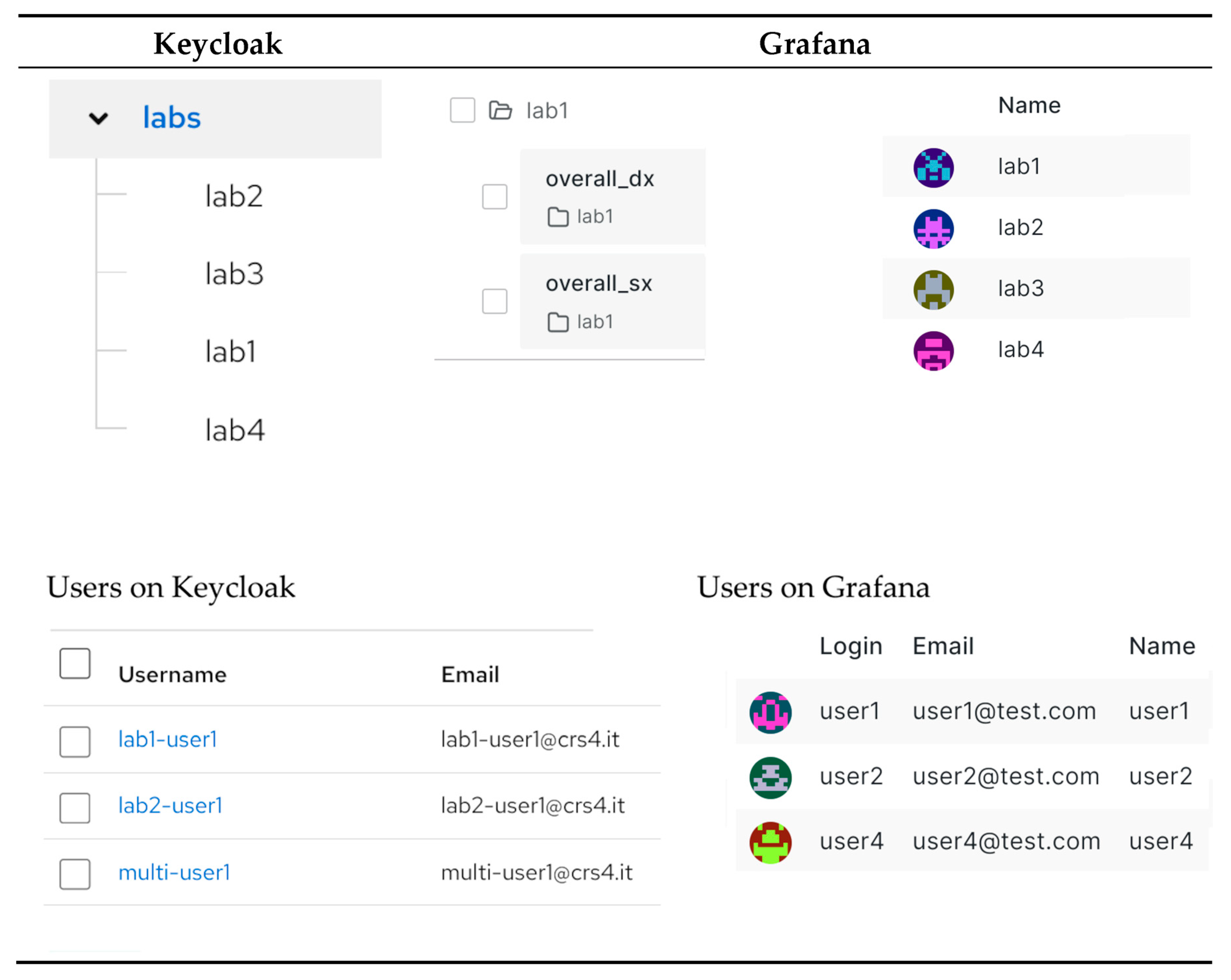
Figure 3 shows the mechanism for synchronizing Keycloak with Grafana, which starts with connecting groups on Keycloak and teams on Grafana. The Grafana API allows this type of operation efficiently. At this stage, folders are created to contain the dashboard with the graphic widgets. The output is intended for the two side panels of the front-end, located on the left and on the right of the central map; these folders were given the naming convention “overall_sx”, “overall_dx”, or, more generically, “_sx” and “_dx”.
This structure allows the system administrator to filter access to each part of the front-end according to team-based criteria, protecting the folders from unauthorised access.
The dashboard-naming convention makes it possible to establish a link between the vertical application, defined by the part of the name preceding the “_” symbol and all the other modules used on the platform that work on the same theme.
In order for Grafana and Keycloak to communicate, some standard configurations are required.
In this case, access to the Grafana platform is achieved according to a configuration that allows the use of the OpenID managed by Keycloak, and this means that the users are not allowed in the Grafana database until they log in for the first time.
However, this behaviour does not work when it is necessary to update and synchronise group permissions, since it is not possible to intercept the user login and registration mechanism in Grafana.
Grafana’s API allows a privileged user to register local users in the local database but not those logging in using OpenID. For this reason, a workaround was used, which is detailed hereafter. First, Grafana was launched, with PostgreSQL as its internal database instead of SQLite. Subsequently, upon analysing each login via OpenID, it was possible to see that this event was reflected in three tables of the internal database (see
Table 2).
Therefore, this synchronization mechanism offers a twofold advantage: it provides direct API access to Grafana and also exploits direct access to the database. Access is limited only to strictly necessary information in order to avoid corrupting any internal mechanisms. This system enables the synchronization of users, groups, and permissions. Moreover, it initializes a basic structure for the dashboards, which will then be displayed in a portal through other mechanisms and services, which will convey the content to the front-end.
Figure 4 shows the results of the syncing action between Keycloak groups and users and Grafana users and teams.
3.4.2. The System to Export the Dashboards
This paragraph explains how to transfer information from the back-end environment to the portal in order to build and populate its structure.
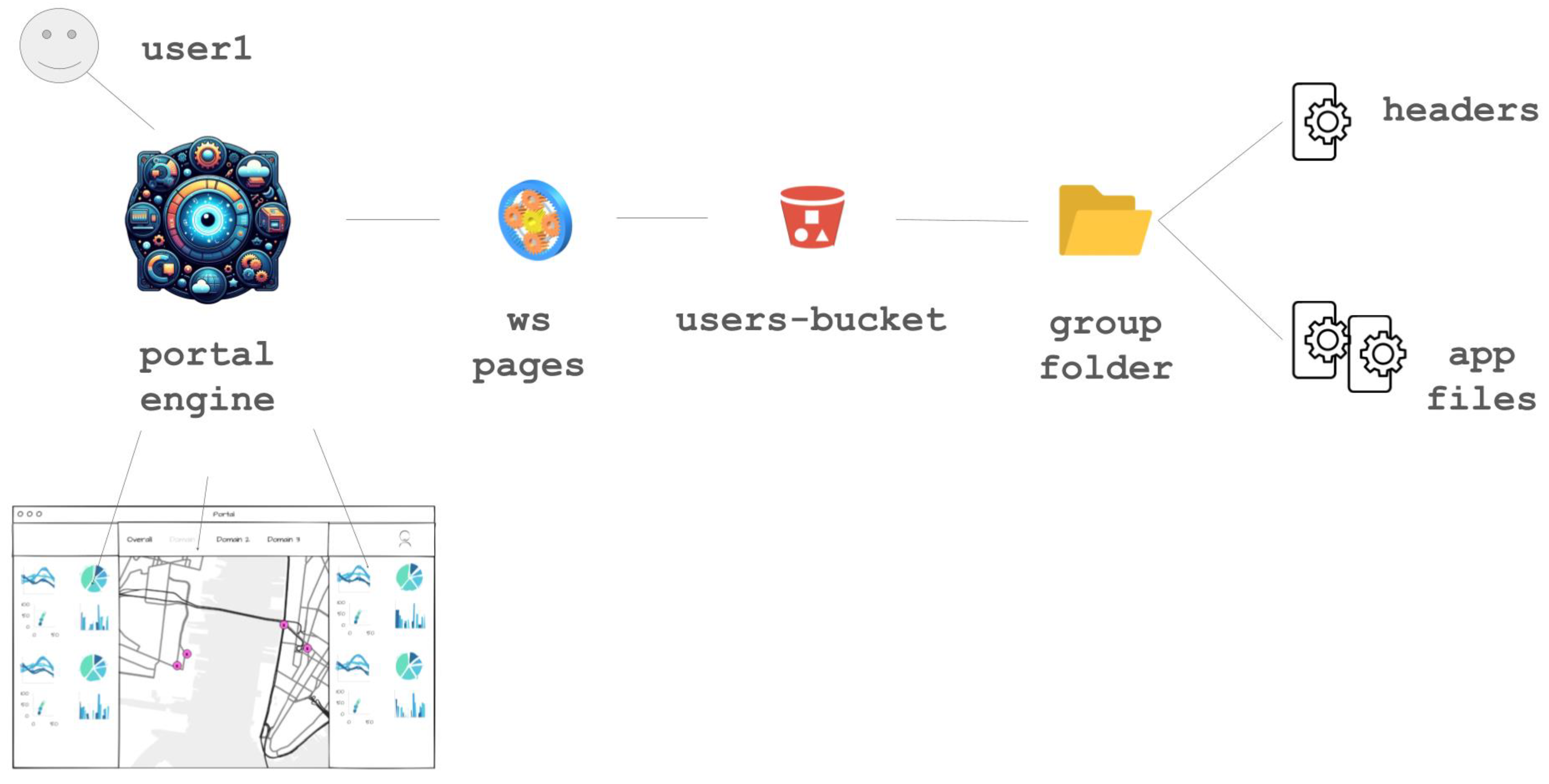
A system that enables a customisation of the presentation was necessary to display the content of the Grafana dashboards in the portal.
The development of a user synchronization service between Keycloak and Grafana also affects the sidebars of the front-end (identified with numbers 2 and 3 in
Figure 2). The information comprises two HTML files that contain the page layout and references of the dashboards that can be exported from Grafana.
The developed module uses asynchronous technology to improve performance and consists of REST APIs that serve as an interface to the underlying logic.
The aim of this module is to supply an interface that powers the portal sidebars by providing files that constitute the structure of the analytical bars, menu, and any data sources to manage additional logic directly on the map upon request.
MinIO [
35] was selected to manage object persistence, specifically for storing unstructured data such as photos and videos. It provides APIs for interactive queries and a web console for easy data updates. MinIO is an open-source project based on Amazon’s S3 standards for managing object storage. Minio natively supports OAuth2 and OpenID Connect, making it ideal to interconnect environments with centralized authentication management, especially in Kubernetes-related infrastructures.
As with Grafana, a new structure was required to reflect the hierarchy of the user, group, and application. Custom access policies have been implemented to ensure correct access to authorised resources. These policies can be modified and bind users to folders through group names.
Policies in Minio are JSON blocks such as in
Figure 5.
In the next block, the “users-bucket” resource for AWS is defined as the object on which the rule will be applied, that is, precisely, a container bucket, like
Figure 6.
Access to the folders will only be granted to users with the ‘profile’ claim in their token, starting with the name of the folder, as shown in
Figure 7.
On the Keycloak side, the “client” used to identify MinIO users has a “client scope” that allows for the propagation of an attribute (also known as “claim”) through the token payload. This claim provides information about the group name of the user that is attempting to access the resource. In this case, the claim must be named “profile” due to some restrictions in MinIO regarding the “claim” field.
The token in
Appendix A has the value “lab1” in “profile”. According to the policy listed above, the user will, therefore, only have access to the following path:
users-bucket / lab1 / *
Figure 8 shows the first folder hierarchy in a boilerplate structure.
The type of operations allowed to this user is defined by the block illustrated in
Figure 9.
In this specific case, any operation is allowed as the wildchar “*” is used.
MinIO is a very stable and solid system that reflects the AWS S3 API quite closely. However, some parts were difficult both to understand and to use; in particular, the use of the policy engine is found to be very time-consuming because it does not send any output to the console log. For this reason, the rules must be written without any assistance in debugging, and bug fixing can be very complicated. Unlike Amazon’s products, which provide a web interface to aid in policy creation, MinIO does not offer this useful functionality. Although the documentation includes a cross-reference to Amazon’s own products, exporting the rules created with these tools can be frustrating because the relationship between Amazon’s and MinIO’s features is not one to one.
The process for feeding dashboards to the sidebars can be described as follows (shown in
Figure 10): A user with a valid token accesses the portal and selects a topic from the main menu. This triggers a request to the service related to the selected topic to obtain the information, which will be shown in the header and in the two sidebars. The service verifies the validity of the token and queries MinIO, based on the group information. At this point, the service returns the header YAML file along with the HTML files defining the two sidebars. The convenience of this approach is that these files can be locally built, updated, and sent to MinIO via the web interface. Another useful feature of this system is that MinIO allows for versioning, although it has not yet been developed in the CDL platform.
3.4.3. The Map Logic
This section explains how to interact with the map, which is the primary component of the front-end and is identified as number 4 in
Figure 2. The central area of the front-end contains the map, which is developed using CesiumJS [
36], and a Javascript GIS library that enables the creation of a virtual globe using maps from different sources. Through the CZML (Cesium Language) format, Cesium enables the creation of web clients that provide graphical descriptions of events on a map, maintaining precise temporal references [
37]. This approach enables the dynamic visualisation of elements on the map, changing features based on their most recent state and, potentially, displaying the states assumed at each time interval [
38].
From here on, we will call “client” a JavaScript application built with the CesiumJS library; in this project, CesiumJS is loaded inside the portal front-end to manage the communication with the modules of the back-end modules, as well as the rendering of the widgets on the map. In order to secure the client and allow for multi-tenancy when displaying information on the map, the client was also integrated with KeyCloak using the specific adapter.
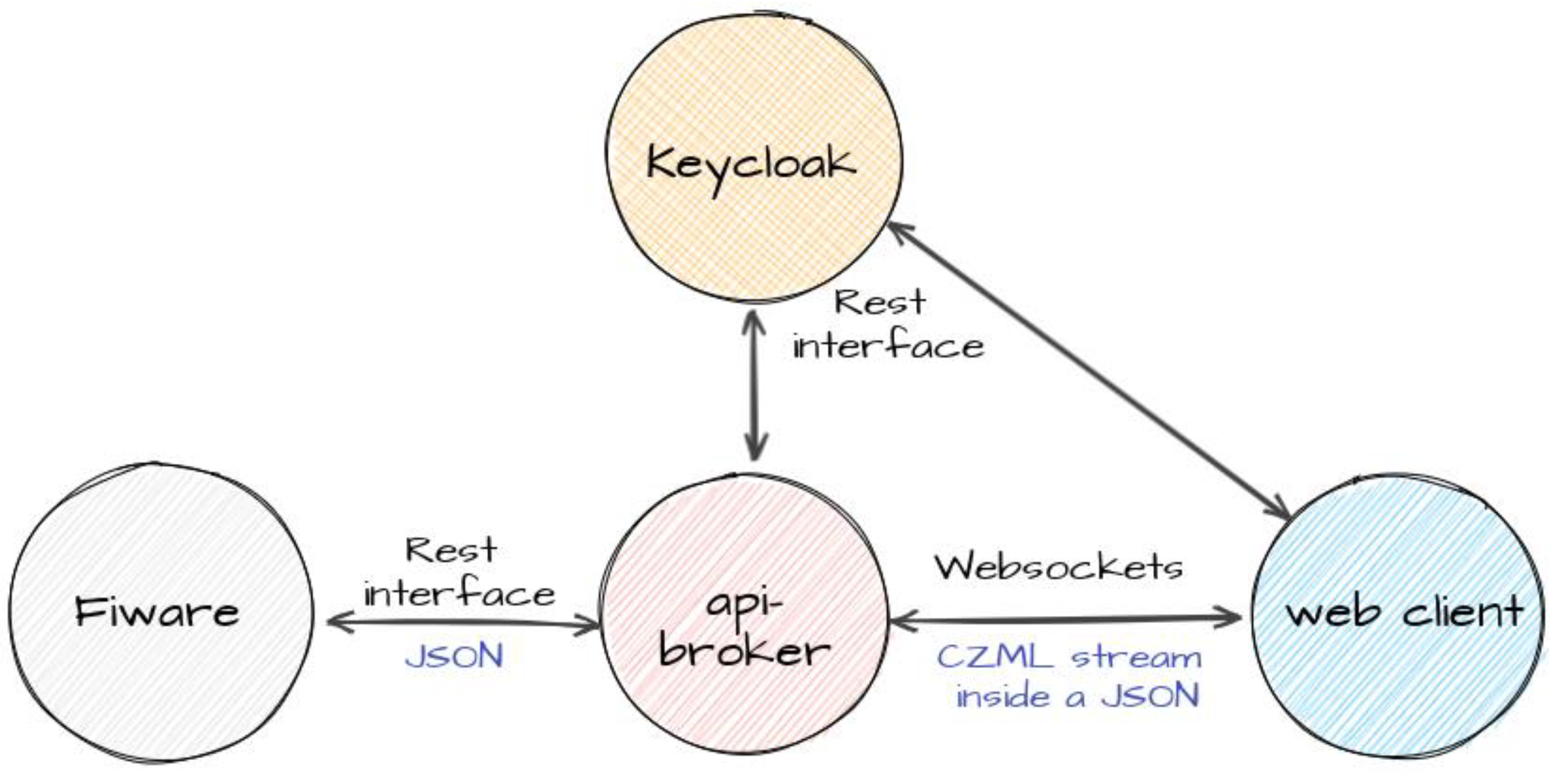
The conversion of the information collected and stored by the FIWARE components into data in a format usable by CesiumJS is handled by the API broker, a microservice that exposes two types of interfaces: the REST APIs to the FIWARE environment and a websockets-based interface to clients running CesiumJS, as shown in
Figure 11.
The CZML format used by Cesium is based on JSON, so a properly corrected CZML file is a valid JSON file designed to efficiently and incrementally stream data to a client built with CesiumJS. The client does not need to have finished loading the entire document before the scene is presented. Individual clients can join and leave the stream as it is transmitted. The CZML file format allows both static and timed information to be dynamically added to extend the functionality of the client, adding information to the objects in the scene.
More specifically, a CZML document consists of a single JSON array, where each object element is a CZML packet. The graphical characteristics and properties of a single object in the scene, such as a single sensor, are described in a CZML packet. Of course, in order to be located on the map, each object must contain information about its position, expressed in coordinates (latitude, longitude, and altitude). A possible document will have the structure illustrated in
Figure 12.
The communication between these clients and the API broker follows two main streams: the first stream is related to the initial connection of the client, and the second stream is related to the push of updates coming from the sensors. This aspect will be described in more detail below.
In the first case, the web client obtains the access token from Keycloak on behalf of the user and establishes the connection on the websocket interface of the API broker. Unfortunately, the WebSocket protocol does not define an authentication and authorisation system, and in the JavaScript WebSockets API, there is no way to specify additional headers to send to the WebSocket server [
39]. A common workaround to achieve this is to pass the token in the URL/query string when establishing a WebSocket connection, but this also means exposing it to possible logging systems. To avoid this problem, the token is included in each message that the client sends to the service, and communication between the two takes place under a Secure Sockets Layer (SSL) certificate. The server will only allow the initial connection to continue if the token is valid.
Websocket communication between the client and the API broker is based on the exchange of JSON messages: the client sends the desired command to the service, which checks the validity of the token contained in it and sends a response. For example, for the client’s first connection, the message will have the structure illustrated in
Figure 13.
The response to this request sent by the API broker to the Cesium client will have the format illustrated in
Figure 14.
Like the other services described so far, the API broker is integrated into the Keycloak infrastructure, and the websocket only accepts commands from clients that are associated with a valid token, as described above. One of the tasks of the API broker is also to recognise which resources a user can access by parsing the “groups” claim contained in the token provided by the client. At the global platform level, Keycloak groups are mapped 1:1 to the tenants implemented by FIWARE.
The FIWARE Orion Context Broker implements a basic multi-tenant model based on a logical database separation. With this implementation, when the Orion receives a request that includes the “FIWARE-Service” HTTP header, this header is used to determine the correct tenant and ensure that the entities/attributes/subscriptions of that tenant are kept “invisible” to the others.
The second type of data flow, relating to updates, follows a similar logic to the first, but in this case, the triggering event is not in the Javascript client but in the FIWARE part. Within the API broker service, the user group is then used to manage all connections that have access to the same set of resources, so that any updates received from FIWARE can be sent to all connected clients. When Orion notifies the API broker using the REST interface, it sets the HTTP header “FIWARE-Service” to match the tenant from which the data were generated. The API broker uses this information to determine the group of users connected to the websocket and propagates the message accordingly after converting it to CZML.
The token in
Appendix A refers to the values “/lab/group1” and “/lab/group2” in the claim “groups”.
Whenever a client connects to the API broker with this token, the connection is added to two different groupings: one for group1 and one for group2. From now on, FIWARE can be queried using the name of each group to retrieve all the information about the two tenants. At this point, the information is transformed into CZML and sent directly over the link to the individual connected client. From now on, when data from the sensors in tenant group1 (or group2) are sent by FIWARE to the API broker, the data received are converted to CZML and sent to the grouping group1 (or group2) of all connected clients.
3.5. The IoT Agent and the Connection of AI-Based Services
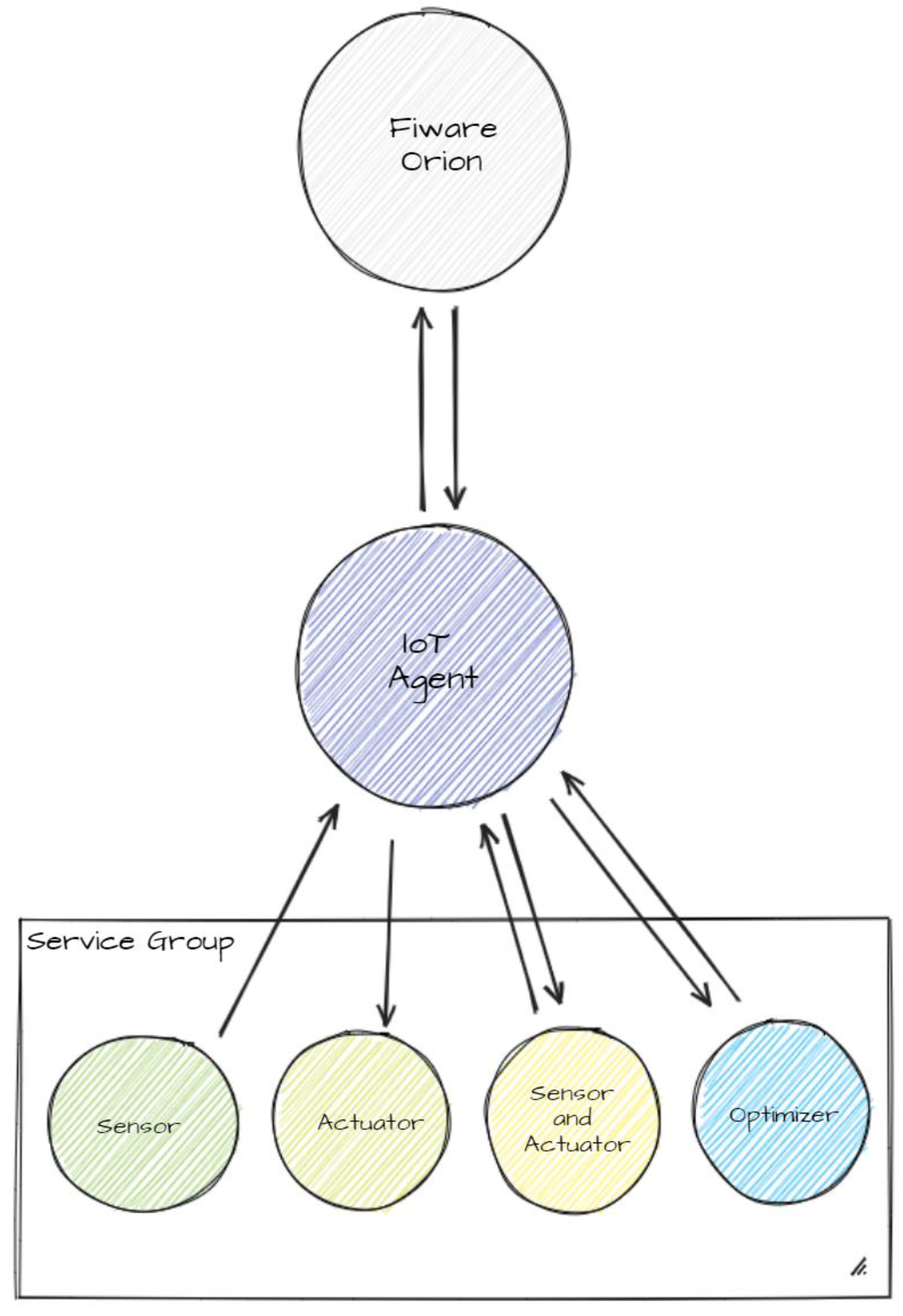
This section describes the components of the platform and the data workflow used to integrate IoT devices, sensors, and actuators in the platform for the CDL, where the same type of mechanism is being developed to integrate AI-based services. In the previous section, the data flow from sensors to the Orion was mentioned; in this section, the focus is more on the IoT agent component, which is the interface between any device (sensor or actuator) and the FIWARE Orion. In order to better explain this aspect, an example of the integration of a service for minimising road itineraries (Optimiser) is described here. Supposing an end user needs the best itinerary to reach a certain location with a certain mode of transport, a request of an optimised itinerary could be sent through the interactive front-end of the application. From there, the request is sent to the Optimiser, and then the best itinerary is asynchronously sent back to the presentation layer, through the same components but in reverse order.
Figure 15 shows the overall architecture of the FIWARE Orion, IoT agent, and devices.
To complete this task, several steps are necessary. Firstly, the components must be configured correctly. The central element of the FIWARE-based architecture is the Orion. It is worth noting that the Orion, when working with linked data (in short LD), is backward compatible and can manage entities without context. The IoT agent JSON (IoTA) component connects Orion with devices such as sensors and actuators. The CDL project platform uses the same connection to integrate AI-based services, such as the Optimiser.
Unlike Orion, two different IoTAs are used to manage entities: IoTA-LD, which is compliant with a specific context (a FIWARE smart data model), and IoTA-v2, which deals with entities that do not refer to any context. For simplicity, we will refer to both as IoTA.
To establish communication between the components, certain operations are necessary.
Figure 15 illustrates the three layers from the Orion to the Optimiser passing through the IoTA.
Table 3 provides an example of IoTA configuration that specifies communication with FIWARE Orion, MongoDB, and devices in general. In the case of IoTA-LD, it is crucial to set the IOTA_JSON_LD_CONTEXT field to the appropriate context that defines the smart data model used in the application. In the configuration, other important parameters are as follows: IOTA_DEFAULT_RESOURCE, which defines the channel used by devices to direct the information; IOTA_TIMESTAMP, which must be set to true to automatically add timestamps to sensor measurements; IOTA_AUTOCAST, which must be set to true to read JSON number values read as numbers instead of strings.
To inform the IoTA of a new group of devices, a provision must be made, specifying a unique combination of apikey and resource. This combination must be equal to the one defined as IOTA_DEFAULT_RESOURCE in the IoTA configuration, and it will work as a separate channel.
After that, each device (such as the Optimiser) must be registered or provided to the IoTA. This registration should include the device’s id, entity_name, entity_type, attributes, commands, and other relevant information. Depending on the type of device, the sensor provision should specify the details of the measures sent to the IoTA. For actuators, the key information is the endpoint used by the device to receive commands from Orion. Devices that work as both sensors and actuators, such as the Optimiser service, must provide all the necessary information for each type. The information from each provision sent to IoTA is shared with the Orion. This allows Orion to store each device as a new entity and can communicate with it through IoTA.
While, in the example, tutorials demonstrate smooth operations, setting up a new actuator can be challenging depending on the versions of IoTA coupled with Orion. This mechanism has undergone changes from one release to another.
The Optimiser is a Node.js application that runs on a Docker container and has an endpoint for each type of unit processing. It will be able to run computations on three different types of processors: a central processing unit (CPU), a graphical processing unit (GPU), or a quantum processing unit (QPU).
Different algorithms are used to optimise an itinerary depending on the type of processor. Therefore, specific input parameters are required along with a set of common static information, such as the road network. This is why the Optimiser’s Node.js application has dedicated endpoints. The output of the Optimiser is the minimum itinerary, enriched with metadata containing information about the algorithm’s input.


 ,
, 










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
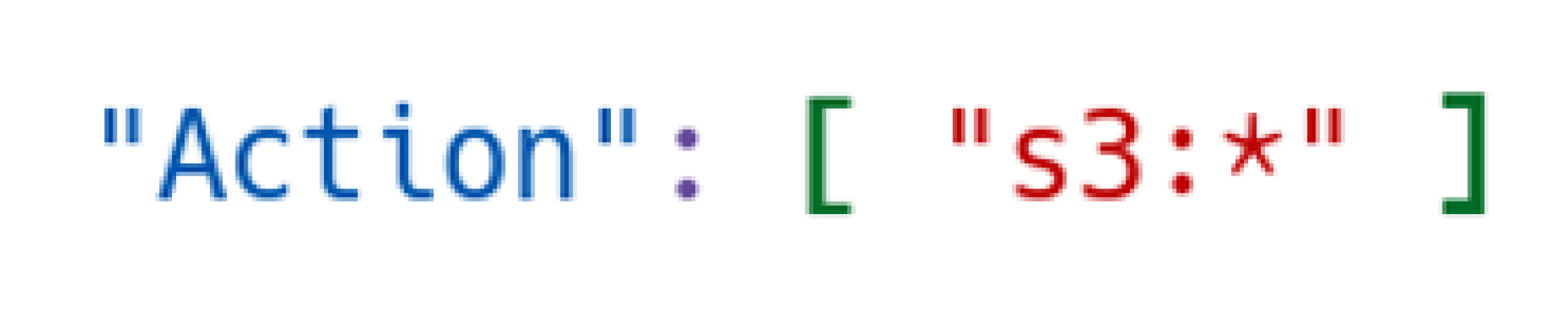{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}