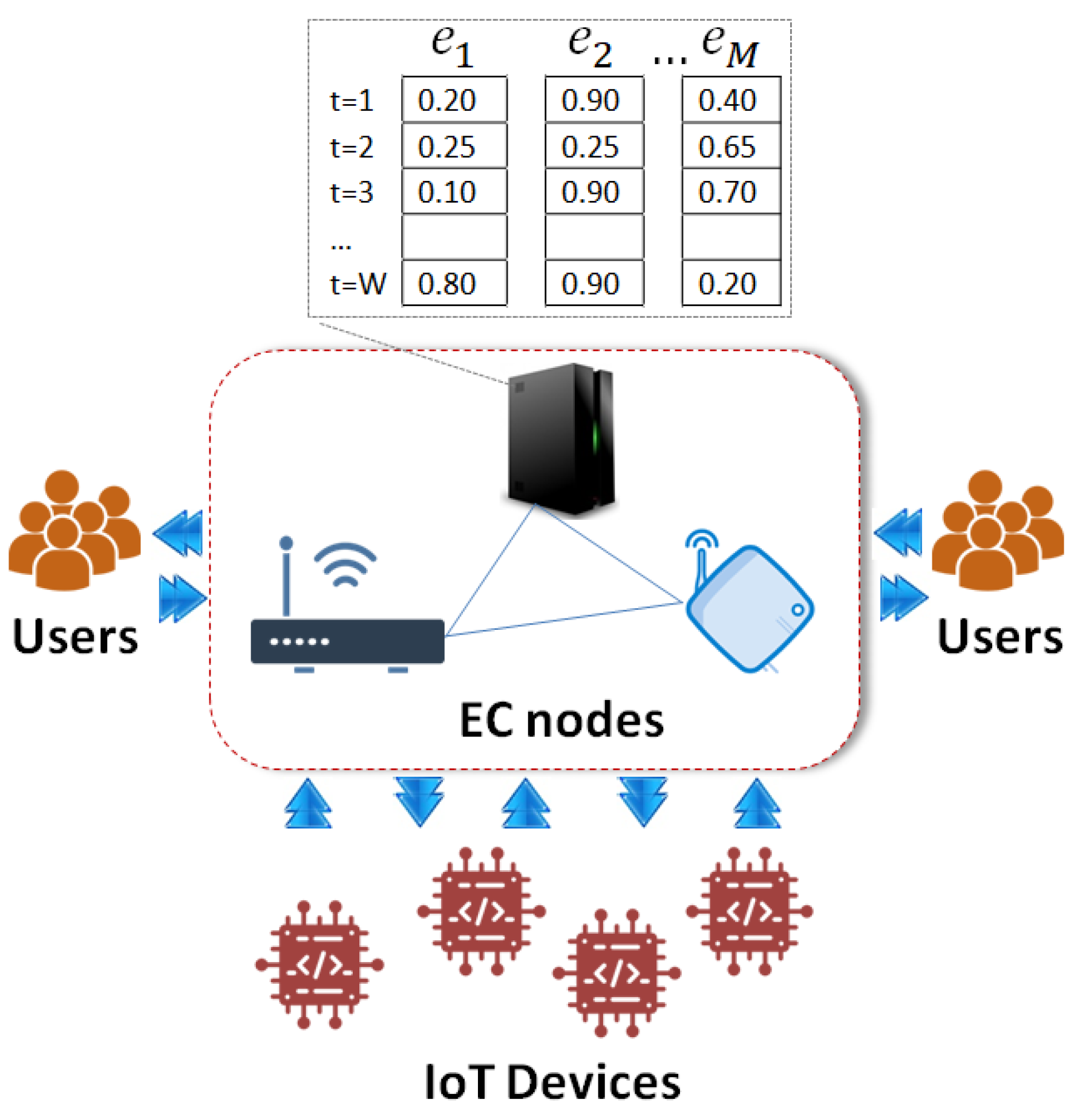
5.1. Performance Indicators and Setup
We report on the performance of the proposed model as far as the conclusion of correct offloading decision concerns. We also focus on time requirements to result in the final decision for tasks that will be offloaded to peer nodes. We planned to expose the ability of the proposed scheme to get real time decisions to be able to support time-critical applications. We performed a high number of experiments and get the mean value and the standard deviation for a set of performance metrics. For each experimental scenario, we performed 100 experiments, defining specific values for each parameter discussed in the remainder of this section. We evaluated the proposed model upon the simulation of the demand realisations, based on a real trace. For simulating the demand for each task, we relied on the dataset discussed in [
45]. The dataset was generated by an energy analysis of 12 different building shapes—i.e., their glazing area, glazing area distribution and their orientation. From this dataset, we “borrow” the data related to the temperature load of each building to represent the demand for our tasks. We noted that the dataset had an “attitude” to low values.
We adopted a set of performance metrics for evaluating our model, as depicted in
Table 1. The following paragraphs are devoted to their description:
(i) The average time
spent to conclude a decision.
was measured for every task as the time spent (CPU time) by the system deciding if a task should be offloaded or not. For this reason,
is calculated as the sum of (a) the time spent to get the outcome of the LSTM; (b) the time spent for the rewarding mechanism to deliver the final reward for each task; (c) the time required to deliver the final rankings of tasks and select those that will be offloaded to peers. We note that
is measured as the mean required time per task in seconds.
(ii) The number of correct decisions
. For realizing
, we assumeed the cost for executing a task locally compared to the cost for offloading it. The cost for executing a task locally is equal to the waiting time in the queue plus the execution time. The cost for offloading a task involves the migration cost, the waiting time in the “remote” queue, the execution time and the time required for getting the response from the peer node. It becames obvious that, depending on the performance of the network, the “typical” case is to have a higher cost when offloading a task. However, EC nodes can undertake this cost for non popular tasks if it is to release resources for assisting in the execution of popular tasks. Hence, we considered a correct decision as the decision that offloads tasks when their
is below the pre-defined threshold
—i.e.,
where
is the number of experiments. Recall that, at every epoch, we offloaded the last-
k tasks of the ranked list. Hence,
depicts the percentage of
k tasks that were correctly offloaded based on the reasoning of our decision-making mechanism.
(iii) We adopted the
metric that depicts the percentage of the offloaded tasks that are among the
k tasks with the smallest popularity. We try to figure out if the proposed model can detect non popular tasks. We had to remind ourselves that, in our decision-making, the demand/popularity was combined with the load that a task adds to an EC node. We strategically decided to keep the execution of non-popular tasks locally when the load they added was very low.
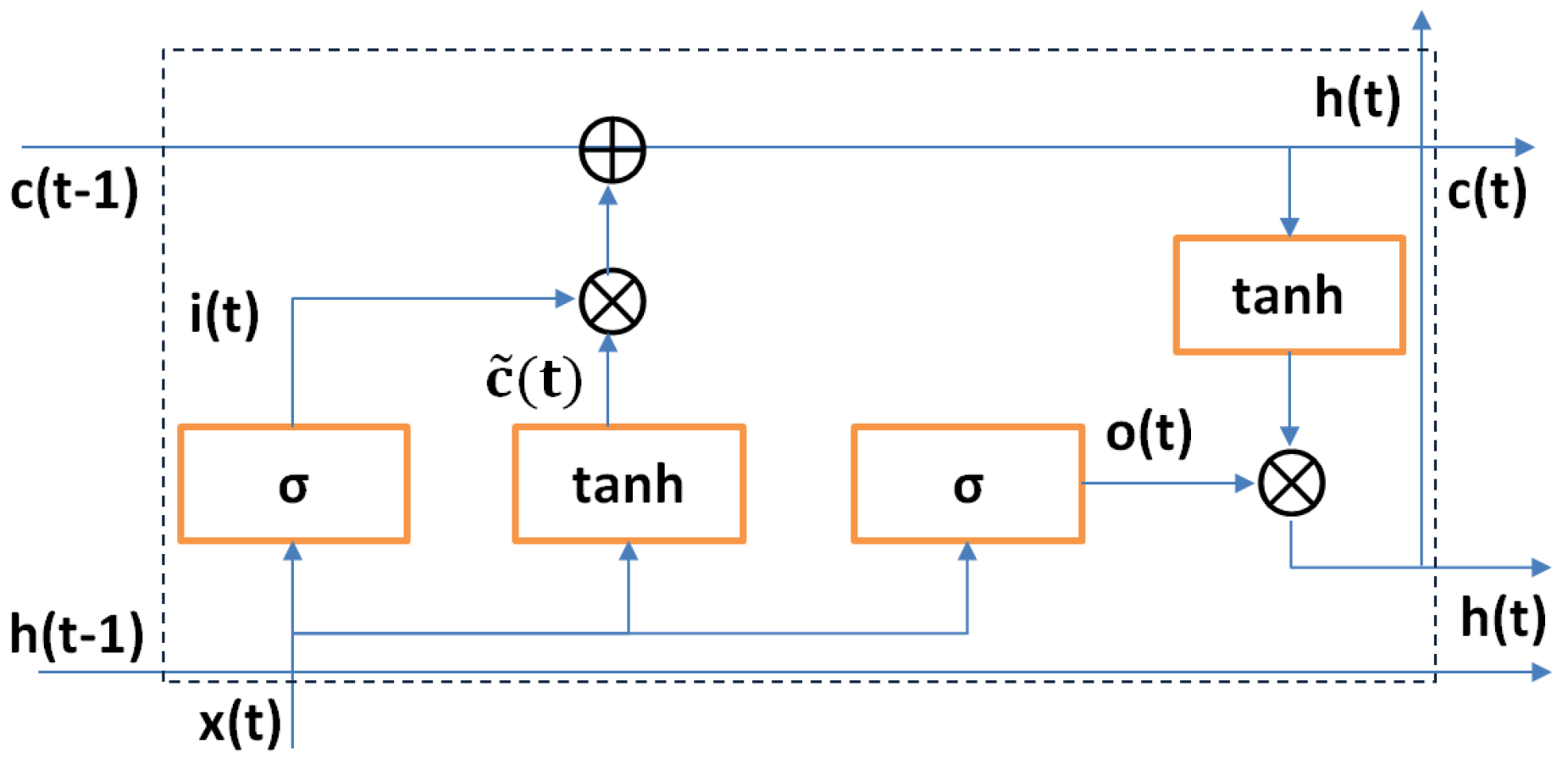
We performed a set of experiments for different W, E, and . We adopt —i.e., different sliding window sizes to measure the effect on , and . The total number of tasks requested by users was set to . Moreover, the weight of past observations was adopted as . The probability of having the demand for a task over a pre-defined threshold was set to . In total, we conducted 100 iterations for each experiment and reported our results for the aforementioned metrics. Our simulator was written in Python adopting the Keras library for building the proposed LSTM. In the LSTM, we adopted the Rectified Linear Unit (ReLU) function to activate the transfer of data in neurons and train the network for 1000 epochs upon data retrieved by the aforementioned dataset. After the training process, the LSTM was fed by values to deliver the final outcomes as described in this paper. The experiments were executed using an Intel i7 CPU with 16gb Ram.
5.2. Performance Assessment
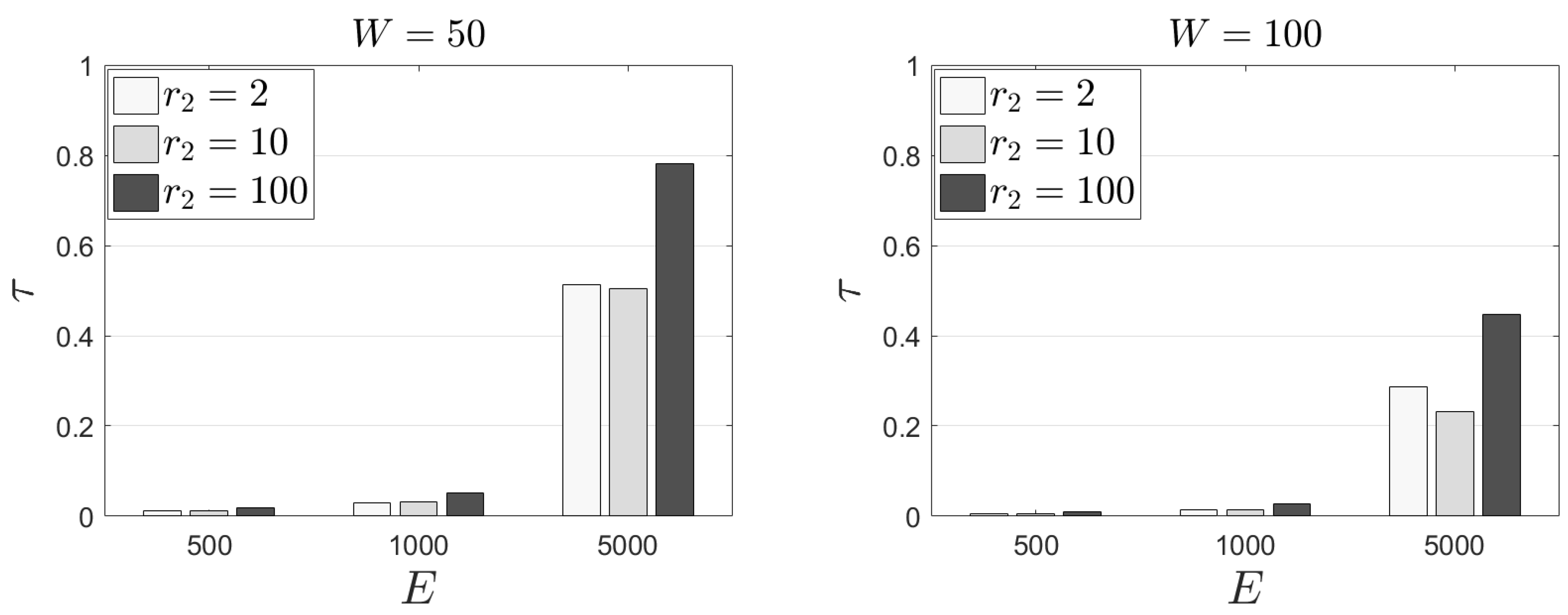
We report on the performance of the proposed model related to the
metric. In this set of experiments, we keep
—i.e., every EC node should “evict” only a small sub-set of the available tasks and
. In
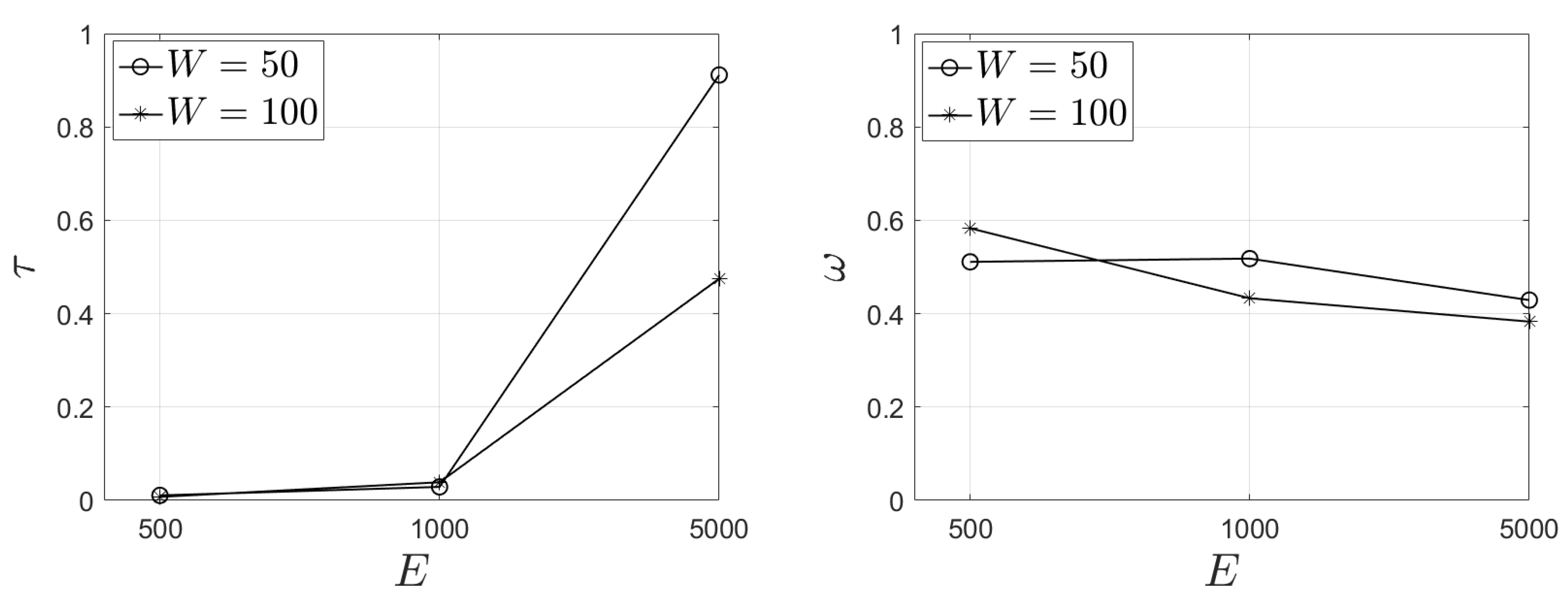
Figure 3, we present our outcomes for
and for different rewards for the load of each task (
). We observe that
E (the number of tasks) heavily affects the outcome of
. An increased number of tasks leads to an increased mean conclusion time per task. Additionally, the size of the window is inversely proportional to the mean required time—i.e., a low
W leads to an increased
and vice versa. These results are naturally delivered; an EC node has to process too many tasks; thus, it requires more time to perform the calculations mandated by our model. In
Table 2, we provide our results related to the standard deviation of
realizations. We observe that, in all the experimental scenarios, the retrieved outcomes are very close to the mean value. This exhibits the “stability” of the approach and proves that the proposed model is capable of minimizing the decision time; thus, being able to support time critical applications. Additionally, a low standard deviation “confirms” the statistical difference between the outcomes retrieved for different experimental scenarios as exposed by mean values. In other words, the mean clearly depicts the performance of our model exhibiting stability and limited fluctuations in the time required to conclude the final decision. To elaborate more on the performance evaluation for the
metric, in
Figure 4, we present the probability density estimate (pde) of the required time to conclude the final decision. We actually confirm our previous observations. The proposed model requires around 0.8 s (on average) to process 5000 tasks when the sliding window is small. In the case of a large window, our scheme requires 0.4 s (in average) to process 5000 tasks. The remaining evaluation outcomes reveal that when
at each EC node, it is possible to manage the requested tasks in times below 0.1 s (on average). This exhibits, again, the ability of the proposed model to react in serving the needs of real time applications requesting the execution of tasks in high rates. This is because we can pre-train the proposed LSTM scheme then upload it at the available EC nodes to be adopted to conclude the offloading decisions. We have to notice that the training process lasts for around 2.5 min (for 1000 epochs). Obviously, the training process can be realized in EC nodes with an increased frequency (if necessary) without jeopardizing their functioning. It should be also noticed that
is equal to unity for all the experimental scenarios no matter the values of the adopted parameters. This means that the demand of the selected tasks to be offloaded in peer nodes is below the pre-defined threshold
; thus, no popular tasks are evicted. Recall that the final decision also takes into consideration the load that every task causes into the hosting node and nodes are eager to locally keep tasks with a very low load.
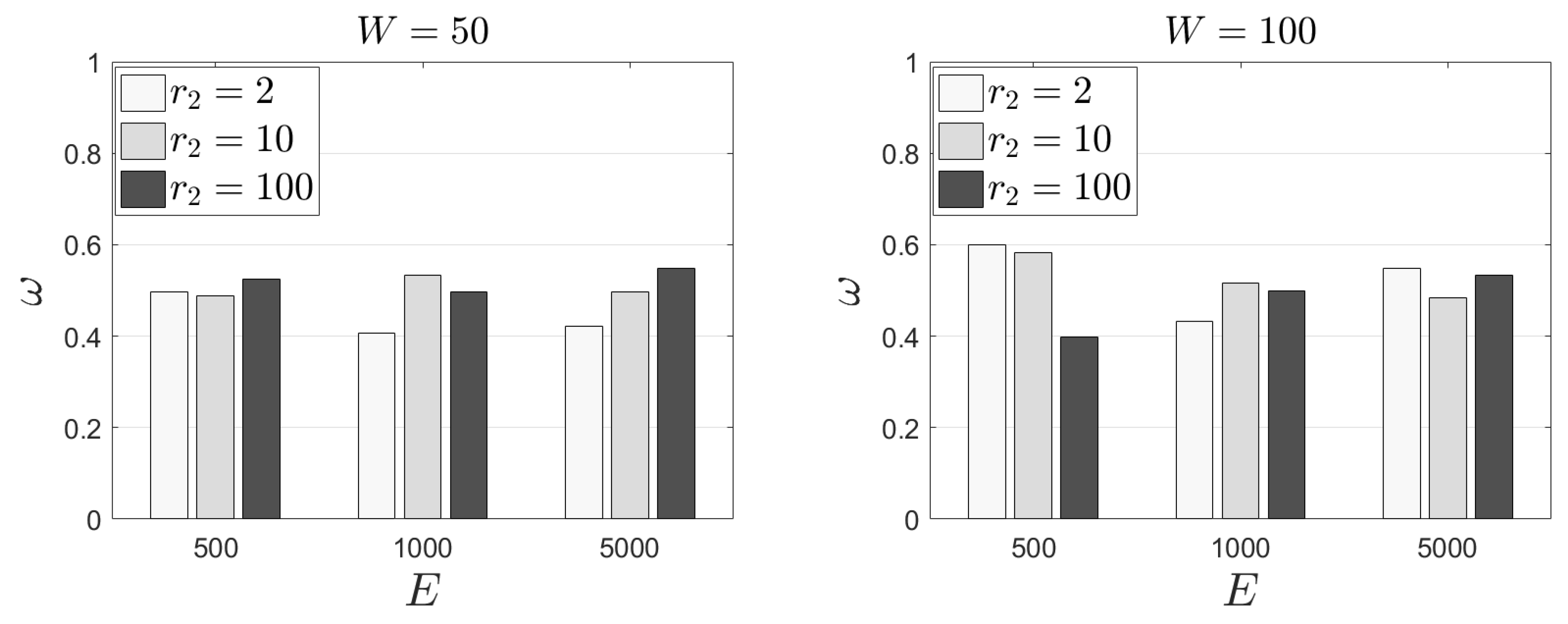
In
Figure 5, we present our results for the
metric. We observe that (approximately) half of the selected tasks are between those with the minimum popularity. Our outcomes are similar no matter the size of the sliding window. The same stands true when we focus on the number of tasks. It seems that all the aforementioned parameters are not heavily affecting the final selection. All the retrieved results are in the interval [0.4, 0.6]. We also conclude that the effect of
and the corresponding reward does not let
get high values. For instance, a task may have a low popularity; however, it may have a very low load as well. This task will get an increased reward and will not be among the last-
k tasks that will be offloaded to peers. In
Table 3, we present the standard deviation of
for the same experimental scenarios. We observe that the retrieved outcomes are in the interval [0.22, 0.33]. These outcomes depict fluctuations in the retrieved mean; thus, the statistical difference between various experimental scenarios is not clear.
We performed a set of experiments adopting
. Now, the focus of our decision making mechanism is on the demand estimation retrieved by the proposed LSTM model. In
Figure 6, we present our results for the
and
metrics. Again, we observe an increased conclusion time when
.
decreases as
, exhibiting more clearly the effect of paying more attention on the outcome of the LSTM instead of past observations in the decision making model. The best results are achieved for a limited sliding window size—i.e.,
. As the number of tasks increases, there are multiple tasks with similar evaluation—thus, the model exhibits a slightly reduced
(the percentage of the offloaded tasks that are among those with the minimum popularity). We have to also notice that
is equal to unity, as in the previous set of experiments.
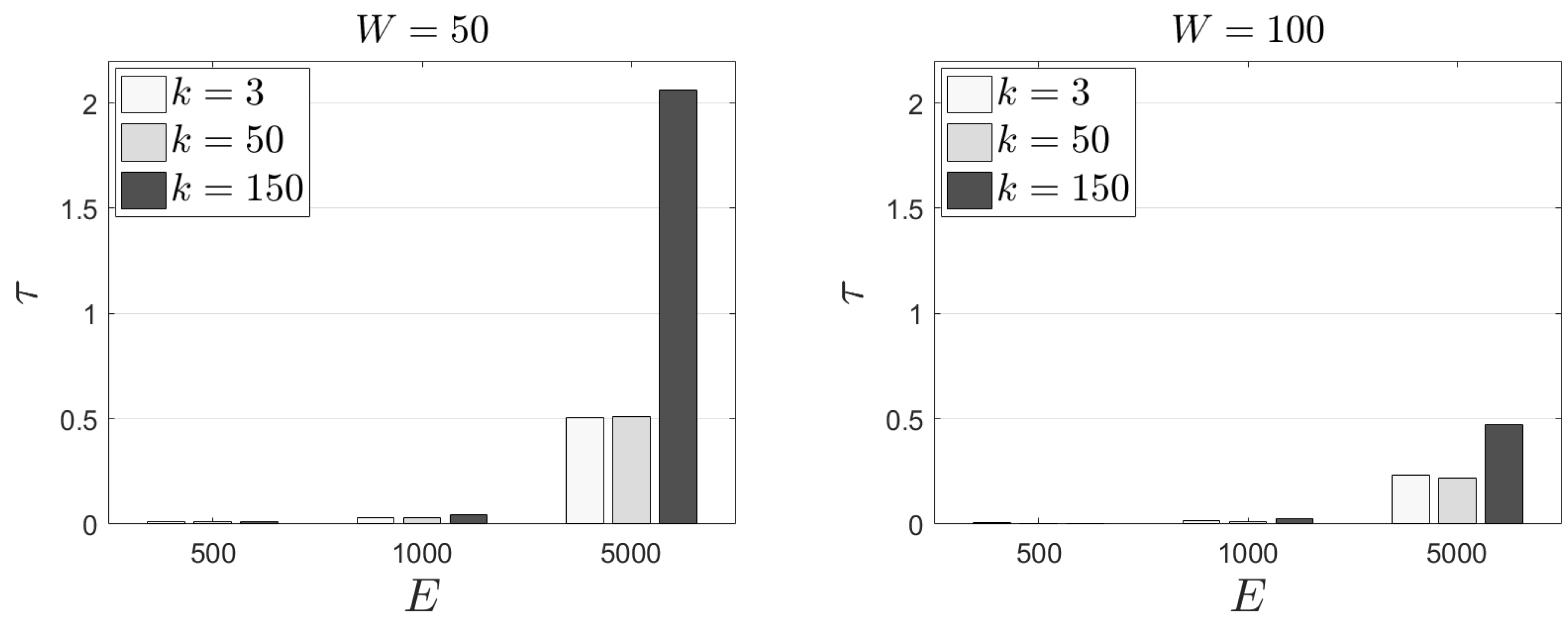
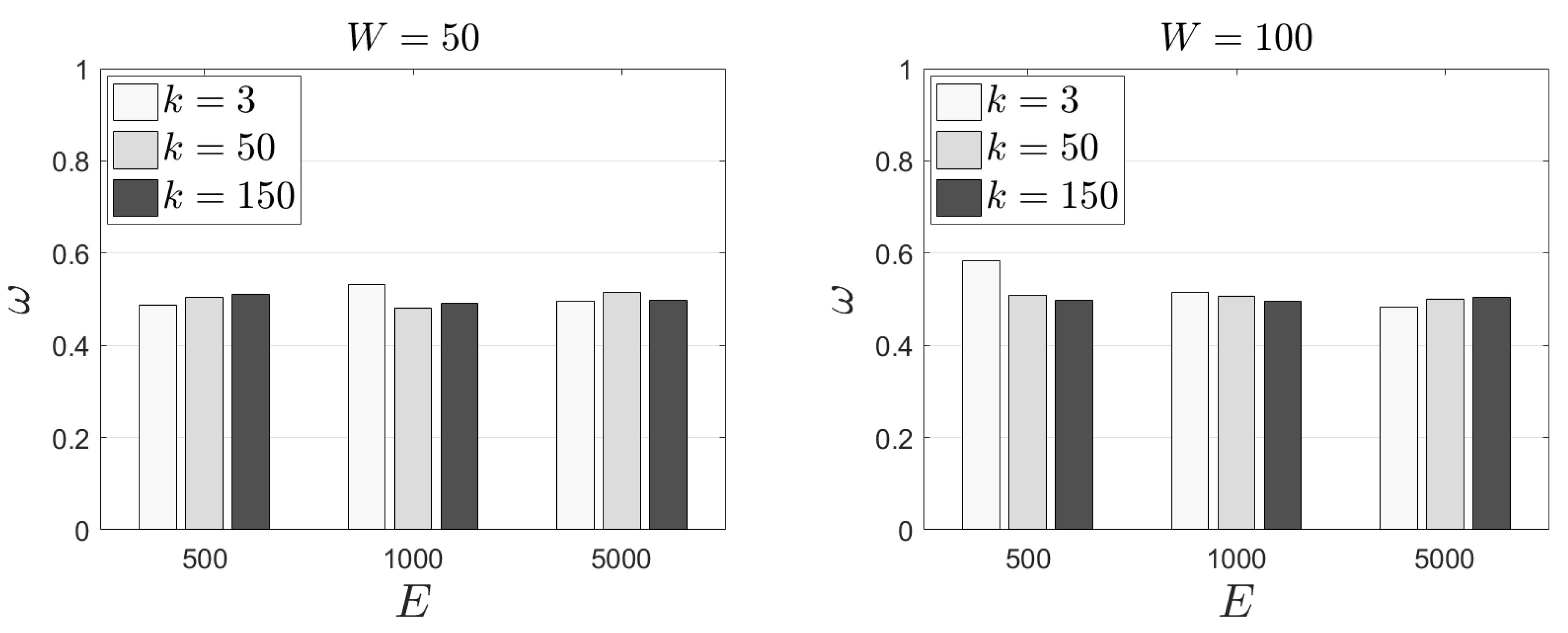
In the following experimental scenarios, we adopt different
k values—i.e., different number of tasks that should be offloaded to peers.
Figure 7 depicts our results. Naturally, increased
k and
E negatively affect the time requirements of our mechanism. The worst case scenario is met when
and
. In this case, the proposed mechanism needs around 2 s per task (in average) to extract the final decision. Concerning the
metric (
Figure 8), we get similar results as in the previous experimental scenarios. Again, around half of the available tasks selected to be offloaded are among those that exhibit the lowest popularity. Finally,
realization is equal to unity except in the scenario where
and
. In this scenario, EC nodes have to evict the 30% (approximately) of the available tasks. In such cases,
is equal to 0.70 and 0.89 for
, respectively. Now, some tasks with demand over
may be offloaded; a decision that is affected by the incorporation of
in the rewarding scheme. Evidently, some tasks with low popularity, with a low load as well, may be kept locally. This decision is fully aligned with the above discussed strategic design of the behaviours of EC nodes. In
Table 4 and
Table 5, we present the performance outcomes for the standard deviation of
and
when
. Both tables exhibit that our results for both performance metrics are very close to their mean. This depicts again the “stability” of the decision making mechanism and a clear view of the increased
when
k increases as well.
We compare our LSTM based model with a model that decides upon on only the past demand observations avoiding to pay attention on future estimates—i.e., the Past Behaviour Based Model (PBBM). The PBBM concludes the final decision, taking into consideration only
. We try to show the difference in the outcomes when adopting the LSTM. Normally, the use of the LSTM should enhance the performance as it involves decision making for future insights about the demand for each task. In
Table 6, we provide our results for the
metric. In this set of experiments, we get
. We observe that the proposed model outperforms the PBBM, especially when
(an exception is observed when
and
). The adopted LSTM manages to assist the decision making process when the number of tasks is low, resulting in the appropriate offloading lists. Performing a t-test, we get that the
outcomes are significant for a confidence of 90% when
and
. We have to notice that, in this set of experiments,
is retrieved as equal to unity due to the very low number of tasks that should be evicted from EC nodes’ queues. In
Table 7 and
Table 8, we see the outcomes of another set of experiments for an increased
k—i.e.,
(
).
Table 7 refers in the
metric while
Table 8 refers in the
metric. We observe that the LSTM model slightly outperforms the PBBM (except one experimental scenario—i.e.,
,
,
) when considering the
metric. This means that the LSTM enhances the number of correct offloading decisions when compared to decisions made upon only past observations. Recall that the provided results represent the means of each metric. Concerning the
outcomes, we observe a similar performance for both models.
We also compare the performance of our model with the scheme presented in [
46] where the authors propose a task scheduling algorithm (ETSI) that is based on a heuristic. This heuristic delivers the final outcome based on the remaining energy, the distance from the edge of the network and the number of neighbours calculating the rank of each node. Actually, it consists of a “cost” evaluation mechanism that pays attention to multiple parameters before it concludes the final outcome. Nodes are ranked based on the collected cost, and the node with the lowest ranking is selected for the final allocation. We additionally compare our scheme with the model presented in [
12]. There, a fuzzy logic model is adopted to decide which tasks will be offloaded to peers. The discussed fuzzy logic system tries to manage the uncertainty related with the decision of offloading any incoming task. The authors present the reasoning mechanism upon the requests of every task and define two demand indicators—i.e., the local and the global demand indicators. The fuzzy logic system is fed by the aforementioned indicators and delivers the decision for offloading the available tasks. The comparative assessment between our model and the two aforementioned schemes is performed for the
metric and depicted by
Figure 9. Specifically,
Figure 9 presents the minimum and maximum values of
in the entire set of the experimental scenarios. Our scheme outperforms both models. For instance, ETSI manages to result in a limited number of correct decisions related to the offloading of tasks. The highest realization of
is 44% (approximately) with the mean and median being around 23–25%. Moreover, the lowest value for
in [
12] is around 84%, depending on the experimental scenario. The proposed model exhibits worse performance than the scheme in [
12] only when EC nodes should evict too many tasks (like in the scenario when
,
and
).
Based on the above presented results, we observe that the proposed model manages to have the initially planned impact if adopted in the EC ecosystem. EC nodes can rely on the proposed approach to administrate the incoming tasks requested by users or applications. Initially, we can argue on the limited required time necessary to deliver the offloading decision. As exposed by our experimental evaluation, the proposed scheme can support real time decisions which is very significant when we focus on the dynamic environments of EC and IoT. This gives us the ability to react and manage tasks coming in at high rates. In the majority of our performance evaluation scenarios, the discussed time is below 0.1 s when . In the case of an increased number of tasks—i.e., —the proposed model requires around half of a second for the majority of the adopted scenarios. Additionally, our approach incorporates a “complex” decision making upon multiple parameters/criteria. The complexity deals with the combination of two trends in tasks demand—i.e., the past and the future. Hence, our scheme becomes the “aggregation” point of demand realizations during the time trying to learn from the past and estimate the future. This means that EC nodes try to proactively administrate their available resources devoted for task execution in the most profitable manner. When using the term “profitable”, we mean that EC nodes should offload tasks for which it is judged that they will burden them and exhibit a low demand. If those tasks are kept locally, EC nodes should spend resources for their execution without gaining from the repeated execution (re-using of resources and previous results) of popular tasks. For concluding efficient decisions, our mechanism relies on multiple parameters/criteria and a rewarding scheme for revealing the less “profitable” tasks that should be offloaded to other peer nodes. If this rationale dictates the behaviour of the entire ecosystem, EC nodes will keep for local execution tasks that are profitable for them supporting a cooperative environment where nodes can exchange data and tasks to optimize the use of the available resources and serve end users in the minimum possible time. The first of our future research plans is the definition of an ageing model for avoiding having tasks continuously offloaded in the network. The discussed ageing mechanism will secure that every task will be, finally, executed by a node or on the Cloud.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}