1. Introduction
The rapid growth of social media platforms, instant messaging applications, and user-generated content has fundamentally transformed the way information is created, distributed, and consumed. This has created an unparalleled information ecosystem where truth and falsehood can spread with equal velocity. In an era where information travels at the speed of light across digital networks, the integrity of news has become one of the most pressing challenges of our time. Within this complex digital landscape, the intentional drafting of Fake News (FN) or misleading information poses a threat to public discourse, democratic processes, and social cohesion. According to a study, almost ∼46% of FN are related to political affairs, and FN are mostly distributed through social networks [
1].
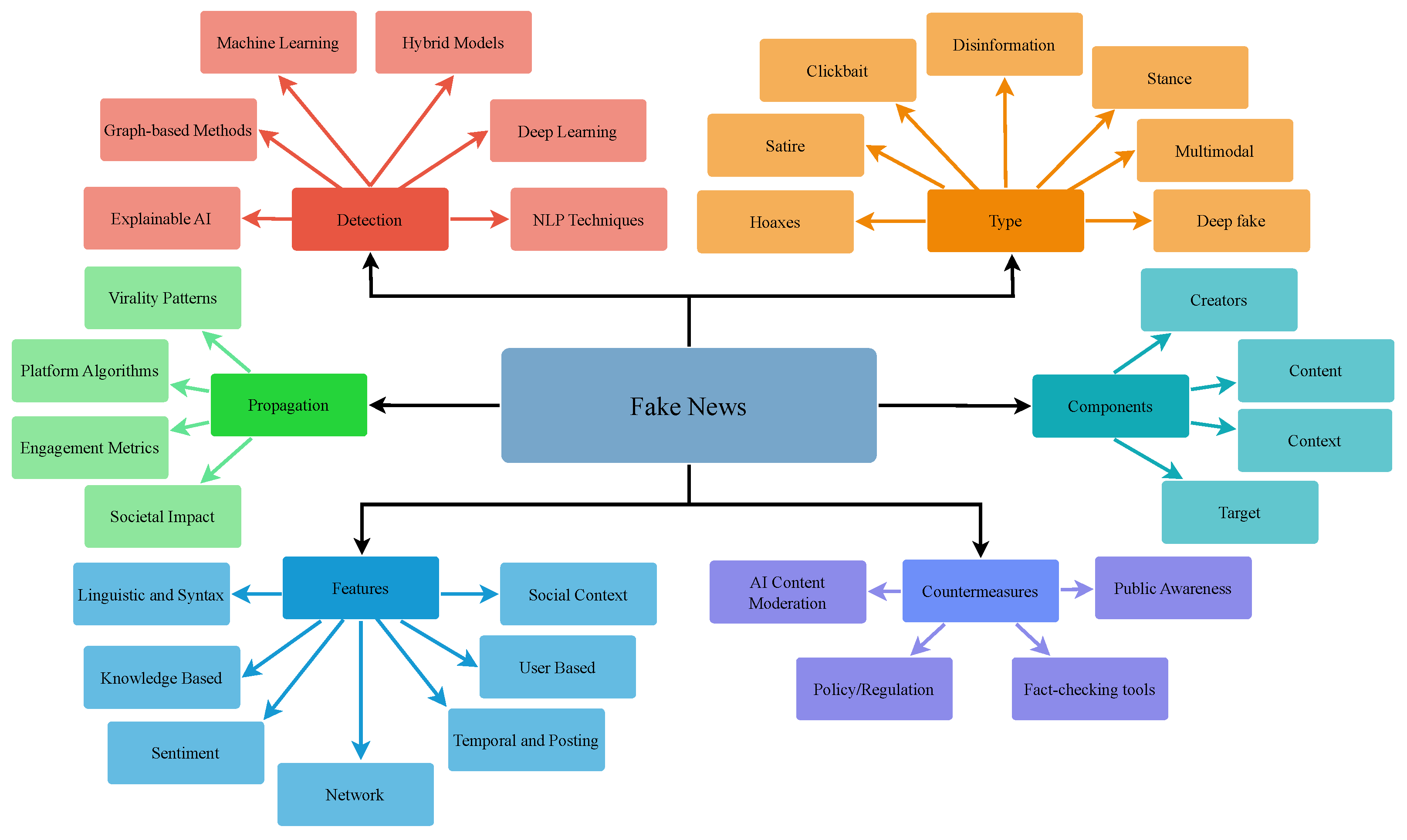
Figure 1 presents a holistic perspective on FN by illustrating its six interconnected dimensions, including detection, propagation, types, components, features, and countermeasures. This comprehensive view signifies the complex nature of FN and the importance of addressing it through interdisciplinary approaches. FN Detection (FND) involves various techniques, such as Machine Learning (ML), Deep Learning (DL), hybrid models, graph-based methods, explainable AI (XAI), and Natural Language Processing (NLP) techniques. Different types of FN include clickbait, satire, hoaxes, disinformation, stance-based content, etc., to ease its spread to a larger audience. Various components of FN refer to its key elements, such as creators, content, context, and goals. The propagation pathway highlights how FN spreads through platform algorithms, virality patterns, engagement metrics, and its societal impact. Different features used to identify FN include linguistic and syntax patterns, sentiment, network structure, knowledge-based elements, temporal and posting behaviors, etc. In addition, its countermeasures aim to mitigate the impact through AI content moderation, policy and regulation, fact-checking tools, and raising public awareness.
The theoretical foundations of FND can be understood through information theory and network dynamics [
2,
3]. When we model information dissemination as signals propagating through a complex network
, where nodes
represent users and edges
represent interactions such as shares, likes, or retweets, we observe that misinformation often exhibits distinct propagation patterns that differ significantly from authentic news. From a probabilistic perspective, the challenge of detecting FN becomes a classification problem in which, given a news article
X, we must estimate the posterior probability
. This determines whether the content is genuine (
) or fabricated (
). What makes this challenge particularly intriguing from a computational point of view is that FN operates as a distorted signal, a noisy representation of reality that has been intentionally manipulated through bias injection, emotional amplification, or contextual distortion. This signal processing perspective transforms FND into an anomaly detection problem, where we must identify whether a given information signal deviates from the expected distribution of truthful content. The complexity is further increased since FN often exploits cognitive biases, emotional triggers, and social dynamics to achieve viral propagation. It makes it statistically more likely to spread than factual information.
Traditional approaches for FND are found to be inadequate to address the scale and sophistication of modern misinformation campaigns [
4]. Although manual fact-checking is accurate, its feasibility cannot match the speed of content creation and distribution [
5]. Rule-based systems and crowdsourcing platforms such as PolitiFact [
6] and ClaimBuster [
7] are valuable but suffer from scalability limitations, subjective interpretations, and language barriers that prevent comprehensive coverage in the global landscape. Classical ML approaches using hand-crafted features such as
n grams, Term Frequency-Inverse Document Frequency (TF-IDF) vectors, and sentiment scores capture surface-level patterns but do not understand the nuanced contextual relationships and implicit semantic structures that characterize sophisticated misinformation.
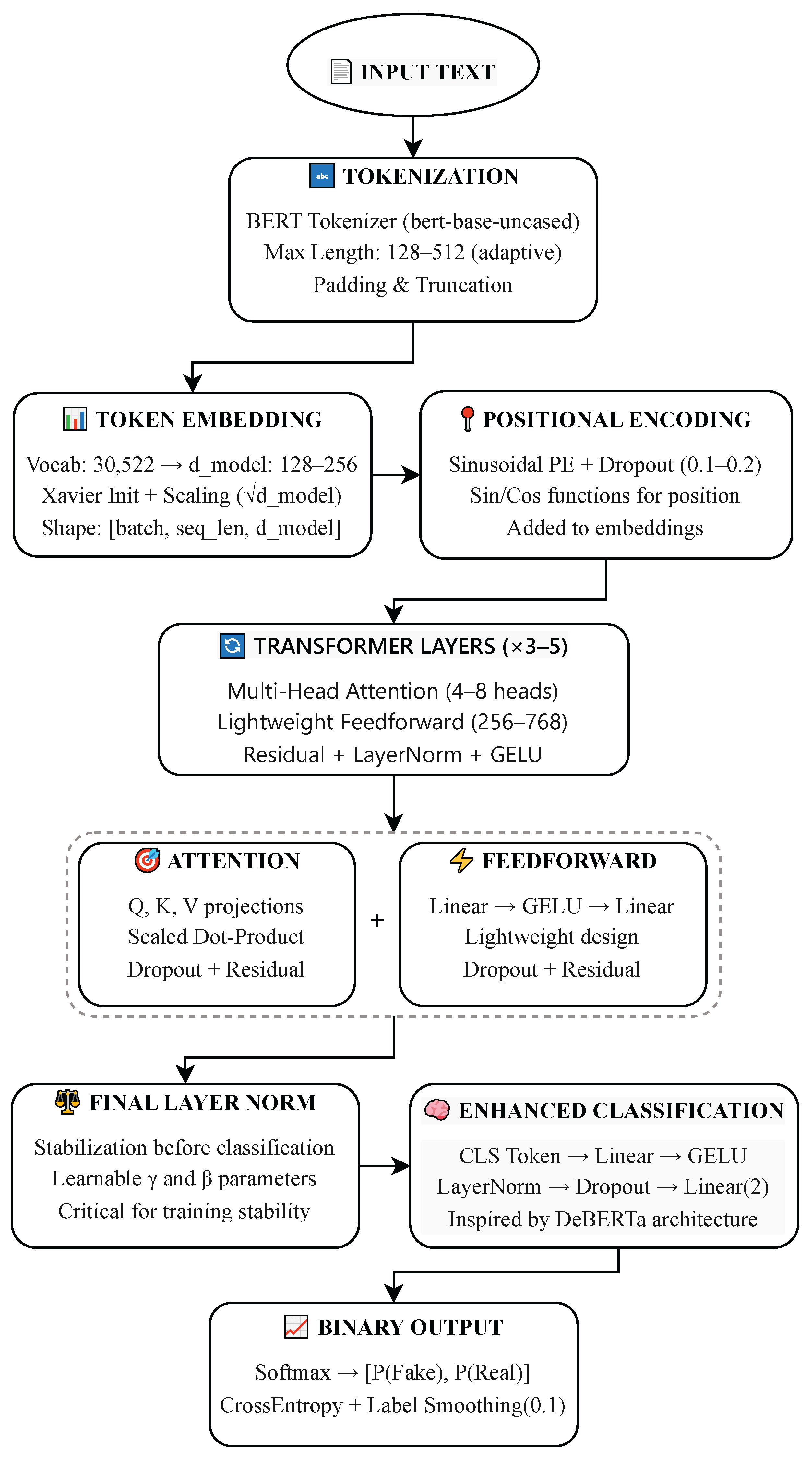
The emergence of transformer-based architectures, particularly Bidirectional Encoder Representations from Transformers (BERT) and its variants, has revolutionized NLP. Their use of powerful self-attention mechanisms can capture long-range dependencies and contextual relationships within text. For a token sequence , BERT generates contextual embeddings that incorporate bidirectional context. It enables the model to understand subtle linguistic cues that can indicate deception or manipulation. When these contextualized representations are processed through sophisticated classification heads, such models demonstrate remarkable performance improvements over traditional approaches.
Despite the promising capabilities of transformer models, current research in FND has several limitations that affect both theoretical understanding and practical deployment. Various studies have observed that these models are treated as black boxes: evaluating their performance without understanding which architectural components contribute the most significantly to their effectiveness [
8]. The lack of systematic ablation studies means that researchers cannot determine whether improvements come from attention mechanisms, positional encodings, layer normalization, or other architectural elements. In addition, existing evaluations often lack rigorous statistical validation, reproducibility protocols, and cross-dataset generalization analysis, making it difficult to assess the true robustness and reliability of proposed solutions. It is also important to find the optimal balance between model complexity, computational efficiency, and performance stability in various datasets.
To address these fundamental challenges, this research introduces a comprehensive framework for transformer-based FND that combines rigorous empirical analysis with principled architectural optimization. This approach recognizes that effective FND requires not only accurate models, but also a deep understanding of why these models work, which components are essential, and how they can be optimized for both performance and practical deployment. The research contributions of this study are presented as follows:
Component-Level Analysis: We present a comprehensive component-level analysis of transformer architectures for FND: systematically evaluating BERT, the Robustly Optimized BERT Pretraining approach (RoBERTa), Decoding-Enhanced BERT with Disentangled attention (DeBERTa), and the distilled version of BERT (DistilBERT). Through rigorous ablation studies that isolate attention mechanisms, layer normalization, residual connections, feedforward networks, dropout regularization, positional encoding, and model-specific components, we quantify the individual contribution of each element to overall performance. Through this analysis, we found that attention mechanisms contribute 19–22% to detection accuracy, layer normalization provides consistent 2–6% improvements, and feedforward networks show context-dependent effectiveness. This establishes empirical benchmarks that have been absent in the existing literature.
Evidence-Based Synthesis: We introduce an enhanced optimal methodology that combines the most effective architectural components of different transformer models (based on rigorous empirical evidence rather than intuitive design choices). Our principled approach integrates BERT’s foundational attention mechanisms, RoBERTa’s GELU activation optimizations, DeBERTa’s enhanced classification capabilities, and DistilBERT’s efficiency innovations into a unified optimal architecture. This synthesis framework uses three quantitative criteria: component criticality, consistency in the cross-dataset, and computational efficiency. It establishes a replicable methodology for the optimization of evidence-based architectures.
Scalable Transformer Variants: We develop a scalable architecture framework that offers three performance variants (0.3M, 1.2M, and 3.1M parameters) while maintaining architectural consistency between different computational constraints. Our optimal base model achieves a reduction in parameters of 85% compared to the BERT base while improving performance. In addition, it demonstrates 70% faster training convergence, requires 60% less memory from the GPU, and provides 3× faster inference speed. This contribution addresses the critical need for deployable FND systems in resource-constrained environments with minimal trade-offs.
Rigorous Evaluation Framework: We establish new standards for experimental rigor in FND research through comprehensive reproducibility protocols, statistical validation frameworks, and multidataset consistency assessment. Our methodology incorporates fixed random seed protocols, the enforcement of deterministic computation, multiple independent runs with variance analysis, paired statistical testing with effect size calculations, and the generalizability evaluation of the dataset. This framework addresses the reproducibility crisis in DL research while providing reliable benchmarks for future studies.
Through this comprehensive approach, our aim is to transform FND from an empirical trial-and-error process into a principled scientific discipline, providing the tools, methodologies, and insights necessary for developing robust, efficient, and reliable systems that can adapt to the evolving landscape of digital misinformation while maintaining the highest standards of scientific rigor and practical applicability.
The remainder of this paper is organized as follows:
Section 2 reviews recent advances in FND.
Section 3 describes the research methodology, the proposed model architecture, and the details of the datasets used.
Section 4 presents the experimental results, ablation studies, and a discussion of the performance of the optimal model. Finally,
Section 5 concludes the study and outlines the directions for future research.
2. Related Works
In this section, we discuss recent models and approaches that have been proposed for FND, highlighting the evolution from traditional ML techniques to more advanced transformer and DL-based methods.
The researchers in [
9] introduce a Balanced Multimodal Learning with Hierarchical Fusion (BMLHF) approach for multimodal FND (MFND), focusing on image and text. It introduces a multimodal information balancing module that balances various modal information during optimization. In addition, a hierarchical fusion module is designed to explore the correlation within and between modalities, enhancing the optimization process. The evaluation was carried out on Fakeddit, Weibo, and Twitter datasets. Similarly, in [
10], Shen et al. proposes a distinct approach for the multimodal modeling approach called GAMED [
10]. It focuses on generating distinctive and discriminative features through modal decoupling. The model was trained on Yang and Fakeddit datasets.
The researchers in [
11] proposed a multilingual transformer-based FND model using various language-independent technologies. It removes the need to convert the input to English for detection. The researchers used a multilingual FND dataset consisting of samples from five different languages. Similarly, the researchers in [
12] performed a comparative analysis on seven BERT-based models using a dataset composed of multilingual news from different sources.
The researchers in [
13] proposed an MFND using a single model that uses features of text, visual, and knowledge graphs. Unlike other models, the proposed model uses a single model to extract features from images and text. The model used a Twitter dataset to evaluate the model. A comparison among 13 models, including the proposed ones, was made. The researchers in [
14] performed an extensive analysis of using FastText word embeddings in different ML and DL models, including the transformers. In addition, the use of XAI further strengthens the approach. Three datasets were used to evaluate the model, namely WELFake, FakeNewsPrediction, and FakeNewsNet.
Zhang et al. proposed ‘RPPG-Fake’ for early FND by generating propagation paths using reinforcement learning along the integration of propagation topology structure and temporal depth information [
15]. Three datasets named Pheme, PoliFact, and GossipCop were used for experimentation. A comparison among ten baseline models was conducted, and the proposed methodology was found to be the best among them. Xie et al. proposed KEHGNN-FD, a Knowledge Graph-Enhanced Graph Neural Network (GNN) enhanced to gain insight from the news, topics, and other entities [
16]. The model was trained on four datasets, named LIAR, FakeNewsNet, COVID-19, and PAN2020. The proposed model was compared with seven baseline models, three based on NLP and four based on GNNs, and the proposed model was found to be the best among them.
The researchers in [
17] proposed a dual-phase methodology to combine text and graphical data (images and video) to identify FN. BERT and CNN were used to analyze text and visual data, respectively. The model was trained using the ISOT dataset and the MediaEval image verification dataset. Various ML algorithms were tested, and RF was found to be the best-performing one. Park and Chai proposed an ML model to detect FN with the concepts of feature selection (using XGBoost) and cross-validation [
18]. The model was trained and evaluated using the LIAR dataset. A comparative analysis was conducted among various ML algorithms and found that the RF worked the best.
Jing et al. proposed a progressive fusion model for MFDN [
19]. To extract features from different data, a BERT-based feature extractor (text), a visual extractor (Discrete Fourier Transformer (DFT) and VGG19), and a progressive multimodal feature fusion process were used. The model was trained and evaluated on the Weibo and Twitter datasets. The approach was compared with and found to be better than various singular approaches as well as multidomain approaches. Raza and Ding proposed an FND model using transformer architecture and Zero-Shot Learning (ZSL) [
20]. In addition, the metadata from the news content and social contexts were used for better decision-making. The model was trained and evaluated using the NELA-GT-19 and Fakeddit datasets.
Seddari et al. proposed a DL model for FND using transformers [
21]. The hybridization of linguistic features and fact verification features strengthened the model. A comparative analysis among various ML models was performed, and the RF was found to be the best when evaluated on the BuzzFeed dataset. Researchers in [
22] proposed a BERT-based approach for FND called ‘FakeBERT.’ It was combined with the parallel blocks of a single-layer deep CNN with different kernel sizes and filters, along with BERT. The real-world FN dataset, available on Kaggle, was utilized in the study. Various combinations of BERT with different algorithms were tested, and the FakeBERT was found to work best with it.
In addition, various research works mentioned in [
23,
24,
25,
26] give an overview of the domain in detail.
It could be observed that the models used in various studies are used as proposed in the general architecture. Architectural optimization remains an overlooked part. In addition, there are no empirical data to support the need for the components used. To address such gaps, we conducted a detailed ablation study to find the impact of each component on the architecture. It was used to design the proposed optimal architecture, trained on three widely used datasets for better adaptability and generalizability.
5. Conclusions and Future Scope
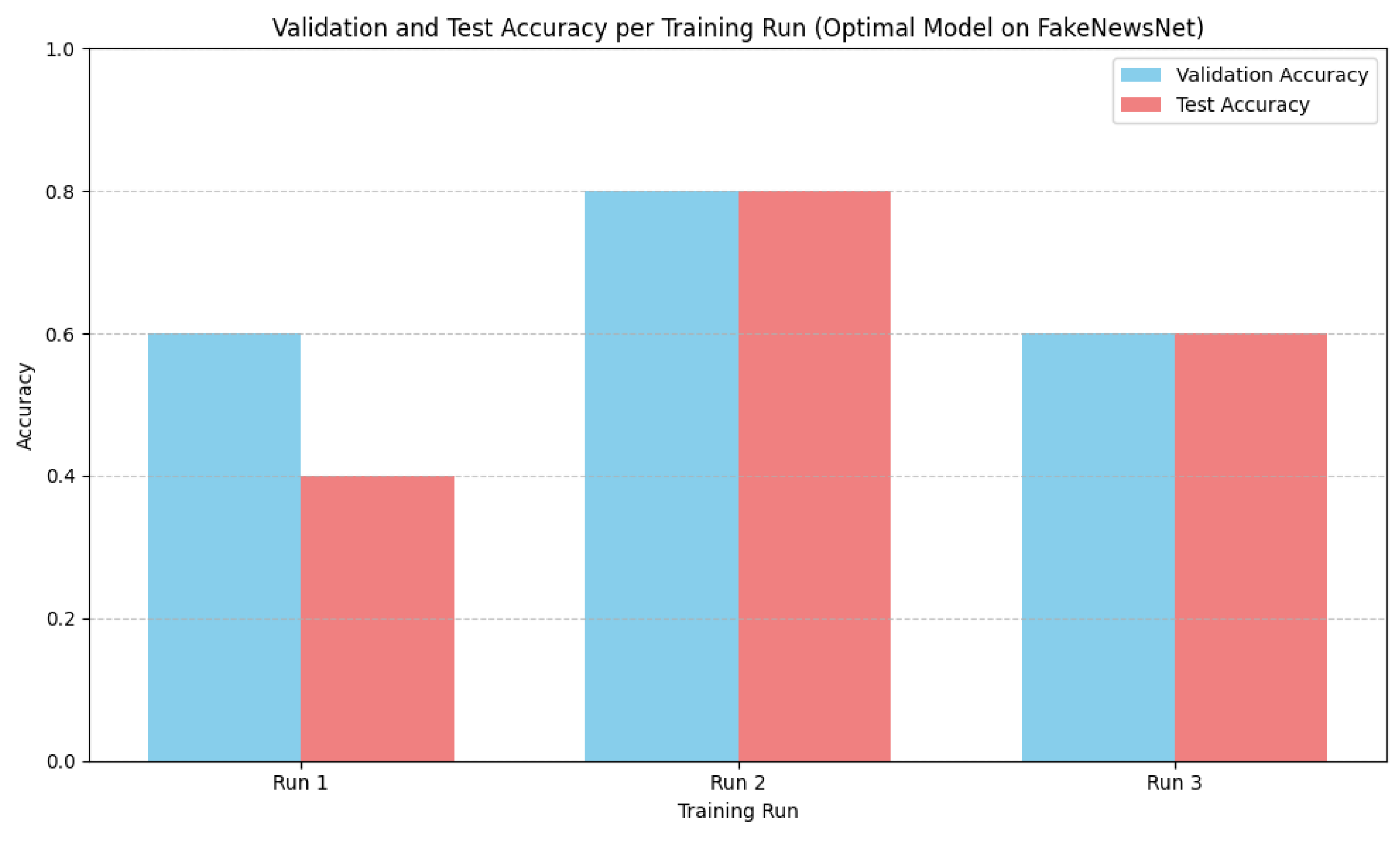
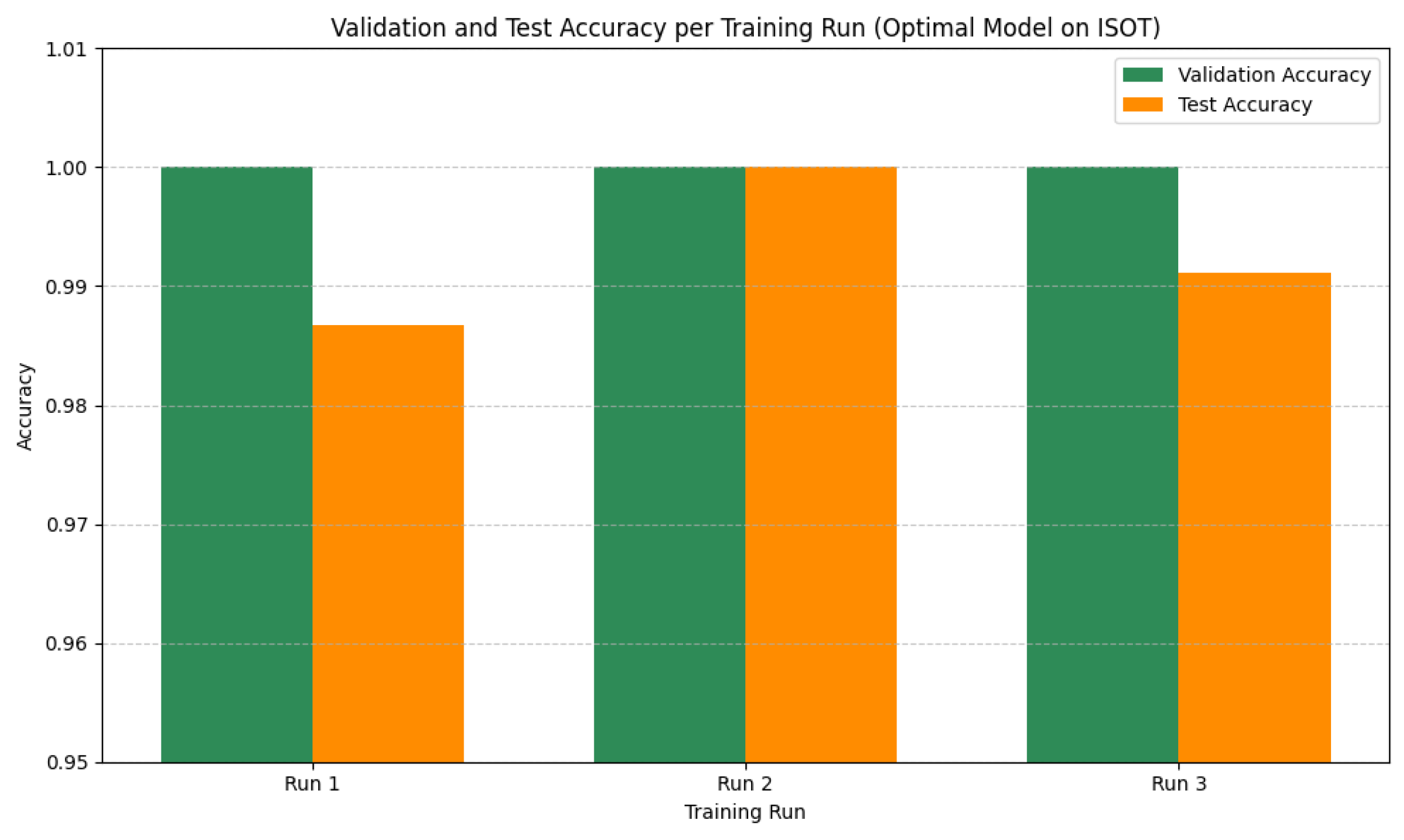
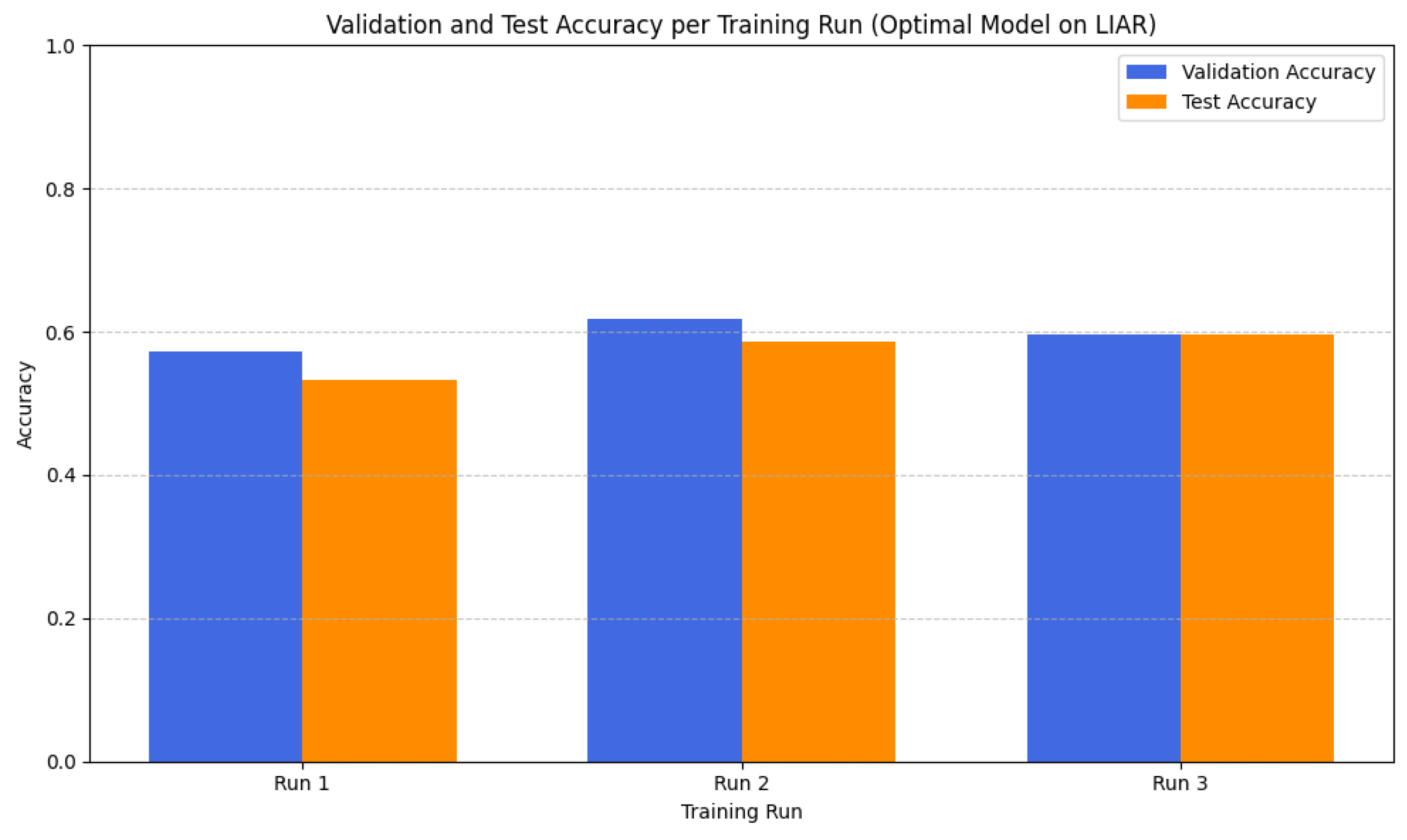
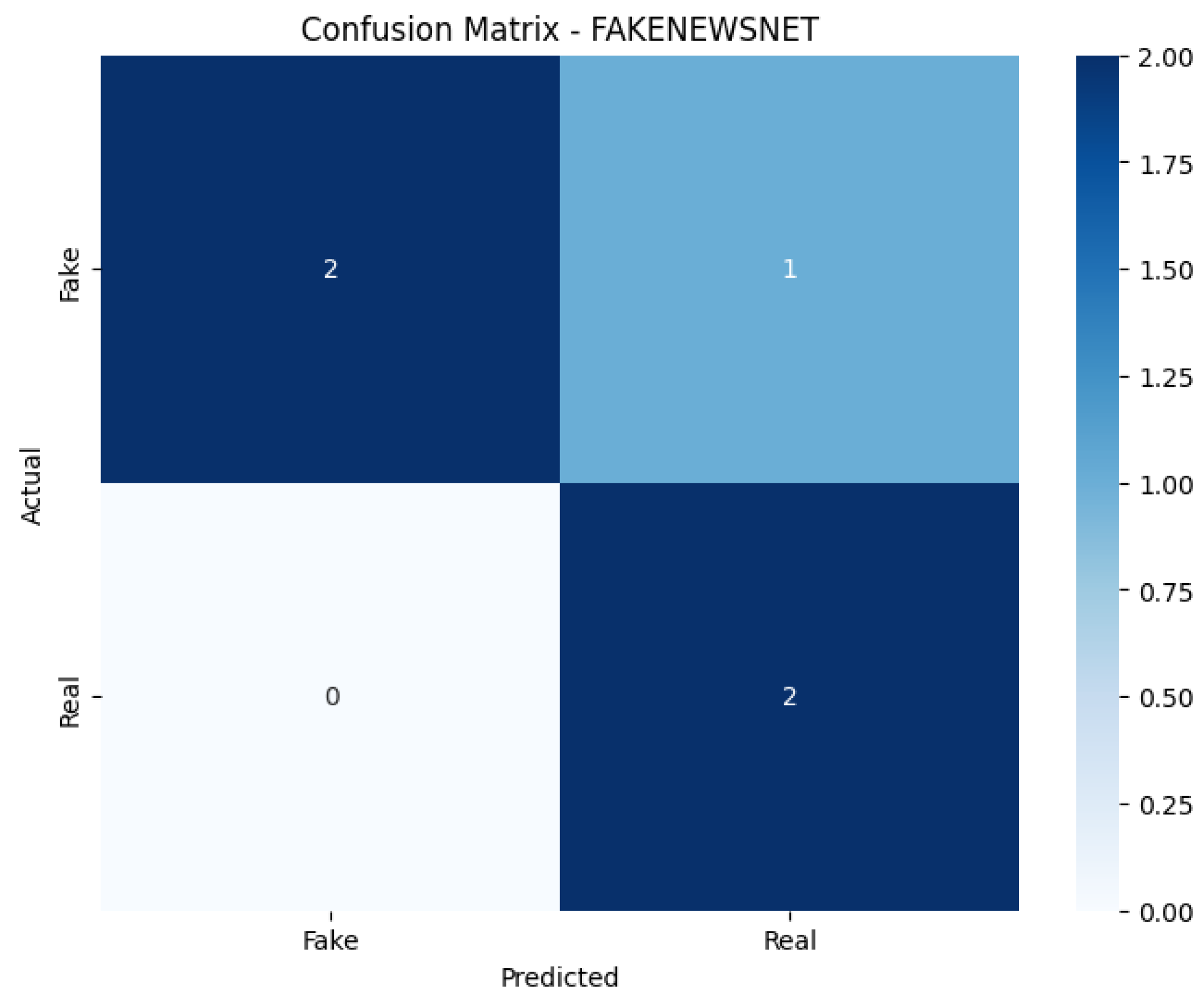
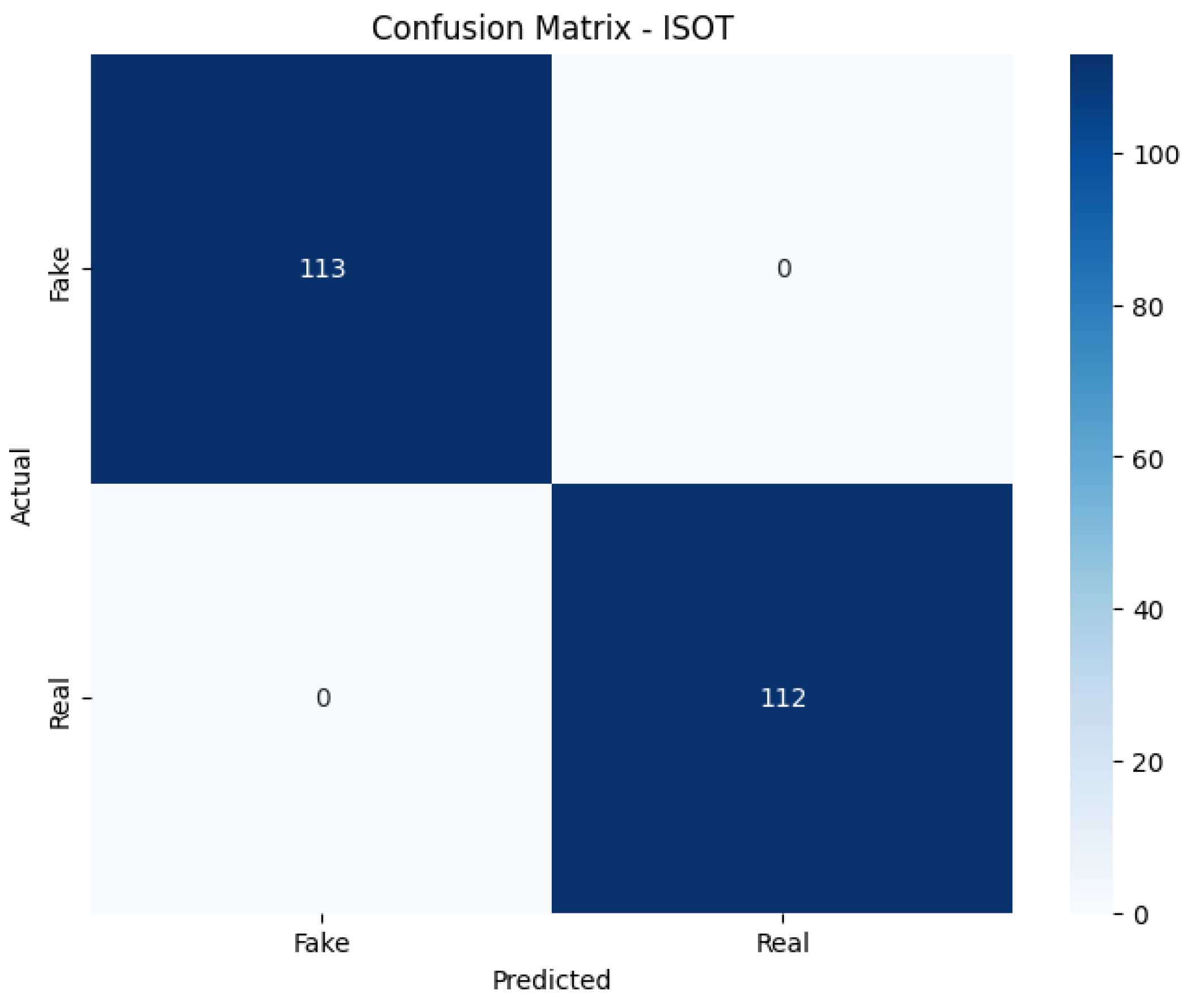
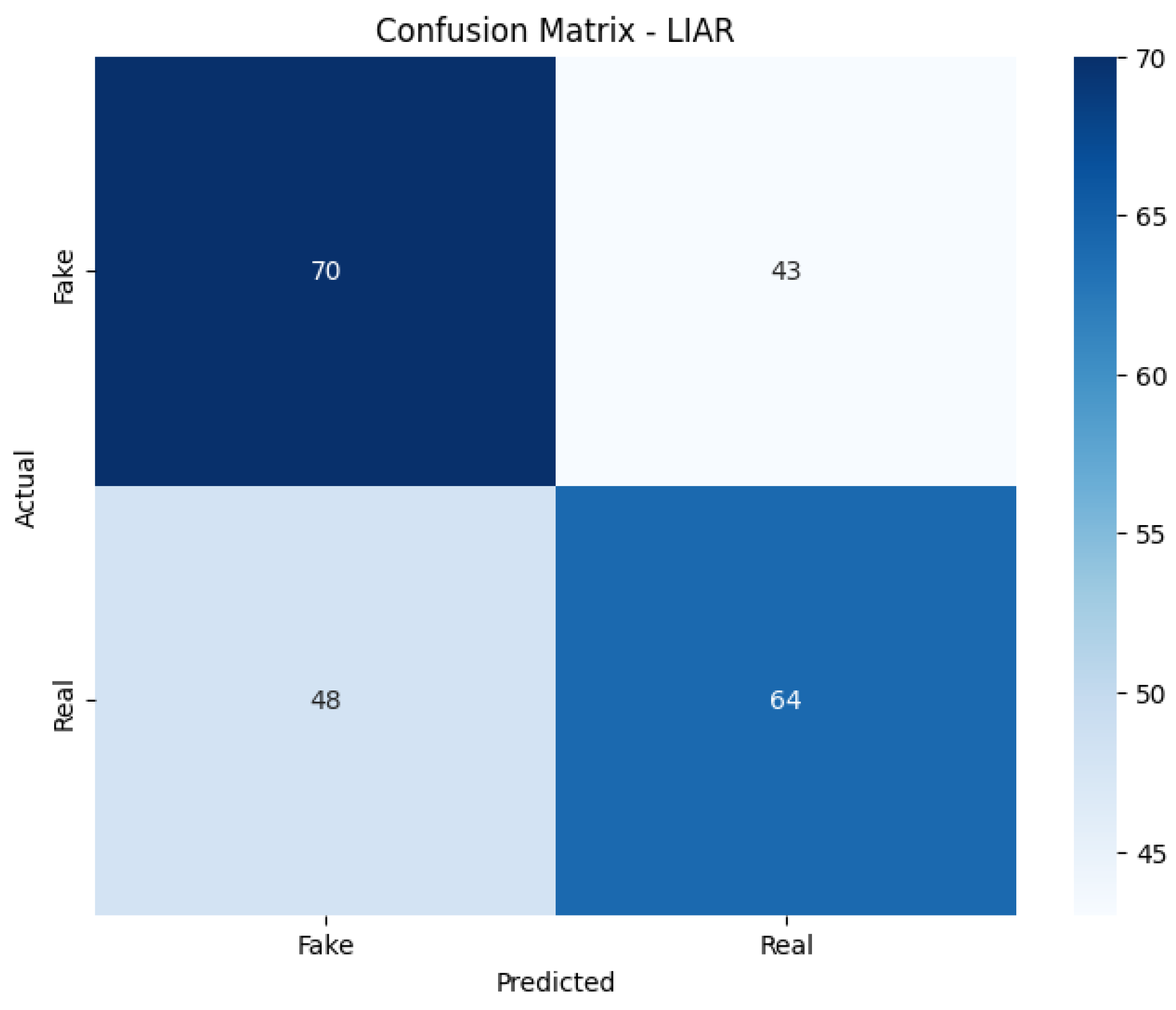
In this study, we introduced an improved transformer-based architecture for FND, developed through comprehensive ablation studies, component-level analysis, and empirical evaluation on benchmark datasets. By integrating advanced multi-head attention, dynamic positional encoding, and a refined classification head, the proposed model achieved strong performance while maintaining computational efficiency with only 3–4 million parameters. Attention mechanisms were found to be the most critical component, with their removal leading to significant performance degradation. Additional stability techniques, such as label smoothing, learning rate warm-up, and reproducible training protocols, further improved training consistency. The model achieved an average accuracy of 79.85% and an F1 score of 79.84%. The accuracies of 80%, 100%, and 59.56% were achieved on FakeNewsNet, ISOT, and LIAR, respectively. It operates with only 3.1 to 4.3 million parameters, representing an 85% reduction in the model size compared to full-sized BERT architectures. These results demonstrate that such FND models are suitable for deployment in resource-constrained environments. In terms of improved performance, its implications in the real world could have been better illustrated with access to a larger volume of labeled data. FND models are very unlikely to be flawless because the problem itself is inherently dynamic, context-dependent, linguistically complex, etc., and any automated system must balance fairness, adaptability, and ethical constraints. To address these limitations further, we aim to explore multilingual FND, cross-domain adaptation, explainable predictions, and integration with multimodal data for comprehensive misinformation detection.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}