AI-Driven Phishing Detection: Enhancing Cybersecurity with Reinforcement Learning

Abstract
1. Introduction
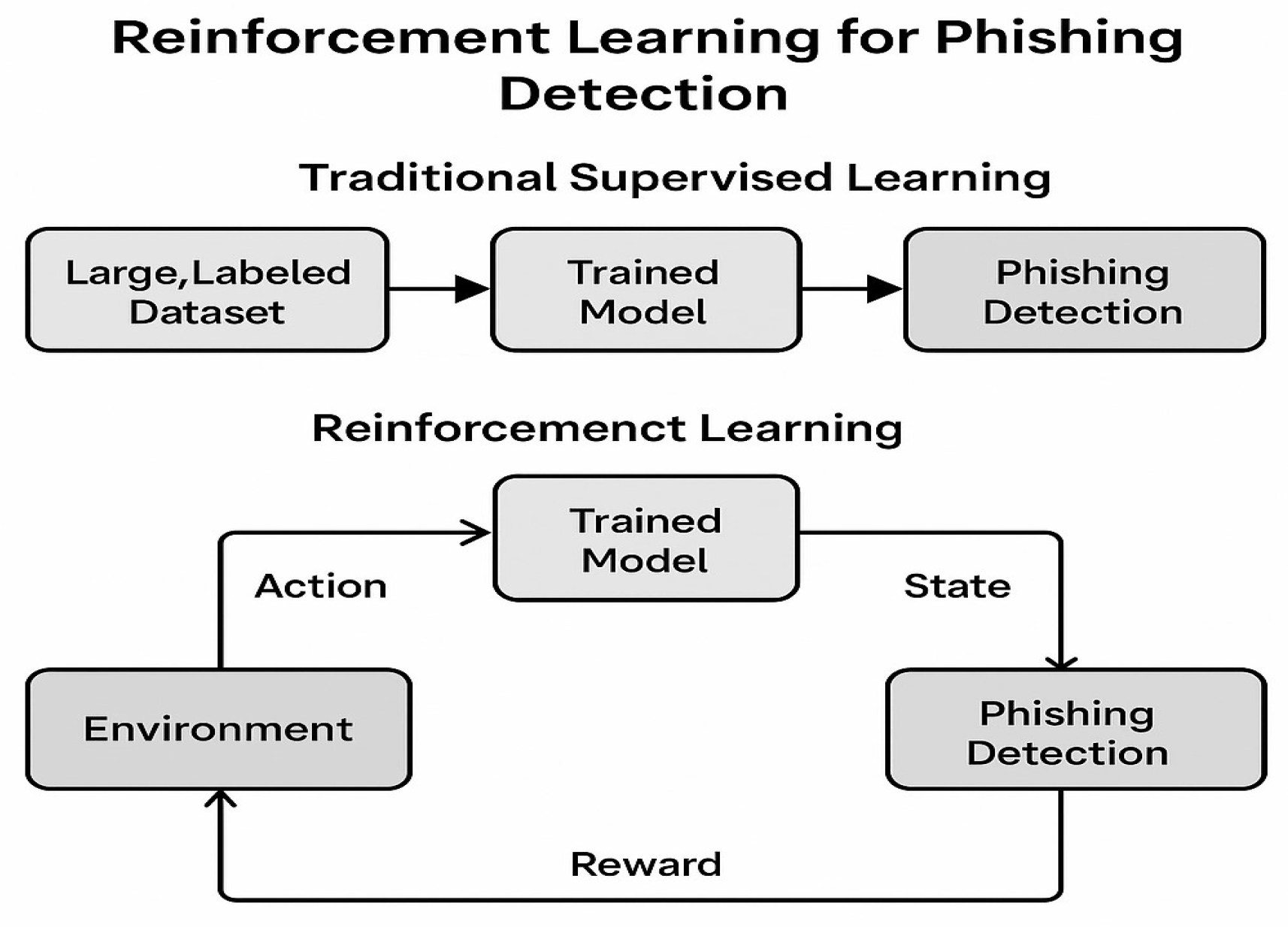
- Introduction of a RL-based phishing detection framework: The paper proposes a new phishing detection framework leveraging RL, specifically using DQN architecture. This approach enables dynamic learning from real-time interactions, which contrasts with static, traditional ML models.
- Enhanced adaptability to emerging phishing threats: Unlike traditional ML models that require frequent retraining with new data, the proposed RL-based model adapts continuously through trial-and-error learning. This makes it highly effective against evolving phishing techniques, including spear-phishing and PaaS attacks.
- Reduction of false positives in phishing detection: One of the key challenges in phishing detection is the high false positive rate. The paper introduces a reward–penalty mechanism within the RL model to penalize false positives, thereby improving decision-making accuracy and reducing false alarms to just 4%, compared to 10–12% in traditional models.
- Benchmarking against developed models: The proposed framework is benchmarked against state-of-the-art models, such as SVMs and Random Forests. The RL-based model achieved a 95% accuracy, outperforming traditional ML models (which achieved an 85–87% accuracy).
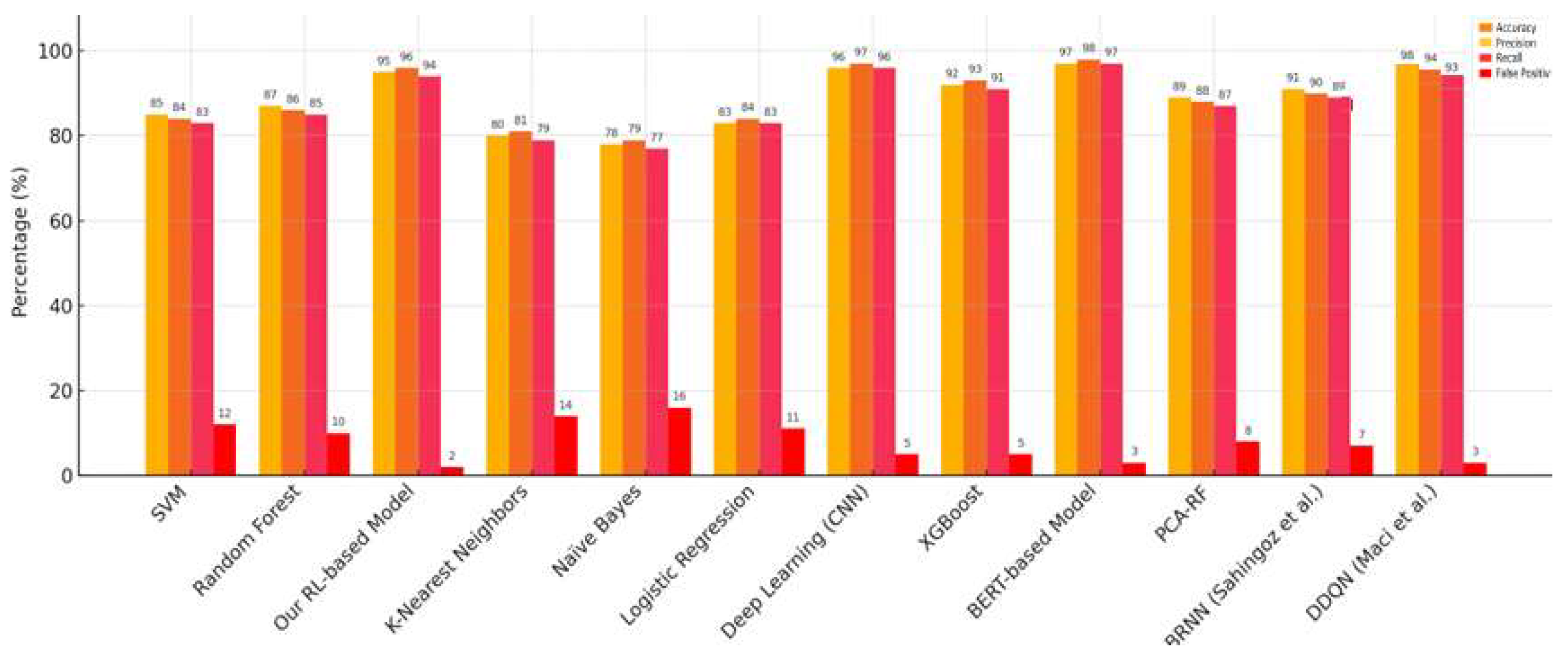
- Comprehensive experimental validation: The model was trained on a real-world dataset comprising 5000 emails (2500 phishing and 2500 benign), with 4000 emails used for training and 1000 emails for testing. It achieved a 95% accuracy, 96% precision, and 94% recall on the real-world dataset and maintained a 93% accuracy and 94% precision and a 4% false positive rate during external validation using a synthetic phishing dataset comprising 1000 generated samples simulating unseen attacks.
2. Background and Related Work
- To contextualize the practical limitations of existing solutions in real-world environments;
- To highlight the specific gaps that our RL-based framework aims to address.
3. Classification of Phishing Detection Strategies
3.1. Rule-Based Methods
- Keyword Matching: Identifying suspicious terms (e.g., “urgent” and “verify account”);
- Pattern Recognition: Validating domain signatures, mismatched sender information, and invalid SSL certificates.
- D(x) is the detection outcome (1 = phishing; 0 = benign).
- Ri(x) represents the rule score for feature i.
- T is the threshold score to trigger detection.
- n is the total number of rules applied.
3.2. Heuristic Approaches
- URL Heuristics: Anomalous URL lengths, presence of IP addresses instead of domain names, and suspicious subdomains;
- Content Analysis: Abnormal HTML structure, deceptive anchor texts, and inconsistencies in page layout [53];
- Sender Verification: Mismatched “From” and “Reply-To” addresses;
- Example of a Heuristic Scoring Algorithm:
3.3. ML Techniques
- Decision Trees: Construct a model based on splitting data by key features;
- SVMs: Identify optimal hyperplanes that separate phishing from legitimate samples [32];
- Neural Networks: Model complex feature interactions, particularly effective in detecting sophisticated phishing attacks;
3.4. RL-Based Systems
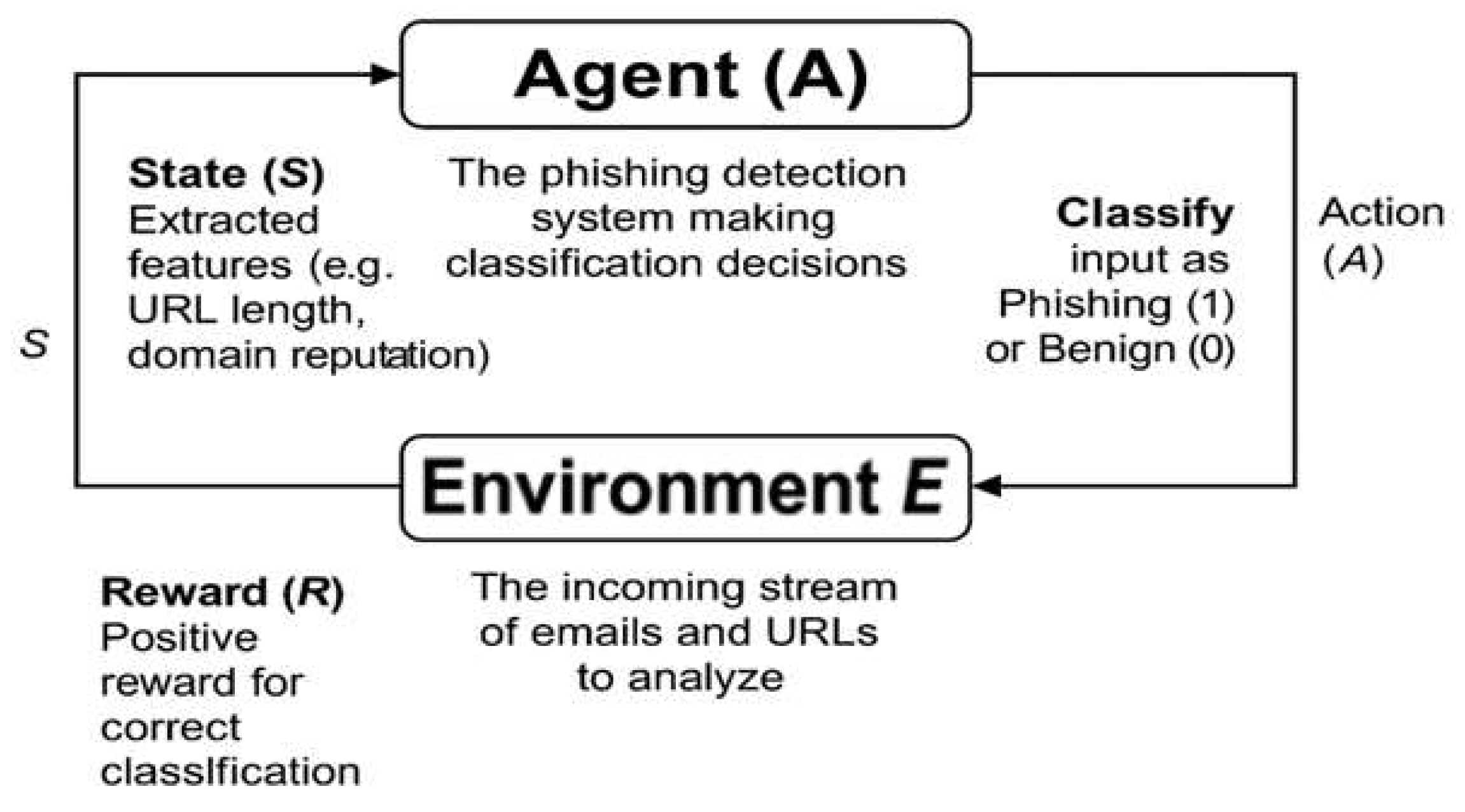
- Environment (E): The incoming stream of emails, websites, or network data that needs analysis;
- State (s): The current representation of features extracted from emails or websites (e.g., URL length, domain age, and sender reputation);
- Action (a): The classification decision—either phishing (1) or benign (0);
- Reward (R): A feedback mechanism where the agent receives positive rewards for correct classifications and penalties for false positives/negatives.
3.4.1. Mathematical Model: Q-Learning for Phishing Detection
3.4.2. Q-Function Definition
3.4.3. Q-Learning Update Rule
3.5. Mathematical Advantages of RL over Traditional ML
3.5.1. Dynamic Adaptation Without Retraining
3.5.2. Optimizing Long-Term Reward vs. Immediate Accuracy
3.5.3. Reduced False Positive Rate Through Reward–Penalty Mechanism
3.5.4. Exploration–Exploitation Trade-Off
4. Methodology
4.1. Data Collection and Feature Extraction
- Dataset 1 (Real-World Dataset): A dataset consisting of 5000 emails, evenly distributed with 2500 phishing emails (sourced from PhishTank and OpenPhish archives) and 2500 benign emails (collected from public corporate email traffic and open datasets);
- Dataset 2 (Synthetic Phishing Dataset): A synthetic dataset containing 1000 phishing emails generated using templates based on real-world phishing attack patterns, including domain spoofing, urgent calls-to-action, credential harvesting requests, and misleading hyperlinks.
- URL Features: Length of URLs, number of subdomains, presence of IP addresses, and suspicious domain patterns;
- HTML Structure: Presence of embedded scripts, hidden form fields, and iframe usage;
- Sender Reputation: Mismatched “From” and “Reply-To” addresses, domain age, and SPF/DKIM validation status;
- Keyword Patterns: Occurrence of phishing-related keywords like “urgent”, “verify your account”, and “password reset”.
4.2. RL Model
4.2.1. Agent–Environment Interaction
4.2.2. Q-Learning Algorithm
4.3. Training and Evaluation
4.4. Linking Back to Previous Strategies
- Real-Time Adaptation: Continuous learning from new phishing patterns;
- Lower False Positive Rates: Optimized through tailored reward mechanisms;
- Scalability: Effective across diverse phishing attack vectors.
5. Model Ongoing Training
5.1. Training Dataset and Feature Processing
- 2500 phishing emails (extracted from the PhishTank database and other public datasets [30]);
- 2500 benign emails (collected from real-world email traffic under controlled conditions).
- Total Training Episodes: 10,000;
- Exploration Strategy: Epsilon-Greedy (balancing exploration of new decisions vs. exploiting known patterns);
- Discount Factor: 0.95 (controlling the influence of future rewards on current decisions);
- Learning Rate: 0.001 (adjusting how quickly the model updates based on new information);
- Batch Size: 64 (number of emails processed per learning step).
- Target Network Update Frequency: Every 100 steps (stabilizing training to avoid policy divergence);
- Reward Function; (phishing or benign): Rewarded
- Correct Classification (phishing or benign): Rewarded;
- False Positives: Penalized;
- False Negatives: Heavily penalized to ensure phishing threats are prioritized.
5.2. Model Performance and Evaluation
5.3. Computational Benchmarking Results
- The RL-based DQN model required approximately 35 min of total training time across 10,000 episodes, with a peak memory consumption of 420 MB.
- The CNN-based phishing detection model required approximately 2.3 h of training and 1.6 GB of memory.
- The BERT-based phishing detection model required 5.5 h of training and 3.8 GB of memory during fine-tuning.
- The RL agent achieved convergence after approximately 7500 episodes, while CNN and BERT models required multiple epochs (25+ epochs for CNN; 5+ epochs for BERT) over the entire dataset.
- These findings demonstrate that the RL-based model achieved strong phishing detection accuracy with substantially reduced computational resource requirements compared to deep learning counterparts.
5.4. Detection Latency and Performance Trade-Off
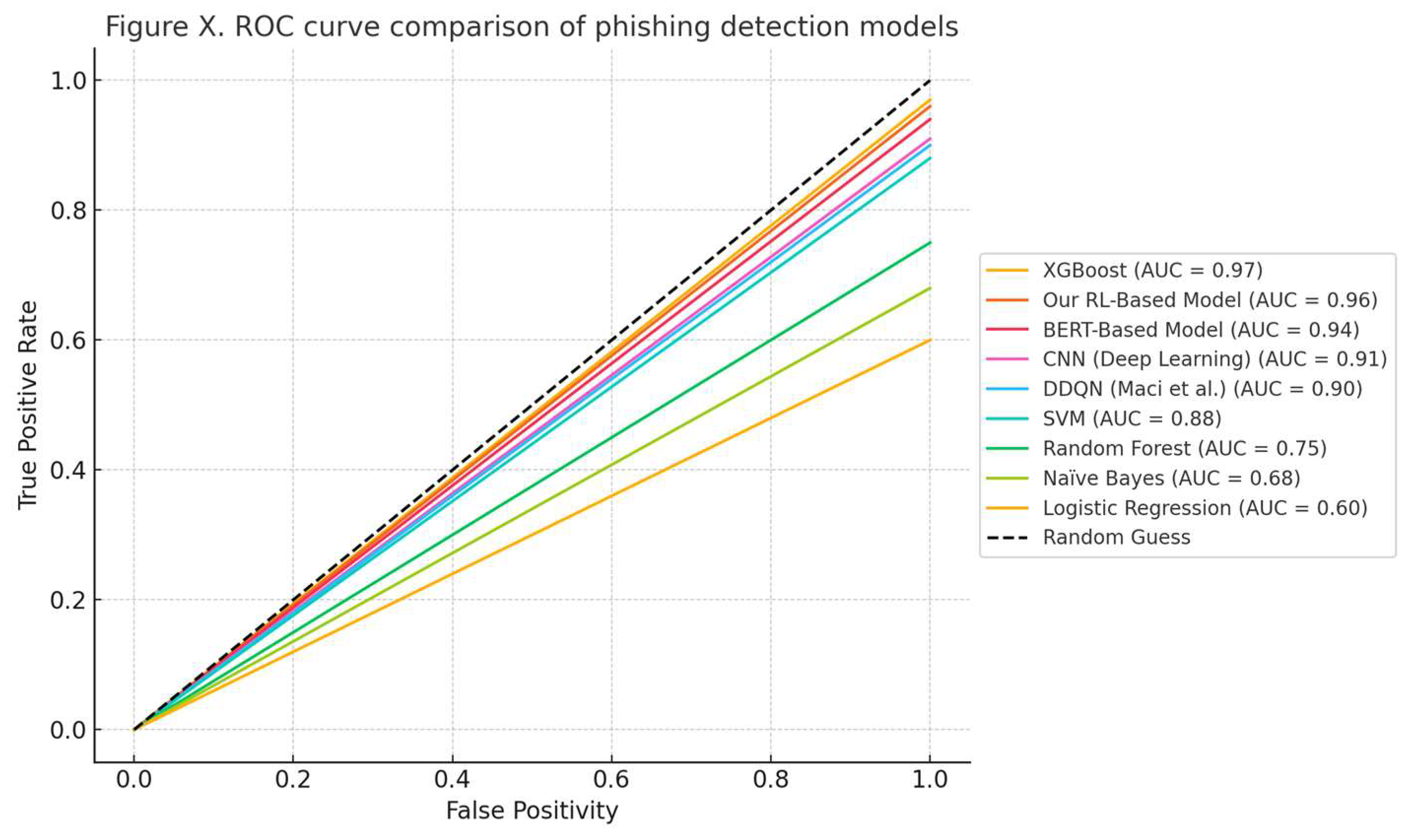
6. Testing and Results
External Validation on Synthetic Dataset
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Anti-Phishing Working Group (APWG). Phishing Activity Trends Report: Q1 2023. Available online: https://www.apwg.org/trendsreports/ (accessed on 1 January 2025).
- Aboud, S.J.; Al-Fayoumi, M.A.; Jabbar, H.S. An Efficient RSA Public Key Encryption Scheme. In Proceedings of the Fifth International Conference on Information Technology: New Generations (ITNG 2008), Las Vegas, NV, USA, 7–9 April 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 127–130. [Google Scholar]
- Asiri, S.; Xiao, Y.; Alzahrani, S.; Li, S.; Li, T. A Survey of Intelligent Detection Designs of HTML URL Phishing Attacks. IEEE Access 2023, 11, 6421–6443. [Google Scholar] [CrossRef]
- Alghenaim, M.F.; Abu Bakar, N.A.; Rahim, F.A.; Alkawsi, G.; Vanduhe, V. Phishing Attack Types and Mitigation: A Survey. In Proceedings of the Conference on Data Science and Emerging Technologies, Khulna, Bangladesh, 15–17 April 2023. [Google Scholar]
- Meijdam, K.; Pieters, W.; van den Berg, J. Phishing as a Service: Designing an Ethical Way of Mimicking Targeted Phishing Attacks to Train Employees. Master’s Thesis, TU Delft, Delft, The Netherlands, 2015. [Google Scholar]
- Aboud, S.J.; Alnuaimi, M.; Jabbar, H.S. Efficient Password Scheme Without Trusted Server. Int. J. Aviat. Technol. Eng. Manag. 2011, 1, 52–57. [Google Scholar] [CrossRef]
- Jabbar, H.S.; Gopal, T.V.; Aboud, S.J. Qualitative Analysis Model for Software Requirements Driven by Interviews. J. Eng. Appl. Sci. 2007, 2, 1–9. [Google Scholar]
- Nahapetyan, A.; Prasad, S.; Childs, K.; Oest, A.; Ladwig, Y.; Kapravelos, A.; Reaves, B. On SMS Phishing Tactics and Infrastructure. In Proceedings of the 2024 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 20–23 May 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1–16. [Google Scholar]
- Curtis, S.R.; Rajivan, P.; Jones, D.N.; Gonzalez, C. Phishing Attempts among the Dark Triad: Patterns of Attack and Vulnerability. Comput. Human Behav. 2018, 87, 174–182. [Google Scholar] [CrossRef]
- Dalvi, S.; Gressel, G.; Achuthan, K. Tuning the False Positive Rate/False Negative Rate with Phishing Detection Models. Int. J. Eng. Adv. Technol. 2019, 9, 7–13. [Google Scholar] [CrossRef]
- Adawadkar, A.M.K.; Kulkarni, N. Cyber-Security and Reinforcement Learning—A Brief Survey. Eng. Appl. Artif. Intell. 2022, 114, 105116. [Google Scholar] [CrossRef]
- Alavizadeh, H.; Alavizadeh, H.; Jang-Jaccard, J. Deep Q-Learning Based RLApproach for Network Intrusion Detection. Computers 2022, 11, 41. [Google Scholar] [CrossRef]
- Anomaly Detection Using Machine Learning Approaches. Azerbaijan J. High Perform. Comput. 2020, 3, 196–206. [CrossRef]
- Ul Haq, I.; Lee, B.S.; Rizzo, D.M.; Perdrial, J.N. An Automated Machine Learning Approach for Detecting Anomalous Peak Patterns in Time Series Data from a Research Watershed in the Northeastern United States Critical Zone. Measurement 2020, 24, 100482. [Google Scholar]
- Jabbar, H.S.; Gopal, T.V.; Aboud, S.J. An Integrated Quantitative Assessment Model for Usability Engineering. In Proceedings of the ECOOP Doctoral Symposium and PhD Workshop Organization, Berlin, Germany, 29–30 July 2007; pp. 114–123. [Google Scholar]
- Jabbar, H.S.; Gopal, T.V. An Integrated Metrics Based Approach for Usability Engineering. Int. Rev. Comput. Softw. 2006, 1, 114–123. [Google Scholar]
- Rao, R.S.; Pais, A.R. Detecting Phishing Websites Using Machine Learning Techniques. J. Comput. Netw. Commun. 2019, 2019, 8070830. [Google Scholar]
- Skula, I.; Kvet, M. URL and Domain Obfuscation Techniques—Prevalence and Trends Observed on Phishing Data. In Proceedings of the 2024 IEEE 22nd World Symposium on Applied Machine Intelligence and Informatics (SAMI), Herlany, Slovakia, 24–27 January 2024; IEEE: Piscataway, NJ, USA, 2024. [Google Scholar]
- Gupta, B.B.; Gupta, R.; Pilli, E.S.; Singh, D. Fighting against Phishing Attacks: State of the Art and Future Challenges. Neural Comput. Appl. 2017, 28, 3629–3654. [Google Scholar] [CrossRef]
- Kamal, H.; Al-Habsi, S.; Jameel, H.; Ghafoor, K.Z.; Khan, M.K.; Shojafar, M. RLModel for Detecting Phishing Websites. In Cybersecurity and Artificial Intelligence: Transformational Strategies and Disruptive Innovation; Springer Nature: Cham, Switzerland, 2024; pp. 309–326. [Google Scholar]
- Kheddar, H.; Benmohammed, M.; Bouras, A.; Abou El Kalam, A.; Guemara El Fatmi, M.H. Reinforcement-Learning-Based Intrusion Detection in Communication Networks: A Review. IEEE Commun. Surv. Tutor. 2024; in press. [Google Scholar]
- Guleria, K.; Sharma, S.; Kumar, S.; Tiwari, S. Early Prediction of Hypothyroidism and Multiclass Classification Using Predictive Machine Learning and Deep Learning. Measurement 2022, 24, 100482. [Google Scholar] [CrossRef]
- Alsubaei, F.S.; Almazroi, A.A.; Ayub, N. Enhancing Phishing Detection: A Novel Hybrid Deep Learning Framework for Cybercrime Forensics. IEEE Access 2024, 12, 8373–8389. [Google Scholar] [CrossRef]
- Routhu, S.R.; Pais, A.R. Detection of Phishing Websites Using an Efficient Feature-Based Machine Learning Framework. Neural Comput. Appl. 2019, 31, 3851–3873. [Google Scholar]
- Sahingoz, O.K.; Buber, E.; Kugu, E. Real-Time Phishing URL Detection Using Deep Learning. IEEE Access 2024, 12, 8052–8070. [Google Scholar] [CrossRef]
- Tanti, R. Study of Phishing Attack and Their Prevention Techniques. Int. J. Adv. Res. Comput. Sci. 2022, 13, 456–470. [Google Scholar] [CrossRef]
- Maci, A.; Santorsola, A.; Coscia, A.; Iannacone, A. Unbalanced Web Phishing Classification through Deep Reinforcement Learning. Computers 2023, 12, 118. [Google Scholar] [CrossRef]
- Sattar, J.A.; Mohammed, A.; Haidar, S.J. A Secure Designated Signature Scheme. Comput. Sci. Telecommun. 2009, 2, 3–10. [Google Scholar]
- Zhang, H.; Maple, C. Deep Reinforcement Learning-Based Intrusion Detection in IoT Systems: A Review. IET Conf. Proc. 2023. [Google Scholar] [CrossRef]
- Yan, C.; Han, X.; Zhu, Y.; Du, D.; Lu, Z.; Liu, Y. Phishing Behavior Detection on Different Blockchains via Adversarial Domain Adaptation. Cybersecurity 2024, 7, 45. [Google Scholar] [CrossRef]
- Aboud, S.J.; Jabbar, H.S. Development of an Efficient Password-Typed Key Agreement Scheme. Al-Mansour J. 2010, 14, 25–36. [Google Scholar]
- Chatterjee, M.; Namin, A.S. Detecting Phishing Websites through Deep Reinforcement Learning. In Proceedings of the 2019 IEEE 43rd Annual Computer Software and Applications Conference (COMPSAC), Milwaukee, WI, USA, 15–19 July 2019; Volume 2, pp. 227–232. [Google Scholar]
- Jabbar, H.; Al-Janabi, S. Securing Smart Supply Chains with Adaptive AI Agents: A Virtual Simulation Framework. In Proceedings of the 2nd International Conference on Information Technology (ICIT 2025), Amman, Jordan, 27–30 May 2025. [Google Scholar]
- PhishTank. Available online: https://www.phishtank.com/ (accessed on 5 February 2025).
- OpenPhish. Available online: https://openphish.com/ (accessed on 5 February 2025).
- PhishProtection. Available online: https://www.phishprotection.com/ (accessed on 5 February 2025).
- MailScanner. Available online: https://www.mailscanner.info/ (accessed on 5 February 2025).
- SpamAssassin. Available online: https://spamassassin.apache.org/ (accessed on 5 February 2025).
- Proofpoint. Available online: https://www.proofpoint.com/ (accessed on 5 February 2025).
- IRONSCALES. Available online: https://ironscales.com/ (accessed on 5 February 2025).
- PhishER. Available online: https://www.knowbe4.com/products/phisher (accessed on 5 February 2025).
- Sophos Email. Available online: https://www.sophos.com/en-us/products/email (accessed on 5 February 2025).
- Microsoft Defender for Office 365. Available online: https://www.microsoft.com/en-us/microsoft-365/exchange/office-365-advanced-threat-protection (accessed on 5 February 2025).
- Barracuda Sentinel. Available online: https://www.barracuda.com/products/sentinel (accessed on 5 February 2025).
- Cofense PhishMe. Available online: https://cofense.com/phishme/ (accessed on 5 February 2025).
- Gophish. Available online: https://getgophish.com/ (accessed on 5 February 2025).
- Phishing Frenzy. Available online: https://www.phishingfrenzy.com/ (accessed on 5 February 2025).
- Haidar, J.; Gopal, T.V. User Centered Design for Adaptive E-Learning Systems. Asian J. Technol. 2006, 5, 429–436. [Google Scholar]
- Al-Janabi, S.J.; Jabbar, H.S.; Syms, F. Securing Autonomous Vehicles with Smart AI Security Agents. In Proceedings of the 3rd International Conference on New Trends in Computing Sciences (ICTCS’25), Amman, Jordan, 16–18 April 2025. [Google Scholar]
- Moghimi, M.; Varjani, A.Y. New Rule-Based Phishing Detection Method. Expert Syst. Appl. 2016, 53, 231–242. [Google Scholar] [CrossRef]
- Al-Janabi, S.; Jabbar, H.; Syms, F. AI-Integrated Cyber Security Risk Management Framework for IT Projects. In Proceedings of the 2024 International Jordanian Cybersecurity Conference (IJCC), Amman, Jordan, 17–18 December 2024; pp. 76–81. [Google Scholar] [CrossRef]
- da Silva, C.M.R.; Feitosa, E.L.; Garcia, V.C. Heuristic-Based Strategy for Phishing Prediction: A Survey of URL-Based Approach. Comput. Secur. 2020, 88, 101613. [Google Scholar] [CrossRef]
- Lakshmi, V.S.; Vijaya, M.S. Efficient Prediction of Phishing Websites Using Supervised Learning Algorithms. Procedia Eng. 2012, 30, 798–805. [Google Scholar] [CrossRef]
- Liew, S.W.; Sani, N.F.M.; Abdullah, M.T.; Yaakob, R.; Sharum, M.Y. An Effective Security Alert Mechanism for Real-Time Phishing Tweet Detection on Twitter. Computers 2019, 83, 201–207. [Google Scholar] [CrossRef]
- Al-Janabi, S.; Jabbar, H.; Syms, F. Cybersecurity Transformation: Cyber-Resilient IT Project Management Framework. Digital 2024, 4, 866–897. [Google Scholar] [CrossRef]
- Zhang, Z.; Yu, X.; Dai, H.; Yang, X.; Ma, Z. Vulnerability of Machine Learning Approaches Applied in IoT-Based Smart Grid: A Review. IEEE Internet Things J. 2024, 11, 18951–18975. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Author(s) | Year | Focus | Approach | Limitations |
|---|---|---|---|---|
| Routhu & Pais [24] | 2019 | Detecting phishing websites | ML (Random Forest and PCA-RF) | Dependency on third-party services; limited focus on evolving phishing tactics; potential feature obsolescence over time. |
| Sahingoz, Buber, & Kugu [25] | 2024 | Real-time phishing URL detection | DL (CNN, RNN, BRNN, and Attention Networks) | High computational cost; dependency on extensive training data; inability to detect URL hijacking; complexity limits adoption in low-resource environments. |
| Tanti [26] | 2022 | Phishing attack and prevention | Comprehensive analysis of phishing and mitigation strategies | Lacks implementation details for modern threats; reliance on generic prevention techniques; no real-world testing or evaluation. |
| Maci, Santorsola Coscia, & Iannacone [27,28] | 2023 | Addressing unbalanced web phishing classification | Double DQN (DDQN) with ICMDP | Significant training time; complex implementation; requires computational resources for real-time applications. |
| Zhang & Maple [29] | 2023 | Intrusion detection in IoT systems | DR-based IDS | Limited resilience to advanced AML techniques; challenges in scaling to highly diverse IoT networks; significant computational overhead. |
| Yan, Han, Zhu, Du, Lu, & Liu [30,31] | 2024 | Phishing behavior detection on blockchains | Adversarial Domain Adaptation (ADA) model | Limited generalizability to non-blockchain phishing; challenges in scaling to new, unseen blockchain platforms. |
| Tool Name | Type | Phishing Detection Approach | Limitation of the Tool |
|---|---|---|---|
| PhishTank [34] | Open Source | Blacklist-based detection | Ineffective against new attacks; lacks adaptive learning. |
| OpenPhish [35] | Commercial | ML-based phishing detection | Requires frequent retraining; lacks dynamic adaptation. |
| PhishProtection [36] | Commercial | Supervised ML | High false positives; lacks RL’s reward-based optimization. |
| MailScanner [37] | Open Source | Rule-based filtering and heuristics | Limited to static rules; cannot evolve with new threats. |
| SpamAssassin [38] | Open Source | Heuristic spam and phishing detection | Prone to false positives; lacks real-time adaptability. |
| Proofpoint [39] | Commercial | RL for email phishing | Focused on emails; limited coverage for multi-vector threats. |
| IRONSCALES [40] | Commercial | AI-based threat hunting and phishing detection | High cost; lacks continuous real-time learning. |
| PhishER [41] | Commercial | ML and AI-driven analysis | Relies on manual input; lacks full automation like RL. |
| Sophos Email [42] | Commercial | AI-powered email protection | Limited against advanced phishing; lacks dynamic learning. |
| Microsoft Defender 365 [43] | Commercial | Integrated AI and machine learning | Microsoft-centric; lacks platform flexibility. |
| Barracuda Sentinel [44] | Commercial | AI-driven spear-phishing detection | Relies on user training; less effective without it. |
| Cofense PhishMe [45] | Commercial | User-based phishing simulations and analysis | Focus on training, not real-time detection. |
| Gophish [46] | Open Source | Open-source phishing simulation platform | Simulation-only; lacks real-time detection capabilities. |
| Phishing Frenzy [47] | Open Source | Automated phishing campaigns and tracking | Simulation-focused; does not adapt to live phishing threats. |
| Model | Accuracy (%) | False Positive Rate (%) |
|---|---|---|
| RL-Based DQN | 95 | 2 |
| SVM | 85 | 12 |
| Random Forest | 87 | 10 |
| Parameter | Value |
|---|---|
| Total Training Episodes | 10,000 |
| Exploration Strategy | Epsilon-Greedy |
| Discount Factor (γ) | 0.95 |
| Learning Rate (α) | 0.001 |
| Batch Size | 64 |
| Target Network Update Frequency | Every 100 steps |
| Reward Function | Positive reward for correct classifications; penalties for false positives, with heavier penalties for false negatives |
| Model | Accuracy (%) | False Positive Rate (%) |
|---|---|---|
| RL-Based DQN | 95 | 2 |
| SVM | 85 | 12 |
| Random Forest | 87 | 10 |
| K-Nearest Neighbors (KNN) | 80 | 14 |
| Naïve Bayes | 78 | 16 |
| Logistic Regression | 83 | 11 |
| CNN | 96 | 5 |
| BERT-Based Detection | 97 | 3 |
| Double [27] | 95 | 3 |
| Model | Training Time | Peak Memory Usage | Model Size (Parameters) | Convergence Speed |
|---|---|---|---|---|
| RL-Based DQN | 35 min | 420 MB | ~1.2 million | 7500 episodes |
| CNN | 2.3 h | 1.6 GB | ~8 million | 25 epochs |
| BERT-Based | 5.5 h | 3.8 GB | ~110 million | 5 epochs |
| Model | Accuracy (%) | Precision (%) | Recall (%) | False Positive Rate (%) |
|---|---|---|---|---|
| SVM | 85 | 84 | 83 | 12 |
| Random Forest | 87 | 86 | 85 | 10 |
| Our RL-Based Model | 95 | 96 | 94 | 2 |
| K-Nearest Neighbors | 80 | 79 | 79 | 14 |
| Naïve Bayes | 78 | 79 | 79 | 16 |
| Logistic Regression | 83 | 84 | 83 | 11 |
| Deep Learning (CNN) | 96 | 97 | 96 | 5 |
| XGBoost | 92 | 93 | 91 | 5 |
| BERT-Based Model | 97 | 98 | 97 | 3 |
| PCA-RF | 89 | 87 | 87 | 8 |
| BRNN [25] | 91 | 90 | 89 | 7 |
| DDQN [27] | 95 | 94 | 93 | 3 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jabbar, H.; Al-Janabi, S. AI-Driven Phishing Detection: Enhancing Cybersecurity with Reinforcement Learning. J. Cybersecur. Priv. 2025, 5, 26. https://doi.org/10.3390/jcp5020026
Jabbar H, Al-Janabi S. AI-Driven Phishing Detection: Enhancing Cybersecurity with Reinforcement Learning. Journal of Cybersecurity and Privacy. 2025; 5(2):26. https://doi.org/10.3390/jcp5020026
Chicago/Turabian StyleJabbar, Haidar, and Samir Al-Janabi. 2025. "AI-Driven Phishing Detection: Enhancing Cybersecurity with Reinforcement Learning" Journal of Cybersecurity and Privacy 5, no. 2: 26. https://doi.org/10.3390/jcp5020026
APA StyleJabbar, H., & Al-Janabi, S. (2025). AI-Driven Phishing Detection: Enhancing Cybersecurity with Reinforcement Learning. Journal of Cybersecurity and Privacy, 5(2), 26. https://doi.org/10.3390/jcp5020026