Partial Fake Speech Attacks in the Real World Using Deepfake Audio


Abstract
1. Introduction
- We conducted a series of experiments with over 80 speakers and found that using DNN speech synthesis tools to create PF speech can effectively deceive modern public and commercial speaker recognition systems with a success rate of 95% to 97%;
- A survey of 148 participants revealed that humans can only distinguish PF speech from real speech with a very low accuracy: 16% for unknown voices and 17.5% for known voices;
- Our study, which involved 148 participants, found that humans can only identify partially fake speech within a completely authentic video with a 24% accuracy when the speaker’s face is close to the camera and an 11% accuracy when the speaker’s face is far from the camera;
- A detailed evaluation of three state-of-the-art defence algorithms revealed an inability to prevent and detect PF speech, highlighting the need for new defences.
2. Motivation
2.1. Financial Gain
2.2. Political Leader and Public Figure Reputation Attacks
2.3. Virtual Kidnapping
2.4. Breaking Customer Trust
2.5. Deepfake Audio in the Court
3. Background
3.1. User Identification Based on Voice
3.2. Automatic Speaker Recognition Challenges
3.3. Speech Synthesis Generation
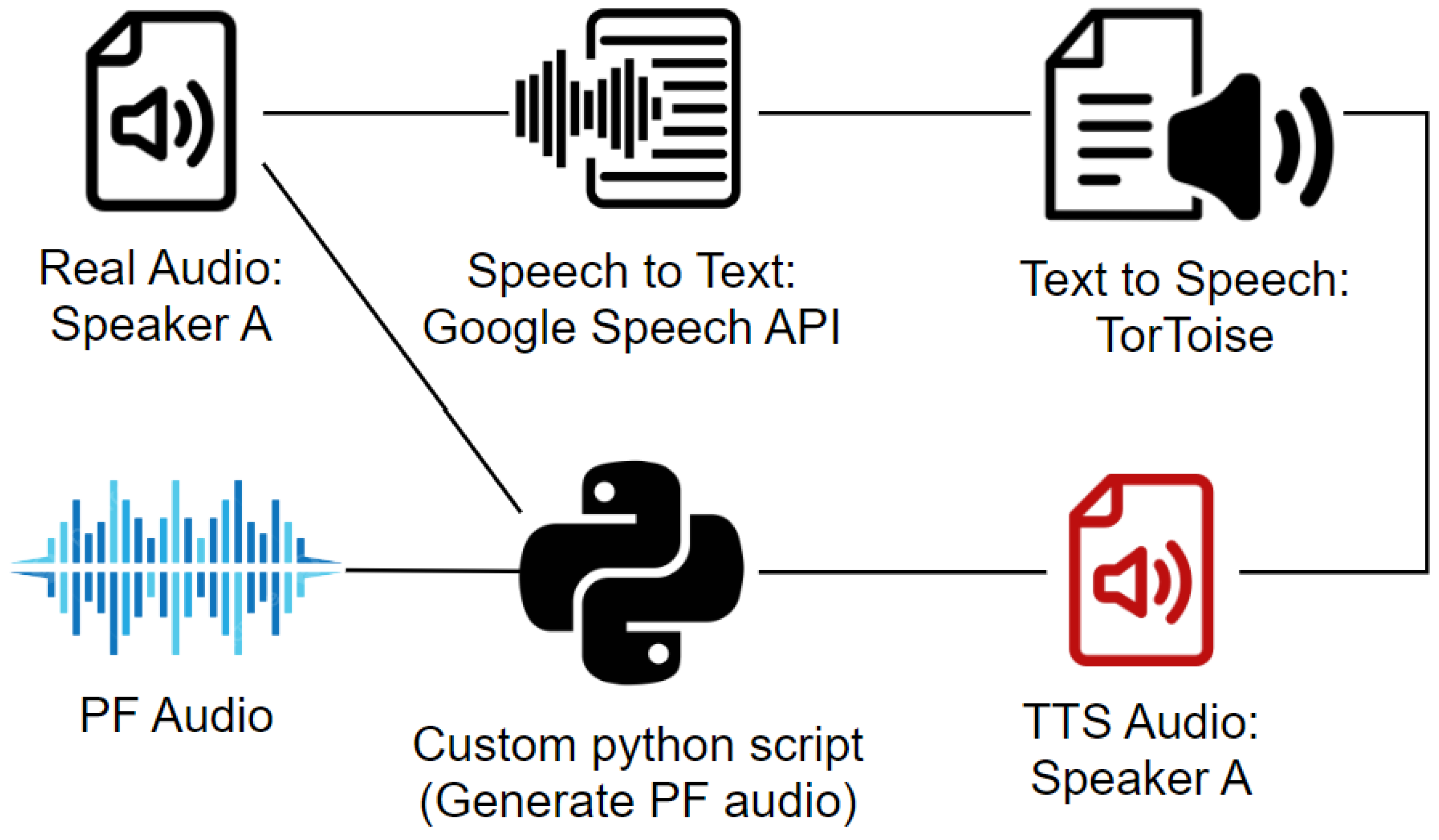
3.4. Partial Fake (PF) Speech Generation
3.5. Partial Fake Speech Attacks
3.6. Partial Fake Speech Detection
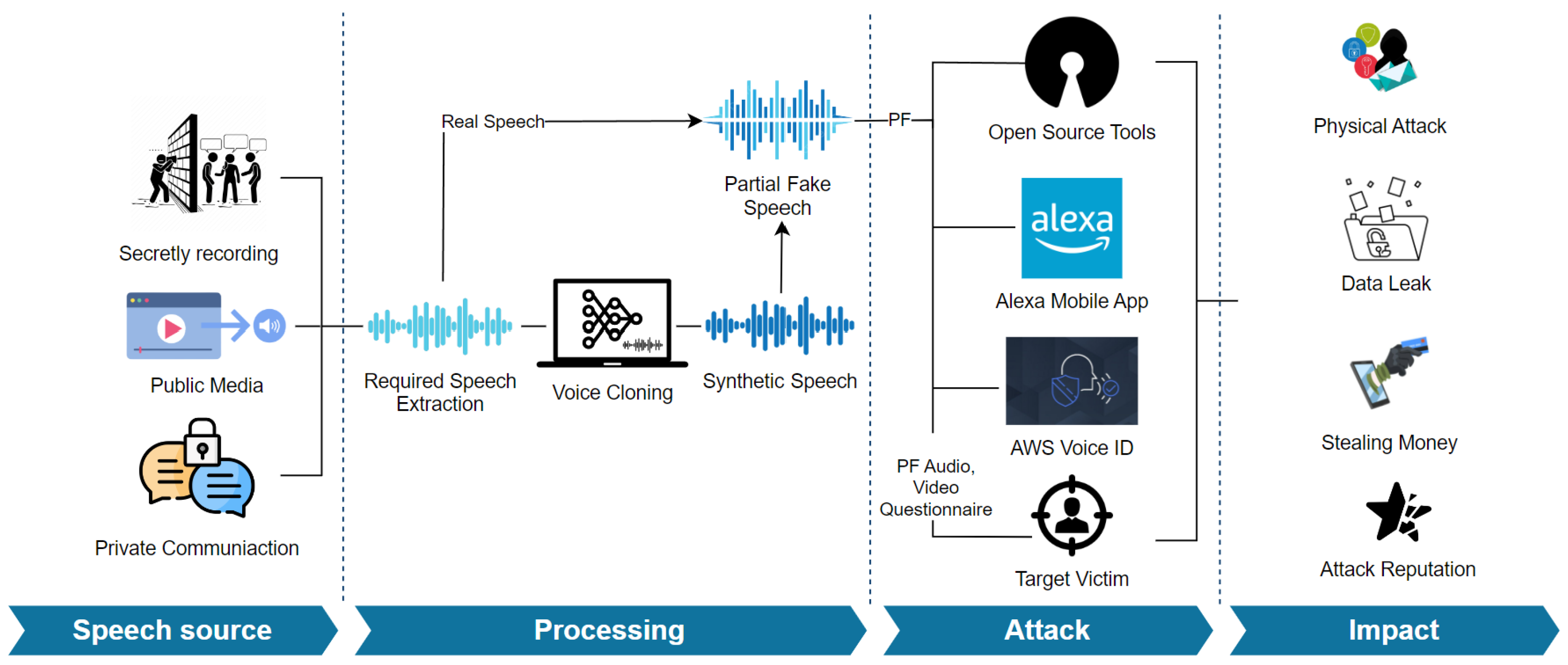
4. Threat Model
4.1. Attacker Model
4.2. Summary of Experiments
- Empirical experiments to see if PF speech attacks can fool Speaker Recognition systems;
- User studies to explore whether humans can differentiate between PF speech and real speech, even when the PF speech is embedded within an entirely legitimate video;
- Empirical experiments to evaluate the effectiveness of existing defences against PF speech attacks.
4.3. DNN-Based Speech Synthesis
4.4. Speaker Recognition (SR) Systems
4.5. Speaker/Speech Sources
- The RFP [66] dataset comprises three types of audio: real, fake, and partially fake. It includes a total of 127,862 utterances spoken by 354 speakers, of which 184 are male and 170 are female. Eleven different methods were used to produce the fake voices, including seven methods for generating TTS and four methods for VC. This dataset is one of the few publicly available that includes PF audio;
- The UK and Irish English Dialect speech dataset [67] consists of 18,779 spoken utterances by 118 individuals. We opted to use this dataset as it includes participants from six different regions in the UK and Ireland who spoke various English dialects, namely, Irish, Midlands, Northern, Scottish, Southern, and Welsh English;
- The VCTK dataset [68] consists of speech data from 110 English speakers with an age range of 18–38 and varied accents. Each speaker reads around 400 sentences picked from a newspaper, the rainbow passage, and an elicitation paragraph used for the speech accent archive;
- YouTube-8M [69] is a video dataset containing over 7 million videos, each labelled with one of 4716 classes using an annotation system. Our use case involves creating PF audio within a real video, which led us to use YouTube-8M;
- We created a custom dataset for our experiments. First, we collected Alexa commands spoken by 15 native male and female English speakers and used the recordings to perform Alexa attacks. Second, we created PF audio with different fake segment weights to perform AWS cloud and Resemblyzer attacks. Lastly, we created PF audio within an entirely real video and used it in the questionnaire.
4.6. Ethics
5. Partial Fake Speech Against Machines
5.1. Partial Fake Attack Against Modern SR Systems
5.2. PF Attack Against Resemblyzer
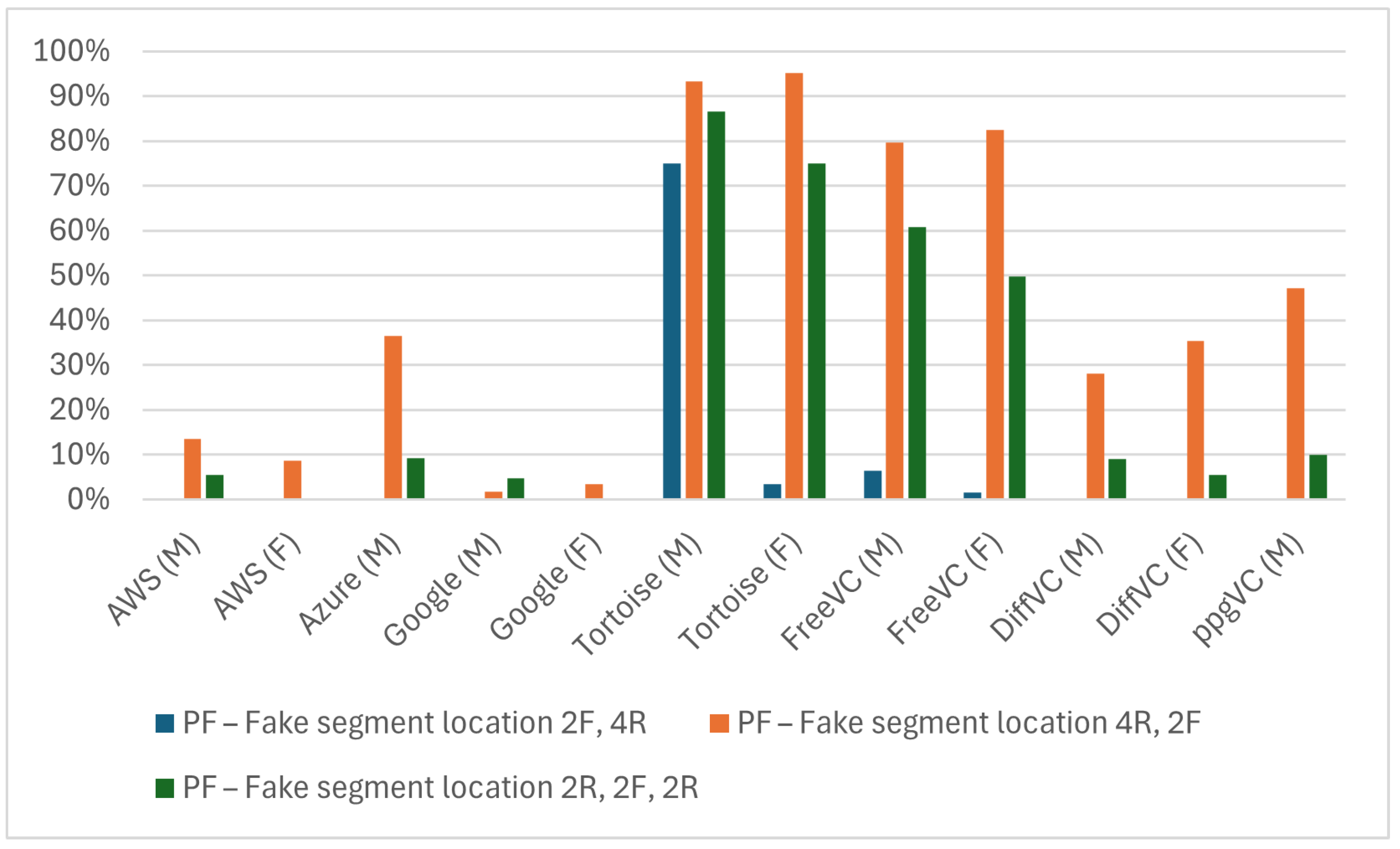
- Synthetic speech generation methods: We evaluated TTS generation methods using AWS, Azure, Google Cloud, and the open-sourced tool Tortoise, and VC generation methods FreeVC, DiffVC, and ppgVC;
- The location of a fake signal within the audio file: We evaluated three options for the location of a fake signal within the audio file. All PF speeches are included in our customised dataset listed in Section 4.5. The three locations of PF speech are as follows: (1) fake segment at the beginning of audio file; (2) fake segment at the middle of audio file; and (3) fake segment at the end of audio file. Table 1 and Table 2 list the attack results of the three fake segment locations within the audio file;
- The varying lengths of the fake segments within the audio file and their effect on the detection process.
5.2.1. Impact of Fake Segment Location
5.2.2. Impact of Fake Segment Speech Content for the Same Speaker
5.2.3. Impact of Synthetic Speech Generation Methods
5.2.4. Impact of Gender
5.2.5. Impact of Target Dialect
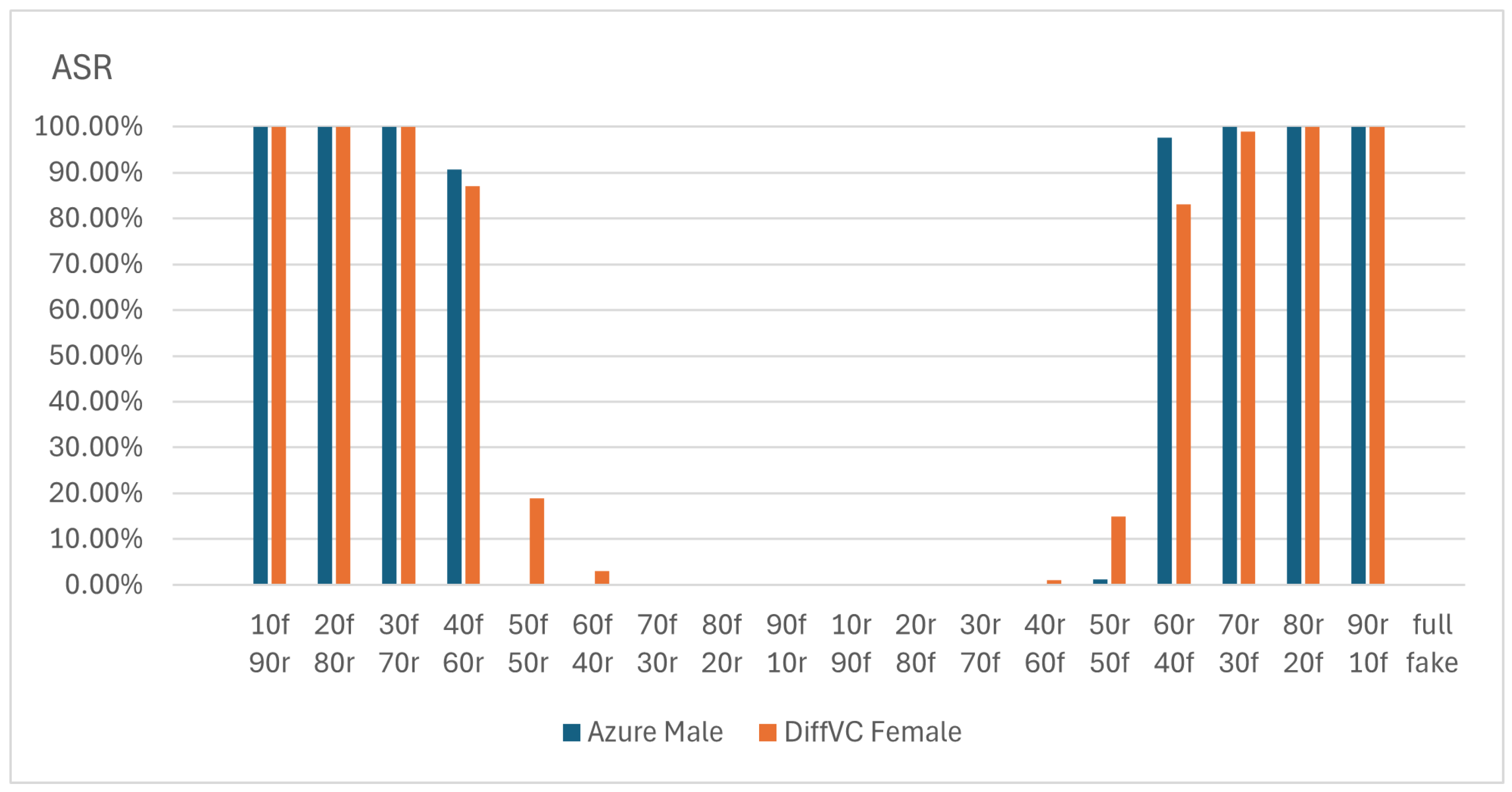
5.2.6. Impact of the Fake Segment Length
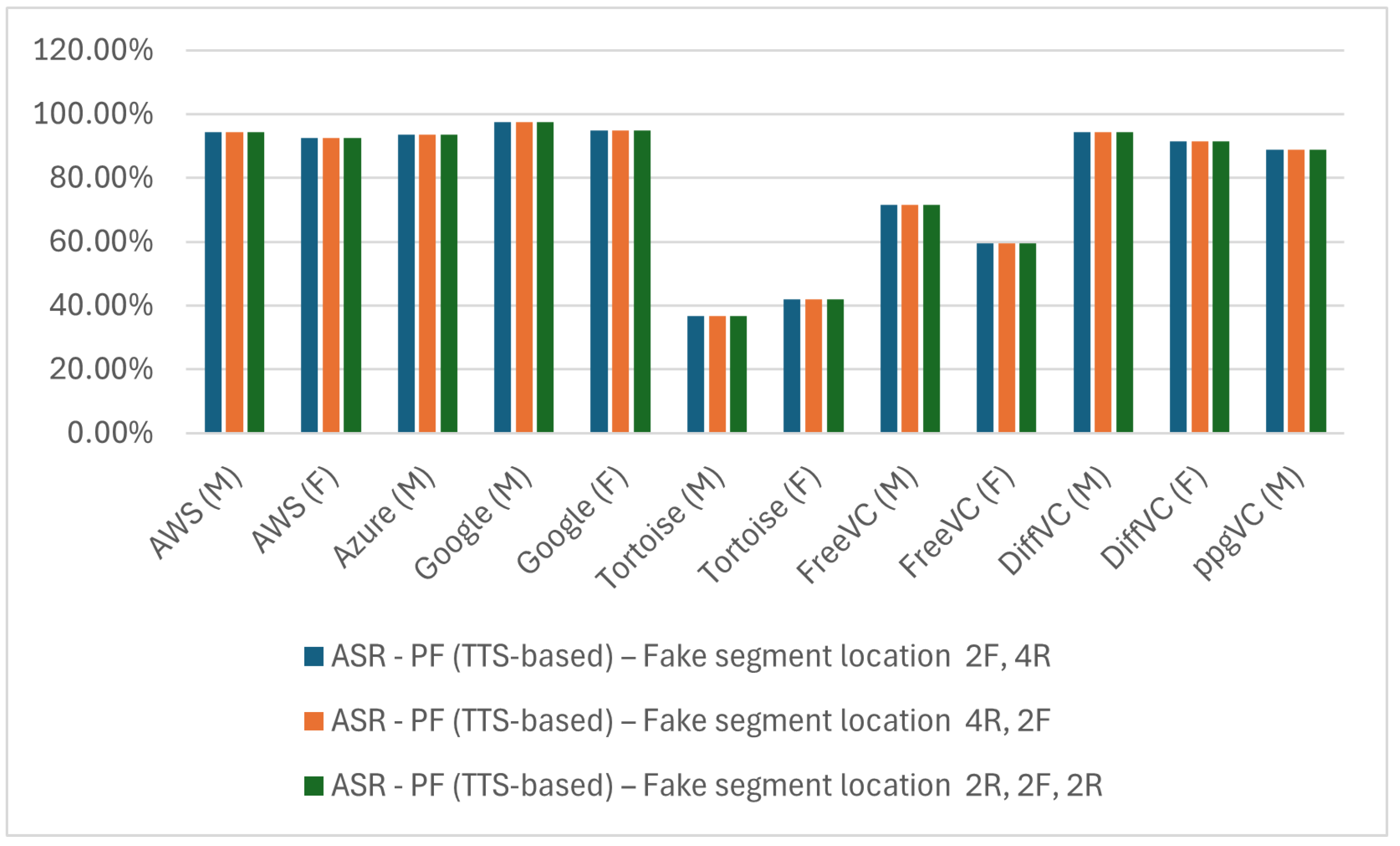
5.3. PF Attack Against AWS (Voice ID Service)
5.3.1. Impact of Fake Segment Location
5.3.2. Impact of Synthetic Speech Generation Methods
5.3.3. Impact of Gender
5.3.4. Impact of Target Dialect
5.3.5. Impact of the Fake Segment Length
6. Amazon Alexa (Mobile App)
- Alexa, can you recognise my voice?
- Alexa, who am I?
7. Partial Fake Speech and Human Speech
7.1. Methodology and Key Findings
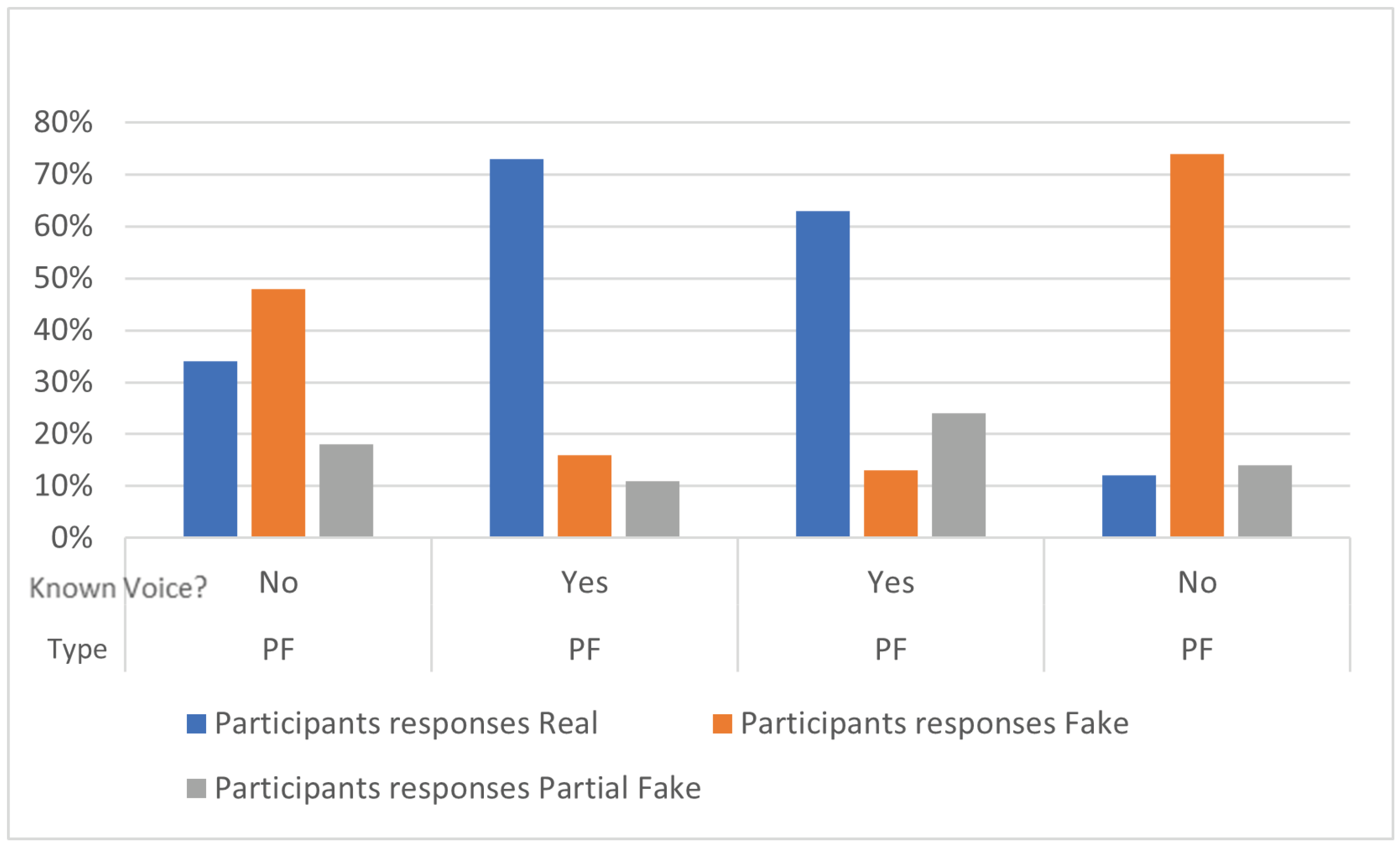
7.2. User Study A: Can Users Identify Partial Fake Speech (as Audio-Only)?
7.3. User Study B: Can Users Identify Partial Fake Speech (Within Entirely Real Video)
8. Assessing State-of-the-Art Defensive Measures
8.1. PartialSpoof: Detection of Short Fake Speech Segments
8.2. SSL_Anti-Spoofing
8.3. Betray Oneself: A Novel Audio DeepFake Detection Model (M2S-ADD)
9. Discussion
10. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Boone, D.R. Is Your Voice Telling on You?: How to Find and Use Your Natural Voice; Plural Publishing: San Diego, CA, USA, 2015. [Google Scholar]
- Kumar, P.; Jakhanwal, N.; Bhowmick, A.; Chandra, M. Gender classification using pitch and formants. In Proceedings of the 2011 International Conference on Communication, Computing & Security, Rourkela Odisha, India, 12–14 February 2011; pp. 319–324. [Google Scholar]
- Casanova, E.; Weber, J.; Shulby, C.D.; Junior, A.C.; Gölge, E.; Ponti, M.A. Yourtts: Towards zero-shot multi-speaker tts and zero-shot voice conversion for everyone. In Proceedings of the 39th International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; PMLR: Cambridge, MA, USA, 2022; pp. 2709–2720. [Google Scholar]
- Wang, C.; Chen, S.; Wu, Y.; Zhang, Z.; Zhou, L.; Liu, S.; Chen, Z.; Liu, Y.; Wang, H.; Li, J.; et al. Neural codec language models are zero-shot text to speech synthesizers. arXiv 2023, arXiv:2301.02111. [Google Scholar]
- Ngoc, P.P.; Quang, C.T.; Chi, M.L. Adapt-Tts: High-Quality Zero-Shot Multi-Speaker Text-to-Speech Adaptive-Based for Vietnamese. J. Comput. Sci. Cybern. 2023, 39, 159–173. [Google Scholar] [CrossRef] [PubMed]
- Saeki, T.; Maiti, S.; Li, X.; Watanabe, S.; Takamichi, S.; Saruwatari, H. Learning to speak from text: Zero-shot multilingual text-to-speech with unsupervised text pretraining. arXiv 2023, arXiv:2301.12596. [Google Scholar]
- Peng, K.; Ping, W.; Song, Z.; Zhao, K. Non-autoregressive neural text-to-speech. In Proceedings of the 37th International Conference on Machine Learning, Virtual, 13–18 July 2020; PMLR: Cambridge, MA, USA, 2020; pp. 7586–7598. [Google Scholar]
- Kawamura, M.; Shirahata, Y.; Yamamoto, R.; Tachibana, K. Lightweight and high-fidelity end-to-end text-to-speech with multi-band generation and inverse short-time fourier transform. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Betker, J. Better speech synthesis through scaling. arXiv 2023, arXiv:2305.07243. [Google Scholar]
- Jiang, Z.; Liu, J.; Ren, Y.; He, J.; Zhang, C.; Ye, Z.; Wei, P.; Wang, C.; Yin, X.; Ma, Z. Mega-tts 2: Zero-shot text-to-speech with arbitrary length speech prompts. arXiv 2023, arXiv:2307.07218. [Google Scholar]
- Jing, X.; Chang, Y.; Yang, Z.; Xie, J.; Triantafyllopoulos, A.; Schuller, B.W. U-DiT TTS: U-Diffusion Vision Transformer for Text-to-Speech. In Proceedings of the 15th ITG Conference on Speech Communication, Aachen, Germany, 20–22 September 2023; VDE: Offenbach, Germany, 2023; pp. 56–60. [Google Scholar]
- Ning, Z.; Xie, Q.; Zhu, P.; Wang, Z.; Xue, L.; Yao, J.; Xie, L.; Bi, M. Expressive-vc: Highly expressive voice conversion with attention fusion of bottleneck and perturbation features. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Meftah, A.H.; Alashban, A.A.; Alotaibi, Y.A.; Selouani, S.A. English emotional voice conversion using StarGAN model. IEEE Access 2023, 11, 67835–67849. [Google Scholar] [CrossRef]
- Fernandez-Martín, C.; Colomer, A.; Panariello, C.; Naranjo, V. Choosing only the best voice imitators: Top-K many-to-many voice conversion with StarGAN. Speech Commun. 2024, 156, 103022. [Google Scholar] [CrossRef]
- ElevenLabs. 2024. Available online: https://elevenlabs.io/ (accessed on 23 July 2024).
- Descript. 2024. Available online: https://www.descript.com/ (accessed on 23 July 2024).
- HSBC Voice ID. 2024. Available online: https://ciiom.hsbc.com/ways-to-bank/phone-banking/voice-id/ (accessed on 26 July 2024).
- WeChat VoicePrint. 2024. Available online: https://blog.wechat.com/2015/05/21/voiceprint-the-new-wechat-password/ (accessed on 26 July 2024).
- Alipay Sound Wave Payment. 2024. Available online: https://opendocs.alipay.com/open/140/104601 (accessed on 4 August 2024).
- What Is Alexa Voice ID. 2024. Available online: https://www.amazon.co.uk/gp/help/customer/display.html?nodeId=GYCXKY2AB2QWZT2X (accessed on 7 August 2024).
- Klepper, D.; Swenson, A. AI-Generated Disinformation Poses Threat of Misleading Voters in 2024 Election. PBS NewsHour. 2023. Available online: https://www.pbs.org/newshour/politics/ai-generated-disinformation-poses-threat-of-misleading-voters-in-2024-election/ (accessed on 16 August 2024).
- Rudy, E. Don’t Watch Sinister Taylor Swift Video or Risk Bank-Emptying Attack That Just Takes Seconds. The Sun. 2024. Available online: https://www.thesun.co.uk/tech/25342162/taylor-swift-fans-ai-attack-dangerous-video/ (accessed on 27 August 2024).
- Stupp, C. Fraudsters Used AI to Mimic CEO’s Voice in Unusual Cybercrime Case. WSJ. 2019. Available online: https://www.wsj.com/articles/fraudsters-use-ai-to-mimic-ceos-voice-in-unusual-cybercrime-case-11567157402/ (accessed on 27 August 2024).
- Brewster, T. Fraudsters Cloned Company Director’s Voice in $35 Million Heist, Police Find. Forbes. 2023. Available online: https://www.forbes.com/sites/thomasbrewster/2021/10/14/huge-bank-fraud-uses-deep-fake-voice-tech-to-steal-millions/ (accessed on 2 September 2024).
- Karimi, F. Mom, These Bad Men Have Me’: She Believes Scammers Cloned Her Daughter’s Voice in a Fake Kidnapping. CNN. 2023. Available online: https://edition.cnn.com/2023/04/29/us/ai-scam-calls-kidnapping-cec/index.html/ (accessed on 20 July 2024).
- Wenger, E.; Bronckers, M.; Cianfarani, C.; Cryan, J.; Sha, A.; Zheng, H.; Zhao, B.Y. “Hello, It’s Me”: Deep Learning-based Speech Synthesis Attacks in the Real World. In Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, Virtual Event, 15–19 November 2021; pp. 235–251. [Google Scholar]
- Bilika, D.; Michopoulou, N.; Alepis, E.; Patsakis, C. Hello me, meet the real me: Voice synthesis attacks on voice assistants. Comput. Secur. 2024, 137, 103617. [Google Scholar] [CrossRef]
- Gao, Y.; Lian, J.; Raj, B.; Singh, R. Detection and evaluation of human and machine generated speech in spoofing attacks on automatic speaker verification systems. In Proceedings of the 2021 IEEE Spoken Language Technology Workshop (SLT), Shenzhen, China, 19–22 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 544–551. [Google Scholar]
- Simmons, D. BBC Fools HSBC Voice Recognition Security System. 2017. Available online: https://www.bbc.co.uk/news/technology-39965545/ (accessed on 8 September 2024).
- Mehrish, A.; Majumder, N.; Bharadwaj, R.; Mihalcea, R.; Poria, S. A review of deep learning techniques for speech processing. Inf. Fusion 2023, 99, 101869. [Google Scholar] [CrossRef]
- Tan, C.B.; Hijazi, M.H.A.; Khamis, N.; Nohuddin, P.N.E.B.; Zainol, Z.; Coenen, F.; Gani, A. A survey on presentation attack detection for automatic speaker verification systems: State-of-the-art, taxonomy, issues and future direction. Multimed. Tools Appl. 2021, 80, 32725–32762. [Google Scholar] [CrossRef]
- Tayebi Arasteh, S.; Weise, T.; Schuster, M.; Noeth, E.; Maier, A.; Yang, S.H. The effect of speech pathology on automatic speaker verification: A large-scale study. Sci. Rep. 2023, 13, 20476. [Google Scholar] [CrossRef]
- Mandasari, M.I.; McLaren, M.; van Leeuwen, D.A. The effect of noise on modern automatic speaker recognition systems. In Proceedings of the 2012 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Kyoto, Japan, 25–30 March 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 4249–4252. [Google Scholar]
- Radha, K.; Bansal, M.; Pachori, R.B. Speech and speaker recognition using raw waveform modeling for adult and children’s speech: A comprehensive review. Eng. Appl. Artif. Intell. 2024, 131, 107661. [Google Scholar] [CrossRef]
- Zhang, W.; Yeh, C.C.; Beckman, W.; Raitio, T.; Rasipuram, R.; Golipour, L.; Winarsky, D. Audiobook synthesis with long-form neural text-to-speech. In Proceedings of the 12th Speech Synthesis Workshop (SSW) 2023, Grenoble, France, 26–28 August 2023. [Google Scholar]
- Kim, M.; Jeong, M.; Choi, B.J.; Kim, S.; Lee, J.Y.; Kim, N.S. Utilizing Neural Transducers for Two-Stage Text-to-Speech via Semantic Token Prediction. arXiv 2024, arXiv:2401.01498. [Google Scholar]
- Vecino, B.T.; Gabrys, A.; Matwicki, D.; Pomirski, A.; Iddon, T.; Cotescu, M.; Lorenzo-Trueba, J. Lightweight End-to-end Text-to-speech Synthesis for low resource on-device applications. In Proceedings of the 12th ISCA Speech Synthesis Workshop (SSW2023), Grenoble, France, 26–28 August 2023; pp. 225–229. [Google Scholar] [CrossRef]
- Donahue, J.; Dieleman, S.; Bińkowski, M.; Elsen, E.; Simonyan, K. End-to-end adversarial text-to-speech. arXiv 2020, arXiv:2006.03575. [Google Scholar]
- Tiomkin, S.; Malah, D.; Shechtman, S.; Kons, Z. A Hybrid Text-to-Speech System That Combines Concatenative and Statistical Synthesis Units. IEEE Trans. Audio Speech Lang. Process. 2011, 19, 1278–1288. [Google Scholar] [CrossRef]
- Zhang, M.; Zhou, Y.; Zhao, L.; Li, H. Transfer learning from speech synthesis to voice conversion with non-parallel training data. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1290–1302. [Google Scholar] [CrossRef]
- Yoon, H.; Kim, C.; Um, S.; Yoon, H.W.; Kang, H.G. SC-CNN: Effective speaker conditioning method for zero-shot multi-speaker text-to-speech systems. IEEE Signal Process. Lett. 2023, 30, 593–597. [Google Scholar] [CrossRef]
- Lian, J.; Zhang, C.; Yu, D. Robust disentangled variational speech representation learning for zero-shot voice conversion. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 6572–6576. [Google Scholar]
- Wang, Z.; Chen, Y.; Xie, L.; Tian, Q.; Wang, Y. Lm-vc: Zero-shot voice conversion via speech generation based on language models. IEEE Signal Process. Lett. 2023, 30, 1157–1161. [Google Scholar] [CrossRef]
- Wu, Y.; Tan, X.; Li, B.; He, L.; Zhao, S.; Song, R.; Qin, T.; Liu, T.Y. Adaspeech 4: Adaptive text to speech in zero-shot scenarios. arXiv 2022, arXiv:2204.00436. [Google Scholar]
- Google Cloud Text-to-Speech API Now Supports Custom Voices. 2017. Available online: https://cloud.google.com/blog/products/ai-machine-learning/create-custom-voices-with-google-cloud-text-to-speech/ (accessed on 19 August 2024).
- Real-Time State-of-the-art Speech Synthesis for Tensorflow 2. 2021. Available online: https://github.com/TensorSpeech/TensorFlowTTS/ (accessed on 19 August 2024).
- An Open Source Text-to-Speech System Built by Inverting Whisper. 2024. Available online: https://github.com/collabora/WhisperSpeech/ (accessed on 10 September 2024).
- Van Niekerk, B.; Carbonneau, M.A.; Zaïdi, J.; Baas, M.; Seuté, H.; Kamper, H. A comparison of discrete and soft speech units for improved voice conversion. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 6562–6566. [Google Scholar]
- Li, J.; Tu, W.; Xiao, L. Freevc: Towards high-quality text-free one-shot voice conversion. In Proceedings of the ICASSP 2023—2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Liu, S.; Cao, Y.; Wang, D.; Wu, X.; Liu, X.; Meng, H. Any-to-many voice conversion with location-relative sequence-to-sequence modeling. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1717–1728. [Google Scholar] [CrossRef]
- Yi, J.; Tao, J.; Fu, R.; Yan, X.; Wang, C.; Wang, T.; Zhang, C.Y.; Zhang, X.; Zhao, Y.; Ren, Y.; et al. Add 2023: The second audio deepfake detection challenge. arXiv 2023, arXiv:2305.13774. [Google Scholar]
- Yi, J.; Fu, R.; Tao, J.; Nie, S.; Ma, H.; Wang, C.; Wang, T.; Tian, Z.; Bai, Y.; Fan, C.; et al. Add 2022: The first audio deep synthesis detection challenge. In Proceedings of the ICASSP 2022–2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 9216–9220. [Google Scholar]
- Martín-Doñas, J.M.; Álvarez, A. The vicomtech audio deepfake detection system based on wav2vec2 for the 2022 add challenge. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 9241–9245. [Google Scholar]
- Li, J.; Li, L.; Luo, M.; Wang, X.; Qiao, S.; Zhou, Y. Multi-grained Backend Fusion for Manipulation Region Location of Partially Fake Audio. In Proceedings of the DADA@ IJCAI, Macau, China, 19 August 2023; pp. 43–48. [Google Scholar]
- Cai, Z.; Wang, W.; Wang, Y.; Li, M. The DKU-DUKEECE System for the Manipulation Region Location Task of ADD 2023. arXiv 2023, arXiv:2308.10281. [Google Scholar]
- Liu, J.; Su, Z.; Huang, H.; Wan, C.; Wang, Q.; Hong, J.; Tang, B.; Zhu, F. TranssionADD: A multi-frame reinforcement based sequence tagging model for audio deepfake detection. arXiv 2023, arXiv:2306.15212. [Google Scholar]
- Ryan, P. Deepfake’ Audio Evidence Used in UK Court to Discredit Dubai Dad. The National. 2020. Available online: https://www.thenationalnews.com/uae/courts/deepfake-audio-evidence-used-in-uk-court-to-discredit-dubai-dad-1.975764/ (accessed on 14 August 2024).
- Zhang, Z.; Zhou, L.; Wang, C.; Chen, S.; Wu, Y.; Liu, S.; Chen, Z.; Liu, Y.; Wang, H.; Li, J.; et al. Speak foreign languages with your own voice: Cross-lingual neural codec language modeling. arXiv 2023, arXiv:2303.03926. [Google Scholar]
- Casanova, E.; Shulby, C.; Gölge, E.; Müller, N.M.; De Oliveira, F.S.; Junior, A.C.; Soares, A.d.S.; Aluisio, S.M.; Ponti, M.A. SC-GlowTTS: An efficient zero-shot multi-speaker text-to-speech model. arXiv 2021, arXiv:2104.05557. [Google Scholar]
- Li, Y.A.; Han, C.; Mesgarani, N. Styletts-vc: One-shot voice conversion by knowledge transfer from style-based tts models. In Proceedings of the 2022 IEEE Spoken Language Technology Workshop (SLT), Doha, Qatar, 9–12 January 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 920–927. [Google Scholar]
- Kang, W.; Hasegawa-Johnson, M.; Roy, D. End-to-End Zero-Shot Voice Conversion with Location-Variable Convolutions. arXiv 2022, arXiv:2205.09784. [Google Scholar]
- Popov, V.; Vovk, I.; Gogoryan, V.; Sadekova, T.; Kudinov, M.; Wei, J. Diffusion-based voice conversion with fast maximum likelihood sampling scheme. arXiv 2021, arXiv:2109.13821. [Google Scholar]
- Resemblyzer. 2023. Available online: https://github.com/resemble-ai/Resemblyzer/ (accessed on 14 July 2024).
- Jia, Y.; Zhang, Y.; Weiss, R.; Wang, Q.; Shen, J.; Ren, F.; Nguyen, P.; Pang, R.; Lopez Moreno, I.; Wu, Y.; et al. Transfer learning from speaker verification to multispeaker text-to-speech synthesis. Adv. Neural Inf. Process. Syst. 2018, 31. Available online: https://proceedings.neurips.cc/paper_files/paper/2018/file/6832a7b24bc06775d02b7406880b93fc-Paper.pdf (accessed on 14 July 2024).
- Amazon Connect Voice ID. 2023. Available online: https://aws.amazon.com/connect/voice-id/ (accessed on 18 July 2024).
- AlAli, A.; Theodorakopoulos, G. An RFP dataset for Real, Fake, and Partially fake audio detection. In Proceedings of the International Conference on Cyber Security, Privacy in Communication Networks, Cardiff, UK, 9–10 December 2023; pp. 1–15. [Google Scholar]
- Demirsahin, I.; Kjartansson, O.; Gutkin, A.; Rivera, C. Open-source Multi-speaker Corpora of the English Accents in the British Isles. In Proceedings of the 12th Language Resources and Evaluation Conference (LREC), Marseille, France, 1 May 2020; pp. 6532–6541. [Google Scholar]
- Yamagishi, J.; Veaux, C.; MacDonald, K. CSTR VCTK Corpus: English Multi-Speaker Corpus for CSTR Voice Cloning Toolkit (Version 0.92); The Centre for Speech Technology Research (CSTR), University of Edinburgh: Edinburgh, UK, 2019. [Google Scholar]
- Abu-El-Haija, S.; Kothari, N.; Lee, J.; Natsev, P.; Toderici, G.; Varadarajan, B.; Vijayanarasimhan, S. Youtube-8m: A large-scale video classification benchmark. arXiv 2016, arXiv:1609.08675. [Google Scholar]
- Köbis, N.C.; Doležalová, B.; Soraperra, I. Fooled twice: People cannot detect deepfakes but think they can. Iscience 2021, 24, 103364. [Google Scholar] [CrossRef]
- Kaate, I.; Salminen, J.; Jung, S.G.; Almerekhi, H.; Jansen, B.J. How do users perceive deepfake personas? Investigating the deepfake user perception and its implications for human-computer interaction. In Proceedings of the 15th Biannual Conference of the Italian SIGCHI Chapter, Torino, Italy, 20–22 September 2023; pp. 1–12. [Google Scholar]
- Ahmed, M.F.B.; Miah, M.S.U.; Bhowmik, A.; Sulaiman, J.B. Awareness to Deepfake: A resistance mechanism to Deepfake. In Proceedings of the 2021 International Congress of Advanced Technology and Engineering (ICOTEN), Taiz, Yemen, 4–5 July 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Zhang, L.; Wang, X.; Cooper, E.; Evans, N.; Yamagishi, J. The partialspoof database and countermeasures for the detection of short fake speech segments embedded in an utterance. IEEE/ACM Trans. Audio Speech Lang. Process. 2022, 31, 813–825. [Google Scholar] [CrossRef]
- Tak, H.; Todisco, M.; Wang, X.; Jung, J.W.; Yamagishi, J.; Evans, N. Automatic speaker verification spoofing and deepfake detection using wav2vec 2.0 and data augmentation. arXiv 2022, arXiv:2202.12233. [Google Scholar]
- Liu, R.; Zhang, J.; Gao, G.; Li, H. Betray Oneself: A Novel Audio DeepFake Detection Model via Mono-to-Stereo Conversion. arXiv 2023, arXiv:2305.16353. [Google Scholar]
- Yu, Z.; Zhai, S.; Zhang, N. Antifake: Using adversarial audio to prevent unauthorized speech synthesis. In Proceedings of the 2023 ACM SIGSAC Conference on Computer and Communications Security, Copenhagen, Denmark, 26–30 November 2023; pp. 460–474. [Google Scholar]
- Akhtar, Z.; Pendyala, T.L.; Athmakuri, V.S. Video and audio deepfake datasets and open issues in deepfake technology: Being ahead of the curve. Forensic Sci. 2024, 4, 289–377. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| PF (TTS-Based)—Fake Segment Location | |||
|---|---|---|---|
| 2F, 4R | 4R, 2F | 2R, 2F, 2R | |
| AWS (M) | 0% | 13.44% | 5.5% |
| AWS (F) | 0% | 8.64% | 0% |
| Azure (M) | 0% | 36.44% | 9.28% |
| Google (M) | 0% | 1.75% | 4.82% |
| Google (F) | 0% | 3.48% | 0% |
| Tortoise (M) | 74.95% | 93.26% | 86.61% |
| Tortoise (F) | 3.48% | 95.15% | 74.95% |
| PF (VC-Based)—Fake Segment Location | |||
|---|---|---|---|
| 2F, 4R | 4R, 2F | 2R, 2F, 2R | |
| FreeVC (M) | 6.39% | 79.68% | 60.73% |
| FreeVC (F) | 1.62% | 82.44% | 49.83% |
| DiffVC (M) | 0% | 28% | 9% |
| DiffVC (F) | 0% | 35.45% | 5.45% |
| ppgVC (M) | 0% | 47.12% | 9.95% |
| Speaker/Dialect | Gender | ASR—(TTS: Tortoise) | ||
|---|---|---|---|---|
| 2F, 4R | 4R, 2F | 2R, 2F, 2R | ||
| Welsh speakers | Male | 67.67% | 97.69% | 92.38% |
| Welsh speakers | Female | 98.41% | 88.94% | 54.03% |
| Scottish speakers | Male | 63.34% | 92.36% | 87.48% |
| Scottish speakers | Female | 49.93% | 91.27% | 78.52% |
| Northern speaker | Male | 95.26% | 98.04% | 69.62% |
| Northern speaker | Female | 54.17% | 93.62% | 75.79% |
| Midlands speakers | Male | 99.54% | 90.02% | 100% |
| Midlands speakers | Female | 56.69% | 95.48% | 71.77% |
| Speaker/Dialect | Gender | ASR—(VC: FreeVC) | ||
|---|---|---|---|---|
| 2F, 4R | 4R, 2F | 2R, 2F, 2R | ||
| Welsh speakers | Male | 8.43% | 93.80% | 69.44% |
| Welsh speakers | Female | 27.93% | 88.94% | 52.21% |
| Scottish speakers | Male | 1.67% | 90.63% | 64.29% |
| Scottish speakers | Female | 9.75% | 84.16% | 48.54% |
| Northern speaker | Male | 19.93% | 86.69% | 42.51% |
| Northern speaker | Female | 1.71% | 89.97% | 55.77% |
| Midlands speakers | Male | 47.22% | 99.18% | 70.12% |
| Midlands speakers | Female | 1.81% | 64.30% | 35.65% |
| Generation Method | ASR-PF (TTS-Based)—Fake Segment Location | ||
|---|---|---|---|
| 2F, 4R | 4R, 2F | 2R, 2F, 2R | |
| AWS (M) | 94.44% | 94.44% | 94.44% |
| AWS (F) | 92.56% | 92.56% | 92.56% |
| Azure (M) | 93.61% | 93.61% | 93.61% |
| Google (M) | 97.6% | 97.6% | 97.6% |
| Google (F) | 94.76% | 94.76% | 94.76% |
| Tortoise (M) | 36.62% | 36.62% | 36.62% |
| Tortoise (F) | 42.03% | 42.03% | 42.03% |
| Generation Method | ASR-PF (VC-Based)—Fake Segment Location | ||
|---|---|---|---|
| 2F, 4R | 4R, 2F | 2R, 2F, 2R | |
| FreeVC (M) | 71.65% | 71.65% | 71.65% |
| FreeVC (F) | 59.60% | 59.60% | 59.60% |
| DiffVC (M) | 94.44% | 94.44% | 94.44% |
| DiffVC (F) | 91.50% | 91.50% | 91.50% |
| ppgVC (M) | 88.89% | 88.89% | 88.89% |
| Speaker/Dialect | Gender | TTS: Tortoise | ||
|---|---|---|---|---|
| 2F, 4R | 4R, 2F | 2R, 2F, 2R | ||
| Welsh speakers | Male | 42.69% | 42.69% | 42.69% |
| Welsh speakers | Female | 36.41% | 36.41% | 36.41% |
| Scottish speakers | Male | 61.58% | 61.58% | 61.58% |
| Scottish speakers | Female | 43.17% | 43.17% | 43.17% |
| Northern speaker | Male | 44.62% | 44.62% | 44.62% |
| Northern speaker | Female | 46.46% | 46.46% | 46.46% |
| Midlands speakers | Male | 54.62% | 54.62% | 54.62% |
| Midlands speakers | Female | 37.61% | 37.61% | 37.61% |
| Speaker/Dialect | Gender | VC: FreeVC | ||
|---|---|---|---|---|
| 2F, 4R | 4R, 2F | 2R, 2F, 2R | ||
| Welsh speakers | Male | 58.17% | 58.17% | 58.17% |
| Welsh speakers | Female | 42.69% | 42.69% | 42.69% |
| Scottish speakers | Male | 64.32% | 64.32% | 64.32% |
| Scottish speakers | Female | 45.97% | 45.97% | 45.97% |
| Northern speaker | Female | 57.59% | 57.59% | 57.59% |
| Northern speaker | Male | 44.62% | 44.62% | 44.62% |
| Midland speakers | Female | 54.23% | 54.23% | 54.23% |
| Midland speakers | Male | 55.43% | 55.43% | 55.43% |
| Audio Type | Familiar Voice? | Accuracy of Participant Responses | ||
|---|---|---|---|---|
| Real | Fake | Partial Fake | ||
| PF | No | 34% | 48% | 18% |
| PF | No | 12% | 74% | 14% |
| PF | Yes | 73% | 16% | 11% |
| PF | Yes | 63% | 13% | 24% |
| Fake | No | 77% | 17% | 6% |
| Fake | yes | 11% | 85% | 4% |
| Fake | No | 36% | 42% | 22% |
| Fake | Yes | 19% | 54% | 27% |
| Real | Yes | 76% | 12% | 12% |
| Real | No | 53% | 23% | 24% |
| Embedded Audi | Face Distance of Camera | Participants Responses Accuracy | ||
|---|---|---|---|---|
| Real | Fake | Partial Fake | ||
| PF | far | 85% | 4% | 11% |
| PF | far | 63% | 14% | 23% |
| PF | front | 77% | 6% | 17% |
| PF | front | 52% | 17% | 31% |
| Real | front | 69% | 10% | 21% |
| Fake | Front/far | 60% | 13% | 27% |
| Detection Methods | SSL_Anti-Spoofing | M2S-ADD | PartialSpoof | |||
|---|---|---|---|---|---|---|
| Dataset | ASVspoof 2021 | RFP | ASVspoof 2019 | RFP | PS | RFP |
| EER | 0.82% | 50.16% | 1.34% | 18.69% | 0.49% | 3.70% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alali, A.; Theodorakopoulos, G. Partial Fake Speech Attacks in the Real World Using Deepfake Audio. J. Cybersecur. Priv. 2025, 5, 6. https://doi.org/10.3390/jcp5010006
Alali A, Theodorakopoulos G. Partial Fake Speech Attacks in the Real World Using Deepfake Audio. Journal of Cybersecurity and Privacy. 2025; 5(1):6. https://doi.org/10.3390/jcp5010006
Chicago/Turabian StyleAlali, Abdulazeez, and George Theodorakopoulos. 2025. "Partial Fake Speech Attacks in the Real World Using Deepfake Audio" Journal of Cybersecurity and Privacy 5, no. 1: 6. https://doi.org/10.3390/jcp5010006
APA StyleAlali, A., & Theodorakopoulos, G. (2025). Partial Fake Speech Attacks in the Real World Using Deepfake Audio. Journal of Cybersecurity and Privacy, 5(1), 6. https://doi.org/10.3390/jcp5010006