
An Investigation to Detect Banking Malware Network Communication Traffic Using Machine Learning Techniques


Abstract
1. Introduction
1.1. Need for Malware Detection
- Determine a methodology that can be used by deep learning and machine learning algorithms for detecting the Zeus malware.
- Determine which ML algorithm produces the best detection results.
- Determine whether the features that produce the best detection results on one dataset will work on other datasets from other sources.
- Determine a minimum set of features that could be used for detecting Zeus.
- Determine whether the features that produce the best detection results work across newer and older versions of Zeus.
- Determine whether the features that produce the best detection results when detecting Zeus also work on additional variants of the Zeus malware.
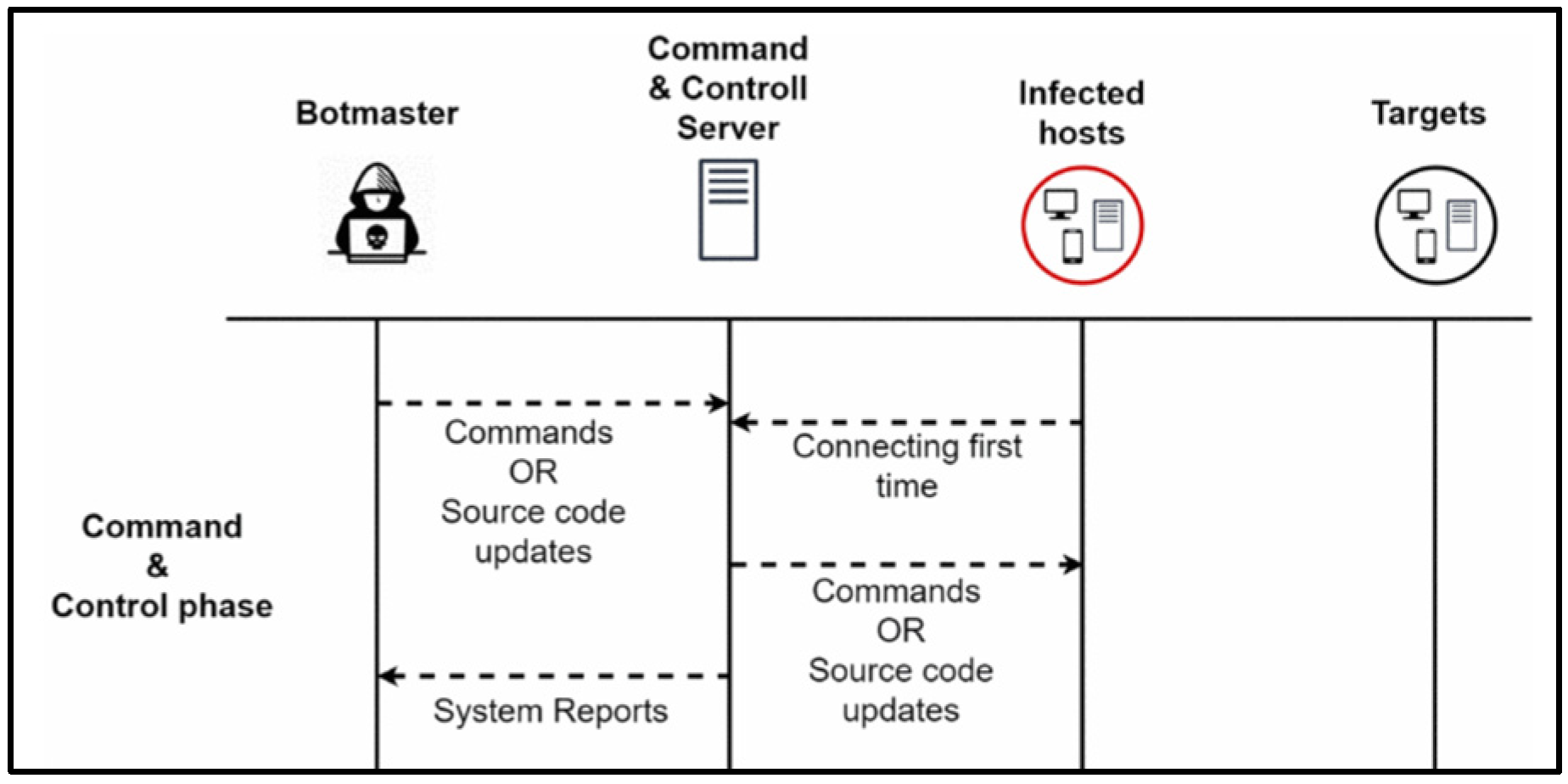
1.2. Zeus Malware Architecture
2. Related Studies
- Hosts that frequently scan external IP addresses.
- Outbound connection failures.
- An evenly distributed communication pattern which is likely to indicate that that communication is malicious.
3. Problem Statement
4. Research Methodology
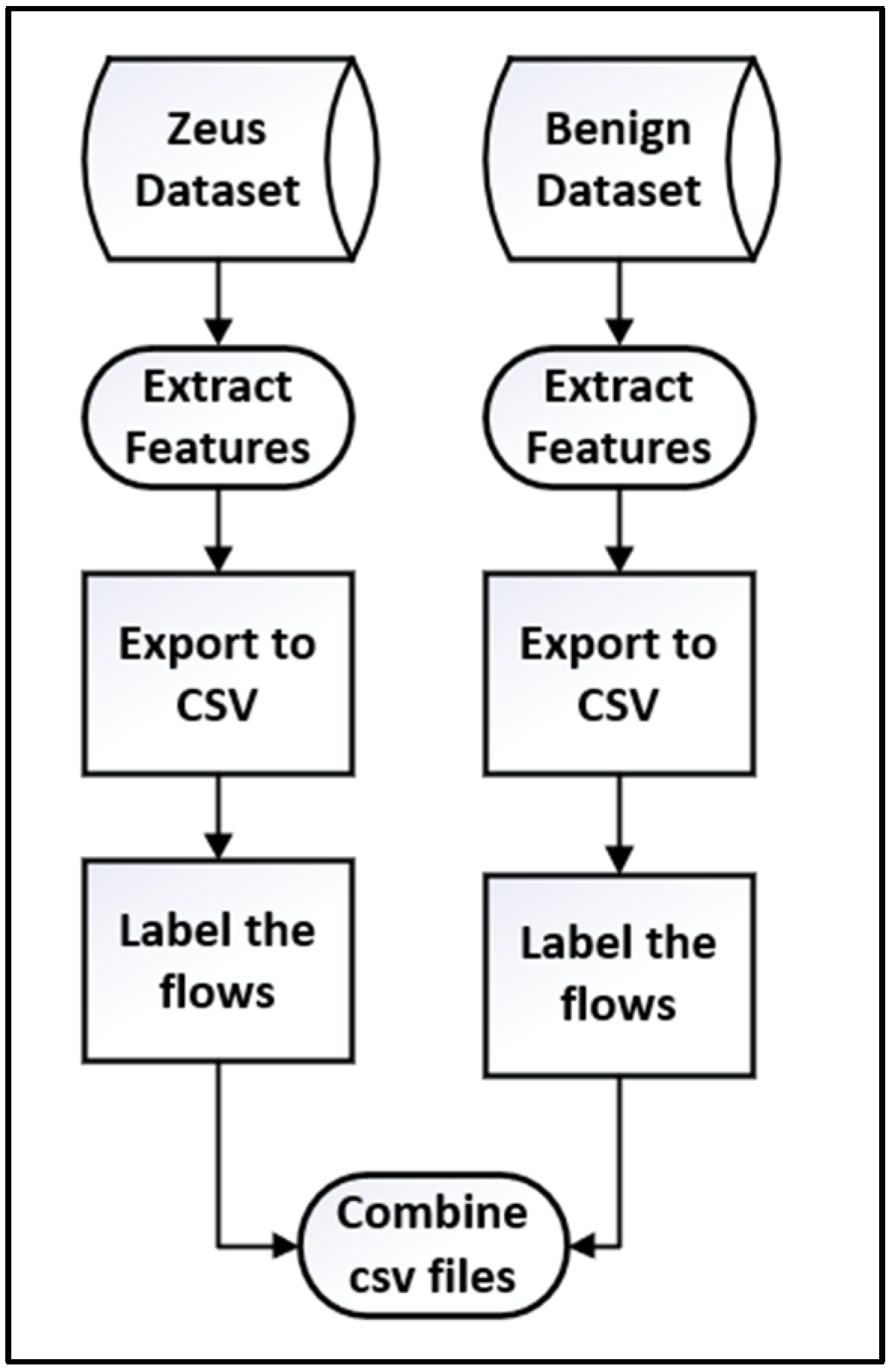
4.1. Data Collection and Preperation
4.2. Feature Selection
- Variance (overfitting) is reduced.
- Computational cost and the time for running the algorithm is reduced.
- Enables the ML algorithm to learn faster.
- Filter method—Feature selection is independent of the ML algorithm.
- Wrapper method—A subset of the features are selected and used to train the ML algorithm. Based on the results, features are either removed or added until the best features are determined.
4.3. Datasets (Samples)
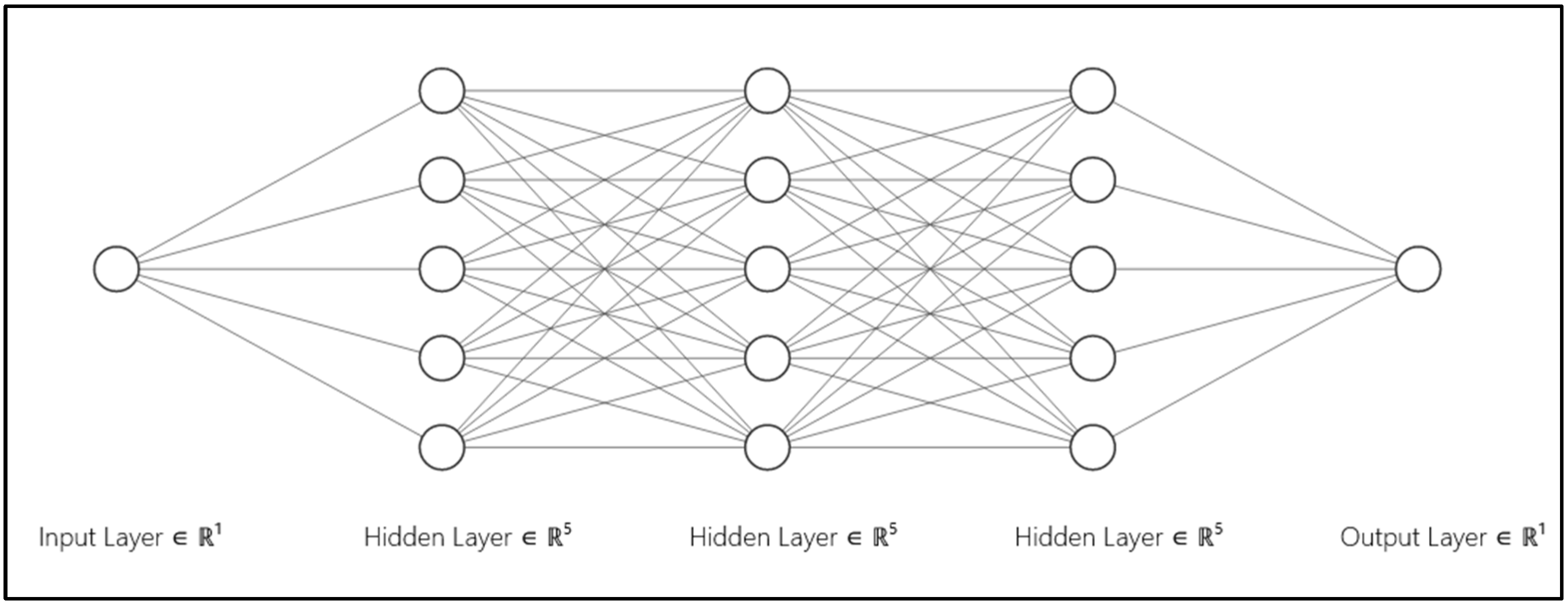
4.4. Machine Learning Algorithms
4.5. System Architecture and Methodology
- The datasets are identified and collected.
- Features are extracted from these datasets.
- The extracted features are transferred to a CSV file and prepared.
- The features are selected for training and testing.
- The algorithm is trained and tested, and a model is created. Only one dataset is used for the training.
- The model is tuned and trained and tested again if required.
- The model is used to test and evaluate the remaining datasets.
- Deploy the final model, test all the data samples and create a report highlighting the evaluation metrics.

4.6. Evaluation
5. Results
5.1. Training and Testing the Machine Learning Algorithms Using the Data Sets
5.2. Training and Testing the Deep Learning Algorithm Using the Data Sets
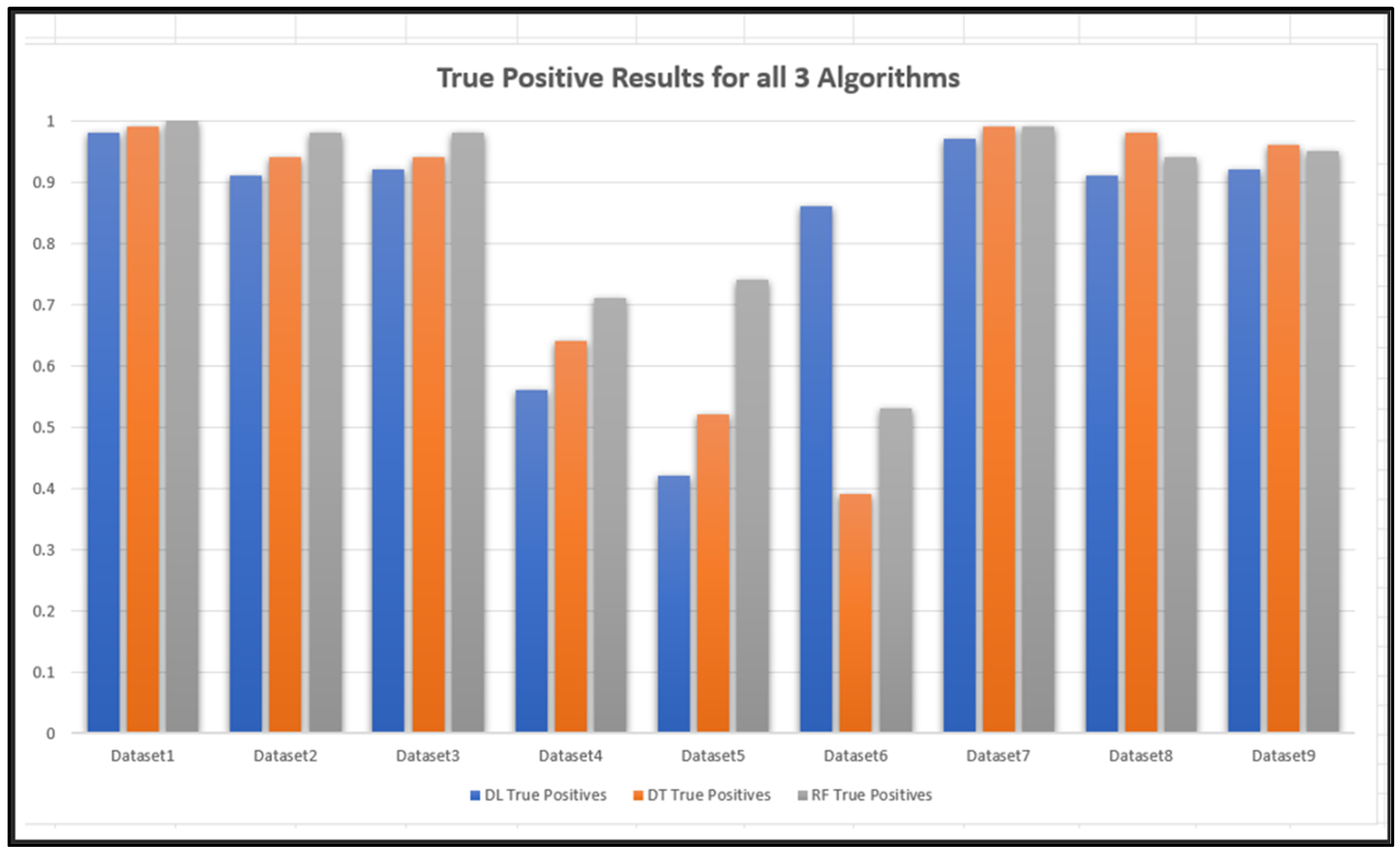
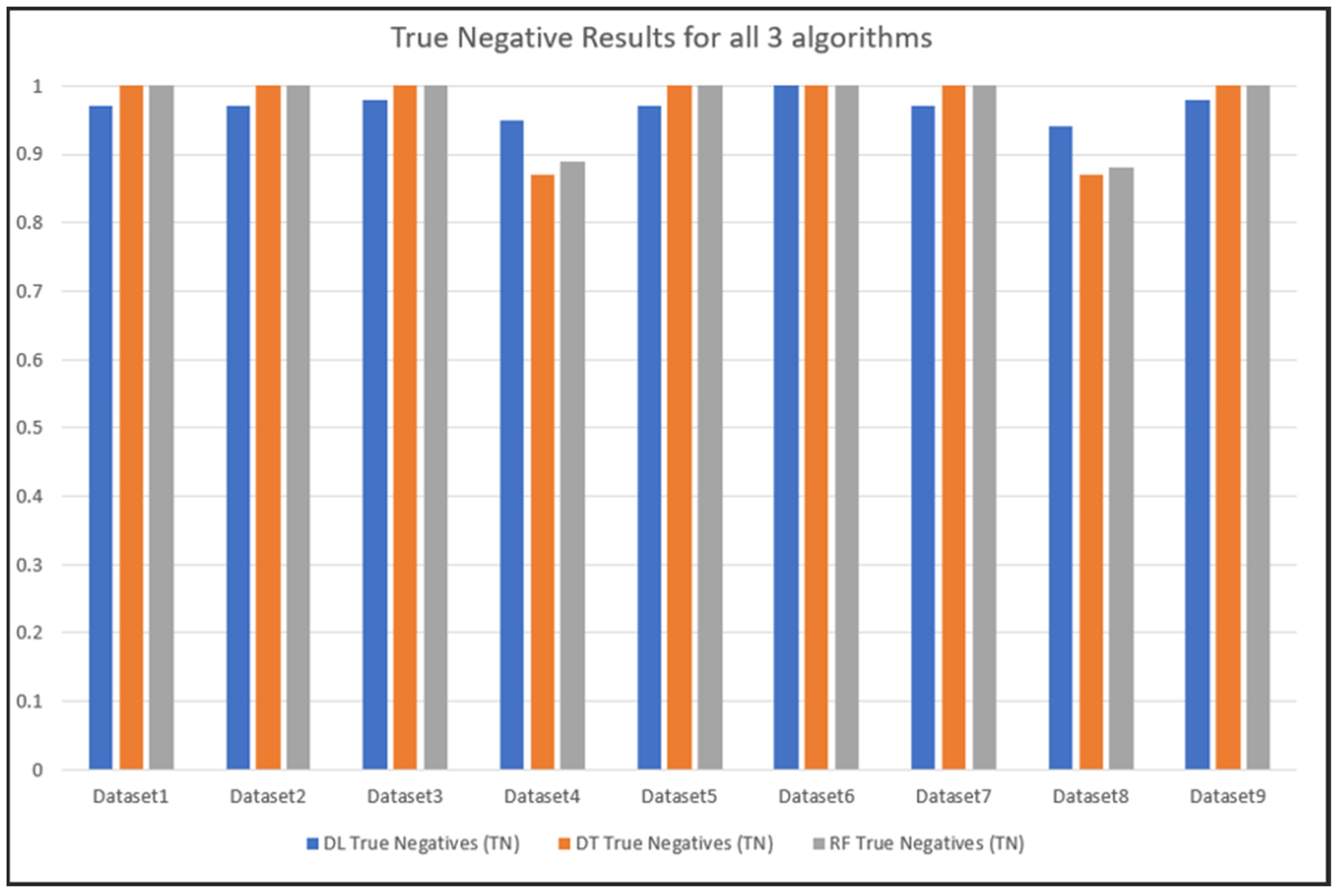
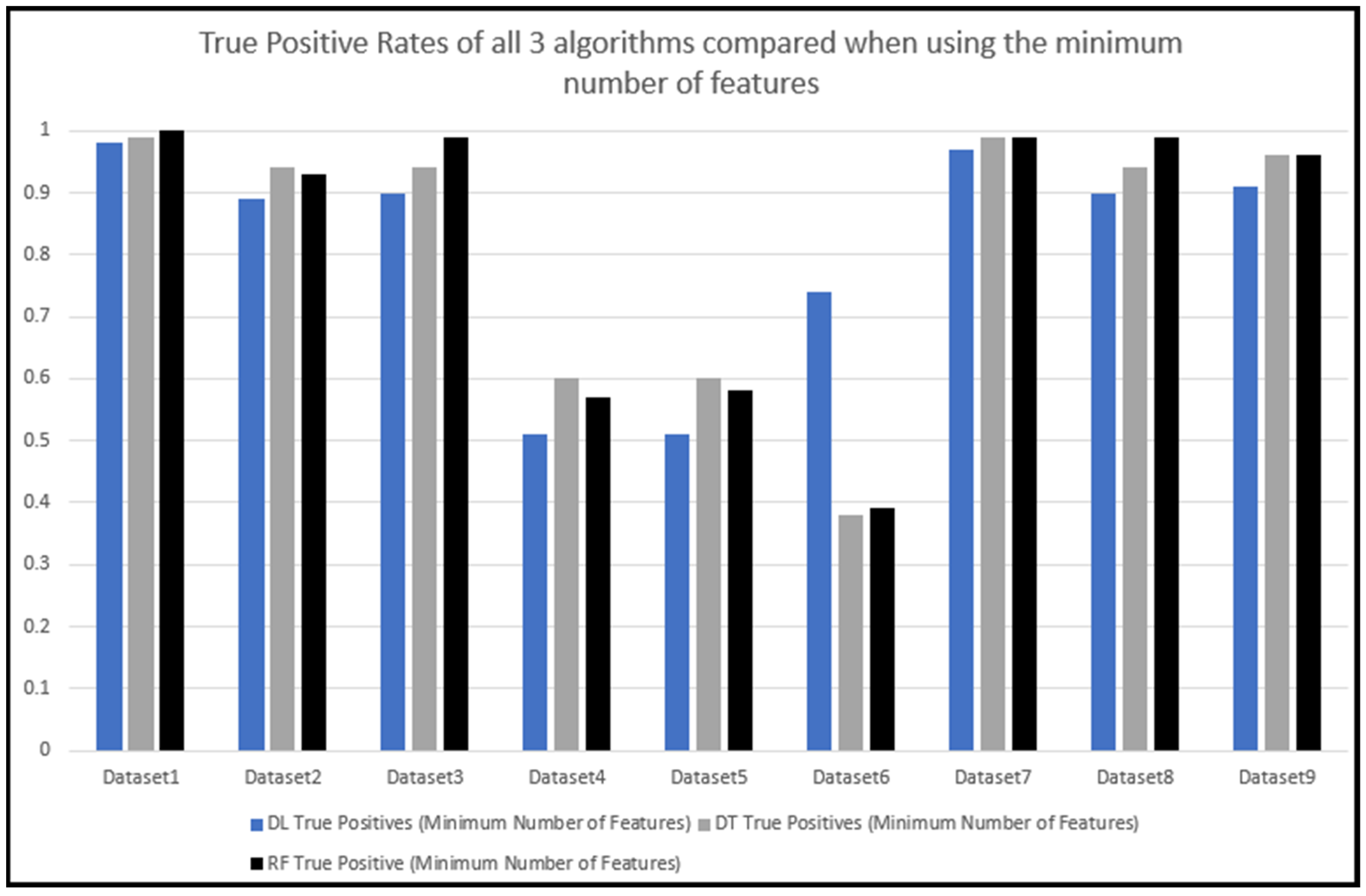
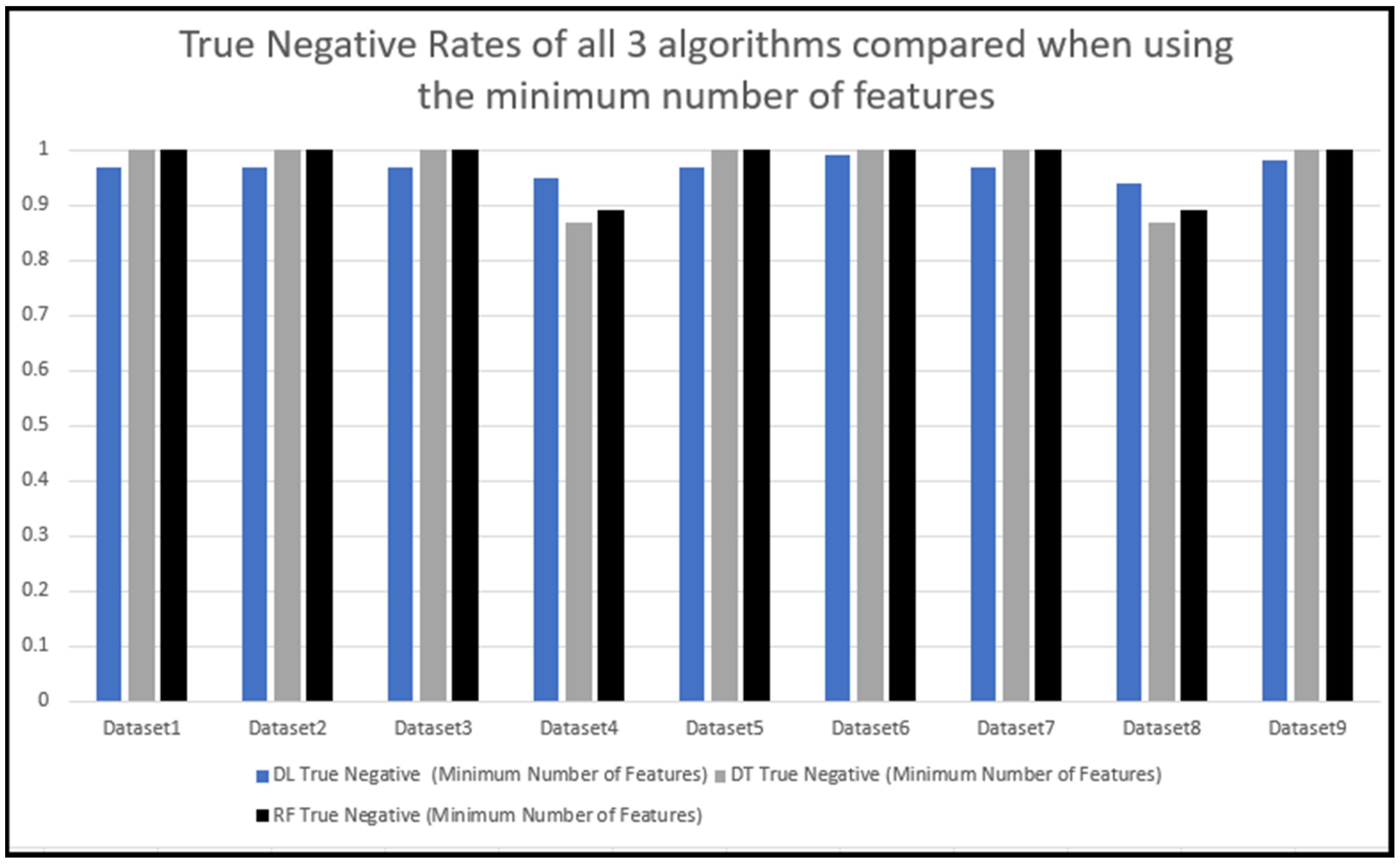
5.3. Comparing the Predication Results of the Three Algorithms Tested
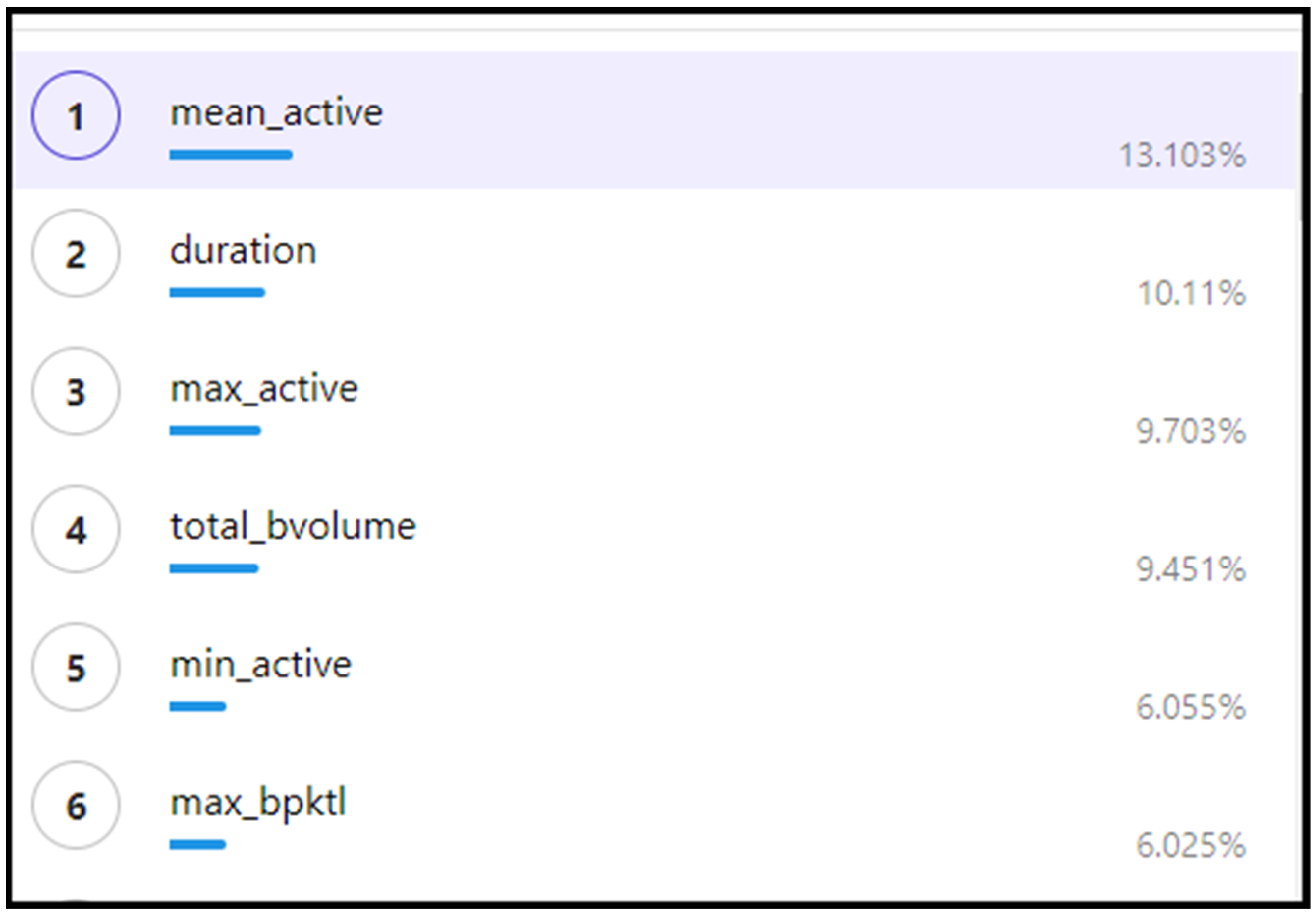
5.4. Reducing the Features to the Minimum Number of Possible Features
- Remove one feature which has the lowest impact score.
- Training a dataset with this one feature redacted.
- Test the remaining datasets.
- Calculate the prediction accuracy and record the results.
- Remove another feature and re-train the dataset.
- Test the remaining datasets.
- Calculate the prediction accuracy and record these results.
- Repeat this process until the accuracy of two of the datasets fall below 50% during testing, as this would mean that more than half of the Zeus samples were misclassified for two or more of the datasets.


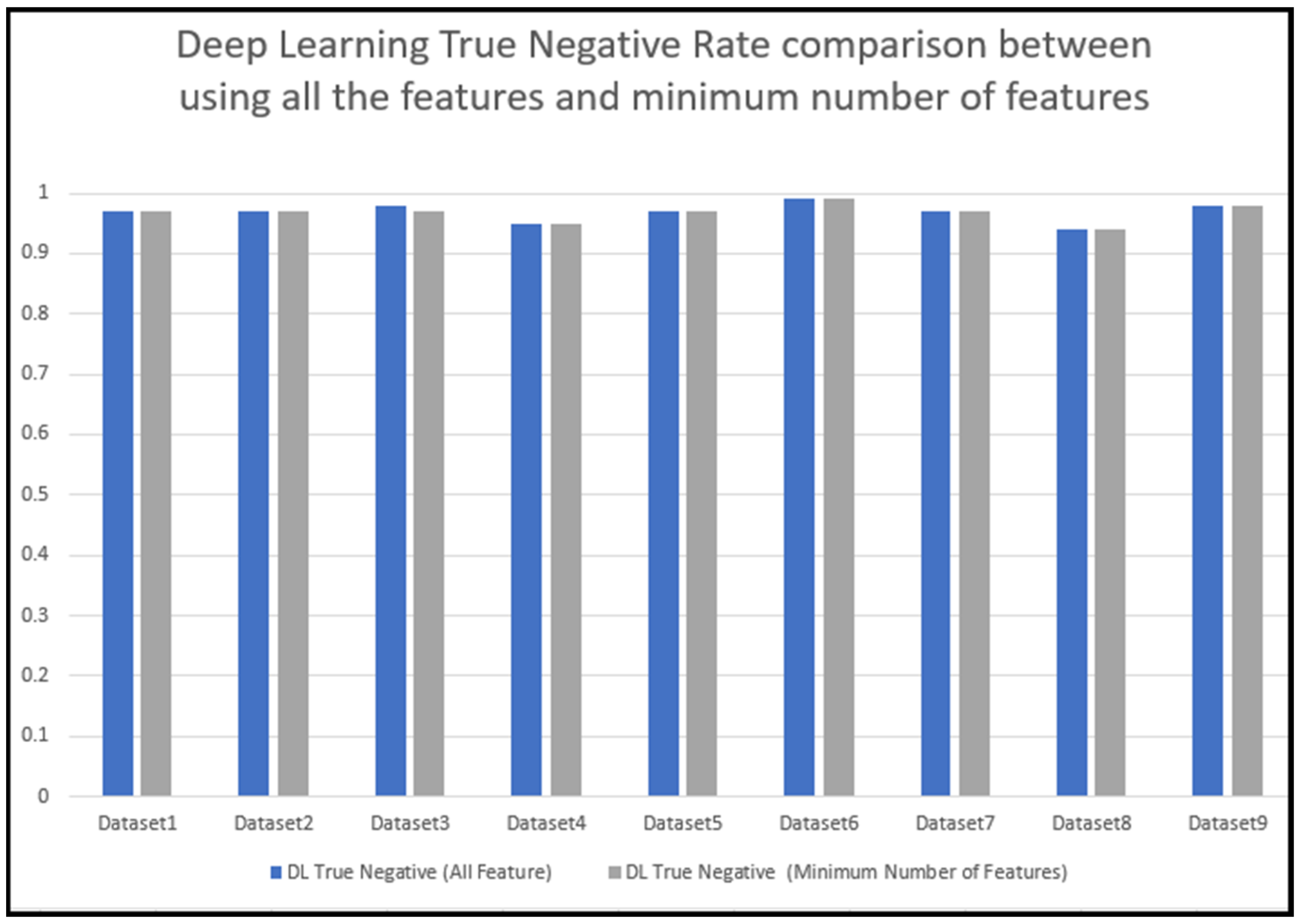
5.5. Training and Testing with the Minimum Number of Features with the DL Algorithm
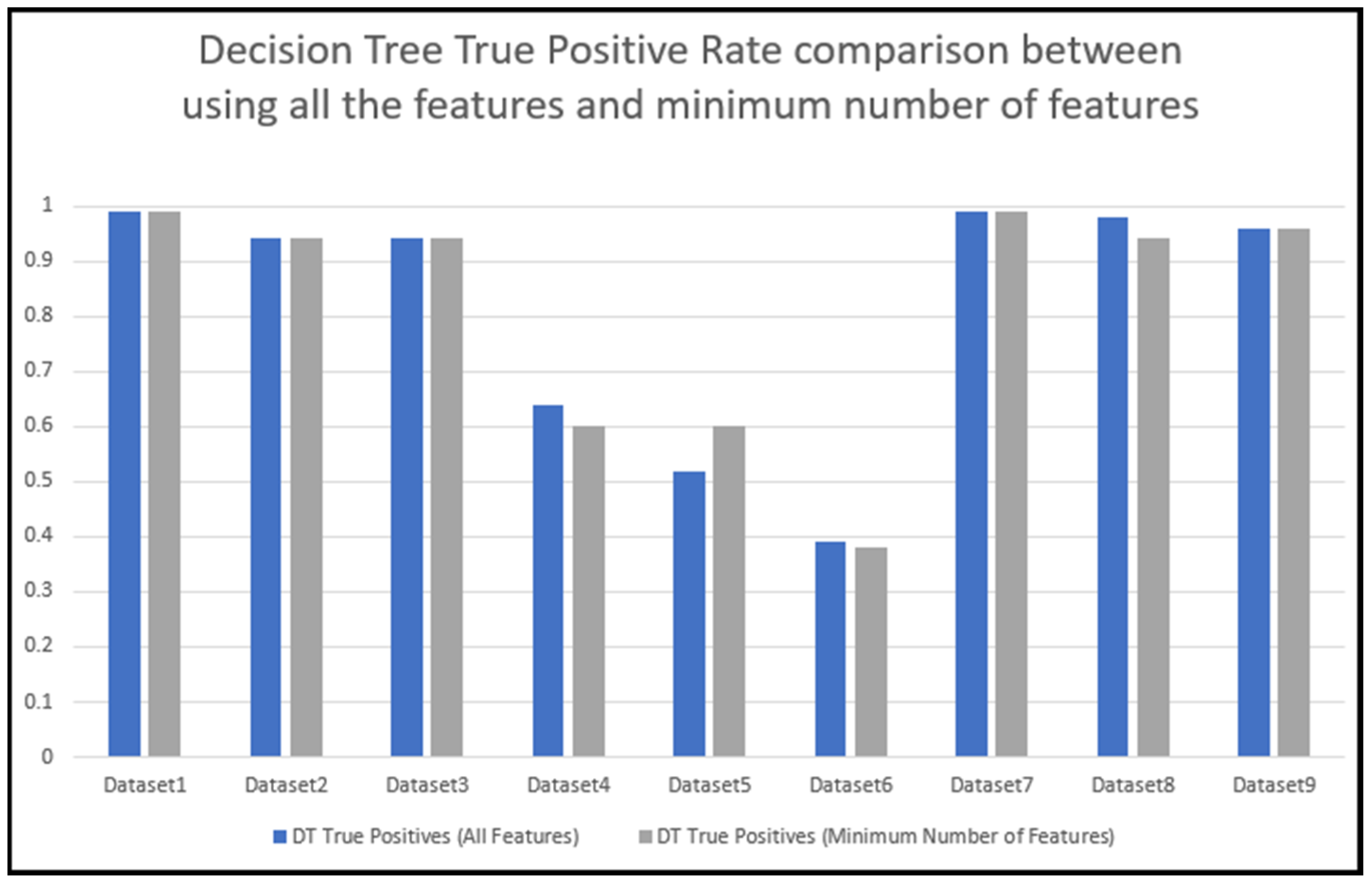
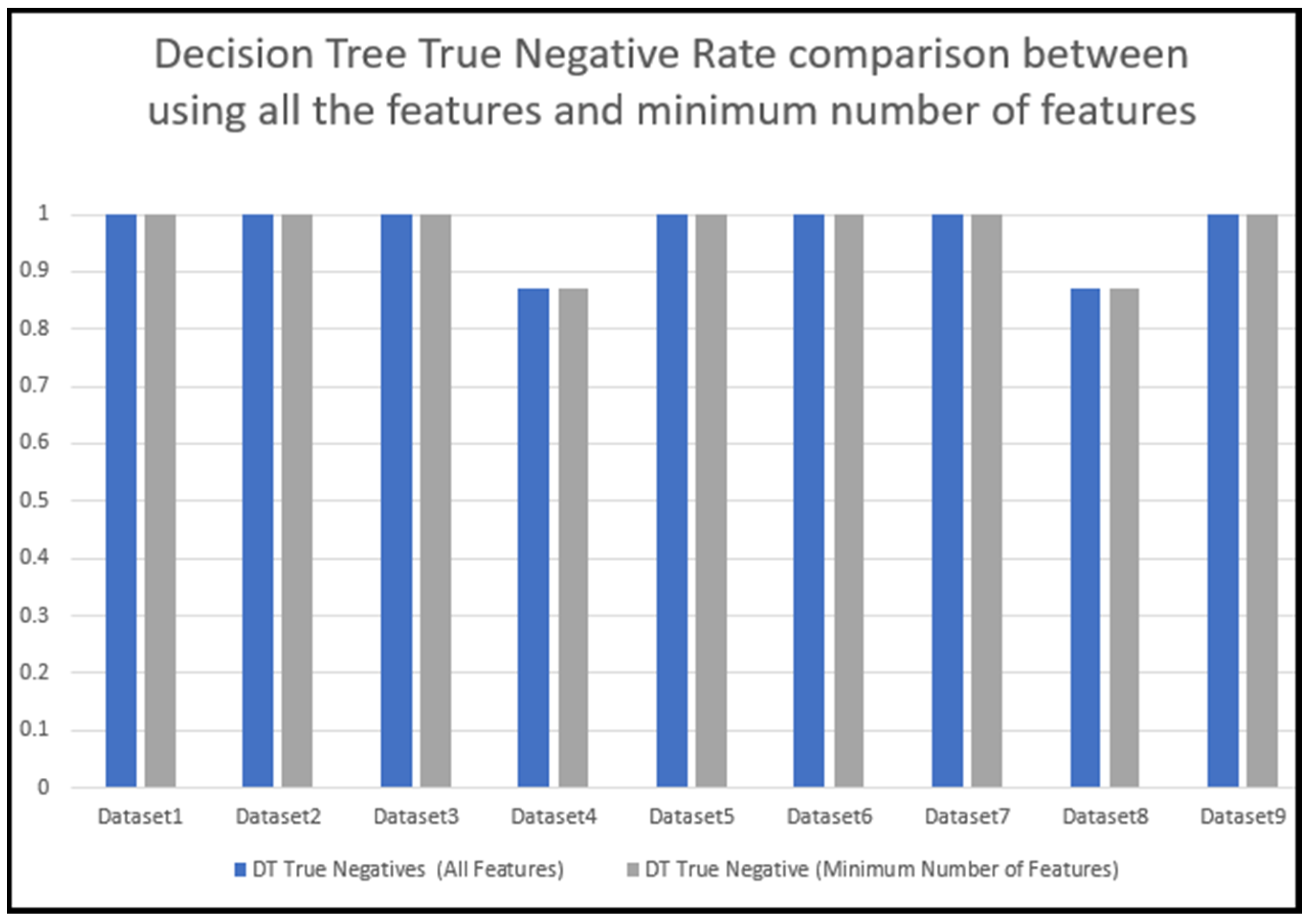
5.6. Training and testing using the minimum number of features with the DT algorithm
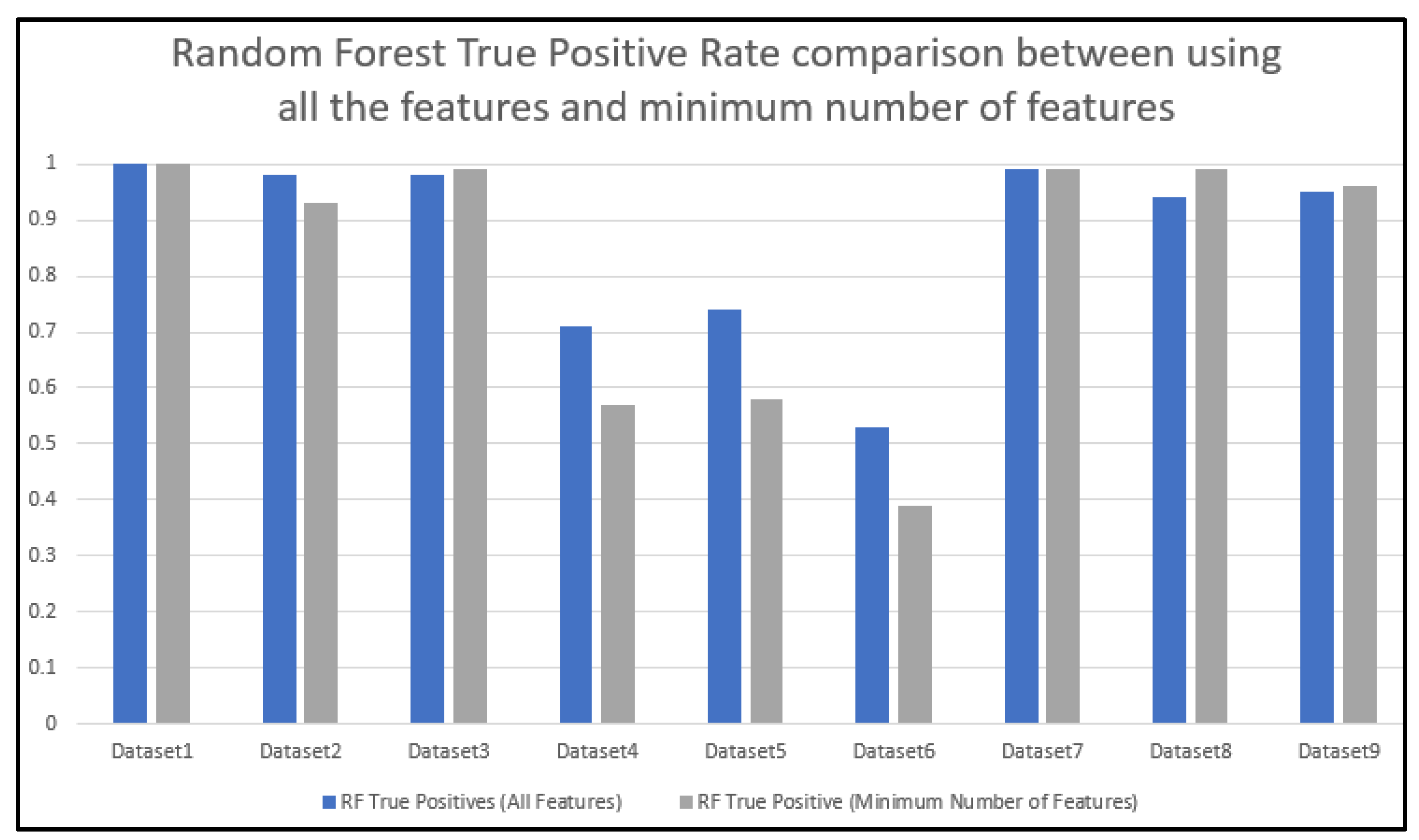
5.7. Training and Testing Using the Minimum Number of Features with the RF Algorithm
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| srcip | (string) The source ip address |
| srcport | The source port number |
| dstip | (string) The destination ip address |
| dstport | The destination port number |
| proto | The protocol (ie. TCP = 6, UDP = 17) |
| total_fpackets | Total packets in the forward direction |
| total_fvolume | Total bytes in the forward direction |
| total_bpackets | Total packets in the backward direction |
| total_bvolume | Total bytes in the backward direction |
| min_fpktl | The size of the smallest packet sent in the forward direction (in bytes) |
| mean_fpktl | The mean size of packets sent in the forward direction (in bytes) |
| max_fpktl | The size of the largest packet sent in the forward direction (in bytes) |
| std_fpktl | The standard deviation from the mean of the packets sent in the forward direction (in bytes) |
| min_bpktl | The size of the smallest packet sent in the backward direction (in bytes) |
| mean_bpktl | The mean size of packets sent in the backward direction (in bytes) |
| max_bpktl | The size of the largest packet sent in the backward direction (in bytes) |
| std_bpktl | The standard deviation from the mean of the packets sent in the backward direction (in bytes) |
| min_fiat | The minimum amount of time between two packets sent in the forward direction (in microseconds) |
| mean_fiat | The mean amount of time between two packets sent in the forward direction (in microseconds) |
| max_fiat | The maximum amount of time between two packets sent in the forward direction (in microseconds) |
| std_fiat | The standard deviation from the mean amount of time between two packets sent in the forward direction (in microseconds) |
| min_biat | The minimum amount of time between two packets sent in the backward direction (in microseconds) |
| mean_biat | The mean amount of time between two packets sent in the backward direction (in microseconds) |
| max_biat | The maximum amount of time between two packets sent in the backward direction (in microseconds) |
| std_biat | The standard deviation from the mean amount of time between two packets sent in the backward direction (in microseconds) |
| duration | The duration of the flow (in microseconds) |
| min_active | The minimum amount of time that the flow was active before going idle (in microseconds) |
| mean_active | The mean amount of time that the flow was active before going idle (in microseconds) |
| max_active | The maximum amount of time that the flow was active before going idle (in microseconds) |
| std_active | The standard deviation from the mean amount of time that the flow was active before going idle (in microseconds) |
| min_idle | The minimum time a flow was idle before becoming active (in microseconds) |
| mean_idle | The mean time a flow was idle before becoming active (in microseconds) |
| max_idle | The maximum time a flow was idle before becoming active (in microseconds) |
| std_idle | The standard devation from the mean time a flow was idle before becoming active (in microseconds) |
| sflow_fpackets | The average number of packets in a sub flow in the forward direction |
| sflow_fbytes | The average number of bytes in a sub flow in the forward direction |
| sflow_bpackets | The average number of packets in a sub flow in the backward direction |
| sflow_bbytes | The average number of packets in a sub flow in the backward direction |
| fpsh_cnt | The number of times the PSH flag was set in packets travelling in the forward direction (0 for UDP) |
| bpsh_cnt | The number of times the PSH flag was set in packets travelling in the backward direction (0 for UDP) |
| furg_cnt | The number of times the URG flag was set in packets travelling in the forward direction (0 for UDP) |
| burg_cnt | The number of times the URG flag was set in packets travelling in the backward direction (0 for UDP) |
| total_fhlen | The total bytes used for headers in the forward direction. |
| total_bhlen | The total bytes used for headers in the backward direction. |
References
- Wadhwa, A.; Arora, N. A Review on Cyber Crime: Major Threats and Solutions. Int. J. Adv. Res. Comput. Sci. 2017, 8, 2217–2221. [Google Scholar]
- Morgan, S. Cybercrime to Cost the World $10.5 Trillion Annually by 2025. Available online: https://cybersecurityventures.com/hackerpocalypse-cybercrime-report-2016/ (accessed on 2 November 2022).
- Nokia Banking Malware Threats Surging as Mobile Banking Increases–Nokia Threat Intelligence Report. Available online: https://www.nokia.com/about-us/news/releases/2021/11/08/banking-malware-threats-surging-as-mobile-banking-increases-nokia-threat-intelligence-report/ (accessed on 2 November 2022).
- Vijayalakshmi, Y.; Natarajan, N.; Manimegalai, P.; Babu, S.S. Study on emerging trends in malware variants. Int. J. Pure Appl. Math. 2017, 116, 479–489. [Google Scholar]
- Etaher, N.; Weir, G.R.; Alazab, M. From zeus to zitmo: Trends in banking malware. In Proceedings of the 2015 IEEE Trustcom/BigDataSE/ISPA, Helsinki, Finland, 20–22 August 2015; IEEE: Washington, DC, USA, 2015; Volume 1, pp. 1386–1391. [Google Scholar]
- Ibrahim, L.M.; Thanon, K.H. Botnet Detection on the Analysis of Zeus Panda Financial Botnet. Int. J. Eng. Adv. Technol. 2019, 8, 1972–1976. [Google Scholar] [CrossRef]
- Owen, H.; Zarrin, J.; Pour, S.M. A Survey on Botnets, Issues, Threats, Methods, Detection and Prevention. J. Cybersecur. Priv. 2022, 2, 74–88. [Google Scholar] [CrossRef]
- Tayyab, U.-E.; Khan, F.B.; Durad, M.H.; Khan, A.; Lee, Y.S. A Survey of the Recent Trends in Deep Learning Based Malware Detection. J. Cybersecur. Priv. 2022, 2, 800–829. [Google Scholar] [CrossRef]
- Aboaoja, F.A.; Zainal, A.; Ghaleb, F.A.; Al-rimy, B.A.S.; Eisa, T.A.E.; Elnour, A.A.H. Malware Detection Issues, Challenges, and Future Directions: A Survey. Appl. Sci. 2022, 12, 8482. [Google Scholar] [CrossRef]
- Ahsan, M.; Nygard, K.E.; Gomes, R.; Chowdhury, M.M.; Rifat, N.; Connolly, J.F. Cybersecurity Threats and Their Mitigation Approaches Using Machine Learning—A Review. J. Cybersecur. Priv. 2022, 2, 527–555. [Google Scholar] [CrossRef]
- Bukvić, L.; Pašagić Škrinjar, J.; Fratrović, T.; Abramović, B. Price Prediction and Classification of Used-Vehicles Using Supervised Machine Learning. Sustainability 2022, 14, 17034. [Google Scholar] [CrossRef]
- Okey, O.D.; Maidin, S.S.; Adasme, P.; Lopes Rosa, R.; Saadi, M.; Carrillo Melgarejo, D.; Zegarra Rodríguez, D. BoostedEnML: Efficient Technique for Detecting Cyberattacks in IoT Systems Using Boosted Ensemble Machine Learning. Sensors 2022, 22, 7409. [Google Scholar] [CrossRef]
- Singh, A.; Thakur, N.; Sharma, A. A review of supervised machine learning algorithms. In Proceedings of the 2016 3rd International Conference on Computing for Sustainable Global Development 2016, (INDIACom), New Delhi, India, 16–18 March 2016; pp. 1310–1315. [Google Scholar]
- Aswathi, K.B.; Jayadev, S.; Krishna, N.; Krishnan, R.; Sarath, G. Botnet Detection using Machine Learning. In Proceedings of the 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Kazi, M.; Woodhead, S.; Gan, D. A contempory Taxonomy of Banking Malware. In Proceedings of the First International Conference on Secure Cyber Computing and Communications, Jalandhar, India, 15–17 December 2018. [Google Scholar]
- Falliere, N.; Chien, E. Zeus: King of the Bots. 2009. Available online: http://bit.ly/3VyFV1 (accessed on 12 November 2022).
- Lelli, A. Zeusbot/Spyeye P2P Updated, Fortifying the Botnet. Available online: https://www.symantec.com/connect/blogs/zeusbotspyeye-p2p-updated-fortifying-botnet (accessed on 5 November 2019).
- Riccardi, M.; Di Pietro, R.; Palanques, M.; Vila, J.A. Titans’ Revenge: Detecting Zeus via Its Own Flaws. Comput. Netw. 2013, 57, 422–435. [Google Scholar] [CrossRef]
- Andriesse, D.; Rossow, C.; Stone-Gross, B.; Plohmann, D.; Bos, H. Highly Resilient Peer-to-Peer Botnets Are Here: An Analysis of Gameover Zeus. In Proceedings of the 2013 8th International Conference on Malicious and Unwanted Software: “The Americas” (MALWARE), Fajardo, PR, USA, 22–24 October 2013; pp. 116–123. [Google Scholar]
- Kazi, M.A.; Woodhead, S.; Gan, D. Comparing the performance of supervised machine learning algorithms when used with a manual feature selection process to detect Zeus malware. Int. J. Grid Util. Comput. 2022, 13, 495–504. [Google Scholar] [CrossRef]
- Md, A.Q.; Jaiswal, D.; Daftari, J.; Haneef, S.; Iwendi, C.; Jain, S.K. Efficient Dynamic Phishing Safeguard System Using Neural Boost Phishing Protection. Electronics 2022, 11, 3133. [Google Scholar] [CrossRef]
- Ibrahim, L.M.; Thanon, K.H. Analysis and detection of the zeus botnet crimeware. Int. J. Comput. Sci. Inf. Secur. 2015, 13, 121. [Google Scholar]
- Gu, G.; Porras, P.; Yegneswaran, V.; Fong, M.; Lee, W. BotHunter: Detecting Malware Infection Through IDS-Driven Dialog Correlation. In Proceedings of the USENIX Conference on Security Symposium, Anaheim, CA, USA, 9–11 August 2007; pp. 167–182. [Google Scholar]
- Thorat, S.A.; Khandelwal, A.K.; Bruhadeshwar, B.; Kishore, K. Payload Content Based Network Anomaly Detection. In Proceedings of the 2008 First International Conference on the Applications of Digital Information and Web Technologies (ICADIWT), Ostrava, Czech Republic, 4–6 August 2008. [Google Scholar] [CrossRef]
- Guofei, G.; Perdisci, R.; Zhang, J.; Lee, W. BotMiner: Clustering analysis of network traffic for protocol- and structure-independent botnet detection. In Proceedings of the 17th Conference on Security Symposium, San Jose, CA, USA, 28 July–1 August 2008; pp. 139–154. [Google Scholar]
- Azab, A.; Alazab, M.; Aiash, M. Machine Learning Based Botnet Identification Traffic. In Proceedings of the 2016 IEEE Trustcom/BigDataSE/ISPA, Tianjin, China, 23–26 August 2016; pp. 1788–1794. [Google Scholar]
- Soniya, B.; Wilscy, M. Detection of Randomized Bot Command and Control Traffic on an End-Point Host. Alex. Eng. J. 2016, 55, 2771–2781. [Google Scholar] [CrossRef][Green Version]
- Venkatesh, G.K.; Nadarajan, R.A. HTTP botnet detection using adaptive learning rate multilayer feed-forward neural network. In Proceedings of the IFIP International Workshop on Information Security Theory and Practice, Egham, UK, 20–22 June 2012; Springer: Berlin/Heidelberg, Germany, 2012; Volume 7322 LNCS, pp. 38–48. [Google Scholar]
- Haddadi, F.; Runkel, D.; Zincir-Heywood, A.N.; Heywood, M.I. On Botnet Behaviour Analysis Using GP and C4.5; Association for Computing Machinery: New York, NY, USA, 2014; pp. 1253–1260. [Google Scholar]
- Fernandez, D.; Lorenzo, H.; Novoa, F.J.; Cacheda, F.; Carneiro, V. Tools for managing network traffic flows: A comparative analysis. In Proceedings of the 2017 IEEE 16th International Symposium on Network Computing and Applications (NCA), Cambridge, MA, USA, 30 October–1 November 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar]
- Fuhr, J.; Wang, F.; Tang, Y. MOCA: A Network Intrusion Monitoring and Classification System. J. Cybersecur. Priv. 2022, 2, 629–639. [Google Scholar] [CrossRef]
- He, S.; Zhu, J.; He, P.; Lyu, M.R. Experience report: System log analysis for anomaly detection. In Proceedings of the 2016 IEEE 27th international symposium on software reliability engineering (ISSRE), Ottawa, ON, Canada, 23–27 October 2016; pp. 207–218. [Google Scholar]
- Zhou, J.; Qian, Y.; Zou, Q.; Liu, P.; Xiang, J. DeepSyslog: Deep Anomaly Detection on Syslog Using Sentence Embedding and Metadata. IEEE Trans. Inf. Forensics Secur. 2022, 17, 3051–3061. [Google Scholar] [CrossRef]
- Ghafir, I.; Prenosil, V.; Hammoudeh, M.; Baker, T.; Jabbar, S.; Khalid, S.; Jaf, S. BotDet: A System for Real Time Botnet Command and Control Traffic Detection. IEEE Access 2018, 6, 38947–38958. [Google Scholar] [CrossRef]
- Agarwal, P.; Satapathy, S. Implementation of signature-based detection system using snort in windows. Int. J. Comput. Appl. Inf. Technol. 2014, 3, 3–4. [Google Scholar]
- Khraisat, A.; Gondal, I.; Vamplew, P.; Kamruzzaman, J. Survey of intrusion detection systems: Techniques, datasets and challenges. Cybersecurity 2019, 2, 1–22. [Google Scholar] [CrossRef]
- Sharma, P.; Said, Z.; Memon, S.; Elavarasan, R.M.; Khalid, M.; Nguyen, X.P.; Arıcı, M.; Hoang, A.T.; Nguyen, L.H. Comparative evaluation of AI-based intelligent GEP and ANFIS models in prediction of thermophysical properties of Fe3O4-coated MWCNT hybrid nanofluids for potential application in energy systems. Int. J. Energy Res. 2022, 37, 19242–19257. [Google Scholar] [CrossRef]
- Arndt, D. DanielArndt/Netmate-Flowcalc. Available online: https://github.com/DanielArndt/netmate-flowcalc (accessed on 6 November 2019).
- Montigny-Leboeuf, A.D.; Couture, M.; Massicotte, F. Traffic Behaviour Characterization Using NetMate. In International Workshop on Recent Advances in Intrusion Detection 2019; Springer: Berlin/Heidelberg, Germany; pp. 367–368.
- De Montigny-Leboeuf, A.; Couture, M.; Massicotte, F. Traffic Behaviour Characterization Using NetMate. Lect. Notes Comput. Sci. 2009, 5758, 367–368. [Google Scholar] [CrossRef]
- de Menezes, N.A.T.; de Mello, F.L. Flow Feature-Based Network Traffic Classification Using Machine Learning. J. Inf. Secur. Cryptogr. 2021, 8, 12–16. [Google Scholar] [CrossRef]
- Miller, S.; Curran, K.; Lunney, T. Multilayer perceptron neural network for detection of encrypted VPN network traffic. In Proceedings of the International Conference On Cyber Situational Awareness, Data Analytics And Assessment (Cyber SA), Glasgow, UK, 11–12 June 2018. [Google Scholar]
- Kasongo, S.M.; Sun, Y. A Deep Learning Method with Filter Based Feature Engineering for Wireless Intrusion Detection System. IEEE Access 2019, 7, 38597–38607. [Google Scholar] [CrossRef]
- Reis, B.; Maia, E.; Praça, I. Selection and Performance Analysis of CICIDS2017 Features Importance. Found. Pract. Secur. 2020, 12056, 56–71. [Google Scholar] [CrossRef]
- Maldonado, S.; Weber, R. A wrapper method for feature selection using Support Vector Machines. Inf. Sci. 2009, 179, 2208–2217. [Google Scholar] [CrossRef]
- Wald, R.; Khoshgoftaar, T.; Napolitano, A. Comparison of Stability for Different Families of Filter-Based and Wrapper-Based Feature Selection. In Proceedings of the 2013 12th International Conference on Machine Learning and Applications, Miami, FL, USA, 4–7 December 2013. [Google Scholar] [CrossRef]
- Schmoll, C.; Zander, S. NetMate-User and Developer Manual. 2004. Available online: https://www.researchgate.net/publication/246926554_NetMate-User_and_Developer_Manual (accessed on 22 December 2022).
- Saghezchi, F.B.; Mantas, G.; Violas, M.A.; de Oliveira Duarte, A.M.; Rodriguez, J. Machine Learning for DDoS Attack Detection in Industry 4.0 CPPSs. Electronics 2022, 11, 602. [Google Scholar] [CrossRef]
- Alshammari, R.; Zincir-Heywood, A.N. Investigating Two Different Approaches for Encrypted Traffic Classification. In Proceedings of the 2008 Sixth Annual Conference on Privacy, Security and Trust, Fredericton, NB, Canada, 1–3 October 2008. [Google Scholar] [CrossRef]
- Yeo, M.; Koo, Y.; Yoon, Y.; Hwang, T.; Ryu, J.; Song, J.; Park, C. Flow-Based Malware Detection Using Convolutional Neural Network. In Proceedings of the 2018 International Conference on Information Networking (ICOIN), Chiang Mai, Thailand, 10–12 January 2018. [Google Scholar] [CrossRef]
- Shomiron. Zeustracker. Available online: https://github.com/dnif-archive/enrich-zeustracker (accessed on 25 July 2022).
- Stratosphere. Stratosphere Laboratory Datasets. Available online: https://www.stratosphereips.org/datasets-overview (accessed on 25 November 2022).
- Abuse, C. Fighting Malware and Botnets. Available online: https://abuse.ch/ (accessed on 13 May 2022).
- Haddadi, F.; Zincir-Heywood, A.N. Benchmarking the effect of flow exporters and protocol filters on botnet traffic classification. IEEE Syst. J. 2014, 10, 1390–1401. [Google Scholar] [CrossRef]
- Khodamoradi, P.; Fazlali, M.; Mardukhi, F.; Nosrati, M. Heuristic metamorphic malware detection based on statistics of assembly instructions using classification algorithms. In Proceedings of the 2015 18th CSI International Symposium on Computer Architecture and Digital Systems (CADS), Tehran, Iran, 7–8 October 2015; pp. 1–6. [Google Scholar]
- Salzberg, S.L. C4.5: Programs for Machine Learning by J. Ross Quinlan; Morgan Kaufmann Publishers, Inc.: Burlington, MA, USA, 1993. [Google Scholar]
- Xhemali, D.; Hinde, C.J.; Stone, R.G. Naïve Bayes vs. Decision Trees vs. Neural Networks in the Classification of Training Web Pages. Int. J. Comput. Sci. Issues 2009, 4, 16–23. [Google Scholar]
- Bernard, S.; Heutte, L.; Adam, S. On the selection of decision trees in random forests. In Proceedings of the 2009 International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009; pp. 302–307. [Google Scholar]
- Maimon, O.; Rokach, L. (Eds.) Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2005. [Google Scholar]
- Liu, Z.; Thapa, N.; Shaver, A.; Roy, K.; Siddula, M.; Yuan, X.; Yu, A. Using Embedded Feature Selection and CNN for Classification on CCD-INID-V1—A New IoT Dataset. Sensors 2021, 21, 4834. [Google Scholar] [CrossRef]
- Oshiro, T.M.; Perez, P.S.; Baranauskas, J.A. How Many Trees in a Random Forest? Mach. Learn. Data Min. Pattern Recognit. 2012, 7376, 154–168. [Google Scholar] [CrossRef]
- Jiang, Z.; Shen, G. Prediction of House Price Based on the Back Propagation Neural Network in the Keras Deep Learning Framework. In Proceedings of the 2019 6th International Conference on Systems and Informatics (ICSAI), Shanghai, China, 2–4 November 2019; pp. 1408–1412. [Google Scholar] [CrossRef]
- Nagisetty, A.; Gupta, G.P. Framework for detection of malicious activities in IoT networks using keras deep learning library. In Proceedings of the 2019 3rd International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 27–29 March 2019; pp. 633–637. [Google Scholar]
- Heller, M. What Is Keras? The Deep Neural Network API Explained. Available online: https://www.infoworld.com/article/3336192/what-is-keras-the-deep-neural-network-api-explained.html (accessed on 25 November 2022).
- Ali, S.; Rehman, S.U.; Imran, A.; Adeem, G.; Iqbal, Z.; Kim, K.-I. Comparative Evaluation of AI-Based Techniques for Zero-Day Attacks Detection. Electronics 2022, 11, 3934. [Google Scholar] [CrossRef]
- Kumar, V.; Lalotra, G.S.; Sasikala, P.; Rajput, D.S.; Kaluri, R.; Lakshmanna, K.; Shorfuzzaman, M.; Alsufyani, A.; Uddin, M. Addressing Binary Classification over Class Imbalanced Clinical Datasets Using Computationally Intelligent Techniques. Healthcare 2022, 10, 1293. [Google Scholar] [CrossRef] [PubMed]
- Maudoux, C.; Boumerdassi, S.; Barcello, A.; Renault, E. Combined Forest: A New Supervised Approach for a Machine-Learning-Based Botnets Detection. In Proceedings of the 2021 IEEE Global Communications Conference (GLOBECOM), Madrid, Spain, 7–11 December 2021. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature That Was Removed | Justification |
|---|---|
| srcip | This is the source IP which was removed to negate any correlation with a network characteristic |
| srcport | The is the source port number which was removed to negate any correlation with a network characteristic |
| dstip | This is the destination IP address which was removed to negate any correlation with a network characteristic |
| dstport | The is the destination port number which was removed to negate any correlation with a network characteristic |
| proto | This is the protocol that was being used (i.e., TCP = 6, UDP = 17) which was removed to negate any correlation with a network characteristic |
| min_fiat | This is the minimum time between two packets sent in the forward direction (in microseconds) which was removed to negate any correlation with a network characteristic |
| mean_fiat | This is the mean amount of time between two packets sent in the forward direction (in microseconds) which was removed to negate any correlation with a network characteristic |
| max_fiat | This is the maximum time between two packets sent in the forward direction (in microseconds) which was removed to negate any correlation with a network characteristic |
| std_fiat | This is the standard deviation from the mean time between two packets sent in the forward direction (in microseconds) |
| min_biat | This is the minimum time between two packets sent in the backward direction (in microseconds) which was removed to negate any correlation with a network characteristic |
| mean_biat | This is the mean time between two packets sent in the backward direction (in microseconds) which was removed to negate any correlation with a network characteristic |
| std_biat | This is the standard deviation from the mean time between two packets sent in the backward direction (in microseconds) which was removed to negate any correlation with a network characteristic |
| Dataset Type | Malware Name/Year | Number of Flows | Name of Dataset for This Paper |
|---|---|---|---|
| Malware Benign | Zeus/2022 | 272,425 | Dataset1 |
| N/A | 272,425 | ||
| Malware Benign | Zeus/2019 | 66,009 | Dataset2 |
| N/A | 66,009 | ||
| Malware Benign | Zeus/2019 | 38,282 | Dataset3 |
| N/A | 38,282 | ||
| Malware Benign | Zeus/2014 | 200,000 | Dataset4 |
| N/A | 200,000 | ||
| Malware Benign | Zeus/2014 | 35,054 | Dataset5 |
| N/A | 35,054 | ||
| Malware Benign | Zeus/2014 | 6049 | Dataset6 |
| N/A | 6049 | ||
| Malware Benign | ZeusPanda/2022 | 11,864 | Dataset7 |
| N/A | 11,864 | ||
| Malware Benign | Ramnit/2022 | 10,204 | Dataset8 |
| N/A | 10,204 | ||
| Malware Benign | Citadel/2022 | 7152 | Dataset9 |
| N/A | 7152 |
| Predicted Benign | Predicted Zeus | |
|---|---|---|
| Actual Benign (Total) | TN | FN |
| Actual Zeus (Total) | FP | TP |
| Dataset Name | Benign Precision Score | Benign Recall Score | Benign f1-Score | Malware Precision Score | Malware Recall Score | Malware f1-Score |
|---|---|---|---|---|---|---|
| Dataset1 | 0.99 | 1 | 0.99 | 1 | 0.99 | 0.99 |
| Dataset2 | 0.94 | 1 | 0.97 | 1 | 0.94 | 0.97 |
| Dataset3 | 0.95 | 1 | 0.97 | 1 | 0.94 | 0.97 |
| Dataset4 | 0.71 | 0.87 | 0.78 | 0.83 | 0.64 | 0.72 |
| Dataset5 | 0.67 | 1 | 0.8 | 1 | 0.52 | 0.68 |
| Dataset6 | 0.62 | 1 | 0.76 | 1 | 0.39 | 0.56 |
| Dataset7 | 0.99 | 1 | 0.99 | 1 | 0.99 | 0.99 |
| Dataset8 | 0.98 | 0.87 | 0.92 | 0.88 | 0.98 | 0.93 |
| Dataset9 | 0.96 | 1 | 0.98 | 1 | 0.96 | 0.98 |
| Dataset Name | Benign Precision Score | Benign Recall Score | Benign f1-Score | Malware Precision Score | Malware Recall Score | Malware f1-Score |
|---|---|---|---|---|---|---|
| Dataset1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Dataset2 | 0.98 | 1 | 0.99 | 1 | 0.98 | 0.99 |
| Dataset3 | 0.98 | 1 | 0.99 | 1 | 0.98 | 0.99 |
| Dataset4 | 0.75 | 0.89 | 0.82 | 0.86 | 0.71 | 0.78 |
| Dataset5 | 0.8 | 1 | 0.89 | 1 | 0.74 | 0.85 |
| Dataset6 | 0.68 | 1 | 0.81 | 1 | 0.53 | 0.69 |
| Dataset7 | 0.99 | 1 | 0.99 | 1 | 0.99 | 0.99 |
| Dataset8 | 0.94 | 0.88 | 0.91 | 0.89 | 0.94 | 0.92 |
| Dataset9 | 0.95 | 1 | 0.98 | 1 | 0.95 | 0.97 |
| Dataset Name | Benign Precision Score | Benign Recall Score | Benign f1-Score | Malware Precision Score | Malware Recall Score | Malware f1-Score |
|---|---|---|---|---|---|---|
| Dataset1 | 272,425 | 271,721 | 704 | 272,425 | 270,109 | 2316 |
| Dataset2 | 66,009 | 65,832 | 177 | 66,009 | 61,920 | 4089 |
| Dataset3 | 38,222 | 38,127 | 95 | 38,282 | 36,061 | 2221 |
| Dataset4 | 200,000 | 173,219 | 26781 | 200,000 | 127,706 | 72,294 |
| Dataset5 | 35,054 | 34,963 | 91 | 35,054 | 18,116 | 16,938 |
| Dataset6 | 6049 | 6040 | 9 | 6049 | 2333 | 3716 |
| Dataset7 | 11,864 | 11,836 | 28 | 11,864 | 11,715 | 149 |
| Dataset8 | 10,204 | 8865 | 1339 | 10,204 | 10,041 | 163 |
| Dataset9 | 7152 | 7138 | 14 | 7152 | 6839 | 313 |
| Dataset Name | Benign Precision Score | Benign Recall Score | Benign f1-Score | Malware Precision Score | Malware Recall Score | Malware f1-Score |
|---|---|---|---|---|---|---|
| Dataset1 | 272,425 | 272,200 | 225 | 272,425 | 271,312 | 1113 |
| Dataset2 | 66,009 | 65,946 | 63 | 66,009 | 64,438 | 1571 |
| Dataset3 | 38,282 | 38,252 | 30 | 38,282 | 37,546 | 736 |
| Dataset4 | 200,000 | 177,309 | 22,691 | 200,000 | 142,286 | 57,714 |
| Dataset5 | 35,054 | 35,025 | 29 | 35,054 | 26,104 | 8950 |
| Dataset6 | 6049 | 6046 | 3 | 6049 | 3179 | 2870 |
| Dataset7 | 11,864 | 11,852 | 12 | 11,864 | 11,740 | 124 |
| Dataset8 | 10,204 | 9014 | 1190 | 10,204 | 9642 | 562 |
| Dataset9 | 7152 | 7145 | 7 | 7152 | 6803 | 349 |
| Dataset Name | Benign Precision Score | Benign Recall Score | Benign f1-Score | Malware Precision Score | Malware Recall Score | Malware f1-Score |
|---|---|---|---|---|---|---|
| Dataset1 | 0.98 | 0.97 | 0.98 | 0.97 | 0.98 | 0.98 |
| Dataset2 | 0.92 | 0.97 | 0.94 | 0.97 | 0.91 | 0.94 |
| Dataset3 | 0.92 | 0.98 | 0.95 | 0.97 | 0.92 | 0.95 |
| Dataset4 | 0.69 | 0.95 | 0.8 | 0.93 | 0.56 | 0.7 |
| Dataset5 | 0.7 | 0.97 | 0.81 | 0.96 | 0.58 | 0.72 |
| Dataset6 | 0.87 | 0.99 | 0.93 | 0.99 | 0.86 | 0.92 |
| Dataset7 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 |
| Dataset8 | 0.91 | 0.94 | 0.93 | 0.94 | 0.91 | 0.92 |
| Dataset9 | 0.92 | 0.98 | 0.95 | 0.98 | 0.92 | 0.95 |
| Dataset Name | Benign Precision Score | Benign Recall Score | Benign f1-Score | Malware Precision Score | Malware Recall Score | Malware f1-Score |
|---|---|---|---|---|---|---|
| Dataset1 | 272,425 | 265,452 | 6973 | 272,425 | 266,091 | 6334 |
| Dataset2 | 66,009 | 64,123 | 1886 | 66,009 | 60,310 | 5699 |
| Dataset3 | 38,282 | 37,356 | 926 | 38,282 | 35,177 | 3105 |
| Dataset4 | 200,000 | 190,935 | 9065 | 200,000 | 112,731 | 87,269 |
| Dataset5 | 35,054 | 34,155 | 899 | 35,054 | 14,753 | 20,301 |
| Dataset6 | 6049 | 5973 | 76 | 6049 | 5180 | 869 |
| Dataset7 | 11,864 | 11,566 | 298 | 11,864 | 11,551 | 313 |
| Dataset8 | 10,204 | 9605 | 599 | 10,204 | 9260 | 944 |
| Dataset9 | 7152 | 7023 | 129 | 7152 | 6547 | 605 |
| Dataset Name | Benign Precision Score | Benign Recall Score | Benign f1-Score | Malware Precision Score | Malware Recall Score | Malware f1-Score |
|---|---|---|---|---|---|---|
| Dataset1 | 0.98 | 0.97 | 0.97 | 0.97 | 0.98 | 0.97 |
| Dataset2 | 0.9 | 0.97 | 0.93 | 0.97 | 0.89 | 0.93 |
| Dataset3 | 0.9 | 0.97 | 0.94 | 0.97 | 0.9 | 0.93 |
| Dataset4 | 0.66 | 0.95 | 0.78 | 0.92 | 0.51 | 0.66 |
| Dataset5 | 0.67 | 0.97 | 0.79 | 0.95 | 0.51 | 0.67 |
| Dataset6 | 0.79 | 0.99 | 0.88 | 0.98 | 0.74 | 0.85 |
| Dataset7 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 | 0.97 |
| Dataset8 | 0.91 | 0.94 | 0.92 | 0.94 | 0.9 | 0.92 |
| Dataset9 | 0.92 | 0.98 | 0.95 | 0.98 | 0.91 | 0.95 |
| Dataset Name | Benign Precision Score | Benign Recall Score | Benign f1-Score | Malware Precision Score | Malware Recall Score | Malware f1-Score |
|---|---|---|---|---|---|---|
| Dataset1 | 272,425 | 265,049 | 7376 | 272,425 | 266,052 | 6373 |
| Dataset2 | 66,009 | 64,028 | 1981 | 66,009 | 58,811 | 7198 |
| Dataset3 | 38,282 | 37,298 | 984 | 38,282 | 34,304 | 3978 |
| Dataset4 | 200,000 | 190,820 | 9180 | 200,000 | 102,371 | 97,629 |
| Dataset5 | 35,054 | 34,103 | 951 | 35,054 | 17,996 | 17,058 |
| Dataset6 | 6049 | 5963 | 86 | 6049 | 4499 | 1550 |
| Dataset7 | 11,864 | 11,553 | 311 | 11,864 | 11,535 | 329 |
| Dataset8 | 10,204 | 9575 | 629 | 10,204 | 9233 | 971 |
| Dataset9 | 7152 | 7015 | 137 | 7152 | 6544 | 608 |
| Dataset Name | Benign Precision Score | Benign Recall Score | Benign f1-Score | Malware Precision Score | Malware Recall Score | Malware f1-Score |
|---|---|---|---|---|---|---|
| Dataset1 | 0.99 | 1 | 0.99 | 1 | 0.99 | 0.99 |
| Dataset2 | 0.94 | 1 | 0.97 | 1 | 0.94 | 0.97 |
| Dataset3 | 0.94 | 1 | 0.97 | 1 | 0.94 | 0.97 |
| Dataset4 | 0.69 | 0.87 | 0.77 | 0.82 | 0.6 | 0.7 |
| Dataset5 | 0.71 | 1 | 0.83 | 0.99 | 0.6 | 0.75 |
| Dataset6 | 0.62 | 1 | 0.76 | 0.99 | 0.38 | 0.55 |
| Dataset7 | 0.99 | 1 | 0.99 | 1 | 0.99 | 0.99 |
| Dataset8 | 0.94 | 0.87 | 0.9 | 0.88 | 0.94 | 0.91 |
| Dataset9 | 0.96 | 1 | 0.98 | 1 | 0.96 | 0.98 |
| Dataset Name | Benign Precision Score | Benign Recall Score | Benign f1-Score | Malware Precision Score | Malware Recall Score | Malware f1-Score |
|---|---|---|---|---|---|---|
| Dataset1 | 272,425 | 271,502 | 923 | 272,425 | 270,408 | 2017 |
| Dataset2 | 66,009 | 65,788 | 221 | 66,009 | 61,804 | 4205 |
| Dataset3 | 38,282 | 38,159 | 123 | 38,282 | 36,018 | 2264 |
| Dataset4 | 200,000 | 174,267 | 25,733 | 200,000 | 120,785 | 79,215 |
| Dataset5 | 35,054 | 34,935 | 119 | 35,054 | 20,984 | 14,070 |
| Dataset6 | 6049 | 6032 | 17 | 6049 | 2328 | 3721 |
| Dataset7 | 11,864 | 11,825 | 39 | 11,864 | 11,724 | 140 |
| Dataset8 | 10,204 | 8857 | 1347 | 10,204 | 9630 | 574 |
| Dataset9 | 7152 | 7130 | 22 | 7152 | 6837 | 315 |
| Dataset Name | Benign Precision Score | Benign Recall Score | Benign f1-Score | Malware Precision Score | Malware Recall Score | Malware f1-Score |
|---|---|---|---|---|---|---|
| Dataset1 | 1 | 1 | 1 | 1 | 1 | 1 |
| Dataset2 | 0.93 | 1 | 0.95 | 1 | 0.93 | 0.95 |
| Dataset3 | 0.94 | 1 | 0.97 | 1 | 0.93 | 0.96 |
| Dataset4 | 0.67 | 0.89 | 0.77 | 0.84 | 0.57 | 0.68 |
| Dataset5 | 0.7 | 1 | 0.83 | 1 | 0.58 | 0.73 |
| Dataset6 | 0.62 | 1 | 0.77 | 1 | 0.39 | 0.56 |
| Dataset7 | 0.99 | 1 | 0.99 | 1 | 0.99 | 0.99 |
| Dataset8 | 0.99 | 0.89 | 0.93 | 0.9 | 0.99 | 0.94 |
| Dataset9 | 0.96 | 1 | 0.98 | 1 | 0.96 | 0.98 |
| Dataset Name | Benign Precision Score | Benign Recall Score | Benign f1-Score | Malware Precision Score | Malware Recall Score | Malware f1-Score |
|---|---|---|---|---|---|---|
| Dataset1 | 272,425 | 272,233 | 192 | 272,425 | 271,328 | 1097 |
| Dataset2 | 66,009 | 65,961 | 48 | 66,009 | 61,230 | 4779 |
| Dataset3 | 38,282 | 38,256 | 26 | 38,282 | 35,641 | 2641 |
| Dataset4 | 200,000 | 178,346 | 21,654 | 200,000 | 114,030 | 85,970 |
| Dataset5 | 35,054 | 35,029 | 25 | 35,054 | 20,221 | 14,833 |
| Dataset6 | 6049 | 6047 | 2 | 6049 | 2352 | 3697 |
| Dataset7 | 11,864 | 11,855 | 9 | 11,864 | 11,743 | 121 |
| Dataset8 | 10,204 | 9033 | 1171 | 10,204 | 10,081 | 123 |
| Dataset9 | 7152 | 7148 | 4 | 7152 | 6849 | 303 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kazi, M.A.; Woodhead, S.; Gan, D. An Investigation to Detect Banking Malware Network Communication Traffic Using Machine Learning Techniques. J. Cybersecur. Priv. 2023, 3, 1-23. https://doi.org/10.3390/jcp3010001
Kazi MA, Woodhead S, Gan D. An Investigation to Detect Banking Malware Network Communication Traffic Using Machine Learning Techniques. Journal of Cybersecurity and Privacy. 2023; 3(1):1-23. https://doi.org/10.3390/jcp3010001
Chicago/Turabian StyleKazi, Mohamed Ali, Steve Woodhead, and Diane Gan. 2023. "An Investigation to Detect Banking Malware Network Communication Traffic Using Machine Learning Techniques" Journal of Cybersecurity and Privacy 3, no. 1: 1-23. https://doi.org/10.3390/jcp3010001
APA StyleKazi, M. A., Woodhead, S., & Gan, D. (2023). An Investigation to Detect Banking Malware Network Communication Traffic Using Machine Learning Techniques. Journal of Cybersecurity and Privacy, 3(1), 1-23. https://doi.org/10.3390/jcp3010001