

Cost-Effective Active Laser Scanning System for Depth-Aware Deep-Learning-Based Instance Segmentation in Poultry Processing

 , , and
, , and 
Abstract
1. Introduction
2. Material and Methods
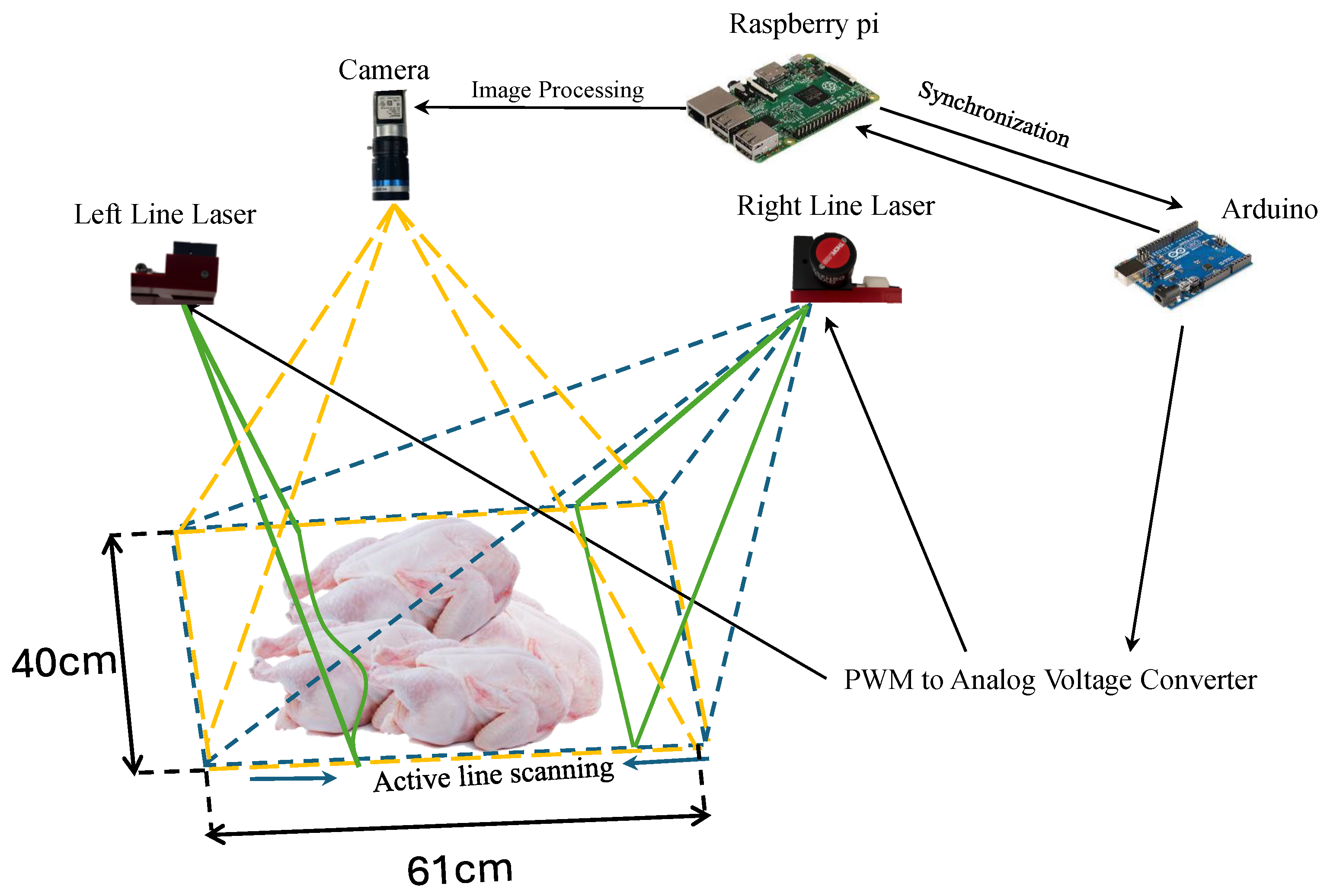
2.1. Dual-Line Laser Active Scanning: A Hardware and Software System for Height Estimation
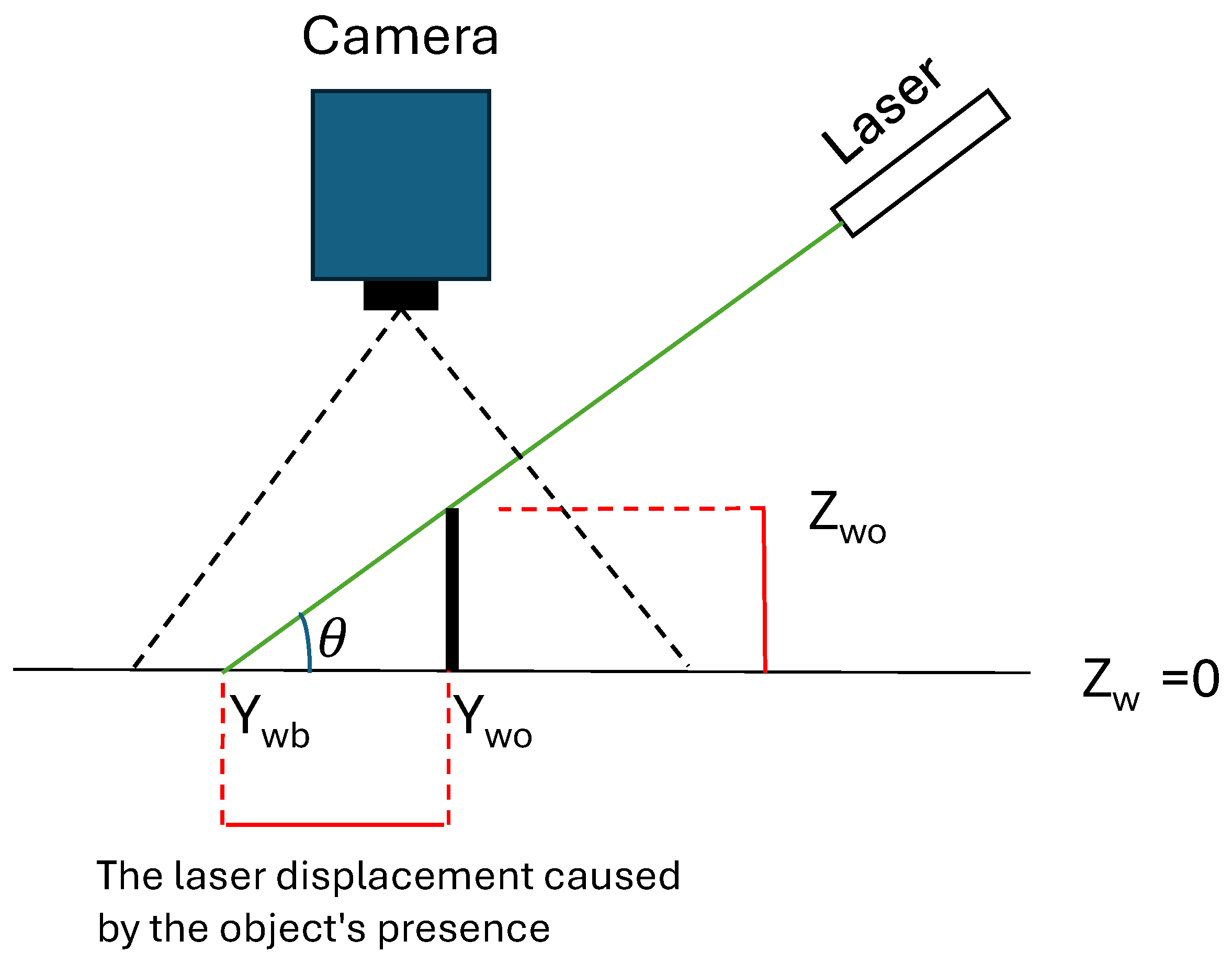
2.2. Optical Triangulation for Object Height Estimation
2.2.1. Baseline Position Collection of Laser Line
2.2.2. Laser Angle Calibration
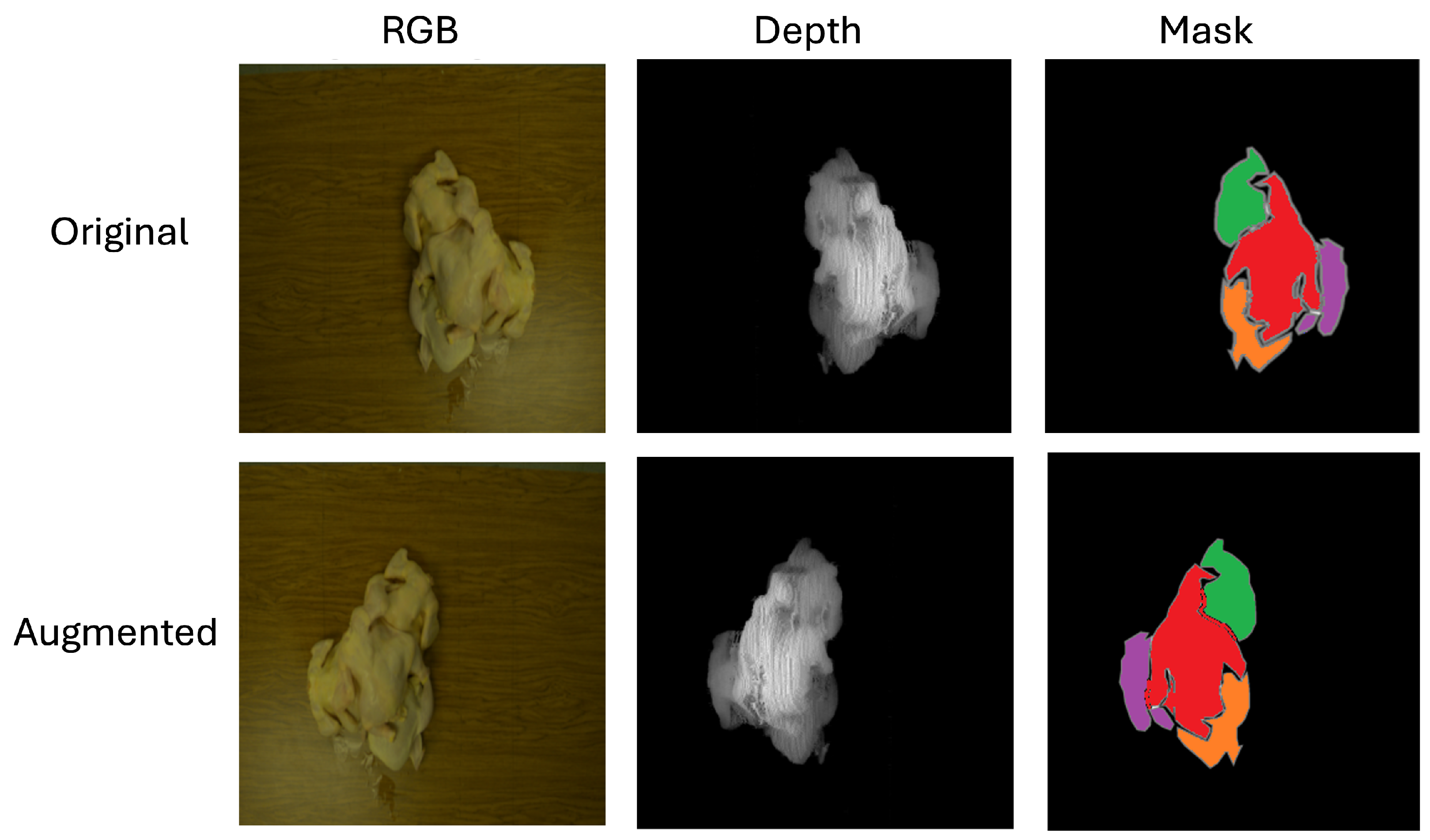
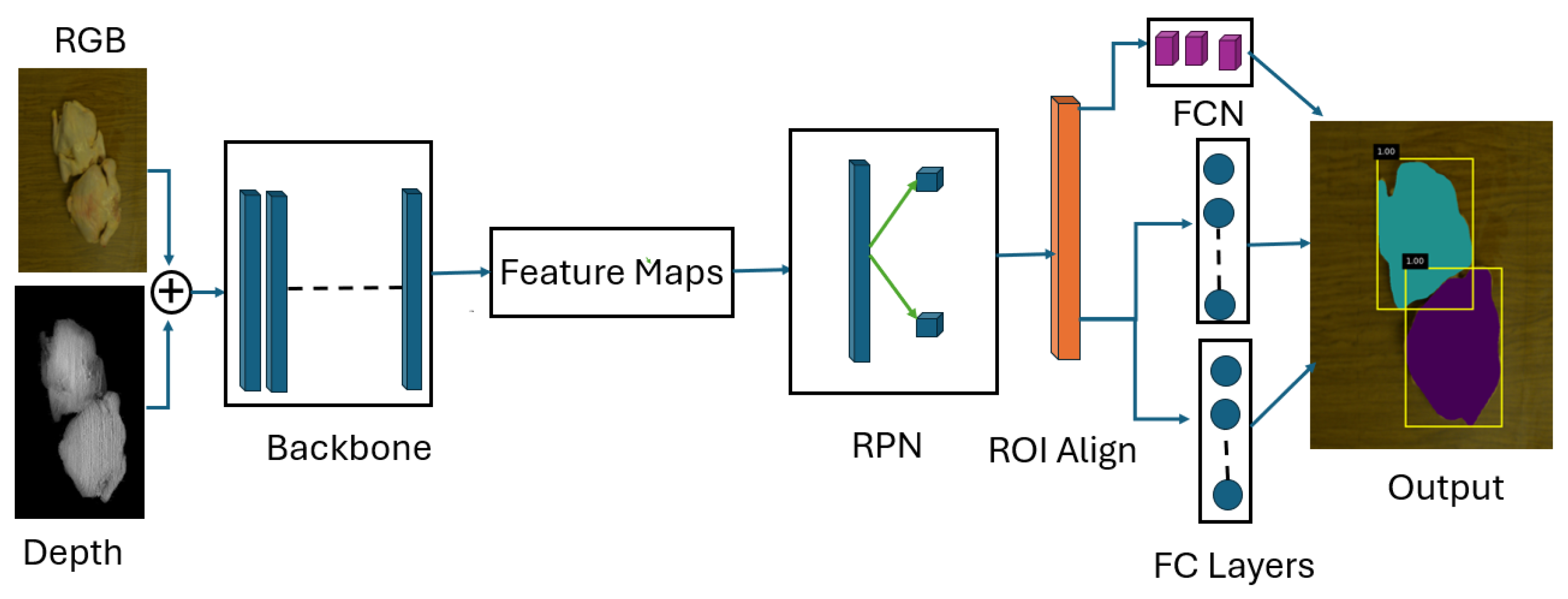
2.3. Instance Segmentation of Chicken Carcass
3. Results
3.1. The Performance Evaluation of Active Laser Scanning System
3.1.1. Laser Calibration Performance
3.1.2. System Depth Estimation Accuracy
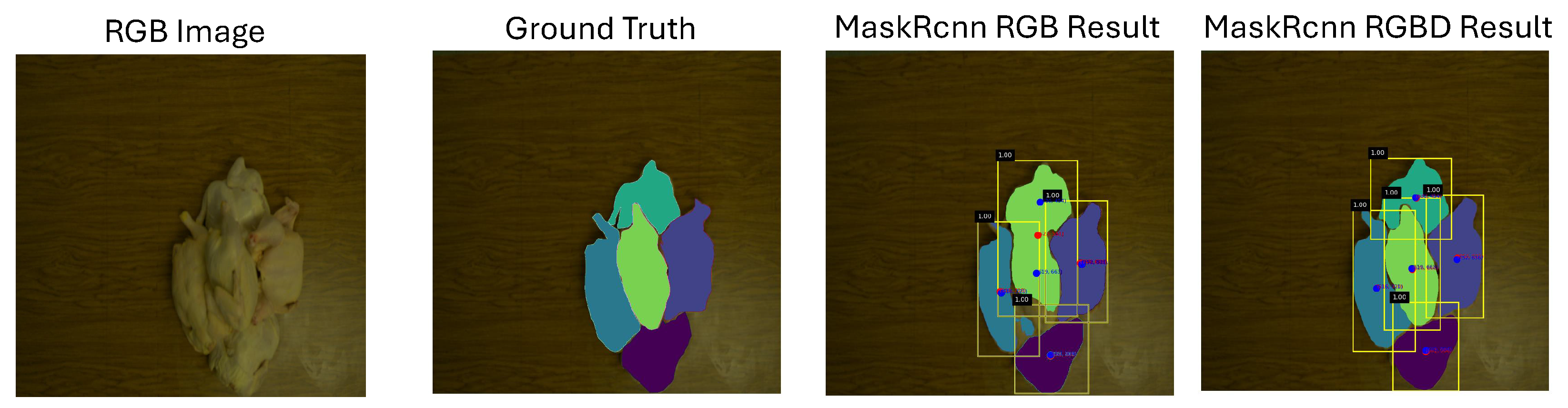
3.2. Performance of Chicken Instance Segmentation
4. Discussion
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- United States Department of Agriculture (USDA). Livestock and Poultry: World Markets and Trade. 2025. Available online: https://www.fas.usda.gov/sites/default/files/2024-10/Livestock_poultry.pdf (accessed on 16 January 2025).
- Kalhor, T.; Rajabipour, A.; Akram, A.; Sharifi, M. Environmental impact assessment of chicken meat production using life cycle assessment. Inf. Process. Agric. 2016, 3, 262–271. [Google Scholar] [CrossRef]
- Derya, Y. Global Poultry Industry and Trends. 2021. Available online: https://www.feedandadditive.com/global-poultry-industry-and-trends/ (accessed on 11 March 2021).
- Wright, R.; Parekh, S.; White, R.; Losey, D.P. Safely and autonomously cutting meat with a collaborative robot arm. Sci. Rep. 2024, 14, 299. [Google Scholar] [CrossRef] [PubMed]
- Templer, R.G.; Nicholls, H.R.; Nicolle, T. Robotics for meat processing—From research to commercialisation. Ind. Robot 1999, 26, 247–252. [Google Scholar] [CrossRef]
- Purnell, G. Robots for the meat industry. Ind. Robot 1995, 22, 22–24. [Google Scholar] [CrossRef]
- Kim, J.; Kwon, Y.; Kim, H.-W.; Seol, K.-H.; Cho, B.-K. Robot Technology for Pork and Beef Meat Slaughtering Process: A Review. Animals 2023, 13, 651. [Google Scholar] [CrossRef]
- Aly, B.A.; Low, T.; Long, D.; Baillie, C.; Brett, P. Robotics and sensing technologies in red meat processing: A review. Trends Food Sci. Technol. 2023, 132, 264–276. [Google Scholar] [CrossRef]
- Choi, S.; Zhang, G.; Fuhlbrigge, T.; Watson, T.; Tallian, R. Applications and requirements of industrial robots in meat processing. In Proceedings of the 2013 IEEE International Conference on Automation Science and Engineering (CASE), Madison, WI, USA, 17–20 August 2013; Volume 1, pp. 1167–1172. [Google Scholar] [CrossRef]
- Chowdhury, E.U.; Morey, A. Application of optical technologies in the US poultry slaughter facilities for the detection of poultry carcass condemnation. J. Sci. Food Agric. 2020, 100, 3736–3744. [Google Scholar] [CrossRef]
- Kang, R.; Yang, K.; Zhang, X.X.; Chen, K. Development of Online Detection and Processing System for Contaminants on Chicken Carcass Surface. Appl. Eng. Agric. 2016, 32, 133–139. [Google Scholar] [CrossRef]
- Joshi, K.; Norton, T.; Frías, J.M.; Tiwari, B.K. Robotics in meat processing. In Emerging Technologies in Meat Processing; Cummins, E.J., Lyngeds, J.G., Eds.; Wiley: Hoboken, NJ, USA, 2017. [Google Scholar]
- Khodabandehloo, K. Achieving robotic meat cutting. Anim. Front. 2022, 12, 3–4. [Google Scholar] [CrossRef]
- Nayik, G.A.; Muzaffar, K.; Gull, A. Robotics and Food Technology: A Mini Review. Food Eng. 2023, 148, 103623. [Google Scholar]
- Joutou, T.; Yanai, K. A food image recognition system with Multiple Kernel Learning. In Proceedings of the 16th IEEE International Conference on Image Processing, Cairo, Egypt, 7–10 November 2009; pp. 285–288. [Google Scholar] [CrossRef]
- Tanno, R.; Okamoto, K.; Yanai, K. DeepFoodCam: A DCNN-Based Real-Time Mobile Food Recognition System; ACM Digital Library: New York, NY, USA, 2016. [Google Scholar] [CrossRef]
- Misimi, E.; Øye, E.R.; Eilertsen, A.; Mathiassen, J.R.B.; Åsebø Berg, O.; Gjerstad, T.B.; Buljo, J.O.; Skotheim, Ø. GRIBBOT—Robotic 3D vision-guided harvesting of chicken fillets. Comput. Electron. Agric. 2016, 121, 84–100. [Google Scholar] [CrossRef]
- Echegaray, N.; Hassoun, A.; Jagtap, S.; Tetteh-Caesar, M.; Kumar, M.; Tomasevic, I.; Goksen, G.; Lorenzo, J.M. Meat 4.0: Principles and Applications of Industry 4.0 Technologies in the Meat Industry. Appl. Sci. 2022, 12, 6986. [Google Scholar] [CrossRef]
- Barbut, S. Automation and meat quality-global challenges. Meat Sci. 2014, 96, 335–345. [Google Scholar] [CrossRef] [PubMed]
- Walker, T.; Ahlin, K.; Joffe, B.P. Robotic Rehang with Machine Vision. In Proceedings of the 2021 ASABE Annual International, Virtual Meeting, 13–15 July 2021; p. 202100519. [Google Scholar] [CrossRef]
- Austin, A. How to Get a Processing Line Speed Waiver. WATTPoultry. 2019. Available online: https://www.wattagnet.com/articles/38224-how-to-get-a-processing-line-speed-waiver?v=preview (accessed on 5 August 2019).
- Ga, C.Q. Poultry Producers Scratch for Workers Amid rising Demand, Prices. The Atlanta Journal-Constitution. 2021. Available online: https://www.ajc.com/news/ga-poultry-producers-scratch-for-workers-amid-rising-demand-prices/AOBN7F6ZRZC2PPBDWDYUOECSY4/ (accessed on 19 May 2021).
- Tran, M.; Truong, S.; Fernandes, A.F.A.; Kidd, M.T.; Le, N. CarcassFormer: An End-to-end Transformer-based Framework for Simultaneous Localization, Segmentation and Classification of Poultry Carcass Defects. arXiv 2024, arXiv:2404.11429. [Google Scholar] [CrossRef]
- Xiong, Z.; Sun, D.W.; Pu, H.; Gao, W.; Dai, Q. Applications of emerging imaging techniques for meat quality and safety detection and evaluation: A review. Crit. Rev. Food Sci. Nutr. 2017, 104, 755–768. [Google Scholar] [CrossRef]
- Modzelewska-Kapituła, M.; Jun, S. The application of computer vision systems in meat science and industry—A review. Meat Sci. 2022, 182, 108904. [Google Scholar] [CrossRef]
- Zhao, S.; Hao, G.; Zhang, Y.; Wang, S. A real-time classification and detection method for mutton parts based on single shot multi-box detector. J. Food Process. Preserv. 2021, 45, e13749. [Google Scholar] [CrossRef]
- Sun, X.; Young, J.; Liu, J.H.; Newman, D. Prediction of pork loin quality using online computer vision system and artificial intelligence model. Meat Sci. 2018, 140, 72–77. [Google Scholar] [CrossRef]
- Pallerla, C.; Feng, Y.; Owens, C.M.; Bist, R.B.; Mahmoudi, S.; Sohrabipour, P.; Davar, A.; Wang, D. Neural network architecture search enabled wide-deep learning (NAS-WD) for spatially heterogeneous property aware chicken woody breast classification and hardness regression. Artif. Intell. Agric. 2024, 14, 73–85. [Google Scholar] [CrossRef]
- Matthews, D.; Pabiou, T.; Evans, R.D.; Beder, C.; Daly, A. Predicting carcass cut yields in cattle from digital images using artificial intelligence. Meat Sci. 2021, 181, 108671. [Google Scholar] [CrossRef]
- De La Iglesia, D.H.; Villarrubia González, G.; Vallejo García, M.; López Rivero, A.J.; De Paz, J.F. Non-invasive automatic beef carcass classification based on sensor network and image analysis. Future Gener. Comput. Syst. 2020, 113, 168–176. [Google Scholar] [CrossRef]
- Vajdi, M.; Varidi, M.J.; Varidi, M.; Mohebbi, M. Using electronic nose to recognize fish spoilage with an optimum classifier. J. Food Meas. Charact. 2019, 13, 1205–1217. [Google Scholar] [CrossRef]
- Ulum, M.F.; Maryani; Rahminiwati, M.; Choridah, L.; Hendra Setyawan, N.; Ain, K.; Mukhaiyar, U.; Pamungkas, F.A.; Jakaria; Garnadi, A.D. Assessment of Meat Content and Foreign Object Detection in Cattle Meatballs Using Ultrasonography, Radiography, and Electrical Impedance Tomography Imaging. Adv. Mech. Eng. 2024, 2024, 9526283. [Google Scholar] [CrossRef]
- Xu, B.; Wang, W.; Guo, L.; Chen, G.; Wang, Y.; Zhang, W.; Li, Y. Evaluation of Deep Learning for Automatic Multi-View Face Detection in Cattle. Agriculture 2021, 11, 1062. [Google Scholar] [CrossRef]
- Qiao, Y.; Truman, M.; Sukkarieh, S. Cattle segmentation and contour extraction based on Mask R-CNN for precision livestock farming. Comput. Electron. Agric. 2019, 164, 104958. [Google Scholar] [CrossRef]
- Jiang, K.; Xie, T.; Yan, R.; Wen, X.; Li, D.; Jiang, H.; Jiang, N.; Feng, L.; Duan, X. An Attention Mechanism-Improved YOLOv7 Object Detection Algorithm for Hemp Duck Count Estimation. Agriculture 2022, 12, 1659. [Google Scholar] [CrossRef]
- Li, H.; Wang, H.; Zhang, Y.; Li, L.; Ren, P. Underwater image captioning: Challenges, models, and datasets. arXiv 2022, arXiv:2201.02027. [Google Scholar] [CrossRef]
- Walter, F.C.; Damrich, S.; Hamprecht, F.A. MultiStar: Instance Segmentation of Overlapping Objects with Star-Convex Polygons. arXiv 2020, arXiv:2011.13228. [Google Scholar]
- Wang, D.; Ali, M.; Cobau, J.; Tao, Y. Designs of a customized active 3D scanning system for food processing applications. In Proceedings of the 2021 ASABE Annual International, Virtual Meeting, 12–16 July 2021; p. 2100388. [Google Scholar] [CrossRef]
- Ali, M.A.; Wang, D.; Tao, Y. Active Dual Line-Laser Scanning for Depth Imaging of Piled Agricultural Commodities for Itemized Processing Lines. Sensors 2024, 24, 2385. [Google Scholar] [CrossRef]
- Kirillov, A.; Mintun, E.; Ravi, N.; Mao, H.; Roll, C.; Gustafson, L.; Xiao, T.; Whitehead, S.; Berg, A.C.; Lo, W.-Y.; et al. Segment Anything: A Foundation Model for Image Segmentation. arXiv 2023, arXiv:2304.02643. [Google Scholar]
- Wang, H.; Köser, K.; Ren, P. Large foundation model empowered discriminative underwater image enhancement. IEEE Trans. Geosci. Remote. Sens. 2025, in press. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Wang, Z. Challenges and Opportunities in Robotic Food Handling: A Review. Front. Robot. 2022, 8, 789107. [Google Scholar] [CrossRef] [PubMed]
- An, G.; Wang, Y.; Zeng, K.; Zhu, Q.; Yuan, X. Deep spatial and discriminative feature enhancement network for stereo matching. Vis. Comput. 2024, 40, 1–16. [Google Scholar] [CrossRef]
- Teledyne Vision Solutions. Accuracy of Stereo Vision Camera Disparity Depth Calculations. 2023. Available online: https://www.teledynevisionsolutions.com/support/support-center/technical-guidance/iis/accuracy-of-stereo-vision-camera-disparity-depth-calculations/ (accessed on 16 January 2025).
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar] [CrossRef]
- Zhao, Z.; Cao, Q.; Zhang, X. Segmentation and Tracking of Vegetable Plants by Exploiting Vegetable Shape Feature for Precision Spray of Agricultural Robots. arXiv 2023, arXiv:2306.13518. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Howard, A.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 10–15 June 2019; Volume 97, pp. 6105–6114. [Google Scholar]
- Chen, A.; Li, X.; He, T.; Zhou, J.; Chen, D. Advancing in RGB-D Salient Object Detection: A Survey. Appl. Sci. 2024, 14, 8078. [Google Scholar] [CrossRef]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step Height (mm) | Height Value (mm) from Right Laser | Height Value (mm) from Left Laser | Final Height Value Using Both Lasers (mm) | Height Value from Real-Sense (mm) |
|---|---|---|---|---|
| 50 | 43.09 | 46.15 | 45.89 | 27.13 |
| 100 | 97.00 | 99.85 | 98.37 | 83.58 |
| 150 | 143.91 | 147.92 | 145.85 | 202.00 |
| Mask R-CNN RGB Backbones | mAP IoU = 0.50:0.95 | Center Offset (Pixels) | Training Time (Min) | Test Time (s/Image) | ||
|---|---|---|---|---|---|---|
| RGB | RGBD | RGB | RGBD | |||
| ResNet50 | 0.631 | 0.680 | 22.09 | 8.99 | 197 | 0.0392 |
| ResNet101 | 0.508 | 0.638 | 22.18 | 13.34 | 327 | 0.0554 |
| VGG16 | 0.132 | 0.466 | 19.57 | 21.19 | 260 | 0.0383 |
| EfficientNet | 0.132 | 0.565 | 22.58 | 16.32 | 181 | 0.0546 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sohrabipour, P.; Pallerla, C.K.R.; Davar, A.; Mahmoudi, S.; Crandall, P.; Shou, W.; She, Y.; Wang, D. Cost-Effective Active Laser Scanning System for Depth-Aware Deep-Learning-Based Instance Segmentation in Poultry Processing. AgriEngineering 2025, 7, 77. https://doi.org/10.3390/agriengineering7030077
Sohrabipour P, Pallerla CKR, Davar A, Mahmoudi S, Crandall P, Shou W, She Y, Wang D. Cost-Effective Active Laser Scanning System for Depth-Aware Deep-Learning-Based Instance Segmentation in Poultry Processing. AgriEngineering. 2025; 7(3):77. https://doi.org/10.3390/agriengineering7030077
Chicago/Turabian StyleSohrabipour, Pouya, Chaitanya Kumar Reddy Pallerla, Amirreza Davar, Siavash Mahmoudi, Philip Crandall, Wan Shou, Yu She, and Dongyi Wang. 2025. "Cost-Effective Active Laser Scanning System for Depth-Aware Deep-Learning-Based Instance Segmentation in Poultry Processing" AgriEngineering 7, no. 3: 77. https://doi.org/10.3390/agriengineering7030077
APA StyleSohrabipour, P., Pallerla, C. K. R., Davar, A., Mahmoudi, S., Crandall, P., Shou, W., She, Y., & Wang, D. (2025). Cost-Effective Active Laser Scanning System for Depth-Aware Deep-Learning-Based Instance Segmentation in Poultry Processing. AgriEngineering, 7(3), 77. https://doi.org/10.3390/agriengineering7030077