

A Data-Driven Method for Water Quality Analysis and Prediction for Localized Irrigation

 , ,
, ,  , , , and
, , , and
Abstract
1. Introduction
- RQ1: What components should be considered to develop a data-driven water quality analysis and monitoring methodology for irrigation-related purposes?
- RQ2: How did the water quality vary in the studied areas for the three hydrological years considered (flood, drought, and average year), considering indices related to soil and irrigation systems?
2. Theoretical Foundations
2.1. Irrigation Water Quality Metrics
2.2. Use of AI for Water Quality Evaluation
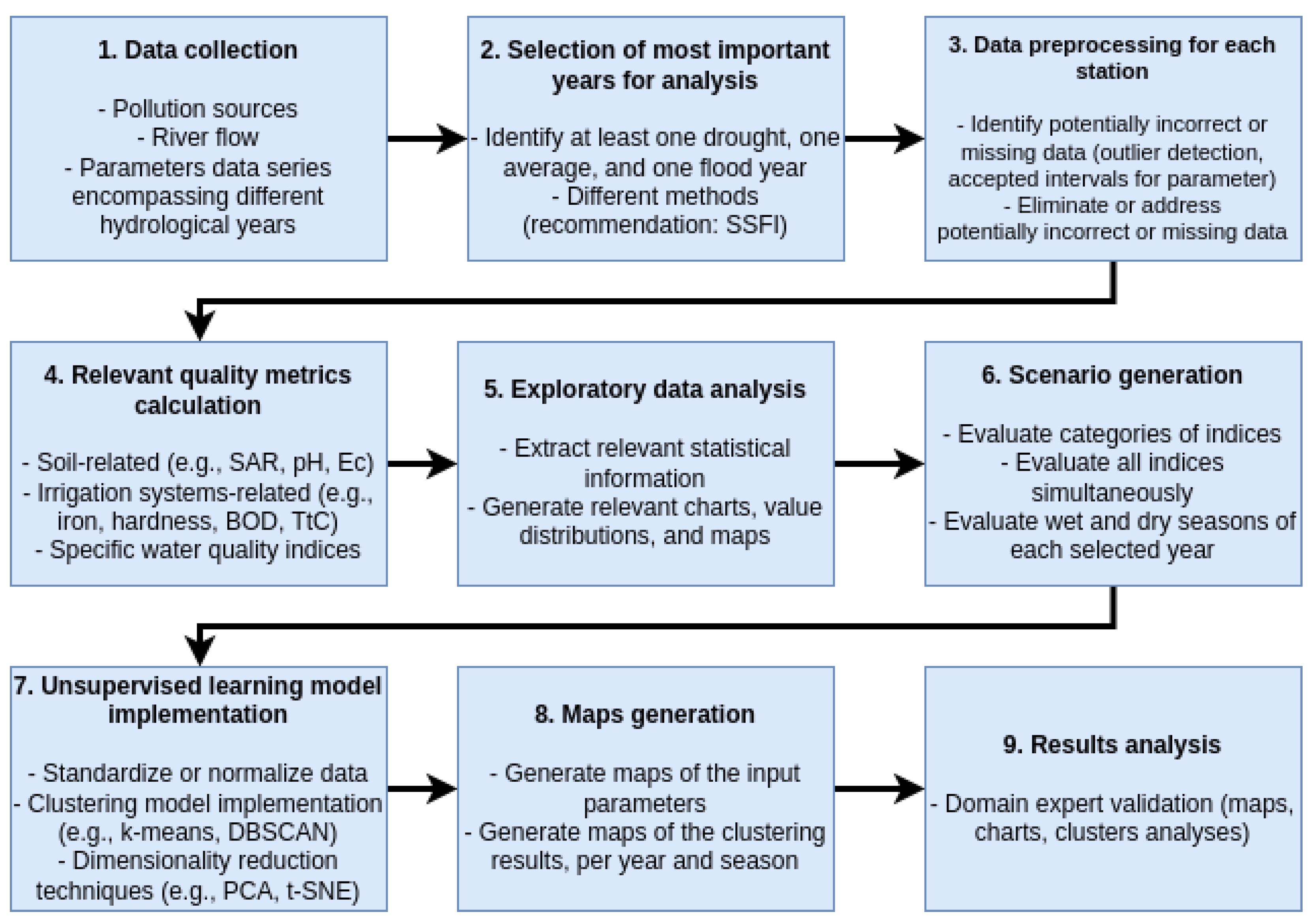
3. Methodology Proposed
- Data collection: This step involves collecting data for all relevant parameters and indices from all stations in the basin that encompass the regions that will be studied. For some decision-makers, the whole basin may be of interest, such as for policy making. For specific farmers, particular regions of the basin may be more critical. Although many factors could be considered, three essential ones are (i) the current presence of pollution sources (such as industries and large-size cities); (ii) the river flow; and (iii) the data series encompassing hydrological years with different characteristics (such as years of floods and of droughts);
- The selection of the most important years for analysis: This step is related to selecting the hydrological years that will be analyzed and should encompass at least one flood and one drought year. We also recommend analyzing one year with average flow (which we refer to as ’average’ in this paper). Several criteria and methods are used to identify in the dataset if each year is a flood, average, or drought year. Nevertheless, we recommend using a simple and easily explainable method based on streamflow, such as the standardized streamflow index (SSFI). This method calculates the average streamflow for the whole basin for each year. Then, a criterion for identifying if the year had excess flow (indicative of a flood year) or a considerably lower flow than average (indicative of a drought year) is applied. Lastly, the years can be selected considering this classification. In the case of domain-expert selection (as was performed in this work), we recommend showing the chart of the SSFI with the triggers for flood and drought for the domain expert and then letting them select the years to be analyzed. However, the whole process can easily be automated by incorporating rules for defining flood and drought years. In the absence of previous knowledge, the years chosen may have the lowest SSFI, the highest SSFI, and the year with the SSFI closest to the average value;
- Data preprocessing for each station: This aims to identify, eliminate, and address potentially incorrect or missing data. In the case of addressing missing data, different imputation methods can be used, or the sample can be discarded, depending on the specific context (with more data available, it is possible to discard data points without losing significant information). In the case of potentially incorrect data, identifying and addressing it is more challenging. We recommend identifying the accepted intervals for the parameter, considering both physical aspects (for example, pH between 0 and 14 or conductivity lower than the limit for freshwater). If data imputation is needed, several methods should be evaluated based on the value distribution for the specific parameter. The main options used are the median, average, or moving average values. If the parameter distribution is close to a normal distribution, the average is traditionally used. The median is more indicated if it differs considerably from a normal distribution.
- Relevant quality metric calculation: In this step, relevant quality metrics or indices are chosen based on a literature review, legislation, or a domain expert recommendation. Several different dimensions can be considered, but the essential ones we recommend are (i) soil-related metrics, such as the sodium adsorption ratio (SAR), pH, and conductivity, which may directly influence the soil and plants; and (ii) irrigation system-related metrics, such as dissolved iron, hardness, biochemical oxygen demand, and the concentration of some microorganisms, which may cause problems such as drip clogging. As unsupervised learning models and techniques extract information directly from the data provided without prior or external knowledge, it is crucial that the dataset generated contains high-quality data. Although evaluating data quality is outside this work’s scope, we refer the reader to the work by Gong et al. [47], which encompasses an in-depth review of several datasets and data quality assessment techniques and criteria.
- Exploratory data analysis: After the quality metrics (also referred to as ’parameters’ in this paper) are selected, they must be analyzed. This encompasses (i) extracting relevant statistical information (such as the mean, mode, median, standard deviation, and variation coefficient); (ii) generating important charts to better understand the data (such as boxplots and line charts); (iii) analyzing the value distributions for each parameter; (iv) identifying outliers; and (v) developing maps to illustrate the average values of each parameter for each season and hydrological year. This step is essential to guiding decisions such as on (i) which scenarios should be generated and evaluated; (ii) if additional data collection or processing is needed; and (iii) the potential outliers impacting the final results. Although the automation of this analysis is outside the scope of this work, it is important to emphasize that part of this evaluation can be automated, as described by Milo and Somech [48].
- Scenario generation: This step aims to define and create the scenarios that will be evaluated. At least the following three aspects must be considered in different scenarios: (i) the evaluation of indices into relevant categories (such as soil-related and irrigation system-related indices); (ii) the evaluation of all indices simultaneously; and (iii) the evaluation of the wet and dry seasons of each selected year. Additional scenarios can be generated using different unsupervised learning models and indices. Additionally, if outliers were detected during the processing or exploratory data analysis steps, it is essential to evaluate scenarios with and without outliers for each parameter that presented outlier values. This is important because sometimes the outliers are not incorrect values but extreme ones with a physical, chemical, or biological explanation. This is the case of the high concentrations of iron and biological-related parameters near populous cities. A traditional outlier detection and removal method, such as the boxplot technique, would eliminate these high values. However, they are essential to understanding water quality in the river basin in those areas. Therefore, we recommend analyzing different scenarios, such as the dataset without outliers, the dataset with all values (including outliers), and a dataset composed only of the outliers.
- Unsupervised learning model implementation: In this step, an unsupervised learning model extracts valuable information from each scenario and helps generate insights for data analysis and decision making. Different methods can be used, depending on the characteristics of the data and the amount of data available. In some cases, a clustering model may be enough to extract information that improves decision making. In other cases, dimensionality reduction techniques (such as principal components analysis, PCA, or t-distributed stochastic neighbor embedding, t-SNE) can improve the results generated. However, data must be standardized or normalized before using such techniques and models, as parameters with intervals with different orders of magnitude may impact the results considerably. In general, we recommend clustering techniques to always be used in the proposed method, as one of the main objectives is to obtain and evaluate clusters of data that may bring important information related to water quality for irrigation purposes. However, in cases where there are many variables, a dimensionality reduction method is indicated to improve the exploratory data analysis and the results of the clustering model. Although there is no clear rule for what can be considered many variables, we recommend using a dimensionality reduction method if there are more than ten parameters, especially if there is the possibility that some of these parameters are partially dependent upon each other. For an in-depth evaluation of unsupervised learning methods and their applications, we refer the reader to the work by Ghahramani [11].
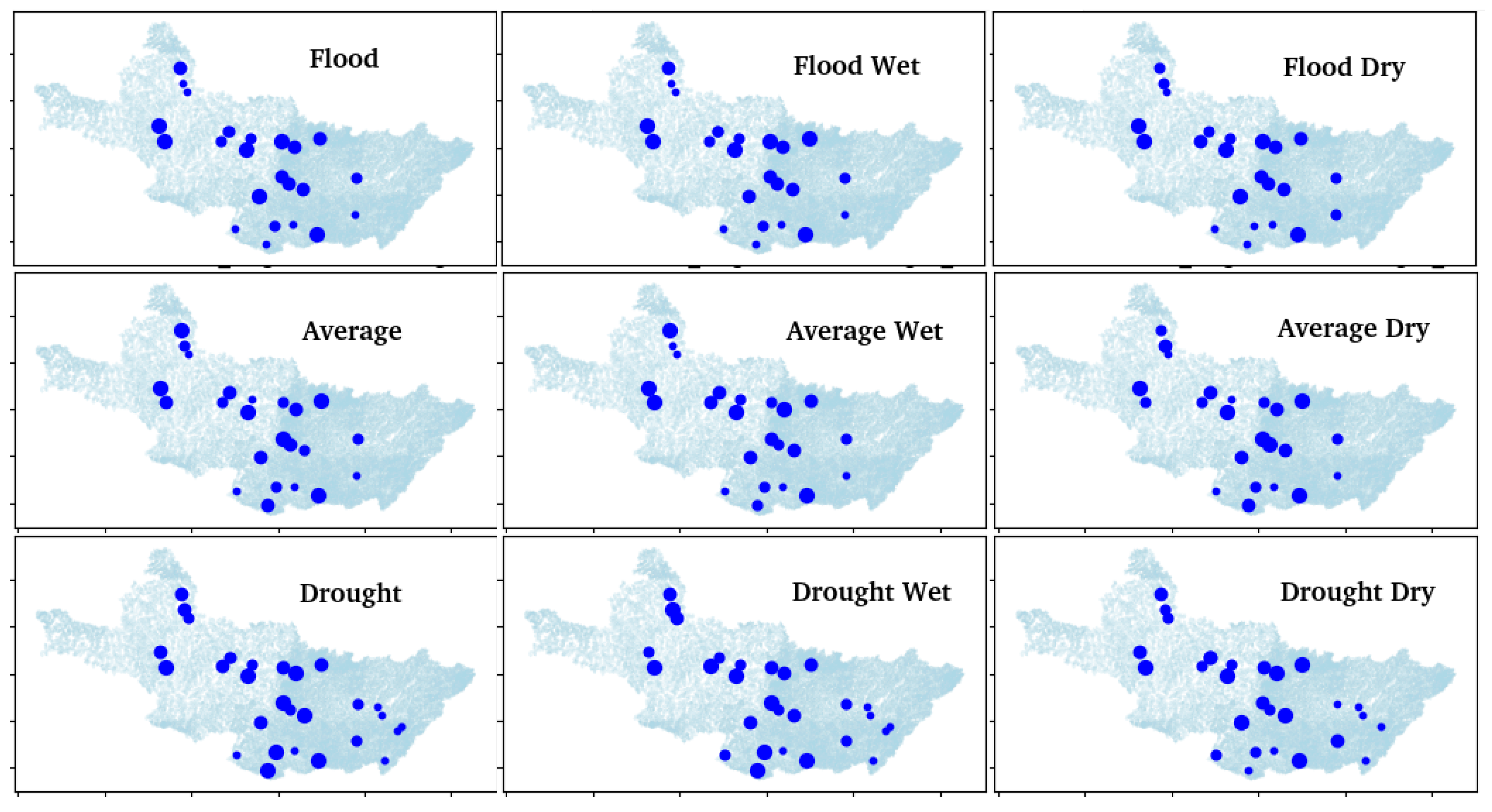
- Map generation: This step encompasses generating maps of the parameters used as inputs for the clustering model (the indices calculated in step 4) and the clustering results used in step 7. At least one map should be generated for the clustering results for each scenario for each year or season, and one map should be generated for each parameter for each year or season. Among the options for map types that can be generated, we recommend creating one map for each parameter, separating the data into quartiles (which improves the expert validation and decision making); displaying the maps of the same parameter (or scenario) together (to make comparisons easier); displaying all scenarios together for the clustering results (to make comparisons easier); and evaluating the possibility of creating maps of differences (e.g., instead of plotting the quantile for the wet and dry seasons of a particular year as separate maps, creating a map of the quantile difference between both seasons).
- Result analysis: The last step of the proposed method, which should be conducted by a domain expert with the results of the previous steps, is crucial for better decision making. In this step, the domain expert (or a group of domain experts) should compare and evaluate each parameter for each season or year (using the results of step 5), the results of the clustering of each scenario (using the results of step 7), and the maps generated (using the results of step 8). A risk analysis and temporal, spatial, and spatiotemporal analyses of each metric or group of metrics can also be conducted. This step is the most difficult to automate, as it may vary from project to project in terms of the indices and parameters used as inputs, their distributions, the presence of outliers, the scenarios generated, and what decisions the decision-makers will make considering the results, among others.
4. Water Quality at the PCJ Basin
4.1. Case Study Description
- Data collection: Official data were collected from the Infoáguas Online System (https://sistemainfoaguas.cetesb.sp.gov.br/), accessed on 2 February 2024. The data download encompassed the interval from 2011 to 2017, considering all stations and cities in the PCJ basin. Then, the stations located near the cities with the highest demand for irrigation were selected (as not all regions in the basin have a high demand for water for irrigation purposes). Figure 3 contains the map of the PCJ basin, illustrating the location of the stations. Although not present in the dataset, Madeira et al. [53] indicated that rivers are very high-risk quotients for pesticides and industrial chemicals, and close to 45 contaminants are present in the PCJ basin, located in an agricultural and industrial area.
- The selection of the most important years for analysis: The SSFI was used to select one hydrological year for each type: higher streamflow (2011–2012, which we called ‘flood’); average streamflow (2012–2013, which we called ‘average’); and lower streamflow (2014–2015, which we called ‘drought’). The domain experts then validated these choices. Figure 4 illustrates the SSFI calculated for the whole dataset, emphasizing the selected years.
- Data preprocessing for each station: As the data were already available after an initial preprocessing, no missing data were identified. First, we aggregated the data monthly. Additionally, considering the accepted intervals for the most important indices available on the dataset, no incorrect data were detected.
- Relevant quality metrics calculation: After consulting the domain experts and evaluating the data available for each quality metric, we decided to consider four relevant metrics [23,26,30,33,54] divided into two groups: (i) soil-related metrics: pH and electrical conductivity EC of water; and (ii) irrigation system-related metrics: total iron Fe, hardness, biochemical oxygen demand (BOD), and the concentration of thermotolerant coliforms (TtC). Other important metrics were lacking for most of the dataset or could not be calculated (such as the case for SAR).
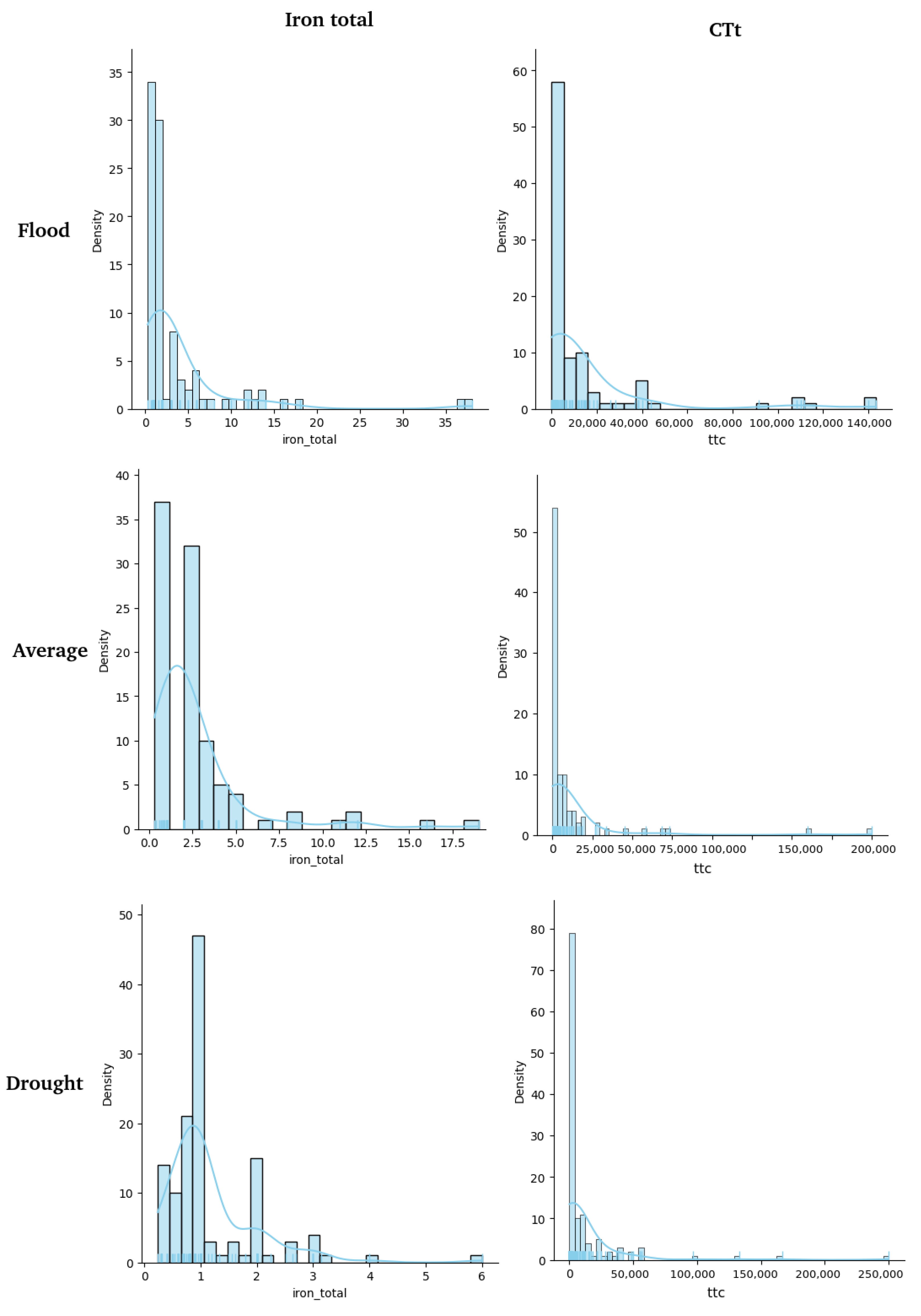
- Exploratory data analysis: In this step, three analyses were conducted for all parameters for each year and season: an (i) analysis of statistical information, considering the mean, median, standard deviation, minimum, and maximum values; (ii) analysis of distribution using a kernel density estimate (KDE) plot; and (iii) analysis of potential outliers using a boxplot. Additionally, maps were generated for all parameters for each year and season, separating the values into four quartiles.
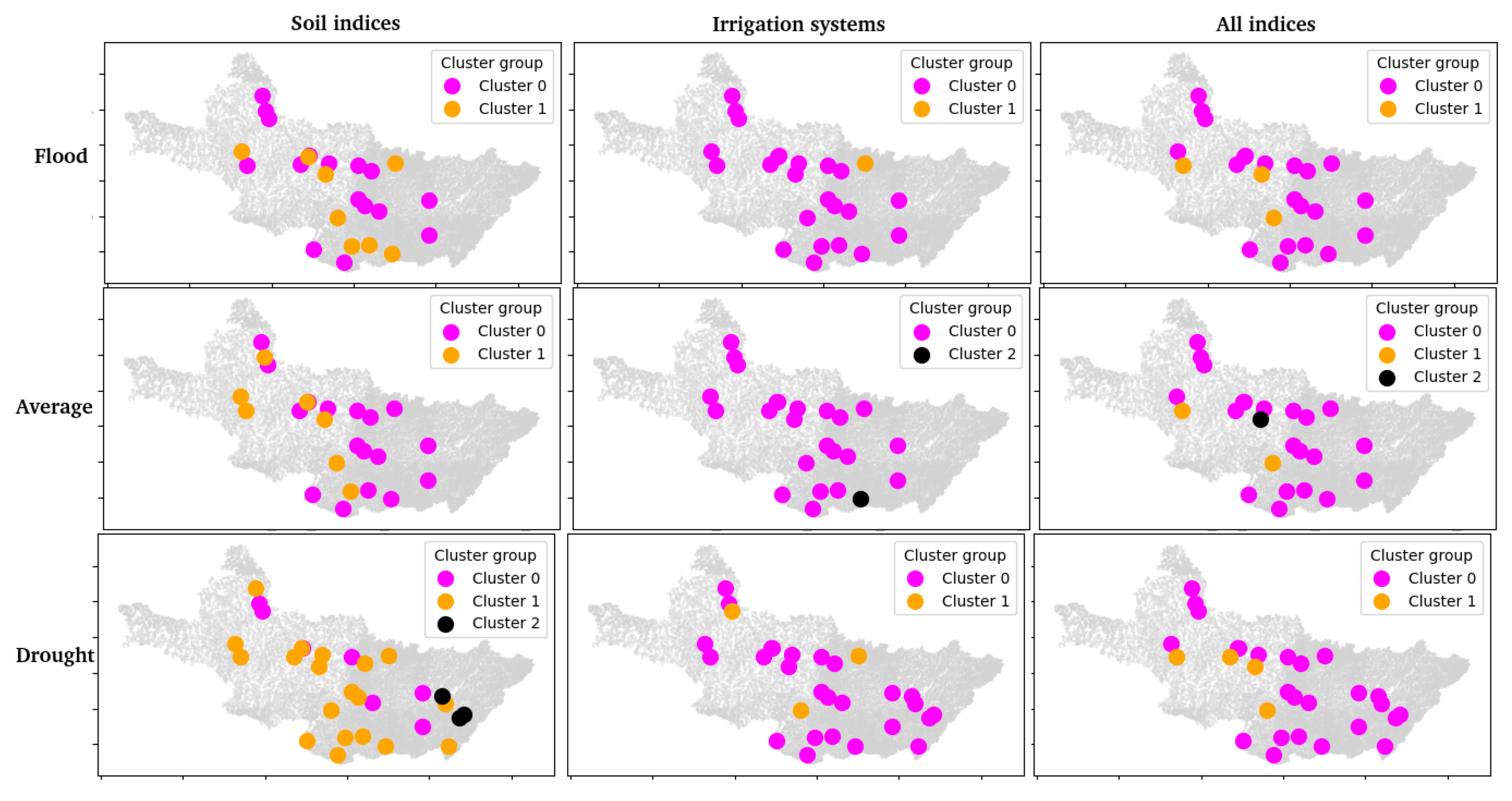
- Scenario generation: Three scenarios (S) were generated for each dataset (flood, average, drought) related to different metrics used as inputs for the clustering of each year. Table 2 contains the scenarios evaluated, considering their inputs and datasets.
- Unsupervised learning model implementation: The k-means method is the most used clustering technique, spanning over 50 years of applications [55,56]. Therefore, it was used in the case study explored in this paper. According to Jain [55] and Steinley [56], the k-means technique has three main steps: (i) creating points to use as cluster centers in an n-dimensional space (the number of dimensions depends on the number of features on the dataset); (ii) associating all points in the dataset with the closest cluster centers (considering a specified distance metric); and (iii) recalculating the cluster centers, considering the new associations. Steps (ii) and (iii) are repeated until a stop criterion is met. This clustering method was implemented in the three scenarios. The most important hyperparameter for defining for the k-means method is the number of clusters or k. To define this hyperparameter for each scenario, three traditional methods were used: the elbow method, the dendrogram, and the silhouette score.
- Map generation: Maps were generated for all the inputs for each season, as well as for the results of the clustering implementation for each scenario.
- Result analysis: Two domain experts from the hydrology and irrigation domains evaluated the results generated in Steps 5, 7, and 8 while also evaluating the usefulness of the proposed methodology in relation to traditional analyses.
4.2. Exploratory Data Analysis
4.3. Result Analysis and Domain Expert Validation
5. Discussion
6. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zuffo, A.C.; Duarte, S.N.; Jacomazzi, M.A.; Cucio, M.S.; Galbetti, M.V. The Cantareira System, the Largest South American Water Supply System: Management History, Water Crisis, and Learning. Hydrology 2023, 10, 132. [Google Scholar] [CrossRef]
- Lopes, T.R.; Folegatti, M.V.; Duarte, S.N.; Moster, C.; Zolin, C.A.; Oliveira, R.K.; Moura, L.B. Economic value of environmental services regulating flow and maintaining water quality in the Piracicaba River basin, Brazil. J. Water Resour. Plan. Manag. 2023, 149, 05023008. [Google Scholar] [CrossRef]
- Laaraj, M.; Benaabidate, L.; Mesnage, V.; Lahmidi, I. Assessment and modeling of surface water quality for drinking and irrigation purposes using water quality indices and GIS techniques in the Inaouene watershed, Morocco. Model. Earth Syst. Environ. 2024, 10, 2349–2374. [Google Scholar] [CrossRef]
- Wu, B.; Tian, F.; Zhang, M.; Piao, S.; Zeng, H.; Zhu, W.; Liu, J.; Elnashar, A.; Lu, Y. Quantifying global agricultural water appropriation with data derived from earth observations. J. Clean. Prod. 2022, 358, 131891. [Google Scholar] [CrossRef]
- Soares, S.R.A.; Fontenelle, T.H.; Ferreira, D.A.C.; Gonçalves, M.V.C.; Dourado Neto, D.; Barretto, A.G.d.O.P.; Fendrich, A.N.; Safanelli, J.L.; Araujo, M.A.d.; Coutinho, P.A.Q.; et al. Atlas Irrigação: Uso da água na Agricultura Irrigada; ANA: Brasília, Brazil, 2021. [Google Scholar]
- Rahu, M.A.; Shaikh, M.M.; Karim, S.; Chandio, A.F.; Dahri, S.A.; Soomro, S.A.; Ali, S.M. An IoT and machine learning solutions for monitoring agricultural water quality: A robust framework. Mehran Univ. Res. J. Eng. Technol. 2024, 43, 192–205. [Google Scholar] [CrossRef]
- Egbueri, J.C.; Mgbenu, C.N.; Digwo, D.C.; Nnyigide, C.S. A multi-criteria water quality evaluation for human consumption, irrigation and industrial purposes in Umunya area, southeastern Nigeria. Int. J. Environ. Anal. Chem. 2023, 103, 3351–3375. [Google Scholar] [CrossRef]
- Pereira, M.A.; Marques, R.C. Sustainable water and sanitation for all: Are we there yet? Water Res. 2021, 207, 117765. [Google Scholar] [CrossRef] [PubMed]
- Wu, Z.; Lai, X.; Li, K. Water quality assessment of rivers in Lake Chaohu Basin (China) using water quality index. Ecol. Indic. 2021, 121, 107021. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R.; Taylor, J. An Introduction to Statistical Learning: With Applications in Python; Springer Nature: Berlin/Heidelberg, Germany, 2023. [Google Scholar]
- Ghahramani, Z. Unsupervised learning. In Advanced Lectures on Machine Learning: ML Summer Schools 2003, Canberra, Australia, 2–14 February 2003, Tübingen, Germany, 4–16 August 2003, Revised Lectures; Springer: Berlin/Heidelberg, Germany, 2004; pp. 72–112. [Google Scholar]
- Aliashrafi, A.; Zhang, Y.; Groenewegen, H.; Peleato, N.M. A review of data-driven modelling in drinking water treatment. Rev. Environ. Sci. Bio/Technol. 2021, 20, 985–1009. [Google Scholar] [CrossRef]
- Muniz, G.L.; Duarte, F.V.; Rakocevic, M. Assessment and optimization of carbonated hard water softening with moringa oleifera seeds. Desalin. Water Treat 2020, 173, 156–165. [Google Scholar] [CrossRef]
- Muniz, G.L.; Camargo, A.P.; Signorelli, F.; Bertran, C.A.; Pereira, D.J.; Frizzone, J.A. Influence of suspended solid particles on calcium carbonate fouling in dripper labyrinths. Agric. Water Manag. 2022, 273, 107890. [Google Scholar] [CrossRef]
- Abou-Shady, A.; Siddique, M.S.; Yu, W. A Critical Review of Innovations and Perspectives for Providing Adequate Water for Sustainable Irrigation. Water 2023, 15, 3023. [Google Scholar] [CrossRef]
- Baeza, R.; Contreras, J.I. Evaluation of thirty-eight models of drippers using reclaimed water: Effect on distribution uniformity and emitter clogging. Water 2020, 12, 1463. [Google Scholar] [CrossRef]
- Coelho, R.D.; de Almeida, A.N.; de Oliveira Costa, J.; de Sousa Pereira, D.J. Mobile drip irrigation (MDI): Clogging of high flow emitters caused by dragging of driplines on the ground and by solid particles in the irrigation water. Agric. Water Manag. 2022, 263, 107454. [Google Scholar] [CrossRef]
- Lv, C.; Niu, W.; Du, Y.; Sun, J.; Dong, A.; Wu, M.; Mu, F.; Zhu, J.; Siddique, K.H. A meta-analysis of labyrinth channel emitter clogging characteristics under Yellow River water drip tape irrigation. Agric. Water Manag. 2024, 291, 108634. [Google Scholar] [CrossRef]
- Li, R.; Han, Q.; Dong, C.; Nan, X.; Li, H.; Sun, H.; Li, H.; Li, P.; Hu, Y. Effect and Mechanism of Micro-Nano Aeration Treatment on a Drip Irrigation Emitter Based on Groundwater. Agriculture 2023, 13, 2059. [Google Scholar] [CrossRef]
- Perboni, A.; Sensibilidade de Gotejadores à Obstrução por Partículas de Areia. Biblioteca Digital de Teses e Dissertações da Universidade de São Paulo. 2016. Available online: https://irriga.fca.unesp.br/index.php/irriga/article/view/2162 (accessed on 15 February 2024).
- Ofori, S.; Abebrese, D.K.; Ruzickova, I.; Wanner, J. Reuse of Treated Wastewater for Crop Irrigation: Water Suitability, Fertilization Potential, and Impact on Selected Soil Physicochemical Properties. Water 2024, 16, 484. [Google Scholar] [CrossRef]
- Storlie, C.; Treating Drip Irrigation System with Chlorine. Ruthgers Cooperative Extension Services Fact Sheet FS795. 1995. Available online: https://njaes.rutgers.edu/FS795/ (accessed on 30 January 2024).
- CETESB. Apêndice D: Índices de Qualidade das Águas. 2020. Available online: https://cetesb.sp.gov.br/aguas-interiores/wp-content/uploads/sites/12/2020/09/Apendice-D-Indices-de-Qualidade-das-Aguas.pdf (accessed on 30 January 2024).
- Gradilla-Hernández, M.S.; de Anda, J.; Garcia-Gonzalez, A.; Montes, C.Y.; Barrios-Piña, H.; Ruiz-Palomino, P.; Díaz-Vázquez, D. Assessment of the water quality of a subtropical lake using the NSF-WQI and a newly proposed ecosystem specific water quality index. Environ. Monit. Assess. 2020, 192, 296. [Google Scholar] [CrossRef] [PubMed]
- Abdul Maulud, K.N.; Fitri, A.; Wan Mohtar, W.H.M.; Wan Mohd Jaafar, W.S.; Zuhairi, N.Z.; Kamarudin, M.K.A. A study of spatial and water quality index during dry and rainy seasons at Kelantan River Basin, Peninsular Malaysia. Arab. J. Geosci. 2021, 14, 1–19. [Google Scholar] [CrossRef]
- Ayers, R.S.; Westcot, D.W. Water Quality for Agriculture; Food and agriculture organization of the United Nations Rome, FAO: Rome, Italy, 1985; Volume 29. [Google Scholar]
- Aliyu, T.; Balogun, O.; Namani, C.; Olatinwo, L.; Aliyu, A. Assessment of the presence of metals and quality of water used for irrigation in Kwara State, Nigeria. Pollution 2017, 3, 461–470. [Google Scholar]
- Aminiyan, M.M.; Aitkenhead-Peterson, J.; Aminiyan, F.M. Evaluation of multiple water quality indices for drinking and irrigation purposes for the Karoon river, Iran. Environ. Geochem. Health 2018, 40, 2707–2728. [Google Scholar] [CrossRef] [PubMed]
- Malakar, A.; Snow, D.D.; Ray, C. Irrigation water quality—A contemporary perspective. Water 2019, 11, 1482. [Google Scholar] [CrossRef]
- Muniz, G.L.; Oliveira, A.L.G.; Benedito, M.G.; Cano, N.D.; da Camargo, A.P.; da Silva, A.J. Risk Evaluation of Chemical Clogging of Irrigation Emitters via Geostatistics and Multivariate Analysis in the Northern Region of Minas Gerais, Brazil. Water 2023, 15, 790. [Google Scholar] [CrossRef]
- Singh, V.K.; Bikundia, D.S.; Sarswat, A.; Mohan, D. Groundwater quality assessment in the village of Lutfullapur Nawada, Loni, District Ghaziabad, Uttar Pradesh, India. Environ. Monit. Assess. 2012, 184, 4473–4488. [Google Scholar] [CrossRef] [PubMed]
- World Health Organization. WHO Guidelines for Drinking-Water Quality: Fourth Edition Incorporating the First Addendum. 2017. Available online: https://iris.who.int/bitstream/handle/10665/254637/9789241549950-eng.pdf?sequence=1 (accessed on 20 May 2024).
- de Almeida, O. Qualidade da água de Irrigação; Embrapa Mandioca e Fruticultura: Cruz das Almas, Brazil, 2010. [Google Scholar]
- Aminu, I.I. A novel approach to predict water quality index using machine learning models: A review of the methods employed and future possibilities. Glob. J. Eng. Technol. Adv. 2022, 13, 026–037. [Google Scholar] [CrossRef]
- Babbar, R.; Babbar, S. Predicting river water quality index using data mining techniques. Environ. Earth Sci. 2017, 76, 1–15. [Google Scholar] [CrossRef]
- Giri, S. Water quality prospective in Twenty First Century: Status of water quality in major river basins, contemporary strategies and impediments: A review. Environ. Pollut. 2021, 271, 116332. [Google Scholar] [CrossRef] [PubMed]
- Mokhtar, A.; Elbeltagi, A.; Gyasi-Agyei, Y.; Al-Ansari, N.; Abdel-Fattah, M.K. Prediction of irrigation water quality indices based on machine learning and regression models. Appl. Water Sci. 2022, 12, 76. [Google Scholar] [CrossRef]
- Nguyen, D.P.; Ha, H.D.; Trinh, N.T.; Nguyen, M.T. Application of artificial intelligence for forecasting surface quality index of irrigation systems in the Red River Delta, Vietnam. Environ. Syst. Res. 2023, 12, 24. [Google Scholar] [CrossRef]
- Singha, S.; Pasupuleti, S.; Singha, S.S.; Singh, R.; Kumar, S. Prediction of groundwater quality using efficient machine learning technique. Chemosphere 2021, 276, 130265. [Google Scholar] [CrossRef] [PubMed]
- Singh, G.; Singh, J.; Wani, O.A.; Egbueri, J.C.; Agbasi, J.C. Assessment of groundwater suitability for sustainable irrigation: A comprehensive study using indexical, statistical, and machine learning approaches. Groundw. Sustain. Dev. 2024, 24, 101059. [Google Scholar] [CrossRef]
- Nasir, N.; Kansal, A.; Alshaltone, O.; Barneih, F.; Sameer, M.; Shanableh, A.; Al-Shamma’a, A. Water quality classification using machine learning algorithms. J. Water Process Eng. 2022, 48, 102920. [Google Scholar] [CrossRef]
- Dritsas, E.; Trigka, M. Efficient data-driven machine learning models for water quality prediction. Computation 2023, 11, 16. [Google Scholar] [CrossRef]
- Storey, M.V.; Van der Gaag, B.; Burns, B.P. Advances in on-line drinking water quality monitoring and early warning systems. Water Res. 2011, 45, 741–747. [Google Scholar] [CrossRef] [PubMed]
- Nafsin, N.; Li, J. Using CANARY event detection software for water quality analysis in the Milwaukee River. J. Hydro-Environ. Res. 2021, 38, 117–128. [Google Scholar] [CrossRef]
- De Silva, D.; Alahakoon, D. An artificial intelligence life cycle: From conception to production. Patterns 2022, 3, 100489. [Google Scholar] [CrossRef] [PubMed]
- Polyzotis, N.; Roy, S.; Whang, S.E.; Zinkevich, M. Data lifecycle challenges in production machine learning: A survey. ACM SIGMOD Rec. 2018, 47, 17–28. [Google Scholar] [CrossRef]
- Gong, Y.; Liu, G.; Xue, Y.; Li, R.; Meng, L. A survey on dataset quality in machine learning. Inf. Softw. Technol. 2023, 162, 107268. [Google Scholar] [CrossRef]
- Milo, T.; Somech, A. Automating exploratory data analysis via machine learning: An overview. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data, Portland, OR, USA, 14–19 June 2020; pp. 2617–2622. [Google Scholar]
- Silva, A.A.F.d.; Esteves, K.E. Ecological and biological patterns of stream fish studies from the Piracicaba-Capivari-Jundiaí Basin (PCJ Basin, SP) assessed through a systematic review. Biota Neotrop. 2023, 23, e20221440. [Google Scholar] [CrossRef]
- ANA. Agência Nacional de Águas e Saneamento Básico: PCJ. 2024. Available online: https://www.gov.br/ana/pt-br/assuntos/gestao-das-aguas/planos-de-recursos-hidricos/planos-de-recursos-hidricos-de-bacias-hidrograficas/planos-de-bacias-hidrograficas-interfederativas/pcj (accessed on 20 February 2024).
- PCJ. Agência das Bacias do PCJ. 2024. Available online: https://agencia.baciaspcj.org.br/bacias-pcj/localizacao/ (accessed on 20 February 2024).
- das Bacias PCJ, C.P. Plano de Recursos Hídricos das Bacias Hidrográficas dos Rios Piracicaba, Capivari e Jundiaí, 2020 a 2035: Relatório Final./Executado por Consórcio Profill-Rhama e Organizado porComitês PCJ/Agência das Bacias PCJ. 2024. Available online: https://drive.google.com/file/d/1Vom4DKOTzTnvrIKOmEJtZlPMzScAcOOe/view (accessed on 20 February 2024).
- Madeira, C.L.; Acayaba, R.D.; Santos, V.S.; Villa, J.E.; Jacinto-Hernández, C.; Azevedo, J.A.T.; Elias, V.O.; Montagner, C.C. Uncovering the impact of agricultural activities and urbanization on rivers from the Piracicaba, Capivari, and Jundiaí basin in São Paulo, Brazil: A survey of pesticides, hormones, pharmaceuticals, industrial chemicals, and PFAS. Chemosphere 2023, 341, 139954. [Google Scholar] [CrossRef]
- Nakayama, F.; Bucks, D. Trickles Irrigation for Crop Production; US Department of Agriculture, Agricultural Research Service, US Water Conservation Laboratory: Phoenix, AZ, USA, 1986; p. 383.
- Jain, A.K. Data clustering: 50 years beyond K-means. Pattern Recognit. Lett. 2010, 31, 651–666. [Google Scholar] [CrossRef]
- Steinley, D. K-means clustering: A half-century synthesis. Br. J. Math. Stat. Psychol. 2006, 59, 1–34. [Google Scholar] [CrossRef] [PubMed]
- Wickham, H.; François, R.; Henry, L.; Müller, K.; Vaughan, D. dplyr: A Grammar of Data Manipulation. 2023. Available online: https://dplyr.tidyverse.org (accessed on 15 February 2024).
- Grolemund, G.; Wickham, H. Dates and Times Made Easy with lubridate. J. Stat. Softw. 2011, 40, 1–25. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef] [PubMed]
- McKinney, W. Data Structures for Statistical Computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; Stéfan van der Walt, S., Millman, J., Eds.; pp. 56–61. [Google Scholar] [CrossRef]
- Hunter, J.D. Matplotlib: A 2D graphics environment. Comput. Sci. Eng. 2007, 9, 90–95. [Google Scholar] [CrossRef]
- Waskom, M.L. seaborn: Statistical data visualization. J. Open Source Softw. 2021, 6, 3021. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed]
- Jordahl, K.; den Bossche, J.V.; Fleischmann, M.; Wasserman, J.; McBride, J.; Gerard, J.; Tratner, J.; Perry, M.; Badaracco, A.G.; Farmer, C.; et al. geopandas/geopandas: v0.8.1. Zenodo 2020. [Google Scholar] [CrossRef]
- de ALMEIDA, O. Entupimento de Emissores em Irrigação Localizada; Embrapa Mandioca e Fruticultura Tropical: Cruz das Almas, Brazil, 2009. [Google Scholar]
- Sreekala, M.; Sareen, S.J.; Rajathi, S. Influence of Geo-environmental and Chemical Factors on Thermotolerant Coliforms and E. coli in the Groundwater of Central Kerala. J. Geol. Soc. India 2018, 91, 621–626. [Google Scholar] [CrossRef]
- Boithias, L.; Ribolzi, O.; Lacombe, G.; Thammahacksa, C.; Silvera, N.; Latsachack, K.; Soulileuth, B.; Viguier, M.; Auda, Y.; Robert, E.; et al. Quantifying the effect of overland flow on Escherichia coli pulses during floods: Use of a tracer-based approach in an erosion-prone tropical catchment. J. Hydrol. 2021, 594, 125935. [Google Scholar] [CrossRef]
- Liu, S.; Xie, Z.; Liu, B.; Wang, Y.; Gao, J.; Zeng, Y.; Xie, J.; Xie, Z.; Jia, B.; Qin, P.; et al. Global river water warming due to climate change and anthropogenic heat emission. Glob. Planet. Change 2020, 193, 103289. [Google Scholar] [CrossRef]
- Paufler, S.; Grischek, T.; Benso, M.R.; Seidel, N.; Fischer, T. The impact of river discharge and water temperature on manganese release from the riverbed during riverbank filtration: A case study from Dresden, Germany. Water 2018, 10, 1476. [Google Scholar] [CrossRef]
- Ansari, M.Y.; Ahmad, A.; Khan, S.S.; Bhushan, G.; Mainuddin. Spatiotemporal clustering: A review. Artif. Intell. Rev. 2020, 53, 2381–2423. [Google Scholar] [CrossRef]
- Shi, Z.; Pun-Cheng, L.S. Spatiotemporal data clustering: A survey of methods. ISPRS Int. J. Geo-Inf. 2019, 8, 112. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Potential Problem | Units | Degree of Restriction on Use | ||
|---|---|---|---|---|
| None | Slight to Moderate | Sever | ||
| Suspended solids | mg·L−1 | Less than 50 | 50 to 100 | More than 100 |
| pH | mg·L−1 | Less than 7 | 7 to 7.5 | More than 7.5 |
| Dissolved solids | mg·L−1 | Less than 500 | 500 to 2000 | More than 2000 |
| Manganese | mg·L−1 | Less than 0.1 | 0.1 to 1.5 | More than 1.5 |
| Iron | mg·L−1 | Less than 0.1 | 0.1 to 1.5 | More than 1.5 |
| Hardness as CaCO3 | mg·L−1 | Less than 150 | 150 to 300 | More than 300 |
| Bacterial population | mL | 10,000 | 10,000 to 50,000 | More than 50,000 |
| Scenario | Dataset | Input Data |
|---|---|---|
| S11 | Flood (2011–2012) | Soil-related metrics |
| S12 | Flood (2011–2012) | Irrigation system-related metrics |
| S13 | Flood (2011–2012) | All metrics |
| S21 | Average (2012–2013) | Soil-related metrics |
| S22 | Average (2012–2013) | Irrigation system-related metrics |
| S23 | Average (2012–2013) | All metrics |
| S31 | Drought (2014–2015) | Soil-related metrics |
| S32 | Drought (2014–2015) | Irrigation system-related metrics |
| S33 | Drought (2014–2015) | All metrics |
| Dataset | EC (µS·cm−1) | pH (U. pH) | Iron Total (mg·L−1) | Hardness (mg CaCO3·L−1) |
|---|---|---|---|---|
| Flood | Mean: 92.90 Std: 51.80 CV: 55.76% Min: 41.00 Max: 285.00 | Mean: 6.94 Std: 0.22 CV: 3.17% Min: 6.30 Max: 7.60 | Mean: 3.92 Std: 6.14 CV: 156.63% Min: 0.30 Max: 38.00 | Mean: 26.49 Std: 18.04 CV: 68.10% Min: 3.48 Max: 97.00 |
| Average | Mean: 109.55 Std: 83.63 CV: 76.34% Min: 37.30 Max: 553.00 | Mean: 6.94 Std: 0.37 CV: 5.33% Min: 6.30 Max: 9.10 | Mean: 2.71 Std: 3.12 CV: 115.13% Min: 0.30 Max: 19.00 | Mean: 24.13 Std: 10.87 CV: 45.05% Min: 10.00 Max: 70.00 |
| Drought | Mean: 147.43 Std: 141.21 CV: 95.78% Min: 37.00 Max: 874.00 | Mean: 7.03 Std: 0.39 CV: 5.55% Min: 6.10 Max: 8.60 | Mean: 1.18 Std: 0.83 CV: 70.34% Min: 0.24 Max: 6.00 | Mean: 26.06 Std: 15.46 CV: 59.32% Min: 9.88 Max: 81.00 |
| Dataset | BOD mg·L−1 | TtC CFU |
|---|---|---|
| Flood | Mean: 3.46 Std: 2.08 CV: 60.16 Min: 2.00 Max: 10.00 | Mean: 14602.11 Std: 29,306.59 CV: 200.70 Min: 11.67 Max: 143,333.33 |
| Average | Mean: 3.82 Std: 1.79 CV: 46.90 Min: 2.00 Max: 8.00 | Mean: 10,796.72 Std: 28,243.45 CV: 261.59 Min: 16.67 Max: 200,000.00 |
| Drought | Mean: 4.01 Std: 2.70 CV: 67.45 Min: 2.00 Max: 14.50 | Mean: 12,552.80 Std: 31770.51 CV: 253.09 Min: 1.67 Max: 250,000.00 |
| Dataset | EC S1/S2 (µS·cm−1) | pH S1/S2 (U. pH) | Iron Total S1/S2 (mg·L−1) | Hardness S1/S2 (mg CaCO3·L−1) |
|---|---|---|---|---|
| Flood | Mean: 90.59/95.17 Std: 45.61/57.61 CV: 50.35%/60.53% Min: 42.50/41.00 Max: 270.00/285.00 | Mean: 6.93/6.95 Std: 0.24/0.20 CV: 3.46%/2.88% Min: 6.30/6.50 Max: 7.40/7.60 | Mean: 5.46/2.41 Std: 7.86/3.22 CV: 143.96%/133.61% Min: 0.90/0.30 Max: 38.00/16.00 | Mean: 31.00/22.06 Std: 23.27/8.97 CV: 75.07%/40.66% Min: 3.48/8.00 Max: 97.00/47.00 |
| Average | Mean: 108.38/110.73 Std: 78.89/88.94 CV: 72.79%/80.32% Min: 37.30/42.70 Max: 424.00/553.00 | Mean: 6.88/7.00 Std: 0.20/0.47 CV: 2.91%/6.71% Min: 6.30/6.50 Max: 7.30/9.10 | Mean: 3.57/1.85 Std: 3.90/1.72 CV: 109.24%/92.97% Min: 0.60/0.30 Max: 19.00/12.00 | Mean: 23.96/24.29 Std: 10.81/11.05 CV: 45.12%/45.49% Min: 10.00/12.00 Max: 61.00/70.00 |
| Drought | Mean: 142.16/154.44 Std: 150.86/128.25 CV: 106.12%/83.04% Min: 37.00/39.00 Max: 874.00/661.00 | Mean: 7.04/7.01 Std: 0.43/0.35 CV: 6.11%/4.99% Min: 6.20/6.10 Max: 8.32/8.60 | Mean: 1.27/1.07 Std: 0.95/0.62 CV: 74.80%/57.94% Min: 0.30/0.24 Max: 6.00/3.00 | Mean: 24.87/27.66 Std: 16.21/14.39 CV: 65.18%/52.02% Min: 9.88/10.30 Max: 81.00/73.00 |
| Dataset | BOD S1/S2 mg·L−1 | TtC S1/S2 CFU |
|---|---|---|
| Flood | Mean: 3.72/3.19 Std: 3.70/1.86 CV: 99.50/58.84 Min: 2.00/2.00 Max: 19.00/9.00 | Mean: 14,107.87/15,086.04 Std: 22,781.35/34,775.29 CV: 161.48/230.51 Min: 86.67/11.67 Max: 110,000.00/143,333.33 |
| Average | Mean: 4.17/3.48 Std: 2.59/2.24 CV: 62.10/64.40 Min: 2.00/2.00 Max: 11.00/11.00 | Mean: 11014.76/10578.68 Std: 31,233.93/25,232.95 CV: 283.56/238.53 Min: 50.00/16.67 Max: 200,000.00/160,000.00 |
| Drought | Mean: 4.33/3.39 Std: 5.95/2.07 CV: 137.32/61.05 Min: 2.00/2.00 Max: 50.00/10.00 | Mean: 11,755.69/13,615.62 Std: 27,652.73/36,799.34 CV: 235.23/270.27 Min: 1.67/1.67 Max: 166,666.67/250,000.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
da Silva, R.F.; Benso, M.R.; Corrêa, F.E.; Messias, T.G.; Mendonça, F.C.; Marques, P.A.A.; Duarte, S.N.; Mendiondo, E.M.; Delbem, A.C.B.; Saraiva, A.M. A Data-Driven Method for Water Quality Analysis and Prediction for Localized Irrigation. AgriEngineering 2024, 6, 1771-1793. https://doi.org/10.3390/agriengineering6020103
da Silva RF, Benso MR, Corrêa FE, Messias TG, Mendonça FC, Marques PAA, Duarte SN, Mendiondo EM, Delbem ACB, Saraiva AM. A Data-Driven Method for Water Quality Analysis and Prediction for Localized Irrigation. AgriEngineering. 2024; 6(2):1771-1793. https://doi.org/10.3390/agriengineering6020103
Chicago/Turabian Styleda Silva, Roberto Fray, Marcos Roberto Benso, Fernando Elias Corrêa, Tamara Guindo Messias, Fernando Campos Mendonça, Patrícia Angelica Alves Marques, Sergio Nascimento Duarte, Eduardo Mario Mendiondo, Alexandre Cláudio Botazzo Delbem, and Antonio Mauro Saraiva. 2024. "A Data-Driven Method for Water Quality Analysis and Prediction for Localized Irrigation" AgriEngineering 6, no. 2: 1771-1793. https://doi.org/10.3390/agriengineering6020103
APA Styleda Silva, R. F., Benso, M. R., Corrêa, F. E., Messias, T. G., Mendonça, F. C., Marques, P. A. A., Duarte, S. N., Mendiondo, E. M., Delbem, A. C. B., & Saraiva, A. M. (2024). A Data-Driven Method for Water Quality Analysis and Prediction for Localized Irrigation. AgriEngineering, 6(2), 1771-1793. https://doi.org/10.3390/agriengineering6020103