


System of Counting Green Oranges Directly from Trees Using Artificial Intelligence

 , , and
, , and
Abstract
:1. Introduction
1.1. Problem Statement and Paper Contributions
1.2. State of the Art and Related Work
2. Materials and Methods
2.1. Creation of the Green Oranges Dataset
2.2. YOLOv4 Model Training
2.3. Orange Counting System
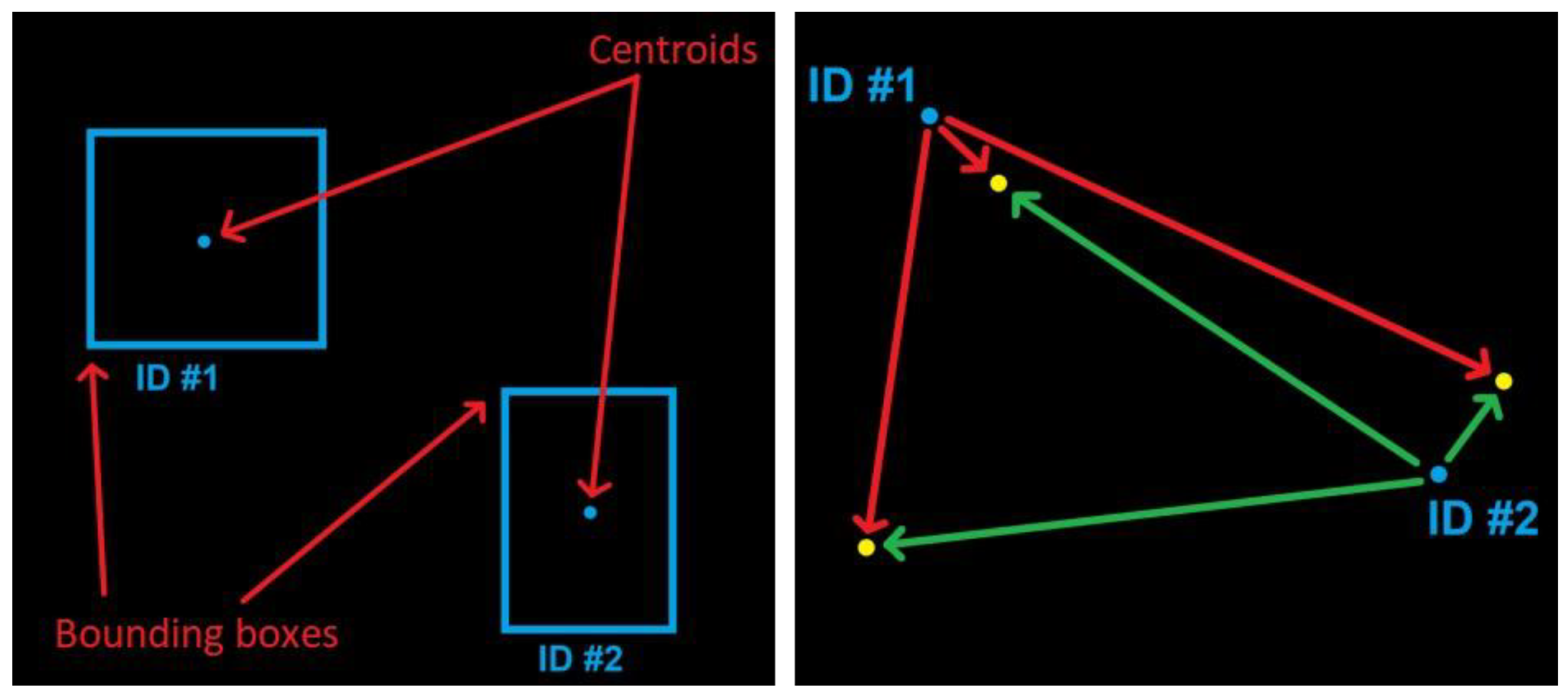
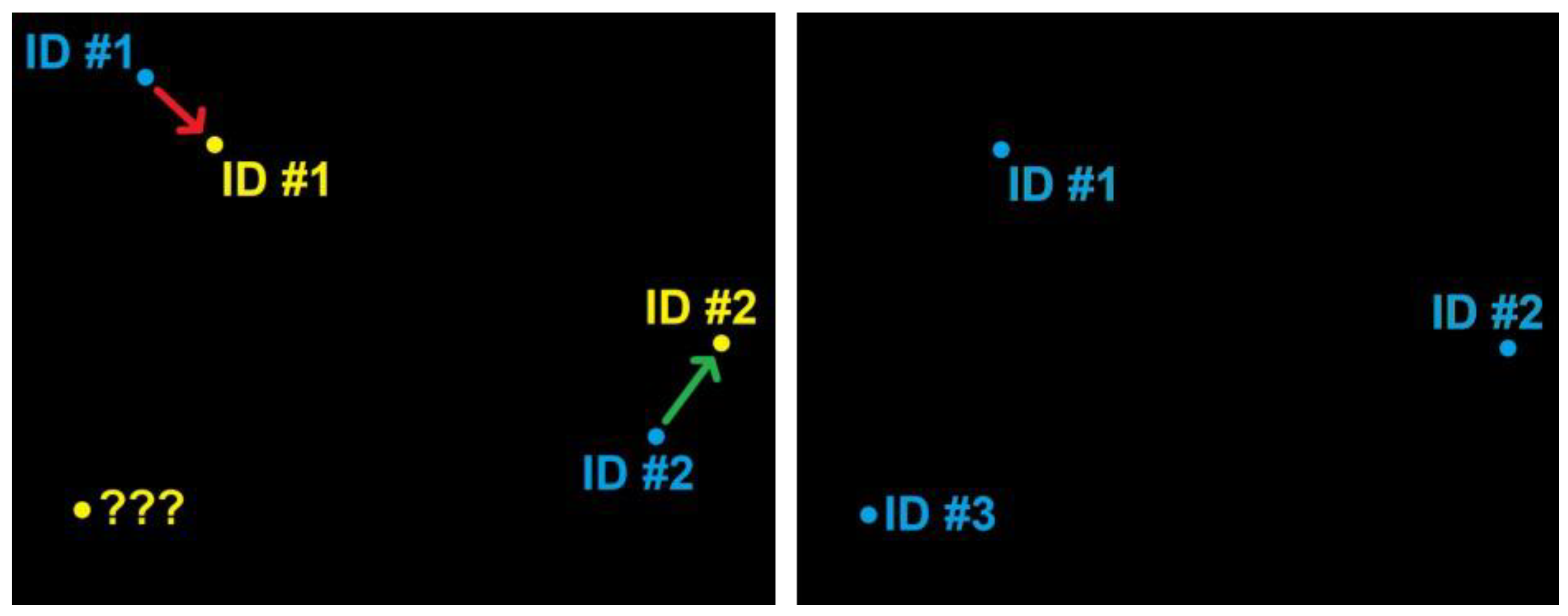
2.4. Object-Tracking Algorithm
- Selecting the object (target) in the initial frame with a bounding box;
- Initializing the tracker with information about the frame and the bounding box of the object;
- Using subsequent frames to find the new bounding box of the object in these frames.
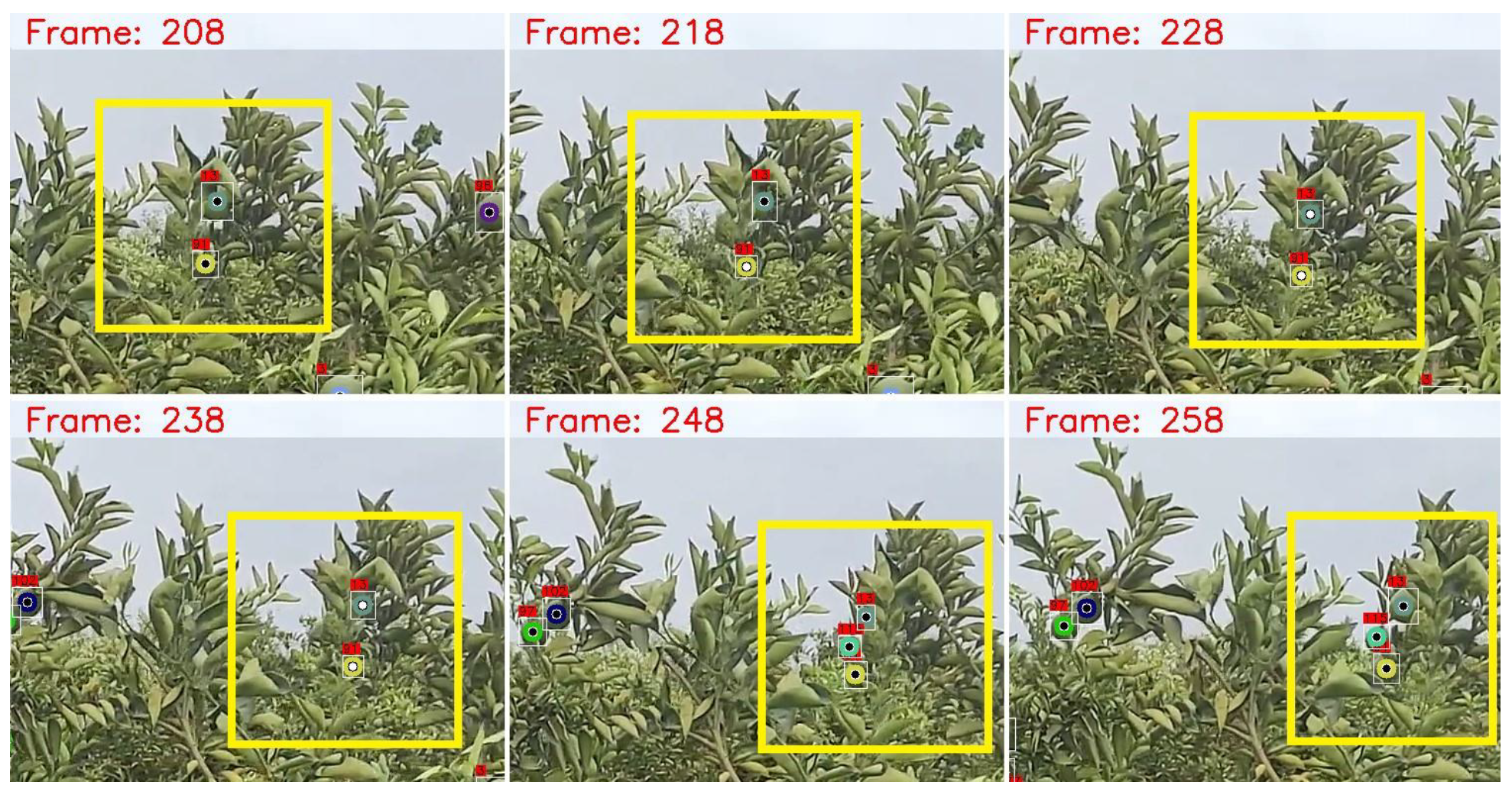
3. Results and Discussions
- The number of that frame;
- The total number of oranges already counted by the algorithm;
- The total number of oranges present in that frame;
- The type of object tracker used;
- The number of oranges being tracked by the object tracker.
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Abdullahi, H.S.; Sheriff, R.; Mahieddine, F. Convolution neural network in precision agriculture for plant image recognition and classification. In Proceedings of the 2017 Seventh International Conference on Innovative Computing Technology (INTECH), Luton, UK, 16–18 August 2017; Volume 10, pp. 256–272. [Google Scholar]
- Gremes, M.F.; Krummenauer, R.; Andrade, C.M.G.; Lima, O.C.d.M. Pre-Harvest Fruit Image Processing: A Brief Review. Braz. J. Exp. Des. Data Anal. Inferent. Stat. 2021, 1, 107–121. [Google Scholar] [CrossRef]
- Yamamoto, K.; Guo, W.; Yoshioka, Y.; Ninomiya, S. On plant detection of intact tomato fruits using image analysis and machine learning methods. Sensors 2014, 14, 12191–12206. [Google Scholar] [CrossRef]
- Wang, Q.; Nuske, S.; Bergerman, M.; Singh, S. Automated crop yield estimation for apple orchards. In Experimental Robotics, Proceedings of the 13th International Symposium on Experimental Robotics, Québec City, QC, Canada, 18–21 June 2012; Springer: Berlin/Heidelberg, Germany, 2013; pp. 745–758. [Google Scholar]
- Zhang, Q.; Liu, Y.; Gong, C.; Chen, Y.; Yu, H. Applications of deep learning for dense scenes analysis in agriculture: A review. Sensors 2020, 20, 1520. [Google Scholar] [CrossRef]
- Fu, L.; Gao, F.; Wu, J.; Li, R.; Karkee, M.; Zhang, Q. Application of consumer RGB-D cameras for fruit detection and localization in field: A critical review. Comput. Electron. Agric. 2020, 177, 105687. [Google Scholar] [CrossRef]
- Zhang, X.; Toudeshki, A.; Ehsani, R.; Li, H.; Zhang, W.; Ma, R. Yield estimation of citrus fruit using rapid image processing in natural background. Smart Agric. Technol. 2022, 2, 100027. [Google Scholar] [CrossRef]
- Dorj, U.-O.; Lee, M.; Yun, S.-S. An yield estimation in citrus orchards via fruit detection and counting using image processing. Comput. Electron. Agric. 2017, 140, 103–112. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, J.; Liu, Y.; Chen, K.; Li, H.; Duan, Y.; Wu, W.; Shi, Y.; Guo, W. Deep-learning-based in-field citrus fruit detection and tracking. Hortic. Res. 2022, 9, uhac003. [Google Scholar] [CrossRef] [PubMed]
- Maldonado, W., Jr.; Barbosa, J.C. Automatic green fruit counting in orange trees using digital images. Comput. Electron. Agric. 2016, 127, 572–581. [Google Scholar] [CrossRef]
- Chen, S.W.; Shivakumar, S.S.; Dcunha, S.; Das, J.; Okon, E.; Qu, C.; Taylor, C.J.; Kumar, V. Counting apples and oranges with deep learning: A data-driven approach. IEEE Robot. Autom. Lett. 2017, 2, 781–788. [Google Scholar] [CrossRef]
- Fermo, I.R.; Cavali, T.S.; Bonfim-Rocha, L.; Srutkoske, C.L.; Flores, F.C.; Andrade, C.M.G. Development of a low-cost digital image processing system for oranges selection using hopfield networks. Food Bioprod. Process. 2021, 125, 181–192. [Google Scholar] [CrossRef]
- Wu, S.; Zhong, S.; Liu, Y. Deep residual learning for image steganalysis. Multimed. Tools Appl. 2018, 77, 10437–10453. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Santos, T.T.; de Souza, L.L.; dos Santos, A.A.; Avila, S. Grape detection, segmentation, and tracking using deep neural networks and threedimensional association. Comput. Electron. Agric. 2020, 170, 105247. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. Deep learning in agriculture: A survey. Comput. Electron. Agric. 2018, 147, 70–90. [Google Scholar] [CrossRef]
- Kamilaris, A.; Prenafeta-Boldú, F.X. A review of the use of convolutional neural networks in agriculture. J. Agric. Sci. 2018, 156, 312–322. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning—Method overview and review of use for fruit detection and yield estimation. Comput. Electron. Agric. 2019, 162, 219–234. [Google Scholar] [CrossRef]
- Bresilla, K.; Perulli, G.D.; Boini, A.; Morandi, B.; Grappadelli, L.C.; Manfrini, L. Single-shot convolution neural networks for real-time fruit detection within the tree. Front. Plant Sci. 2019, 10, 611. [Google Scholar] [CrossRef]
- Ge, Y.; Xiong, Y.; Tenorio, G.L.; From, P.J. Fruit localization and environment perception for strawberry harvesting robots. IEEE Access 2019, 7, 147642–147652. [Google Scholar] [CrossRef]
- Liu, X.; Chen, S.W.; Liu, C.; Shivakumar, S.S.; Das, J.; Taylor, C.J.; Underwood, J.; Kumar, V. Monocular camera based fruit counting and mapping with semantic data association. IEEE Robot. Autom. Lett. 2019, 4, 2296–2303. [Google Scholar] [CrossRef]
- Sozzi, M.; Cantalamessa, S.; Cogato, A.; Kayad, A.; Marinello, F. Automatic bunch detection in white grape varieties using YOLOv3, YOLOv4, and YOLOv5 deep learning algorithms. Agronomy 2022, 12, 319. [Google Scholar] [CrossRef]
- Cardellicchio, A.; Solimani, F.; Dimauro, G.; Petrozza, A.; Summerer, S.; Cellini, F.; Renò, V. Detection of tomato plant phenotyping traits using YOLOv5-based single stage detectors. Comput. Electron. Agric. 2023, 207, 107757. [Google Scholar] [CrossRef]
- Wang, D.; He, D. Channel pruned YOLO V5s-based deep learning approach for rapid and accurate apple fruitlet detection before fruit thinning. Biosyst. Eng. 2021, 210, 271–281. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Naranjo-Torres, J.; Mora, M.; Hernández-García, R.; Barrientos, R.J.; Fredes, C.; Valenzuela, A. A review of convolutional neural network applied to fruit image processing. Appl. Sci. 2020, 10, 3443. [Google Scholar] [CrossRef]
- Itakura, K.; Narita, Y.; Noaki, S.; Hosoi, F. Automatic pear and apple detection by videos using deep learning and a Kalman filter. OSA Contin. 2021, 4, 1688–1695. [Google Scholar] [CrossRef]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1440–1448. [Google Scholar]
- Wang, C.-Y.; Bochkovskiy, A.; Liao, H.-Y.M. Scaled-yolov4: Scaling cross stage partial network. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13029–13038. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.109342020. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo algorithm developments. Procedia Comput. Sci. 2022, 199, 1066–1073. [Google Scholar] [CrossRef]
- Koirala, A.; Walsh, K.B.; Wang, Z.; McCarthy, C. Deep learning for realtime fruit detection and orchard fruit load estimation: Benchmarking of ‘MangoYOLO’. Precis. Agric. 2019, 20, 1107–1135. [Google Scholar] [CrossRef]
- Liu, G.; Nouaze, J.C.; Mbouembe, P.L.T.; Kim, J.H. YOLO-tomato: A robust algorithm for tomato detection based on YOLOv3. Sensors 2020, 20, 2145. [Google Scholar] [CrossRef]
- Wu, L.; Ma, J.; Zhao, Y.; Liu, H. Apple detection in complex scene using the improved YOLOv4 model. Agronomy 2021, 11, 476. [Google Scholar] [CrossRef]
- Yan, B.; Fan, P.; Lei, X.; Liu, Z.; Yang, F. A real-time apple targets detection method for picking robot based on improved YOLOv5. Remote Sens. 2021, 13, 1619. [Google Scholar] [CrossRef]
- Junior, R.P.L. A Citricultura no Paraná; IAPAR: Londrina, Brazil, 1992. [Google Scholar]
- Roberts, D.; Wang, M.; Calderon, W.T.; Golparvar-Fard, M. An annotation tool for benchmarking methods for automated construction worker pose estimation and activity analysis. In Proceedings of the International Conference on Smart Infrastructure and Construction 2019 (ICSIC), Cambridge, UK, 8–10 July 2019; pp. 307–313. [Google Scholar]
- Rauf, H.T.; Saleem, B.A.; Lali, M.I.U.; Khan, M.A.; Sharif, M.; Bukhari, S.A.C. A citrus fruits and leaves dataset for detection and classification of citrus diseases through machine learning. Data Brief 2019, 26, 104340. [Google Scholar] [CrossRef] [PubMed]
- Tang, Y. TF.Learn: TensorFlow’s high-level module for distributed machine learning. arXiv 2016, arXiv:1612.04251. [Google Scholar]
- Wotherspoon, J. GitHub—theAIGuysCode/tensorflow-yolov4-tflite: YOLOv4, YOLOv4tiny, YOLOv3, YOLOv3-tiny Implemented in Tensorflow 2.0, Android. Convert YOLO. 2021. Available online: https://github.com/theAIGuysCode/tensorflow-yolov4-tflite (accessed on 20 December 2021).
- Wu, Y.; Lim, J.; Yang, M.-H. Online object tracking: A benchmark. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013; pp. 2411–2418. [Google Scholar]
- Brdjanin, A.; Dardagan, N.; Dzigal, D.; Akagic, A. Single object trackers in opencv: A benchmark. In Proceedings of the 2020 International Conference on INnovations in Intelligent SysTems and Applications (INISTA), Novi Sad, Serbia, 24–26 August 2020; pp. 1–6. [Google Scholar]
- Danelljan, M.; Häger, G.; Khan, F.; Felsberg, M. Accurate scale estimation for robust visual tracking. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Grabner, H.; Grabner, M.; Bischof, H. Real-time tracking via on-line boosting. Bmvc 2006, 1, 6. [Google Scholar]
- Babenko, B.; Yang, M.-H.; Belongie, S. Visual tracking with online multiple instance learning. In Proceedings of the 2009 IEEE Conference on computer vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 983–990. [Google Scholar]
- Kalal, Z.; Mikolajczyk, K.; Matas, J. Forward-backward error: Automatic detection of tracking failures. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; pp. 2756–2759. [Google Scholar]
- Lukezic, A.; Vojir, T.; Zajc, L.Č.; Matas, J.; Kristan, M. Discriminative correlation filter with channel and spatial reliability. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6309–6318. [Google Scholar]
- King, D.E. Dlib-ml: A machine learning toolkit. J. Mach. Learn. Res. 2009, 10, 1755–1758. [Google Scholar]
- Culjak, I.; Abram, D.; Pribanic, T.; Dzapo, H.; Cifrek, M. A brief introduction to OpenCV. In Proceedings of the 2012 Proceedings of the 35th International Convention MIPRO, Opatija, Croatia, 21–25 May 2012; pp. 1725–1730. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | mAP50 | mAP50:95 | Precision | Recall | F1-Score | Average IoU |
|---|---|---|---|---|---|---|
| YOLOv4 | 80.16% | 53.83% | 0.92 | 0.93 | 0.93 | 82.08% |
| Tracker | Omission of Detection − | Wrong Detection + | Double Count + | Repeated ID − | Number of Oranges Counted | Correct Number of Oranges Counted |
|---|---|---|---|---|---|---|
| No tracker | 0 | 0 | 10 | 2 | 216 | 208 |
| Dlib | 0 | 0 | 8 | 0 | 216 | 208 |
| Boosting | 0 | 0 | 7 | 0 | 215 | 208 |
| Csrt | 0 | 0 | 8 | 1 | 215 | 208 |
| Kcf | 0 | 0 | 10 | 0 | 218 | 208 |
| Medianflow | 0 | 0 | 8 | 0 | 216 | 208 |
| Mil | 0 | 0 | 9 | 0 | 217 | 208 |
| Tracker | Omission of Detection − | Wrong Detection + | Double Count + | Repeated ID − | Number of Oranges Counted | Correct Number of Oranges Counted |
|---|---|---|---|---|---|---|
| No tracker | 15 | 2 | 25 | 5 | 215 | 208 |
| Dlib | 15 | 2 | 10 | 1 | 204 | 208 |
| Boosting | 15 | 2 | 10 | 1 | 204 | 208 |
| Csrt | 15 | 2 | 10 | 1 | 204 | 208 |
| Kcf | 15 | 2 | 16 | 1 | 210 | 208 |
| Medianflow | 15 | 2 | 10 | 1 | 204 | 208 |
| Mil | 15 | 2 | 9 | 1 | 203 | 208 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gremes, M.F.; Fermo, I.R.; Krummenauer, R.; Flores, F.C.; Andrade, C.M.G.; Lima, O.C.d.M. System of Counting Green Oranges Directly from Trees Using Artificial Intelligence. AgriEngineering 2023, 5, 1813-1831. https://doi.org/10.3390/agriengineering5040111
Gremes MF, Fermo IR, Krummenauer R, Flores FC, Andrade CMG, Lima OCdM. System of Counting Green Oranges Directly from Trees Using Artificial Intelligence. AgriEngineering. 2023; 5(4):1813-1831. https://doi.org/10.3390/agriengineering5040111
Chicago/Turabian StyleGremes, Matheus Felipe, Igor Rossi Fermo, Rafael Krummenauer, Franklin César Flores, Cid Marcos Gonçalves Andrade, and Oswaldo Curty da Motta Lima. 2023. "System of Counting Green Oranges Directly from Trees Using Artificial Intelligence" AgriEngineering 5, no. 4: 1813-1831. https://doi.org/10.3390/agriengineering5040111
APA StyleGremes, M. F., Fermo, I. R., Krummenauer, R., Flores, F. C., Andrade, C. M. G., & Lima, O. C. d. M. (2023). System of Counting Green Oranges Directly from Trees Using Artificial Intelligence. AgriEngineering, 5(4), 1813-1831. https://doi.org/10.3390/agriengineering5040111