
Prediction of Rice Cultivation in India—Support Vector Regression Approach with Various Kernels for Non-Linear Patterns

 ,
,  , , and
, , and
Abstract
:1. Introduction
2. Review of the Literature
3. Materials and Methods
3.1. Data Collection
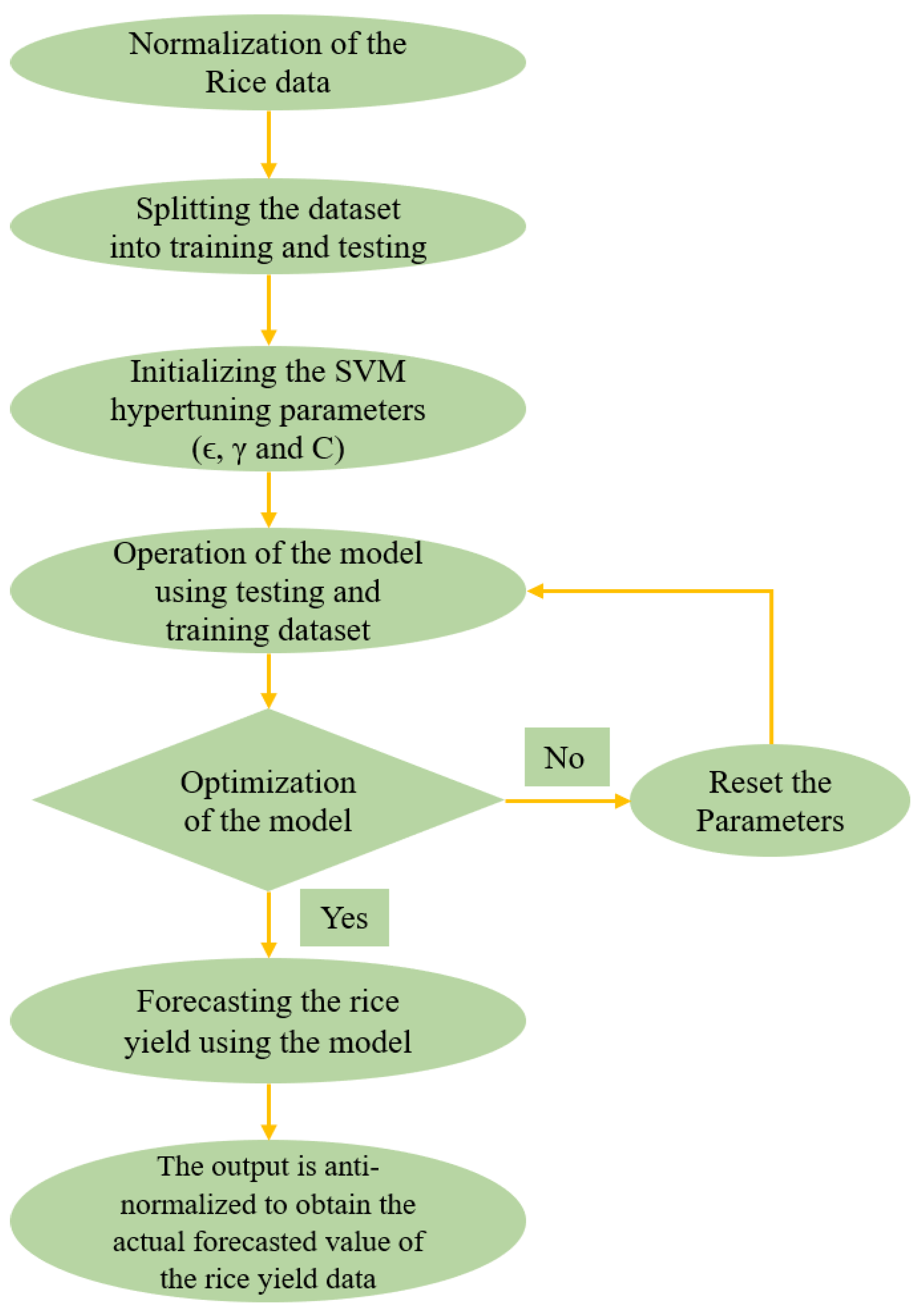
3.2. Methodology
3.2.1. Support Vector Regression
| 1 | Linear | |
| 2 | Polynomial | |
| 3 | Radial Basis Function |
3.2.2. Hyperparameter Optimization
- Regularization parameter, C: If the hyper-dimensionality plane’s is random, it can be perfectly fitted to the training dataset, resulting in overfitting. As the value of C increases, the hyperplane’s margin shrinks, increasing the number of correctly classified samples.
- Kernel parameter, : This implies the radius of influence, the higher values closer the sample points. This is very sensitive to the model, as when becomes large, the radii of influence of the support vectors tend to be too small, leading to overfitting.
- Error Parameter, ε: Generally used in regression, it is an additional value of tolerance, when there is no penalty in the errors. The errors are penalized as ε approaches zero, and the higher the values, the greater the model error.
- The non-linear SVR is used in the study to forecast rice yield data. The kernel function is applied to each data set in order to map the nonlinear observations into a higher-dimensional space where they can be separated. The SVR’s efficiency is determined by the hypertuning parameters, which are interdependent [19,20,21,22]
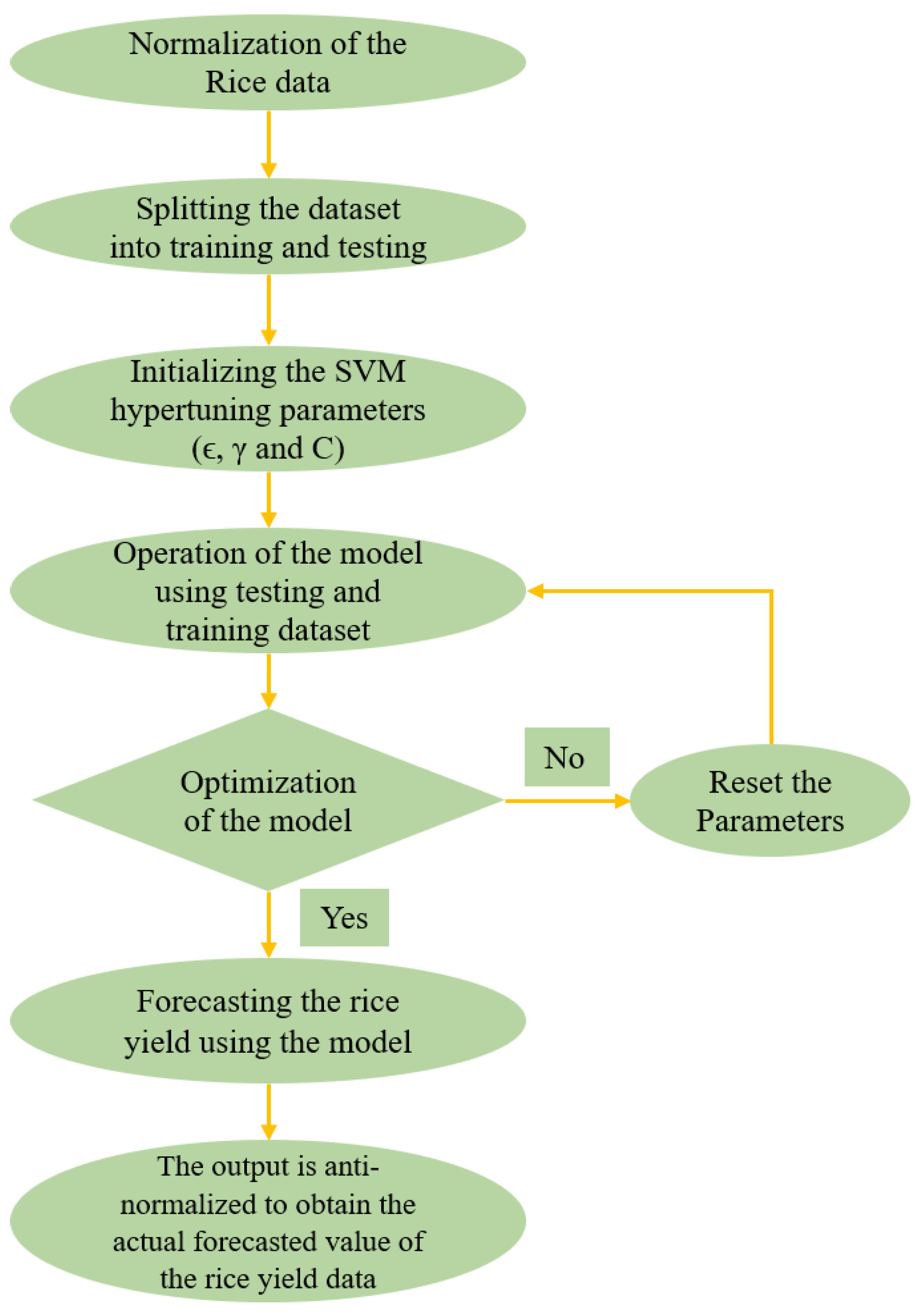
3.2.3. Schematic Diagram of Performing SVR
3.3. Cross-Validation Method
4. Results and Discussion
4.1. Summary Statistics of Rice Parameters
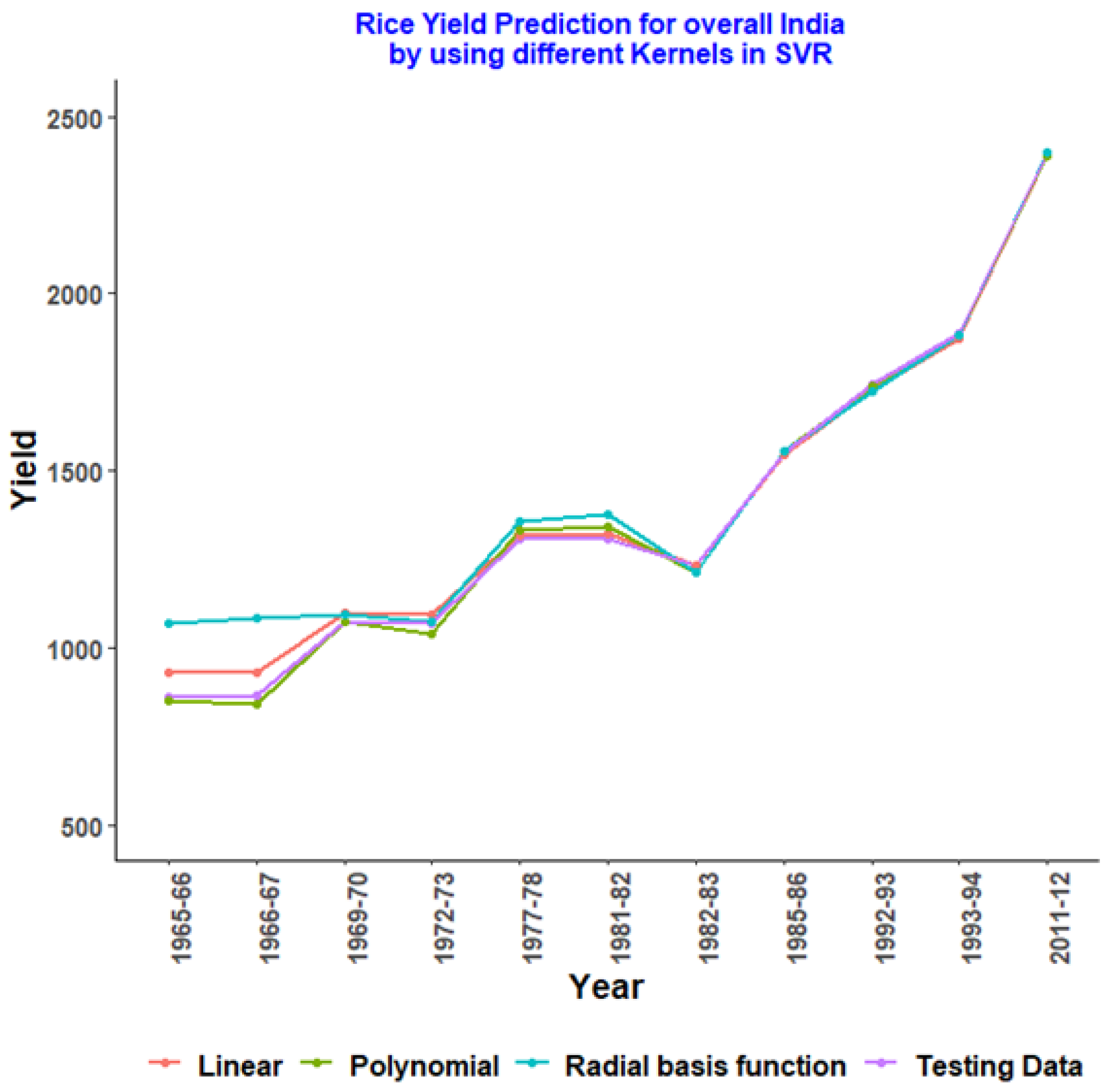
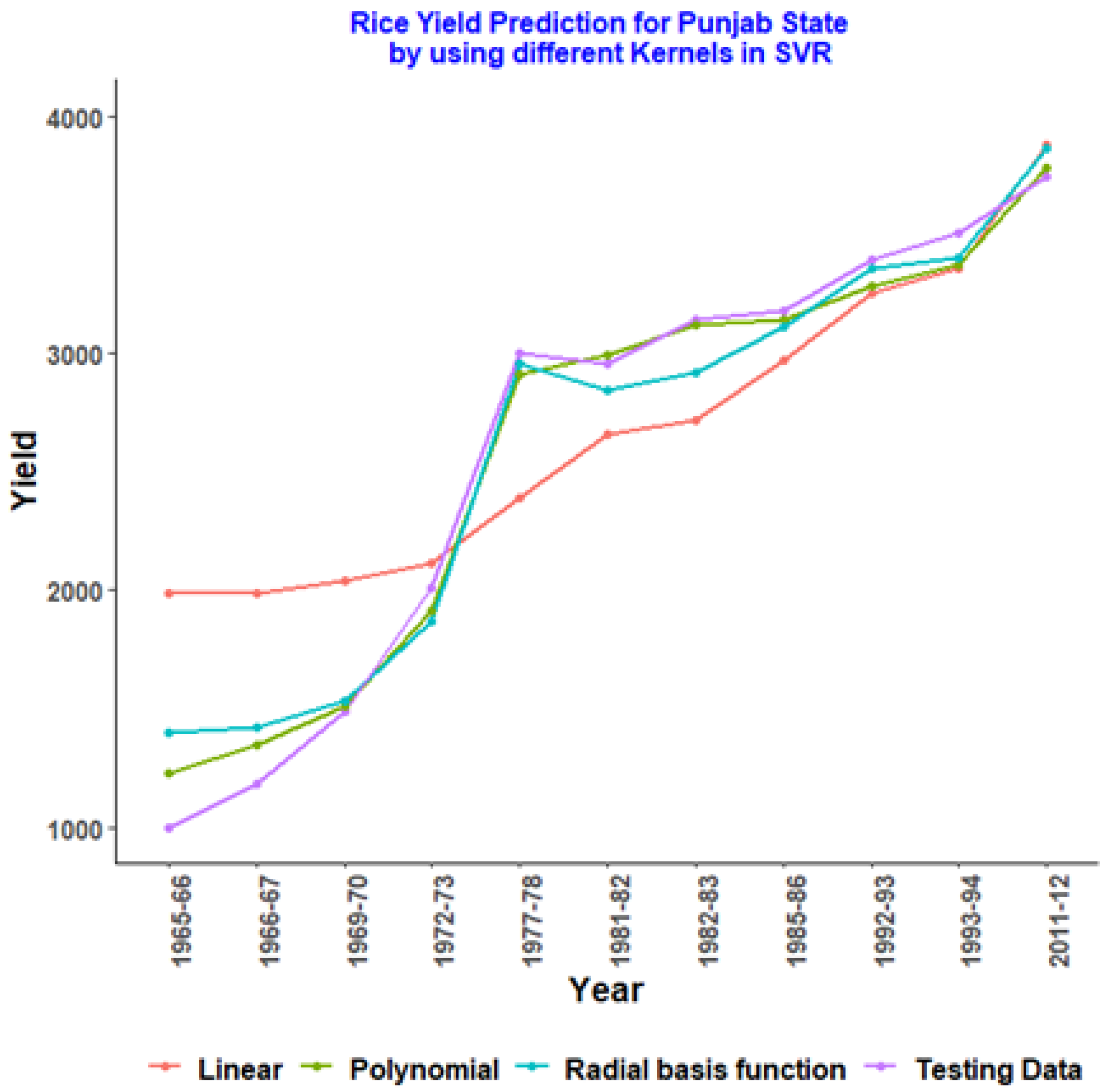
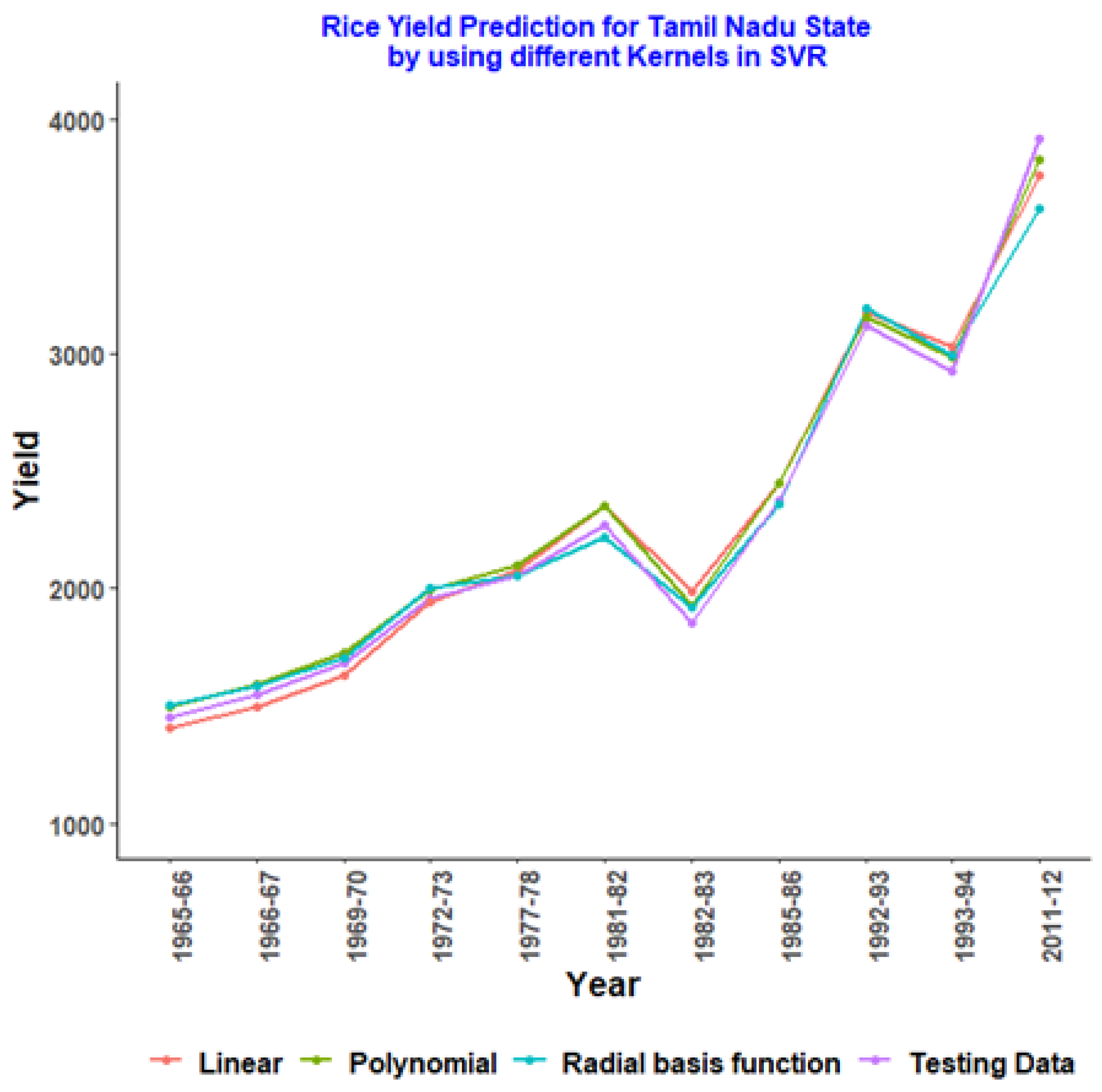
4.2. Rice Yield Prediction of Overall India and Major Producing States Using Various Kernels of SVR with Hypertuning Parameters
4.3. SVR with Different Kernels for Randomly Allocated Testing Data of Rice Yield
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kubo, M.; Purevdorj, M. The future of rice production and consumption. J. Food Distrib. Res. 2004, 35, 128–142. [Google Scholar]
- Ramesh, D.; Vardhan, B.V. Analysis of crop yield prediction using data mining techniques. Int. J. Res. Eng. Technol. 2015, 4, 47–473. [Google Scholar]
- Nishant, P.S.; Venkat, P.S.; Avinash, B.L.; Jabber, B. Crop Yield Prediction based on Indian Agriculture using Machine Learning. In Proceedings of the 2020 International Conference for Emerging Technology (INCET), Belgaum, India, 5–7 June 2020; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2020; pp. 1–4. [Google Scholar]
- Jaikla, R.; Auephanwiriyakul, S.; Jintrawet, A. Rice yield prediction using a support vector regression method. In Proceedings of the 2008 5th International Conference on Electrical Engineering/Electronics, Computer, Telecommunications and Information Technology, Krabi, Thailand, 14–17 May 2008; IEEE: Piscataway, NJ, USA, 2008; Volume 1, pp. 29–32. [Google Scholar] [CrossRef]
- Medar, R.A.; Rajpurohit, V.S. A survey on data mining techniques for crop yield prediction. Int. J. Adv. Res. Comput. Sci. Manag. Stud. 2014, 2, 59–64. [Google Scholar]
- Yousefi, M.; Khoshnevisan, B.; Shamshirband, S.; Motamedi, S.; Nasir, M.H.N.M.; Arif, M.; Ahmad, R. Retracted Article: Support vector regression methodology for prediction of output energy in rice production. Stoch. Environ. Res. Risk Assess. 2015, 29, 2115–2126. [Google Scholar] [CrossRef]
- Chen, H.; Wu, W.; Liu, H.-B. Assessing the relative importance of climate variables to rice yield variation using support vector machines. Theor. Appl. Clim. 2016, 126, 105–111. [Google Scholar] [CrossRef]
- Su, Y.-X.; Xu, H.; Yan, L.-J. Support vector machine-based open crop model (SBOCM): Case of rice production in China. Saudi J. Biol. Sci. 2017, 24, 537–547. [Google Scholar] [CrossRef] [PubMed]
- Govardhan, P.; Korde, R.; Lanjewar, R. Survey on Crop Yield Prediction Using Data Mining Techniques. Int. J. Adv. Comput. Electron. Eng. 2018, 3, 1–6. [Google Scholar]
- Oguntunde, P.G.; Lischeid, G.; Dietrich, O. Relationship between rice yield and climate variables in southwest Nigeria using multiple linear regression and support vector machine analysis. Int. J. Biometeorol. 2017, 62, 459–469. [Google Scholar] [CrossRef] [PubMed]
- Gandhi, N.; Armstrong, L.J. Rice crop yield forecasting of tropical wet and dry climatic zone of India using data mining techniques. In Proceedings of the 2016 IEEE International Conference on Advances in Computer Applications (ICACA), Coimbatore, India, 24 October 2016; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2016; pp. 357–363. [Google Scholar]
- Rahman, M.M.; Haq, N.; Rahman, R.M. Machine learning facilitated rice prediction in Bangla-desh. In Proceedings of the 2014 Annual Global Online Conference on Information and Computer Technology, Louisville, KY, USA, 3–5 December 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 1–4. [Google Scholar]
- Kumar, R.; Singh, M.; Kumar, P. Crop Selection Method to maximize crop yield rate using machine learning technique. In Proceedings of the 2015 International Conference on Smart Technologies and Management for Computing, Communication, Controls, Energy and Materials (ICSTM), Chennai, India, 6–8 May 2015; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2015; pp. 138–145. [Google Scholar]
- Shakoor, T.; Rahman, K.; Rayta, S.N.; Chakrabarty, A. Agricultural production output prediction using Supervised Machine Learning techniques. In Proceedings of the 2017 1st International Conference on Next Generation Computing Applications (NextComp), Mauritius, 19–21 July 2017; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2017; pp. 182–187. [Google Scholar]
- Palanivel, K.; Surianarayanan, C. An Approach for Prediction of Crop Yield Using Machine Learning and Big Data Techniques. Int. J. Comput. Eng. Technol. 2019, 10, 110–118. [Google Scholar] [CrossRef]
- Khosla, E.; Dharavath, R.; Priya, R. Crop yield prediction using aggregated rainfall-based modular artificial neural networks and support vector regression. Environ. Dev. Sustain. 2019, 22, 5687–5708. [Google Scholar] [CrossRef]
- Alkaff, M.; Khatimi, H.; Puspita, W.; Sari, Y. Modelling and predicting wetland rice production using support vector regression. Telkomnika 2019, 17, 819–825. [Google Scholar] [CrossRef]
- Abbas, F.; Afzaal, H.; Farooque, A.A.; Tang, S. Crop Yield Prediction through Proximal Sensing and Machine Learning Algorithms. Agronomy 2020, 10, 1046. [Google Scholar] [CrossRef]
- Drucker, H.; Burges, C.J.; Kaufman, L.; Smola, A.J.; Vapnik, V. Support vector regression machines. Adv. Neural Inf. Process. Syst. 1997, 9, 155–161. [Google Scholar]
- Gunn, S.R. Support vector machines for classification and regression. ISIS Tech. Rep. 1998, 14, 5–16. [Google Scholar]
- Kassambara, A. Machine Learning Essentials: Practical Guide in R; CreateSpace: Scotts Valley, CA, USA, 2017. [Google Scholar]
- Lantz, B. Machine Learning with R; Packt Publishing Ltd.: Birmingham, UK, 2013. [Google Scholar]
- Mishra, S.; Mishra, D.; Santra, G.H. Applications of Machine Learning Techniques in Agricultural Crop Production: A Review Paper. Indian J. Sci. Technol. 2016, 9, 1–14. [Google Scholar] [CrossRef]
- Nagini, S.; Kanth, T.V.R.; Kiranmayee, B.V. Agriculture yield prediction using predictive analytic techniques. In Proceedings of the 2016 2nd International Conference on Contemporary Computing and Informatics (IC3I), Noida, India, 14–17 December 2016; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2016; pp. 783–788. [Google Scholar]
- Basso, B.; Liu, L. Seasonal crop yield forecast: Methods, applications, and accuracies. Adv. Agron. 2019, 154, 201–255. [Google Scholar] [CrossRef]
- Gandhi, N.; Petkar, O.; Armstrong, L.J. Rice crop yield prediction using artificial neural networks. In Proceedings of the 2016 IEEE Technological Innovations in ICT for Agriculture and Rural Development (TIAR), Chennai, India, 15–16 July 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 105–110. [Google Scholar]
- Gandge, Y. A study on various data mining techniques for crop yield prediction. In Proceedings of the 2017 International Conference on Electrical, Electronics, Communication, Computer, and Optimization Techniques (ICEECCOT), Mysuru, India, 15–16 December 2017; Institute of Electrical and Electronics Engineers (IEEE): Piscataway, NJ, USA, 2017; pp. 420–423. [Google Scholar]
- Paidipati, K.K.; Banik, A. Forecasting of Rice Cultivation in India–A Comparative Analysis with ARIMA and LSTM-NN Models. ICST Trans. Scalable Inf. Syst. 2020, 7, 1–11. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| States | Mean | Standard Deviation | Skewness | Kurtosis |
|---|---|---|---|---|
| All India | 1653.105 | 498.9388 | 0.115 | −1.235 |
| Bihar | 1187.512 | 458.9505 | 1.215 | 1.243 |
| Punjab | 2991.355 | 923.6729 | −0.84 | −0.345 |
| Tamil Nadu | 2477.671 | 734.8786 | 0.033 | −1.022 |
| Uttar Pradesh | 1519.801 | 610.1552 | −0.217 | −1.443 |
| West Bengal | 1876.755 | 629.6552 | 0.107 | −1.521 |
| States | Mean | Standard Deviation | Skewness | Kurtosis |
|---|---|---|---|---|
| All India | 41037.68 | 2911.21 | −0.48 | −0.945 |
| Bihar | 4576.484 | 897.5415 | −0.644 | −1.33 |
| Punjab | 1739.461 | 945.8439 | −0.29 | −1.464 |
| Tamil Nadu | 2198.466 | 386.5147 | −0.033 | −0.828 |
| Uttar Pradesh | 5278.316 | 572.2343 | −0.404 | −1.18 |
| West Bengal | 5375.904 | 432.7927 | −0.336 | −0.829 |
| States | Mean | Standard Deviation | Skewness | Kurtosis |
|---|---|---|---|---|
| All India | 69143.93 | 24644.12 | 0.067 | −1.316 |
| Bihar | 5179.959 | 1378.052 | 0.000107 | −0.005 |
| Punjab | 5999.512 | 4040.386 | −0.033 | −1.384 |
| Tamil Nadu | 5301.673 | 1346.065 | −0.128 | −0.133 |
| Uttar Pradesh | 8332.887 | 3942.218 | −0.117 | −1.453 |
| West Bengal | 10268.23 | 3896.285 | −0.038 | −1.659 |
| Dataset | States | RMSE | MAE | Cost |
|---|---|---|---|---|
| Train | All India | 27.52055 | 23.05118 | 1.1 |
| Bihar | 80.40918 | 68.36108 | 1.1 | |
| Punjab | 297.4711 | 224.2278 | 0.25 | |
| Tamil Nadu | 68.64182 | 57.58319 | 0.35 | |
| Uttar Pradesh | 43.47316 | 39.07503 | 1.1 | |
| West Bengal | 41.00673 | 35.04825 | 1.05 | |
| Test | All India | 31.05632 | 22.72886 | 1.1 |
| Bihar | 62.60574 | 50.93586 | 1.1 | |
| Punjab | 493.5309 | 401.1693 | 0.25 | |
| Tamil Nadu | 84.2756 | 72.35583 | 0.35 | |
| Uttar Pradesh | 61.46972 | 52.59493 | 1.1 | |
| West Bengal | 35.11301 | 30.23646 | 1.05 |
| Dataset | States | RMSE | MAE | Degree | Cost | |
|---|---|---|---|---|---|---|
| Train | All India | 28.97924 | 25.07671 | 2 | 1 | 0.35 |
| Bihar | 31.2602 | 26.9666 | 3 | 0.5 | 0.25 | |
| Punjab | 90.38687 | 74.10524 | 4 | 1.1 | 0.4 | |
| Tamil Nadu | 49.27959 | 42.12796 | 2 | 0.85 | 0.25 | |
| Uttar Pradesh | 35.82643 | 29.72098 | 4 | 1 | 0.25 | |
| West Bengal | 37.9135 | 29.82876 | 1 | 1.1 | 0.4 | |
| Test | All India | 18.23377 | 14.55882 | 2 | 1 | 0.35 |
| Bihar | 37.3793 | 31.71476 | 3 | 0.5 | 0.25 | |
| Punjab | 109.3165 | 89.24507 | 4 | 1.1 | 0.4 | |
| Tamil Nadu | 60.88977 | 58.1863 | 2 | 0.85 | 0.25 | |
| Uttar Pradesh | 36.31511 | 31.64557 | 4 | 1 | 0.25 | |
| West Bengal | 35.79188 | 27.48669 | 1 | 1.1 | 0.4 |
| Dataset | States | RMSE | MAE | Sigma | Cost |
|---|---|---|---|---|---|
| Train | All India | 47.90525 | 37.5891 | 0.5 | 1.1 |
| Bihar | 65.09703 | 45.87701 | 0.25 | 1.1 | |
| Punjab | 196.5431 | 150.9922 | 2.75 | 1.1 | |
| Tamil Nadu | 131.1512 | 94.32958 | 0.25 | 1.1 | |
| Uttar Pradesh | 71.06016 | 53.27636 | 0.25 | 1.1 | |
| West Bengal | 69.99749 | 58.21759 | 0.25 | 1 | |
| Test | All India | 94.60944 | 55.98602 | 0.5 | 1.1 |
| Bihar | 161.7523 | 85.16538 | 0.25 | 1.1 | |
| Punjab | 174.8837 | 140.0258 | 2.75 | 1.1 | |
| Tamil Nadu | 102.7245 | 67.17755 | 0.25 | 1.1 | |
| Uttar Pradesh | 98.70091 | 69.96868 | 0.25 | 1.1 | |
| West Bengal | 69.12172 | 59.52803 | 0.25 | 1 |
| Year | Testing Data | Linear | Polynomial | Radial Basis Function |
|---|---|---|---|---|
| 1965–66 | 862 | 927.3773 | 848.0545 | 1067.776 |
| 1966–67 | 863 | 928.2253 | 841.4404 | 1082.654 |
| 1969–70 | 1073 | 1099.57 | 1074.2819 | 1095.163 |
| 1972–73 | 1070 | 1092.218 | 1040.5272 | 1071.356 |
| 1977–78 | 1308 | 1316.539 | 1331.4916 | 1354.699 |
| 1981–82 | 1308 | 1321.101 | 1342.5861 | 1374.131 |
| 1982–83 | 1231 | 1233.836 | 1214.1736 | 1211.379 |
| 1985–86 | 1552 | 1542.52 | 1555.7508 | 1556.554 |
| 1992–93 | 1744 | 1726.412 | 1737.1086 | 1725.277 |
| 1993–94 | 1888 | 1873.587 | 1883.6489 | 1883.61 |
| 2011–12 | 2393 | 2388.328 | 2389.0101 | 2399.779 |
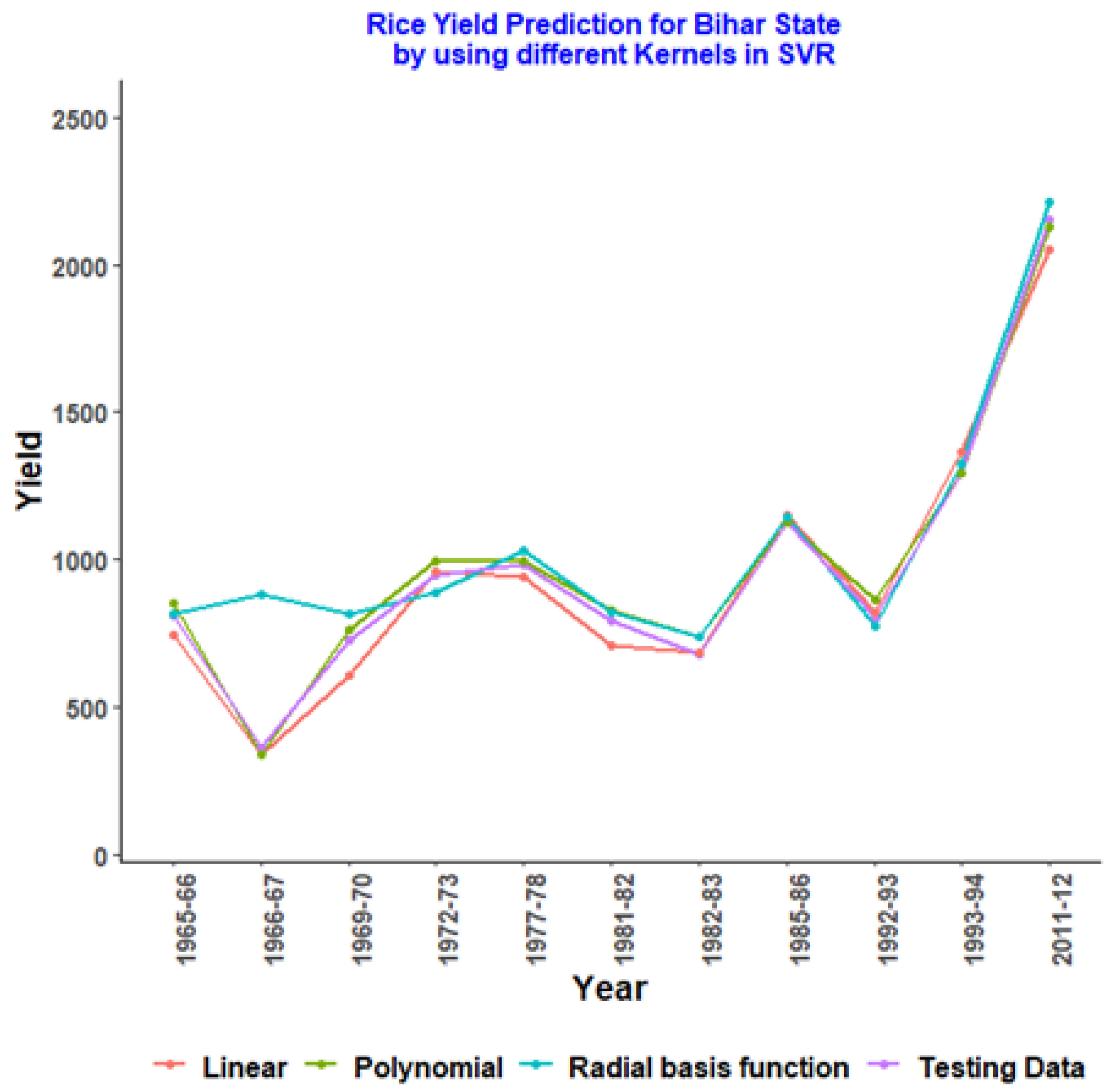
| Year | Testing Data | Linear | Polynomial | Radial Basis Function |
|---|---|---|---|---|
| 1965–66 | 812.06 | 749.3555 | 854.4835 | 820.106 |
| 1966–67 | 365.93 | 342.1535 | 342.8664 | 880.7237 |
| 1969–70 | 729.85 | 612.1557 | 761.4629 | 816.3171 |
| 1972–73 | 946.77 | 963.1515 | 995.7426 | 889.5958 |
| 1977–78 | 983.18 | 945.5241 | 997.2016 | 1029.8179 |
| 1981–82 | 793.07 | 711.3524 | 831.4973 | 826.7751 |
| 1982–83 | 681.44 | 688.4047 | 738.9844 | 739.2374 |
| 1985–86 | 1127.61 | 1151.086 | 1128.1617 | 1142.9612 |
| 1992–93 | 806.16 | 823.3341 | 867.6472 | 778.268 |
| 1993–94 | 1294.78 | 1364.048 | 1293.5672 | 1325.887 |
| 2011–12 | 2154.85 | 2051.369 | 2125.3052 | 2212.6976 |
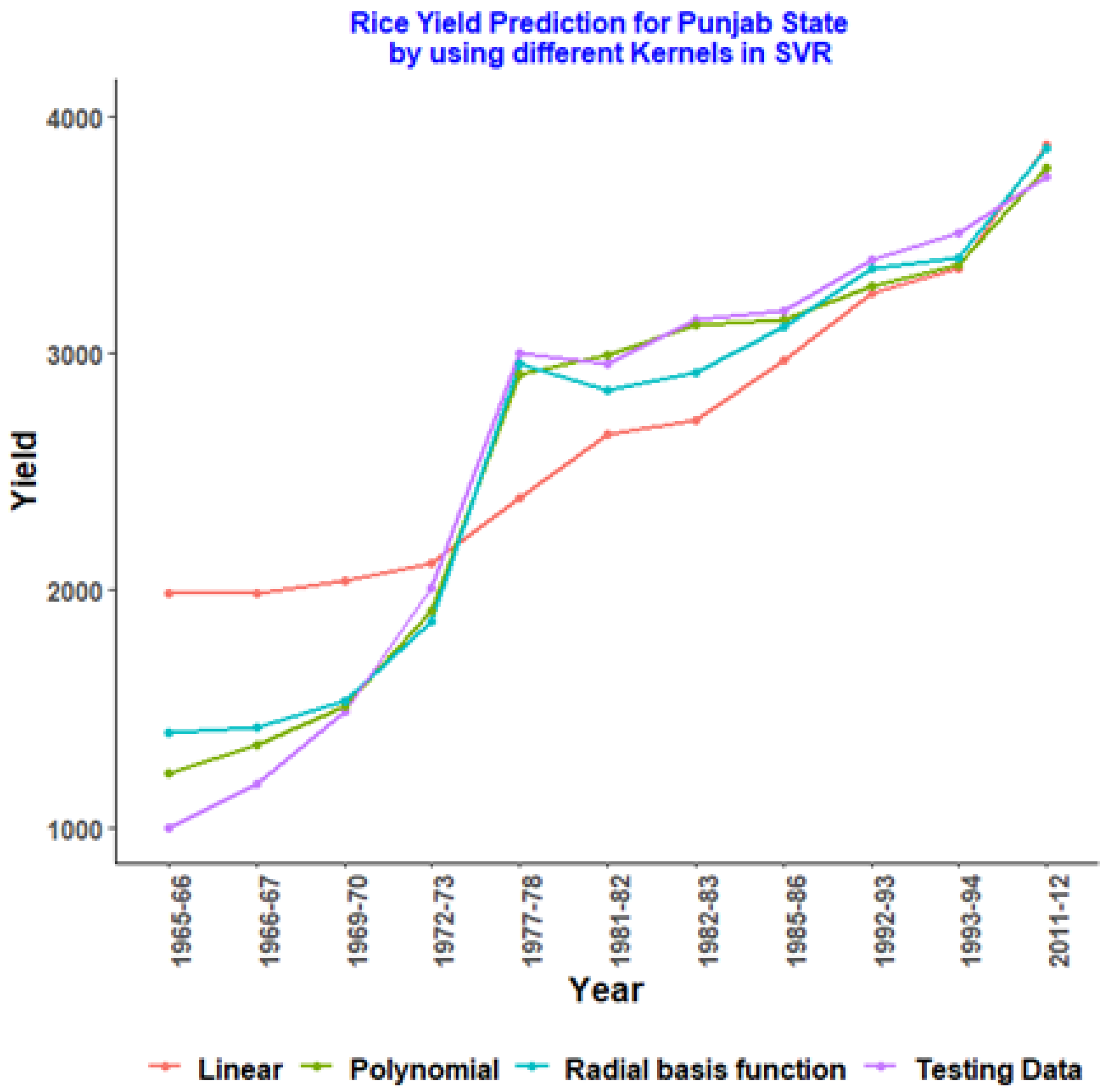
| Year | Testing Data | Linear | Polynomial | Radial Basis Function |
|---|---|---|---|---|
| 1965–66 | 1000 | 1984.915 | 1231.086 | 1400.547 |
| 1966–67 | 1185.96 | 1987.467 | 1344.406 | 1421.784 |
| 1969–70 | 1490.37 | 2040.976 | 1510.019 | 1531.768 |
| 1972–73 | 2008.41 | 2110.805 | 1910.526 | 1869.862 |
| 1977–78 | 3001.2 | 2389.271 | 2913.105 | 2953.451 |
| 1981–82 | 2956.69 | 2653.454 | 2994.668 | 2844.673 |
| 1982–83 | 3144.05 | 2714.251 | 3115.535 | 2918.069 |
| 1985–86 | 3179.05 | 2972.802 | 3140.217 | 3107.372 |
| 1992–93 | 3390.8 | 3251.927 | 3282.86 | 3357.642 |
| 1993–94 | 3507.11 | 3359.478 | 3371.527 | 3397.523 |
| 2011–12 | 3740.95 | 3876.672 | 3778.639 | 3864.746 |
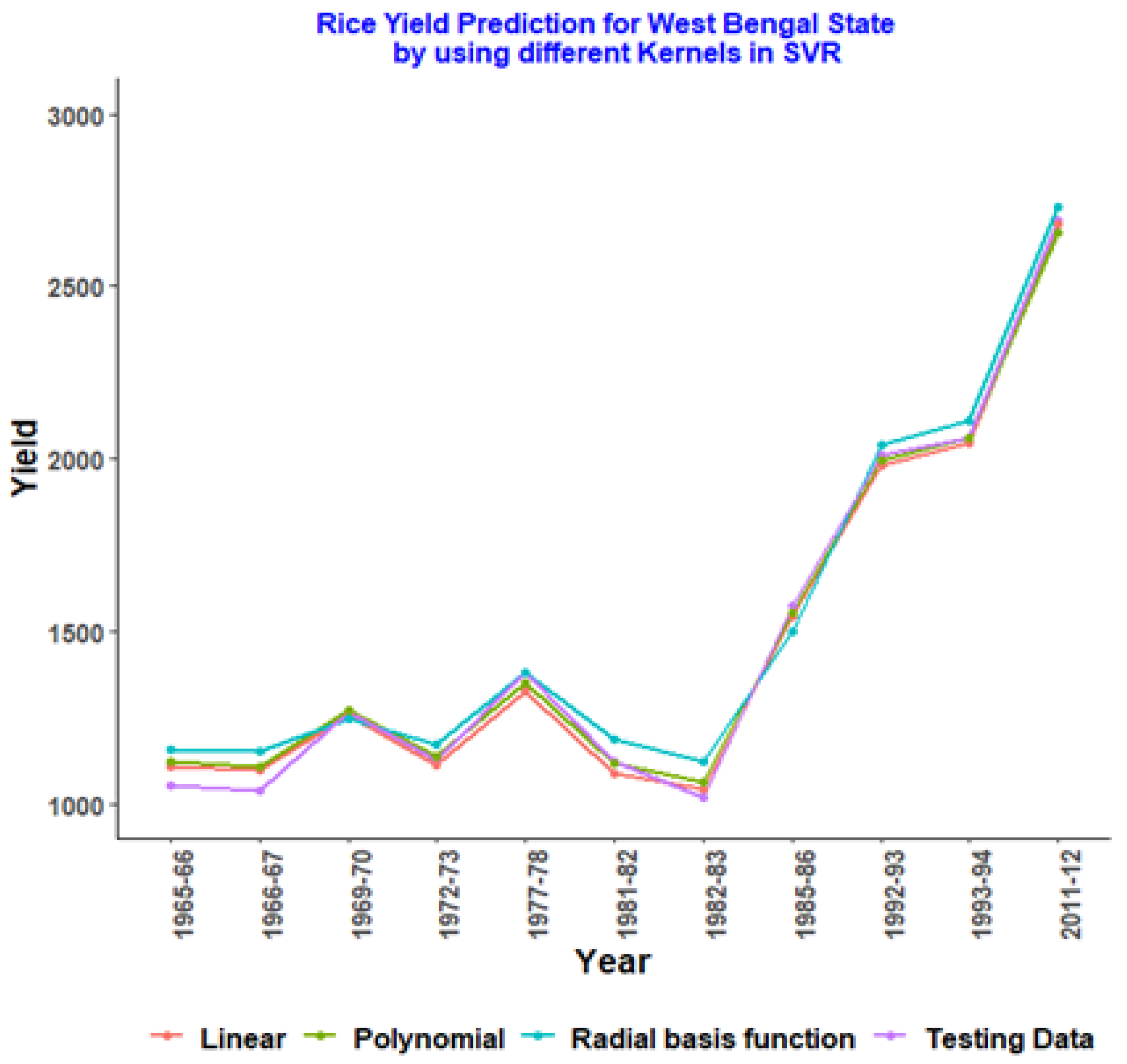
| Year | Testing Data | Linear | Polynomial | Radial Basis Function |
|---|---|---|---|---|
| 1965–66 | 1454.21 | 1409.09 | 1493.528 | 1503.597 |
| 1966–67 | 1551.08 | 1495.778 | 1593.943 | 1586.809 |
| 1969–70 | 1681.58 | 1632.861 | 1728.835 | 1700.689 |
| 1972–73 | 1953.66 | 1941.907 | 1996.371 | 2000.905 |
| 1977–78 | 2050.46 | 2072.662 | 2100.432 | 2052.946 |
| 1981–82 | 2272.8 | 2349.43 | 2347.931 | 2216.156 |
| 1982–83 | 1854.75 | 1989.945 | 1925.694 | 1923.1 |
| 1985–86 | 2371.81 | 2449.183 | 2450.186 | 2355.629 |
| 1992–93 | 3115.59 | 3177.199 | 3156.456 | 3190.227 |
| 1993–94 | 2926.68 | 3027.936 | 2984.151 | 2993.174 |
| 2011–12 | 3917.8 | 3757.044 | 3822.656 | 3615.108 |
| Year | Testing Data | Linear | Polynomial | Radial Basis Function |
|---|---|---|---|---|
| 1965–66 | 556.72 | 673.1853 | 540.2164 | 763.3959 |
| 1966–67 | 452.81 | 566.0447 | 423.2931 | 669.2615 |
| 1969–70 | 779.22 | 819.2724 | 799.4894 | 777.9589 |
| 1972–73 | 748.22 | 805.2615 | 759.5732 | 778.4787 |
| 1977–78 | 1068.93 | 1049.531 | 1115.0186 | 1017.2877 |
| 1981–82 | 1094.45 | 1067.715 | 1157.0251 | 1155.563 |
| 1982–83 | 1114.85 | 1088.614 | 1167.6177 | 1103.6731 |
| 1985–86 | 1488.21 | 1458.631 | 1533.773 | 1548.5288 |
| 1992–93 | 1772.77 | 1729.739 | 1777.3107 | 1820.2415 |
| 1993–94 | 1902.14 | 1841.217 | 1881.8026 | 1923.9034 |
| 2011–12 | 2357.83 | 2403.677 | 2319.2443 | 2296.3077 |
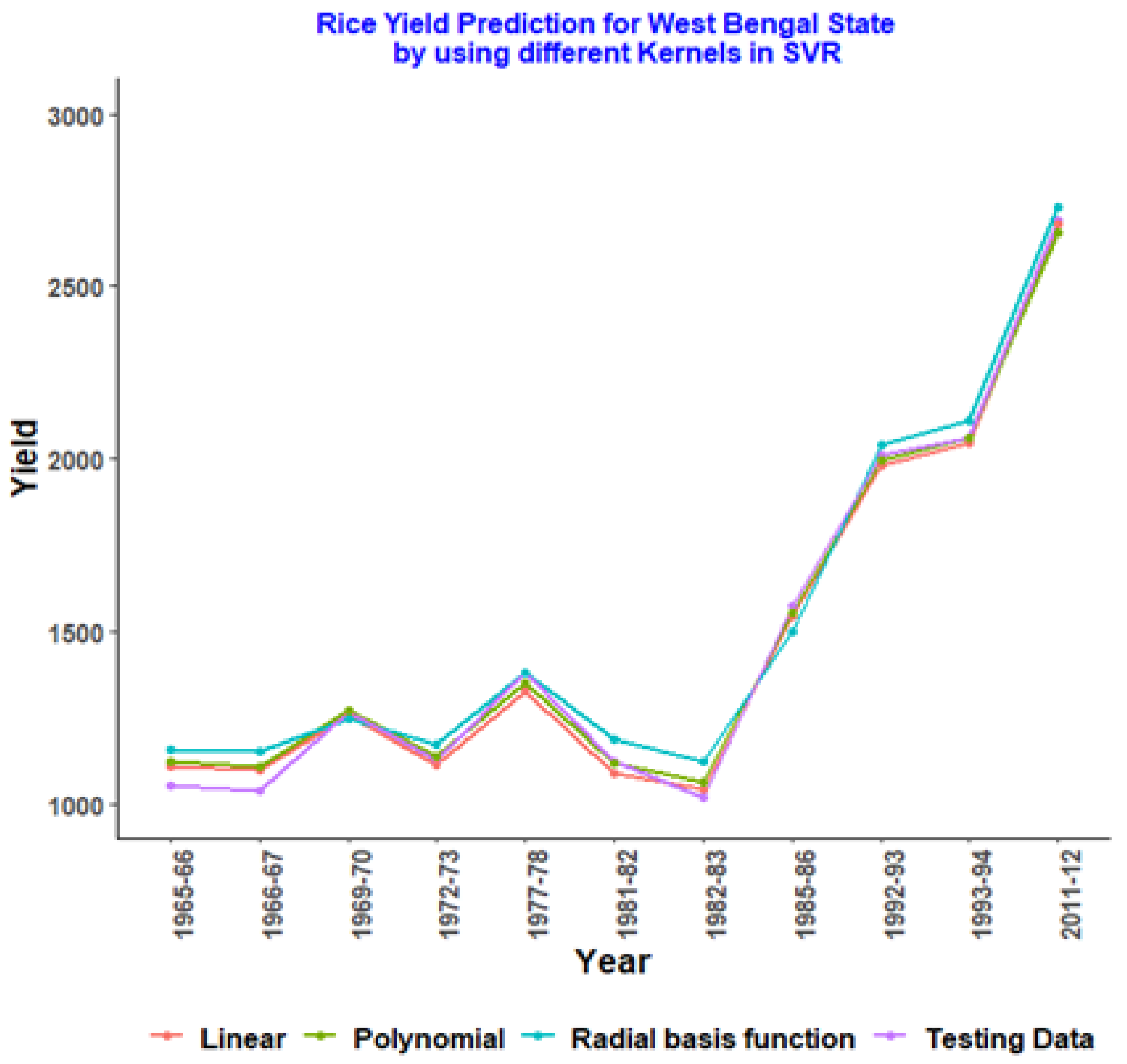
| Year | Testing Data | Linear | Polynomial | Radial Basis Function |
|---|---|---|---|---|
| 1965–66 | 1051.91 | 1108.185 | 1119.508 | 1156.513 |
| 1966–67 | 1037.77 | 1095.963 | 1107.669 | 1152.406 |
| 1969–70 | 1266.08 | 1254.931 | 1271.739 | 1246.331 |
| 1972–73 | 1127.41 | 1114.321 | 1137.813 | 1172.415 |
| 1977–78 | 1381.57 | 1325.851 | 1352.202 | 1377.464 |
| 1981–82 | 1119.5 | 1086.001 | 1114.68 | 1184.133 |
| 1982–83 | 1018.02 | 1043.034 | 1062.954 | 1123.664 |
| 1985–86 | 1573.43 | 1545.416 | 1553.579 | 1499.179 |
| 1992–93 | 2009.9 | 1982.777 | 1993.333 | 2039.329 |
| 1993–94 | 2061.25 | 2044.542 | 2058.219 | 2110.904 |
| 2011–12 | 2688 | 2680.183 | 2657.777 | 2731.098 |
| States | Dataset | RMSE | MAE | Best Fitted SVR Kernels |
|---|---|---|---|---|
| All India | Training | 27.52055 | 23.05118 | Linear |
| Testing | 31.05632 | 22.72886 | ||
| Bihar | Training | 31.2602 | 26.9666 | Polynomial |
| Testing | 37.3793 | 31.71476 | ||
| Punjab | Training | 90.3869 | 74.1052 | Polynomial |
| Testing | 109.3165 | 89.2451 | ||
| Tamil Nadu | Training | 49.2756 | 42.1280 | Polynomial |
| Testing | 60.8898 | 58.1863 | ||
| Uttar Pradesh | Training | 35.8264 | 29.7210 | Polynomial |
| Testing | 36.3151 | 31.6456 | ||
| West Bengal | Training | 37.9135 | 29.8288 | Polynomial |
| Testing | 35.11301 | 30.23646 | Linear |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Paidipati, K.K.; Chesneau, C.; Nayana, B.M.; Kumar, K.R.; Polisetty, K.; Kurangi, C. Prediction of Rice Cultivation in India—Support Vector Regression Approach with Various Kernels for Non-Linear Patterns. AgriEngineering 2021, 3, 182-198. https://doi.org/10.3390/agriengineering3020012
Paidipati KK, Chesneau C, Nayana BM, Kumar KR, Polisetty K, Kurangi C. Prediction of Rice Cultivation in India—Support Vector Regression Approach with Various Kernels for Non-Linear Patterns. AgriEngineering. 2021; 3(2):182-198. https://doi.org/10.3390/agriengineering3020012
Chicago/Turabian StylePaidipati, Kiran Kumar, Christophe Chesneau, B. M. Nayana, Kolla Rohith Kumar, Kalpana Polisetty, and Chinnarao Kurangi. 2021. "Prediction of Rice Cultivation in India—Support Vector Regression Approach with Various Kernels for Non-Linear Patterns" AgriEngineering 3, no. 2: 182-198. https://doi.org/10.3390/agriengineering3020012
APA StylePaidipati, K. K., Chesneau, C., Nayana, B. M., Kumar, K. R., Polisetty, K., & Kurangi, C. (2021). Prediction of Rice Cultivation in India—Support Vector Regression Approach with Various Kernels for Non-Linear Patterns. AgriEngineering, 3(2), 182-198. https://doi.org/10.3390/agriengineering3020012