
Camera-Based Crime Behavior Detection and Classification

 ,
, Highlights
- An efficient crime detection system based on deep learning multi-model integration accurately detects arson, burglary, and vandalism.
- Optimal models and ensemble techniques enhance detection accuracy, robustness, and generalization.
- An automated crime identification system with real-time SMS alerts can improve the effectiveness of crime prevention.
- A Gradio-based web system integrated with Twilio facilitates user alert management and customization.
Abstract
1. Introduction
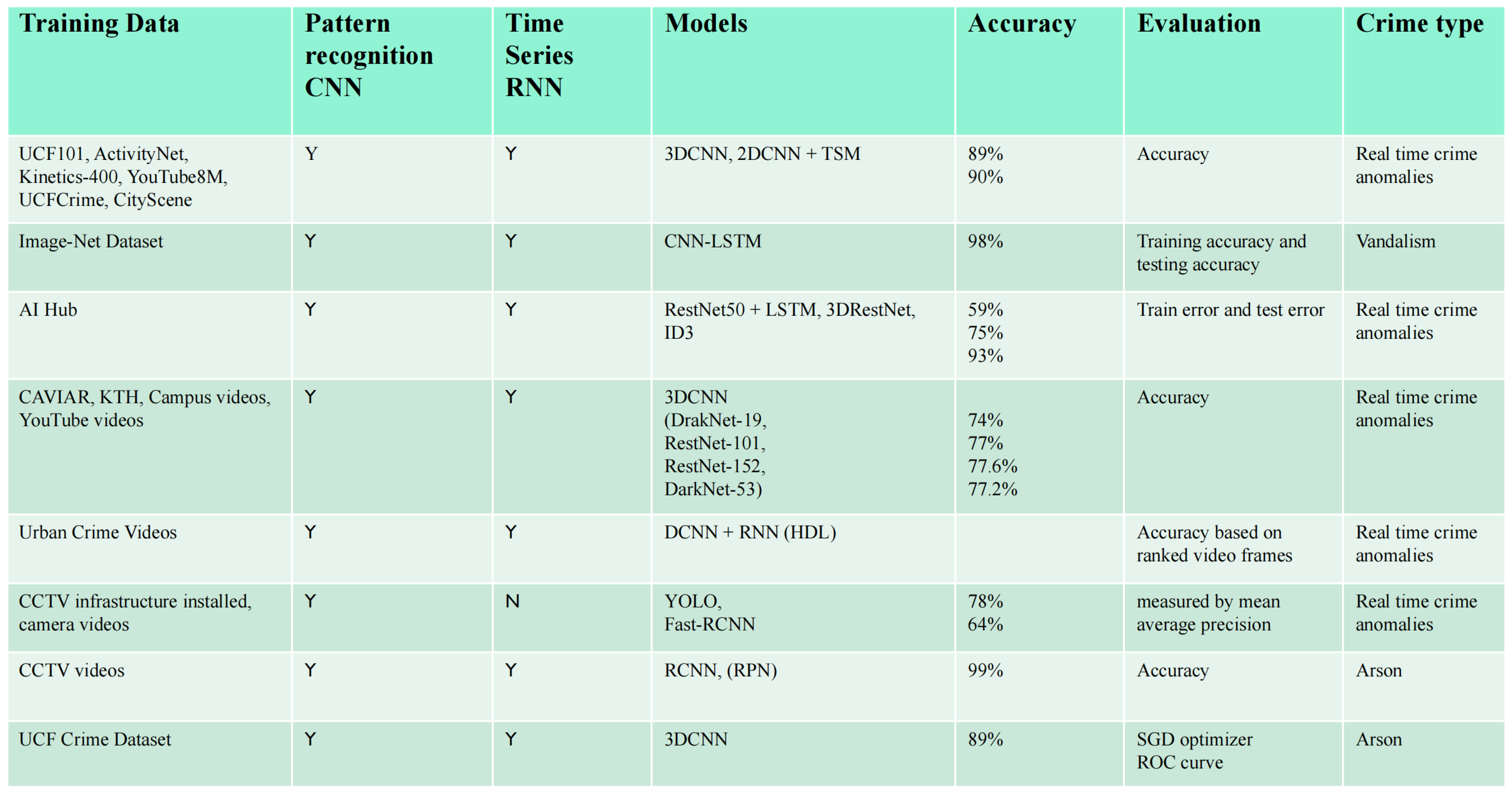
2. Data Engineering
2.1. Data Process
2.2. Data Collection
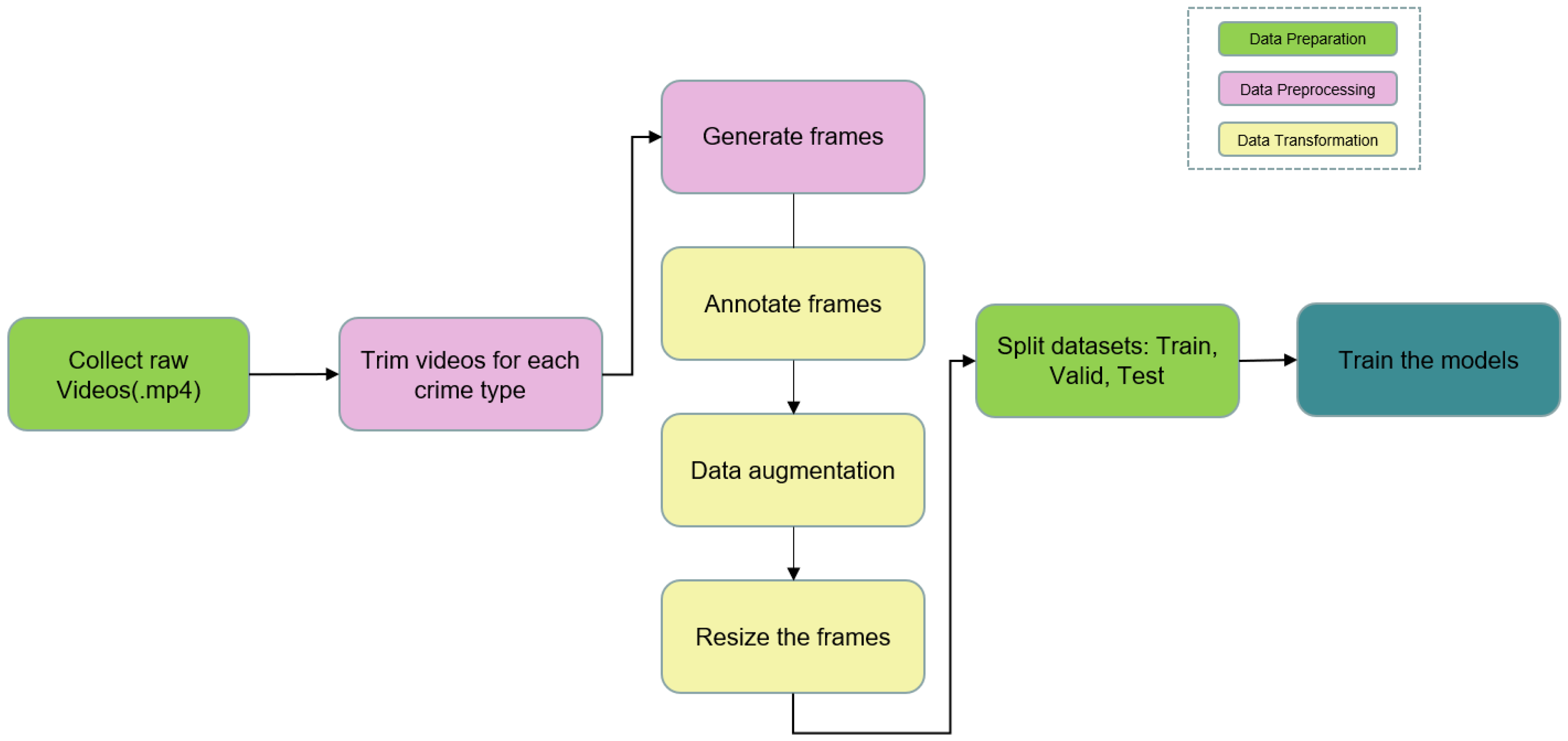
2.3. Data Preprocessing
- (1)
- Step 1 involves data cleaning by selecting good resolution videos in each crime type to get good results.
- (2)
- Step 2 is finding an anomalous event in a video and defining the objective of abnormal activity.
- (3)
- Step 3 is video trimming for suspicious and normal events using inbuilt video trimming software tools from Mac and Windows.
- (4)
- Step 4 is generating frames from each video by developing Python code.
- (5)
- When extracting frames, each frame name will be annotated. We created annotations for each frame using Roboflow and assigned class names for each target object.
- (6)
- The generated video frame dimensions might be different but we changed the dimensions of the extracted frames to different heights, weights, and widths as input size for the models in the data transformation section.
- (7)
- To increase our training data, data augmentation was applied: horizontal and vertical flips, sheer, rotating, and zooming for existing frames that provide different camera views of crime activities.
2.4. Data Transformation
2.4.1. Data Transformation—Resizing the Frames
2.4.2. Data Augmentation
2.5. Data Preparation
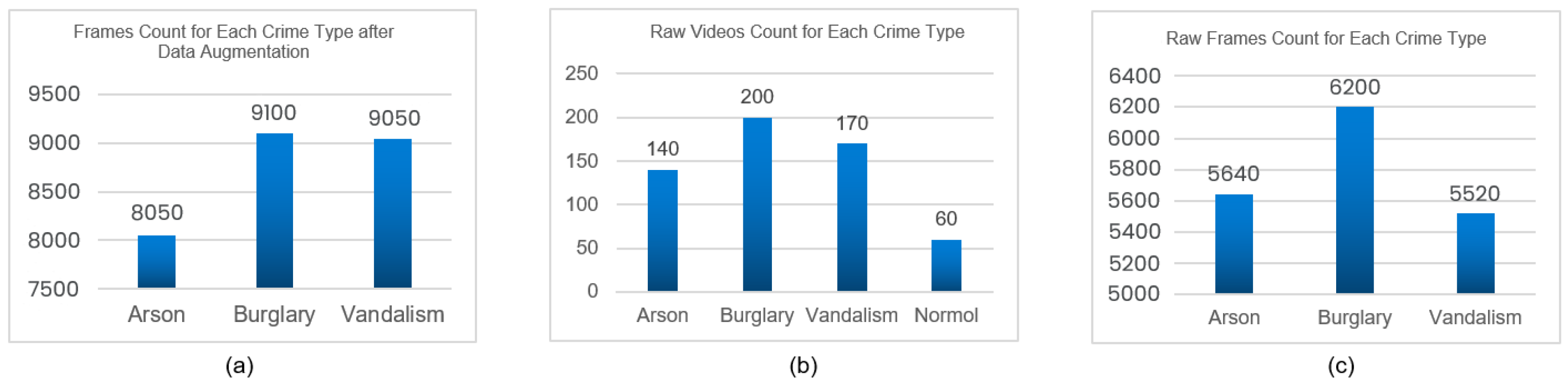
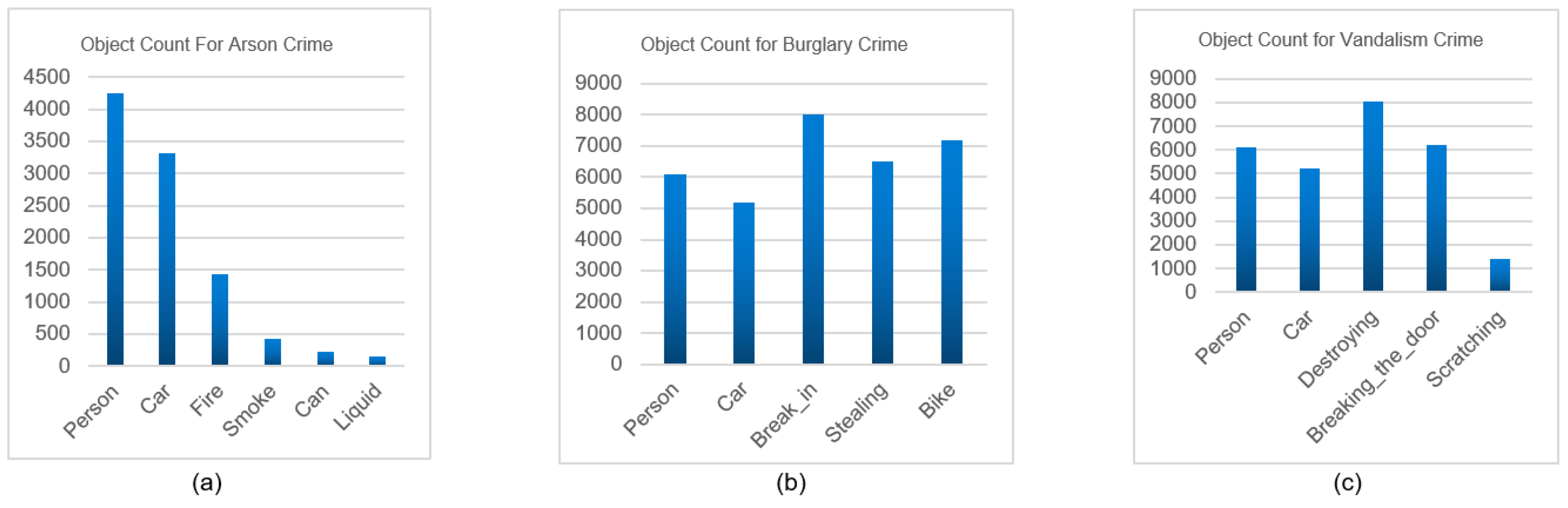
2.6. Data Statistics
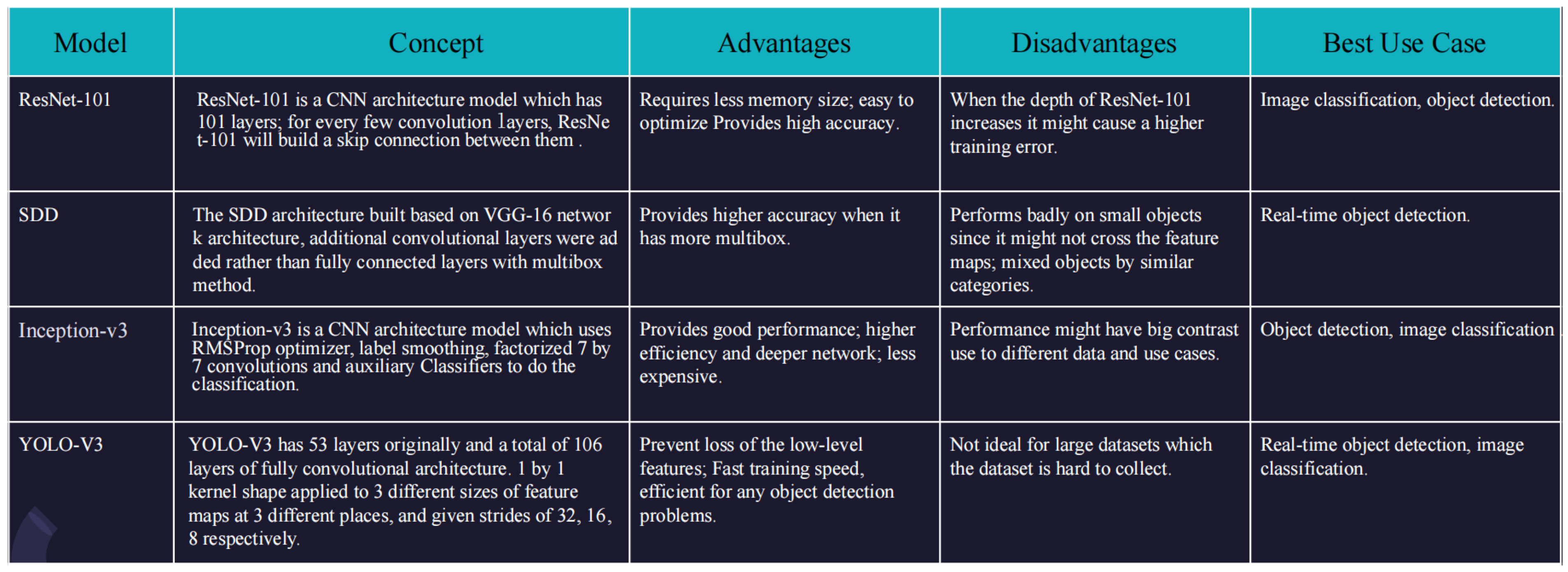
3. Model Development
3.1. Model Proposals
3.1.1. Improved Faster RCNN ResNet101
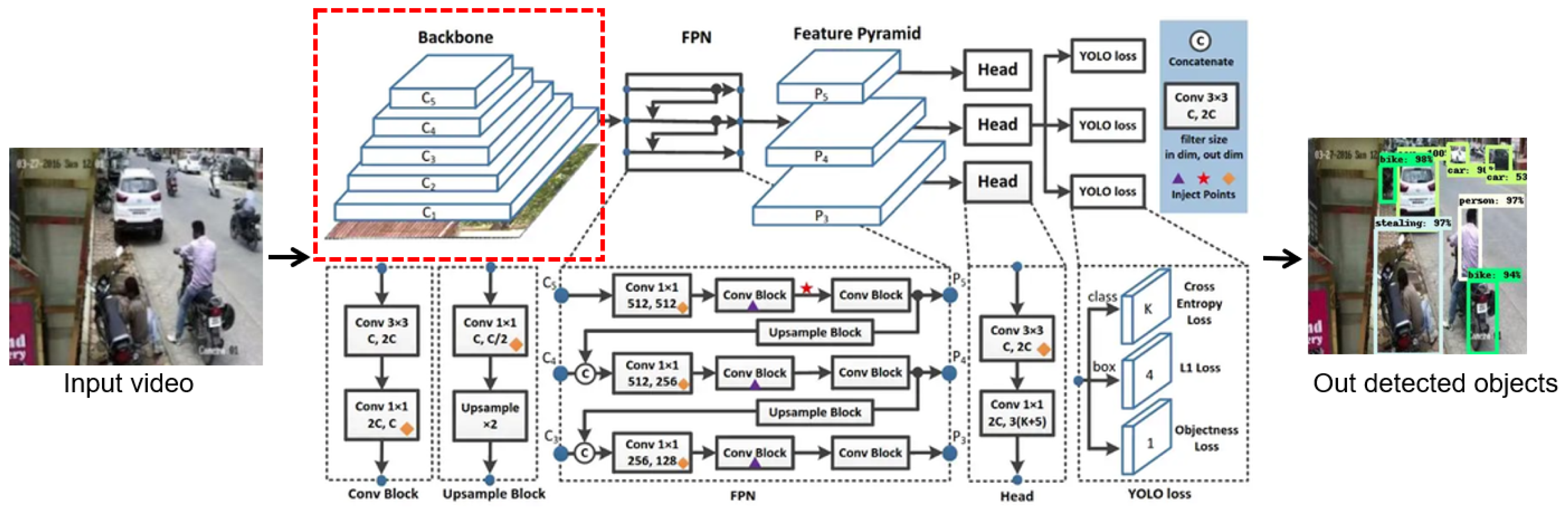
3.1.2. Improved YOLOv7
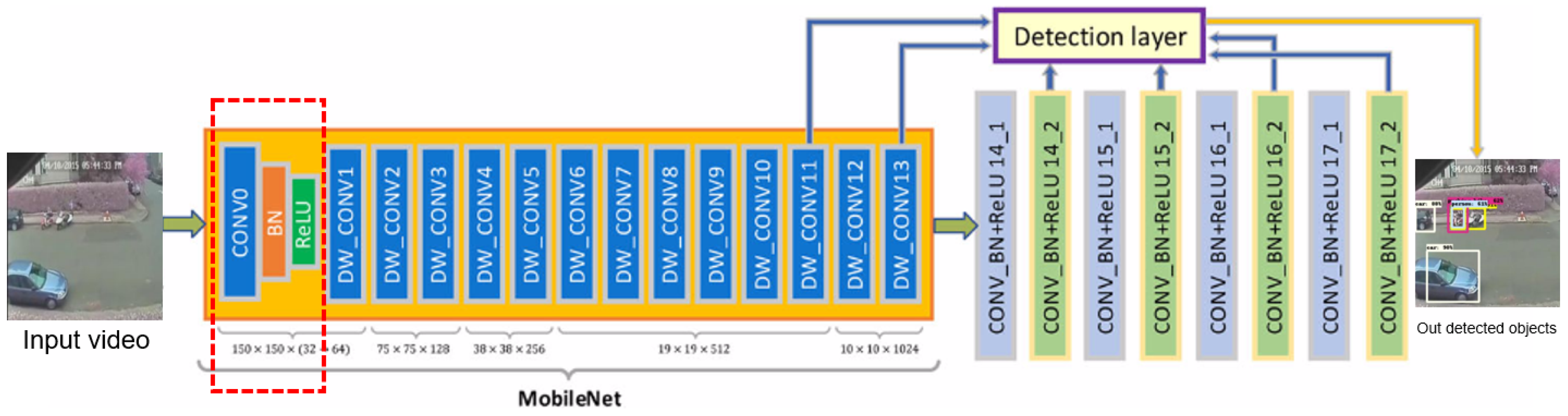
3.1.3. Improved SSD Mobilenetv2
3.1.4. Improved YOLOv6
3.1.5. Integrated Model
3.2. Model Support
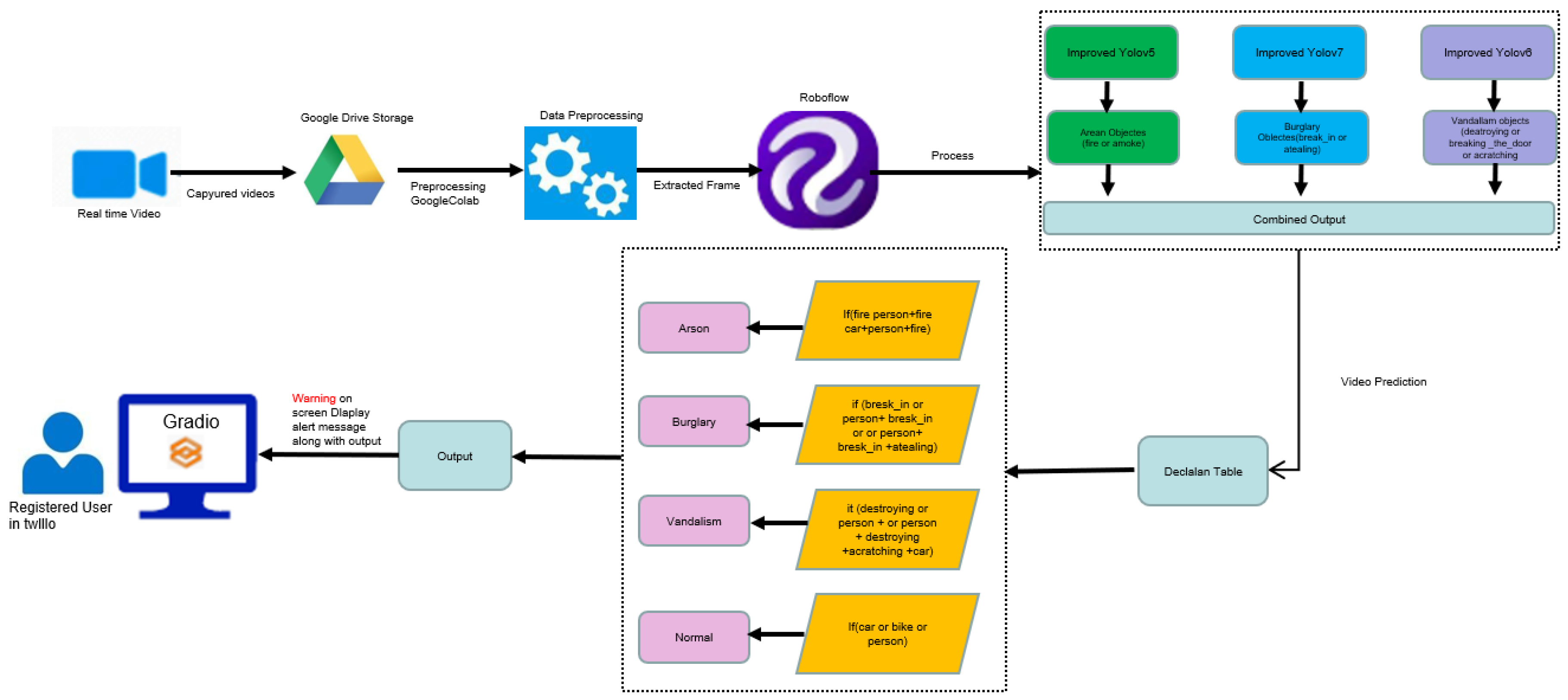
3.2.1. Project Workflow
3.2.2. System Architecture
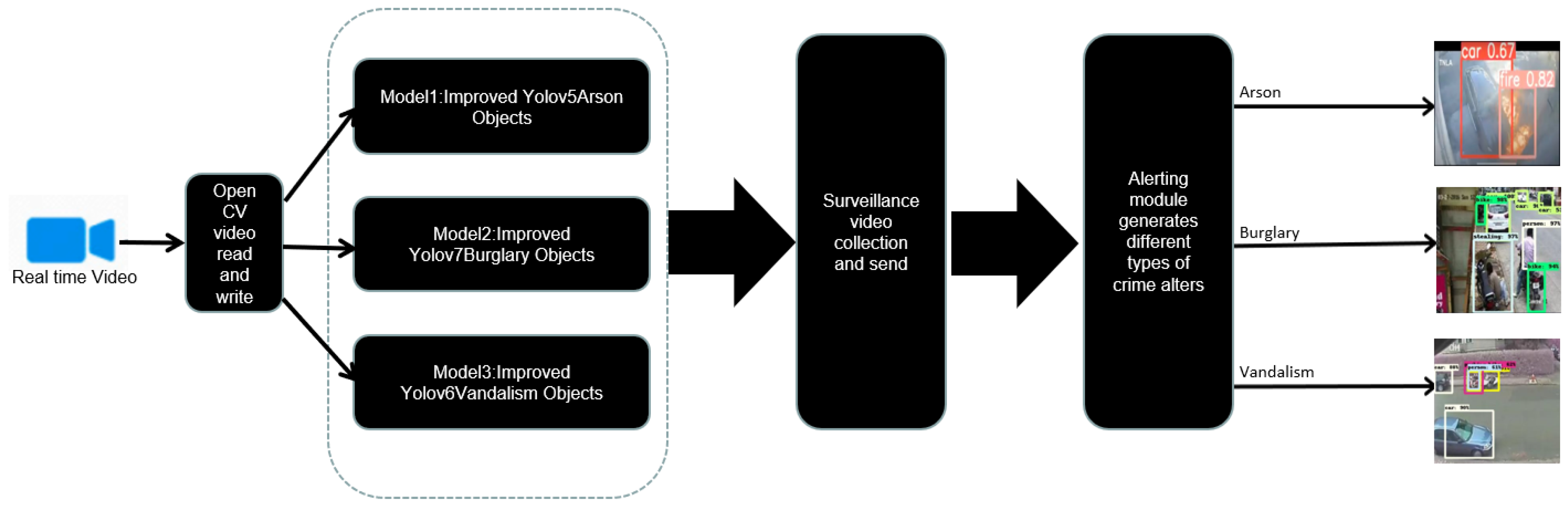
- Preprocess Module: When an input video is passed to the system, it generates video frames and processes the frames with resizing and data augmentation techniques by each model.
- Object detection: Each model processes these frames and may or may not provide detected objects for a specific crime type. This function is supported by three models: YOLOv5 provides arson objects, YOLOv7 provides burglary objects, and YOLOv6 provides vandalism objects.
- Classifiers: The detected objects are then classified based on the threshold to see whether a crime exists or not. Based on the threshold scores, the decision system will decide which crime the objects belong to.
- Display summary: Decision system crime type is displayed to the registered user along with bounding box, predicted scores, crime type objects, and classified crime. Additionally, a notification is sent as soon as the decision system classifies crime.
3.3. Model Comparison and Justification
Model Comparison
3.4. Model Evaluation Methods
- Intersection over union (IOU): The metric provides true objects detected correctly and true objects detected incorrectly with respect to the ground-truth of labeled regions and detected regions.
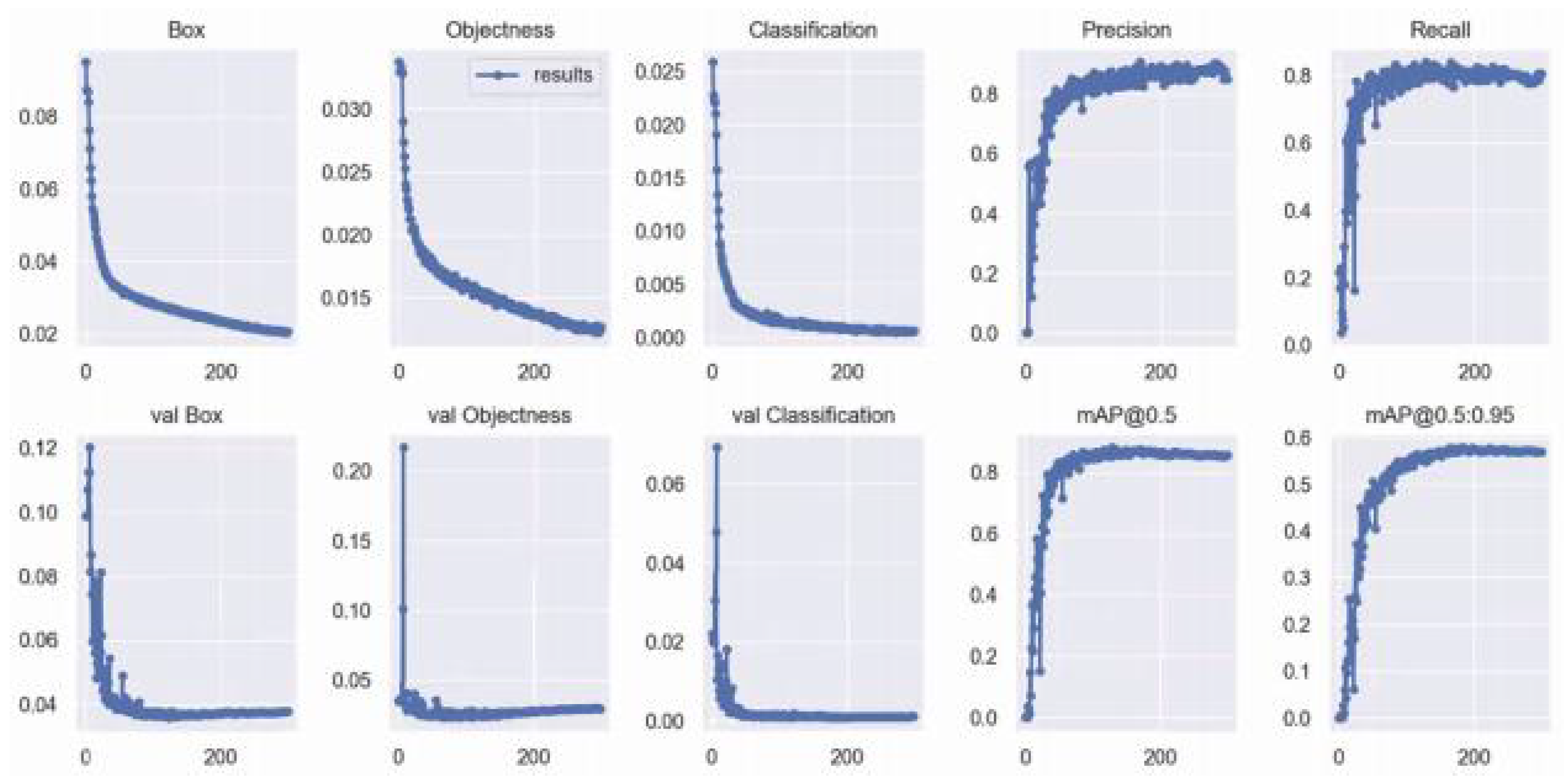
- Mean Average Precision (mAP): To evaluate the valid set and test test, we will use mAP. As shown in Figure 14, it provides the area under precision and recall curve that helps to understand the burglary, arson, and vandalism objects detected correctly and incorrectly.
- We evaluated using the training loss and validation loss to see whether the model trade-off for bias and variance was acceptable.
- mAP accuracy was also utilized in evaluating the training, and validation sets.
- We evaluated the speed at which our object detection model processed a video and produced the correct output, measured in frames per second (FPS).
- For machine learning classification issues with multi-class output, we evaluated them using a confusion matrix.
3.5. Model Validation and Evaluation Results
3.5.1. Improved YOLOv5
3.5.2. Improved YOLOv7
3.5.3. Improved YOLOv6
3.5.4. Model Comparison
4. Data Analytics and Intelligent System
4.1. System Requirements Analysis
System Boundary and Use Cases
4.2. System Design
4.2.1. System Architecture and Infrastructure
4.2.2. System Data Management Solution
4.3. System Development
4.3.1. AI and Machine Learning Model Development
- The framing and observations used to teach the model.
- Preparation of the training, validation, and test data.
- Teaching the algorithm to fit the model on the training data.
- Evaluating the models’ performance using different metrics.
4.3.2. Implement Designed System
4.3.3. Input and Output Requirements, Supporting Systems, and Solution APIs
- Input datasets: The input dataset could be recorded from a surveillance camera and could be any videos that are available to detect. Once the videos are uploaded to the system which is the open platform, it will process the input information and will be saved into the system as the user enters. Both crime videos and normal videos are accepted with different scenarios, such as nighttime and daytime videos, and also it is better to upload high resolution input videos, which lead to better detection as well as getting a clear output.
- Expected output: As we mentioned in the previous section, the designed interactive system shows the output containing the input video along with their target objects with corresponding bounding boxes, labels, scores, and classified crime based on time. Furthermore, a message tells our user whether the input dataset is a crime video or a normal video; an alert will pop out if it belongs to a crime video and is also classified crime type.
- Arson crime expected output: output contains target objects such as fire, person, car, and more within the video.
- Burglary crime expected output: output contains target objects such as break in, stealing, person, and more within the video.
- Vandalism crime expected output: output contains target objects such as breaking the door, scratching, destroying, and more within the video.
- Supporting system contexts: Surveillance camera or required videos in good resolution which could capture the crime behaviors within the videos.
- Solution APIs: For the better development of this project, we planned to use the Gradio’s API built specifically for ML and Data Science projects; it is as close to the recognition as we could get, and it pre-configured most of the common recognition tasks. On the other hand, Gradio’s API could build websites in dozens of lines for Python and create an API simply, and also provide comprehensive deep learning packages and libraries, which are the most common uses of it. The following lists some features and functionalities of Gradio.
- Track and contact real estate agents as well as house buyers.
- Users can communicate with each other without revealing their private information.
- Staff can help customers via their web interface.
- Staff receives auto-alerts at the time when vending machines need maintenance.
4.4. System Supporting Environment
5. System Evaluation and Visualization
5.1. Analysis of Model Execution and Evaluation Results
5.2. Achievements and Constraints
- Implement model for each crime type and integrate in one hybrid model.
- Present all crime type results for the user interface.
- Improve crime recognition system using OpenCV.
- Create an interactive user interface platform by using Gradio API.
5.3. System Quality Evaluation of Model Functions and Performance
6. Conclusions
6.1. Summary
6.2. Prospect and Future Work
- Provide more security [45] for arson, burglary, and vandalism crimes in the public and private space such as HOA communities, apartment buildings, street or public parkings, and for individual homeowners.
- Easy to use website where a user can do simple free registration by creating a Twilio account to get an SMS alert as soon as the video classifies any crime.
- Since we are using YOLO models, it is easy to use the OpenCV library to detect our customized objects in videos.
- Different object detection models [46] helped us to understand how other models performed, which benefited us to navigate for new YOLO models compared to Faster RCNN and SSD MobileNet and assisted in saving training time and computation cost as the other two models had huge parameters.
- To get the detections and classification on any given video, we have assembled all three models rather than using a single model for each crime type.Shortcoming of the solution:
- To get alerts for crime types, users have to register through Twilio accounts. However, users can use a free trial for up to 30 days. In order to have an active account, users have to pay monthly or annually.
- As of now, we have trained models for arson, burglary, and vandalism crime types. Hence, our models will not be used to detect other types of crimes.
- Our class annotations are restricted due to the limited data accessibility, high resolution videos, and the given time constraint of the semester. We can annotate more classes of all categories and increase the datasets in future for further distinctions of classes.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Norkobil Saydirasulovich, S.; Abdusalomov, A.; Jamil, M.K.; Nasimov, R.; Kozhamzharova, D.; Cho, Y.I. A YOLOv6-Based Improved Fire Detection Approach for Smart City Environments. Sensors 2023, 23, 3161. [Google Scholar] [CrossRef] [PubMed]
- Navalgund, U.V.; Priyadharshini, K. Crime intention detection system using deep learning. In Proceedings of the 2018 International Conference on Circuits and Systems in Digital Enterprise Technology (ICCSDET), Kottayam, India, 21–22 December 2018; pp. 1–6. [Google Scholar]
- Ali, L.; Alnajjar, F.; Jassmi, H.A.; Gocho, M.; Khan, W.; Serhani, M.A. Performance evaluation of deep CNN-based crack detection and localization techniques for concrete structures. Sensors 2021, 21, 1688. [Google Scholar] [CrossRef] [PubMed]
- Shah, N.; Bhagat, N.; Shah, M. Crime forecasting: A machine learning and computer vision approach to crime prediction and prevention. Vis. Comput. Ind. Biomed. Art 2021, 4, 9. [Google Scholar] [CrossRef] [PubMed]
- Chackravarthy, S.; Schmitt, S.; Yang, L. Intelligent crime anomaly detection in smart cities using deep learning. In Proceedings of the 2018 IEEE 4th International Conference on Collaboration and Internet Computing (CIC), Philadelphia, PA, USA, 18–20 October 2018; pp. 399–404. [Google Scholar]
- Jonathan, H. mAP (Mean Average Precision) for Object Detection. Available online: https://jonathan-hui.medium.com/map-mean-average-precision-for-object-detection-45c121a31173 (accessed on 25 February 2024).
- Padilla, R.; Netto, S.L.; Da Silva, E.A. A survey on performance metrics for object-detection algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niterói, Brazil, 1–3 July 2020; pp. 237–242. [Google Scholar]
- Maqsood, R.; Bajwa, U.I.; Saleem, G.; Raza, R.H.; Anwar, M.W. Anomaly recognition from surveillance videos using 3D convolution neural network. Multimed. Tools Appl. 2021, 80, 18693–18716. [Google Scholar] [CrossRef]
- Yuan, C.; Zhang, J. Violation detection of live video based on deep learning. Sci. Program. 2020, 2020, 1895341. [Google Scholar] [CrossRef]
- Zamri, N.; Tahir, N.; Ali, M.; Ashar, N.; Al-misreb, A. Mini-review of street crime prediction and classification methods. J. Kejuruter 2021, 33, 391. [Google Scholar] [CrossRef] [PubMed]
- Mohandas, R.; Bhattacharya, M.; Penica, M.; Van Camp, K.; Hayes, M.J. TensorFlow Enabled Deep Learning Model Optimization for enhanced Realtime Person Detection using Raspberry Pi operating at the Edge. In Proceedings of the AICS, Dublin, Ireland, 7–8 December 2020; pp. 157–168. [Google Scholar]
- Yang, F.; Zhang, X.; Liu, B. Video object tracking based on yolov7 and deepsort. arXiv 2022, arXiv:2207.12202. [Google Scholar]
- Sultani, W.; Chen, C.; Shah, M. Real-world anomaly detection in surveillance videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6479–6488. [Google Scholar]
- Abraham, M.; Suryawanshi, N.; Joseph, N.; Hadsul, D. Future Predicting Intelligent Camera Security System. In Proceedings of the 2021 International Conference on Innovative Trends in Information Technology (ICITIIT), Kottayam, India, 11–12 February 2021; pp. 1–6. [Google Scholar]
- Nyajowi, T.; Oyie, N.; Ahuna, M. CNN Real-Time Detection of Vandalism Using a Hybrid-LSTM Deep Learning Neural Networks. In Proceedings of the 2021 IEEE AFRICON, Arusha, Tanzania, 13–15 September 2021; pp. 1–6. [Google Scholar]
- Lee, J.; Shin, S.J. A Study of Video-Based Abnormal Behavior Recognition Model Using Deep Learning. Int. J. Adv. Smart Converg. 2020, 9, 115–119. [Google Scholar]
- Tulbure, A.A.; Tulbure, A.A.; Dulf, E.H. A review on modern defect detection models using DCNNs–Deep convolutional neural networks. J. Adv. Res. 2022, 35, 33–48. [Google Scholar] [CrossRef]
- Abid, A.; Abdalla, A.; Abid, A.; Khan, D.; Alfozan, A.; Zou, J. Gradio: Hassle-free sharing and testing of ml models in the wild. arXiv 2019, arXiv:1906.02569. [Google Scholar]
- Sylvester, R.; Greenidge, W.l. Digital storytelling: Extending the potential for struggling writers. Read. Teach. 2009, 63, 284–295. [Google Scholar] [CrossRef]
- Li, Y.; Zhu, D.; Fan, H. An Improved Faster RCNN Marine Fish Classification Identification Algorithm. In Proceedings of the 2021 2nd International Conference on Artificial Intelligence and Computer Engineering (ICAICE), Hangzhou, China, 5–7 November 2021; pp. 126–129. [Google Scholar]
- Khandhar, H.M.; Bhatt, C.; Le, D.N.; Sharaf, H.; Mansoor, W. Plant Disease Identification Based on Leaf Images Using Deep Learning. In Evolution in Signal Processing and Telecommunication Networks, Proceedings of the Sixth International Conference on Microelectronics, Electromagnetics and Telecommunications (ICMEET 2021), Bhubaneswar, India, 27–28 August 2021; Springer: Berlin/Heidelberg, Germany, 2022; Volume 2, pp. 215–224. [Google Scholar]
- Cheng, M.; Cai, K.; Li, M. RWF-2000: An open large scale video database for violence detection. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 4183–4190. [Google Scholar]
- Amrutha, C.; Jyotsna, C.; Amudha, J. Deep learning approach for suspicious activity detection from surveillance video. In Proceedings of the 2020 2nd International Conference on Innovative Mechanisms for Industry Applications (ICIMIA), Bangalore, India, 5–7 March 2020; pp. 335–339. [Google Scholar]
- Vandaele, R.; Nervo, G.A.; Gevaert, O. Topological image modification for object detection and topological image processing of skin lesions. Sci. Rep. 2020, 10, 21061. [Google Scholar] [CrossRef] [PubMed]
- Annisaa’F, N.; Soekirno, S.; Aminah, S. Implementation of Single Shot Detector (SSD) MobileNet V2 on Disabled Patient’s Hand Gesture Recognition as a Notification System. In Proceedings of the 2021 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Virtual, 23–26 October 2021; pp. 1–6. [Google Scholar]
- Iee, J.-Y.; Cho, C.-J.; Han, D.K.; Ko, H. Hierarchical spatial object detection for atm vandalism surveillance. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; pp. 1–5. [Google Scholar]
- Quon, J.; Bala, W.; Chen, L.; Wright, J.; Kim, L.; Han, M.; Shpanskaya, K.; Lee, E.; Tong, E.; Iv, M.; et al. Deep learning for pediatric posterior fossa tumor detection and classification: A multi-institutional study. Am. J. Neuroradiol. 2020, 41, 1718–1725. [Google Scholar] [CrossRef] [PubMed]
- Lin, C.; Li, L.; Luo, W.; Wang, K.C.; Guo, J. Transfer learning based traffic sign recognition using inception-v3 model. Period. Polytech. Transp. Eng. 2019, 47, 242–250. [Google Scholar] [CrossRef]
- Guo, G.; Zhang, Z. Road damage detection algorithm for improved YOLOv5. Sci. Rep. 2022, 12, 15523. [Google Scholar] [CrossRef] [PubMed]
- Available online: https://www.ijraset.com/research-paper/crime-activity-detection-using-ml (accessed on 25 February 2024).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Liu, Y. An improved faster R-CNN for object detection. In Proceedings of the 2018 11th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 8–9 December 2018; pp. 119–123. [Google Scholar]
- Zhang, M.; Li, L.; Wang, H.; Liu, Y.; Qin, H.; Zhao, W. Optimized compression for implementing convolutional neural networks on FPGA. Electronics 2019, 8, 295. [Google Scholar] [CrossRef]
- Cao, C.; Wang, B.; Zhang, W.; Zeng, X.; Yan, X.; Feng, Z.; Liu, Y.; Wu, Z. An improved faster R-CNN for small object detection. IEEE Access 2019, 7, 106838–106846. [Google Scholar] [CrossRef]
- Al-Haija, Q.A.; Smadi, M.A.; Zein-Sabatto, S. Multi-class weather classification using ResNet-18 CNN for autonomous IoT and CPS applications. In Proceedings of the 2020 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 16–18 December 2020; pp. 1586–1591. [Google Scholar]
- VGG16—Convolutional Network for Classification and Detection. Available online: https://neurohive.io/en/popular-networks/vgg16/ (accessed on 25 February 2024).
- Rajapakshe, C.; Balasooriya, S.; Dayarathna, H.; Ranaweera, N.; Walgampaya, N.; Pemadasa, N. Using cnns rnns and machine learning algorithms for real-time crime prediction. In Proceedings of the 2019 International Conference on Advancements in Computing (ICAC), Malabe, Sri Lanka, 5–6 December 2019; pp. 310–316. [Google Scholar]
- Alderliesten, K. Yolov3—Real-Time Object Detection. Available online: https://medium.com/analytics-vidhya/yolov3-real-time-object-detection-54e69037b6d0 (accessed on 25 February 2024).
- Chong, Y.S.; Tay, Y.H. Abnormal event detection in videos using spatiotemporal autoencoder. In Advances in Neural Networks-ISNN 2017, Proceedings of the 14th International Symposium, ISNN 2017, Sapporo, Hakodate, and Muroran, Hokkaido, Japan, 21–26 June 2017; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Atrey, J.; Regunathan, R.; Rajasekaran, R. Real-world application of face mask detection system using YOLOv6. Int. J. Crit. Infrastruct. 2023. [Google Scholar] [CrossRef]
- Sung, C.S.; Park, J.Y. Design of an intelligent video surveillance system for crime prevention: Applying deep learning technology. Multimed. Tools Appl. 2021, 80, 34297–34309. [Google Scholar] [CrossRef]
- Jiang, B.; He, J.; Yang, S.; Fu, H.; Li, T.; Song, H.; He, D. Fusion of machine vision technology and AlexNet-CNNs deep learning network for the detection of postharvest apple pesticide residues. Artif. Intell. Agric. 2019, 1, 1–8. [Google Scholar] [CrossRef]
- Forson, E. Understanding SSD Multibox—Real-Time Object Detection in Deep Learning. Available online: https://towardsdatascience.com/understanding-ssd-multibox-real-time-object-detection-in-deep-learning-495ef744fab (accessed on 25 February 2024).
- Inception V3 Model Architecture. Available online: https://iq.opengenus.org/inception-v3-model-architecture/ (accessed on 25 February 2024).
- Sivakumar, P.; Jayabalaguru, V.; Ramsugumar, R.; Kalaisriram, S. Real Time Crime Detection Using Deep Learning Algorithm. In Proceedings of the 2021 International Conference on System, Computation, Automation and Networking (ICSCAN), Puducherry, India, 30–31 July 2021; pp. 1–5. [Google Scholar]
- Phadtare, M.; Choudhari, V.; Pedram, R.; Vartak, S. Comparison between YOLO and SSD mobile net for object detection in a surveillance drone. Int. J. Sci. Res. Eng. Manag 2021, 5, 1–5. [Google Scholar]
- Liu, K.; Zhu, M.; Fu, H.; Ma, H.; Chua, T.S. Enhancing anomaly detection in surveillance videos with transfer learning from action recognition. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 4664–4668. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Crime | Places |
|---|---|
| Arson | Parking lots. |
| Arson | Neighborhoods, houses, streets, etc. |
| Burglary | Parking lots. |
| Burglary | Neighborhoods, houses, vehicles, streets, etc. |
| Vandalism | Parking lots. |
| Vandalism | Neighborhoods, houses, streets, etc. |
| Dataset | Crime Type | Untrimmed Videos | Total Videos | Raw Video Frames | Data Augmentation | Total Frames | Manual Annotation |
|---|---|---|---|---|---|---|---|
| UCF [8] | Arson | 60 | 3000 | 5500 | |||
| YouTube | Arson | 40 | 140 | 1640 | 1500 | 8050 | YES |
| Storyblocks [12] | Arson | 40 | 1000 | 1050 | |||
| UCF [8] | Burglary | 110 | 4000 | 5500 | |||
| YouTube | Burglary | 50 | 200 | 1200 | 2100 | 9100 | YES |
| Storyblocks [12] | Burglary | 40 | 1000 | 1500 | |||
| UCF [8] | Vandalism | 50 | 3060 | 4405 | |||
| YouTube | Vandalism | 80 | 170 | 1460 | 2945 | 9050 | YES |
| Storyblocks [12] | Vandalism | 40 | 1000 | 1700 |
| Crime Type | Crime Video Quantity (mp4) |
|---|---|
| Arson | 140 |
| Burglary | 200 |
| Vandalism | 170 |
| Normal | 60 |
| Crime Type | Source | Raw Frames | After Augmentation (Total Frames) | Train (80%) | Valid (15%) | Test (5%) |
|---|---|---|---|---|---|---|
| Arson | UCF, Youtube, Story Blocks | 5640 | 8050 | 6440 | 1208 | 402 |
| Burglary | UCF, Youtube, Story Blocks | 6200 | 9100 | 7280 | 1365 | 455 |
| Vandalism | UCF, Youtube, Story Blocks | 5520 | 9050 | 7140 | 1524 | 386 |
| Crime Type | Sources | Total Dataset | Models | Average Precision | Average Recall | mAP@50 |
|---|---|---|---|---|---|---|
| Arson | UCF, Youtube, Storyblocks | 8050 | YOLOv5 | 0.95 | 0.86 | 0.80 |
| Burglary | UCF, Youtube, Storyblocks | 9100 | YOLOv7 | 0.89 | 0.86 | 0.87 |
| Vandalism | UCF, Youtube, Storyblocks | 9050 | YOLOv6 | 0.88 | 0.79 | 0.86 |
| Crime Type | Model Object Detection | Existing Model | mAP@50 |
|---|---|---|---|
| Arson | Improved YOLOv5 | No | 80% |
| Burglary | Improved Faster RCNN | No | 61% |
| Improved YOLOv7 | No | 87% | |
| Vandalism | Improved SSD MobileNet | No | 67% |
| Improved YOLOv6 | No | 86% |
| Crime Type | Model | Dataset Size | Average Precision | Average Recall | mAP@50 | FPS (ms) |
|---|---|---|---|---|---|---|
| Arson | YOLOv5 | 8050 | 0.95 | 0.86 | 0.80 | 15 |
| Burglary | YOLOv7 | 9100 | 0.89 | 0.86 | 0.87 | 12 |
| Vandalism | YOLOv6 | 9050 | 0.88 | 0.79 | 0.86 | 15 |
| Tasks | Data Requirements | Labeling Tool | Label Export Format |
|---|---|---|---|
| Detect objects in arson and classify the crime type (during daytime and night time) | High spatial resolution videos | Roboflow | .txt |
| Detect objects in burglary and classify the crime type (during daytime and nighttime) | High spatial resolution videos | Roboflow | .txt |
| Detect objects in vandalism and classify the crime type (during daytime and nighttime) | High spatial resolution videos | Roboflow | .txt |
| Crime Type | Model | Previous mAP@50 | Current mAP@50 |
|---|---|---|---|
| Arson | YOLOv5 | 0.50 | 0.80 |
| Burglary | YOLOv7 | 0.61 | 0.87 |
| Vandalism | YOLOv6 | 0.67 | 0.86 |
| Features | Device Specifications | Average Run Time (s) | Google Collab Pro | Average Run Time (s) |
|---|---|---|---|---|
| Arson object detection | Macbook Pro Processor: 2.6 GHz 6-Core Intel Core i8 Memory: 16 GB 2667 MHz | 1.93 | Google Cloud Pro Platform Deep learning VM with GPU (NVDIA Tesla K80, P100, T4) 32 GB RAM | 1.23 |
| Burglary object detection | Macbook Pro Processor: 2.6 GHz 6-Core Intel Core i7 Memory: 16 GB 2667 MHz | 2.14 | Google Cloud Pro Platform Deep learning VM with GPU (NVDIA Tesla K80, P100, T4) 32 GB RAM | 1.12 |
| Vandalism object detection | HP Windows 10 (64bit OS) Processor: Intel® Core™ i7-10510U Memory: 16 GB 2300 MHz | 2.31 | Google Cloud Pro Platform Deep learning VM with GPU (NVDIA Tesla K80, P100, T4) 32 GB RAM | 1.26 |
| Integrated Model | Macbook Pro Processor: 2.6 GHz 6-Core Intel Core i7 Memory: 16 GB 2667 MHz | 2.45 | Google Cloud Pro Platform Deep learning VM with GPU (NVDIA Tesla K80, P100, T4) 32 GB RAM | 2.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gao, J.; Shi, J.; Balla, P.; Sheshgiri, A.; Zhang, B.; Yu, H.; Yang, Y. Camera-Based Crime Behavior Detection and Classification. Smart Cities 2024, 7, 1169-1198. https://doi.org/10.3390/smartcities7030050
Gao J, Shi J, Balla P, Sheshgiri A, Zhang B, Yu H, Yang Y. Camera-Based Crime Behavior Detection and Classification. Smart Cities. 2024; 7(3):1169-1198. https://doi.org/10.3390/smartcities7030050
Chicago/Turabian StyleGao, Jerry, Jingwen Shi, Priyanka Balla, Akshata Sheshgiri, Bocheng Zhang, Hailong Yu, and Yunyun Yang. 2024. "Camera-Based Crime Behavior Detection and Classification" Smart Cities 7, no. 3: 1169-1198. https://doi.org/10.3390/smartcities7030050
APA StyleGao, J., Shi, J., Balla, P., Sheshgiri, A., Zhang, B., Yu, H., & Yang, Y. (2024). Camera-Based Crime Behavior Detection and Classification. Smart Cities, 7(3), 1169-1198. https://doi.org/10.3390/smartcities7030050