Concept Drift Adaptation Techniques in Distributed Environment for Real-World Data Streams

 ,
,  ,
,  and
and
Abstract
1. Introduction
2. Literature Review
2.1. Overview on Advances in Smart Cities
2.2. Concept Drift Detection and Adaption: Active and Passive Approaches
2.2.1. Active Approaches
2.2.2. Passive Approaches
3. Approach
- Implement selected concept drift methods in distributed environment;
- Test the performance of implemented algorithms with synthetic datasets;
- Implement time series prediction models to real-world datasets;
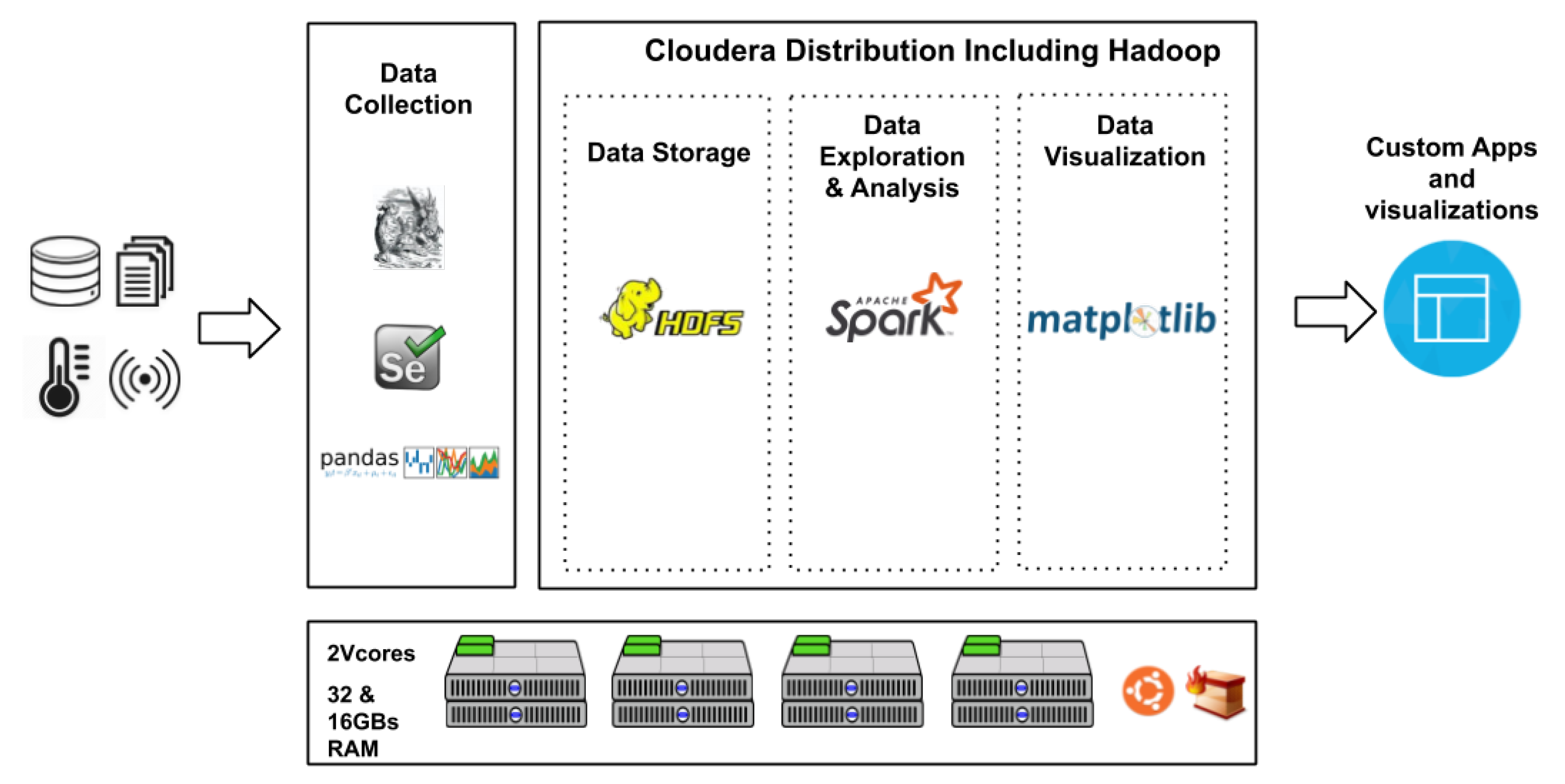
- Integrate concept drift detection methods with time series prediction models (check Figure 1);
- Implement time series prediction models integrated with concept drift detection to real-world datasets (refer to item 4);
- Results analysis.
3.1. Concept Drift Detection Methods
3.2. Datasets
3.3. Models
3.4. Evaluation
3.5. Architecture
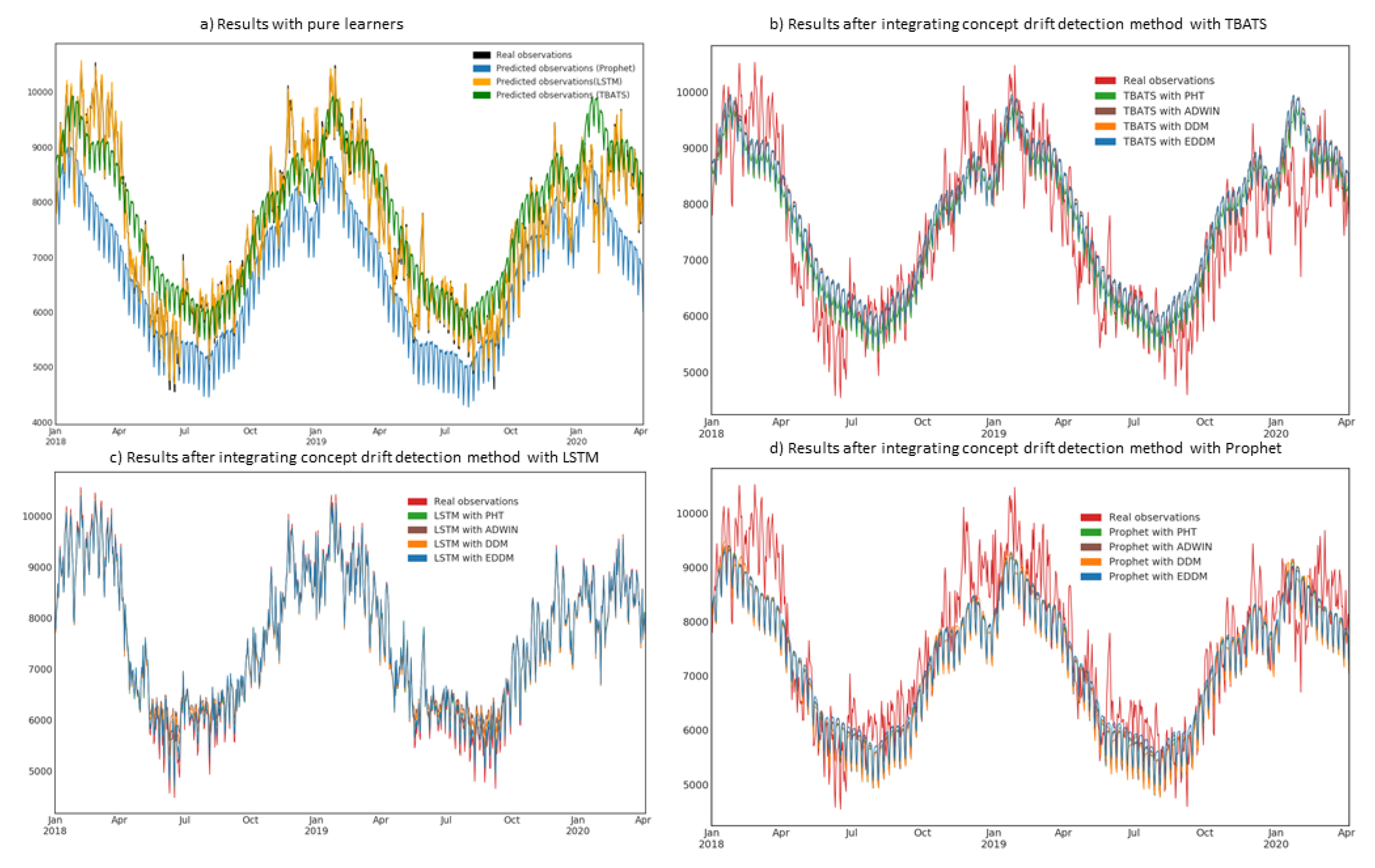
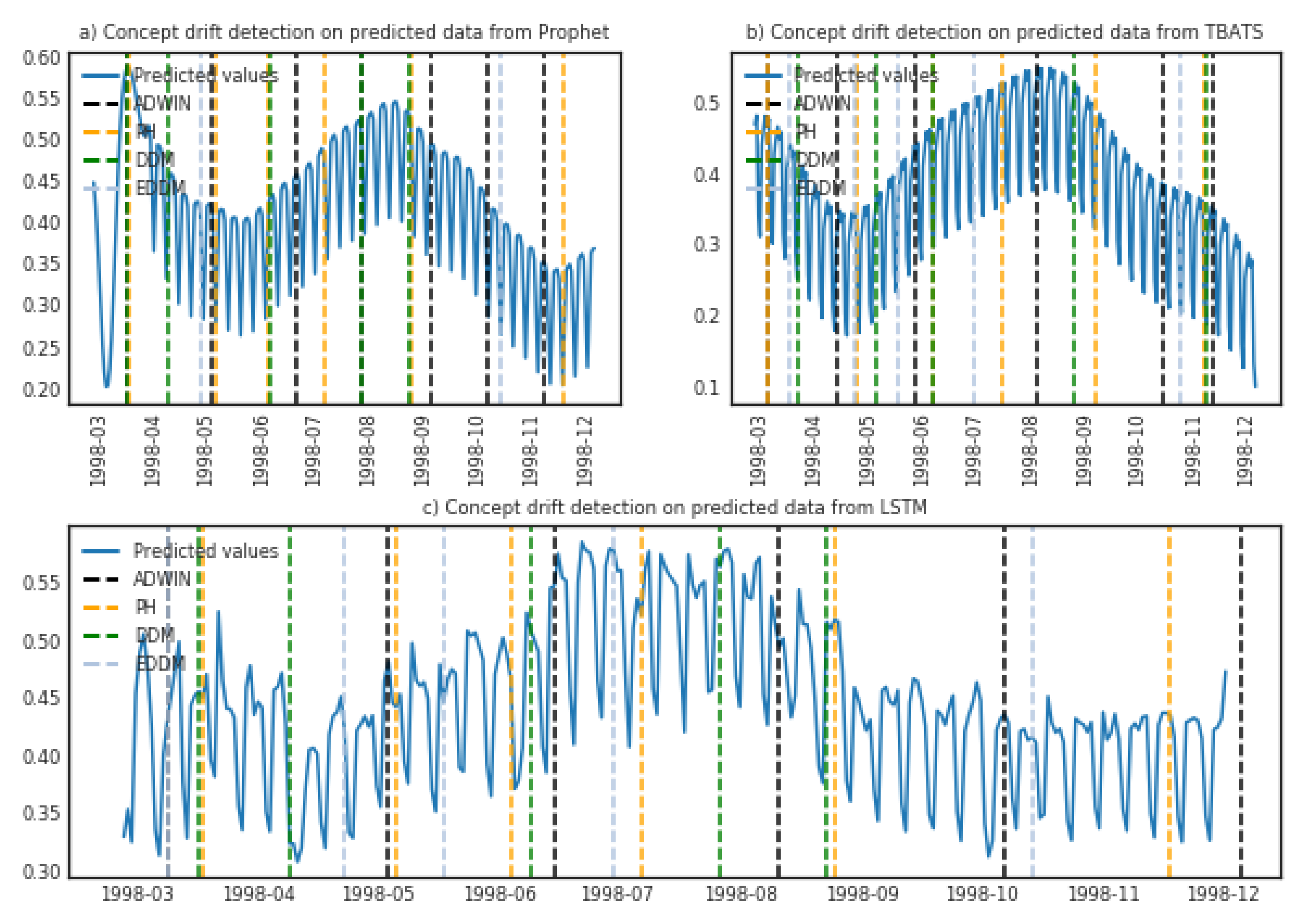
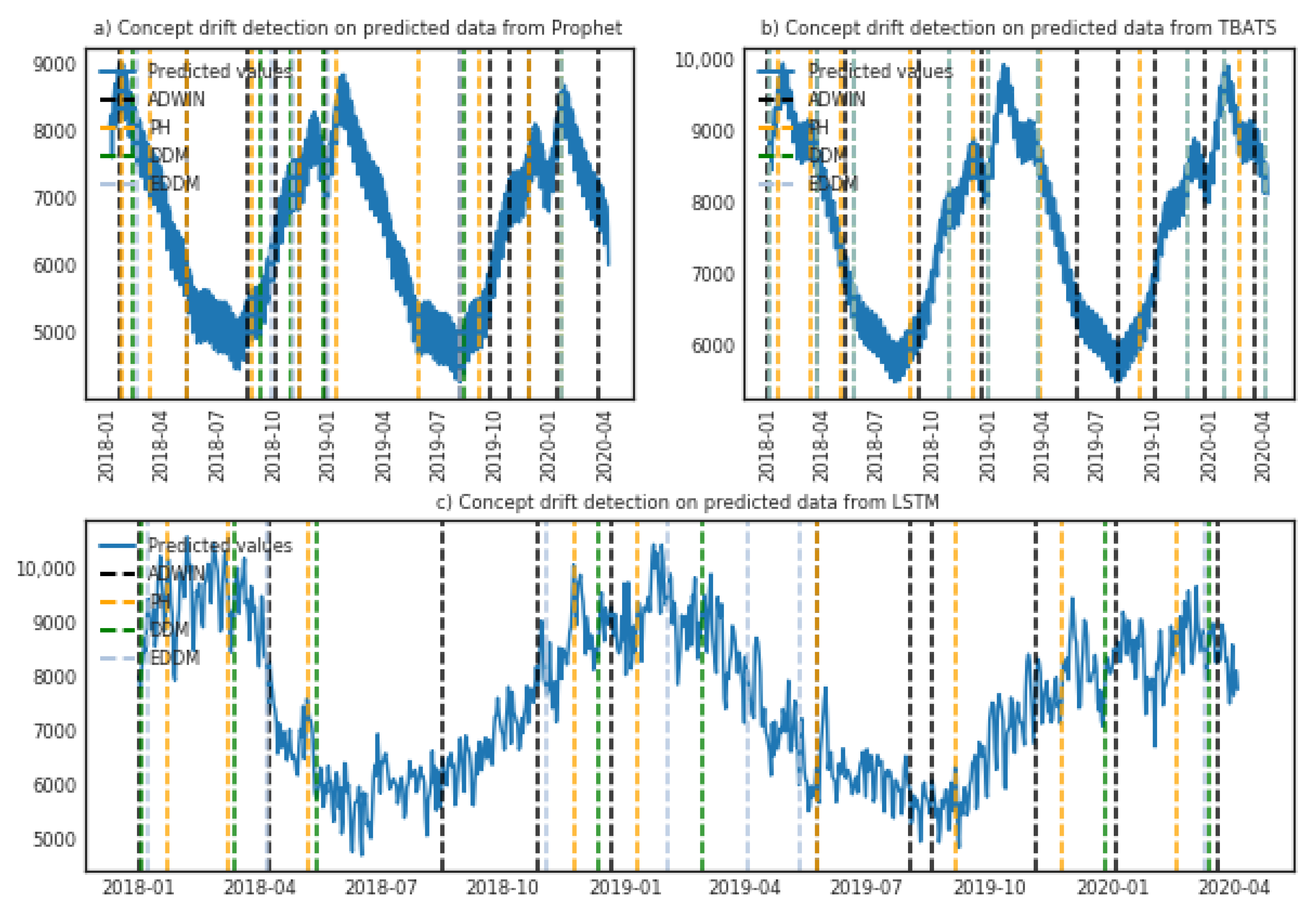
4. Results
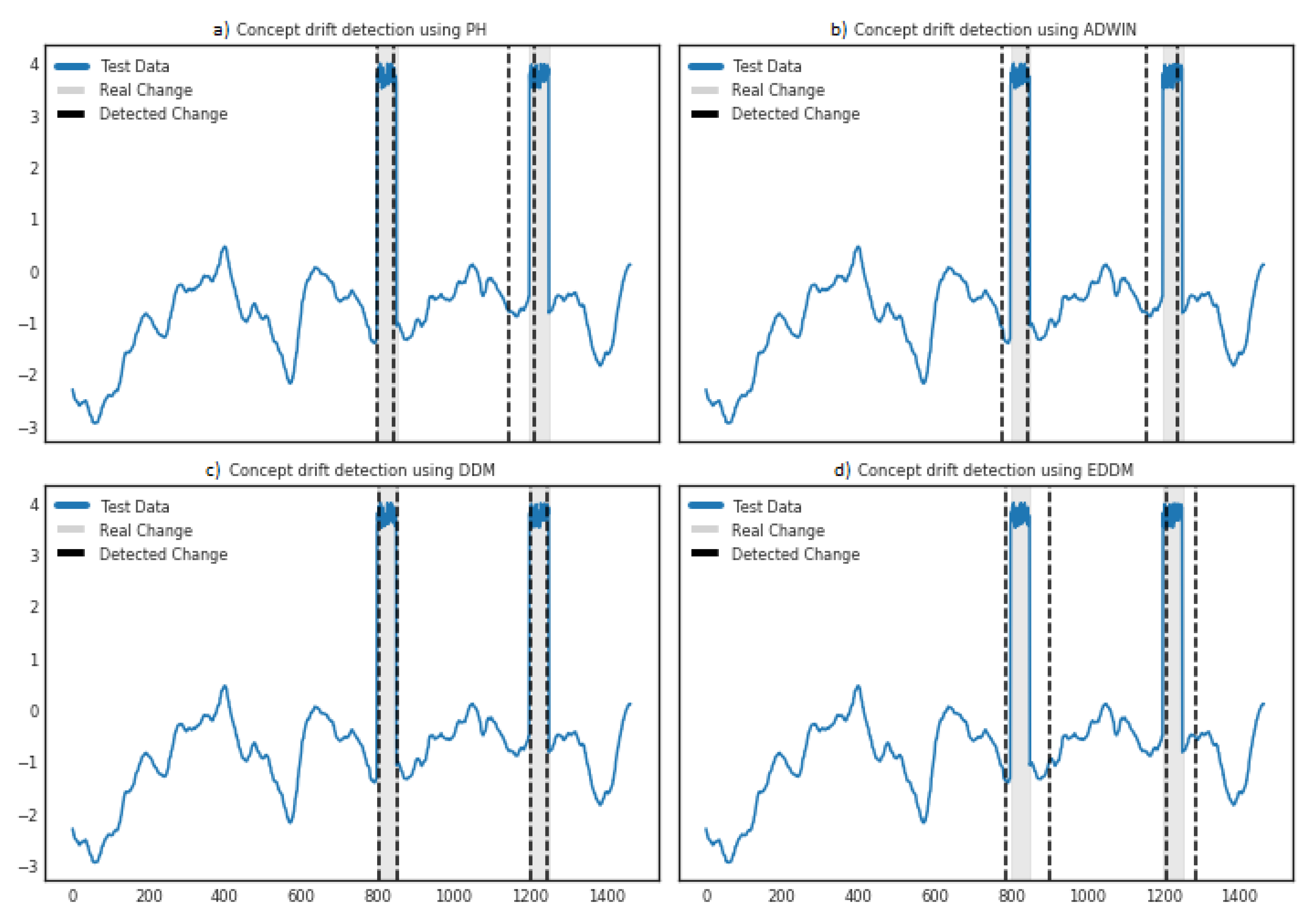
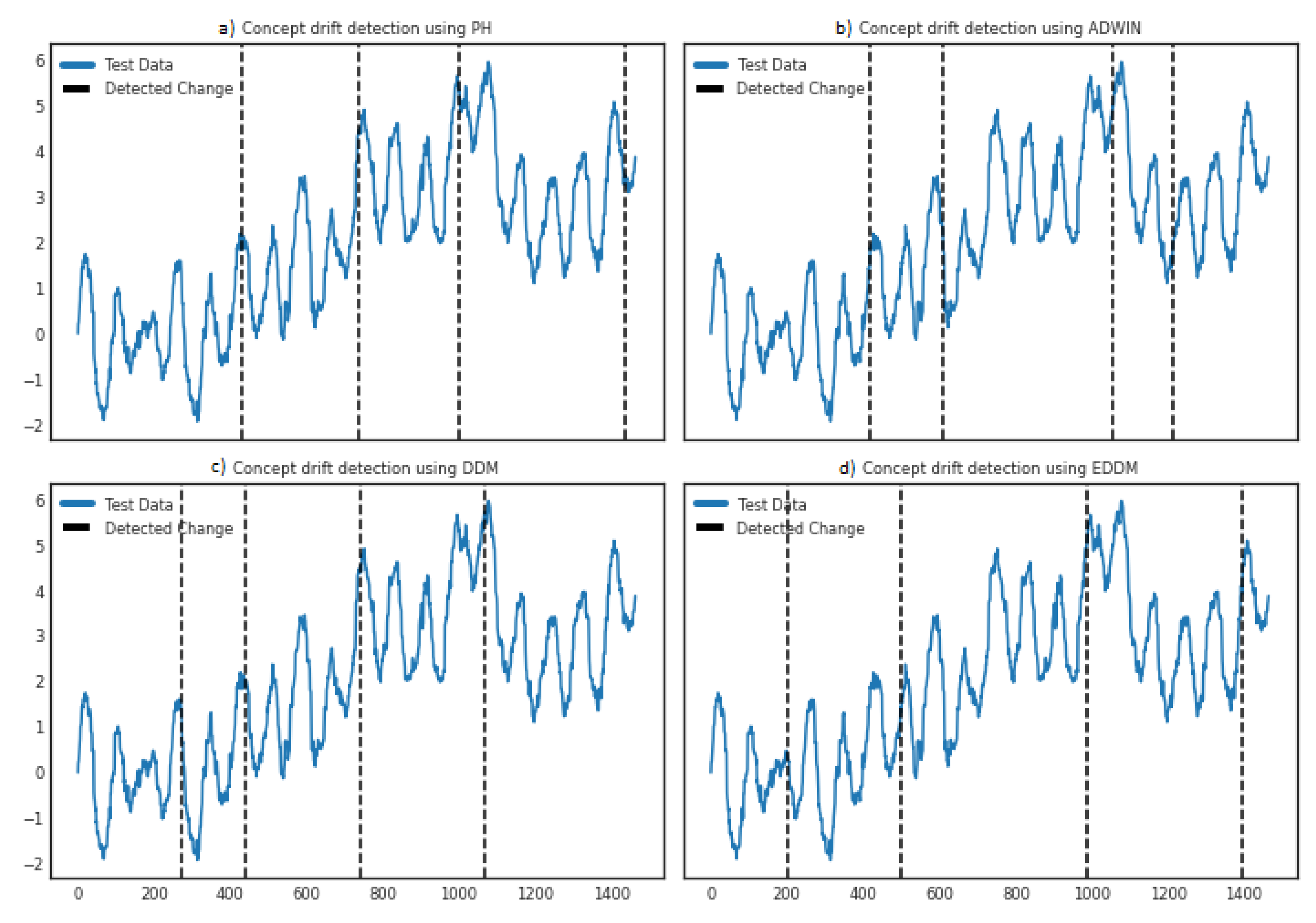
4.1. Implementation Evaluation Using Synthetic Datasets
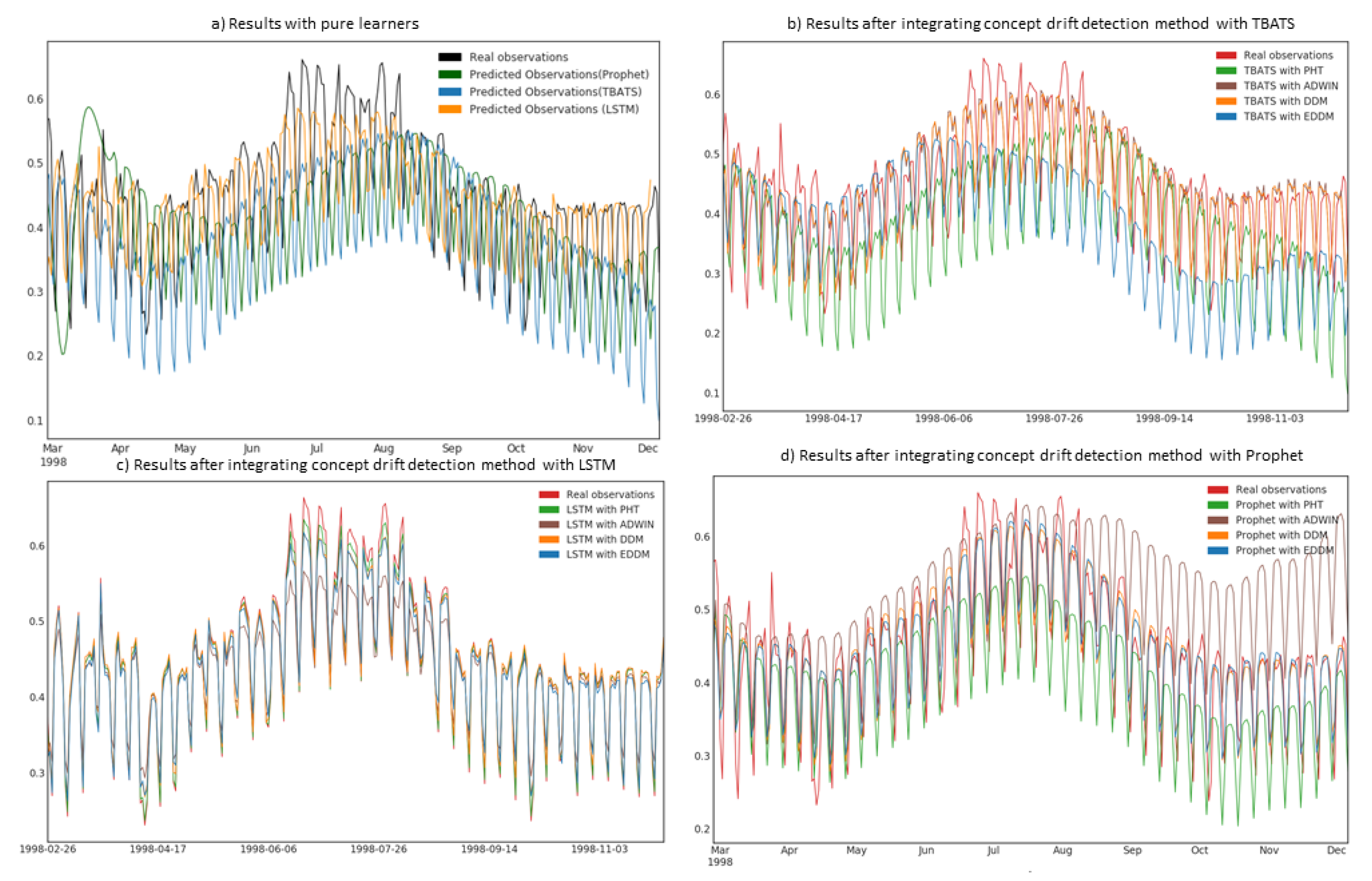
4.2. Prediction Evaluation Using Real-World Datasets
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- UN. United Nations Department of Economic and Social Affairs, Urban and Rural Population Growth and World Urbanization Prospects; United Nations: Rome, Italy, 2019; pp. 9–31. [Google Scholar] [CrossRef]
- Pesaranghader, A.; Viktor, H.L.; Paquet, E. McDiarmid drift detection methods for evolving data streams. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–9. [Google Scholar]
- Elwell, R.; Polikar, R. Incremental learning of concept drift in nonstationary environments. IEEE Trans. Neural Netw. 2011, 22, 1517–1531. [Google Scholar] [CrossRef]
- Gama, J.; Žliobaitė, I.; Bifet, A.; Pechenizkiy, M.; Bouchachia, A. A survey on concept drift adaptation. ACM Comput. Surv. (CSUR) 2014, 46, 1–37. [Google Scholar] [CrossRef]
- Ditzler, G.; Polikar, R. Incremental learning of concept drift from streaming imbalanced data. IEEE Trans. Knowl. Data Eng. 2012, 25, 2283–2301. [Google Scholar] [CrossRef]
- Beyene, A.A.; Welemariam, T.; Persson, M.; Lavesson, N. Improved concept drift handling in surgery prediction and other applications. Knowl. Inf. Syst. 2015, 44, 177–196. [Google Scholar] [CrossRef]
- Lu, J.; Liu, A.; Song, Y.; Zhang, G. Data-driven decision support under concept drift in streamed big data. Complex Intell. Syst. 2020, 6, 157–163. [Google Scholar] [CrossRef]
- Mehmood, H. Predicting Parking Space Availability Based on Heterogeneous Data Using Machine Learning Techniques. Master’s Thesis, University of Oulu, Oulu, Finland, 2019. [Google Scholar]
- Somasundaram, A.; Reddy, S. Parallel and incremental credit card fraud detection model to handle concept drift and data imbalance. Neural Comput. Appl. 2019, 31, 3–14. [Google Scholar] [CrossRef]
- Ditzler, G.; Roveri, M.; Alippi, C.; Polikar, R. Learning in nonstationary environments: A survey. IEEE Comput. Intell. Mag. 2015, 10, 12–25. [Google Scholar] [CrossRef]
- Žliobaitė, I.; Pechenizkiy, M.; Gama, J. An overview of concept drift applications. In Big Data Analysis: New Algorithms for a New Society; Studies in Big Data; Springer: Cham, Switzerland, 2016; Volume 16, pp. 91–114. [Google Scholar] [CrossRef]
- Kamel, M.; Stastny, T.; Alexis, K.; Siegwart, R. Model predictive control for trajectory tracking of unmanned aerial vehicles using robot operating system. In Robot Operating System (ROS): The Complete Reference (Volume 2); Koubaa, A., Ed.; Springer International Publishing: Cham, Switzerland, 2017; pp. 3–39. [Google Scholar] [CrossRef]
- Deshmukh, S.; Dhavale, S. Automated real-time email classification system based on machine learning. In 2020 International Conference on Computational Science and Applications; Springer: Singapore, 2020; pp. 369–379. [Google Scholar]
- Suárez-Cetrulo, A.L.; Cervantes, A.; Quintana, D. Incremental Market Behavior Classification in Presence of Recurring Concepts. Entropy 2019, 21, 25. [Google Scholar] [CrossRef] [PubMed]
- Gonçalves, P.M., Jr.; de Carvalho Santos, S.G.; Barros, R.S.; Vieira, D.C. A comparative study on concept drift detectors. Expert Syst. Appl. 2014, 41, 8144–8156. [Google Scholar] [CrossRef]
- Brzezinski, D.; Stefanowski, J. Reacting to different types of concept drift: The accuracy updated ensemble algorithm. IEEE Trans. Neural Netw. Learn. Syst. 2013, 25, 81–94. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, Z.; Bai, Y.; Dai, H.; Nahavandi, S. A Classifier Graph Based Recurring Concept Detection and Prediction Approach. Comput. Intell. Neurosci. 2018, 2018. [Google Scholar] [CrossRef]
- Perera, C.; Qin, Y.; Estrella, J.C.; Reiff-Marganiec, S.; Vasilakos, A.V. Fog computing for sustainable smart cities: A survey. ACM Comput. Surv. (CSUR) 2017, 50, 1–43. [Google Scholar] [CrossRef]
- Mehmood, H.; Gilman, E.; Cortes, M.; Kostakos, P.; Byrne, A.; Valta, K.; Tekes, S.; Riekki, J. Implementing big data lake for heterogeneous data sources. In Proceedings of the 2019 IEEE 35th International Conference on Data Engineering Workshops (Icdew), Macao, China, 8–12 April 2019; pp. 37–44. [Google Scholar]
- Frost & Sullivan. Smart City Adoption Timeline; Global Information, Inc.: Santa Clara, CA, USA, 2018. [Google Scholar]
- Morello, R.; Mukhopadhyay, S.C.; Liu, Z.; Slomovitz, D.; Samantaray, S.R. Advances on sensing technologies for smart cities and power grids: A review. IEEE Sens. J. 2017, 17, 7596–7610. [Google Scholar] [CrossRef]
- Lim, C.; Maglio, P.P. Data-driven understanding of smart service systems through text mining. Serv. Sci. 2018, 10, 154–180. [Google Scholar] [CrossRef]
- Liu, J.; Li, T.; Xie, P.; Du, S.; Teng, F.; Yang, X. Urban big data fusion based on deep learning: An overview. Inf. Fusion 2020, 53, 123–133. [Google Scholar] [CrossRef]
- Pandya, A.; Kostakos, P.; Mehmood, H.; Cortes, M.; Gilman, E.; Oussalah, M.; Pirttikangas, S. Privacy preserving sentiment analysis on multiple edge data streams with Apache NiFi. In Proceedings of the 2019 European Intelligence and Security Informatics Conference (EISIC), Oulu, Finland, 26–27 November 2019; pp. 130–133. [Google Scholar]
- Bibri, S.E. The IoT for smart sustainable cities of the future: An analytical framework for sensor-based big data applications for environmental sustainability. Sustain. Cities Soc. 2018, 38, 230–253. [Google Scholar] [CrossRef]
- Santana, E.F.Z.; Chaves, A.P.; Gerosa, M.A.; Kon, F.; Milojicic, D.S. Software platforms for smart cities: Concepts, requirements, challenges, and a unified reference architecture. ACM Comput. Surv. 2017, 50, 1–37. [Google Scholar] [CrossRef]
- london.gov.uk, What We Do | London City Hall. 2020. Available online: https://www.london.gov.uk/what-we-do (accessed on 16 January 2021).
- Chalikias, A.P.; Tsampoulatidis, I.; Tsalakanidou, F.; Nikolopoulos, S.; Kompatsiaris, I.; Komninos, N.; Doudouliakis, K.; Papastergios, G.; Papafilis, P.; Karkaletsi, S.; et al. Evidence-driven policy-making using heterogeneous data sources—The case of a controlled parking system in Thessaloniki. Data Policy 2020, 22. [Google Scholar] [CrossRef]
- Office of the Governor for Policy Planning. The Action Plan for 2020. 2020. Available online: https://www.seisakukikaku.metro.tokyo.lg.jp/en/basic-plan/actionplan-for-2020/ (accessed on 16 January 2021).
- Janajreh, I.; Su, L.; Alan, F. Wind energy assessment: Masdar City case study. Renew. Energy 2013, 52, 8–15. [Google Scholar] [CrossRef]
- Liu, P.; Peng, Z. China’s smart city pilots: A progress report. Computer 2013, 47, 72–81. [Google Scholar] [CrossRef]
- Fortes, M.Z.; Ferreira, V.H.; Sotelo, G.G.; Cabral, A.S.; Correia, W.F.; Pacheco, O.L.C. Deployment of smart metering in the Búzios City. In Proceedings of the 2014 IEEE PES Transmission & Distribution Conference and Exposition-Latin America (PES T&D-LA), Medellin, Colombia, 10–13 September 2014; pp. 1–6. [Google Scholar]
- hadoop.apache.org. Apache Hadoop. Available online: https://hadoop.apache.org/ (accessed on 18 January 2020).
- Zaharia, M. Apache Spark™—Unified Analytics Engine for Big Data. Available online: https://spark.apache.org/ (accessed on 16 January 2020).
- Gormley, C.; Tong, Z. Elasticsearch: The Definitive Guide: A Distributed Real-Time Search and Analytics Engine; O’Reilly Media, Inc.: Sevastopol, CA, USA, 2015. [Google Scholar]
- Cenedese, A.; Zanella, A.; Vangelista, L.; Zorzi, M. Padova smart city: An urban internet of things experimentation. In Proceedings of the IEEE International Symposium on a World of Wireless, Mobile and Multimedia Networks 2014, Sydney, Australia, 19 June 2014; pp. 1–6. [Google Scholar]
- Cheng, B.; Longo, S.; Cirillo, F.; Bauer, M.; Kovacs, E. Building a big data platform for smart cities: Experience and lessons from santander. In Proceedings of the 2015 IEEE International Congress on Big Data, New York, NY, USA, 27 June–2 July 2015; pp. 592–599. [Google Scholar]
- Petrolo, R.; Loscri, V.; Mitton, N. Towards a smart city based on cloud of things. In Proceedings of the 2014 ACM International Workshop on Wireless and Mobile Technologies for Smart Cities, Philadelphia, PA, USA, 11–14 August 2014; pp. 61–66. [Google Scholar]
- Costa, C.; Santos, M.Y. BASIS: A big data architecture for smart cities. In Proceedings of the 2016 SAI Computing Conference (SAI), London, UK, 13–15 July 2016; pp. 1247–1256. [Google Scholar]
- Habibzadeh, H.; Kaptan, C.; Soyata, T.; Kantarci, B.; Boukerche, A. Smart city system design: A comprehensive study of the application and data planes. ACM Comput. Surv. (CSUR) 2019, 52, 1–38. [Google Scholar] [CrossRef]
- Lau, B.P.L.; Marakkalage, S.H.; Zhou, Y.; Hassan, N.U.; Yuen, C.; Zhang, M.; Tan, U.X. A survey of data fusion in smart city applications. Inf. Fusion 2019, 52, 357–374. [Google Scholar] [CrossRef]
- Cerquitelli, T.; Proto, S.; Ventura, F.; Apiletti, D.; Baralis, E. Automating concept-drift detection by self-evaluating predictive model degradation. arXiv 2019, arXiv:1907.08120. [Google Scholar]
- Huang, T.; Xu, B.; Cai, H.; Du, J.; Chao, K.M.; Huang, C. A fog computing based concept drift adaptive process mining framework for mobile APPs. Future Gener. Comput. Syst. 2018, 89, 670–684. [Google Scholar] [CrossRef]
- Song, X.; He, H.; Niu, S.; Gao, J. A data streams analysis strategy based on hoeffding tree with concept drift on hadoop system. In Proceedings of the 2016 International Conference on Advanced Cloud and Big Data (CBD), Chengdu, China, 13–16 August 2016; pp. 45–48. [Google Scholar]
- Alberg, D.; Last, M.; Kandel, A. Knowledge discovery in data streams with regression tree methods. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2012, 2, 69–78. [Google Scholar] [CrossRef]
- Bifet, A.; Gavalda, R. Learning from time-changing data with adaptive windowing. In Proceedings of the 2007 SIAM International Conference on Data Mining, Minneapolis, MN, USA, 26–28 April 2007; pp. 443–448. [Google Scholar]
- Kuncheva, L.I. Change detection in streaming multivariate data using likelihood detectors. IEEE Trans. Knowl. Data Eng. 2011, 25, 1175–1180. [Google Scholar] [CrossRef]
- Dong, F.; Zhang, G.; Lu, J.; Li, K. Fuzzy competence model drift detection for data-driven decision support systems. Knowl. Based Syst. 2018, 143, 284–294. [Google Scholar] [CrossRef]
- Liu, A.; Lu, J.; Zhang, G. Concept drift detection via equal intensity k-means space partitioning. IEEE Trans. Cybern. 2020. [Google Scholar] [CrossRef] [PubMed]
- Carrera, D. Learning and adaptation to detect changes and anomalies in high-dimensional data. In Special Topics in Information Technology; Springer: Cham, Switzerland, 2020; pp. 63–75. [Google Scholar]
- Boracchi, G.; Carrera, D.; Cervellera, C.; Maccio, D. Quanttree: Histograms for change detection in multivariate data streams. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 639–648. [Google Scholar]
- Santos, S.G.; Barros, R.S.; Gonçalves, P.M., Jr. A differential evolution based method for tuning concept drift detectors in data streams. Inf. Sci. 2019, 485, 376–393. [Google Scholar] [CrossRef]
- Kadwe, Y.; Suryawanshi, V. A review on concept drift. IOSR J. Comput. Eng 2015, 17, 20–26. [Google Scholar]
- Harel, M.; Mannor, S.; El-Yaniv, R.; Crammer, K. Concept drift detection through resampling. In Proceedings of the International Conference on Machine Learning, Beijing, China, 21–26 June 2014; pp. 1009–1017. [Google Scholar]
- Cavalcante, R.C.; Oliveira, A.L. An approach to handle concept drift in financial time series based on Extreme Learning Machines and explicit Drift Detection. In Proceedings of the 2015 International Joint Conference on Neural Networks (IJCNN), Killarney, Ireland, 12–17 July 2015; pp. 1–8. [Google Scholar]
- Patil, M.M. Handling concept drift in data streams by using drift detection methods. In Data Management, Analytics and Innovation; Springer: Singapore, 2019; pp. 155–166. [Google Scholar]
- Kaneko, R.; Miyaguchi, K.; Yamanishi, K. Detecting changes in streaming data with information-theoretic windowing. In Proceedings of the 2017 IEEE International Conference on Big Data (Big Data), Boston, MA, USA, 11–14 December 2017; pp. 646–655. [Google Scholar]
- Domingos, P.; Hulten, G. Mining high-speed data streams. In Proceedings of the Sixth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Boston, MA, USA, 20–23 August 2000; pp. 71–80. [Google Scholar]
- Nguyen, H.L.; Woon, Y.K.; Ng, W.K.; Wan, L. Heterogeneous ensemble for feature drifts in data streams. In Pacific-Asia Conference on Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2012; pp. 1–12. [Google Scholar]
- Kumar, A.; Kaur, P.; Sharma, P. A survey on Hoeffding tree stream data classification algorithms. CPUH-Res. J. 2015, 1, 28–32. [Google Scholar]
- Cohen, L.; Avrahami-Bakish, G.; Last, M.; Kandel, A.; Kipersztok, O. Real-time data mining of non-stationary data streams from sensor networks. Inf. Fusion 2008, 9, 344–353. [Google Scholar] [CrossRef]
- Ditzler, G. A study of an incremental spectral meta-learner for nonstationary environments. In Proceedings of the 2016 International Joint Conference on Neural Networks (IJCNN), Vancouver, BC, Canada, 24–29 July 2016; pp. 38–44. [Google Scholar]
- Cano, A.; Krawczyk, B. Kappa Updated Ensemble for drifting data stream mining. Mach. Learn. 2020, 109, 175–218. [Google Scholar] [CrossRef]
- Pocock, A.; Yiapanis, P.; Singer, J.; Luján, M.; Brown, G. Online non-stationary boosting. In International Workshop on Multiple Classifier Systems; Springer: Singapore, 2010; pp. 205–214. [Google Scholar]
- Yang, Z.; Al-Dahidi, S.; Baraldi, P.; Zio, E.; Montelatici, L. A novel concept drift detection method for incremental learning in nonstationary environments. IEEE Trans. Neural Netw. Learn. Syst. 2019, 31, 309–320. [Google Scholar] [CrossRef] [PubMed]
- Whitley, E.; Ball, J. Statistics review 6: Nonparametric methods. Crit. Care 2002, 6, 509. [Google Scholar] [CrossRef]
- Baena-Garcıa, M.; del Campo-Ávila, J.; Fidalgo, R.; Bifet, A.; Gavalda, R.; Morales-Bueno, R. Early drift detection method. In Proceedings of the Fourth International Workshop on Knowledge Discovery from Data Streams. 2006, Volume 6, pp. 77–86. Available online: https://www.researchgate.net/profile/Albert-Bifet/publication/245999704_Early_Drift_Detection_Method/links/53e582cd0cf21cc29fd06017/Early-Drift-Detection-Method.pdf (accessed on 30 January 2021).
- Tsymbal, A.; Pechenizkiy, M.; Cunningham, P.; Puuronen, S. Dynamic integration of classifiers for handling concept drift. Inf. Fusion 2008, 9, 56–68. [Google Scholar] [CrossRef]
- Hu, Y.; Feng, B.; Zhang, X.; Ngai, E.; Liu, M. Stock trading rule discovery with an evolutionary trend following model. Expert Syst. Appl. 2015, 42, 212–222. [Google Scholar] [CrossRef]
- Sebastião, R.; Fernandes, J.M. Supporting the page-hinkley test with empirical mode decomposition for change detection. In International Symposium on Methodologies for Intelligent Systems; Springer: Cham, Switzerland, 2017; pp. 492–498. [Google Scholar]
- Melkumyan, A.; Ramos, F. Multi-kernel Gaussian processes. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Aranovskiy, S.; Bobtsov, A.; Kremlev, A.; Nikolaev, N.; Slita, O. Identification of frequency of biased harmonic signal. Eur. J. Control 2010, 16, 129–139. [Google Scholar] [CrossRef]
- Harries, M.; Wales, N.S. Splice-2 Comparative Evaluation: Electricity Pricing; Citeseer: Pennsylvania, PA, USA, 1999. [Google Scholar]
- fingrid.fi. Fingrid. Available online: https://data.fingrid.fi/en/organization/fingrid (accessed on 15 December 2020).
- Naim, I.; Mahara, T.; Idrisi, A.R. Effective short-term forecasting for daily time series with complex seasonal patterns. Procedia Comput. Sci. 2018, 132, 1832–1841. [Google Scholar] [CrossRef]
- Taylor, S.J.; Letham, B. Forecasting at scale. Am. Stat. 2018, 72, 37–45. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Cherrie, M.P.; Nichols, G.; Iacono, G.L.; Sarran, C.; Hajat, S.; Fleming, L.E. Pathogen seasonality and links with weather in England and Wales: A big data time series analysis. BMC Public Health 2018, 18, 1067. [Google Scholar] [CrossRef] [PubMed]
- Jifri, M.H.; Hassan, E.E.; Miswan, N.H. Forecasting performance of time series and regression in modeling electricity load demand. In Proceedings of the 2017 7th IEEE International Conference on System Engineering and Technology (ICSET), Shah Alam, Malaysia, 2–3 October 2017; pp. 12–16. [Google Scholar]
- Fang, W.X.; Lan, P.C.; Lin, W.R.; Chang, H.C.; Chang, H.Y.; Wang, Y.H. Combine Facebook prophet and LSTM with BPNN forecasting financial markets: The Morgan Taiwan Index. In Proceedings of the 2019 International Symposium on Intelligent Signal Processing and Communication Systems (ISPACS), Taipei, Taiwan, 3–6 December 2019; pp. 1–2. [Google Scholar]
- Asha, J.; Rishidas, S.; SanthoshKumar, S.; Reena, P. Analysis of temperature prediction using random forest and facebook prophet algorithms. In Proceedings of the International Conference on Innovative Data Communication Technologies and Application, Coimbatore, India, 17–18 October 2019; Springer: Cham, Switzerland, 2019; pp. 432–439. [Google Scholar]
- Filonov, P.; Lavrentyev, A.; Vorontsov, A. Multivariate industrial time series with cyber-attack simulation: Fault detection using an lstm-based predictive data model. arXiv 2016, arXiv:1612.06676. [Google Scholar]
- Althelaya, K.A.; El-Alfy, E.S.M.; Mohammed, S. Evaluation of bidirectional lstm for short-and long-term stock market prediction. In Proceedings of the 2018 9th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 3–5 April 2018; pp. 151–156. [Google Scholar]
- Liu, Y.; Wang, Y.; Yang, X.; Zhang, L. Short-term travel time prediction by deep learning: A comparison of different LSTM-DNN models. In Proceedings of the 2017 IEEE 20th International Conference on Intelligent Transportation Systems (ITSC), Yokohama, Japan, 16–19 October 2017; pp. 1–8. [Google Scholar]
- Richardson, L. Beautiful Soup Documentation. Available online: https://www.crummy.com/software/BeautifulSoup/bs4/doc/ (accessed on 16 December 2020).
- Selenium Automates Browsers. That’s It. Available online: https://www.selenium.dev/ (accessed on 16 December 2020).
- Pandas. Available online: https://pandas.pydata.org/ (accessed on 16 December 2020).
- Yu, S.; Wang, X.; Principe, J.C. Request-and-reverify: Hierarchical hypothesis testing for concept drift detection with expensive labels. arXiv 2018, arXiv:1806.10131. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Approach | Goal | Task Support |
|---|---|---|---|
| The Page Hinkley Test (PHT) | Active | Method was developed to detect change from Gaussian signal and is suitable for abrupt drift scenarios [4]. | classification and regression [45,46] |
| Semi-parametric log-likelihood (SPLL) | Active | Method has been tested with abrupt drift. However, it may not be as sensitive to progressive changes in the data distribution [47]. | classification [47] |
| Fuzzy competence model drift detection (FCM) | Active | Method uses competence model to identify the change (abrupt and gradual) in data distribution without any prior knowledge [48] | classification and regression [48] |
| QuantTree | Active | Approach uses a recursive binary splitting strategy to define histograms for change detection; its suitability for drift type that is, abrupt or gradual, still requires experimentation [49,50]. | classification [51] |
| Drift detection method (DDM) | Active | The method is suitable for both abrupt and gradual drift [52], providing increased performance in abrupt drift [53]. | classification and regression [54,55] |
| Early drift detection method (EDDM) | Active | It is an extension of DDM to overcome the limitations of detecting gradual drift in the data [53]. | classification and regression [54] |
| Adaptive windowing (ADWIN) | Active | This method uses a sliding windowing approach with variable size to detect concept drift [15]. Both abrupt and gradual drift scenarios have been tested with this method [56]. | classification and regression [57] |
| Very fast decision tree (VFDT) | Passive | The model adapts to changes in streaming data; however, basic incremental learning is not sufficient to handle concept drift in the data [16]. | classification and regression [16,58] |
| Concept drift very fast decision tree (CVFDT) | Passive | CVFDT is extenstion of VFDT that adapts to concept drift in data [59]. However, it cannot efficiently adapt to sudden drifts [16,59]. | classification and regression [16,60] |
| Online information network (OLIN) | Passive | The model learns by building a network using window and detects concept drift through increase in classification error. However, requires higher computational cost [61] | classification [61] |
| Streaming ensemble algorithm (SEA) | Passive | The method may not efficiently react to sudden drift in data. As learners generated from outdated data can still be valid, regardless of their inaccurate weight [16] | classification and regression [3,62] |
| Dynamic Adaption to Concept Changes (DACC) | Passive | It follows higher deletion rate strategy to expel bad learners, entailing higher reactivity to concept drift, and supports sudden and gradual drift [63] | classification [63] |
| Online Non-stationary Boosting (ONSBOOST) | Passive | The method can learn in dynamically changing environments, also it has been tested with hidden contexts (i.e., can be abrupt, gradual) [64] | classification [64] |
| Online Sequential Extreme Learning Machine (OS-ELM) | Passive | OS-ELM by [65] has shown superior performance in detecting different kinds of concept drift (sudden, gradual, etc.). Also it is capable of notifying when model needs to be updated. | classification and regression [65] |
| Method | ELEC2 [73] | Fingrid [74] | |
|---|---|---|---|
| LSTM | pure LSTM | 5.10 | 0.57 |
| with PHT | 0.97 | 0.24 | |
| with ADWIN | 5.75 | 0.45 | |
| with DDM | 2.28 | 0.48 | |
| with EDDM | 3.51 | 0.83 | |
| Prophet | pure Prophet | 15.58 | 6.1 |
| with PHT | 9.86 | 5.68 | |
| with ADWIN | 20.66 | 6.48 | |
| with DDM | 10.06 | 6.80 | |
| with EDDM | 9.94 | 6.92 | |
| TBATS | “pure” TBATS | 21.35 | 7.0 |
| with PHT | 17.25 | 6.45 | |
| with ADWIN | 17.37 | 7.05 | |
| with DDM | 16.94 | 7.08 | |
| with EDDM | 23.81 | 7.11 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mehmood, H.; Kostakos, P.; Cortes, M.; Anagnostopoulos, T.; Pirttikangas, S.; Gilman, E. Concept Drift Adaptation Techniques in Distributed Environment for Real-World Data Streams. Smart Cities 2021, 4, 349-371. https://doi.org/10.3390/smartcities4010021
Mehmood H, Kostakos P, Cortes M, Anagnostopoulos T, Pirttikangas S, Gilman E. Concept Drift Adaptation Techniques in Distributed Environment for Real-World Data Streams. Smart Cities. 2021; 4(1):349-371. https://doi.org/10.3390/smartcities4010021
Chicago/Turabian StyleMehmood, Hassan, Panos Kostakos, Marta Cortes, Theodoros Anagnostopoulos, Susanna Pirttikangas, and Ekaterina Gilman. 2021. "Concept Drift Adaptation Techniques in Distributed Environment for Real-World Data Streams" Smart Cities 4, no. 1: 349-371. https://doi.org/10.3390/smartcities4010021
APA StyleMehmood, H., Kostakos, P., Cortes, M., Anagnostopoulos, T., Pirttikangas, S., & Gilman, E. (2021). Concept Drift Adaptation Techniques in Distributed Environment for Real-World Data Streams. Smart Cities, 4(1), 349-371. https://doi.org/10.3390/smartcities4010021