1. Introduction
Water, a vital resource for humanity, faces increasing demand due to population growth and economic development. However, the problem is not just the increasing demand for water; poor water quality also makes it unsuitable for many purposes [
1]. Therefore, it is important to ensure not only the quantity but also the quality of water to prevent shortages. Thus, the sixth sustainable development goal of the United Nations [
2] aims to ensure the availability of water and sanitation, as well as the sustainable management of these resources. Given the presence of more than 350,000 chemicals and their combinations in the world [
3], water pollution stands out as one of the key environmental problems we face [
4]. This directly affects human health, especially in the context of providing safe drinking water. Given the complexity and diversity of chemicals, analyzing each of them with high frequency is expensive and practically impossible. An alternative to such analysis is the use of living organisms as bioindicators, which provides a comprehensive assessment of the state of the aquatic environment. Biological early warning systems, known as BEWS [
5], have become widespread in recent decades in assessing the quality of water resources and activating alarms in emergency situations [
6]. Freshwater mussels are a widespread and relatively long-lived group of aquatic organisms [
7]. Mussels are considered effective indicators of environmental change, responding to both long-term and acute changes caused by stressors [
8]. Behavioral characteristics of mussels, such as valves opening, reflect their natural circadian rhythms, feeding and breathing activity, and can also serve as an indicator of external stress factors [
9]. Assessing anomalies from the effects of stress factors using experts is possible, but this approach does not provide a quick response to emergency situations. The key challenge is still to effectively detect abnormal situations and to trigger alarms in a timely manner.
Time series anomaly detection models use a calculated numerical metric, known as an anomaly score, to determine the status of each data point as an anomaly or normal value [
10]. The anomaly score is determined based on the difference between the predicted and actual values. If the score value exceeds a set threshold, the data point is classified as an anomaly [
11]. In some situations, a static threshold may be applicable, but often, this approach is unsuitable, due to the variability of the variance and the mathematical expectation of the time series.
Machine learning algorithms allow the building of models to predict data with seasonal variability. Algorithms are widely used in making business forecasts, for example, forecasting purchasing power [
12], product prices [
13,
14], and others. In the last decade, algorithms began to be used to predict climatic, environmental, and biological processes. Solving time series forecasting problems is possible using different types of machine learning algorithms, for example, forecasting algorithms, algorithms based on Bayesian statistics, and others. The Prophet forecasting model was used to predict both short-term and long-term air pollution in Seoul, Korea and China [
15,
16]. Using sensor data from a wastewater treatment plant system, Kramar and Alchakov [
17] applied various machine learning methods (seasonal autoregressive integrated moving average SARIMA, Holt–Winters exponential smoothing, ETS, Facebook Prophet, extreme gradient boosting XGBoost, and long short-term memory) for time series forecasting. The XGBoost method turned out to be the best method for their purposes. An important direction for future research is to explore how these approaches can better support forecasting in practice [
18]. A Bayesian approach is used to predict the possibility of large earthquakes using thermal anomalies from satellite observations [
19].
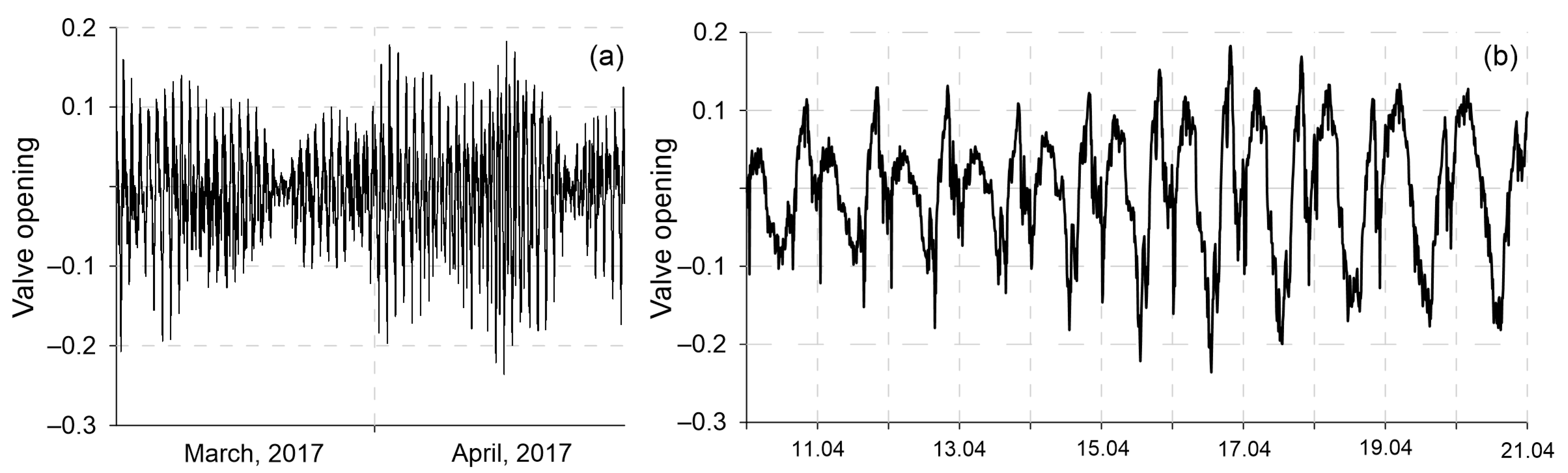
In a previous work, we investigated the ability to detect anomalies in bivalves’ activity data using four unsupervised machine learning algorithms (elliptic envelope, isolation forest (iForest), one-class support vector machine (SVM), and local outlier level (LOF) [
20], the autoregressive integrated moving average (ARIMA) forecast model with a seasonal component in the same data [
21], obtained by biological early warning system [
22]). In this paper, we further analyzed machine learning forecasting algorithms for identifying anomalies and generating alarms in bivalves’ activity data. The main parameter for the success of forecasting the developed models will be the speed of identifying an anomaly, since data from the BEWS is sent to the server in real time, and the algorithm is planned to be implemented in the software of BEWS. In addition, the developed algorithm for detecting an anomaly and subsequently generating an alarm signal should not require significant computing resources. The novelty of the work lies in the application of machine learning algorithms for activity data of bivalve mollusks used as biosensors in the biomonitoring system of water bodies. Previously, Valletta et al. [
23] and Bertolini et al. [
24] demonstrated the feasibility of using machine learning algorithms in animal behavior studies, particularly to identify consistent behavioral patterns in the activity of the bivalves
Mytilus galloprovincialis and
Mytilus edulis. Meyer et al. [
25] combined statistical-analysis techniques with machine learning approaches to study the prediction of the movement patterns of ruminants. However, to the best of our knowledge, no study has applied machine learning algorithms to forecast bivalves’ activity data.
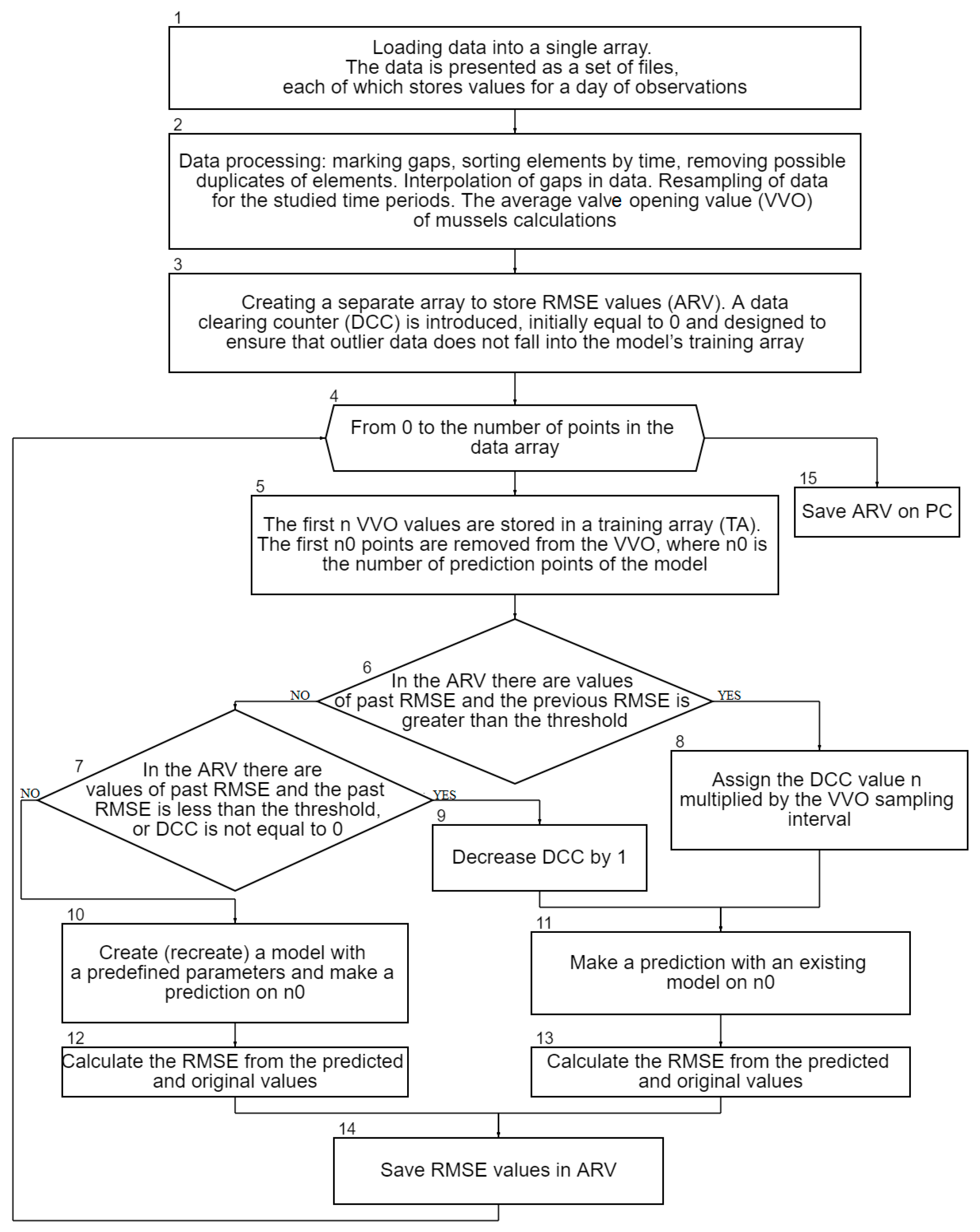
Section 2 describes data, three machine learning algorithms, and data preprocessing. The block diagram of the anomaly detection algorithm is presented.
Section 3 provides the main results. The graphical results of choosing a fixed RMSE threshold are given. In
Section 4, we discuss results and compare the anomaly detection time obtained by different methods. Finally,
Section 4 summarizes the findings and outlines their scope.
3. Results
The fixed threshold of the RMSE, at which the largest error occurred in the absence of an anomaly, plus a ten percent safety margin required to work in a real system for each method, was selected to exclude false positives (
Table 1,
Table 2 and
Table 3). It turned out to be impossible to detect anomalies using the Theta method with a 10 s averaging, since false positives turned out to be higher than real anomalies in the data. With one-minute data averaging, false positives of the models were obtained at the same level with real anomalies by all three methods. For example,
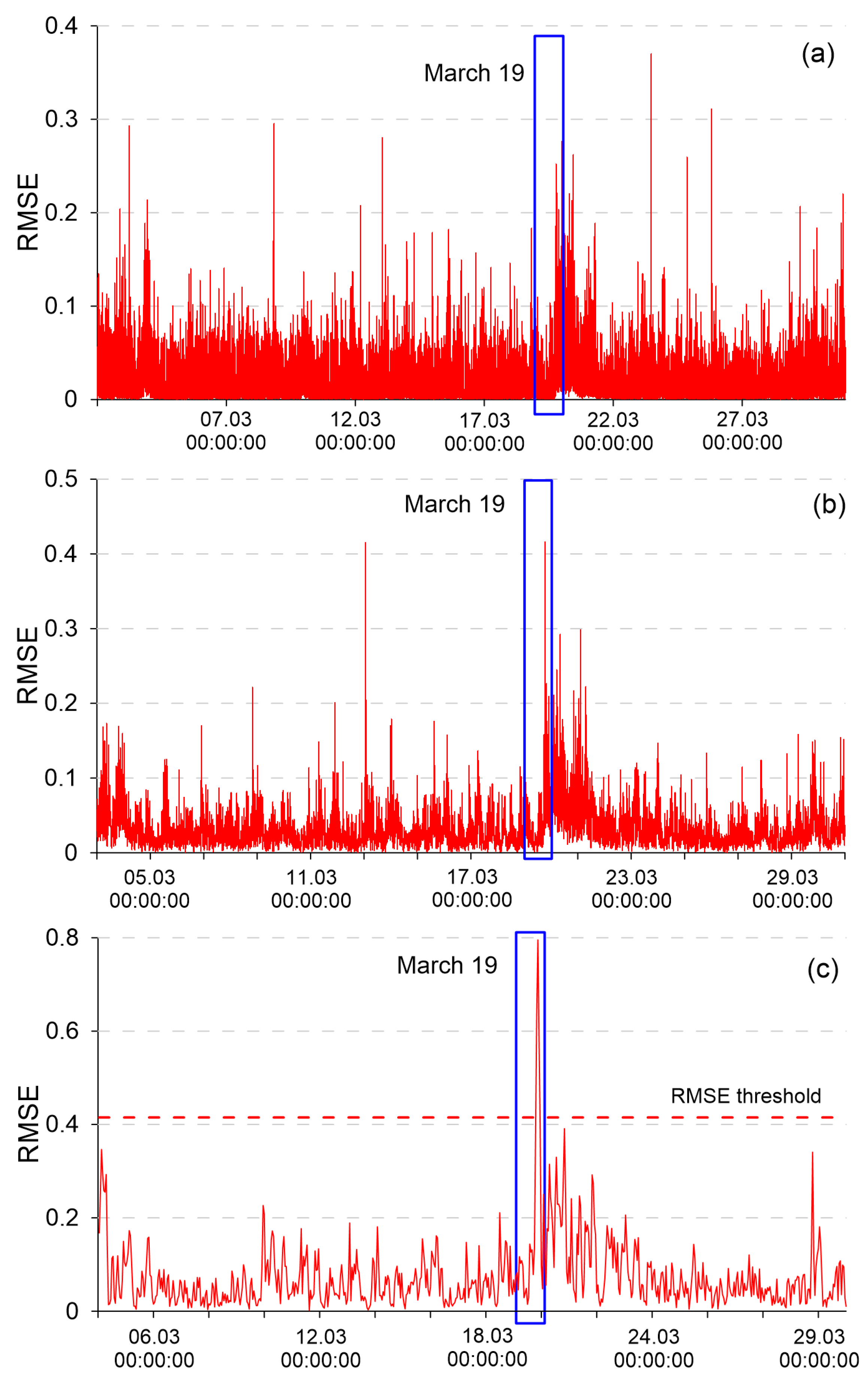
Figure 4 shows RMSE graphs for a false alarm above the real anomaly (a) (Theta method, 10 s averaging), for a false alarm at the same level with real anomalies (b) (Prophet method, 1 min data averaging), as well as for the normal operation of the model, where an anomaly was clearly visible in the RMSE values (c) (Prophet, 20 min data averaging).
Using the calculated values of RMSE for certain model settings, the detection times of three anomalies were determined (
Table 4). The best time (17:20) for detecting the first anomaly (19 March 2017) was obtained by the Prophet method, with a 20 min averaging and with the number of forecast points equal to 3 (one-hour forecast). The best time to detect the second anomaly (14 April 2017) turned out to be the same for the three methods, with the same model settings (5 min of data averaging and 6 prediction points, with a one-hour forecast). The third anomaly (24 April 2017), similar to the second, was detected using three methods at the same time. The number of days in the training set did not affect the time it took to detect an anomaly, although it did affect the threshold level.
Figure 5 shows the RMSE values and their fixed thresholds for highlighting the anomaly on 19 March 2017.
4. Discussion and Conclusions
The algorithms used separately or together with other models (hybrid approaches) were actively applied to different types of data. For example, algorithms were applied to predict the amount of waste per capita in the states of the European Union using the Prophet model [
45]. De Oliviera et al. [
46] proposed a new multi-functional methodology based on auto-encoder and traditional time series models, including ARIMA and Prophet, for COVID-19 time series forecasting. Time series forecasting models (SARIMA and Prophet) and technologies based on artificial neural networks were compared to model the dynamics and conditions of soils and the efficiency of agroecosystems [
47]. A hybrid model combining wavelet transform, support vector regression (SVR), and Prophet was used for a precipitation forecast [
48]. Using several methods, including Croston, an inventory planning system was developed for a tire retailer [
49].
In the paper, we compared three machine learning prediction methods (Theta, Croston, and Prophet) for detecting anomalies in bivalves’ activity data. The results showed that for one of the anomalies, Prophet was the best method, and for the other two, the anomaly detection time did not differ between the methods. A comparison of the results obtained in the work with the results of predicting anomalies in the activity data of bivalve mollusks by the SARIMA model [
21] showed the preferable use of the selected algorithms. The Prophet method was able to detect the first anomaly 1 hour and 20 min faster than the SARIMA model. The detection time of the second anomaly by the three analyzed algorithms improved by 25 min, and the third anomaly improved by 40 min, compared to the SARIMA model.
The results of the methods in terms of computation time were compared. Calculations were performed on Windows 10 Pro System Version 22H2 Build 19045.4170, processor Intel(R) Core(TM) i5-10500 CPU @ 3.10GHz, RAM 16 GB, NVIDIA GeForce GTX 1650 video card. Croston’s method turned out to be the fastest for all model settings (averaging time and number of prediction points) (
Table 5). The computation time for the best model parameters obtained for the second anomaly (5 min, 6 points) showed that the fastest was the Croston method, which was 5.4 times faster compared to the Theta method (40 s, 3 min, and 36 s, respectively) and 18 times faster compared to the Prophet method (40 s and 12 min, respectively). The shortest computation time for the best model parameters obtained for the third anomaly (10 min, 6 points, one-hour forecast) was also obtained for the Croston method (27 s), while the Theta method gave the result in 46 s, and the Prophet in 7 min (
Table 5). The SARIMA model turned out to be the slowest computationally. Computation time for the SARIMA model, with settings of averaging time 5 min and 6 forecasting points (the best detection time for the second anomaly by Theta, Croston, and Prophet methods), was 1 h and 40 min.
Comparison with estimates presented in [
20], which describes the possibility of detecting anomalies in the same bivalves’ data using four unsupervised machine learning algorithms: elliptic envelope, isolation forest (iForest), one-class support vector machine (SVM), and local outlier level (LOF), showed using the example of the first anomaly (anomaly 3 in [
20]) that the use of machine learning algorithms lost by almost an hour in the speed of anomaly detection, compared to the Prophet method (
Table 6).
Thus, the algorithms discussed in the article turned out to be better in terms of anomaly detection time and faster in computational complexity, compared to the SARIMA model.
The advantage of the algorithms used in the article compared to the ARIMA model has been shown in many works using different data. For example, the advantage (less errors) of the Prophet model compared to SARIMA was obtained when predicting solar and wind resources in the Doomadgee area of Far North Queensland, Australia [
50]. Despite being extremely useful, empirical evaluations, such as the M4 competition [
51], have shown that no automatic selection algorithm (e.g., ETS, or automatic ARIMA) has been able to significantly outperform established benchmarks such as Theta [
28], which became popular due to its superiority over other competitors in the M3 competition [
52]. Prophet outperformed two other algorithms, ARIMA and ThymeBoost, in predicting monthly rainfall data in India [
53]. Xiao et al. [
54] found that Prophet improved runoff modeling in the Zhou River Basin. Bolick et al. [
55] used the Prophet method to predict hourly water level changes in an urban stream (South Carolina, USA) and obtained very accurate estimates, with coefficient of determination values greater than 0.9.
The work carried out is important for improving the efficiency of forecasting anomalies in the activity data of bivalve mollusks used in the environmental monitoring of the state of the aquatic environment, which will help reduce costs associated with operational, tactical, and strategic planning.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}