1. Introduction
Predicting and measuring a sector’s or firm’s performance is a critical problem in planning and managing economic growth. A practically valuable group of performance measures is based on the economic profit term, or alternatively, the profit level after the deduction of an alternative cost of capital. In this case, market and accounting data are combined, and economic value added (EVA) is a practically useful financial performance measure. This measure is complex and reflects many factors and their interrelationships. Therefore, a decomposition approach can be fruitful.
A probability distribution forecast can give more valuable information in comparison to a point forecast. For instance, the authors of [
1] state that the “density forecast especially provides a complete description of the uncertainty associated with a prediction and stands in contrast to a point forecast, which contains no description of the associated uncertainty”.
The automotive sector, with an above-standard share in the Czech economy, is an important economic segment influencing the effectiveness and performance of the national economy. The sector is designated 29 in the NACE categorisation—Manufacture of motor vehicles, trailers and semi-trailers. Sector share in the C-Manufacturing sector is significant and is as follows: assets, 25.44%; fixed assets, 24.80%; current assets, 27.45%; equity, 21.57%; debt, 28.86%; sales, 37.60%; cost, 39.10%; salaries, 29.51%; EBIT, 30.30%; and value added, 30.48%. With regard to production, other sectors are also connected. Therefore, the analysis and prediction of the performance measure of sector 29 constitute a very important problem.
This paper’s objective is to predict the relative EVA measure probability distribution of sector 29 in the Czech economy using advanced methods, including distribution precision testing. The proposed model and procedure consist of the following elements: (a) a decomposed financial performance measure, (b) forecasting via the Monte Carlo simulation method, (c) a mean reversion random process with NIG (normal inverse Gaussian) distribution, (d) modelling the statistical interdependencies with t-copula, and (e) testing the precision of distribution forecasting. To be more precise:
- (a)
Approaches for measuring a sector’s performance have evolved and reflect the technical-economic type of economy, information possibilities, data reachability, and knowledge of economic systems management. Among performance indicators, traditional groups based on accounting profitability measures can be found, such as ROE, ROA, ROC, ROI, and RONA, as well as measures based on financial cash flow, such as CFROI, NPV, and CROGA. Researchers deal with various financial performance measures (see, e.g., [
2,
3]). The compromise between accounting and market data is the measures combining both data types, so economic value added (EVA) and refined economic value added (REVA) measures were developed. Three authors [
4,
5,
6,
7] have, for instance, applied EVA performance measures. A financial performance measure can be decomposed by the pyramid (DuPont) method in several financial ratios and simulated as their function with correlations, obtaining a more robust prediction (see [
8,
9,
10,
11,
12,
13]).
- (b)
A crucial problem in financial decision making is achieving good financial forecasting, and researchers have verified various methods (see [
14,
15,
16,
17,
18,
19]). Interesting forecasting approaches were introduced in [
20,
21,
22,
23]. One of the forecasting approaches and conceptions is applying the simulation method with dependencies modelled by the copula function [
24,
25,
26]. The generalised random processes are mean-reversion processes, e.g., [
27,
28].
- (c)
The probability distributions of financial variables are asymmetric, with fat tails, leptokurtic distributions, jumps, and mean reversion. To model such variables, Levy distributions were proposed and verified. A suitable probability distribution for the modelling of financial ratios and electricity and energy prices is the so-called NIG distribution, coined by the author of [
29]. The distribution parameters can be estimated by the likelihood method or the method of moments, and possible approaches have been described, e.g., [
30,
31,
32,
33]. Subsequently, for example, refs. [
34,
35,
36,
37,
38] applied the NIG distribution in option valuation and value at risk prediction. The authors of [
39] first proposed and verified the Levy-driven mean-reversion process, also known as the Levy-driven Ornstein–Uhlenbeck or non-Gaussian Ornstein–Uhlenbeck random processes. The first term is used in this paper exclusively because of the financial modelling background. Other researchers further analysed and developed this problem, e.g., [
28,
40,
41,
42,
43,
44,
45,
46]. Several authors [
1,
47,
48,
49,
50,
51,
52] dealt with probability distribution forecasting for predicting uncertainty.
- (d)
The procedures and advantages of disaggregated (multifactor) forecasting are described in [
53,
54,
55]. A multifactor simulation needs to model dependencies, and copula functions can usually be used. Furthermore, refs. [
19,
20] are authors who have dealt with such a conception. The precision of the simulation and the number of replications (interactions) are investigated in, e.g., [
25,
56,
57,
58,
59].
- (e)
A particular problem in distribution forecasting is stating forecasting precision and choosing the more suitable probability distribution. Two conceptions exist, absolute and relative ones. The first one is based on the probability integral transform of the distribution and a comparison with the uniform distribution. The closer the uniform distribution, the better the forecasting distribution is (see [
49,
52,
60,
61]). The scoring method investigates the relative evaluation of two distributions, and a higher score means a better forecast distribution [
47,
62,
63,
64,
65]. The statistical difference significance can be tested by a paired
t-test.
This paper’s novelty lies in using the advanced prediction methods of the decomposed relative EVA measure of the Czech automotive NACE sector 29. Whereas prediction is based on the pyramid decomposition expressed by an exact mathematical function, the applied advanced stochastic processes (mean-reversion, skew t-regression, NIG distribution, t-copula) suitably reflect the behaviour and features of financial ratios. These characteristics are significant not only because of these reflections but also due to fundamental features such as economic and technical shocks (particularly COVID-19), shortages of spare parts and commodities, product transportation disorders, and military operations in the sector. With an above-standard share in the small open Czech economy, the automotive sector is also crucial for national economic performance and public finance. Furthermore, empirical verification and prediction are therefore desirable.
The paper is structured as follows: (i) a conceptual and methodological background description, (ii) a proposal and description of the applied decomposed methodology, (iii) a description of the compared direct (non-decomposed) methodology, (iv) input data, solution procedures and interpretation of the results, (v) probability distributions precision testing, and (vi) discussion and conclusion.
2. Methodology and Procedure Description
The relative EVA measure,
, is decomposed on the pyramid decomposition basis on two levels. Firstly, the EVA is divided into
and
; subsequently,
is decomposed into
. Summarising
is expressed by the exact function of six basic influencing financial ratios:
where
is a return on equity,
is earnings after tax,
is earnings before tax,
is earnings before interest and tax,
is sales,
is an asset value,
is the equity value, and
is the cost of equity capital. Therefore, performance is given by tax reduction, debt coverage, revenue profitability, asset turnover, financial leverage, and the equity cost of capital. The proposed decomposition is used in the analysis and prediction part.
2.1. Prediction of Performance Measure by Simulation
The primary goal is to predict a relative EVA measure distribution based on decomposition (1) using a simulation approach. Due to the Levy-driven mean-reversion process with an NIG distribution, particular ratios are supposed to develop along the way. The arithmetic Levy-driven mean-reversion (LDAMR) process is presented, e.g., in [
42,
46], and expressed in (2). The Levy-driven, one-factor Schwartz mean-reversion (LDSMR) process [
44] is formulated in (3):
where
represents the changes in ratios,
is the speed parameter,
is the long-term equilibrium,
is the time interval, and
is the random NIG process.
The LDAMR process is suitable for ratios with positive or negative values. LDSMR is applicable only for positive financial ratio values, e.g., prices and turnovers. The solution to the equations are as follows:
The advantages of these processes are in their generalisation because, for , the process is reduced in a Levy process and the exponential Levy process, respectively; for , the process reduces in an arithmetic and exponential (geometric) Levy process, respectively.
Since the intention is to predict a relative EVA distribution, the stochastic integral with respect to the Levy process is simulated by a sum method, such as the Riemann–Stieltjes sum method (see, e.g., [
34,
66]):
where
,
, and
.
The approximate simulation formulas of processes (4) and (5) for
steps are as follows:
The applied estimation and simulation procedure steps of a decomposed conception
The estimations of the processes of the indices were obtained using Stata software (Version 15.1); for other operations, Matlab software (Version R2020b) was used.
- (i)
Statistical estimation of Equations (2) and (3) using skew-t regression
An estimation of parameters
and
is carried out using the skew-t regression with parameters using the Stata function
, as in [
67], where
is a shape parameter (
skewness to the right;
skewness to the left),
is a scale parameter, and
is the degree of freedom (the tails parameter). The choice of a suitable process, (2) or (3), is made based on the Akaike (AIC) and the Bayesian (BIC) information criterion values.
- (ii)
Estimation of the chosen models regarding the NIG distribution parameters of the residuals
NIG distribution, including jumps and asymmetry, is parametrised as follows:
, where
is the tail heaviness,
is skewness,
is a location,
is a scale parameter, and
. The NIG distribution parameters are estimated using the method of moments (see, e.g., [
32]).
- (iii)
Estimation of the t-copula function
The t-copula function models the mutual interdependencies of the ratio residuals for a t-distribution with parameters of the correlation matrix
and degree of freedom
(see [
18]).
- (iv)
Simulation of the one scenario with N steps of the development of financial ratios and the following calculation of relative EVA
Financial ratios are simulated according to (7) or (8). Relative EVA is calculated using (1). The Matlab functions and are applied to generate the random numbers of stochastic processes.
- (v)
Repeating step (iv) for M scenarios, the result is one replication of the EVA distribution
- (vi)
Replication (iteration) of step (v) r-times for a given precision
According to [
56], the precision criterion of the distribution parameters (expected value, median, quantiles) is the relative confidence interval of a standard error,
, where
and
are parameters (mean, quantiles) of the expected value and expected value standard error of the
replications;
is the Student-t distribution with the significance
; and
is the degree of freedom. Furthermore,
is a coefficient, with a mean value
and for quantiles
with
and
, respectively, equal to a density function.
is the quantile of the standard normal distribution.
- (vii)
Calculating the chosen parameters and graphical presentation of the results
Mean, medians, and quantile development values are tabulated, and the predicted relative EVA distribution is graphically presented.
2.2. The Evaluation of Forecast Prediction Precision
The absolute precision evaluation is based on probability integral transform (PIT), creating a random variable
. Following [
60],
, where
is the distribution,
is the density function, and
is the real relative EVA. The variable is compared with uniform distribution
. The closer the forecast distribution is to a uniform distribution, including statistical significance, the more suitable the distribution is for prediction. To verify its significance, the STATA Epps–Singleton Two-Sample Empirical Characteristic Function test is applied as in [
68]. Here, hypothesis H0 states the distributions are identical, and HA states the distributions are not identical. The W2 statistics are calculated.
The relative precision conception compares two distributions using to any score measure. A suitable score approach for distribution
is the logarithmic scoring rule, where, according to [
63],
, and the whole score is
. The bigger the whole score is, the better the distribution. To test the significance of the difference (diff) of the two distributions
and
, the STATA paired t-stat is calculated,
.
Hypothesis H0. and HA: .
3. Results
The relative EVA measure decomposition is used to predict four quarters using a simulation procedure, including precision testing. A particular decomposition equation is introduced in (1). The applied methodology follows the procedures described in
Section 2.1 and
Section 2.2.
Furthermore, a direct (non-decomposed) EVA measure to predict four quarters using the simulation procedure is applied for comparison.
3.1. Input Data
The input data of the exact pyramid decomposition financial ratios are obtained quarterly and are calculated from MPO ČR (see [
69]). The data of MPO ČR are obtained on a cumulative yearly basis every month. Therefore, the necessary transformation procedure for quarterly data is as follows: for flow data, two subsequent quarters are subtracted; for returns, the yearly returns are divided four times. Data are divided into two groups: in the sample and out of the sample. The first one is the period from 2007 to 2019 (
Table 1). The period finishes in 2019 because it marks the end of the pre-COVID-19 period. The last row of
Table 1 contains the first real set of data used for prediction; in particular, the relative EVA is 1.0605%. The second group includes the prediction period and is shown in
Table 2.
3.2. The Prediction Results of Relative Decomposed EVA Performance Measure by Simulation
In step (i), the skew-t regression is realised for all ratios, as well as for LDAMR and LDSMR models. The best models are chosen following the AIC and the BIC (see
Table 3). The estimated parameters are statistically significant. Furthermore, parameter
shows the asymmetry of the distributions on the left or right side; nothing equals zero, meaning symmetry is maintained. Four ratios are left-skewed, and two are right-skewed, showing non-positive tendencies. The parameters
illustrate a scale which is not high. The parameters
are small, confirming the fat tails of distributions. The empirical results confirm a correct regression model choice and financial ratio features. The last two rows present estimated parameters
and
, including the selected best models. The empirical results show that all the best models are of the LDAMR (arithmetic) type, except for the ratio A/E model, which is of the LDSMR (Schwartz) type.
Step (ii) consists of estimating the NIG distribution parameters of the residuals. Parameters are estimated using the method of moments (see, e.g., [
32]), where the Matlab
function is used. The results are presented in
Table 4. The estimated parameters indicate heaviness
, high skewness
, a location close to zero
, and a not large scale
. The NIG distributions adequately fit the data.
In step (iii), the parameters of the t-copula function from residuals are estimated. The Matlab function
was used for parameter estimation as the average of the one million simulations, particularly the degree of freedom
.
Table 5 displays the correlation matrix
.
Steps (iv) and (v) encompass the simulation of six particular ratios and the relative EVA measure’s calculation—400 steps were used in one scenario for the year with 10
6 scenarios. The special Matlab functions
and
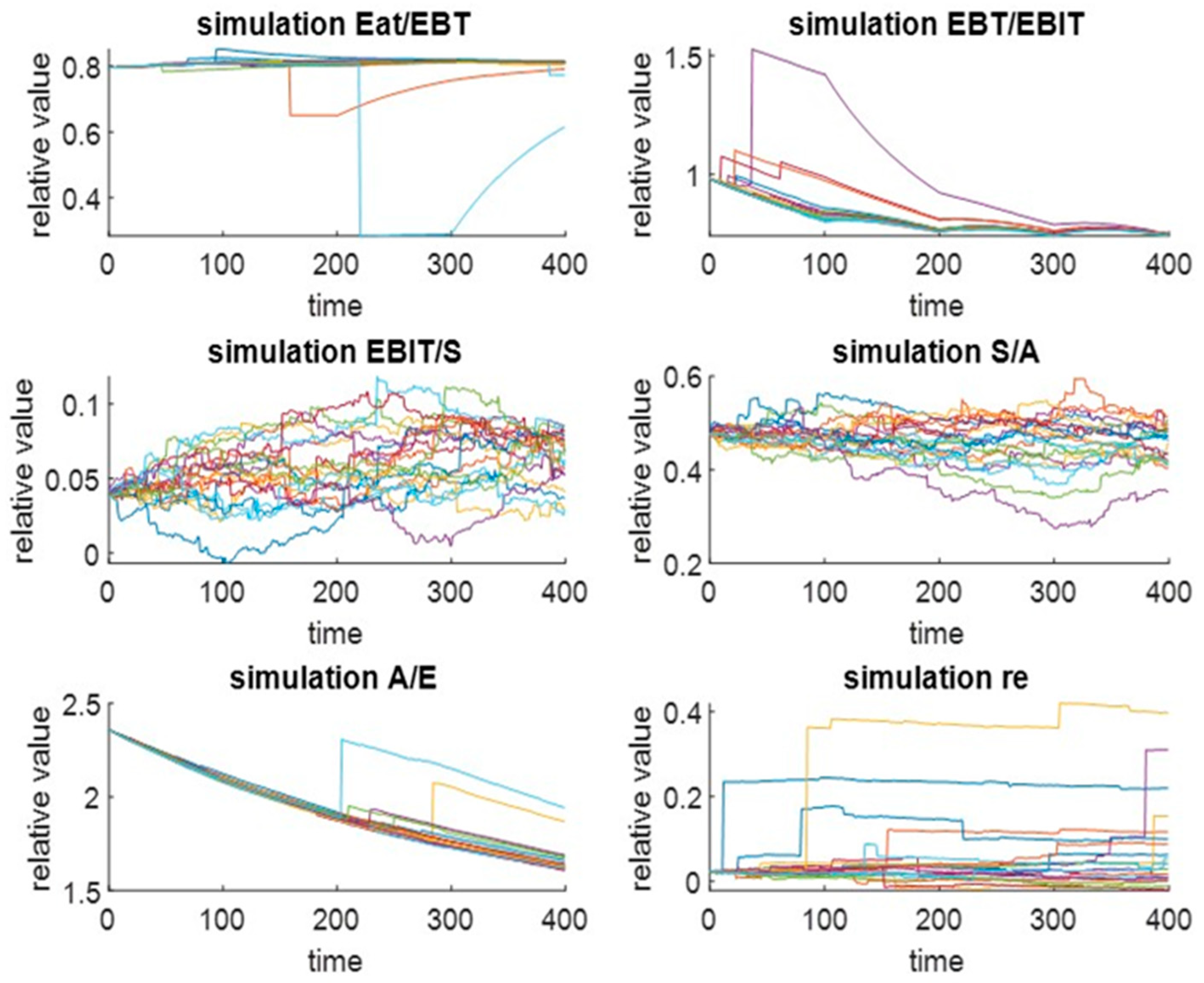
reflecting the t-copula function were utilised to generate random numbers and simulations. A presentation of 20 scenarios (colored), including their interdependencies, is shown in
Figure 1, where asymmetry, fat tails, and jumps are apparent and verified. Likewise, every ratio demonstrates a different and unique distribution shape. Furthermore, the distribution of the relative EVA measure for one replication is illustrated in
Figure 2 with decreasing distribution quantiles and negative asymmetry.
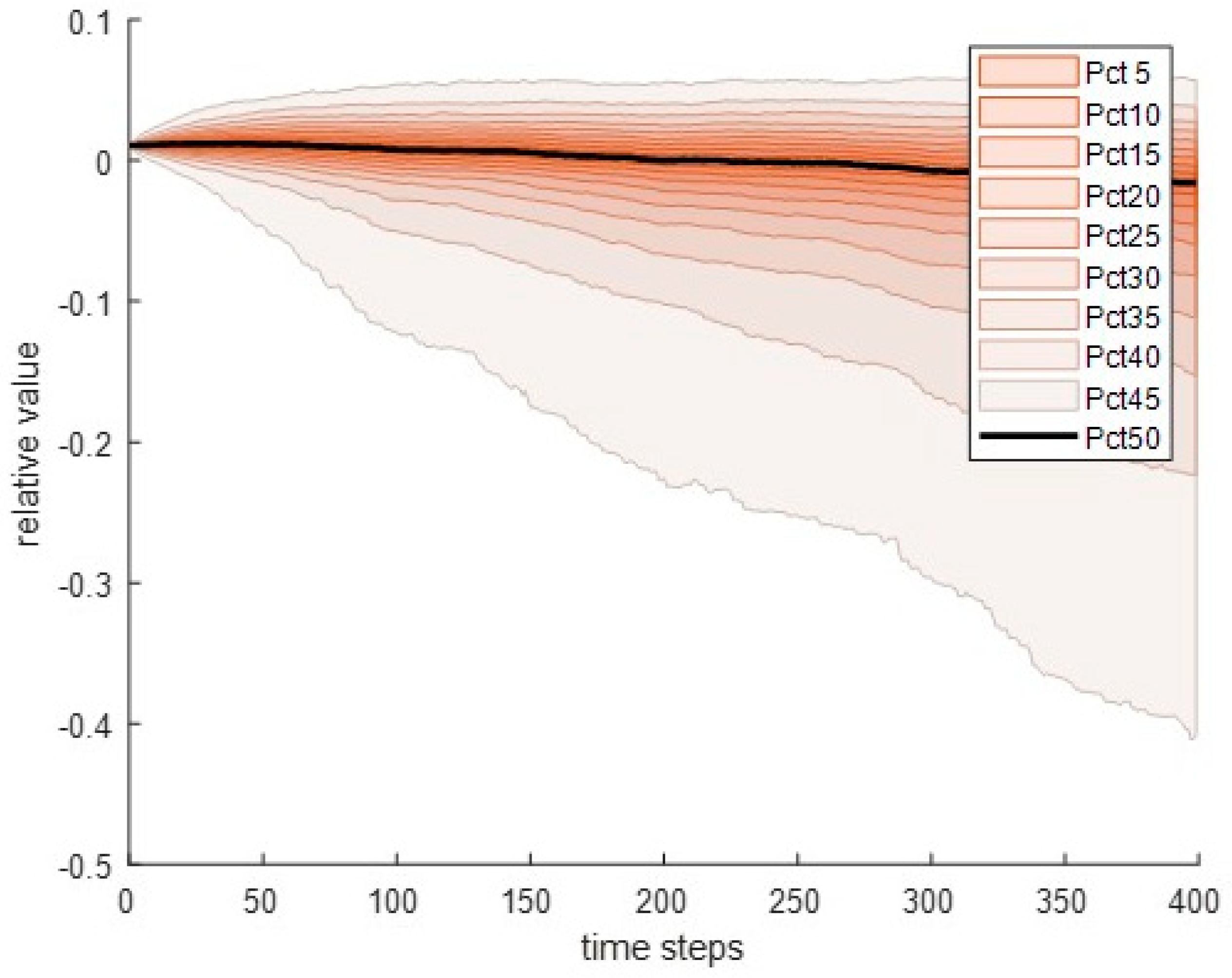
Step (vi) consists of the replication of step (v) 110 times due to the relative confidence interval of a standard error being less than 0.1. The results are shown in
Table 6 for the mean value and quantiles, including the standard error and the parameter of preciseness. The predicted probability distribution development is presented in
Figure 3.
Apparently, the precision of distribution parameters is commonly less than 10% and mostly less than 5%.
3.3. The Prediction Results of Relative Direct EVA Performance Measure by Simulation
The direct approach is simplified by comparing the decomposition approach (
Section 3.1) in forecasting using only one measure and not using interdependencies. In step (i), the skew-t regression is realised for the direct relative EVA measure for the LDAMR and LDSMR models. The best model selected according to the AIC and the BIC is the LADMR model (see
Table 7). Moreover, parameter
shows the right skewness of the direct relative EVA distribution, and parameter
confirms the existence of fat tails. The value of parameter
demonstrates a smaller scale.
In step (ii), the parameters of the NIG distribution residuals of the direct relative EVA are estimated by the method of moments, as in, e.g., [
32], applying the Matlab
function (see
Table 4). The estimated parameters indicate lower heaviness
, high skewness
, a location close to zero
, and a small scale
.
The last step (iii) involves a simulation of the direct relative EVA measure using 400 steps in one scenario for a year with 10
5 scenarios. The Matlab function
is used to generate random numbers and simulations. In step (iv), step (iii) is replicated ten times, and the distribution of the direct relative EVA is obtained due to the relative confidence interval of a standard error being determined to be less than 0.1 (see the results in
Table 8 and
Figure 4). The precision of the distribution in all parameters is less than 5%.
3.4. The Evaluation of Predictive Precision of EVAr Distribution Forecasts
The precision evaluation is focused on a one-quarter prediction. Firstly, quarterly predicted distributions for particular months are estimated using a simulation procedure stemming from the estimated models’ parameters. The parameters of the decomposed EVA are presented in
Table 3,
Table 4 and
Table 5 and those for the direct EVA in
Table 4 and
Table 7. One simulation represents 10
6 scenarios, and 80 replications are applied. The resulting distribution quantiles, including relative precision, are show in
Table 9 and
Table 10.
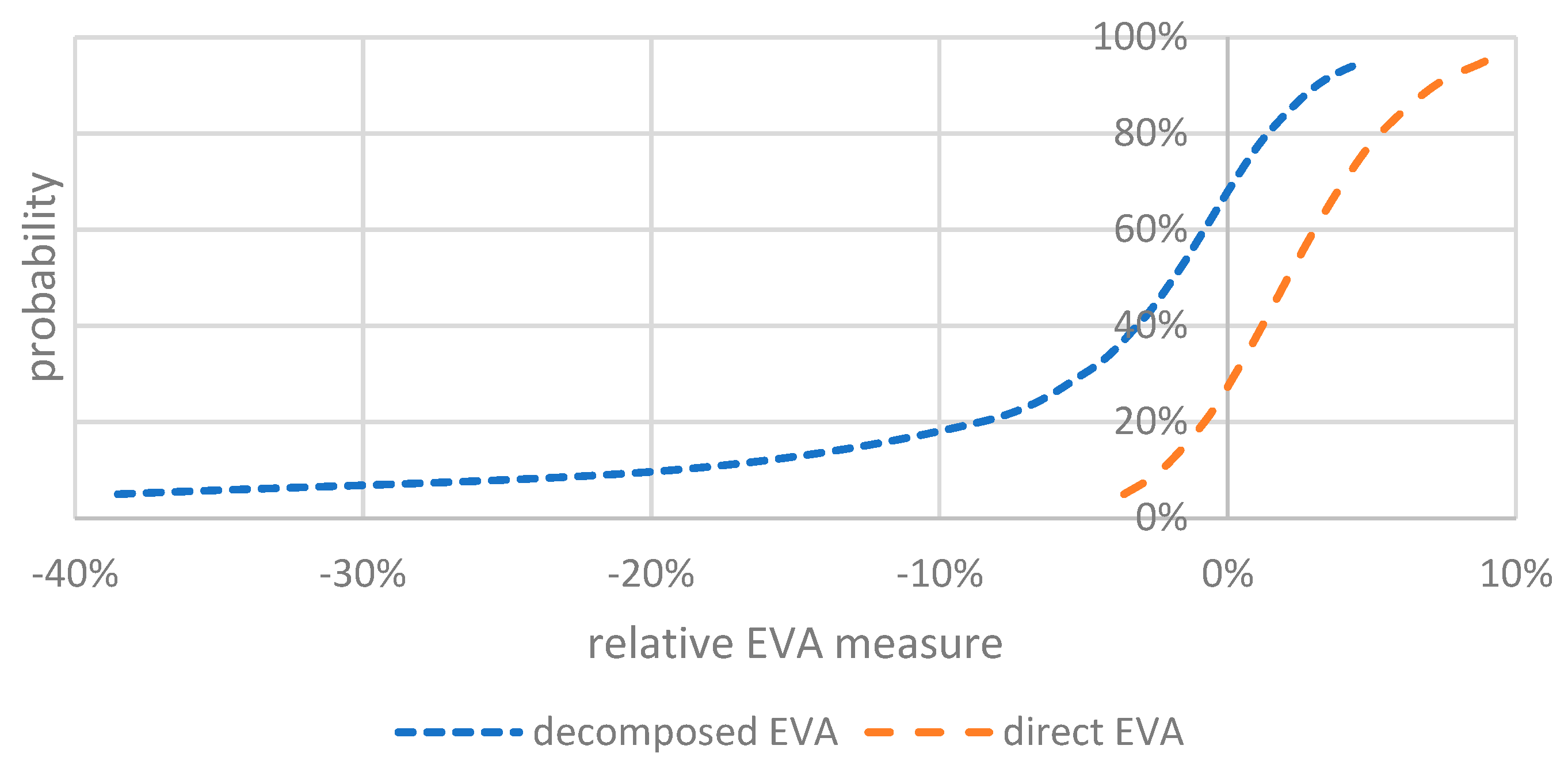
The precision of the forecasted distribution was verified by the absolute and relative tests comparing the decomposed and direct EVA predicted distribution. The STATA esftest test, as in [
68], was applied for the absolute test. For decomposed EVA, the W2 statistic is 2.492, with a significance of 0.6461, and for direct EVA, the W2 statistic is 2.669, with a significance of 0.61459. The H0 hypothesis was confirmed in both cases. Lower values affirm that the decomposed EVA coincides more with a uniform distribution and is more suitable. The relative test is evaluated using the logarithmic scoring rule, and STATA paired
t-test. The score of the decomposed EVA is −1.9788, and the score of the direct EVA is −2.0718 (see
Table 11). So, a bigger value means that the decomposed EVA forecasts the probability distribution better. The value of the STATA paired t-statistic is 2.5099, with a significance of 0.029. Therefore, hypothesis H0 is not confirmed, and the estimated forecasting models of EVA differ. Consequently, the decomposed model, when compared, is better as well.
4. Discussion and Conclusions
The relative EVA (
Section 3.1) shows that the mean value decreases and so does the median. The quarterly forecast decreased from a starting value of 1.0605% for the mean value to −7.570%, and the median value decreased to −1.875%. The median looks more stable compared to the expected value, even with the same negative trend. The characteristics are huge and include negatively skewed quantile intervals. This is caused, among other things, by considering the interdependencies of ratios under the asymmetry of financial ratios and jumps. This phenomenon is hidden in relations among decomposed financial ratios.
The results of direct relative EVA distribution prediction (
Section 3.2) show and confirm the historical behaviour of the measure. The median slightly increases to 2.086%, and the mean value is 2.307%. Quantiles are almost symmetrically distributed, with positive skewness. This approach does not include the possibility of using the hidden relations of the system behaviour in the prediction.
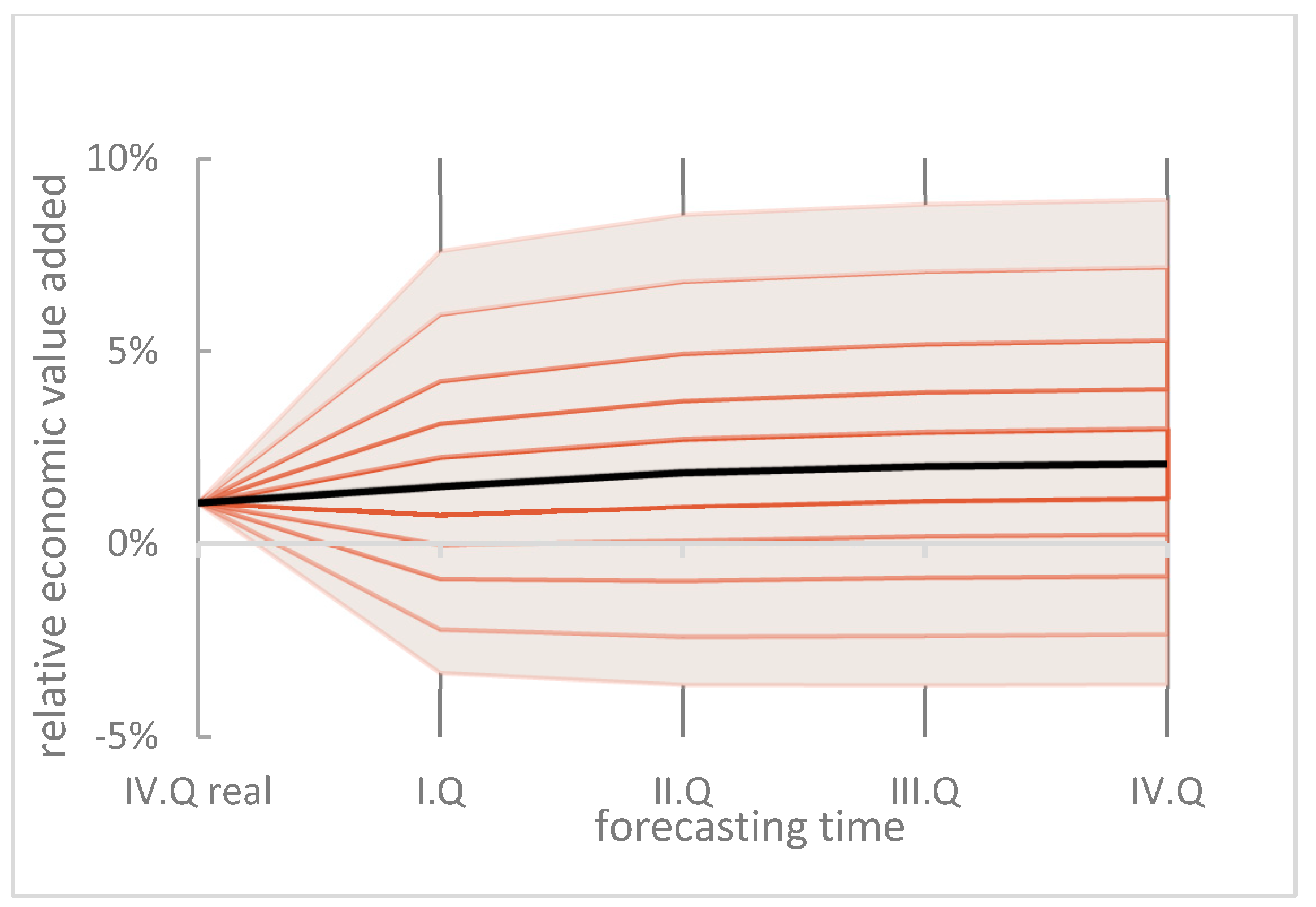
A comparison of the predicted distributions is apparent in
Table 6 and
Table 7, and a graphical comparison for the fourth quarter is demonstrated in
Figure 5.
The comparison of the decomposed and direct relative EVA one-quarter prediction (
Section 3.3) was tested using absolute and relative tests. The absolute test showed that the distribution prediction for the decomposed EVA is more accurate in comparison with the direct EVA. Similarly, the relative scoring logarithm test and the paired t-statistic confirmed the better accuracy of the decomposed EVA. Both applied tests verified the superiority of the decomposed EVA forecast model in the particular data case.
The proposed and applied probability distribution decomposition forecasting method is a more adequate and precise approach allowing the prediction of complete uncertainty compared to point prediction.
The proposed innovative advanced forecasting simulation method was verified as a proper conception for the problem of modelling and reflecting empirical data. The LDAMR and LDSMR processes sufficiently fit the chosen financial ratios, and the skew t-regression estimation was valid. The Monte-Carlo simulation of the NIG distribution with a t-copula adequately serves for a decomposed relative EVA distribution prediction, including its precision. It was shown that the direct relative EVA distribution prediction captures the historical behaviour of the complex measure only superficially and simplistically. Therefore, the direct EVA approach is unsuitable for predicting complex, synthetic, and risk measures, such as an EVA indicator. The EVA measure can be explained by reflecting the complexity and comprehensiveness of particular indicators, including their relationship phenomena hidden in financial performance.
The empirical results were verified, proving that the mean value and median of the decomposed relative EVA of the Czech automotive production sector tends to decrease in the future, with negative asymmetry and high volatility hidden in the decomposition of the financial ratios. The median is more stable in comparison to the mean value, even with a negative trend. The applied model led to huge volatility, with extreme values. This volatility is caused, among other things, by considering the ratios’ interdependencies and jumps. This phenomenon is hidden in the empirical historical data and in the relations among exact pyramid-decomposed financial ratios, and it looks both realistic and interesting.
The prediction of the decomposed relative EVA confirms that the sector is exposed to some fundamental structural changes. It is influenced by the limited qualified workers’ capacity, the efficiency of production, and industry competition. The sector is also affected by economic shocks caused by regulatory ecological measures, competitiveness, and substantial technological changes. New phenomena not considered in the model are pandemics, military attacks, and the shortage of spare parts and input material sources.
Further research can be devoted to developing other pyramid decomposition, Levy model types, copula functions, parameter estimations, and simulation approaches. Time series can be prolonged, and crisis periods can be included in them. For comparison, the financial performance of other sectors can also be analysed and predicted.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}