
Predicting Credit Scores with Boosted Decision Trees


Abstract
1. Introduction
1.1. Decision Trees
1.2. Boosting
2. Empirical Analysis
2.1. Data Sample
2.2. Performance Tuning
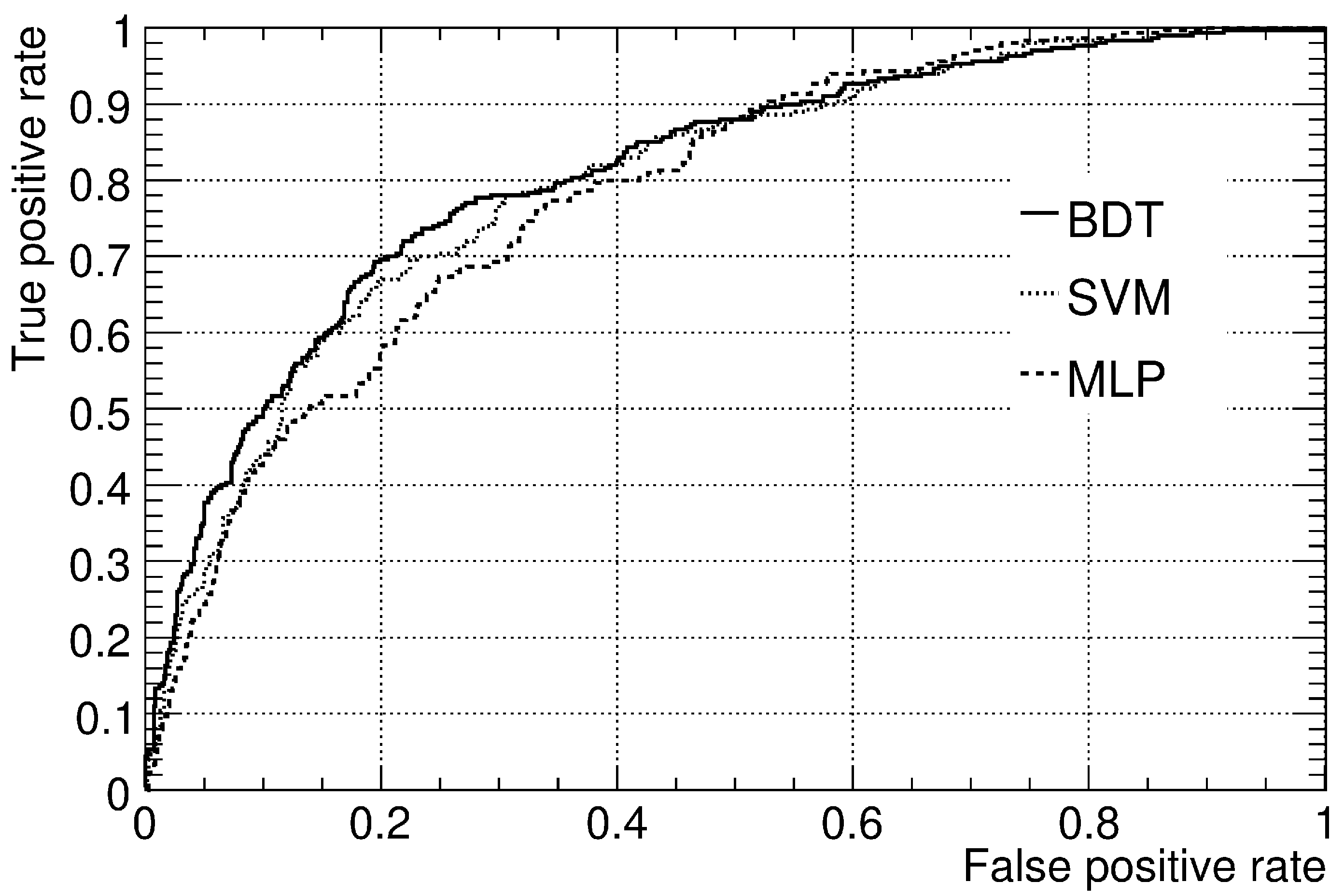
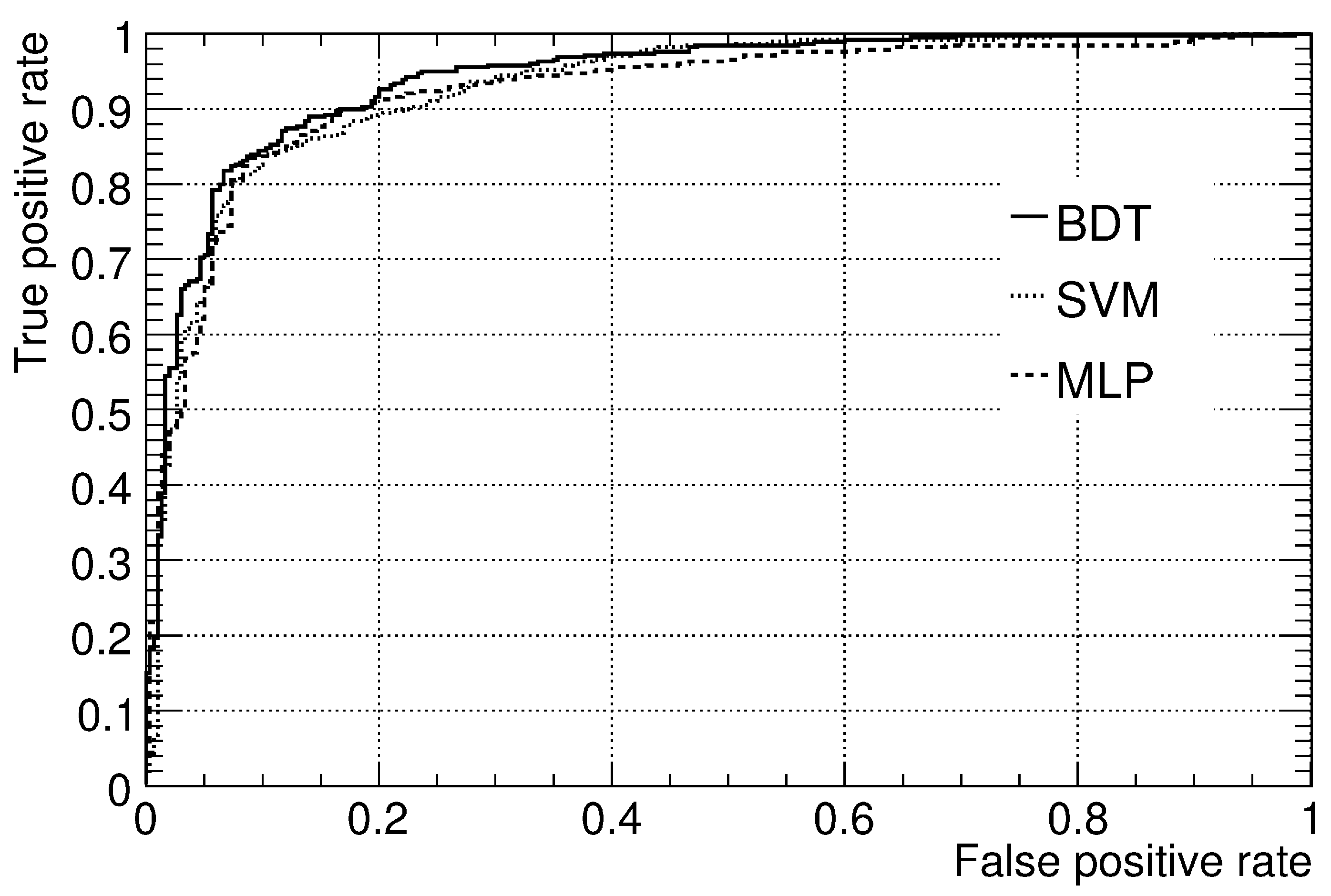
2.3. Results
2.4. Comparison of the AUC Estimates
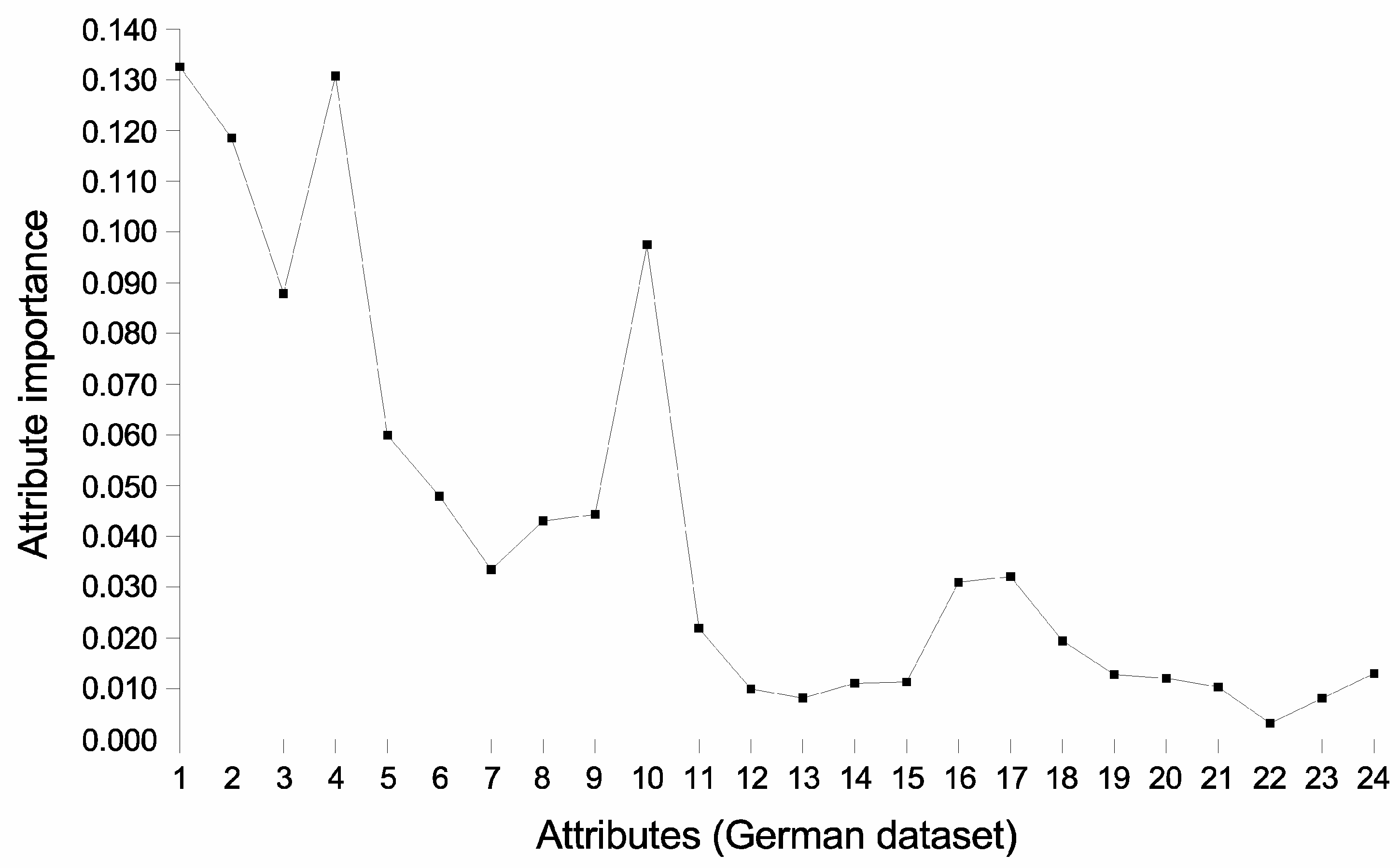
2.5. Relative Importance of the Attributes
3. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attribute | Description |
|---|---|
| 1 | Status of the client’s existing checking account |
| 2 | Duration of the credit |
| 3 | Client’s credit history |
| 4 | Credit amount requested |
| 5 | Client’s savings account/bonds balance |
| 6 | Client’s present employment status |
| 7 | Marital status and gender |
| 8 | Number of years spent at present residence |
| 9 | Type of property owned by the client |
| 10 | Age |
| 11 | Whether the client has other installment plans |
| 12 | Number of existing credits at the bank |
| 13 | Number of people for whom the client is liable to provide maintenance for |
| 14 | Whether the client has a telephone |
| 15 | Whether the client is a foreign worker |
| 16,17 | Dummy variables indicating the purpose of the credit |
| 18,19 | Dummy variables indicating whether the client is a debtor or guarantor of credit granted by another institution |
| 20,21 | Dummy variables indicating the client’s housing arrangement |
| 22,23,24 | Dummy variables indicating the employment status |
References
- Crook, J.N.; Edelman, D.B.; Thomas, L.C. Recent developments in consumer credit risk assessment. Eur. J. Oper. Res. 2007, 183, 1447–1465. [Google Scholar] [CrossRef]
- West, D. Neural network credit scoring models. Comput. Oper. Res. 2000, 27, 1131–1152. [Google Scholar] [CrossRef]
- Reichert, A.K.; Cho, C.C.; Wagner, G.M. An examination of the conceptual issues involved in developing credit-scoring models. J. Bus. Econ. Stat. 1983, 1, 101–114. [Google Scholar]
- Wiginton, J.C. A note on the comparison of logit and discriminant models of consumer credit behavior. J. Financ. Quant. Anal. 1980, 15, 757–770. [Google Scholar] [CrossRef]
- Henley, W.E.; Hand, D.J. A k-nearest neighbor classifier for assessing consumer risk. Statistician 1996, 44, 77–95. [Google Scholar] [CrossRef]
- Frydman, H.E.; Altman, E.I.; Kao, D.-L. Introducing recursive partitioning for financial classification: The case of financial distress. J. Financ. 1985, 40, 269–291. [Google Scholar] [CrossRef]
- Davis, R.H.; Edelman, D.B.; Gammerman, A.J. Machine learning algorithms for credit-card applications. Ima J. Manag. Math. 1992, 4, 43–51. [Google Scholar] [CrossRef]
- Jensen, H.L. Using neural networks for credit scoring. Manag. Financ. 1992, 18, 15–26. [Google Scholar] [CrossRef]
- Blanco, A.; Pino-Mejías, R.; Lara, J.; Rayo, S. Credit scoring models for the microfinance industry using neural networks: Evidence from Peru. Expert Syst. Appl. 2013, 40, 356–364. [Google Scholar] [CrossRef]
- Zhao, Z.; Xu, S.; Kang, B.O.; Kabir, M.M.J.; Liu, Y.; Wasinger, R. Investigation and improvement of multi-layer perceptron neural networks for credit scoring. Expert Syst. Appl. 2015, 42, 3508–3516. [Google Scholar] [CrossRef]
- Ong, C.-S.; Huang, J.-J.; Tzeng, G.-H. Building credit scoring models using genetic programming. Expert Syst. Appl. 2005, 29, 41–47. [Google Scholar] [CrossRef]
- Baesens, B.; Van Gestel, T.; Viaene, S.; Stepanova, M.; Suykens, J.; Vanthienen, J. Benchmarking state-of-the-art classification algorithms for credit scoring. J. Oper. Res. Soc. 2003, 54, 1028–1088. [Google Scholar] [CrossRef]
- Li, S.-T.; Shiue, W.; Huang, M.-H. The evaluation of consumer loans using support vector machines. Expert Syst. Appl. 2006, 30, 772–782. [Google Scholar] [CrossRef]
- Bellotti, T.; Crook, J. Support vector machines for credit scoring and discovery of significant features. Expert Syst. Appl. 2009, 36, 3302–3308. [Google Scholar] [CrossRef]
- Harris, T. Credit scoring using the clustered support vector machine. Expert Syst. Appl. 2015, 42, 741–750. [Google Scholar] [CrossRef]
- Plawiak, P.; Abdar, M.; Acharya, R. Application of new deep genetic cascade ensemble of SVM classifiers to predict the Australian credit scoring. Appl. Soft Comput. 2019, 84, 105740. [Google Scholar] [CrossRef]
- Lee, T.-S.; Chiu, C.-C.; Lu, C.-J.; Chen, I.-F. Credit scoring using the hybrid neural discriminant technique. Expert Syst. Appl. 2002, 23, 245–254. [Google Scholar] [CrossRef]
- Hsieh, N.-C. Hybrid mining approach in the design of credit scoring models. Expert Syst. Appl. 2005, 28, 655–665. [Google Scholar] [CrossRef]
- Lee, T.-S.; Chen, I.-F. A two-stage hybrid credit scoring model using artificial neural networks and multivariate adaptive regression splines. Expert Syst. Appl. 2005, 28, 743–752. [Google Scholar] [CrossRef]
- Bastos, J.A. Ensemble predictions of recovery rates. J. Financ. Serv. Res. 2014, 46, 177–193. [Google Scholar] [CrossRef]
- West, D.; Dellana, S.; Qian, J. Neural network ensemble strategies for financial decision applications. Comput. Oper. Res. 2005, 32, 2543–2559. [Google Scholar] [CrossRef]
- Asuncion, A.; Newman, D.J. UCI Machine Learning Repository. University of California, Irvine, School of Information and Computer Science. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 4 November 2022).
- Bastos, J.A. Credit Scoring with Boosted Decision Trees. Mpra Pap. 8034. 2008. Available online: https://mpra.ub.uni-muenchen.de/8034/ (accessed on 5 November 2022).
- Tsai, C.-F.; Hsu, Y.-F.; Yen, D.C. A comparative study of classifier ensembles for bankruptcy prediction. Appl. Soft Comput. 2014, 24, 977–984. [Google Scholar] [CrossRef]
- Abellán, J.; Castellano, J.G. A comparative study on base classifiers in ensemble methods for credit scoring. Expert Syst. Appl. 2017, 73, 1–10. [Google Scholar] [CrossRef]
- Xia, Y.; Liu, C.; Li, Y.Y.; Liu, N. A boosted decision tree approach using Bayesian hyper-parameter optimization for credit scoring. Expert Syst. Appl. 2017, 78, 225–241. [Google Scholar] [CrossRef]
- Zhou, J.; Li, W.; Wang, J.; Ding, S.; Xia, C. Default prediction in P2P lending from high-dimensional data based on machine learning. Phys. Stat. Mech. Its Appl. 2019, 534, 122370. [Google Scholar] [CrossRef]
- Liu, W.; Fan, H.; Xia, M. Credit scoring based on tree-enhanced gradient boosting decision trees. Expert Syst. Appl. 2022, 189, 116034. [Google Scholar] [CrossRef]
- Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Wadworth International Group: Belmont, CA, USA, 1984. [Google Scholar]
- Freund, Y.; Schapire, R.E. A short introduction to boosting. J. Jpn. Soc. Artif. Intell. 1991, 14, 771–780. [Google Scholar]
- Schapire, R.E. The boosting approach to machine learning: An overview. Nonlinear Estim. Classif. 2002, 149–173. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a new boosting algorithm. In Proceedings of the 13th International Conference on Machine Learning, Bari, Italy, 3–6 July 1996; pp. 148–156. [Google Scholar]
- Hornik, K.; Stinchcombe, M.; White, H. Multilayer feedforward networks are universal approximators. Neural Netw. 1989, 2, 359–366. [Google Scholar] [CrossRef]
- Hsu, C.-W.; Chang, C.-C.; Lin, C.-J. A Pratical Guide to Support Vector Classification. 2007. Available online: https://www.google.com.hk/url?sa=t&rct=j&q=&esrc=s&source=web&cd=&ved=2ahUKEwjRiJ3yybT7AhXMklYBHcQfAEQQFnoECBEQAQ&url=https%3A%2F%2Fwww.csie.ntu.edu.tw%2F~cjlin%2Fpapers%2Fguide%2Fguide.pdf&usg=AOvVaw3va31QH9SMVmNquoUoRfdN (accessed on 4 November 2022).
- Hoecker, A.; Speckmayer, P.; Stelzer, J.; Tegenfeldt, F.; Voss, H.; Voss, K. TMVA—Toolkit for Multivariate Data Analysis. arXiv 2007, arXiv:physics/0703039. [Google Scholar]
- DeLong, E.; DeLong, D.; Clarke-Pearson, D. Comparing the area under two or more correlated receiver operating characteristic curves: A nonparametric approach. Biometrics 1988, 44, 837–845. [Google Scholar] [CrossRef] [PubMed]





| Model | German Data | Australian Data |
|---|---|---|
| MLP | 78.3% | 92.3% |
| SVM | 79.9% | 92.9% |
| BDT | 81.1% | 94.0% |
| Test | German Data | Australian Data | ||
|---|---|---|---|---|
| T | p-Value | T | p-Value | |
| MLP – SVM | 2.781 | 0.095 | 1.132 | 0.288 |
| MLP – BDT | 4.916 | 0.027 | 6.778 | 0.009 |
| SVM – BDT | 1.774 | 0.183 | 3.737 | 0.053 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bastos, J.A. Predicting Credit Scores with Boosted Decision Trees. Forecasting 2022, 4, 925-935. https://doi.org/10.3390/forecast4040050
Bastos JA. Predicting Credit Scores with Boosted Decision Trees. Forecasting. 2022; 4(4):925-935. https://doi.org/10.3390/forecast4040050
Chicago/Turabian StyleBastos, João A. 2022. "Predicting Credit Scores with Boosted Decision Trees" Forecasting 4, no. 4: 925-935. https://doi.org/10.3390/forecast4040050
APA StyleBastos, J. A. (2022). Predicting Credit Scores with Boosted Decision Trees. Forecasting, 4(4), 925-935. https://doi.org/10.3390/forecast4040050