1. Introduction
A cryptocurrency is a digital asset designed to work as a medium of exchange. It is self-regulated, decentralized and independent of any governmental or other national or international regulator. Financial transactions with cryptocurrencies are verified and secured using blockchain technology that is based on cryptography. Bitcoin was the first such cryptocurrency and was introduced by [
1]. It is designed as a decentralized digital currency: transactions are permanently recorded in an open distributed ledger, the blockchain, and is verified by a peer-to-peer network instead of a central authority. The process of creating new Bitcoins is referred to as “mining”. New Bitcoins are created and awarded to the nodes (miners) that manage to verify and add new blocks of transactions to Bitcoin’s blockchain. Bitcoin is the most important cryptocurrency in terms of market capitalization. In September 2022, its market capitalization exceeded
$377 billion (According to
http://www.coinmarketcap.com, accessed on 8 June 2019). Bitcoin is driving cryptocurrency markets and its evolution may have the potential to impact the global economy. Bitcoin is often used as a digital asset for portfolio diversification; see among others [
2,
3,
4,
5].
Cryptocurrency markets experience episodic high volatility, resulting in significant fluctuations and extreme changes in the returns times series. Risk increases during these moments of severe volatility, and investors typically reduce their market positions or resort to the costly solution of hedging to mitigate risk exposure. These investing reactions may contribute to inefficient and inconsistent short-term portfolio management. We term the extreme fluctuations “spikes” and our study aims to forecast them in Bitcoin’s returns time-series.
Traditional econometric models make the strict assumption of homoscedasticity, which implies that the random variables at hand have a constant variance throughout time. Nonetheless, several financial time-series display periods of relative imperturbability and periods of high volatility [
6]. This is directly translated in serial dependence at the higher conditional moments of the data. In these cases, the homoscedasticity assumption is not true, and the data are called heteroskedastic. The empirical results of [
7] showed that long-tail events are observed in the returns of cryptocurrencies; the volatility of such returns exhibits significant clustering. They provided empirical evidence that cryptocurrency returns time series are heteroscedastic.
Many studies model and forecast the variance in financial time series using various Generalized Autoregressive Conditional Heteroscedasticity (GARCH) models [
8,
9]. The same is also true specifically for cryptocurrencies; see, among others [
7,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19].
One of the novel aspects of our analysis is that we do not utilize a fixed over time threshold to identify the sharp swings in Bitcoin returns that we call spikes. The use of a fixed over time threshold on heteroskedastic time-series may yield two cases of error: it may over-identify spikes during high market disturbances (high variance) and it may under-identify spikes occurring during relative tranquility (low variance). Instead, in this study, we use the conditional second moment of the returns (standard deviation) that is estimated using the best fit GARCH model. We define the “normal” (non-spike) fluctuation band as a two conditional standard deviations band around the mean. When this setup is used, the fluctuation band width varies over time in response to the actual volatility.
Once we define the concept of spikes using the conditional standard deviation and identify them in the returns of the Bitcoin time series, we then proceed in forecasting these extreme deviations. The arsenal of machine learning (ML) has been extensively used in the wide field of financial forecasting and especially in the cryptocurrencies market. Ref. [
20] used a recurrent neural network (RNN) and a long short-term memory (LSTM) model to directional forecast the Bitcoin price. They showed that the LSTM models outperformed the RNN ones by a small margin and required significantly more computational time. Ref. [
21] used the LSTM models to forecast Bitcoin price levels. The AR(2)-LSTM model that they proposed, outperformed the conventional LSTM models. Ref. [
22] tested the LSTM and the generalized regression neural networks (GRNN) models to the forecasting of three cryptocurrencies (Bitcoin, Digital Cash and Ripple) levels. The LSTM models, in their tests, outperformed the GRNN ones. Ref. [
23], in a meta-research, reviewed 171 articles regarding forecasting cryptocurrencies with ARIMA and various ML techniques. The authors concluded that the ML models are more accurate at forecasting cryptocurrency evolution than the econometrics models. Ref. [
24] compared backpropagation neural network (BPNN), genetic algorithm neural network (GANN), genetic algorithm backpropagation neural network (GABPNN), and neuro-evolution of augmenting topologies (NEAT) in forecasting the price of Bitcoin. The results showed that the BPNN model outperformed the competition.
Ref. [
25] introduced the support vector machines (SVM) as a supervised machine learning algorithm for binary classification tasks. The methodology is computationally attractive, it can treat linear and non-linear problems as well, and it can be extended to multiclass classification problems and in general it can find the overall optimal solution in every setup. These important advantages attracted many scientists, making the SVM model quite popular in the forecasting community. Ref. [
26] showed that the SVM models outperform the ANN ones in forecasting financial markets with fewer computational cost. Ref. [
27] forecasted the electricity price spikes using the SVM model with great success.
In the cryptocurrency market domain, Ref. [
28] used various ML algorithms to forecast the Bitcoin price direction and concluded that the SVM model outperformed the rest of the methods. Ref. [
29] used SVM and ANN models to forecast Bitcoin price levels. Their empirical evidence suggests that traders can increase their profits using SVM forecasting models. Ref. [
30] used ANN, SVM, and random forest (RF) models, combined with sentiment analysis input data, in forecasting the price movement of four cryptocurrencies (Bitcoin, Ethereum, Ripple, and Litecoin). Ref. [
31] used SVM model for predicting intraday (current day’s) trend of Bitcoin returns. In most cases, the SVM model provided high accuracy for both upward and downward spikes. In this paper we use the SVM methodology to forecast the spikes in the evolution of the Bitcoin market.
The remaining paper has the following structure: In
Section 2, we present the proposed methodology in detail.
Section 3 is devoted to the dataset that we used and the empirical results of our tests. The paper finalizes with the conclusions in
Section 4.
2. Methodology
The support vector machine (SVM) is a set of machine learning (ML) algorithms introduced by [
25]. SVM acts as a binary classifier that can also treat regression after being properly modified. It is a supervised learning algorithm, meaning that all the training data are correctly labeled. In this paper, the SVM binary classification model is used to forecast the presence or not of spikes in the next time instance of the Bitcoin evolution. SVMs’ main concept is identifying a linear hyperplane in the data space that maintain the largest gap between the two classes. To make sure that SVM always reaches an optimal solution, the SVMs optimization task is formulated in a convex way.
The machine learning process is divided into two steps: training and testing. In training, the biggest chunk of the data is used to identify the hyperplane that optimally separates the classes. During the testing step, a smaller part of the dataset that kept away from the training is used to evaluate the models’ generalization capability. The mathematical derivation of the SVM models is presented shortly in the following section.
2.1. Linearly Separable Data
Each data point (vector)
xi∈ℝ
n (
i = 1, 2,…,
N) corresponds to one of the two classes (output)
yi ∈ {−1, +1}. In the case of linearly separable data, the boundary is defined as:
Subject to the contents:
while , the vector of weights is w, and the bias is b.
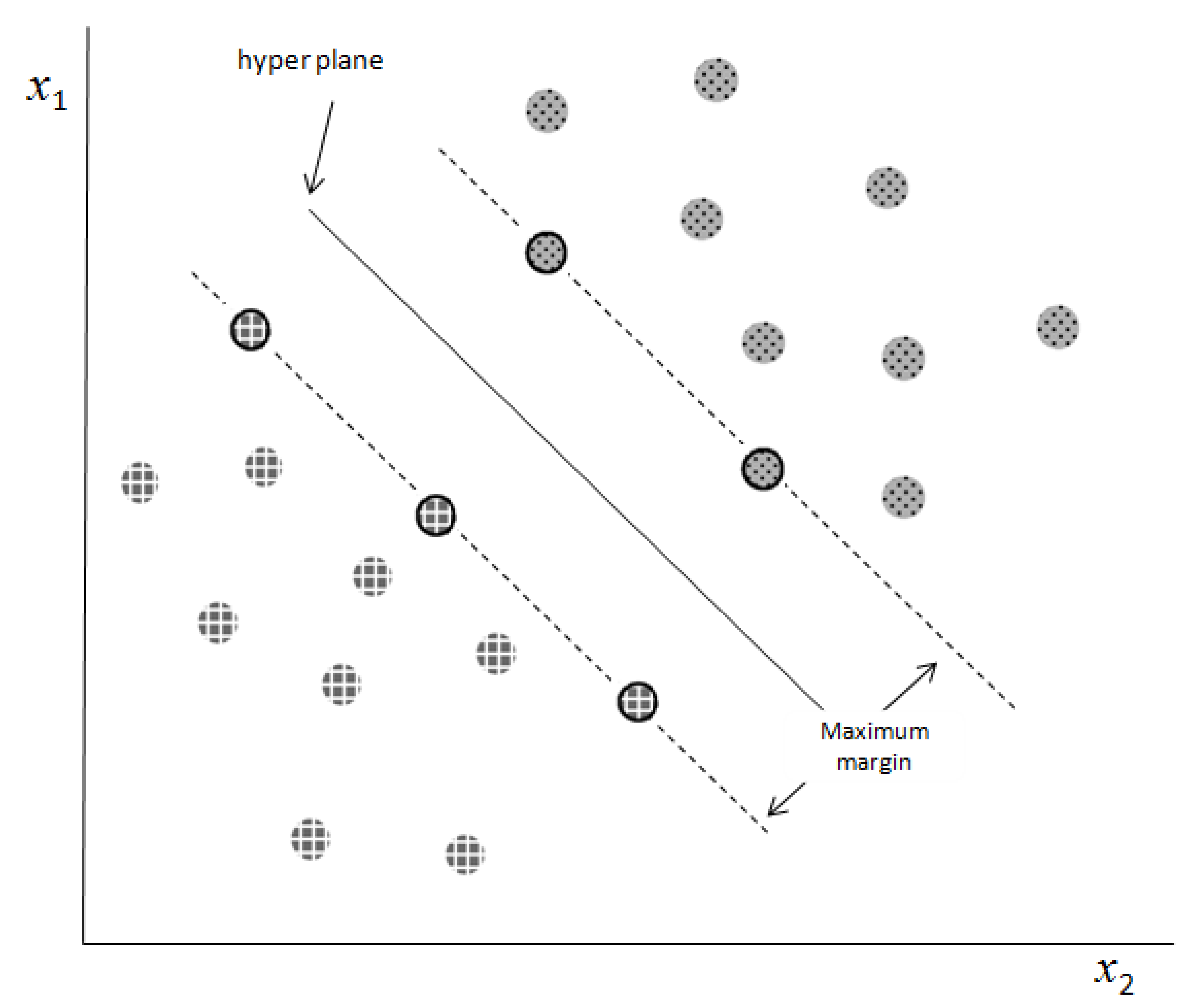
The decision boundary that classifies each data (vector) into its associated class and has the largest distance, referred to as the “margin”—from both classes is known as the separator (the optimal separation hyperplane). The marginal data points that define the position of the decision boundary are called support vectors (SVs). In
Figure 1, the prominent contour represents the SVs, the dashed lines indicate the margin lines (which define the distance of the hyperplane from each class), and the continuous line represents the hyperplane.
Using the Lagrange optimization process, the following equation can be used to discover the solution to the problem of finding the hyperplane position:
where
are the non-negative Lagrange multipliers. Equation (4) is never used to estimate the solution. Instead we always solve the dual problem, defined as:
while
and
The solution of Equation (5) yields the location of the separating hyperplane, which is defined as:
where the collection of support vector indices is denoted by
.
2.2. Error-Tolerant SVM
Only linearly separable data can be treated using the presented methodology. Actual data, on the other hand, frequently contain noise and outliers. In such cases, the misclassified data can have a severe impact on the position of the separating hyperplane and create large classification errors. Ref. [
25] proposed the error-tolerant SVM model to address this problem. In order to deal with erroneously categorized observations, their main idea was to introduce in the minimization process, non-negative slack variables ξ
i ≥ 0, ∀
i, which are regulated by a penalty parameter C. Equation (5) now reads as follows:
When vector xi is misclassified, ξi denotes the distance between it and the hyperplane.
The hyperplane of optimal separation is defined as follows:
where the collection of support vector indices is denoted by
.
2.3. Kernel Methods
Numerous real-world processes generate data in a nonlinear fashion, and linear classifiers are incapable of dealing with the generated data. The SVM setup can be extended to non-linear problems via the projection of the data space to a space of higher dimensionality, called feature space. In this step, we seek iteratively the projection that will create a feature space where the two classes are linearly separable. This process of mapping the initial data into spaces of higher dimensionality is made possible using the so-called “kernel functions”: the projection functions of the data-points. When the kernel function is non-linear, the SVM model generated is also non-linear (see
Figure 2).
The dual problem solution with projection of Equation (5) in this case becomes:
and are the constrains, while is the kernel function. Kernel method implementation via dot multiplication is a computationally efficient technique that enables projection to a space of higher dimensionality.
In our tests we used the linear and non-linear Radial Basis Function (RBF) kernels:
Linear:
RBF:
where γ is the RBF kernel’s internal hyper-parameter that needs to be tuned.
2.4. Overfitting
Overfitting is a problem that might arise when training SVM models. This is a circumstance in which the trained model fits the in-sample data quite well but fails to reflect the underlying data generation process. The problem of model overfitting is addressed via k-fold cross validation (In this study, 5-fold cross validation was used).
3. Data and Empirical Results
Our dataset consists of daily Bitcoin returns and 90 additional financial variables (the full list of the variables can be found in
Appendix A Table A1) for the period from 10 May 2013 to 29 April 2019, for a total of 2145 observations. The data were obtained from CoinMarketCap (
https://coinmarketcap.com, accessed on 8 June 2019), Yahoo Finance (
https://finance.yahoo.com, accessed on 8 June 2019) and FRED, the Federal Reserve Bank of Saint Louis (
https://fred.stlouisfed.org, accessed on 8 June 2019) database.
We used the natural logarithmic return transformation to determine the Bitcoin returns:
where
stands for the returns and
stands for Bitcoin’s daily prices.
Our scheme starts by investigate the best autoregressive model
. The first step is to identify the number of autoregressive lags that can remove any serial correlation. To test for serial correlation, we use the Ljung-Box Q(36) statistic at the 1% significance level. For
we reject the null hypothesis of no autocorrelation and we steadily increase the number of lags until the test cannot reject it. In our data this happened for AR(11). After eliminating autocorrelation, we then try to identify the best fitted autoregressive forecasting model with
, based on the minimum Bayesian information criterion (BIC) introduced by [
32]. We estimated 14 alternative
models with
. As reported to the results in
Table 1, the minimum BIC is achieved with the
model.
We test for any remaining non-linear dependencies that imply the existence of conditional heteroscedasticity, after initially removing any linear dependencies in the error term We utilized [
8] ARCH test to detect any non-linear dependence (conditional heteroscedasticity). At the 1% significance level (with
p-value < 0.001 and F-statistic = 241.51), the null hypothesis that there are no ARCH effects in the residuals was rejected, meaning that we did find statistical evidence for the presence of non-linear dependence in the error term. In order to model this non-linear dependence, we estimated multiple GARCH(p,q) formats, as suggested by [
8,
9], for all combinations of
and
and calculated the corresponding BIC. We tested three distributional assumptions: the normal, Student’s t and the Generalized Error Distribution (GED). These corresponding results are presented in
Table 2. In
Table 3, we repeated the process for the Exponential form of GARCH, also known as the EGARCH(p,q) model, which was proposed by Nelson (1991).
The best GARCH model is the GARCH(1,1), and the best EGARCH model is the EGARCH(1,1) using GED, according to the BIC. These findings suggest that the EGARCH(1,1) utilizing the GED is the overall optimal model that minimizes the BIC (BIC = −4.05039 for the optimal AR(11)-EGARCH(1,1) utilizing GED distribution), as shown in
Table 3.
As mentioned before, in this paper, we identify as spikes the Bitcoin returns that fall outside a 2 conditional standard deviation band. This band is defined by the optimal AR(11)-EGARCH(1,1) conditional variance model format as chosen above. According to this, there is a total of 234 spikes, accounting for nearly 11% of all Bitcoin return observations. The remaining 1911 observations were labeled as non-spikes.
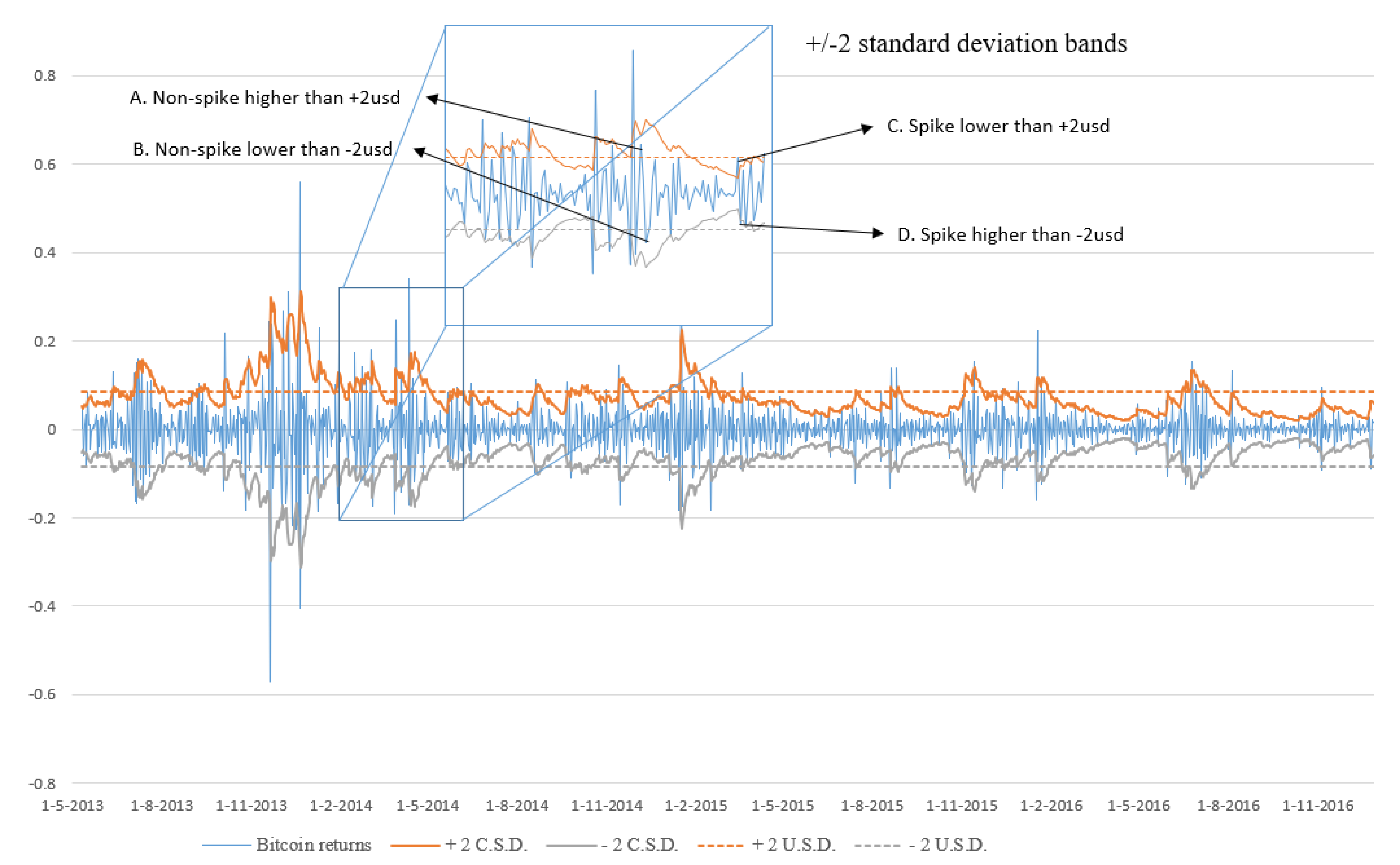
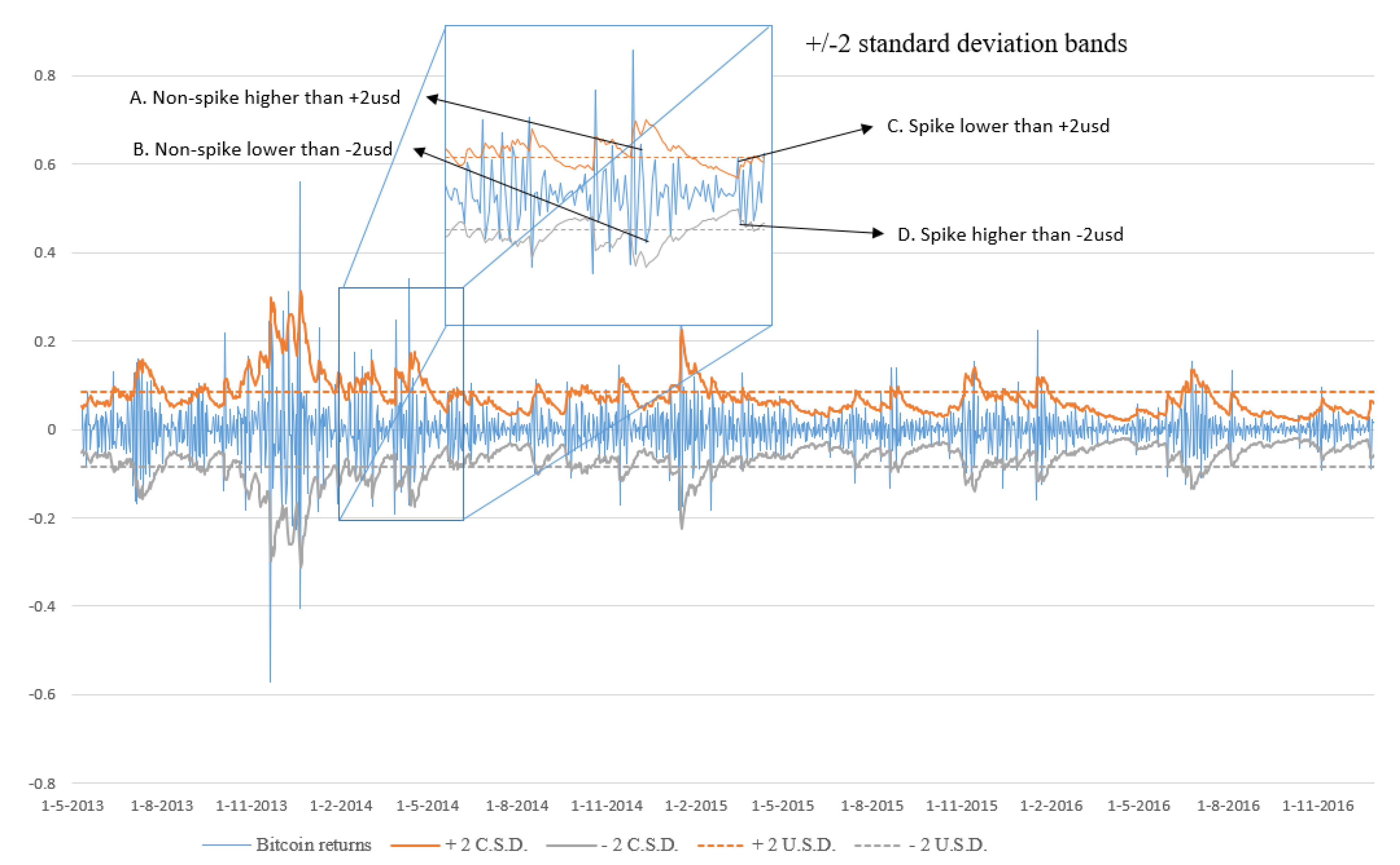
In
Figure 3, we graph the Bitcoin returns along with the +/−2 conditional (2-csd) and unconditional standard deviations (2-usd) bands. The spikes we try to predict are those that fall outside the 2-csd band. Both bands are depicted in the figure to emphasize the difference between the conditional and unconditional standard deviations. The unconditional standard deviation band is defined by the straight dashed lines and is constant over time; the conditional standard deviation band is defined by the continuous squiggly line around the mean of the time series and has a variable width over time. We offer four illustrative situations in the zoomed portion of
Figure 3 that valid our analysis as these are treated differently from the two bands. If we used the USD band, points A and B would be classified as spikes. Nonetheless, the suggested csd band classifies them as non-spikes. The latter approach is more important for an investor’s behavior and daily decision-making process. Investors are not concerned with the index’s volatility over time; instead, they are concerned with estimating the immediate risk associated with probable short-term investment decisions. This is more significant in terms of the risk a market participant takes throughout the course of his or her investment horizon. The unconditional standard deviation treats points C and D as non-spikes, while the conditional standard deviation treats them as spikes.
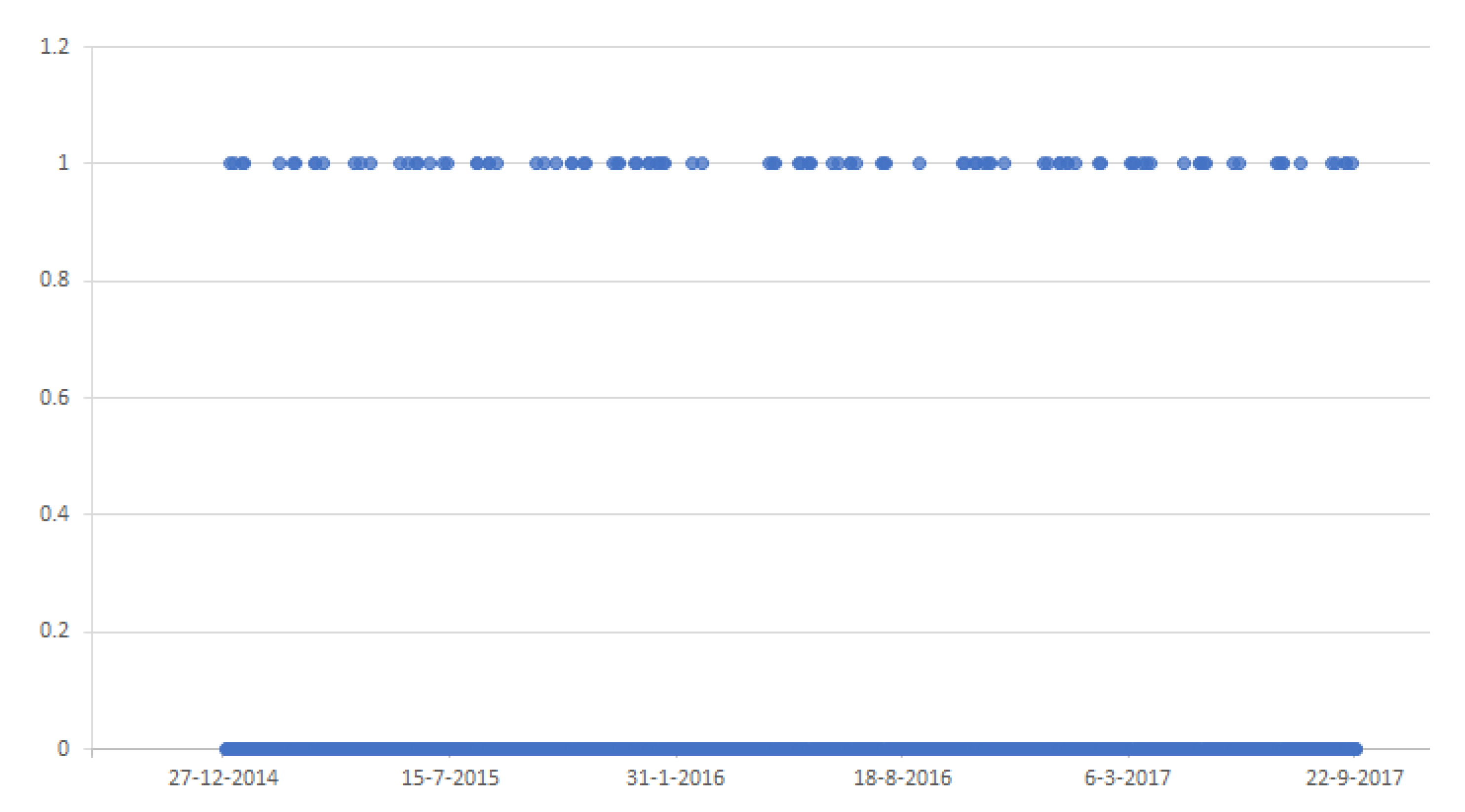
The binary time series of the spikes and non-spikes instances can be seen in
Figure 4. The spikes are depicted with 1; the non-spike instances are denoted with 0.
3.1. Autoregressive SVM Models
Multiple predictive models were trained using the SVM method to predict the spikes in Bitcoin daily returns coupled with the linear and the RBF kernel. We must note that the binary time series is highly imbalanced: the spikes are 11% and the non-spikes (in-band) cases are 89% of the dataset. This makes the goal of accurately forecasting the time series unreachable. It is straightforward to verify, that every model “forecasting” only non-spike instances will rich an accuracy of 89% (and it will miss all the spikes). To overcome this drawback, we incorporated weights in the minimization procedure to deal with the extremely imbalanced classes. The misclassification of a spike instance weights 8 times more than the weight of the miss-classification of a non-spike instance. This simple and classic trick nullifies the effect of the imbalanced dataset in the identification of the optimal separation hyperplane.
We excluded 10% of our total data from the training procedure to use it as the out-of-sample dataset. These observations are used to assess the generalizability of our optimum models (i.e., the accuracy of our model to data that were not used during the training step).
We used a five-fold cross-validation approach to tackle the issue of overfitting. The optimal parameters for each model were estimated via a coarse to fine grid search at each fold (C for the linear and C, γ for the RBF kernel). We identified the optimal autoregressive forecasting model AR(q *), with q * denotes the optimum lag length when up to 31 lags were included. The results are shown in
Table 4, while a detailed list is placed in
Appendix B.
3.2. Augmented SVM Models
Next, the 90 extra explanatory variables were sequentially incorporated, one by one, to the best AR(q *) models. The variable, if any, that improved forecasting accuracy was included in the AR(q *) model, and the process was repeated for the remaining variables until no more improvement was observed.
Table 5 outlines the findings of this procedure about the optimal models.
By integrating Litecoin and Namecoin returns as explanatory variables, the AR(21) model paired with the linear kernel was improved. The AR(5) model with the RBF kernel was improved by the addition of Litecoin returns, Namecoin returns and Momentum(4) (
, where
is the close price at day t) or ROC(4) (
, where
is the close price at day t) of Bitcoin’s returns as explanatory variables. The AR(5)-RBF model achieved the highest overall forecasting accuracy. This model reached an overall (both classes) 86.51% out-of-sample forecasting accuracy. The discrete accuracies for the spikes and non-spikes were 79.17% and 87.43%, respectively. The confusion matrices of all these models are summarized
Table 6. In addition to the SVM models, logit models were estimated for the given task but failed to give meaningful results (Logit models were used to forecast spikes in Bitcoin’s returns. Attempts to fine tune logit models were not successful. Logit models either over-estimated observations as spikes or non-spikes (depending on the threshold given). Logit models were not able to capture the nonlinear nature of the data generating phenomenon of spikes. In general, logit models are more appropriate for binary classification in balanced data sets).
4. Conclusions
Our goal, in this study, is to accurately forecast steep fluctuations to Bitcoin returns while sustaining high accuracy for normal instances. In this manuscript, the spikes are defined as the returns that fall outside a +/−2 conditional standard deviation band. The spikes identified in our sample represent approximately 11% of the total observations.
One of the novel aspects of our method is that, in identifying the spikes, we do not simply apply the unconditional standard deviation as a measure of volatility. The time series of the returns exhibit significant anomalies, with periods of extreme volatility followed by periods of relative calm. As a result, using the overall unconditional standard deviation may not always be the suitable choice. In our dataset, we identified non-linear patterns, that the investors may model and exploit. Thus, we model the conditional standard deviation of Bitcoin returns to reflect these non-linear processes applying alternative GARCH models and selecting the one that best fits these non-linearities in the data. Based on this optimal GARCH model, we identify the spikes using a +/−2 conditional standard deviations band. The conditional standard deviation is more critical to the investor since he/she is less interested in the index’s overall historical swings and more concerned with what occurs next, in the short term, in his/her holding period.
Following the extraction of spikes using the conditional standard deviation, we use an SVM model paired with two kernel functions. When compared to traditional statistical and economic models, these models typically better capture the non-linearities observed in the data generation mechanism of the sample at hand. Additionally, they do not impose or require any presumptions on the data.
First, we model the data using the best autoregressive model. Then, we iteratively augment our models and test as potential forecasters, a total of 90 financial time series. This procedure selects the Litecoin and the Namecoin returns for both the linear and RBF kernels, and Momentum(4) or ROC(4) only for the RBF kernel.
The results indicate that the overall optimum forecasting SVM model is the one using the non-linear RBF kernel. The best model can achieve high forecasting accuracy for both spikes and non-spikes: 79.17% correct identification of the spikes and 87.43% accuracy for the non-spikes in out-of-sample data. Thus, we find evidence that the returns of alternative cryptocurrencies provide important information on Bitcoin return spikes that ML algorithms can exploit. This is evidence that the cryptocurrencies markets are not segmented between them and are becoming more integrated with information spillovers from one cryptocurrency to the other. Moreover, what is also interesting, is that the cryptocurrencies market, as a whole, seems to still behave as an independent habitat of assets with no direct linkages to the main financial, stock energy, and commodities markets. No such variable from a total of more than 40 variables tested in our analysis, seems to play any role in forecasting the Bitcoin and its spikes. Thus, the users and investors in the cryptocurrencies markets seem segmented and focused on a preferred habitat and not the whole financial market.






{kind=link}
{kind=link}
{kind=link}
{kind=link}