1. Introduction
Since its identification in December 2019, COVID-19 has posed critical challenges for the public health and economies of essentially every country in the world [
1,
2,
3]. Government officials have taken a wide range of measures in an effort to contain this pandemic, including closing schools and workplaces, setting restrictions on air travel, and establishing stay at home requirements [
4]. Accurately forecasting the number of new infected people in the short and medium term is critical for the timely decisions about policies and for the proper allocation of medical resources [
5,
6].
There are three basic approaches for predicting the dynamics of an epidemic: compartmental models, statistical methods, and ML-based methods [
5,
7]. Compartmental models subdivide a population into mutually exclusive categories, with a set of dynamical equations that explain the transitions among categories [
8]. The Susceptible-Infected-Removed (SIR) model [
9] is a common choice for the modelling of infectious diseases. Statistical methods extract general statistics from the data to fit mathematical models that explain the evolution of the epidemic [
6]. Finally, ML-based methods use machine learning algorithms to analyze historical data and find patterns that lead to accurate predictions of the number of new infected people [
7,
10].
Arguably, when any approach is used to make high-stake decisions, it is important that it be not just accurate, but also interpretable: It should give the decision-maker enough information to justify the recommendation [
11]. Here, we propose SIMLR, which is an interpretable probabilistic graphical model (PGM) that combines compartmental models and ML-based methods. As its name suggests, it incorporates machine learning (ML) within an SIR model. This combines the strength of curve fitting models that allow accurate predictions in the short-term, involving many features, with mechanistic models that allow to extend the range to predictions in the medium and long terms [
12].
SIMLR uses a mixture of experts approach [
13], where the contribution of each expert to the final forecast depends on the changes in the government policies implemented at various earlier time points. When there is no recent change in policies (two to four weeks before the week to be predicted), SIMLR relies on an SIR model with time-varying parameters that are fitted using machine learning methods. When a change in policy occurs, SIMLR instead relies on a simpler model that predicts that the new number of infections will remain constant. Note that forecasting the number of new infections one and two weeks in advance (
and
) is relatively easy as SIMLR knows, at the time of the prediction, whether the policy has changed recently. However, for three- or four-week forecasts (
and
), our model needs to estimate the likelihood of a future change of policy. SIMLR incorporates prior domain knowledge to estimate such policy-change probabilities.
The use of such prior models—here epidemiological models—is particularly important when the available data is scarce [
14]. At the same time, machine learning models need to acknowledge that the reported data on COVID-19 is imperfect [
15,
16]. The use of probabilistic graphical models allows SIMLR to account for this uncertainty on the data. At the same time, the probability tables associated with this graphical model can be manually modified to adapt SIMLR to the specific characteristics of a region.
This work makes three important contributions. (1) It empirically shows that an SIR model with time-varying parameters can describe the complex dynamics of COVID-19. (2) It describes an interpretable model that predicts the new number of infections one to four weeks in advance, achieving state-of-the-art results, in terms of mean absolute percentage error (MAPE), on data from Canada and the United States. (3) It presents a machine learning model that incorporates the uncertainty of the input data and can be tailored to the specific situations of a particular region.
The rest of
Section 1 describes the related work and the basics of the SIR compartmental model.
Section 2 then describes in detail our proposed SIMLR approach.
Section 3 shows the results of the predicting the number of new infections in the United States and provinces of Canada. Finally,
Section 4 presents our final remarks.
1.1. Basic SIR Model
The Susceptible-Infected-Removed (SIR) compartmental model [
9] is a mathematical model of infectious disease dynamics that divide the population into three disjoint groups [
8]. Susceptible (S) refers to the set of people who have never been infected but can acquire the disease. Infected (I) refers to the set of people who have and can transmit the infection. Removed (R) refers to the people who have either recovered or died from the infection and cannot transmit the disease anymore. This model is defined by the differential equations:
SIR assumes an homogeneous and constant population, and it is fully defined by the parameters
(transmission rate) and
(recovery rate). The intuition behind this model is that every infected patient gets in contact with
people. Since only the susceptible people can become infected, the chance of interacting with a susceptible person is simply the proportion of susceptible people in the entire population,
. Likewise, at every time point,
proportion of the infected people is removed from the system.
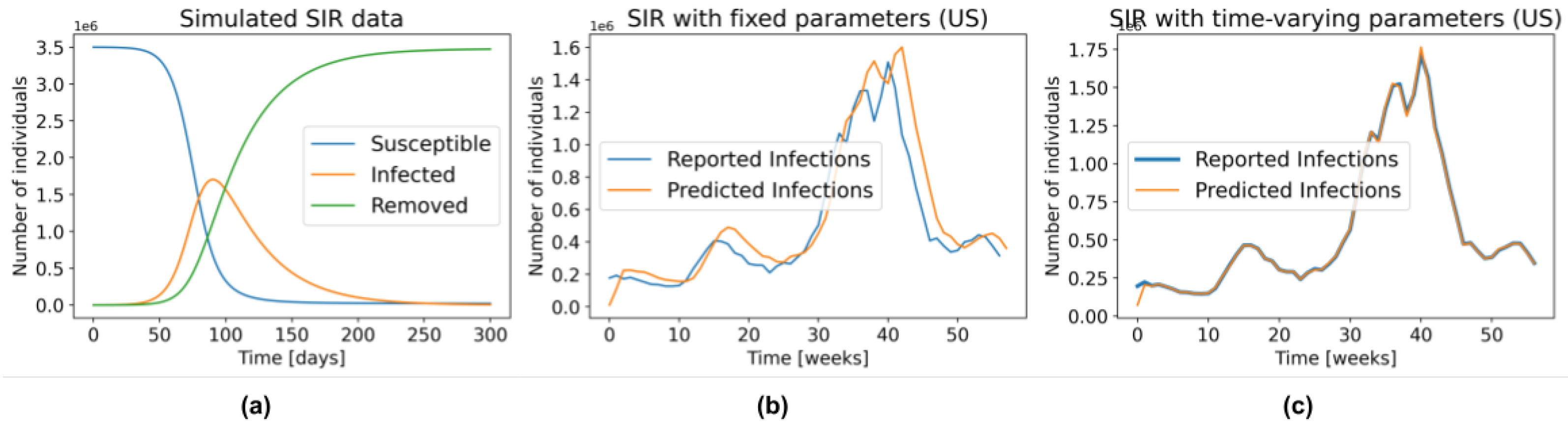
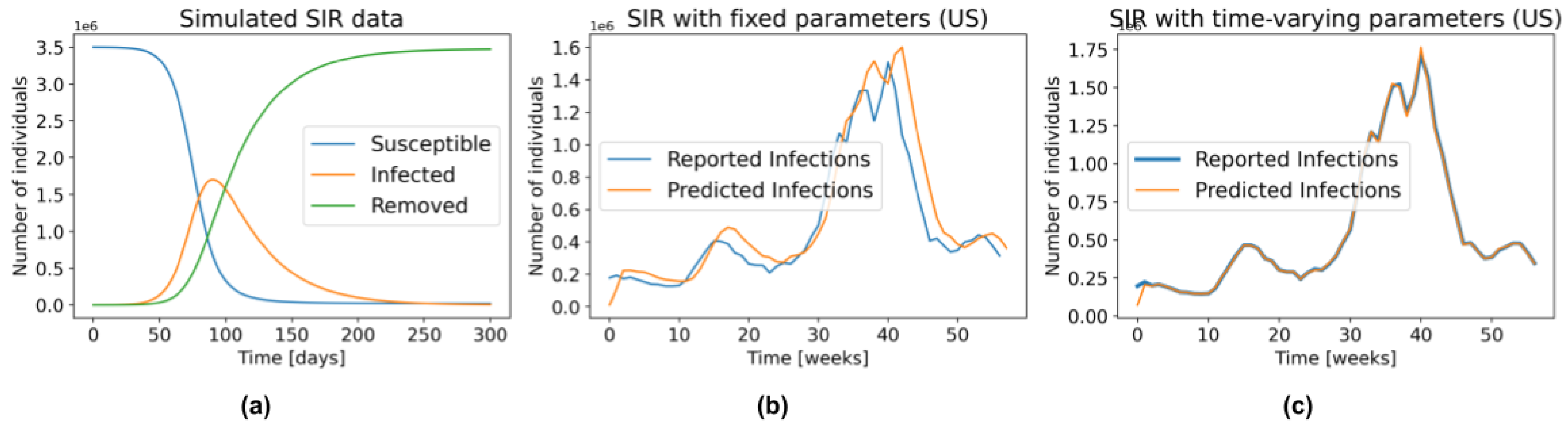
Figure 1a depicts the general behaviour of an SIR model.
1.2. Related Work
The main idea behind combining compartmental models with machine learning is to replace the fixed parameters of the former with time-varying parameters that can be learned from data [
6,
17,
18,
19]. However, most of the approaches focus on finding the parameters that can explain the past data, and not on predicting the number of newly infected people. Although those approaches are useful for obtaining insight into the dynamics of the disease, it does not mean that those parameters will accurately predict the behaviour in the future.
Particularly relevant to our approach is the work by Arik et al. [
5], who used latent variables and autoencoders to model extra compartments in an extended Susceptible-Exposed-Infected-Removed (SEIR) model. Those additional compartments bring further insight into how the disease impacts the population [
20,
21]; however, our experiments suggest that they are not needed for an accurate prediction of the number of new infections. One limitation of their model is a decrease in performance when the trend in the number of new infections changes. We hypothesize that those changes in trend are related to the government policies that are in place at a specific point in time. SIMLR is able to capture those changes by tracking the policies implemented at the government level.
A different line of work replaces epidemiological models with machine learning methods to directly predict the number of new infections [
22,
23,
24,
25]. Importantly, Yeung et al. [
26] added non-pharmaceutical interventions (policies) as features in their models; however, their approach is limited to make predictions up to two weeks in advance, since information about the policies that will be implemented in the future is not available at inference time. Our SIMLR approach differs by being interpretable and also by forecasting policy changes, which allows it to extend the horizon of the
predictions.
There are many models that attempt to predict the evolution of the COVID-19 epidemic. The Center for Disease Control and Prevention (CDC) in the United States allows different research teams across the globe to submit their forecasts of the number of cases and deaths 1 to 8 weeks in advance [
27]. More than 100 teams have submitted at least one prediction to this competition. We compare SIMLR with all of the models that made predictions 1 to 4 weeks in advance in the same time span as our study.
2. Materials and Methods
We view SIMLR as a probabilistic graphical model that uses a mixture of experts approach to forecast the number of new COVID-19 infections, 1 to 4 weeks in advance.
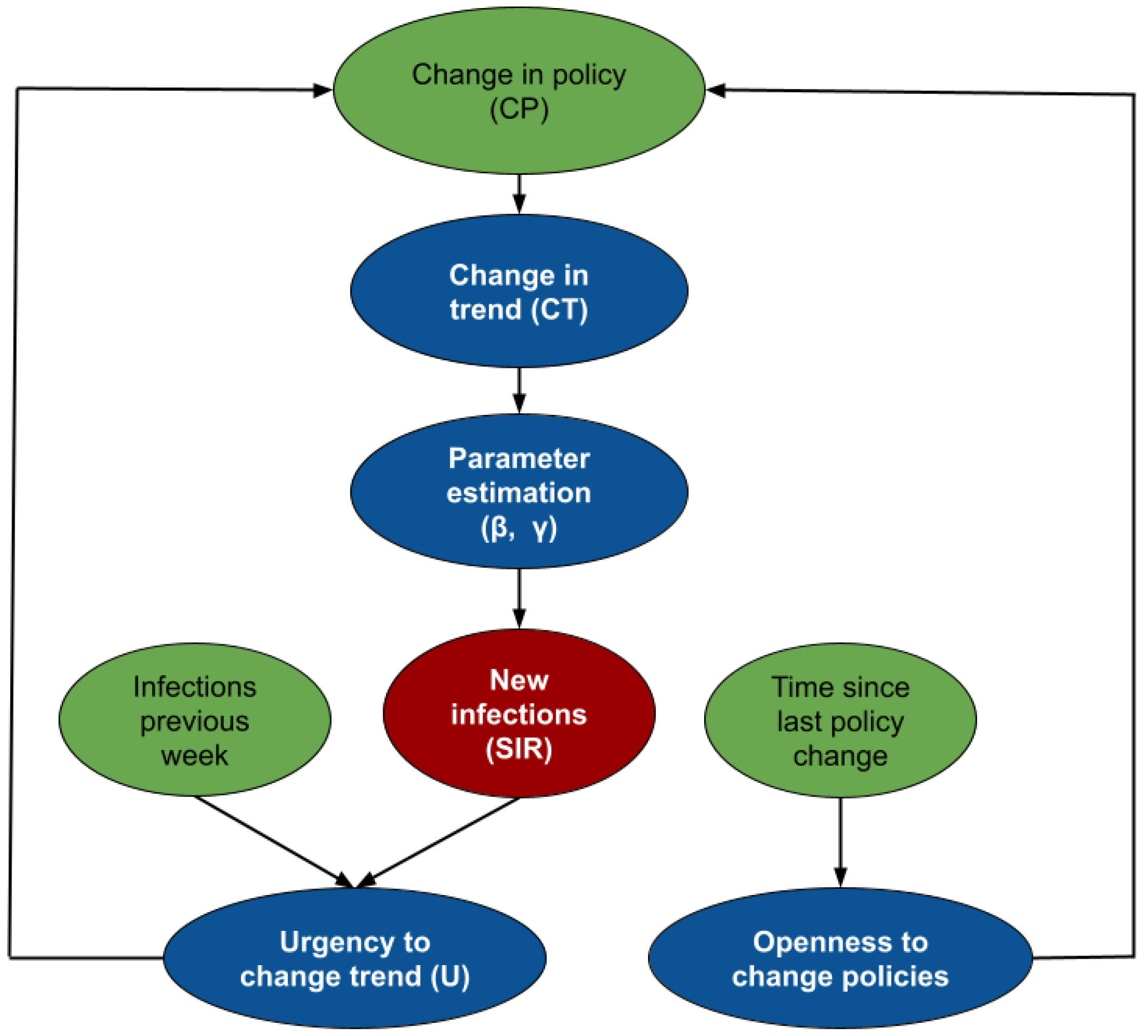
Figure 2 shows the intuition behind SIMLR. Changes in the government policies are likely to modify the trend of the number of new infections. We assume that stronger policies are likely to decrease the number of new infections, while the opposite effect is likely to occur when relaxing the policies. These changes are reflected as a change in the parameters of the SIR model. Using those parameters, we can then predict the number of new infections, then use that to compute the likelihood of observing other new policy changes in the short term.
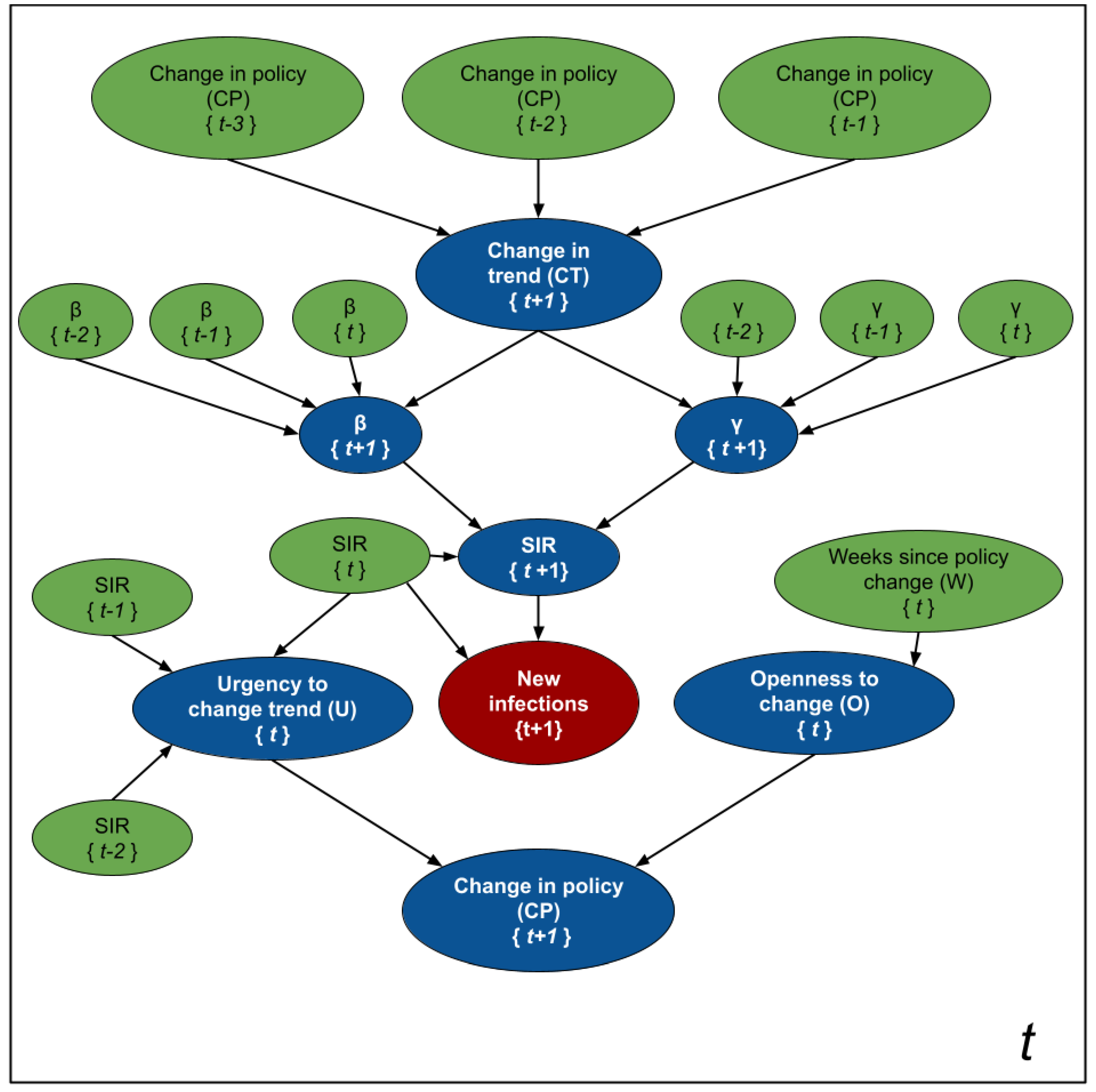
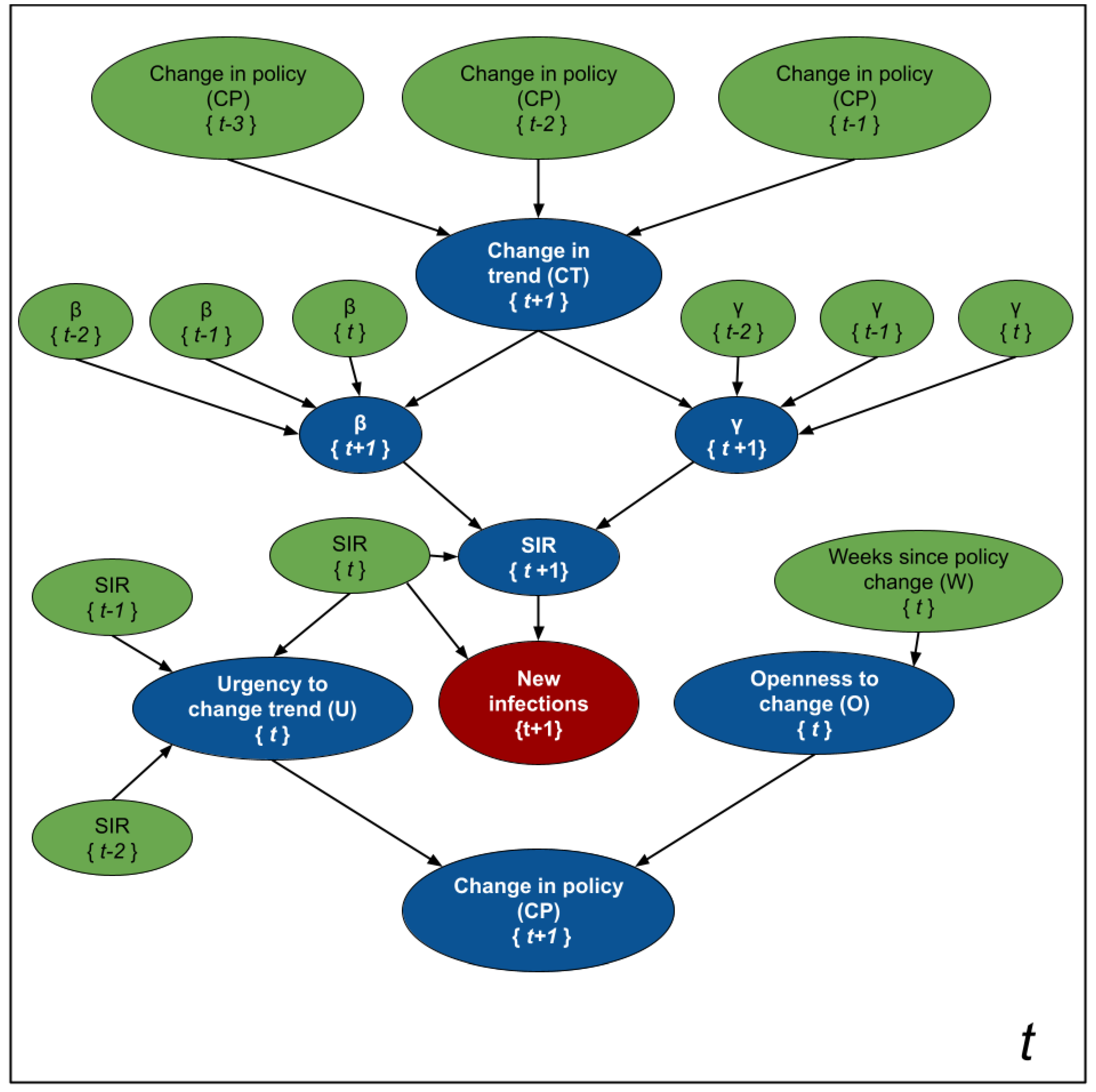
While
Figure 2 is an schematic diagram used for pedagogical purposes;
Figure 3 depicts the formal probabilistic graphical model, as a plate model, that we use to estimate the parameters of the SIR model, the number of new infections, and the likelihood of observing changes in policies 1 to 4 weeks in advance. The blue nodes are estimated at every time point, while the values of the green nodes are either known as part of the historical data, or inferred in a previous time point. The random variables are assumed to have the following distributions:
where
t indexes the current week,
,
is given below by Equation (
3 and
are linear combinations of the three previous values of
and
, (respectively). The coefficients of those linear combinations depend on the value of the random variable
. We did not specify a distribution for the node
because its value is deterministically computed as
.
Informally, the assignment means that we expect a change in trend from an increasing number of infections to a decreasing one. The opposite happens when , while means that we expect the population to follow the current trend (either increasing or decreasing). We assume these changes in trend depend on changes in the government policies 2 to 4 weeks prior to the week of our forecast—e.g., we use when predicting the number of new infections at , , and we need when predicting . Note that, at time t, we will not know nor . We chose this interval based on the assumption that the incubation period of the virus is 2 weeks.
The status of
defines the coefficients that relate
and
with their three previous values
and
, respectively. Since
and
fully parameterize the SIR model in Equation (
1), we can estimate the new number of infected people,
, from these parameters (as well as the SIR values at time
t).
The random variables and are auxiliary variables designed to predict the probability of observing a change in policy at time . Intuitively, represents the "urgency" of modifying a policy. As the number of cases per 100K inhabitants and the rate of change between the number of cases in two consecutive time points increases, the urgency to set stricter government policies increases. As the number (and rate of change) of cases decreases, the urgency to relax the policies increases. Finally, models the “willingness” to execute a change in government policies. As the number of time points without a change increases, so does this “willingness”.
2.1. SIR with Time-Varying Parameters
We can approximate an SIR model by transforming the differential Equation (
1) into the equations of differences:
where
are the number of individuals in the groups Susceptible, Infected and Removed, respectively, at time
t. Similarly
represent the number individuals in each group at time
.
is the transmission rate, and
is the recovery rate.
While the SIR model is non-linear with respect to the states (S, I, R), it is linear with respect to the parameters
and
. Therefore, under the assumption of constant and known population size (i.e.,
) we can re-write the set of Equation (
3) as:
Given a sequence of states
, where
, it is possible to estimate the optimal parameters of the SIR model as:
where
is computed using Equation (
4), and
and
are optional regularization parameters that allow the incorporation of the priors
and
. For the case of Gaussian priors—i.e.,
and
—we use
and
[
28]. Intuitively, Equation (
5) computes the transmission rate (
) and the recovery rate (
) that best explain the number of new infections, deaths, and recovered people in a fixed time frame. If we know a standard recovery rate and transmission rate a priori
, it is possible to incorporate them into the Equation (
5) as regularization parameters. The weights
and
control how much to weight those prior parameters. Small weights means we basically use the parameters learned by the data, and large weights mean more emphasis on the prior information.
In the traditional SIR model, we set
and fit a single
and
to the entire time series. However, as shown in
Figure 1a, an SIR model with fixed parameters is unable to accurately model several waves of infections. As illustration,
Figure 1b shows the predictions produced by fitting an SIR with fixed parameters (Equation (
5)) to the US data from 29 March 2020 to 3 May 2021, and then using those parameters to make predictions one week in advance, over this same interval. That is, using this learned
, and the number of people in the
S,
I, and
R compartments on 28 March 2020, we predicted the number of observed cases during the week of 29 March 2020 to 4 April 2020. We repeated the same procedure for the entire time series. Note that even though the parameters
and
were found using the entire time series – i.e., using information that was not available at the time of prediction—the resulting model still does a poor job fitting the reported data.
Figure 1c, on the other hand, was created by allowing
and
to change every week. Here, we first found the parameters that fit the data from 29 March 2020 to 4 April 2020—call them
and
—then used those parameters along with the SIR state on 28 March 2020 to predict the number of new infections one week ahead—i.e., the sampled week of 29 March 2020 to 4 April 2020. By repeating this procedure during the entire time series we obtained an almost perfect fit to the data. Of course, these are also not “legal” predictions since they too use information that is not available at prediction time—i.e., they used the number of reported infections during this first week to find the parameters, which were then used to estimate the number of cases over this time. However, this “cheating” example shows that an SIR model, with the optimal time-varying parameters, can model the complex dynamics of COVID-19. Recall from
Figure 1b that this is not the case in the SIR model with fixed parameters, which cannot even properly fit the training data.
2.2. Estimating and
Naturally, the challenge is “legally” computing the appropriate values of
and
, for each week, using only the data that is known at time
t.
Figure 3 shows that computing
and
depends on the status of the random variable
. When
—i.e., there is no change in the current trend—we assume that:
At time
t, we can use the historical daily data
to find the weekly parameters
and
. Note that the is just one value for each week, so is there are 140 days, there are 140/7 = 20 weeks. The first weekly pair
is found by fitting Equation (
5) to
;
to
; and so on. Finally, we find the parameters
and
in Equation (
6) by maximizing the likelihood of the computed pairs. After finding those parameters, it is straightforward to infer
. Note that this approach is the probabilistic version of linear regression. To estimate the parameters
and
we can simply estimate the variance of the residuals. An advantage of also computing these variances is that it is possible to obtain confidence intervals by sampling from the distribution in Equation (
6) and then using those samples along with Equation (
3) to estimate the distribution of the new infected people.
We estimated
and
as a function of the 3 previous values of those parameters since this allows them to incorporate the velocity and acceleration at which the parameters change. We computed the velocity of
as
and its acceleration as
. Then, estimating
is equivalent to the model in Equation (
6). The same reasoning applies to the computation of
. We call this approach the “trend-following varying-time parameters SIR”, tf-v-SIR.
For the case of
and
(which represents a change in trend from increasing number of infections to decreasing number of infections or vice-versa), we set
and
to values such that the predicted number of new cases at week
is identical to the one at week
t. We call this the “Same as the Last Observed Week” (SLOW) model. As shown in
Section 3, SLOW is a baseline with very good performance despite its simplicity. Given that the pandemic is a physical phenomenon that changes relatively slowly from one week to the next, making a prediction that assumes that the new number of cases will remain constant is not a bad prediction.
2.3. Estimating
The random variables
and
in
Figure 3 are all discrete nodes with discrete parents, meaning their probability mass functions are fully defined by conditional probability tables (CPTs). Learning the parameters of such CPTs from data is challenging due to the scarcity of historical information. The random variable
depends on the random variable changes in policy (
) at times
; however, there are very few changes in policy in a given region, meaning it is difficult to accurately estimate those probabilities from data. For the random variable
O, which represents the “willingness” of the government to implement a change in policy, there is no observable data at all. We therefore relied on prior expert knowledge to set the parameters of the conditional probability tables for these random variables.
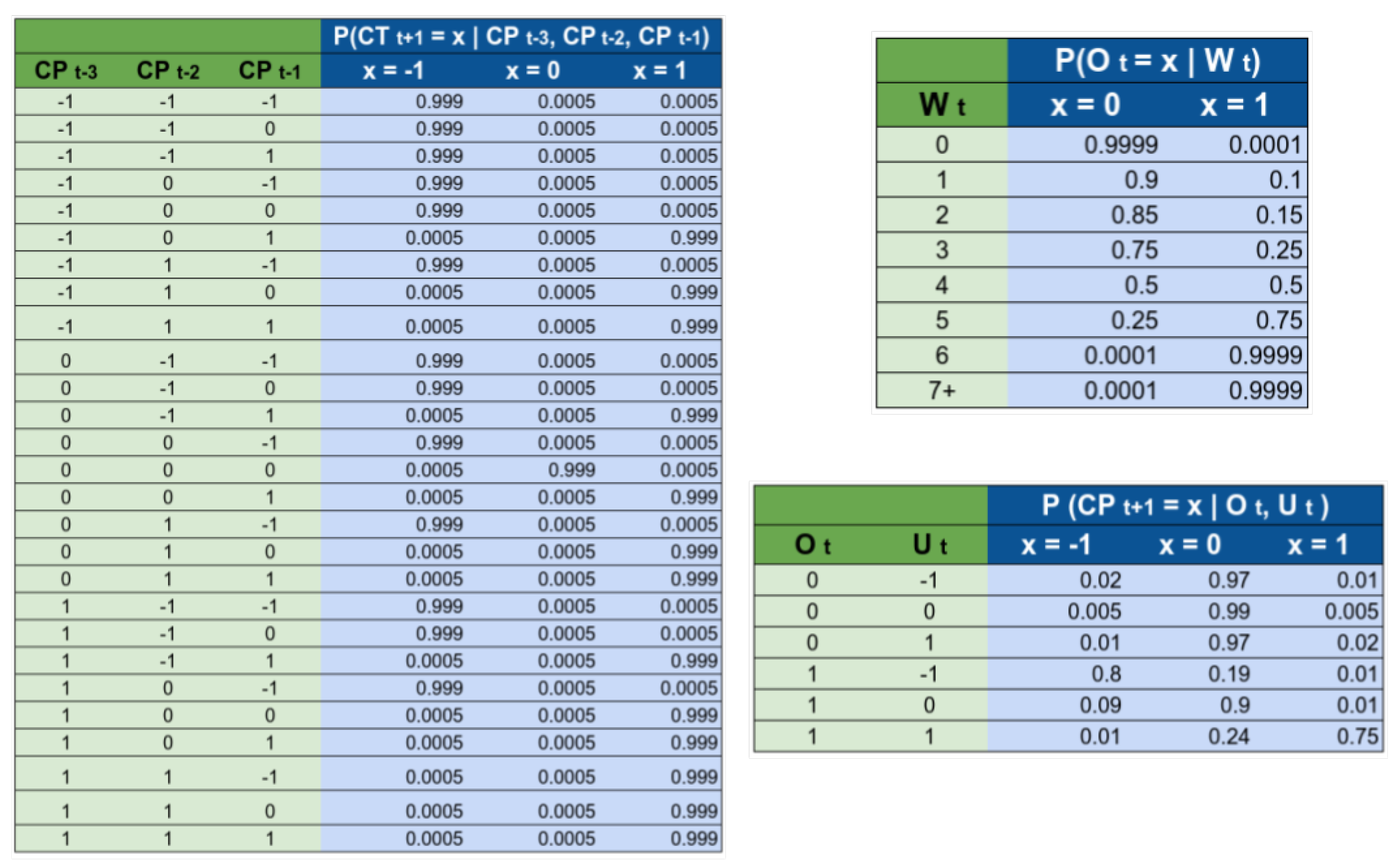
Figure 4 shows the conditional probability tables (CPT) for the random variables
,
,
. The intuition used to generate the CPT’s is as follows:
We considered that a change in trend in the current week depends on changes in policies during the previous three weeks. We chose 3 weeks using the hypothesis that the incubation period for the virus is 2 weeks. Then the effects of a policy will be reflected approximately 2 weeks after a change. We decided to analyze also one week after, and one week before this period, giving as a result the tracking of to . Secondly, we also assume that whenever we observe a change of policy that will move the trend from going up to going down, then that event will most likely happen. This is why most of the probability mass is located in a single column. For example, if we observe that the policies are relaxed at any point during the weeks t − 3, t − 2, or t − 1, then we assume that we will observe a change in trend with 99.9% probability.
The rationale for the CPT is that the government becomes more open to implement changes after long periods of ‘inactivity’. For example, if they implement a change in policy this week , then the probability of considering a second change of policy during the same week is very small (0.01%). We are assuming that, after a change in policy, the government will wait to see the effect of that change before taking further action. If 4 weeks have passed since the last change in policy, we estimated the probability of considering a change in the policy as 50%, while if more than 7 weeks have passed, then they are fully open to the possibility of implementing a new change.
estimates the probability of considering a change in the policy. The probability of actually implementing a change, depends not only on how willing the government is, but also on how urgent it is to make a change. In general, if the government is open to implement a change, and the urgency is “high”, then the probability of changing a policy is high. We also considered that the government “prefers” to either not make changes in policy or relax the policies, rather than to implement more strict policies.
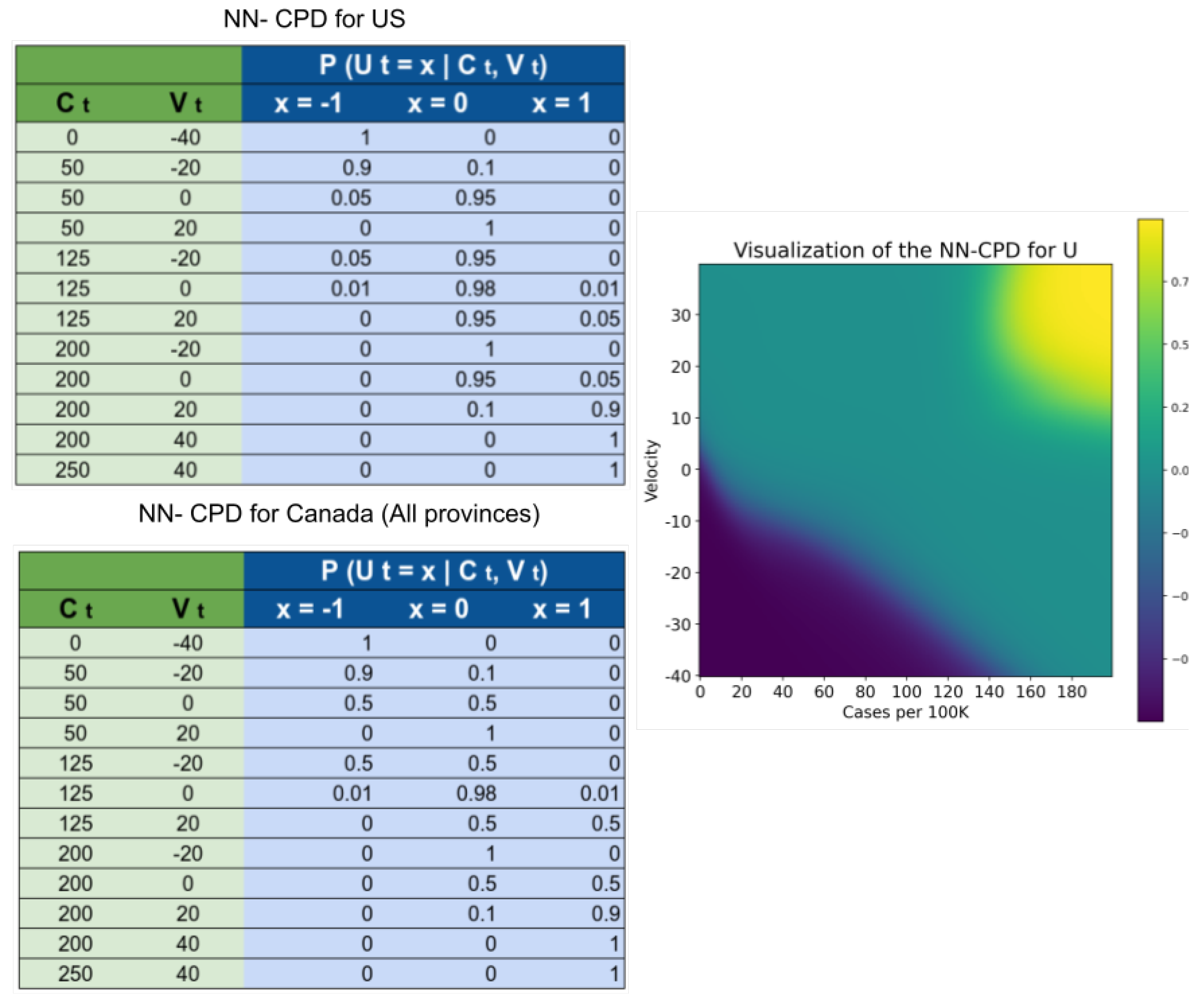
2.4. Estimating
For modelling the random variable
, which represents the “Urgency to change the trend”, we use an NN-CPD (neural-network conditional probability distribution), which is a modified version of the multinomial logistic conditional probability distribution [
29].
Definition 1 (NN-CPD). Let be an m-valued random variable with k parents that each take on numerical values. The conditional probability distribution is an NN-CPD if there is an function , represented as a neural network with parameters θ, such that , where represents the i-th entry of z.
Note is a latent variable, so there is no observable data at all. We again rely on domain knowledge to estimate its probabilities. To compute , we extract two features: , which represents the number of new reported infections per 100K inhabitants; and , which estimates the rate of change of . Then define .
To learn the parameters
we created the dataset shown in
Figure 5. Note that the targets in such dataset are probabilities. We relied on the probabilistic labels approach proposed by Vega et al. [
30] to use a dataset with few training instances along with their probabilities to learn the parameters of a neural network more efficiently. We trained and a simple neural network with a single hidden layers with 64 units, and 3 output units with softmax activation.
The random variables and are auxiliary variables designed to predict the probability of observing a change in policy at time . Intuitively, represents the “urgency” of modifying a policy. As the number of cases per 100 K inhabitants and the rate of change between the number of cases in two consecutive time points increases, the urgency to set stricter government policies increases. As the number (and rate of change) of cases decreases, the urgency to relax the policies increases. Most of the parameters in both NN-CPD tables are similar for the US and Canada, the difference arises from a perceived preference for not setting very strict policies in the US during the first year of the pandemic.
2.5. Evaluation
We evaluated the performance of SIMLR, in terms of the mean absolute percentage error (MAPE) and mean absolute error (MAE), for forecasting the number of new infections one to four weeks in advance, in data from United States (as a country and individually for every state) and the six biggest provinces of Canada: Alberta (AB), British Columbia (BC), Manitoba (MN), Ontario (ON), Quebec (QB), and Saskatchewan (SK). For each of the regions, the predictions are done on a weekly basis, over the 39 weeks from 26 July 2020 to 1 May 2021. This time span captures different waves of infections. Equation (
7) show the computation of the metrics used for evaluating our approach.
At the end of every week, we fitted the SIMLR parameters using the data that was available until that week. For example, on 25 July 2020, we used all the data available from 1 January 2020 to 25 July 2020 to fit the parameters of SIMLR. Then, we made the predictions for the number of new infections during the weeks: 26 July 2020–1 August 2020 (one week in advance), 2 August 2020–8 August 2020 (two weeks in advance), 9 August 2020–15 August 2020 (three weeks in advance), and 16 August 2020–22 August 2020 (four weeks in advance). After this, we then fitted the parameters with data up to 1 August 2020 and repeated the same process, for 38 more iterations, until we covered the entire range of predictions.
We compared the performance of SIMLR with the SIR compartmental model with time-varying parameters learned using Equation (
6) but no other random variable (tf-v-SIR), and with the simple model that forecasts that the number of cases one to four weeks in advance is the “Same as the Last Observed Week” (SLOW). For the United States data, we also compared the performance of SIMLR against the publicly available predictions at the COVID-19 Forecast Hub, which are the predictions submitted to the Center for Disease Control and Prevention (CDC) [
31].
For training, we used the publicly available dataset OxCGRT [
4], which contains the policies implemented by different regions, as well as the time period over which they were implemented. We limited our analysis to three policy decisions:
Workplace closing,
Stay at home requirements, and
Cancellation of public events in the case of Canada. For the case of the United States we used
Restrictions on gatherings,
Vaccination policy, and
Cancellation of public events. For information about the new number of reported cases and deaths, we used the publicly available COVID-19 Data Repository by the Center for Systems Science and Engineering at Johns Hopkins University [
1]. The code for reproducing the results presented here are discussed in
Appendix A.
4. Discussion
Figure 8 illustrates the actual predictions of SIMLR one week in advance for the province of Alberta, Canada; and two weeks in advance for the US as a country. These two cases exemplify the behaviour of SIMLR. As noted above, there is a 2- to 4-week lag after a policy changes, before we see the effects. This means the task of making 1-week forecasts is relatively simple, as the relevant policy (at times
to
) is fully observable. This allows SIMLR to directly compute
, which can then choose whether to continue using the SIR with time-varying parameters if no policy changed at time
,
, or
, or using the SLOW predictor if the policy changed.
Figure 8a shows a change in the trend of reported new cases at week 22. However, just by looking at the evolution of number of new infections before week 22, there is no way to predict this change, which is why tf-v-SIR predicts that the number of new infections will continue growing. However, since SIMLR observed a change in the government policies at week 20, it realized it could no longer rely on its estimation of parameters and so switched to the SLOW model, which is why it was more accurate here. A similar behaviour occurs in week 34, when the third wave of cases in Alberta started. Due to a relaxation in the policies on week 31, SIMLR (at week 31) correctly predicted a change of trend around weeks 33–35.
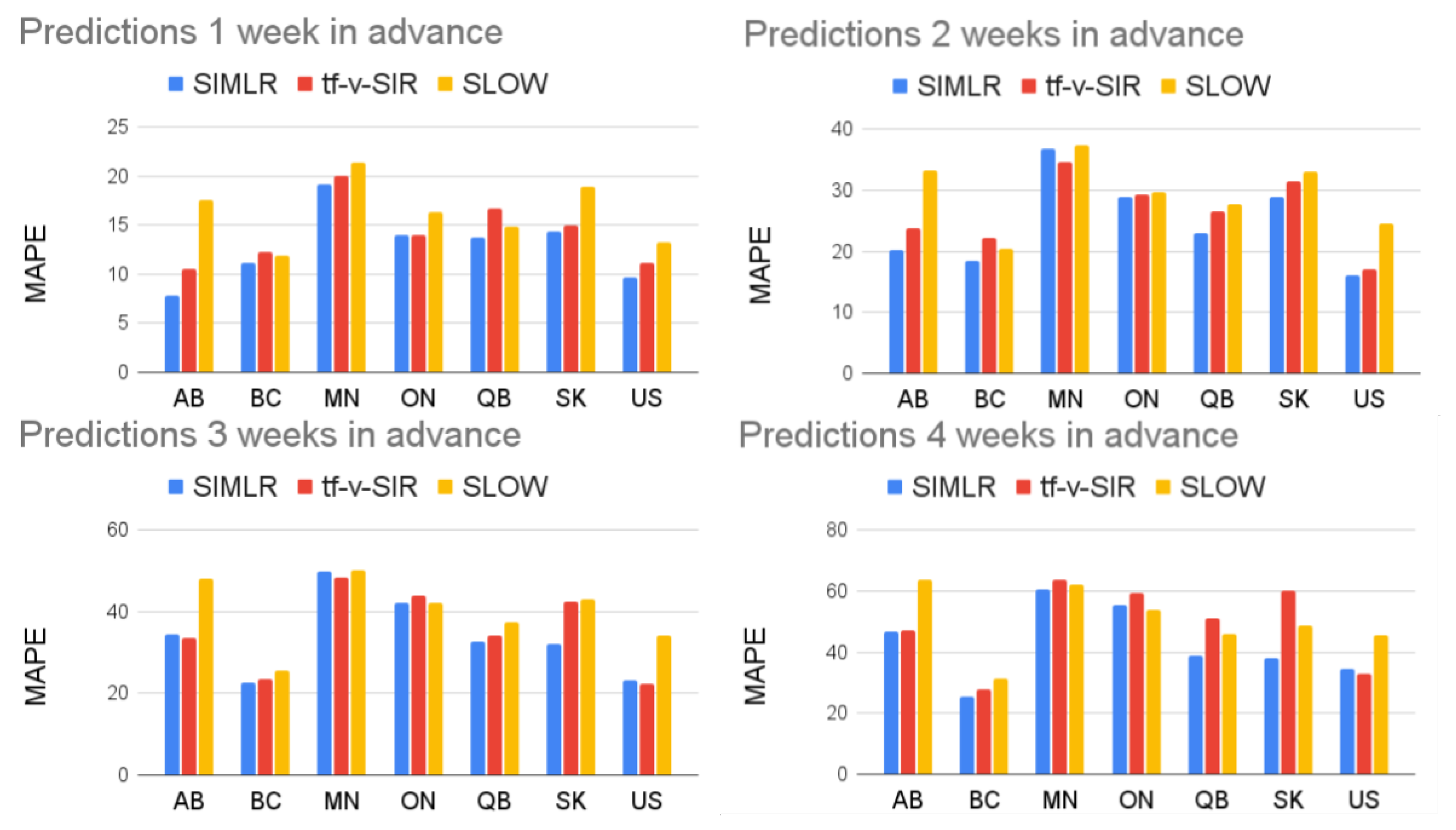
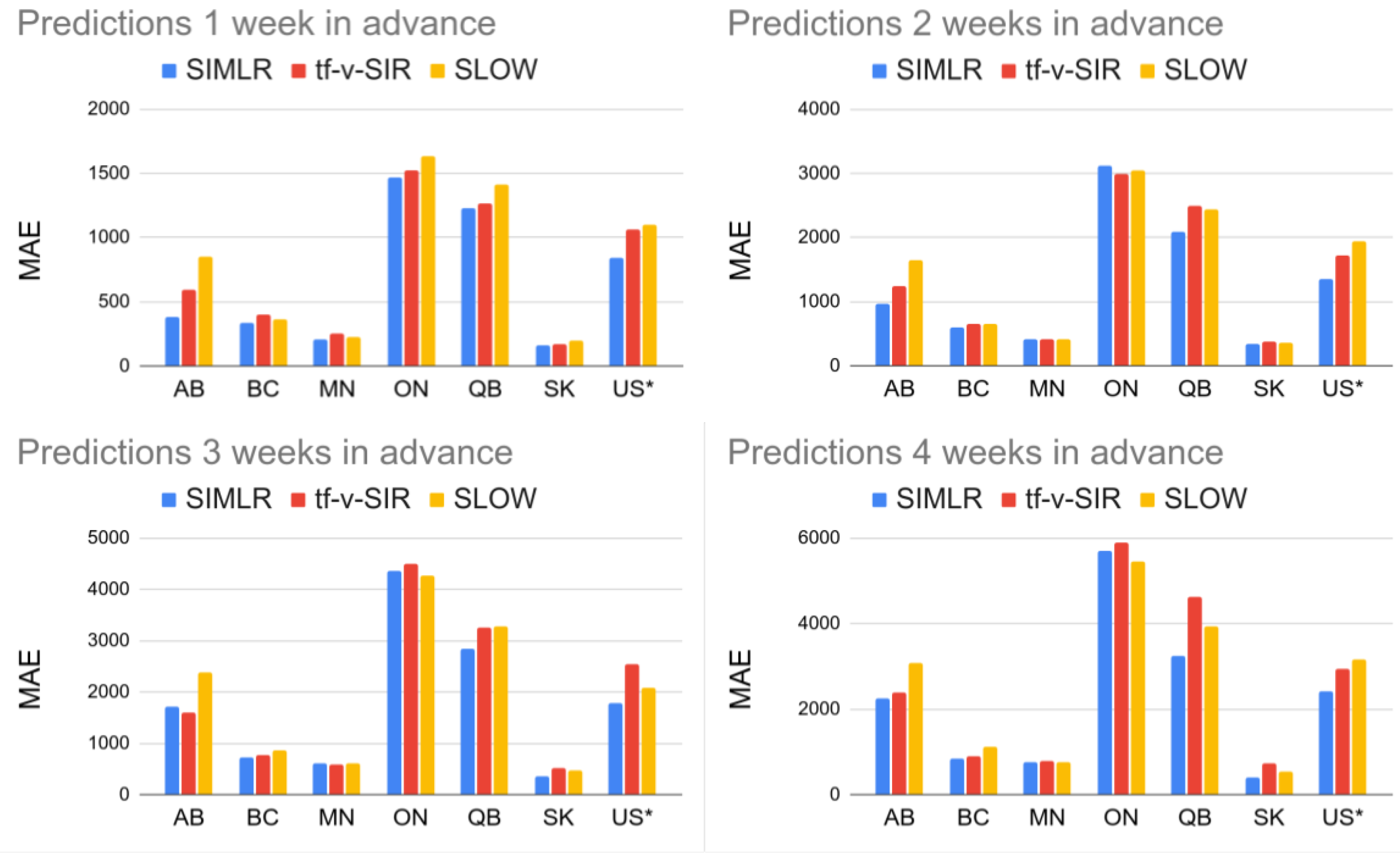
This behavior is not exclusive for the data of Alberta and it explains why the performance of SIMLR is consistently higher than the baselines used for comparison in
Figure 6 and
Figure 8c. A striking result is how hard it is to beat the simple SLOW model (COVIDhub-baseline). Out of the 19 models considered here, only five (including SIMLR) do better than this simple baseline when predicting three to four weeks ahead. This brings some insight into the challenge of making accurate prediction in the medium term—probably due to the need to predict, then use, policy change information.
Table A1,
Table A2,
Table A3 and
Table A4 in the
Appendix B show a comparison between our proposed SIMLR and tf-v-SIR against the models submitted to the CDC for all the states in the US. SIMLR consistently ranks among the best performers, with the advantage of being an interpretable model.
A deeper analysis of
Table A1,
Table A2,
Table A3 and
Table A4 shows that, in some states, the performance of SIMLR degrades for longer range predictions. This occurs because we are monitoring only the same three policies for all the states; however, different states might have implemented different policies and reacted differently to them. For example, closing schools might be a relevant policy in a state where there is an outbreak that involves children, but not as relevant if most of the cases are in older people.
Tracking irrelevant policies might degrade the performance of SIMLR. If the status of an irrelevant policy changes, then the dynamics of the disease will not be affected. The model however, will assume that the change in the policy will cause a change of trend and it will rely on the SLOW model, instead of the more accurate tf-v-SIR. Although SIMLR can be adapted to track different policies, the policies that are relevant for a given state must be given as an input. So while we think our overall approach applies in general, our specific model (tracking these specific policies, etc.) might not perform accurate predictions across all the regions. This is also a strength, in that it is trivial to adapt our specific model to track the policies of interest within a given region.
Predictions at the country level are more complicated, since most of the time policies are implemented at the state (or province) level instead of nationally. For making predictions for an entire country, as well as predictions three or four weeks in advance, SIMLR first predicts, then uses, the likelihood of observing a change in trend, at every week. In these cases, the random variable no longer acts like a “switch”, but instead it mixes the predictions of the tf-v-SIR and SLOW models, according to the probability of observing a change in the trend.
Figure 8b shows that whenever there is a stable trend in the number of new reported infections—which suggests there have been no recent policy changes—SIMLR relies on the predictions of the tf-v-SIR model; however, as the number (and rate of change) of new infections increases, so does the probability of observing a change in the policy. Therefore, SIMLR starts giving more weight to the predictions of the SLOW model. Note this behavior in the same figure during weeks 13–20.
One limitation of SIMLR is that it relies on conditional probabilities that are hard to learn due to lack of data, which forced us to build them based on domain knowledge. If this prior knowledge is inaccurate, then the predictions might be also misleading. Also, different regions might have different “thresholds” for taking action. Despite this limitation, SIMLR produced state-of-the-art results in both forecasting in the US as a country and at the provincial level in Canada, as well as very competitive results in predictions at the state level in the US.
Note that modelling SIMLR as a PGM does not imply causality. Although changes in the observed policy influence changes in the trend of new reported cases, the opposite is also true in reality. However, using probabilistic graphical models does makes it interpretable. It also allows us to incorporate domain knowledge that compensates for the relatively scarce data. SIMLR’s excellent performance—comparable to state-of-the-art systems in this competitive task—show that it is possible to design interpretable machine learning models without sacrificing performance.
5. Conclusions
Forecasting the number of new COVID-19 infections is a very challenging task. Many factors play a role on how the disease spreads, including the government policies and the adherence of citizens to such policies. These elements are difficult to model mathematically; however, the collected data (number of new infections and deaths, for example) are a reflection of all those complex interactions.
Machine learning, on the other side, excels at learning patterns directly from the data. Unfortunately, training many models from scratch can require a great deal of data, especially to learn complex patterns, such as the evolution of a pandemic.
We proposed SIMLR, a methodology that uses machine learning (ML) techniques to learn a model that can set, and adjust, the parameters of mathematical model for epidemiology (SIR). SIMLR augments that SIR model by incorporating expert knowledge in the form of a probabilistic graphical model. In this way, human experts can incorporate their believes in the likelihood that a policy will change, and when. By combining both components we substantially reduce the data that machine learning usually requires to produce models that can make accurate predictions.
Importantly, besides providing state-of-the-art predictions in terms of MAPE in the short and medium term, the resulting SIMLR model is interpretable and probabilistic. The first means that we can justify the predictions given by the algorithm—e.g., “SIMLR predicts 1000 cases for the next week due to a change in the government policies that will decrease the transmission rate“. The second means we can produce probabilistic values—so instead of predicting a single value, it can predict the entire probability distribution—e.g., the probability of 100 cases next week, or of 200 cases or of 1000, etc.
This paper demonstrated that a model that explicitly models and incorporates government policy decisions can accurately produce one- to four-week forecasts of the number of COVID-19 infections. This involved showing that an SIR model with time-varying parameters is enough to describe the complex dynamics of this pandemic, including the different waves of infections. We expect that this approach will be useful not only for modelling COVID-19, but other infectious diseases as well. We also hope that its interpretability will leads to its adoption by researchers, and users, in epidemiology and other non-ML fields.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}