
Is It Possible to Forecast the Price of Bitcoin?



Abstract
1. Introduction
- Readability: For important investment choices or setting up an investment process, we cannot simply rely on a model. In most cases, it is necessary to have a specific thesis, which must be explained based on simple econometric relations, whether for investors or the CEO of a fund, rarely a specialist. From this point of view, an AR(1) model which would link the BTC to two or three indices could be, from the point of view of investment strategy, more important than a better, more complex model, because it would allow us to better explain and then justify overtime to investors what their money is used for.
- Far out-of-sample robustness: In setting up complex strategies comparable to derivatives, valuations and measurements of risks are generally based on the simulation of the dynamics of an underlying process (an economic driver of the value of various products). In this case, the input simulations (in addition, calibrated in neutral risk) will generally go well beyond what has been observed in the past, and we have no idea of the relevance of the “black-box” model that will come out. It is then preferable to have a precisely specified model for which the behavior in these out-of-sample areas has been consciously established.
- Do drivers exist for Bitcoin forecasts (inside the variables we retain)?
- Can we accurately produce forecasts (models in question, and how to compare them)?
- Is it possible to propose robust trading strategies?
2. Background
3. Methodology
‘Horse Race’ of Machine Learning Models
- Linear regression. Denoting Y the output and X the centered and standardized inputs, and considering a data set , , the elastic net regression approach solves the following problemwhere (here T is used for transpose), and the elastic net penalty is determined by the value of :This elastic-net penalty term is a compromise between the Ridge regression () and the Lasso penalty (): the constraint for minimization is that for some t. Historically, this method has been developed when the number of variables p is vast comparing to n, the sample size. The Ridge method is known to shrink the correlated predictors’ coefficients towards each other, borrowing strength from each other. Ridge regression typically fits a model that can predict the probability of a binary response to one class or the other. Lasso is indifferent to correlated predictors. Thus, the role of is determinant: in presence of correlation, we expect close to 1 (, for small ). It also exists some link between and . Generally, a grid is considered for as soon as is fixed. A () penalty term could be also considered for prediction. The regularization done with this penalty term permits to avoid over-fitting.The algorithm also proposes a way to update the computation, optimizing the number of operations needed. It is possible to associate a weight to each observation, which does not increase the computational cost of the algorithm as long as the weights remain fixed. In the following, we use linear regression. Thus the response belongs to R. The parameter of interest is , other parameters to estimate are . The existence of correlation must be taken into account to verify whether the values used for those parameters are efficient. For estimation, the parameter has to be chosen first. Simple least-squares estimates are used for linear regression, but a soft threshold is introduced to consider the penalty term through the decrementation of the parameter using loops.
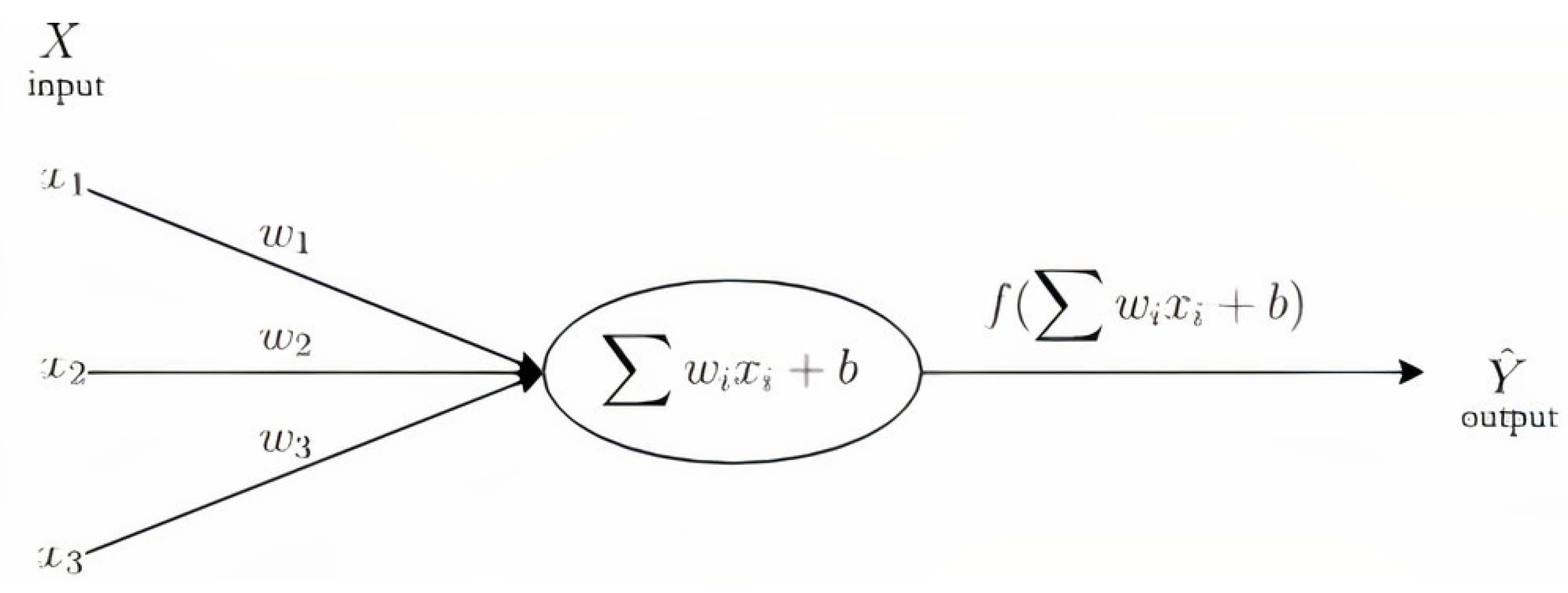
- Artificial Neural Network (ANN). Inspired by the human brain, a neural network consists of highly interconnected neurons that relate the inputs to the desired outputs. The network is trained by iteratively modifying the connections’ strengths to map the given inputs to the correct response. ANNs are best-used for modeling highly nonlinear systems, when the data is available incrementally, and when there could be expected changes in the input data. Supervised ANNs were essentially variants of linear regression methods. A standard neural network consists of many simple, connected processors called neurons, producing a sequence of real-valued activations. Input neurons get activated through sensors perceiving the environment. Other neurons get activated through weighted connections from previously active neurons. An efficient gradient descent method for teacher-based supervised learning in discrete, differentiable networks of arbitrary depth called back-propagation is used to attain the algorithm’s convergence. This paper uses stochastic gradient descent, a stochastic approximation of the gradient descent optimization, and an iterative method for minimizing the objective function f written as a sum of differentiable functions.The classical neural network layer performs a convolution on a given sequence X, outputting another sequence Y whose value at time t is:where are the parameters of the layer trained by back-propagation. The parameters to choose are the number of layers and the stopping criteria for convergence purposes.In this paper, we consider an Artificial Neural Network. The ANN is an algorithm that allows for drawing more complex patterns and relationships. Training an ANN to make predictions using back-propagation requires iterating over a two-step process described as follows. (i) We computed the predictions using the previous weights, also known as a forward process; for the first iteration, the weights are often initialized randomly to prevent symmetry issues. (ii) We calculated the gradients to amend the weights for the next iteration, using the same weights as in step one and the freshly computed prediction. The stochastic gradient descent uses a penalty term (for regularization) based on the derivatives making computational the method for finding the approximate optimum and convergence slow. This process generally leads to a local optimum (instead of a global optimum), which would minimize the mean squared errors between the estimated and valid values only locally.Thus, in more detail, an ANN is a structure of multiple layers, themselves composed of several units, known as neurons of the form, at a step j figures:where is a non-linear activation function, basically the sigmoid function. Assuming the same function is used for the whole structure, it is then used recursively throughout the neural network, inputting each previously computed function into the next layer’s neurons. A description step by step yields clarity to this black-box structure: (i) a first layer gathers the raw data, thus representing the model’s inputs . It is composed of as many neurons as there are samples, each containing . These are forwarded to the next (hidden) layer’s neurons via the synapses; (ii) a second layer follows, called the hidden layer (since no true visibility is gained on the meaning of its calculations). Each of its neurons computes a weighted average of all the previous layers’ output and incorporates it as in its activation function. Then, it, in turn, forwards the computed value to the next layer; (iii) the last layer, called the output layer, finally computes a weighted average of the hidden layer’s neurons outputs and produces a prediction .Details on neural networks can be found in Maclin et al. [79], Vapnik [80] and Scholkopf [81]. Recent references are Windisch [82] and Hinton and Salakhutdinov [83]. A review paper is the one by Schmidhuber [84]. Note that in the present paper, we do not use deep learning modelings as soon as the set of data we consider is not sufficiently large to justify the expectation of having good results with this sophisticated method, which is appropriate for a huge amount of data and specific data sets.
- Random forests. Random forest is an ensemble learning method used for classification. Ho [85] first proposed it. Breiman [86] further developed it. Random forest builds a set of decision trees. Each tree is developed from a bootstrap sample from the training data. When developing individual trees, an arbitrary subset of attributes is drawn (hence the term ‘random’), from which the best attribute for the split is selected. The number of branches and the values of weights are determined in the training process. The final model is based on the majority vote from individually developed trees in the forest.An additive tree model (ATM) is an ensemble of p decision trees. Let X be the vector of individual features. Each decision tree outputs a real value. Let be the output from tree p. For both classification and regression purpose, the output f of the additive tree model is a weighted sum of all the tree outputs as follows:where is the weight associated to tree j.The previous formulation is very general and includes some popular models as special cases, like random forests. This additive tree model is widely used in real-world applications and appears to be the most popular and influential off-the-shelf classifier. It can cope with regression and multi-class classification on both categorical and numerical datasets with superior accuracy. In these ensemble methods, several weaker decision trees are combined into a more robust ensemble. A bagged decision tree consists of trees trained independently on data that is bootstrapped from the input data. In essence, the random forest is a bagging model ([87]) of trees where each tree is trained independently on a group of randomly sampled instances with randomly selected features.The random forest consists in combining the p regression-type predictors to build another predictorfor every . The vector of weights has to be chosen carefully. Even if the weights could depend on x, we keep them constant for simplicity. In the usual case, they are all equal to , even if some attempts have been made to add another degree of flexibility with different weights.If X have uniform distribution on , then the response of the modeling iswhere S is a non-empty subset of d features. We chose the following parameters with this modeling: the number of trees and the stopping criteria used to choose among the most significant variables. Depending on the context and the selection procedure, the informative probability may obey certain constraints positiveness and . It is well-known that for randomized methods, the behavior of prediction error is a monotonically decreasing function of p, so in principle, the higher the value of M, the better from the accuracy point of view.Thus, the question is how to introduce flexibility in the regression functions used in regression trees and their extension to random forests. One splits the sample into sub-samples and estimates the regression function within the sub-samples simply as the average outcome. The splits are sequential and based on a single co-variate at a time exceeding a threshold c. The outcomes are provided minimizing the average squared error over all co-variates k and all thresholds c, then repeating this over the sub-samples and leaves: At each split, the average squared error is further reduced (or stays the same). Therefore, we need regularization to avoid the over-fitting that would result from splitting the sample too often. One approach is to add a penalty term to the sum of squared residuals linear in the number of sub-samples (the leaves). The coefficient on this penalty term is then chosen through cross-validation.Random forests has been proposed by Breiman [86] for building a predictor ensemble with a set of decision trees that grow in randomly selected sub-spaces of data, see also Geurts et al. [88] or Biau [89], and for a review, Genuer et al. [90]. The bagging approach is due to Breiman [87]. The discussion on the choice of the weights was done by Maudes et al. [91].
- Support Vector Machines (SVM). SVM map inputs to higher-dimensional feature spaces. It has been introduced within the context of statistical learning theory and structural risk minimization. The SVM classifies data by finding the linear decision boundary (e.g., hyperplane) that separates all data points of one class from those of the other class. This machine-learning algorithm separates the attribute space with a hyperplane, maximizing the margin between the instances of different classes or class values. It can be used when the researcher needs a classifier that is simple, easy to interpret, and accurate.If we consider SVM from a regression approach, it performs linear regression in a high-dimension feature using a - insensitive loss. Its estimation accuracy depends on a suitable setting of the different parameters. The SVM map inputs X to higher-dimensional feature spaces. The support vector machine accommodates nonlinear class boundaries. It is intended for the binary classification setting in which there are two classes. The basic idea is to divide a p-dimensional space (called hyperplane) into two halves. In dimension two, a hyperplane is a line.Considering a data set , , The linear support vector classifier can be represented asTo estimate the parameters , all we need are the products between all pairs of training observations, where and . So, if S is the collection of indices of these support points , we can rewrite any solution function of the previous form asNote that a more general representation of the nonlinear function has the formwhere is some function that we will refer to as a kernel. A kernel is a function that quantifies the similarity between two observations.
- k-Nearest-Neighbors (k-NN). k-NN categorizes objects based on the classes of their nearest neighbors in the dataset. Distance metrics are used to find the nearest neighbor. The k-NN algorithm searches for k closest training instances in the feature space and uses their average prediction. k-NN predictions assume that objects near each other are similar. When mobilizing k-NNs, memory usage and prediction speed of the trained model are of lesser concern to the modeler.The k-NN regression method is probably the simplest non-parametric method we can propose. It works as follows: given a value for k and a prediction point of , k-NN regression first identifies the k training observations closest to , represented by . Then it estimates using the average of all the training responses in . In other words, we getIn general, the optimal value for k will depend on the bias–variance trade-off. A small value for k provides the most flexible fit, which will have low bias but high variance (because the prediction, in that case, can be entirely dependent on just one observation). In contrast, larger values of k provide a smoother and less variable fit; the prediction in a region is an average of several points. Changing one observation has a more negligible effect.Using this method, we need to estimate the parameter k and decide the weights associated with each point. We often use uniform weight : all points in each neighborhood are weighted equally. It is also important to note that closer neighbors of a query point have a more substantial influence than the neighbors further away.
- Ada-boosting. In these methods, several “weaker” decision trees are combined into a “stronger” ensemble. Adaptive boosting is an approach to machine learning based on creating a highly accurate prediction rule by combining many relatively weak and inaccurate rules. Further on this, boosting involves creating a strong learner by iteratively adding weak learners and adjusting each weak learner’s weight to focus on misclassified examples. It adapts to the hardness of each training sample. The AdaBoost algorithm of Schapire [98] was the first practical boosting algorithm and remained one of the most widely used and studied applications in numerous fields.Given a training set , , and , for each learning round () using m training examples, a distribution is computed (corresponding to the ) and a learning algorithm is applied to find a target function , where the aim of the weak learner is to find h with low weighted error relative to . The final result computes the sign of a weighted combination of weak classifiers:Adaboost can be used to perform classification or regression. It can be understood as a procedure for greedily minimizing what has come to be called the exponential loss, namely:with f introduced in the previous equation. In other words, it can be shown that the choices of and on each training round appear to be chosen so as to cause the most significant decrease in this loss.In this paper, we use this approach to improve the classifier introduced in the random forest approach. In that case, the boosting method improves the convergence of the estimated regression function, using the new residuals of the proceeding leaf at each step. This being done many times. This algorithm uses an iterative process of convergence with residuals computed at each stage.
4. Data
4.1. Dataset Quality: A ‘Financial Markets’ Approach
4.2. Sub-Samples Decomposition
- Different sets of data: To predict the Bitcoin price, described as a cryptocurrency without clearly established fundamentals, we follow an approach based on financial markets. That is to say, we include in the pool of predictors several underlying and analyze their contribution in explaining Bitcoin. As shown in Table 1, we retain 56 variables (besides the Bitcoin price) that belong to the following categories: (i) cryptocurrencies, (ii) stocks, (iii) bonds, (iv) foreign exchange rates, and (v) commodities. To predict Bitcoin following the schemes proposed in Section 3, , we proceed step-by-step for the choice of the variables using up to five different vectors : (1) composed of sixteen cryptocurrencies, (2) composed of eleven stocks, (3) composed of four bonds, (4) composed of four foreign exchange rates, (5) composed of twenty-one commodities, and (6) is composed of fifty-six variables. For each step, we train and test the samples using seven modelings (one AR(1) and six machine learning algorithms, see Section 5.1 for details). This approach permits us to detect each subsample of variables in the forecasts of Bitcoin.
- Training and testing set: for each period considered, we need to specify the length of the training set (e.g., a known set of input data) and the testing set (e.g., new input data) to test the models’ predictions.
- The choice of the period:
- We consider the whole sample from 13 January 2015 to 31 December 2020. In this sample, we use only six cryptocurrencies (Litecoin, Ethereum, Stellar, Ripple, Monero, Dash). We train the inputs from 13 January 2015 to 31 December 2016 and then test our predictions from 1 January 2017 to 31 December 2020.
- As robustness checks, we further assess the accuracy of our predictions on four sub-samples.
- (a)
- We favor the availability of cryptocurrency prices during 24 January 2018 to 31 December 2020 to include up to 17 (some newly created) cryptocurrencies (Bitcoin Spot, Bitcoin Futures, Ethereum, Ethereum Classic, Litecoin, Bitcoin Cash, Ripple, Stellar, Tether, Monero, Dash, EOS, Zcash, Neo, NANO, Cardano, IOTA). = 24 January 2018 to 31 December 2018. = 1 January 2019 to 31 December 2020.
- (b)
- We introduce the stable coin (any crypto-currency pegged to either fiat currency or government-backed security (like a bond) counts as a stable coin. The idea is that this crypto-currency will be more stable or less volatile. Asset-backed cryptocurrencies are not necessarily centralized since there may be a decentralized vaults and commodity holders network rather than a centralized controlling body. The advantages of asset-backed cryptocurrencies are that coins are stabilized by assets that fluctuate outside the cryptocurrency space reducing financial risk. The Tether currency is backed by the dollar (1:1). For more details, we refer to Abraham and Guegan [108]). Tether (rumored 1 US$ = 1 Tether) available since 12 April 2017. = 12 April 2017 to 30 November 2018. = 1 December 2018 to 31 December 2020.
- (c)
- We consider a ‘classical economic cycle’ (e.g., expansion-crisis-depression-recovery) for Bitcoin during the years 2016 to 2018. = 01 January 2016 to 31 December 2016. = 01 January 2017 to 31 December 2018.
- (d)
- Lastly, we use the last historical year of trading to make predictions. = 1 January 2019 to 30 June 2019. = 01 July 2019 to 31 December 2020.
4.3. Software
- Timeseries.ARIMA (AR(1)),
- classification.neuralnetwork.MLPClassifierWCallback/NNClassificationLearner (Artificial Neural Network with Multi-Layer Perceptron),
- sklearn.ensemble.forest.RandomForestClassifier/Learner (Random forest),
- sklearn.svm.classes.SVC (Support Vector Machines) based on libsvm,
- sklearn.neighbors.classification.KNeighborsClassifier/KNNLearner (K-Nearest Neighbors),
- SAMME.R (AdaBoosting method),
- regression.linear.LinearRegressionLearner/ridgelambda with lambda the parameter controlling the regularization (Ridge regression).
5. Main Results
5.1. Parameterization
- AR(1): the autoregressive regression of order one is estimated and tested to predict the Bitcoin spot or futures price.
- Artificial Neural Network: to predict Bitcoin, we choose the perceptron algorithm with backpropagation. We compute 200 iterations with 10 neurons in the hidden layer. The ReLu activation is used. The optimizer is the Adam solver, and the regularization parameter is set to 0.0001.
- Random Forest: we predict Bitcoin using an ensemble of 10 decision trees, with a depth of 3 trees. The stopping parameter is .
- SVM: the support vector machine inputs to higher-dimensional feature spaces. To predict Bitcoin, we resort to the RBF kernel, with 100 iterations, the cost set to , and the parameter set to 0.1. The cost is a penalty term for loss and applies to classification and regression tasks. In SVM, applies to the regression tasks. It defines the distance from true values within which no penalty is associated with predicted values.
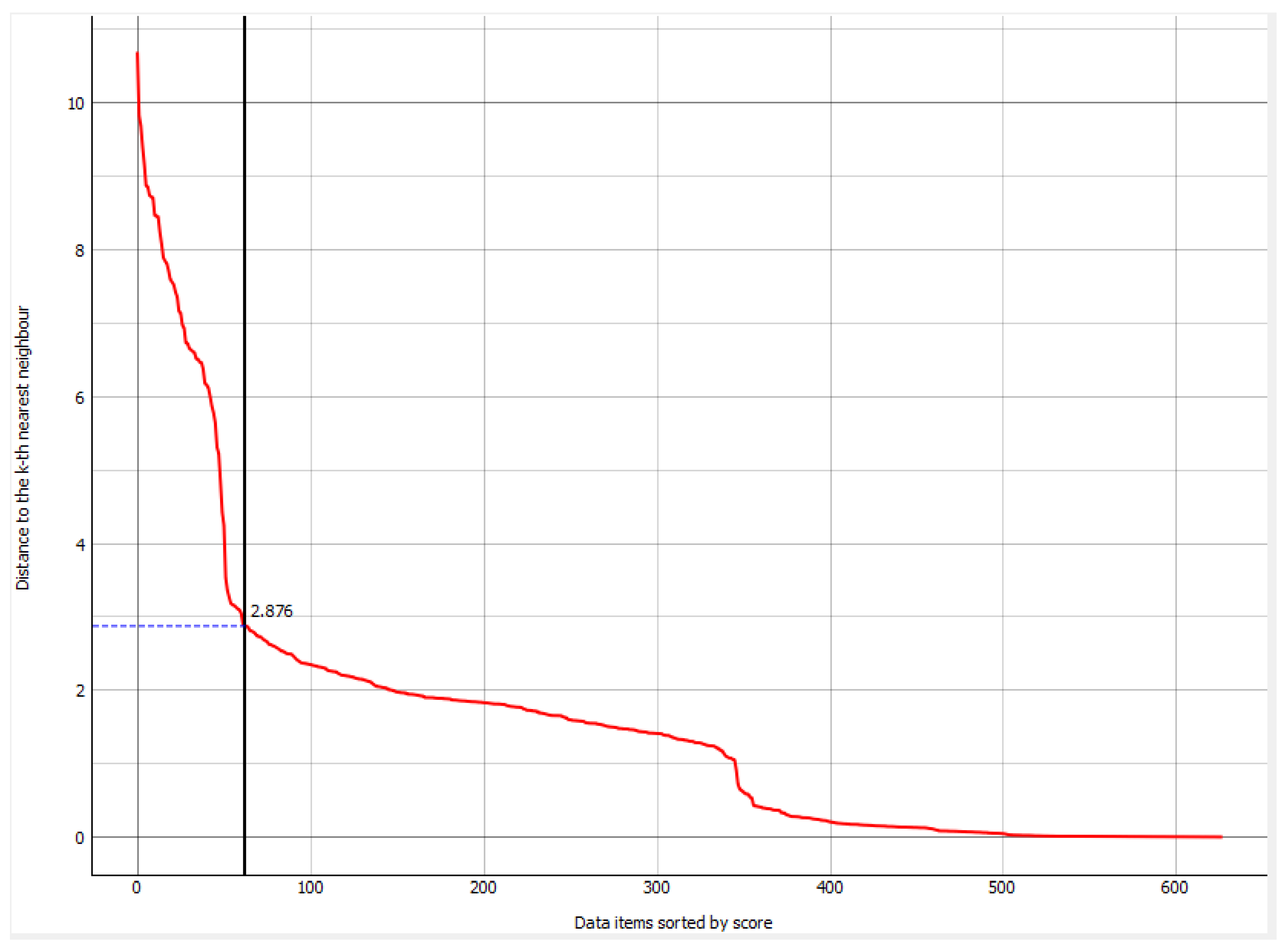
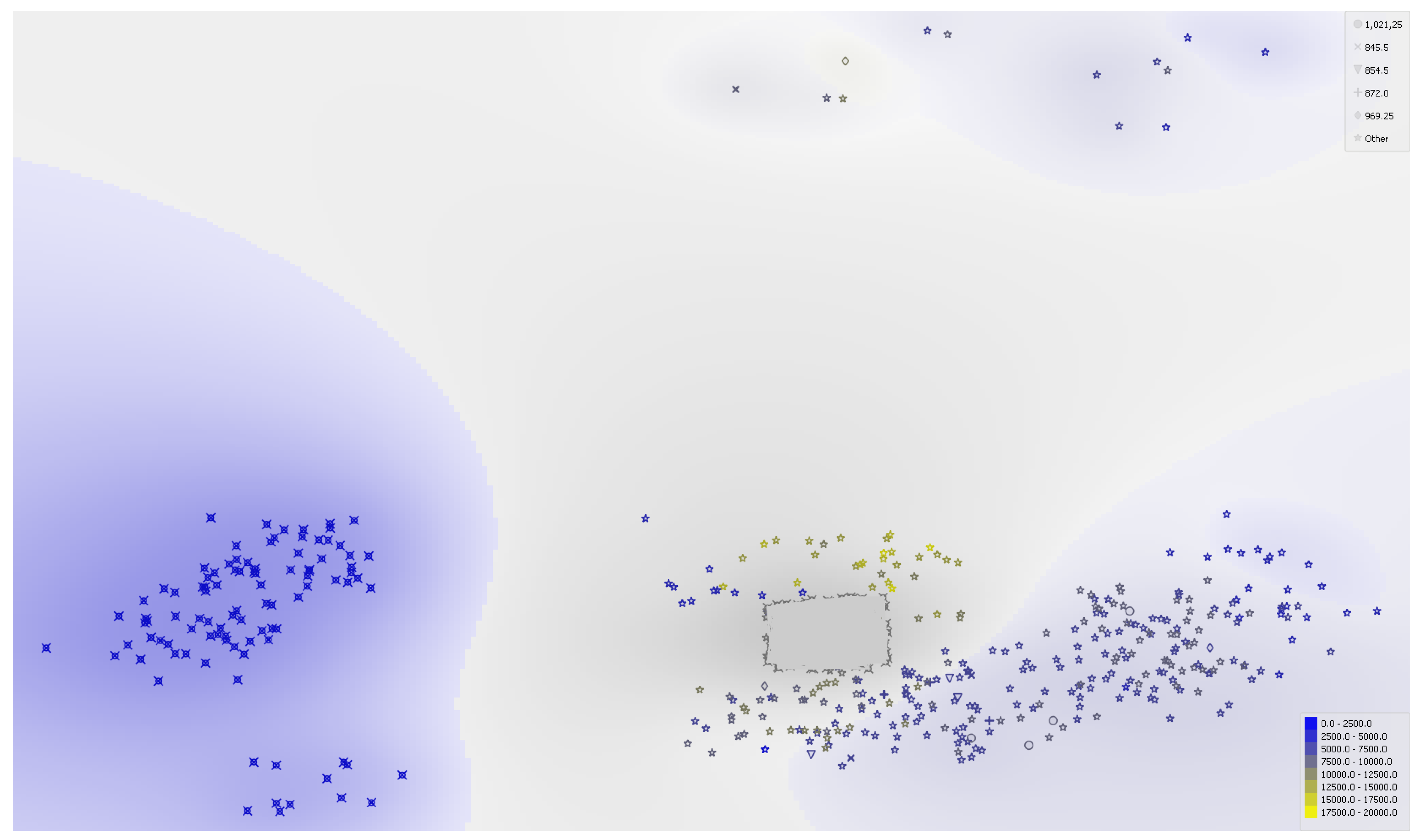
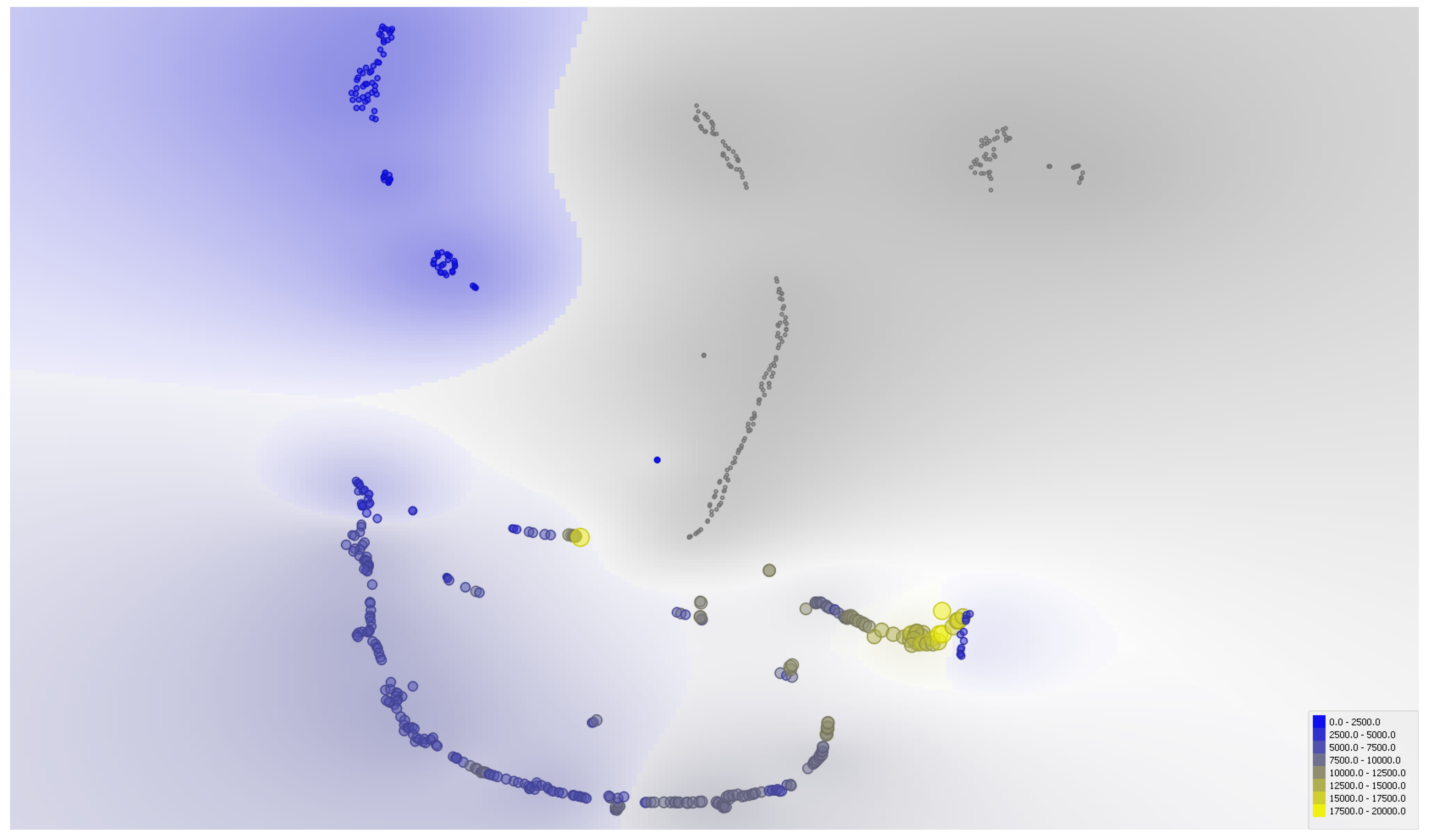
- kNN: we predict Bitcoin according to the nearest training distances using three neighbors with uniform weight, as measured by the Euclidean metric. Figure 4 contains the Density-based spatial clustering from which the number of neighbors has been detected.
- AdaBoost: this ensemble meta-algorithm combines weak learners and adapts to the ‘hardness’ of each training sample. The boosting is performed thanks to the SAMME.R classification algorithm, which exhibits a linear regression loss function.
- Ridge regression: this latter method minimizes an objective function using a stochastic approximation of gradient descent. In the classification (Hinge) and regression (Squared) loss functions, is set to 0.10. The Ridge L2 regularization is used (Lasso and elastic net) with strength 0.00001, mixing 0.15, constant learning rate, 0.01 initial learning rate, 1000 iterations, and a stopping criterion set at 0.001. To predict Bitcoin, we shuffle data after each iteration.
Forecast Statistics
5.2. Forecasting Results for the Coinbase Bitcoin Spot Price
Main Results
5.3. Forecasting Results for the CME Bitcoin Futures Price
5.4. Visualization
6. Robustness Checks
6.1. ‘Crypto Select’
6.2. 2017 Tether’s Introduction
Sub-Sample Results
6.3. 2016–18 Bitcoin’s Economic Cycle
6.4. Year 2019
Sub-Sample Results
6.5. 2020: The Next “Bull Run”?
6.6. Trading Strategies
6.6.1. Hit Rates
6.6.2. ML Trading Results Contrasted with HODL Strategy
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Misheva, B.H.; Osterrieder, J.; Hirsa, A.; Kulkarni, O.; Lin, S.F. Explainable AI in Credit Risk Management. arXiv 2021, arXiv:2103.00949. [Google Scholar]
- Bussmann, N.; Giudici, P.; Marinelli, D.; Papenbrock, J. Explainable machine learning in credit risk management. Comput. Econ. 2021, 57, 203–216. [Google Scholar] [CrossRef]
- Islam, S.R.; Eberle, W.; Bundy, S.; Ghafoor, S.K. Infusing domain knowledge in ai-based “black box” models for better explainability with application in bankruptcy prediction. arXiv 2019, arXiv:1905.11474. [Google Scholar]
- Cohen, G. Forecasting Bitcoin Trends Using Algorithmic Learning Systems. Entropy 2020, 22, 838. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Zheng, Z.; Dai, H.N. Enhancing Bitcoin Price Fluctuation Prediction Using Attentive LSTM and Embedding Network. Appl. Sci. 2020, 10, 4872. [Google Scholar] [CrossRef]
- Livieris, I.E.; Kiriakidou, N.; Stavroyiannis, S.; Pintelas, P. An Advanced CNN-LSTM Model for Cryptocurrency Forecasting. Electronics 2021, 10, 287. [Google Scholar] [CrossRef]
- Chen, T.H.; Chen, M.Y.; Du, G.T. The determinants of bitcoin’s price: Utilization of GARCH and machine learning approaches. Comput. Econ. 2021, 57, 267–280. [Google Scholar] [CrossRef]
- Zhao, Q.; Hastie, T. Causal interpretations of black-box models. J. Bus. Econ. Stat. 2021, 39, 272–281. [Google Scholar] [CrossRef]
- Farrell, M.H.; Liang, T.; Misra, S. Deep neural networks for estimation and inference. Econometrica 2021, 89, 181–213. [Google Scholar] [CrossRef]
- De Prado, M.M.L. Machine Learning for Asset Managers; Cambridge University Press: Cambridge, UK, 2020. [Google Scholar]
- Abadie, A.; Kasy, M. Choosing among regularized estimators in empirical economics: The risk of machine learning. Rev. Econ. Stat. 2019, 101, 743–762. [Google Scholar] [CrossRef]
- Athey, S.; Imbens, G.W. Machine learning methods that economists should know about. Annu. Rev. Econ. 2019, 11, 685–725. [Google Scholar] [CrossRef]
- Nakamoto, S. Bitcoin: A Peer-to-Peer Electronic Cash System; White Paper; Bitcoin.org: New York, NY, USA, 2009. [Google Scholar]
- Reuters. Bitcoin Hits $1 Trillion Market Cap, Surges to Fresh All-Time Peak. Technical Report. Available online: https://www.reuters.com/article/us-crypto-currency-bitcoin-idUSKBN2AJ0GC (accessed on 19 February 2021).
- Abedifar, P.; Giudici, P.; Hashem, S.Q. Heterogeneous market structure and systemic risk: Evidence from dual banking systems. J. Financ. Stab. 2017, 33, 96–119. [Google Scholar] [CrossRef]
- Ahelegbey, D.F.; Billio, M.; Casarin, R. Bayesian graphical models for structural vector autoregressive processes. J. Appl. Econom. 2016, 31, 357–386. [Google Scholar] [CrossRef]
- Billio, M.; Getmansky, M.; Lo, A.W.; Pelizzon, L. Econometric measures of connectedness and systemic risk in the finance and insurance sectors. J. Financ. Econ. 2012, 104, 535–559. [Google Scholar] [CrossRef]
- Baumöhl, E. Are cryptocurrencies connected to forex? A quantile cross-spectral approach. Financ. Res. Lett. 2019, 29, 363–372. [Google Scholar] [CrossRef]
- Dahir, A.M.; Mahat, F.; Noordin, B.A.A.; Ab Razak, N.H. Dynamic connectedness between Bitcoin and equity market information across BRICS countries: Evidence from TVP-VAR connectedness approach. Int. J. Manag. Financ. 2019, 16, 357–371. [Google Scholar] [CrossRef]
- Le, T.L.; Abakah, E.J.A.; Tiwari, A.K. Time and frequency domain connectedness and spill-over among fintech, green bonds and cryptocurrencies in the age of the fourth industrial revolution. Technol. Forecast. Soc. Chang. 2021, 162, 120382. [Google Scholar] [CrossRef] [PubMed]
- Mensi, W.; Sensoy, A.; Aslan, A.; Kang, S.H. High-frequency asymmetric volatility connectedness between Bitcoin and major precious metals markets. N. Am. J. Econ. Financ. 2019, 50, 101031. [Google Scholar] [CrossRef]
- Cao, L.; Gu, Q. Dynamic support vector machines for non-stationary time series forecasting. Intell. Data Anal. 2002, 6, 67–83. [Google Scholar] [CrossRef]
- Kurbatsky, V.G.; Sidorov, D.N.; Spiryaev, V.A.; Tomin, N.V. Forecasting nonstationary time series based on Hilbert-Huang transform and machine learning. Autom. Remote. Control 2014, 75, 922–934. [Google Scholar] [CrossRef]
- Wang, X.; Han, M. Online sequential extreme learning machine with kernels for nonstationary time series prediction. Neurocomputing 2014, 145, 90–97. [Google Scholar] [CrossRef]
- Rosenblatt, F. Perceptron simulation experiments. Proc. IRE 1960, 48, 301–309. [Google Scholar] [CrossRef]
- Russell, S.J.; Norvig, P. Artificial Intelligence: A Modern Approach; Pearson Education Limited: Kuala Lumpur, Malaysia, 2016. [Google Scholar]
- Iworiso, J.; Vrontos, S. On the Directional Predictability of Equity Premium Using Machine Learning Techniques. J. Forecast. 2020, 39, 449–469. [Google Scholar] [CrossRef]
- Foley, S.; Karlsen, J.R.; Putniņš, T.J. Sex, drugs, and bitcoin: How much illegal activity is financed through cryptocurrencies? Rev. Financ. Stud. 2019, 32, 1798–1853. [Google Scholar] [CrossRef]
- Easley, D.; O’Hara, M.; Basu, S. From mining to markets: The evolution of bitcoin transaction fees. J. Financ. Econ. 2019, 134, 91–109. [Google Scholar] [CrossRef]
- Prat, J.; Walter, B. An equilibrium model of the market for bitcoin mining. J. Political Econ. 2021. [Google Scholar] [CrossRef]
- Makarov, I.; Schoar, A. Trading and arbitrage in cryptocurrency markets. J. Financ. Econ. 2020, 135, 293–319. [Google Scholar] [CrossRef]
- Cheng, S.F.; De Franco, G.; Jiang, H.; Lin, P. Riding the blockchain mania: Public firms’ speculative 8-K disclosures. Manag. Sci. 2019, 65, 5901–5913. [Google Scholar]
- Wei, Y.; Dukes, A. Cryptocurrency Adoption with Speculative Price Bubbles. Mark. Sci. 2021, 40, 241–260. [Google Scholar] [CrossRef]
- Pagnotta, E. Decentralizing Money: Bitcoin Prices and Blockchain Security. Rev. Financ. Stud. 2020. [Google Scholar] [CrossRef]
- Fantazzini, D.; Nigmatullin, E.; Sukhanovskaya, V.; Ivliev, S. Everything You Always Wanted to Know about Bitcoin Modelling but Were Afraid to Ask; MPRA Paper No. 71946; MPRA: Munich, Germany, 2016; 50p. [Google Scholar]
- Briere, M.; Oosterlinck, K.; Szafarz, A. Virtual currency, tangible return: Portfolio diversification with bitcoin. J. Asset Manag. 2015, 16, 365–373. [Google Scholar] [CrossRef]
- Aslanidis, N.; Bariviera, A.F.; Martínez-Ibañez, O. An analysis of cryptocurrencies conditional cross correlations. Financ. Res. Lett. 2019, 31, 130–137. [Google Scholar] [CrossRef]
- Caporale, G.M.; Zekokh, T. Modelling volatility of cryptocurrencies using Markov-Switching GARCH models. Res. Int. Bus. Financ. 2019, 48, 143–155. [Google Scholar] [CrossRef]
- Bariviera, A.F.; Basgall, M.J.; Hasperué, W.; Naiouf, M. Some stylized facts of the Bitcoin market. Phys. A Stat. Mech. Appl. 2017, 484, 82–90. [Google Scholar] [CrossRef]
- Alvarez-Ramirez, J.; Rodriguez, E.; Ibarra-Valdez, C. Long-range correlations and asymmetry in the Bitcoin market. Phys. A Stat. Mech. Appl. 2018, 492, 948–955. [Google Scholar] [CrossRef]
- Begušić, S.; Kostanjčar, Z.; Stanley, H.E.; Podobnik, B. Scaling properties of extreme price fluctuations in Bitcoin markets. Phys. A Stat. Mech. Appl. 2018, 510, 400–406. [Google Scholar] [CrossRef]
- Khuntia, S.; Pattanayak, J. Adaptive long memory in volatility of intra-day bitcoin returns and the impact of trading volume. Financ. Res. Lett. 2020, 32, 101077. [Google Scholar] [CrossRef]
- Al-Yahyaee, K.H.; Mensi, W.; Yoon, S.M. Efficiency, multifractality, and the long-memory property of the Bitcoin market: A comparative analysis with stock, currency, and gold markets. Financ. Res. Lett. 2018, 27, 228–234. [Google Scholar] [CrossRef]
- Phillip, A.; Chan, J.; Peiris, S. On long memory effects in the volatility measure of Cryptocurrencies. Financ. Res. Lett. 2019, 28, 95–100. [Google Scholar] [CrossRef]
- Mensi, W.; Al-Yahyaee, K.H.; Kang, S.H. Structural breaks and double long memory of cryptocurrency prices: A comparative analysis from Bitcoin and Ethereum. Financ. Res. Lett. 2019, 29, 222–230. [Google Scholar] [CrossRef]
- Su, C.W.; Li, Z.Z.; Tao, R.; Si, D.K. Testing for Multiple Bubbles in Bitcoin Markets: A. Econ. Bull. 2017, 36, 843–850. [Google Scholar]
- Guegan, D.; Frunza, M. Is the Bitcoin Rush Over? In Handbook: Cryptofinance and Mechanism of Exchange; Springer: Berlin, Germany, 2018. [Google Scholar]
- Geuder, J.; Kinateder, H.; Wagner, N.F. Cryptocurrencies as financial bubbles: The case of Bitcoin. Financ. Res. Lett. 2019, 31, 179–184. [Google Scholar] [CrossRef]
- Guesmi, K.; Saadi, S.; Abid, I.; Ftiti, Z. Portfolio diversification with virtual currency: Evidence from bitcoin. Int. Rev. Financ. Anal. 2019, 63, 431–437. [Google Scholar] [CrossRef]
- Dyhrberg, A.H. Hedging capabilities of bitcoin. Is it the virtual gold? Financ. Res. Lett. 2016, 16, 139–144. [Google Scholar] [CrossRef]
- Polasik, M.; Piotrowska, A.I.; Wisniewski, T.P.; Kotkowski, R.; Lightfoot, G. Price fluctuations and the use of Bitcoin: An empirical inquiry. Int. J. Electron. Commer. 2015, 20, 9–49. [Google Scholar] [CrossRef]
- Bouri, E.; Molnár, P.; Azzi, G.; Roubaud, D.; Hagfors, L.I. On the hedge and safe haven properties of Bitcoin: Is it really more than a diversifier? Financ. Res. Lett. 2017, 20, 192–198. [Google Scholar] [CrossRef]
- Selmi, R.; Mensi, W.; Hammoudeh, S.; Bouoiyour, J. Is Bitcoin a hedge, a safe haven or a diversifier for oil price movements? A comparison with gold. Energy Econ. 2018, 74, 787–801. [Google Scholar] [CrossRef]
- Kurka, J. Do cryptocurrencies and traditional asset classes influence each other? Financ. Res. Lett. 2019, 31, 38–46. [Google Scholar] [CrossRef]
- Zargar, F.N.; Kumar, D. Informational inefficiency of Bitcoin: A study based on high-frequency data. Res. Int. Bus. Financ. 2019, 47, 344–353. [Google Scholar] [CrossRef]
- Fang, L.; Bouri, E.; Gupta, R.; Roubaud, D. Does global economic uncertainty matter for the volatility and hedging effectiveness of Bitcoin? Int. Rev. Financ. Anal. 2019, 61, 29–36. [Google Scholar] [CrossRef]
- Gillaizeau, M.; Jayasekera, R.; Maaitah, A.; Mishra, T.; Parhi, M.; Volokitina, E. Giver and the receiver: Understanding spillover effects and predictive power in cross-market Bitcoin prices. Int. Rev. Financ. Anal. 2019, 63, 86–104. [Google Scholar] [CrossRef]
- Wołk, K. Advanced social media sentiment analysis for short-term cryptocurrency price prediction. Expert Syst. 2020, 37, e12493. [Google Scholar] [CrossRef]
- Shen, D.; Urquhart, A.; Wang, P. Does twitter predict Bitcoin? Econ. Lett. 2019, 174, 118–122. [Google Scholar] [CrossRef]
- Philippas, D.; Rjiba, H.; Guesmi, K.; Goutte, S. Media attention and Bitcoin prices. Financ. Res. Lett. 2019, 30, 37–43. [Google Scholar] [CrossRef]
- Guégan, D.; Renault, T. Does investor sentiment on social media provide robust information for Bitcoin returns predictability? Financ. Res. Lett. 2021, 38, 101494. [Google Scholar] [CrossRef]
- Dey, A.K.; Akcora, C.G.; Gel, Y.R.; Kantarcioglu, M. On the role of local blockchain network features in cryptocurrency price formation. Can. J. Stat. 2020, 48, 561–581. [Google Scholar] [CrossRef]
- Nicola, G.; Cerchiello, P.; Aste, T. Information network modeling for US banking systemic risk. Entropy 2020, 22, 1331. [Google Scholar] [CrossRef]
- Atsalakis, G.S.; Atsalaki, I.G.; Pasiouras, F.; Zopounidis, C. Bitcoin price forecasting with neuro-fuzzy techniques. Eur. J. Oper. Res. 2019, 276, 770–780. [Google Scholar] [CrossRef]
- Jang, H.; Lee, J. An empirical study on modeling and prediction of bitcoin prices with bayesian neural networks based on blockchain information. IEEE Access 2017, 6, 5427–5437. [Google Scholar] [CrossRef]
- Mallqui, D.C.; Fernandes, R.A. Predicting the direction, maximum, minimum and closing prices of daily Bitcoin exchange rate using machine learning techniques. Appl. Soft Comput. 2019, 75, 596–606. [Google Scholar] [CrossRef]
- Nakano, M.; Takahashi, A.; Takahashi, S. Bitcoin technical trading with artificial neural network. Phys. A Stat. Mech. Appl. 2018, 510, 587–609. [Google Scholar] [CrossRef]
- Sun, X.; Liu, M.; Sima, Z. A novel cryptocurrency price trend forecasting model based on LightGBM. Financ. Res. Lett. 2020, 32, 101084. [Google Scholar] [CrossRef]
- Giudici, P.; Polinesi, G. Crypto price discovery through correlation networks. Ann. Oper. Res. 2021, 299, 443–457. [Google Scholar] [CrossRef]
- Jay, P.; Kalariya, V.; Parmar, P.; Tanwar, S.; Kumar, N.; Alazab, M. Stochastic neural networks for cryptocurrency price prediction. IEEE Access 2020, 8, 82804–82818. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B (Methodol.) 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2005, 67, 301–320. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Zou, H. The adaptive lasso and its oracle properties. J. Am. Stat. Assoc. 2006, 101, 1418–1429. [Google Scholar] [CrossRef]
- Zhao, P.; Yu, B. On model selection consistency of Lasso. J. Mach. Learn. Res. 2006, 7, 2541–2563. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso: A retrospective. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2011, 73, 273–282. [Google Scholar] [CrossRef]
- Epprecht, C.; Guegan, D.; Veiga, Á. Comparing Variable Selection Techniques for Linear Regression: Lasso and Autometrics; Centre D’économie de la Sorbonne: Paris, France, 2013. [Google Scholar]
- Maclin, R.; Shavlik, J.W. Combining the predictions of multiple classifiers: Using competitive learning to initialize neural networks. IJCAI 1995, 95, 524–531. [Google Scholar]
- Vapnik, V.N. An overview of statistical learning theory. IEEE Trans. Neural Netw. 1999, 10, 988–999. [Google Scholar] [CrossRef] [PubMed]
- Scholkopf, B. Support vector machines: A practical consequence of learning theory. IEEE Intell. Syst. 1998, 13, 4. [Google Scholar]
- Windisch, D. Loading deep networks is hard: The pyramidal case. Neural Comput. 2005, 17, 487–502. [Google Scholar] [CrossRef]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Schmidhuber, J. Deep learning in neural networks: An overview. Neural Netw. 2015, 61, 85–117. [Google Scholar] [CrossRef]
- Ho, T.K. The random subspace method for constructing decision forests. IEEE Trans. Pattern Anal. Mach. Intell. 1998, 20, 832–844. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Geurts, P.; Ernst, D.; Wehenkel, L. Extremely randomized trees. Mach. Learn. 2006, 63, 3–42. [Google Scholar] [CrossRef]
- Biau, G. Analysis of a random forests model. J. Mach. Learn. Res. 2012, 13, 1063–1095. [Google Scholar]
- Genuer, R.; Poggi, J.M.; Tuleau-Malot, C. Variable selection using random forests. Pattern Recognit. Lett. 2010, 31, 2225–2236. [Google Scholar] [CrossRef]
- Maudes, J.; Rodríguez, J.J.; García-Osorio, C.; García-Pedrajas, N. Random feature weights for decision tree ensemble construction. Inf. Fusion 2012, 13, 20–30. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer: New York, NY, USA, 2001; Volume 1, Number 10. [Google Scholar]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning; Springer: Berlin/Heidelberg, Germany, 2013; Volume 112. [Google Scholar]
- Friedman, J.H.; Baskett, F.; Shustek, L.J. An algorithm for finding nearest neighbors. IEEE Trans. Comput. 1975, 100, 1000–1006. [Google Scholar] [CrossRef]
- Dasarathy, B.V.; Belur, S. A composite classifier system design: Concepts and methodology. Proc. IEEE 1979, 67, 708–713. [Google Scholar] [CrossRef]
- Papadopoulos, A.N.; Manolopoulos, Y. Nearest Neighbor Search: A Database Perspective; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2006. [Google Scholar]
- Sorjamaa, A.; Hao, J.; Reyhani, N.; Ji, Y.; Lendasse, A. Methodology for long-term prediction of time series. Neurocomputing 2007, 70, 2861–2869. [Google Scholar] [CrossRef]
- Schapire, R.E. Explaining adaboost. In Empirical Inference; Springer: Berlin/Heidelberg, Germany, 2013; pp. 37–52. [Google Scholar]
- Ridgeway, G.; Madigan, D.; Richardson, T. Boosting methodology for regression problems. In Proceedings of the Seventh International Workshop on Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 3–6 January 1999. [Google Scholar]
- Busa-Fekete, R.; Kégl, B.; Élteto, T.; Szarvas, G. A robust ranking methodology based on diverse calibration of AdaBoost. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Athens, Greece, 5–9 September 2011; pp. 263–279. [Google Scholar]
- Ying, C.; Qi-Guang, M.; Jia-Chen, L.; Lin, G. Advance and prospects of AdaBoost algorithm. Acta Autom. Sin. 2013, 39, 745–758. [Google Scholar]
- Baur, D.G.; Dimpfl, T. Price discovery in bitcoin spot or futures? J. Futur. Mark. 2019, 39, 803–817. [Google Scholar] [CrossRef]
- Ji, Q.; Bouri, E.; Kristoufek, L.; Lucey, B. Realised volatility connectedness among Bitcoin exchange markets. Financ. Res. Lett. 2019, 38, 101391. [Google Scholar] [CrossRef]
- Koutmos, D. Market risk and Bitcoin returns. Ann. Oper. Res. 2020, 294, 453–477. [Google Scholar] [CrossRef]
- Blondel, V.D.; Guillaume, J.L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 2008, P10008. [Google Scholar] [CrossRef]
- Lambiotte, R.; Delvenne, J.C.; Barahona, M. Laplacian dynamics and multiscale modular structure in networks. arXiv 2008, arXiv:0812.1770. [Google Scholar]
- Clauset, A.; Newman, M.E.; Moore, C. Finding community structure in very large networks. Phys. Rev. E 2004, 70, 066111. [Google Scholar] [CrossRef]
- Abraham, L.; Guegan, D. The other side of the Coin: Risks of the Libra Blockchain. arXiv 2019, arXiv:1910.07775. [Google Scholar] [CrossRef]
- Klein, T.; Thu, H.P.; Walther, T. Bitcoin is not the New Gold–A comparison of volatility, correlation, and portfolio performance. Int. Rev. Financ. Anal. 2018, 59, 105–116. [Google Scholar] [CrossRef]
- Kapar, B.; Olmo, J. An analysis of price discovery between Bitcoin futures and spot markets. Econ. Lett. 2019, 174, 62–64. [Google Scholar] [CrossRef]
- Entrop, O.; Frijns, B.; Seruset, M. The Determinants of Price Discovery on Bitcoin Markets. J. Futur. Mark. 2020, 40, 816–837. [Google Scholar] [CrossRef]
- Riedwyl, H.; Schüpbach, M. Parquet diagram to plot contingency tables. Softstat 1994, 93, 293–299. [Google Scholar]
- Kohonen, T. The self-organizing map. Proc. IEEE 1990, 78, 1464–1480. [Google Scholar] [CrossRef]
- Wickelmaier, F. An Introduction to MDS; Sound Quality Research Unit, Aalborg University: Aalborg Øst, Denmark, 2003; Volume 46, pp. 1–26. [Google Scholar]
- Maaten, L.v.d.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Van Der Maaten, L. Accelerating t-SNE using tree-based algorithms. J. Mach. Learn. Res. 2014, 15, 3221–3245. [Google Scholar]
- Alexander, C.; Choi, J.; Park, H.; Sohn, S. BitMEX bitcoin derivatives: Price discovery, informational efficiency, and hedging effectiveness. J. Futur. Mark. 2020, 40, 23–43. [Google Scholar] [CrossRef]
- Griffin, J.M.; Shams, A. Is Bitcoin really untethered? J. Financ. 2020, 75, 1913–1964. [Google Scholar] [CrossRef]
- Kraken, I.R.D. Born to Run: December 2020 Market Recap & Outlook; Technical Report; Ordo AB Crypto, Blockchain Consulting & Cryptocurrency Financial Services Information: San Francisco, CA, USA, 2020. [Google Scholar]
- Shynkevich, A. Bitcoin Futures, Technical Analysis and Return Predictability in Bitcoin Prices. J. Forecast. 2020. [Google Scholar] [CrossRef]
- Fischer, T.; Krauss, C. Deep learning with long short-term memory networks for financial market predictions. Eur. J. Oper. Res. 2018, 270, 654–669. [Google Scholar] [CrossRef]
- Saad, M.; Choi, J.; Nyang, D.; Kim, J.; Mohaisen, A. Toward characterizing blockchain-based cryptocurrencies for highly accurate predictions. IEEE Syst. J. 2019, 14, 321–332. [Google Scholar] [CrossRef]
- Akyildirim, E.; Goncu, A.; Sensoy, A. Prediction of cryptocurrency returns using machine learning. Ann. Oper. Res. 2021, 297, 3–36. [Google Scholar] [CrossRef]
- Hudson, R.; Urquhart, A. Technical trading and cryptocurrencies. Ann. Oper. Res. 2021, 297, 191–220. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Asset Class | Name | Code |
|---|---|---|
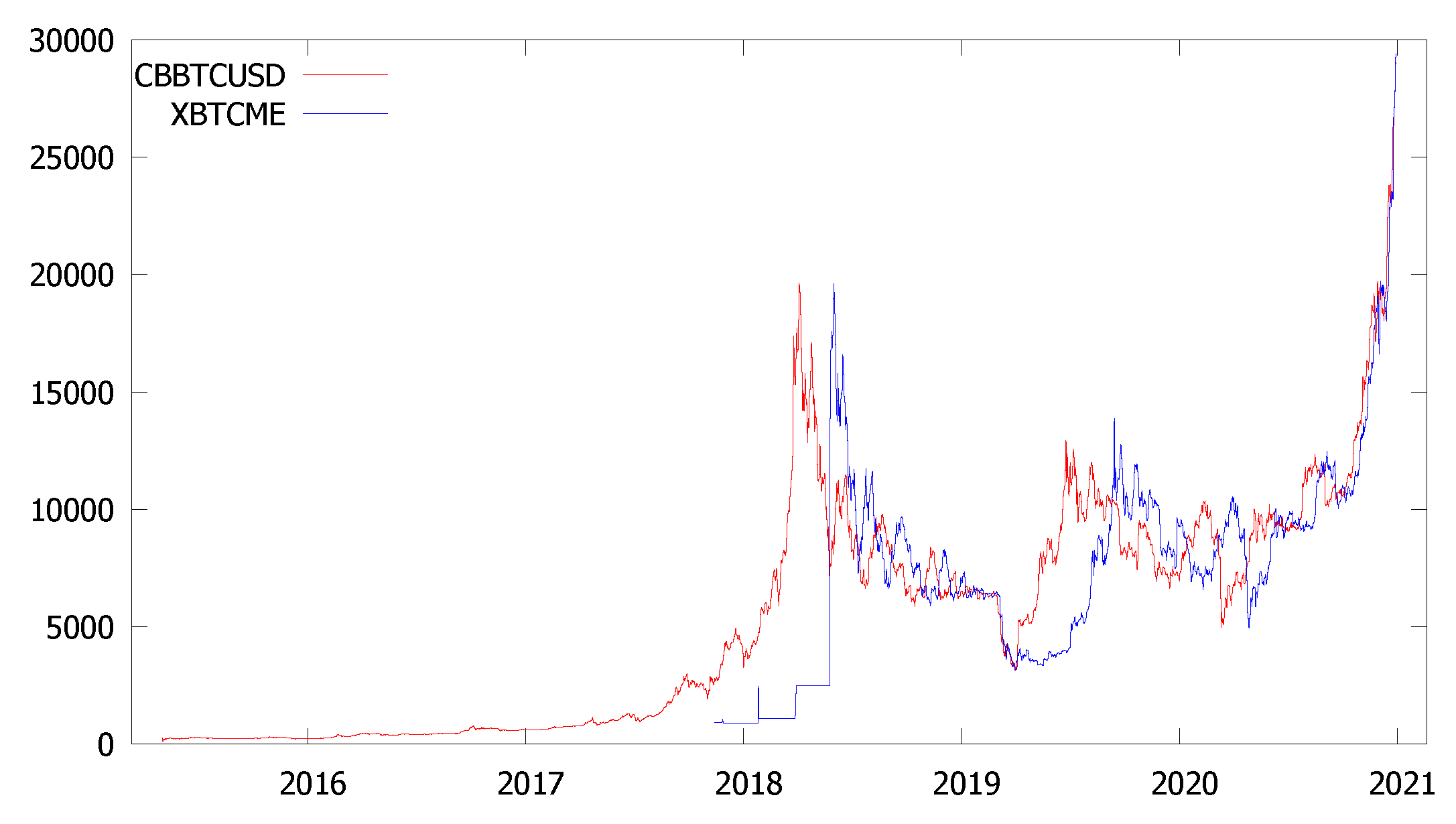
| CRYPTO: | 1. Bitcoin Spot | CBBTCUSD |
| 2. Bitcoin Futures | XBTCME | |
| 3. Ethereum | CBETHUSD | |
| 4. Ethereum Classic | ETHCLASSIC | |
| 5. Litecoin | CBLTCUSD | |
| 6. Bitcoin Cash | CBBCHUSD | |
| 7. Ripple | XRP | |
| 8. STELLAR | STELLAR | |
| 9. TETHER | TETHER | |
| 10. MONERO | MONERO | |
| 11. DASH | DASH | |
| 12. EOS | EOS | |
| 13. ZCASH | ZCASH | |
| 14. NEO | NEO | |
| 15. NANO | NANO | |
| 16. CARDANO | CARDANO | |
| 17. IOTA | IOTA | |
| STOCKS: | 18. SP500 | STOCKSSP500 |
| 19. VIX | VIXCLS | |
| 20. Dow Jones Industrial Average | DJIA | |
| 21. NASDAQ | NASDAQCOM | |
| 22. FTSE 100 | FTSE100 | |
| 23. Euro Stoxx 50 | STOXX50E | |
| 24. NIKKEI225 | NIKKEI225 | |
| 25. Shanghai Composite | SSEC | |
| 26. KOSPI | KS11 | |
| 27. Toronto Exchange TSX | GSPTSE | |
| 28. Bovespa Brazil | BVSP | |
| BONDS: | 29. BAA Corporate Bond Yield relative to 10-Year Treasury rate | BONDSBAA10Y |
| 30. 3-Month Treasury rate | DGS3MO | |
| 31. EURO BUND Futures | EUROBUND | |
| 32. 10-year Treasury Inflation-Indexed Security | DFII10 | |
| FX: | 33. Trade-Weighted US Dollar Index | FXDTWEXM |
| 34. US / Euro Foreign Exchange Rate | DEXUSEU | |
| 35. US / UK Foreign Exchange Rate | DEXUSUK | |
| 36. China / US Foreign Exchange Rate | DEXCHUS | |
| ENERGY: | 37. Crude Oil WTI Futures | ENERGYDCOILWTICO |
| 38. Ethanol Futures | ETHANOL | |
| 39. Gasoline Futures | RBF9 | |
| 40. Natural Gas Futures | NGAS | |
| METALS: | 41. GOLD | METALSGOLDAMGBD228NLBM |
| 42. SILVER | SILVER | |
| 43. ALUMINUM | ALUMINUM | |
| 44. COPPER | COPPER | |
| 45. LEAD | LEAD | |
| 46. NICKEL | NICKEL | |
| 47. ZINC | ZINC | |
| GRAINS: | 48. US Corn Futures | GRAINSZCH9 |
| 49. US Soybean Futures | ZSF9 | |
| 50. US Wheat Futures | ZWH9 | |
| SOFTS: | 51. Orange Juice Futures | SOFTSOJF9 |
| 52. US Cocoa Futures | CCH9 | |
| 53. US Coffee C Futures | KCH9 | |
| 54. US Cotton \#2 Futures | CTH9 | |
| 55. US Sugar \#11 Futures | SBH9 | |
| CATTLE: | 56. Live Cattle Futures | CATTLELEG9 |
| 57. Lean Hogs Futures | HEG9 |
| Code | Mean | Median | Maximum | Minimum | Std. Dev. | Skewness | Kurtosis | Observations | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | ALUMINUM | 1821.02 | 1794.00 | 2539.50 | 175.25 | 200.24 | 0.04 | 5.00 | 1940 |
| 2 | BONDS_BAA10Y | 2.74 | 2.67 | 5.15 | 0.00 | 0.83 | −0.52 | 4.26 | 1940 |
| 3 | BVSP | 73,588.92 | 68,253.30 | 125,076.60 | 37,497.48 | 22,374.22 | 0.36 | 1.76 | 1940 |
| 4 | CARDANO | 0.13 | 0.08 | 1.10 | 0.02 | 0.14 | 3.62 | 19.10 | 990 |
| 5 | CATTLE_LEG9 | 488.12 | 295.11 | 3695.00 | 76.87 | 483.56 | 2.68 | 11.35 | 1115 |
| 6 | CBBCHUSD | 5240.90 | 5053.17 | 29,026.97 | 120.00 | 4949.29 | 0.94 | 4.06 | 2070 |
| 7 | CBETHUSD | 265.42 | 219.01 | 1386.02 | 0.00 | 235.91 | 1.43 | 5.48 | 1579 |
| 8 | CBLTCUSD | 65.14 | 52.26 | 359.40 | 0.00 | 55.18 | 1.81 | 7.42 | 1488 |
| 9 | CCH9 | 2589.58 | 2534.50 | 3410.00 | 1780.00 | 403.87 | 0.03 | 1.90 | 1940 |
| 10 | COPPER | 2.74 | 2.72 | 3.63 | 1.94 | 0.35 | −0.18 | 2.44 | 1940 |
| 11 | CBBTCUSD | 69.99 | 67.76 | 95.25 | 48.85 | 9.18 | 0.68 | 2.73 | 1940 |
| 12 | CTH9 | 207.36 | 118.34 | 1432.50 | 36.02 | 214.77 | 2.51 | 9.83 | 1292 |
| 13 | DASH | 55.66 | 53.19 | 107.95 | −36.98 | 20.17 | 0.43 | 4.52 | 1939 |
| 14 | DEXCHUS | 6.48 | 6.66 | 7.18 | 0.00 | 1.05 | −5.45 | 33.94 | 1940 |
| 15 | DEXUSEU | 1.13 | 1.13 | 1.39 | 0.00 | 0.19 | −4.52 | 27.88 | 1940 |
| 16 | DEXUSUK | 1.35 | 1.32 | 1.72 | 0.00 | 0.25 | −3.33 | 19.71 | 1940 |
| 17 | DFII10 | 0.55 | 0.45 | 2.82 | −1.08 | 0.84 | 0.85 | 3.97 | 1940 |
| 18 | DGS3MO | 0.84 | 0.34 | 2.47 | 0.00 | 0.86 | 0.56 | 1.72 | 1940 |
| 19 | DJIA | 21,566.14 | 21,730.87 | 31,097.97 | 0.00 | 5469.05 | −1.23 | 6.40 | 1940 |
| 20 | ENERGY_DCOILWTICO | 92.83 | 91.67 | 126.47 | 0.00 | 19.47 | −2.38 | 13.67 | 1940 |
| 21 | EOS | 4.66 | 3.58 | 21.42 | 0.49 | 3.32 | 1.69 | 6.27 | 1172 |
| 22 | ETHANOL | 1.52 | 1.47 | 3.52 | 0.82 | 0.28 | 1.91 | 9.62 | 1940 |
| 23 | ETHCLASSIC | 9.45 | 6.57 | 43.23 | 0.74 | 7.80 | 1.48 | 5.22 | 1511 |
| 24 | EUROBUND | 162.57 | 162.72 | 179.44 | 138.96 | 9.44 | −0.35 | 2.66 | 1940 |
| 25 | FTSE100 | 6887.99 | 6914.96 | 7877.45 | 4993.90 | 540.51 | −0.51 | 2.49 | 1940 |
| 26 | FX_DTWEXM | 1327.06 | 1289.38 | 2069.40 | 0.00 | 283.67 | −1.47 | 11.61 | 1940 |
| 27 | GRAINS_ZCH9 | 15,269.14 | 15,312.67 | 18,042.07 | 11,228.49 | 1189.11 | −0.28 | 2.68 | 1940 |
| 28 | GSPTSE | 72.36 | 67.74 | 133.38 | 37.33 | 17.30 | 1.33 | 5.01 | 1940 |
| 29 | HEG9 | 0.69 | 0.35 | 5.32 | 0.11 | 0.82 | 2.71 | 10.86 | 1190 |
| 30 | IOTA | 127.31 | 121.10 | 221.90 | 86.65 | 27.21 | 1.12 | 3.77 | 1940 |
| 31 | KCH9 | 2126.93 | 2063.05 | 3152.18 | 1457.64 | 204.33 | 1.25 | 5.38 | 1940 |
| 32 | KS11 | 2031.29 | 2030.88 | 2669.00 | 1563.50 | 234.66 | 0.36 | 2.57 | 1940 |
| 33 | LEAD | 123.56 | 119.71 | 171.00 | 83.83 | 18.65 | 0.63 | 2.59 | 1940 |
| 34 | METALS_GOLDAMGBD228NLBM | 67.14 | 49.60 | 475.00 | 0.10 | 78.35 | 1.84 | 6.94 | 2056 |
| 35 | MONERO | 2.35 | 1.10 | 20.46 | 0.35 | 3.23 | 3.04 | 12.63 | 963 |
| 36 | NANO | 6562.38 | 6365.63 | 13,201.98 | 0.00 | 2278.63 | 0.25 | 3.92 | 1940 |
| 37 | NASDAQCOM | 25.91 | 15.76 | 189.45 | 5.38 | 26.54 | 2.30 | 8.66 | 1104 |
| 38 | NEO | 2.85 | 2.76 | 6.15 | 1.48 | 0.74 | 1.03 | 4.27 | 1940 |
| 39 | NGAS | 13,039.22 | 12,930.00 | 21,174.00 | 7590.00 | 2774.20 | 0.31 | 2.46 | 1940 |
| 40 | NICKEL | 19,815.93 | 20,124.25 | 28,698.26 | 13,910.16 | 2929.49 | −0.11 | 2.41 | 1940 |
| 41 | NIKKEI225 | 135.73 | 136.00 | 232.85 | 91.25 | 27.22 | 0.61 | 3.29 | 1940 |
| 42 | RBF9 | 1.61 | 1.61 | 2.78 | 0.41 | 0.36 | 0.11 | 3.85 | 1940 |
| 43 | SBH9 | 14.32 | 13.73 | 23.81 | 9.21 | 2.79 | 0.96 | 3.53 | 1940 |
| 44 | SILVER | 17.16 | 16.66 | 29.26 | 11.81 | 2.64 | 2.14 | 8.14 | 1940 |
| 45 | SOFTS_OJF9 | 2463.59 | 2463.02 | 3824.68 | 0.00 | 618.50 | −1.13 | 6.92 | 1940 |
| 46 | SSEC | 2981.13 | 2999.48 | 5166.35 | 1991.25 | 506.87 | 0.45 | 4.99 | 1940 |
| 47 | STELLAR | 0.13 | 0.08 | 0.89 | 0.00 | 0.12 | 1.84 | 7.18 | 1302 |
| 48 | STOCKS_SP500 | 3320.98 | 3333.71 | 3865.18 | 2385.82 | 247.03 | −0.28 | 2.55 | 1940 |
| 49 | STOXX50E | 1.00 | 1.00 | 1.06 | 0.90 | 0.01 | −2.54 | 20.59 | 1250 |
| 50 | TETHER | 16.59 | 14.47 | 82.69 | 0.00 | 7.96 | 2.69 | 16.77 | 1940 |
| 51 | VIXCLS | 8111.91 | 8100.00 | 29,385.00 | 888.00 | 4311.86 | 1.08 | 6.05 | 1143 |
| 52 | XBTCME | 0.24 | 0.20 | 2.78 | 0.00 | 0.31 | 3.17 | 19.44 | 2064 |
| 53 | XRP | 143.53 | 74.55 | 1900.00 | 24.56 | 146.46 | 3.66 | 30.31 | 1418 |
| 54 | ZCASH | 374.88 | 368.75 | 515.75 | 301.50 | 35.86 | 1.30 | 5.41 | 1940 |
| 55 | ZINC | 2383.54 | 2327.50 | 3579.50 | 1460.50 | 430.92 | 0.43 | 2.88 | 1940 |
| 56 | ZSF9 | 942.31 | 920.62 | 1310.25 | 803.50 | 80.27 | 1.14 | 4.58 | 1580 |
| 57 | ZWH9 | 505.81 | 504.44 | 738.88 | 384.12 | 63.07 | 0.74 | 3.82 | 1940 |
| CRYPTO → SPOT BTC | AR(1) | ann | random | svm | knn | boost | ridge |
|---|---|---|---|---|---|---|---|
| RMSE | 1207.51 | 1607.31 | 137.65 | 1043.32 | 395.29 | 23.42 | 304.77 |
| MAE | 990.45 | 1185.68 | 88.54 | 772.18 | 280.84 | 9.94 | 238.1 |
| MAPE | 14.29 | 19.97 | 1.22 | 12.96 | 3.45 | 0.15 | 3.54 |
| STOCKS-BONDS-FX | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 1207.51 | 1652.17 | 221.95 | 1065.93 | 589.97 | 46.21 | 915.98 |
| MAE | 990.45 | 1215.37 | 139.48 | 829.05 | 399.96 | 21.39 | 751.81 |
| MAPE | 14.29 | 19.52 | 1.93 | 12.59 | 6.082 | 0.36 | 10.58 |
| COMMO | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 1207.51 | 1112.14 | 207.4 | 848.86 | 532.17 | 54.86 | 793.8 |
| MAE | 990.45 | 817.07 | 141.96 | 684.43 | 352.37 | 24.94 | 639.16 |
| MAPE | 14.29 | 12.95 | 1.96 | 10.36 | 4.61 | 0.39 | 8.86 |
| ALL | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 1207.51 | 1484.09 | 131.27 | 938.52 | 463.32 | 19.18 | 230.12 |
| MAE | 990.45 | 1117.8 | 85.32 | 704.11 | 285.23 | 7.23 | 180.67 |
| MAPE | 14.29 | 18.84 | 1.13 | 11.65 | 4.08 | 0.11 | 2.6 |
| CRYPTO → FUT BTC | AR(1) | ann | random | svm | knn | boost | ridge |
|---|---|---|---|---|---|---|---|
| RMSE | 1050.27 | 3186.26 | 546.17 | 2943.21 | 1616.74 | 122.45 | 1568.51 |
| MAE | 402.17 | 2300.306 | 272.66 | 2093.4 | 771.56 | 64.88 | 1147.17 |
| MAPE | 5.72 | 35.98 | 4.15 | 35.23 | 12.53 | 0.99 | 17.54 |
| STOCKS-BONDS-FX | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 1050.27 | 2742.52 | 558.81 | 2619.05 | 1102.24 | 88.31 | 2228.131 |
| MAE | 402.17 | 1921.73 | 304.33 | 1807.49 | 566.96 | 37.41 | 1576.706 |
| MAPE | 5.72 | 28.1 | 4.7 | 26.94 | 8.36 | 0.61 | 25.59 |
| COMMO | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 1050.27 | 2598.26 | 590.71 | 2693.82 | 1403.53 | 79.09 | 2341.55 |
| MAE | 402.17 | 1784.42 | 301.08 | 1877.07 | 722.64 | 40.45 | 1660.21 |
| MAPE | 5.72 | 29.61 | 4.26 | 32.11 | 11.79 | 0.7 | 28.33 |
| ALL | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 1050.27 | 2795.35 | 369.63 | 2625.96 | 938.52 | 86.15 | 1317.23 |
| MAE | 402.17 | 1984.95 | 187.86 | 1850.06 | 426.76 | 44.53 | 915.82 |
| MAPE | 5.72 | 34.6 | 2.62 | 32.62 | 6.075 | 0.73 | 15.56 |
| CRYPTO → SPOT BTC | AR(1) | ann | random | svm | knn | boost | ridge |
|---|---|---|---|---|---|---|---|
| RMSE | 2099.45 | 1882.68 | 215.45 | 1909.24 | 364.80 | 39.24 | 1249.79 |
| MAE | 1714.52 | 1399.44 | 131.41 | 1548.98 | 231.11 | 16.04 | 955.87 |
| MAPE | 26.61 | 21.34 | 1.64 | 22.34 | 2.86 | 0.24 | 13.20 |
| CRYPTO → FUT BTC | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 2880.50 | 2759.37 | 417.65 | 2685.02 | 825.13 | 76.98 | 1835.26 |
| MAE | 2146.53 | 2065.76 | 239.82 | 2002.00 | 415.26 | 32.37 | 1389.52 |
| MAPE | 32.29 | 33.84 | 3.25 | 32.88 | 6.65 | 0.51 | 20.02 |
| CRYPTO → SPOT BTC | AR(1) | ann | random | svm | knn | boost | ridge |
|---|---|---|---|---|---|---|---|
| RMSE | 3358.14 | 2582.10 | 296.02 | 2655.41 | 451.34 | 45.54 | 1529.02 |
| MAE | 2536.31 | 2025.75 | 157.97 | 2103.93 | 261.27 | 21.22 | 1130.54 |
| MAPE | 50.10 | 47.97 | 2.26 | 45.31 | 3.60 | 0.53 | 19.38 |
| STOCKS / BONDS / FX | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 3358.14 | 2867.13 | 319.45 | 2225.41 | 774.69 | 49.49 | 1801.17 |
| MAE | 2536.31 | 2035.10 | 192.76 | 1633.83 | 481.59 | 20.01 | 1286.77 |
| MAPE | 50.10 | 42.21 | 2.91 | 26.09 | 6.99 | 0.48 | 21.47 |
| COMMO | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 3358.14 | 2745.22 | 262.66 | 1734.43 | 1002.35 | 50.90 | 1339.07 |
| MAE | 2536.31 | 1928.04 | 148.56 | 1240.58 | 540.81 | 19.64 | 1011.37 |
| MAPE | 50.10 | 36.58 | 2.22 | 21.29 | 8.13 | 0.46 | 18.56 |
| ALL | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 3358.14 | 1776.32 | 228.64 | 1674.18 | 641.75 | 31.83 | 770.54 |
| MAE | 2536.31 | 1284.93 | 132.58 | 1297.20 | 367.47 | 12.04 | 617.04 |
| MAPE | 50.10 | 23.04 | 1.85 | 24.04 | 5.41 | 0.31 | 12.36 |
| CRYPTO → FUT BTC | AR(1) | ann | random | svm | knn | boost | ridge |
|---|---|---|---|---|---|---|---|
| RMSE | 3512.26 | 3008.13 | 472.54 | 3330.54 | 830.46 | 57.91 | 2022.13 |
| MAE | 2787.25 | 2533.75 | 207.79 | 2772.72 | 314.74 | 23.50 | 1567.53 |
| MAPE | 86.68 | 78.49 | 3.79 | 93.93 | 5.71 | 0.53 | 36.73 |
| STOCKS / BONDS / FX | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 3512.26 | 3235.90 | 439.44 | 2959.64 | 976.71 | 59.26 | 2295.76 |
| MAE | 2787.25 | 2466.18 | 217.48 | 2041.73 | 527.01 | 26.70 | 1586.74 |
| MAPE | 86.68 | 74.46 | 4.79 | 55.09 | 10.32 | 0.70 | 34.53 |
| COMMO | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 3512.26 | 2922.43 | 354.82 | 3121.00 | 1239.65 | 46.20 | 1613.32 |
| MAE | 2787.25 | 2018.50 | 169.06 | 2299.30 | 556.34 | 16.29 | 1140.27 |
| MAPE | 86.68 | 71.33 | 3.43 | 89.71 | 14.79 | 0.34 | 26.40 |
| ALL | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 3512.26 | 2495.86 | 424.99 | 2382.42 | 762.66 | 54.96 | 1440.18 |
| MAE | 2787.25 | 1984.92 | 182.68 | 1785.06 | 349.76 | 21.40 | 960.85 |
| MAPE | 86.68 | 55.38 | 5.36 | 55.33 | 6.35 | 0.41 | 22.73 |
| CRYPTO → SPOT BTC | AR(1) | ann | random | svm | knn | boost | ridge |
|---|---|---|---|---|---|---|---|
| RMSE | 3347.17 | 2247.75 | 198.81 | 2182.41 | 331.18 | 22.50 | 701.02 |
| MAE | 2525.98 | 1888.10 | 79.46 | 1586.54 | 136.24 | 9.38 | 474.80 |
| MAPE | 165.32 | 141.22 | 2.32 | 85.90 | 3.31 | 0.82 | 29.41 |
| STOCKS / BONDS / FX | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 3347.17 | 2331.98 | 226.00 | 2161.75 | 556.07 | 31.85 | 1544.24 |
| MAE | 2525.98 | 1474.18 | 103.14 | 1515.32 | 252.90 | 14.69 | 1108.46 |
| MAPE | 165.32 | 79.01 | 3.53 | 107.53 | 5.83 | 1.42 | 75.59 |
| COMMO | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 3347.17 | 2456.96 | 239.60 | 1996.15 | 744.25 | 29.21 | 1350.50 |
| MAE | 2525.98 | 1391.29 | 101.55 | 1417.36 | 304.57 | 12.55 | 1000.99 |
| MAPE | 165.32 | 77.35 | 3.47 | 122.91 | 8.60 | 1.07 | 77.55 |
| ALL | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 3347.17 | 1592.95 | 185.40 | 2086.46 | 472.07 | 17.61 | 524.18 |
| MAE | 2525.98 | 1016.83 | 69.02 | 1567.12 | 207.21 | 7.78 | 360.27 |
| MAPE | 165.32 | 57.03 | 1.90 | 137.19 | 5.02 | 0.89 | 21.66 |
| CRYPTO → FUT BTC | AR(1) | ann | random | svm | knn | boost | ridge |
|---|---|---|---|---|---|---|---|
| RMSE | 4363.09 | 3614.50 | 631.89 | 3802.03 | 1255.64 | 116.83 | 2006.04 |
| MAE | 3239.82 | 2960.70 | 298.57 | 3329.58 | 528.87 | 52.08 | 1408.66 |
| MAPE | 121.15 | 101.87 | 8.03 | 121.45 | 12.20 | 0.98 | 39.79 |
| STOCKS / BONDS / FX | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 4363.09 | 3900.97 | 711.14 | 3518.95 | 1208.71 | 98.46 | 3284.64 |
| MAE | 3239.82 | 2781.09 | 319.38 | 2384.01 | 550.15 | 45.42 | 2252.96 |
| MAPE | 121.15 | 81.72 | 6.93 | 53.42 | 10.85 | 1.05 | 49.91 |
| COMMO | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 4363.09 | 3749.76 | 650.19 | 3523.16 | 1763.10 | 89.78 | 2379.86 |
| MAE | 3239.82 | 2713.36 | 294.69 | 2806.55 | 855.68 | 38.94 | 1577.59 |
| MAPE | 121.15 | 72.63 | 6.43 | 106.25 | 21.38 | 0.98 | 43.29 |
| ALL | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 4363.09 | 2864.04 | 564.27 | 2954.87 | 1027.13 | 96.35 | 1612.76 |
| MAE | 3239.82 | 1911.06 | 188.29 | 2309.58 | 439.60 | 44.54 | 1123.03 |
| MAPE | 121.15 | 46.05 | 3.30 | 77.10 | 8.25 | 1.02 | 31.65 |
| CRYPTO → SPOT BTC | AR(1) | ann | random | svm | knn | boost | ridge |
|---|---|---|---|---|---|---|---|
| RMSE | 2004.38 | 1839.90 | 269.78 | 1242.31 | 482.95 | 56.39 | 948.21 |
| MAE | 1621.48 | 1480.75 | 188.88 | 944.23 | 334.25 | 22.33 | 753.79 |
| MAPE | 19.15 | 19.03 | 2.20 | 11.47 | 3.77 | 0.31 | 8.99 |
| STOCKS / BONDS / FX | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 2004.38 | 1161.05 | 207.41 | 789.85 | 658.27 | 52.20 | 796.62 |
| MAE | 1621.48 | 960.84 | 146.26 | 658.62 | 494.73 | 23.82 | 641.54 |
| MAPE | 19.15 | 12.09 | 1.66 | 7.71 | 5.58 | 0.32 | 7.65 |
| COMMO | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 2004.38 | 1842.40 | 301.12 | 951.06 | 565.41 | 48.58 | 572.25 |
| MAE | 1621.48 | 1501.78 | 154.87 | 778.14 | 415.79 | 22.93 | 449.21 |
| MAPE | 19.15 | 19.21 | 1.72 | 9.65 | 4.80 | 0.30 | 5.51 |
| ALL | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 2004.38 | 1680.12 | 207.25 | 893.35 | 458.88 | 32.68 | 427.80 |
| MAE | 1621.48 | 1320.86 | 140.69 | 707.09 | 317.84 | 13.14 | 328.80 |
| MAPE | 19.15 | 17.21 | 1.59 | 8.52 | 3.60 | 0.18 | 3.86 |
| CRYPTO → FUT BTC | AR(1) | ann | random | svm | knn | boost | ridge |
|---|---|---|---|---|---|---|---|
| RMSE | 2526.17 | 2274.59 | 336.84 | 2274.13 | 774.28 | 51.70 | 859.54 |
| MAE | 2161.69 | 1844.83 | 216.16 | 1843.04 | 400.58 | 19.00 | 665.93 |
| MAPE | 28.19 | 27.87 | 2.85 | 27.79 | 4.76 | 0.28 | 8.54 |
| STOCKS / BONDS / FX | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 2526.17 | 2261.82 | 262.58 | 1486.93 | 870.11 | 39.54 | 1141.02 |
| MAE | 2161.69 | 1812.25 | 156.25 | 1133.90 | 627.91 | 12.06 | 889.87 |
| MAPE | 28.19 | 27.70 | 1.93 | 14.25 | 7.89 | 0.20 | 10.98 |
| COMMO | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 2526.17 | 2246.32 | 240.88 | 1699.47 | 784.03 | 34.63 | 837.17 |
| MAE | 2161.69 | 1847.42 | 142.97 | 1360.78 | 426.04 | 11.74 | 663.65 |
| MAPE | 28.19 | 28.10 | 1.63 | 19.23 | 5.25 | 0.18 | 8.62 |
| ALL | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 2526.17 | 2112.05 | 232.87 | 1844.38 | 507.67 | 38.29 | 598.87 |
| MAE | 2161.69 | 1753.21 | 150.59 | 1428.00 | 338.29 | 16.17 | 463.48 |
| MAPE | 28.19 | 26.91 | 1.82 | 20.40 | 4.16 | 0.23 | 6.07 |
| CRYPTO → SPOT BTC | AR(1) | ann | random | svm | knn | boost | ridge |
|---|---|---|---|---|---|---|---|
| RMSE | 1414.49 | 3307.80 | 197.38 | 2900.38 | 349.39 | 33.70 | 338.91 |
| MAE | 1070.73 | 2459.54 | 103.34 | 2052.99 | 234.06 | 17.80 | 241.83 |
| MAPE | 11.22 | 24.93 | 0.84 | 17.58 | 2.25 | 0.20 | 2.39 |
| STOCKS / BONDS / FX | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 1414.49 | 2512.15 | 311.51 | 2529.41 | 740.23 | 78.17 | 1471.50 |
| MAE | 1070.73 | 1975.08 | 180.96 | 1894.31 | 459.15 | 38.99 | 1163.68 |
| MAPE | 11.22 | 18.58 | 1.71 | 16.96 | 4.23 | 0.41 | 11.20 |
| COMMO | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 1414.49 | 2883.19 | 357.88 | 2420.39 | 676.30 | 96.19 | 1304.25 |
| MAE | 1070.73 | 2249.76 | 184.10 | 1728.99 | 417.52 | 46.36 | 996.39 |
| MAPE | 11.22 | 22.40 | 1.76 | 14.71 | 4.09 | 0.47 | 9.49 |
| ALL | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 1414.49 | 1644.56 | 196.82 | 2632.90 | 358.02 | 44.44 | 262.89 |
| MAE | 1070.73 | 1382.10 | 101.25 | 1860.75 | 249.53 | 22.85 | 187.06 |
| MAPE | 11.22 | 13.66 | 0.85 | 15.90 | 2.41 | 0.25 | 1.80 |
| CRYPTO → FUT BTC | AR(1) | ann | random | svm | knn | boost | ridge |
|---|---|---|---|---|---|---|---|
| RMSE | 1410.81 | 3312.17 | 215.78 | 3393.32 | 707.28 | 58.42 | 534.98 |
| MAE | 1067.87 | 2445.28 | 134.71 | 2490.83 | 306.53 | 26.25 | 385.49 |
| MAPE | 11.01 | 24.57 | 1.28 | 24.85 | 2.89 | 0.27 | 3.77 |
| STOCKS / BONDS / FX | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 1410.81 | 1962.39 | 324.59 | 2734.47 | 771.51 | 46.64 | 2074.45 |
| MAE | 1067.87 | 1486.87 | 167.88 | 1937.63 | 465.15 | 17.82 | 1598.52 |
| MAPE | 11.01 | 14.34 | 1.46 | 17.68 | 4.25 | 0.18 | 15.33 |
| COMMO | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 1410.81 | 2888.13 | 455.97 | 2350.38 | 709.81 | 60.48 | 1396.80 |
| MAE | 1067.87 | 2251.41 | 223.21 | 1670.00 | 429.37 | 22.26 | 1105.12 |
| MAPE | 11.01 | 22.37 | 2.14 | 15.51 | 4.04 | 0.22 | 10.72 |
| ALL | AR(1) | ann | random | svm | knn | boost | ridge |
| RMSE | 1410.81 | 1520.44 | 401.66 | 1910.55 | 352.58 | 53.12 | 659.22 |
| MAE | 1067.87 | 1217.22 | 148.97 | 1268.20 | 248.24 | 20.27 | 515.52 |
| MAPE | 11.01 | 11.96 | 1.44 | 12.25 | 2.32 | 0.20 | 5.43 |
| Full sample/Spot | AR(1) | ann | random | svm | knn | boost | ridge |
|---|---|---|---|---|---|---|---|
| Hit rate (%) CRYPTO → SPOT BTC | <50% | <50% | 61.59% | <50% | 52.74% | 83.84% | 51.83% |
| Hit rate (%) STOCKS / BONDS / FX | <50% | <50% | 63.72% | 50.30% | 51.83% | 83.54% | 50.61% |
| Hit rate (%) COMMO | <50% | <50% | 60.06% | <50% | 53.35% | 85.37% | 51.22% |
| Hit rate (%) ALL | <50% | <50% | 57.93% | <50% | 51.83% | 88.41% | 51.83% |
| Full sample/Futures | AR(1) | ann | random | svm | knn | boost | ridge |
| Hit rate (%) CRYPTO → FUT BTC | <50% | <50% | 73.17% | 50.91% | 57.32% | 70.43% | 50.91% |
| Hit rate (%) STOCKS / BONDS / FX | <50% | <50% | 66.16% | <50% | 56.40% | 82.32% | 51.22% |
| Hit rate (%) COMMO | <50% | <50% | 67.07% | 50.30% | 52.74% | 80.79% | 50.91% |
| Hit rate (%) ALL | <50% | <50% | 70.12% | 50.30% | 57.93% | 77.74% | 50.30% |
| Sub sample/Crypto-select/Spot | AR(1) | ann | random | svm | knn | boost | ridge |
| Hit rate (%) CRYPTO → SPOT BTC | <50% | <50% | 58.84% | 50.30% | 55.18% | 85.37% | 50.30% |
| Sub sample/Crypto-select/Futures | AR(1) | ann | random | svm | knn | boost | ridge |
| Hit rate (%) CRYPTO → FUT BTC | <50% | 50.00% | 62.50% | 50.91% | 52.74% | 83.23% | 50.61% |
| Sub sample/Tether/Spot | AR(1) | ann | random | svm | knn | boost | ridge |
| Hit rate (%) CRYPTO → SPOT BTC | <50% | <50% | 60.98% | 50.30% | 54.27% | 84.15% | 50.30% |
| Hit rate (%) STOCKS / BONDS / FX | <50% | <50% | 58.54% | 50.30% | 53.35% | 86.89% | 50.91% |
| Hit rate (%) COMMO | <50% | <50% | 61.59% | 50.61% | 52.74% | 84.15% | 50.91% |
| Hit rate (%) ALL | <50% | <50% | 58.23% | <50% | 53.05% | 87.80% | 50.91% |
| Sub sample/Tether/Futures | AR(1) | ann | random | svm | knn | boost | ridge |
| Hit rate (%) CRYPTO → FUT BTC | <50% | <50% | 66.46% | <50% | 54.88% | 78.05% | 50.61% |
| Hit rate (%) STOCKS / BONDS / FX | <50% | <50% | 64.33% | 51.22% | 57.32% | 76.52% | 50.91% |
| Hit rate (%) COMMO | <50% | <50% | 63.41% | 50.30% | 54.88% | 81.10% | 50.30% |
| Hit rate (%) ALL | <50% | <50% | 64.02% | 50.30% | 55.18% | 79.88% | 51.22% |
| Sub sample/BTC cycle/Spot | AR(1) | ann | random | svm | knn | boost | ridge |
| Hit rate (%) CRYPTO → SPOT BTC | <50% | <50% | 58.54% | 50.30% | 52.74% | 87.50% | 50.91% |
| Hit rate (%) STOCKS / BONDS / FX | <50% | <50% | 56.40% | <50% | 52.13% | 91.16% | 50.30% |
| Hit rate (%) COMMO | <50% | <50% | 58.84% | <50% | 51.83% | 89.33% | <50% |
| Hit rate (%) ALL | <50% | <50% | 54.88% | <50% | 50.91% | 93.90% | 50.30% |
| Sub sample/BTC cycle/Futures | AR(1) | ann | random | svm | knn | boost | ridge |
| Hit rate (%) CRYPTO → FUT BTC | <50% | <50% | 70.73% | 50.30% | 57.01% | 70.73% | 51.22% |
| Hit rate (%) STOCKS / BONDS / FX | <50% | <50% | 72.87% | <50% | 54.27% | 72.26% | 51.22% |
| Hit rate (%) COMMO | <50% | <50% | 66.46% | <50% | 54.57% | 77.74% | 51.22% |
| Hit rate (%) ALL | <50% | <50% | 74.09% | <50% | 56.10% | 69.51% | 51.52% |
| Sub sample/2019/Spot | AR(1) | ann | random | svm | knn | boost | ridge |
| Hit rate (%) CRYPTO → SPOT BTC | <50% | <50% | 58.54% | 50.30% | 53.66% | 61.89% | 50.91% |
| Hit rate (%) STOCKS / BONDS / FX | <50% | <50% | 55.49% | 50.91% | 52.13% | 65.55% | 51.22% |
| Hit rate (%) COMMO | <50% | <50% | 58.54% | <50% | 52.13% | 64.02% | 50.61% |
| Hit rate (%) ALL | <50% | <50% | 57.01% | 50.30% | 52.44% | 64.63% | 50.91% |
| Sub sample/2019/Futures | AR(1) | ann | random | svm | knn | boost | ridge |
| Hit rate (%) CRYPTO → FUT BTC | <50% | <50% | 56.40% | <50% | 51.83% | 66.77% | 50.30% |
| Hit rate (%) STOCKS / BONDS / FX | <50% | <50% | 54.57% | <50% | 52.44% | 68.60% | 50.30% |
| Hit rate (%) COMMO | <50% | <50% | 54.88% | <50% | 51.83% | 68.60% | <50% |
| Hit rate (%) ALL | <50% | <50% | 57.01% | <50% | 52.13% | 66.77% | <50% |
| Sub sample/2020/Spot | AR(1) | ann | random | svm | knn | boost | sgd |
| Hit rate (%) CRYPTO → SPOT BTC | <50% | <50% | 60.06% | 50.30% | 53.05% | 62.50% | 50.00% |
| Hit rate (%) STOCKS / BONDS / FX | <50% | <50% | 61.28% | 50.91% | 54.57% | 57.93% | 50.61% |
| Hit rate (%) COMMO | <50% | <50% | 66.46% | 50.91% | 53.05% | 53.66% | 51.22% |
| Hit rate (%) ALL | <50% | <50% | 59.76% | 50.30% | 51.83% | 60.67% | 52.74% |
| Sub sample/2020/Futures | AR(1) | ann | random | svm | knn | boost | sgd |
| Hit rate (%) CRYPTO → FUT BTC | <50% | <50% | 61.28% | <50% | 52.13% | 61.89% | <50% |
| Hit rate (%) STOCKS / BONDS / FX | <50% | <50% | 59.15% | <50% | 53.66% | 62.50% | 50.30% |
| Hit rate (%) COMMO | <50% | <50% | 58.54% | <50% | 52.13% | 64.94% | <50% |
| Hit rate (%) ALL | <50% | <50% | 60.06% | <50% | 51.83% | 61.59% | 51.83% |
| Strategy | Bitcoin RoR |
|---|---|
| HODL | 26.88% |
| Cryptos only | |
| AR(1) | 25.55% |
| ann | 12.26% |
| random | 18.93% |
| svm | 0.05% |
| knn | 19.00% |
| boost | 22.47% |
| ridge | 21.53% |
| Stocks/bonds/fx only | |
| AR(1) | 25.55% |
| ann | 5.13% |
| random | 21.50% |
| svm | 0.04% |
| knn | 17.48% |
| boost | 22.48% |
| ridge | 21.48% |
| Commodities only | |
| AR(1) | 25.55% |
| ann | 26.00% |
| random | 18.04% |
| svm | 0.07% |
| knn | 16.77% |
| boost | 22.48% |
| ridge | 13.00% |
| All | |
| AR(1) | 25.55% |
| ann | 15.20% |
| random | 22.75% |
| svm | 0.05% |
| knn | 24.23% |
| boost | 22.37% |
| ridge | 30.47% |
| Strategy | Bitcoin RoR |
|---|---|
| HODL | 27.46% |
| Cryptos only | |
| AR(1) | 26.13% |
| ann | 12.79% |
| random | 19.55% |
| svm | 0.06% |
| knn | 19.61% |
| boost | 23.06% |
| ridge | 22.09% |
| Stocks/bonds/fx only | |
| AR(1) | 26.13% |
| ann | 5.68% |
| random | 21.98% |
| svm | 0.05% |
| knn | 18.06% |
| boost | 23.05% |
| ridge | 22.06% |
| Commodities only | |
| AR(1) | 26.13% |
| ann | 26.58% |
| random | 18.56% |
| svm | 0.65% |
| knn | 17.36% |
| boost | 23.05% |
| ridge | 13.61% |
| All | |
| AR(1) | 26.13% |
| ann | 15.81% |
| random | 23.32% |
| svm | 0.07% |
| knn | 24.81% |
| boost | 23% |
| ridge | 31.05% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chevallier, J.; Guégan, D.; Goutte, S. Is It Possible to Forecast the Price of Bitcoin? Forecasting 2021, 3, 377-420. https://doi.org/10.3390/forecast3020024
Chevallier J, Guégan D, Goutte S. Is It Possible to Forecast the Price of Bitcoin? Forecasting. 2021; 3(2):377-420. https://doi.org/10.3390/forecast3020024
Chicago/Turabian StyleChevallier, Julien, Dominique Guégan, and Stéphane Goutte. 2021. "Is It Possible to Forecast the Price of Bitcoin?" Forecasting 3, no. 2: 377-420. https://doi.org/10.3390/forecast3020024
APA StyleChevallier, J., Guégan, D., & Goutte, S. (2021). Is It Possible to Forecast the Price of Bitcoin? Forecasting, 3(2), 377-420. https://doi.org/10.3390/forecast3020024