Time Series Analysis of Forest Dynamics at the Ecoregion Level



Abstract
1. Introduction
1.1. Background
1.2. Forecasting of Forest Dynamics: From Individual Trees to Ecoregions
1.3. Our Contributions
2. Materials and Methods
2.1. Data Mining of the Forest Inventory and Analysis Data
2.2. Autoregressive Model Ar(1) for Basal Area on Individual Forest Plots
2.3. Autoregressive Model Ar(1) for Basal Area Yearly Averages
2.3.1. Frequentist Analysis
2.3.2. Bayesian Analysis
- (i)
- Suppose that for every year t and for every patch, each observation is retained with equal probability , independently of other observations.
- (ii)
- Assume that for every year t, basal area logarithms have finite mean and variance.
2.4. Autoregressive Integrated Moving Average (ARIMA) Models for Basal Area Yearly Averages
3. Results and Discussion
3.1. General Statistics
3.2. Autoregressive Model Ar(1) for Basal Area on Individual Patches
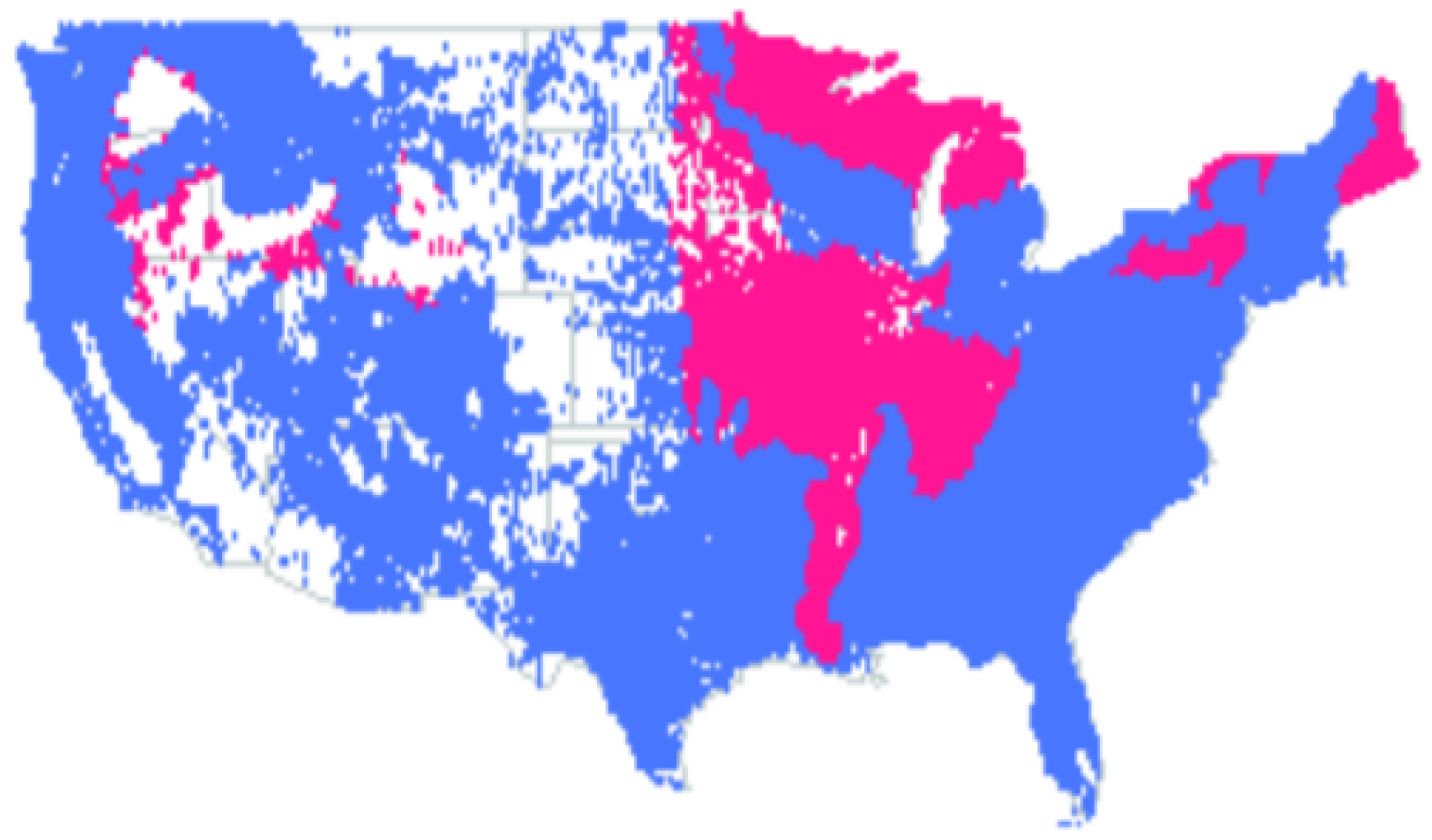
- In ecoregions 211, 212, 221, 222, 223, 231, 232, 234, 251, 255, 313, 321, 322, 331, 332, 341, 342, 411, M211, M221, M223, M231, M313, M331, M332, M333, M334 and M341, the standard error is minimal when parameter , which makes the model (34) for basal area into random walk. However, the residuals for this random walk are not normally distributed according to Shapiro–Wilk normality test.
- In ecoregions 242, M242, M261 and M262 the values minimize the standard error. For we have random walk, while the case is not physical. The residuals for the random walk are not normally distributed.
- In ecoregions 261 and 263 the standard error is minimal when parameter ; hence we have random walk. The random walk has normal increments in this case.
- Ecoregions 262 and 315 have a very few observations to model basal area dynamics: in ecoregion 262 we have only five observations, while in ecoregion 315 we do not have paired observations (observations of basal area at the same forest patch in subsequent years).
3.3. Autoregressive Model Ar(1) for Basal Area Yearly Averages
3.3.1. Frequentist Analysis
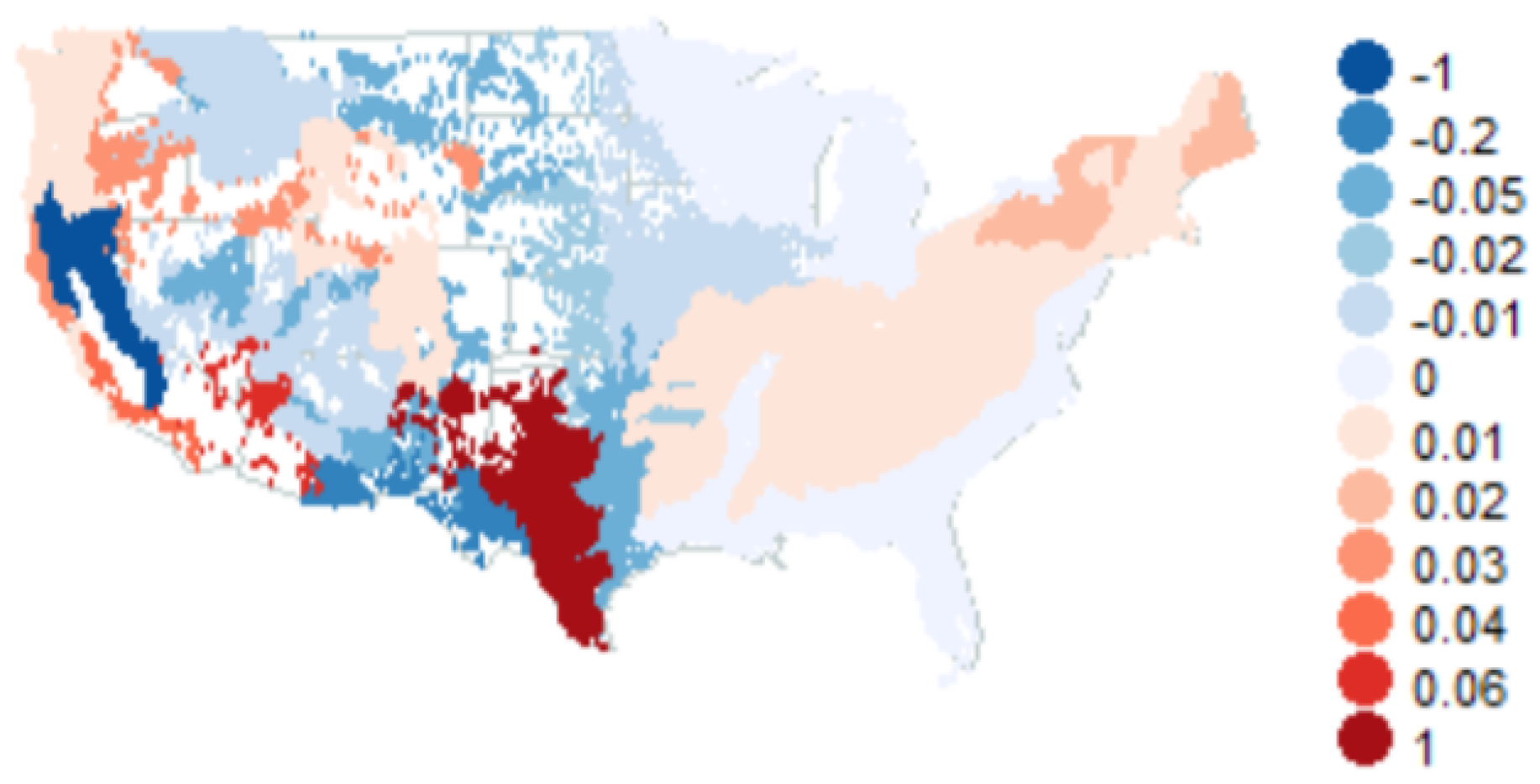
- Basal area annual means follow a random walk with Gaussian increments in the following ecoregions: 221, 222, 231, 232, 242, 255, 261, 262, 263, 313, 315, 321, 322, 331, 332, 341, 411, M211, M221, M223, M231, M242, M261, M262, M313, M331, M332, M333, M334 and M341;
- In all the rest ecoregions (211, 212, 223, 234, 251 and 342), we need a better model for basal area yearly averages.
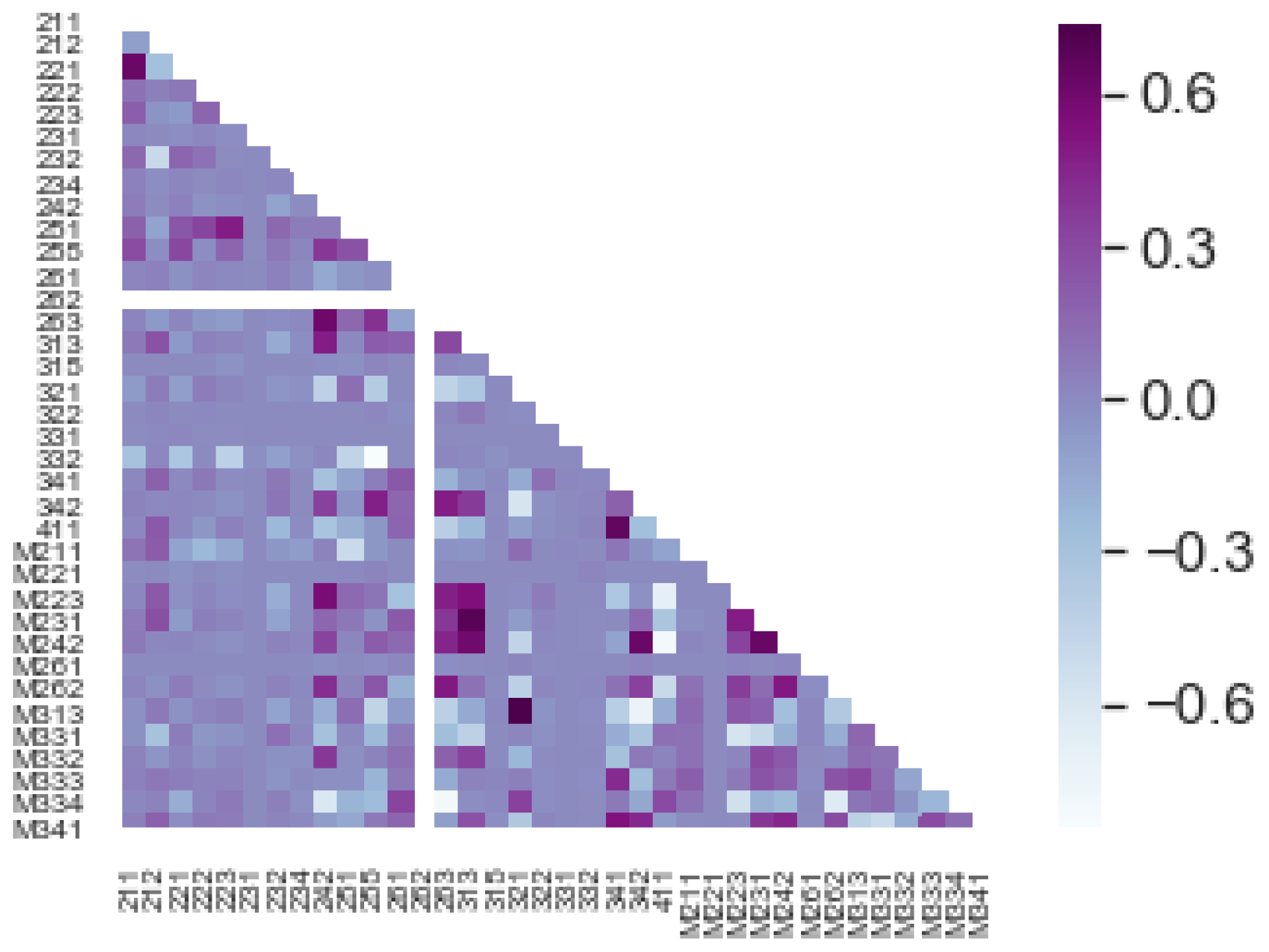
3.3.2. Bayesian Analysis
3.4. Testing Models Using Synthetic Data
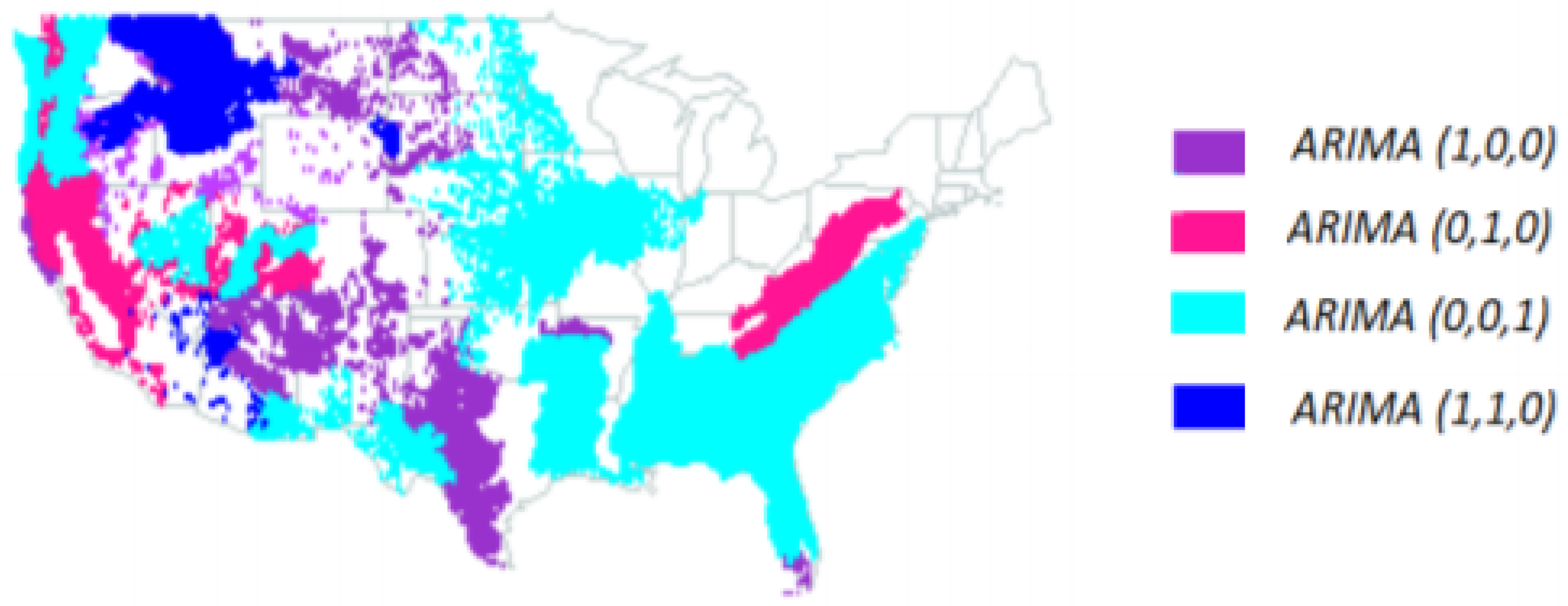
3.5. ARIMA (Autoregressive Integrated Moving Average) Models for Basal Area Annual Averages
- ARIMA(1,0,0) (AR(1) model (30))—ecoregions 263, 313, 315, 331, 342, 411 and M223.
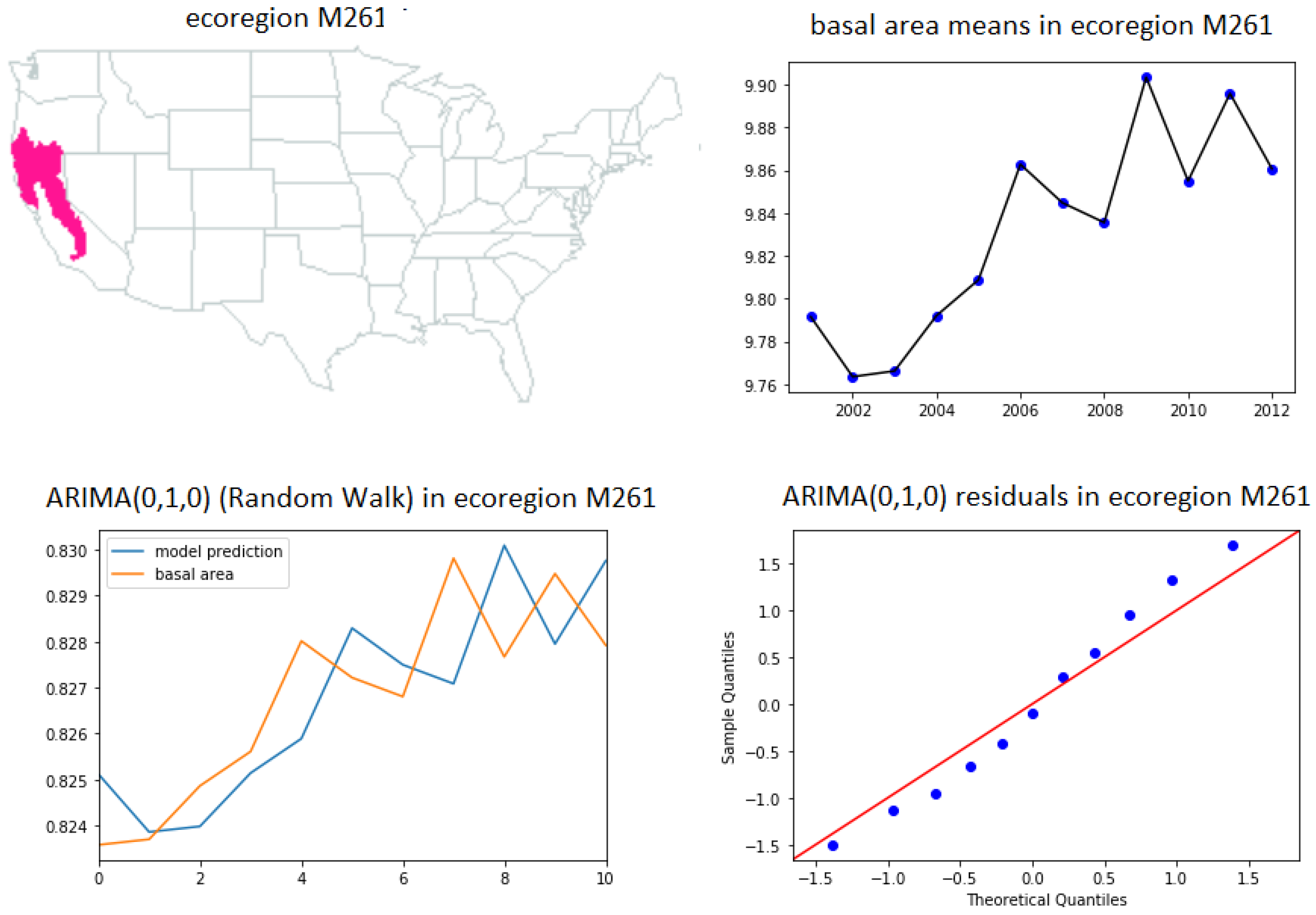
- ARIMA(0,1,0) (random walk (31))—ecoregions 232, 242, 341, M221, M261 and M262.
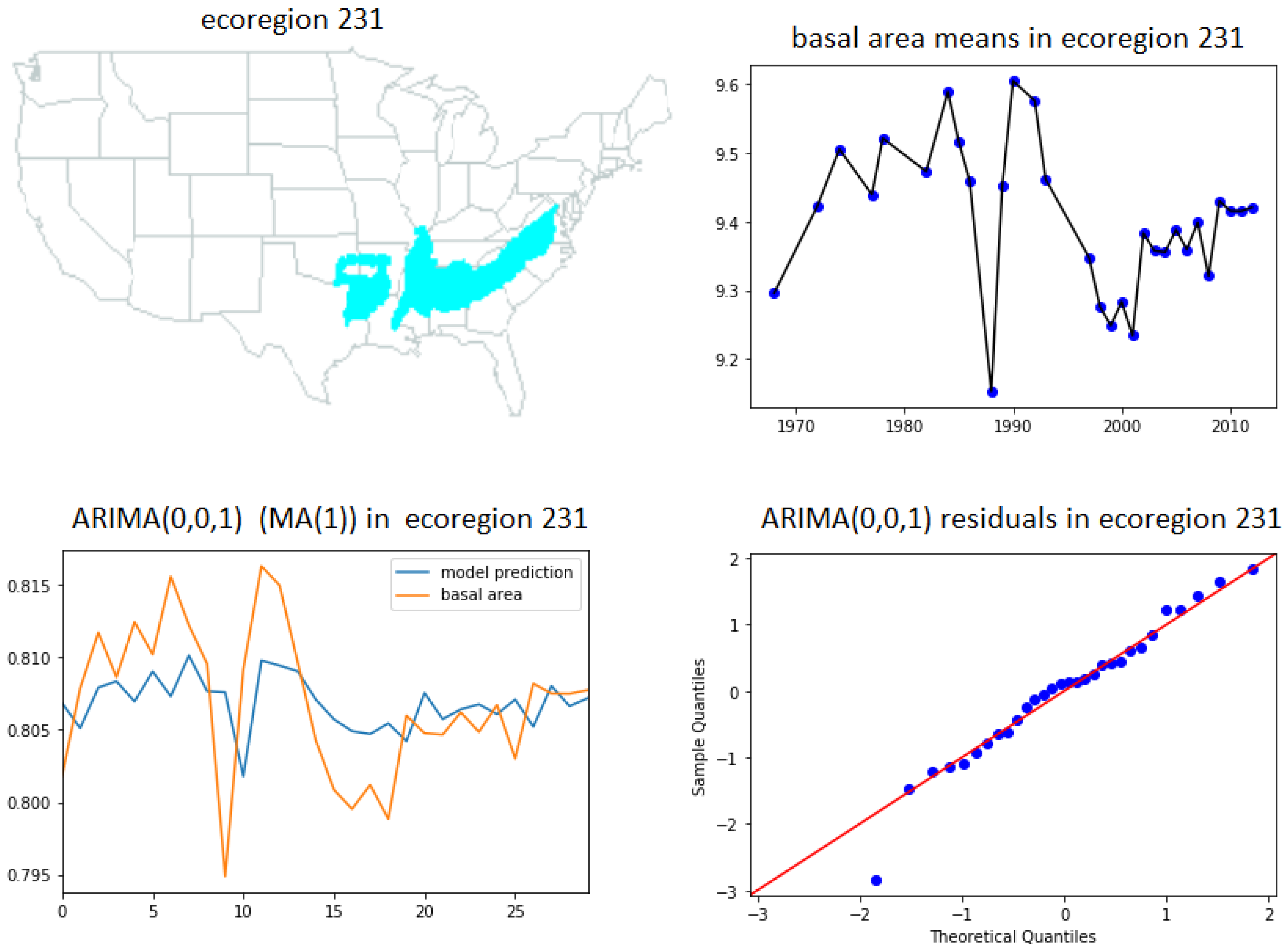
- ARIMA(0,0,1) (MA(1) model (32))—ecoregions 231, 251, 321, 332, M231, M242 and M341.
- ARIMA(1,1,0) model (33)—ecoregions 322, M332, M333 and M334.
3.6. General Discussion
Autoregressive Modeling of Forest Dynamics
3.7. Challenges, Limitations and Future Research
4. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| quantile-quantile (for a plot) | |
| AR | autoregressive process |
| AR(1) | autoregressive process of order 1 |
| ARIMA | autoregressive integrated moving average model |
| USDA | United States Department of Agriculture |
| FIA | USDA Forest Service Forest Inventory and Analysis Program |
| GIS | Geographic Information Systems |
| i.i.d. | independent and identically distributed (random variables) |
| almost sure convergence |
Appendix A. Usa Ecological Subdivisions
- 211: Northeastern Mixed Forest Province
- 212: Laurentian Mixed Forest Province
- 221: Eastern Broadleaf Forest Province
- 222: Midwest Broadleaf Forest Province
- 223: Central Interior Broadleaf Forest Province
- 231: Southeastern Mixed Forest Province
- 232: Outer Coastal Plain Mixed Forest Province
- 234: Lower Mississippi Riverine Forest Province
- 242: Pacific Lowland Mixed Forest Province
- 251: Prairie Parkland (Temperate) Province
- 255: Prairie Parkland (Subtropical) Province
- 261: California Coastal Chaparral Forest and Shrub Province
- 262: California Dry Steppe Province
- 263: California Coastal Steppe, Mixed Forest and Redwood Forest Province
- 313: Colorado Plateau Semidesert Province
- 315: Southwest Plateau and Plains Dry Steppe and Shrub Province
- 321: Chihuahuan Semidesert Province
- 322: American Semidesert and Desert Province
- 331: Great Plains Palouse Dry Steppe Province
- 332: Great Plains Steppe Province
- 341: Intermountain semidesert and Desert Province
- 342: Intermountain semidesert Province
- 411: Everglades Province
- M211: Adirondack New England Mixed Forest and Coniferous Forest, Alpine Meadow Province
- M221: Central Appalachian Broadleaf Forest Coniferous Forest Meadow Province
- M223: Ozark Broadleaf Forest Meadow Province
- M231: Ouachita Mixed Forest Meadow Province
- M242: Cascade Mixed Forest and Coniferous Forest Alpine Meadow Province
- M261: Sierran Steppe Mixed Forest and Coniferous Forest Alpine Meadow Province
- M262: California Coastal Range Open Woodland and Shrub Coniferous Forest Meadow Province
- M313: Arizona-New Mexico Mountains Semidesert and Open Woodland Coniferous Forest Alpine Meadow Province
- M331: Southern Rocky Mountain Steppe and Open Woodland Coniferous Forest Alpine Meadow Province
- M332: Middle Rocky Mountain Steppe and Coniferous Forest Alpine Meadow Province
- M333: Northern Rocky Mountain Forest and Steppe Coniferous Forest Alpine Meadow Province
- M334: Black Hills Coniferous Forest Province
- M341: Nevada-Utah Mountains Semidesert and Coniferous Forest Alpine Meadow Province
Appendix B. Gamma and Gamma Inverse Distributions
Appendix C. Posterior Distributions Calculation
Appendix D. ARIMA Models Results


References
- Levin, S.A. Complex adaptive systems: Exploring the known, the unknown and the unknowable. Am. Math. Soc. 2003, 40, 3–19. [Google Scholar] [CrossRef]
- Stephens, G.R.; Waggoner, P.E. A half century of natural transitions in mixed hardwood forests. Bull. Conn. Agric. Exp. Stn. 1980, 783, 44. [Google Scholar]
- Pastor, J.; Sharp, A.; Wolter, P. An application of Markov models to the dynamics of Minnesota’s forests. Can. J. For. Res. 2005, 35, 3011–3019. [Google Scholar] [CrossRef]
- Strigul, N.; Florescu, I. Statistical characteristics of forest succession. In Abstracts of 97th ESA Annual Meeting; Ecological Society of America: Washington, DC, USA, 2012. [Google Scholar]
- Liénard, J.F.; Strigul, N.S. Modelling of hardwood forest in Quebec under dynamic disturbance regimes: A time-inhomogeneous Markov chain approach. J. Ecol. 2016, 104, 806–816. [Google Scholar] [CrossRef]
- Botkin, D.B. Forest Dynamics: An Ecological Model; Oxford University Press: Oxford, UK, 1993. [Google Scholar]
- Bugmann, H. A review of forest gap models. Clim. Chang. 2001, 51, 259–305. [Google Scholar] [CrossRef]
- Pacala, S.W.; Canham, C.D.; Silander, J.A., Jr. Forest models defined by field measurements: I. The design of a northeastern forest simulator. Can. J. For. Res. 1993, 23, 1980–1988. [Google Scholar] [CrossRef]
- Pacala, S.W.; Canham, C.D.; Saponara, J.; Silander, J.A., Jr.; Kobe, R.K.; Ribbens, E. Forest models defined by field measurements: Estimation, error analysis and dynamics. Ecol. Monogr. 1996, 66, 1–43. [Google Scholar] [CrossRef]
- Moorcroft, P.; Hurtt, G.; Pacala, S.W. A method for scaling vegetation dynamics: The ecosystem demography model (ED). Ecol. Monogr. 2001, 71, 557–586. [Google Scholar] [CrossRef]
- Strigul, N.; Pristinski, D.; Purves, D.; Dushoff, J.; Pacala, S. Scaling from trees to forests: Tractable macroscopic equations for forest dynamics. Ecol. Monogr. 2008, 78, 523–545. [Google Scholar] [CrossRef]
- Strigul, N. Individual-Based Models and Scaling Methods for Ecological Forestry: Implications of Tree Phenotypic Plasticity. In Sustainable Forest Management; Garcia, J.M., Casero, J.J.D., Eds.; IntechOpen: Rijeka, Croatia, 2012; Chapter 20; pp. 359–384. [Google Scholar] [CrossRef]
- Strigul, N.; Florescu, I.; Welden, A.R.; Michalczewski, F. Modelling of forest stand dynamics using Markov chains. Environ. Model. Softw. 2012, 31, 64–75. [Google Scholar] [CrossRef]
- Liénard, J.F.; Gravel, D.; Strigul, N.S. Data-intensive modeling of forest dynamics. Environ. Model. Softw. 2015, 67, 138–148. [Google Scholar] [CrossRef]
- Liénard, J.; Florescu, I.; Strigul, N. An Appraisal of the Classic Forest Succession Paradigm with the Shade Tolerance Index. PLoS ONE 2015, 10, e0117138. [Google Scholar] [CrossRef] [PubMed]
- Rumyantseva, O.; Sarantsev, A.; Strigul, N. Autoregressive modeling of forest dynamics. Forests 2019, 10, 1074. [Google Scholar] [CrossRef]
- Erickson, A.; Strigul, N. A Forest Model Intercomparison Framework and Application at Two Temperate Forests Along the East Coast of the United States. Forests 2019, 10, 180. [Google Scholar] [CrossRef]
- Mitchell, K.J. Dynamics and simulated yield of Douglas-fir. For. Sci. Monogr. 1975, 17, 1–39. [Google Scholar]
- Shugart, H.H. A Theory of Forest Dynamics: The Ecological Implications of Forest Succession Models; Springer: Berlin, Germany, 1984. [Google Scholar]
- Dubé, P.; Fortin, M.; Canham, C.; Marceau, D. Quantifying gap dynamics at the patch mosaic level using a spatially-explicit model of a northern hardwood forest ecosystem. Ecol. Model. 2001, 142, 39–60. [Google Scholar] [CrossRef]
- Zhang, B.; DeAngelis, D.L. An overview of agent-based models in plant biology and ecology. Ann. Bot. 2020. [Google Scholar] [CrossRef]
- Kohyama, T.; Suzuki, E.; Partomihardjo, T.; Yamada, T. Dynamic steady state of patch-mosaic tree size structure of a mixed dipterocarp forest regulated by local crowding. Ecol. Res. 2001, 16, 85–98. [Google Scholar] [CrossRef]
- Botkin, D.B.; Janak, J.F.; Wallis, J.R. Some ecological consequences of a computer model of forest growth. J. Ecol. 1972, 60, 849–872. [Google Scholar] [CrossRef]
- Kovats, M. A comparison of British, Swedish and British Columbian growth and yield predictions for lodgepole pine. For. Chron. 1993, 69, 450–457. [Google Scholar] [CrossRef][Green Version]
- Pretzsch, H.; Biber, P.; Ďurskỳ, J. The single tree-based stand simulator SILVA: Construction, application and evaluation. For. Ecol. Manag. 2002, 162, 3–21. [Google Scholar] [CrossRef]
- Grote, R.; Pretzsch, H. A model for individual tree development based on physiological processes. Plant Biol. 2002, 4, 167–180. [Google Scholar] [CrossRef]
- García, O. Cohort aggregation modelling for complex forest stands: Spruce–aspen mixtures in British Columbia. Ecol. Model. 2017, 343, 109–122. [Google Scholar] [CrossRef]
- Zambrano, J.; Fagan, W.F.; Worthy, S.J.; Thompson, J.; Uriarte, M.; Zimmerman, J.K.; Umaña, M.N.; Swenson, N.G. Tree crown overlap improves predictions of the functional neighbourhood effects on tree survival and growth. J. Ecol. 2019, 107, 887–900. [Google Scholar] [CrossRef]
- Fisher, R.A.; Koven, C.D.; Anderegg, W.R.; Christoffersen, B.O.; Dietze, M.C.; Farrior, C.E.; Holm, J.A.; Hurtt, G.C.; Knox, R.G.; Lawrence, P.J.; et al. Vegetation demographics in Earth System Models: A review of progress and priorities. Glob. Chang. Biol. 2018, 24, 35–54. [Google Scholar] [CrossRef]
- Collalti, A.; Thornton, P.E.; Cescatti, A.; Rita, A.; Borghetti, M.; Nolè, A.; Trotta, C.; Ciais, P.; Matteucci, G. The sensitivity of the forest carbon budget shifts across processes along with stand development and climate change. Ecol. Appl. 2019, 29, e01837. [Google Scholar] [CrossRef] [PubMed]
- Martínez Cano, I.; Shevliakova, E.; Malyshev, S.; Wright, S.J.; Detto, M.; Pacala, S.W.; Muller-Landau, H.C. Allometric constraints and competition enable the simulation of size structure and carbon fluxes in a dynamic vegetation model of tropical forests (LM3PPA-TV). Glob. Chang. Biol. 2020, 26, 4478–4494. [Google Scholar] [CrossRef]
- Kohyama, T. The effect of patch demography on the community structure of forest trees. Ecol. Res. 2006, 21, 346–355. [Google Scholar] [CrossRef]
- Bailey, R.G. Description of the ecoregions of the United States, 2nd ed.; Number 1391, US Department of Agriculture, U.S. Forest Service: Washington, DC, USA, 1995. [Google Scholar]
- Bailey, R.G. Identifying Ecoregion Boundaries. Environ. Manag. 2004, 34, S14–S26. [Google Scholar] [CrossRef]
- Jenkins, J.; Chojnacky, D.; Heath, L.; Birdsey, R. National-Scale Biomass Estimators for United States Tree Species. For. Sci. 2003, 49, 12–35. [Google Scholar]
- Levin, S.A.; Paine, R.T. Disturbance, patch formation, and community structure. Proc. Natl. Acad. Sci. USA 1974, 71, 2744–2747. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Loucks, O.L. From balance of nature to hierarchical patch dynamics: A paradigm shift in ecology. Q. Rev. Biol. 1996, 70, 439–466. [Google Scholar] [CrossRef]
- Hanson, P.J.; Weltzin, J.F. Drought disturbance from climate change: Response of United States forests. Sci. Total. Environ. 2000, 262, 205–220. [Google Scholar] [CrossRef]
- McCarthy, J. Gap dynamics of forest trees: A review with particular attention to boreal forests. Environ. Rev. 2001, 9, 1–59. [Google Scholar] [CrossRef]
- Omernik, J.M.; Griffith, G.E. Ecoregions of the conterminous United States: Evolution of a hierarchical spatial framework. Environ. Manag. 2014, 54, 1249–1266. [Google Scholar] [CrossRef] [PubMed]
- Liénard, J.; Harrison, J.; Strigul, N. US forest response to projected climate-related stress: A tolerance perspective. Glob. Chang. Biol. 2016, 22, 2875–2886. [Google Scholar] [CrossRef]
- Liénard, J.; Strigul, N. Linking forest shade tolerance and soil moisture in North America. Ecol. Indic. 2015, 58, 332–334. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| US Results-General | |
|---|---|
| Number of FIA observations totally: | 409 868 |
| 36 ecoregions observed(48 states-all except AK and HI): | 211,212,221,222,223,231,232,234,242, 251,255 |
| 261,262,263,313,315,321,322,331,332,341,342 | |
| 411,M211,M221,M223,M231,M242,M261,M262 | |
| M313,M331,M332,M333,M334,M341 | |
| 40 years:1968–2013 | 1968,1970,1972,1974,1977,1978,1980,1981,1982 |
| 1983,1984,1985,1986,1987,1988,1989,1990,1991 | |
| 1992,1993,1994,1995,1996,1997,1998,1999,2000 | |
| 2001,2002,2003,2004,2005,2006,2007,2008,2009 | |
| 2010,2011,2012,2013 | |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rumyantseva, O.; Sarantsev, A.; Strigul, N. Time Series Analysis of Forest Dynamics at the Ecoregion Level. Forecasting 2020, 2, 364-386. https://doi.org/10.3390/forecast2030020
Rumyantseva O, Sarantsev A, Strigul N. Time Series Analysis of Forest Dynamics at the Ecoregion Level. Forecasting. 2020; 2(3):364-386. https://doi.org/10.3390/forecast2030020
Chicago/Turabian StyleRumyantseva, Olga, Andrey Sarantsev, and Nikolay Strigul. 2020. "Time Series Analysis of Forest Dynamics at the Ecoregion Level" Forecasting 2, no. 3: 364-386. https://doi.org/10.3390/forecast2030020
APA StyleRumyantseva, O., Sarantsev, A., & Strigul, N. (2020). Time Series Analysis of Forest Dynamics at the Ecoregion Level. Forecasting, 2(3), 364-386. https://doi.org/10.3390/forecast2030020